‘decision theory’ directory
- See Also
- Gwern
- “Self-Experiment Risk-Taking Interview”, Nostrand & Gwern 2026
- “Rock-Paper-Scissors Optimality”, Gwern 2024
- “Self-Blinded Mineral Water Taste Test”, Gwern 2017
- “Statistical Notes”, Gwern 2014
- “Problem 14 Dynamic Programming Solutions”, Gwern et al 2022
- “A/B Testing Long-Form Readability on Gwern.net”, Gwern 2012
- “Dog Cloning For Special Forces: Breed All You Can Breed”, Gwern 2018
- “Evolution As Backstop for Reinforcement Learning”, Gwern 2018
- “Local Optima & Greedy Choices”, Gwern 2021
- “Banner Ads Considered Harmful”, Gwern 2017
- “Embryo Selection For Intelligence”, Gwern 2016
- “Redshift Sleep Experiment”, Gwern 2012
- “Solving Pascal’s Mugging With Dynamic Programming”, Gwern 2019
- “How Should We Critique Research?”, Gwern 2019
- “Timing Technology: Lessons From The Media Lab”, Gwern 2012
- “Are Sunk Costs Fallacies?”, Gwern 2012
- “The Explore-Exploit Dilemma in Media Consumption”, Gwern 2016
- “Embryo Editing for Intelligence”, Gwern 2016
- “History of Iterated Embryo Selection”, Gwern 2019
- “The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
- “Life Extension Cost-Benefits”, Gwern 2015
- “When Should I Check The Mail?”, Gwern 2015
- “Internet WiFi Improvement”, Gwern 2016
- “AI Risk Demos”, Gwern 2016
- “Caffeine Wakeup Experiment”, Gwern 2013
- “Bitter Melon for Blood Glucose”, Gwern 2015
- “Ethics of Lithotomy”, Gwern 2014
- “Console Insurance Is A Ripoff”, Gwern 2009
- Links
- “13 Questions I Ask My Marketing Clients (And Why): Distilled from 20 Years of Marketing Experience”, Veerasamy 2026
- “Optimal Caverna Gameplay via Formal Methods”, Diehl 2026
- “When Is It Worth Working?”, foodforthought 2025
- “Cognitive Tech from Algorithmic Information Theory [Heuristics]”, Wyeth 2025
- “Researchers Discover the Optimal Way To Optimize: The Leading Approach to the Simplex Method, a Widely Used Technique for Balancing Complex Logistical Constraints, Can’t Get Any Better”, Nadis 2025
- “Spooky Collusion at a Distance With Superrational AI”, bira 2025
- “Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
- “The Marginal Parent: Dad Is Often the Last Gallon of Fuel in the Parenthood Tank”, Williamson 2025
- “Comprehension in Economic Games”, Koppel et al 2025
- “That Survivorship Bias Plane: The Exact Backstory to That Picture of an Airplane With Red Dots on top of It”, Liu 2025
- “People Are More Moral in Uncertain Environments”, Chen & Zhong 2025
- “Decisions under Risk Are Decisions under Complexity: Comment”, Banki et al 2025
- “Strategizing With AI: Insights from a Beauty Contest Experiment”, Alekseenko et al 2025
- “How Different LLMs Answered the PhilPapers 2020 Survey”, Satron 2025
- “Learning Solver Design: Automating Factorio Balancers”, Venturini 2024
- “When Kelly Can’t Fail”
- “Cultural Evolution of Cooperation among LLM Agents”, Vallinder & Hughes 2024
- “Decisions under Risk Are Decisions under Complexity”, Oprea 2024
- “Disequilibrium Play in Tennis”, Anderson et al 2024
- “Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
- “Towards a Law of Iterated Expectations for Heuristic Estimators”, Christiano et al 2024
- “An Intuitive Explanation of Black-Scholes: I Explain the Black-Scholes Formula Using Only Basic Probability Theory and Calculus, With a Focus on the Big Picture and Intuition over Technical Details”, Gundersen 2024
- “Song Pong: Synchronizing Pong to Music With Constrained Optimization”, Tao 2024
- “An Abundance of Katherines: The Game Theory of Baby Naming”, Blumer et al 2024
- “KTO: Model Alignment As Prospect Theoretic Optimization”, Ethayarajh et al 2024
- “Escalation Risks from Language Models in Military and Diplomatic Decision-Making”, Rivera et al 2024
- “A Cellular Basis for Mapping Behavioral Structure”, El-Gaby et al 2023
- “UDT Shows That Decision Theory Is More Puzzling Than Ever”, Dai 2023
- “A/B Interactions: A Call to Relax”, Research 2023
- “Using Temperature to Analyze the Neural Basis of a Time-Based Decision”, Monteiro et al 2023
- “Large Language Models for Supply Chain Optimization”, Li et al 2023
- “Combining Human Expertise With Artificial Intelligence: Experimental Evidence from Radiology”, Agarwal et al 2023
- “Replicability & Generalisability: A Guide to CEA Discounts”, Bettle 2023
- “You And Your Research”, Hamming 2023
- “Reinforcement Learning in Newcomb-Like Environments”, Bell et al 2023
- “Conditional Causal Decision Theory Reduces to Evidential Decision Theory”, Mohajeri 2023
- “The Nematode Worm C. Elegans Chooses between Bacterial Foods As If Maximizing Economic Utility”, Katzen et al 2023
- “Can GPT-3 Produce New Ideas? Partially Automating Robin Hanson and Others § If You Never Miss a Plane…”, Sempere 2023
- “How Honey Bees Make Fast and Accurate Decisions”, MaBouDi et al 2023
- “Simulated Automated Facial Recognition Systems As Decision-Aids in Forensic Face Matching Tasks”, Carragher & Hancock 2022
- “Too Much Efficiency Makes Everything Worse: Overfitting and the Strong Version of Goodhart’s Law”
- “Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation”, Mulligan 2022
- “Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning”, Anonymous 2022
- “Learning With Differentiable Algorithms”, Petersen 2022
- “Revisiting the Temporal Pattern of Regret in Action Versus Inaction: Replication of Gilovich & Medvec 1994 With Extensions Examining Responsibility”, Yeung & Feldman 2022
- “This Is Air: The ‘Non-Health’ Effects of Air Pollution”, Aguilar-Gomez et al 2022
- “The Forecast Trap”, Boettiger 2022
- “Efficiently Irrational: Deciphering the Riddle of Human Choice”, Glimcher 2022
- “A Systematic Review of Human Challenge Trials, Designs, and Safety”, Adams-Phipps et al 2022
- “Which Findings Should Be Published?”, Frankel & Kasy 2022
- “The InterModel Vigorish (IMV): A Flexible and Portable Approach for Quantifying Predictive Accuracy With Binary Outcomes”, Domingue et al 2022
- “False Discovery in A/B Testing”, Berman & Bulte 2021
- “Noise Increases Anchoring Effects”, Lee & Morewedge 2021
- “A Rational Reinterpretation of Dual-Process Theories”, Milli et al 2021
- “Ν-SDDP: Neural Stochastic Dual Dynamic Programming”, Dai et al 2021
- “Prior Knowledge Elicitation: The Past, Present, and Future”, Mikkola et al 2021
- “In Preparing for Disasters, Museums Face Tough Choices: Making ‘Grab Lists’ Forces Institutions to Rank and Value Their Holdings”, Economist 2021
- “Rational Regulation of Water-Seeking Effort in Rodents”, Reinagel 2021
- “Flinch”, Munroe 2021
- “Strategically Overconfident (To a Fault): How Self-Promotion Motivates Advisor Confidence”, Zant 2021
- “A Confirmation Bias in Perceptual Decision-Making due to Hierarchical Approximate Inference”, Lange et al 2021
- “On Tilted Losses in Machine Learning (TERM): Theory and Applications”, Li et al 2021
- “Enhanced Rationality in Autism Spectrum Disorder”, Rozenkrantz et al 2021
- “TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands”, Shapiro et al 2021
- “Steps of Reasoning in Children and Adolescents”, Brocas & Carrillo 2021
- “Learning to Hesitate”, Descamps et al 2021
- “Alignment Problems With Current Forecasting Platforms”, Sempere & Lawsen 2021
- “Agent Incentives: A Causal Perspective”, Everitt et al 2021
- “Solving Mixed Integer Programs Using Neural Networks”, Nair et al 2020
- “The Causal Foundations of Applied Probability and Statistics”, Greenland 2020
- “Adversarial Vulnerabilities of Human Decision-Making”, Dezfouli et al 2020
- “Targeting for Long-Term Outcomes”, Yang et al 2020
- “The Temporal Dynamics of Opportunity Costs: A Normative Account of Cognitive Fatigue and Boredom”, Agrawal et al 2020
- “Optimal Peanut Butter and Banana Sandwiches”, Rosenthal 2020
- “Robust Decision Theory and Econometrics”, Chamberlain 2020
- “Be Impatient”, Kuhn 2020
- “Speed-Accuracy Trade-Off in Plants”, Ceccarini et al 2020
- “Modeling Imprecision in Perception, Valuation, and Choice”, Woodford 2020
- “A Comparison of Methods for Treatment Assignment With an Application to Playlist Generation”, Fernández-Loría et al 2020
- “The Secret History of Facial Recognition: Sixty Years Ago, a Sharecropper’s Son Invented a Technology to Identify Faces. Then the Record of His Role All but Vanished. Who Was Woody Bledsoe, and Who Was He Working For?”, Raviv 2020
- “How People Decide What They Want to Know”, Sharot 2020
- “The Gambler’s Problem and Beyond”, Wang et al 2019
- “On ‘Statistical Inference Enables Bad Science; Statistical Thinking Enables Good Science’, Tong 2019”, Gelman 2019
- “The Vulnerable World Hypothesis”, Bostrom 2019
- “A/B Testing With Fat Tails”, Azevedo et al 2019
- “A Scientific Approach to Entrepreneurial Decision Making: Evidence from a Randomized Control Trial”, Camuffo et al 2019
- “Bayesian Persuasion and Information Design”, Kamenica 2019
- “Generalizable and Robust TV Advertising Effects”, Shapiro et al 2019
- “Is the FDA Too Conservative or Too Aggressive?: A Bayesian Decision Analysis of Clinical Trial Design”, Isakov et al 2019
- “Using the Results from Rigorous Multisite Evaluations to Inform Local Policy Decisions”, Orr et al 2019
- “Reinventing the Wheel: Discovering the Optimal Rolling Shape With PyTorch”, Wiener 2019
- “Test Driving ‘Power of Two Random Choices’ Load Balancing”, Tarreau 2019
- “Accounting Theory As a Bayesian Discipline”, Johnstone 2018
- “Test & Roll: Profit-Maximizing A/B Tests”, Feit & Berman 2018
- “Computational Noise in Reward-Guided Learning Drives Behavioral Variability in Volatile Environments”, Findling et al 2018
- “Effects of Non-Normal Performance Distributions on the Accuracy of Utility Analysis”, Aguinis et al 2018
- “Evaluating Groups With the Generalized Shapley Value”, Flores et al 2018
- “ActiveRemediation: The Search for Lead Pipes in Flint, Michigan”, Abernethy et al 2018
- “Delayed Impact of Fair Machine Learning”, Liu et al 2018
- “Ordered Preference Elicitation Strategies for Supporting Multi-Objective Decision Making”, Zintgraf et al 2018
- “Differentiable Dynamic Programming for Structured Prediction and Attention”, Mensch & Blondel 2018
- “P-Hacking and False Discovery in A/B Testing”, Berman et al 2018
- “How to Train Your Oracle: The Delphi Method and Its Turbulent Youth in Operations Research and the Policy Sciences”, Dayé 2018
- “Correlation Neglect in Belief Formation”, Enke & Zimmermann 2017
- “Law without Law: from Observer States to Physics via Algorithmic Information Theory”, Mueller 2017
- “Functional Decision Theory: A New Theory of Instrumental Rationality”, Yudkowsky & Soares 2017
- “Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation”, Dallow et al 2017
- “Willpower Satisficing”, Chappell 2017
- “Toward a Rational and Mechanistic Account of Mental Effort”, Shenhav et al 2017
- “On the Glitch Phenomenon”, Lamport & Palais 2017
- “Pricing the Future in the 17th Century: Calculating Technologies in Competition”, Deringer 2017
- “The Reinhardt Conjecture As an Optimal Control Problem”, Hales 2017
- “Bamboo Garden Trimming Problem (Perpetual Maintenance of Machines With Different Attendance Urgency Factors)”, Gąsieniec et al 2017
- “Rational Decision-Making Under Uncertainty: Observed Betting Patterns on a Biased Coin”, Haghani & Dewey 2017
- “Was Angelina Jolie Right? Optimizing Cancer Prevention Strategies Among BRCA Mutation Carriers”, Nohdurft et al 2017
- “The Risk Elicitation Puzzle”, Pedroni et al 2017
- “Search in Patchy Media: Exploitation-Exploration Tradeoff”
- “The Performance Pay Nobel”, Tabarrok 2016
- “Blood Sugar Level Follows Perceived Time rather than Actual Time in People With Type 2 Diabetes”, Park et al 2016
- “Open Games: Compositional Game Theory”, Ghani et al 2016
- “Brainless but Multi-Headed: Decision Making by the Acellular Slime Mould Physarum Polycephalum”, Beekman & Latty 2015
- “Deep DPG (DDPG): Continuous Control With Deep Reinforcement Learning”, Lillicrap et al 2015
- “Reflective Oracles: A Foundation for Classical Game Theory”, Fallenstein et al 2015
- “Costs and Benefits of Iodine Supplementation for Pregnant Women in a Mildly to Moderately Iodine-Deficient Population: a Modeling Analysis”, Monahan et al 2015
- “The Unfavorable Economics of Measuring the Returns to Advertising”, Lewis & Rao 2015
- “When Causation Does Not Imply Correlation: Robust Violations of the Faithfulness Axiom”, Kennaway 2015
- “Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments”, Deng 2015
- “Selectiongain: an R Package for Optimizing Multi-Stage Selection”, Mi et al 2015
- “Focusing on the Long-Term: It’s Good for Users and Business”, Hohnhold et al 2015
- “Red Black Card Game and Generalized Catalan Numbers”, Howe 2014
- “Your Life in Weeks”, Why 2014
- “Entanglement Guarantees Emergence of Cooperation in Quantum Prisoner’s Dilemma Games on Networks”, Li & Yong 2014
- “[What Deals Should the Devil Optimally Betray in Any given Social Graph?]”, Schou 2013
- “On the Near Impossibility of Measuring the Returns to Advertising”, Lewis & Rao 2013
- “Your Right Arm For A Publication In AER?”, Attema et al 2013
- “The Wait Calculation: The Broader Consequences of the Minimum Time from Now to Interstellar Destinations and Its Statistical-Significance to the Space Economy”, Kennedy 2013
- “Rerandomization to Improve Covariate Balance in Experiments”, Morgan & Rubin 2012
- “Thermodynamics As a Theory of Decision-Making With Information Processing Costs”, Ortega & Braun 2012
- “Buridan’s Principle”, Lamport 2012
- “Buridan’s Principle [Publication Problems Delaying 1984 → 2012]”, Lamport 2012
- “Does Retail Advertising Work? Measuring the Effects of Advertising on Sales Via a Controlled Experiment on Yahoo”, Lewis & Reiley 2011
- “Utility of Human-Computer Interactions: Toward a Science of Preference Measurement”, Toomim et al 2011
- “Here, There, and Everywhere: Correlated Online Behaviors Can Lead to Overestimates of the Effects of Advertising”, Lewis et al 2011
- “Travelers’ Types”, Brãnas-Garza et al 2011
- “Up Or Down? A Male Economist’s Manifesto On The Toilet Seat Etiquette”, Choi 2011
- “Improving Vineyard Sampling Efficiency via Dynamic Spatially Explicit Optimization”, Meyers et al 2011
- “The Time Resolution of the St Petersburg Paradox”, Peters 2011
- “On the Heritability of Consumer Decision Making: An Exploratory Approach for Studying Genetic Effects on Judgment and Choice”, Simonson & Sela 2010
- “How to Improve R&D Productivity: the Pharmaceutical Industry’s Grand Challenge”, Paul et al 2010
- “Drug Harms in the UK: a Multicriteria Decision Analysis”, Nutt et al 2010
- “Are Birds Smarter Than Mathematicians? Pigeons (Columba Livia) Perform Optimally on a Version of the Monty Hall Dilemma”, Herbranson & Schroeder 2010
- “Convergence of Expected Utility for Universal AI”, Blanc 2009
- “A Formal Proof of the Born Rule from Decision-Theoretic Assumptions”, Wallace 2009
- “When to Stop: How to Gamble If You Must—The Mathematics of Optimal Stopping”, Hill 2009
- “Anp060–79 407..506”
- “Adversarial Risk Analysis”, Insua et al 2009
- “Strategic Reliabilism: A Naturalistic Approach to Epistemology”, Bishop & Trout 2008
- “Retrospectives Guinnessometrics: The Economic Foundation of ‘Student’s’ t”, Ziliak 2008
- “Infinite Certainty”, Blanc 2008
- “Convergence of Expected Utilities With Algorithmic Probability Distributions”, Blanc 2007
- “Logarithmic Regret Algorithms for Online Convex Optimization”, Hazan et al 2007
- “The Guidelines Manual—Chapter 8: Incorporating Health Economics in Guidelines and Assessing Resource Impact”, NICE 2007
- “On the Evolution of Investment Strategies and the Kelly Rule—A Darwinian Approach”, Lensberg & Schenk-Hoppé 2007
- “The Cambist and Lord Iron: A Fairy Tale of Economics”, Abraham 2007
- “Cognition and Behavior in Two-Person Guessing Games: An Experimental Study”, Costa-Gomes & Crawford 2006
- “Information Systems Project Continuation in Escalation Situations: A Real Options Model”, Tiwana et al 2006
- “On Some Winning Strategies for the Iterated Prisoner’s Dilemma or Mr. Nice Guy and the Cosa Nostra”, Slany & Kienreich 2006
- “Decision by Sampling”, Stewart et al 2006
- “Interstellar Travel: The Wait Calculation and the Incentive Trap of Progress”, Kennedy 2006
- “The Optimizer’s Curse: Skepticism and Postdecision Surprise in Decision Analysis”, Smith & Winkler 2006
- Good and Real: Demystifying Paradoxes from Physics to Ethics, Drescher 2006
- “The Kelly Criterion in Blackjack Sports Betting, and the Stock Market”, Thorp 2006
- “Investing in the Unknown and Unknowable”, Zeckhauser 2006
- “A Systematic Review on Communicating With Patients about Evidence”, Trevena et al 2005
- “Uncertainty and the Value of Diagnostic Information, With Application to Axillary Lymph Node Dissection in Breast Cancer”
- “Bayesian Informal Logic and Fallacy”, Korb 2004
- “The Problem of Thinking Too Much”, Diaconis & Mazur 2003
- “Policy Mining: Learning Decision Policies from Fixed Sets of Data”, Zadrozny 2003
- “John W. Tukey: His Life and Professional Contributions”, Brillinger 2002
- “DART: Revolutionizing Logistics Planning”, Hedberg 2002
- “Comments on the Origin and Application of Markov Decision Processes”, Howard 2002
- “William Sealy Gosset”, Fienberg & Lazar 2001
- “Bayesian Value-Of-Information Analysis: an Application to a Policy Model of Alzheimer’s Disease”, Caxton 2001
- “The Power of Two Random Choices: A Survey of Techniques and Results”, Mitzenmacher et al 2001
- “The Contributions of the Economics of Information to 20th Century Economics”, Stiglitz 2000
- “Should We Take Measurements at an Intermediate Design Point?”, Gelman 2000
- “Rational Choice Theory”, Scott 2000
- “Averaging Expert Predictions”, Kivinen & Warmuth 1999
- “Comparing Classifiers When the Misallocation Costs Are Uncertain”, Adams & Hand 1999
- “Quantum Theory of Probability and Decisions”, Deutsch 1999
- “The Ecology of Fear: Optimal Foraging, Game Theory, and Trophic Interactions”, Brown et al 1999
- “Adding Risks: Samuelson's Fallacy of Large Numbers Revisited”, Ross 1999
- “A Representation Theorem for Causal Decision Theory”, Joyce 1999
- “A Conversation With I. Richard Savage (With the Assistance of Bruce Spencer)”, Sampson 1999
- “Information Theory and an Extension of the Maximum Likelihood Principle”, Akaike 1998
- “‘Improving Ratings’: Audit in the British University System”, Strathern 1997
- “The Cold War, RAND, and the Generation of Knowledge, 1946–1962”, Hounshell 1997
- “The ‘Awful Idea of Accountability’: Inscribing People into the Measurement of Objects”, Hoskin 1996
- “Comments on Tengs Et Al ‘Comparative Study of the Cost-Effectiveness of Life-Saving Interventions’”
- “Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means”, Lubinski & Humphreys 1996b
- “Five-Hundred Life-Saving Interventions and Their Cost-Effectiveness”
- “Noise and Learning in Semiconductor Manufacturing”, Bohn 1995
- “Processing Linguistic Probabilities: General Principles and Empirical Evidence”, Budescu & Wallsten 1995
- Introduction to Statistical Decision Theory, Pratt 1995
- “Computer Based Horse Race Handicapping and Wagering Systems: A Report”, Hausch et al 1994
- “The Temporal Pattern to the Experience of Regret”, Gilovich & Medvec 1994
- “Bayesian Updating in Hierarchic Markov Processes Applied to the Animal Replacement Problem”, Kristensen 1993
- “Universal Portfolios”, Cover 1991
- “Ensuring Two Bird Deaths With One Throw”, Leslie 1991
- “Learning from Coarse Information: Biased Contests and Career Profiles”, Meyer 1991
- F. P. Ramsey: Philosophical Papers, Ramsey & Mellor 1990
- “‘Student’: A Statistical Biography of William Sealy Gosset”, Pearson et al 1990
- “Weight or the Value of Knowledge”, Ramsey 1990
- “The Total Evidence Theorem for Probability Kinematics”, Graves 1989
- “Nonlinear Preference and Utility Theory”, Fishburn 1988
- “A Shortest Augmenting Path Algorithm for Dense and Sparse Linear Assignment Problems”
- “Measuring the Vague Meanings of Probability Terms”, Wallsten et al 1986
- “Noise”, Black 1986
- “Search in a Known Pattern”, Perry & Wigderson 1986
- “Can People Behave ‘Randomly’?: The Role of Feedback”, Neuringer 1986
- “Searching for Positive Returns at the Track: A Multinomial Logit Model for Handicapping Horse Races”
- “An Examination of Two Alternative Techniques to Estimate the Standard Deviation of Job Performance in Dollars”, Reilly & Smither 1985
- “Game Theoretic Analysis of a Bankruptcy Problem from the Talmud”, Aumann & Maschler 1985
- “Re-Evaluation of Decision Alternatives Dependent upon the Reversibility of a Decision and the Passage of Time”
- “Influence Diagrams”, Howard & Matheson 1984
- “The Citation Bias: Fad and Fashion in the Judgment and Decision Literature”, Christensen-Szalanski & Beach 1984
- “Readings on the Principles and Applications of Decision Analysis: Volume 1: General Collection”, Howard & Matheson 1983
- “Readings on the Principles and Applications of Decision Analysis: Volume 2: Professional Collection”, Howard & Matheson 1983
- “Belief in God: A Game-Theoretic Paradox”, Brams 1982
- “The Variance of Discounted Markov Decision Processes”
- “What Good Are Warfare Models?”, Anger 1981
- “Multi-Bayesian Statistical Decision Theory”, Weerahandi & Zidek 1981
- “Reversible and Irreversible Decisions: Preference for Consonant Information As a Function of Attractiveness of Decision Alternatives”, Frey 1981
- “The Statistical Research Group, 1942–1945”, Wallis 1980
- “Prisoners' Dilemma Is a Newcomb Problem”, Lewis 1979
- “Impact of Valid Selection Procedures on Work-Force Productivity”, Schmidt et al 1979
- “Robustness in the Strategy of Scientific Model Building”, Box 1979
- Tools for Thought, Waddington 1977
- “Science and Statistics”, Box 1976
- Boundaries of Analysis: An Inquiry into the Tocks Island Dam Controversy, Feiveson et al 1976
- When Values Conflict: Essays on Environmental Analysis, Discourse, and Decision, Tribe et al 1976
- “Portfolio Choice and the Kelly Criterion”, Thorp 1975
- “Linear Models in Decision Making”, Dawes & Corrigan 1974
- “Cross-Modality Matching of Money Against Other Continua”, Galanter & Pliner 1974
- “The General Impossibility of Normative Accounting Standards”, Demski 1973
- “An Evaluation of Consumer Protection Legislation: The 1962 Drug Amendments”, Peltzman 1973
- “The Theory of Social Choice”, Fishburn 1973
- “The Foundations of Statistics (Second Revised Edition)”, Savage 1972
- “What Makes for a Beautiful Problem in Science?”, Samuelson 1970
- “The Practicality Gap”, Howard 1968
- “General Proof That Diversification Pays”, Samuelson 1967
- “Optimal Dairy Cow Replacement Policies”, Giaever 1966
- “Systems Analysis Problems of Limited War”, Weiss 1966
- “Measuring Utility by a Single-Response Sequential Method”, Becker et al 1964
- “Sequential Medical Trials”
- “A Model for Selecting One of Two Medical Treatments”, Colton 1963
- “Probability, Statistical Decision Theory, and Accounting”, Bierman 1962
- “Studies of War, Nuclear and Conventional”
- Applied Statistical Decision Theory, Raiffa & Schlaifer 1961
- “Gradient Theory of Optimal Flight Paths”, Kelley 1960
- “Letter to the Editor—A Classroom Example of Linear Programming (Lesson Number 2)”, Jewell 1960
- “Rational Decision-Making In Portfolio Management”, Latané 1959b
- “Criteria for Choice Among Risky Ventures”, Latané 1959
- “Testing Statistical Hypotheses (First Edition)”, Lehmann 1959
- Probability and Statistics for Business Decisions: An Introduction to Managerial Economics Under Uncertainty, Schlaifer 1959
- “An Optimum Character Recognition System Using Decision Functions”, Chow 1957
- “Evolutionary Operation: A Method for Increasing Industrial Productivity”
- “Rational Decision Making in Portfolio Management”, Latané 1957
- “Unsolved Problems of Experimental Statistics”, Tukey 1954
- “Non-Cooperative Games”, Nash 1951
- “The Economic Life of Industrial Equipment”, Preinreich 1940
- “The Relationship Of Validity Coefficients To The Practical Effectiveness Of Tests In Selection: Discussion And Tables”
- “"Student" As Statistician”, Pearson 1939
- “Presidential Address to the First Indian Statistical Congress”, Fisher 1938
- “On the Theory of Apportionment”
- “The Lanarkshire Milk Experiment”, Elderton 1933
- “Pasteurised and Raw Milk”, Fisher & Bartlett 1931
- “The Lanarkshire Milk Experiment [Student]”, Gosset 1931
- “On Testing Varieties of Cereals”, Gosset 1923
- “The Application Of The ‘Law Of Error’ To The Work Of The Brewery”, Gosset 1904
- “Brian Christian on Computer Science Algorithms That Tackle Fundamental and Universal Problems”
- “When RAND Made Magic in Santa Monica”
- Bayesian Optimization Book
- “The Final Cut [Ford-Fulkerson’s Max-Flow Min-Cut As Planning Paradigm]”
- “In Praise of Sparsity and Convexity”, Tibshirani 2026 (page 518)
- “Cole Wyeth’s Personal Website”, Wyeth 2026
- “Measurement, Benchmarking, and Data Analysis Are Underrated”
- “Buy More Copies”, Dynomight 2026
- “Integer Programming Easily Encloses Horse”, Dynomight 2026
- “Solving Probabilistic Tic-Tac-Toe”, Abraham 2026
- “Is Sending Factorio to Your Competitors’ Engineers a Cost-Effective Means of Sabotage?”, Bo 2026
- “Jury Theorems”
- “Quantum-Bayesian and Pragmatist Views of Quantum Theory”
- “Scaling up Linear Programming With PDLP”
- “The Median Is Not the Message”, Gould 2026
- “Why a Pro/con List Is 75% As Good As Your Fancy Machine Learning Algorithm”
- “The Science of Production”, Potter 2026
- “Flight From Perfection—Motorcycling: Is It worth the Risk?”, Griffes 2026
- “The Battleships Game That Countered German U-Boat Attacks During WW2”
- “New Winning Strategies for the Iterated Prisoner’s Dilemma”
- “The Hidden Cost of Our Lies to AI”
- “In Strategic Time, Open-Source Games Are Loopy”
- “VDT: a Solution to Decision Theory”
- “Research Update: Towards a Law of Iterated Expectations for Heuristic Estimators”
- “Why We Can’t Take Expected Value Estimates Literally (Even When They’re Unbiased)”
- “Fat Tails Discourage Compromise”
- “Introducing LIMBO: Managing the Simulation to Maintain Optimal P(DOOM)”
- “Optimizing Crop Planting With Mixed Integer Linear Programming in Stardew Valley”
- “Leaky Delegation: You Are Not a Commodity”
- “Inside vs Outside View”, LessWrong 2026
- “Probable Points and Credible Intervals, Part 2: Decision Theory”
- Sort By Magic
- Wikipedia (22)
- Miscellaneous
- Bibliography
See Also
Gwern
“Self-Experiment Risk-Taking Interview”, Nostrand & Gwern 2026
“Rock-Paper-Scissors Optimality”, Gwern 2024
“Self-Blinded Mineral Water Taste Test”, Gwern 2017
“Statistical Notes”, Gwern 2014
“Problem 14 Dynamic Programming Solutions”, Gwern et al 2022
“A/B Testing Long-Form Readability on Gwern.net”, Gwern 2012
“Dog Cloning For Special Forces: Breed All You Can Breed”, Gwern 2018
“Evolution As Backstop for Reinforcement Learning”, Gwern 2018
“Local Optima & Greedy Choices”, Gwern 2021
“Embryo Selection For Intelligence”, Gwern 2016
“Redshift Sleep Experiment”, Gwern 2012
“Solving Pascal’s Mugging With Dynamic Programming”, Gwern 2019
“How Should We Critique Research?”, Gwern 2019
“Timing Technology: Lessons From The Media Lab”, Gwern 2012
“Are Sunk Costs Fallacies?”, Gwern 2012
“The Explore-Exploit Dilemma in Media Consumption”, Gwern 2016
“Embryo Editing for Intelligence”, Gwern 2016
“History of Iterated Embryo Selection”, Gwern 2019
“The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
“Life Extension Cost-Benefits”, Gwern 2015
“When Should I Check The Mail?”, Gwern 2015
“Internet WiFi Improvement”, Gwern 2016
“AI Risk Demos”, Gwern 2016
“Caffeine Wakeup Experiment”, Gwern 2013
“Bitter Melon for Blood Glucose”, Gwern 2015
“Ethics of Lithotomy”, Gwern 2014
“Console Insurance Is A Ripoff”, Gwern 2009
Links
“13 Questions I Ask My Marketing Clients (And Why): Distilled from 20 Years of Marketing Experience”, Veerasamy 2026
13 questions I ask my marketing clients (and why): distilled from 20 years of marketing experience
“Optimal Caverna Gameplay via Formal Methods”, Diehl 2026
“When Is It Worth Working?”, foodforthought 2025
“Cognitive Tech from Algorithmic Information Theory [Heuristics]”, Wyeth 2025
Cognitive Tech from Algorithmic Information Theory [heuristics]
“Researchers Discover the Optimal Way To Optimize: The Leading Approach to the Simplex Method, a Widely Used Technique for Balancing Complex Logistical Constraints, Can’t Get Any Better”, Nadis 2025
“Spooky Collusion at a Distance With Superrational AI”, bira 2025
“Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
Strategic Intelligence in Large Language Models: Evidence from evolutionary Game Theory
“The Marginal Parent: Dad Is Often the Last Gallon of Fuel in the Parenthood Tank”, Williamson 2025
The Marginal Parent: Dad is often the last gallon of fuel in the parenthood tank
“Comprehension in Economic Games”, Koppel et al 2025
“That Survivorship Bias Plane: The Exact Backstory to That Picture of an Airplane With Red Dots on top of It”, Liu 2025
“People Are More Moral in Uncertain Environments”, Chen & Zhong 2025
“Decisions under Risk Are Decisions under Complexity: Comment”, Banki et al 2025
Decisions under Risk Are Decisions under Complexity: Comment
“Strategizing With AI: Insights from a Beauty Contest Experiment”, Alekseenko et al 2025
Strategizing with AI: Insights from a Beauty Contest Experiment
“How Different LLMs Answered the PhilPapers 2020 Survey”, Satron 2025
“Learning Solver Design: Automating Factorio Balancers”, Venturini 2024
“When Kelly Can’t Fail”
“Cultural Evolution of Cooperation among LLM Agents”, Vallinder & Hughes 2024
“Decisions under Risk Are Decisions under Complexity”, Oprea 2024
“Disequilibrium Play in Tennis”, Anderson et al 2024
“Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
“Towards a Law of Iterated Expectations for Heuristic Estimators”, Christiano et al 2024
Towards a Law of Iterated Expectations for Heuristic Estimators
“An Intuitive Explanation of Black-Scholes: I Explain the Black-Scholes Formula Using Only Basic Probability Theory and Calculus, With a Focus on the Big Picture and Intuition over Technical Details”, Gundersen 2024
“Song Pong: Synchronizing Pong to Music With Constrained Optimization”, Tao 2024
Song Pong: Synchronizing Pong to music with constrained optimization
“An Abundance of Katherines: The Game Theory of Baby Naming”, Blumer et al 2024
“KTO: Model Alignment As Prospect Theoretic Optimization”, Ethayarajh et al 2024
“Escalation Risks from Language Models in Military and Diplomatic Decision-Making”, Rivera et al 2024
Escalation Risks from Language Models in Military and Diplomatic Decision-Making
“A Cellular Basis for Mapping Behavioral Structure”, El-Gaby et al 2023
“UDT Shows That Decision Theory Is More Puzzling Than Ever”, Dai 2023
“A/B Interactions: A Call to Relax”, Research 2023
“Using Temperature to Analyze the Neural Basis of a Time-Based Decision”, Monteiro et al 2023
Using temperature to analyze the neural basis of a time-based decision
“Large Language Models for Supply Chain Optimization”, Li et al 2023
“Combining Human Expertise With Artificial Intelligence: Experimental Evidence from Radiology”, Agarwal et al 2023
Combining Human Expertise with Artificial Intelligence: Experimental Evidence from Radiology
“Replicability & Generalisability: A Guide to CEA Discounts”, Bettle 2023
“You And Your Research”, Hamming 2023
“Reinforcement Learning in Newcomb-Like Environments”, Bell et al 2023
“Conditional Causal Decision Theory Reduces to Evidential Decision Theory”, Mohajeri 2023
Conditional causal decision theory reduces to evidential decision theory :
“The Nematode Worm C. Elegans Chooses between Bacterial Foods As If Maximizing Economic Utility”, Katzen et al 2023
The nematode worm C. elegans chooses between bacterial foods as if maximizing economic utility
“Can GPT-3 Produce New Ideas? Partially Automating Robin Hanson and Others § If You Never Miss a Plane…”, Sempere 2023
“How Honey Bees Make Fast and Accurate Decisions”, MaBouDi et al 2023
“Simulated Automated Facial Recognition Systems As Decision-Aids in Forensic Face Matching Tasks”, Carragher & Hancock 2022
Simulated automated facial recognition systems as decision-aids in forensic face matching tasks
“Too Much Efficiency Makes Everything Worse: Overfitting and the Strong Version of Goodhart’s Law”
Too much efficiency makes everything worse: overfitting and the strong version of Goodhart’s law
“Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation”, Mulligan 2022
Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation
“Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning”, Anonymous 2022
“Learning With Differentiable Algorithms”, Petersen 2022
“Revisiting the Temporal Pattern of Regret in Action Versus Inaction: Replication of Gilovich & Medvec 1994 With Extensions Examining Responsibility”, Yeung & Feldman 2022
“This Is Air: The ‘Non-Health’ Effects of Air Pollution”, Aguilar-Gomez et al 2022
“The Forecast Trap”, Boettiger 2022
“Efficiently Irrational: Deciphering the Riddle of Human Choice”, Glimcher 2022
Efficiently irrational: deciphering the riddle of human choice
“A Systematic Review of Human Challenge Trials, Designs, and Safety”, Adams-Phipps et al 2022
A Systematic Review of Human Challenge Trials, Designs, and Safety
“Which Findings Should Be Published?”, Frankel & Kasy 2022
“The InterModel Vigorish (IMV): A Flexible and Portable Approach for Quantifying Predictive Accuracy With Binary Outcomes”, Domingue et al 2022
“False Discovery in A/B Testing”, Berman & Bulte 2021
“Noise Increases Anchoring Effects”, Lee & Morewedge 2021
“A Rational Reinterpretation of Dual-Process Theories”, Milli et al 2021
“Ν-SDDP: Neural Stochastic Dual Dynamic Programming”, Dai et al 2021
“Prior Knowledge Elicitation: The Past, Present, and Future”, Mikkola et al 2021
“In Preparing for Disasters, Museums Face Tough Choices: Making ‘Grab Lists’ Forces Institutions to Rank and Value Their Holdings”, Economist 2021
“Rational Regulation of Water-Seeking Effort in Rodents”, Reinagel 2021
“Flinch”, Munroe 2021
“Strategically Overconfident (To a Fault): How Self-Promotion Motivates Advisor Confidence”, Zant 2021
Strategically overconfident (to a fault): How self-promotion motivates advisor confidence
“A Confirmation Bias in Perceptual Decision-Making due to Hierarchical Approximate Inference”, Lange et al 2021
A confirmation bias in perceptual decision-making due to hierarchical approximate inference
“On Tilted Losses in Machine Learning (TERM): Theory and Applications”, Li et al 2021
On Tilted Losses in Machine Learning (TERM): Theory and Applications
“Enhanced Rationality in Autism Spectrum Disorder”, Rozenkrantz et al 2021
“TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands”, Shapiro et al 2021
TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands
“Steps of Reasoning in Children and Adolescents”, Brocas & Carrillo 2021
“Learning to Hesitate”, Descamps et al 2021
“Alignment Problems With Current Forecasting Platforms”, Sempere & Lawsen 2021
“Agent Incentives: A Causal Perspective”, Everitt et al 2021
“Solving Mixed Integer Programs Using Neural Networks”, Nair et al 2020
“The Causal Foundations of Applied Probability and Statistics”, Greenland 2020
The causal foundations of applied probability and statistics
“Adversarial Vulnerabilities of Human Decision-Making”, Dezfouli et al 2020
“Targeting for Long-Term Outcomes”, Yang et al 2020
“The Temporal Dynamics of Opportunity Costs: A Normative Account of Cognitive Fatigue and Boredom”, Agrawal et al 2020
The Temporal Dynamics of Opportunity Costs: A Normative Account of Cognitive Fatigue and Boredom
“Optimal Peanut Butter and Banana Sandwiches”, Rosenthal 2020
“Robust Decision Theory and Econometrics”, Chamberlain 2020
“Be Impatient”, Kuhn 2020
“Speed-Accuracy Trade-Off in Plants”, Ceccarini et al 2020
“Modeling Imprecision in Perception, Valuation, and Choice”, Woodford 2020
“A Comparison of Methods for Treatment Assignment With an Application to Playlist Generation”, Fernández-Loría et al 2020
A Comparison of Methods for Treatment Assignment with an Application to Playlist Generation
“The Secret History of Facial Recognition: Sixty Years Ago, a Sharecropper’s Son Invented a Technology to Identify Faces. Then the Record of His Role All but Vanished. Who Was Woody Bledsoe, and Who Was He Working For?”, Raviv 2020
“The Gambler’s Problem and Beyond”, Wang et al 2019
“On ‘Statistical Inference Enables Bad Science; Statistical Thinking Enables Good Science’, Tong 2019”, Gelman 2019
On ‘Statistical Inference Enables Bad Science; Statistical Thinking Enables Good Science’, Tong 2019
“The Vulnerable World Hypothesis”, Bostrom 2019
“A/B Testing With Fat Tails”, Azevedo et al 2019
“A Scientific Approach to Entrepreneurial Decision Making: Evidence from a Randomized Control Trial”, Camuffo et al 2019
A Scientific Approach to Entrepreneurial Decision Making: Evidence from a Randomized Control Trial
“Bayesian Persuasion and Information Design”, Kamenica 2019
“Generalizable and Robust TV Advertising Effects”, Shapiro et al 2019
“Is the FDA Too Conservative or Too Aggressive?: A Bayesian Decision Analysis of Clinical Trial Design”, Isakov et al 2019
“Using the Results from Rigorous Multisite Evaluations to Inform Local Policy Decisions”, Orr et al 2019
Using the Results from Rigorous Multisite Evaluations to Inform Local Policy Decisions :
View PDF:
“Reinventing the Wheel: Discovering the Optimal Rolling Shape With PyTorch”, Wiener 2019
Reinventing the Wheel: Discovering the Optimal Rolling Shape with PyTorch
“Test Driving ‘Power of Two Random Choices’ Load Balancing”, Tarreau 2019
“Accounting Theory As a Bayesian Discipline”, Johnstone 2018
“Test & Roll: Profit-Maximizing A/B Tests”, Feit & Berman 2018
“Computational Noise in Reward-Guided Learning Drives Behavioral Variability in Volatile Environments”, Findling et al 2018
Computational noise in reward-guided learning drives behavioral variability in volatile environments
“Effects of Non-Normal Performance Distributions on the Accuracy of Utility Analysis”, Aguinis et al 2018
Effects of Non-normal Performance Distributions on the Accuracy of Utility Analysis
“Evaluating Groups With the Generalized Shapley Value”, Flores et al 2018
“ActiveRemediation: The Search for Lead Pipes in Flint, Michigan”, Abernethy et al 2018
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
“Delayed Impact of Fair Machine Learning”, Liu et al 2018
“Ordered Preference Elicitation Strategies for Supporting Multi-Objective Decision Making”, Zintgraf et al 2018
Ordered Preference Elicitation Strategies for Supporting Multi-Objective Decision Making
“Differentiable Dynamic Programming for Structured Prediction and Attention”, Mensch & Blondel 2018
Differentiable Dynamic Programming for Structured Prediction and Attention
“P-Hacking and False Discovery in A/B Testing”, Berman et al 2018
“How to Train Your Oracle: The Delphi Method and Its Turbulent Youth in Operations Research and the Policy Sciences”, Dayé 2018
“Correlation Neglect in Belief Formation”, Enke & Zimmermann 2017
“Law without Law: from Observer States to Physics via Algorithmic Information Theory”, Mueller 2017
Law without law: from observer states to physics via algorithmic information theory
“Functional Decision Theory: A New Theory of Instrumental Rationality”, Yudkowsky & Soares 2017
Functional Decision Theory: A New Theory of Instrumental Rationality
“Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation”, Dallow et al 2017
Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation
“Willpower Satisficing”, Chappell 2017
“Toward a Rational and Mechanistic Account of Mental Effort”, Shenhav et al 2017
“On the Glitch Phenomenon”, Lamport & Palais 2017
“Pricing the Future in the 17th Century: Calculating Technologies in Competition”, Deringer 2017
Pricing the Future in the 17th Century: Calculating Technologies in Competition
“The Reinhardt Conjecture As an Optimal Control Problem”, Hales 2017
“Bamboo Garden Trimming Problem (Perpetual Maintenance of Machines With Different Attendance Urgency Factors)”, Gąsieniec et al 2017
“Rational Decision-Making Under Uncertainty: Observed Betting Patterns on a Biased Coin”, Haghani & Dewey 2017
Rational Decision-Making Under Uncertainty: Observed Betting Patterns on a Biased Coin
“Was Angelina Jolie Right? Optimizing Cancer Prevention Strategies Among BRCA Mutation Carriers”, Nohdurft et al 2017
Was Angelina Jolie Right? Optimizing Cancer Prevention Strategies Among BRCA Mutation Carriers :
“The Risk Elicitation Puzzle”, Pedroni et al 2017
“Search in Patchy Media: Exploitation-Exploration Tradeoff”
“The Performance Pay Nobel”, Tabarrok 2016
“Blood Sugar Level Follows Perceived Time rather than Actual Time in People With Type 2 Diabetes”, Park et al 2016
Blood sugar level follows perceived time rather than actual time in people with type 2 diabetes
“Open Games: Compositional Game Theory”, Ghani et al 2016
“Brainless but Multi-Headed: Decision Making by the Acellular Slime Mould Physarum Polycephalum”, Beekman & Latty 2015
Brainless but Multi-Headed: Decision Making by the Acellular Slime Mould Physarum polycephalum
“Deep DPG (DDPG): Continuous Control With Deep Reinforcement Learning”, Lillicrap et al 2015
Deep DPG (DDPG): Continuous control with deep reinforcement learning
“Reflective Oracles: A Foundation for Classical Game Theory”, Fallenstein et al 2015
“Costs and Benefits of Iodine Supplementation for Pregnant Women in a Mildly to Moderately Iodine-Deficient Population: a Modeling Analysis”, Monahan et al 2015
“The Unfavorable Economics of Measuring the Returns to Advertising”, Lewis & Rao 2015
The Unfavorable Economics of Measuring the Returns to Advertising
“When Causation Does Not Imply Correlation: Robust Violations of the Faithfulness Axiom”, Kennaway 2015
When causation does not imply correlation: robust violations of the Faithfulness axiom
“Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments”, Deng 2015
Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments
“Selectiongain: an R Package for Optimizing Multi-Stage Selection”, Mi et al 2015
Selectiongain: an R package for optimizing multi-stage selection :
View PDF:
“Focusing on the Long-Term: It’s Good for Users and Business”, Hohnhold et al 2015
“Red Black Card Game and Generalized Catalan Numbers”, Howe 2014
“Your Life in Weeks”, Why 2014
“Entanglement Guarantees Emergence of Cooperation in Quantum Prisoner’s Dilemma Games on Networks”, Li & Yong 2014
Entanglement guarantees emergence of cooperation in quantum prisoner’s dilemma games on networks
“[What Deals Should the Devil Optimally Betray in Any given Social Graph?]”, Schou 2013
[What deals should the Devil optimally betray in any given social graph?]
“On the Near Impossibility of Measuring the Returns to Advertising”, Lewis & Rao 2013
On the Near Impossibility of Measuring the Returns to Advertising
“Your Right Arm For A Publication In AER?”, Attema et al 2013
“The Wait Calculation: The Broader Consequences of the Minimum Time from Now to Interstellar Destinations and Its Statistical-Significance to the Space Economy”, Kennedy 2013
“Rerandomization to Improve Covariate Balance in Experiments”, Morgan & Rubin 2012
“Thermodynamics As a Theory of Decision-Making With Information Processing Costs”, Ortega & Braun 2012
Thermodynamics as a theory of decision-making with information processing costs
“Buridan’s Principle”, Lamport 2012
“Buridan’s Principle [Publication Problems Delaying 1984 → 2012]”, Lamport 2012
Buridan’s Principle [publication problems delaying 1984 → 2012]
“Does Retail Advertising Work? Measuring the Effects of Advertising on Sales Via a Controlled Experiment on Yahoo”, Lewis & Reiley 2011
“Utility of Human-Computer Interactions: Toward a Science of Preference Measurement”, Toomim et al 2011
Utility of Human-Computer Interactions: Toward a Science of Preference Measurement
“Here, There, and Everywhere: Correlated Online Behaviors Can Lead to Overestimates of the Effects of Advertising”, Lewis et al 2011
“Travelers’ Types”, Brãnas-Garza et al 2011
“Up Or Down? A Male Economist’s Manifesto On The Toilet Seat Etiquette”, Choi 2011
Up Or Down? A Male Economist’s Manifesto On The Toilet Seat Etiquette
“Improving Vineyard Sampling Efficiency via Dynamic Spatially Explicit Optimization”, Meyers et al 2011
Improving vineyard sampling efficiency via dynamic spatially explicit optimization :
View PDF:
“The Time Resolution of the St Petersburg Paradox”, Peters 2011
“On the Heritability of Consumer Decision Making: An Exploratory Approach for Studying Genetic Effects on Judgment and Choice”, Simonson & Sela 2010
“How to Improve R&D Productivity: the Pharmaceutical Industry’s Grand Challenge”, Paul et al 2010
How to improve R&D productivity: the pharmaceutical industry’s grand challenge
“Drug Harms in the UK: a Multicriteria Decision Analysis”, Nutt et al 2010
Drug harms in the UK: a multicriteria decision analysis :
View PDF:
“Are Birds Smarter Than Mathematicians? Pigeons (Columba Livia) Perform Optimally on a Version of the Monty Hall Dilemma”, Herbranson & Schroeder 2010
“Convergence of Expected Utility for Universal AI”, Blanc 2009
“A Formal Proof of the Born Rule from Decision-Theoretic Assumptions”, Wallace 2009
A formal proof of the Born rule from decision-theoretic assumptions
“When to Stop: How to Gamble If You Must—The Mathematics of Optimal Stopping”, Hill 2009
When to Stop: How to gamble if you must—the mathematics of optimal stopping :
View PDF:
“Anp060–79 407..506”
“Adversarial Risk Analysis”, Insua et al 2009
“Strategic Reliabilism: A Naturalistic Approach to Epistemology”, Bishop & Trout 2008
Strategic Reliabilism: A Naturalistic Approach to Epistemology
“Retrospectives Guinnessometrics: The Economic Foundation of ‘Student’s’ t”, Ziliak 2008
Retrospectives Guinnessometrics: The Economic Foundation of ‘Student’s’ t
“Infinite Certainty”, Blanc 2008
“Convergence of Expected Utilities With Algorithmic Probability Distributions”, Blanc 2007
Convergence of Expected Utilities with Algorithmic Probability Distributions
“Logarithmic Regret Algorithms for Online Convex Optimization”, Hazan et al 2007
Logarithmic regret algorithms for online convex optimization
“The Guidelines Manual—Chapter 8: Incorporating Health Economics in Guidelines and Assessing Resource Impact”, NICE 2007
“On the Evolution of Investment Strategies and the Kelly Rule—A Darwinian Approach”, Lensberg & Schenk-Hoppé 2007
On the Evolution of Investment Strategies and the Kelly Rule—A Darwinian Approach
“The Cambist and Lord Iron: A Fairy Tale of Economics”, Abraham 2007
“Cognition and Behavior in Two-Person Guessing Games: An Experimental Study”, Costa-Gomes & Crawford 2006
Cognition and Behavior in Two-Person Guessing Games: An Experimental Study
“Information Systems Project Continuation in Escalation Situations: A Real Options Model”, Tiwana et al 2006
Information Systems Project Continuation in Escalation Situations: A Real Options Model
“On Some Winning Strategies for the Iterated Prisoner’s Dilemma or Mr. Nice Guy and the Cosa Nostra”, Slany & Kienreich 2006
On some winning strategies for the Iterated Prisoner’s Dilemma or Mr. Nice Guy and the Cosa Nostra
“Decision by Sampling”, Stewart et al 2006
“Interstellar Travel: The Wait Calculation and the Incentive Trap of Progress”, Kennedy 2006
Interstellar Travel: The Wait Calculation and the Incentive Trap of Progress
“The Optimizer’s Curse: Skepticism and Postdecision Surprise in Decision Analysis”, Smith & Winkler 2006
The Optimizer’s Curse: Skepticism and Postdecision Surprise in Decision Analysis
Good and Real: Demystifying Paradoxes from Physics to Ethics, Drescher 2006
Good and Real: Demystifying Paradoxes from Physics to Ethics
“The Kelly Criterion in Blackjack Sports Betting, and the Stock Market”, Thorp 2006
The Kelly Criterion in Blackjack Sports Betting, and the Stock Market
“Investing in the Unknown and Unknowable”, Zeckhauser 2006
“A Systematic Review on Communicating With Patients about Evidence”, Trevena et al 2005
A systematic review on communicating with patients about evidence
“Uncertainty and the Value of Diagnostic Information, With Application to Axillary Lymph Node Dissection in Breast Cancer”
“Bayesian Informal Logic and Fallacy”, Korb 2004
“The Problem of Thinking Too Much”, Diaconis & Mazur 2003
“Policy Mining: Learning Decision Policies from Fixed Sets of Data”, Zadrozny 2003
Policy Mining: Learning Decision Policies from Fixed Sets of Data
“John W. Tukey: His Life and Professional Contributions”, Brillinger 2002
“DART: Revolutionizing Logistics Planning”, Hedberg 2002
DART: Revolutionizing logistics planning :
View PDF:
“Comments on the Origin and Application of Markov Decision Processes”, Howard 2002
Comments on the Origin and Application of Markov Decision Processes
“William Sealy Gosset”, Fienberg & Lazar 2001
“Bayesian Value-Of-Information Analysis: an Application to a Policy Model of Alzheimer’s Disease”, Caxton 2001
Bayesian value-of-information analysis: an application to a policy model of Alzheimer’s disease :
“The Power of Two Random Choices: A Survey of Techniques and Results”, Mitzenmacher et al 2001
The Power of Two Random Choices: A Survey of Techniques and Results
“The Contributions of the Economics of Information to 20th Century Economics”, Stiglitz 2000
The Contributions of the Economics of Information to 20th Century Economics
“Should We Take Measurements at an Intermediate Design Point?”, Gelman 2000
Should we take measurements at an intermediate design point?
“Rational Choice Theory”, Scott 2000
View PDF:
“Averaging Expert Predictions”, Kivinen & Warmuth 1999
“Comparing Classifiers When the Misallocation Costs Are Uncertain”, Adams & Hand 1999
Comparing classifiers when the misallocation costs are uncertain
“Quantum Theory of Probability and Decisions”, Deutsch 1999
“The Ecology of Fear: Optimal Foraging, Game Theory, and Trophic Interactions”, Brown et al 1999
The Ecology of Fear: Optimal Foraging, Game Theory, and Trophic Interactions
“Adding Risks: Samuelson's Fallacy of Large Numbers Revisited”, Ross 1999
Adding Risks: Samuelson's Fallacy of Large Numbers Revisited :
View PDF:
“A Representation Theorem for Causal Decision Theory”, Joyce 1999
“A Conversation With I. Richard Savage (With the Assistance of Bruce Spencer)”, Sampson 1999
A conversation with I. Richard Savage (with the assistance of Bruce Spencer)
“Information Theory and an Extension of the Maximum Likelihood Principle”, Akaike 1998
Information Theory and an Extension of the Maximum Likelihood Principle
“‘Improving Ratings’: Audit in the British University System”, Strathern 1997
“The Cold War, RAND, and the Generation of Knowledge, 1946–1962”, Hounshell 1997
The Cold War, RAND, and the Generation of Knowledge, 1946–1962 :
View PDF:
“The ‘Awful Idea of Accountability’: Inscribing People into the Measurement of Objects”, Hoskin 1996
The ‘awful idea of accountability’: inscribing people into the measurement of objects :
View PDF:
“Comments on Tengs Et Al ‘Comparative Study of the Cost-Effectiveness of Life-Saving Interventions’”
Comments on Tengs et al ‘Comparative Study of the Cost-Effectiveness of Life-Saving Interventions’ :
View PDF:
“Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means”, Lubinski & Humphreys 1996b
Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means
“Five-Hundred Life-Saving Interventions and Their Cost-Effectiveness”
Five-Hundred Life-Saving Interventions and Their Cost-Effectiveness :
View PDF:
“Noise and Learning in Semiconductor Manufacturing”, Bohn 1995
Noise and Learning in Semiconductor Manufacturing :
View PDF:
“Processing Linguistic Probabilities: General Principles and Empirical Evidence”, Budescu & Wallsten 1995
Processing Linguistic Probabilities: General Principles and Empirical Evidence
Introduction to Statistical Decision Theory, Pratt 1995
“Computer Based Horse Race Handicapping and Wagering Systems: A Report”, Hausch et al 1994
Computer Based Horse Race Handicapping and Wagering Systems: A Report :
View PDF:
“The Temporal Pattern to the Experience of Regret”, Gilovich & Medvec 1994
“Bayesian Updating in Hierarchic Markov Processes Applied to the Animal Replacement Problem”, Kristensen 1993
Bayesian updating in hierarchic Markov processes applied to the animal replacement problem
“Universal Portfolios”, Cover 1991
View PDF:
“Ensuring Two Bird Deaths With One Throw”, Leslie 1991
Ensuring Two Bird Deaths With One Throw :
View PDF:
“Learning from Coarse Information: Biased Contests and Career Profiles”, Meyer 1991
Learning from Coarse Information: Biased Contests and Career Profiles
F. P. Ramsey: Philosophical Papers, Ramsey & Mellor 1990
“‘Student’: A Statistical Biography of William Sealy Gosset”, Pearson et al 1990
‘Student’: A Statistical Biography of William Sealy Gosset :
“Weight or the Value of Knowledge”, Ramsey 1990
Weight or the Value of Knowledge :
View PDF:
“The Total Evidence Theorem for Probability Kinematics”, Graves 1989
“Nonlinear Preference and Utility Theory”, Fishburn 1988
“A Shortest Augmenting Path Algorithm for Dense and Sparse Linear Assignment Problems”
A shortest augmenting path algorithm for dense and sparse linear assignment problems :
View PDF:
“Measuring the Vague Meanings of Probability Terms”, Wallsten et al 1986
“Noise”, Black 1986
“Search in a Known Pattern”, Perry & Wigderson 1986
“Can People Behave ‘Randomly’?: The Role of Feedback”, Neuringer 1986
“Searching for Positive Returns at the Track: A Multinomial Logit Model for Handicapping Horse Races”
Searching for Positive Returns at the Track: A Multinomial Logit Model for Handicapping Horse Races :
View PDF:
“An Examination of Two Alternative Techniques to Estimate the Standard Deviation of Job Performance in Dollars”, Reilly & Smither 1985
“Game Theoretic Analysis of a Bankruptcy Problem from the Talmud”, Aumann & Maschler 1985
Game theoretic analysis of a bankruptcy problem from the Talmud :
View PDF:
“Re-Evaluation of Decision Alternatives Dependent upon the Reversibility of a Decision and the Passage of Time”
View PDF:
“Influence Diagrams”, Howard & Matheson 1984
View PDF:
“The Citation Bias: Fad and Fashion in the Judgment and Decision Literature”, Christensen-Szalanski & Beach 1984
The Citation Bias: Fad and Fashion in the Judgment and Decision Literature
“Readings on the Principles and Applications of Decision Analysis: Volume 1: General Collection”, Howard & Matheson 1983
Readings on the Principles and Applications of Decision Analysis: Volume 1: General Collection :
“Readings on the Principles and Applications of Decision Analysis: Volume 2: Professional Collection”, Howard & Matheson 1983
Readings on the Principles and Applications of Decision Analysis: Volume 2: Professional Collection :
“Belief in God: A Game-Theoretic Paradox”, Brams 1982
“The Variance of Discounted Markov Decision Processes”
The Variance of Discounted Markov Decision Processes :
View PDF:
“What Good Are Warfare Models?”, Anger 1981
What Good Are Warfare Models? :
View PDF:
“Multi-Bayesian Statistical Decision Theory”, Weerahandi & Zidek 1981
“Reversible and Irreversible Decisions: Preference for Consonant Information As a Function of Attractiveness of Decision Alternatives”, Frey 1981
View PDF:
“The Statistical Research Group, 1942–1945”, Wallis 1980
The Statistical Research Group, 1942–1945 :
View PDF:
“Prisoners' Dilemma Is a Newcomb Problem”, Lewis 1979
Prisoners' Dilemma is a Newcomb Problem :
View PDF:
“Impact of Valid Selection Procedures on Work-Force Productivity”, Schmidt et al 1979
Impact of valid selection procedures on work-force productivity
“Robustness in the Strategy of Scientific Model Building”, Box 1979
Tools for Thought, Waddington 1977
“Science and Statistics”, Box 1976
Boundaries of Analysis: An Inquiry into the Tocks Island Dam Controversy, Feiveson et al 1976
Boundaries of Analysis: An Inquiry into the Tocks Island Dam Controversy
When Values Conflict: Essays on Environmental Analysis, Discourse, and Decision, Tribe et al 1976
When Values Conflict: Essays on Environmental Analysis, Discourse, and Decision
“Portfolio Choice and the Kelly Criterion”, Thorp 1975
“Linear Models in Decision Making”, Dawes & Corrigan 1974
“Cross-Modality Matching of Money Against Other Continua”, Galanter & Pliner 1974
“The General Impossibility of Normative Accounting Standards”, Demski 1973
The General Impossibility of Normative Accounting Standards :
View PDF:
“An Evaluation of Consumer Protection Legislation: The 1962 Drug Amendments”, Peltzman 1973
An Evaluation of Consumer Protection Legislation: The 1962 Drug Amendments
“The Theory of Social Choice”, Fishburn 1973
“The Foundations of Statistics (Second Revised Edition)”, Savage 1972
The Foundations of Statistics (Second Revised Edition) :
View PDF (29MB):
/doc/statistics/decision/1972-savage-foundationsofstatistics.pdf
“What Makes for a Beautiful Problem in Science?”, Samuelson 1970
“The Practicality Gap”, Howard 1968
“General Proof That Diversification Pays”, Samuelson 1967
“Optimal Dairy Cow Replacement Policies”, Giaever 1966
“Systems Analysis Problems of Limited War”, Weiss 1966
Systems Analysis Problems of Limited War :
View PDF:
“Measuring Utility by a Single-Response Sequential Method”, Becker et al 1964
“Sequential Medical Trials”
“A Model for Selecting One of Two Medical Treatments”, Colton 1963
“Probability, Statistical Decision Theory, and Accounting”, Bierman 1962
“Studies of War, Nuclear and Conventional”
Applied Statistical Decision Theory, Raiffa & Schlaifer 1961
“Gradient Theory of Optimal Flight Paths”, Kelley 1960
“Letter to the Editor—A Classroom Example of Linear Programming (Lesson Number 2)”, Jewell 1960
Letter to the Editor—A Classroom Example of Linear Programming (Lesson Number 2) :
View PDF:
“Rational Decision-Making In Portfolio Management”, Latané 1959b
“Criteria for Choice Among Risky Ventures”, Latané 1959
Criteria for Choice Among Risky Ventures :
View PDF:
“Testing Statistical Hypotheses (First Edition)”, Lehmann 1959
Probability and Statistics for Business Decisions: An Introduction to Managerial Economics Under Uncertainty, Schlaifer 1959
“An Optimum Character Recognition System Using Decision Functions”, Chow 1957
An Optimum Character Recognition System Using Decision Functions
“Evolutionary Operation: A Method for Increasing Industrial Productivity”
Evolutionary Operation: A Method for Increasing Industrial Productivity :
View PDF:
“Rational Decision Making in Portfolio Management”, Latané 1957
Rational Decision Making in Portfolio Management :
View PDF (20MB):
“Unsolved Problems of Experimental Statistics”, Tukey 1954
Unsolved Problems of Experimental Statistics :
View PDF:
“Non-Cooperative Games”, Nash 1951
“The Economic Life of Industrial Equipment”, Preinreich 1940
“The Relationship Of Validity Coefficients To The Practical Effectiveness Of Tests In Selection: Discussion And Tables”
“"Student" As Statistician”, Pearson 1939
“Presidential Address to the First Indian Statistical Congress”, Fisher 1938
Presidential address to the first Indian statistical congress :
View PDF:
“On the Theory of Apportionment”
“The Lanarkshire Milk Experiment”, Elderton 1933
“Pasteurised and Raw Milk”, Fisher & Bartlett 1931
View PDF:
“The Lanarkshire Milk Experiment [Student]”, Gosset 1931
“On Testing Varieties of Cereals”, Gosset 1923
“The Application Of The ‘Law Of Error’ To The Work Of The Brewery”, Gosset 1904
The Application Of The ‘Law Of Error’ To The Work Of The Brewery
“Brian Christian on Computer Science Algorithms That Tackle Fundamental and Universal Problems”
Brian Christian on computer science algorithms that tackle fundamental and universal problems
“When RAND Made Magic in Santa Monica”
Bayesian Optimization Book
“The Final Cut [Ford-Fulkerson’s Max-Flow Min-Cut As Planning Paradigm]”
The Final Cut [Ford-Fulkerson’s max-flow min-cut as planning paradigm]
“In Praise of Sparsity and Convexity”, Tibshirani 2026 (page 518)
“Cole Wyeth’s Personal Website”, Wyeth 2026
“Measurement, Benchmarking, and Data Analysis Are Underrated”
Measurement, benchmarking, and data analysis are underrated
View External Link:
“Buy More Copies”, Dynomight 2026
View External Link:
“Integer Programming Easily Encloses Horse”, Dynomight 2026
“Solving Probabilistic Tic-Tac-Toe”, Abraham 2026
Solving Probabilistic Tic-Tac-Toe
View External Link:
https://louisabraham.github.io/articles/probabilistic-tic-tac-toe
“Is Sending Factorio to Your Competitors’ Engineers a Cost-Effective Means of Sabotage?”, Bo 2026
Is sending Factorio to your competitors’ engineers a cost-effective means of sabotage?
“Jury Theorems”
View External Link:
“Quantum-Bayesian and Pragmatist Views of Quantum Theory”
“Scaling up Linear Programming With PDLP”
“The Median Is Not the Message”, Gould 2026
“Why a Pro/con List Is 75% As Good As Your Fancy Machine Learning Algorithm”
Why a pro/con list is 75% as good as your fancy machine learning algorithm
“The Science of Production”, Potter 2026
“Flight From Perfection—Motorcycling: Is It worth the Risk?”, Griffes 2026
“The Battleships Game That Countered German U-Boat Attacks During WW2”
The Battleships Game That Countered German U-boat Attacks During WW2
“New Winning Strategies for the Iterated Prisoner’s Dilemma”
“The Hidden Cost of Our Lies to AI”
“In Strategic Time, Open-Source Games Are Loopy”
“VDT: a Solution to Decision Theory”
“Research Update: Towards a Law of Iterated Expectations for Heuristic Estimators”
Research update: Towards a Law of Iterated Expectations for Heuristic Estimators
“Why We Can’t Take Expected Value Estimates Literally (Even When They’re Unbiased)”
Why We Can’t Take Expected Value Estimates Literally (Even When They’re Unbiased)
“Fat Tails Discourage Compromise”
“Introducing LIMBO: Managing the Simulation to Maintain Optimal P(DOOM)”
Introducing LIMBO: Managing the Simulation to Maintain Optimal P(DOOM)
“Optimizing Crop Planting With Mixed Integer Linear Programming in Stardew Valley”
Optimizing crop planting with mixed integer linear programming in Stardew Valley
“Leaky Delegation: You Are Not a Commodity”
“Inside vs Outside View”, LessWrong 2026
“Probable Points and Credible Intervals, Part 2: Decision Theory”
Probable Points and Credible Intervals, Part 2: Decision Theory
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
regret-analysis
advertising-effectiveness
decision-theory
Wikipedia (22)
Miscellaneous
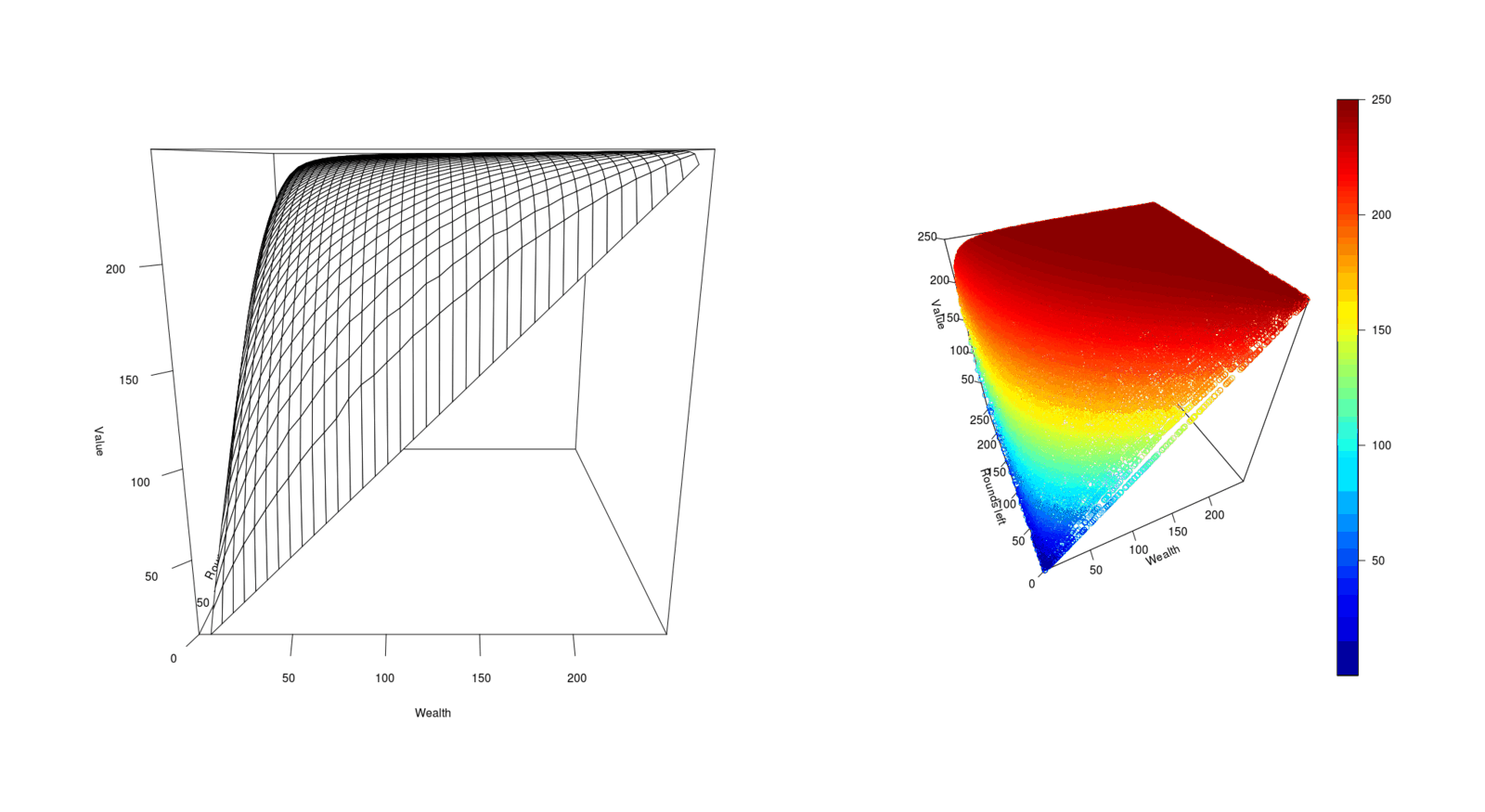
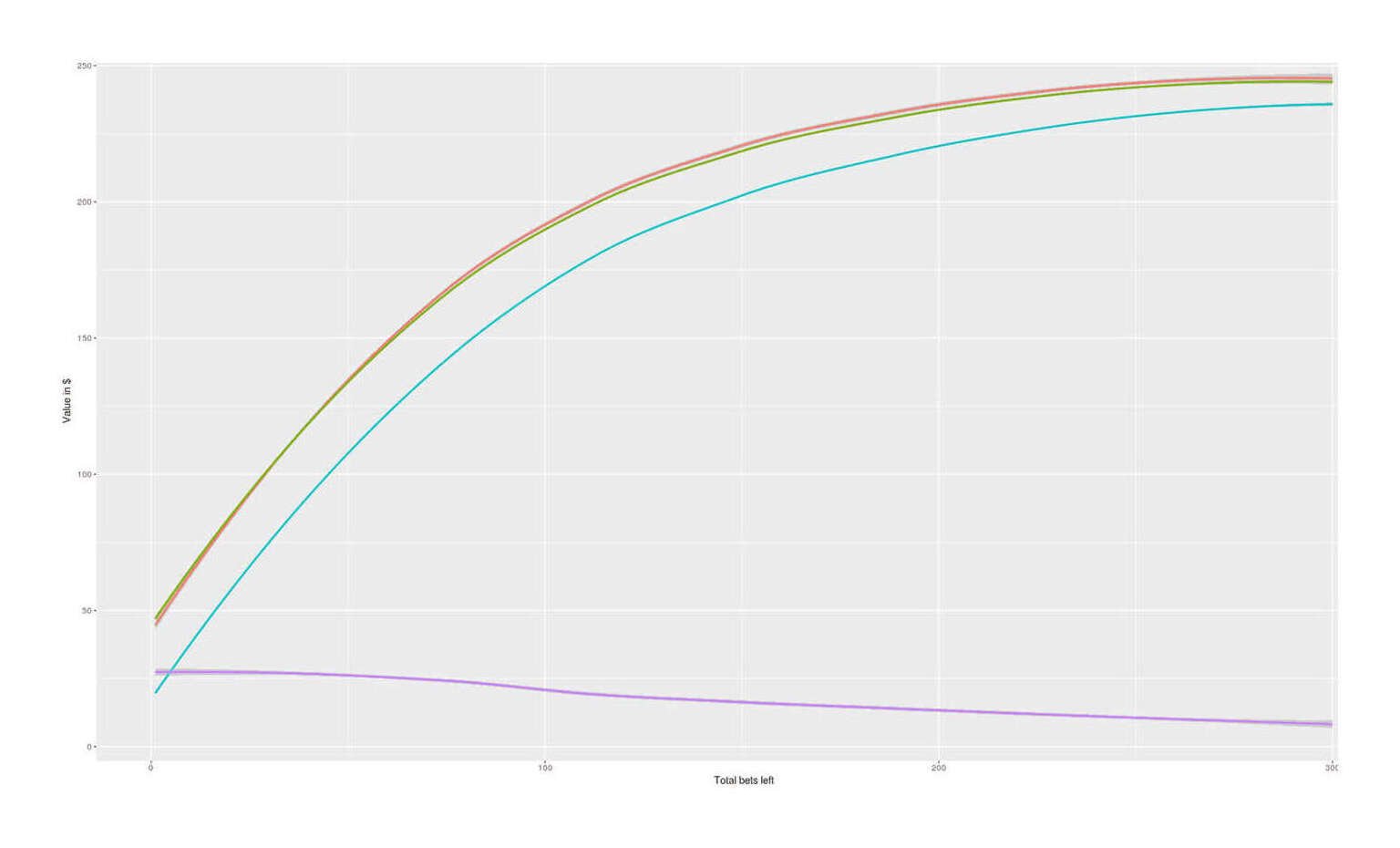
/doc/statistics/decision/2022-10-03-feepingcreature-problem14-bottomup-values0to22974.txt/doc/statistics/decision/2018-cohen.pdf:View PDF:
/doc/statistics/decision/2017-pal.pdf:View PDF:
/doc/statistics/decision/2016-08-20-candyjapan-decisiontree-n9.csv/doc/statistics/decision/2013-06-24-schou-devilgametheory.html/doc/statistics/decision/2007-07-15-davidkronemyer-mydaysatrandcorporation.html/doc/statistics/decision/2004-ades.pdf:View PDF:
/doc/statistics/decision/2000-gelman-figure2-meansquarederroroflinearvsquadraticexperiments.jpg/doc/statistics/decision/1997-mcclelland-optimalexperimentdesign.pdf:/doc/statistics/decision/1995-bohn-2.pdf:View PDF:
/doc/statistics/decision/1995-budescu-figure2-forecastingphrasesasprobabilities.jpg/doc/statistics/decision/1991-tsevat.pdf:View PDF:
/doc/statistics/decision/1987-fishburn-interprofileconditionsimpossibility.pdf:/doc/statistics/decision/1986-lehmann-testingstatisticalhypotheses.pdf:/doc/statistics/decision/1986-stephens-foragingtheory.pdf:View PDF (23MB):
/doc/statistics/decision/1984-tidman-theoperationsevaluationgroup.pdf:/doc/statistics/decision/1984-thorp-themathematicsofgambling-ch4.pdf:/doc/statistics/decision/1983-hauer.pdf:View PDF:
/doc/statistics/decision/1974-balch-essayseconomicbehavioruncertainty.pdf:/doc/statistics/decision/1968-cohen.pdf:View PDF:
/doc/statistics/decision/1965-black.pdf:View PDF:
/doc/statistics/decision/1960-howard-dynamicprogrammingmarkovprocesses.pdf:/doc/statistics/decision/1957-bellman-dynamicprogramming.pdf:View PDF (23MB):
/doc/statistics/decision/1957-bellman-dynamicprogramming.pdf/doc/statistics/decision/1957-luce-gamesanddecisions.pdf:View PDF (45MB):
/doc/statistics/decision/1957-savage.pdf:View PDF:
/doc/statistics/decision/1954-hodges.pdf:View PDF:
/doc/statistics/decision/1952-yates.pdf:View PDF:
/doc/statistics/decision/1950-wald-statisticaldecisionfunctions.pdf:/doc/statistics/decision/1937-fisher-thedesignofexperiments.pdf:/doc/statistics/decision/1930-leighton-lanarkshiremilkreport.pdf:/doc/statistics/decision/gwern-coinflip-action-valuecurves.jpghttps://andrewpwheeler.com/2022/07/01/using-linear-programming-to-assess-spatial-access/https://donellameadows.org/archives/leverage-points-places-to-intervene-in-a-system/https://hope.econ.duke.edu/sites/hope.econ.duke.edu/files/Banzhaf.pdf:https://maximumeffort.substack.com/p/the-tyranny-of-the-wagon-equationhttps://plato.stanford.edu/entries/ramsey/View External Link:
https://research.google/blog/robust-online-allocation-with-dual-mirror-descent/https://www.cell.com/current-biology/fulltext/S0960-9822(19)31431-9https://www.channelfireball.com/article/PV-s-Rule/0d7fbcf6-570b-458a-bf02-ae46f097d515/https://www.lesswrong.com/posts/R3eDrDoX8LisKgGZe/sum-threshold-attacksView External Link:
https://www.lesswrong.com/posts/R3eDrDoX8LisKgGZe/sum-threshold-attackshttps://www.lesswrong.com/posts/RQpNHSiWaXTvDxt6R/coherent-decisions-imply-consistent-utilitieshttps://www.lesswrong.com/posts/no5jDTut5Byjqb4j5/six-and-a-half-intuitions-for-kl-divergencehttps://www.lesswrong.com/posts/pEZoTSCxHY3mfPbHu/catastrophic-goodhart-in-rl-with-kl-penaltyhttps://www.lesswrong.com/posts/sTwW3QLptTQKuyRXx/the-first-sample-gives-the-most-informationhttps://www.scientificamerican.com/article/can-a-cell-make-decisions/https://www.theatlantic.com/magazine/archive/1962/06/a-prof-beats-the-gamblers/657997/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2502.03158: “Strategizing With AI: Insights from a Beauty Contest Experiment”,2024-oprea.pdf: “Decisions under Risk Are Decisions under Complexity”,https://arxiv.org/abs/2404.00732: “An Abundance of Katherines: The Game Theory of Baby Naming”,https://www.nber.org/papers/w31422: “Combining Human Expertise With Artificial Intelligence: Experimental Evidence from Radiology”,1986-hamming: “You And Your Research”,https://nunosempere.com/blog/2023/01/11/can-gpt-produce-ideas/#if-you-never-miss-a-plane: “Can GPT-3 Produce New Ideas? Partially Automating Robin Hanson and Others § If You Never Miss a Plane…”,2022-carragher.pdf: “Simulated Automated Facial Recognition Systems As Decision-Aids in Forensic Face Matching Tasks”,2022-mulligan.pdf: “Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation”,https://openreview.net/forum?id=DY1pMrmDkm: “Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning”,2022-glimcher.pdf: “Efficiently Irrational: Deciphering the Riddle of Human Choice”,2021-berman.pdf: “False Discovery in A/B Testing”,https://pmc.ncbi.nlm.nih.gov/articles/PMC8640740/: “Rational Regulation of Water-Seeking Effort in Rodents”,2021-shapiro.pdf: “TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands”,2021-brocas.pdf: “Steps of Reasoning in Children and Adolescents”,https://www.ethanrosenthal.com/2020/08/25/optimal-peanut-butter-and-banana-sandwiches/: “Optimal Peanut Butter and Banana Sandwiches”,https://link.springer.com/article/10.3758/s13423-020-01753-4: “Speed-Accuracy Trade-Off in Plants”,https://journals.aom.org/doi/abs/10.5465/AMBPP.2018.12279abstract: “Effects of Non-Normal Performance Distributions on the Accuracy of Utility Analysis”,2017-enke.pdf: “Correlation Neglect in Belief Formation”,2017-gasieniec.pdf: “Bamboo Garden Trimming Problem (Perpetual Maintenance of Machines With Different Attendance Urgency Factors)”,https://marginalrevolution.com/marginalrevolution/2016/10/performance-pay-nobel.html: “The Performance Pay Nobel”,2015-deng.pdf: “Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments”,2013-kennedy.pdf: “The Wait Calculation: The Broader Consequences of the Minimum Time from Now to Interstellar Destinations and Its Statistical-Significance to the Space Economy”,2007-hazan.pdf: “Logarithmic Regret Algorithms for Online Convex Optimization”,https://www.freesfonline.net/content/Abraham1.pdf: “The Cambist and Lord Iron: A Fairy Tale of Economics”,2006-kennedy.pdf: “Interstellar Travel: The Wait Calculation and the Incentive Trap of Progress”,https://www.ic.unicamp.br/~celio/peer2peer/math/mitzenmacher-power-of-two.pdf: “The Power of Two Random Choices: A Survey of Techniques and Results”,1996-lubinski-2.pdf: “Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means”,1979-box.pdf: “Robustness in the Strategy of Scientific Model Building”,