‘AI’ directory
- See Also
- Gwern
- Links
- “FBI Is Buying Data That Can Be Used to Track People, Patel Says: This Is the First Confirmation That the FBI Has Resumed Actively Buying People’s Data for Investigations”
- “Celebrating Flickr Technology”, Steerpike 2026
- “The Homogenizing Effect of Large Language Models on Human Expression and Thought”, Sourati et al 2026
- “The World Is Too Much With Us”, Chatti & Pro 2026
- “Gyre”, vgel 2026
- “Notable Progress Has Been Made in Whole Brain Emulation”
- “Fighting Fire With Fire: Scalable Oral Exams With an 11Labs Voice AI Agent”, Ipeirotis 2025
- “How AI and Wikipedia Have Sent Vulnerable Languages into a Doom Spiral: Machine Translators Have Made It Easier Than Ever to Create Error-Plagued Wikipedia Articles in Obscure Languages. What Happens When AI Models Get Trained on Junk Pages?”, Judah 2025
- “Elon Musk XAI Dropped Public Benefit Corp Status While Fighting OpenAI”
- “
unfake.js: Fix AI Pixel Art and Vector Images Right in Your Browser”, jenissimo 2025 - henloitsjoyce @ "2025-08-07"
- “What Web Browsing Data Tells Us About How AI Appears Online: An Analysis of One Month of Browsing Data Finds ~6⁄10 Respondents Visited a Search Page With AI-Generated Summary. But Visits to More In-Depth Content about AI Were Relatively Rare”, Chapekis et al 2025
- “AI, Materials, and Fraud, Oh My! The Red Flags We Should Have Seen Earlier for a Too-Good-To-Be-True Paper on AI Tool Adoption at a Materials Research Firm”, Shindel 2025
- “I Knew AI Was Coming for My Job. I Wasn’t Prepared for It to Come for My Heart”, Baird 2025
- “Pope Leo XIV: AI Inspired Name Choice”, Service 2025
- “Chilean Cardinal Gives Insight to the Conclave That Elected Pope Leo XIV [‘Leo’ Choice Motivated by AI]”, Martin 2025
- “As ‘Bot’ Students Continue to Flood In, Community Colleges Struggle to Respond”, McWhinney 2025
- “Born in the Wrong Generation: You Have Gone Nowhere. There Is Nowhere for You to Go”, Kriss 2025
- “
cyc-Archive: An Archive of Material Related to the Cyc Project”, Liu 2025 - “The Cultural Divide between Mathematics and AI: A Reflection on Cultural Differences Observed at the 2025 Joint Mathematics Meeting”, Furman 2025
- “A Man Stalked a Professor for 6 Years. Then He Used AI Chatbots to Lure Strangers to Her Home”
- “AI Will Write Complex Laws”, Schneier & Sanders 2025
- “AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking”, Gerlich 2025
- “About Jasmine Sun”, Sun 2025
- “To Whom Does the World Belong? The Battle over Copyright in the Age of ChatGPT”, Hartley 2024
- “An 83-Year-Old Short Story [‘The Library of Babel’] by Jorge Luis Borges Portends a Bleak Future for the Internet”, Kreuz 2024
- “More to Lose: The Adverse Effect of High Performance Ranking on Employees’ Pre-Implementation Attitudes Toward the Integration of Powerful AI Aids”, SimanTov-Nachlieli 2024
- “How to Build the Virtual Cell With Artificial Intelligence: Priorities and Opportunities”, Bunne et al 2024
- “Wu’s Method Can Boost Symbolic AI to Rival Silver Medalists and AlphaGeometry to Outperform Gold Medalists at IMO Geometry”, Sinha et al 2024
- “Thousands of AI Authors on the Future of AI”, Grace et al 2024
- “Bayesian Regression Markets”, Falconer et al 2023
- “A Quantitative Study of Inappropriate Image Duplication in the Journal Toxicology Reports”, David 2023
- “Getting from Generative AI to Trustworthy AI: What LLMs Might Learn from Cyc”, Lenat & Marcus 2023
- “How AI Can Distort Human Beliefs”, Kidd & Birhane 2023
- “On Herbert A. Simon And Jorge Luis Borges About Free Will”, Crespo 2023
- “Defending Humankind: Anthropocentric Bias in the Appreciation of AI Art”, Millet et al 2023
- “Exposure to Automation Explains Religious Declines”, Jackson et al 2023
- “Impossibility Theorems for Feature Attribution”, Bilodeau et al 2022
- “Who Made the Paintings: Artists or Artificial Intelligence? The Effects of Identity on Liking and Purchase Intention”, Gu & Li 2022
- “Would You Pass the Turing Test? Influencing Factors of the Turing Decision”, Ujhelyi et al 2022
- “Machine Learning Reveals Cryptic Dialects That Explain Mate Choice in a Songbird”, Wang et al 2022
- “The Human Black-Box: The Illusion of Understanding Human Better Than Algorithmic Decision-Making”, Bonezzi et al 2022
- “National Security Commission On Artificial Intelligence Final Report”, Schmidt et al 2021
- “How Humans Impair Automated Deception Detection Performance”, Kleinberg & Verschuere 2021
- “Neuroprosthesis for Decoding Speech in a Paralyzed Person With Anarthria [Supplementary Appendix]”, Moses et al 2021
- “Underspecification Presents Challenges for Credibility in Modern Machine Learning”, D’Amour et al 2020
- “A Time Leap Challenge for SAT Solving”, Fichte et al 2020
- “Superexponential [Modeling the Human Trajectory]”, Roodman 2020
- “A Promising Path Towards Autoformalization and General Artificial Intelligence”, Szegedy 2020
- “Ball k-Means: A Fast Adaptive k-Means With No Bounds”, Xia et al 2020b
- “Modeling the Human Trajectory”, Roodman 2020
- “I Worked for Cycorp for a Few Years Recently. AMA, I Guess?”, catpolice 2019
- “Video-Guided Real-To-Virtual Parameter Transfer for Viscous Fluids”, Takahashi & Lin 2019
- This Could Be Important: My Life and Times With the Artificial Intelligentsia, McCorduck 2019
- “A Mulching Proposal”, Keyes et al 2019
- “Monte Carlo Gradient Estimation in Machine Learning”, Mohamed et al 2019
- “Living With Harmony: A Personal Companion System by Realbotix™”, Coursey et al 2019
- “SageDB: A Learned Database System”, Kraska 2019
- “The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities”, Lehman et al 2018
- “Generation of Character Illustrations from Stick Figures Using a Modification of Generative Adversarial Network”, Fukumoto et al 2018
- “Reply to ‘Man against Machine: Diagnostic Performance of a Deep Learning Convolutional Neural Network for Dermoscopic Melanoma Recognition in Comparison to 58 Dermatologists’ by H. A. Haenssle Et Al”, Oakden-Rayner 2018
- “Preprint Déjà Vu: an FAQ”, Ginsparg 2017
- “When Will AI Exceed Human Performance? Evidence from AI Experts”, Grace et al 2017
- “The Implications of Modern Business-Entity Law for the Regulation of Autonomous Systems”, Bayern 2016
- “Is Spearman’s Law of Diminishing Returns (SLODR) Meaningful for Artificial Agents?”, Hernandez-Orallo 2016
- “Reflective Oracles: A Foundation for Classical Game Theory”, Fallenstein et al 2015
- “Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education”, Zhu 2015b
- “Bounded Kolmogorov Complexity Based on Cognitive Models”, Strannegård et al 2013
- “Indefinite Survival through Backup Copies”, Sandberg & Armstrong 2012
- “Electron Imaging Technology For Whole Brain Neural Circuit Mapping”, Hayworth 2012
- “The International SAT Solver Competitions”, Järvisalo et al 2012
- “Experimental Evolution of Multicellularity”, Ratcliff et al 2012
- “Why Philosophers Should Care About Computational Complexity”, Aaronson 2011
- “What Is the Semantic Apocalypse?”, Bakker 2011
- “Ontological Crises in Artificial Agents’ Value Systems”, Blanc 2011
- “Extracting Social Networks from Literary Fiction”, Elson et al 2010
- “Robots Should Be Slaves”, Bryson 2010
- “A Monte Carlo AIXI Approximation”, Veness et al 2009
- “Machine Learning Attacks against the Asirra CAPTCHA”, Golle 2008
- “InterNyet: Why the Soviet Union Did Not Build a Nationwide Computer Network”, Gerovitch 2008
- “The Basic AI Drives”, Omohundro 2008
- “Asirra: a CAPTCHA That Exploits Interest-Aligned Manual Image Categorization”, Elson et al 2007
- “On Universal Prediction and Bayesian Confirmation”, Hutter 2007
- “Self-Taught Learning: Transfer Learning from Unlabeled Data”, Raina et al 2007
- “An Example of Statistical Investigation of the Text Eugene Onegin Concerning the Connection of Samples in Chains”, Markov 2006
- “Is There an Elegant Universal Theory of Prediction?”, Legg 2006
- “Assessing the Impact of the Green Revolution, 1960–2000”, Evenson & Gollin 2003
- “The Fastest and Shortest Algorithm for All Well-Defined Problems”, Hutter 2002
- “DART: Revolutionizing Logistics Planning”, Hedberg 2002
- “Effects of Experience and Social Context on Prospective Caching Strategies by Scrub Jays”, Emery & Clayton 2001
- “Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine”, Taylor & Massey 2001 (page 6)
- “Efficient Progressive Sampling”, Provost et al 1999b
- “On the Optimality of the Simple Bayesian Classifier under Zero-One Loss”, Domingos & Pazzani 1997
- “An Evolved Circuit, Intrinsic in Silicon, Entwined With Physics”, Thompson 1997
- “The Psychology of Thinking: Embedding Artifice in Nature”, Simon 1996
- “Mazes Without Minotaurs”, Simon & Borges 1996b
- “A Personal View of Average-Case Complexity”, Impagliazzo 1995
- “Measuring the Complexity of Writing Systems”, Bosch et al 1994
- “Artificial Life: A Report from the Frontier Where Computers Meet Biology”, Levy 1992
- “Where’s the AI?”, Schank 1991
- “Oral History Interview With Terry Allen Winograd (OH #237) § SHRDLU”, Winograd & Norberg 1991 (page 7)
- “The Clarke Tax As a Consensus Mechanism among Automated Agents”, Ephrati & Rosenschein 1991
- “Making a Mind Versus Modeling the Brain: Artificial Intelligence Back at the Branchpoint”, Dreyfus & Dreyfus 1991
- “Copycat: A Computer Model of High-Level Perception and Conceptual Slippage in Analogy Making”, Mitchell 1990
- “In Memory of Henry J. Kelley”, Cliff 1989
- “Machine Learning As an Experimental Science”, Langley 1988
- “The Rise of the Expert Company: How Visionary Companies Are Using Artificial Intelligence to Archieve Higher Productivity and Profits”, Feigenbaum et al 1988
- “One AI or Many?”, Papert 1988
- “Acoustic Markov Models Used in the Tangora Speech Recognition System”, Bahl et al 1988
- “Profile of Claude Shannon”, Liversidge & Shannon 1987
- “Experiments With the Tangora 20,000 Word Speech Recognizer”, Averbuch et al 1987
- “A Critique of Pure Reason”, McDermott 1987
- “On Machine Intelligence, Second Edition”, Michie 1986
- “The Universal Machine: Confessions of a Technological Optimist”, McCorduck 1985
- “Human Window on the World”, Michie 1985
- “Randomness Conservation Inequalities; Information and Independence in Mathematical Theories”, Levin 1984
- “Epigrams on Programming”, Perlis 1982
- Interstellar Communication: Scientific Perspectives, Ponnamperuma & Cameron 1974
- “Universal Sequential Search Problems”, Levin 1973
- Evolutionsstrategie: Optimierung Technischer Systeme Nach Prinzipien Der Biologischen Evolution, Rechenberg 1973
- “Scene Of Change: A Lifetime in American Science”, Weaver 1970
- “Experiments in the Recognition of Hand-Printed Text, Part II: Context Analysis”, Duda & Hart 1968
- “Experiments in the Recognition of Hand-Printed Text, Part I: Character Recognition”, Munson 1968b
- “Cybernetic Predicting Devices”, Ivakhnenko & Lapa 1966
- “Speculations Concerning the First Ultraintelligent Machine”, Good 1966
- “Singular Extremals In Lawden’s Problem Of Optimal Rocket Flight”, Kelley 1963
- “A Steepest-Ascent Method for Solving Optimum Programming Problems”, Bryson & Denham 1962
- “The Social Implications of Artificial Intelligence”, Good 1962
- “Method of Gradients”, Kelley 1962
- “Design for an Intelligence-Amplifier”, Ashby 1956
- “A Proposal For The Dartmouth Summer Research Project On Artificial Intelligence”, McCarthy 1955
- “Intelligent Machinery, A Heretical Theory”, Turing 1951
- “Review of a Book by D. R. Hartree”, Good 1951
- “Computing Machinery And Intelligence”, Turing 1950
- “Chance Remarks”, Pierce 1949
- “Principles of the Self-Organizing Dynamic System”, Ashby 1947
- “2022 Expert Survey on Progress in AI”
- “The Ethics of Reward Shaping”
- “What Was Radiant AI, Anyway?”
- “Rules of Machine Learning”, Google 2026
- “David Gros Homepage”, Gros 2026
- “Using Artificial Intelligence to Augment Human Intelligence”
- “Branch Specialization”
- “A Thinking Ape’s Critique of Trans-Simianism”
- “Blendshape and Kinematics Calculator for Mediapipe/Tensorflow.js Face, Eyes, Pose, and Finger Tracking Models.”
- “The Nature of Art”, Leroi 2026
- “Tomás Bjartur: The Last Prodigy”, Linch 2026
- “About My Writing”, Chapman 2026
- “Niplav’s Homepage”, niplav 2026
- “Some Thoughts on Education and Political Priorities, Cummings 2013”
- “Alexey Turchin”
- “Submission #6347: Chef Stef’s NES Arkanoid
warplessin 11:11.18” - “Optical Character Recognition (OCR) in Google Docs”
- “Policy for LLM Writing on LessWrong”
- “Recent Progress in the Theory of Neural Networks”
- “A Primer on Why Computational Predictive Toxicology Is Hard”
- “Polly Wants a Better Argument [More Debunking of Bender & Koller 2020]”
- “The ACLU Fights for Your Constitutional Right to Make Deepfakes”
- Sort By Magic
- Wikipedia (19)
- Miscellaneous
- Bibliography
See Also
Gwern
“Towards a Better Hutter Prize”, Gwern 2026
“Copyright & AI”, Gwern 2023
“LLM Acceptable-Use Policy”, Gwern 2024
“The Existential Risk of Math Errors”, Gwern 2012
“Complexity No Bar to AI”, Gwern 2014
Links
“FBI Is Buying Data That Can Be Used to Track People, Patel Says: This Is the First Confirmation That the FBI Has Resumed Actively Buying People’s Data for Investigations”
“Celebrating Flickr Technology”, Steerpike 2026
“The Homogenizing Effect of Large Language Models on Human Expression and Thought”, Sourati et al 2026
The homogenizing effect of large language models on human expression and thought
“The World Is Too Much With Us”, Chatti & Pro 2026
“Gyre”, vgel 2026
“Notable Progress Has Been Made in Whole Brain Emulation”
“Fighting Fire With Fire: Scalable Oral Exams With an 11Labs Voice AI Agent”, Ipeirotis 2025
Fighting Fire with Fire: Scalable Oral Exams with an 11Labs Voice AI Agent
“How AI and Wikipedia Have Sent Vulnerable Languages into a Doom Spiral: Machine Translators Have Made It Easier Than Ever to Create Error-Plagued Wikipedia Articles in Obscure Languages. What Happens When AI Models Get Trained on Junk Pages?”, Judah 2025
“Elon Musk XAI Dropped Public Benefit Corp Status While Fighting OpenAI”
Elon Musk xAI dropped public benefit corp status while fighting OpenAI
“unfake.js: Fix AI Pixel Art and Vector Images Right in Your Browser”, jenissimo 2025
unfake.js: Fix AI pixel art and vector images right in your browser
henloitsjoyce @ "2025-08-07"
“What Web Browsing Data Tells Us About How AI Appears Online: An Analysis of One Month of Browsing Data Finds ~6⁄10 Respondents Visited a Search Page With AI-Generated Summary. But Visits to More In-Depth Content about AI Were Relatively Rare”, Chapekis et al 2025
“AI, Materials, and Fraud, Oh My! The Red Flags We Should Have Seen Earlier for a Too-Good-To-Be-True Paper on AI Tool Adoption at a Materials Research Firm”, Shindel 2025
“I Knew AI Was Coming for My Job. I Wasn’t Prepared for It to Come for My Heart”, Baird 2025
I knew AI was coming for my job. I wasn’t prepared for it to come for my heart
“Pope Leo XIV: AI Inspired Name Choice”, Service 2025
“Chilean Cardinal Gives Insight to the Conclave That Elected Pope Leo XIV [‘Leo’ Choice Motivated by AI]”, Martin 2025
“As ‘Bot’ Students Continue to Flood In, Community Colleges Struggle to Respond”, McWhinney 2025
As ‘Bot’ Students Continue to Flood In, Community Colleges Struggle to Respond
“Born in the Wrong Generation: You Have Gone Nowhere. There Is Nowhere for You to Go”, Kriss 2025
Born in the wrong generation: You have gone nowhere. There is nowhere for you to go
“cyc-Archive: An Archive of Material Related to the Cyc Project”, Liu 2025
cyc-archive: An archive of material related to the Cyc project
“The Cultural Divide between Mathematics and AI: A Reflection on Cultural Differences Observed at the 2025 Joint Mathematics Meeting”, Furman 2025
“A Man Stalked a Professor for 6 Years. Then He Used AI Chatbots to Lure Strangers to Her Home”
A man stalked a professor for 6 years. Then he used AI chatbots to lure strangers to her home
“AI Will Write Complex Laws”, Schneier & Sanders 2025
“AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking”, Gerlich 2025
AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking
“About Jasmine Sun”, Sun 2025
“To Whom Does the World Belong? The Battle over Copyright in the Age of ChatGPT”, Hartley 2024
To Whom Does the World Belong? The battle over copyright in the age of ChatGPT
“An 83-Year-Old Short Story [‘The Library of Babel’] by Jorge Luis Borges Portends a Bleak Future for the Internet”, Kreuz 2024
“More to Lose: The Adverse Effect of High Performance Ranking on Employees’ Pre-Implementation Attitudes Toward the Integration of Powerful AI Aids”, SimanTov-Nachlieli 2024
“How to Build the Virtual Cell With Artificial Intelligence: Priorities and Opportunities”, Bunne et al 2024
How to Build the Virtual Cell with Artificial Intelligence: Priorities and Opportunities
“Wu’s Method Can Boost Symbolic AI to Rival Silver Medalists and AlphaGeometry to Outperform Gold Medalists at IMO Geometry”, Sinha et al 2024
“Thousands of AI Authors on the Future of AI”, Grace et al 2024
“Bayesian Regression Markets”, Falconer et al 2023
“A Quantitative Study of Inappropriate Image Duplication in the Journal Toxicology Reports”, David 2023
A Quantitative Study of Inappropriate Image Duplication in the Journal Toxicology Reports
“Getting from Generative AI to Trustworthy AI: What LLMs Might Learn from Cyc”, Lenat & Marcus 2023
Getting from Generative AI to Trustworthy AI: What LLMs might learn from Cyc
“How AI Can Distort Human Beliefs”, Kidd & Birhane 2023
“On Herbert A. Simon And Jorge Luis Borges About Free Will”, Crespo 2023
“Defending Humankind: Anthropocentric Bias in the Appreciation of AI Art”, Millet et al 2023
Defending humankind: Anthropocentric bias in the appreciation of AI art
“Exposure to Automation Explains Religious Declines”, Jackson et al 2023
“Impossibility Theorems for Feature Attribution”, Bilodeau et al 2022
“Who Made the Paintings: Artists or Artificial Intelligence? The Effects of Identity on Liking and Purchase Intention”, Gu & Li 2022
“Would You Pass the Turing Test? Influencing Factors of the Turing Decision”, Ujhelyi et al 2022
Would You Pass the Turing Test? Influencing Factors of the Turing Decision
“Machine Learning Reveals Cryptic Dialects That Explain Mate Choice in a Songbird”, Wang et al 2022
Machine learning reveals cryptic dialects that explain mate choice in a songbird
“The Human Black-Box: The Illusion of Understanding Human Better Than Algorithmic Decision-Making”, Bonezzi et al 2022
The Human Black-Box: The Illusion of Understanding Human Better Than Algorithmic Decision-Making
“National Security Commission On Artificial Intelligence Final Report”, Schmidt et al 2021
National Security Commission On Artificial Intelligence Final Report
“How Humans Impair Automated Deception Detection Performance”, Kleinberg & Verschuere 2021
“Neuroprosthesis for Decoding Speech in a Paralyzed Person With Anarthria [Supplementary Appendix]”, Moses et al 2021
Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria [Supplementary Appendix]
“Underspecification Presents Challenges for Credibility in Modern Machine Learning”, D’Amour et al 2020
Underspecification Presents Challenges for Credibility in Modern Machine Learning
“A Time Leap Challenge for SAT Solving”, Fichte et al 2020
“Superexponential [Modeling the Human Trajectory]”, Roodman 2020
“A Promising Path Towards Autoformalization and General Artificial Intelligence”, Szegedy 2020
A Promising Path Towards Autoformalization and General Artificial Intelligence
“Ball k-Means: A Fast Adaptive k-Means With No Bounds”, Xia et al 2020b
“Modeling the Human Trajectory”, Roodman 2020
“I Worked for Cycorp for a Few Years Recently. AMA, I Guess?”, catpolice 2019
“Video-Guided Real-To-Virtual Parameter Transfer for Viscous Fluids”, Takahashi & Lin 2019
Video-Guided Real-to-Virtual Parameter Transfer for Viscous Fluids
This Could Be Important: My Life and Times With the Artificial Intelligentsia, McCorduck 2019
This Could Be Important: My Life and Times with the Artificial Intelligentsia
“A Mulching Proposal”, Keyes et al 2019
“Monte Carlo Gradient Estimation in Machine Learning”, Mohamed et al 2019
“Living With Harmony: A Personal Companion System by Realbotix™”, Coursey et al 2019
Living with Harmony: A Personal Companion System by Realbotix™
“SageDB: A Learned Database System”, Kraska 2019
“The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities”, Lehman et al 2018
“Generation of Character Illustrations from Stick Figures Using a Modification of Generative Adversarial Network”, Fukumoto et al 2018
“Reply to ‘Man against Machine: Diagnostic Performance of a Deep Learning Convolutional Neural Network for Dermoscopic Melanoma Recognition in Comparison to 58 Dermatologists’ by H. A. Haenssle Et Al”, Oakden-Rayner 2018
“Preprint Déjà Vu: an FAQ”, Ginsparg 2017
“When Will AI Exceed Human Performance? Evidence from AI Experts”, Grace et al 2017
When Will AI Exceed Human Performance? Evidence from AI Experts
“The Implications of Modern Business-Entity Law for the Regulation of Autonomous Systems”, Bayern 2016
The Implications of Modern Business-Entity Law for the Regulation of Autonomous Systems
“Is Spearman’s Law of Diminishing Returns (SLODR) Meaningful for Artificial Agents?”, Hernandez-Orallo 2016
Is Spearman’s law of diminishing returns (SLODR) meaningful for artificial agents?
“Reflective Oracles: A Foundation for Classical Game Theory”, Fallenstein et al 2015
“Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education”, Zhu 2015b
Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education
“Bounded Kolmogorov Complexity Based on Cognitive Models”, Strannegård et al 2013
“Indefinite Survival through Backup Copies”, Sandberg & Armstrong 2012
“Electron Imaging Technology For Whole Brain Neural Circuit Mapping”, Hayworth 2012
Electron Imaging Technology For Whole Brain Neural Circuit Mapping
“The International SAT Solver Competitions”, Järvisalo et al 2012
“Experimental Evolution of Multicellularity”, Ratcliff et al 2012
“Why Philosophers Should Care About Computational Complexity”, Aaronson 2011
“What Is the Semantic Apocalypse?”, Bakker 2011
“Ontological Crises in Artificial Agents’ Value Systems”, Blanc 2011
“Extracting Social Networks from Literary Fiction”, Elson et al 2010
“Robots Should Be Slaves”, Bryson 2010
“A Monte Carlo AIXI Approximation”, Veness et al 2009
“Machine Learning Attacks against the Asirra CAPTCHA”, Golle 2008
“InterNyet: Why the Soviet Union Did Not Build a Nationwide Computer Network”, Gerovitch 2008
InterNyet: why the Soviet Union did not build a nationwide computer network
“The Basic AI Drives”, Omohundro 2008
“Asirra: a CAPTCHA That Exploits Interest-Aligned Manual Image Categorization”, Elson et al 2007
Asirra: a CAPTCHA that exploits interest-aligned manual image categorization
“On Universal Prediction and Bayesian Confirmation”, Hutter 2007
“Self-Taught Learning: Transfer Learning from Unlabeled Data”, Raina et al 2007
“An Example of Statistical Investigation of the Text Eugene Onegin Concerning the Connection of Samples in Chains”, Markov 2006
“Is There an Elegant Universal Theory of Prediction?”, Legg 2006
“Assessing the Impact of the Green Revolution, 1960–2000”, Evenson & Gollin 2003
“The Fastest and Shortest Algorithm for All Well-Defined Problems”, Hutter 2002
The Fastest and Shortest Algorithm for All Well-Defined Problems
“DART: Revolutionizing Logistics Planning”, Hedberg 2002
“Effects of Experience and Social Context on Prospective Caching Strategies by Scrub Jays”, Emery & Clayton 2001
Effects of experience and social context on prospective caching strategies by scrub jays
“Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine”, Taylor & Massey 2001 (page 6)
“Efficient Progressive Sampling”, Provost et al 1999b
“On the Optimality of the Simple Bayesian Classifier under Zero-One Loss”, Domingos & Pazzani 1997
On the Optimality of the Simple Bayesian Classifier under Zero-One Loss
“An Evolved Circuit, Intrinsic in Silicon, Entwined With Physics”, Thompson 1997
An evolved circuit, intrinsic in silicon, entwined with physics
“The Psychology of Thinking: Embedding Artifice in Nature”, Simon 1996
“Mazes Without Minotaurs”, Simon & Borges 1996b
“A Personal View of Average-Case Complexity”, Impagliazzo 1995
“Measuring the Complexity of Writing Systems”, Bosch et al 1994
“Artificial Life: A Report from the Frontier Where Computers Meet Biology”, Levy 1992
Artificial Life: A Report from the Frontier Where Computers Meet Biology
“Where’s the AI?”, Schank 1991
“Oral History Interview With Terry Allen Winograd (OH #237) § SHRDLU”, Winograd & Norberg 1991 (page 7)
Oral History Interview with Terry Allen Winograd (OH #237) § SHRDLU
“The Clarke Tax As a Consensus Mechanism among Automated Agents”, Ephrati & Rosenschein 1991
The Clarke tax as a consensus mechanism among automated agents
“Making a Mind Versus Modeling the Brain: Artificial Intelligence Back at the Branchpoint”, Dreyfus & Dreyfus 1991
Making a Mind Versus Modeling the Brain: Artificial Intelligence Back at the Branchpoint
“Copycat: A Computer Model of High-Level Perception and Conceptual Slippage in Analogy Making”, Mitchell 1990
Copycat: A computer model of high-level perception and conceptual slippage in analogy making
“In Memory of Henry J. Kelley”, Cliff 1989
“Machine Learning As an Experimental Science”, Langley 1988
“The Rise of the Expert Company: How Visionary Companies Are Using Artificial Intelligence to Archieve Higher Productivity and Profits”, Feigenbaum et al 1988
“One AI or Many?”, Papert 1988
“Acoustic Markov Models Used in the Tangora Speech Recognition System”, Bahl et al 1988
Acoustic Markov models used in the Tangora speech recognition system
“Profile of Claude Shannon”, Liversidge & Shannon 1987
“Experiments With the Tangora 20,000 Word Speech Recognizer”, Averbuch et al 1987
“A Critique of Pure Reason”, McDermott 1987
“On Machine Intelligence, Second Edition”, Michie 1986
“The Universal Machine: Confessions of a Technological Optimist”, McCorduck 1985
The Universal Machine: Confessions of a Technological Optimist
“Human Window on the World”, Michie 1985
“Randomness Conservation Inequalities; Information and Independence in Mathematical Theories”, Levin 1984
Randomness conservation inequalities; information and independence in mathematical theories
“Epigrams on Programming”, Perlis 1982
Interstellar Communication: Scientific Perspectives, Ponnamperuma & Cameron 1974
“Universal Sequential Search Problems”, Levin 1973
Evolutionsstrategie: Optimierung Technischer Systeme Nach Prinzipien Der Biologischen Evolution, Rechenberg 1973
Evolutionsstrategie: Optimierung technischer Systeme nach Prinzipien der biologischen Evolution
“Scene Of Change: A Lifetime in American Science”, Weaver 1970
“Experiments in the Recognition of Hand-Printed Text, Part II: Context Analysis”, Duda & Hart 1968
Experiments in the recognition of hand-printed text, part II: context analysis
“Experiments in the Recognition of Hand-Printed Text, Part I: Character Recognition”, Munson 1968b
Experiments in the recognition of hand-printed text, part I: character recognition
“Cybernetic Predicting Devices”, Ivakhnenko & Lapa 1966
“Speculations Concerning the First Ultraintelligent Machine”, Good 1966
“Singular Extremals In Lawden’s Problem Of Optimal Rocket Flight”, Kelley 1963
Singular Extremals In Lawden’s Problem Of Optimal Rocket Flight
“A Steepest-Ascent Method for Solving Optimum Programming Problems”, Bryson & Denham 1962
A Steepest-Ascent Method for Solving Optimum Programming Problems
“The Social Implications of Artificial Intelligence”, Good 1962
“Method of Gradients”, Kelley 1962
“Design for an Intelligence-Amplifier”, Ashby 1956
“A Proposal For The Dartmouth Summer Research Project On Artificial Intelligence”, McCarthy 1955
A Proposal For The Dartmouth Summer Research Project On Artificial Intelligence
“Intelligent Machinery, A Heretical Theory”, Turing 1951
“Review of a Book by D. R. Hartree”, Good 1951
“Computing Machinery And Intelligence”, Turing 1950
“Chance Remarks”, Pierce 1949
“Principles of the Self-Organizing Dynamic System”, Ashby 1947
“2022 Expert Survey on Progress in AI”
“The Ethics of Reward Shaping”
“What Was Radiant AI, Anyway?”
“Rules of Machine Learning”, Google 2026
“David Gros Homepage”, Gros 2026
“Using Artificial Intelligence to Augment Human Intelligence”
Using Artificial Intelligence to Augment Human Intelligence
View External Link:
“Branch Specialization”
“A Thinking Ape’s Critique of Trans-Simianism”
“Blendshape and Kinematics Calculator for Mediapipe/Tensorflow.js Face, Eyes, Pose, and Finger Tracking Models.”
“The Nature of Art”, Leroi 2026
“Tomás Bjartur: The Last Prodigy”, Linch 2026
“About My Writing”, Chapman 2026
“Niplav’s Homepage”, niplav 2026
“Some Thoughts on Education and Political Priorities, Cummings 2013”
Some thoughts on education and political priorities, Cummings 2013
“Alexey Turchin”
“Submission #6347: Chef Stef’s NES Arkanoid warpless in 11:11.18”
Submission #6347: Chef Stef’s NES Arkanoid warpless in 11:11.18
“Optical Character Recognition (OCR) in Google Docs”
“Policy for LLM Writing on LessWrong”
“Recent Progress in the Theory of Neural Networks”
Recent Progress in the Theory of Neural Networks
View External Link:
“A Primer on Why Computational Predictive Toxicology Is Hard”
“Polly Wants a Better Argument [More Debunking of Bender & Koller 2020]”
Polly Wants a Better Argument [more debunking of Bender & Koller 2020]
“The ACLU Fights for Your Constitutional Right to Make Deepfakes”
The ACLU Fights for Your Constitutional Right to Make Deepfakes
View External Link:
https://www.wired.com/story/aclu-artificial-intelligence-deepfakes-free-speech/
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
bot-management
impact-assessment
personalized-companions
virtual-cell
adversarial-learning
evolutionary-computation
Wikipedia (19)
Miscellaneous
/doc/ai/2021-anonymous-meme-virginvschad-journalpapervsblogpost.jpghttps://cdn.aaai.org/ojs/12468/12468-52-15996-1-2-20201228.pdf/doc/ai/2020-09-01-gwern-meme-thesilentprotector-tensorfork.png/doc/ai/2020-adiwardana-meena-figure1-humanratingsvslikelihood.png/doc/ai/2019-11-26-gwern-deeplearning-kaibadeafeatmeme-tensorflowupgrading.png/doc/ai/2018-mahajan-figure5-imagenetclassificationscalingcurvebymodelparametersize.jpg/doc/ai/2015-01-28-spidermanandthexmen-vol1-no2-sauron-cancerdinosaurs.jpg/doc/ai/2014-02-rameznaam-thesingularityisfurtherthanitappears-chemicalmodelingexponential.jpg/doc/ai/2014-02-whyaiswontascend-figure1-intelligencegrowthunderdifficulty.png/doc/ai/2012-jarvisalo-figure2-satsolverimprovementovertime20022011.jpg/doc/ai/2003-11-07-clayshirky-thesemanticwebsyllogismandworldview.html/doc/fiction/science-fiction/1990-dansimmons-thefallofhyperion-ch41-ummonquotesoceanus.pnghttps://gidishperber.medium.com/what-ive-learned-from-kaggle-s-fisheries-competition-92342f9ca779https://markusstrasser.org/extracting-knowledge-from-literature/https://people.csail.mit.edu/tzumao/diffvg/View External Link:
https://www.exag.org/papers/Retcon%20A%20Least-Commitment%20Story-World%20System.pdfhttps://www.gutenberg.org/cache/epub/16550/pg16550-images.html#Cpage445https://www.quantamagazine.org/secret-messages-can-hide-in-ai-generated-media-20230518/https://www.schneier.com/blog/archives/2023/03/how-ai-could-write-our-laws.html
{kind=link}
{kind=link}
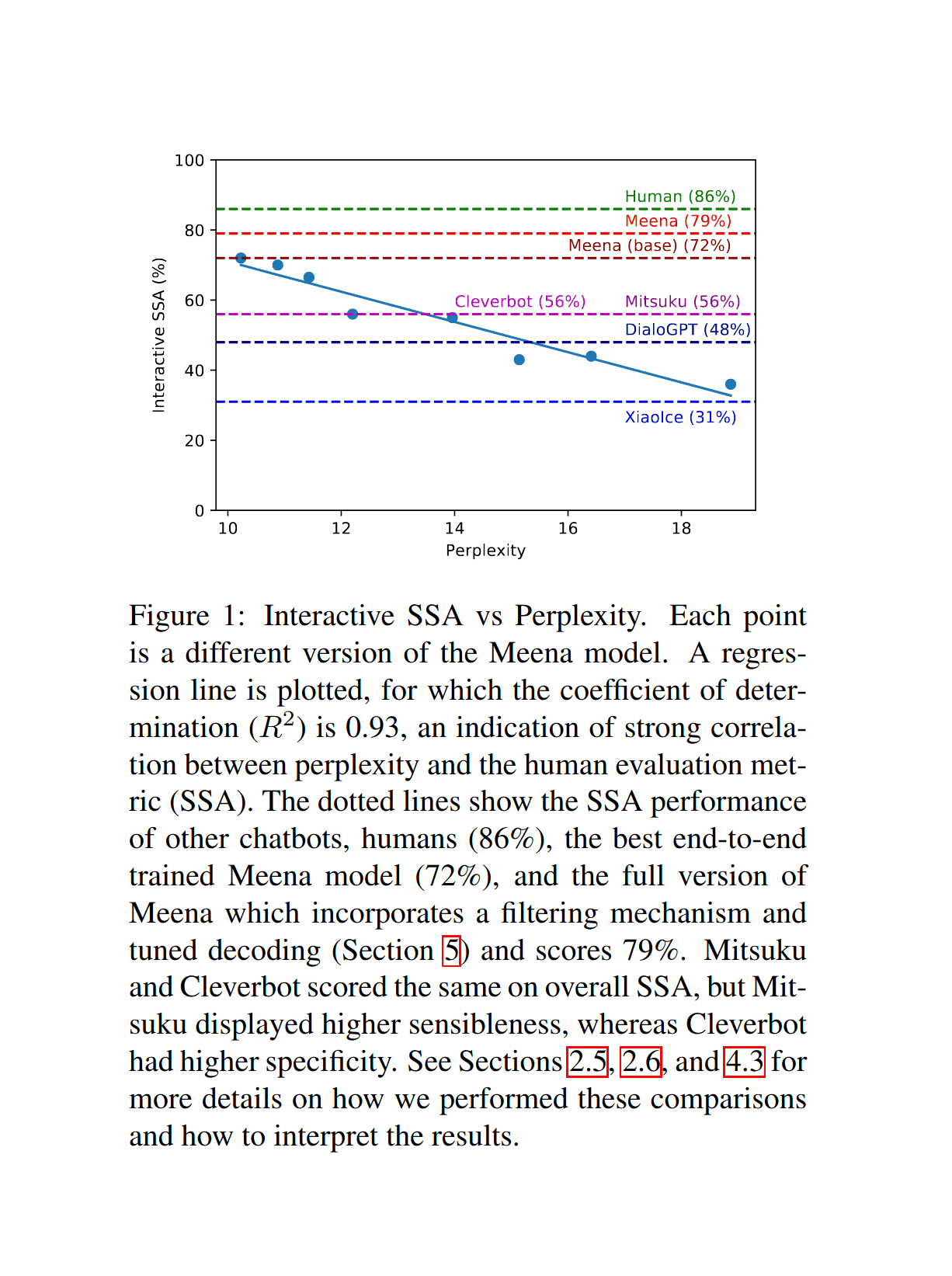{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
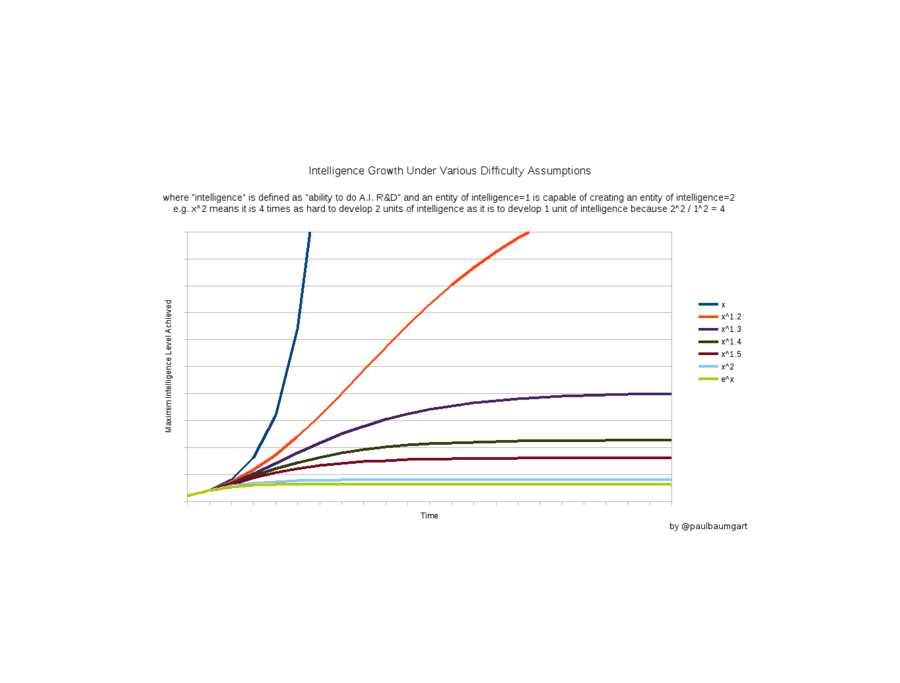{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://poets.org/poem/world-too-much-us-0: “The World Is Too Much With Us”,https://arxiv.org/abs/2401.02843: “Thousands of AI Authors on the Future of AI”,https://arxiv.org/abs/2308.04445: “Getting from Generative AI to Trustworthy AI: What LLMs Might Learn from Cyc”,https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2022.941163/full: “Who Made the Paintings: Artists or Artificial Intelligence? The Effects of Identity on Liking and Purchase Intention”,2022-ujhelyi.pdf: “Would You Pass the Turing Test? Influencing Factors of the Turing Decision”,2019-mccorduck-thiscouldbeimportant.epub: This Could Be Important: My Life and Times With the Artificial Intelligentsia,2015-zhu-2.pdf: “Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education”,2010-bryson.pdf: “Robots Should Be Slaves”,2008-gerovitch.pdf: “InterNyet: Why the Soviet Union Did Not Build a Nationwide Computer Network”,2001-taylor.pdf#page=6: “Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine”,1994-vandenbosch.pdf: “Measuring the Complexity of Writing Systems”,1991-winograd.pdf#page=7: “Oral History Interview With Terry Allen Winograd (OH #237) § SHRDLU”,1966-good.pdf: “Speculations Concerning the First Ultraintelligent Machine”,1951-turing.pdf: “Intelligent Machinery, A Heretical Theory”,