September 2018 News
September 2018 Gwern.net newsletter with links on genetics, human evolution, genetic engineering, LSD, and 1 book review.
This is the September 2018 edition of the Gwern.net newsletter; previous, August 2018 (archives). This is a collation of links and summary of major changes, overlapping with my Changelog; brought to you by my donors on Patreon.
Writings
Media
Links
Genetics:
Everything Is Heritable:
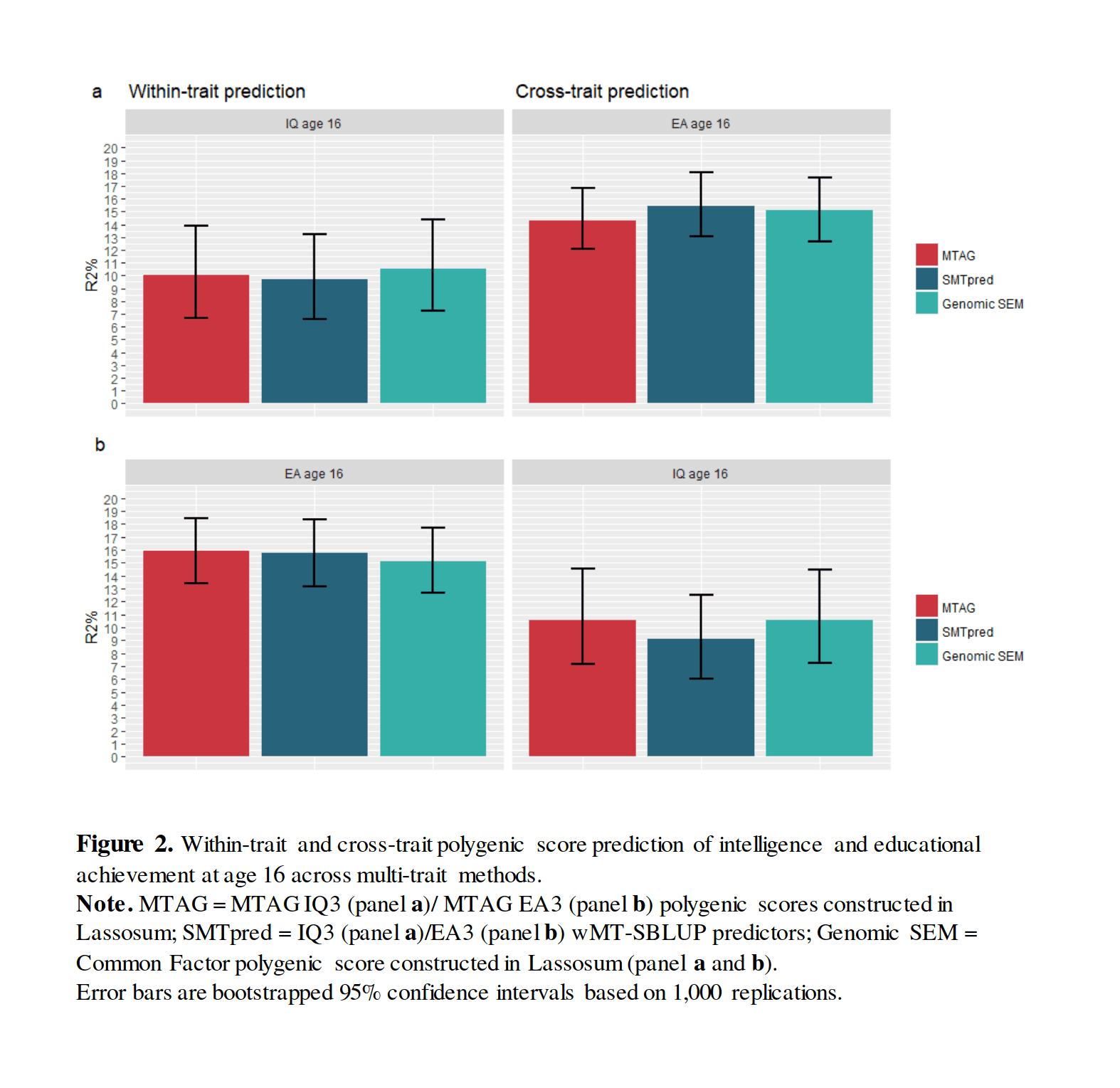
“Genomic prediction of cognitive traits in childhood and adolescence”, Allegrini et al 2018 (More replication of Lee et 2018: 11% IQ/16% education, boosted by genetic correlations—Figure 2: multi-trait boosted PGSes)
“A Polygenic Score for Higher Educational Attainment is Associated With Larger Brains”, Elliott et al 2018; “The genetic architecture of the human cerebral cortex”, Grasby et al 2018
“The genetics of the mood disorder spectrum: GWASes of over 185,000 cases and 439,000 controls”, Coleman et al 2018
“Genetic influences on eight psychiatric disorders based on family data of 4 408 646 full and half-siblings, and genetic data of 333 748 cases and controls”, Pettersson et al 2018 (population registry methods using siblings/half-siblings continue to confirm twin study results)
“Machine Learning to Predict Osteoporotic Fracture Risk from Genotypes”, Forgetta et al 2018 (Lasso regression improves osteoporosis fracture prediction from 18% to 25%—the cost of using uninformative priors & stock linear regression)
“Genome-wide association study results for educational attainment aid in identifying genetic heterogeneity of schizophrenia”, Bansal et al 2018 (The IQ/schizophrenia relationship is clearly negative, for a variety of reasons, but some studies have found contrary results; Bansal et al 2018 may resolve this by finding heterogeneity within schizophrenia genetics—a BPD/education (and thus potentially IQ) and a sub-schizophrenia trait. Something like this may also explain the puzzling IQ/autism spectrum symptoms genetic correlation, pace Grove et al 2017…)
“Association Between Population Density and Genetic Risk for Schizophrenia”, Colodro-Conde et al 2018; “Genetic evidence of assortative mating in humans”, Robinson et al 2017 (confounding)
“Evidence for gene-environment correlation in child feeding: Links between common genetic variation for BMI in children and parental feeding practices”, Selzam et al 2018
“Analysis of the genetic basis of height in large Jewish nuclear families”, Zeevi et al 2018
“Genetics of self-reported risk-taking behavior, trans-ethnic consistency and relevance to brain gene expression”, Strawbridge et al 2018
“Common DNA Variants Accurately Rank an Individual of Extreme Height”, Sexton et al 2018 (media; Shawn Bradley, 7-foot-6, is +4.2SD above the mean on the GIANT height PGS)
Recent Evolution:
“Detecting past and ongoing natural selection among ethnically Tibetan women at high altitude in Nepal”, Jeong et al 2018 (more on the Tibetan altitude adaptations)
“Combination of 247 Genome-Wide Association Studies Reveals High Cancer Risk as a Result of Evolutionary Adaptation”, Voskarides 2018
“Evolutionary history and adaptation of a human pygmy population of Flores Island, Indonesia”, Tucci et al 2018 (convergent evolution of hobbits & contemporary pygmies on Flores Island)
“The palaeogenetics of cat dispersal in the ancient world”, Ottoni et al 2017 (media)
Engineering:
“Generation of human oogonia from induced pluripotent stem cells in vitro”, Yamashiro et al 2018 (media: “The successful accomplishment of the same in human [cells] is just a matter of time. We’re not there yet, but this cannot be denied as a spectacular next step”; steps towards massive/iterated embryo selection)
“A CRISPR-Cas9 gene drive targeting
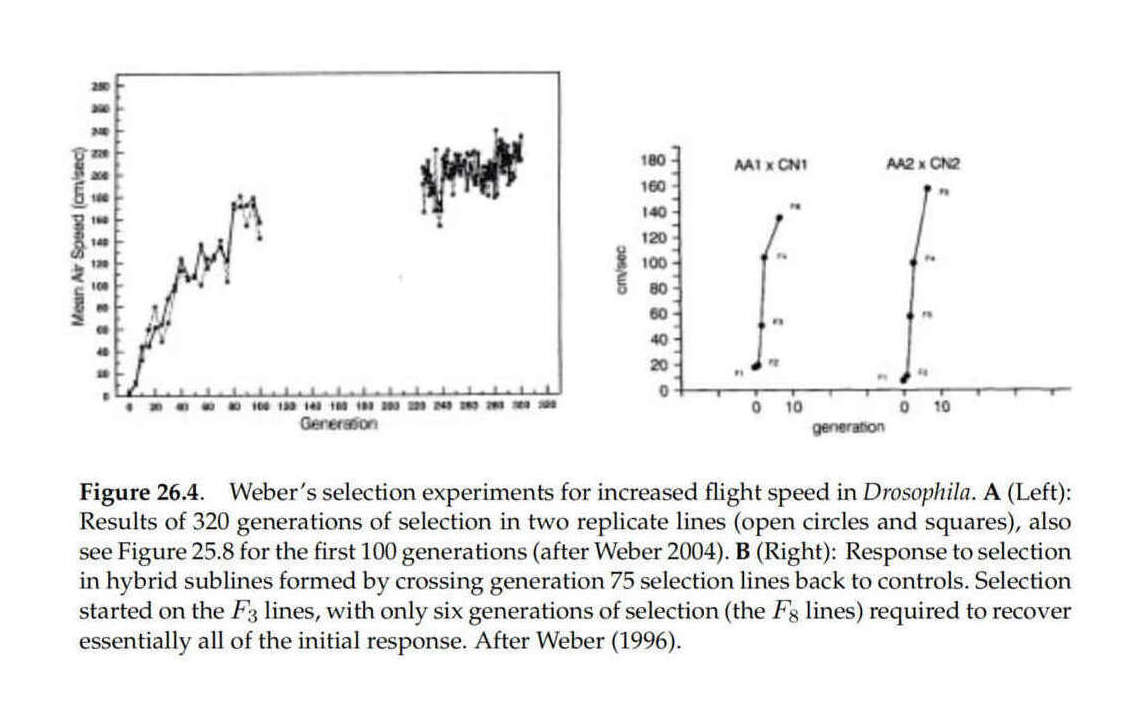
doublesexcauses complete population suppression in caged Anopheles gambiae mosquitoes”, Kyrou et al 2018 (Lab demo of driving malaria mosquitoes to extinction with CRISPR gene drive and no evolved resistance)“Large Genetic Change at Small Fitness Cost in Large Populations of Drosophila melanogaster Selected for Wind Tunnel Flight: Rethinking Fitness Surfaces”, Weber 199630ya; “Population Size and Long-term Selection”, Weber 200422ya; Walsh & Lynch 2018 discussion, graph of selection effects (The power of intense selection in large populations: Weber’s fruit-fly flying speed experiment was able to increase peak flying speed in a wind tunnel by >85x over 100 generations. See also the viral evolution lagoon which uses a similar mechanism to efficiently rank & select en masse.)
“Accurate classification of BRCA1 variants with saturation genome editing”, Findlay et al 2018 (Creating 4000 BRCA mutations with CRISPR to measure their harmful effects)
“Scientists Are Retooling Bacteria to Cure Disease” (Treating phenylketonuria (PKU) by ingesting bacteria genetically engineered to breakdown phenylalanine in the microbiome!)
“Genome-edited skin epidermal stem cells protect mice from cocaine-seeking behavior and cocaine overdose”, Li et al 2018
“First test of in-body gene editing shows promise” (Gene editing people’s livers with zinc finger nucleases—unclear if it worked, but genetic editing keeps expanding.)
{kind=link}
{kind=link}
AI:
Vast.ai (Vast.ai attempts to create a two-sided market for renting GPU servers from people with idle GPUs, substantially undercutting AWS/GCP. Looks interesting—eg Nvidia 1070s at $2.63$22018/day.)
Statistics/Meta-Science:
“The prehistory of biology preprints: A forgotten experiment from the 1960s”, Cobb 2017 (Who killed preprints the first time? The commercial academic publishing cartel did. Copyright is why we can’t have nice things.)
“Replication Failures Highlight Biases in Ecology and Evolution Science”
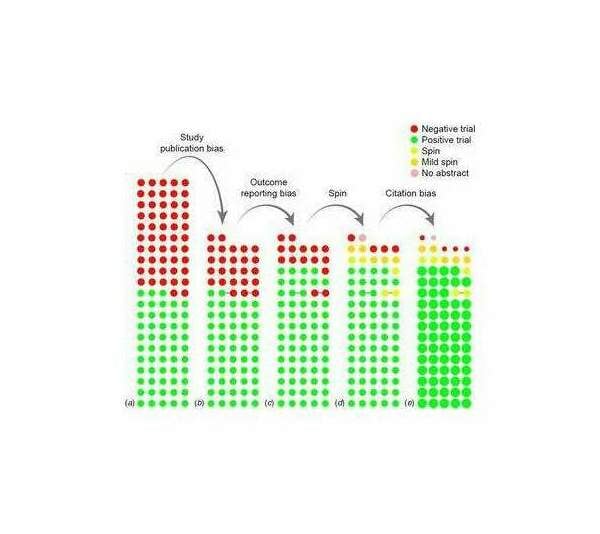
“The cumulative effect of reporting and citation biases on the apparent efficacy of treatments: the case of depression”, de Vries et al 2018 (Figure 1: the flowchart of bias)
“Two curious integrals and a graphic proof”, Schmid 201412ya (perils of induction: the treacherous identities of the
2*cost(t)integral)On Victorian vibrators and peer review: “A Failure of Academic Quality Control: The Technology of Orgasm”, Lieberman & Schatzberg 2018
“Testing the ability of the ‘surprisingly popular’ method to predict NFL games”, Lee et al 2018 (An interesting opinion aggregation method—/ if you’re contrarian & you know it, clap your hands / Connected to the Bayesian truth serum for measuring/forecasting.)
{kind=link}
{kind=link}
Politics/religion:
“Conspiracy As Governance”, Assange 2006
Government crime labs are still criminally incompetent at DNA testing: Butler et al 2018
Psychology/biology:
“Is Romantic Desire Predictable? Machine Learning Applied to Initial Romantic Attraction”, Joel et al 2018 (The heart has its reasons reason knows not…)
“What Use is Intelligence?”, Hunt 201115ya (Earl Hunt reviews some of the predictive power of IQ for education, careers, the military, and elsewhere.)
“Dynamic Human Environmental Exposome Revealed by Longitudinal Personal Monitoring”, Jiang et al 2018 (media; towards the non-shared-environment)
“California Teenagers Could Sleep Later Under School Start Bill”
Technology:
“The Effect of Ad Blocking on User Engagement with the Web”, Miroglio et al 2018 (“we find statistically-significant increases in both active time spent in the browser (+28% over control) and the number of pages viewed (+15% over control)”—parallel results to my A/B test of advertising effects and the Pandora experiment)
“SonarSnoop: Active Acoustic Side-Channel Attacks”, Cheng et al 2018
Economics:
“Examining Wikipedia With a Broader Lens: Quantifying the Value of Wikipedia’s Relationships with Other Large-Scale Online Communities”, Vincent et al 2018
Trial testimony transcripts from the trial of noted LSD manufacturer William Leonard Pickard, offering interesting insights into the business:
Philosophy:
Books
Nonfiction:
Plant Breeding Reviews: Part 1: Long-term Selection: Maize, Volume 24, ed Janick 200422ya (an anthology of papers on plant breeding efforts in, primarily, the Midwest, centering mostly on the famous long-term maize selection experiment; I was particularly interested in “Population Size and Long-term Selection”, Weber 200422ya, but was amazed to learn that the maize selection experiment, despite running for a century and still producing gains on some traits, was founded on a maize population size of just 4! This illustrates the untapped potential in existing genetic variance.)
Music
Touhou:
“Kid’s Festival ~ Innocent Treasures” (Clonesoldier; Affect a mind {SC42}) [folk]
“White Flag of Usa Shrine” (Clonesoldier; Affect a mind {SC42}) [folk]
“Memory of Forgathering Dream” (U2; Affect a mind {SC42}) [folk]
Vocaloid:
“Reverberations (Reverberations3 Remix)” (Clean Tears feat. Miku; Reverberations 3 {C92}) [trance]
“Reminiscence” (Clean Tears feat. Miku; Reverberations 3 {C92}) [trance]
“Into the Blue” (Bernis feat. Miku; On the shore of the Eden {M3-38}) [trance]
“On the shore of the Eden” (Bernis feat. Miku; On the shore of the Eden {M3-38}) [trance]
“みどりのつばさ” (You.T. feat. Miku; vita ex machina -inDiscipline- {VM2}) [electronic]
Misc:
“You Are Enough” (El Ten Eleven; Banker’s Hill) [postrock]
“We Don’t Have A Sail But We Have A Rudder” (El Ten Eleven; Banker’s Hill) [postrock]
“Reverie” (El Ten Eleven; Banker’s Hill) [postrock]
“This Morning With Her, Having Coffee” (El Ten Eleven; Banker’s Hill) [postrock]