July 2018 News
July 2018 Gwern.net newsletter with links on genetics, RL, true crime, tech economics, and 4 book reviews
This is the July 2018 edition of the Gwern.net newsletter; previous, June 2018 (archives). This is a collation of links and summary of major changes, overlapping with my Changelog; brought to you by my donors on Patreon. This month I’d like to particularly thank my 2 anonymous donors, who gave $20,000.
Writings
Nothing completed
Media
Links
Genetics:
Everything Is Heritable:
“Genetic analysis of social-class mobility in five longitudinal studies”, Belsky et al 2018a (Incredible followup to Belsky et al 2016)
IQ GWASes beyond Lee et al 2018: “Polygenic scores predict >9% of variance in IQ and >15% of variance in educational attainment at age 16.
#bga2018” (r = 0.30/0.39 respectively; this appears to have been a preview of Allegrini et al 2018.)“The Nature of Nurture: Using a Virtual-Parent Design to Test Parenting Effects on Children’s Educational Attainment in Genotyped Families”, Bates et al 2018 (Kong et al 2018’s nature-of-nurture seems to be mostly operating through causing parental SES)
“A Chinese province is sequencing 1 million of its residents’ genomes” in 4 years; “Gigantic study of Chinese babies yields slew of health data” (the Born in Guangzhou Cohort Study: n = 33k, increasing to n = 50k by 2020)
“Modeling functional enrichment improves polygenic prediction accuracy in UK Biobank and 23andMe data sets”, Marquez-Luna et al 2018 (Informative priors for Bayesian GWAS leads to a new height PGS record, 42% of variance—+2% from Lello et al 2017’s lasso)
“GWAS Round 2” (New public release of UK Biobank GWASes/PGSes: 2,419 → 4,203 trait PGSes, with sex-stratified versions.)
“Polygenic risk scores applied to a single cohort reveal pleiotropy among hundreds of human phenotypes”, Socrates et al 2017 (everything is correlated; supplement w/full heatmaps)
“Elucidating the genetic basis of social interaction and isolation”, Day et al 2018
“Genomic underpinnings of lifespan allow prediction and reveal basis in modern risks”, Timmers et al 2018
“Critical Need for Family-Based, Quasi-Experimental Designs in Integrating Genetic and Social Science Research”, D’Onofrio et al 201313ya (Correlation ≠ causation: many “maternal smoking effects” are simply genetic or family-level confounds.)
“Genetics & the Geography of Health, Behavior, and Attainment”, Belsky et al 2018b
“Genealogists Turn to Cousins’ DNA and Family Trees to Crack Five More Cold Cases”
Recent Evolution:
“Genome-wide association analyses identify 143 risk variants and putative regulatory mechanisms for type 2 diabetes”, Xue et al 2018 (selection against diabetes risk alleles)
“Darwinian positive selection on the pleiotropic effects of KITLG explain skin pigmentation and winter temperature adaptation in Eurasians”, Yang et al 2018
Engineering:
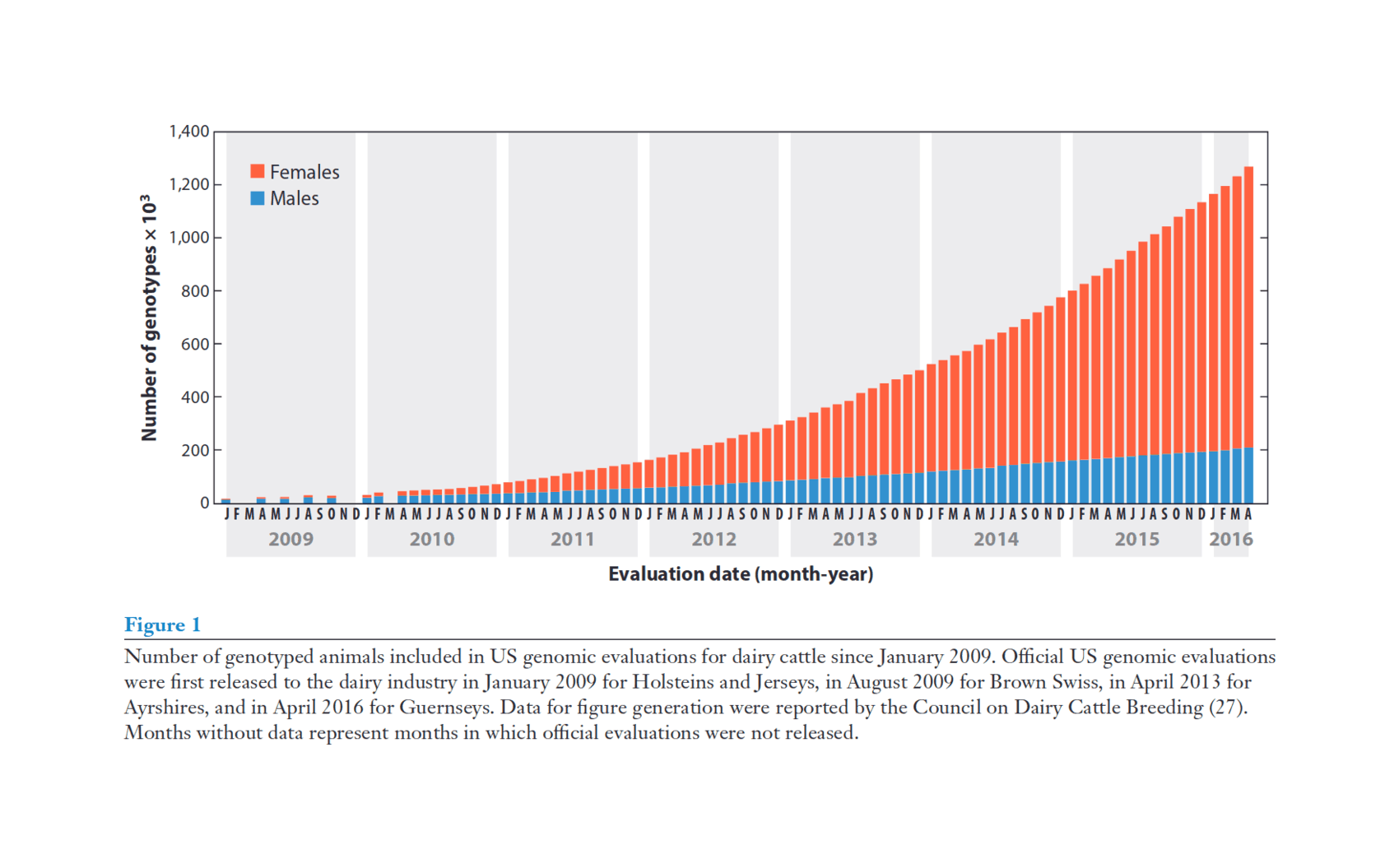
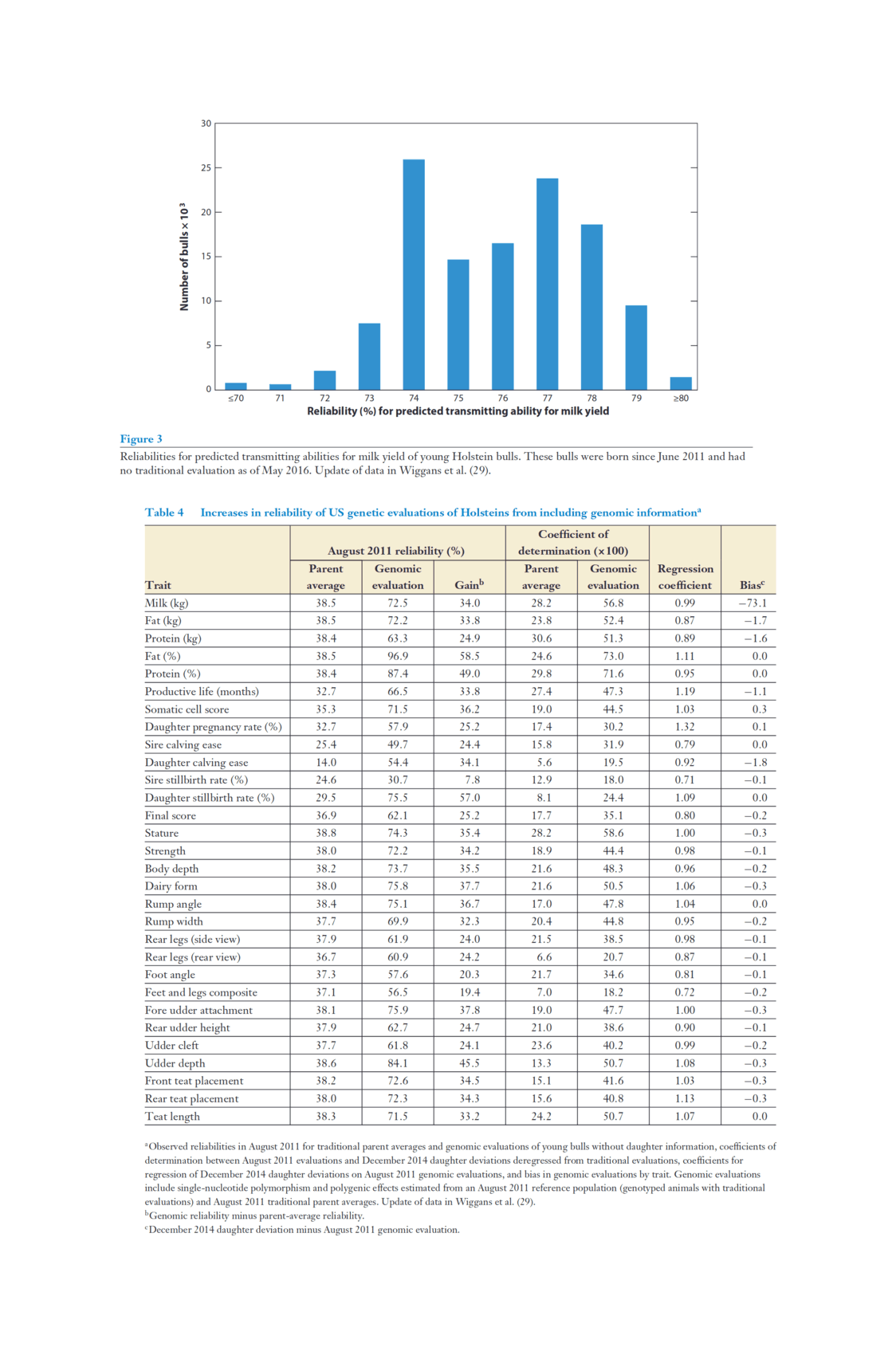
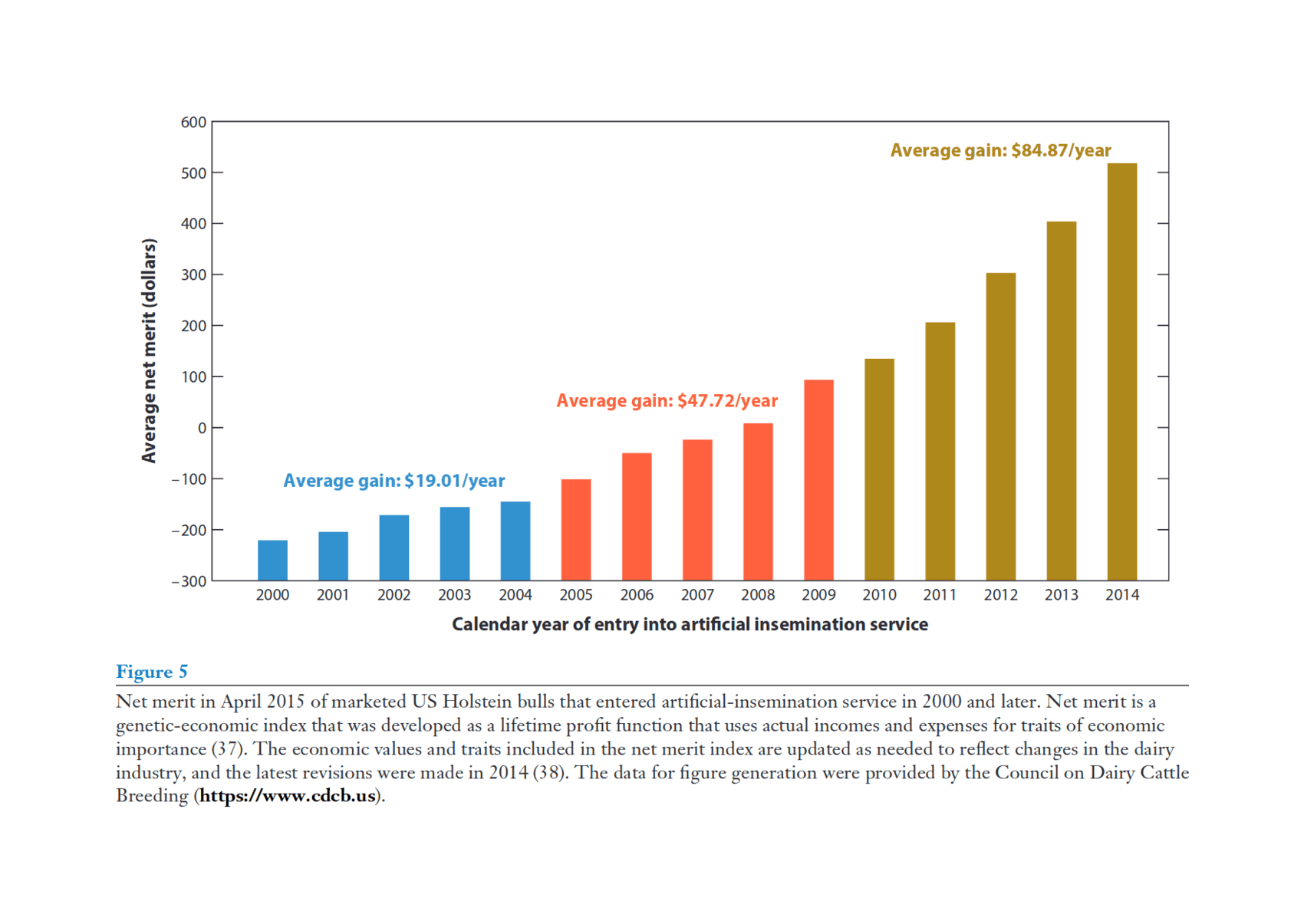
“Genomic Selection in Dairy Cattle: The USDA Experience”, Wiggans et al 2017 (What has marker-assisted selection done for us lately? It’s “doubled the rate of genetic progress for traits of economic importance, decreased generation interval, increased selection accuracy, reduced previous costs of progeny testing, and allowed identification of recessive lethals.” Figure 1/Table 4/Figure 5.)
{kind=link}
{kind=link}
{kind=link}
AI:
Google Waymo’s Arizona self-driving car program after 1 year; “Inside the Life of the World’s First Self-Driving Teen” (>400 daily riders, >39k kilometers daily; no fatalities or major injuries)
Dactyl: “Learning Dexterous In-Hand Manipulation”, OpenAI 2018 (blog; videos: 1/2; PPO-LSTM+domain-randomization in MuJoCo/Unity for sim2real transfer in a robotic hand grasper—nothing really new here but it is yet another demonstration of what brute force + systems engineering can do with existing DRL.)
“Large-Scale Visual Speech Recognition”, Shillingford et al 2018 (New SOTA for lipreading)
“Adversarial Reprogramming of Neural Networks”, Elsayed et al 2018 (NNs as “weird machines”)
“The challenge of realistic music generation: modeling raw audio at scale”, Dieleman et al 2018 (WaveNet samples; getting surprisingly good and starting to pick up rhythm/melody)
RL sample-efficiency progress:
“Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models”, Chua et al 2018
“Model-Ensemble Trust-Region Policy Optimization”, Kurutach et al 2018
“Sample-Efficient Deep RL with Generative Adversarial Tree Search”, Azizzadenesheli et al 2018
“Learning Real-World Robot Policies by Dreaming”, Piergiovanni et al 2018
“RUDDER: Return Decomposition for Delayed Rewards”, Arjona-Medina et al 2018
“General Value Function Networks”, Schlegel et al 2018
“Adversarial Exploration Strategy for Self-Supervised Imitation Learning”, Hong et al 2018
“The Sound of Pixels”, Zhao et al 2018 (samples; I can’t believe this works)
“How to Fix Reinforcement Learning” (meta-learning)
Danbooru2017 is now on Kaggle (a version of the SFW subset—n = 300k tagged anime images—is now available on Kaggle, which should be convenient for people in that ecosystem)
Statistics/Meta-Science:
“p-Hacking and False Discovery in A/B Testing”, Berman et al 2018 (Informative priors: Internet A/B tests are >70% testing null effects.)
“Validating Teacher Effects On Students’ Attitudes And Behaviors: Evidence From Random Assignment Of Teachers To Students”, Blazar 2017 (How often does correlation=causation? 1 of 4 education measures’ teacher correlation w/grades is near-identical with the causal effect, 2 moderately biased, and 1 severely misleading.)
“Sex matters in experiments on party drug—in mice: Ketamine lifts rodents’ mood only if administered by male researchers” (A reminder of why you can’t take animal experiments too seriously.)
“22 Case Studies Where Phase 2 and Phase 3 Trials had Divergent Results”, FDA 2017 (Small study biases)
Politics/religion:
“The Origins of WEIRD Psychology”, Schulz et al 2018
“The Cynical Genius Illusion: Exploring and Debunking Lay Beliefs About Cynicism and Competence”, Stavrova & Ehlebracht 2018
Psychology/biology:
“Effects of the Tennessee Prekindergarten Program on children’s achievement and behavior through third grade”, Lipsey et al 2018 (fadeout of initial benefits and evidence of harm; the Iron Law strikes again)
“Flynn effect and its reversal are both environmentally caused”, Bratsberg & Rogeberg 2018 (supplement; more on the anti-Flynn effect in Norway operating since the mid-1970s)
“Senolytics improve physical function and increase lifespan in old age”, Xu et al 2018 (Dasatinib+quercetin senolytics reduce mortality in old mice; interestingly, transplanting even tiny numbers of senescent cells into young mice appears to cause systemic harm.)
“A comprehensive meta-analysis of the predictive validity of the Graduate Record Examinations: Implications for graduate student selection and performance”, Kuncel et al 2001
“Augmenting Long-term Memory” With Spaced Repetition (Michael Nielsen)
“Melatonin: Much More Than You Wanted To Know”, Scott Alexander
“The high abortion cost of human reproduction”, Rice 2018 (This is the trolliest paper I’ve seen in a while.)
“Placebo Effects on the Neurological Pain Signature: A Meta-analysis of Individual Participant Functional Magnetic Resonance Imaging Data”, Zunhammer et al 2018 (Placebo effects are tiny on objective neural correlates of pain.)
Technology:
“Ice Poseidon’s Lucrative, Stressful Life as a Live Streamer”
“StarCraft II: How Blizzard Brought the King of E-sports Back From the Dead” (E-sports is more popular than ever; but what happened to the original e-sports, SC? Quite a bit.)
“Resistant protocols: How decentralization evolves” (John Backus)
Economics:
Myhrvold’s patent troll funds suffering enormous losses (karma)
“Hunting the Con Queen of Hollywood: Who’s the ‘Crazy Evil Genius’ Behind a Global Racket?”
“How an Ex-Cop Rigged McDonald’s Monopoly Game and Stole Millions”
“How to spot a perfect fake: the world’s top art forgery detective”
Philosophy:
“Last Call: A Buddhist monk confronts Japan’s suicide culture” (how to do good well?)
“Complicity, crime and conjoined twins”, Davis 2017
Fiction:
Tale of an Industrious Rogue: “Part I”/II/III, by Kroft (A D&D campaign in which humble salt traders eventually wind up destroying the world.)
“Man of Steel, Woman of Kleenex”, Larry Niven
Books
Nonfiction:
Intellectual Talent: Research and Development, ed Keating 197650ya; Mathematical Talent: Discovery, description, and development, ed Stanley 197452ya (early SMPY anthologies, recording the early results of the talent search and the immediate success of accelerating gifted students into Johns Hopkins college, the overall health of the participants, and SMPY’s unsuccessful struggle to get rid of the male overrepresentation at their extreme of math scores)
Hanging Out with the Dream King: Conversations with Neil Gaiman and His Collaborators, ed. McCabe 200521ya (review)
Fiction:
Three Parts Dead (Craft Sequence #1), Gladstone 201214ya (urban fantasy, sold to me as being unusually legal and economic-themed; not bad, but those aspects turn out to be minimal, arguably less than, say, Spice and Wolf, and some parts are a little derivative—City of Doors, anyone? I was a little more intrigued by the overall worldbuilding, with a geopolitical order polarized between upstart immortal human mage-kings seizing power with magic-science, and retrenched old gods.)
The Japanese Family Storehouse, or, The Millionaire’s Gospel Modernised, Saikaku 1688338ya, trans. Sargent (review)
Music
Touhou:
“aquamarine” (AnayamaSoh; Have A GoodTrip. {M3-38}) [house]