2018 News
Annual summary of 2018 Gwern.net newsletters, selecting my best writings, the best 2018 links by topic, and the best books/movies/anime I saw in 2018, with some general discussion of the year.
This is the 2018 summary edition of the Gwern.net newsletter (archives), summarizing the best of the monthly 2018 newsletters:
Previous annual newsletters: 2017, 2016, 2015.
Writings
2018 went well, with much interesting news and several stimulating trips. My 2018 writings included:
Danbooru2017: a new dataset of 2.94m anime images (1.9tb) with 77.5m descriptive tags
Embryo selection: Overview of major current approaches for complex-trait genetic engineering, FAQ, multi-stage selection, chromosome/gamete selection, optimal search of batches, & robustness to error in utility weights
reviews:
Site traffic (more detailed breakdown) was again up as compared with the year before: 2018 saw 736,486 pageviews by 332,993 unique users (vs 551,635 by 265,836 in 2017).
Media
Overview
Overall, 2018 was much like 2017 was, but more so. In all of AI, genetics, VR, Bitcoin, and general culture/politics, the trends of 2017 continued through 2018 or even accelerated.
AI: In 2018, the DL revolution came for NLP. Convolutions, attention, and bigger compute created ever larger NNs which could then kick benchmark ass and take names. Additional seeds were planted for logical/relational/numerical reasoning (wasn’t logic another one of those things deep learning would never be able to do…?).
Elsewhere, reinforcement learning was hot (eg. the RL subreddit traffic stats increased severalfold over 2017, which itself had increased severalfold), with Go followed by human-level DoTA 2. OA5 was an amazing achievement given how complex DoTA is, with fog of war, team tactics, and far larger state space, integrating the full spectrum of strategy from twitch tactics up to long-term strategy and pre-selection of units. (Given OA5’s progress, I was disappointed to see minimal DM progress on the Starcraft II front in 2018, but it turned out I just needed more patience.) DRL of course enjoyed additional progress, notably robotics: sample-efficient robotic control and learning from observations/imitation are closer than ever.
Thinking a little more broadly about where DL/DRL has seen successes, the rise of DL has been the fall of Moravec’s paradox.
No one is now surprised in the least bit when a computer masters some complex symbolic task like chess or Go these days; we are surprised by the details like it happening about 10 years before many would’ve predicted, or that the Go player can be trained overnight in wallclock time, or that the same architecture can be applied with minimal modification to give a top chess engine. For all the fuss over AlphaGo, no one paying attention was really surprised. If you went back 10 years ago and told someone, ‘by the way, by 2030, both Go and Arimaa can be played at a human level by an AI’, they’d shrug.
People are much more surprised to see DoTA 2 agents, or Google Waymo cars driving around entire metropolitan areas, or generation of photorealistic faces or totally realistic voices. The progress in robotics has also been exciting to anyone paying attention to the space: the DRL approaches are getting ever better and sample-efficient and good at imitation. I don’t know how many blue-collar workers they will put out of work—even if software is solved, the robotic hardware is still expensive! But factories will be salivating over them, I’m sure. (The future of self-driving cars is in considerably more doubt.)
A standard-issue minimum-wage Homo sapiens worker-unit has a lot of advantages. I expect there will be a lot of blue-collar jobs for a long time to come, for those who want them. But they’ll be increasingly crummy jobs. This will make a lot of people unhappy. I think of Turchin’s ‘elite overproduction’ concept—how much of political strife now is simply that we’ve overeducated so many people in degrees that were almost entirely signaling-based and not of intrinsic value in the real world and there were no slots available for them and now their expectations & lack of useful skills are colliding with reality? In political science, they say revolutions happen not when things are going badly, but when things are going not as well as everyone expected.
We’re at an interesting point—as LeCun put it, I think, ‘anything a human can do with <1s of thought, deep learning can do now’, while older symbolic methods can outperform humans in a number of domains where they use >>1s of thought. As NNs get bigger and the training methods and architectures and datasets are refined, the ‘<1s’ will gradually expand. So there’s a pincer movement going on, and sometimes hybrid approaches can crack a human redoubt (eg. AlphaGo combined the hoary tree search for long-term >>1s thought with CNNs for the intuitive instantaneous gut-reaction evaluation of a board <1s, and together they could learn to be superhuman). As long as what humans do with <1s of thought was out of reach, as long as the ‘simple’ primitives of vision and movement couldn’t be handled, the symbol grounding and frame problems were hopeless. “How does your design turn a photo of a cat into the symbol CAT which is useful for inference/planning/learning, exactly?” But now we have a way to reliably go from chaotic real-world data to rich semantic numeric encodings like vector embeddings. That’s why people are so excited about the future of DL.
The biggest disappointment, by far, in AI was self-driving cars.
2018 was going to be the year of self-driving cars, as Waymo promised all & sundry a full public launch and the start of scaling out, and every report of expensive deals & investments bade fair to launch, but the launch kept not happening—and then the Uber pedestrian fatality happened. This fatality was the result of a cascade of internal decisions & pressure to put an unstable, erratic, known dangerous self-driving car on the road, then deliberately disable its emergency braking, deliberately disable the car’s emergency braking, not provide any alerts to the safety drivers, and then remove half the safety drivers, resulting in a fatality happening under what should have been near-ideal circumstances, and indeed the software detected the pedestrian long in advance and would have braked if it had been allowed (“Preliminary NTSB Report: Highway HWY18MH010”); particularly egregious given Uber’s past incidents (like covering up running a red light). Comparisons to Challenger come to mind.
The incident should not have affected perception of self-driving cars—the fact that a far-below-SOTA system is unsafe when its brakes are deliberately disabled so it cannot avoid a foreseen accident tells us nothing about the safety of the best self-driving cars. That self-driving cars are dangerous when done badly should not come as news to anyone or change any beliefs, but it blackened perceptions of self-driving cars nevertheless. Perhaps because of it, the promised Waymo launch was delayed all the way to December and then was purely a ‘paper launch’, with no discernible difference from its previous small-scale operations.
Which leads me to question why the credible buildup beforehand of vehicles & personnel & deals if the paper launch was what was always intended; did the Uber incident trigger an internal review and a major re-evaluation of how capable & safe their system really is and a resort to a paper launch to save face? What went wrong, not at Uber but at Waymo? As Waymo goes, so the sector goes.
2018 for genetics saw many of the fruits of 2017 begin to mature: the usual large-scale GWASes continued to come out, including both SSGAC3 (Lee et al 2018) and an immediate boost by better analysis in Allegrini et al 2018 (as I predicted last year); uses of PGSes in other studies, such as the forbidden examination of life outcome differences predicted by IQ/EDU PGSes, are increasingly routine. In particular, medical PGSes are now reaching levels of clinical utility that even doctors can see their value.
This trend need not peter out, as the oncoming datasets keep getting more enormous; consumer DTC extrapolating from announced sales numbers has reached staggering numbers and potentially into the hundreds of millions, and there are various announcements like the UKBB aiming for 5 million whole-genomes, which would’ve been bonkers even a few years ago. (Why now? Prices have fallen enough. Perhaps an enterprising journalist could dig into why Illumina could keep WGS prices so high for so long…) The promised land is being reached.
The drumbeat of CRISPR successes reached a peak in the case of He Jiankui, who—completely out of the blue—presented the world with the fait accompli of CRISPR babies. The most striking aspect is the tremendous backlash: not just from Westerners (which is to be expected, and is rather hypocritical of many of the geneticists involved, who talked previously of being worried about potential backlash from premature CRISPR use and then, when that happened, did their level best to make the backlash happen by competing for the most hyperbolic condemnation), but also from China. Almost as striking was how quickly commentators settled on a Narrative, interpreting everything as negatively as possible even where that required flatly ignoring reporting (claiming he launched a PR blitz, when the AP scooped him) or strains credulity (how can we believe the hospital’s face-saving claims that Jiankui ‘forged’ everything, when they were so effusive before the backlash began? Or any government statements coming out of China, of all places, about an indefinitely imprisoned scientist?), or citing the most dubious possible research (like candidate-gene or animal model research on CCR5).
Regardless, the taboo has been broken. Only time will tell if this will spur more rigorously-conducted CRISPR research to do it right, or will set back the field for decades & be an example of the unilateralist’s curse. I am cautiously optimistic that it will be the former.
Genome synthesis work appears to continue to roll along, although nothing of major note occurred in 2018. Probably the most interesting area in terms of fundamental work was the progress on both mice & human gametogenesis and stem cell control. This is the key enabling technology for both massive embryo selection (breaking the egg bottleneck by allowing generation of hundreds or thousands of embryos and thus multiple-SD gains from selection) and then IES (Iterated Embryo Selection).
VR continued steady gradual growth; with no major new hardware releases (Oculus Go doesn’t count), there was not much to tell beyond the Steam statistics or Sony announcing PSVR sales >3m. (I did have an opportunity to play the popular Beat Saber with my mother & sister; all of us enjoyed it.) More interesting will be the 2019 launch of Oculus Quest which comes close to the hypothetical mass-consumer breakthrough VR headset: mobile/no wires, with a resolution boost and full hand/position tracking, in a reasonably priced package, with a promised large library of established VR games ported to it. It lacks foveated rendering or retina resolution, but otherwise seems like a major upgrade in terms of mass appeal; if it continues to eke out modest sales, that will be consistent with the narrative that VR is on the long slow slog adoption path similar to early PCs or the Internet (instantly appealing & clearly the future to the early adopters who try it, but still taking decades to achieve any mass penetration) rather than post-iPhone smartphones.
Bitcoin: the long slide from the bubble continued, to my considerable schadenfreude (2017 but more so…). The most interesting story of the year for me was the reasonably successful launch of the long-awaited Augur prediction market, which had no ‘DAO moment’ and the overall mechanism appears to be working. Otherwise, not much to remark on.
A short note on politics: I maintain my 2017 comments (but more so…). For all the emotion invested in the ‘great awokening’ and the continued Girardian scapegoating/backlash, now 3 years in, it is increasingly clear that Donald Trump’s presidency has been absurdly overrated in importance. Despite his ability to do substantial damage like launching trade wars or distortionary tax cuts, that is hardly unprecedented as most presidents do severe economic damage of some form or another; while other blunders like his ineffectual North Korea policy merely continues a long history of ineffective policy (and was inevitable once the South Korean population chose to elect Moon Jae-in). Every minute you spend obsessing over stuff like the Mueller Report has been wasted: Trump remains what New Yorkers have always known him to be—an incompetent narcissist.
Let’s try to focus more on long-term issues such as global economic growth or genetic engineering.
Links
Genetics:
Everything Is Heritable:
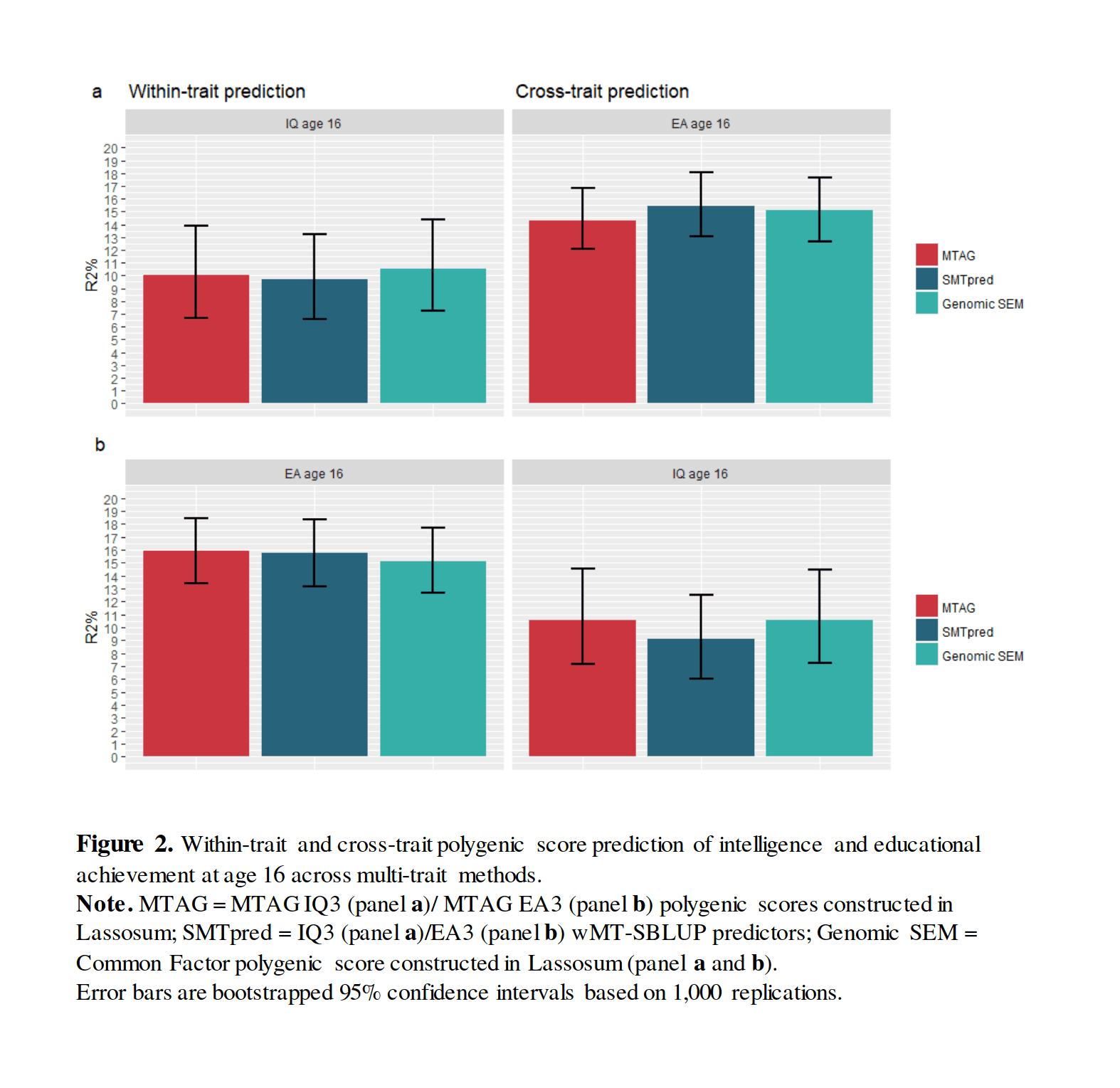
“Gene discovery and polygenic prediction from a GWAS of educational attainment in 1.1 million individuals”, Lee et 2018; “Genomic prediction of cognitive traits in childhood and adolescence”, Allegrini et al 2018 (boosts Lee et al 2018 to 11% IQ/16% education, using genetic correlations—Figure 2: multi-trait boosted PGSes)
EDU/IQ PGSes and life outcomes: “Genetic Endowments and Wealth Inequality”, Barth et al 2020; “Genes, Education, And Labor Market Outcomes: Evidence From The Health And Retirement Study”, Papageorge & Thom 2018; “Polygenic Score Analysis Of Educational Achievement And Intergenerational Mobility”, Rustichini et al 2018; “Genetic Consequences of Social Stratification in Great Britain”, Abdellaoui et al 2018; “Genetic analysis of social-class mobility in five longitudinal studies”, Belsky et al 2018a; “The Genetics of Success: How Single-Nucleotide Polymorphisms Associated With Educational Attainment Relate to Life-Course Development”, Belsky et al 2016; “Genetics & the Geography of Health, Behavior, and Attainment”, Belsky et al 2018b
“Consumer genomics will change your life, whether you get tested or not”, Khan & Mittelman 2018; “There could be 100 million genotyping kits sold by 2020-01-01”
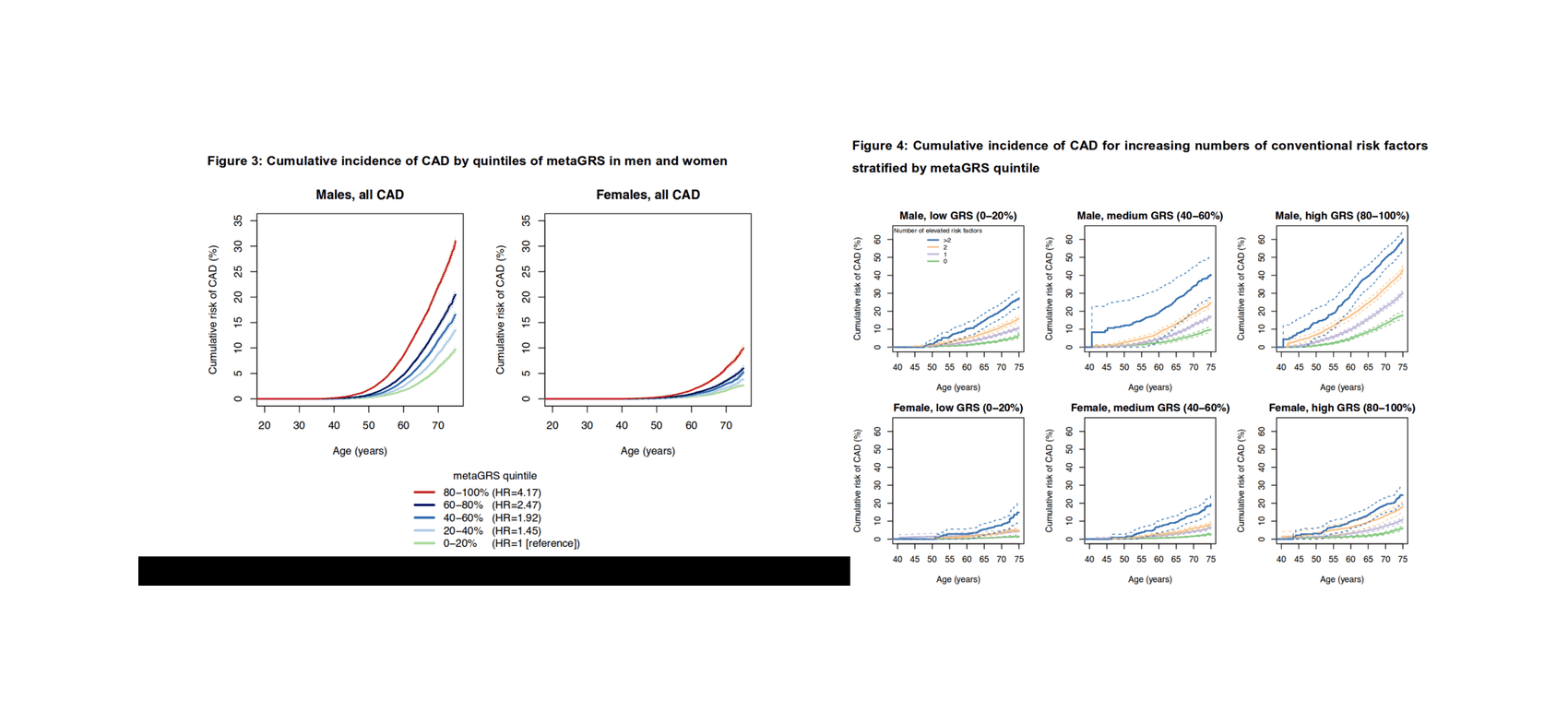
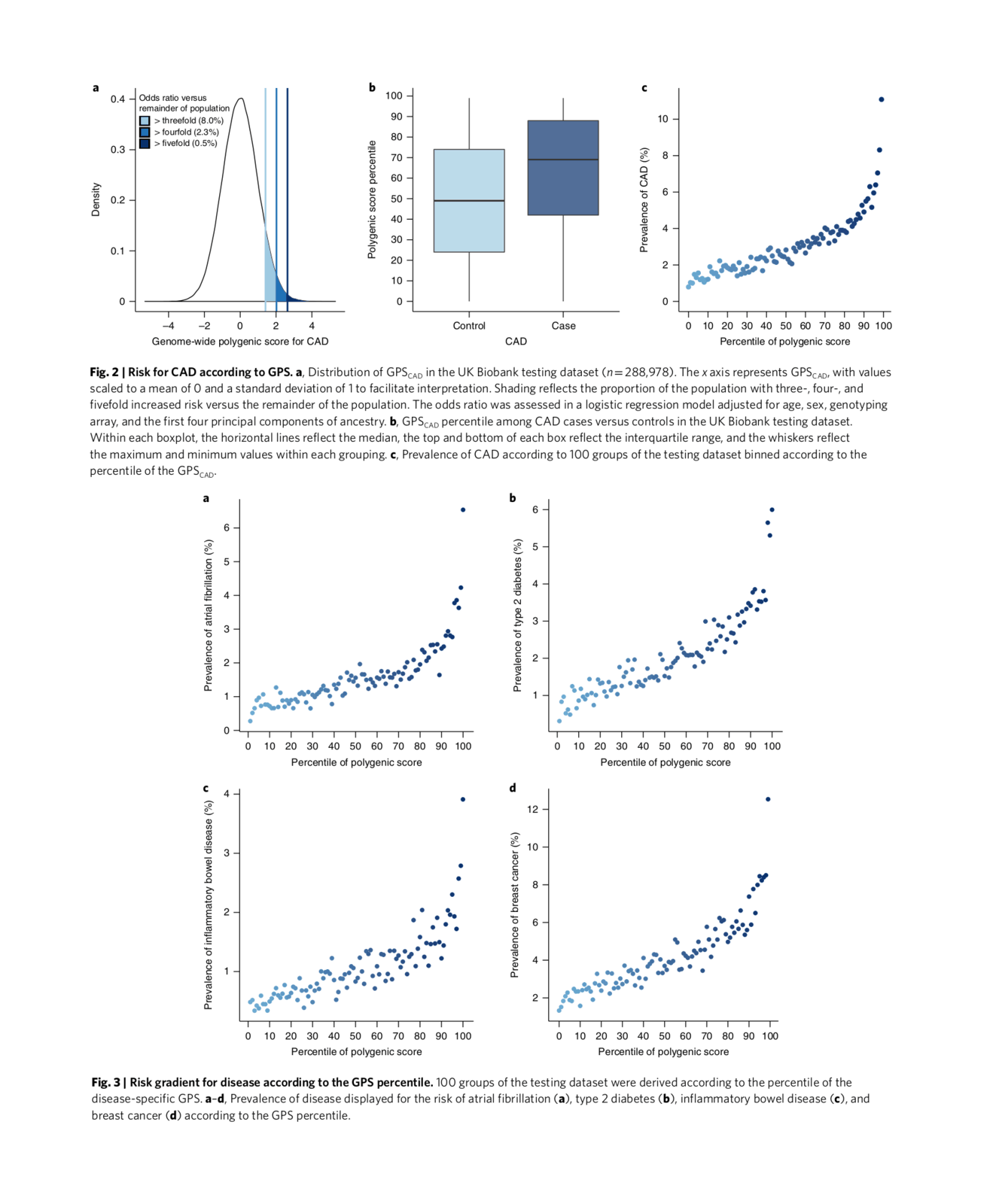
PGS move into the clinic: “Genomic risk prediction of coronary artery disease in nearly 500,000 adults: implications for early screening and primary prevention”, Inouye et al 2018 (Risk prediction graph); “Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations”, Khera et al 2018 (PGSes for coronary artery disease, atrial fibrillation, type 2 diabetes, inflammatory bowel disease, and breast cancer are now clinically useful: figure 2/3—more extremizing for visualizing PGS power); “The personal and clinical utility of polygenic risk scores”, Torkamani et al 2018; the value of accurate PGSes—can predict unnecessary chemotherapy in 70% of breast cancer patients: “Adjuvant Chemotherapy Guided by a 21-Gene Expression Assay in Breast Cancer”, Sparano et al 2018
“Comparison of Genotypic and Phenotypic Correlations: Cheverud’s Conjecture in Humans”, Sodini et al 2018 (Human phenotypic correlations are genetic correlations—everything is heritable & confounded. See also Cheverud 1988, Roff 1996, Kruuk et al 2008, & Dochtermann 2011.)
genetic engineering/selection/CRISPR:
the first CRISPR babies are born somewhat surprisingly soon: “Chinese researcher claims first gene-edited babies”; “Gene-editing Chinese scientist kept much of his work secret”; “Amid uproar, Chinese scientist defends creating gene-edited babies”; “The first CRISPRed babies are here, what’s next? 1. Develop international policy. 2. Communicate responsibly. 3. Recognize that editing is here to stay. 4. A global, collaborative project to edit”
toward IES/massive embryo selection: “Metaphase II oocytes from human unilaminar follicles grown in a multi-step culture system”, McLaughlin et al 2018 (media); “Generation of human oogonia from induced pluripotent stem cells in vitro”, Yamashiro et al 2018 (media: “The successful accomplishment of the same in human [cells] is just a matter of time. We’re not there yet, but this cannot be denied as a spectacular next step.”); “Same-Sex Mice Parents Give Birth to Healthy Brood: Gene editing and stem cell research have allowed for alternative rodent reproduction”
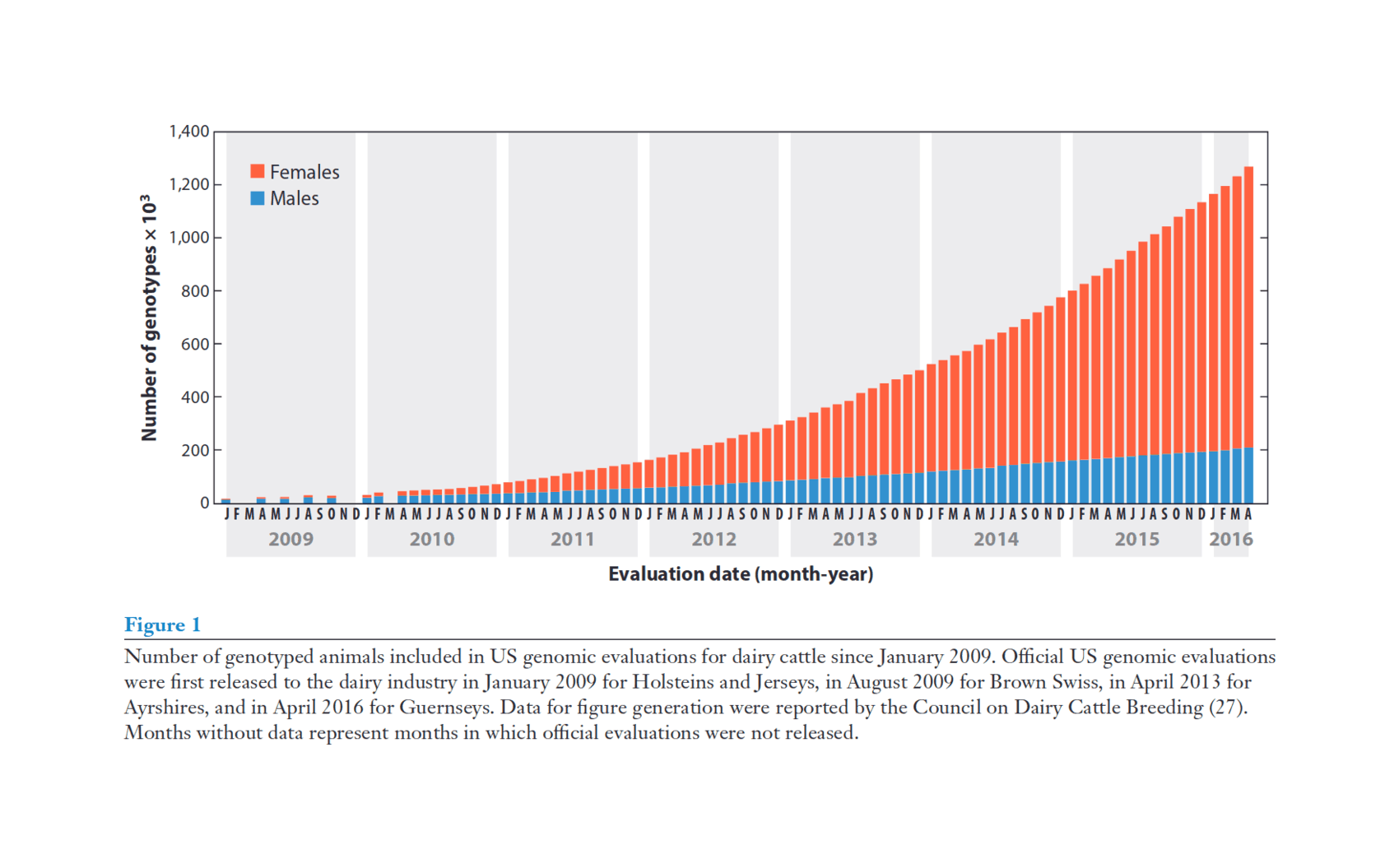
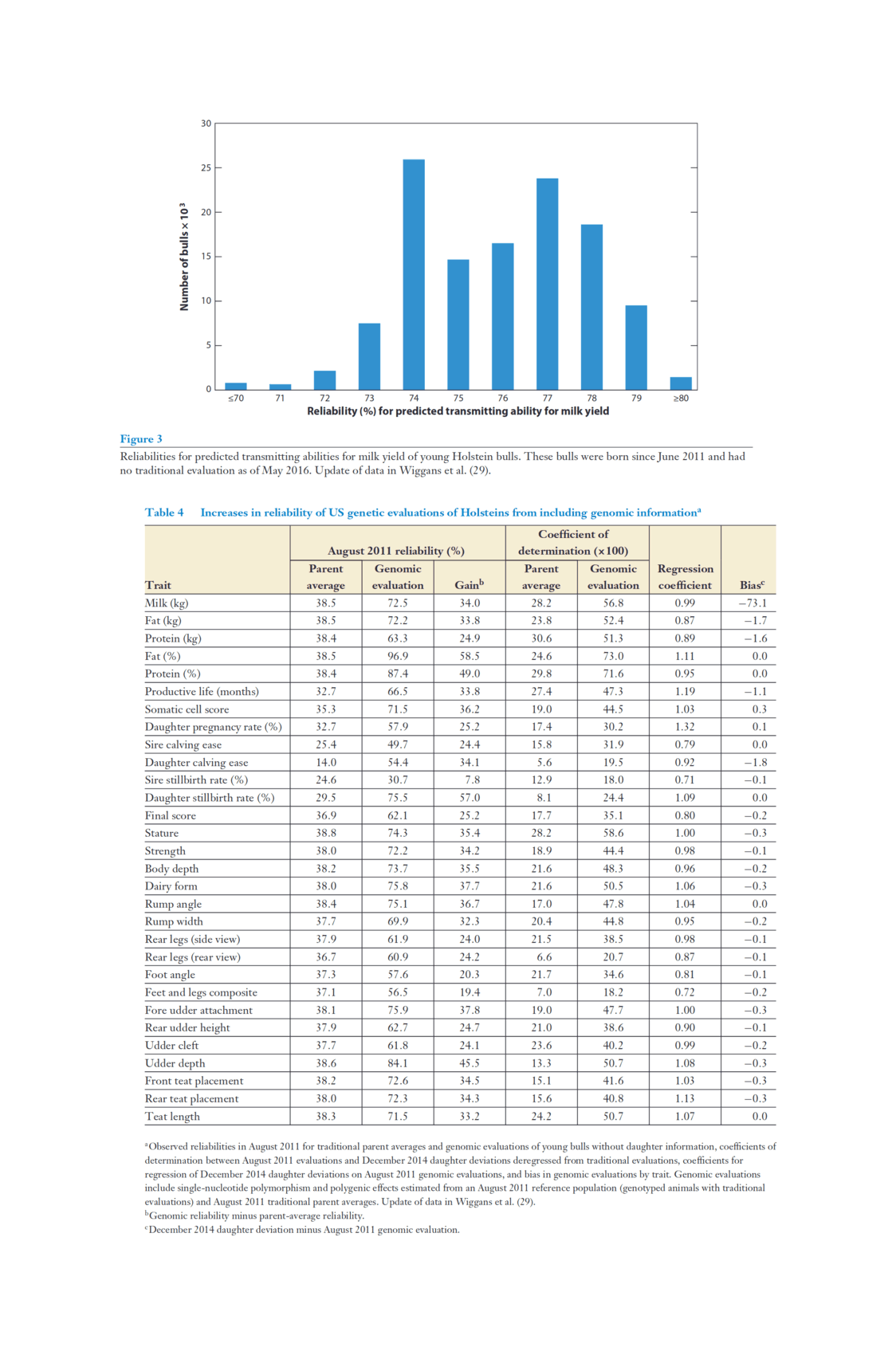
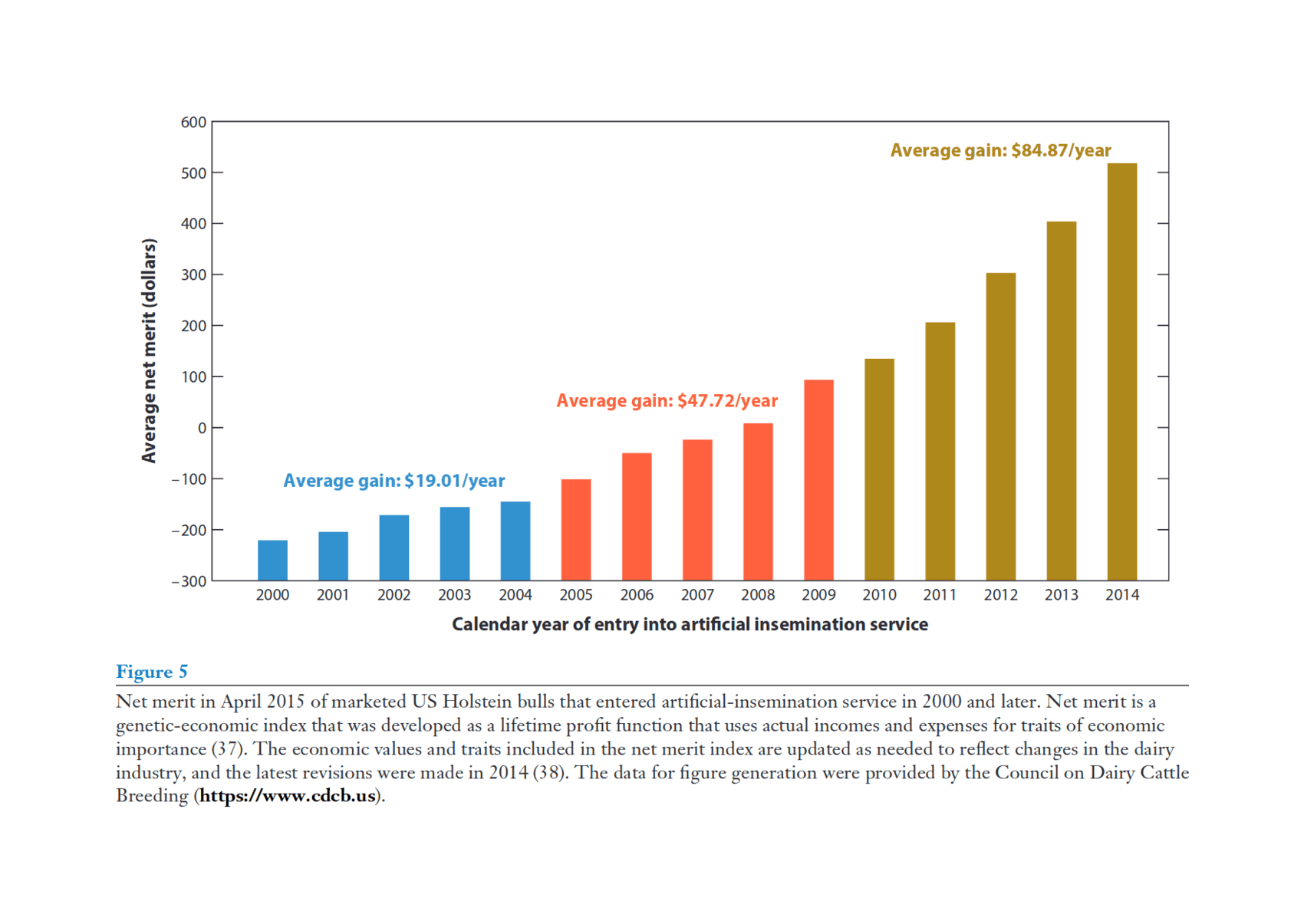
“Genomic Selection in Dairy Cattle: The USDA Experience”, Wiggans et al 2017 (It’s “doubled the rate of genetic progress for traits of economic importance, decreased generation interval, increased selection accuracy, reduced previous costs of progeny testing, and allowed identification of recessive lethals.” Figure 1/Table 4/Figure 5.)
“Inside the Very Big, Very Controversial Business of Dog Cloning” (update on Hwang Woo-suk’s Sooam Biotech—bigger than ever)
“Early Canid Domestication: The Farm-Fox Experiment: Foxes bred for tamability in a 40-year experiment exhibit remarkable transformations that suggest an interplay between behavioral genetics and development”, Trut 199927ya; “Red fox genome assembly identifies genomic regions associated with tame and aggressive behaviors”, Kukekova et al 2018 (media; on the Russian domesticated foxes)
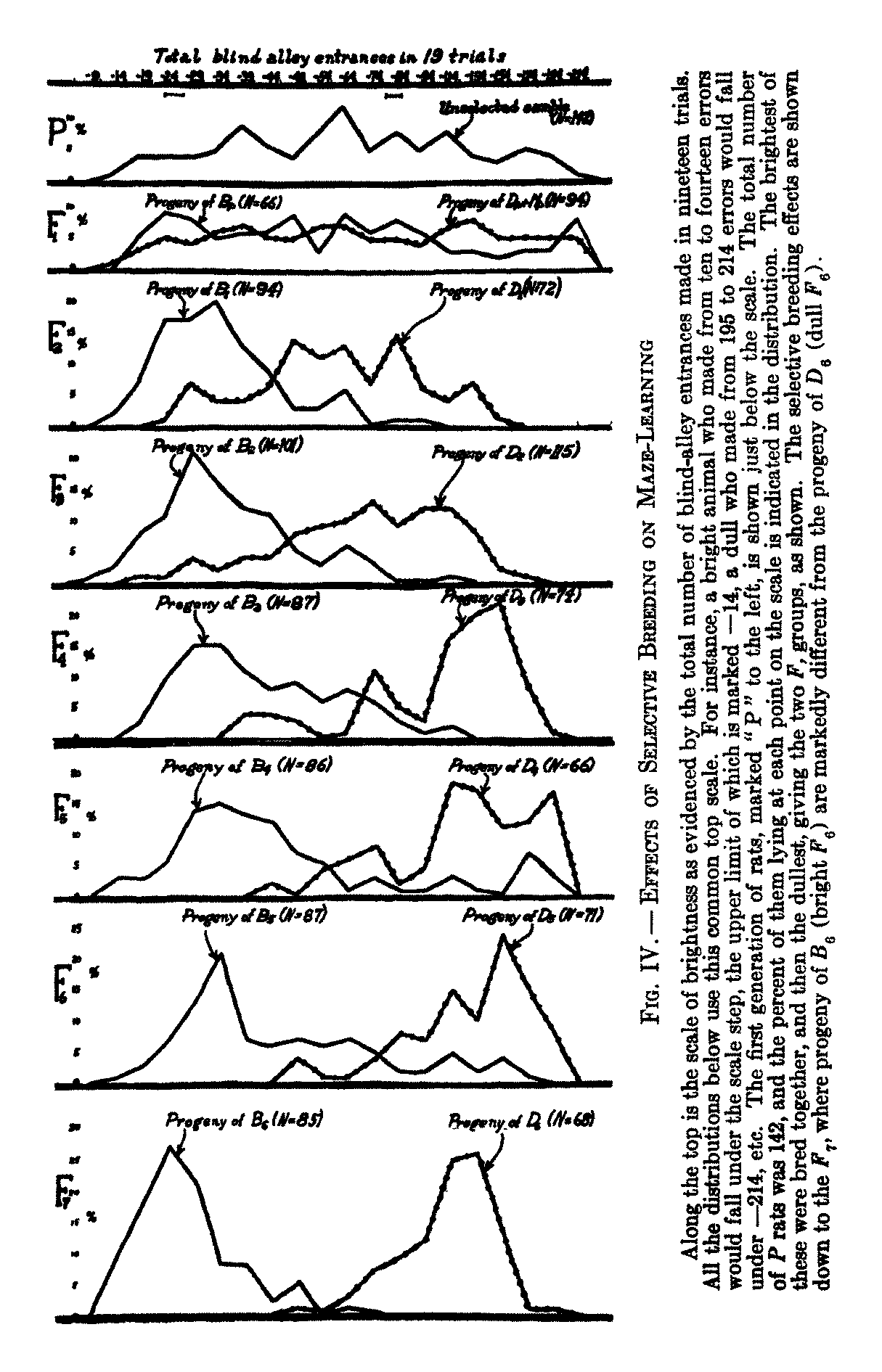
Tryon’s maze-bright rats (Wahlsten 1972; selective breeding can affect heritable psychological traits in mammals like maze-running in just a few generations and produce total separation & non-overlapping distributions after ~7 generations. The mechanization of testing is also quite clever to allow large data & avoid any experimenter bias.)
“Besting Johnny Appleseed: With a few tricks, and a lot of patience, fruit geneticists are undoing the work of an American legend”, Kean 201016ya (genomic selection; cryogenic storage; accelerated maturation; and intensified environments for accurate measurement)
“A CRISPR-Cas9 gene drive targeting
doublesexcauses complete population suppression in caged Anopheles gambiae mosquitoes”, Kyrou et al 2018 (Lab demo of driving malaria mosquitoes to extinction with CRISPR gene drive and no evolved resistance)
Recent human evolution/dysgenics:
“Polygenicity of complex traits is explained by negative selection”, O’Connor et al 2018
“Common schizophrenia alleles are enriched in mutation-intolerant genes and in regions under strong background selection”, Pardiñas et al 2018 (‘Background selection’ as the mechanism driving all the human mutation load in common schizophrenia variants? Could this also explain other traits like intelligence?)
“Mega-analysis of 31,396 individuals from 6 countries uncovers strong gene-environment interaction for human fertility”, Tropf et al 2016
“Enrichment of genetic markers of recent human evolution in educational and cognitive traits”, Srinivasan et al 2018 (Net selection for human intelligence from 400kya-present)
“Global genetic differentiation of complex traits shaped by natural selection in humans”, Guo et al 2018
“Evidence of a nonadaptive buildup of mutational load in human populations over the past 40,000 years”, Aris-Brosou 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI:
“Large Scale GAN Training for High Fidelity Natural Image Synthesis”, Brock et al 2018 (source; a new GAN paper for a single 512px GAN scaling to all ImageNet categories & Google’s internal 290m+ image dataset. The samples are hilarious because some of them are astoundingly good—like dogs—but many are bizarre or well into the ‘uncanny valley’: crowdsourced amusing samples, released models & notebook, Artbreeder for latent-space exploration; Dune-like samples)
“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, Devlin et al 2018 (blog)
“Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning”, Poplin et al 2018 (age/gender/smoking/blood pressure/diabetes/heart attacks—predicted from eye photographs using CNNs)
“Large-Scale Visual Speech Recognition”, Shillingford et al 2018 (New SOTA for lipreading)
“Reward learning from human preferences and demonstrations in Atari”, Ibarz et al 2018
Style2Paints NN: V4 now released (paper for V3; multiple layers of anime lineart coloring now supported: flat colors, then adding lines, then color gradients/shading, then illumination. Uses Danbooru2017 for training data via data-augmentation/corruption to train recoloring. Discussion: 1/2/Twitter)
reinforcement learning research is coming out too frequently to single out more than a few papers; see subscribe to the /r/ReinforcementLearning & /r/DecisionTheory subreddits for updates
OA5: a year of DoTA progress: OpenAI progress on 5x5 DoTA: amateur human level (commentary); “OpenAI Five Benchmark: Results” (link roundup & commentary); “The International 2018: Results” (0/2) (commentary: game 1, game 2)
“A general reinforcement learning algorithm that masters chess, shogi and Go through self-play”, Silver et al 2018 (expanded Alpha Zero paper; link compilation)
“World Models: Can agents learn inside their own dreams?”, 2018 (Planning & learning in deep environment models; in-browser JS demos for Car Racing/ViZDoom!)
“Planning chemical syntheses with deep neural networks and symbolic AI”, Segler et al 2018
“Learning Dexterous In-Hand Manipulation”, OpenAI 2018 (blog; videos: 1/2; PPO-LSTM+domain-randomization in MuJoCo/Unity for sim2real transfer in a robotic hand grasper—nothing really new here but it is yet another demonstration of what brute force + systems engineering can do with existing DRL.)
“Safety-first AI for autonomous data center cooling and industrial control”, Kasparik/Gamble/Gao (Finally, DeepMind provides some details: +12% efficiency, increasing to 30%. The July patent provides more details on the RL implementation, implying it uses standard LSTM RNNs w/Osband’s bootstrap ensemble for exploration etc.)
transfer/multitask learning: “Unicorn: Continual Learning with a Universal, Off-policy Agent”, Mankowitz et al 2018; “IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures”, Espeholt et al 2018 (blog; real transfer learning, and even more wallclock speedups/parallel scaling, on ALE); “Multi-task Deep Reinforcement Learning with PopArt”, Hessel et al 2018 (blog; median human performance on 57 ALE tasks w/1 NN using reward normalization+Impala)
“The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities”, Lehman et al 2018
WBE and DRL: a Middle Way of imitation learning from the human brain (a paradigm to keep an eye on)
Statistics/meta-science:
“Many Labs 2: Investigating Variation in Replicability Across Sample and Setting”, Klein et al 2018 (28 targets, k = 60, n = 7000 each, Registered Reports: 14⁄28 replication rate w/few moderators/country differences & remarkably low heterogeneity)
Eva Vivalt on development economics & charities (high variance in development study effects of ±100% in replications, expert elicitation of study quality & informative priors, publication bias/p-hacking)
“A Rational Choice Framework for Collective Behavior”, Krafft 2017 (large noisy/mimicking human groups can approximate distributed Bayesian inference for Thompson sampling, as a kind of particle filtering)
“Disentangling Bias and Variance in Election Polls”, Shirani-Mehr et al 2018 (systematic bias is as large as random sampling error in US election forecasting; Trump & Brexit are well within expected total error)
“Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results”, Silberzahn et al 2018
“Two Cheers For Corporate Experimentation: The A/B Illusion And The Virtues Of Data-Driven Innovation”, Meyer 2015
“Teacher Expectations and Self-Fulfilling Prophecies: Knowns and Unknowns, Resolved and Unresolved Controversies”, Jussim & Harber 200521ya; “We’ve Been Here Before: The Replication Crisis over the ‘Pygmalion Effect’”
“Evaluating replicability of laboratory experiments in economics”, Camerer et al 2016 (“About 40% of economics experiments fail replication survey”)
“Agreement of treatment effects for mortality from routinely collected data and subsequent randomized trials: meta-epidemiological survey”, Hemkens et al 2016 (How often does correlation=causation?)
“Tacit Knowledge, Trust, And The Q Of Sapphire”, Collins 200125ya (Tacit knowledge in replicating physics experiments measuring the Q factor: you need to grease the thread it hangs from, but the experiment works only with specific people’s skin grease)
Politics/religion:
“Dagger and Swagger: The History of Russian Terrorism” (revolutionary terror and literature; see also “Toward a [J-curve] theory of revolution”, Davies 196264ya)
“The Impact of Media Censorship: Evidence from a Randomized Field Experiment in China”, Chen & Yang 2018
“The Elusive Backfire Effect: Mass Attitudes’ Steadfast Factual Adherence”, Wood & Porter 2017 (Big failed replication: n = 10100/k = 52.)
“How the GOP Gave Up on Porn”; “Legalizing Marijuana and Gay Marriage Seemed Impossible—but losing taught libertarians how to win” (postmortems)
“Conspiracy As Governance”, Assange 2006
“Violence and the Sacred: College as an incubator of Girardian terror”, Dan Wang
“Book Review: History Of The Fabian Society” (small group tactics: how to change the world without really trying)
“The American Voter in 193294ya: Evidence from a Confidential Survey”, Norporth 2018
Government crime labs are still dangerously incompetent at DNA testing: Butler et al 2018
Psychology:
“Why do humans reason? Arguments for an argumentative theory”, Mercier & Sperber 2011
“What Use is Intelligence?”, Hunt 201115ya (Earl Hunt reviews a tiny fraction of the literature on the predictive power of IQ for education, careers, the military, and elsewhere.)
“Searching for the bottom of the ego well: failure to uncover ego depletion in Many Labs 3”, Vadillo et al 2018
“Personality, IQ, and lifetime earnings”, Gensowski 2018
“Effects of the Tennessee Prekindergarten Program on children’s achievement and behavior through third grade”, Lipsey et al 2018 (fadeout of initial benefits and evidence of harm; the Iron Law strikes again)
“Is Romantic Desire Predictable? Machine Learning Applied to Initial Romantic Attraction”, Joel et al 2018 (The heart has its reasons reason knows not…)
“Academic achievement across the day: Evidence from randomized class schedules”, Williams & Shapiro 2018
“Are bigger brains smarter? Evidence from a large-scale pre-registered study”, Nave et al 2018 (yes)
Biology:
“Azithromycin to Reduce Childhood Mortality in Sub-Saharan Africa”, Keenan et al 2018 (media; Surprisingly large mortality reduction from prophylactic antibiotics in children—do we continue to underestimate how pervasive infections are in mortality & morbidity?)
Technology:
“The Epic Saga of The Well” (early forums: offline meetups, SJWs, stalkers, marriages)
“The Untold Story of NotPetya, the Most Devastating Cyberattack in History” (“Few firms have paid more dearly for dragging their feet on security…”)
“Augur: a Decentralized Oracle and Prediction Market Platform”, Peterson et al 2018 (forks for consensus)
“Measuring Consumer Sensitivity to Audio Advertising: A Field Experiment on Pandora Internet Radio”, Huang et al 2018 (Media. Do ads work, are they harmful, and can even extremely large-scale but short-term experiments show their harms? Yes, yes, and no. Results parallel my ad A/B test; w/bonus correlation ≠ causation analysis); “The Effect of Ad Blocking on User Engagement with the Web”, Miroglio et al 2018
“Lessons of Amish Hackers” (chapter 10 of Kevin Kelly, What Technology Wants 201016ya)
“Resistant protocols: How decentralization evolves” (John Backus)
“Revisiting ‘The Rise and Decline’ in a Population of Peer Production Projects [769 wikis]”, TeBlunthuis et al 2018 (discussion)
“StarCraft II: How Blizzard Brought the King of E-sports Back From the Dead” (E-sports is more popular than ever; but what happened to the original e-sports, SC? Quite a bit.)
“Ice Poseidon’s Lucrative, Stressful Life as a Live Streamer”
Economics:
“Uber insiders describe infighting and questionable decisions before its self-driving car killed a pedestrian” (Challenger redux)
“Taxi Industry Regulation, Deregulation, and Reregulation: The Paradox of Market Failure”, Dempsey 199630ya (after using Uber for 2 weeks to get around SF, I’m impressed how elegantly & effectively the ridesharing system of smartphones+GPSes+two-sided marketplace solves all the historical problems which caused taxis to be regulated & then degenerate into rent-seeking regulatory capture.)
“The Shape of Human Progress: 40 Ways the World Is Getting Better”
“Private Ordering at the World’s First Futures Exchange”, West 200026ya (Edo-period Japan developed a remarkably complete rice futures market centuries before you would expect such a thing, roughly contemporaneous with the more famous Dutch stock exchange which had futures for the Dutch East India Company)
Deku-shrub & Besa Mafia: “The unbelievable tale of a fake hitman, a kill list, a darknet vigilante… and a murder”
“Effects Of Copyrights On Science—Evidence From The US Book Republication Program”, Biasi & Moser 2018 (Estimating the large deadweight losses of copyright using the natural experiment of US expropriation of German copyrights in WWII)
“500 Life-Saving Interventions and Their Cost-Effectiveness”, Tengs et al 199531ya (Doing good is easy to not do well, and there are astronomical differences between charities: estimates of intervention cost-benefits range over 11 orders of magnitude.)
Philosophy:
“Last Call: A Buddhist monk confronts Japan’s suicide culture” (how to do good well?)
“Words”, Radiolab 201016ya (language & abstraction: a deaf adult learning what words are for the first time; brain damage causing enlightenment)
“Loyal to the Group of Seventeen’s Story: ‘The Just Man’”, Gene Wolfe
Fiction:
Lu Chi’s The Art of Writing (cf. Snyder)
The haphazard invention of the “clue” in detective fiction: “The Slaughterhouse of Literature”, Moretti 200026ya/“Trees”, Moretti 200521ya/“Adventures of a Man of Science”, Batuman 200521ya
Touhou lossless music collection (TLMC): version 19 released
Tale of an Industrious Rogue: “Part I”/II/III, by Kroft (A D&D campaign in which humble salt traders eventually wind up destroying the world.)
“The Hours: How Christian Marclay created the ultimate digital mosaic” (the making of The Clock, a 24h supercut; watching it: 1/2)
“Slow Tuesday Night” (R. A. Lafferty’s classic 196561ya (SF?) short story; see also Robin Hanson’s ems & “The Hyperbolic Time Chamber”)
“Losing Your Grip: Futility and Dramatic Necessity in Shadow of the Colossus”, Fortugno 200917ya (from Well-Played 1.0)
“Time War // Briefing for Neolemurian Agents”, Yves Cross (?)
“Imperialism, Translation, Gunbuster”: “Introduction”/“Episode One”/“Episode Two (NSFW)”/“Episode Three”/“Episode Four”/“Episode Five”/“Episode Six” (nationalist subtexts in Gainax anime)
Books
Nonfiction:
McNamara’s Folly: The Use of Low-IQ Troops in the Vietnam War, Gregory 2015
Bad Blood: Secrets and Lies in a Silicon Valley Startup, Carreyrou 2018
The Vaccinators: Smallpox, Medical Knowledge, and the ‘Opening’ of Japan, Jannetta 200719ya (review)
Like Engendr’ing Like: Heredity and Animal Breeding in Early Modern England, Russell 198640ya (review)
Cat Sense: How the New Feline Science Can Make You a Better Friend to Your Pet, Bradshaw 201313ya (review)
Strategic Computing: DARPA and the Quest for Machine Intelligence, 1983–10199333ya, Roland & Shiman 200224ya (review)
The Operations Evaluation Group: A History of Naval Operations Analysis, Tidman 1984
Fiction:
TV/movies
Nonfiction movies:
Fiction:
Shadow of the Vampire (200026ya)
Anime:
My Little Pony: Friendship is Magic, seasons 1–8 (review)