‘order statistics’ directory
- See Also
- Gwern
- “Anti-Spaced Repetition for Serendipity”, Gwern 2017
- “Visualizing Active Learning Sample-Efficiency”, Gwern 2022
- “Best Student Ever!”, Gwern 2023
- “Simulating ‘tail Collapse’ in R”, Gwern 2024
- “Statistical Notes”, Gwern 2014
- “Open Questions”, Gwern 2018
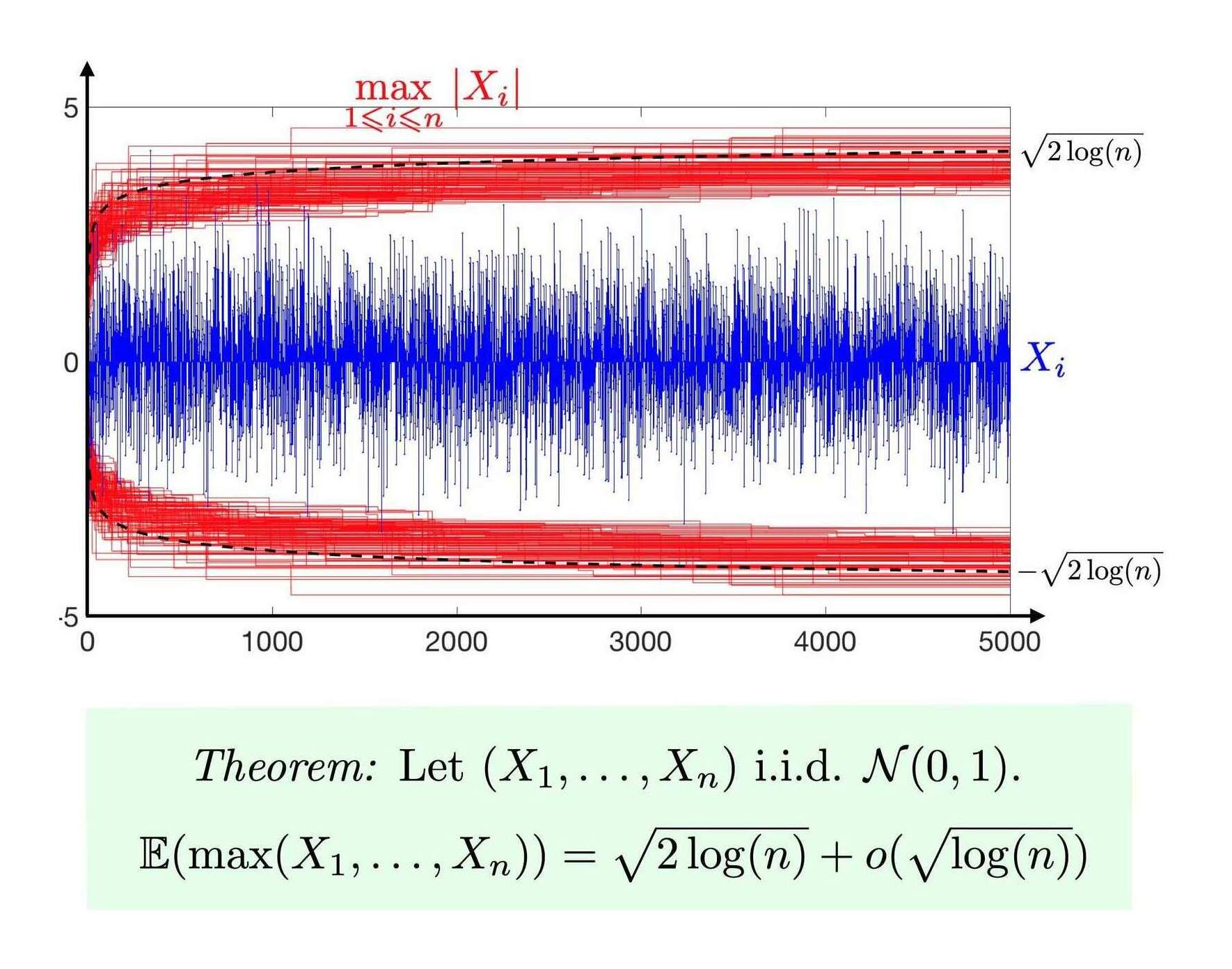
- “Calculating The Gaussian Expected Maximum”, Gwern 2016
- “Dog Cloning For Special Forces: Breed All You Can Breed”, Gwern 2018
- “Common Selection Scenarios”, Gwern 2021
- “Embryo Selection For Intelligence”, Gwern 2016
- “Genius Revisited Revisited”, Gwern 2016
- “The Explore-Exploit Dilemma in Media Consumption”, Gwern 2016
- “History of Iterated Embryo Selection”, Gwern 2019
- “Life Extension Cost-Benefits”, Gwern 2015
- “Conscientiousness & Online Education”, Gwern 2012
- Links
- “The Biggest Trackmania Pathfinding Competition”, Wirtual 2026
- “What Does 10×-Ing Effective Compute Get You? Once AIs Match Top Humans, What Are the Returns to Further Scaling and Algorithmic Improvement?”, Greenblatt 2025
- “Why Have Secretariat’s Records Never Been Broken? It’s Simple and Complicated [Luck + Racetrack Changes + Doping?]”, Clay 2025
- “The Dead Planet Theory: No One Does Anything, the Bar Is Lower Than You Think”, A_REAL_SOCIETY 2025
- tamaybes @ "2025-02-13"
- “The Number of ‘Exceptional’ People: Fewer Than 85 per 1 Million across Key Traits”, Gignac 2025
- “Is Intelligence Really Normally Distributed? a Left-Tailed Bell Curve”, Jensen 2024
- “The Global Pattern of Centenarians Highlights Deep Problems in Demography”, Newman 2024
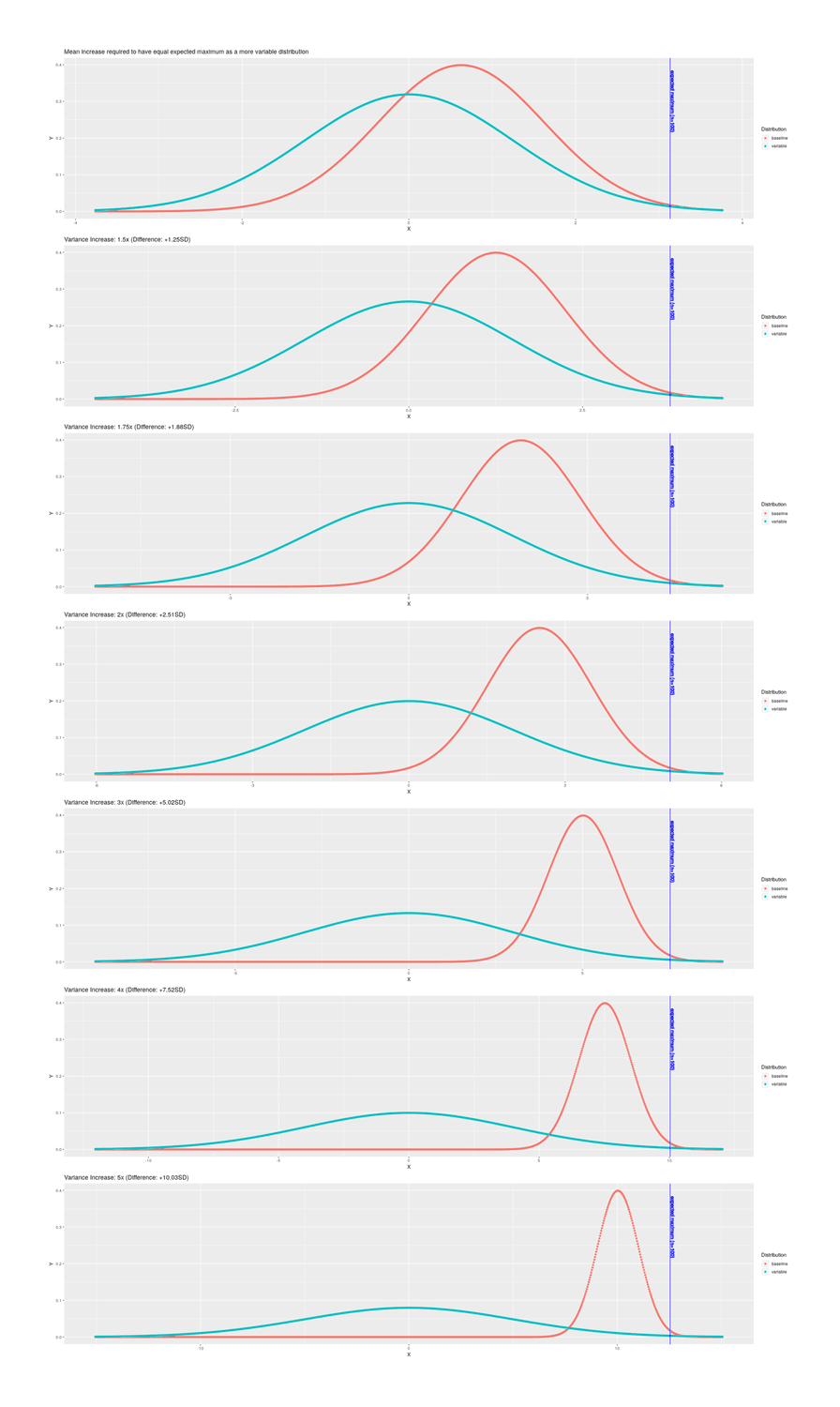
- “Variance Matters More Than Mean in the Extremes”, Cook 2024
- “BoNBoN Alignment for Large Language Models and the Sweetness of Best-Of-n Sampling”, Gui et al 2024
- “Asymptotics of Language Model Alignment”, Yang et al 2024
- “Theoretical Guarantees on the Best-Of-n Alignment Policy”, Beirami et al 2024
- “The Hacker Who Hunts Video Game Speedrunning Cheaters”
- “Scientific Productivity As a Random Walk”, Zhang et al 2023
- “Micromouse: The Fastest Maze-Solving Competition On Earth”, Veritasium 2023
- “Power Law Trends in Speedrunning and Machine Learning”, Erdil & Sevilla 2023
- “Distinct Elements in Streams: An Algorithm for the (Text) Book”, Chakraborty et al 2023
- “Scaling Laws for Reward Model Overoptimization”, Gao et al 2022
- “Accurate Detection of Shared Genetic Architecture from GWAS Summary Statistics in the Small-Sample Context”, Willis & Wallace 2022
- “Predictive Validity in Drug Discovery: What It Is, Why It Matters and How to Improve It”, Scannell et al 2022
- “What Was Not Said and What to Do About It”, Kuncel & Worrell 2022
- “Improving Graduate-School Admissions by Expanding Rather Than Eliminating Predictors”, Nye & Ryan 2022
- “Bias, Fairness, and Validity in Graduate-School Admissions: A Psychometric Perspective”, Woo et al 2022
- “The Promise of Potential: A Study on the Effectiveness of Jury Selection to a Prestigious Visual Arts Program”, Kackovic et al 2022
- “Effective Mutation Rate Adaptation through Group Elite Selection”, Kumar et al 2022
- “Assessing the Response to Genomic Selection by Simulation”, Buntaran et al 2022
- “On Extensions of Rank Correlation Coefficients to Multivariate Spaces”, Han 2021
- “A Review of the Gumbel-Max Trick and Its Extensions for Discrete Stochasticity in Machine Learning”, Huijben et al 2021
- “Human Mortality at Extreme Age”, Belzile et al 2021
- “On Boosting the Power of Chatterjee’s Rank Correlation”, Lin & Han 2021
- “Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail”, Jones 2021
- “A New Coefficient of Correlation: Supplementary Material: Proofs”, Chatterjee 2020
- “A New Coefficient of Correlation”, Chatterjee 2020
- “Supercentenarian and Remarkable Age Records Exhibit Patterns Indicative of Clerical Errors and Pension Fraud”, Newman 2020
- “A Simple Measure of Conditional Dependence”, Azadkia & Chatterjee 2019
- “Low Base Rates Prevented Terman from Identifying Future Nobelists”, Warne et al 2019
- “Test Driving ‘Power of Two Random Choices’ Load Balancing”, Tarreau 2019
- “Right-Tail Range Restriction: A Lurking Threat to Detecting Associations between Traits and Skill among Experts”, Kell & Wai 2019
- “Nature versus Nurture: Have Performance Gaps Between Men and Women Reached an Asymptote?”, Millard-Stafford et al 2018
- “Categorizing Variants of Goodhart’s Law”, Manheim & Garrabrant 2018
- “Innovation and Cumulative Culture through Tweaks and Leaps in Online Programming Contests”, Miu et al 2018
- “Is Individual Job Performance Distributed According to a Power Law? A Review of Methods for Comparing Heavy-Tailed Distributions”, Spain et al 2017
- “Comparing the Pearson and Spearman Correlation Coefficients across Distributions and Sample Sizes: A Tutorial Using Simulations and Empirical Data”, Winter et al 2016
- “The Gatlin Dilemma [An Ex-Doper With Too-Good-To-Be-True Track Records?]”, Tucker 2015
- “Why the Tails Come Apart”, Thrasymachus 2014
- “The Discovery of First-In-Class Drugs: Origins and Evolution”, Eder et al 2014
- “Spearman’s Rho for the AMH Copula: a Beautiful Formula”, Machler 2014
- “A Copula-Based Non-Parametric Measure of Regression Dependence”, Dette et al 2012
- “On the Distribution of Time-To-Proof of Mathematical Conjectures”, Hisano & Sornette 2012
- “How Were New Medicines Discovered?”, Swinney & Anthony 2011
- “Exact Distribution of the Max/Min of Two Gaussian Random Variables”, Nadarajah & Kotz 2008
- “Copula Associated to Order Statistics”, Anjos et al 2005
- “Computing the Distribution and Expected Value of the Concomitant Rank-Order Statistics”, Barakat & El-Shandidy 2004
- “Accurate Approximation to the Extreme Order Statistics of Gaussian Samples”, Chen & Tyler 1999
- “Research, Patenting, and Technological Change”, Kortum 1997
- “Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means”, Lubinski & Humphreys 1996b
- “The Relevance of Group Membership for Personnel Selection: A Demonstration Using Bayes’ Theorem”, Miller 1994
- “Validity of the GRE without Restriction of Range”, Huitema & Stein 1993
- “Fairness in Employment Testing: Validity Generalization, Minority Issues, and the General Aptitude Test Battery”, Hartigan & Wigdor 1989
- “Maxima of Normal Random Vectors: Between Independence and Complete Dependence”, Hüsler & Reiss 1989
- “Forecasting Records by Maximum Likelihood”, Smith 1988
- “The Asymptotic Theory of Extreme Order Statistics, Second Edition”, Galambos 1987
- “An Examination of Two Alternative Techniques to Estimate the Standard Deviation of Job Performance in Dollars”, Reilly & Smither 1985
- “Expected Normal Order Statistics (Exact and Approximate)”, Royston 1982
- “Impact of Valid Selection Procedures on Work-Force Productivity”, Schmidt et al 1979
- “How Deviant Can You Be?”, Samuelson 1968
- “Asymptotic Independence of Certain Statistics Connected With the Extreme Order Statistics in a Bivariate Distribution”, Srivastava 1967
- “Estimating Bounds on Athletic Performance”, Deakin 1967
- “Asymptotic Independence of Bivariate Extremes”, Mardia 1964
- “Expected Values of Normal Order Statistics”, Harter 1961
- “The Double Dixie Cup Problem”, Newman 1960
- “Bivariate Extreme Statistics, I”, Sibuya 1960
- “Statistical Estimates and Transformed Beta-Variables”, Blom 1958
- “The Asymptotical Distribution of Range in Samples from a Normal Population”, Elfving 1947
- “The Relationship Of Validity Coefficients To The Practical Effectiveness Of Tests In Selection: Discussion And Tables”
- Statistical Method, Kelley 1923
- “How Many Hottest Days of the Year (So Far)?”
- “What Does It Mean to Have a Low R2? A Warning about Misleading Interpretation”
- “Approximate Order Statistics for Normal Random Variables”
- “Univariate Distributional Analysis With L-Moment Statistics Using R”
- “Modelling a Time Series of Records With PyMC3”
- “Rényi’s Parking Constant”
- “Analyzing DeepMind’s Probabilistic Methods for Evaluating Agent Capabilities”
- “The 4-Minute Mile Effect § Trivial Threshold Effect?”
- “All Nobel Prizes”
- Wikipedia (9)
- Miscellaneous
- Bibliography
See Also
Gwern
“Anti-Spaced Repetition for Serendipity”, Gwern 2017
“Visualizing Active Learning Sample-Efficiency”, Gwern 2022
“Best Student Ever!”, Gwern 2023
“Simulating ‘tail Collapse’ in R”, Gwern 2024
“Statistical Notes”, Gwern 2014
“Open Questions”, Gwern 2018
“Calculating The Gaussian Expected Maximum”, Gwern 2016
“Dog Cloning For Special Forces: Breed All You Can Breed”, Gwern 2018
“Common Selection Scenarios”, Gwern 2021
“Embryo Selection For Intelligence”, Gwern 2016
“Genius Revisited Revisited”, Gwern 2016
“The Explore-Exploit Dilemma in Media Consumption”, Gwern 2016
“History of Iterated Embryo Selection”, Gwern 2019
“Life Extension Cost-Benefits”, Gwern 2015
“Conscientiousness & Online Education”, Gwern 2012
Links
“The Biggest Trackmania Pathfinding Competition”, Wirtual 2026
“What Does 10×-Ing Effective Compute Get You? Once AIs Match Top Humans, What Are the Returns to Further Scaling and Algorithmic Improvement?”, Greenblatt 2025
“Why Have Secretariat’s Records Never Been Broken? It’s Simple and Complicated [Luck + Racetrack Changes + Doping?]”, Clay 2025
“The Dead Planet Theory: No One Does Anything, the Bar Is Lower Than You Think”, A_REAL_SOCIETY 2025
The Dead Planet Theory: No one does anything, the bar is lower than you think
tamaybes @ "2025-02-13"
“The Number of ‘Exceptional’ People: Fewer Than 85 per 1 Million across Key Traits”, Gignac 2025
The number of ‘exceptional’ people: Fewer than 85 per 1 million across key traits
“Is Intelligence Really Normally Distributed? a Left-Tailed Bell Curve”, Jensen 2024
Is intelligence really normally distributed? a left-tailed bell curve
“The Global Pattern of Centenarians Highlights Deep Problems in Demography”, Newman 2024
The global pattern of centenarians highlights deep problems in demography
“Variance Matters More Than Mean in the Extremes”, Cook 2024
“BoNBoN Alignment for Large Language Models and the Sweetness of Best-Of-n Sampling”, Gui et al 2024
BoNBoN Alignment for Large Language Models and the Sweetness of Best-of-n Sampling
“Asymptotics of Language Model Alignment”, Yang et al 2024
“Theoretical Guarantees on the Best-Of-n Alignment Policy”, Beirami et al 2024
“The Hacker Who Hunts Video Game Speedrunning Cheaters”
“Scientific Productivity As a Random Walk”, Zhang et al 2023
“Micromouse: The Fastest Maze-Solving Competition On Earth”, Veritasium 2023
“Power Law Trends in Speedrunning and Machine Learning”, Erdil & Sevilla 2023
“Distinct Elements in Streams: An Algorithm for the (Text) Book”, Chakraborty et al 2023
Distinct Elements in Streams: An Algorithm for the (Text) Book
“Scaling Laws for Reward Model Overoptimization”, Gao et al 2022
“Accurate Detection of Shared Genetic Architecture from GWAS Summary Statistics in the Small-Sample Context”, Willis & Wallace 2022
“Predictive Validity in Drug Discovery: What It Is, Why It Matters and How to Improve It”, Scannell et al 2022
Predictive validity in drug discovery: what it is, why it matters and how to improve it :
View PDF:
“What Was Not Said and What to Do About It”, Kuncel & Worrell 2022
“Improving Graduate-School Admissions by Expanding Rather Than Eliminating Predictors”, Nye & Ryan 2022
Improving Graduate-School Admissions by Expanding Rather Than Eliminating Predictors
“Bias, Fairness, and Validity in Graduate-School Admissions: A Psychometric Perspective”, Woo et al 2022
Bias, Fairness, and Validity in Graduate-School Admissions: A Psychometric Perspective
“The Promise of Potential: A Study on the Effectiveness of Jury Selection to a Prestigious Visual Arts Program”, Kackovic et al 2022
“Effective Mutation Rate Adaptation through Group Elite Selection”, Kumar et al 2022
Effective Mutation Rate Adaptation through Group Elite Selection
“Assessing the Response to Genomic Selection by Simulation”, Buntaran et al 2022
“On Extensions of Rank Correlation Coefficients to Multivariate Spaces”, Han 2021
On extensions of rank correlation coefficients to multivariate spaces
“A Review of the Gumbel-Max Trick and Its Extensions for Discrete Stochasticity in Machine Learning”, Huijben et al 2021
A Review of the Gumbel-max Trick and its Extensions for Discrete Stochasticity in Machine Learning
“Human Mortality at Extreme Age”, Belzile et al 2021
“On Boosting the Power of Chatterjee’s Rank Correlation”, Lin & Han 2021
“Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail”, Jones 2021
Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail
“A New Coefficient of Correlation: Supplementary Material: Proofs”, Chatterjee 2020
A New Coefficient of Correlation: Supplementary material: Proofs :
“A New Coefficient of Correlation”, Chatterjee 2020
“Supercentenarian and Remarkable Age Records Exhibit Patterns Indicative of Clerical Errors and Pension Fraud”, Newman 2020
“A Simple Measure of Conditional Dependence”, Azadkia & Chatterjee 2019
“Low Base Rates Prevented Terman from Identifying Future Nobelists”, Warne et al 2019
Low Base Rates Prevented Terman from Identifying Future Nobelists
“Test Driving ‘Power of Two Random Choices’ Load Balancing”, Tarreau 2019
“Right-Tail Range Restriction: A Lurking Threat to Detecting Associations between Traits and Skill among Experts”, Kell & Wai 2019
“Nature versus Nurture: Have Performance Gaps Between Men and Women Reached an Asymptote?”, Millard-Stafford et al 2018
Nature versus Nurture: Have Performance Gaps Between Men and Women Reached an Asymptote?
“Categorizing Variants of Goodhart’s Law”, Manheim & Garrabrant 2018
“Innovation and Cumulative Culture through Tweaks and Leaps in Online Programming Contests”, Miu et al 2018
Innovation and cumulative culture through tweaks and leaps in online programming contests
“Is Individual Job Performance Distributed According to a Power Law? A Review of Methods for Comparing Heavy-Tailed Distributions”, Spain et al 2017
“Comparing the Pearson and Spearman Correlation Coefficients across Distributions and Sample Sizes: A Tutorial Using Simulations and Empirical Data”, Winter et al 2016
View PDF:
“The Gatlin Dilemma [An Ex-Doper With Too-Good-To-Be-True Track Records?]”, Tucker 2015
The Gatlin dilemma [an ex-doper with too-good-to-be-true track records?]
“Why the Tails Come Apart”, Thrasymachus 2014
“The Discovery of First-In-Class Drugs: Origins and Evolution”, Eder et al 2014
The discovery of first-in-class drugs: origins and evolution
“Spearman’s Rho for the AMH Copula: a Beautiful Formula”, Machler 2014
“A Copula-Based Non-Parametric Measure of Regression Dependence”, Dette et al 2012
A Copula-Based Non-parametric Measure of Regression Dependence
“On the Distribution of Time-To-Proof of Mathematical Conjectures”, Hisano & Sornette 2012
On the distribution of time-to-proof of mathematical conjectures
“How Were New Medicines Discovered?”, Swinney & Anthony 2011
“Exact Distribution of the Max/Min of Two Gaussian Random Variables”, Nadarajah & Kotz 2008
Exact Distribution of the Max/Min of Two Gaussian Random Variables
“Copula Associated to Order Statistics”, Anjos et al 2005
“Computing the Distribution and Expected Value of the Concomitant Rank-Order Statistics”, Barakat & El-Shandidy 2004
Computing the Distribution and Expected Value of the Concomitant Rank-Order Statistics
“Accurate Approximation to the Extreme Order Statistics of Gaussian Samples”, Chen & Tyler 1999
Accurate approximation to the extreme order statistics of Gaussian samples
“Research, Patenting, and Technological Change”, Kortum 1997
“Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means”, Lubinski & Humphreys 1996b
Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means
“The Relevance of Group Membership for Personnel Selection: A Demonstration Using Bayes’ Theorem”, Miller 1994
The Relevance of Group Membership for Personnel Selection: A Demonstration Using Bayes’ Theorem
“Validity of the GRE without Restriction of Range”, Huitema & Stein 1993
“Fairness in Employment Testing: Validity Generalization, Minority Issues, and the General Aptitude Test Battery”, Hartigan & Wigdor 1989
“Maxima of Normal Random Vectors: Between Independence and Complete Dependence”, Hüsler & Reiss 1989
Maxima of normal random vectors: Between independence and complete dependence :
View PDF:
“Forecasting Records by Maximum Likelihood”, Smith 1988
“The Asymptotic Theory of Extreme Order Statistics, Second Edition”, Galambos 1987
The Asymptotic Theory of Extreme Order Statistics, Second Edition
“An Examination of Two Alternative Techniques to Estimate the Standard Deviation of Job Performance in Dollars”, Reilly & Smither 1985
“Expected Normal Order Statistics (Exact and Approximate)”, Royston 1982
Expected Normal Order Statistics (Exact and Approximate) :
View PDF:
“Impact of Valid Selection Procedures on Work-Force Productivity”, Schmidt et al 1979
Impact of valid selection procedures on work-force productivity
“How Deviant Can You Be?”, Samuelson 1968
“Asymptotic Independence of Certain Statistics Connected With the Extreme Order Statistics in a Bivariate Distribution”, Srivastava 1967
“Estimating Bounds on Athletic Performance”, Deakin 1967
“Asymptotic Independence of Bivariate Extremes”, Mardia 1964
“Expected Values of Normal Order Statistics”, Harter 1961
Expected Values of Normal Order Statistics :
View PDF:
“The Double Dixie Cup Problem”, Newman 1960
“Bivariate Extreme Statistics, I”, Sibuya 1960
“Statistical Estimates and Transformed Beta-Variables”, Blom 1958
“The Asymptotical Distribution of Range in Samples from a Normal Population”, Elfving 1947
The Asymptotical Distribution of Range in Samples from a Normal Population
“The Relationship Of Validity Coefficients To The Practical Effectiveness Of Tests In Selection: Discussion And Tables”
Statistical Method, Kelley 1923
View PDF:
“How Many Hottest Days of the Year (So Far)?”
“What Does It Mean to Have a Low R2? A Warning about Misleading Interpretation”
What does it mean to have a low R2? A warning about misleading interpretation
“Approximate Order Statistics for Normal Random Variables”
“Univariate Distributional Analysis With L-Moment Statistics Using R”
Univariate Distributional Analysis with L-moment Statistics using R
“Modelling a Time Series of Records With PyMC3”
“Rényi’s Parking Constant”
“Analyzing DeepMind’s Probabilistic Methods for Evaluating Agent Capabilities”
Analyzing DeepMind’s Probabilistic Methods for Evaluating Agent Capabilities
“The 4-Minute Mile Effect § Trivial Threshold Effect?”
“All Nobel Prizes”
Wikipedia (9)
Miscellaneous
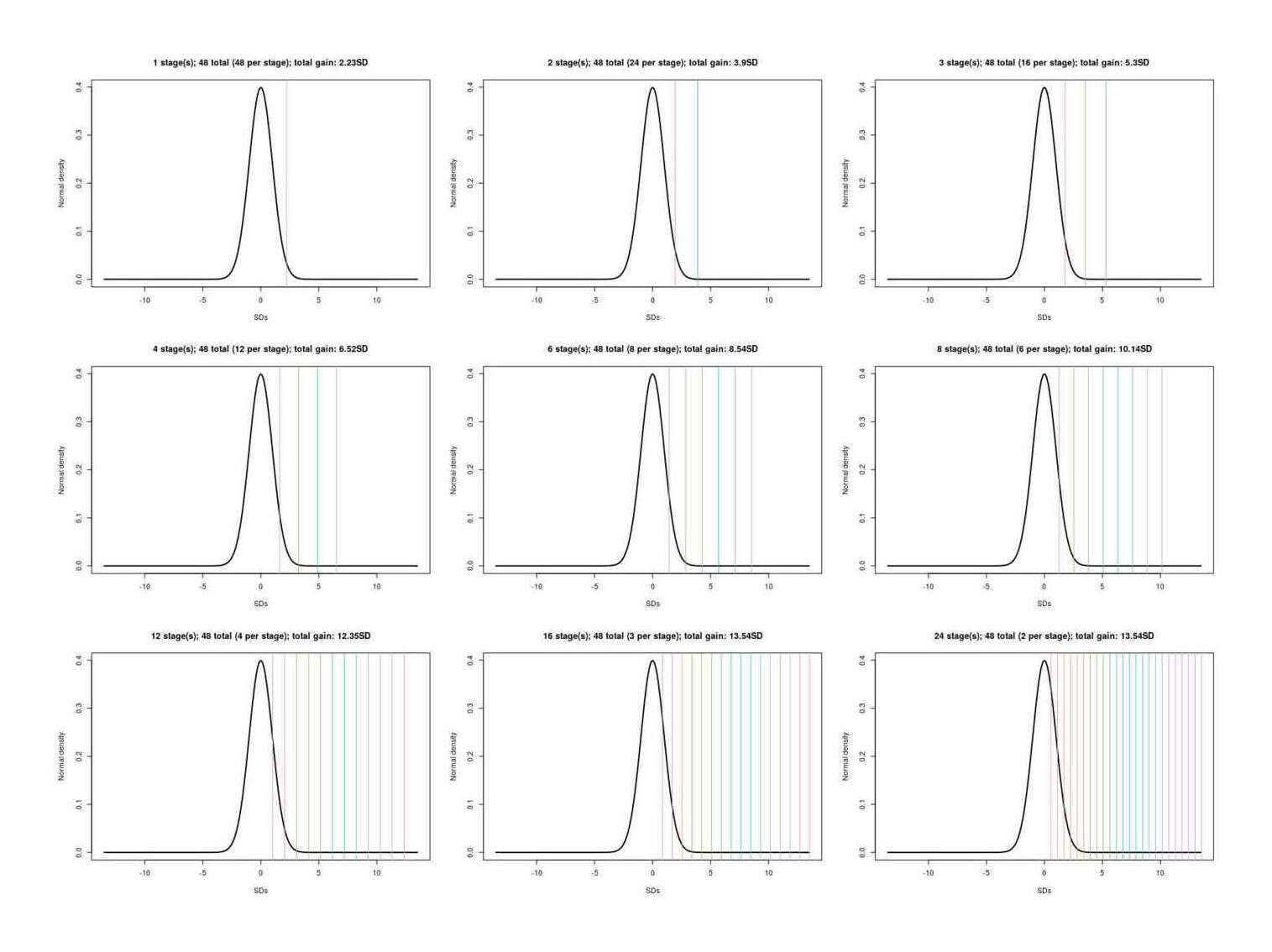
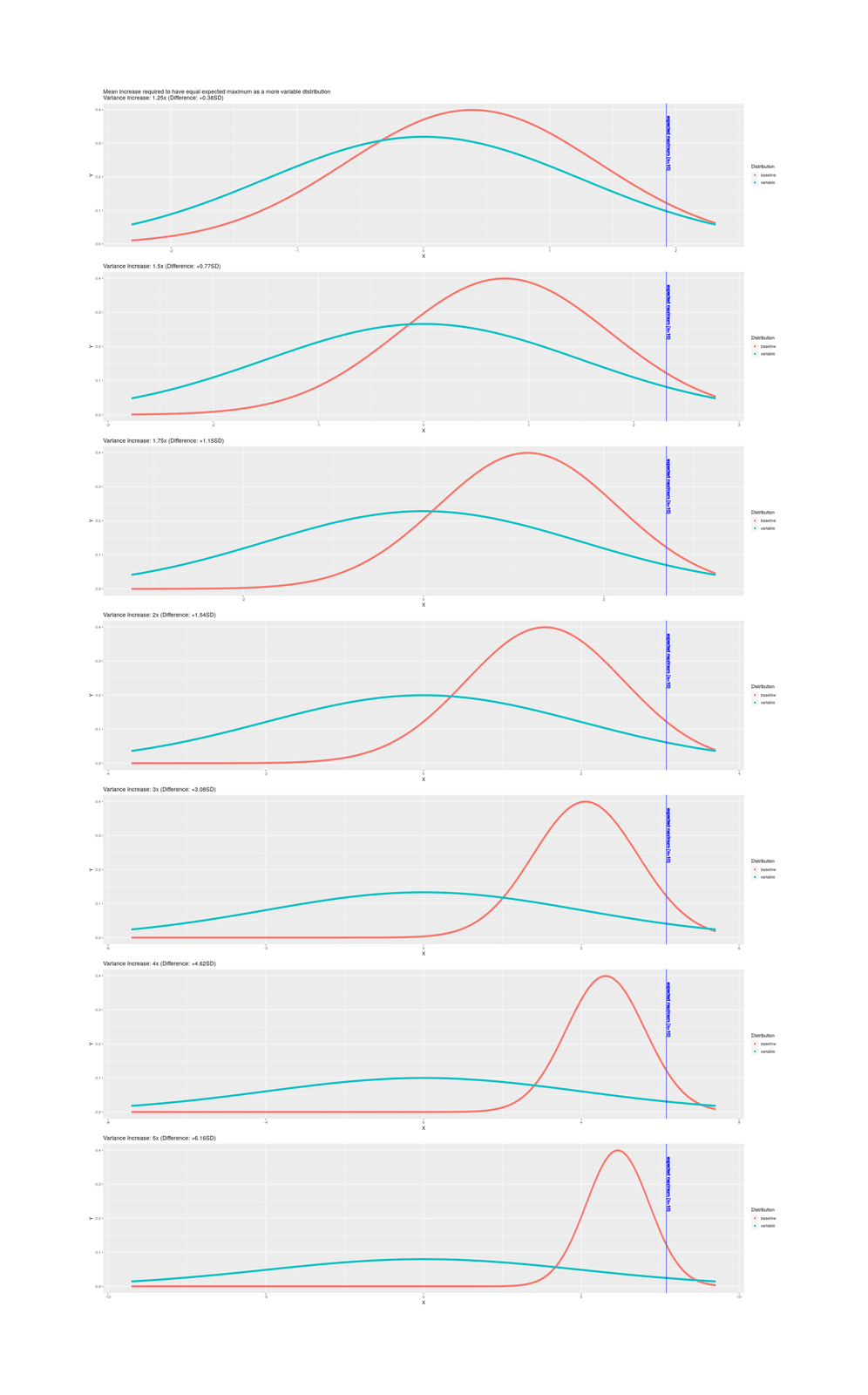
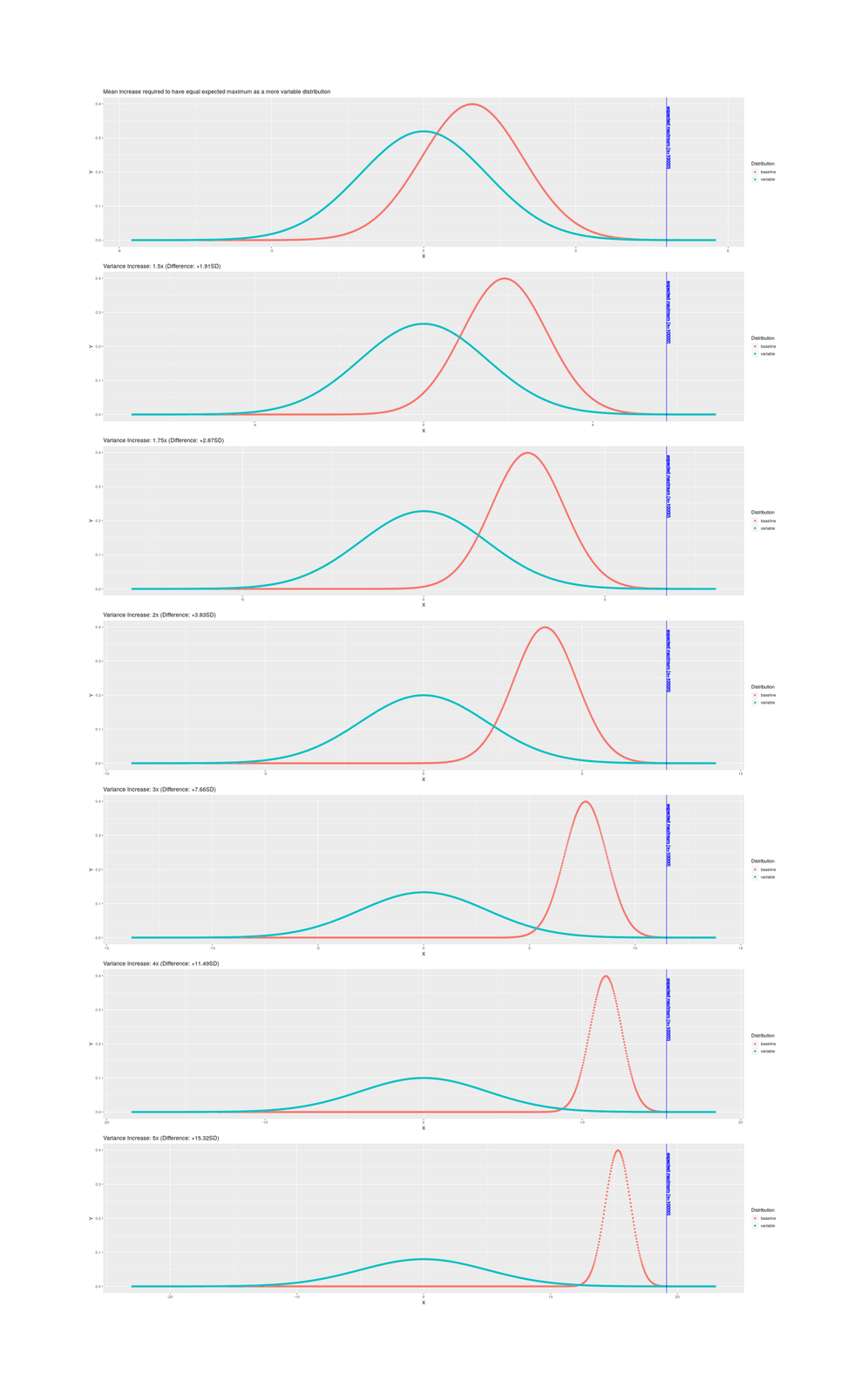
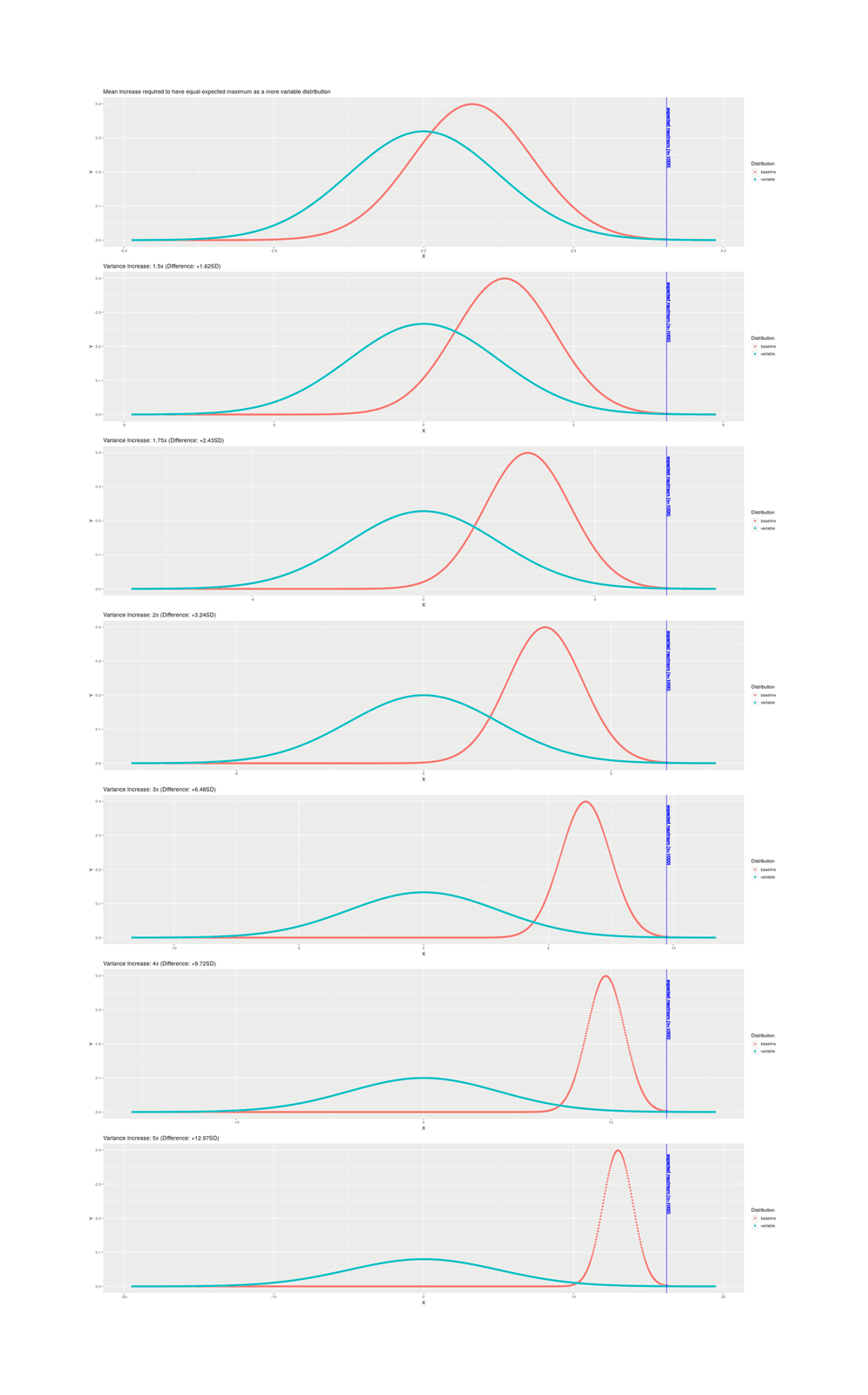
/doc/statistics/order/2022-07-25-gwern-activelearningvsrandomsearch-200simulationruns.webm/doc/statistics/order/2020-11-26-gabrielpeyre-maxgaussianclt.jpg/doc/statistics/order/1996-lubinski-figure1-pilotselection.jpg/doc/statistics/order/gwern-topp-necessarycorrelationstrengthtoreach50percent.jpg/doc/statistics/order/gwern-orderstatistics-selection-multivssingle.jpg/doc/statistics/order/gwern-orderstatistics-selection-bivariate-negativecorrelation.png/doc/statistics/order/gwern-orderstatistics-multistageselection-n48.jpg/doc/statistics/order/gwern-orderstatistics-increasedvarianceadvantage.png/doc/statistics/order/gwern-orderstatistics-increasedvarianceadvantage-n10000.png/doc/statistics/order/gwern-orderstatistics-increasedvarianceadvantage-n1000.png/doc/statistics/order/gwern-orderstatistics-increasedvarianceadvantage-n100.pnghttps://web.archive.org/web/20191122044527/https://blog.paralleluniverse.co/2014/02/04/littles-law/https://www.johndcook.com/blog/2023/05/30/reviewing-a-thousand-things/View External Link:
https://www.johndcook.com/blog/2023/05/30/reviewing-a-thousand-things/https://www.johndcook.com/blog/2023/06/09/coupon-collector-2/View External Link:
https://www.johndcook.com/blog/2023/06/09/coupon-collector-2/https://www.johndcook.com/blog/2023/09/30/consecutive-coupon-collector-problem/View External Link:
https://www.johndcook.com/blog/2023/09/30/consecutive-coupon-collector-problem/https://www.lesswrong.com/posts/EbFABnst8LsidYs5Y/goodhart-taxonomyhttps://www.quantamagazine.org/computer-scientists-invent-an-efficient-new-way-to-count-20240516/https://www.science.org/content/blog-post/target-based-drug-discovery-waste-time
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2210.10760#openai: “Scaling Laws for Reward Model Overoptimization”,https://www.nber.org/system/files/working_papers/w28340/w28340.pdf: “Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail”,2020-chatterjee.pdf: “A New Coefficient of Correlation”,2017-spain.pdf: “Is Individual Job Performance Distributed According to a Power Law? A Review of Methods for Comparing Heavy-Tailed Distributions”,https://www.lesswrong.com/posts/dC7mP5nSwvpL65Qu5/why-the-tails-come-apart: “Why the Tails Come Apart”,1997-kortoum.pdf: “Research, Patenting, and Technological Change”,1996-lubinski-2.pdf: “Seeing The Forest From The Trees: When Predicting The Behavior Or Status Of Groups, Correlate Means”,1994-miller.pdf: “The Relevance of Group Membership for Personnel Selection: A Demonstration Using Bayes’ Theorem”,1964-mardia.pdf: “Asymptotic Independence of Bivariate Extremes”,