March 2016 News
This is the March 2016 edition of the Gwern.net newsletter; previous, February 2016. This is a collation of links and summary of major changes, overlapping with Changelog; brought to you by my donors on Patreon.
Writings
Media
Links
Genetics:
Everything Is Heritable:
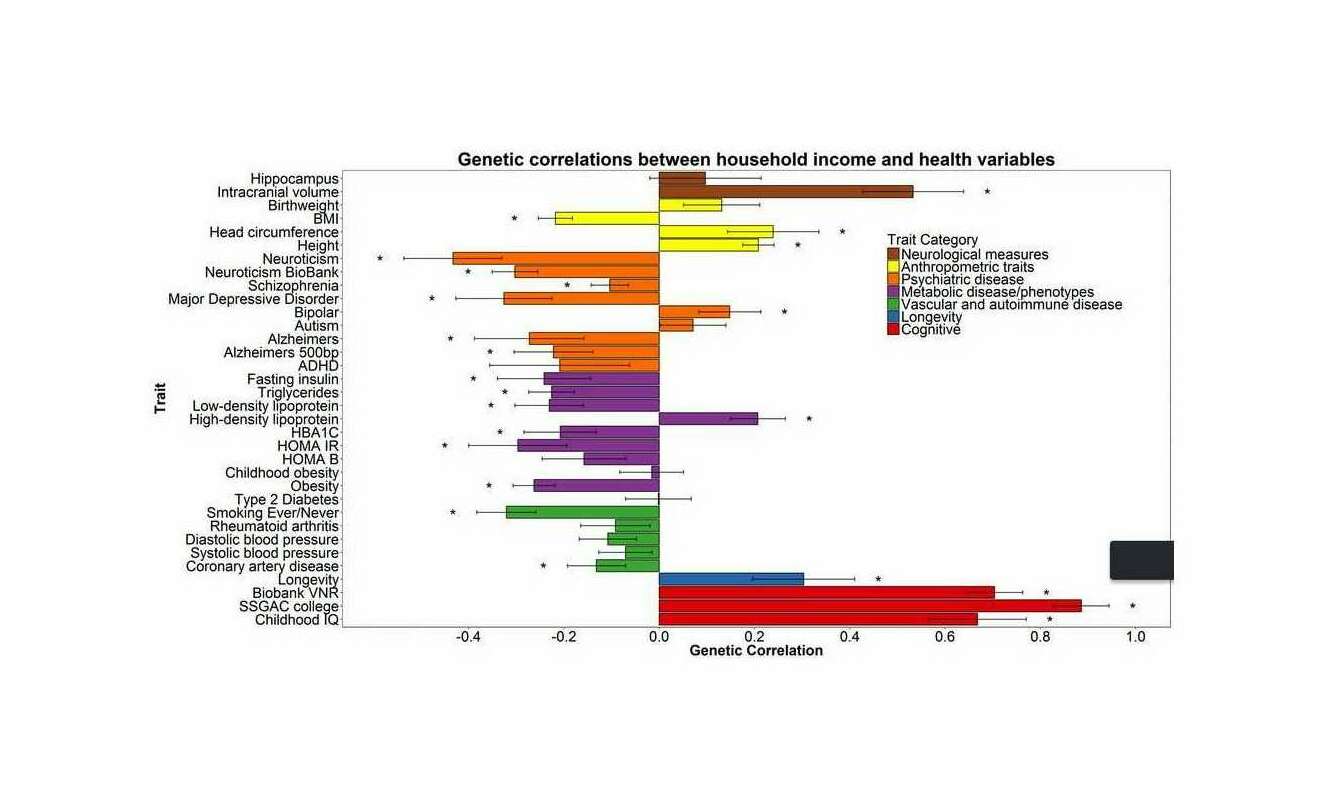
“Molecular genetic contributions to social deprivation and household income in UK Biobank (n = 112,151)”, et al 2016 (correlation graph)
“Genetic risk for autism spectrum disorders and neuropsychiatric variation in the general population”, et al 2016
“Genetic relationship between five psychiatric disorders estimated from genome-wide SNPs”, Psychiatric Genomics 2013
“Height, body mass index, and socioeconomic status: Mendelian Randomization study in UK Biobank”, et al 2016
Recent Evolution:
Engineering:
“Welcome to the CRISPR Zoo” (roundup of recent & planned CRISPR applications in animals)
{kind=link}
Politics/religion:
AI:
“Dynamic Memory Networks for Visual and Textual Question Answering”, et al 2016
“Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection”, et al 2016 (video)
“Generating images with recurrent adversarial networks”, et al 2016 (Another nice improvement in the state-of-the-art; getting RNNs working with adversarial training is believed to be pretty tricky.)
“Deep Exploration via Bootstrapped DQN”, et al 2016 (Who’d’ve thought there was a way to combine bootstrapping and deep q-networks?)
AlphaGo as AI risk example (Inside View beat Outside View 4–1)
Statistics/meta-science:
“Underreporting in Psychology Experiments: Evidence From a Study Registry”, et al 2015 (previously: et al 2014)
“The Scientific Impact of Positive and Negative Phase 3 Cancer Clinical Trials”, et al 2016
“The Stress Test: Rivalries, intrigue, and fraud in the world of stem-cell research”
Psychology/biology:
“Evolution of the Human Brain: From Matter to Mind”, 2015 (plenty of room at the top)
“‘High’ Achievers? Cannabis Access and Academic Performance”, Marie & 2015 (Dutch natural experiment in selective marijuana ban in a university town)
“Correlation and Causation in the Study of Personality”, 2012
Technology:
Economics:
Fiction:
“With No Inkling of the Contents: Viewing Narnia Through a Hindu Lens” (creative hermeneutics)
Books
Nonfiction:
Film/TV
The Tale of Princess Kaguya (extraordinarily beautiful but enigmatic; my eventual review)
Music
Touhou:
“Longing of Forest” (ハム; _Re*Collection_ {C89}) [jazz/folk]
“Doloza (Fires of Hokkai)” (Maurits”禅”Cornelis feat.舞花 & W.nova; Spatial Moving {C89}) [trance]
“Reawakening ~ ‘second’ chance, for the tenth time or so” (the distant journey to you; untitled {C89}) [postrock]
“音の瓶詰—神さびた古戦場 ~ Suwa Foughten Field” (ジャム; 守矢幻燈録 ~ Separation of Spirit {R12}) [classical]
“死霊の夜桜” (Marasy; 幻想遊戯<神> ~ Museum of marasy {R12}) [classical]
“素敵な墓場で暮らしましょ” (Marasy; 幻想遊戯<神> ~ Museum of marasy {R12}) [classical]
“神社の新しい風” (Marasy; 幻想遊戯<神> ~ Museum of marasy {R12}) [classical]
“佐渡の二ッ岩” (Marasy; 幻想遊戯<神> ~ Museum of marasy {R12}) [classical]
“デザイアドリーム” (Marasy; 幻想遊戯<神> ~ Museum of marasy {R12}) [classical]
Doujin:
“Magic” (Chroma; Black Magic {C89}) [vocal/Jpop]
“THE GREAT VOYAGE” (Tenmon; MEMORY OF THE GREEN {C89}) [progressive rock]
“Sāi-bak-hō (HiRoSYO Remix)” (kamome sano; tatsuta compilation 4 {201511ya}) [electronic]
Vocaloid
“Paradox” (Kimkim feat. Miku; MONOPHOBIA {201511ya}) [electronic]