‘tech’ directory
- See Also
- Gwern
- “Trace of the True Self”, Gwern et al 2026
- “‘Elegy in a Craneyard’ Graveyard Notes”, Gwern et al 2026
- “Silver Bird Above San Francisco”, Gwern et al 2025
- “Peak Pre-Modern Human Speed”, Gwern 2022
- “Plumbing vs Internet, Revisited”, Gwern 2025
- “Research Bounties On Fulltexts”, Gwern 2018
- “Epigrams”, Gwern 2014
- “Startup Ideas”, Gwern 2017
- “Adjusting Linux Pulseaudio Frequency Settings for Hearing Loss”, Gwern 2014
- “CO2 Coin: Decentralized Carbon Capture Blockchains”, Gwern 2021
- “Newton’s System of the World and Comets”, Gwern 2016
- “Evolution As Backstop for Reinforcement Learning”, Gwern 2018
- “Progress In Beauty”, Gwern 2016
- “About Gwern”, Gwern 2009
- “Music and Distraction”, Gwern 2012
- “Girl Scouts & Good Corporate Governance”, Gwern 2011
- “Choosing Software”, Gwern 2008
- “Wikipedia and Other Wikis”, Gwern 2009
- “Resilient Haskell Software”, Gwern 2008
- Links
- “Inventing the ‘Methods’ Section: What the Evolution of Scientific Methods Says about Their Future”, Hunt 2026
- “How Getting Richer Made Teenagers Less Free: We Value Children More Than Ever. But We’re Suffocating Them”, Piper 2025
- “Want a Fortell Hearing Aid? Well, Who Do You Know? AI-Powered Startup Fortell Has Become a Secret Handshake for the Privileged Hearing-Impaired Crowd Who Swear by the Product. Now, It Wants to Be in Your Ears”, Levy 2025
- “Air Lab Is the Flipper Zero of Air Quality Monitors”, Geerling 2025
- “Marble Fountain [Evolving a 3D-Printed Marble Run]”, Morrison 2025
- “Bacteriophage-Loaded Microneedle Patches for Targeted and Minimally Disruptive Foodborne Pathogen Decontamination”, Prasad et al 2025
- “Masonry Techniques of the Inca’s Master Builders”, Trupp 2025
- “How Pen Caps Work”, MacIver 2025
- “On Factory Tours”, Colman 2025
- “Kirigami-Inspired Parachutes With Programmable Reconfiguration”, Lamoureux et al 2025
- “Could You Defeat A Tyrannosaurus Rex? [Testing Elephant Guns on Dino-Sized Ballistic Gel]”, Ballistics 2025
- “Pulse-Fi: A Low-Cost System for Accurate Heart Rate Monitoring Using Wi-Fi Channel State Information”, Kocheta et al 2025
- “Falsehoods Programmers Believe About Aviation”, Burwell 2025
- “Ordinary Life Improvements Since 2018”, Smagin 2025
- “Near-Infrared Spatiotemporal Color Vision in Humans Enabled by Upconversion Contact Lenses”
- “Nikolai Agnivtsev’s Little Screw (1925)”
- “Subtitling Your Life: Hearing Aids and Cochlear Implants Have Been Getting Better for Years, but a New Type of Device—Eyeglasses That Display Real-Time Speech Transcription on Their Lenses—Are a Game-Changing Breakthrough”, Owen 2025
- “Flushed Away: The Crappy Lie Americans Still Believe about Their Toilets”, Gibbs 2025
- “Teach Your Microscope How to Print: Low-Cost and Rapid-Iteration Microfabrication for Biology”, Hinderling et al 2025
- “Undersea Nuclear Forces: Survivability of Chinese, Russian, and US SSBNs”, Stefanick 2025
- “Norman Foster’s Architectural Empire”
- “Texas v. NRC Complaint”, Texas et al 2024
- “The Global Race For Talent: Brain Drain, Knowledge Transfer, And Growth”, Marta 2024
- “Y Combinator Often Backs Startups That Duplicate Other YC Companies, Data Shows—Not Just AI Code Editors”
- “‘You Tried to Tell Yourself I Wasn’t Real’: What Happens When People With Acute Psychosis Meet the Voices in Their Heads?”
- “Satu Rämö’s Novel Received 1-Star Reviews on Amazon UK Because the Wrong Story Was Published on the Cover of the Hildur Book”, Koivuranta 2024
- “The Value of Space Activity”, Lowe 2024
- “Automated Photogrammetric Close-Range Imaging System for Small Invertebrates Using Acoustic Levitation”, Klug et al 2024
- “The Hidden Engineering of Landfills”
- “The World’s Loudest Lisp Program to the Rescue [Designing a Network of Tunnel Alarms]”, Zaikonnikov 2024
- “Battle Over Startup Leaves Early Investor With No Equity, $2.6 Million Legal Bill § The Information PR War”, McBride 2024
- “The Ant And The Grasshopper: Seasonality And The Invention Of Agriculture”, Matranga 2024
- “Shell Buckling for Programmable Metafluids”, Djellouli et al 2024
- “The Road to Zero: The 50-Year Effort to Eliminate Roof Fall Fatalities from US Underground Coal Mines”, Mark 2024
- “Are We Safe from Lightning Inside Buildings? A Study of Lightning Fatalities Inside Buildings Using Smartphones”, Souza et al 2024
- “What Happens When You Touch a Pickle to an AM Radio Tower?”, Geerling 2024
- “Open Source Data Programs From Low-Earth Orbit Synthetic Aperture Radar Companies: Questions and Answers [Industry Profiles and Activities]”, Patel 2023
- “Lord of the Roths: How Tech Mogul Peter Thiel Turned a Retirement Account for the Middle Class Into a $5 Billion Tax-Free Piggy Bank”
- “America, Jump-Started: World War II R&D and the Takeoff of the US Innovation System”, Gross & Sampat 2023
- “Taxonomy and Nomenclature for the Stone Domain in New England”, Thorson 2023
- “Testing My Speech Jammer In Public”, Jordan 2023
- “Testing My Speech Jammer In Public § Speech Jammer Immunity”, Jordan 2023
- “Application of the Thermodynamics of Radiation to Dyson Spheres As Work Extractors and Computational Engines, and Their Observational Consequences”, Wright 2023
- “The Oxygen Bottleneck for Technospheres”, Balbi & Frank 2023
- “Solecooler’s Reversible Insoles ‘Climfeet’ Adjust Foot Temperature to Keep Them Warm or Cool”
- “Insights from a Laboratory Fire”, Jones et al 2023
- “Elephant Rifle Annihilates Ballistic Gel at 82,000FPS § Combustion by Compression”, Guys 2023
- “Rebecca Struthers on Watches, Watchmaking, and the Hands of Time § Practical Challenges With Marine Chronometers”, Struthers & Roberts 2023
- “Fusion Power by 2028? Microsoft Is Betting on It”, Halper 2023
- “Founder Personality and Entrepreneurial Outcomes: A Large-Scale Field Study of Technology Startups”, Freiberg & Matz 2023
- “Taxing Uber”, Agrawal & Zhao 2023
- “Travel Time ≈ 750 · distance0.6”, Buterin 2023
- “Effectiveness of an Over-The-Counter Self-Fitting Hearing Aid Compared With an Audiologist-Fitted Hearing Aid: A Randomized Clinical Trial”, Sousa et al 2023
- “All-Way Stops”, Li 2023
- “Invention and the Life Course: Age Differences in Patenting”, Kaltenberg et al 2023
- “How Pokemon 8-Bit Music Was Inspired by Classical Music”, Bennett 2022
- “The Mechanics of the Industrial Revolution”, Kelly et al 2022b
- “Linux, Amazon, Meta, and Microsoft Want to Break the Google Maps Monopoly: Overture Maps Foundation Wants to End the Oppressive Rule of the Google Maps API”, Amadeo 2022
- “Dynamic Soaring As a Means to Exceed the Solar Wind Speed”, Larrouturou et al 2022
- “Are Ideas Being Fished Out?”, Klüppel & Knott 2022
- “Active Pixel Sensor Matrix Based on Monolayer MoS2 Phototransistor Array”, Dodda et al 2022
- “Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Rakhmatulin et al 2022
- “Communication And The Role Of The Medieval Tower In Greece: A Re-Appraisal”, Blackler 2022
- “Following the Herds? A New Distribution of Hunting Kites in Southwest Asia”, Fradley et al 2022
- “Connecting the Scientific and Industrial Revolutions: The Role of Practical Mathematics”, Kelly & Gráda 2022
- “The Charming Bloke Who Dominates GeoGuessr: Tom Davies Has Become a Beloved Icon of the Google Maps Guessing Game”, Norman 2022
- “Searching for Cyclic TV Reference Paradoxes”, Pinheiro 2022
- “Then What? Assessing the Military Implications of Chinese Control of Taiwan”, Green & Talmadge 2022
- sniko_ @ "2022-05-09"
- “Light-Driven Microdrones”, Wu et al 2022
- “‘I Think I Discovered a Military Base in the Middle of the Ocean’—Null Island, the Most Real of Fictional Places”, Juhasz & Mooney 2022
- “Apple and Meta Gave User Data to Hackers Who Used Forged Legal Requests: Hackers Compromised the Emails of Law Enforcement Agencies; Data Was Used to Enable Harassment, May Aid Financial Fraud”, Turton 2022
- “Joan Rohlfing on How to Avoid Catastrophic Nuclear Blunders: The Interaction between Nuclear Weapons and Cybersecurity”, Wiblin & Rohlfing 2022
- “Hackers Gaining Power of Subpoena Via Fake ‘Emergency Data Requests’”, Krebs 2022
- “The Golden Age of Japanese Pencils, 1952–1967”, Monetti 2022
- “A Data-Driven Approach for Learning to Control Computers”, Humphreys et al 2022
- “From Fish out of Water to New Insights on Navigation Mechanisms in Animals”, Givon et al 2022
- “The Road Not Taken: Technological Uncertainty and the Evaluation of Innovations”, Tan 2022
- “Learning to Cycle: From Training Wheels to Balance Bike”, Mercê et al 2022
- “Moore’s Not Enough: 4 New Laws of Computing: Moore’s and Metcalfe’s Conjectures Are Taught in Classrooms Every Day—These Four Deserve Consideration, Too”, Dedeke 2022
- “Surprisingly Robust In-Hand Manipulation: An Empirical Study”, Bhatt et al 2022
- LG München: 3 O 17493/20 Vom 20.01.2022, Munich & Chamber 2022
- “Latency”, Munroe 2022
- “Fooled by Beautiful Data: Visualization Esthetics Bias Trust in Science, News, and Social Media”, Lin & Thornton 2022
- “A Large-Scale Characterization of How Readers Browse Wikipedia”, Piccardi et al 2021
- “Hyperspecialization and Hyperscaling: A Resource-Based Theory of the Digital Firm”, Giustiziero et al 2021
- “Steam Deck Won’t Have Any Exclusive Games, Valve Confirms”, Palumbo 2021
- “You Don’t Need to Answer Right Away! Receivers Overestimate How Quickly Senders Expect Responses to Non-Urgent Work Emails”, Giurge & Bohns 2021
- “Design and Control of the First Foldable Single-Actuator Rotary Wing Micro Aerial Vehicle”, Win et al 2021
- “Tokyo Says Long Goodbye to Beloved Floppy Disks: Reliability Cherished by Bureaucrats, but Maintenance Fees Had Become a Burden”, Sugimoto 2021
- “Dexterous Magnetic Manipulation of Conductive Non-Magnetic Objects”, Pham et al 2021
- “Synthetic Fat from Petroleum As a Resilient Food for Global Catastrophes: Preliminary Techno-Economic Assessment and Technology Roadmap”, Martínez et al 2021
- “Streamers Teaching Programming, Art, and Gaming: Cognitive Apprenticeship, Serendipitous Teachable Moments, and Tacit Expert Knowledge”, Drosos & Guo 2021
- “From Stroke to Stoke: The Multiple Sporting Legacies of the Southern California Home Swimming Pool”, Ryan & Tolga 2021
- “Technological Change and Obsolete Skills: Evidence from Men’s Professional Tennis”, Fillmore & Hall 2021
- “Eau De Cleopatra: Mendesian Perfume and Tell Timai”, Littman et al 2021
- “Blood, Sweat, & Tears: Extraterrestrial Regolith Biocomposites With In Vivo Binders”, Roberts et al 2021
- “How Noiseless Props Are Made For Movies And TV Shows”, Reeder & Schultz 2021
- “The Rise of Intelligent Matter”, Kaspar et al 2021
- “Personality Computing: New Frontiers in Personality Assessment”, Phan & Rauthmann 2021
- “Ripple: An Investigation of the World’s Most Advanced High-Yield Thermonuclear Weapon Design”, Grams 2021
- “One Man’s Amazing Journey to the Center of the Bowling Ball: Mo Pinel Spent a Career Reshaping the Ball’s Inner Core to Harness the Power of Physics. He Revolutionized the Sport—And Spared No Critics along the Way”, Koerner 2021
- “Google Details New AI Accelerator Chips”, Wiggers 2021
- “It’s Trust or Risk? Chemosensory Anxiety Signals Affect Bargaining in Women”, Meister & Pause 2021
- “The Age of Invention: Matching Inventor Ages to Patents Based on Web-Scraped Sources”, Kaltenberg et al 2021 (page 3)
- “WORF (Write Once, Read Forever) Next Generation Archival Big Data Storage”, Solomon et al 2021
- “Oil Import Portfolio Risk and Spillover Volatility”, Bigerna et al 2021
- “[Edo Japan Did Not Give up the Gun]”, ParallelPain 2021
- “Seismic Crustal Imaging Using Fin Whale Songs”, Kuna & Nábělek 2021
- “Neutron Tomography of Van Leeuwenhoek’s Microscopes”, Cocquyt et al 2021
- “Goodreads Plans to Retire API Access, Disables Existing API Keys”, Alcorn 2020
- “AIR-FI: Generating Covert Wi-Fi Signals from Air-Gapped Computers”, Guri 2020
- “What Is the Meta-Rational Thing to Do Here? [Comments]”, Pace 2020
- “Time Travel: A Live Demo of the Intermedia Hypertext System—Circa 1989”, Meyrowitz 2020
- “The Death of a Technical Skill”, Horton & Tambe 2020
- “The Elusive Peril of Space Junk”, Khatchadourian 2020
- “The Perfection Premium”, Isaac & Spangenberg 2020
- “Tripping over the Potholes in Too Many Libraries”, Kroll 2020
- “How Hair Deforms Steel”, Roscioli et al 2020
- “The Rise and Fall of Adobe Flash: Before Flash Player Sunsets This December, We Talk Its Legacy With Those Who Built It”, Moss 2020
- “The Incredible Story of the US Army’s Earth-Shaking, Off-Road Land Trains: Oh, Your Pickup Has a Lift? That’s Cute”, Holderith 2020
- “Volitional Control of Individual Neurons in the Human Brain”, Patel et al 2020
- “Fruit Trenches: Cultivating Subtropical Plants in Freezing Temperatures”
- “How to See the World’s Reflection From a Bag of Chips: Computer Scientists Reconstructed the Image of a Whole Room Using the Reflection from a Snack Package. It’s Useful for AR/VR Research—And Possibly Spying”, Chen 2020
- “
darkmode.js”, Achmiz 2020 - “What Does Your Gaze Reveal About You? On the Privacy Implications of Eye Tracking”, Kröger et al 2020
- “Listen to Your Key: Towards Acoustics-Based Physical Key Inference”, Ramesh et al 2020
- “In the 1970s, the CIA Created a Robot Dragonfly Spy. Now We Know How It Works. Newly Released Documents Show How the CIA Created One of the World’s First Examples of Insect Robotics.”, Hambling 2020
- “‘The Intelligence Coup of the Century’: For Decades, the CIA Read the Encrypted Communications of Allies and Adversaries”, Miller 2020
- “Draining the Swamp: How Sanitation Conquered Disease Long Before Vaccines or Antibiotics”, Crawford 2020
- “Enriched Environment Exposure Accelerates Rodent Driving Skills”, Crawford et al 2020
- “Seeing the World in a Bag of Chips”, Park et al 2020
- “All the Money in the World Couldn’t Make Kinect Happen: For a Moment a Decade Ago, the Game Industry Looked like a Very Different Place”, Hester 2020
- “Air Pollution, Evolution, and the Fate of Billions of Humans: It’s Not Just a Modern Problem. Airborne Toxins Are so Pernicious That They May Have Shaped Our DNA over Millions of Years”, Zimmer 2020
- “A Body Bag Can save Your Life: a Novel Method of Cold Water Immersion for Heat Stroke Treatment”, Kim et al 2020
- “‘Shattered’: Inside the Secret Battle to save America’s Undercover Spies in the Digital Age”, McLaughlin & Dorfman 2019
- “Guide To Using Reverse Image Search For Investigations”, Toller 2019
- “Mental Chronometry in the Pocket? Timing Accuracy of Web Applications on Touchscreen and Keyboard Devices”, Pronk et al 2019
- “Cool Links of the Decade: 2010s”, Condor 2019
- “SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms”, Tsykunov et al 2019
- “Building Personal Search Infrastructure for Your Knowledge and Code: Overview of Search Tools for Desktop and Mobile; Using Emacs and Ripgrep As Desktop Search Engine”, Gerasimov 2019
- “‘What’s Wrong With The Way I Talk?’ The Effect Of Sound Motion Pictures On Actor Careers”, Hanssen 2019
- “Learning to Seek: Autonomous Source Seeking With Deep Reinforcement Learning Onboard a Nano Drone Microcontroller”, Duisterhof et al 2019
- “The ‘Terrascope’: On the Possibility of Using the Earth As an Atmospheric Lens”, Kipping 2019
- “Why Did We Wait so Long for the Bicycle?”, Crawford 2019
- “Episode 13: Masters of Scale Episode Transcript: Stewart Butterfield [2018]”
- “Behavioral Patterns in Smartphone Usage Predict Big Five Personality Traits”, Stachl et al 2019
- “5 Years of Graduate CS Education Online and at Scale”, Joyner et al 2019
- “Hard Drive of Hearing: Disks That Eavesdrop With a Synthesized Microphone”, Kwong et al 2019
- “The Iron Streets of Pompeii”, Poehler et al 2019
- “Hearing Your Touch: A New Acoustic Side Channel on Smartphones”, Shumailov et al 2019
- “Real-Time Continuous Transcription With Live Transcribe”, Savla 2019
- “Squeezing the Bears: Cornering Risk and Limits on Arbitrage during the ‘British Bicycle Mania’, 1896–1898”, Quinn 2019
- “Invisible Nuclear-Armed Submarines, or Transparent Oceans? Are Ballistic Missile Submarines Still the Best Deterrent for the United States?”, Cote 2019
- “What Every Engineer Should Know About Inventing § Chapter 4: Theories of Creativity [Wine/printing]”, Middendorf 2019 (page 5)
- “Entrepreneurial Uncertainty and Expert Evaluation: An Empirical Analysis”, Scott et al 2019
- “Privacy Implications of Accelerometer Data: a Review of Possible Inferences”, Kröger et al 2019
- “Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs”, Broockman et al 2018
- “Replication Data For: ‘Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs’”, Broockman et al 2018
- “Criticality Analysis of the Louis Slotin Accident”, Oettingen 2018
- “Energy Storage for Electricity Generation and Related Processes: Technologies Appraisal and Grid Scale Applications”, Argyrou et al 2018
- “Paving Pompeii: The Archaeology of Stone-Paved Streets”, Poehler & Crowther 2018
- “Dark Motives and Elective Use of Brainteaser Interview Questions”, Highhouse et al 2018
- “Can Behavioral Tools Improve Online Student Outcomes? Experimental Evidence from a Massive Open Online Course”, Patterson 2018
- “SonarSnoop: Active Acoustic Side-Channel Attacks”, Cheng et al 2018
- “Tradition Is Smarter Than You Are”, Greer 2018
- “What Cyber-War Will Look Like”, Greer 2018
- “Ionospheric Disturbances Triggered by SpaceX Falcon Heavy”, Chou et al 2018
- “The Trade Journal Cooperative: A Niche Trade Journal Delivered To Your Door, Quarterly”, Hwang 2018
- “Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations”, Bertsekas 2018
- “The Silurian Hypothesis: Would It Be Possible to Detect an Industrial Civilization in the Geological Record?”, Schmidt & Frank 2018
- “Super-Earths in Need for Extremely Big Rockets”, Hippke 2018
- “Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration”, Liu et al 2018
- “Serendipity: Towards a Taxonomy and a Theory”, Yaqub 2018
- “The Second Century CE Roman Watermills of Barbegal: Unraveling the Enigma of One of the Oldest Industrial Complexes”, Sürmelihindi 2018
- “Bronze Age Iron: Meteoritic or Not? A Chemical Strategy”, Jambon 2017
- “Intentional Fire-Spreading by ‘Firehawk’ Raptors in Northern Australia”, Bonta et al 2017
- “Amazon Celebrates 10th Holiday Season of Frustration-Free Packaging—An Invention That’s Helped Eliminate 181,000 Tons of Packaging and 307 Million Boxes, and Given Millions of Customers Holidays Without ‘Wrap Rage’”, Amazon 2017
- “Threading Is Sticky: How Threaded Conversations Promote Comment System User Retention”, Budak et al 2017
- “Film Review: The Haunting (1963)”, Dean 2017
- “Malware Detection by Eating a Whole EXE”, Raff et al 2017
- “Changing Their Tune: How Consumers’ Adoption of Online Streaming Affects Music Consumption and Discovery”, Datta et al 2017
- “Information Flow Reveals Prediction Limits in Online Social Activity”, Bagrow et al 2017
- “DeepXplore: Automated Whitebox Testing of Deep Learning Systems”, Pei et al 2017
- “2016 Letter to Shareholders”, Bezos 2017
- “Stone Walls That Stay Built: A Master Waller Shares How to Dry-Lay Stone Walls That Hold Their Ground for Centuries”, Post 2017
- “How Well Do Experience Curves Predict Technological Progress? A Method for Making Distributional Forecasts”, Lafond et al 2017
- “Making and Shooting a Solid 24k Gold Bullet”, 15 & 2017 2017
- “Cleaning up After WWII”, jwh1975 2017
- “Sensory Augmentation: Integration of an Auditory Compass Signal into Human Perception of Space”, Schumann & O’Regan 2017
- “The Esthetic-Usability Effect”, Moran 2017
- “Autonomous Precision Landing of Space Rockets”, 5.5.315 2017
- “General Pencil”, Payne 2017
- “Hyper-Realistic Face Masks: a New Challenge in Person Identification”, Sanders et al 2017
- “Hunt for Red October, 1990”, Cinema 2016
- “Deep Learning Reinvents the Hearing Aid: Finally, Wearers of Hearing Aids Can Pick out a Voice in a Crowded Room”, Wang 2016b
- “Digital Health: Tracking Physiomes and Activity Using Wearable Biosensors Reveals Useful Health-Related Information”, Li et al 2016
- “Survey of Alternative Displays”, Neal 2016
- “Blade Runner (Typeset In The Future)”, Addey 2016
- “Interactive Comparison of Pyramid Sizes SMIL”, Lee 2016
- “Looking Across and Looking Beyond the Knowledge Frontier: Intellectual Distance, Novelty, and Resource Allocation in Science”, Boudreau et al 2016
- “No Great Technological Stagnation”, Ricón 2016
- “Deep-Spying: Spying Using Smartwatch and Deep Learning”, Beltramelli & Risi 2015
- “Direct Combustion of Recyclable Metal Fuels for Zero-Carbon Heat and Power”, Bergthorson et al 2015
- “Woz’s Metal Business Card”, Luckow 2015
- “Why the Hell Do They Still Make Car Alarms? They Add to Noise Pollution While failing to Prevent Car Theft. It’s Time for Them to Go.”, George 2015
- “Identifying the Source of Perytons at the Parkes Radio Telescope”, Petroff et al 2015
- “Disappearing Polymorphs Revisited”, Bučar et al 2015
- “How Those Plush Easter Bunnies Got so Cuddly”, Postrel 2015
- “Reviving a Ghost in the History of Technology: The Social Construction of the Recumbent Bicycle”, Ahmed et al 2015
- “Evolution of the Human Brain: From Matter to Mind”, Hofman 2015
- “RF Fingerprint Measurements for the Identification of Devices in Wireless Communication Networks Based on Feature Reduction and Subspace Transformation”, Padilla et al 2014
- “Automatic Personality Assessment Through Social Media Language”, Park et al 2014
- “Harvard Innovation Lab Visualizes the Evolution of the Desk”, Azzarello 2014
- “Akin’s Laws of Spacecraft Design”, Akin 2014
- “Card Cheat Who Used Invisible Ink, Special Contact Lenses Is Banned from Connecticut Casinos”, Press 2014
- “If We Insulate Our Houses, Why Not Our Cooking Pots?”
- “The Retention of Manual Flying Skills in the Automated Cockpit”, Casner et al 2014
- “The Perfect Heist: Recipes from Around the World [Combined Papers + Slides]”, Lafleur et al 2014
- “Paging Inspector Sands: The Costs of Public Information”, Kapoor & Magesan 2014
- “Everything from 1991 Radio Shack Ad I Now Do With My Phone”, Cichon 2014
- “Killing Time: Dracula and Social Discoordination”, Robbins 2014
- “Voices From A Virtual Past: An Oral History of a Technology [VR] Whose Time Has Come Again”
- “A Survey on Computational Displays: Pushing the Boundaries of Optics, Computation, and Perception”, Masia et al 2013
- “The Story Of Thanksgiving Is A Science-Fiction Story”, Alexander 2013
- “Supporting Interaction in Public Space With Electrical Muscle Stimulation”, Pfeiffer et al 2013
- “StallTalk: Graffiti, Toilets, and Anonymous Location Based Micro Blogging”, Friedman & Horn 2013
- “Palm: I’m Ready to Wallow Now”, Holwerda 2013
- “The Third User, Or, Exactly Why Apple Keeps Doing Foolish Things”, Tognazzini 2013
- “Cuboro Marble Run: ‘Route 66’”, murmelwelt 2013
- “The Black Arts of SaaS Pricing”, McKenzie 2013
- “Perceiving Invisible Light through a Somatosensory Cortical Prosthesis”, Thomson et al 2013
- “Blackout Tracker United Kingdom Annual Report 2013 § Top 5 Most Unusual Outages/causes”, Eaton 2013 (page 5)
- “Prevented Mortality and Greenhouse Gas Emissions from Historical and Projected Nuclear Power”, Karecha & Hansen 2013
- “The Caenorhabditis Elegans Lifespan Machine”, Stroustrup et al 2013
- “The Olivetti Valentine Typewriter”, Hill 2012
- “Statistical Basis for Predicting Technological Progress”, Nagy et al 2012
- “How to Make a Raptor Suit”, Rosengrant 2012
- “At the Interface: The Case of the Electric Push Button, 1880–1923”, Plotnick 2012
- “I Put a Toaster in the Dishwasher”, Stillwater 2012
- “A Quiet Opening: North Koreans in a Changing Media Environment”, Kretchun & Kim 2012
- “The Floppy Toast”, Buttersafe 2012
- “Hall’s Law: The 19th Century Prequel to Moore’s Law”, Rao 2012
- “SpeechJammer”, Kurihara & Tsukada 2012
- “SpeechJammer: A System Utilizing Artificial Speech Disturbance With Delayed Auditory Feedback”, Kurihara & Tsukada 2012
- “Why Does Attention to Web Articles Fall With Time?”, Simkin & Roychowdhury 2012
- “Salary Negotiation: Make More Money, Be More Valued”, McKenzie 2012
- “It’s All about the Benjamins: An Empirical Study on Incentivizing Users to Ignore Security Advice”, Christin et al 2012
- “Rethinking Real-Time Electricity Pricing”, Allcott 2011
- “A Bicycle Can Be Self-Stable Without Gyroscopic or Caster Effects”, Kooijman et al 2011
- “‘An Unused Esperanto’: Internationalism and Pictographic Design, 1930–1970”, Bresnahan 2011
- “‘Globalization With Hardware’: ITER’s Fusion of Technology, Policy, and Politics”, McCray 2010
- “Wanamaker's Department Store and the Origins of Electronic Media, 1910–1922”, Arceneaux 2010
- “Cool Things in the McMaster-Carr Catalog”, Ketterer 2010
- “Online Labor Markets”, Horton 2010
- “Victorian Pioneers of Corporate Sustainability”, Desrochers 2009
- “Beware Trivial Inconveniences”, Alexander 2009
- “Did America Forget How to Make the H-Bomb? Inside an Institutional Memory Lapse of Nuclear Proportions”, Baumann 2009
- “Mark of Integrity”, Allen 2009
- “Keep Your Identity Small”, Graham 2009
- “The Concept of Efficiency: An Historical Analysis”, Alexander 2009
- “Blog Statistics and Demographics”, Arnold 2009
- “Three Doors to Other Worlds”, Crompton 2008
- “Silver Bullet Pages: History Channel Shoot”, Briggs 2008
- “Ferrari’s Formula One Handovers and Handovers from Surgery to Intensive Care [Great Ormond Street Hospital for Children]”, Sower et al 2008
- “Up and Then Down: The Lives of Elevators”, Paumgarten 2008
- “High Tech Cowboys of the Deep Seas: The Race to Save the Cougar Ace”, Davis 2008
- “Electricity Generation and Health”, Markandya & Wilkinson 2007
- “Seam Carving for Content-Aware Image Resizing”, Avidan & Shamir 2007
- “Founders at Work: Stories of Startups' Early Days: Introduction”, Livingstone 2007
- “Https://web.archive.org/web/20071020051936/http://iq.org/”
- Distributed Remote Sensing for Naval Undersea Warfare: Abbreviated Version, Council 2007
- “Barnard’s Star and the ‘Wait Equation’”
- “Jurassic Park: The Evolution of a Raptor Suit With John Rosengrant”, Duncan 2006
- “Lawrence Bragg’s Role in the Development of Sound-Ranging in World War I”, Kloot 2005
- “A Group Is Its Own Worst Enemy”, Shirky 2005
- “Moore’s Law and the Technology S-Curve”, Bowden 2004
- “A Sea Story: One of the Worst Maritime Disasters in European History Took Place a Decade Ago. It Remains Very Much in the Public Eye. On a Stormy Night on the Baltic Sea, More Than 850 People Lost Their Lives When a Luxurious Ferry Sank below the Waves. From a Mass of Material, including Official and Unofficial Reports and Survivor Testimony, Our Correspondent Has Distilled an Account of the Estonia’s Last Moments—Part of His Continuing Coverage for the Magazine of Anarchy on the High Seas”, Langewiesche 2004
- “Demography and Cultural Evolution: How Adaptive Cultural Processes Can Produce Maladaptive Losses: The Tasmanian Case”, Henrich 2004
- “"One in a Million" Is next Tuesday”, Osterman 2004
- “A Century of Ramjet Propulsion Technology Evolution”, Fry 2004
- “Https://web.archive.org/web/20110726001925/http://diveintomark.org/archives/2004/05/14/freedom-0”
- “The Economics of Has-Beens”, MacDonald & Weisbach 2004
- “Headcase”, Chivers 2004
- “The Jargon File (Version 4.4.7): H: Holy Wars”, Raymond 2003
- “The Evolution of the Grocery Bag”, Petroski 2003
- “Destruction of Nuclear Bombs Using Ultra-High Energy Neutrino Beam”, Sugawara et al 2003
- “Alarmingly Useless: The Case for Banning Car Alarms in New York City”, Friedman et al 2003
- “Forest Dewey Dodrill: Heart Surgery Pioneer. Michigan Heart, Part II”, Stephenson et al 2002b
- “The Michigan Heart: The World’s First Successful Open Heart Operation? Part I”, Stephenson et al 2002
- “Joel on Software: Strategy Letter V”, Spolsky 2002
- “Stung by Security Flaws, Microsoft Makes Software Safety a Top Goal”, Markoff 2002
- Henry Maudslay And The Pioneers Of The Machine Age, Cantrell & Cookson 2002
- “This Is Your Father’s IBM, Only Smarter: How a Former Has-Been Kicked Its Old Habits, Got Open-Source Religion, and Regained Its Status As One of the Biggest, Baddest Tech Companies on Earth.”
- “Resolution of Distinct Rotational Substeps by Sub-Millisecond Kinetic Analysis of F1-ATPase”, Yasuda et al 2001
- “Altered Beast [Tomato Sauce, Bathtub, Sega Console, CRT TV]”, Woodeson 2001
- “Skytherm: an Approach to Year-Round Thermal Energy Sufficient Houses”, Raeissi & Taheri 2000
- “The Little Engines That Could: Modeling the Performance of World Wide Web Search Engines”, Bradlow & Schmittlein 2000
- “Area Man Consults Internet Whenever Possible”, Onion 2000
- “How Complex Systems Fail: Being a Short Treatise on the Nature of Failure; How Failure Is Evaluated; How Failure Is Attributed to Proximate Cause; and the Resulting New Understanding of Patient Safety”, Cook 2000
- “A Nuclear Engine Design With 242mAm As a Nuclear Fuel”, Ronen et al 2000
- “Norvir Advisory”, Care 2000
- “Engineering Success and Disaster: American Railroad Bridges, 1840–1900”, Aldrich 1999
- The Last Man on the Moon, Cernan & Davis 1999
- “Patent Buyouts: A Mechanism for Encouraging Innovation”, Kremer 1998
- “Who Is Arguing About the Cat? Moral Action and Enlightenment According to Dōgen”, Mikkelson 1997
- “Fantastic Voyage: Creating the Futurescape for The Fifth Element; Digital Domain’s Imagery Experts Help to Create Eye-Boggling Visual Effects for Luc Besson’s Sci-Fi Fantasy”, Magid 1997
- “The Conquest of Hellgate”
- “Technology and Courage”, Sutherland 1996
- “The Gravel Page: the Most Frightening Crimes Have No Witnesses except the Ground on Which They Were Committed. And from That Alone Forensic Geologists Illuminate Cases in a Way That Would Impress Sherlock Holmes, the Science's First Practitioner [Balloons of War] [Death of an Agent]”, McPhee 1996
- “Anthropological Invariants in Travel Behavior”, Marchetti 1994 (page 6)
- “The Role Of The CIA In Economic And Technological Intelligence”, Foley 1994
- “Expert Judgment on Markers to Deter Inadvertent Human Intrusion into the Waste Isolation Pilot Plant”, Trauth et al 1993
- “A Purple Barium Copper Silicate Pigment from Early China”, FitzHugh & Zycherman 1992
- “Terminal Delinquents: Once, They Stole Hubcaps And Shot Out Street-Lights. Now They’re Stealing Your Social Security Number And Shooting Out Your Credit Rating. A Layman’s Guide To Computer High Jinks”, Hitt & Tough 1990
- “CO2 Disposal by means of Silicates”, Seifritz 1990
- “The Statite—A Non-Orbiting Spacecraft”, Forward 1989
- “On the Fracture of Pencil Points”, Petroski 1987
- “Henry Adams, the Second Law of Thermodynamics, and the Course of History”, Burich 1987
- “Urban Sanitation in Preindustrial Japan”, Hanley 1987
- “Atchafalaya”, McPhee 1987
- “The Little Can That Could”, Daniel 1987
- “Two Theories of Home Heat Control”, Kempton 1986
- “Zero-Gravity Distillation Using the Heat Pipe Principle (Micro-Distillation)”, Seok & Hwang 1985
- “Effectiveness of Measures to Prevent Unintentional Deaths of Infants and Children from Suffocation and Strangulation”, Krauss 1985
- “The Trouble With Fusion: Long Touted As an Inexhaustible Energy Source for the next Century, Fusion As It Is Now Being Developed Will Almost Certainly Be Too Expensive and Unreliable for Commercial Use”, Lidsky 1983
- “Breaking Paragraphs into Lines”, Knuth & Plass 1981
- “Breaking Paragraphs into Lines § A Historical Summary”, Knuth & Plass 1981 (page 48)
- “Major Crimes As Analogs to Potential Threats to Nuclear Facilities and Programs”, Reinstedt & Westbury 1980 (page 6)
- “Are Humans Maximizing Reproductive Success? [With Reply]”, Lande & Weinrich 1978
- “A Dead Reckoning/map Correlation System for Automatic Vehicle Tracking”, Lezniak et al 1977
- “Human Sociobiology: Pair-Bonding and Resource Predictability (Effects of Social Class and Race)”, Weinrich 1977
- “Space Settlements: A Design Study”, Johnson & Holbrow 1977
- “Human Reproductive Strategy: I. Environmental Predictability And Reproductive Strategy; Effects Of Social Class And Race. II. Homosexuality And Non-Reproduction; Some Evolutionary Models”, Weinrich 1976
- “The Health Hazards of NOT Going Nuclear”, Beckmann 1976
- “An Urban Agro-Ecosystem: The Example of 19th-Century Paris”, Stanhill 1976
- An Anthropological Analysis of Food-Getting Technology, Oswalt 1976
- “The Amateur Scientist: Diverse Topics, Starting With How to Supply Electric Power to Something That Is Turning”, Stong 1975
- My Years With Xerox: The Billions Nobody Wanted, Dessauer 1971
- “The Fire Piston and Its Origins in Europe”, Fox 1969
- “Xerography of the Breast”, Wolfe 1969
- “Human Adjustment to an Exotic Environment: The Nuclear Submarine”, Earls 1969
- “Saul Bass Pitch Video for Bell System Logo Redesign”, Bass 1969
- “Thin Silicone Membranes—Their Permeation Properties And Some Applications”, Robb 1968
- “On The Obsolescence Of Scientists And Engineers”, Ferdinand 1966
- “The Pigeon Towers of Iṣfahān”, Bealy 1966
- “The Pattern of Streets”, Alexander 1966
- “The German V-2”, Dornberger 1963
- “The Economics of Invention: A Survey of the Literature”, Nelson 1959
- “Behavior Of Young Children Under Conditions Simulating Entrapment In Refrigerators”, Bain et al 1958
- “Transmission Properties of Laminated Clogston Type Conductors”, Vaage 1953
- “Some Transient Properties of Transistors”, Bassett & Tillman 1953
- “Turbidity Currents and Submarine Slumps, and the 1929 Grand Banks [Newfoundland] Earthquake”, Heezen & Ewing 1952
- “Mathematical Theory of Laminated Transmission Lines-Part 2”, Morgan 1952b
- “Mathematical Theory of Laminated Transmission Lines—Part I”, Morgan 1952
- “What Price Speed? Specific Power Required for Propulsion of Vehicles”, Gabrielli & Kármán 1950
- “Secrets by the Thousands”, Walker 1946
- “Dawn Of The Space Age”, Harper 1946
- “Winged World: The Coming of the Air Age”, Harper 1946
- “The Effect of Size on the Equipment of the Queen’s Dolls’ House”, O’Gorman 1924
- “On the Part Played by Philosophy in the Progress of Man”, Seneca & Gummere 1920
- “Aerial Navigation: The Power Required”, Maxim 1891
- “Unfathomable”
- “Recent Works [Exploded-Diagram Sculptures]”, Peralta 2026
- “Latin Sundial Mottoes With Spanish Translations”, Calle 2026
- “All That Is Solid Bursts into Flame: Capitalism and Fire in the 19th-Century United States”
- “Making Is Show Business Now”
- “Stargate Physics 101”
- “A Manifesto on Shower Temperature Control”, Holmen 2026
- “Piezoelectric Bagworm Silk”
- “The Dream of an Alpine Waterway”
- Web Typography, Rutter 2026
- “Domes Are Overrated”
- “Technology Transfer and Early Industrial Development: The Case of the Sino-Soviet Alliance”
- “ChatGPT—Poem Review and Critique”
- “How the Shroud of Turin Was Made”
- “Hypertext Tools from the 80s”
- “Lippmann Security”
- “Fan Is A Tool-Using Animal”
- “BitWhisper: Covert Signaling Channel between Air-Gapped Computers Using Thermal Manipulations”
- “You Have No Idea How Insanely Complex Modern Headlights Can Be I Mean Holy Crap They Have GPS”
- “The Mastermind Episode 1: An Arrogant Way of Killing”
- “How to Tell When a Robot Has Written You a Letter”
- “The GE Beetle: Our Giant Atomic Robot”
- “The Price of Batteries Has Declined by 97% in the Last Three Decades”
- “Why Did Renewables Become so Cheap so Fast?”
- “Performance Curve Database”
- “Alexander Graham Bell’s Tetrahedral Kites (1903–9) [Image Gallery]”, Review 2026
- “Japanese Firemen’s Coats (19th Century)”
- “John Locke’s Method for Common-Place Books (1685)”
- “Stuffed Ox, Dummy Tree, Artificial Rock: Deception in the Work of Richard and Cherry Kearton”
- “SpeechJammer Homepage”, Kurihara & Tsukada 2026
- “Akin’s Laws of Spacecraft Design”
- “No Human Can Match This High-Speed Box-Unloading Robot Named After a Pickle”
- “Education of a Programmer. When I Left Microsoft in October 2016”, Crowley 2026
- “How a Handful of Prehistoric Geniuses Launched Humanity’s Technological Revolution”
- “Toshi Omagari”
- “A Collection of Nerdy Interviews Asking People from All Walks of Life What They Use to Get the Job Done.”
- “Forget It!”, Asimov 2026
- “Offshore Nuclear Power Plants”
- “The Japanese Luggage Forwarding Edition”
- “Getting Materials out of the Lab”
- “Steam Networks”
- “Why Skyscrapers Are so Short”
- “The Rise of Niche Consumption”
- “The Hum That Helps to Fight Crime”
- “This Company’s Robots Are Making Everything”
- “Inside the Crash of Fling, the Startup Whose Founder Partied on an Island While His Company Burned through $21 Million”
- “Marc Andreessen Says The 1990s Dot-Com Bubble Startups Were ‘All Right But Just Early’”
- “How We Can Mine Asteroids for Space Food”
- “Why It’s so Hard to Build a Jet Engine”
- “Absolute Zero Is 0K”
- “Deciphering China’s AI Dream”
- “Microwave Smelter: 8 Steps (With Pictures)”
- “New Look, Same Great Look”
- “Olivetti Valentine”, Soul 2026
- “How a Naked Skydive Inspired a Way to Keep Pilots Oriented in Flight”
- “Learning to Cycle: A Cross-Cultural and Cross-Generational Comparison”, Cordovil et al 2026
- “X-Ray Decks: the Lost Bone Music of the Soviet Union”
- “The Man Who Broke the Music Business”
- “The Age of Robot Farmers”
- “Paging Dr. Robot”
- “Putting Spiders On Treadmills In Virtual-Reality Worlds”
- “CD-Loving Japan Resists Move to Online Music”
- “A Tiny Robot That Can Fly And, Amazingly, Rest”
- “No Sailors Needed: Robot Sailboats Scour the Oceans for Data”
- “The Microbots Are on Their Way”
- “‘We Don’t Need Another Michelangelo’: In Italy, It’s Robots’ Turn to Sculpt”
- “Are You Ready for Sentient Disney Robots?”
- “This Robot Looks Like a Pancake and Jumps Like a Maggot”
- “How European Royals Once Shared Their Most Important Secrets”
- “The Man Who Controls Computers With His Mind”
- “Why Is It So Hard for New Musical Instruments to Catch On?”
- The Diff, Hobart 2026
- “Stewart Brand’s Whole Earth Catalog, the Book That Changed the World: Stewart Brand Was at the Heart of 60s Counterculture and Is Now Widely Revered As the Tech Visionary Whose Book Anticipated the Web. We Meet the Man for Whom Big Ideas Are a Way of Life”
- “World’s First Raspberry Picking Robot Cracks the Toughest Nut: Soft Fruit Food & Drink Industry”
- “In a Blind Test, Audiophiles Couldn’t Tell the Difference between Audio Signals Sent through Copper Wire, a Banana, or Wet Mud—’The Mud Should Sound Perfectly Awful, but It Doesn’t’, Notes the Experiment Creator”
- “GSMem: Data Exfiltration from Air-Gapped Computers over GSM Frequencies”
- “The Decades-Long Quest to Design a Car Stereo That Can’t Be Stolen: Car Stereos Have Traditionally Been Both Valuable and Easy to Spot in an Idle Vehicle, Making Them a Key Target for Thieves. Why Aren’t They Getting Stolen Nearly As Much Anymore?”
- “Freeman Dyson’s Brain”
- “The Search for a More Perfect Kilogram”
- “Inside a Startup’s Plan to Turn a Swarm of DIY Satellites Into an All-Seeing Eye”
- “Turns Out the Dot-Com Bust’s Worst Flops Were Actually Fantastic Ideas”
- “Modern Love: Are We Ready for Intimacy With Robots?”
- “This 22-Year-Old Builds Chips in His Parents’ Garage”
- “You’ve Never Heard of China’s Greatest Sci-Fi Novel”
- “An Oral History of the 2004 Darpa Grand Challenge”
- “Robots Are Fueling the Quiet Ascendance of the Electric Motor”
- “Science Has Spun Spider-Man’s Web-Slinging Into Reality”
- “Watch a Homemade Robot Crack a SentrySafe Combination Safe in 15 Minutes”
- “You Can Now Buy Spot the Robot Dog—If You’ve Got $74,500”
- “Cats, Rats, AI, Oh My!”
- “SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms [Video]”
- “Green Hill Zone [Sonic The Hedgehog OST]”
- “LEGO Uses 18 Cucumbers to Build Real Log House”
- “HUMAN’20: ‘A Live Demo of the Intermedia Hypertext System’ (Norman K. Meyrowitz)”
- “How a Solar Farm Is Constructed From Beginning to End”
- Sort By Magic
- Wikipedia (73)
- Miscellaneous
- Bibliography
See Also
Gwern
“Trace of the True Self”, Gwern et al 2026
{kind=link}
“‘Elegy in a Craneyard’ Graveyard Notes”, Gwern et al 2026
“Silver Bird Above San Francisco”, Gwern et al 2025
“Peak Pre-Modern Human Speed”, Gwern 2022
“Plumbing vs Internet, Revisited”, Gwern 2025
“Research Bounties On Fulltexts”, Gwern 2018
“Epigrams”, Gwern 2014
“Startup Ideas”, Gwern 2017
“Adjusting Linux Pulseaudio Frequency Settings for Hearing Loss”, Gwern 2014
Adjusting Linux Pulseaudio frequency settings for hearing loss
“CO2 Coin: Decentralized Carbon Capture Blockchains”, Gwern 2021
“Newton’s System of the World and Comets”, Gwern 2016
“Evolution As Backstop for Reinforcement Learning”, Gwern 2018
“Progress In Beauty”, Gwern 2016
“About Gwern”, Gwern 2009
“Music and Distraction”, Gwern 2012
“Girl Scouts & Good Corporate Governance”, Gwern 2011
“Choosing Software”, Gwern 2008
“Wikipedia and Other Wikis”, Gwern 2009
“Resilient Haskell Software”, Gwern 2008
Links
“Inventing the ‘Methods’ Section: What the Evolution of Scientific Methods Says about Their Future”, Hunt 2026
Inventing the ‘Methods’ Section: What the evolution of scientific methods says about their future
“How Getting Richer Made Teenagers Less Free: We Value Children More Than Ever. But We’re Suffocating Them”, Piper 2025
“Want a Fortell Hearing Aid? Well, Who Do You Know? AI-Powered Startup Fortell Has Become a Secret Handshake for the Privileged Hearing-Impaired Crowd Who Swear by the Product. Now, It Wants to Be in Your Ears”, Levy 2025
“Air Lab Is the Flipper Zero of Air Quality Monitors”, Geerling 2025
“Marble Fountain [Evolving a 3D-Printed Marble Run]”, Morrison 2025
“Bacteriophage-Loaded Microneedle Patches for Targeted and Minimally Disruptive Foodborne Pathogen Decontamination”, Prasad et al 2025
“Masonry Techniques of the Inca’s Master Builders”, Trupp 2025
“How Pen Caps Work”, MacIver 2025
“On Factory Tours”, Colman 2025
“Kirigami-Inspired Parachutes With Programmable Reconfiguration”, Lamoureux et al 2025
Kirigami-inspired parachutes with programmable reconfiguration
“Could You Defeat A Tyrannosaurus Rex? [Testing Elephant Guns on Dino-Sized Ballistic Gel]”, Ballistics 2025
Could You Defeat A Tyrannosaurus Rex? [testing elephant guns on dino-sized ballistic gel]
“Pulse-Fi: A Low-Cost System for Accurate Heart Rate Monitoring Using Wi-Fi Channel State Information”, Kocheta et al 2025
Pulse-Fi: A Low-Cost System for Accurate Heart Rate Monitoring Using Wi-Fi Channel State Information
“Falsehoods Programmers Believe About Aviation”, Burwell 2025
“Ordinary Life Improvements Since 2018”, Smagin 2025
“Near-Infrared Spatiotemporal Color Vision in Humans Enabled by Upconversion Contact Lenses”
Near-infrared spatiotemporal color vision in humans enabled by upconversion contact lenses
“Nikolai Agnivtsev’s Little Screw (1925)”
“Subtitling Your Life: Hearing Aids and Cochlear Implants Have Been Getting Better for Years, but a New Type of Device—Eyeglasses That Display Real-Time Speech Transcription on Their Lenses—Are a Game-Changing Breakthrough”, Owen 2025
“Flushed Away: The Crappy Lie Americans Still Believe about Their Toilets”, Gibbs 2025
Flushed Away: The crappy lie Americans still believe about their toilets
“Teach Your Microscope How to Print: Low-Cost and Rapid-Iteration Microfabrication for Biology”, Hinderling et al 2025
Teach your microscope how to print: Low-cost and rapid-iteration microfabrication for biology
“Undersea Nuclear Forces: Survivability of Chinese, Russian, and US SSBNs”, Stefanick 2025
Undersea nuclear forces: Survivability of Chinese, Russian, and US SSBNs
“Norman Foster’s Architectural Empire”
“Texas v. NRC Complaint”, Texas et al 2024
“The Global Race For Talent: Brain Drain, Knowledge Transfer, And Growth”, Marta 2024
The Global Race For Talent: Brain Drain, Knowledge Transfer, And Growth
“Y Combinator Often Backs Startups That Duplicate Other YC Companies, Data Shows—Not Just AI Code Editors”
“‘You Tried to Tell Yourself I Wasn’t Real’: What Happens When People With Acute Psychosis Meet the Voices in Their Heads?”
“Satu Rämö’s Novel Received 1-Star Reviews on Amazon UK Because the Wrong Story Was Published on the Cover of the Hildur Book”, Koivuranta 2024
“The Value of Space Activity”, Lowe 2024
View PDF:
“Automated Photogrammetric Close-Range Imaging System for Small Invertebrates Using Acoustic Levitation”, Klug et al 2024
“The Hidden Engineering of Landfills”
“The World’s Loudest Lisp Program to the Rescue [Designing a Network of Tunnel Alarms]”, Zaikonnikov 2024
The World’s Loudest Lisp Program to the Rescue [designing a network of tunnel alarms]
“Battle Over Startup Leaves Early Investor With No Equity, $2.6 Million Legal Bill § The Information PR War”, McBride 2024
“The Ant And The Grasshopper: Seasonality And The Invention Of Agriculture”, Matranga 2024
The Ant And The Grasshopper: Seasonality And The Invention Of Agriculture
“Shell Buckling for Programmable Metafluids”, Djellouli et al 2024
“The Road to Zero: The 50-Year Effort to Eliminate Roof Fall Fatalities from US Underground Coal Mines”, Mark 2024
“Are We Safe from Lightning Inside Buildings? A Study of Lightning Fatalities Inside Buildings Using Smartphones”, Souza et al 2024
“What Happens When You Touch a Pickle to an AM Radio Tower?”, Geerling 2024
“Open Source Data Programs From Low-Earth Orbit Synthetic Aperture Radar Companies: Questions and Answers [Industry Profiles and Activities]”, Patel 2023
View PDF:
“Lord of the Roths: How Tech Mogul Peter Thiel Turned a Retirement Account for the Middle Class Into a $5 Billion Tax-Free Piggy Bank”
“America, Jump-Started: World War II R&D and the Takeoff of the US Innovation System”, Gross & Sampat 2023
America, Jump-Started: World War II R&D and the Takeoff of the US Innovation System
“Taxonomy and Nomenclature for the Stone Domain in New England”, Thorson 2023
Taxonomy and Nomenclature for the Stone Domain in New England
“Testing My Speech Jammer In Public”, Jordan 2023
“Testing My Speech Jammer In Public § Speech Jammer Immunity”, Jordan 2023
“Application of the Thermodynamics of Radiation to Dyson Spheres As Work Extractors and Computational Engines, and Their Observational Consequences”, Wright 2023
“The Oxygen Bottleneck for Technospheres”, Balbi & Frank 2023
“Solecooler’s Reversible Insoles ‘Climfeet’ Adjust Foot Temperature to Keep Them Warm or Cool”
solecooler’s reversible insoles ‘climfeet’ adjust foot temperature to keep them warm or cool
“Insights from a Laboratory Fire”, Jones et al 2023
“Elephant Rifle Annihilates Ballistic Gel at 82,000FPS § Combustion by Compression”, Guys 2023
Elephant Rifle Annihilates Ballistic Gel at 82,000FPS § combustion by compression
“Rebecca Struthers on Watches, Watchmaking, and the Hands of Time § Practical Challenges With Marine Chronometers”, Struthers & Roberts 2023
“Fusion Power by 2028? Microsoft Is Betting on It”, Halper 2023
“Founder Personality and Entrepreneurial Outcomes: A Large-Scale Field Study of Technology Startups”, Freiberg & Matz 2023
Founder personality and entrepreneurial outcomes: A large-scale field study of technology startups
“Taxing Uber”, Agrawal & Zhao 2023
“Travel Time ≈ 750 · distance0.6”, Buterin 2023
“Effectiveness of an Over-The-Counter Self-Fitting Hearing Aid Compared With an Audiologist-Fitted Hearing Aid: A Randomized Clinical Trial”, Sousa et al 2023
“All-Way Stops”, Li 2023
“Invention and the Life Course: Age Differences in Patenting”, Kaltenberg et al 2023
“How Pokemon 8-Bit Music Was Inspired by Classical Music”, Bennett 2022
“The Mechanics of the Industrial Revolution”, Kelly et al 2022b
“Linux, Amazon, Meta, and Microsoft Want to Break the Google Maps Monopoly: Overture Maps Foundation Wants to End the Oppressive Rule of the Google Maps API”, Amadeo 2022
“Dynamic Soaring As a Means to Exceed the Solar Wind Speed”, Larrouturou et al 2022
“Are Ideas Being Fished Out?”, Klüppel & Knott 2022
“Active Pixel Sensor Matrix Based on Monolayer MoS2 Phototransistor Array”, Dodda et al 2022
Active pixel sensor matrix based on monolayer MoS2 phototransistor array
“Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Rakhmatulin et al 2022
Selective neutralization and deterring of cockroaches with laser automated by machine vision
“Communication And The Role Of The Medieval Tower In Greece: A Re-Appraisal”, Blackler 2022
Communication And The Role Of The Medieval Tower In Greece: A Re-Appraisal
“Following the Herds? A New Distribution of Hunting Kites in Southwest Asia”, Fradley et al 2022
Following the herds? A new distribution of hunting kites in Southwest Asia
“Connecting the Scientific and Industrial Revolutions: The Role of Practical Mathematics”, Kelly & Gráda 2022
Connecting the Scientific and Industrial Revolutions: The Role of Practical Mathematics
“The Charming Bloke Who Dominates GeoGuessr: Tom Davies Has Become a Beloved Icon of the Google Maps Guessing Game”, Norman 2022
“Searching for Cyclic TV Reference Paradoxes”, Pinheiro 2022
“Then What? Assessing the Military Implications of Chinese Control of Taiwan”, Green & Talmadge 2022
Then What? Assessing the Military Implications of Chinese Control of Taiwan
sniko_ @ "2022-05-09"
“Light-Driven Microdrones”, Wu et al 2022
“‘I Think I Discovered a Military Base in the Middle of the Ocean’—Null Island, the Most Real of Fictional Places”, Juhasz & Mooney 2022
“Apple and Meta Gave User Data to Hackers Who Used Forged Legal Requests: Hackers Compromised the Emails of Law Enforcement Agencies; Data Was Used to Enable Harassment, May Aid Financial Fraud”, Turton 2022
“Joan Rohlfing on How to Avoid Catastrophic Nuclear Blunders: The Interaction between Nuclear Weapons and Cybersecurity”, Wiblin & Rohlfing 2022
“Hackers Gaining Power of Subpoena Via Fake ‘Emergency Data Requests’”, Krebs 2022
Hackers Gaining Power of Subpoena Via Fake ‘Emergency Data Requests’
“The Golden Age of Japanese Pencils, 1952–1967”, Monetti 2022
“A Data-Driven Approach for Learning to Control Computers”, Humphreys et al 2022
“From Fish out of Water to New Insights on Navigation Mechanisms in Animals”, Givon et al 2022
From fish out of water to new insights on navigation mechanisms in animals
“The Road Not Taken: Technological Uncertainty and the Evaluation of Innovations”, Tan 2022
The Road Not Taken: Technological Uncertainty and the Evaluation of Innovations
“Learning to Cycle: From Training Wheels to Balance Bike”, Mercê et al 2022
“Moore’s Not Enough: 4 New Laws of Computing: Moore’s and Metcalfe’s Conjectures Are Taught in Classrooms Every Day—These Four Deserve Consideration, Too”, Dedeke 2022
“Surprisingly Robust In-Hand Manipulation: An Empirical Study”, Bhatt et al 2022
Surprisingly Robust In-Hand Manipulation: An Empirical Study
LG München: 3 O 17493/20 Vom 20.01.2022, Munich & Chamber 2022
“Latency”, Munroe 2022
“Fooled by Beautiful Data: Visualization Esthetics Bias Trust in Science, News, and Social Media”, Lin & Thornton 2022
Fooled by beautiful data: Visualization esthetics bias trust in science, news, and social media
“A Large-Scale Characterization of How Readers Browse Wikipedia”, Piccardi et al 2021
A Large-Scale Characterization of How Readers Browse Wikipedia
“Hyperspecialization and Hyperscaling: A Resource-Based Theory of the Digital Firm”, Giustiziero et al 2021
Hyperspecialization and hyperscaling: A resource-based theory of the digital firm
“Steam Deck Won’t Have Any Exclusive Games, Valve Confirms”, Palumbo 2021
“You Don’t Need to Answer Right Away! Receivers Overestimate How Quickly Senders Expect Responses to Non-Urgent Work Emails”, Giurge & Bohns 2021
“Design and Control of the First Foldable Single-Actuator Rotary Wing Micro Aerial Vehicle”, Win et al 2021
Design and control of the first foldable single-actuator rotary wing micro aerial vehicle
“Tokyo Says Long Goodbye to Beloved Floppy Disks: Reliability Cherished by Bureaucrats, but Maintenance Fees Had Become a Burden”, Sugimoto 2021
“Dexterous Magnetic Manipulation of Conductive Non-Magnetic Objects”, Pham et al 2021
Dexterous magnetic manipulation of conductive non-magnetic objects
“Synthetic Fat from Petroleum As a Resilient Food for Global Catastrophes: Preliminary Techno-Economic Assessment and Technology Roadmap”, Martínez et al 2021
“Streamers Teaching Programming, Art, and Gaming: Cognitive Apprenticeship, Serendipitous Teachable Moments, and Tacit Expert Knowledge”, Drosos & Guo 2021
“From Stroke to Stoke: The Multiple Sporting Legacies of the Southern California Home Swimming Pool”, Ryan & Tolga 2021
From Stroke to Stoke: The Multiple Sporting Legacies of the Southern California Home Swimming Pool
“Technological Change and Obsolete Skills: Evidence from Men’s Professional Tennis”, Fillmore & Hall 2021
Technological change and obsolete skills: Evidence from men’s professional tennis
“Eau De Cleopatra: Mendesian Perfume and Tell Timai”, Littman et al 2021
“Blood, Sweat, & Tears: Extraterrestrial Regolith Biocomposites With In Vivo Binders”, Roberts et al 2021
Blood, sweat, & tears: extraterrestrial regolith biocomposites with In Vivo binders
“How Noiseless Props Are Made For Movies And TV Shows”, Reeder & Schultz 2021
“The Rise of Intelligent Matter”, Kaspar et al 2021
“Personality Computing: New Frontiers in Personality Assessment”, Phan & Rauthmann 2021
Personality computing: New frontiers in personality assessment
“Ripple: An Investigation of the World’s Most Advanced High-Yield Thermonuclear Weapon Design”, Grams 2021
Ripple: An Investigation of the World’s Most Advanced High-Yield Thermonuclear Weapon Design
“One Man’s Amazing Journey to the Center of the Bowling Ball: Mo Pinel Spent a Career Reshaping the Ball’s Inner Core to Harness the Power of Physics. He Revolutionized the Sport—And Spared No Critics along the Way”, Koerner 2021
“Google Details New AI Accelerator Chips”, Wiggers 2021
“It’s Trust or Risk? Chemosensory Anxiety Signals Affect Bargaining in Women”, Meister & Pause 2021
It’s trust or risk? Chemosensory anxiety signals affect bargaining in women
“The Age of Invention: Matching Inventor Ages to Patents Based on Web-Scraped Sources”, Kaltenberg et al 2021 (page 3)
The Age of Invention: Matching Inventor Ages to Patents Based on Web-scraped Sources
“WORF (Write Once, Read Forever) Next Generation Archival Big Data Storage”, Solomon et al 2021
WORF (Write Once, Read Forever) Next Generation Archival Big Data Storage
“Oil Import Portfolio Risk and Spillover Volatility”, Bigerna et al 2021
“[Edo Japan Did Not Give up the Gun]”, ParallelPain 2021
“Seismic Crustal Imaging Using Fin Whale Songs”, Kuna & Nábělek 2021
“Neutron Tomography of Van Leeuwenhoek’s Microscopes”, Cocquyt et al 2021
“Goodreads Plans to Retire API Access, Disables Existing API Keys”, Alcorn 2020
Goodreads plans to retire API access, disables existing API keys
“AIR-FI: Generating Covert Wi-Fi Signals from Air-Gapped Computers”, Guri 2020
AIR-FI: Generating Covert Wi-Fi Signals from Air-Gapped Computers
“What Is the Meta-Rational Thing to Do Here? [Comments]”, Pace 2020
“Time Travel: A Live Demo of the Intermedia Hypertext System—Circa 1989”, Meyrowitz 2020
Time Travel: A Live Demo of the Intermedia Hypertext System—Circa 1989
“The Death of a Technical Skill”, Horton & Tambe 2020
“The Elusive Peril of Space Junk”, Khatchadourian 2020
“The Perfection Premium”, Isaac & Spangenberg 2020
“Tripping over the Potholes in Too Many Libraries”, Kroll 2020
“How Hair Deforms Steel”, Roscioli et al 2020
“The Rise and Fall of Adobe Flash: Before Flash Player Sunsets This December, We Talk Its Legacy With Those Who Built It”, Moss 2020
“The Incredible Story of the US Army’s Earth-Shaking, Off-Road Land Trains: Oh, Your Pickup Has a Lift? That’s Cute”, Holderith 2020
“Volitional Control of Individual Neurons in the Human Brain”, Patel et al 2020
“Fruit Trenches: Cultivating Subtropical Plants in Freezing Temperatures”
Fruit Trenches: Cultivating Subtropical Plants in Freezing Temperatures
“How to See the World’s Reflection From a Bag of Chips: Computer Scientists Reconstructed the Image of a Whole Room Using the Reflection from a Snack Package. It’s Useful for AR/VR Research—And Possibly Spying”, Chen 2020
“darkmode.js”, Achmiz 2020
“What Does Your Gaze Reveal About You? On the Privacy Implications of Eye Tracking”, Kröger et al 2020
What Does Your Gaze Reveal About You? On the Privacy Implications of Eye Tracking
“Listen to Your Key: Towards Acoustics-Based Physical Key Inference”, Ramesh et al 2020
Listen to Your Key: Towards Acoustics-based Physical Key Inference
“In the 1970s, the CIA Created a Robot Dragonfly Spy. Now We Know How It Works. Newly Released Documents Show How the CIA Created One of the World’s First Examples of Insect Robotics.”, Hambling 2020
“‘The Intelligence Coup of the Century’: For Decades, the CIA Read the Encrypted Communications of Allies and Adversaries”, Miller 2020
“Draining the Swamp: How Sanitation Conquered Disease Long Before Vaccines or Antibiotics”, Crawford 2020
Draining the swamp: How sanitation conquered disease long before vaccines or antibiotics
“Enriched Environment Exposure Accelerates Rodent Driving Skills”, Crawford et al 2020
Enriched environment exposure accelerates rodent driving skills
“Seeing the World in a Bag of Chips”, Park et al 2020
“All the Money in the World Couldn’t Make Kinect Happen: For a Moment a Decade Ago, the Game Industry Looked like a Very Different Place”, Hester 2020
“Air Pollution, Evolution, and the Fate of Billions of Humans: It’s Not Just a Modern Problem. Airborne Toxins Are so Pernicious That They May Have Shaped Our DNA over Millions of Years”, Zimmer 2020
“A Body Bag Can save Your Life: a Novel Method of Cold Water Immersion for Heat Stroke Treatment”, Kim et al 2020
A body bag can save your life: a novel method of cold water immersion for heat stroke treatment
“‘Shattered’: Inside the Secret Battle to save America’s Undercover Spies in the Digital Age”, McLaughlin & Dorfman 2019
‘Shattered’: Inside the secret battle to save America’s undercover spies in the digital age
“Guide To Using Reverse Image Search For Investigations”, Toller 2019
“Mental Chronometry in the Pocket? Timing Accuracy of Web Applications on Touchscreen and Keyboard Devices”, Pronk et al 2019
“Cool Links of the Decade: 2010s”, Condor 2019
“SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms”, Tsykunov et al 2019
SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms
“Building Personal Search Infrastructure for Your Knowledge and Code: Overview of Search Tools for Desktop and Mobile; Using Emacs and Ripgrep As Desktop Search Engine”, Gerasimov 2019
“‘What’s Wrong With The Way I Talk?’ The Effect Of Sound Motion Pictures On Actor Careers”, Hanssen 2019
‘What’s Wrong With The Way I Talk?’ The Effect Of Sound Motion Pictures On Actor Careers
“Learning to Seek: Autonomous Source Seeking With Deep Reinforcement Learning Onboard a Nano Drone Microcontroller”, Duisterhof et al 2019
“The ‘Terrascope’: On the Possibility of Using the Earth As an Atmospheric Lens”, Kipping 2019
The ‘Terrascope’: On the Possibility of Using the Earth as an Atmospheric Lens
“Why Did We Wait so Long for the Bicycle?”, Crawford 2019
“Episode 13: Masters of Scale Episode Transcript: Stewart Butterfield [2018]”
Episode 13: Masters of Scale Episode Transcript: Stewart Butterfield [2018] :
“Behavioral Patterns in Smartphone Usage Predict Big Five Personality Traits”, Stachl et al 2019
Behavioral Patterns in Smartphone Usage Predict Big Five Personality Traits
“5 Years of Graduate CS Education Online and at Scale”, Joyner et al 2019
“Hard Drive of Hearing: Disks That Eavesdrop With a Synthesized Microphone”, Kwong et al 2019
Hard Drive of Hearing: Disks that Eavesdrop with a Synthesized Microphone
“The Iron Streets of Pompeii”, Poehler et al 2019
“Hearing Your Touch: A New Acoustic Side Channel on Smartphones”, Shumailov et al 2019
Hearing your touch: A new acoustic side channel on smartphones
“Real-Time Continuous Transcription With Live Transcribe”, Savla 2019
“Squeezing the Bears: Cornering Risk and Limits on Arbitrage during the ‘British Bicycle Mania’, 1896–1898”, Quinn 2019
“Invisible Nuclear-Armed Submarines, or Transparent Oceans? Are Ballistic Missile Submarines Still the Best Deterrent for the United States?”, Cote 2019
“What Every Engineer Should Know About Inventing § Chapter 4: Theories of Creativity [Wine/printing]”, Middendorf 2019 (page 5)
What Every Engineer Should Know About Inventing § Chapter 4: Theories of Creativity [wine/printing] :
“Entrepreneurial Uncertainty and Expert Evaluation: An Empirical Analysis”, Scott et al 2019
Entrepreneurial Uncertainty and Expert Evaluation: An Empirical Analysis
“Privacy Implications of Accelerometer Data: a Review of Possible Inferences”, Kröger et al 2019
Privacy implications of accelerometer data: a review of possible inferences
“Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs”, Broockman et al 2018
“Replication Data For: ‘Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs’”, Broockman et al 2018
“Criticality Analysis of the Louis Slotin Accident”, Oettingen 2018
“Energy Storage for Electricity Generation and Related Processes: Technologies Appraisal and Grid Scale Applications”, Argyrou et al 2018
“Paving Pompeii: The Archaeology of Stone-Paved Streets”, Poehler & Crowther 2018
“Dark Motives and Elective Use of Brainteaser Interview Questions”, Highhouse et al 2018
Dark Motives and Elective Use of Brainteaser Interview Questions
“Can Behavioral Tools Improve Online Student Outcomes? Experimental Evidence from a Massive Open Online Course”, Patterson 2018
“SonarSnoop: Active Acoustic Side-Channel Attacks”, Cheng et al 2018
“Tradition Is Smarter Than You Are”, Greer 2018
“What Cyber-War Will Look Like”, Greer 2018
“Ionospheric Disturbances Triggered by SpaceX Falcon Heavy”, Chou et al 2018
“The Trade Journal Cooperative: A Niche Trade Journal Delivered To Your Door, Quarterly”, Hwang 2018
The Trade Journal Cooperative: A Niche Trade Journal Delivered To Your Door, Quarterly
“Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations”, Bertsekas 2018
Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations
“The Silurian Hypothesis: Would It Be Possible to Detect an Industrial Civilization in the Geological Record?”, Schmidt & Frank 2018
“Super-Earths in Need for Extremely Big Rockets”, Hippke 2018
“Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration”, Liu et al 2018
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
“Serendipity: Towards a Taxonomy and a Theory”, Yaqub 2018
“The Second Century CE Roman Watermills of Barbegal: Unraveling the Enigma of One of the Oldest Industrial Complexes”, Sürmelihindi 2018
“Bronze Age Iron: Meteoritic or Not? A Chemical Strategy”, Jambon 2017
“Intentional Fire-Spreading by ‘Firehawk’ Raptors in Northern Australia”, Bonta et al 2017
Intentional Fire-Spreading by ‘Firehawk’ Raptors in Northern Australia
“Amazon Celebrates 10th Holiday Season of Frustration-Free Packaging—An Invention That’s Helped Eliminate 181,000 Tons of Packaging and 307 Million Boxes, and Given Millions of Customers Holidays Without ‘Wrap Rage’”, Amazon 2017
“Threading Is Sticky: How Threaded Conversations Promote Comment System User Retention”, Budak et al 2017
Threading is Sticky: How Threaded Conversations Promote Comment System User Retention
“Film Review: The Haunting (1963)”, Dean 2017
“Malware Detection by Eating a Whole EXE”, Raff et al 2017
“Changing Their Tune: How Consumers’ Adoption of Online Streaming Affects Music Consumption and Discovery”, Datta et al 2017
“Information Flow Reveals Prediction Limits in Online Social Activity”, Bagrow et al 2017
Information flow reveals prediction limits in online social activity
“DeepXplore: Automated Whitebox Testing of Deep Learning Systems”, Pei et al 2017
DeepXplore: Automated Whitebox Testing of Deep Learning Systems
“2016 Letter to Shareholders”, Bezos 2017
“Stone Walls That Stay Built: A Master Waller Shares How to Dry-Lay Stone Walls That Hold Their Ground for Centuries”, Post 2017
View PDF:
“How Well Do Experience Curves Predict Technological Progress? A Method for Making Distributional Forecasts”, Lafond et al 2017
“Making and Shooting a Solid 24k Gold Bullet”, 15 & 2017 2017
“Cleaning up After WWII”, jwh1975 2017
“Sensory Augmentation: Integration of an Auditory Compass Signal into Human Perception of Space”, Schumann & O’Regan 2017
Sensory augmentation: integration of an auditory compass signal into human perception of space
“The Esthetic-Usability Effect”, Moran 2017
“Autonomous Precision Landing of Space Rockets”, 5.5.315 2017
Autonomous Precision Landing of Space Rockets :
View PDF:
“General Pencil”, Payne 2017
“Hyper-Realistic Face Masks: a New Challenge in Person Identification”, Sanders et al 2017
Hyper-realistic face masks: a new challenge in person identification
“Hunt for Red October, 1990”, Cinema 2016
“Deep Learning Reinvents the Hearing Aid: Finally, Wearers of Hearing Aids Can Pick out a Voice in a Crowded Room”, Wang 2016b
“Digital Health: Tracking Physiomes and Activity Using Wearable Biosensors Reveals Useful Health-Related Information”, Li et al 2016
“Survey of Alternative Displays”, Neal 2016
“Blade Runner (Typeset In The Future)”, Addey 2016
“Interactive Comparison of Pyramid Sizes SMIL”, Lee 2016
{kind=link}
“Looking Across and Looking Beyond the Knowledge Frontier: Intellectual Distance, Novelty, and Resource Allocation in Science”, Boudreau et al 2016
“No Great Technological Stagnation”, Ricón 2016
No Great Technological Stagnation
View External Link:
“Deep-Spying: Spying Using Smartwatch and Deep Learning”, Beltramelli & Risi 2015
“Direct Combustion of Recyclable Metal Fuels for Zero-Carbon Heat and Power”, Bergthorson et al 2015
Direct combustion of recyclable metal fuels for zero-carbon heat and power
“Woz’s Metal Business Card”, Luckow 2015
“Why the Hell Do They Still Make Car Alarms? They Add to Noise Pollution While failing to Prevent Car Theft. It’s Time for Them to Go.”, George 2015
“Identifying the Source of Perytons at the Parkes Radio Telescope”, Petroff et al 2015
Identifying the source of perytons at the Parkes radio telescope
“Disappearing Polymorphs Revisited”, Bučar et al 2015
“How Those Plush Easter Bunnies Got so Cuddly”, Postrel 2015
“Reviving a Ghost in the History of Technology: The Social Construction of the Recumbent Bicycle”, Ahmed et al 2015
Reviving a ghost in the history of technology: The Social construction of the recumbent bicycle
“Evolution of the Human Brain: From Matter to Mind”, Hofman 2015
“RF Fingerprint Measurements for the Identification of Devices in Wireless Communication Networks Based on Feature Reduction and Subspace Transformation”, Padilla et al 2014
“Automatic Personality Assessment Through Social Media Language”, Park et al 2014
Automatic Personality Assessment Through Social Media Language
“Harvard Innovation Lab Visualizes the Evolution of the Desk”, Azzarello 2014
“Akin’s Laws of Spacecraft Design”, Akin 2014
“Card Cheat Who Used Invisible Ink, Special Contact Lenses Is Banned from Connecticut Casinos”, Press 2014
Card cheat who used invisible ink, special contact lenses is banned from Connecticut casinos
“If We Insulate Our Houses, Why Not Our Cooking Pots?”
“The Retention of Manual Flying Skills in the Automated Cockpit”, Casner et al 2014
The Retention of Manual Flying Skills in the Automated Cockpit
“The Perfect Heist: Recipes from Around the World [Combined Papers + Slides]”, Lafleur et al 2014
The Perfect Heist: Recipes from Around the World [combined papers + slides]
“Paging Inspector Sands: The Costs of Public Information”, Kapoor & Magesan 2014
“Everything from 1991 Radio Shack Ad I Now Do With My Phone”, Cichon 2014
“Killing Time: Dracula and Social Discoordination”, Robbins 2014
“Voices From A Virtual Past: An Oral History of a Technology [VR] Whose Time Has Come Again”
Voices From A Virtual Past: An oral history of a technology [VR] whose time has come again
“A Survey on Computational Displays: Pushing the Boundaries of Optics, Computation, and Perception”, Masia et al 2013
A survey on computational displays: Pushing the boundaries of optics, computation, and perception
“The Story Of Thanksgiving Is A Science-Fiction Story”, Alexander 2013
“Supporting Interaction in Public Space With Electrical Muscle Stimulation”, Pfeiffer et al 2013
Supporting Interaction in Public Space with Electrical Muscle Stimulation
“StallTalk: Graffiti, Toilets, and Anonymous Location Based Micro Blogging”, Friedman & Horn 2013
StallTalk: graffiti, toilets, and anonymous location based micro blogging
“Palm: I’m Ready to Wallow Now”, Holwerda 2013
“The Third User, Or, Exactly Why Apple Keeps Doing Foolish Things”, Tognazzini 2013
The Third User, or, Exactly Why Apple Keeps Doing Foolish Things
“Cuboro Marble Run: ‘Route 66’”, murmelwelt 2013
“The Black Arts of SaaS Pricing”, McKenzie 2013
“Perceiving Invisible Light through a Somatosensory Cortical Prosthesis”, Thomson et al 2013
Perceiving invisible light through a somatosensory cortical prosthesis
“Blackout Tracker United Kingdom Annual Report 2013 § Top 5 Most Unusual Outages/causes”, Eaton 2013 (page 5)
Blackout Tracker United Kingdom Annual Report 2013 § Top 5 most unusual outages/causes :
View PDF:
“Prevented Mortality and Greenhouse Gas Emissions from Historical and Projected Nuclear Power”, Karecha & Hansen 2013
Prevented mortality and greenhouse gas emissions from historical and projected nuclear power
“The Caenorhabditis Elegans Lifespan Machine”, Stroustrup et al 2013
“The Olivetti Valentine Typewriter”, Hill 2012
“Statistical Basis for Predicting Technological Progress”, Nagy et al 2012
“How to Make a Raptor Suit”, Rosengrant 2012
“At the Interface: The Case of the Electric Push Button, 1880–1923”, Plotnick 2012
At the Interface: The Case of the Electric Push Button, 1880–1923
“I Put a Toaster in the Dishwasher”, Stillwater 2012
“A Quiet Opening: North Koreans in a Changing Media Environment”, Kretchun & Kim 2012
A Quiet Opening: North Koreans in a Changing Media Environment :
View PDF:
“The Floppy Toast”, Buttersafe 2012
“Hall’s Law: The 19th Century Prequel to Moore’s Law”, Rao 2012
“SpeechJammer”, Kurihara & Tsukada 2012
“SpeechJammer: A System Utilizing Artificial Speech Disturbance With Delayed Auditory Feedback”, Kurihara & Tsukada 2012
SpeechJammer: A System Utilizing Artificial Speech Disturbance with Delayed Auditory Feedback
“Why Does Attention to Web Articles Fall With Time?”, Simkin & Roychowdhury 2012
“Salary Negotiation: Make More Money, Be More Valued”, McKenzie 2012
“It’s All about the Benjamins: An Empirical Study on Incentivizing Users to Ignore Security Advice”, Christin et al 2012
It’s All about the Benjamins: An Empirical Study on Incentivizing Users to Ignore Security Advice
“Rethinking Real-Time Electricity Pricing”, Allcott 2011
“A Bicycle Can Be Self-Stable Without Gyroscopic or Caster Effects”, Kooijman et al 2011
A Bicycle Can Be Self-Stable Without Gyroscopic or Caster Effects
“‘An Unused Esperanto’: Internationalism and Pictographic Design, 1930–1970”, Bresnahan 2011
‘An Unused Esperanto’: Internationalism and Pictographic Design, 1930–1970
“‘Globalization With Hardware’: ITER’s Fusion of Technology, Policy, and Politics”, McCray 2010
‘Globalization with hardware’: ITER’s fusion of technology, policy, and politics
“Wanamaker's Department Store and the Origins of Electronic Media, 1910–1922”, Arceneaux 2010
Wanamaker's Department Store and the Origins of Electronic Media, 1910–1922 :
View PDF:
“Cool Things in the McMaster-Carr Catalog”, Ketterer 2010
“Online Labor Markets”, Horton 2010
“Victorian Pioneers of Corporate Sustainability”, Desrochers 2009
“Beware Trivial Inconveniences”, Alexander 2009
“Did America Forget How to Make the H-Bomb? Inside an Institutional Memory Lapse of Nuclear Proportions”, Baumann 2009
“Mark of Integrity”, Allen 2009
“Keep Your Identity Small”, Graham 2009
“The Concept of Efficiency: An Historical Analysis”, Alexander 2009
“Blog Statistics and Demographics”, Arnold 2009
“Three Doors to Other Worlds”, Crompton 2008
“Silver Bullet Pages: History Channel Shoot”, Briggs 2008
“Ferrari’s Formula One Handovers and Handovers from Surgery to Intensive Care [Great Ormond Street Hospital for Children]”, Sower et al 2008
“Up and Then Down: The Lives of Elevators”, Paumgarten 2008
“High Tech Cowboys of the Deep Seas: The Race to Save the Cougar Ace”, Davis 2008
High Tech Cowboys of the Deep Seas: The Race to Save the Cougar Ace
“Electricity Generation and Health”, Markandya & Wilkinson 2007
“Seam Carving for Content-Aware Image Resizing”, Avidan & Shamir 2007
“Founders at Work: Stories of Startups' Early Days: Introduction”, Livingstone 2007
Founders at Work: Stories of Startups' Early Days: Introduction :
“Https://web.archive.org/web/20071020051936/http://iq.org/”
Distributed Remote Sensing for Naval Undersea Warfare: Abbreviated Version, Council 2007
Distributed Remote Sensing for Naval Undersea Warfare: Abbreviated Version
“Barnard’s Star and the ‘Wait Equation’”
“Jurassic Park: The Evolution of a Raptor Suit With John Rosengrant”, Duncan 2006
Jurassic Park: The Evolution of a Raptor Suit with John Rosengrant
“Lawrence Bragg’s Role in the Development of Sound-Ranging in World War I”, Kloot 2005
Lawrence Bragg’s role in the development of sound-ranging in World War I
“A Group Is Its Own Worst Enemy”, Shirky 2005
“Moore’s Law and the Technology S-Curve”, Bowden 2004
“A Sea Story: One of the Worst Maritime Disasters in European History Took Place a Decade Ago. It Remains Very Much in the Public Eye. On a Stormy Night on the Baltic Sea, More Than 850 People Lost Their Lives When a Luxurious Ferry Sank below the Waves. From a Mass of Material, including Official and Unofficial Reports and Survivor Testimony, Our Correspondent Has Distilled an Account of the Estonia’s Last Moments—Part of His Continuing Coverage for the Magazine of Anarchy on the High Seas”, Langewiesche 2004
“Demography and Cultural Evolution: How Adaptive Cultural Processes Can Produce Maladaptive Losses: The Tasmanian Case”, Henrich 2004
“"One in a Million" Is next Tuesday”, Osterman 2004
“A Century of Ramjet Propulsion Technology Evolution”, Fry 2004
“Https://web.archive.org/web/20110726001925/http://diveintomark.org/archives/2004/05/14/freedom-0”
https://web.archive.org/web/20110726001925/http://diveintomark.org/archives/2004/05/14/freedom-0
View HTML:
“The Economics of Has-Beens”, MacDonald & Weisbach 2004
“Headcase”, Chivers 2004
“The Jargon File (Version 4.4.7): H: Holy Wars”, Raymond 2003
“The Evolution of the Grocery Bag”, Petroski 2003
The Evolution of the Grocery Bag :
View PDF:
“Destruction of Nuclear Bombs Using Ultra-High Energy Neutrino Beam”, Sugawara et al 2003
Destruction of Nuclear Bombs Using Ultra-High Energy Neutrino Beam
“Alarmingly Useless: The Case for Banning Car Alarms in New York City”, Friedman et al 2003
Alarmingly Useless: The Case for Banning Car Alarms in New York City
“Forest Dewey Dodrill: Heart Surgery Pioneer. Michigan Heart, Part II”, Stephenson et al 2002b
Forest Dewey Dodrill: Heart Surgery Pioneer. Michigan Heart, Part II :
View PDF:
“The Michigan Heart: The World’s First Successful Open Heart Operation? Part I”, Stephenson et al 2002
The Michigan Heart: The World’s First Successful Open Heart Operation? Part I
“Joel on Software: Strategy Letter V”, Spolsky 2002
“Stung by Security Flaws, Microsoft Makes Software Safety a Top Goal”, Markoff 2002
Stung by Security Flaws, Microsoft Makes Software Safety a Top Goal
Henry Maudslay And The Pioneers Of The Machine Age, Cantrell & Cookson 2002
“This Is Your Father’s IBM, Only Smarter: How a Former Has-Been Kicked Its Old Habits, Got Open-Source Religion, and Regained Its Status As One of the Biggest, Baddest Tech Companies on Earth.”
“Resolution of Distinct Rotational Substeps by Sub-Millisecond Kinetic Analysis of F1-ATPase”, Yasuda et al 2001
Resolution of distinct rotational substeps by sub-millisecond kinetic analysis of F1-ATPase
“Altered Beast [Tomato Sauce, Bathtub, Sega Console, CRT TV]”, Woodeson 2001
“Skytherm: an Approach to Year-Round Thermal Energy Sufficient Houses”, Raeissi & Taheri 2000
Skytherm: an approach to year-round thermal energy sufficient houses
“The Little Engines That Could: Modeling the Performance of World Wide Web Search Engines”, Bradlow & Schmittlein 2000
The Little Engines That Could: Modeling the Performance of World Wide Web Search Engines
“Area Man Consults Internet Whenever Possible”, Onion 2000
“How Complex Systems Fail: Being a Short Treatise on the Nature of Failure; How Failure Is Evaluated; How Failure Is Attributed to Proximate Cause; and the Resulting New Understanding of Patient Safety”, Cook 2000
“A Nuclear Engine Design With 242mAm As a Nuclear Fuel”, Ronen et al 2000
“Norvir Advisory”, Care 2000
“Engineering Success and Disaster: American Railroad Bridges, 1840–1900”, Aldrich 1999
Engineering Success and Disaster: American Railroad Bridges, 1840–1900 :
View PDF:
The Last Man on the Moon, Cernan & Davis 1999
“Patent Buyouts: A Mechanism for Encouraging Innovation”, Kremer 1998
“Who Is Arguing About the Cat? Moral Action and Enlightenment According to Dōgen”, Mikkelson 1997
Who Is Arguing About the Cat? Moral Action and Enlightenment According to Dōgen
“Fantastic Voyage: Creating the Futurescape for The Fifth Element; Digital Domain’s Imagery Experts Help to Create Eye-Boggling Visual Effects for Luc Besson’s Sci-Fi Fantasy”, Magid 1997
“The Conquest of Hellgate”
“Technology and Courage”, Sutherland 1996
View PDF:
“The Gravel Page: the Most Frightening Crimes Have No Witnesses except the Ground on Which They Were Committed. And from That Alone Forensic Geologists Illuminate Cases in a Way That Would Impress Sherlock Holmes, the Science's First Practitioner [Balloons of War] [Death of an Agent]”, McPhee 1996
View PDF:
“Anthropological Invariants in Travel Behavior”, Marchetti 1994 (page 6)
“The Role Of The CIA In Economic And Technological Intelligence”, Foley 1994
The Role Of The CIA In Economic And Technological Intelligence
“Expert Judgment on Markers to Deter Inadvertent Human Intrusion into the Waste Isolation Pilot Plant”, Trauth et al 1993
Expert judgment on markers to deter inadvertent human intrusion into the Waste Isolation Pilot Plant
“A Purple Barium Copper Silicate Pigment from Early China”, FitzHugh & Zycherman 1992
“Terminal Delinquents: Once, They Stole Hubcaps And Shot Out Street-Lights. Now They’re Stealing Your Social Security Number And Shooting Out Your Credit Rating. A Layman’s Guide To Computer High Jinks”, Hitt & Tough 1990
“CO2 Disposal by means of Silicates”, Seifritz 1990
CO2 disposal by means of silicates :
View PDF:
“The Statite—A Non-Orbiting Spacecraft”, Forward 1989
“On the Fracture of Pencil Points”, Petroski 1987
On the Fracture of Pencil Points :
View PDF:
“Henry Adams, the Second Law of Thermodynamics, and the Course of History”, Burich 1987
Henry Adams, the Second Law of Thermodynamics, and the Course of History
“Urban Sanitation in Preindustrial Japan”, Hanley 1987
Urban Sanitation in Preindustrial Japan :
View PDF:
“Atchafalaya”, McPhee 1987
“The Little Can That Could”, Daniel 1987
“Two Theories of Home Heat Control”, Kempton 1986
“Zero-Gravity Distillation Using the Heat Pipe Principle (Micro-Distillation)”, Seok & Hwang 1985
Zero-gravity distillation using the heat pipe principle (micro-distillation)
“Effectiveness of Measures to Prevent Unintentional Deaths of Infants and Children from Suffocation and Strangulation”, Krauss 1985
“The Trouble With Fusion: Long Touted As an Inexhaustible Energy Source for the next Century, Fusion As It Is Now Being Developed Will Almost Certainly Be Too Expensive and Unreliable for Commercial Use”, Lidsky 1983
View PDF:
“Breaking Paragraphs into Lines”, Knuth & Plass 1981
“Breaking Paragraphs into Lines § A Historical Summary”, Knuth & Plass 1981 (page 48)
“Major Crimes As Analogs to Potential Threats to Nuclear Facilities and Programs”, Reinstedt & Westbury 1980 (page 6)
Major Crimes as Analogs to Potential Threats to Nuclear Facilities and Programs
“Are Humans Maximizing Reproductive Success? [With Reply]”, Lande & Weinrich 1978
“A Dead Reckoning/map Correlation System for Automatic Vehicle Tracking”, Lezniak et al 1977
A dead reckoning/map correlation system for automatic vehicle tracking
“Human Sociobiology: Pair-Bonding and Resource Predictability (Effects of Social Class and Race)”, Weinrich 1977
Human sociobiology: Pair-bonding and resource predictability (effects of social class and race)
“Space Settlements: A Design Study”, Johnson & Holbrow 1977
“Human Reproductive Strategy: I. Environmental Predictability And Reproductive Strategy; Effects Of Social Class And Race. II. Homosexuality And Non-Reproduction; Some Evolutionary Models”, Weinrich 1976
“The Health Hazards of NOT Going Nuclear”, Beckmann 1976
“An Urban Agro-Ecosystem: The Example of 19th-Century Paris”, Stanhill 1976
An Anthropological Analysis of Food-Getting Technology, Oswalt 1976
“The Amateur Scientist: Diverse Topics, Starting With How to Supply Electric Power to Something That Is Turning”, Stong 1975
My Years With Xerox: The Billions Nobody Wanted, Dessauer 1971
“The Fire Piston and Its Origins in Europe”, Fox 1969
The Fire Piston and Its Origins in Europe :
View PDF:
“Xerography of the Breast”, Wolfe 1969
“Human Adjustment to an Exotic Environment: The Nuclear Submarine”, Earls 1969
Human Adjustment to an Exotic Environment: The Nuclear Submarine
“Saul Bass Pitch Video for Bell System Logo Redesign”, Bass 1969
“Thin Silicone Membranes—Their Permeation Properties And Some Applications”, Robb 1968
Thin Silicone Membranes—Their Permeation Properties And Some Applications :
View PDF:
“On The Obsolescence Of Scientists And Engineers”, Ferdinand 1966
On The Obsolescence Of Scientists And Engineers :
View PDF:
“The Pigeon Towers of Iṣfahān”, Bealy 1966
The Pigeon Towers of Iṣfahān :
View PDF:
“The Pattern of Streets”, Alexander 1966
“The German V-2”, Dornberger 1963
View PDF:
“The Economics of Invention: A Survey of the Literature”, Nelson 1959
“Behavior Of Young Children Under Conditions Simulating Entrapment In Refrigerators”, Bain et al 1958
Behavior Of Young Children Under Conditions Simulating Entrapment In Refrigerators
“Transmission Properties of Laminated Clogston Type Conductors”, Vaage 1953
Transmission Properties of Laminated Clogston Type Conductors
“Some Transient Properties of Transistors”, Bassett & Tillman 1953
“Turbidity Currents and Submarine Slumps, and the 1929 Grand Banks [Newfoundland] Earthquake”, Heezen & Ewing 1952
Turbidity currents and submarine slumps, and the 1929 Grand Banks [Newfoundland] earthquake
“Mathematical Theory of Laminated Transmission Lines-Part 2”, Morgan 1952b
“Mathematical Theory of Laminated Transmission Lines—Part I”, Morgan 1952
“What Price Speed? Specific Power Required for Propulsion of Vehicles”, Gabrielli & Kármán 1950
What price speed? Specific power required for propulsion of vehicles
“Secrets by the Thousands”, Walker 1946
“Dawn Of The Space Age”, Harper 1946
“Winged World: The Coming of the Air Age”, Harper 1946
“The Effect of Size on the Equipment of the Queen’s Dolls’ House”, O’Gorman 1924
The Effect of Size on the Equipment of the Queen’s Dolls’ House
“On the Part Played by Philosophy in the Progress of Man”, Seneca & Gummere 1920
“Aerial Navigation: The Power Required”, Maxim 1891
Aerial Navigation: The Power Required :
View PDF:
“Unfathomable”
“Recent Works [Exploded-Diagram Sculptures]”, Peralta 2026
“Latin Sundial Mottoes With Spanish Translations”, Calle 2026
“All That Is Solid Bursts into Flame: Capitalism and Fire in the 19th-Century United States”
All That Is Solid Bursts into Flame: Capitalism and Fire in the 19th-Century United States
“Making Is Show Business Now”
“Stargate Physics 101”
“A Manifesto on Shower Temperature Control”, Holmen 2026
“Piezoelectric Bagworm Silk”
“The Dream of an Alpine Waterway”
Web Typography, Rutter 2026
“Domes Are Overrated”
“Technology Transfer and Early Industrial Development: The Case of the Sino-Soviet Alliance”
Technology transfer and early industrial development: The case of the Sino-Soviet Alliance
“ChatGPT—Poem Review and Critique”
“How the Shroud of Turin Was Made”
“Hypertext Tools from the 80s”
“Lippmann Security”
“Fan Is A Tool-Using Animal”
“BitWhisper: Covert Signaling Channel between Air-Gapped Computers Using Thermal Manipulations”
BitWhisper: Covert Signaling Channel between Air-Gapped Computers Using Thermal Manipulations
“You Have No Idea How Insanely Complex Modern Headlights Can Be I Mean Holy Crap They Have GPS”
You Have No Idea How Insanely Complex Modern Headlights Can Be I Mean Holy Crap They Have GPS
“The Mastermind Episode 1: An Arrogant Way of Killing”
“How to Tell When a Robot Has Written You a Letter”
“The GE Beetle: Our Giant Atomic Robot”
“The Price of Batteries Has Declined by 97% in the Last Three Decades”
The price of batteries has declined by 97% in the last three decades
View External Link:
“Why Did Renewables Become so Cheap so Fast?”
“Performance Curve Database”
“Alexander Graham Bell’s Tetrahedral Kites (1903–9) [Image Gallery]”, Review 2026
Alexander Graham Bell’s Tetrahedral Kites (1903–9) [image gallery]
“Japanese Firemen’s Coats (19th Century)”
“John Locke’s Method for Common-Place Books (1685)”
“Stuffed Ox, Dummy Tree, Artificial Rock: Deception in the Work of Richard and Cherry Kearton”
Stuffed Ox, Dummy Tree, Artificial Rock: Deception in the Work of Richard and Cherry Kearton
“SpeechJammer Homepage”, Kurihara & Tsukada 2026
“Akin’s Laws of Spacecraft Design”
“No Human Can Match This High-Speed Box-Unloading Robot Named After a Pickle”
No Human Can Match This High-Speed Box-Unloading Robot Named After a Pickle
“Education of a Programmer. When I Left Microsoft in October 2016”, Crowley 2026
Education of a Programmer. When I left Microsoft in October 2016
“How a Handful of Prehistoric Geniuses Launched Humanity’s Technological Revolution”
How a handful of prehistoric geniuses launched humanity’s technological revolution
“Toshi Omagari”
“A Collection of Nerdy Interviews Asking People from All Walks of Life What They Use to Get the Job Done.”
“Forget It!”, Asimov 2026
“Offshore Nuclear Power Plants”
“The Japanese Luggage Forwarding Edition”
“Getting Materials out of the Lab”
“Steam Networks”
“Why Skyscrapers Are so Short”
“The Rise of Niche Consumption”
“The Hum That Helps to Fight Crime”
“This Company’s Robots Are Making Everything”
“Inside the Crash of Fling, the Startup Whose Founder Partied on an Island While His Company Burned through $21 Million”
“Marc Andreessen Says The 1990s Dot-Com Bubble Startups Were ‘All Right But Just Early’”
Marc Andreessen Says The 1990s Dot-Com Bubble Startups Were ‘All Right But Just Early’
“How We Can Mine Asteroids for Space Food”
“Why It’s so Hard to Build a Jet Engine”
“Absolute Zero Is 0K”
“Deciphering China’s AI Dream”
“Microwave Smelter: 8 Steps (With Pictures)”
“New Look, Same Great Look”
“Olivetti Valentine”, Soul 2026
“How a Naked Skydive Inspired a Way to Keep Pilots Oriented in Flight”
How a Naked Skydive Inspired a Way to Keep Pilots Oriented in Flight
“Learning to Cycle: A Cross-Cultural and Cross-Generational Comparison”, Cordovil et al 2026
Learning to Cycle: A Cross-Cultural and Cross-Generational Comparison
“X-Ray Decks: the Lost Bone Music of the Soviet Union”
“The Man Who Broke the Music Business”
“The Age of Robot Farmers”
“Paging Dr. Robot”
“Putting Spiders On Treadmills In Virtual-Reality Worlds”
“CD-Loving Japan Resists Move to Online Music”
“A Tiny Robot That Can Fly And, Amazingly, Rest”
“No Sailors Needed: Robot Sailboats Scour the Oceans for Data”
No Sailors Needed: Robot Sailboats Scour the Oceans for Data
“The Microbots Are on Their Way”
“‘We Don’t Need Another Michelangelo’: In Italy, It’s Robots’ Turn to Sculpt”
‘We Don’t Need Another Michelangelo’: In Italy, It’s Robots’ Turn to Sculpt
“Are You Ready for Sentient Disney Robots?”
“This Robot Looks Like a Pancake and Jumps Like a Maggot”
“How European Royals Once Shared Their Most Important Secrets”
How European Royals Once Shared Their Most Important Secrets
“The Man Who Controls Computers With His Mind”
“Why Is It So Hard for New Musical Instruments to Catch On?”
The Diff, Hobart 2026
“Stewart Brand’s Whole Earth Catalog, the Book That Changed the World: Stewart Brand Was at the Heart of 60s Counterculture and Is Now Widely Revered As the Tech Visionary Whose Book Anticipated the Web. We Meet the Man for Whom Big Ideas Are a Way of Life”
“World’s First Raspberry Picking Robot Cracks the Toughest Nut: Soft Fruit Food & Drink Industry”
World’s first raspberry picking robot cracks the toughest nut: soft fruit Food & drink industry
“In a Blind Test, Audiophiles Couldn’t Tell the Difference between Audio Signals Sent through Copper Wire, a Banana, or Wet Mud—’The Mud Should Sound Perfectly Awful, but It Doesn’t’, Notes the Experiment Creator”
“GSMem: Data Exfiltration from Air-Gapped Computers over GSM Frequencies”
GSMem: Data Exfiltration from Air-Gapped Computers over GSM Frequencies
“The Decades-Long Quest to Design a Car Stereo That Can’t Be Stolen: Car Stereos Have Traditionally Been Both Valuable and Easy to Spot in an Idle Vehicle, Making Them a Key Target for Thieves. Why Aren’t They Getting Stolen Nearly As Much Anymore?”
“Freeman Dyson’s Brain”
View External Link:
“The Search for a More Perfect Kilogram”
The Search for a More Perfect Kilogram
View External Link:
“Inside a Startup’s Plan to Turn a Swarm of DIY Satellites Into an All-Seeing Eye”
Inside a Startup’s Plan to Turn a Swarm of DIY Satellites Into an All-Seeing Eye
View External Link:
“Turns Out the Dot-Com Bust’s Worst Flops Were Actually Fantastic Ideas”
Turns Out the Dot-Com Bust’s Worst Flops Were Actually Fantastic Ideas
View External Link:
“Modern Love: Are We Ready for Intimacy With Robots?”
Modern Love: Are We Ready for Intimacy With Robots?
View External Link:
https://www.wired.com/2017/10/hiroshi-ishiguro-when-robots-act-just-like-humans/
“This 22-Year-Old Builds Chips in His Parents’ Garage”
This 22-Year-Old Builds Chips in His Parents’ Garage
View External Link:
https://www.wired.com/story/22-year-old-builds-chips-parents-garage/
“You’ve Never Heard of China’s Greatest Sci-Fi Novel”
“An Oral History of the 2004 Darpa Grand Challenge”
An Oral History of the 2004 Darpa Grand Challenge
View External Link:
https://www.wired.com/story/darpa-grand-challenge-2004-oral-history/
“Robots Are Fueling the Quiet Ascendance of the Electric Motor”
Robots Are Fueling the Quiet Ascendance of the Electric Motor
View HTML (26MB):
/doc/www/www.wired.com/f7b40f275a1312b6822ca8254dbe376527e51c36.html
“Science Has Spun Spider-Man’s Web-Slinging Into Reality”
Science Has Spun Spider-Man’s Web-Slinging Into Reality
View External Link:
https://www.wired.com/story/science-has-spun-spideys-web-slinging-into-reality/
“Watch a Homemade Robot Crack a SentrySafe Combination Safe in 15 Minutes”
Watch a Homemade Robot Crack a SentrySafe Combination Safe in 15 Minutes
View External Link:
“You Can Now Buy Spot the Robot Dog—If You’ve Got $74,500”
You Can Now Buy Spot the Robot Dog—If You’ve Got $74,500
View HTML (24MB):
/doc/www/www.wired.com/6b01f088e5ae5fbb5d05533fedcd8a928b108b49.html
“Cats, Rats, AI, Oh My!”
“SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms [Video]”
SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms [video]
“Green Hill Zone [Sonic The Hedgehog OST]”
“LEGO Uses 18 Cucumbers to Build Real Log House”
“HUMAN’20: ‘A Live Demo of the Intermedia Hypertext System’ (Norman K. Meyrowitz)”
HUMAN’20: ‘A Live Demo of the Intermedia Hypertext System’ (Norman K. Meyrowitz)
“How a Solar Farm Is Constructed From Beginning to End”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
fusion-power
safety-engineering
hearing-aids
Wikipedia (73)
Miscellaneous
/doc/technology/2024-09-04-gwern-meme-wifehusbandinbed-housewidecoolingusingheatpipeandheatsink.pnghttps://steveblank.com/2024/05/16/secret-history-when-kodak-went-to-war-with-polaroid/https://www.theguardian.com/world/2023/dec/05/one-swedish-zoo-seven-escaped-chimpanzees/doc/technology/2023-02-24-yougov-whenwatchingtshowsdoyouprefersubsordubs.jpg/doc/technology/2022-cordovil-figure2-decreasingmeanagetolearnhowtobicyclebygeneration.jpg/doc/technology/2022-cordovil-figure3-meanagetolearnhowtobicyclesplitbygenerationandcountry.jpg/doc/technology/2022-warburton-figure4-vrheadsetlatencies.jpg/doc/technology/2022-warburton-figure5-latencyofoculusriftvsvalveindexat90hertz.jpg/doc/history/uighur/2021-xu.pdf:View PDF:
/doc/technology/2018-07-25-johnbackus-howdecentralizationevolves.html/doc/technology/2017-budak-figure2-theguardiancommentrateincreaseusingthreadedcomments.jpg/doc/technology/2015-11-harvard-innovationlabs-bestreviews-evolutionofthedesk-vi.jpg/doc/technology/2015-bergthorson-graphicalabstract-burningmetalasfuel.jpg/doc/technology/2014-rogers-adolphinstalethestoryofgamecube.html/doc/technology/2013-02-07-nyrb-rich-divingdeepintodanger.html/doc/technology/2011-chrisdone-programmeratworkstatisticsfromatwoyearproject.html/doc/economics/2009-friedman-seasteadingapracticalguide.pdf:/doc/philosophy/ontology/2005-04-shirky-ontologyisoverratedcategorieslinksandtags.html/doc/technology/2002-battin.pdf:View PDF:
/doc/technology/2000-ronen-figure1-schematicdrawingofamericiumpoweredottocycleengine.png/doc/technology/2000-ronen-figure2-amerciumottocyclenuclearenginephasediagram.png/doc/technology/1997-04-11-davidreid-microwavemeltingofmetals.html/doc/technology/1985-krauss-figure3-californianchildrefrigerationdeathsovertime.png/doc/technology/1976-stanhill-figure2-flowchartofelementalmassthroughparisianagriculturaleconomy.jpghttps://ai.meta.com/blog/teaching-robots-to-perceive-understand-and-interact-through-touch/https://anarchonomicon.substack.com/p/the-antagonists-tech-treehttps://asianometry.substack.com/p/the-soviet-unions-nuclear-icebreakershttps://blog.rootsofprogress.org/american-genesis-part-2-technocracy-to-counterculturehttps://blog.rootsofprogress.org/wright-brothers-and-safe-technology-developmentView External Link:
https://blog.rootsofprogress.org/wright-brothers-and-safe-technology-developmenthttps://brickexperimentchannel.wordpress.com/2023/04/29/lego-googol-machine/View External Link:
https://brickexperimentchannel.wordpress.com/2023/04/29/lego-googol-machine/https://cacm.acm.org/research/software-defined-cooking-using-a-microwave-oven/View External Link:
https://cacm.acm.org/research/software-defined-cooking-using-a-microwave-oven/https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.648.1155https://contrary.com/foundations-and-frontiers/molecular-manufacturinghttps://crimereads.com/the-rise-and-fall-of-the-bank-robbery-capital-of-the-world/https://ifpmag.mdmpublishing.com/firefighting-foam-making-water-wetter/https://mattsclancy.substack.com/p/the-size-of-firms-and-the-naturehttps://ngwa.onlinelibrary.wiley.com/doi/full/10.1111/gwat.12958https://onlinelibrary.wiley.com/doi/full/10.1002/admi.202101447https://publicdomainreview.org/collection/fire-tests-with-textiles/https://publicdomainreview.org/essay/the-early-history-of-the-channel-tunnel/https://shopify.github.io/spatial-commerce-projects/WonkaVision/View External Link:
https://shopify.github.io/spatial-commerce-projects/WonkaVision/https://slate.com/human-interest/2023/06/life-before-cell-phones-internet-after-work.htmlhttps://solar.lowtechmagazine.com/2011/12/the-chinese-wheelbarrowhttps://solar.lowtechmagazine.com/2022/11/when-lethal-weapons-grew-on-trees.htmlhttps://spectrum.ieee.org/automaton/robotics/robotics-hardware/robot-sticks-to-ceilingshttps://whyisthisinteresting.substack.com/p/the-worlds-most-dangerous-toy-editionhttps://worksinprogress.co/issue/how-mathematics-built-the-modern-world/https://www.ageofinvention.xyz/p/age-of-invention-the-beacons-arehttps://www.atlasobscura.com/articles/flying-circus-aerial-mapshttps://www.atlasobscura.com/articles/pneumatic-tube-table-phone-flirting-berlinhttps://www.atlasobscura.com/articles/the-public-shaming-of-englands-first-umbrella-userhttps://www.bloomberg.com/features/2016-bateman-airplane-safety-device/https://www.collectorsweekly.com/articles/how-the-soviets-revolutionized-wristwatches/https://www.construction-physics.com/p/could-chatgpt-become-an-architecthttps://www.construction-physics.com/p/how-did-solar-power-get-cheap-parthttps://www.construction-physics.com/p/the-birth-of-the-gridhttps://www.construction-physics.com/p/the-story-of-titaniumhttps://www.construction-physics.com/p/what-happened-to-the-us-machine-toolhttps://www.construction-physics.com/p/why-are-nuclear-power-construction-c3chttps://www.construction-physics.com/p/why-did-supersonic-airliners-failhttps://www.cremieux.xyz/p/the-cultural-power-of-high-skilledhttps://www.derekau.net/blog/2019/07/10/paintings-of-the-traditional-porcelain-processhttps://www.fadedpage.com/link.php?file=20160325.html#Page_107https://www.fhi.ox.ac.uk/wp-content/uploads/2021/08/QNRs_FHI-TR-2021-3.0.pdfhttps://www.freaktakes.com/p/how-did-places-like-bell-labs-knowhttps://www.hemmings.com/stories/article/steaming-sensation-1925-doblehttps://www.high-capacity.com/p/how-china-uses-foreign-firms-to-turbochargehttps://www.lowtechmagazine.com/2022/11/when-lethal-weapons-grew-on-trees.htmlhttps://www.newyorker.com/magazine/1994/01/10/e-mail-from-bill-gateshttps://www.newyorker.com/magazine/2016/02/29/a-new-generation-of-airships-is-bornhttps://www.nytimes.com/2023/12/29/science/puzzles-mechanical-miller.htmlhttps://www.palladiummag.com/2022/10/28/how-finlands-green-party-chose-nuclear-power/https://www.palladiummag.com/2023/01/27/how-america-lost-the-atomic-age/View External Link:
https://www.palladiummag.com/2023/01/27/how-america-lost-the-atomic-age/https://www.palladiummag.com/2023/04/04/the-golden-age-of-aerospace/View External Link:
https://www.palladiummag.com/2023/04/04/the-golden-age-of-aerospace/https://www.popularmechanics.com/military/aviation/a36548281/sr-71-blackbird-history/https://www.schedium.net/2023/01/the-window-trick-of-las-vegas-hotels.htmlhttps://www.smithsonianmag.com/air-space-magazine/airships-rise-again-180979343/https://www.spoon-tamago.com/animated-gifs-illustrating-the-art-of-japanese-wood-joinery/https://www.theverge.com/23743095/apple-watch-band-release-x206-assembly-button-of-the-month
{kind=link}
{kind=link}
{kind=link}
{kind=link}
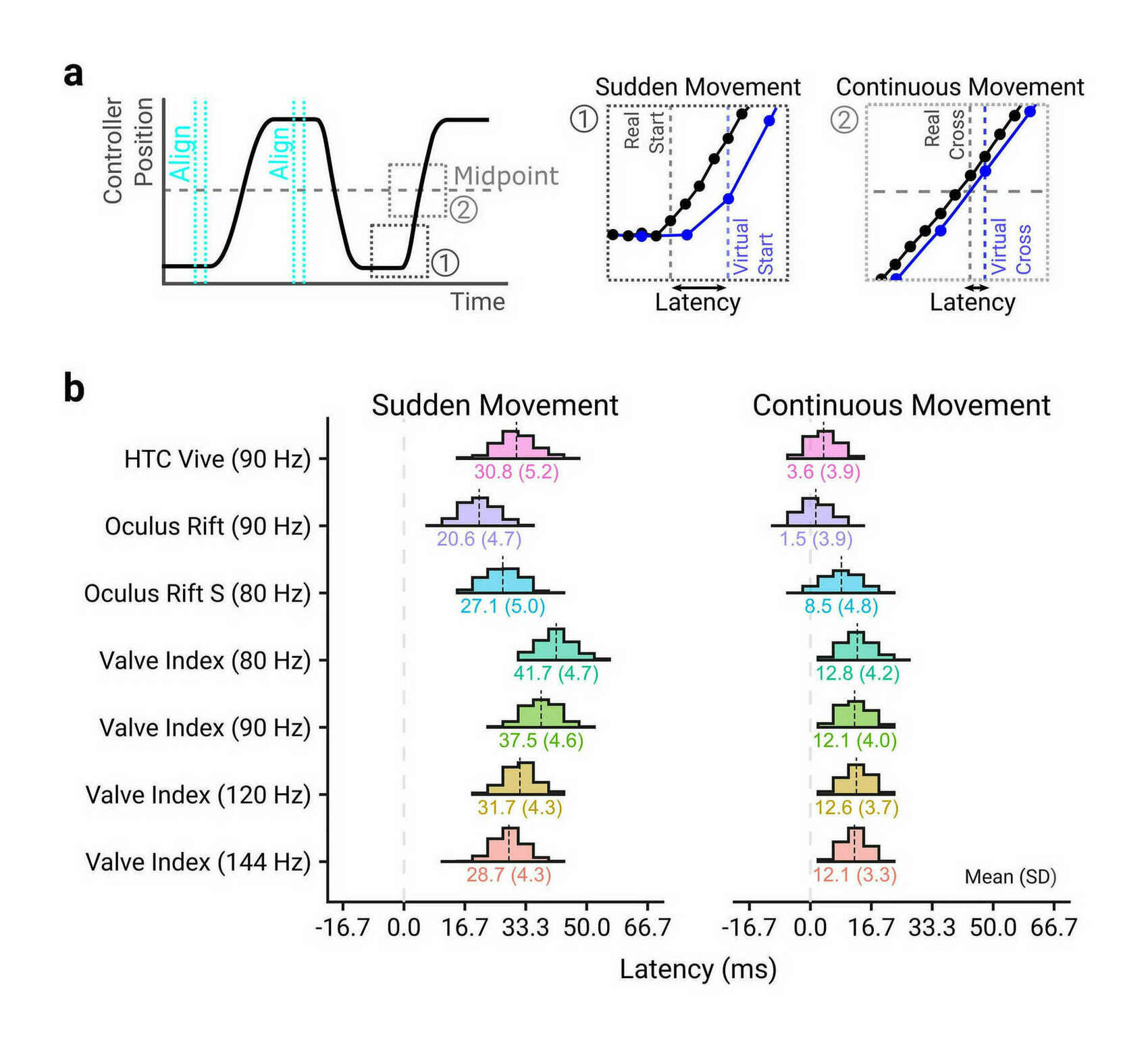{kind=link}
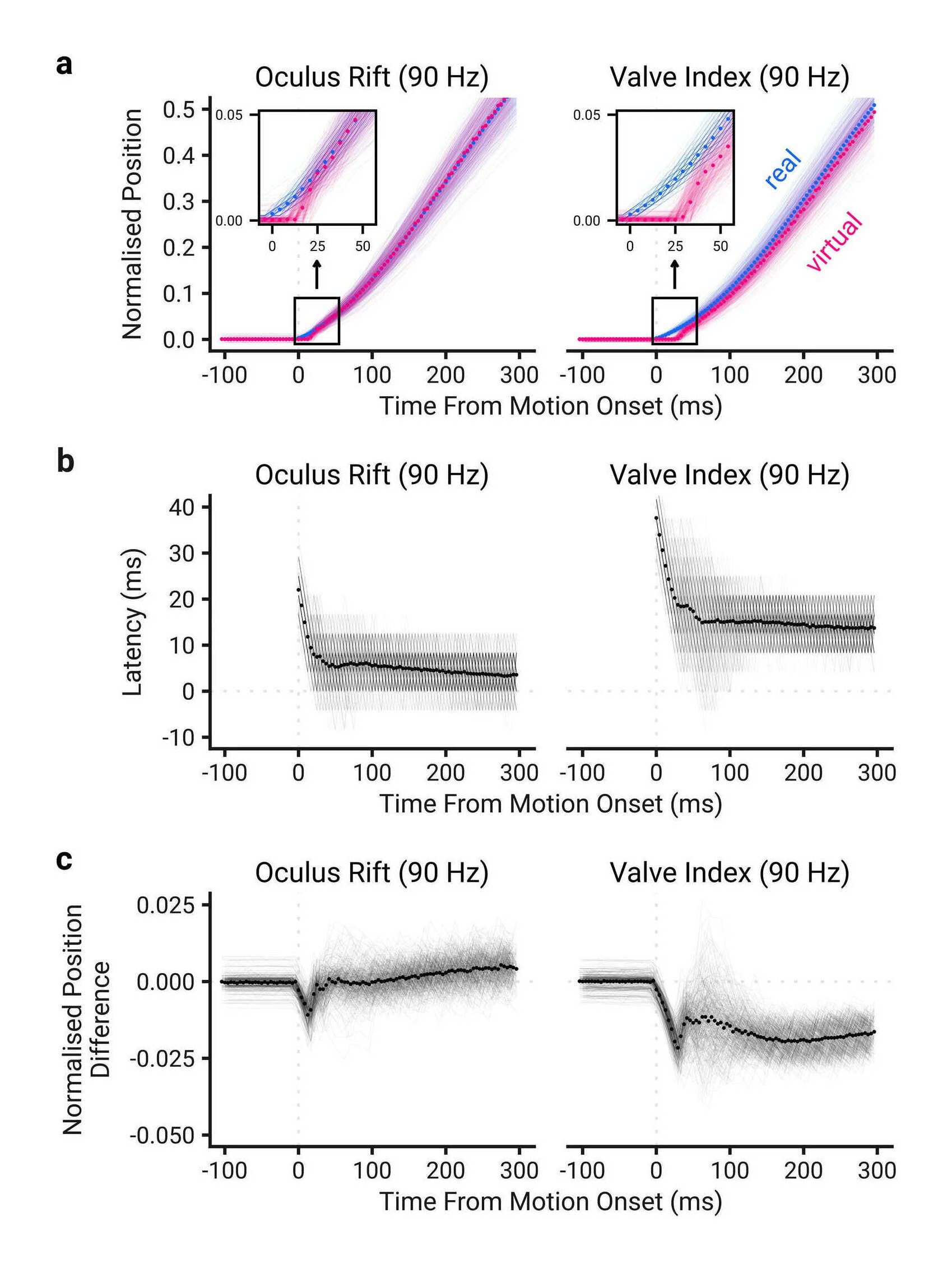{kind=link}
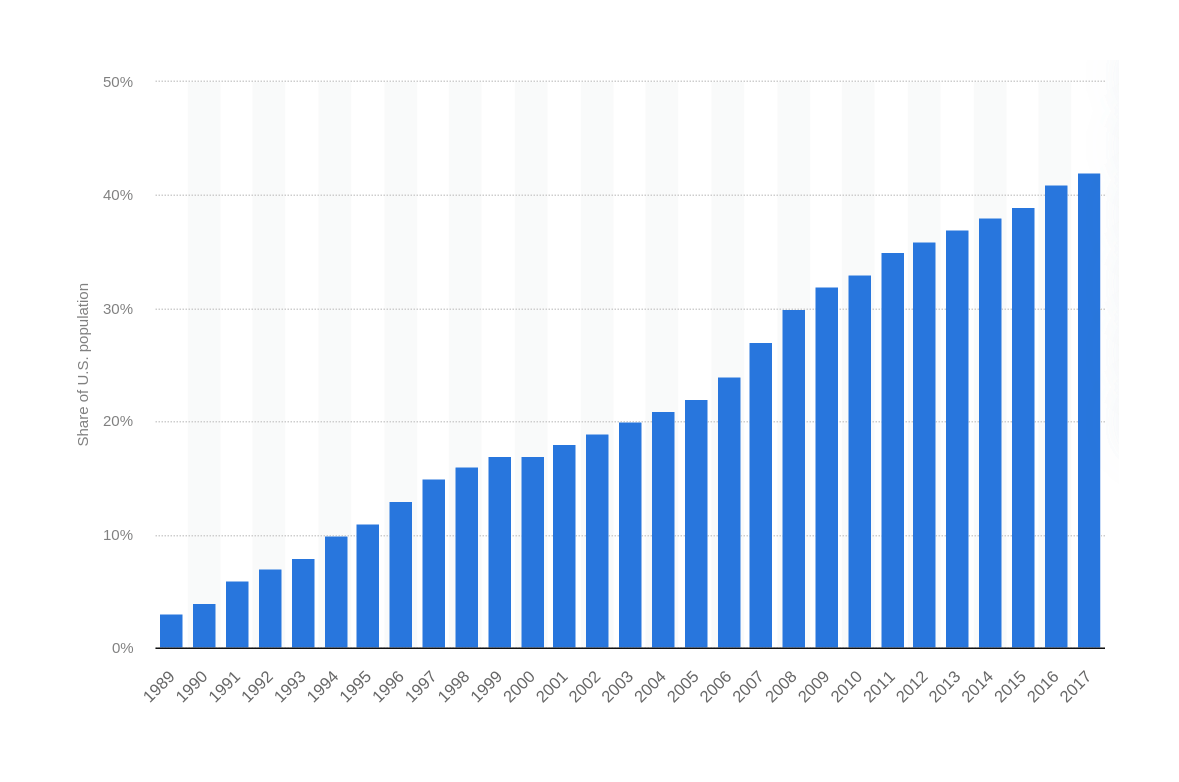{kind=link}
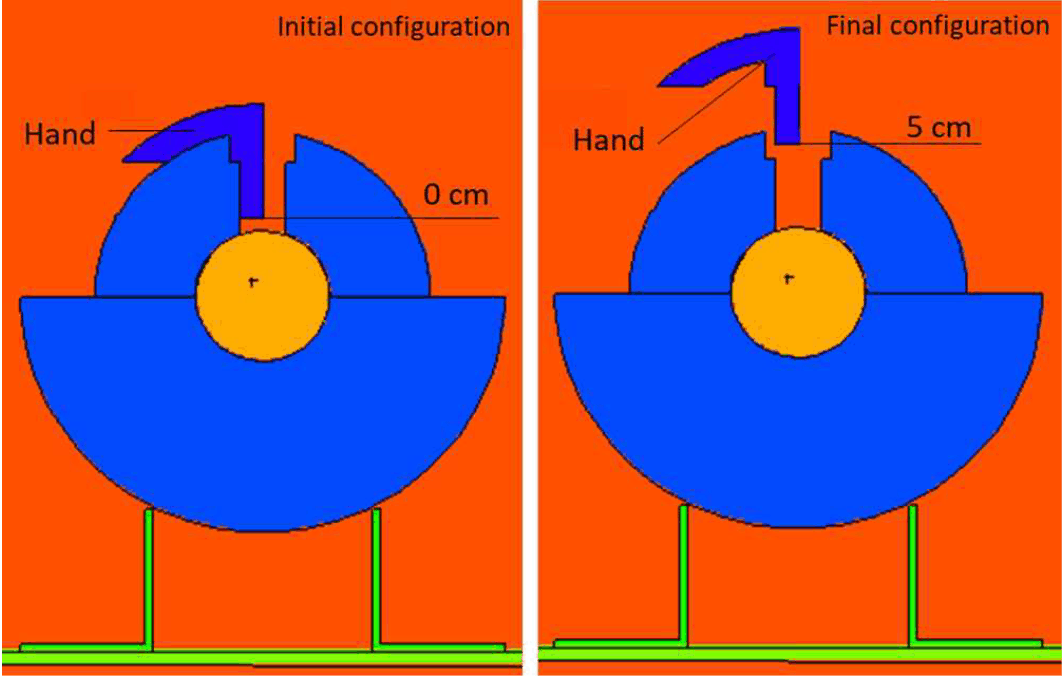{kind=link}
{kind=link}
{kind=link}
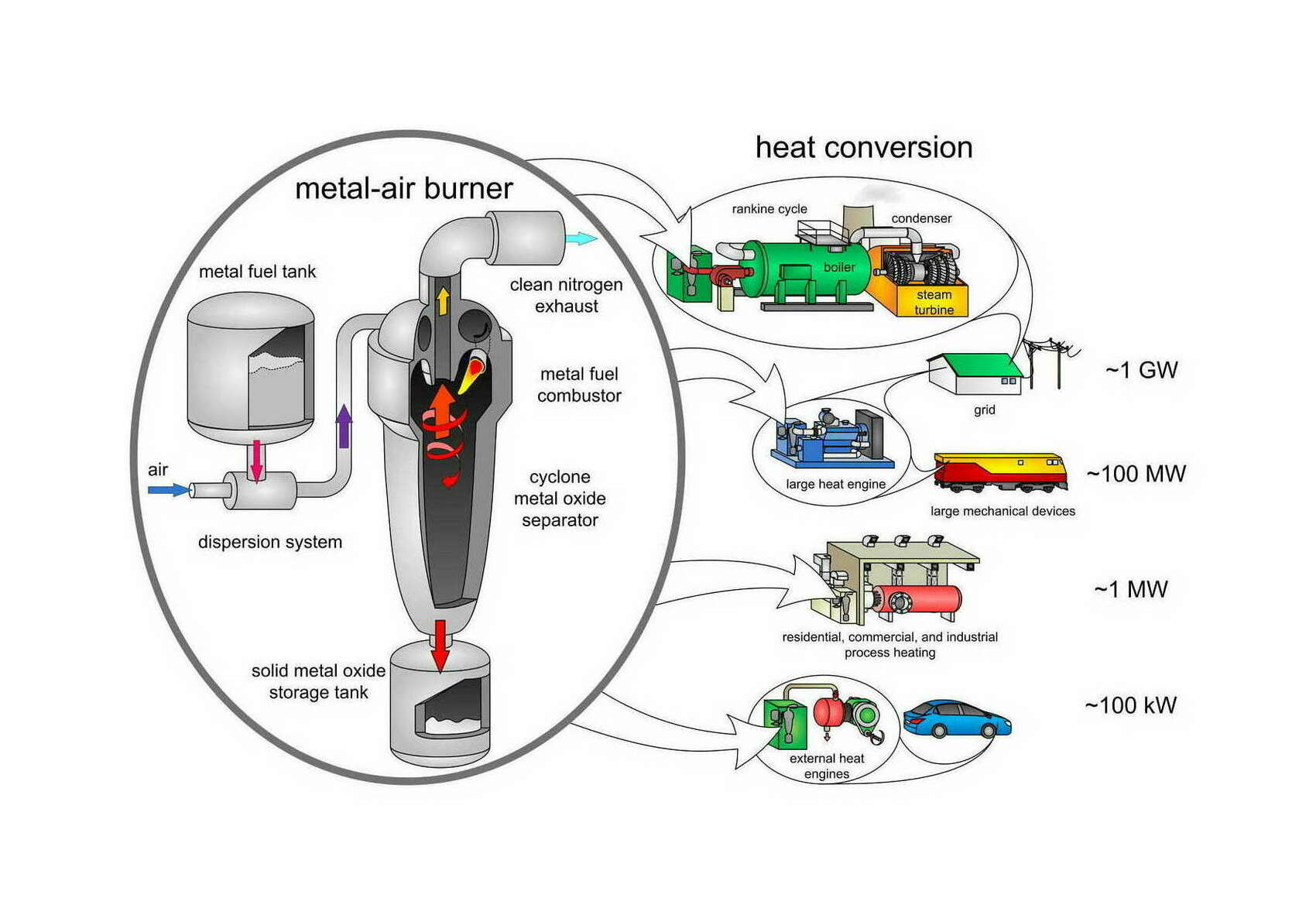{kind=link}
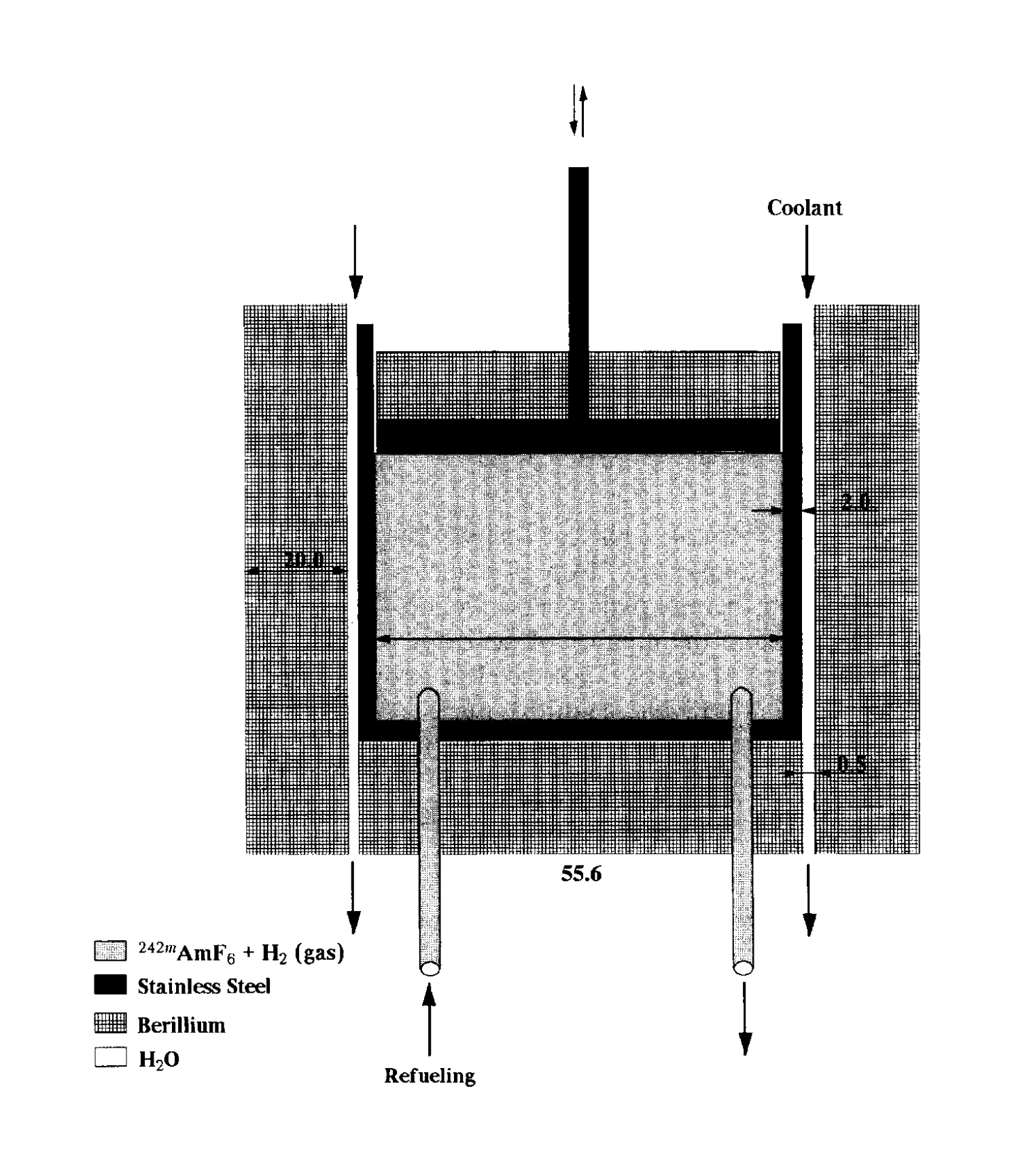{kind=link}
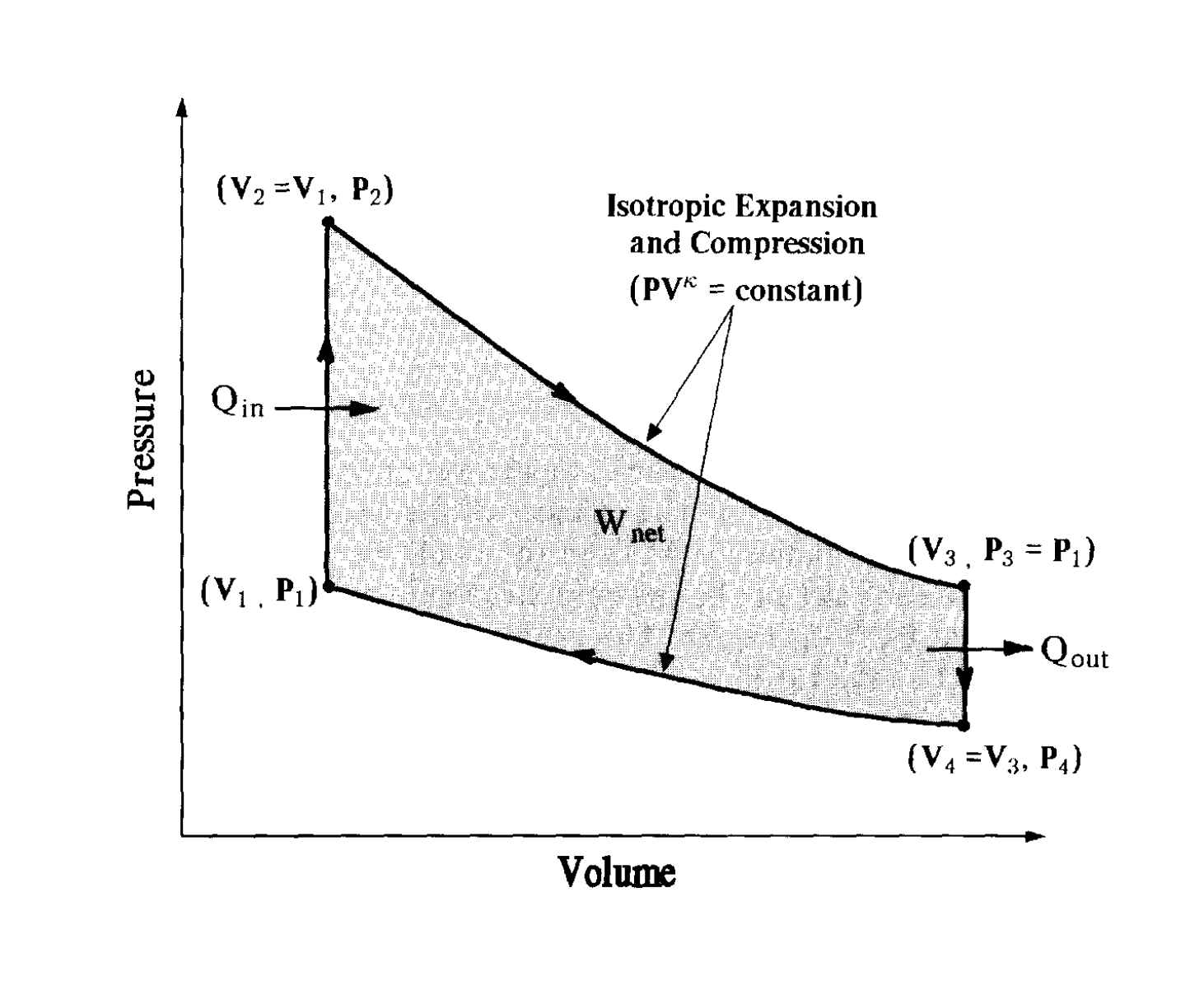{kind=link}
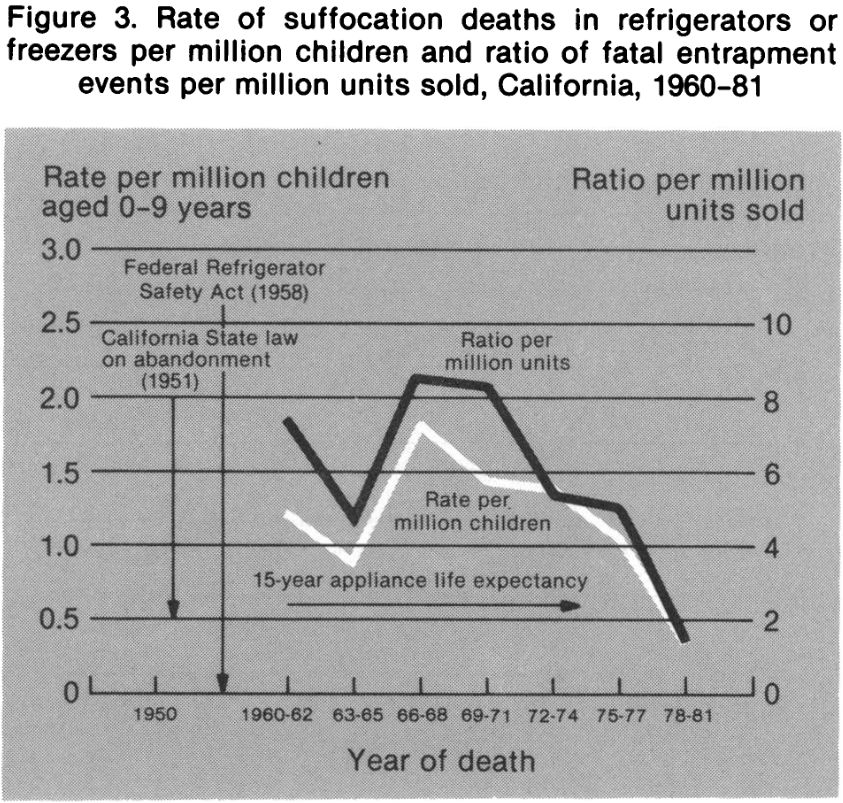{kind=link}
{kind=link}
{kind=link}
Bibliography
2025-lamoureux.pdf: “Kirigami-Inspired Parachutes With Programmable Reconfiguration”,https://www.bloomberg.com/news/articles/2024-04-24/toptal-founder-and-investor-tensions-spark-lawsuit: “Battle Over Startup Leaves Early Investor With No Equity, $2.6 Million Legal Bill § The Information PR War”,https://www.pnas.org/doi/10.1073/pnas.2215829120: “Founder Personality and Entrepreneurial Outcomes: A Large-Scale Field Study of Technology Startups”,2023-agrawal.pdf: “Taxing Uber”,https://www.sciencedirect.com/science/article/pii/S0048733322001500: “Invention and the Life Course: Age Differences in Patenting”,2022-kelly-2.pdf: “The Mechanics of the Industrial Revolution”,https://arstechnica.com/gadgets/2022/12/linux-amazon-meta-and-microsoft-want-to-break-the-google-maps-monopoly/: “Linux, Amazon, Meta, and Microsoft Want to Break the Google Maps Monopoly: Overture Maps Foundation Wants to End the Oppressive Rule of the Google Maps API”,https://www.tandfonline.com/doi/full/10.1080/00305316.2022.2121777: “Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”,https://www.newyorker.com/culture/rabbit-holes/the-charming-bloke-who-dominates-geoguessr: “The Charming Bloke Who Dominates GeoGuessr: Tom Davies Has Become a Beloved Icon of the Google Maps Guessing Game”,https://levelup.gitconnected.com/searching-for-cyclic-tv-reference-paradoxes-d125ff014279: “Searching for Cyclic TV Reference Paradoxes”,https://80000hours.org/podcast/episodes/joan-rohlfing-avoiding-catastrophic-nuclear-blunders/#the-interaction-between-nuclear-weapons-and-cybersecurity-011018: “Joan Rohlfing on How to Avoid Catastrophic Nuclear Blunders: The Interaction between Nuclear Weapons and Cybersecurity”,2022-givon.pdf: “From Fish out of Water to New Insights on Navigation Mechanisms in Animals”,https://osf.io/preprints/psyarxiv/dnr9s/: “Fooled by Beautiful Data: Visualization Esthetics Bias Trust in Science, News, and Social Media”,https://arxiv.org/abs/2112.11848: “A Large-Scale Characterization of How Readers Browse Wikipedia”,https://onlinelibrary.wiley.com/doi/full/10.1002/smj.3365: “Hyperspecialization and Hyperscaling: A Resource-Based Theory of the Digital Firm”,2021-giurge.pdf: “You Don’t Need to Answer Right Away! Receivers Overestimate How Quickly Senders Expect Responses to Non-Urgent Work Emails”,2021-murtha.pdf: “From Stroke to Stoke: The Multiple Sporting Legacies of the Southern California Home Swimming Pool”,2021-fillmore.pdf: “Technological Change and Obsolete Skills: Evidence from Men’s Professional Tennis”,https://venturebeat.com/ai/google-details-new-ai-accelerator-chips/: “Google Details New AI Accelerator Chips”,https://www.sciencedirect.com/science/article/pii/S0166432819311763: “Enriched Environment Exposure Accelerates Rodent Driving Skills”,https://href.cool/2010s/: “Cool Links of the Decade: 2010s”,https://beepb00p.xyz/pkm-search.html: “Building Personal Search Infrastructure for Your Knowledge and Code: Overview of Search Tools for Desktop and Mobile; Using Emacs and Ripgrep As Desktop Search Engine”,2019-hanssen.pdf: “‘What’s Wrong With The Way I Talk?’ The Effect Of Sound Motion Pictures On Actor Careers”,2018-patterson.pdf: “Can Behavioral Tools Improve Online Student Outcomes? Experimental Evidence from a Massive Open Online Course”,2017-budak.pdf: “Threading Is Sticky: How Threaded Conversations Promote Comment System User Retention”,2014-lafleur.pdf: “The Perfect Heist: Recipes from Around the World [Combined Papers + Slides]”,https://www.trendingbuffalo.com/life/uncle-steves-buffalo/everything-from-1991-radio-shack-ad-now/: “Everything from 1991 Radio Shack Ad I Now Do With My Phone”,https://arxiv.org/abs/1202.6106: “SpeechJammer: A System Utilizing Artificial Speech Disturbance With Delayed Auditory Feedback”,2010-mccray.pdf: “‘Globalization With Hardware’: ITER’s Fusion of Technology, Policy, and Politics”,2009-desrochers.pdf: “Victorian Pioneers of Corporate Sustainability”,2009-alexander.pdf: “The Concept of Efficiency: An Historical Analysis”,https://nap.nationalacademies.org/catalog/11927/distributed-remote-sensing-for-naval-undersea-warfare-abbreviated-version: Distributed Remote Sensing for Naval Undersea Warfare: Abbreviated Version,2004-henrich.pdf: “Demography and Cultural Evolution: How Adaptive Cultural Processes Can Produce Maladaptive Losses: The Tasmanian Case”,http://www.catb.org/jargon/html/H/holy-wars.html: “The Jargon File (Version 4.4.7): H: Holy Wars”,2000-raeissi.pdf: “Skytherm: an Approach to Year-Round Thermal Energy Sufficient Houses”,1976-stanhill.pdf: “An Urban Agro-Ecosystem: The Example of 19th-Century Paris”,1966-alexander.pdf: “The Pattern of Streets”,1952-morgan-2.pdf: “Mathematical Theory of Laminated Transmission Lines-Part 2”,1952-morgan.pdf: “Mathematical Theory of Laminated Transmission Lines—Part I”,1950-gabrielli.pdf: “What Price Speed? Specific Power Required for Propulsion of Vehicles”,1924-ogorman.pdf: “The Effect of Size on the Equipment of the Queen’s Dolls’ House”,