‘CS’ directory
- See Also
- Gwern
- “You Can Never Reproduce The Same Bug Twice [Demotivational Poster] ”, Gwern 2025
- “Utext: Rich Unicode Documents ”, Gwern 2023
- “Computer Optimization: Your Computer Is Faster Than You Think ”, Gwern 2021
- “The 3 Grenades and the 4 Noble Truths ”, Gwern 2008
- “AI Risk Demos ”, Gwern 2016
- “Isomorphisms & Meaning ”, Gwern 2009
- “Evolutionary Software Licenses ”, Gwern 2009
- “Aria’s Past, Present, and Future ”, Gwern 2011
- “Simulation Inferences ”, Gwern 2009
- Links
- “Perl’s Decline Was Cultural ”, Strickland 2025
- “Mystical Notation for PostScript ”, Denis 2025
- layer07_yuxi @ "2025-05-06"
- “A LLM Assisted Exploitation of AI-Guardian ”, Carlini 2023
- “The Effect of Perceptual Load on Performance within IDE in People With ADHD Symptoms ”, Kasatskii et al 2023
- “Historical Decline in
wwwSubdomain Use? ”, Farrugia 2023 - “Catala: A Programming Language for the Law ”, Merigoux et al 2021
- “There’s a Tendency of Ideologues to Value Ideological Purity over Fitness ”, kristopolous 2021
- “Energy Conservation With Open Source Ad Blockers ”, Pearce 2020
- “Open Source Migrates With Emotional Distress ”, Ronacher 2019
- “Founding and Growing Adobe Systems, Inc ”, Warnock & Geschke 2019
- “Spooky Fizz Buzz § Pg42 ”, Menghrajani 2019 (page 42)
- “The Origins of PostScript ”, Warnock 2018
- “Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects ”, Baltes & Diehl 2018
- “Preprint Déjà Vu: an FAQ ”, Ginsparg 2017
- “Designing Better File Organization around Tags, Not Hierarchies ”, Nayuki 2017
- “Software Engineering at Google ”, Henderson 2017
- “Shared Misery ”, Strandh 2016
- “Evaluating Lehman’s Laws of Software Evolution within Software Product Lines: A Preliminary Empirical Study ”, Oliveira et al 2014
- “The Evolution of the Laws of Software Evolution: A Discussion Based on a Systematic Literature Review ”, Herraiz et al 2013
- “On the Evolution of Lehman’s Laws ”, Godfrey & German 2013
- “An Empirical Study of Lehman’s Law on Software Quality Evolution ”, Yu & Mishra 2013
- “Programmer Information Needs After Memory Failure ”, Parnin & Rugaber 2012
- Sweating Bullets: Notes about Inventing PowerPoint, Gaskins 2012
- “Report to the President and Congress: Designing a Digital Future: Federally Funded R&D in Networking and IT ”
- “The Biological Half-Life of Software Engineering Ideas ”, Kruchten 2008
- “The Technical Development of Internet Email ”, Partridge 2008
- “Dynamic Languages Strike Back ”, Yegge 2008
- “PL-Detective: A System for Teaching Programming Language Concepts ”, Diwan et al 2004
- “The Learning Curve and the Yield Factor: the Case of Korea’s Semiconductor Industry ”, Chung 2001
- “How to Become a Hacker ”, Raymond 2001
- “A Whirlwind Tutorial on Creating Really Teensy ELF Executables for Linux ”
- “Web Precursor Xanadu Project Goes Open Source: A Brilliant Collection of Ideas That Was Never Going to Ship—So Is It Relevant? ”, Lea 1999
- “A Software Fault Prevention Approach in Coding and Root Cause Analysis ”, Yu 1998
- “Questions and Answers With Professor Donald E. Knuth ”, Knuth 1996 (page 7)
- “Questions and Answers With Professor Donald E. Knuth § How to Customize TeX ”, Knuth 1996 (page 7 topic bible)
- “Laws of Software Evolution Revisited ”, Lehman 1996
- “Crabs: the Bitmap Terror ”, Cardelli 1985
- Program Evolution: Processes of Software Change, Lehman & Bélády 1985
- “Design Principles Behind Smalltalk ”, Ingalls 1981
- “Bouvet and Leibniz: A Scholarly Correspondence ”, Swiderski 1980
- “Programs, Life Cycles, and Laws of Software Evolution ”, Lehman 1980
- “On Understanding Laws, Evolution, and Conservation in the Large-Program Life Cycle ”, Lehman 1979
- “The Dollars and Sense of Continuing Education ”, Jones 1966
- “The Turing Complete User ”
- “Catb.org Site Page ”, Raymond 2025
- “Big Ball of Mud ”
- “The World’s First Code-Free Sparkline Typeface: Displaying Charts in Text without Having to Use Code ”
- “Operant Conditioning by Software Bugs ”, Regehr 2025
- “Rules of Machine Learning ”, Google 2025
- “Falsehoods Programmers Believe About X ”
- “The 3-Page Paper That Shook Philosophy: Gettiers in Software Engineering ”
- “Things That Used to Be Hard and Are Now Easy ”
- “Old Vintage Computing Research: Prior-Art-Dept.: ProleText, Encoding HTML Before Markdown (And a Modern Reimplementation) ”
- “SWAGGINZZZ ”
- “Turing-Complete Chess Computation ”
- “Using Learning Curve Theory to Redefine Moore’s Law ”
- “Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks ”
- “Now Anyone Can Train ImageNet in 18 Minutes ”
- “Are We Really Engineers? ”, Wayne 2025
- “What Engineering Can Teach (And Learn From) Us ”, Wayne 2025
- “A Closer Look at Chess Scalings (Into the Past) ”
- “Benchmarking an Old Chess Engine on New Hardware ”
- “Towards Moore’s Law Software: Part 3 of 3 ”
- “Which Computational Universe Do We Live In? Cryptographers Want to Know Which of Five Possible Worlds We Inhabit, Which Will Reveal Whether Truly Secure Cryptography Is Even Possible. ”
- “ProleText Information ”
- “Music on Demand ”
- “Keynote: Linus Torvalds in Conversation With Dirk Hohndel ”
- pid_eins
- Sort By Magic
- Wikipedia (5)
- Miscellaneous
- Bibliography
See Also
Gwern
“You Can Never Reproduce The Same Bug Twice [Demotivational Poster] ”, Gwern 2025
You Can Never Reproduce The Same Bug Twice [demotivational poster]
![You Can Never Reproduce The Same Bug Twice [demotivational poster]](/doc/math/humor/2025-05-03-gwern-gpto3-demotivationalposter-heraclitus-youcanneverreproducethesamebugtwice.png){kind=link}
“Utext: Rich Unicode Documents ”, Gwern 2023
“Computer Optimization: Your Computer Is Faster Than You Think ”, Gwern 2021
Computer Optimization: Your Computer Is Faster Than You Think
“The 3 Grenades and the 4 Noble Truths ”, Gwern 2008
“AI Risk Demos ”, Gwern 2016
“Isomorphisms & Meaning ”, Gwern 2009
“Evolutionary Software Licenses ”, Gwern 2009
“Aria’s Past, Present, and Future ”, Gwern 2011
“Simulation Inferences ”, Gwern 2009
Links
“Perl’s Decline Was Cultural ”, Strickland 2025
“Mystical Notation for PostScript ”, Denis 2025
layer07_yuxi @ "2025-05-06"
“A LLM Assisted Exploitation of AI-Guardian ”, Carlini 2023
“The Effect of Perceptual Load on Performance within IDE in People With ADHD Symptoms ”, Kasatskii et al 2023
The Effect of Perceptual Load on Performance within IDE in People with ADHD Symptoms
“Historical Decline in www Subdomain Use? ”, Farrugia 2023
“Catala: A Programming Language for the Law ”, Merigoux et al 2021
“There’s a Tendency of Ideologues to Value Ideological Purity over Fitness ”, kristopolous 2021
There’s a tendency of ideologues to value ideological purity over fitness :
“Energy Conservation With Open Source Ad Blockers ”, Pearce 2020
“Open Source Migrates With Emotional Distress ”, Ronacher 2019
“Founding and Growing Adobe Systems, Inc ”, Warnock & Geschke 2019
“Spooky Fizz Buzz § Pg42 ”, Menghrajani 2019 (page 42)
“The Origins of PostScript ”, Warnock 2018
“Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects ”, Baltes & Diehl 2018
Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects
“Preprint Déjà Vu: an FAQ ”, Ginsparg 2017
“Designing Better File Organization around Tags, Not Hierarchies ”, Nayuki 2017
Designing better file organization around tags, not hierarchies
“Software Engineering at Google ”, Henderson 2017
“Shared Misery ”, Strandh 2016
“Evaluating Lehman’s Laws of Software Evolution within Software Product Lines: A Preliminary Empirical Study ”, Oliveira et al 2014
“The Evolution of the Laws of Software Evolution: A Discussion Based on a Systematic Literature Review ”, Herraiz et al 2013
“On the Evolution of Lehman’s Laws ”, Godfrey & German 2013
“An Empirical Study of Lehman’s Law on Software Quality Evolution ”, Yu & Mishra 2013
An Empirical Study of Lehman’s Law on Software Quality Evolution
“Programmer Information Needs After Memory Failure ”, Parnin & Rugaber 2012
Sweating Bullets: Notes about Inventing PowerPoint, Gaskins 2012
“Report to the President and Congress: Designing a Digital Future: Federally Funded R&D in Networking and IT ”
View PDF:
“The Biological Half-Life of Software Engineering Ideas ”, Kruchten 2008
“The Technical Development of Internet Email ”, Partridge 2008
The Technical Development of Internet Email :
View PDF:
“Dynamic Languages Strike Back ”, Yegge 2008
“PL-Detective: A System for Teaching Programming Language Concepts ”, Diwan et al 2004
PL-detective: A system for teaching programming language concepts
“The Learning Curve and the Yield Factor: the Case of Korea’s Semiconductor Industry ”, Chung 2001
The learning curve and the yield factor: the case of Korea’s semiconductor industry :
“How to Become a Hacker ”, Raymond 2001
“A Whirlwind Tutorial on Creating Really Teensy ELF Executables for Linux ”
A Whirlwind Tutorial on Creating Really Teensy ELF Executables for Linux
“Web Precursor Xanadu Project Goes Open Source: A Brilliant Collection of Ideas That Was Never Going to Ship—So Is It Relevant? ”, Lea 1999
“A Software Fault Prevention Approach in Coding and Root Cause Analysis ”, Yu 1998
A software fault prevention approach in coding and root cause analysis
“Questions and Answers With Professor Donald E. Knuth ”, Knuth 1996 (page 7)
“Questions and Answers With Professor Donald E. Knuth § How to Customize TeX ”, Knuth 1996 (page 7 topic bible)
Questions and Answers with Professor Donald E. Knuth § How to customize TeX
“Laws of Software Evolution Revisited ”, Lehman 1996
“Crabs: the Bitmap Terror ”, Cardelli 1985
Program Evolution: Processes of Software Change, Lehman & Bélády 1985
Program Evolution: Processes of Software Change :
View PDF (48MB):
“Design Principles Behind Smalltalk ”, Ingalls 1981
Design Principles Behind Smalltalk :
View PDF:
“Bouvet and Leibniz: A Scholarly Correspondence ”, Swiderski 1980
“Programs, Life Cycles, and Laws of Software Evolution ”, Lehman 1980
“On Understanding Laws, Evolution, and Conservation in the Large-Program Life Cycle ”, Lehman 1979
On understanding laws, evolution, and conservation in the large-program life cycle
“The Dollars and Sense of Continuing Education ”, Jones 1966
“The Turing Complete User ”
“Catb.org Site Page ”, Raymond 2025
“Big Ball of Mud ”
“The World’s First Code-Free Sparkline Typeface: Displaying Charts in Text without Having to Use Code ”
The world’s first code-free sparkline typeface: Displaying charts in text without having to use code
“Operant Conditioning by Software Bugs ”, Regehr 2025
“Rules of Machine Learning ”, Google 2025
“Falsehoods Programmers Believe About X ”
“The 3-Page Paper That Shook Philosophy: Gettiers in Software Engineering ”
The 3-page paper that shook philosophy: Gettiers in software engineering
“Things That Used to Be Hard and Are Now Easy ”
“Old Vintage Computing Research: Prior-Art-Dept.: ProleText, Encoding HTML Before Markdown (And a Modern Reimplementation) ”
“SWAGGINZZZ ”
“Turing-Complete Chess Computation ”
“Using Learning Curve Theory to Redefine Moore’s Law ”
“Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks ”
Google workloads for consumer devices: mitigating data movement bottlenecks :
“Now Anyone Can Train ImageNet in 18 Minutes ”
“Are We Really Engineers? ”, Wayne 2025
“What Engineering Can Teach (And Learn From) Us ”, Wayne 2025
“A Closer Look at Chess Scalings (Into the Past) ”
“Benchmarking an Old Chess Engine on New Hardware ”
“Towards Moore’s Law Software: Part 3 of 3 ”
“Which Computational Universe Do We Live In? Cryptographers Want to Know Which of Five Possible Worlds We Inhabit, Which Will Reveal Whether Truly Secure Cryptography Is Even Possible. ”
“ProleText Information ”
“Music on Demand ”
“Keynote: Linus Torvalds in Conversation With Dirk Hohndel ”
pid_eins
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
programming-language
computer-history
lehman-laws
biological-software
Wikipedia (5)
Miscellaneous
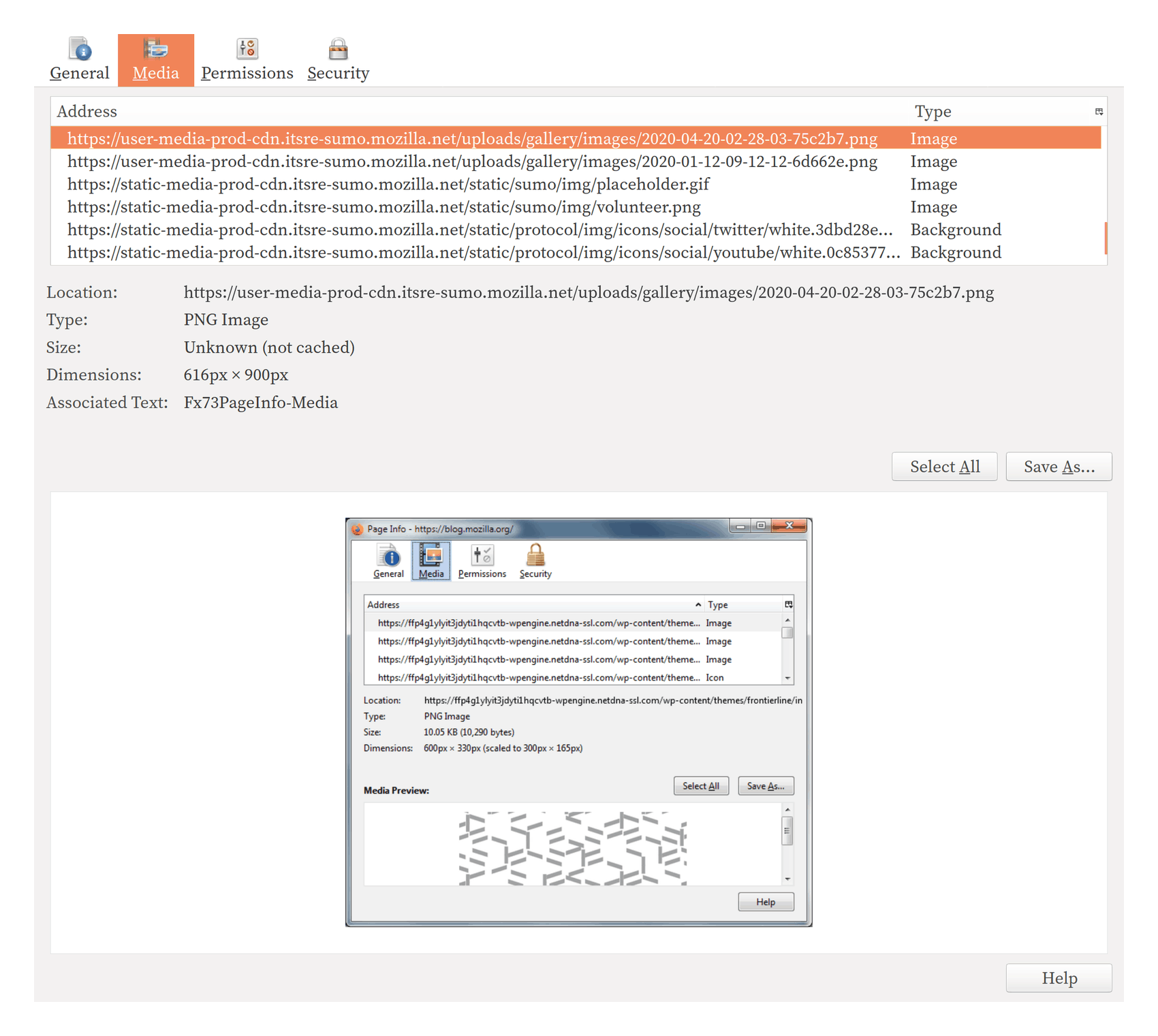
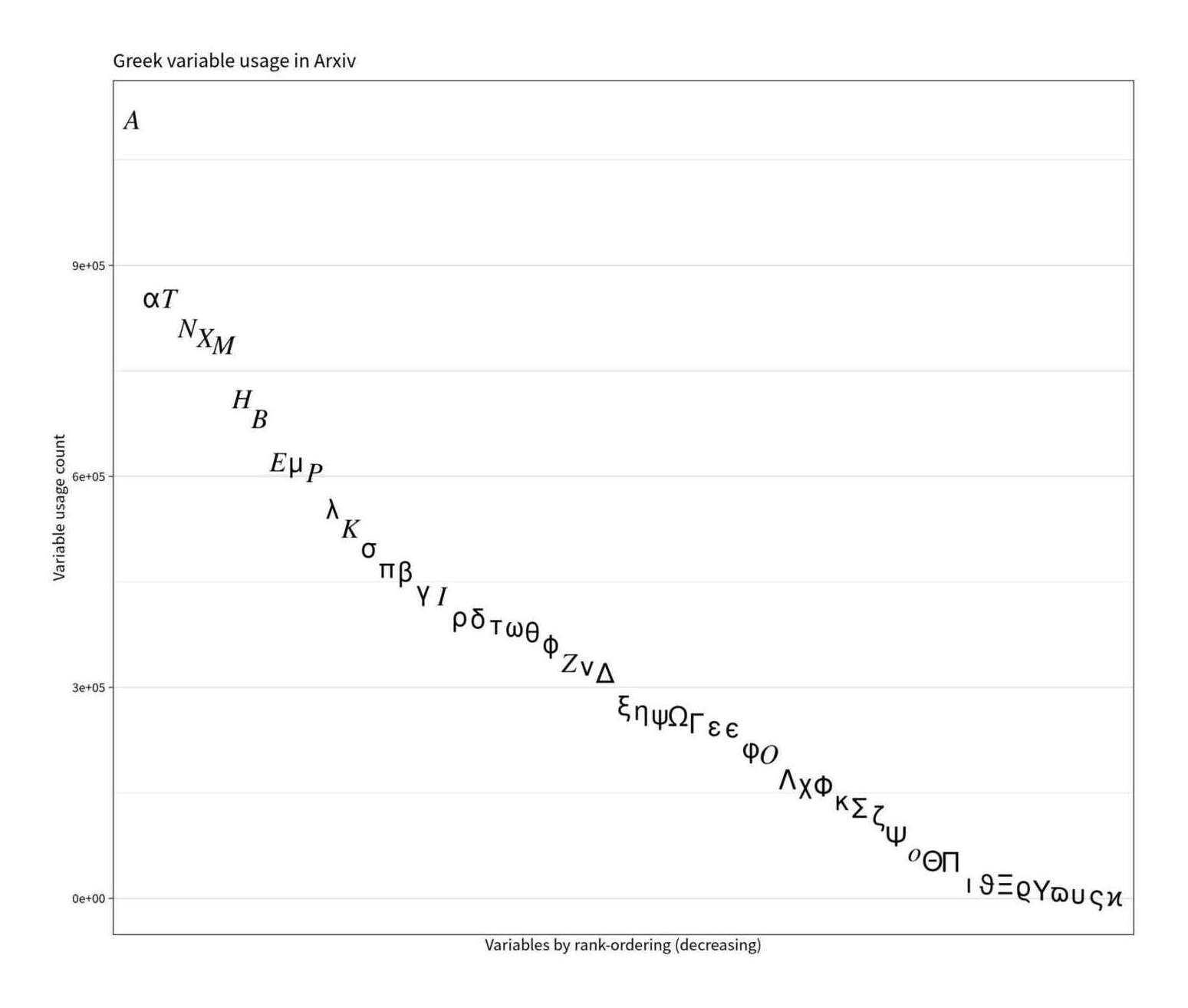
/doc/cs/2021-04-18-gwern-firefox-viewpageinfo-mediatab.png:/doc/cs/2021-04-08-gwern-raregreekvariables-arxivfrequencycount.jpg:/doc/cs/2019-12-27-spiritual_quail-chromecast-bluescreenofdeath-photo.jpg:/doc/cs/2019-07-15-danielbali-citiesskylineisturingcomplete.html:View HTML (21MB):
/doc/cs/2019-07-15-danielbali-citiesskylineisturingcomplete.html/doc/cs/2011-11-08-deved-windows95-runcconcon-windowsbluescreenofdeath.png:/doc/philosophy/ontology/2005-04-shirky-ontologyisoverratedcategorieslinksandtags.html/doc/cs/1985-cardelli-figure3-crabsgraphicdemopartwaythroughscreendestruction.jpg:http://itre.cis.upenn.edu/~myl/languagelog/archives/000606.html:https://cacm.acm.org/research/why-google-stores-billions-of-lines-of-code-in-a-single-repository/https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.648.1155-
View External Link:
https://dustri.org/b/horrible-edge-cases-to-consider-when-dealing-with-music.html:https://read.engineerscodex.com/p/how-instagram-scaled-to-14-million:https://web.archive.org/web/20150525235536/http://www.bloodbathsoftworks.com/xylemon/xlennart.php:https://www.amazon.com/Turings-Cathedral-Origins-Digital-Universe/dp/1400075998/https://www.inkandswitch.com/end-user-programming/:View External Link:
https://www.nytimes.com/2024/03/06/technology/john-walker-dead.htmlhttps://www.quantamagazine.org/quantum-mischief-rewrites-the-laws-of-cause-and-effect-20210311/:https://www.theverge.com/22684730/students-file-folder-directory-structure-education-gen-zhttps://www.wired.com/2014/10/a-spreadsheet-way-of-knowledge/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
2019-warnock.pdf: “Founding and Growing Adobe Systems, Inc ”,2018-warnock.pdf: “The Origins of PostScript ”,2014-deoliveira.pdf: “Evaluating Lehman’s Laws of Software Evolution within Software Product Lines: A Preliminary Empirical Study ”,1996-tug-issuev17no4-knuthqanda.pdf#page=7: “Questions and Answers With Professor Donald E. Knuth ”,1996-lehman.pdf: “Laws of Software Evolution Revisited ”,1979-lehman.pdf: “On Understanding Laws, Evolution, and Conservation in the Large-Program Life Cycle ”,1966-jones.pdf: “The Dollars and Sense of Continuing Education ”,