2016 News
This is the 2016 summary edition of the Gwern.net newsletter, summarizing the best of the monthly 2016 newsletters:
Previously: 2015.
Writings
Despite taking two long trips and some personal troubles (plumbing, an epic laptop failure, & law enforcement), 2016 was a much better year for my statistics & writing than 201511ya:
Adding metadata to an RNN for mimicking individual author style
Wikipedia articles on Genome-wide complex trait analysis (GCTA) & genetic correlations
“The Power of Twins: Revisiting Student’s Scottish Milk Experiment Example”
Genius Revisited: Critiquing the Value of High IQ Elementary Schools
Site traffic was healthy: 635,123 pageviews by 312,659 users.
Media
Overview
Continuing the 201511ya trends, 2016 was a banner year for AI & genetics.
In AI, demonstrating the potential for rapid advance, AlphaGo went from low professional level as of October 201511ya to world champion level, crushing Lee Sedol 4-1 with substantial margin, and just when everyone had forgotten, then a refined (presumably pure self-play) version of AlphaGo went 60-0 in blitz matches online with many of the top Go players (including Ke Jie). The translation RNNs finally made their long-awaited appearance in commercial production with Google Translate, making for the largest jump in translation quality in decades, bringing many translation pairs up to surprisingly high quality (even Japanese⟺English translations are now semi-comprehensible, as opposed to the status quo total gibberish); combined with the rapid progress in voice transcription and the surprising results of human-level lipreading, one can now imagine a NN-powered Babelfish (which, combined with HUDs, could be revolutionary for the deaf & hearing-impaired). Generative adversarial networks (GANs) remained a central topic of AI research, with better theoretical understanding (linking them to reinforcement learning), and many tweaks and incremental refinements increasing the size of feasible generated images (eg. StackGAN’s large bird/flower image generation capability); however, GANs currently have not delivered any meaningful increases on any applied tasks & remain a solution in search of a problem, so that is something to hope for in 2017—demonstration that the unsupervised or generative aspects of GANs can be usefully employed for planning or something. Perhaps the most exciting work in 2016 was the long-term work on architecture in providing large-scale memory mechanisms (in the form of efficient external memory or encoded into the weights of large expanding or sharded NNs), in learning to train large-scale NNs (“synthetic gradients”), and in a particularly surprising set of papers, demonstrating that NNs+reinforcement-learning can efficiently learn how to design NN architectures & units. (This was not something anyone doubted could be done, but previous RL work suggested that it was years away & no one could manage it without whole GPU farms; but as far as Google was concerned… “You see, I told you it couldn’t be done without turning the whole country into a factory. You have done just that.”) Since NNs do not decay like biological neurons, and are not hard-limited by skull volumes or calories, and since all tasks share mutual information & form informative priors for each other critical to sample-efficient learning, there is a lot of inherent pressure towards large growing multi-task NNs which do transfer learning & can optimize at multiple levels end-to-end; as GPU RAM limits lift, we’ll see more of these. Aside from the important work in “NNs all the way down” vein, reinforcement learning grew in importance and it is increasingly common to use RL methods to control memory or network components, interact with an environment (often broadly interpreted, as anything which can be turned into a tree, which goes far beyond games like Go or chess & includes theorem proving or program optimization), or learn to optimize a non-differentiable reward/loss function, and I am excited to see planning re-emerge as a theme after the dominance of model-free methods over the past 3 years; we will see more of that in 2017, doubtless, especially as some of the architectural tweaks from 2016 (some of which claim as much as an order of magnitude improvement on ALE sample-efficiency) get tried out & reused.
In genetics, the growth of UK Biobank and the introduction of LD score regression & other summary-statistic-only methods continued driving large-scale results; the study of human genetic correlations made an absurd amount of progress in 2016, demonstrating shared genetic influences on countless phenotypic traits and pervasive intercorrelations of good traits and disease traits, respectively. Detecting recent human evolution has been difficult due to lack of ancient DNA to compare with, but the supply of that has grown steadily, permitting some specific examples to be nailed down, and a new method based on contemporary whole genomes may blow the area wide open as whole genomes have recently crossed the $1,384.61$1,0002016 mark and in coming years, scientific projects & medical biobanks will shift over to whole genomes. Another possible field explosion is “genome synthesis”—I was astonished to learn that it is now feasible to synthesize from scratch entire chromosomes of arbitrary design, and that a human genome could potentially be synthesized for ~$1,384,607,951.18$1,000,000,0002016, which would render totally obsolete any considerations of embryo selection/CRISPR/iterated embryo selection, with an active advocacy effort for a genome synthesis project to be launched. 2017 will bring further discoveries of how humans have adapted to local environments and their societies over the past centuries & millennia. Honorable mentions should also go to the steady (and disquieting) progress towards iterated embryo selection, and a scattering of results from the continuously-growing-sample-sizes GWASes: as predicted, the education/intelligence hits have increased drastically as sample size increased, and the historically difficult targets of personality & depression have finally yielded some more hits. One particularly intriguing GWAS focused on violence & criminal behavior with good results, so that trait will yield as well to further study. Past GWASes continued to be applied; the results of et al 2016 will come as no surprise, but will frustrate the critics who insist that all non-disease results are methodological artifacts or merely reflect population structure. CRISPR progress continues as expected, with the first uses in humans in 2016 by Chinese & American scientists.
Less cosmically, one of the big tech stories of 2016 was the rollout of consumer VR—successful but not epochal, clearly the (or at least, a) future of gaming but no killer app. Oculus had a rocky launch caused by its decision to launch prematurely, without motion controls, which the launch of HTC/Valve’s Vive made clear is not an optional feature for truly compelling VR (and my own brief experience with an Oculus Rift at a Best Buy demo left me longing, after just 20 seconds in The Climb, for hand tracking), but the lack of motion controls & compelling content made for a slow launch. The Vive had a better launch with excellent motion controls & tracking, the comparable Oculus Touch controls only really shipping half a year later in December, demonstrating why Oculus launched when it did—it was either bite the bullet of a bad launch, or let Vive rule unopposed. Somewhat to my surprise, Sony’s quiet Project Morpheus launched successfully as PlayStation VR, making for 3 high-quality competing VR headsets/ecosystems. (Sony had not seemed serious about the whole VR thing so I doubted it would launch in 2016 or at all.) While most gamers, much less people, do not feel a burning need for getting into VR at the moment (myself included, as I think the screen resolutions need improvement), what is notable is what didn’t happen: we did not see widespread reports of vomiting, of people swearing off VR forever, of VR being discarded as a 3D-TV-like gimmick, of developers flooding in & getting burned, of sales plummeting and being well below the million-mark, of the initial trickle of games sputtering out… In short, of any of the things that the naysayers predicted would doom consumer VR. The worst that the early adopters, critics, and regular people have to say is that there are not enough good games (decreasingly true by the end of 2016), that the headsets and GPUs cost too much (true but will predictably be fixed as time passes), that the Oculus Rift lacked motion controls (fixed as of December 2016), and the resolution is too low / devices are wired / require external tracking (likely improved substantially in the second generation, possibly fixed entirely by the third or fourth)—nothing fatal or important, in other words. So it looks like VR is here to stay! It’s nice that at least one part of my childhood’s future has finally happened.
Links
Genetics:
Everything Is Heritable:
“Top 10 Replicated Findings From Behavioral Genetics”, et al 2016
“The Genetics of Success: How Single-Nucleotide Polymorphisms Associated With Educational Attainment Relate to Life-Course Development”, et al 2016; “Genome-wide association study of cognitive functions and educational attainment in UK Biobank (n = 112151)”, et al 2016a; “Genome-wide association study identifies 74 [162] loci associated with educational attainment”, et al 2016b; “Predicting educational achievement from DNA”, et al 2016 (supplement; polygenic scores now predict 3.5% of intelligence, 7% of family SES, and 9% of education)
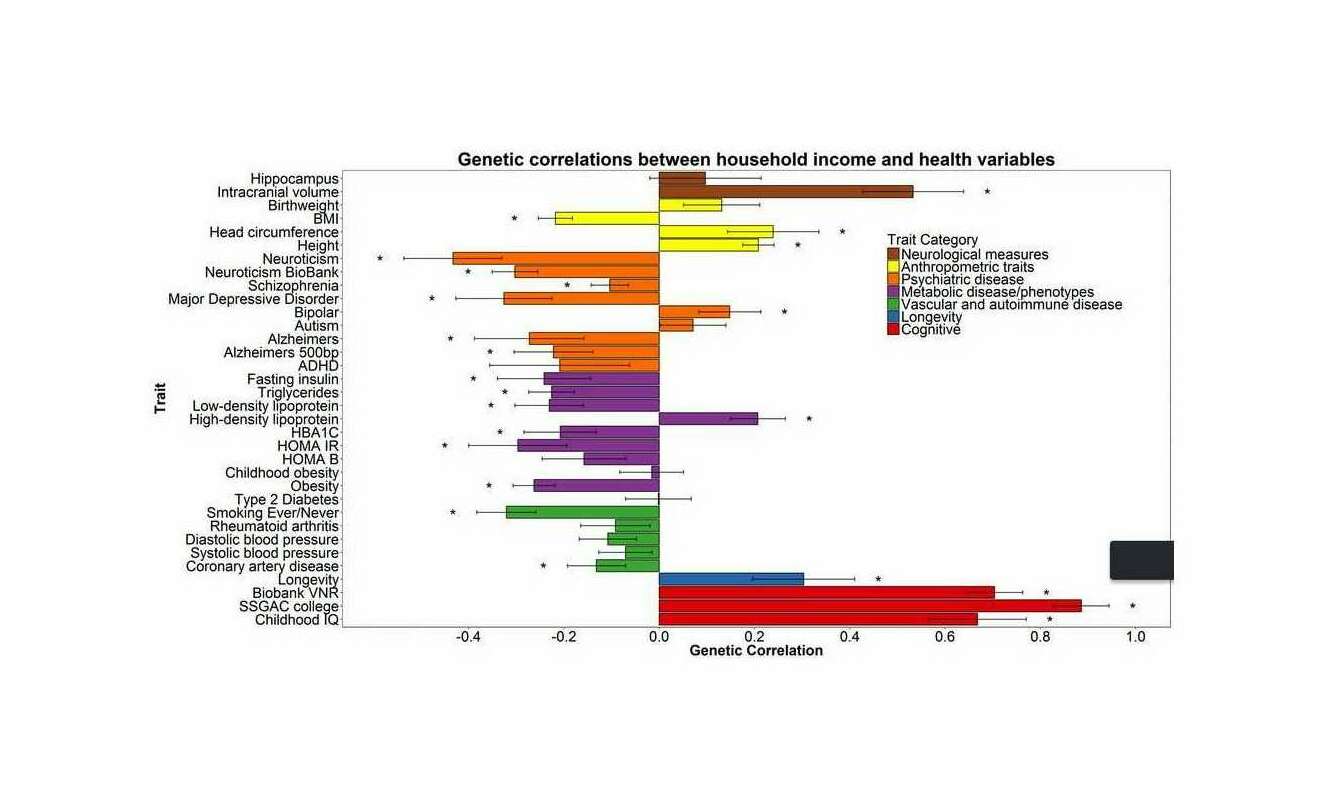
“Molecular genetic contributions to social deprivation and household income in UK Biobank (n = 112,151)”, et al 2016 (correlation graph); “Genetic link between family socioeconomic status and children’s educational achievement estimated from genome-wide SNPs”, 2016
“Genome-wide association study of antisocial personality disorder”, et al 2016 (GWAS hits on crime)
“Genetic risk for autism spectrum disorders and neuropsychiatric variation in the general population”, et al 2016
“Schizophrenia and subsequent neighborhood deprivation: revisiting the social drift hypothesis using population, twin and molecular genetic data”, et al 2016 (good use of polygenic scores for confirmation)
“Ultra-rare disruptive and damaging mutations influence educational attainment in the general population”, et al 2016; “Cognitive Performance Among Carriers of Pathogenic Copy Number Variants: Analysis of 152,000 UK Biobank Subjects”, et al 2016
“Older fathers’ children have lower evolutionary fitness across four centuries and in four populations”, et al 2016
Pleiotropy:
“Shared genetic aetiology between cognitive functions and physical and mental health in UK Biobank (n = 112151) and 24 GWAS consortia”, et al 2016; “Detection and interpretation of shared genetic influences on 42 human traits”, et al 2016; “An Atlas of Genetic Correlations across Human Diseases and Traits”, Bulik- et al 2015; “Phenome-wide Heritability Analysis of the UK Biobank”, et al 2016
“Genetic relationship between five psychiatric disorders estimated from genome-wide SNPs”, Psychiatric Genomics 2013; “Analysis of shared heritability in common disorders of the brain”, et al 2016; “Genome-wide analyses for personality traits identify six genomic loci and show correlations with psychiatric disorders”, et al 2016; “Genetic variants associated with subjective well-being, depressive symptoms, and neuroticism identified through genome-wide analyses”, et al 2016a; “Association between stressful life events and psychotic experiences in adolescence: evidence for gene-environment correlations”, et al 2016; “Associations between Polygenic Risk for Psychiatric Disorders and Substance Involvement”, et al 2016
“Shared genetic aetiology of puberty timing between sexes and with health-related outcomes”, et al 2015; “Physical and neurobehavioral determinants of reproductive onset and success”, et al 2016
“The Causal Effects of Education on Health, Mortality, Cognition, Well-being, and Income in the UK Biobank”, et al 2016b
“Educational attainment and personality are genetically intertwined”, et al 2016
Recent Evolution:
Engineering:
“Improved CRISPR-Cas9: Safe and Effective?”: “High-fidelity CRISPR-Cas9 nucleases with no detectable genome-wide off-target effects”/“Rationally engineered Cas9 nucleases with improved specificity”
“Introducing precise genetic modifications into human 3PN embryos by CRISPR/Cas-mediated genome editing”, et al 2016 (see also et al 2015)
“The Genome Project-Write”, et al 2016 (media)
{kind=link}
AI:
“Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”, et al 2016; “Found in translation: More accurate, fluent sentences in Google Translate”
“Hybrid computing using a neural network with dynamic external memory”, et al 2016 (blog); scaling to extremely large external memories: “Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes”, et al 2016
“Progressive Neural Networks”, et al 2016a; “Sim-to-Real Robot Learning from Pixels with Progressive Nets”, et al 2016b; “Overcoming catastrophic forgetting in neural networks”, et al 2016 (see also “Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning”, et al 2015)
“Decoupled Neural Interfaces using Synthetic Gradients”, et al 2016 (DeepMind explainer; potentially allows for extreme parallelization of neural nets across GPUs)
“Outrageously large neural networks: the sparsely-gated mixture-of-experts layer”, et al 2016
“One-shot Learning with Memory-Augmented Neural Networks”, et al 2016
“Programming with a Differentiable Forth Interpreter”, et al 2016; “DeepCoder: Learning to Write Programs”, et al 2016; “Learning to superoptimize programs”, et al 2016; DeepMath/“HolStep: A Machine Learning Dataset for Higher-order Logic Theorem Proving”, et al 2016 (continuing the AlphaGo theme of tree search+NN heuristics; see also “Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning”, et al 2014)
“Achieving Human Parity in Conversational Speech Recognition”, et al 2016
“Lip Reading Sentences in the Wild”, et al 2016 (video); “LipNet: Sentence-level Lipreading”, et al 2016 (video)
reinforcement learning:
“Mastering the game of Go with deep neural networks and tree search”, et al 2016
“Neural architecture search with reinforcement learning”, 2016; “Designing Neural Network Architectures using Reinforcement Learning”, et al 2016; “Learning to reinforcement learn”, et al 2016
“Value Iteration Networks”, et al 2016; “The Predictron: End-To-End Learning and Planning”, et al 2016
“Unifying Count-Based Exploration and Intrinsic Motivation”, et al 2016 (Video)
“Asynchronous Methods for Deep Reinforcement Learning (A3C)”, et al 2016
“Reinforcement Learning with Unsupervised Auxiliary Tasks”, et al 2016; “Loss is Its Own Reward: Self-supervision for Reinforcement Learning”, et al 2016
“Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection”, et al 2016 (video); “Deep Reinforcement Learning for Robotic Manipulation”, et al 2016 (video; blog)
Statistics/meta-science:
“When Quality Beats Quantity: Decision Theory, Drug Discovery, and the Reproducibility Crisis”, 2016
“Online Controlled Experiments: Introduction, Learnings, and Humbling Statistics”, 2012
“Underreporting in Psychology Experiments: Evidence From a Study Registry”, et al 2015 (previously: et al 2014)
How often does correlation=causation?
“Comparison of Evidence of Treatment Effects in Randomized and Nonrandomized Studies”, et al 2001
“Comparison of Effects in Randomized Controlled Trials With Observational Studies in Digestive Surgery”, et al 2006
“A Comparison of Approaches to Advertising Measurement: Evidence from Big Field Experiments at Facebook”, et al 2019
“Peer review: Troubled from the start”; “Saving Science: Science isn’t self-correcting, it’s self-destructing. To save the enterprise, scientists must come out of the lab and into the real world.”
“Generalized Network Psychometrics: Combining Network and Latent Variable Models”, et al 2016
“Statistically Controlling for Confounding Constructs Is Harder than You Think”, 2016 (Even a structural equation model (SEM) which explicitly incorporates measurement error may still have enough leakage to render ‘controlling’ misleading. See also 1936/1942/1965.)
Psychology:
“When Lightning Strikes Twice: Profoundly Gifted, Profoundly Accomplished”, et al 2016; “Ann Roe’s scientists: original published papers”; “From Terman to Today: A Century of Findings on Intellectual Precocity”, 2016
“Heads or tails: the impact of a coin toss on major life decisions and subsequent happiness”, 2020
“A Meta-Analysis of Blood Glucose Effects on Human Decision Making”, 2016; “Is Ego-Depletion a Replicable Effect? A Forensic Meta-Analysis of 165 Ego Depletion Articles”
Do Portia spiders have a mind? (commentary on Portia spiders)
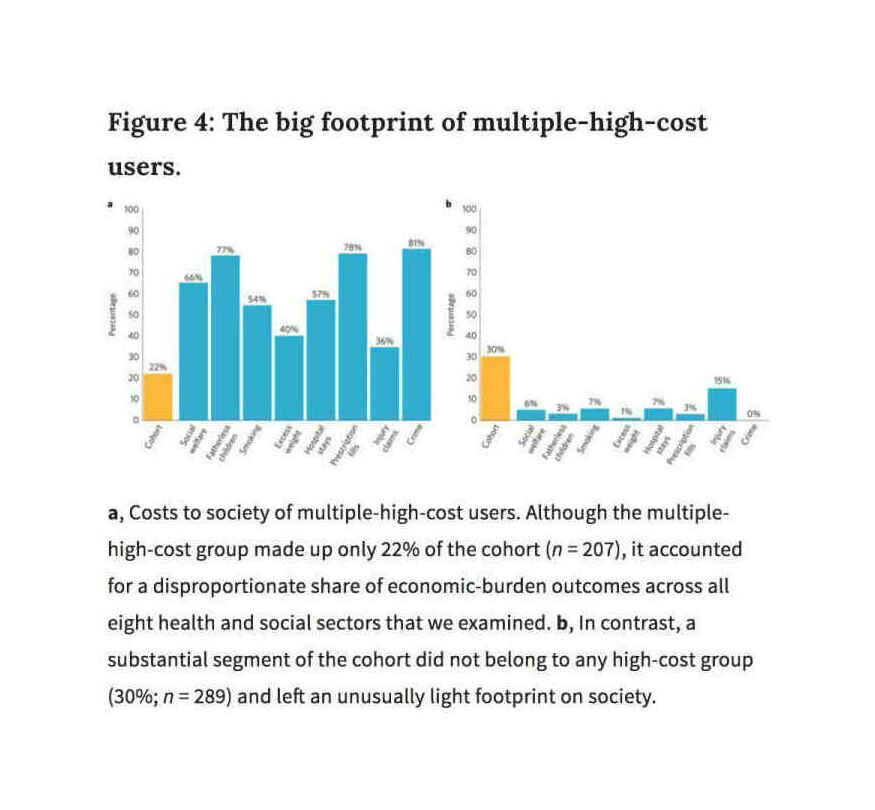
“Childhood forecasting of a small segment of the population with large economic burden”, et al 2016 (“Figure 4: The Big Footprint of Multiple-High-Cost-Users”; for the genetic version, see et al 2016); “Clustering of health, crime and social-welfare inequality in 4 million citizens from two nations”, Richmond- et al 2020
Psychedelics & psychological well-being (media):
“The paradoxical psychological effects of lysergic acid diethylamide (LSD)”, Carhart- et al 2016
{kind=link}
Biology:
“Aldehyde-stabilized cryopreservation”, 2015 wins the Small Mammal Brain Preservation Prize by passing their evaluation (commentary)
Politics/religion:
“The Strategic Consequences of Chinese Racism: A Strategic Asymmetry for the United States”, 2013
“Okhrana: The Paris Operations of the Russian Imperial Police”
“Once Upon a Jihad” / “Experiencing Ecstasy: How Bad It Is to Be 20 Years Old” / “My Year in San Francisco’s $2 Million Secret Society Startup”
“How a detachment of U.S. Army soldiers smoked out the original Ku Klux Klan”
“Wealth, Health, and Child Development: Evidence from Administrative Data on Swedish Lottery Players”, et al 2016
“At Tampa Bay farm-to-table restaurants, you’re being fed fiction” (Qui vult decipi decipiatur.)
Technology:
“The Slow Winter”, Mickens
“DDoSCoin: Cryptocurrency with a Malicious Proof-of-Work”, Wustrow & Vander2016
“Beaver: A Decentralized Anonymous Marketplace with Secure Reputation”, et al 2016
“The Distribution of Users’ Computer Skills: Worse Than You Think”
Economics:
“Typhoid Fever, Water Quality, and Human Capital Formation”, et al 2016; “When It Rains It Pours: The Long-run Economic Impacts of Salt Iodization in the United States”, et al 2016; “The Production of Human Capital in Developed Countries: Evidence from 196 Randomized Field Experiments”, 2016
Abuse of ‘arbitration’ clauses in international trade treaties to escape criminal liability
“The View from Above: Applications of Satellite Data in Economics”, 2016
“Adam Smith, Watch Prices, and the Industrial Revolution”, 2016 (commentary)
“Elephants and Mammoths: Can Ice Ivory Save Blood Ivory?”, 2015
“The Case Against Everyone’s Favorite Tax Break: The Mortgage Interest Deduction”
Philosophy:
“Logical Induction”, et al 2016
“Towards an integration of deep learning and neuroscience”, et al 2016
“Probing the Improbable: Methodological Challenges for Risks with Low Probabilities and High Stakes”, et al 2008
Fiction:
There Is No Anti-Memetics Division, by Sam Hughes
“Suminoe Beach”, by Kuramochi Chitose
“Poverty”, by Moon Byung-ran
“Design”, by Robert Frost
Books
Nonfiction:
Don’t Sleep, There Are Snakes: Life and Language in the Amazonian Jungle, Everett 200917ya (on the Pirahã people)
The Sports Gene, Epstein
Fortune’s Formula, 2005
The Genius Factory, 2005
Fiction:
Poems of Gerard Manley Hopkins, Gerard Manley Hopkins
TV/movies
Nonfiction movies:
Fiction:
Anime: