‘Bayes’ directory
- See Also
- Gwern
- “Anti-Spaced Repetition for Serendipity”, Gwern 2017
- “Explain Free Energy Minimization Right Now, You Piece of S—T!”, Gwern & GPT-5 2025
- “Self-Blinded Mineral Water Taste Test”, Gwern 2017
- “Acne: a Good Quantified Self Topic”, Gwern 2019
- “Statistical Notes”, Gwern 2014
- “Amanda Knox: Post Mortem”, Gwern 2011
- “Calculating The Gaussian Expected Maximum”, Gwern 2016
- “One Man’s Modus Ponens”, Gwern 2012
- “Evolution As Backstop for Reinforcement Learning”, Gwern 2018
- “Banner Ads Considered Harmful”, Gwern 2017
- “Magnesium Self-Experiments”, Gwern 2013
- “The Most ‘Abandoned’ Books on GoodReads”, Gwern 2019
- “Why Correlation Usually ≠ Causation”, Gwern 2014
- “How Should We Critique Research?”, Gwern 2019
- “Catnip Immunity and Alternatives”, Gwern 2015
- “Prediction Markets”, Gwern 2009
- “The Explore-Exploit Dilemma in Media Consumption”, Gwern 2016
- “Embryo Editing for Intelligence”, Gwern 2016
- “Nootropics”, Gwern 2010
- “The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
- “World Catnip Surveys”, Gwern 2015
- “Life Extension Cost-Benefits”, Gwern 2015
- “Resorting Media Ratings”, Gwern 2015
- “Bacopa Quasi-Experiment”, Gwern 2014
- “ZMA Sleep Experiment”, Gwern 2017
- “Zeo Sleep Self-Experiments”, Gwern 2010
- “When Should I Check The Mail?”, Gwern 2015
- “Biased Information As Anti-Information”, Gwern 2012
- “Death Note: L, Anonymity & Eluding Entropy”, Gwern 2011
- “Potassium Sleep Experiments”, Gwern 2012
- “Caffeine Wakeup Experiment”, Gwern 2013
- “Vitamin D Sleep Experiments”, Gwern 2012
- “Candy Japan’s New Box A/B Test”, Gwern 2016
- “Bitter Melon for Blood Glucose”, Gwern 2015
- “Who Wrote The Death Note Script?”, Gwern 2009
- “Charity Is Not about Helping”, Gwern 2011
- “2012 Election Predictions”, Gwern 2012
- Links
- “Penalization for Small n Problems: Case Study of Steam Games”, Kirkegaard 2026
- “
fullrank: An Interactive CLI Tool and Python Library for Bayesian Inference of List Rankings Based on Noisy Comparisons”, Niederman 2025 - “Fullrank: Bayesian Noisy Sorting”, Niederman 2025
- “Quirks of Cognition Explain Why We Dramatically Overestimate the Size of Minority Groups”, Guay et al 2025
- “Deep Learning Is Not So Mysterious or Different”, Wilson 2025
- “Estimating the Probability of Sampling a Trained Neural Network at Random”, Scherlis & Belrose 2025
- “Meta-Statistical Learning: Supervised Learning of Statistical Inference”, Peyrard & Cho 2025
- “Where Does In-Context Learning Happen in Large Language Models?”, Sia et al 2025
- “Towards a Law of Iterated Expectations for Heuristic Estimators”, Christiano et al 2024
- “The Economic Way of Thinking in a Pandemic”, Tabarrok 2024
- “Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
- “Learning to Continually Learn With the Bayesian Principle”, Lee et al 2024
- “The Matrix: A Bayesian Learning Model for LLMs”, Dalal & Misra 2024
- “Deep De Finetti: Recovering Topic Distributions from Large Language Models”, Zhang et al 2023
- “The Virtue of Complexity in Return Prediction”, Kelly et al 2023
- “Hitting the Jackpot: The Birth of the Monte Carlo Method”, Summerscales 2023
- “Bayesian Regression Markets”, Falconer et al 2023
- “Model Merging by Uncertainty-Based Gradient Matching”, Daheim et al 2023
- “How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?”, Wu et al 2023
- “Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition”, Chen et al 2023
- “Bayesian Flow Networks”, Graves et al 2023
- “Supervised Pretraining Can Learn In-Context Reinforcement Learning”, Lee et al 2023
- “Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression”, Raventós et al 2023
- “From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”, Wong et al 2023
- “Replicability & Generalisability: A Guide to CEA Discounts”, Bettle 2023
- “Posterior Sampling for Multi-Agent Reinforcement Learning: Solving Extensive Games With Imperfect Information”, Zhou et al 2023
- “Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
- “Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
- “What Makes Mathematicians Believe Unproven Mathematical Statements?”, Gowers 2023
- “Modern Bayesian Experimental Design”, Rainforth et al 2023
- “Unifying Approaches in Active Learning and Active Sampling via Fisher Information and Information-Theoretic Quantities”, Kirsch & Gal 2023
- “Mortality Postponement and Compression at Older Ages in Human Cohorts”, McCarthy & Wang 2023
- “How Do Psychology Researchers Interpret the Results of Multiple Replication Studies?”, Akker et al 2023
- “Robust Bayesian Meta-Analysis: Addressing Publication Bias With Model-Averaging”, Maier et al 2023
- “Robust Bayesian Meta-Analysis: Model-Averaging across Complementary Publication Bias Adjustment Methods”, Bartoš et al 2023
- “AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong”, Blüml et al 2023
- “What Learning Algorithm Is In-Context Learning? Investigations With Linear Models”, Akyürek et al 2022
- “Laplace’s Demon in Biology: Models of Evolutionary Prediction”, Gompert et al 2022
- “Are Most Published Criminological Research Findings Wrong? Taking Stock of Criminological Research Using a Bayesian Simulation Approach”, Niemeyer et al 2022
- “Simulators”, Janus 2022
- “A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning”, Dann et al 2022
- “Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training”, You et al 2022
- “Language Model Cascades”, Dohan et al 2022
- “Language Models (Mostly) Know What They Know”, Kadavath et al 2022
- “Offline RL Policies Should Be Trained to Be Adaptive”, Ghosh et al 2022
- “Greedy Bayesian Posterior Approximation With Deep Ensembles”, Tiulpin & Blaschko 2022
- “Teaching Models to Express Their Uncertainty in Words”, Lin et al 2022
- “RL With KL Penalties Is Better Viewed As Bayesian Inference”, Korbak et al 2022
- “Fast and Accurate Bayesian Polygenic Risk Modeling With Variational Inference”, Zabad et al 2022
- “On-The-Fly Strategy Adaptation for Ad-Hoc Agent Coordination”, Zand et al 2022
- “Parallel MCMC Without Embarrassing Failures”, Souza et al 2022
- “The InterModel Vigorish (IMV): A Flexible and Portable Approach for Quantifying Predictive Accuracy With Binary Outcomes”, Domingue et al 2022
- “PFNs: Transformers Can Do Bayesian Inference”, Müller et al 2021
- “The Science of Visual Data Communication: What Works”, Franconeri et al 2021
- “How to Learn and Represent Abstractions: An Investigation Using Symbolic Alchemy”, AlKhamissi et al 2021
- “An Experimental Design Perspective on Model-Based Reinforcement Learning”, Mehta et al 2021
- “Prior Knowledge Elicitation: The Past, Present, and Future”, Mikkola et al 2021
- “Bayesian Inference of the Climbing Grade Scale”, Drummond & Popinga 2021
- “Improving GWAS Discovery and Genomic Prediction Accuracy in Biobank Data”, Orliac et al 2021
- “An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
- “Unifying Individual Differences in Personality, Predictability and Plasticity: A Practical Guide”, O’Dea et al 2021
- “A Confirmation Bias in Perceptual Decision-Making due to Hierarchical Approximate Inference”, Lange et al 2021
- “MegaLMM: Mega-Scale Linear Mixed Models for Genomic Predictions With Thousands of Traits”, Runcie et al 2021
- “Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability”, Ghosh et al 2021
- “The Bayesian Learning Rule”, Khan & Rue 2021
- “No Need to Choose: Robust Bayesian Meta-Analysis With Competing Publication Bias Adjustment Methods”, Bartoš et al 2021
- “What Are Bayesian Neural Network Posteriors Really Like?”, Izmailov et al 2021
- “Bayesian Optimization Is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020”, Turner et al 2021
- “Maximal Positive Controls: A Method for Estimating the Largest Plausible Effect Size”, Hilgard 2021
- “Informational Herding, Optimal Experimentation, and Contrarianism”, Smith et al 2021
- “Image Completion via Inference in Deep Generative Models”, Harvey et al 2021
- “The Statistical Properties of RCTs and a Proposal for Shrinkage”, Zwet et al 2020
- “Hot under the Collar: A Latent Measure of Interstate Hostility”, Terechshenko 2020
- “Bayesian Workflow”, Gelman et al 2020
- “From Probability to Consilience: How Explanatory Values Implement Bayesian Reasoning”, Wojtowicz & DeDeo 2020
- “Meta-Trained Agents Implement Bayes-Optimal Agents”, Mikulik et al 2020
- “Learning Not to Learn: Nature versus Nurture in Silico”, Lange & Sprekeler 2020
- “A Bayesian Approach to the Simulation Argument”, Kipping 2020
- “Is SGD a Bayesian Sampler? Well, Almost”, Mingard et al 2020
- “A Tutorial on VAEs: From Bayes’ Rule to Lossless Compression”, Yu 2020
- “DreamCoder: Growing Generalizable, Interpretable Knowledge With Wake-Sleep Bayesian Program Learning”, Ellis et al 2020
- “Laplace’s Theories of Cognitive Illusions, Heuristics and Biases”, Miller & Gelman 2020
- “Exploring Bayesian Optimization: Breaking Bayesian Optimization into Small, Sizeable Chunks”, Agnihotri & Batra 2020
- “Bayesian REX: Safe Imitation Learning via Fast Bayesian Reward Inference from Preferences”, Brown et al 2020
- “Bayesian Deep Learning and a Probabilistic Perspective of Generalization”, Wilson & Izmailov 2020
- “Bayesian Evolving-To-Extinction”, Demski 2020
- “The Case for Bayesian Deep Learning”, Wilson 2020
- “Why the Increasing Use of Complex Causal Models Is a Problem: On the Danger Sophisticated Theoretical Narratives Pose to Truth”, Saylors & Trafimow 2020
- “Improved Polygenic Prediction by Bayesian Multiple Regression on Summary Statistics”, Lloyd-Jones et al 2019
- “Approximate Inference in Discrete Distributions With Monte Carlo Tree Search and Value Functions”, Buesing et al 2019
- “Bayesian Parameter Estimation Using Conditional Variational Autoencoders for Gravitational-Wave Astronomy”, Gabbard et al 2019
- “New Paradigms in the Psychology of Reasoning”, Oaksford & Chater 2019
- “Estimating Distributional Models With Brms: Additive Distributional Models”, Bürkner 2019
- “Dirichlet-Hawkes Processes With Applications to Clustering Continuous-Time Document Streams”, Du et al 2019
- “Evolutionary Implementation of Bayesian Computations”, Czégel et al 2019
- “Reinforcement Learning, Fast and Slow”, Botvinick et al 2019
- “Meta Reinforcement Learning As Task Inference”, Humplik et al 2019
- “Structural Equation Models As Computation Graphs”, Kesteren & Oberski 2019
- “Meta-Learning of Sequential Strategies”, Ortega et al 2019
- “Meta-Learners’ Learning Dynamics Are unlike Learners’”, Rabinowitz 2019
- “Is the FDA Too Conservative or Too Aggressive?: A Bayesian Decision Analysis of Clinical Trial Design”, Isakov et al 2019
- “Bayesian Statistics in Sociology: Past, Present, and Future”, Lynch & Bartlett 2019
- “Accounting Theory As a Bayesian Discipline”, Johnstone 2018
- “The Bayesian Superorganism III: Externalized Memories Facilitate Distributed Sampling”, Hunt et al 2018
- “Exploration in the Wild”, Schulz et al 2018
- “Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
- “The Bayesian Superorganism I: Collective Probability Estimation”, Hunt et al 2018
- “Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning”, Foerster et al 2018
- “Computational Mechanisms of Curiosity and Goal-Directed Exploration”, Schwartenbeck et al 2018
- “Accurate Uncertainties for Deep Learning Using Calibrated Regression”, Kuleshov et al 2018
- “The Alignment Problem for Bayesian History-Based Reinforcement Learners”, Everitt & Hutter 2018
- “Deep Learning Generalizes Because the Parameter-Function Map Is Biased towards Simple Functions”, Valle-Pérez et al 2018
- “Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling”, Riquelme et al 2018
- “The Description Length of Deep Learning Models”, Blier & Ollivier 2018
- “Posterior Sampling for Large Scale Reinforcement Learning”, Theocharous et al 2017
- “Implicit Causal Models for Genome-Wide Association Studies”, Tran & Blei 2017
- “Analogical-Based Bayesian Optimization”, Le et al 2017
- “DropoutDAgger: A Bayesian Approach to Safe Imitation Learning”, Menda et al 2017
- “A Rational Choice Framework for Collective Behavior”, Krafft 2017
- “Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation”, Dallow et al 2017
- “The Prior Can Generally Only Be Understood in the Context of the Likelihood”, Gelman et al 2017
- “A Tutorial on Thompson Sampling”, Russo et al 2017
- “Structured Bayesian Pruning via Log-Normal Multiplicative Noise”, Neklyudov et al 2017
- “PBO: Preferential Bayesian Optimization”, Gonzalez et al 2017
- “Bayesian Recurrent Neural Networks”, Fortunato et al 2017
- “Black-Box Data-Efficient Policy Search for Robotics”, Chatzilygeroudis et al 2017
- “A Conceptual Introduction to Hamiltonian Monte Carlo”, Betancourt 2017
- “Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles”, Lakshminarayanan et al 2016
- “Bayesian Reinforcement Learning: A Survey”, Ghavamzadeh et al 2016
- “Human Collective Intelligence As Distributed Bayesian Inference”, Krafft et al 2016
- “Universal Darwinism As a Process of Bayesian Inference”, Campbell 2016
- “The Logical Primitives of Thought: Empirical Foundations for Compositional Cognitive Models”, Piantadosi et al 2016
- “PHENIX: A Multiple-Phenotype Imputation Method for Genetic Studies”, Dahl et al 2016
- “Probabilistic Integration: A Role in Statistical Computation?”, Briol et al 2015
- “Practical Probabilistic Programming With Monads”, Ścibior et al 2015
- “Don’t Fight the Power (Analysis)”, Westfall 2015
- “Bayesian Dark Knowledge”, Korattikara et al 2015
- “Dropout As a Bayesian Approximation: Representing Model Uncertainty in Deep Learning”, Gal & Ghahramani 2015
- “Optimal Regret Analysis of Thompson Sampling in Stochastic Multi-Armed Bandit Problem With Multiple Plays”, Komiyama et al 2015
- “Probabilistic Line Searches for Stochastic Optimization”, Mahsereci & Hennig 2015
- “Gaussian Processes for Data-Efficient Learning in Robotics and Control”, Deisenroth et al 2015
- “LDpred: Modeling Linkage Disequilibrium Increases Accuracy of Polygenic Risk Scores”, Vilhjálmsson et al 2015
- “Simultaneous Discovery, Estimation and Prediction Analysis of Complex Traits Using a Bayesian Mixture Model”, Moser et al 2014
- “Predictive Distributions for Between-Study Heterogeneity and Simple Methods for Their Application in Bayesian Meta-Analysis”, Turner et al 2014
- “One Hundred Years of Statistical Developments in Animal Breeding”, Gianola & Rosa 2014
- “Thompson Sampling With the Online Bootstrap”, Eckles & Kaptein 2014
- “Freeze-Thaw Bayesian Optimization”, Swersky et al 2014
- “Search for the Wreckage of Air France Flight AF 447”, Stone et al 2014
- “Bayesian Model Selection: The Steepest Mountain to Climb”, Tenan et al 2014
- “Decision Making Using Thompson Sampling”
- “Bayesian Inferences about the Self (And Others): a Review”, Moutoussis et al 2014
- “SGVB: Auto-Encoding Variational Bayes”, Kingma & Welling 2013
- “Machine Teaching for Bayesian Learners in the Exponential Family”, Zhu 2013
- “(More) Efficient Reinforcement Learning via Posterior Sampling”, Osband et al 2013
- “Model-Based Bayesian Exploration”, Dearden et al 2013
- “Understanding Predictive Information Criteria for Bayesian Models”, Gelman 2013
- “(More) Efficient Reinforcement Learning via Posterior Sampling [PSRL]”, Osband 2013
- “Deep Gaussian Processes”, Damianou & Lawrence 2012
- “WBIC: A Widely Applicable Bayesian Information Criterion”, Watanabe 2012
- “Bayesian Estimation Supersedes the t-Test”, Kruschke 2012
- “Practical Bayesian Optimization of Machine Learning Algorithms”, Snoek et al 2012
- “Learning Is Planning: near Bayes-Optimal Reinforcement Learning via Monte-Carlo Tree Search”, Asmuth & Littman 2012
- “Learning Performance of Prediction Markets With Kelly Bettors”, Beygelzimer et al 2012
- “Bayesian Active Learning for Classification and Preference Learning”, Houlsby et al 2011
- “Estimating the Evidence—A Review”, Friel & Wyse 2011
- “PILCO: A Model-Based and Data-Efficient Approach to Policy Search”, Deisenroth & Rasmussen 2011
- “Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments”, Sun et al 2011
- “An Empirical Evaluation of Thompson Sampling”, Chapelle & Li 2011
- “Mice: Multivariate Imputation by Chained Equations in R”, Buuren & Groothuis-Oudshoorn 2011
- “Bayesian Data Analysis”, Kruschke 2010
- “Darwin, Galton and the Statistical Enlightenment”, Stigler 2010b
- “Monte-Carlo Planning in Large POMDPs”, Silver & Veness 2010
- “Case Studies in Bayesian Computation Using INLA”, Martino & Rue 2010
- “Are Birds Smarter Than Mathematicians? Pigeons (Columba Livia) Perform Optimally on a Version of the Monty Hall Dilemma”, Herbranson & Schroeder 2010
- “A Monte Carlo AIXI Approximation”, Veness et al 2009
- “Observed Universality of Phase Transitions in High-Dimensional Geometry, With Implications for Modern Data Analysis and Signal Processing”, Donoho & Tanner 2009
- “Models for Potentially Biased Evidence in Meta-Analysis Using Empirically Based Priors”, Welton et al 2008
- “Optimal Approximation of Signal Priors”, Hyvarinen 2008
- “Verbal Probability Expressions In National Intelligence Estimates: A Comprehensive Analysis Of Trends From The Fifties Through Post-9/11”, Kesselman 2008
- “Infinite Certainty”, Blanc 2008
- “On Universal Prediction and Bayesian Confirmation”, Hutter 2007
- “Experiments on Partisanship and Public Opinion: Party Cues, False Beliefs, and Bayesian Updating”, Bullock 2007
- “De Finetti’s Theorem for Abstract Finite Exchangeable Sequences”, Kerns & Székely 2006
- “A Free Energy Principle for the Brain”, Friston et al 2006
- “Estimation of Non-Normalized Statistical Models by Score Matching”, Hyvarinen 2005
- “The Bayesian Brain: the Role of Uncertainty in Neural Coding and Computation”, Knill & Pouget 2004
- “Bayesian Informal Logic and Fallacy”, Korb 2004
- “Two Statistical Paradoxes in the Interpretation of Group Differences: Illustrated With Medical School Admission and Licensing Data”, Wainer & Brown 2004
- “Bayesian Computation: a Statistical Revolution”, Brooks 2003
- “Constructing a Logic of Plausible Inference: A Guide to Cox’s Theorem”, Horn 2003
- “Bayesian Adaptive Exploration”, Loredo & Chernoff 2003
- “Simplifying Likelihood Ratios”, McGee 2002
- “A Tour of Accounting: Random Number Generator [Dilbert]”, Adams 2001
- “Bayesianism in Mathematics”, Corfield 2001
- “A Bayesian Framework for Reinforcement Learning”, Strens 2000
- “Classical Multilevel and Bayesian Approaches to Population Size Estimation Using Multiple Lists”, Fienberg et al 1999
- “A Conversation With I. Richard Savage (With the Assistance of Bruce Spencer)”, Sampson 1999
- “On the Optimality of the Simple Bayesian Classifier under Zero-One Loss”, Domingos & Pazzani 1997
- “Statistical Issues in the Analysis of Data Gathered in the New Designs”, Kadane & Seidenfeld 1996
- “Bayesian Estimation and the Kalman Filter”, Barker et al 1995
- “Is There Sufficient Historical Evidence to Establish the Resurrection of Jesus?”, Cavin 1995
- “Perceptual-Cognitive Universals As Reflections of the World”, Shepard 1994
- “Subjective Probability”, Wright & Ayton 1994
- “The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality”, Koehler 1993
- “Statistical Theory of Learning Curves under Entropic Loss Criterion”, Amari & Murata 1993
- “Some Formulas for Use With Bayesian Ability Estimates”, Mislevy 1993
- “Information-Based Objective Functions for Active Data Selection”, MacKay 1992
- “Bayes-Hermite Quadrature”, O’Hagan 1991
- “Probability Theory As Logic”, Jaynes 1990
- “Explanatory Coherence”, Thagard 1989
- “Clearing up Mysteries—The Original Goal”, Jaynes 1989
- “Informal Conceptions of Probability”
- “The Double Exponential Distribution: Using Calculus to Find a Maximum Likelihood Estimator”, Norton 1984
- “This Week’s Citation Classic: Nearest Neighbor Pattern Classification”, Cover 1982
- “Lindley’s Paradox”, Shafer 1982
- “Computer-Aided Diagnosis Of Acute Abdominal Pain”, Dombal et al 1972
- “Nearest Neighbor Pattern Classification”, Cover & Hart 1967
- “Inference in an Authorship Problem: A Comparative Study of Discrimination Methods Applied to the Authorship of the Disputed Federalist Papers”, Mosteller & Wallace 1963
- “Probability, Statistical Decision Theory, and Accounting”, Bierman 1962
- “A Statistical Paradox”, Lindley 1957
- “The Argentine Writer and Tradition”, Borges 1951
- “Probability and the Weighing of Evidence”, Good 1950
- “Mr Keynes on Probability [Review of J. M. Keynes, A Treatise on Probability, 1921]”, Ramsey 1922
- “Philosophical Essay on Probabilities, Chapter 11: Concerning the Probabilities of Testimonies”, Laplace 1814
- “Shuffles, Bayes’ Theorem and Continuations.”
- A Philosophical Essay on Probabilities, Laplace 2026
- “Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability [Blog]”
- Bayesian Optimization Book
- “An Experimental Design Perspective on Model-Based Reinforcement Learning [Blog]”
- “In Praise of Sparsity and Convexity”, Tibshirani 2026 (page 518)
- “Diederik P. (Durk) Kingma”
- “Hauntsaninja/git_bayesect: Bayesian Git Bisect”
- “Brms: an R Package for Bayesian Generalized Multivariate Non-Linear Multilevel Models Using Stan”, Bürkner 2026
- “The Elements of Statistical Learning § 16.2.2, ‘The Bet-On-Sparsity Principle’”
- “Active Learning”
- Probability Theory: The Logic Of Science, Jaynes 2026
- “Approximate Bayes Optimal Policy Search Using Neural Networks”
- “Visualizing Bayes’ Theorem”
- “Bayesian Epistemology”
- “Quantum-Bayesian and Pragmatist Views of Quantum Theory”
- “A Weakly Informative Default Prior Distribution for Logistic and Other Regression Models”
- Bayesian Data Analysis, Gelman et al 2026
- “Modelling a Time Series of Records With PyMC3”
- “How a Kalman Filter Works, in Pictures”
- “Research Update: Towards a Law of Iterated Expectations for Heuristic Estimators”
- “Why We Can’t Take Expected Value Estimates Literally (Even When They’re Unbiased)”
- “A Computational No-Coincidence Principle”
- “Why Neural Networks Generalise, and Why They Are (Kind Of) Bayesian”
- “Language Models Model Us”
- “Why Rationalists Get Depressed”
- “Simple versus Short: Higher-Order Degeneracy and Error-Correction”
- “A Time-Invariant Version of Laplace’s Rule”
- “From Classical Methods to Generative Models: Tackling the Unreliability of Neuroscientific Measures in Mental Health Research”
- “AAAAH”, Weinersmith 2026
- “Probable Points and Credible Intervals, Part 2: Decision Theory”
- “An Intuitive Explanation of Bayes’ Theorem”, Yudkowsky 2026
- “A Technical Explanation of ‘Technical Explanation’”, Yudkowsky 2026
- “Random Number”, Munroe 2026
- Sort By Magic
- Wikipedia (18)
- Miscellaneous
- Bibliography
See Also
Gwern
“Anti-Spaced Repetition for Serendipity”, Gwern 2017
“Explain Free Energy Minimization Right Now, You Piece of S—T!”, Gwern & GPT-5 2025
Explain Free Energy Minimization Right Now, You Piece of S—t!
{kind=link}
“Self-Blinded Mineral Water Taste Test”, Gwern 2017
“Acne: a Good Quantified Self Topic”, Gwern 2019
“Statistical Notes”, Gwern 2014
“Amanda Knox: Post Mortem”, Gwern 2011
“Calculating The Gaussian Expected Maximum”, Gwern 2016
“One Man’s Modus Ponens”, Gwern 2012
“Evolution As Backstop for Reinforcement Learning”, Gwern 2018
“Magnesium Self-Experiments”, Gwern 2013
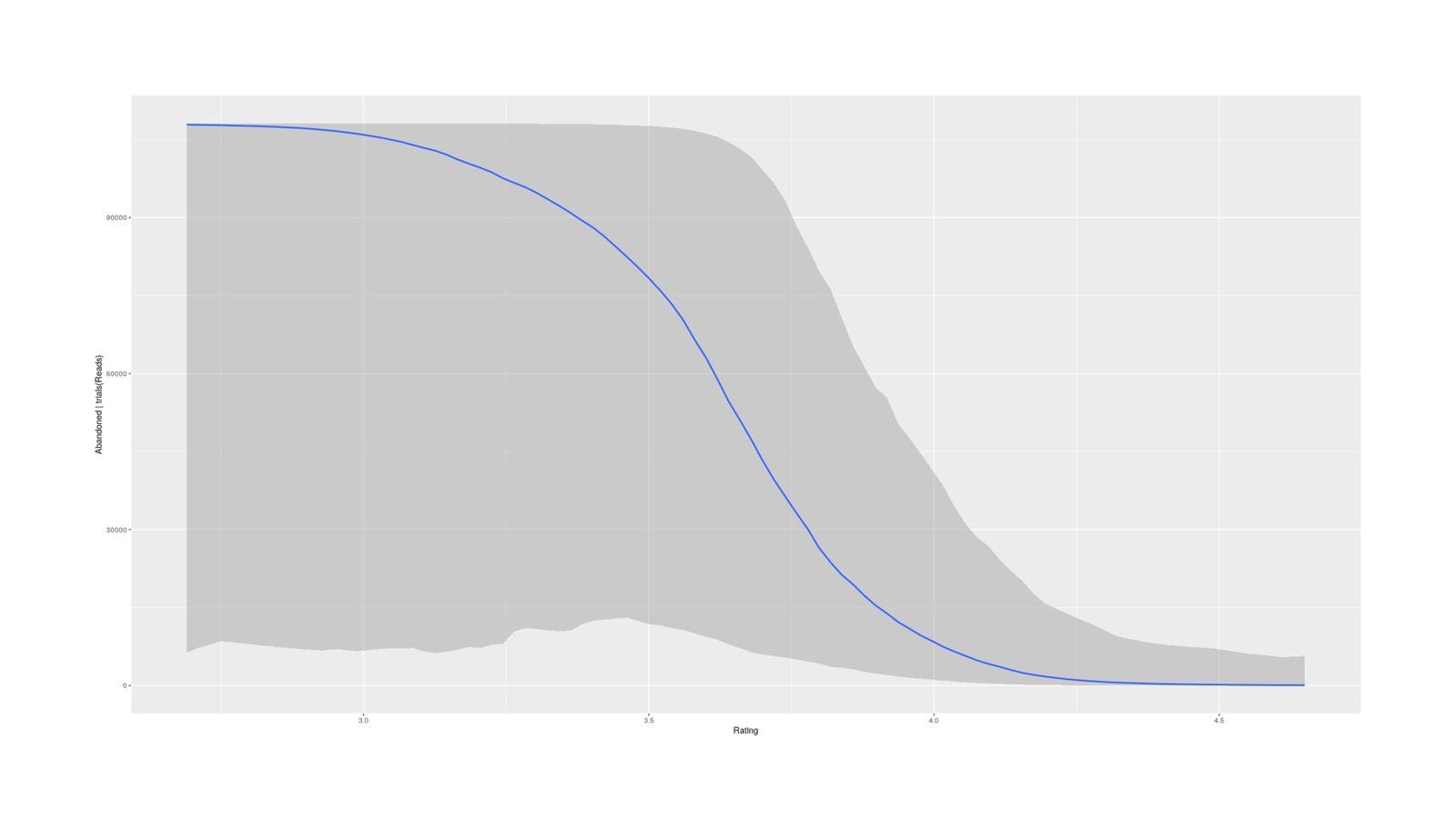
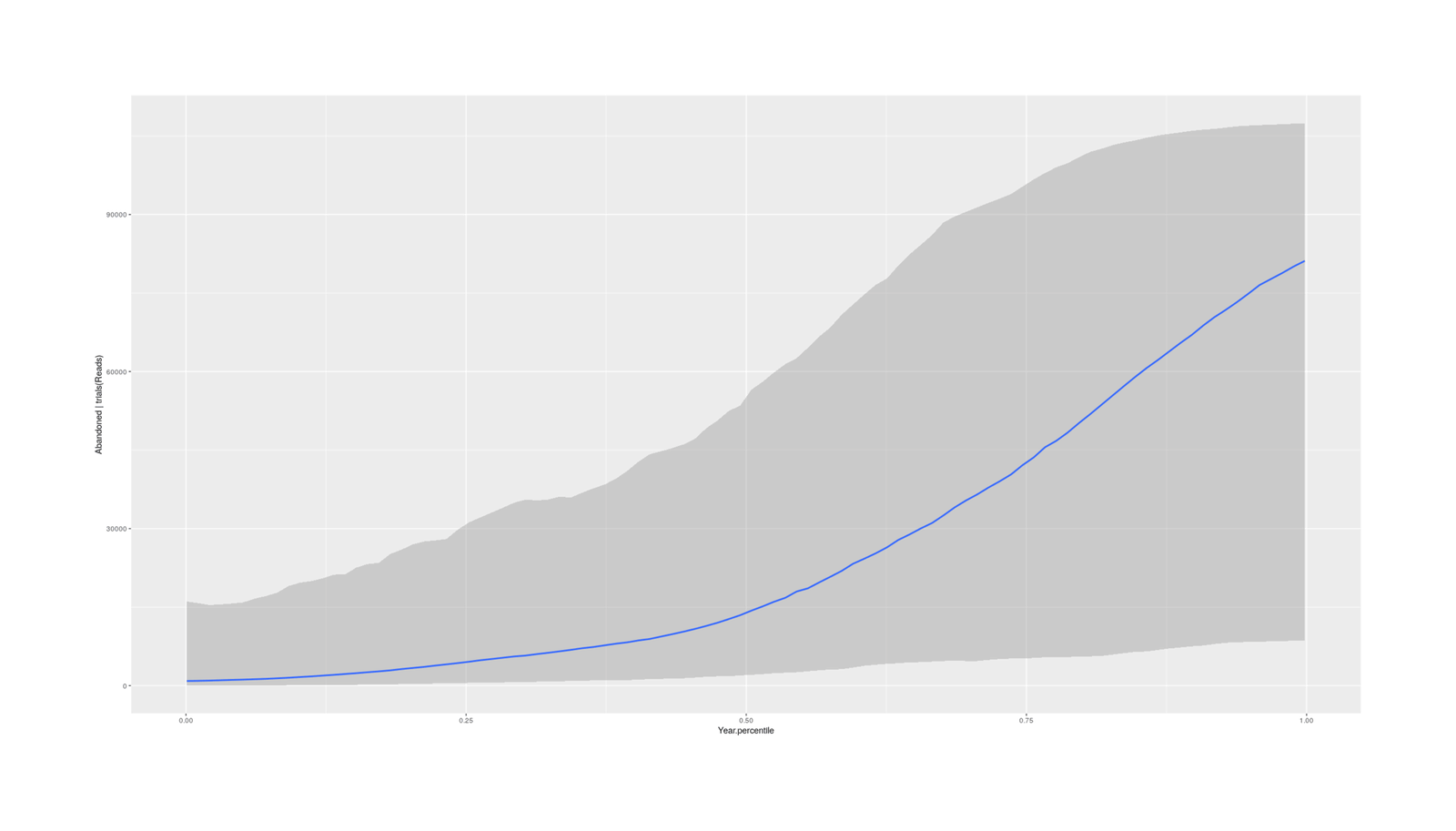
“The Most ‘Abandoned’ Books on GoodReads”, Gwern 2019
“Why Correlation Usually ≠ Causation”, Gwern 2014
“How Should We Critique Research?”, Gwern 2019
“Catnip Immunity and Alternatives”, Gwern 2015
“Prediction Markets”, Gwern 2009
“The Explore-Exploit Dilemma in Media Consumption”, Gwern 2016
“Embryo Editing for Intelligence”, Gwern 2016
“Nootropics”, Gwern 2010
“The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
“World Catnip Surveys”, Gwern 2015
“Life Extension Cost-Benefits”, Gwern 2015
“Resorting Media Ratings”, Gwern 2015
“Bacopa Quasi-Experiment”, Gwern 2014
“ZMA Sleep Experiment”, Gwern 2017
“Zeo Sleep Self-Experiments”, Gwern 2010
“When Should I Check The Mail?”, Gwern 2015
“Biased Information As Anti-Information”, Gwern 2012
“Death Note: L, Anonymity & Eluding Entropy”, Gwern 2011
“Potassium Sleep Experiments”, Gwern 2012
“Caffeine Wakeup Experiment”, Gwern 2013
“Vitamin D Sleep Experiments”, Gwern 2012
“Candy Japan’s New Box A/B Test”, Gwern 2016
“Bitter Melon for Blood Glucose”, Gwern 2015
“Who Wrote The Death Note Script?”, Gwern 2009
“Charity Is Not about Helping”, Gwern 2011
“2012 Election Predictions”, Gwern 2012
Links
“Penalization for Small n Problems: Case Study of Steam Games”, Kirkegaard 2026
Penalization for small n problems: case study of Steam games
“fullrank: An Interactive CLI Tool and Python Library for Bayesian Inference of List Rankings Based on Noisy Comparisons”, Niederman 2025
“Fullrank: Bayesian Noisy Sorting”, Niederman 2025
“Quirks of Cognition Explain Why We Dramatically Overestimate the Size of Minority Groups”, Guay et al 2025
Quirks of cognition explain why we dramatically overestimate the size of minority groups
“Deep Learning Is Not So Mysterious or Different”, Wilson 2025
“Estimating the Probability of Sampling a Trained Neural Network at Random”, Scherlis & Belrose 2025
Estimating the Probability of Sampling a Trained Neural Network at Random
“Meta-Statistical Learning: Supervised Learning of Statistical Inference”, Peyrard & Cho 2025
Meta-Statistical Learning: Supervised Learning of Statistical Inference
“Where Does In-Context Learning Happen in Large Language Models?”, Sia et al 2025
Where does In-context Learning Happen in Large Language Models?
“Towards a Law of Iterated Expectations for Heuristic Estimators”, Christiano et al 2024
Towards a Law of Iterated Expectations for Heuristic Estimators
“The Economic Way of Thinking in a Pandemic”, Tabarrok 2024
“Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
“Learning to Continually Learn With the Bayesian Principle”, Lee et al 2024
“The Matrix: A Bayesian Learning Model for LLMs”, Dalal & Misra 2024
“Deep De Finetti: Recovering Topic Distributions from Large Language Models”, Zhang et al 2023
Deep de Finetti: Recovering Topic Distributions from Large Language Models
“The Virtue of Complexity in Return Prediction”, Kelly et al 2023
“Hitting the Jackpot: The Birth of the Monte Carlo Method”, Summerscales 2023
“Bayesian Regression Markets”, Falconer et al 2023
“Model Merging by Uncertainty-Based Gradient Matching”, Daheim et al 2023
“How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?”, Wu et al 2023
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?
“Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition”, Chen et al 2023
Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition
“Bayesian Flow Networks”, Graves et al 2023
“Supervised Pretraining Can Learn In-Context Reinforcement Learning”, Lee et al 2023
Supervised Pretraining Can Learn In-Context Reinforcement Learning
“Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression”, Raventós et al 2023
Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression
“From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”, Wong et al 2023
“Replicability & Generalisability: A Guide to CEA Discounts”, Bettle 2023
“Posterior Sampling for Multi-Agent Reinforcement Learning: Solving Extensive Games With Imperfect Information”, Zhou et al 2023
“Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
Fundamental Limitations of Alignment in Large Language Models
“Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
Emergence of belief-like representations through reinforcement learning
“What Makes Mathematicians Believe Unproven Mathematical Statements?”, Gowers 2023
What Makes Mathematicians Believe Unproven Mathematical Statements?
“Modern Bayesian Experimental Design”, Rainforth et al 2023
“Unifying Approaches in Active Learning and Active Sampling via Fisher Information and Information-Theoretic Quantities”, Kirsch & Gal 2023
“Mortality Postponement and Compression at Older Ages in Human Cohorts”, McCarthy & Wang 2023
Mortality postponement and compression at older ages in human cohorts
“How Do Psychology Researchers Interpret the Results of Multiple Replication Studies?”, Akker et al 2023
How do psychology researchers interpret the results of multiple replication studies?
“Robust Bayesian Meta-Analysis: Addressing Publication Bias With Model-Averaging”, Maier et al 2023
Robust Bayesian meta-analysis: Addressing publication bias with model-averaging
“Robust Bayesian Meta-Analysis: Model-Averaging across Complementary Publication Bias Adjustment Methods”, Bartoš et al 2023
“AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong”, Blüml et al 2023
AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
“What Learning Algorithm Is In-Context Learning? Investigations With Linear Models”, Akyürek et al 2022
What learning algorithm is in-context learning? Investigations with linear models
“Laplace’s Demon in Biology: Models of Evolutionary Prediction”, Gompert et al 2022
Laplace’s demon in biology: Models of evolutionary prediction
“Are Most Published Criminological Research Findings Wrong? Taking Stock of Criminological Research Using a Bayesian Simulation Approach”, Niemeyer et al 2022
“Simulators”, Janus 2022
“A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning”, Dann et al 2022
A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning
“Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training”, You et al 2022
Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training
“Language Model Cascades”, Dohan et al 2022
“Language Models (Mostly) Know What They Know”, Kadavath et al 2022
“Offline RL Policies Should Be Trained to Be Adaptive”, Ghosh et al 2022
“Greedy Bayesian Posterior Approximation With Deep Ensembles”, Tiulpin & Blaschko 2022
“Teaching Models to Express Their Uncertainty in Words”, Lin et al 2022
“RL With KL Penalties Is Better Viewed As Bayesian Inference”, Korbak et al 2022
“Fast and Accurate Bayesian Polygenic Risk Modeling With Variational Inference”, Zabad et al 2022
Fast and Accurate Bayesian Polygenic Risk Modeling with Variational Inference
“On-The-Fly Strategy Adaptation for Ad-Hoc Agent Coordination”, Zand et al 2022
On-the-fly Strategy Adaptation for ad-hoc Agent Coordination
“Parallel MCMC Without Embarrassing Failures”, Souza et al 2022
“The InterModel Vigorish (IMV): A Flexible and Portable Approach for Quantifying Predictive Accuracy With Binary Outcomes”, Domingue et al 2022
“PFNs: Transformers Can Do Bayesian Inference”, Müller et al 2021
“The Science of Visual Data Communication: What Works”, Franconeri et al 2021
“How to Learn and Represent Abstractions: An Investigation Using Symbolic Alchemy”, AlKhamissi et al 2021
How to Learn and Represent Abstractions: An Investigation using Symbolic Alchemy
“An Experimental Design Perspective on Model-Based Reinforcement Learning”, Mehta et al 2021
An Experimental Design Perspective on Model-Based Reinforcement Learning
“Prior Knowledge Elicitation: The Past, Present, and Future”, Mikkola et al 2021
“Bayesian Inference of the Climbing Grade Scale”, Drummond & Popinga 2021
“Improving GWAS Discovery and Genomic Prediction Accuracy in Biobank Data”, Orliac et al 2021
Improving GWAS discovery and genomic prediction accuracy in Biobank data
“An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
An Explanation of In-context Learning as Implicit Bayesian Inference
“Unifying Individual Differences in Personality, Predictability and Plasticity: A Practical Guide”, O’Dea et al 2021
Unifying individual differences in personality, predictability and plasticity: A practical guide
“A Confirmation Bias in Perceptual Decision-Making due to Hierarchical Approximate Inference”, Lange et al 2021
A confirmation bias in perceptual decision-making due to hierarchical approximate inference
“MegaLMM: Mega-Scale Linear Mixed Models for Genomic Predictions With Thousands of Traits”, Runcie et al 2021
MegaLMM: Mega-scale linear mixed models for genomic predictions with thousands of traits
“Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability”, Ghosh et al 2021
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
“The Bayesian Learning Rule”, Khan & Rue 2021
“No Need to Choose: Robust Bayesian Meta-Analysis With Competing Publication Bias Adjustment Methods”, Bartoš et al 2021
No Need to Choose: Robust Bayesian Meta-Analysis with Competing Publication Bias Adjustment Methods
“What Are Bayesian Neural Network Posteriors Really Like?”, Izmailov et al 2021
“Bayesian Optimization Is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020”, Turner et al 2021
“Maximal Positive Controls: A Method for Estimating the Largest Plausible Effect Size”, Hilgard 2021
Maximal positive controls: A method for estimating the largest plausible effect size
“Informational Herding, Optimal Experimentation, and Contrarianism”, Smith et al 2021
Informational Herding, Optimal Experimentation, and Contrarianism
“Image Completion via Inference in Deep Generative Models”, Harvey et al 2021
“The Statistical Properties of RCTs and a Proposal for Shrinkage”, Zwet et al 2020
The statistical properties of RCTs and a proposal for shrinkage
“Hot under the Collar: A Latent Measure of Interstate Hostility”, Terechshenko 2020
Hot under the collar: A latent measure of interstate hostility
“Bayesian Workflow”, Gelman et al 2020
“From Probability to Consilience: How Explanatory Values Implement Bayesian Reasoning”, Wojtowicz & DeDeo 2020
From Probability to Consilience: How Explanatory Values Implement Bayesian Reasoning
“Meta-Trained Agents Implement Bayes-Optimal Agents”, Mikulik et al 2020
“Learning Not to Learn: Nature versus Nurture in Silico”, Lange & Sprekeler 2020
“A Bayesian Approach to the Simulation Argument”, Kipping 2020
“Is SGD a Bayesian Sampler? Well, Almost”, Mingard et al 2020
“A Tutorial on VAEs: From Bayes’ Rule to Lossless Compression”, Yu 2020
A Tutorial on VAEs: From Bayes’ Rule to Lossless Compression
“DreamCoder: Growing Generalizable, Interpretable Knowledge With Wake-Sleep Bayesian Program Learning”, Ellis et al 2020
DreamCoder: Growing generalizable, interpretable knowledge with wake-sleep Bayesian program learning
“Laplace’s Theories of Cognitive Illusions, Heuristics and Biases”, Miller & Gelman 2020
Laplace’s Theories of Cognitive Illusions, Heuristics and Biases
“Exploring Bayesian Optimization: Breaking Bayesian Optimization into Small, Sizeable Chunks”, Agnihotri & Batra 2020
Exploring Bayesian Optimization: Breaking Bayesian Optimization into small, sizeable chunks
“Bayesian REX: Safe Imitation Learning via Fast Bayesian Reward Inference from Preferences”, Brown et al 2020
Bayesian REX: Safe Imitation Learning via Fast Bayesian Reward Inference from Preferences
“Bayesian Deep Learning and a Probabilistic Perspective of Generalization”, Wilson & Izmailov 2020
Bayesian Deep Learning and a Probabilistic Perspective of Generalization
“Bayesian Evolving-To-Extinction”, Demski 2020
“The Case for Bayesian Deep Learning”, Wilson 2020
“Why the Increasing Use of Complex Causal Models Is a Problem: On the Danger Sophisticated Theoretical Narratives Pose to Truth”, Saylors & Trafimow 2020
“Improved Polygenic Prediction by Bayesian Multiple Regression on Summary Statistics”, Lloyd-Jones et al 2019
Improved polygenic prediction by Bayesian multiple regression on summary statistics
“Approximate Inference in Discrete Distributions With Monte Carlo Tree Search and Value Functions”, Buesing et al 2019
Approximate Inference in Discrete Distributions with Monte Carlo Tree Search and Value Functions
“Bayesian Parameter Estimation Using Conditional Variational Autoencoders for Gravitational-Wave Astronomy”, Gabbard et al 2019
“New Paradigms in the Psychology of Reasoning”, Oaksford & Chater 2019
“Estimating Distributional Models With Brms: Additive Distributional Models”, Bürkner 2019
Estimating Distributional Models with brms: Additive Distributional Models
“Dirichlet-Hawkes Processes With Applications to Clustering Continuous-Time Document Streams”, Du et al 2019
Dirichlet-Hawkes Processes with Applications to Clustering Continuous-Time Document Streams
“Evolutionary Implementation of Bayesian Computations”, Czégel et al 2019
“Reinforcement Learning, Fast and Slow”, Botvinick et al 2019
“Meta Reinforcement Learning As Task Inference”, Humplik et al 2019
“Structural Equation Models As Computation Graphs”, Kesteren & Oberski 2019
“Meta-Learning of Sequential Strategies”, Ortega et al 2019
“Meta-Learners’ Learning Dynamics Are unlike Learners’”, Rabinowitz 2019
“Is the FDA Too Conservative or Too Aggressive?: A Bayesian Decision Analysis of Clinical Trial Design”, Isakov et al 2019
“Bayesian Statistics in Sociology: Past, Present, and Future”, Lynch & Bartlett 2019
“Accounting Theory As a Bayesian Discipline”, Johnstone 2018
“The Bayesian Superorganism III: Externalized Memories Facilitate Distributed Sampling”, Hunt et al 2018
The Bayesian Superorganism III: externalized memories facilitate distributed sampling
“Exploration in the Wild”, Schulz et al 2018
“Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
“The Bayesian Superorganism I: Collective Probability Estimation”, Hunt et al 2018
The Bayesian Superorganism I: collective probability estimation
“Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning”, Foerster et al 2018
Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
“Computational Mechanisms of Curiosity and Goal-Directed Exploration”, Schwartenbeck et al 2018
Computational mechanisms of curiosity and goal-directed exploration
“Accurate Uncertainties for Deep Learning Using Calibrated Regression”, Kuleshov et al 2018
Accurate Uncertainties for Deep Learning Using Calibrated Regression
“The Alignment Problem for Bayesian History-Based Reinforcement Learners”, Everitt & Hutter 2018
The Alignment Problem for Bayesian History-Based Reinforcement Learners
“Deep Learning Generalizes Because the Parameter-Function Map Is Biased towards Simple Functions”, Valle-Pérez et al 2018
Deep learning generalizes because the parameter-function map is biased towards simple functions
“Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling”, Riquelme et al 2018
“The Description Length of Deep Learning Models”, Blier & Ollivier 2018
“Posterior Sampling for Large Scale Reinforcement Learning”, Theocharous et al 2017
“Implicit Causal Models for Genome-Wide Association Studies”, Tran & Blei 2017
“Analogical-Based Bayesian Optimization”, Le et al 2017
“DropoutDAgger: A Bayesian Approach to Safe Imitation Learning”, Menda et al 2017
DropoutDAgger: A Bayesian Approach to Safe Imitation Learning
“A Rational Choice Framework for Collective Behavior”, Krafft 2017
“Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation”, Dallow et al 2017
Better Decision Making in Drug Development Through Adoption of Formal Prior Elicitation
“The Prior Can Generally Only Be Understood in the Context of the Likelihood”, Gelman et al 2017
The prior can generally only be understood in the context of the likelihood
“A Tutorial on Thompson Sampling”, Russo et al 2017
“Structured Bayesian Pruning via Log-Normal Multiplicative Noise”, Neklyudov et al 2017
Structured Bayesian Pruning via Log-Normal Multiplicative Noise
“PBO: Preferential Bayesian Optimization”, Gonzalez et al 2017
“Bayesian Recurrent Neural Networks”, Fortunato et al 2017
“Black-Box Data-Efficient Policy Search for Robotics”, Chatzilygeroudis et al 2017
“A Conceptual Introduction to Hamiltonian Monte Carlo”, Betancourt 2017
“Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles”, Lakshminarayanan et al 2016
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
“Bayesian Reinforcement Learning: A Survey”, Ghavamzadeh et al 2016
“Human Collective Intelligence As Distributed Bayesian Inference”, Krafft et al 2016
Human collective intelligence as distributed Bayesian inference
“Universal Darwinism As a Process of Bayesian Inference”, Campbell 2016
“The Logical Primitives of Thought: Empirical Foundations for Compositional Cognitive Models”, Piantadosi et al 2016
The Logical Primitives of Thought: Empirical Foundations for Compositional Cognitive Models
“PHENIX: A Multiple-Phenotype Imputation Method for Genetic Studies”, Dahl et al 2016
PHENIX: A multiple-phenotype imputation method for genetic studies
“Probabilistic Integration: A Role in Statistical Computation?”, Briol et al 2015
Probabilistic Integration: A Role in Statistical Computation?
“Practical Probabilistic Programming With Monads”, Ścibior et al 2015
“Don’t Fight the Power (Analysis)”, Westfall 2015
“Bayesian Dark Knowledge”, Korattikara et al 2015
“Dropout As a Bayesian Approximation: Representing Model Uncertainty in Deep Learning”, Gal & Ghahramani 2015
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
“Optimal Regret Analysis of Thompson Sampling in Stochastic Multi-Armed Bandit Problem With Multiple Plays”, Komiyama et al 2015
“Probabilistic Line Searches for Stochastic Optimization”, Mahsereci & Hennig 2015
“Gaussian Processes for Data-Efficient Learning in Robotics and Control”, Deisenroth et al 2015
Gaussian Processes for Data-Efficient Learning in Robotics and Control
“LDpred: Modeling Linkage Disequilibrium Increases Accuracy of Polygenic Risk Scores”, Vilhjálmsson et al 2015
LDpred: Modeling Linkage Disequilibrium Increases Accuracy of Polygenic Risk Scores
“Simultaneous Discovery, Estimation and Prediction Analysis of Complex Traits Using a Bayesian Mixture Model”, Moser et al 2014
“Predictive Distributions for Between-Study Heterogeneity and Simple Methods for Their Application in Bayesian Meta-Analysis”, Turner et al 2014
“One Hundred Years of Statistical Developments in Animal Breeding”, Gianola & Rosa 2014
One Hundred Years of Statistical Developments in Animal Breeding
“Thompson Sampling With the Online Bootstrap”, Eckles & Kaptein 2014
“Freeze-Thaw Bayesian Optimization”, Swersky et al 2014
“Search for the Wreckage of Air France Flight AF 447”, Stone et al 2014
“Bayesian Model Selection: The Steepest Mountain to Climb”, Tenan et al 2014
Bayesian model selection: The steepest mountain to climb :
View PDF:
“Decision Making Using Thompson Sampling”
“Bayesian Inferences about the Self (And Others): a Review”, Moutoussis et al 2014
“SGVB: Auto-Encoding Variational Bayes”, Kingma & Welling 2013
“Machine Teaching for Bayesian Learners in the Exponential Family”, Zhu 2013
Machine Teaching for Bayesian Learners in the Exponential Family
“(More) Efficient Reinforcement Learning via Posterior Sampling”, Osband et al 2013
(More) Efficient Reinforcement Learning via Posterior Sampling
“Model-Based Bayesian Exploration”, Dearden et al 2013
“Understanding Predictive Information Criteria for Bayesian Models”, Gelman 2013
Understanding predictive information criteria for Bayesian models :
“(More) Efficient Reinforcement Learning via Posterior Sampling [PSRL]”, Osband 2013
(More) efficient reinforcement learning via posterior sampling [PSRL] :
“Deep Gaussian Processes”, Damianou & Lawrence 2012
“WBIC: A Widely Applicable Bayesian Information Criterion”, Watanabe 2012
“Bayesian Estimation Supersedes the t-Test”, Kruschke 2012
“Practical Bayesian Optimization of Machine Learning Algorithms”, Snoek et al 2012
Practical Bayesian Optimization of Machine Learning Algorithms
“Learning Is Planning: near Bayes-Optimal Reinforcement Learning via Monte-Carlo Tree Search”, Asmuth & Littman 2012
Learning is planning: near Bayes-optimal reinforcement learning via Monte-Carlo tree search
“Learning Performance of Prediction Markets With Kelly Bettors”, Beygelzimer et al 2012
Learning Performance of Prediction Markets with Kelly Bettors
“Bayesian Active Learning for Classification and Preference Learning”, Houlsby et al 2011
Bayesian Active Learning for Classification and Preference Learning
“Estimating the Evidence—A Review”, Friel & Wyse 2011
“PILCO: A Model-Based and Data-Efficient Approach to Policy Search”, Deisenroth & Rasmussen 2011
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
“Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments”, Sun et al 2011
Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments
“An Empirical Evaluation of Thompson Sampling”, Chapelle & Li 2011
“Mice: Multivariate Imputation by Chained Equations in R”, Buuren & Groothuis-Oudshoorn 2011
“Bayesian Data Analysis”, Kruschke 2010
View PDF:
“Darwin, Galton and the Statistical Enlightenment”, Stigler 2010b
“Monte-Carlo Planning in Large POMDPs”, Silver & Veness 2010
“Case Studies in Bayesian Computation Using INLA”, Martino & Rue 2010
“Are Birds Smarter Than Mathematicians? Pigeons (Columba Livia) Perform Optimally on a Version of the Monty Hall Dilemma”, Herbranson & Schroeder 2010
“A Monte Carlo AIXI Approximation”, Veness et al 2009
“Observed Universality of Phase Transitions in High-Dimensional Geometry, With Implications for Modern Data Analysis and Signal Processing”, Donoho & Tanner 2009
“Models for Potentially Biased Evidence in Meta-Analysis Using Empirically Based Priors”, Welton et al 2008
Models for potentially biased evidence in meta-analysis using empirically based priors
“Optimal Approximation of Signal Priors”, Hyvarinen 2008
“Verbal Probability Expressions In National Intelligence Estimates: A Comprehensive Analysis Of Trends From The Fifties Through Post-9/11”, Kesselman 2008
“Infinite Certainty”, Blanc 2008
“On Universal Prediction and Bayesian Confirmation”, Hutter 2007
“Experiments on Partisanship and Public Opinion: Party Cues, False Beliefs, and Bayesian Updating”, Bullock 2007
Experiments on partisanship and public opinion: Party cues, false beliefs, and Bayesian updating
“De Finetti’s Theorem for Abstract Finite Exchangeable Sequences”, Kerns & Székely 2006
De Finetti’s Theorem for Abstract Finite Exchangeable Sequences
“A Free Energy Principle for the Brain”, Friston et al 2006
“Estimation of Non-Normalized Statistical Models by Score Matching”, Hyvarinen 2005
Estimation of Non-Normalized Statistical Models by Score Matching
“The Bayesian Brain: the Role of Uncertainty in Neural Coding and Computation”, Knill & Pouget 2004
The Bayesian brain: the role of uncertainty in neural coding and computation
“Bayesian Informal Logic and Fallacy”, Korb 2004
“Two Statistical Paradoxes in the Interpretation of Group Differences: Illustrated With Medical School Admission and Licensing Data”, Wainer & Brown 2004
“Bayesian Computation: a Statistical Revolution”, Brooks 2003
“Constructing a Logic of Plausible Inference: A Guide to Cox’s Theorem”, Horn 2003
Constructing a Logic of Plausible Inference: A Guide to Cox’s Theorem
“Bayesian Adaptive Exploration”, Loredo & Chernoff 2003
“Simplifying Likelihood Ratios”, McGee 2002
“A Tour of Accounting: Random Number Generator [Dilbert]”, Adams 2001
![A Tour of Accounting: Random Number Generator [Dilbert]](/doc/statistics/probability/2001-11-25-scottadams-dilbert-tourofaccounting-randomness.jpg){kind=link}
“Bayesianism in Mathematics”, Corfield 2001
“A Bayesian Framework for Reinforcement Learning”, Strens 2000
“Classical Multilevel and Bayesian Approaches to Population Size Estimation Using Multiple Lists”, Fienberg et al 1999
Classical Multilevel and Bayesian Approaches to Population Size Estimation Using Multiple Lists
“A Conversation With I. Richard Savage (With the Assistance of Bruce Spencer)”, Sampson 1999
A conversation with I. Richard Savage (with the assistance of Bruce Spencer)
“On the Optimality of the Simple Bayesian Classifier under Zero-One Loss”, Domingos & Pazzani 1997
On the Optimality of the Simple Bayesian Classifier under Zero-One Loss
“Statistical Issues in the Analysis of Data Gathered in the New Designs”, Kadane & Seidenfeld 1996
Statistical Issues in the Analysis of Data Gathered in the New Designs :
View PDF:
“Bayesian Estimation and the Kalman Filter”, Barker et al 1995
“Is There Sufficient Historical Evidence to Establish the Resurrection of Jesus?”, Cavin 1995
Is There Sufficient Historical Evidence to Establish the Resurrection of Jesus? :
View PDF:
“Perceptual-Cognitive Universals As Reflections of the World”, Shepard 1994
“Subjective Probability”, Wright & Ayton 1994
View PDF (18MB):
“The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality”, Koehler 1993
The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality
“Statistical Theory of Learning Curves under Entropic Loss Criterion”, Amari & Murata 1993
Statistical Theory of Learning Curves under Entropic Loss Criterion
“Some Formulas for Use With Bayesian Ability Estimates”, Mislevy 1993
Some Formulas for Use with Bayesian Ability Estimates :
View PDF:
“Information-Based Objective Functions for Active Data Selection”, MacKay 1992
Information-Based Objective Functions for Active Data Selection
“Bayes-Hermite Quadrature”, O’Hagan 1991
View PDF:
“Probability Theory As Logic”, Jaynes 1990
“Explanatory Coherence”, Thagard 1989
“Clearing up Mysteries—The Original Goal”, Jaynes 1989
“Informal Conceptions of Probability”
“The Double Exponential Distribution: Using Calculus to Find a Maximum Likelihood Estimator”, Norton 1984
The Double Exponential Distribution: Using Calculus to Find a Maximum Likelihood Estimator :
View PDF:
“This Week’s Citation Classic: Nearest Neighbor Pattern Classification”, Cover 1982
This Week’s Citation Classic: Nearest Neighbor Pattern Classification
“Lindley’s Paradox”, Shafer 1982
“Computer-Aided Diagnosis Of Acute Abdominal Pain”, Dombal et al 1972
Computer-Aided Diagnosis Of Acute Abdominal Pain :
View PDF:
“Nearest Neighbor Pattern Classification”, Cover & Hart 1967
“Inference in an Authorship Problem: A Comparative Study of Discrimination Methods Applied to the Authorship of the Disputed Federalist Papers”, Mosteller & Wallace 1963
“Probability, Statistical Decision Theory, and Accounting”, Bierman 1962
“A Statistical Paradox”, Lindley 1957
View PDF:
“The Argentine Writer and Tradition”, Borges 1951
“Probability and the Weighing of Evidence”, Good 1950
“Mr Keynes on Probability [Review of J. M. Keynes, A Treatise on Probability, 1921]”, Ramsey 1922
Mr Keynes on Probability [review of J. M. Keynes, A Treatise on Probability, 1921] :
View PDF:
“Philosophical Essay on Probabilities, Chapter 11: Concerning the Probabilities of Testimonies”, Laplace 1814
Philosophical Essay on Probabilities, Chapter 11: Concerning the Probabilities of Testimonies
“Shuffles, Bayes’ Theorem and Continuations.”
A Philosophical Essay on Probabilities, Laplace 2026
A philosophical essay on probabilities
View External Link:
“Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability [Blog]”
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability [blog]
Bayesian Optimization Book
“An Experimental Design Perspective on Model-Based Reinforcement Learning [Blog]”
An Experimental Design Perspective on Model-Based Reinforcement Learning [blog]
“In Praise of Sparsity and Convexity”, Tibshirani 2026 (page 518)
“Diederik P. (Durk) Kingma”
“Hauntsaninja/git_bayesect: Bayesian Git Bisect”
“Brms: an R Package for Bayesian Generalized Multivariate Non-Linear Multilevel Models Using Stan”, Bürkner 2026
brms: an R package for Bayesian generalized multivariate non-linear multilevel models using Stan
“The Elements of Statistical Learning § 16.2.2, ‘The Bet-On-Sparsity Principle’”
The Elements of Statistical Learning § 16.2.2, ‘The Bet-on-Sparsity Principle’ :
“Active Learning”
Probability Theory: The Logic Of Science, Jaynes 2026
“Approximate Bayes Optimal Policy Search Using Neural Networks”
Approximate Bayes Optimal Policy Search using Neural Networks :
“Visualizing Bayes’ Theorem”
“Bayesian Epistemology”
“Quantum-Bayesian and Pragmatist Views of Quantum Theory”
“A Weakly Informative Default Prior Distribution for Logistic and Other Regression Models”
A weakly informative default prior distribution for logistic and other regression models
Bayesian Data Analysis, Gelman et al 2026
“Modelling a Time Series of Records With PyMC3”
“How a Kalman Filter Works, in Pictures”
“Research Update: Towards a Law of Iterated Expectations for Heuristic Estimators”
Research update: Towards a Law of Iterated Expectations for Heuristic Estimators
“Why We Can’t Take Expected Value Estimates Literally (Even When They’re Unbiased)”
Why We Can’t Take Expected Value Estimates Literally (Even When They’re Unbiased)
“A Computational No-Coincidence Principle”
“Why Neural Networks Generalise, and Why They Are (Kind Of) Bayesian”
Why Neural Networks Generalise, and Why They Are (Kind of) Bayesian
“Language Models Model Us”
“Why Rationalists Get Depressed”
“Simple versus Short: Higher-Order Degeneracy and Error-Correction”
Simple versus Short: Higher-order degeneracy and error-correction
“A Time-Invariant Version of Laplace’s Rule”
“From Classical Methods to Generative Models: Tackling the Unreliability of Neuroscientific Measures in Mental Health Research”
“AAAAH”, Weinersmith 2026
“Probable Points and Credible Intervals, Part 2: Decision Theory”
Probable Points and Credible Intervals, Part 2: Decision Theory
“An Intuitive Explanation of Bayes’ Theorem”, Yudkowsky 2026
“A Technical Explanation of ‘Technical Explanation’”, Yudkowsky 2026
“Random Number”, Munroe 2026
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
learning-theory
image-inference
parameter-estimation
bayesian-optimization
Wikipedia (18)
Miscellaneous
/doc/statistics/bayes/2019-12-09-gwern-goodreads-abandonment-bayesian-averageratingspline.png/doc/statistics/bayes/2019-12-09-gwern-goodreads-abandonment-bayesian-yearspline.png/doc/statistics/bayes/2013-dunson.pdf:View PDF:
/doc/statistics/bayes/2009-kaas.htmlView HTML:
/doc/statistics/bayes/2007-teigen.pdf:View PDF:
/doc/statistics/bayes/1989-shimojo.pdf:View PDF:
/doc/statistics/bayes/1988-jaynes-maximumentropyandbayesianmethods.pdf:/doc/statistics/bayes/1987-ayton.pdf:View PDF:
http://vision.psych.umn.edu/groups/schraterlab/dearden98bayesian.pdfhttps://github.com/cranmer/active_sciencing/blob/master/README.mdhttps://joe-antognini.github.io/machine-learning/steins-paradoxhttps://joecarlsmith.com/2023/05/08/predictable-updating-about-ai-risk/https://math.ucr.edu/home/baez/information/information_geometry_8.htmlhttps://statmodeling.stat.columbia.edu/2023/04/18/chatgpt4-writes-stan-code-so-i-dont-have-to/https://towardsdatascience.com/neural-networks-are-fundamentally-bayesian-bee9a172fad8https://www.astralcodexten.com/p/against-learning-from-dramatic-eventshttps://www.lesswrong.com/posts/GveDmwzxiYHSWtZbv/shannon-s-surprising-discovery-1https://www.lesswrong.com/posts/S54HKhxQyttNLATKu/deconfusing-direct-vs-amortised-optimizationhttps://www.lesswrong.com/posts/ZwshvqiqCvXPsZEct/the-learning-theoretic-agenda-status-2023https://www.probabilistic-numerics.org/assets/ProbabilisticNumerics.pdf#page=3
{kind=link}
{kind=link}
{kind=link}
Bibliography
2024-tabarrok.pdf: “The Economic Way of Thinking in a Pandemic”,https://arxiv.org/abs/2306.14892: “Supervised Pretraining Can Learn In-Context Reinforcement Learning”,https://openreview.net/forum?id=UVDAKQANOW: “Unifying Approaches in Active Learning and Active Sampling via Fisher Information and Information-Theoretic Quantities”,2023-maier.pdf: “Robust Bayesian Meta-Analysis: Addressing Publication Bias With Model-Averaging”,https://arxiv.org/abs/2211.15661#google: “What Learning Algorithm Is In-Context Learning? Investigations With Linear Models”,https://osf.io/mhv8f/: “Are Most Published Criminological Research Findings Wrong? Taking Stock of Criminological Research Using a Bayesian Simulation Approach”,https://arxiv.org/abs/2207.05221#anthropic: “Language Models (Mostly) Know What They Know”,https://arxiv.org/abs/2205.11275: “RL With KL Penalties Is Better Viewed As Bayesian Inference”,https://arxiv.org/abs/2112.10510: “PFNs: Transformers Can Do Bayesian Inference”,2021-odea.pdf: “Unifying Individual Differences in Personality, Predictability and Plasticity: A Practical Guide”,https://osf.io/preprints/psyarxiv/kvsp7/: “No Need to Choose: Robust Bayesian Meta-Analysis With Competing Publication Bias Adjustment Methods”,https://arxiv.org/abs/2011.15004: “The Statistical Properties of RCTs and a Proposal for Shrinkage”,https://arxiv.org/abs/1905.01320#deepmind: “Meta-Learners’ Learning Dynamics Are unlike Learners’”,2018-everitt.pdf: “The Alignment Problem for Bayesian History-Based Reinforcement Learners”,https://onlinelibrary.wiley.com/doi/full/10.1002/sim.6381: “Predictive Distributions for Between-Study Heterogeneity and Simple Methods for Their Application in Bayesian Meta-Analysis”,2012-kruschke.pdf: “Bayesian Estimation Supersedes the t-Test”,2010-stigler-2.pdf: “Darwin, Galton and the Statistical Enlightenment”,2010-silver.pdf: “Monte-Carlo Planning in Large POMDPs”,https://www.jmlr.org/papers/volume6/hyvarinen05a/hyvarinen05a.pdf: “Estimation of Non-Normalized Statistical Models by Score Matching”,1994-shepard.pdf: “Perceptual-Cognitive Universals As Reflections of the World”,1982-cover.pdf: “This Week’s Citation Classic: Nearest Neighbor Pattern Classification”,