‘causality’ directory
- See Also
- Gwern
- “Against Caring About Subtle Poisons ”, Gwern 2023
- “Statistical Notes ”, Gwern 2014
- “Timecrimes: Time Travel In Hell ”, Gwern 2023
- “Everything Is Correlated ”, Gwern 2014
- “How Often Does Correlation=Causality? ”, Gwern 2014
- “Why Correlation Usually ≠ Causation ”, Gwern 2014
- “The Replication Crisis: Flaws in Mainstream Science ”, Gwern 2010
- “How Should We Critique Research? ”, Gwern 2019
- “‘Story Of Your Life’ Is Not A Time-Travel Story ”, Gwern 2012
- Links
- “Does Driver’s License Training Work? [Hard to Tell] ”, Kirkegaard 2025
- “Everything Is Correlated (2014–2023) ”
- “Is the World’s Big Idea for Greener Air Travel a Flight of Fancy? Suspicions of Fraud, ‘Ridiculous’ Data and a Dearth of Supplies—Our Investigation Exposes the Flaws in the Airline Industry’s Big Green Hope: Sustainable Aviation Fuel ”, Civillini et al 2025
- “Three Promising Directions in the Study of Intelligence With Genetic Methods ”, Lee & Morris 2025b
- “Cardiorespiratory Fitness in Adolescence and Premature Mortality: Widespread Bias Identified Using Negative Control Outcomes and Sibling Comparisons [Supplement] ”, Ballin 2025
- “Cardiorespiratory Fitness in Adolescence and Premature Mortality: Widespread Bias Identified Using Negative Control Outcomes and Sibling Comparisons ”, Ballin et al 2025
- “Causal Emergence 2.0: Quantifying Emergent Complexity ”, Hoel 2025
- “Evaluating Agreement between Individual Nutrition Randomized Controlled Trials and Cohort Studies: a Meta-Epidemiological Study ”, Stadelmaier et al 2025
- “When Machine Learning Tells the Wrong Story ”
- “Causal Inference on Human Behaviour ”, Bailey et al 2024
- “Missed Causes and Ambiguous Effects: Counterfactuals Pose Challenges for Interpreting Neural Networks ”, Mueller 2024
- “Evaluating the World Model Implicit in a Generative Model ”, Vafa et al 2024
- “Automated Social Science: Language Models As Scientist and Subjects ”, Manning et al 2024
- “Covid-19 Is (Probably) Not an Exogenous Shock or Valid Instrument ”, Clement 2024
- “Troubleshooting: The Skill That Never Goes Obsolete ”, Curiositry 2024
- “Robust Agents Learn Causal World Models ”, Richens & Everitt 2024
- “Correcting for Endogeneity in Models With Bunching ”, Carolina et al 2023
- “A/B Interactions: A Call to Relax ”, Research 2023
- “Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations ”, Chen et al 2023
- “Attributing Agnostically Detected Large Reductions in Road CO2 Emissions to Policy Mixes ”, Koch et al 2022
- “The Magnitude Heuristic: Larger Differences Increase Perceived Causality ”, Daniels & Kupor 2022
- “Can Foundation Models Talk Causality? ”, Willig et al 2022
- “Clarifying the Causes of Consistent and Inconsistent Findings in Genetics ”, Dattani et al 2022
- “Generalizability and Effect Measure Modification in Sibling Comparison Studies ”, Sjölander et al 2022
- “Residual Confounding in Health Plan Performance Assessments: Evidence From Randomization in Medicaid ”, Wallace et al 2022
- “Sibling Comparison Studies ”, Sjölander et al 2022
- “Learning Causal Overhypotheses through Exploration in Children and Computational Models ”, Kosoy et al 2022
- “Causal Emergence Is Widespread across Measures of Causation ”, Comolatti & Hoel 2022
- “Megastudies Improve the Impact of Applied Behavioral Science ”, Milkman et al 2021
- “Inducing Causal Structure for Interpretable Neural Networks (IIT) ”, Geiger et al 2021
- “Testing the Structure of Human Cognitive Ability Using Evidence Obtained from the Impact of Brain Lesions over Abilities ”, Protzko & Colom 2021
- “Providing a Lower-Bound Estimate for Psychology’s ‘Crud Factor’: The Case of Aggression ”, Ferguson & Heene 2021
- “Is Coffee the Cause or the Cure? Conflicting Nutrition Messages in 2 Decades of Online New York Times’ Nutrition News Coverage ”, Ihekweazu 2021
- “Causal Inference With Latent Treatments ”, Fong & Grimmer 2021
- “Causal and Associational Linking Language From Observational Research and Health Evaluation Literature in Practice: A Systematic Language Evaluation ”, Haber et al 2021
- “Common Elective Orthopaedic Procedures and Their Clinical Effectiveness: Umbrella Review of Level 1 Evidence ”, Blom et al 2021
- “Drug Users Use A Lot Of Drugs ”, Alexander 2021
- “What Is Your Estimand? Defining the Target Quantity Connects Statistical Evidence to Theory ”, Lundberg et al 2021
- “The Revolution Will Be Hard to Evaluate: How Co-Occurring Policy Changes Affect Research on the Health Effects of Social Policies ”, Matthay et al 2021
- “The Piranha Problem: Large Effects Swimming in a Small Pond ”, Tosh et al 2021
- “My Cat Chester’s Dynamical Systems Analysyyyyy7777777777777777y7is of the Laser Pointer and the Red Dot on the Wall: Correlation, Causation, or SARS-Cov-2 Hallucination? ”, Armstrong & Chester 2021
- “Interpolating Causal Mechanisms: The Paradox of Knowing More ”, Stephan et al 2021
- “Agent Incentives: A Causal Perspective ”, Everitt et al 2021
- “Quantifying Causality in Data Science With Quasi-Experiments ”, Liu et al 2021
- “Intelligence and General Psychopathology in the Vietnam Experience Study: A Closer Look ”, Kirkegaard & Nyborg 2021
- “The Causal Foundations of Applied Probability and Statistics ”, Greenland 2020
- “Collider Bias in Economic History Research ”, Schneider 2020b
- “Objecting to Experiments Even While Approving of the Policies or Treatments They Compare ”, Heck et al 2020
- “Commentary: Cynical Epidemiology ”, Kaufman 2020
- “Generative Adversarial Phonology: Modeling Unsupervised Phonetic and Phonological Learning With Neural Networks ”, Beguš 2020
- “Rethinking Causation for Data-Intensive Biology: Constraints, Cancellations, and Quantized Organisms: Causality in Complex Organisms Is Sculpted by Constraints rather than Instigators, With Outcomes Perhaps Better Described by Quantized Patterns Than Rectilinear Pathways ”, Brash 2020
- “Health Recommendations and Selection in Health Behaviors ”, Oster 2020
- “Bayesian Evolving-To-Extinction ”, Demski 2020
- “Why the Increasing Use of Complex Causal Models Is a Problem: On the Danger Sophisticated Theoretical Narratives Pose to Truth ”, Saylors & Trafimow 2020
- “Designing Agent Incentives to Avoid Reward Tampering ”, Everitt et al 2019
- “Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective ”, Everitt et al 2019
- “More Confounders [Sleep Disorders and Correlation With Everything] ”, Alexander 2019
- “A Comparison of Approaches to Advertising Measurement: Evidence from Big Field Experiments at Facebook ”, Gordon et al 2019
- “Correlation = Causation? Music Training, Psychology, and Neuroscience ”, Schellenberg 2019
- “Effect of a Workplace Wellness Program on Employee Health and Economic Outcomes: A Randomized Clinical Trial ”, Song & Baicker 2019
- “Why Scatter Plots Suggest Causality, and What We Can Do about It ”, Bergstrom & West 2018
- “Using Genetic Data to Strengthen Causal Inference in Observational Research ”, Pingault et al 2018
- “Causal Language and Strength of Inference in Academic and Media Articles Shared in Social Media (CLAIMS): A Systematic Review ”, Haber et al 2018
- “Measuring Consumer Sensitivity to Audio Advertising: A Field Experiment on Pandora Internet Radio ”, Huang et al 2018
- “A Combined Analysis of Genetically Correlated Traits Identifies 187 Loci and a Role for Neurogenesis and Myelination in Intelligence ”, Hill et al 2018
- “Polygenic Prediction of the Phenome, across Ancestry, in Emerging Adulthood ”, Docherty et al 2017
- “Percutaneous Coronary Intervention in Stable Angina (ORBITA): a Double-Blind, Randomized Controlled Trial ”, Al-Lamee et al 2017
- “Implicit Causal Models for Genome-Wide Association Studies ”, Tran & Blei 2017
- “Benzodiazepines and Risk of All Cause Mortality in Adults: Cohort Study ”
- “Bias and High-Dimensional Adjustment in Observational Studies of Peer Effects ”, Eckles & Bakshy 2017
- “The Surprising Implications of Familial Association in Disease Risk ”, Valberg et al 2017
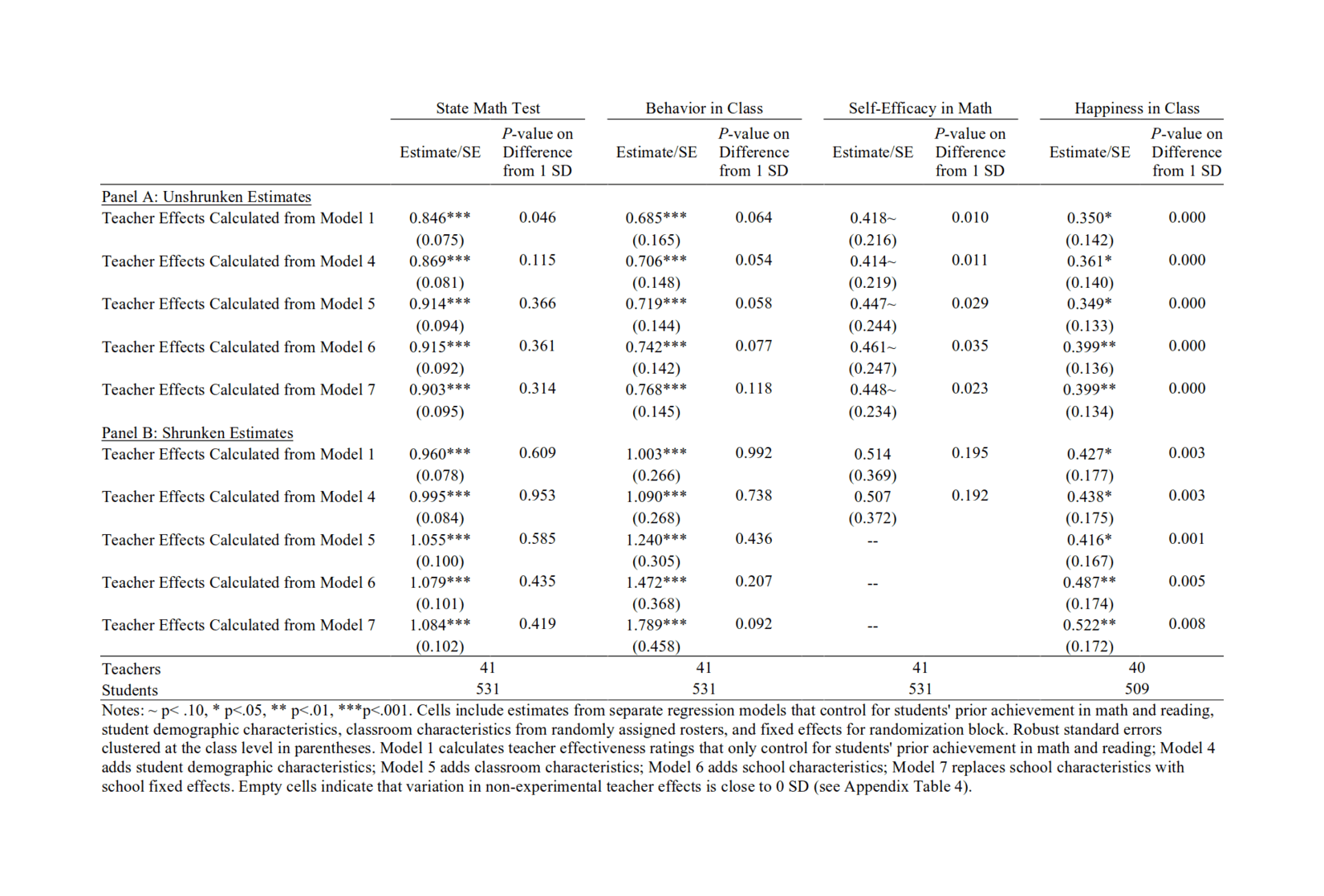
- “An Evaluation of Bias in 3 Measures of Teacher Quality: Value-Added, Classroom Observations, and Student Surveys ”, Bacher-Hicks et al 2017
- “Graphical Models for Quasi-Experimental Designs ”, Steiner et al 2017
- “Could a Neuroscientist Understand a Microprocessor? ”, Jonas & Kording 2016
- “Redundancy, Unilateralism and Bias beyond GDP—Results of a Global Index Benchmark ”, Dill & Gebhart 2016
- “Coz: Finding Parallel Code That Counts With Causal Profiling ”, Curtsinger & Berger 2016
- “Agreement of Treatment Effects for Mortality from Routinely Collected Data and Subsequent Randomized Trials: Meta-Epidemiological Survey ”, Hemkens et al 2016
- “Shared Genetic Aetiology between Cognitive Functions and Physical and Mental Health in UK Biobank (n = 112,151) and 24 GWAS Consortia ”, Hagenaars et al 2016
- “Beyond GDP? Welfare across Countries and Time ”, Jones & Klenow 2016
- “A Test of Exogeneity Without Instrumental Variables in Models With Bunching ”, Caetano 2015
- “The Unfavorable Economics of Measuring the Returns to Advertising ”, Lewis & Rao 2015
- “Mendelian Randomization With Invalid Instruments: Effect Estimation and Bias Detection through Egger Regression (MR-Egger) ”, Bowden et al 2015
- “Bounding a Linear Causal Effect Using Relative Correlation Restrictions ”, Krauth 2015
- “When Causation Does Not Imply Correlation: Robust Violations of the Faithfulness Axiom ”, Kennaway 2015
- “When Correcting for Unreliability of Job Performance Ratings, the Best Estimate Is Still 0.52 ”, Shen et al 2014
- “The Mystery Machine: End-To-End Performance Analysis of Large-Scale Internet Services ”, Chow et al 2014 (page 2)
- “Alcohol Exposure In Utero and Child Academic Achievement ”, Scholder et al 2014
- “Converting Rejections into Positive Stimuli ”, Rubin 2014
- “Observational Studies Often Make Clinical Practice Recommendations: an Empirical Evaluation of Authors' Attitudes ”, Prasad et al 2013
- “A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices ”, Prasad 2013
- “The Iron Law Of Evaluation And Other Metallic Rules ”, Rossi 2012
- “Correlation and Causation in the Study of Personality ”, Lee 2012
- “Does Retail Advertising Work? Measuring the Effects of Advertising on Sales Via a Controlled Experiment on Yahoo ”, Lewis & Reiley 2011
- “High-Dimensional Propensity Score Adjustment in Studies of Treatment Effects Using Health Care Claims Data ”
- “Here, There, and Everywhere: Correlated Online Behaviors Can Lead to Overestimates of the Effects of Advertising ”, Lewis et al 2011
- “The Possibility of Unmeasured Confounding Variables in Observational Studies: a Forgotten Fact? ”, Byrd & Ho 2011
- “Deming, Data and Observational Studies ”
- “Overestimation of the Effects of Adherence on Outcomes: a Case Study in Healthy User Bias and Hypertension ”, LaFleur et al 2011
- “Negative Controls: A Tool for Detecting Confounding and Bias in Observational Studies ”, Lipsitch et al 2010
- “Causal Inference and Developmental Psychology ”, Foster 2010
- “Causal Inference and Observational Research: The Utility of Twins ”, McGue et al 2010
- “Association of Bisphenol A With Diabetes and Other Abnormalities ”
- “Retrospectives Guinnessometrics: The Economic Foundation of ‘Student’s’ t ”, Ziliak 2008
- “Systematic Reviews of Animal Experiments Demonstrate Poor Contributions Toward Human Healthcare ”, Knight 2008
- “Observational Research, Randomized Trials, and Two Views of Medical Science ”, Vandenbroucke 2008
- “Clustered Environments and Randomized Genes: A Fundamental Distinction between Conventional and Genetic Epidemiology ”, Smith et al 2007
- “Causal Inference in Multisensory Perception ”, Körding et al 2007
- “How Close Is Close Enough? Evaluating Propensity Score Matching Using Data from a Class Size Reduction Experiment ”, Wilde & Hollister 2007
- “Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments ”, Rutter 2007
- “Personality and the Prediction of Consequential Outcomes ”, Ozer & Benet-Martínez 2006
- “Comparison of Evidence on Harms of Medical Interventions in Randomized and Nonrandomized Studies ”, Papanikolaou et al 2006
- “Contradicted and Initially Stronger Effects in Highly Cited Clinical Research ”, Ioannidis 2005
- “Looking to the 21st Century: Have We Learned from Our Mistakes, or Are We Doomed to Compound Them? ”, Shapiro 2004
- “New Evidence for the Theory of the Stork ”, Höfer 2004
- “Observational versus Randomized Trial Evidence ”, Lawlor 2004
- “Testing Hypotheses about the Relationship between Cannabis Use and Psychosis ”, Degenhardt et al 2003
- “MDRC’s The Higher Education Randomized Controlled Trials Restricted Access File (THE-RCT RAF), United States, 2003–2019 ”, MDRC 2003
- “Personal Reflections on Lessons Learned from Randomized Trials Involving Newborn Infants, 1951–1967 ”, Silverman 2003
- “Nonexperimental Replications of Social Experiments: A Systematic Review ”, Glazerman et al 2002
- “It Pays to Be Ignorant: A Simple Political Economy of Rigorous Program Evaluation ”, Pritchett 2002
- “Can Nonexperimental Comparison Group Methods Match the Findings from a Random Assignment Evaluation of Mandatory Welfare-To-Work Programs? MDRC Working Papers on Research Methodology ”, Bloom et al 2002
- “Comparison of Evidence of Treatment Effects in Randomized and Nonrandomized Studies ”, Ioannidis et al 2001
- “Crosstalk and Specificity in Signaling: Are We Crosstalking Ourselves into General Confusion? ”, Dumont et al 2001
- “Storks Deliver Babies (p = 0.008) ”, Matthews 2001
- “Study Design and Estimates of Effectiveness ”, MacLehose et al 2000
- “Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs ”, Dehejia & Wahba 1999
- “Interpreting the Evidence: Choosing between Randomized and Non-Randomized Studies ”, McKee et al 1999
- “Superadditive Correlation ”, Giraud et al 1999
- “Causality in Complex Systems ”, Wagner 1999
- “Spurious Precision? Meta-Analysis of Observational Studies ”, Egger et al 1998
- “Choosing Between Randomized and Non-Randomized Studies ”, Britton et al 1998
- “Who Goes First? The Story of Self-Experimentation in Medicine ”, Altman 1998
- “The Unpredictability Paradox: Review of Empirical Comparisons of Randomized and Non-Randomized Clinical Trials ”, Kunz & Oxman 1998
- “There Is a Time and a Place for Significance Testing ”, Mulaik et al 1997
- “Evaluating Program Evaluations: New Evidence on Commonly Used Nonexperimental Methods ”, Friedlander & Robins 1995
- “Inferring the Direction of Causation in Cross-Sectional Twin Data: Theoretical and Empirical Considerations ”, Duffy & Martin 1994
- “Testing Hypotheses about Direction of Causation Using Cross-Sectional Family Data ”, Heath et al 1993
- “Bias in Relative Odds Estimation owing to Imprecise Measurement of Correlated Exposures ”, Phillips & Smith 1992
- “Smoking As ‘Independent’ Risk Factor for Suicide: Illustration of an Artifact from Observational Epidemiology? ”, Smith et al 1992
- “Force Concept Inventory ”
- “How Independent Are ‘Independent’ Effects? Relative Risk Estimation When Correlated Exposures Are Measured Imprecisely ”, Phillips & Smith 1991
- “Developing Improved Observational Methods for Evaluating Therapeutic Effectiveness ”, Horwitz et al 1990
- “Coaching for the Scholastic Aptitude Test: Further Synthesis and Appraisal ”, Becker 1990
- “Memories of the British Streptomycin Trial in Tuberculosis: The First Randomized Trial ”, Hill 1990
- “A Collection of 56 Topics With Contradictory Results in Case-Control Research ”, Mayes et al 1988
- “Evaluating the Effectiveness of Family Therapies: an Integrative Review and Analysis ”, Hazelrigg et al 1987
- “The Adequacy of Comparison Group Designs for Evaluations of Employment-Related Programs ”, Fraker & Maynard 1987
- “Evaluating the Econometric Evaluations of Training Programs With Experimental Data ”, LaLonde 1986
- “Why Do We Need Some Large, Simple Randomized Trials? ”, Yusuf et al 1984
- “A Random Effects Model for Effect Sizes ”, Hedges 1983
- “Comparative Therapy Outcome Research: Methodological Implications of Meta-Analysis ”, Shapiro & Shapiro 1983
- “Essence of Statistics (Second Edition) ”, Loftus & Loftus 1982
- “The Paradoxes of Time Travel ”, Lewis 1976
- Heredity, Environment, & Personality: A Study of 850 Sets of Twins, Loehlin & Nichols 1976
- “On the Alleged Falsity of the Null Hypothesis ”, Oakes 1975
- “Theory Confirmation in Psychology ”, Swoyer & Monson 1975
- “On Prior Probabilities of Rejecting Statistical Hypotheses ”, Keuth 1973
- “The Correlation between Targets and Instruments ”, Peston 1972
- “A Computer Movie Simulating Urban Growth in the Detroit Region ”, Tobler 1970
- “Use and Abuse of Regression ”, Box 1966
- “Distributions of Correlation Coefficients in Economic Time Series ”, Ames & Reiter 1961
- “The Fallacy Of The Null-Hypothesis Statistical-Significance Test ”, Rozeboom 1960
- “Cigarettes, Cancer, And Statistics ”, Fisher 1958
- “The Influence of ‘Statistical Methods for Research Workers’ on the Development of the Science of Statistics ”, Yates 1951
- “‘Superstition’ in the Pigeon ”, Skinner 1948
- “A New Measure of Introversion-Extroversion ”, Evans & McConnell 1941
- “"Student" As Statistician ”, Pearson 1939
- “Why Do We Sometimes Get Nonsense-Correlations between Time-Series?--A Study in Sampling and the Nature of Time-Series ”
- “Behavior Genetic Frameworks of Causal Reasoning for Personality Psychology ”
- “The Initial Knowledge State of College Physics Students ”
- “Inventing the Randomized Double-Blind Trial: The Nürnberg Salt Test of 1835 ”
- “Intellectual Hipsters and Meta-Contrarianism ”
- “Guessing the Teacher’s Password ”
- NoahHaber
- “Confounding Variables ”
- “Correlation ”, Munroe 2025
- Sort By Magic
- Wikipedia (7)
- Miscellaneous
- Bibliography
See Also
Gwern
“Against Caring About Subtle Poisons ”, Gwern 2023
“Statistical Notes ”, Gwern 2014
“Timecrimes: Time Travel In Hell ”, Gwern 2023
“Everything Is Correlated ”, Gwern 2014
“How Often Does Correlation=Causality? ”, Gwern 2014
“Why Correlation Usually ≠ Causation ”, Gwern 2014
“The Replication Crisis: Flaws in Mainstream Science ”, Gwern 2010
“How Should We Critique Research? ”, Gwern 2019
“‘Story Of Your Life’ Is Not A Time-Travel Story ”, Gwern 2012
Links
“Does Driver’s License Training Work? [Hard to Tell] ”, Kirkegaard 2025
Does driver’s license training work? [hard to tell] :
View External Link:
https://emilkirkegaard.dk/en/2025/12/does-drivers-license-training-work/
“Everything Is Correlated (2014–2023) ”
“Is the World’s Big Idea for Greener Air Travel a Flight of Fancy? Suspicions of Fraud, ‘Ridiculous’ Data and a Dearth of Supplies—Our Investigation Exposes the Flaws in the Airline Industry’s Big Green Hope: Sustainable Aviation Fuel ”, Civillini et al 2025
“Three Promising Directions in the Study of Intelligence With Genetic Methods ”, Lee & Morris 2025b
Three Promising Directions in the Study of Intelligence With Genetic Methods
“Cardiorespiratory Fitness in Adolescence and Premature Mortality: Widespread Bias Identified Using Negative Control Outcomes and Sibling Comparisons [Supplement] ”, Ballin 2025
“Cardiorespiratory Fitness in Adolescence and Premature Mortality: Widespread Bias Identified Using Negative Control Outcomes and Sibling Comparisons ”, Ballin et al 2025
“Causal Emergence 2.0: Quantifying Emergent Complexity ”, Hoel 2025
“Evaluating Agreement between Individual Nutrition Randomized Controlled Trials and Cohort Studies: a Meta-Epidemiological Study ”, Stadelmaier et al 2025
“When Machine Learning Tells the Wrong Story ”
“Causal Inference on Human Behaviour ”, Bailey et al 2024
“Missed Causes and Ambiguous Effects: Counterfactuals Pose Challenges for Interpreting Neural Networks ”, Mueller 2024
“Evaluating the World Model Implicit in a Generative Model ”, Vafa et al 2024
“Automated Social Science: Language Models As Scientist and Subjects ”, Manning et al 2024
Automated Social Science: Language Models as Scientist and Subjects
“Covid-19 Is (Probably) Not an Exogenous Shock or Valid Instrument ”, Clement 2024
Covid-19 is (Probably) Not an Exogenous Shock or Valid Instrument
“Troubleshooting: The Skill That Never Goes Obsolete ”, Curiositry 2024
“Robust Agents Learn Causal World Models ”, Richens & Everitt 2024
“Correcting for Endogeneity in Models With Bunching ”, Carolina et al 2023
“A/B Interactions: A Call to Relax ”, Research 2023
“Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations ”, Chen et al 2023
Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations
“Attributing Agnostically Detected Large Reductions in Road CO2 Emissions to Policy Mixes ”, Koch et al 2022
Attributing agnostically detected large reductions in road CO2 emissions to policy mixes
“The Magnitude Heuristic: Larger Differences Increase Perceived Causality ”, Daniels & Kupor 2022
The Magnitude Heuristic: Larger Differences Increase Perceived Causality
“Can Foundation Models Talk Causality? ”, Willig et al 2022
“Clarifying the Causes of Consistent and Inconsistent Findings in Genetics ”, Dattani et al 2022
Clarifying the causes of consistent and inconsistent findings in genetics
“Generalizability and Effect Measure Modification in Sibling Comparison Studies ”, Sjölander et al 2022
Generalizability and effect measure modification in sibling comparison studies
“Residual Confounding in Health Plan Performance Assessments: Evidence From Randomization in Medicaid ”, Wallace et al 2022
Residual Confounding in Health Plan Performance Assessments: Evidence From Randomization in Medicaid
“Sibling Comparison Studies ”, Sjölander et al 2022
“Learning Causal Overhypotheses through Exploration in Children and Computational Models ”, Kosoy et al 2022
Learning Causal Overhypotheses through Exploration in Children and Computational Models
“Megastudies Improve the Impact of Applied Behavioral Science ”, Milkman et al 2021
Megastudies improve the impact of applied behavioral science
“Inducing Causal Structure for Interpretable Neural Networks (IIT) ”, Geiger et al 2021
Inducing Causal Structure for Interpretable Neural Networks (IIT)
“Testing the Structure of Human Cognitive Ability Using Evidence Obtained from the Impact of Brain Lesions over Abilities ”, Protzko & Colom 2021
“Providing a Lower-Bound Estimate for Psychology’s ‘Crud Factor’: The Case of Aggression ”, Ferguson & Heene 2021
Providing a lower-bound estimate for psychology’s ‘crud factor’: The case of aggression
“Is Coffee the Cause or the Cure? Conflicting Nutrition Messages in 2 Decades of Online New York Times’ Nutrition News Coverage ”, Ihekweazu 2021
“Causal Inference With Latent Treatments ”, Fong & Grimmer 2021
“Causal and Associational Linking Language From Observational Research and Health Evaluation Literature in Practice: A Systematic Language Evaluation ”, Haber et al 2021
“Common Elective Orthopaedic Procedures and Their Clinical Effectiveness: Umbrella Review of Level 1 Evidence ”, Blom et al 2021
“Drug Users Use A Lot Of Drugs ”, Alexander 2021
“What Is Your Estimand? Defining the Target Quantity Connects Statistical Evidence to Theory ”, Lundberg et al 2021
What Is Your Estimand? Defining the Target Quantity Connects Statistical Evidence to Theory
“The Revolution Will Be Hard to Evaluate: How Co-Occurring Policy Changes Affect Research on the Health Effects of Social Policies ”, Matthay et al 2021
“The Piranha Problem: Large Effects Swimming in a Small Pond ”, Tosh et al 2021
“My Cat Chester’s Dynamical Systems Analysyyyyy7777777777777777y7is of the Laser Pointer and the Red Dot on the Wall: Correlation, Causation, or SARS-Cov-2 Hallucination? ”, Armstrong & Chester 2021
“Interpolating Causal Mechanisms: The Paradox of Knowing More ”, Stephan et al 2021
Interpolating Causal Mechanisms: The Paradox of Knowing More
“Agent Incentives: A Causal Perspective ”, Everitt et al 2021
“Quantifying Causality in Data Science With Quasi-Experiments ”, Liu et al 2021
Quantifying causality in data science with quasi-experiments
“Intelligence and General Psychopathology in the Vietnam Experience Study: A Closer Look ”, Kirkegaard & Nyborg 2021
Intelligence and General Psychopathology in the Vietnam Experience Study: A Closer Look
“The Causal Foundations of Applied Probability and Statistics ”, Greenland 2020
The causal foundations of applied probability and statistics
“Collider Bias in Economic History Research ”, Schneider 2020b
“Objecting to Experiments Even While Approving of the Policies or Treatments They Compare ”, Heck et al 2020
Objecting to experiments even while approving of the policies or treatments they compare
“Commentary: Cynical Epidemiology ”, Kaufman 2020
“Generative Adversarial Phonology: Modeling Unsupervised Phonetic and Phonological Learning With Neural Networks ”, Beguš 2020
“Rethinking Causation for Data-Intensive Biology: Constraints, Cancellations, and Quantized Organisms: Causality in Complex Organisms Is Sculpted by Constraints rather than Instigators, With Outcomes Perhaps Better Described by Quantized Patterns Than Rectilinear Pathways ”, Brash 2020
“Health Recommendations and Selection in Health Behaviors ”, Oster 2020
“Bayesian Evolving-To-Extinction ”, Demski 2020
“Why the Increasing Use of Complex Causal Models Is a Problem: On the Danger Sophisticated Theoretical Narratives Pose to Truth ”, Saylors & Trafimow 2020
“Designing Agent Incentives to Avoid Reward Tampering ”, Everitt et al 2019
“Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective ”, Everitt et al 2019
“More Confounders [Sleep Disorders and Correlation With Everything] ”, Alexander 2019
More Confounders [sleep disorders and correlation with everything]
“A Comparison of Approaches to Advertising Measurement: Evidence from Big Field Experiments at Facebook ”, Gordon et al 2019
“Correlation = Causation? Music Training, Psychology, and Neuroscience ”, Schellenberg 2019
Correlation = causation? Music training, psychology, and neuroscience :
“Effect of a Workplace Wellness Program on Employee Health and Economic Outcomes: A Randomized Clinical Trial ”, Song & Baicker 2019
View PDF:
“Why Scatter Plots Suggest Causality, and What We Can Do about It ”, Bergstrom & West 2018
Why scatter plots suggest causality, and what we can do about it
“Using Genetic Data to Strengthen Causal Inference in Observational Research ”, Pingault et al 2018
Using genetic data to strengthen causal inference in observational research
“Causal Language and Strength of Inference in Academic and Media Articles Shared in Social Media (CLAIMS): A Systematic Review ”, Haber et al 2018
“Measuring Consumer Sensitivity to Audio Advertising: A Field Experiment on Pandora Internet Radio ”, Huang et al 2018
Measuring Consumer Sensitivity to Audio Advertising: A Field Experiment on Pandora Internet Radio
“A Combined Analysis of Genetically Correlated Traits Identifies 187 Loci and a Role for Neurogenesis and Myelination in Intelligence ”, Hill et al 2018
“Polygenic Prediction of the Phenome, across Ancestry, in Emerging Adulthood ”, Docherty et al 2017
Polygenic prediction of the phenome, across ancestry, in emerging adulthood
“Percutaneous Coronary Intervention in Stable Angina (ORBITA): a Double-Blind, Randomized Controlled Trial ”, Al-Lamee et al 2017
“Implicit Causal Models for Genome-Wide Association Studies ”, Tran & Blei 2017
“Benzodiazepines and Risk of All Cause Mortality in Adults: Cohort Study ”
Benzodiazepines and risk of all cause mortality in adults: cohort study
“Bias and High-Dimensional Adjustment in Observational Studies of Peer Effects ”, Eckles & Bakshy 2017
Bias and high-dimensional adjustment in observational studies of peer effects
“The Surprising Implications of Familial Association in Disease Risk ”, Valberg et al 2017
The surprising implications of familial association in disease risk
“An Evaluation of Bias in 3 Measures of Teacher Quality: Value-Added, Classroom Observations, and Student Surveys ”, Bacher-Hicks et al 2017
“Graphical Models for Quasi-Experimental Designs ”, Steiner et al 2017
“Could a Neuroscientist Understand a Microprocessor? ”, Jonas & Kording 2016
“Redundancy, Unilateralism and Bias beyond GDP—Results of a Global Index Benchmark ”, Dill & Gebhart 2016
Redundancy, Unilateralism and Bias beyond GDP—results of a Global Index Benchmark
“Coz: Finding Parallel Code That Counts With Causal Profiling ”, Curtsinger & Berger 2016
Coz: Finding Parallel Code that Counts with Causal Profiling
“Agreement of Treatment Effects for Mortality from Routinely Collected Data and Subsequent Randomized Trials: Meta-Epidemiological Survey ”, Hemkens et al 2016
“Shared Genetic Aetiology between Cognitive Functions and Physical and Mental Health in UK Biobank (n = 112,151) and 24 GWAS Consortia ”, Hagenaars et al 2016
“Beyond GDP? Welfare across Countries and Time ”, Jones & Klenow 2016
“A Test of Exogeneity Without Instrumental Variables in Models With Bunching ”, Caetano 2015
A Test of Exogeneity Without Instrumental Variables in Models With Bunching
“The Unfavorable Economics of Measuring the Returns to Advertising ”, Lewis & Rao 2015
The Unfavorable Economics of Measuring the Returns to Advertising
“Mendelian Randomization With Invalid Instruments: Effect Estimation and Bias Detection through Egger Regression (MR-Egger) ”, Bowden et al 2015
“Bounding a Linear Causal Effect Using Relative Correlation Restrictions ”, Krauth 2015
Bounding a Linear Causal Effect Using Relative Correlation Restrictions
“When Causation Does Not Imply Correlation: Robust Violations of the Faithfulness Axiom ”, Kennaway 2015
When causation does not imply correlation: robust violations of the Faithfulness axiom
“When Correcting for Unreliability of Job Performance Ratings, the Best Estimate Is Still 0.52 ”, Shen et al 2014
When Correcting for Unreliability of Job Performance Ratings, the Best Estimate Is Still 0.52
“The Mystery Machine: End-To-End Performance Analysis of Large-Scale Internet Services ”, Chow et al 2014 (page 2)
The Mystery Machine: End-to-end performance analysis of large-scale Internet services
“Alcohol Exposure In Utero and Child Academic Achievement ”, Scholder et al 2014
“Converting Rejections into Positive Stimuli ”, Rubin 2014
“Observational Studies Often Make Clinical Practice Recommendations: an Empirical Evaluation of Authors' Attitudes ”, Prasad et al 2013
“A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices ”, Prasad 2013
A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices
“The Iron Law Of Evaluation And Other Metallic Rules ”, Rossi 2012
“Correlation and Causation in the Study of Personality ”, Lee 2012
“Does Retail Advertising Work? Measuring the Effects of Advertising on Sales Via a Controlled Experiment on Yahoo ”, Lewis & Reiley 2011
“High-Dimensional Propensity Score Adjustment in Studies of Treatment Effects Using Health Care Claims Data ”
“Here, There, and Everywhere: Correlated Online Behaviors Can Lead to Overestimates of the Effects of Advertising ”, Lewis et al 2011
“The Possibility of Unmeasured Confounding Variables in Observational Studies: a Forgotten Fact? ”, Byrd & Ho 2011
The possibility of unmeasured confounding variables in observational studies: a forgotten fact? :
View PDF:
“Deming, Data and Observational Studies ”
“Overestimation of the Effects of Adherence on Outcomes: a Case Study in Healthy User Bias and Hypertension ”, LaFleur et al 2011
“Negative Controls: A Tool for Detecting Confounding and Bias in Observational Studies ”, Lipsitch et al 2010
Negative Controls: A Tool for Detecting Confounding and Bias in Observational Studies
“Causal Inference and Developmental Psychology ”, Foster 2010
“Causal Inference and Observational Research: The Utility of Twins ”, McGue et al 2010
Causal Inference and Observational Research: The Utility of Twins
“Association of Bisphenol A With Diabetes and Other Abnormalities ”
Association of Bisphenol A With Diabetes and Other Abnormalities :
View PDF:
“Retrospectives Guinnessometrics: The Economic Foundation of ‘Student’s’ t ”, Ziliak 2008
Retrospectives Guinnessometrics: The Economic Foundation of ‘Student’s’ t
“Systematic Reviews of Animal Experiments Demonstrate Poor Contributions Toward Human Healthcare ”, Knight 2008
Systematic Reviews of Animal Experiments Demonstrate Poor Contributions Toward Human Healthcare
“Observational Research, Randomized Trials, and Two Views of Medical Science ”, Vandenbroucke 2008
Observational Research, Randomized Trials, and Two Views of Medical Science
“Clustered Environments and Randomized Genes: A Fundamental Distinction between Conventional and Genetic Epidemiology ”, Smith et al 2007
“Causal Inference in Multisensory Perception ”, Körding et al 2007
“How Close Is Close Enough? Evaluating Propensity Score Matching Using Data from a Class Size Reduction Experiment ”, Wilde & Hollister 2007
“Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments ”, Rutter 2007
Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments
“Personality and the Prediction of Consequential Outcomes ”, Ozer & Benet-Martínez 2006
“Comparison of Evidence on Harms of Medical Interventions in Randomized and Nonrandomized Studies ”, Papanikolaou et al 2006
Comparison of evidence on harms of medical interventions in randomized and nonrandomized studies
“Contradicted and Initially Stronger Effects in Highly Cited Clinical Research ”, Ioannidis 2005
Contradicted and Initially Stronger Effects in Highly Cited Clinical Research
“Looking to the 21st Century: Have We Learned from Our Mistakes, or Are We Doomed to Compound Them? ”, Shapiro 2004
Looking to the 21st century: have we learned from our mistakes, or are we doomed to compound them? :
“New Evidence for the Theory of the Stork ”, Höfer 2004
“Observational versus Randomized Trial Evidence ”, Lawlor 2004
“Testing Hypotheses about the Relationship between Cannabis Use and Psychosis ”, Degenhardt et al 2003
Testing hypotheses about the relationship between cannabis use and psychosis
“MDRC’s The Higher Education Randomized Controlled Trials Restricted Access File (THE-RCT RAF), United States, 2003–2019 ”, MDRC 2003
“Personal Reflections on Lessons Learned from Randomized Trials Involving Newborn Infants, 1951–1967 ”, Silverman 2003
Personal reflections on lessons learned from randomized trials involving newborn infants, 1951–1967
“Nonexperimental Replications of Social Experiments: A Systematic Review ”, Glazerman et al 2002
Nonexperimental Replications of Social Experiments: A Systematic Review
“It Pays to Be Ignorant: A Simple Political Economy of Rigorous Program Evaluation ”, Pritchett 2002
It pays to be ignorant: A simple political economy of rigorous program evaluation
“Can Nonexperimental Comparison Group Methods Match the Findings from a Random Assignment Evaluation of Mandatory Welfare-To-Work Programs? MDRC Working Papers on Research Methodology ”, Bloom et al 2002
“Comparison of Evidence of Treatment Effects in Randomized and Nonrandomized Studies ”, Ioannidis et al 2001
Comparison of Evidence of Treatment Effects in Randomized and Nonrandomized Studies
“Crosstalk and Specificity in Signaling: Are We Crosstalking Ourselves into General Confusion? ”, Dumont et al 2001
Crosstalk and specificity in signaling: Are we crosstalking ourselves into general confusion?
“Storks Deliver Babies (p = 0.008) ”, Matthews 2001
“Study Design and Estimates of Effectiveness ”, MacLehose et al 2000
“Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs ”, Dehejia & Wahba 1999
Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs
“Interpreting the Evidence: Choosing between Randomized and Non-Randomized Studies ”, McKee et al 1999
Interpreting the evidence: choosing between randomized and non-randomized studies
“Superadditive Correlation ”, Giraud et al 1999
“Causality in Complex Systems ”, Wagner 1999
“Spurious Precision? Meta-Analysis of Observational Studies ”, Egger et al 1998
“Choosing Between Randomized and Non-Randomized Studies ”, Britton et al 1998
“Who Goes First? The Story of Self-Experimentation in Medicine ”, Altman 1998
Who Goes First? The Story of Self-Experimentation in Medicine :
“The Unpredictability Paradox: Review of Empirical Comparisons of Randomized and Non-Randomized Clinical Trials ”, Kunz & Oxman 1998
“There Is a Time and a Place for Significance Testing ”, Mulaik et al 1997
“Evaluating Program Evaluations: New Evidence on Commonly Used Nonexperimental Methods ”, Friedlander & Robins 1995
Evaluating Program Evaluations: New Evidence on Commonly Used Nonexperimental Methods :
“Inferring the Direction of Causation in Cross-Sectional Twin Data: Theoretical and Empirical Considerations ”, Duffy & Martin 1994
“Testing Hypotheses about Direction of Causation Using Cross-Sectional Family Data ”, Heath et al 1993
Testing hypotheses about direction of causation using cross-sectional family data
“Bias in Relative Odds Estimation owing to Imprecise Measurement of Correlated Exposures ”, Phillips & Smith 1992
Bias in relative odds estimation owing to imprecise measurement of correlated exposures
“Smoking As ‘Independent’ Risk Factor for Suicide: Illustration of an Artifact from Observational Epidemiology? ”, Smith et al 1992
“Force Concept Inventory ”
“How Independent Are ‘Independent’ Effects? Relative Risk Estimation When Correlated Exposures Are Measured Imprecisely ”, Phillips & Smith 1991
“Developing Improved Observational Methods for Evaluating Therapeutic Effectiveness ”, Horwitz et al 1990
Developing improved observational methods for evaluating therapeutic effectiveness
“Coaching for the Scholastic Aptitude Test: Further Synthesis and Appraisal ”, Becker 1990
Coaching for the Scholastic Aptitude Test: Further Synthesis and Appraisal
“Memories of the British Streptomycin Trial in Tuberculosis: The First Randomized Trial ”, Hill 1990
Memories of the British streptomycin trial in tuberculosis: The First Randomized Trial :
View PDF:
“A Collection of 56 Topics With Contradictory Results in Case-Control Research ”, Mayes et al 1988
A Collection of 56 Topics with Contradictory Results in Case-Control Research
“Evaluating the Effectiveness of Family Therapies: an Integrative Review and Analysis ”, Hazelrigg et al 1987
Evaluating the effectiveness of family therapies: an integrative review and analysis
“The Adequacy of Comparison Group Designs for Evaluations of Employment-Related Programs ”, Fraker & Maynard 1987
The Adequacy of Comparison Group Designs for Evaluations of Employment-Related Programs
“Evaluating the Econometric Evaluations of Training Programs With Experimental Data ”, LaLonde 1986
Evaluating the Econometric Evaluations of Training Programs with Experimental Data
“Why Do We Need Some Large, Simple Randomized Trials? ”, Yusuf et al 1984
Why do we need some large, simple randomized trials? :
View PDF:
“A Random Effects Model for Effect Sizes ”, Hedges 1983
“Comparative Therapy Outcome Research: Methodological Implications of Meta-Analysis ”, Shapiro & Shapiro 1983
Comparative therapy outcome research: Methodological implications of meta-analysis
“Essence of Statistics (Second Edition) ”, Loftus & Loftus 1982
Essence of Statistics (Second Edition) :
View PDF (90MB):
/doc/statistics/causality/1982-loftus-essenceofstatistics.pdf
“The Paradoxes of Time Travel ”, Lewis 1976
Heredity, Environment, & Personality: A Study of 850 Sets of Twins, Loehlin & Nichols 1976
Heredity, Environment, & Personality: A Study of 850 Sets of Twins
“On the Alleged Falsity of the Null Hypothesis ”, Oakes 1975
On the alleged falsity of the null hypothesis :
View PDF:
“Theory Confirmation in Psychology ”, Swoyer & Monson 1975
“On Prior Probabilities of Rejecting Statistical Hypotheses ”, Keuth 1973
On Prior Probabilities of Rejecting Statistical Hypotheses :
View PDF:
“The Correlation between Targets and Instruments ”, Peston 1972
“A Computer Movie Simulating Urban Growth in the Detroit Region ”, Tobler 1970
A computer movie simulating urban growth in the Detroit region :
“Use and Abuse of Regression ”, Box 1966
View PDF:
“Distributions of Correlation Coefficients in Economic Time Series ”, Ames & Reiter 1961
Distributions of Correlation Coefficients in Economic Time Series
“The Fallacy Of The Null-Hypothesis Statistical-Significance Test ”, Rozeboom 1960
The Fallacy Of The Null-Hypothesis Statistical-Significance Test
“Cigarettes, Cancer, And Statistics ”, Fisher 1958
“The Influence of ‘Statistical Methods for Research Workers’ on the Development of the Science of Statistics ”, Yates 1951
View PDF:
“‘Superstition’ in the Pigeon ”, Skinner 1948
“A New Measure of Introversion-Extroversion ”, Evans & McConnell 1941
“"Student" As Statistician ”, Pearson 1939
“Why Do We Sometimes Get Nonsense-Correlations between Time-Series?--A Study in Sampling and the Nature of Time-Series ”
View PDF:
“Behavior Genetic Frameworks of Causal Reasoning for Personality Psychology ”
Behavior Genetic Frameworks of Causal Reasoning for Personality Psychology
“The Initial Knowledge State of College Physics Students ”
“Inventing the Randomized Double-Blind Trial: The Nürnberg Salt Test of 1835 ”
Inventing the randomized double-blind trial: The Nürnberg salt test of 1835
“Intellectual Hipsters and Meta-Contrarianism ”
“Guessing the Teacher’s Password ”
NoahHaber
“Confounding Variables ”
View External Link:
“Correlation ”, Munroe 2025
View External Link:
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
causal-attribution
causal-bias
causal-interpretation
causal-evaluation
Wikipedia (7)
Miscellaneous
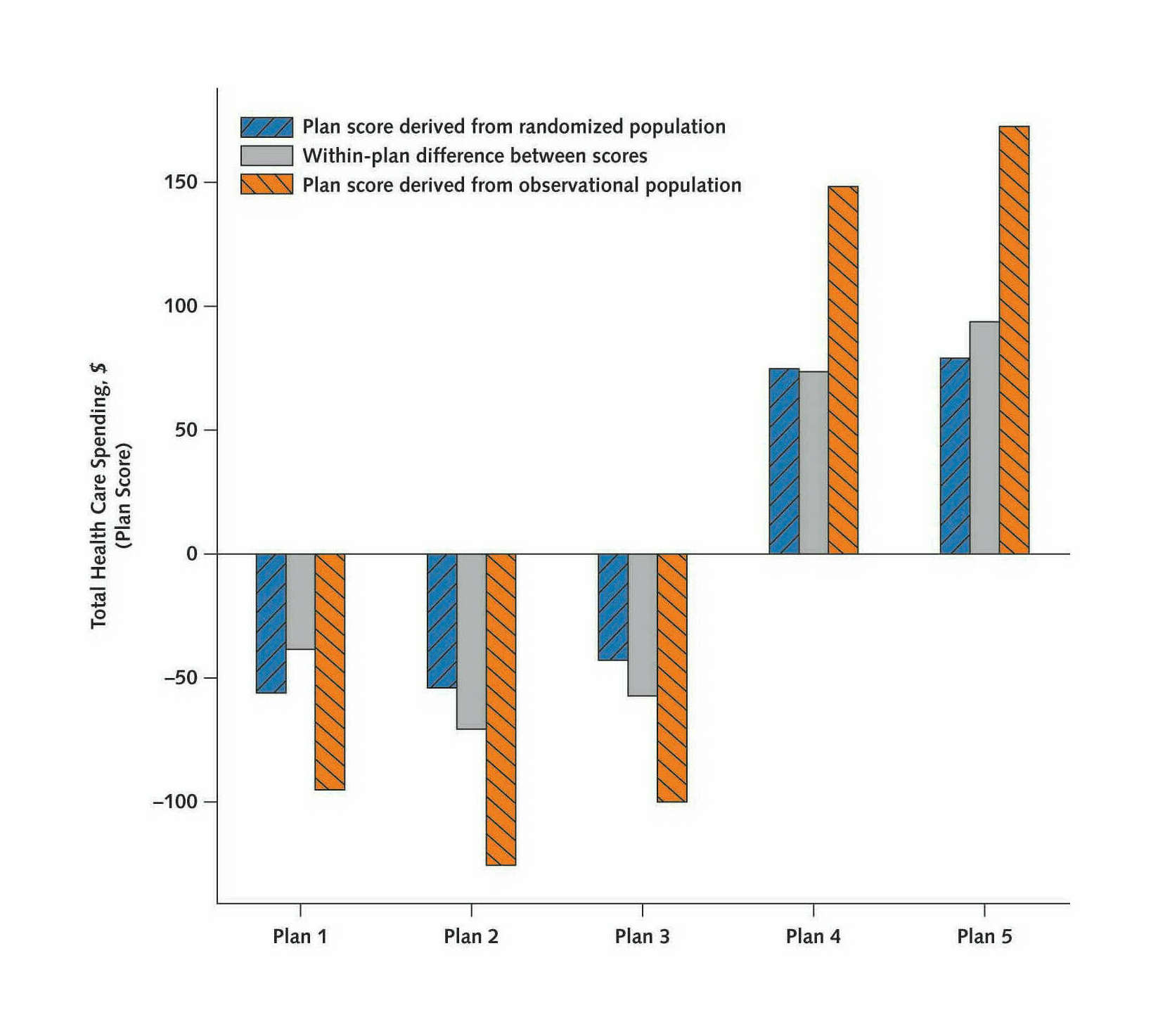
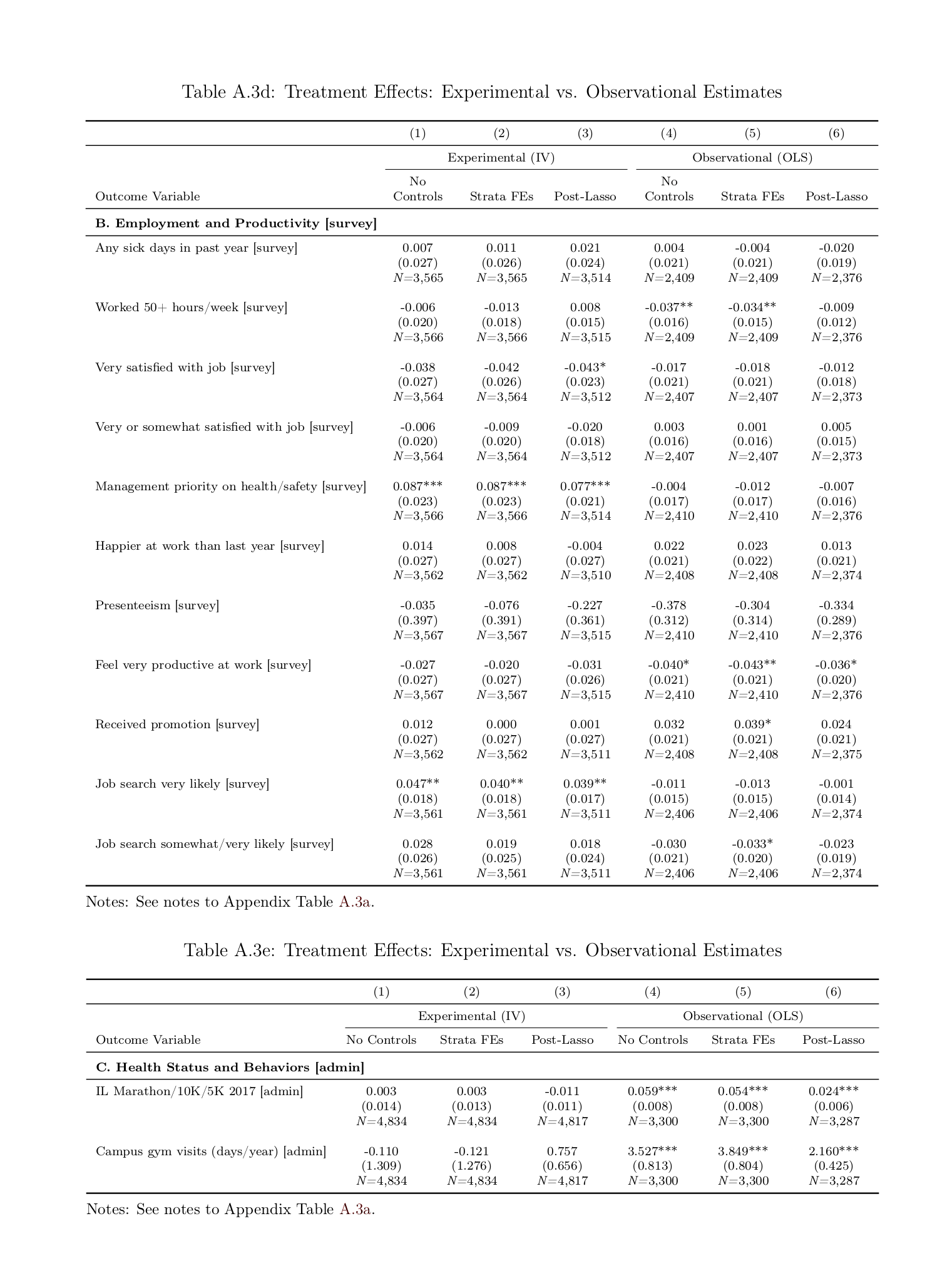
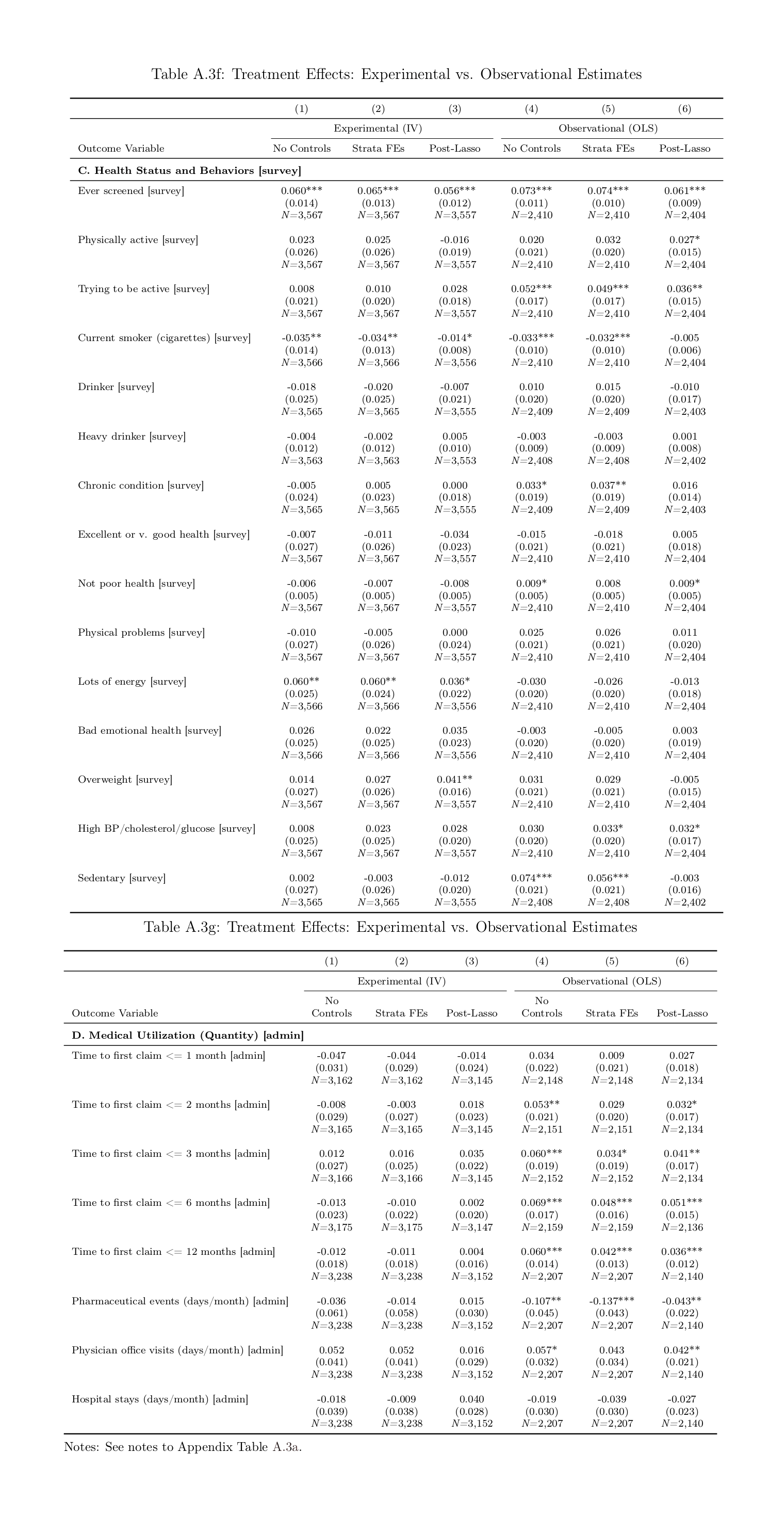
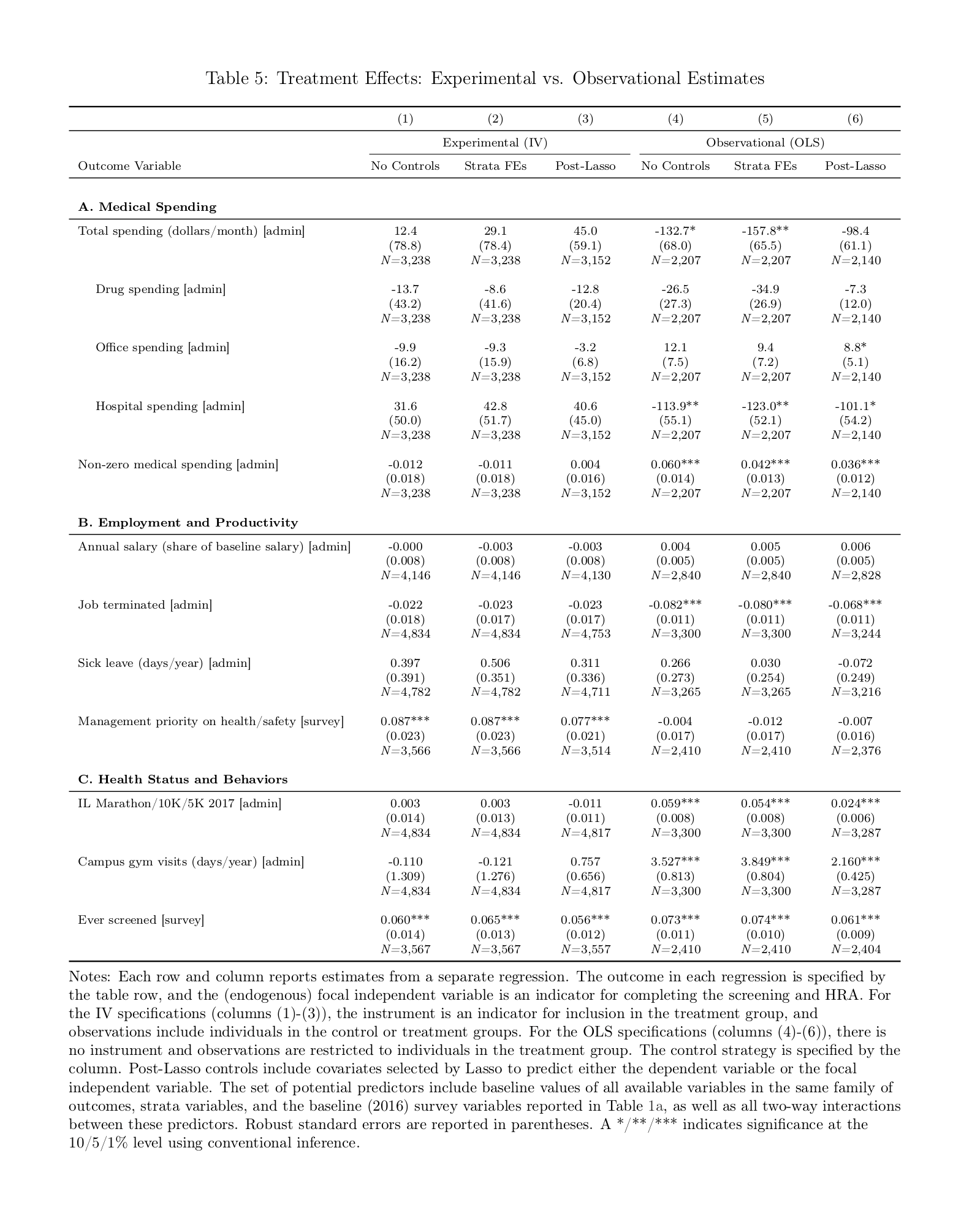
/doc/statistics/causality/2021-05-21-meme-theyrethesamephoto-judeapearl-colliderbias.jpg:/doc/statistics/causality/2019-12-21-gwern-meme-ancientaliens-correlationcausation.jpg:/doc/statistics/causality/2018-05-11-isthisapigeonmeme-causation.jpg:/doc/statistics/causality/2018-jones-figure8-randomizedvscorrelationliterature.png:/doc/statistics/causality/2018-jones-supplement-randomizedvscorrelation-tablea3-ac.png:/doc/statistics/causality/2018-jones-supplement-randomizedvscorrelation-tablea3-de.png:/doc/statistics/causality/2018-jones-supplement-randomizedvscorrelation-tablea3-fg.png:/doc/statistics/causality/2018-jones-table5-correlationvsrandomized.png:/doc/statistics/causality/2017-adams.pdf:View PDF:
/doc/statistics/causality/2017-blazar-table5-correlationvscausation.png:/doc/statistics/causality/2015-setter.html:View HTML:
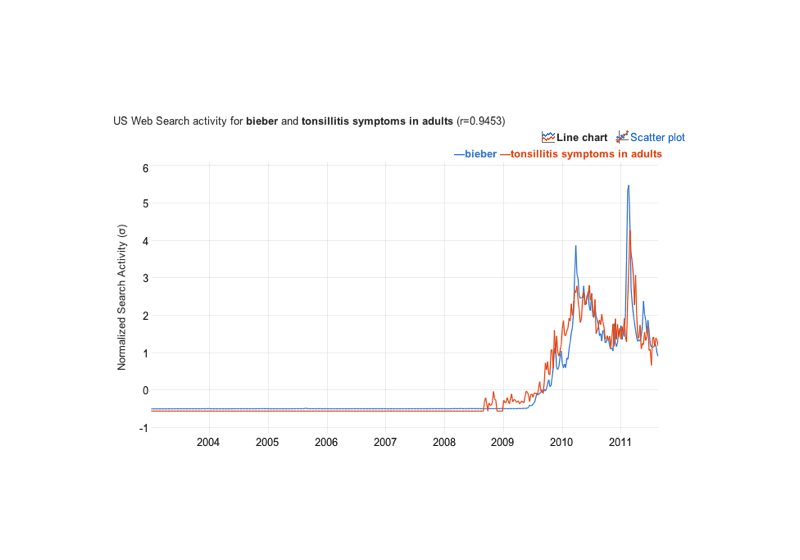
https://www.harvardmagazine.com/2012/02/twilight-of-the-lecture/doc/statistics/causality/2011-09-slacktory-correlations-biebertonsillitis.png:/doc/statistics/causality/2007-wilde-table5-experimentalvsnonexperimentalestimatesinprojectstar.jpg:/doc/statistics/causality/2001-thompson.html:View HTML:
/doc/statistics/causality/1982-sacks.pdf:View PDF:
/doc/statistics/causality/1973-hays.pdf:View PDF:
/doc/statistics/causality/1973-wendell-anmmpisourcebook.pdf:View PDF (42MB):
/doc/statistics/causality/1960-smith.pdf:View PDF:
http://www.stat.columbia.edu/~gelman/research/unpublished/reversecausal_13oct05.pdf:https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.648.1155https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4022745:View External Link:
https://www.chess.com/article/view/no-castling-chess-kramnik-alphazerohttps://www.the100.ci/2023/03/07/non-representative-samples-what-could-possibly-go-wrong/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://academic.oup.com/eurjpc/advance-article/doi/10.1093/eurjpc/zwaf267/8128214: “Cardiorespiratory Fitness in Adolescence and Premature Mortality: Widespread Bias Identified Using Negative Control Outcomes and Sibling Comparisons ”,https://arxiv.org/abs/2406.03689: “Evaluating the World Model Implicit in a Generative Model ”,https://onlinelibrary.wiley.com/doi/full/10.1002/gepi.22459: “Clarifying the Causes of Consistent and Inconsistent Findings in Genetics ”,2021-milkman.pdf: “Megastudies Improve the Impact of Applied Behavioral Science ”,https://arxiv.org/abs/2105.13445: “The Piranha Problem: Large Effects Swimming in a Small Pond ”,https://arxiv.org/abs/1608.03676: “Coz: Finding Parallel Code That Counts With Causal Profiling ”,1987-rossi: “The Iron Law Of Evaluation And Other Metallic Rules ”,2011-lafleur.pdf: “Overestimation of the Effects of Adherence on Outcomes: a Case Study in Healthy User Bias and Hypertension ”,1994-duffy.pdf: “Inferring the Direction of Causation in Cross-Sectional Twin Data: Theoretical and Empirical Considerations ”,1986-lalonde.pdf: “Evaluating the Econometric Evaluations of Training Programs With Experimental Data ”,
“Causal Emergence Is Widespread across Measures of Causation ”, Comolatti & Hoel 2022
Causal emergence is widespread across measures of causation