Dual n-Back FAQ
A compendium of DNB, WM, IQ information up to 2015.
- The Argument
- Training
- Terminology
- Notes from the Author
- N-Back Training
- What’s Some Relevant Research?
- Support
- Criticism
- Moody 200917ya (Re: Jaeggi 200818ya)
- Seidler 2010
- Jonasson 2011
- Chooi 2011
- Preece 201115ya / Palmer 2011
- Kundu Et Al 2012
- Salminen 2012
- Redick Et Al 2012
- Rudebeck 2012
- Heinzel Et Al 2013
- Thompson Et Al 2013
- Smith Et Al 2013
- Nussbaumer Et Al 2013
- Oelhafen Et Al 2013
- Sprenger Et Al 2013
- Colom Et Al 2013
- Burki Et Al 2014
- Pugin Et Al 2014
- Heffernan 2014
- Hancock 2013
- Waris Et Al 2015
- Baniqued Et Al 2015
- Kuper & Karbach 2015
- Lindeløv Et Al 2016
- Schwarb Et Al 2015
- Lawlor-Savage & Goghari 2016
- Studer-Luethi Et Al 2015
- Minear Et Al 2016
- Studer-Luethi Et Al 2016
- Meta-Analysis
- Does It Really Work?
- Non-IQ or Non-DNB Gains
- Saccading
- Sleep
- Lucid Dreaming
- Aging
- TODO
- Software
- What Else Can I Do?
- See Also
- Appendix
Dual n-Back is a kind of cognitive training intended to expand your working memory (WM), and hopefully your intelligence (IQ1).
The theory originally went that novel2 cognitive processes tend to overlap and seem to go through one central bottleneck. As it happens, WM predicts and correlates with IQ3 and may use the same neural networks4, suggesting that WM might be IQ5. WM is known to be trainable, and so improving WM would hopefully improve IQ. And N-back is a family of tasks which stress attention and WM.
Later research found that performance and improvement on N-back seems to correlate better with IQ rather than classic measures of WM like reciting lists of numbers, raising the question of whether N-back works via increasing WM or by improving self-control or improving manipulation of WM contents (rather than WM’s size) or somehow training IQ directly.6 Performance on DNB has complicated correlations with performance on other tests of working memory or IQ, so it’s not clear what it is tapping into. (And the link between WM and performance on IQ tests has been disputed; high WM as measured by OSPAN does not correlate well with performance on hard Raven’s questions7 and the validity of single tests of WM training has been questioned8.)
Brain Workshop offers many modes, some far more elaborate than simple Dual N-back; no research has been done on them, so little can be said about what they are good for or what they train or what improvements they may offer; Jaeggi 2010 seemed to find Single N-back better than Dual N-back. Some of the more elaborate modes seem to focus heavily on shifting the correct response among various modalities - not just sound, but left/right, eg. - and so stress context switches; there are results that task switching can be trained and that it transfers9, but how useful this is and how well the BW modes train this are unknown.
The Argument
Working memory is important stuff for learning and also just general intelligence.10 It’s not too hard to see why working memory could be so important. Working memory boils down to ‘how much stuff you can think about at the same time’.
Imagine a poor programmer who has suffered brain damage and has only enough working memory for 1 definition at a time. How could he write anything? To write a correct program, he needs to know simultaneously 2 things - what a variable, say, contains, and what is valid input for a program. But unfortunately, our programmer can know that the variable foo contains a string with the input, or he can know that the function processInput uses a string, but he can’t remember these 2 things simultaneously! He will deadlock forever, unsure either what to do with this foo, or unsure what exactly processInput was supposed to work on.
More seriously, working memory can be useful since it allows one to grasp more of the structure of something at any one time. Commentators on programming often write that one of the great challenges of programming (besides the challenge of accepting & dealing with the reality that a computer really is just a mindless rule-following machine), is that programming requires one to keep in mind dozens of things and circumstances - any one of which could completely bollix things up. Focus is absolutely essential. One of the characteristics of great programmers is their apparent omniscience. Obsession grants them this ability to know what they are actually doing:
“With programmers, it’s especially hard. Productivity depends on being able to juggle a lot of little details in short term memory all at once. Any kind of interruption can cause these details to come crashing down. When you resume work, you can’t remember any of the details (like local variable names you were using, or where you were up to in implementing that search algorithm) and you have to keep looking these things up, which slows you down a lot until you get back up to speed.” –Joel Spolsky, “Where do These People Get Their (Unoriginal) Ideas?”
“Several friends mentioned hackers’ ability to concentrate - their ability, as one put it, to ‘tune out everything outside their own heads.’ I’ve certainly noticed this. And I’ve heard several hackers say that after drinking even half a beer they can’t program at all. So maybe hacking does require some special ability to focus. Perhaps great hackers can load a large amount of context into their head, so that when they look at a line of code, they see not just that line but the whole program around it. John McPhee wrote that Bill Bradley’s success as a basketball player was due partly to his extraordinary peripheral vision. ‘Perfect’ eyesight means about 47° of vertical peripheral vision. Bill Bradley had 70; he could see the basket when he was looking at the floor. Maybe great hackers have some similar inborn ability. (I cheat by using a very dense language, which shrinks the court.) This could explain the disconnect over cubicles. Maybe the people in charge of facilities, not having any concentration to shatter, have no idea that working in a cubicle feels to a hacker like having one’s brain in a blender.” –Paul Graham, “Great Hackers”
It’s surprising, but bugs have a close relationship to number of lines of code - no matter whether the language is as low-level as assembler or high-level as Haskell (humorously, Norris’ number); is this because each line takes up a similar amount of working and short-term memory and there’s only so much memory to go around?11
The Silver Bullet
It’s not all that obvious, but just about every productivity innovation in computing is about either cutting down on how much a programmer needs to know (eg. garbage collection), or making it easier for him to shuffle things in and out of his ‘short term memory’. Why are some commentators like Jeff Atwood so focused12 on having multiple monitors? For that matter, why are there real studies showing surprisingly large productivity boosts by simply adding a second monitor?13 It’s not like the person is any different afterwards. And arguably multiple or larger monitors come with damaging overheads14.
Or, why does Steve Yegge think touch-typing is one of the few skills programmers must know (along with reading)?15 Why is Unix guru Ken Thompson’s one regret not learning typing?16 Typing hardly seems very important - it’s what you say, not how you say it. The compiler doesn’t care if you typed the source code in at 30WPM or 120WPM, after all.
I love being able to type that without looking! It’s empowering, being able to type almost as fast as you can think. Why would you want it any other way?
The thing is, multiple monitors, touch-typing, speed-reading17 - they’re all about making the external world part of your mind. What’s the real difference between having a type signature in your short-term memory or prominently displayed in your second monitor? What’s the real difference between writing a comment in your mind or touch-typing it as fast as you create it?

WM problems
Just some speed. Just some time. And the more visible that type signature is, the faster you can type out that comment, the larger your ‘memory’ gets. And the larger your memory is, the more intelligent/productive you can be. (Think of this as the Extended Mind thesis as applied to programming!) Great programmers often1819 talk vaguely about ‘keeping a system in your head’ or ‘having a model’, and hate distractions20, saying they destroy one’s carefully developed thoughts; I think what they are talking about is trying to store all the relevant details inside their short-term or working memory. Learning programming has a correlation with WM.21 (Once you start looking, you see this everywhere. Games, for example.22) Or in bug rates - WM has been proposed as the reason why small or large chunks of programs have more proportional errors than medium sized chunks23. It remains to be seen whether programming tools designed with an eye to memory will be helpful, though.
But as great as things like garbage collection & touch-typing & multiple monitors are (I am a fan & user of the foregoing), they are still imperfect substitutes. Wouldn’t it be better if one could just improve one’s short-term/working memory directly? It might be more effective, and certainly would be more portable!
Training
Unfortunately, in general, IQ/g and memory don’t seem to be trainable. Many apparent effects are swamped by exercise or nutrition or by simple practice. And when practice does result in gains on tasks or expensive games24, said benefits often do not transfer; many popular ‘brain games’ & exercises fail this criterion or at least have not been shown to transfer252627, even brainy skilled exercises like music28 or chess29 or memory competitions30. Catch-22 summed it up:
…General Dreedle wants his [pilots] to spend as much time on the skeet-shooting range as the facilities and their flight schedule would allow. Shooting skeet eight hours a month was excellent training for them. It trained them to shoot skeet.
Indeed, the general history of attempts to increase IQ in any children or adults remains essentially what it was when Arthur Jensen wrote his 196957ya paper “How Much Can We Boost IQ and Scholastic Achievement?”—a history of failure. The exceptions prove the rule by either applying to narrow groups with specific deficits or work only before birth, like iodization. (See also Algernon’s Law: if there were an easy fitness-increasing way to make us smarter, evolution would have already used it.)
But hope springs eternal, and there are possible exceptions. The one this FAQ focuses on is Dual N-back, and it’s a variant on an old working-memory test.
One of the nice things about N-back is that while it may or may not improve your IQ, it may help you in other ways. WM training helps alcoholics reduce their consumption31 and increases patience in recovering stimulant addicts (cocaine & methamphetamine)32. The self-discipline or willpower of students correlates better with grades than even IQ33, WM correlates with grades and lower behavioral problems34 & WM out-predicts grades 6 years later in 5-year olds & 2 years later in older children35. WM training has been shown to help children with ADHD36 and also preschoolers without ADHD37; Lucas 2008 found behavior improvements at a summer camp. Another intervention using a miscellany of ‘reasoning’ games with young (7-9 years old) poor children found a Forwards Digit Span (but not Backwards) and IQ gains, with no gain to the subjects playing games requiring “rapid visual detection and rapid motor responses”38, but it’s worth remembering that IQ scores are unreliable in childhood39 or perhaps, as an adolescent brain imaging study indicates40, they simply are much more malleable at that point. (WM training in teenagers doesn’t seem much studied but given their issues, may help; see “Beautiful Brains” or “The Trouble With Teens”.)
There are many kinds of WM training. One review worth reading is “Does working memory training work? The promise and challenges of enhancing cognition by training working memory”, Morrison & Chein 2011; “Is Working Memory Training Effective?”, Shipstead et al 2012 discusses the multiple methodological difficulties of designing WM training experiments (at least, they are difficult if you want to show genuine improvements which transfer to non-WM skills).
N-Back
The original N-back test simply asked that you remember a single stream of letters, and signal if any letters were precisely, say, 2 positions apart. ‘A S S R’ wouldn’t merit a signal, but ‘A S A R’ would since there are ‘A’ characters exactly 2 positions away from each other. The program would give you another letter, you would signal or not, and so on. This is simple enough once you understand it, but is a little hard to explain. It may be best to read the Brain Workshop tutorial, or watch a video.
Dual N-Back
In 200323ya, Susan Jaeggi and her team began fMRI studies using a variant of N-back which tried to increase the burden on each turn - remembering multiple things instead of just 1. The abstract describes the reason why:
With reference to single tasks, activation in the prefrontal cortex (PFC) commonly increases with incremental memory load, whereas for dual tasks it has been hypothesized previously that activity in the PFC decreases in the face of excessive processing demands, ie. if the capacity of the working memory’s central executive system is exceeded. However, our results show that during both single and dual tasks, prefrontal activation increases continuously as a function of memory load. An increase of prefrontal activation was observed in the dual tasks even though processing demands were excessive in the case of the most difficult condition, as indicated by behavioral accuracy measures. The hypothesis concerning the decrease in prefrontal activation could not be supported and was discussed in terms of motivation factors.41
In this version, called “dual N-back” (to distinguish it from the classic single N-back), one is still playing a turn-based game. In the Brain Workshop version, you are presented with a 3x3 grid in which every turn, a block appears in 1 of the 9 spaces and a letter is spoken aloud. (There are any number of variants: the NATO phonetic alphabet, piano keys, etc. And Brain Workshop has any number of modes, like ‘Arithmetic N-back’ or ‘Quintuple N-back’.)
1-Back
In 1-back, the task is to correctly answer whether the letter is the same as the previous round, and whether the position is the same as the previous round. It can be both, making 4 possible responses (position, sound, position+sound, & neither).
This stresses working memory since you need to keep in mind 4 things simultaneously: the position and letter of the previous turn, and the position and letter of the current turn (so you can compare the current letter with the old letter and the current position with the old position). Then on the next turn you need to immediately forget the old position & letter (which are now useless) and remember the new position and letter. So you are constantly remembering and forgetting and comparing.
2-Back
But 1-back is pretty easy. The turns come fast enough that you could easily keep the letters in your phonological loop and lighten the load on your working memory. Indeed, after 10 rounds or so of 1-back, I mastered it - I now get 100%, unless I forget for a second that it’s 1-back and not 2-back (or I simply lose my concentration completely). Most people find 1-back very easy to learn, although a bit challenging at first since the pressure is constant (games and tests usually have some slack or rest periods).
The next step up is a doozy: 2-back. In 2-back, you do the same thing as 1-back but as the name suggests, you are instead matching against 2 turns ago. So before you would be looking for repeated letters - ‘AA’ - but now you need to look for separated letters - ‘ABA’. And of course, you can’t forget so quickly, since you still need to match against something like ‘ABABA’.
2-back stresses your working memory even more, as now you are remembering 6 things, not 4: 2 turns ago, the previous turn, and the current turn - all of which have 2 salient features. At 6 items, we’re also in the mid-range of estimates for normal working memory capacity:
Working memory is generally considered to have limited capacity. The earliest quantification of the capacity limit associated with short-term memory was the “magical number seven” introduced by Miller (195670ya). He noticed that the memory span of young adults was around seven elements, called chunks, regardless whether the elements were digits, letters, words, or other units. Later research revealed that span does depend on the category of chunks used (eg. span is around seven for digits, around six for letters, and around five for words), and even on features of the chunks within a category….Several other factors also affect a person’s measured span, and therefore it is difficult to pin down the capacity of short-term or working memory to a number of chunks. Nonetheless, Cowan (200125ya) has proposed that working memory has a capacity of about four chunks in young adults (and fewer in children and old adults).
And even if there are only a few things to remember, the number of responses you have to choose between go up exponentially with how many ‘modes’ there are, so Triple N-back has not ⅓ more possible responses than Dual N-back, but more than twice as many: if m is the number of modes, then the number of possible responses is 2m-1 (the -1 is there because one can nothing in every mode, but that’s boring and requires no choice or thought), so DNB has 3 possible responses42, while TNB has 743, Quadruple N-back 1544, and Quintuple N-back 3145!
Worse, the temporal gap between elements is deeply confusing. It’s particularly bad when there’s repetition involved - if the same square is selected twice with the same letter, you might wind up forgetting both!
So 2-back is where the challenge first really manifests. After about 20 games I started to get the hang of it. (It helped to play a few games focusing only on one of the stimuli, like the letters; this helps you get used to the ‘reaching back’ of 2-back.)
Personal Reflection on Results
Have I seen any benefits yet? Not really. Thus far it’s like meditation: I haven’t seen any specific improvements, but it’s been interesting just to explore concentration—I’ve learned that my ability to focus is much less than I thought it was! It is very sobering to get 30% scores on something as trivial as 1-back and strain to reach D2B, and even more sobering to score 60% and minutes later score 20%. Besides the intrinsic interest of changing one’s brain through a simple exercise - meditation is equally interesting for how one’s mind refuses to cooperate with the simple work of meditating, and I understand that there are even vivid hallucinations at the higher levels - N-back might function as a kind of mental calisthenics. Few people exercise and stretch because they find the activities intrinsically valuable, but they serve to further some other goal; some people jog because they just enjoy running, but many more jog so they can play soccer better or live longer. I am young, and it’s good to explore these sorts of calisthenics while one has a long life ahead of one; then one can reap the most benefits.
Terminology
N-back training is sometimes referred to simply as ‘N-backing’, and participants in such training are called ‘N-backers’. Almost everyone uses the Free, featureful & portable program Brain Workshop, abbreviated “BW” (but see the software section for alternatives).
There are many variants of N-back training. A 3-letter acronym ending in ‘B’ specifies one of the possibilities. For example, ‘D2B’ and ‘D6B’ both refer to a dual N-back task, but in the former the depth of recall is 2 turns, while in the latter one must remember back 6 rounds; the ‘D’, for ‘Dual’, indicates that each round presents 2 stimuli (usually the position of the square, and a spoken letter).
But one can add further stimuli: spoken letter, position of square, and color of square. That would be ‘Triple N-back’, and so one might speak of how one is doing on ‘T4B’.
One can go further. Spoken letter, position, color, and geometric shape. This would be ‘Quad N-back’, so one might discuss one’s performance on ‘Q3B’. (It’s unclear how to compare the various modes, but it seems to be much harder to go from D2B to T3B than to go from D2B to D3B.)
Past QNB, there is Pentuple N-back (PNB) which was added in Brain Workshop 4.7 (video demonstration). The 5th modality is added by a second audio channel - that is, now sounds are in stereo.
Other abbreviations are in common use: ‘WM’ for ‘working memory’, ‘gf’ for ‘fluid intelligence’, and ‘g’ for the general intelligence factor measured by IQ tests.
N-Back Training
Should I Do Multiple Daily Sessions, or Just One?
Most users seem to go for one long N-back session, pointing out that exercises one’s focus. Others do one session in the morning and one in the evening so they can focus better on each one. There is some scientific support for the idea that evening sessions are better than morning sessions, though; see Kuriyama 2008 on how practice before bedtime was more effective than after waking up.
If you break up sessions into more than 2, you’re probably wasting time due to overhead, and may not be getting enough exercise in each session to really strain yourself like you need to.
Strategies
The simplest mental strategy, and perhaps the most common, is to mentally think of a list, and forget the last one each round, remembering the newest in its place. This begins to break down on higher levels - if one is repeating the list mentally, the repetition can just take too long.
Surcer writes up a list of strategies for different levels in his “My System, let’s share strategies” thread.
Are Strategies Good or Bad?
People frequently ask and discuss whether they should use some sort of strategy, and if so, what.
A number of N-backers adopt an ‘intuition’ strategy. Rather than explicitly rehearsing sequences of letters (‘f-up, h-middle; f-up, h-middle; g-down, f-up…’), they simply think very hard and wait for a feeling that they should press ‘a’ (audio match), or ‘l’ (location match). Some, like SwedishChef can be quite vociferous about it:
The challenges are in helping people understand that dual-n-back is NOT about remembering n number of visual and auditory stimuli. It’s about developing a new mental process that intuitively recognizes when it has seen or heard a stimuli n times ago.
Initially, most students of dual n-back want to remember n items as fast as they can so they can conquer the dual-n-back hill. They use their own already developed techniques to help them remember. They may try to hold the images in their head mentally and review them every time a new image is added and say the sounds out loud and review the sounds every time a new sound is added. This is NOT what we want. We want the brain to learn a new process that intuitively recognizes if an item and sound was shown 3 back or 4 back. It’s sort of like playing a new type of musical instrument.
I’ve helped some students on the site try to understand this. It’s not about how much you can remember, it’s about learning a new process. In theory, this new process translates into a better working memory, which helps you make connections better and faster.
Other N-backers think that intuition can’t work, or at least doesn’t very well:
I don’t believe that much in the “intuitive” method. I mean, sure, you can intuitively remember you heard the same letter or saw the square at the same position a few times ago, but I fail to see how you can “feel” it was exactly 6 or 7 times ago without some kind of “active” remembering. –Gaël DEEST
I totally agree with Gaël about the intuitive method not holding much water…For me a lot of times the intuitive method can be totally unreliable. You’ll be doing 5-back one game and a few games later your failing miserably at 3-back..your score all over the place. Plus, intuitive-wise, it’s best to play the same n-back level over and over because then you train your intuition…and that doesn’t seem right. –MikeM (same thread)
Few N-backers have systematically tracked intuitive versus strategic playing; DarkAlrx reports on his blog the results of his experiment, and while he considers them positive, others find them inconclusive, or like Pheonexia, even unfavorable for the intuitive approach:
Looking at your graphs and the overall drop in your performance, I think it’s clear that intuitive doesn’t work. On your score sheet, the first picture, using the intuitive method over 38 days of TNB training in 44 days your average n-back increased by less than .25. You were performing much better before. With your neurogenesis experiment, your average n-back actually decreased.
Jaeggi herself was more moderate in ~2008:
I would NOT recommend you [train the visual and auditory task separately] if you want to train the dual-task (the one we used in our study). The reason is that the combination of both modalities is an entirely different task than doing both separately! If you do the task separately, I assume you use some “rehearsal strategies”, eg. you repeat the letters or positions for yourself. In the dual-task version however, these strategies might be more difficult to apply (since you have to do 2 things simultaneously…), and that is exactly what we want… We don’t want to train strategies, we want to train processes. Processes that then might help you in the performance of other, non-trained tasks (and that is our ultimate goal). So, it is not important to reach a 7- or 8-back… It is important to fully focus your attention on the task as well as possible.
I can assure you, it is a very tough training regimen…. You can’t divert your attention even 1 second (I’m sure you have noticed…). But eventually, you will see that you get better at it and maybe you notice that you are better able to concentrate on certain things, to remember things more easily, etc. (hopefully).
(Unfortunately, doubt has been cast on this advice by the apparent effectiveness of single n-back in Jaeggi 2010. If single (visual/position) n-back is effective in increasing IQ, then maybe training just audio or just visual is actually a good idea.)
this is a question i am being asked a lot and unfortunately, i don’t really know whether i can help with that. i can only tell you what we tell (or rather not tell) our participants and what they tell us. so, first of all, we don’t tell people at all what strategy to use - it is up to them. thing is, there are some people that tell us what you describe above, i.e. some of them tell us that it works best if they don’t use a strategy at all and just “let the squares/letters flow by”. but of course, many participants also use more conscious strategies like rehearsing or grouping items together. but again - we let people chose their strategies themselves! ref
But it may make no difference. Even if you are engaged in a complex mnemonic-based strategy, you’re still working your memory. Strategies may not work; quoting from Jaeggi’s 200818ya paper:
By this account, one reason for having obtained transfer between working memory and measures of gf is that our training procedure may have facilitated the ability to control attention. This ability would come about because the constant updating of memory representations with the presentation of each new stimulus requires the engagement of mechanisms to shift attention. Also, our training task discourages the development of simple task-specific strategies that can proceed in the absence of controlled allocation of attention.
Even if they do, they may not be a good idea; quoting from Jaeggi 2010:
We also proposed that it is important that participants only minimally learn task-specific strategies in order to prevent specific skill acquisition. We think that besides the transfer to matrix reasoning, the improvement in the near transfer measure provides additional evidence that the participants trained on task-underlying processes rather than relying on material-specific strategies.
Hopefully even if a trick lets you jump from 3-back to 5-back, Brain Workshop will just keep escalating the difficulty until you are challenged again. It’s not the level you reach, but the work you do.
And the Flashing Right/wrong Feedback?
A matter of preference, although those in favor of disabling the visual feedback (SHOW_FEEDBACK = False) seem to be slightly more vocal or numerous. Brain Twister apparently doesn’t give feedback. Jaeggi says:
the gaming literature also disagrees on this issue - there are different ways to think about this: whereas feedback after each trial gives you immediate feedback whether you did right or wrong, it can also be distracting as you are constantly monitoring (and evaluating) your performance. we decided that we wanted people to fully and maximally concentrate on the task itself and thus chose the approach to only give feedback at the end of the run. however, we have newer versions of the task for kids in which we give some sort of feedback (points) for each trial. thus - i can’t tell you what the optimal way is - i guess there are interindividual differences and preferences as well.
Jonathan Toomim writes:
When I was doing visual psychophysics research, I heard from my labmates that this question has been investigated empirically (at least in the context of visual psychophysics), and that the consensus in the field is that using feedback reduces immediate performance but improves learning rates. I haven’t looked up the research to confirm their opinion, but it sounds plausible to me. I would also expect it to apply to Brain Workshop. The idea, as I see it, is that feedback reduces performance because, when you get an answer wrong and you know it, your brain goes into an introspective mode to analyze the reason for the error and (hopefully) correct it, but while in this mode your brain will be distracted from the task at hand and will be more likely to miss subsequent trials.
How Can I Do Better on N-Back?
Focus harder. Play more. Sleep well, and eat healthily. Use natural lighting57. Space out practice. The less stressed you are, the better you can do.
Spacing
This study compared a high intensity working memory training (45 minutes, 4 times per week for 4 weeks) with a distributed training (45 minutes, 2 times per week for 8 weeks) in middle-aged, healthy adults…Our results indicate that the distributed training led to increased performance in all cognitive domains when compared to the high intensity training and the control group without training. The most significant differences revealed by interaction contrasts were found for verbal and visual working memory, verbal short-term memory and mental speed.
This is reminiscent of sleep’s involvement in other forms of memory and cognitive change, and Kuriyama 2008.
Hardcore
Curtis Warren has noticed that when he underwent a 4-day routine of practicing more than 4 hours a day, he jumped an entire level on even quad N-back58:
For example, over the past week I have been trying a new training routine. My goal was to increase my intelligence as quickly as possible. To that end, over the past 4 days I’ve done a total of roughly 360 sessions @ 2 seconds per trial (≈360 minutes of training). I had to rest on Wednesday, and I’m resting again today (I only plan on doing about 40 trials today). But I intend to finish off the week by doing 100 sessions on Saturday and another 100 on Sunday. Or more, if I can manage it.
But he cautions us that besides being a considerable time investment, it may only work for him:
The point is, while I can say without a doubt that this schedule has been effective for me, it might not be effective for you. Are the benefits worth the amount of work needed? Will you even notice an improvement? Is this healthy? These are all factors which depend entirely upon the individual actually doing the training.
Raman started DNB training, and in his first 30 days, he “took breaks every 5 days or so, and was doing about 20-30 session each day and n-back wise I made good gains (2 → 7 touching 9 on the way).”; he kept a journal on the mailing list about the experience with daily updates.
Alas, neither Raman nor Warren took an IQ or digit-span test before starting, so they can only report DNB level increases & subjective assessments.
The research does suggest that diminishing returns does not set in with training regimes of 10 or 15 minutes a day; for example, Nutley 2011 trained 4-year-olds in WM exercises, gf (NVR) exercises, or both:
…These analyses took into account that the groups differed in the amount of training received, full dose for NVR or WM groups or half dose for the CB group (Table 3). Even though the pattern is not consistent across all tests (see Figure 2), this is interpreted as confirmation of the linear dose effect that was expected to be seen. Our results suggest that the amount of transfer to non-trained tasks within the trained construct was roughly proportionate to the amount of training on that construct. A similar finding, with transfer proportional to amount of training, was reported by Jaeggi et al 2008. This has possible implications for the design of future cognitive training paradigms and suggests that the training should be intensive enough to lead to significant transfer and that training more than one construct does not entail any advantages in itself. The training effect presumably reaches asymptote, but where this occurs is for future studies to determine. It is probably important to ensure that participants spend enough time on each task in order to see clinically-significant transfer, which may be difficult when increasing the number of tasks being trained. This may be one of the explanations for the lack of transfer seen in the Owen et al. study (201016ya) (training six tasks in 10 minutes).
Plateauing, Or, Am I Wasting Time If I Can’t Get past 4-Back?
Some people start n-backing with great vigor and rapidly ascend levels until suddenly they stop improving and panic, wondering if something is wrong with them. Not at all! Reaching a high level is a good thing, and if one does so in just a few weeks, all the more impressive since most members take much longer than, say, 2 weeks to reach good scores on D4B. In fact, if you look at the reports in the Group survey, most reports are of plateauing at D4B or D5B months in.
The crucial thing about N-back is just that you are stressing your working memory, that’s all. The actual level doesn’t matter very much, just whether you can barely manage it; it is somewhat like lifting weights, in that regard. From Jaeggi 200818ya:
The finding that the transfer to gf remained even after taking the specific training effect into account seems to be counterintuitive, especially because the specific training effect is also related to training time. The reason for this capacity might be that participants with a very high level of n at the end of the training period may have developed very task specific strategies, which obviously boosts n-back performance, but may prevent transfer because these strategies remain too task-specific (5, 20). The averaged n-back level in the last session is therefore not critical to predicting a gain in gf; rather, it seems that working at the capacity limit promotes transfer to gf.
Mailing list members report benefits even if they have plateaued at 3 or 4-back; see the benefits section.
One commonly reported tactic to break a plateauing is to deliberately advance a level (or increase modalities), and practice hard on that extra difficult task, the idea being that this will spur adaptation and make one capable of the lower level.
Do Breaks Undo My Work?
Some people have wondered if not n-backing for a day/week/month or other extended period undoes all their hard work, and hence n-backing may not be useful in the long-term.
Multiple group members have pointed to long gaps in their training, sometimes multiple months up to a year, which did not change their scores significantly (immediately after the break, scores may dip a level or a few percentage points in accuracy, but quickly rises to the old level). Some members have ceased n-backing for 2 or 3 years, and found their scores dropped by only 2-4 levels - far from 1 or 2-back. (Pontus Granström, on the other hand, took a break for several months and fell for a long period from D8B-D9B to D6B-D7B; he speculates it might reflect a lack of motivation.) huhwhat/Nova fell 5 levels from D9B but recovered quickly:
I’ve been training with n-back on and off, mostly off, for the past few years. I started about 3 years ago and was able to get up to 9-n back, but on average I would be doing around 6 or 7 n back. Then I took a break for a few years. Now after coming back, even though I have had my fair share of partying, boxing, light drugs, even polyphasic sleep, on my first few tries I was able to get back up to 5-6, and a week into it I am back at getting up to 9 n back.
This anecdotal evidence is supported by at least one WM-training letter, Chrabaszcz 201016ya:
Figure 1b illustrates the degree to which training transferred to an ostensibly different (and untrained) measure of verbal working memory compared to a no-contact control group. Not only did training significantly increase verbal working memory, but these gains persisted 3 months following the cessation of training!
Similarly, Dahlin 2008 found WM training gains which were durable over more than a year:
The authors investigated immediate training gains, transfer effects, and 18-month maintenance after 5 weeks of computer-based training in updating of information in working memory in young and older subjects. Trained young and older adults improved significantly more than controls on the criterion task (letter memory), and these gains were maintained 18 months later. Transfer effects were in general limited and restricted to the young participants, who showed transfer to an untrained task that required updating (3-back)…
I Heard 12-Back Is Possible
Some users have reported being able to go all the way up to 12-back; Ashirgo regularly plays at D13B, but the highest at other modes seems to be T9B and Q6B.
Ashirgo offers up her 8-point scheme as to how to accomplish such feats:
’Be focused at all cost. The fluid intelligence itself is sometimes called “the strength of focus”.
You had better not rehearse the last position/sound . It will eventually decrease your performance! I mean the rehearsal “step by step”: it will slow you down and distract. The only rehearsal allowed should be nearly unconscious and “effortless” (you will soon realize its meaning :)
Both points 1 & 2 thus imply that you must be focused on the most current stimulus as strongly as you can. Nevertheless, you cannot forget about the previous stimuli. How to do that? You should hold the image of them (image, picture, drawing, whatever you like) in your mind. Notice that you still do not rehearse anything that way.
Consider dividing the stream of data (n) on smaller parts. 6-back will be then two 3-back, for instance.
Follow square with your eyes as it changes its position.
Just turn on the Jaeggi mode with all the options to ensure your task is closest to the original version.
Consider doing more than 20 trials. I am on my way to do no less than 30 today. It may also help.
You may lower the difficulty by reducing the fall-back and advance levels from >75 and =<90 to 70 and 85 respectively (for instance).’
What’s Some Relevant Research?
Training WM tasks has yielded a literature of mixed results - for every positive, there’s a negative, it seems. The following sections of positive and null results illustrate that, as do the papers themselves; from Nutley 2011:
However, there are some studies using several WM tasks to train that have also shown transfer effects to reasoning tasks (Klingberg, Fernell, Olesen, Johnson, Gustafsson, Dahlstrçm, Gillberg, Forssberg & Westerberg, 2005; Klingberg, Forssberg & Westerberg, 2002), while other WM training studies have failed to show such transfer (Dahlin, Neely, Larsson, Backman & Nyberg, 2008; Holmes, Gathercole, Place, Dunning, Hilton & Elliott, 2009; Thorell, Lindqvist, Bergman Nutley, Bohlin & Klingberg, 200917ya). Thus, it is still unclear under which conditions effects of WM training transfer to gf.
Other intervention studies have included training of attention or executive functions. Rueda and colleagues trained attention in a sample of 4- and 6-year-olds and found significant gains in intelligence (as measured with the Kaufman Brief Intelligence Test) in the 4-year-olds but only a tendency in the group of 6-year-olds (Rueda, Rothbart, McCandliss, Saccomanno & Posner, 2005). A large training study with 11,430 participants revealed practically no transfer after a 6-week intervention (10 min ⧸ day, 3 days a week) of a broader range of tasks including reasoning and planning or memory, visuo-spatial skills, mathematics and attention (Owen, Hampshire, Grahn, Stenton, Dajani, Burns, Howard & Ballard, 2010). However, this study lacked control in sample selection and compliance. In summary, it is still an open question to what extent gf can be improved by targeted training.
Working memory training including variants on dual n-back has been shown to physically change/increase the distribution of white matter in the brain59
Physical changes have been linked to WM training and n-backing. For example, Olesen PJ, Westerberg H, Klingberg T (200422ya) Increased prefrontal and parietal activity after training of working memory. Nat Neuroscience 7:75-79; about this study, Kuriyama writes:
“Olesen et al 200422ya presented progressive evidence obtained by functional magnetic resonance imaging that repetitive training improves spatial WM performance [both accuracy and response time (RT)] associated with increased cortical activity in the middle frontal gyrus and the superior and inferior parietal cortices. Such a finding suggests that training-induced improvement in WM performance could be based on neural plasticity, similar to that for other skill-learning characteristics.”
Westerberg 200719ya, “Changes in cortical activity after training of working memory—a single-subject analysis”:
“…Practice on the WM tasks gradually improved performance and this effect lasted several months. The effect of practice also generalized to improve performance on a non-trained WM task and a reasoning task. After training, WM-related brain activity was significantly increased in the middle and inferior frontal gyrus. The changes in activity were not due to activations of any additional area that was not activated before training. Instead, the changes could best be described by small increases in the extent of the area of activated cortex. The effect of training of WM is thus in several respects similar to the changes in the functional map observed in primate studies of skill learning, although the physiological effect in WM training is located in the prefrontal association cortex.”
Executive functions, including working memory and inhibition, are of central importance to much of human behavior. Interventions intended to improve executive functions might therefore serve an important purpose. Previous studies show that working memory can be improved by training, but it is unknown if this also holds for inhibition, and whether it is possible to train executive functions in preschoolers. In the present study, preschool children received computerized training of either visuo-spatial working memory or inhibition for 5 weeks. An active control group played commercially available computer games, and a passive control group took part in only pre- and posttesting. Children trained on working memory improved significantly on trained tasks; they showed training effects on non-trained tests of spatial and verbal working memory, as well as transfer effects to attention. Children trained on inhibition showed a significant improvement over time on two out of three trained task paradigms, but no significant improvements relative to the control groups on tasks measuring working memory or attention. In neither of the two interventions were there effects on non-trained inhibitory tasks. The results suggest that working memory training can have significant effects also among preschool children. The finding that inhibition could not be improved by either one of the two training programs might be due to the particular training program used in the present study or possibly indicate that executive functions differ in how easily they can be improved by training, which in turn might relate to differences in their underlying psychological and neural processes.
“Training, maturation, and genetic influences on the development of executive attention”, Rueda et al 200521ya:
A neural network underlying attentional control involves the anterior cingulate in addition to lateral prefrontal areas. An important development of this network occurs between 3 and 7 years of age. We have examined the efficiency of attentional networks across age and after 5 days of attention training (experimental group) compared with different types of no training (control groups) in 4-year-old and 6-year-old children. Strong improvement in executive attention and intelligence was found from ages 4 to 6 years. Both 4- and 6-year-olds showed more mature performance after the training than did the control groups. This finding applies to behavioral scores of the executive attention network as measured by the attention network test, event-related potentials recorded from the scalp during attention network test performance, and intelligence test scores. We also documented the role of the temperamental factor of effortful control and the DAT1 gene in individual differences in attention. Overall, our data suggest that the executive attention network appears to develop under strong genetic control, but that it is subject to educational interventions during development.
Behavioral findings indicate that the core executive functions of inhibition and working memory are closely linked, and neuroimaging studies indicate overlap between their neural correlates. There has not, however, been a comprehensive study, including several inhibition tasks and several working memory tasks, performed by the same subjects. In the present study, 11 healthy adult subjects completed separate blocks of 3 inhibition tasks (a stop task, a go/no-go task and a flanker task), and 2 working memory tasks (one spatial and one verbal). Activation common to all 5 tasks was identified in the right inferior frontal gyrus, and, at a lower threshold, also the right middle frontal gyrus and right parietal regions (BA 40 and BA 7). Left inferior frontal regions of interest (ROIs) showed a significant conjunction between all tasks except the flanker task. The present study could not pinpoint the specific function of each common region, but the parietal region identified here has previously been consistently related to working memory storage and the right inferior frontal gyrus has been associated with inhibition in both lesion and imaging studies. These results support the notion that inhibitory and working memory tasks involve common neural components, which may provide a neural basis for the interrelationship between the two systems.
Huijbers et al 200917ya “When Learning and Remembering Compete: A Functional MRI Study”
Recent functional neuroimaging evidence suggests a bottleneck between learning new information and remembering old information. In two behavioral experiments and one functional MRI (fMRI) experiment, we tested the hypothesis that learning and remembering compete when both processes happen within a brief period of time. In the first behavioral experiment, participants intentionally remembered old words displayed in the foreground, while incidentally learning new scenes displayed in the background. In line with a memory competition, we found that remembering old information was associated with impaired learning of new information. We replicated this finding in a subsequent fMRI experiment, which showed that this behavioral effect was coupled with a suppression of learning-related activity in visual and medial temporal areas. Moreover, the fMRI experiment provided evidence that left mid-ventrolateral prefrontal cortex is involved in resolving the memory competition, possibly by facilitating rapid switching between learning and remembering. Critically, a follow-up behavioral experiment in which the background scenes were replaced with a visual target detection task provided indications that the competition between learning and remembering was not merely due to attention. This study not only provides novel insight into our capacity to learn and remember, but also clarifies the neural mechanisms underlying flexible behavior.
(There’s also a worthwhile blog article on this one: “Training The Mind: Transfer Across Tasks Requiring Interference Resolution”.)
“How distractible are you? The answer may lie in your working memory capacity”
Jennifer C. McVay, Michael J. Kane (200917ya). “Conducting the train of thought: Working memory capacity, goal neglect, and mind wandering in an executive-control task”. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35 (1), 196-204 DOI: 10.1037/a0014104:
On the basis of the executive-attention theory of working memory capacity (WMC; eg. M. J. Kane, A. R. A. Conway, D. Z. Hambrick, & R. W. Engle, 200719ya), the authors tested the relations among WMC, mind wandering, and goal neglect in a sustained attention to response task (SART; a go/no-go task). In 3 SART versions, making conceptual versus perceptual processing demands, subjects periodically indicated their thought content when probed following rare no-go targets. SART processing demands did not affect mind-wandering rates, but mind-wandering rates varied with WMC and predicted goal-neglect errors in the task; furthermore, mind-wandering rates partially mediated the WMC-SART relation, indicating that WMC-related differences in goal neglect were due, in part, to variation in the control of conscious thought.
“Working memory capacity and its relation to general intelligence”; Andrew R.A. Conway et al; TRENDS in Cognitive Sciences Vol.7 No.2003-12-12
Several recent latent variable analyses suggest that (working memory capacity) accounts for at least one-third and perhaps as much as one-half of the variance in (intelligence).What seems to be important about WM span tasks is that they require the active maintenance of information in the face of concurrent processing and interference and therefore recruit an executive attention-control mechanism to combat interference. Furthermore, this ability seems to be mediated by portions of the prefrontal cortex.
Support
Jaeggi 2005
“Capacity Limitations in Human Cognition: Behavioral and Biological Contributions”; Jaeggi thesis:
…Experiment 6 and 7 finally tackle the issue, whether capacity limitations are trait-like, ie. fixed, or whether it is be possible to extend these limitations with training and whether generalized effects on other domains can be observed. In the last section, all the findings are integrated and discussed, and further issues remaining to be investigated are pointed out.
…In this experiment [6], the effects of a 10-day training of an adaptive version of an n-back dual task were studied. The adaptive version should be very directly depending on the actual performance of the participant: Not being too easy, but also not too difficult; always providing a sense of achievement in the participant in order to keep the motivation high. Comparing pre and post measures, effects on the task itself were evaluated, but also effects on other WM measures, and on a measure of fluid intelligence.
…As stated before, this study [7] was conducted in order to replicate and extend the findings of Experiment 6: I was primarily interested to see whether an asymptotic curve regarding performance would be reached after nearly twice of the training sessions used in Experiment 6, and further, whether generalized and differential effects on various cognitive tasks could be obtained with this training. Therefore, more tasks were included compared to Experiment 6, covering many aspects of WM (ie. verbal tasks, visuospatial tasks), executive functions, as well as control tasks not used in Experiment 6 in order to investigate whether the WM training has a selective effect on tasks which are related to the concept of WM and executive functions with no effect on these control tasks. With respect to fluid intelligence, a more appropriate task than the APM, ie. the ‘Bochumer Matrizentest’ (BOMAT; Hossiep, Turck, & Hasella, 199927ya) was used, which has the advantage that full parallel-versions are available and that the task was explicitly developed in order not to yield ceiling effects in student samples. The experiment was carried out together with Martin Buschkuehl and Daniela Blaser; the latter writing her Master thesis on the topic.
Jaeggi 2008
“Improving fluid intelligence with training on working memory”, Jaeggi et al 200818ya (supplement; all the data in Jaeggi 200521ya was used in this as well); this article was widely covered (eg. Science Daily’s “Brain-Training To Improve Memory Boosts Fluid Intelligence” or Wired’s “Forget Brain Age: Researchers Develop Software That Makes You Smarter”) and sparked most people’s interest in the topic. The abstract:
Fluid intelligence (gf) refers to the ability to reason and to solve new problems independently of previously acquired knowledge. gf is critical for a wide variety of cognitive tasks, and it is considered one of the most important factors in learning. Moreover, gf is closely related to professional and educational success, especially in complex and demanding environments. Although performance on tests of gf can be improved through direct practice on the tests themselves, there is no evidence that training on any other regimen yields increased gf in adults. Furthermore, there is a long history of research into cognitive training showing that, although performance on trained tasks can increase dramatically, transfer of this learning to other tasks remains poor. Here, we present evidence for transfer from training on a demanding working memory task to measures of gf. This transfer results even though the trained task is entirely different from the intelligence test itself. Furthermore, we demonstrate that the extent of gain in intelligence critically depends on the amount of training: the more training, the more improvement in gf. That is, the training effect is dosage-dependent. Thus, in contrast to many previous studies, we conclude that it is possible to improve gf without practicing the testing tasks themselves, opening a wide range of applications.
Brain Workshop includes a special ‘Jaeggi mode’ which replicates almost exactly the settings described for the “Brain Twister” software used in the study.
No study is definitive, of course, but Jaeggi 200818ya is still one of the major studies that must be cited in any DNB discussion. There are some issues - not as many subjects as one would like, and the researchers (quoted in the Wired article) obviously don’t know if the WM or gf gains are durable; more technical issues like the administered gf IQ tests being speeded and thus possibly reduced in validity have been raised by Moody and others.
Qiu 2009
“Study on Improving Fluid Intelligence through Cognitive Training System Based on Gabor Stimulus”, 200917ya First International Conference on Information Science and Engineering, abstract:
General fluid intelligence (gf) is a human ability to reason and solve new problems independently of previously acquired knowledge and experience. It is considered one of the most important factors in learning. One of the issues which academic people concentrates on is whether gf of adults can be improved. According to the Dual N-back working memory theory and the characteristics of visual perceptual learning, this paper put forward cognitive training pattern based on Gabor stimuli. A total of 20 undergraduate students at 24 years old participated in the experiment, with ten training sessions for ten days. Through using Raven’s Standard Progressive Matrices as the evaluation method to get and analyze the experimental results, it was proved that training pattern can improve fluid intelligence of adults. This will promote a wide range of applications in the field of adult intellectual education.
Discussion and criticism of this Chinese6061 paper took place in 2 threads; the SPM was administer in 25 minutes, which while not as fast as Jaeggi 200818ya, is still not the normal length. An additional anomaly is that according to the final graph, the control group’s IQ dropped massively in the post-test (driving much of the improvement). As part of my meta-analysis, I tried to contact the 4 authors in May, June, July & September 201214ya; they eventually replied with data.
Polar (June 200917ya)
A group member, polar, conducted a small experiment at his university where he was a student; his results seemed to show an improvement. As polar would be the first to admit, the attrition in subjects (few to begin with), relatively short time of training and whatnot make the power of his study weak.
Jaeggi 2010
“The relationship between n-back performance and matrix reasoning - implications for training and transfer”, Jaeggi et al (coded as Jaeggi2 in meta-analysis); abstract:
…In the first study, we demonstrated that dual and single n-back task performances are approximately equally correlated with performance on two different tasks measuring gf, whereas the correlation with a task assessing working memory capacity was smaller. Based on these results, the second study was aimed on testing the hypothesis that training on a single n-back task yields the same improvement in gf as training on a dual n-back task, but that there should be less transfer to working memory capacity. We trained two groups of students for four weeks with either a single or a dual n-back intervention. We investigated transfer effects on working memory capacity and gf comparing the two training groups’ performance to controls who received no training of any kind. Our results showed that both training groups improved more on gf than controls, thereby replicating and extending our prior results.
The 2 studies measured gf using Raven’s APM and the BOMAT. In both studies, the tests were administered speeded to 10 or 15 minutes as in Jaeggi 200818ya. The experimental groups saw average gains of 1 or 2 additional correct answers on the BOMAT and APM. It’s worth noting that the Single N-Back was done with a visual modality (and the DNB with the standard visual & audio).
Followup work:
Schneiders et al 2012 trained audio WM and found no transfer to visual WM tasks; unfortunately, they did not measure any far transfer tasks like RAPM/BOMAT.
Beavon 2012 reports n = 47, experimentals trained on single n-back & controls on “combined verbal tasks Definetime and Who wants to be a millionaire (Millionaire)”; no improvements on “STM span and attention, short term auditory memory span and divided attention, and WM as operationalised through the Woodcock-Johnson III: Tests of cognitive abilities (WJ-III)”.
Studer-Luethi 2012
The second study’s data was reused for a Big Five personality factor analysis in Studer-Luethi, Jaeggi, et al 201214ya, “Influence of neuroticism and conscientiousness on working memory training outcome”.62
The lack of n-back score correlation with WM score seems in line with an earlier study; “Working Memory, Attention Control, and the N-Back Task: A Question of Construct Validity”:
…Participants also completed a verbal WM span task (operation span task) and a marker test of general fluid intelligence (Gf; Ravens Advanced Progressive Matrices Test; J. C. Raven, J. E. Raven, & J. H. Court, 199828ya). N-back and WM span correlated weakly, suggesting they do not reflect primarily a single construct; moreover, both accounted for independent variance in gf. N-back has face validity as a WM task, but it does not demonstrate convergent validity with at least 1 established WM measure.
Stephenson 2010
“Does training to increase working memory capacity improve fluid intelligence?”:
The current study was successful in replicating Jaeggi et al.’s (200818ya) results. However, the current study also observed improvements in scores on the Raven’s Advanced Progressive Matrices for participants who completed a variation of the dual n-back task or a short-term memory task training program. Participants’ scores improved significantly for only two of the four tests of GJ, which raises the issue of whether the tests measure the construct gf exclusively, as defined by Cattell (196363ya), or whether they may be sensitive to other factors. The concern is whether the training is actually improving gf or if the training is improving attentional control and/or visuospatial skills, which improves performance on specific tests of gf. The findings are discussed in terms of implications for conceptualizing and assessing gf.
136 participants split over 25-28 subjects in experimental groups and the control group. Visual n-back improved more than audio n-back; the control group was a passive control group (they did nothing but served as controls for test-retest effects).
Stephenson & Halpern 2013
“Improved matrix reasoning is limited to training on tasks with a visuospatial component”, Stephenson & Halpern 201313ya:
Recent studies (eg. Jaeggi et al 200818ya, 201016ya) have provided evidence that scores on tests of fluid intelligence can be improved by having participants complete a four week training program using the dual n-back task. The dual n-back task is a working memory task that presents auditory and visual stimuli simultaneously. The primary goal of our study was to determine whether a visuospatial component is required in the training program for participants to experience gains in tests of fluid intelligence. We had participants complete variations of the dual n-back task or a short-term memory task as training. Participants were assessed with four tests of fluid intelligence and four cognitive tests. We were successful in corroborating Jaeggi et al.’s results, however, improvements in scores were observed on only two out of four tests of fluid intelligence for participants who completed the dual n-back task, the visual n-back task, or a short-term memory task training program. Our results raise the issue of whether the tests measure the construct of fluid intelligence exclusively, or whether they may be sensitive to other factors. The findings are discussed in terms of implications for conceptualizing and assessing fluid intelligence…The data in the current paper was part of Clayton Stephenson’s doctoral dissertation.
Jaeggi 2011
Jaeggi, Buschkuehl, Jonides & Shah 201115ya “Short-term & long-term benefits of cognitive training” (coded as Jaeggi3 in the meta-analysis); the abstract:
We trained elementary and middle school children by means of a videogame-like working memory task. We found that only children who considerably improved on the training task showed a performance increase on untrained fluid intelligence tasks. This improvement was larger than the improvement of a control group who trained on a knowledge-based task that did not engage working memory; further, this differential pattern remained intact even after a 3-mo hiatus from training. We conclude that cognitive training can be effective and long-lasting, but that there are limiting factors that must be considered to evaluate the effects of this training, one of which is individual differences in training performance. We propose that future research should not investigate whether cognitive training works, but rather should determine what training regimens and what training conditions result in the best transfer effects, investigate the underlying neural and cognitive mechanisms, and finally, investigate for whom cognitive training is most useful.
(This paper is not to be confused with the 201115ya poster, “Working Memory Training and Transfer to gf. Evidence for Domain Specificity?”, Jaeggi et al 201115ya.)
It is worth noting that the study used Single N-back (visual). Unlike Jaeggi 200818ya, “despite the experimental group’s clear training effect, we observed no significant group × test session interaction on transfer to the measures of gf. (so perhaps the training was long enough for subjects to hit their ceilings). The group which did n-back could be split, based on final IQ & n-back scores, into 2 groups; interestingly”Inspection of n-back training performance revealed that there were no group differences in the first 3 wk of training; thus, it seems that group differences emerge more clearly over time [first 3 wk: t(30) < 1; P = ns; last week: t(16) = 3.00; P < 0.01] (Fig. 3).” 3 weeks is ~21 days, or >19 days (the longest period in Jaeggi 200818ya). It’s also worth noting that Jaeggi 201115ya seems to avoid Moody’s most cogent criticism, the speeding of the IQ tests; from the paper’s “Material and Methods” section;
We assessed matrix reasoning with two different tasks, the Test of Nonverbal Intelligence (TONI) (23) and Raven’s Standard Progressive Matrices (SPM) (24). Parallel versions were used for the pre, post-, and follow-up test sessions in counterbalanced order. For the TONI, we used the standard procedure (45 items, five practice items; untimed), whereas for the SPM, we used a shortened version (split into odd and even items; 29 items per version; two practice items; timed to 10 min after completion of the practice items. Note that virtually all of the children completed this task within the given timeframe).
The IQ results were, specifically, the control group averaged 15.33/16.20 (before/after) correct answers on the SPM and 20.87/22.50 on the TONI; the n-back group averaged 15.44/16.94 SPM and 20.41/22.03 TONI. 1.5 more right questions rather than ~1 may not seem like much, but the split groups look quite different - the ‘small training gain’ n-backing group actually fell on its second SPM and improved by <0.2 questions on the TONI, while the ‘large training gain’ increased >3 questions on the SPM and TONI. The difference is not so dramatic in the followup 3 months later: the small group is now 17.43/23.43 (SPM/TONI), and the large group 15.67/24.67. Strangely in the followup, the control group has a higher SPM than the large group (but not the small group), and a higher TONI than either group; the control group has higher IQ scores on both TONI & SPM in the followup than the aggregate n-back group. (The splitting of groups is also unorthodox63.)
UoM produced a video with Jonides; Jaeggi 201115ya has also been discussed in mainstream media. From the Wall Street Journal’s “Boot Camp for Boosting IQ”:
…when several dozen elementary- and middle-school kids from the Detroit area used this exercise for 15 minutes a day, many showed significant gains on a widely used intelligence test. Most impressive, perhaps, is that these gains persisted for three months, even though the children had stopped training…these schoolchildren showed gains in fluid intelligence roughly equal to five IQ points after one month of training…There are two important caveats to this research. The first is that not every kid showed such dramatic improvements after training. Initial evidence suggests that children who failed to increase their fluid intelligence found the exercise too difficult or boring and thus didn’t fully engage with the training.
From Discover’s blogs, “Can intelligence be boosted by a simple task? For some…”, come additional details:
She [Jaeggi] recruited 62 children, aged between seven and ten. While half of them simply learned some basic general knowledge questions, the other half trained with a cheerful computerised n-back task. They saw a stream of images where a target object appeared in one of six locations - say, a frog in a lily pond. They had to press a button if the frog was in the same place as it was two images ago, forcing them to store a continuously updated stream of images in their minds. If the children got better at the task, this gap increased so they had to keep more images in their heads. If they struggled, the gap was shortened.
Before and after the training sessions, all the children did two reasoning tests designed to measure their fluid intelligence. At first, the results looked disappointing. On average, the n-back children didn’t become any better at these tests than their peers who studied the knowledge questions. But according to Jaeggi, that’s because some of them didn’t take to the training. When she divided the children according to how much they improved at the n-back task, she saw that those who showed the most progress also improved in fluid intelligence. The others did not. Best of all, these benefits lasted for 3 months after the training. That’s a first for this type of study, although Jaeggi herself says that the effect is “not robust.” Over this time period, all the children showed improvements in their fluid intelligence, “probably [as] a result of the natural course of development”.
…Philip Ackerman, who studies learning and brain training at the University of Illinois, says, “I am concerned about the small sample, especially after splitting the groups on the basis of their performance improvements.” He has a point - the group that showed big improvements in the n-back training only included 18 children….Why did some of the children benefit from the training while others did not? Perhaps they were simply uninterested in the task, no matter how colorfully it was dressed up with storks and vampires. In Jaeggi’s earlier study with adults, every volunteer signed up themselves and were “intrinsically motivated to participate and train.” By contrast, the kids in this latest study were signed up by their parents and teachers, and some might only have continued because they were told to do so.
It’s also possible that the changing difficulty of the game was frustrating for some of the children. Jaeggi says, “The children who did not benefit from the training found the working memory intervention too effortful and difficult, were easily frustrated, and became disengaged. This makes sense when you think of physical training - if you don’t try and really run and just walk instead, you won’t improve your cardiovascular fitness.” Indeed, a recent study on IQ testing which found that they reflect motivation as well as intelligence.
Schweizer Et Al 2011
This study investigated whether brain-training (working memory [WM] training) improves cognitive functions beyond the training task (transfer effects), especially regarding the control of emotional material since it constitutes much of the information we process daily. Forty-five participants received WM training using either emotional or neutral material, or an undemanding control task. WM training, regardless of training material, led to transfer gains on another WM task and in fluid intelligence. However, only brain-training with emotional material yielded transferable gains to improved control over affective information on an emotional Stroop task. The data support the reality of transferable benefits of demanding WM training and suggest that transferable gains across to affective contexts require training with material congruent to those contexts. These findings constitute preliminary evidence that intensive cognitively demanding brain-training can improve not only our abstract problem-solving capacity, but also ameliorate cognitive control processes (eg. decision-making) in our daily emotive environments.
Notes:
There seems to be an IQ increase of around one question on the RPM (but there’s an oddity with the control group which they think they correct for64)
The RPM does not seem to have been administered speeded65
The emotional aspect seems to be just replacing the ‘neutral’ existing stimuli like colors or letters or piano keys with more loaded ones66, nor does this tweak seem to change the DNB/WM/IQ scores of that group67
Their later study “Training the Emotional Brain: Improving Affective Control through Emotional Working Memory Training” did not use any measure of fluid intelligence.
Kundu Et Al 2011
“Relating individual differences in short-term memory-derived EEG to cognitive training effects” (coded as Kundu1 in the meta-analysis); 3 controls (Tetris), 3 experimentals (Brain Workshop) for 1000 minutes. RAPM showed a slight increase. Extremely small experimental size, which may form part of the data for Kundu et al 2012.
Zhong 2011
“The Effect Of Training Working Memory And Attention On Pupils’ Fluid Intelligence” (abstract), Zhong 201115ya; original encrypted file (8M), screenshots of all pages in thesis (20M); discussion
Appears to have found IQ gains, but no dose-response effect, using a no-contact control group. Difficult to understand: translation assistance from Chinese speakers would be appreciated.
Jausovec 2012
“Working memory training: Improving intelligence - Changing brain activity”, Jaušovec 201214ya:
The main objectives of the study were: to investigate whether training on working memory (WM) could improve fluid intelligence, and to investigate the effects WM training had on neuroelectric (electroencephalography - EEG) and hemodynamic (near-infrared spectroscopy - NIRS) patterns of brain activity. In a parallel group experimental design, respondents of the working memory group after 30 h of training significantly increased performance on all tests of fluid intelligence. By contrast, respondents of the active control group (participating in a 30-h communication training course) showed no improvements in performance. The influence of WM training on patterns of neuroelectric brain activity was most pronounced in the theta and alpha bands. Theta and lower-1 alpha band synchronization was accompanied by increased lower-2 and upper alpha desynchronization. The hemodynamic patterns of brain activity after the training changed from higher right hemispheric activation to a balanced activity of both frontal areas. The neuroelectric as well as hemodynamic patterns of brain activity suggest that the training influenced WM maintenance functions as well as processes directed by the central executive. The changes in upper alpha band desynchronization could further indicate that processes related to long term memory were also influenced.
14 experimental & 15 controls; the testing was a little unusual:
Respondents solved four test-batteries, for which the procedure was the same during pre- and post-testing. The same test-batteries were used on pre- and post-testing. The digit span subtest (WAIS-R) was administered separately, according to the directions in the test manual (Wechsler, 198145ya). The other three tests (RAPM, verbal analogies and spatial rotation) were administered while the respondents’ EEG and NIRS measures were recorded.
The RAPM was based on a modified version of Raven’s progressive matrices (Raven, 199036ya), a widely used and well established test of fluid intelligence (Sternberg, Ferrari, Clinkenbeard, & Grigorenko, 199630ya). The correlation between this modified version of RAPM and WAIS-R was r = .56, (p < .05, n = 97). Similar correlations of the order of 0.40-0.75, were also reported for the standard version of RAPM (Court & Raven, 199531ya). Therefore it can be concluded that the modified application of the RAPM did not significantly alter its metric characteristics. Used were 50 test items - 25 easy (Advanced Progressive Matrices Set I - 12 items and the B Set of the Colored Progressive Matrices), and 25 difficult items (Advanced Progressive Matrices Set II, items 12-36). Participants saw a figural matrix with the lower right entry missing. They had to determine which of the four options fitted into the missing space. The tasks were presented on a computer screen (positioned about 80-100 cm in front of the respondent), at fixed 10 or 14 s interstimulus intervals. They were exposed for 6 s (easy) or 10 s (difficult) following a 2-s interval, when a cross was presented. During this time the participants were instructed to press a button on a response pad (1-4) which indicated their answer.
At 25 hard questions, and <14s a question, that implies the RAPM was administered in <5.8 minutes. They comment:
To further investigate possible influences of task difficulty on the observed performance gains on the RAPM a GLM for repeated measures test/retest  easy/difficult-items  group (WM, AC) was conducted. The analysis showed only a significant interaction effect for the test/retest condition and type of training used in the two groups (F(1, 27) = 4.47; p < .05; partial eta2 = .15). A GLM conducted for the WM group showed only a significant test/retest effect (F(1, 13) = 30.11; p < .05; partial eta2 = .70), but no interaction between the test/retest conditions and the difficulty level (F(1, 13) = 1.79; p = .17 not-significant; partial eta2 = .12). As can be seen in Fig. 4 after WM training an about equal increase in respondents’ performance for the easy and difficult test items was observed. On the other hand, no increases in performance, neither for the easy nor for the difficult test items, in respondents of the active control group were observed (F(1, 14) = .47; p = .50 not- significant; partial eta2 = .03).
(Even on the “easy” questions, no group performed better than 76% accuracy.)
Clouter 2013
“The Effects of Dual n-back Training on the Components of Working Memory and Fluid Intelligence: An Individual Differences Approach”, Clouter 201313ya:
A number of recent studies have provided evidence that training working memory can lead to improvements in fluid intelligence, working memory span, and performance on other untrained tasks. However, in addition to a number of mixed results, many of these studies suffer from design limitations. The aim of the present study was to experimentally investigate the effects of a dual n-back working memory training task on a variety of measures of fluid intelligence, reasoning, working memory span, and attentional control. The present study compared a training group with an active control group (a placebo group), using appropriate methods that overcame the limitations of previous studies. The dual n-back training group improved more than the active control group on some, but not all outcome measures. Differential improvement for the training group was observed on fluid intelligence, working memory capacity, and response times on conflict trials in the Stroop task. In addition, individual differences in pre-training fluid intelligence scores and initial performance on the training task explain some of the variance in outcome measure improvements. We discuss these results in the context of previous studies, and suggest that additional work is needed in order to further understand the variables responsible for transfer from training.
Jaeggi Et Al 2013
“The role of individual differences in cognitive training and transfer”:
Working memory (WM) training has recently become a topic of intense interest and controversy. Although several recent studies have reported near- and far-transfer effects as a result of training WM-related skills, others have failed to show far transfer, suggesting that generalization effects are elusive. Also, many of the earlier intervention attempts have been criticized on methodological grounds. The present study resolves some of the methodological limitations of previous studies and also considers individual differences as potential explanations for the differing transfer effects across studies. We recruited intrinsically motivated participants and assessed their need for cognition (NFC; Cacioppo & Petty Journal of Personality and Social Psychology 42:116-131, 198244ya) and their implicit theories of intelligence (Dweck, 199927ya) prior to training. We assessed the efficacy of two interventions by comparing participants’ improvements on a battery of fluid intelligence tests against those of an active control group. We observed that transfer to a composite measure of fluid reasoning resulted from both WM interventions. In addition, we uncovered factors that contributed to training success, including motivation, need for cognition, preexisting ability, and implicit theories about intelligence.
This is quite a complex study, with a lot of analysis I don’t think I entirely understand. The quick summary is table 2 on pg10: the DNB group fell on APM, rose on BOMAT (neither statistically-significant); the SNB group increased on APM & BOMAT (but only BOMAT was statistically-significant).
Michael J. Kane has written some critical comments on the results.
Savage 2013
“Near and Far Transfer of Working Memory Training Related Gains in Healthy Adults”, Savage 201313ya:
Enhancing intelligence through working memory training is an attractive concept, particularly for middle-aged adults. However, investigations of working memory training benefits are limited to younger or older adults, and results are inconsistent. This study investigates working memory training in middle age-range adults. Fifty healthy adults, aged 30-60, completed measures of working memory, processing speed, and fluid intelligence before and after a 5-week web-based working memory (experimental) or processing speed (active control) training program. Baseline intelligence and personality were measured as potential individual characteristics associated with change. Improved performance on working memory and processing speed tasks were experienced by both groups; however, only the working memory training group improved in fluid intelligence. Agreeableness emerged as a personality factor associated with working memory training related change. Albeit limited by power, findings suggest that dual n-back working memory training not only enhances working memory but also fluid intelligence in middle-aged healthy adults.
The personality correlations seem to differ with Studer-Luethi.
Stepankova Et Al 2013
“The Malleability of Working Memory and Visuospatial Skills: A Randomized Controlled Study in Older Adults”, Stepankova et al 201313ya:
There is accumulating evidence that training on working memory (WM) generalizes to other nontrained domains, and there are reports of transfer effects extending as far as to measures of fluid intelligence. Although there have been several demonstrations of such transfer effects in young adults and children, they have been difficult to demonstrate in older adults. In this study, we investigated the generalizing effects of an adaptive WM intervention on nontrained measures of WM and visuospatial skills. We randomly assigned healthy older adults to train on a verbal n-back task over the course of a month for either 10 or 20 sessions. Their performance change was compared with that of a control group. Our results revealed reliable group effects in nontrained standard clinical measures of WM and visuospatial skills in that both training groups outperformed the control group. We also observed a dose-response effect, that is, a positive relationship between training frequency and the gain in visuospatial skills; this finding was further confirmed by a positive correlation between training improvement and transfer. The improvements in visuospatial skills emerged even though the intervention was restricted to the verbal domain. Our work has important implications in that our data provide further evidence for plasticity of cognitive functions in old age.
Horvat 2014
“The effect of working memory training on cognitive abilities”, Horvat 201412ya; Slovenian, English abstract:
In the last few years, there is a growing evidence in psychological literature indicating that working memory training could serve as a useful tool to improve performance on non-trained tasks that measure higher cognitive abilities; however, results of different studies remain inconsistent. The aim of the present master thesis was to discover whether working memory training could improve short-term memory capacity and increase test scores on test of fluid intelligence in normal developing children.
Final sample consisted of 29 participants, between 13 to 15 years old; 14 of them were in experimental group, 15 was controls. Experimental group completed series of ten working memory trainings, based on adaptive dual n-back task. Control group was passive and did not do any training in the meantime.
Results of our study showed that all participants in experimental group improved their performance on trained task. There was no statistically-significant effect of experimental group on measures of digit span and visuospatial memory span before and after training, when comparing with performance of control group. However, experimental group improved more on measure of fluid intelligence compared with control group.
Finding of our study suggest the importance of investigating factors associated with effectiveness of working memory training in future research.
Heinzel Et Al 2016
“Neural correlates of training and transfer effects in working memory in older adults”, Heinzel et al 2016:
As indicated by previous research, aging is associated with a decline in working memory (WM) functioning, related to alterations in fronto-parietal neural activations. At the same time, previous studies showed that WM training in older adults may improve the performance in the trained task (training effect), and more importantly, also in untrained WM tasks (transfer effects). However, neural correlates of these transfer effects that would improve understanding of its underlying mechanisms, have not been shown in older participants as yet. In this study, we investigated blood-oxygen-level-dependent (BOLD) signal changes during n-back performance and an untrained delayed recognition (Sternberg) task following 12 sessions (45 minutes each) of adaptive n-back training in older adults. The Sternberg task used in this study allowed to test for neural training effects independent of specific task affordances of the trained task and to separate maintenance from updating processes. Thirty-two healthy older participants (60-75 years) were assigned either to an n-back training or a no-contact control group. Before (t1) and after (t2) training/waiting period, both the n-back task and the Sternberg task were conducted while BOLD signal was measured using functional Magnetic Resonance Imaging (fMRI) in all participants. In addition, neuropsychological tests were performed outside the scanner. WM performance improved with training and behavioral transfer to tests measuring executive functions, processing speed, and fluid intelligence was found. In the training group, BOLD signal in right lateral middle frontal gyrus/ caudal superior frontal sulcus (Brodmann area, BA 6/8) decreased in both the trained n-back and the updating condition of the untrained Sternberg task at t2, compared to the control group. FMRI findings indicate a training-related increase in processing efficiency of WM networks, potentially related to the process of WM updating. Performance gains in untrained tasks suggest that transfer to other cognitive tasks remains possible in aging.
Criticism
Moody 200917ya (Re: Jaeggi 200818ya)
Jaeggi 2008, you may remember, showed that training on N-back improved working memory, but it also boosted scores on tests of gf. The latter would be a major result - indeed, unique - and is one of the main research results encouraging people to do N-back in a non-research setting. People want to believe that N-back is efficacious and particularly that it will do more than boost working memory. So we need to be wary of confirmation bias (for those of you who read too much fantasy, you’ll know this as Wizard’s First Rule).
Fortunately, we can discuss at length the work of one David E. Moody who has published a criticism of how the odd methodology of Jaeggi 200818ya undermines this result. He’s worth quoting at length, since besides being important to understanding Jaeggi’s study, it’s an interesting example of how subtle issues can be important in psychology:
“The subjects were divided into four groups, differing in the number of days of training they received on the task of working memory. The group that received the least training (8 days) was tested on Raven’s Advanced Progressive Matrices (Raven, 199036ya), a widely used and well-established test of fluid intelligence. This group, however, demonstrated negligible improvement between pre- and post-test performance.
The other three groups were not tested using Raven’s Matrices, but rather on an alternative test of much more recent origin. The Bochumer Matrices Test (BOMAT) (Hossiep, Turck, & Hasella, 199927ya) is similar to Raven’s in that it consists of visual analogies. In both tests, a series of geometric and other figures is presented in a matrix format and the subject is required to infer a pattern in order to predict the next figure in the series. The authors provide no reason for switching from Raven’s to the BOMAT.
The BOMAT differs from Raven’s in some important respects, but is similar in one crucial attribute: both tests are progressive in nature, which means that test items are sequentially arranged in order of increasing difficulty. A high score on the test, therefore, is predicated on subjects’ ability to solve the more difficult items.
However, this progressive feature of the test was effectively eliminated by the manner in which Jaeggi et al. administered it. The BOMAT is a 29-item test which subjects are supposed to be allowed 45 min to complete. Remarkably, however, Jaeggi et al. reduced the allotted time from 45 min to 10. The effect of this restriction was to make it impossible for subjects to proceed to the more difficult items on the test. The large majority of the subjects-regardless of the number of days of training they received-answered less than 14 test items correctly.
By virtue of the manner in which they administered the BOMAT, Jaeggi et al. transformed it from a test of fluid intelligence into a speed test of ability to solve the easier visual analogies. The time restriction not only made it impossible for subjects to proceed to the more difficult items, it also limited the opportunity to learn about the test-and so improve performance-in the process of taking it. This factor cannot be neglected because test performance does improve with practice, as demonstrated by the control groups in the Jaeggi study, whose improvement from pre- to post-test was about half that of the experimental groups. The same learning process that occurs from one administration of the test to the next may also operate within a given administration of the test-provided subjects are allowed sufficient time to complete it.Since the whole weight of their conclusion rests upon the validity of their measure of fluid intelligence, one might assume the authors would present a careful defense of the manner in which they administered the BOMAT. Instead they do not even mention that subjects are normally allowed 45 min to complete the test. Nor do they mention that the test has 29 items, of which most of their subjects completed less than half.
The authors’ entire rationale for reducing the allotted time to 10 min is confined to a footnote. That footnote reads as follows:
Although this procedure differs from the standardized procedure, there is evidence that this timed procedure has little influence on relative standing in these tests, in that the correlation of speeded and non-speeded versions is very high (r = 0.95; ref. 37).
The reference given in the footnote is to a 198838ya study (Frearson & Eysenck 198640ya) that is not in fact designed to support the conclusion stated by Jaeggi et al. The 198838ya study merely contains a footnote of its own, which refers in turn to unpublished research conducted forty years earlier. That research involved Raven’s matrices, not the BOMAT, and entailed a reduction in time of at most 50%, not more than 75%, as in the Jaeggi study.
So instead of offering a reasoned defense of their procedure, Jaeggi et al. provide merely a footnote which refers in turn to a footnote in another study. The second footnote describes unpublished results, evidently recalled by memory over a span of 40 years, involving a different test and a much less severe reduction in time.
In this context it bears repeating that the group that was tested on Raven’s matrices (with presumably the same time restriction) showed virtually no improvement in test performance, in spite of eight days’ training on working memory. Performance gains only appeared for the groups administered the BOMAT. But the BOMAT differs in one important respect from Raven’s. Raven’s matrices are presented in a 3 × 3 format, whereas the BOMAT consists of a 5 × 3 matrix configuration.
With 15 visual figures to keep track of in each test item instead of 9, the BOMAT puts added emphasis on subjects’ ability to hold details of the figures in working memory, especially under the condition of a severe time constraint. Therefore it is not surprising that extensive training on a task of working memory would facilitate performance on the early and easiest BOMAT test items-those that present less of a challenge to fluid intelligence.
This interpretation acquires added plausibility from the nature of one of the two working-memory tasks administered to the experimental groups. The authors maintain that those tasks were “entirely different” from the test of fluid intelligence. One of the tasks merits that description: it was a sequence of letters presented auditorily through headphones.
But the other working-memory task involved recall of the location of a small square in one of several positions in a visual matrix pattern. It represents in simplified form precisely the kind of detail required to solve visual analogies. Rather than being “entirely different” from the test items on the BOMAT, this task seems well-designed to facilitate performance on that test.”
Sternberg reviewed Jaeggi 2008
Email from Jaeggi to Pontus about the timelimit; visual problems bias RPM against women who have a slightly lower average visuospatial performance.
Nutley 2011 discusses why one test may be insufficient when an experimental intervention is done:
Since the definition of gf itself stems from factor analytical methods, using the shared variance of several tests to define the gf factor, a similar method should be used to measure gains in gf. Another issue raised by Sternberg (200818ya) is that the use of only one single training task makes it difficult to infer if the training effect was due to some specific aspect of the task rather than the general effect of training a construct.
Shipstead, Redick, & Engle 201214ya elaborate on how, while matrix-style IQ tests are considered gold standards, they are not perfect measures of IQ such that an increase in performance must reflect an increase in underlying intelligence:
…far transfer tasks are not perfect measures of ability. In many training studies, Raven’s Progressive Matrices (Ravens; Raven, 199036ya, 199531ya, 199828ya) serves as the sole indicator of gf. This “matrix reasoning” task presents test takers with a series of abstract pictures that are arranged in a grid. One piece of the grid is missing, and the test taker must choose an option (from among several) that completes the sequence. Jensen 1998 estimates that 64% of the variance in Ravens performance can be explained by gf. Similarly, Figure 3 indicates that in the study of Kane et al 200422ya, 58% of the Ravens variance was explained by gf. It is clear that Ravens is strongly related to gf. However, 30%-40% of the variance in Ravens is attributable to other influences. Thus, when Ravens (or any other task) serves as the sole indicator of far transfer, performance improvements can be explained without assuming that a general ability has changed. Instead, it can be parsimoniously concluded that training has influenced something that is specific to performing Ravens, but not necessarily applicable to other reasoning contexts (Carroll, 199333ya; Jensen, 199828ya; Moody, 200917ya; Schmiedek et al 201016ya; te Nijenhuis, van Vianen, & van der Flier, 200719ya).
…Preemption of criticisms such as Moody’s (200917ya) is, however, readily accomplished through demonstration of transfer to several measures of an ability. Unfortunately, the practice of equating posttest improvement on one task with change to cognitive abilities is prevalent within the WM training literature (cf. Jaeggi et al 200818ya; Klingberg, 201016ya). This is partially driven by the time and monetary costs associated with conducting multisession, multiweek studies. Regardless, training studies can greatly improve the persuasiveness of their results by measuring transfer via several tasks that differ in peripheral aspects but converge on an ability of interest (eg. a verbal, gf. and spatial task from Figure 3). If a training effect is robust, it should be apparent in all tasks.
Explicit attempts at measuring speeding:
Chuderski 201313ya, “When are fluid intelligence and working memory isomorphic and when are they not?”
Colom et al 201511ya, “Fluid intelligence and working memory capacity: Is the time for working on intelligence problems relevant for explaining their large relationship?”
Chuderski 201511ya, “The broad factor of working memory is virtually isomorphic to fluid intelligence tested under time pressure”
Seidler 2010
“Cognitive Training As An Intervention To Improve Driving Ability In The Older Adult”, a technical report by a group which includes Susanne Jaeggi, studied the effect of DNB on the driving ability of younger/older adults. As part of the before/after test battery, a Raven’s was administered:
Type 2 tests included Raven’s matrices (Raven et al 199036ya), which is a standardized test of fluid intelligence, and the BOMAT and verbal analogies tests of intelligence (Hossiep et al 199531ya). We have previously shown that working memory training transfers to performance on this task (Jaeggi et al 200818ya), and we included it here for the sake of replication.
They found the null result:
There were no significant group by test session interactions for the intelligence measures or complex motor tasks for the young adults, although one of the intelligence measures exhibited a trend for transfer effects that scaled with training task gains.
…Unlike in our previous work (Jaeggi et al 200818ya) we did not observe transfer to measures of intelligence. This may have been a by-product of the rather extensive pre and post test battery of assessments that we performed, particularly given that one of the intelligence measures was always performed last in the sequence of tests. Given this, participants may have been too fatigued and / or unmotivated to perform these tests well.
Jonasson 2011
“Investigating training and transfer in complex tasks with dual n-back”, bachelor degree thesis:
No clear consensus exists in the scientific community of what constitutes efficient dual-tasking abilities. Moreover, the training of executive components has been given increased attention in the literature in recent years. Investigating transferability of cognitive training in a complex task setting, thirty subjects practiced for five days on a Name-Tag task (controls) or a Dual n-Back task (experimental), subsequently being tested on two transfer tasks; the Automated Operation Span and a dual task (Trail Making task + Mathematical Addition task). Dual n-Back training previously transferred to unrelated intelligence tests and in this study is assumed to rely primarily on executive attention. Executive attention, functioning to resolve interference and maintaining task-relevant information in working memory, has previously been linked to fluid intelligence and to dual-tasking. However, no transfer effects were revealed. The length of training may have been too short to reveal any such effects. However, the three complex tasks correlated significantly, suggesting common resources, and therefore having potentials as transfer tasks. Notably, subjects with the highest task-specific improvements performed worse on the transfer tasks than subjects improving less, suggesting that task-specific gains do not directly correlate with any transfer effect. At present, if transfer exists in these settings, data implies that five days of training is insufficient for a transfer to occur. Important questions for future research relates to the necessary conditions for transfer to occur, such as the amount of training, neural correlates, attention, and motivation.
Caveats for this study:
It did not attempt to measure any form of gf
It used 30 total subjects, or 15 in each group
Training was over 5-6 days, 16-20 minutes each day (although the DNB subjects did increase their scores), which may not be enough; although Jonasson comments (pg44–45):
Nevertheless, training for five days or less has also led to significant improvements in performance on transfer tasks (Damos & Wickens, 1980; Kramer et al 1995; Rueda et al 2005). However, the study by Kramer et al 199531ya may have transferred a strategy rather than training a specific component, and the study by Rueda et al 200521ya found transfer in children between ages four and six, the children possibly being more susceptible to training than adults.
Jonasson suggests that subjects were unmotivated, perhaps by the training being done at home on
Lumosity.com; only one did the full 6 days of training, and incentives often increase performance on IQ and other tests.
Chooi 2011
“Improving Intelligence by Increasing Working Memory Capacity”, PhD thesis:
…The current study aimed to replicate and extend the original study conducted by Jaeggi et al 200818ya in a well-controlled experiment that could explain the cause or causes of such transfer if indeed the case. There were a total of 93 participants who completed the study, and they were randomly assigned to one of three groups - a passive control group, active control group and experimental group. Half of the participants were randomly assigned to the 8-day condition and the other half to the 20-day condition. All participants completed a battery of tests at pre- and post-tests that consisted of short timed tests, a complex working memory span and a [untimed] matrix reasoning task. Participants in the active control group practiced for either 8 days or 20 days on the same task as the one used in the experimental group, the dual n-back, but at the easiest level to control for Hawthorne effect. Results from the current study did not suggest any significant improvement in the mental abilities tested, especially fluid intelligence and working memory capacity, after training for 8 days or 20 days. This leads to the conclusion that increasing one’s working memory capacity by training and practice did not transfer to improvement on fluid intelligence as asserted by Jaeggi and her colleagues (200818ya, 201016ya).
Jonathan Toomim points out a concern about statistical power: the multiple control groups means that the number of subjects doing actual n-backing is small and the null result is only trustworthy if one expects a dramatic effect from n-backing, a huge effect size taken from Jaeggi 201016ya (but not Jaeggi 2008’s smaller effect size). He comments: “the effect size for DNB training is probably less than 0.98. (Of course, that’s what I believed anyway before I saw this.) The effect size could quite reasonably still be as high as 0.75.” Chooi 201115ya seems to have been summarized as Chooi & Thompson 2012, which discusses the power issue further:
A major limitation of the study was the small sample size and possibly sample characteristic, which may have lowered the power of analyses conducted. When Jaeggi et al 201016ya repeated the study with 25 students who trained on the Raven’s Advanced Progressive Matrices (RAPM) for 20 days, they obtained an effect size (Cohen’s d) of 0.98. Additionally, participants in the Jaeggi et al 201016ya study were culturally different from the participants in the current study. Participants from the former study were undergraduates from an university in Taiwan (mean age=19.4), while those from the current study were mostly American students attending a Midwestern university. The current study was designed according to the claims put forth by Jaeggi et al 200818ya as a study of replication and extension. In that study, participants were healthy, young adults who were slightly older (mean age=25.6 years) than the current sample (mean age= 20.0), and they were recruited from an university in Bern, Switzerland. Effect sizes obtained from our study for RAPM were not as high as reported by Jaeggi et al (200818ya, 201016ya) - d = 0.65 and d = 0.98 respectively. With such large effect sizes, the analysis of paired t-test could achieve a power of 0.80 with 10- 12 participants. Referring to Table 4, the highest RAPM effect size (d = 0.50) was from the 8-day passive control group that had 22 participants and this achieved a power of 0.83. The 20-day training group (n = 13) had an effect size of 0.06 in RAPM, and to achieve a power of 0.80 this group would need more than 1700326ya participants. On the other hand, the effect size from the 20-day active control group with 11 participants was 0.40, and power could be improved by increasing the number of participants to 34. These observations led us to believe that the lack of improvements in the test variables was probably due to a combination of low sample size and differences in sample characteristics, of which participants in our study had restriction of range in intellectual ability.
Preece 201115ya / Palmer 2011
“The Effect of Working Memory (n-back) Training on Fluid Intelligence”, David Preece 201115ya:
The present study replicated and extended these results by testing the fluid intelligence construct using a different type of fluid intelligence test, and employing an ‘active’ rather than ‘no-contact’ control group to account for motivational effects on intelligence test performance. 58 participants were involved and their fluid intelligence was assessed pre-training using the Figure Weights subtest from the Wechsler Adult Intelligence Scale - Fourth Edition (WAIS-IV). Participants were randomly assigned to two groups (experimental or active control), and both groups did a training task on their home computer for 20 days, for 20 minutes a day. The experimental group trained using a single n-back task whilst the control group completed general knowledge and vocabulary questions. After training, participants were retested using the Figure Weights subtest. Participants’ Figure Weights scores were analysed using an analysis of covariance (ANCOVA). The results of this analysis revealed no significant difference between the training groups in terms of performance on the Figure Weights subtest, suggesting that the n-back task was not effective in increasing fluid reasoning ability. These findings were in contrast to those of Jaeggi et al 200818ya and Jaeggi et al 201016ya and suggested that differences between the working memory group and control group found in these studies were likely the result of placebo/motivational effects rather than the properties of the n-back task itself.
Subjects were also tested on the RAPM pre/post, but that was reported in a separate thesis, Vaughan Palmer’s “Improving fluid intelligence (gf) though training”, which is not available. I have emailed the supervising professor for more information.
2 closely related theses are “Improving Memory Using N-Back Training”, Beavon 201214ya (short-term & working memory); and “Visual Memory Improvement in Recognition”, Prandl 201214ya.
Kundu Et Al 2012
“Behavioral and EEG Effects of Working Memory Training” (RAPM supplement); 13 controls and 13 experimentals trained for 1000 minutes on dual n-back (Brain Workshop) or Tetris. “Training does not appear to transfer to gf [RAPM] or complex span [OSPAN].” This is not a published study but a conference poster, so details such as RAPM scores are not included. It may be related to Kundu et al 2011.
Kundu Et Al 2013
The interim posters Kundu 201115ya & 201214ya were published as “Strengthened effective connectivity underlies transfer of working memory training to tests of short-term memory and attention”, Kundu et al 201313ya:
Although long considered a natively endowed and fixed trait, working memory (WM) ability has recently been shown to improve with intensive training. What remains controversial and poorly understood, however, are the neural bases of these training effects, and the extent to which WM training gains transfer to other cognitive tasks. Here we present evidence from human electrophysiology (EEG) and simultaneous transcranial magnetic stimulation (TMS) and EEG that the transfer of WM training to other cognitive tasks is supported by changes in task-related effective connectivity in frontoparietal and parieto-occipital networks that are engaged by both the trained and transfer tasks. One consequence of this effect is greater efficiency of stimulus processing, as evidenced by changes in EEG indices of individual differences in short-term memory capacity and in visual search performance. Transfer to search-related activity provides evidence that something more fundamental than task-specific strategy or stimulus-specific representations have been learned. Furthermore, these patterns of training and transfer highlight the role of common neural systems in determining individual differences in aspects of visuospatial cognition.
Salminen 2012
“On the impacts of working memory training on executive functioning”, Salminen & Strobach & Schubert, Frontiers in Human Neuroscience:
Recent studies have reported improvements in a variety of cognitive functions following sole working memory (WM) training. In spite of the emergence of several successful training paradigms, the scope of transfer effects has remained mixed. This is most likely due to the heterogeneity of cognitive functions that have been measured and tasks that have been applied. In the present study, we approached this issue systematically by investigating transfer effects from WM training to different aspects of executive functioning. Our training task was a demanding WM task that requires simultaneous performance of a visual and an auditory n-back task, while the transfer tasks tapped WM updating, coordination of the performance of multiple simultaneous tasks (ie. dual-tasks) and sequential tasks (ie. task switching), and the temporal distribution of attentional processing. Additionally, we examined whether WM training improves reasoning abilities; a hypothesis that has so far gained mixed support. Following training, participants showed improvements in the trained task as well as in the transfer WM updating task. As for the other executive functions, trained participants improved in a task switching situation and in attentional processing. There was no transfer to the dual-task situation or to reasoning skills. These results, therefore, confirm previous findings that WM can be trained, and additionally, they show that the training effects can generalize to various other tasks tapping on executive functions.
Passive control group; unspeeded RAPM test.
Redick Et Al 2012
“No evidence of transfer after working memory training: A controlled, randomized study” (supplement), Redick et al 201214ya; abstract:
Numerous recent studies seem to provide evidence for the general intellectual benefits of working memory training. In reviews of the training literature, Shipstead, Redick, and Engle (201016ya, in press) argued that the field should treat recent results with a critical eye. Many published working memory training studies suffer from design limitations (no-contact control groups, single measures of cognitive constructs), mixed results (transfer of training gains to some tasks but not others, inconsistent transfer to the same tasks across studies), and lack of theoretical grounding (identifying the mechanisms responsible for observed transfer). The current study compared young adults who received 20 sessions of practice on an adaptive dual n-back program (working memory training group) or an adaptive visual search program (active placebo-control group) with a no-contact control group that received no practice. In addition, all subjects completed pre-test, mid-test, and post-test sessions, comprising multiple measures of fluid intelligence, multitasking, working memory capacity, crystallized intelligence, and perceptual speed. Despite improvements on both the dual n-back and visual search tasks with practice, and despite a high level of statistical power, there was no positive transfer to any of the cognitive ability tests. We discuss these results in the context of previous working memory training research, and address issues for future working memory training studies.
75 subjects; RAPM was speeded.
Rudebeck 2012
“A Potential Spatial Working Memory Training Task to Improve Both Episodic Memory and Fluid Intelligence”, Rudebeck et al 201214ya:
One current challenge in cognitive training is to create a training regime that benefits multiple cognitive domains, including episodic memory, without relying on a large battery of tasks, which can be time-consuming and difficult to learn. By giving careful consideration to the neural correlates underlying episodic and working memory, we devised a computerized working memory training task in which neurologically healthy participants were required to monitor and detect repetitions in two streams of spatial information (spatial location and scene identity) presented simultaneously (ie. a dual n-back paradigm). Participants’ episodic memory abilities were assessed before and after training using two object and scene recognition memory tasks incorporating memory confidence judgments. Furthermore, to determine the generalizability of the effects of training, we also assessed fluid intelligence using a matrix reasoning task. By examining the difference between pre- and post-training performance (ie. gain scores), we found that the trainers, compared to non-trainers, exhibited a significant improvement in fluid intelligence after 20 days. Interestingly, pre-training fluid intelligence performance, but not training task improvement, was a significant predictor of post-training fluid intelligence improvement, with lower pre-training fluid intelligence associated with greater post-training gain. Crucially, trainers who improved the most on the training task also showed an improvement in recognition memory as captured by d-prime scores and estimates of recollection and familiarity memory. Training task improvement was a significant predictor of gains in recognition and familiarity memory performance, with greater training improvement leading to more marked gains. In contrast, lower pre-training recollection memory scores, and not training task improvement, led to greater recollection memory performance after training. Our findings demonstrate that practice on a single working memory task can potentially improve aspects of both episodic memory and fluid intelligence, and that an extensive training regime with multiple tasks may not be necessary.
Speeded BOMAT (“Due to time restrictions and the possibility of ceiling effects associated with some gf tests, participants were given 10 minutes to complete as many patterns as they could in each assessment session (for a similar procedure see Jaeggi et al 200818ya).”); 55 subjects total, experimentals trained for 400 minutes, passive control group. The improvement predictor sounds like a post hoc analysis and may be something like regression to a mean.
Heinzel Et Al 2013
“Working memory training improvements and gains in non-trained cognitive tasks in young and older adults”, Heinzel et al 201313ya:
Previous studies on working memory training have indicated that transfer to non-trained tasks of other cognitive domains may be possible. The aim of this study is to compare working memory training and transfer effects between younger and older adults (n = 60). A novel approach to adaptive n-back training (12 sessions) was implemented by varying the working memory load and the presentation speed. All participants completed a neuropsychological battery of tests before and after the training. On average, younger training participants achieved difficulty level 12 after training, while older training participants only reached difficulty level 5. In younger participants, transfer to Verbal Fluency and Digit Symbol Substitution test was found. In older participants, we observed a transfer to Digit Span Forward, CERAD Delayed Recall, and Digit Symbol Substitution test. Results suggest that working memory training may be a beneficial intervention for maintaining and improving cognitive functioning in old age.
Single n-back; passive control group; no transfer in young or old training group to “Raven’s Standard Progressive Matrices (Raven’s SPM) and the Figural Relations subtest of a German intelligence test (Leistungspruefsystem, LPS, Horn, 198343ya)” (increased but sample size is too small to reach statistical-significance in the young group); RPM speeded (7.5 minutes). See pg19 for graphs of the IQ test performance.
Onken 2013
“Transfer von Arbeitsgedächtnistraining auf die fluide Intelligenz”, Johanna Onken 201313ya; some sort of re-reporting or version of the Heinzel data.
Fluid intelligence describes the ability to think abstract, to adapt to new situations and to solve unknown problems. It is important for learning as well as for academic and professional success. Working memory is characterized as a cognitive system, that saves information over a short period of time in spite of possible distractions. Moreover, working memory is able to assess the relevance of information while requirements change. Effective implicit training is able to increase the working memory capacity. Furthermore it was shown that working memory training may also cause transfer effects to higher cognitive abilities such as fluid intelligence. To clarify the underlying processes of this transfer, various transfer models were presented, which either accentuate the relevance of processing speed, executive functions or short time memory. The purpose of this survey was to confirm transfer effects of working memory training to different cognitive abilities and, on the other hand, to investigate the mechanism of the transfer according to the proposed transfer models. 30 healthy subjects [age 22-30 years] participated in the study and were randomly assigned to either training or control group. The training group practiced an adaptive N-back working memory task for four weeks. Before, after one week and after four weeks of the training, a range of neuropsychological tasks was performed by the participants, testing for different cognitive abilities. Relative to the control group that did not participate in the training, transfer effects to processing speed, executive functions and fluid intelligence tasks have been found. Additionally, the training resulted in a significant shortening of reaction time. In summary, the present study demonstrates that complex cognitive abilities can be improved through effective working memory training. The question on which cognitive mechanisms the transfer is based could not be answered definitively by this study. The results suggest that the adaptive working memory training has led mainly to faster basal cognitive processes, which in turn resulted in a faster processing of intelligence tests.
30 subjects, passive control group, 4 weeks; controls paid 50 euros, experimentals 150 euros, 480 minutes of training, single n-back. IQ tests administered: RPM, LPS, MWT-B. On pg40 are all the post-test results: “Tabelle 3.7: Deskriptive Daten der Neuropsychologie im Posttest (t3)”; discussion of RPM results on pg46.
Thompson Et Al 2013
“Failure of Working Memory Training to Enhance Cognition or Intelligence”:
…The current study attempted to replicate and expand those results by administering a broad assessment of cognitive abilities and personality traits to young adults who underwent 20 sessions of an adaptive dual n-back working memory training program and comparing their post-training performance on those tests to a matched set of young adults who underwent 20 sessions of an adaptive attentional tracking program. Pre- and post-training measurements of fluid intelligence, standardized intelligence tests, speed of processing, reading skills, and other tests of working memory were assessed. Both training groups exhibited substantial and specific improvements on the trained tasks that persisted for at least 6 months post-training, but no transfer of improvement was observed to any of the non-trained measurements when compared to a third untrained group serving as a passive control. These findings fail to support the idea that adaptive working memory training in healthy young adults enhances working memory capacity in non-trained tasks, fluid intelligence, or other measures of cognitive abilities.
Covariate details:
…Two groups of young adults, stratified so as to be equated on initial fluid IQ scores, were randomly assigned to two conditions (a randomized controlled trial or RCT). The experimental group performed the dual n-back task (as in the original Jaeggi et al 2008 study [6]) for approximately 40 minutes per day, 5 days per week for 4 weeks (20 sessions of 30 blocks per session, exceeding the maximum of 19 sessions of 20 blocks per day in the original Jaeggi et al 2008 study). An active control group performed a visuospatial skill learning task, multiple object tracking (or MOT), on an identical training schedule. We also tested a no-contact group equated for initial fluid IQ in case both kinds of training enhanced cognitive abilities…Participants were given 25 minutes to complete each half of the RAPM…Participants in the training groups were paid $20 per training session, with a $20 bonus per week for completing all five training sessions in that week. All participants were paid $20 per hour for behavioral testing, and $30 per hour for imaging sessions (data from imaging sessions are reported separately)….After recruitment, participants underwent approximately six hours of behavioral testing spread across three days and two hours of structural and functional magnetic resonance imaging. [Thompson says there were additional payments for imaging not mentioned, so the true expected-value of participation was $740.]
In line with my meta-analysis’s null on a dose-response effect:
One method of assessing whether the amount of training improvement affects the degree of transfer is to measure the correlation between training and transfer gains. For both the n-back and MOT groups, a positive correlation was observed between the amount of improvement during training and the amount of improvement on the trained task between the pre- and post-assessment (n-back r = .85, p<.0001; MOT r = .77, p<.0001). However, the amount of training gain did not significantly predict improvement on any transfer task; participants who improved to a greater extent on the training tasks did not improve more or less on potential transfer tasks than did participants who improved to a lesser extent (all n-back r values <.33, all p’s >.15; all MOT r values <.38, all p’s >.11). Figure S2 depicts the absence of a relation between improvement on trained tasks and the post-training changes in the RAPM and the combined span tasks.
Note also that the post hoc split of children into ‘improvers’ and not in that Jaeggi paper does not replicate here either:
Another analysis that has previously revealed a difference in transfer between participants who exhibited larger or smaller training gains has been a division of participants into groups based on training gains above or below the group median (median split) [15]. Such a median split of participants in the present study who performed the n-back training yielded no significant differences in transfer between groups (all n-back t-ratios <1.78, all p’s >.09). The only transfer measure that approached significance (at p = .09) was on the RAPM test, in which the participants who improved less on the trained n-back task had higher scores on the post-training behavioral testing. Similarly, when separating the MOT participants into two groups based on median MOT improvement, the two groups showed no significant differences in transfer performance (all MOT t-ratios <1.74, all p’s >.10).
The personality correlates from Studer-Luethi 201214ya also don’t work:
We also examined whether personality assessments were associated with different training or transfer outcomes. Neither the Dweck measure of attitude toward intelligence (a “growth mindset”) nor measures of conscientiousness or grit correlated significantly with training gains on either training task, although there was a trend toward a significant negative correlation between the growth mindset and improvement on the n-back training task (r = −.44, p = .051), such that participants who viewed intelligence as more malleable had less improvement across their n-back training. A greater growth mindset score was positively correlated, however, with improvement on the Ravens Advanced Progressive Matrices in the n-back group (r = .53, p = .017) and in the passive control group (r = .51, p = .027), but not in the MOT control group (r = .031, p>.9). No other transfer measures were significantly predicted by growth mindset scores.
Although the conscientiousness scores and “grit” scores were highly correlated in each of the three treatment groups (n-back r = .75, p<.001; MOT r = .70, p<.001; passive r = .76, p<.001), the two measures differed in their correlations with the behavioral outcome measures. A higher “grit” score predicted less improvement on the RAPM for the n-back group (r = −.45, p = .049) and the MOT group (r = −.58, p = .009), such that participants who viewed themselves as having more “grit” improved less on the RAPM after training, although this relationship did not hold for the No-Contact group (r = .17, p = .5). Similarly, a higher score on the conscientiousness measure predicted less improvement on the RAPM for the MOT group (r = −.57, p = .01), such that participants who saw themselves as more conscientious improved less on the RAPM after training, although this was not observed in either of the other two groups (n-back r = −.21, p = .37; no-contact r = −.04, p = .85). Finally, a high conscientiousness score predicted a lower Pair Cancellation improvement within the MOT group (r = −.47, p = .04), but not in the n-back or no-contact control groups (n-back r = −.07, p = .77; no-contact r = −.13, p = .58). No other transfer measures were significantly predicted by either conscientiousness or grit scores.
Smith Et Al 2013
“Exploring the effectiveness of commercial and custom-built games for cognitive training”, Smith et al 2013
There is increasing interest in quantifying the effectiveness of computer games in non-entertainment domains. We have explored general intelligence improvements for participants using either a commercial-off-the-shelf (COTS) game [Brain Age], a custom do-it-yourself (DIY) training system for a working memory task [DNB] or an online strategy game to a control group (without training). Forty university level participants were divided into four groups (COTS, DIY, Gaming, [Passive] Control) and were evaluated three times (pre-intervention, post-intervention, 1-week follow-up) with three weeks of training. In general intelligence tests both cognitive training systems (COTS and DIY groups) failed to produce [statistically-]significant improvements in comparison to a control group or a gaming group. Also neither cognitive training system produced [statistically-]significant improvements over the intervention or follow-up periods.
Dual n-back; RAPM (10 minutes each test); 1 passive control group, 2 actives; 340 minutes training; minimal compensation (course credit & entry into “a prize draw”, which was worth 100£). Very small sample sizes (~10 in each of the 4 groups).
Nussbaumer Et Al 2013
“Limitations and chances of working memory training”, Nussbaumer et al 201313ya:
Recent studies show controversial results on the trainability of working memory (WM) capacity being a limiting factor of human cognition. In order to contribute to this open question we investigated if participants improve in trained tasks and whether gains generalize to untrained WM tasks, mathematical problem solving and intelligence tests.
83 adults trained over a three week period (7.5 hours total) in one of the following conditions: A high, a medium or a low WM load group. The present findings show that task specific characteristics could be learned but that there was no transfer between trained and untrained tasks which had no common elements. Positive transfer occurred between two tasks focusing on inhibitory processes. It might be possible to enhance this specific component of WM but not WM capacity as such. A possible enhancement in a learning test is of high educational interest and worthwhile to be investigated further.
One of the two IQ tests was the RAPM; this was dual n-back, but it was adaptive only in the “high” experimental group (so the “medium” and “low” groups are largely irrelevant). Paper does not provide RAPM score details, so I emailed the lead author.
Oelhafen Et Al 2013
“Increased parietal activity after training of interference control”,
…In the current study, we examined whether training on two variants of the adaptive dual n-back task would affect untrained task performance and the corresponding electrophysiological event-related potentials (ERPs). 43 healthy young adults trained for three weeks with a high or low interference training variant of the dual n-back task, or they were assigned to a passive control group. While n-back training with high interference led to partial improvements in the Attention Network Test (ANT), we did not find transfer to measures of working memory and fluid intelligence. ERP analysis in the n-back task and the ANT indicated overlapping processes in the P3 time range. Moreover, in the ANT, we detected increased parietal activity for the interference training group alone. In contrast, we did not find electrophysiological differences between the low interference training and the control group. These findings suggest that training on an interference control task leads to higher electrophysiological activity in the parietal cortex, which may be related to improvements in processing speed, attentional control, or both.
Sprenger Et Al 2013
“Training working memory: Limits of transfer”, Sprenger et al 201313ya; abstract:
In two experiments (totaling 253 adult participants), we examined the extent to which intensive working memory training led to improvements on untrained measures of cognitive ability. Although participants showed improvement on the trained task and on tasks that either shared task characteristics or stimuli, we found no evidence that training led to general improvements in working memory. Using Bayes Factor analysis, we show that the data generally support the hypothesis that working memory training was ineffective at improving general cognitive ability. This conclusion held even after controlling for a number of individual differences, including need for cognition, beliefs in the malleability of intelligence, and age.
Colom Et Al 2013
“Adaptive n-back training does not improve fluid intelligence at the construct level; gains on individual tests suggest training may enhance visuospatial processing”, Colom et al 201313ya:
Short-term adaptive cognitive training based on the n-back task is reported to increase scores on individual ability tests, but the key question of whether such increases generalize to the intelligence construct is not clear. Here we evaluate fluid/abstract intelligence (gf), crystallized/verbal intelligence (Gc), working memory capacity (WMC), and attention control (ATT) using diverse measures, with equivalent versions, for estimating any changes at the construct level after training. Beginning with a sample of 169 participants, two groups of twenty-eight women each were selected and matched for their general cognitive ability scores and demographic variables. Under strict supervision in the laboratory, the training group completed an intensive adaptive training program based on the n-back task (visual, auditory, and dual versions) across twenty-four sessions distributed over twelve weeks. Results showed this group had the expected systematic improvements in n-back performance over time; this performance systematically correlated across sessions with gf. Gc, and WMC, but not with ATT. However, the main finding showed no significant changes in the assessed psychological constructs for the training group as compared with the control group. Nevertheless, post-hoc analyses suggested that specific tests and tasks tapping visuospatial processing might be sensitive to training.
<– One hundred and sixty nine psychology undergraduates completed a battery of twelve intelligence tests and cognitive tasks measuring fluid-abstract and crystallized-verbal intelligence, working memory capacity, and attention control. After computing a general index from the six intelligence tests, two groups of twenty-eight females were recruited for the study. They were paid for their participation€. Members of each group were carefully matched for their general intelligence index, so they were perfectly overlapped and represented a wide range of scores. All participants were right handed, as assessed by the Edinburgh Test (Oldfield, 1971). They also completed a set of questions asking for medical or psychiatric disorders, as well as substance intake. The recruitment process followed the Helsinki guidelines (World Medical Association, 2008) and the local ethics committee approved the study. Descriptive statistics for the demographic variables and performance on the cognitive measures for the two groups of participants (training and control) can be seen in the Appendix (Table A.1.). [200€ if assigned to the training group and 100€ if assigned to the control group.] [150 euros in dollars is $204]
The collective psychological assessment for the pretest stage was done from September 19 to October 14 201115ya. Participants were assessed in groups not greater than twenty-five. The data obtained for the complete group (n = 169) were analyzed for recruiting the training (n = 28) and control (n = 28) groups based on the general index computed from the measures of fluid and crystallized intelligence (Table A.1.). The adaptive cognitive training program began in November 14 201115ya, remained active until 2012-02-17, and lasted for twelve weeks (with a break from December 24 201115ya to January 9 201214ya). The psychological assessment for the posttest was done individually from February 20 to March 09 (intelligence tests) and from March 12 to March 30 (cognitive tasks) 201214ya.
Intelligence and cognitive constructs were assessed by three measures each. As noted above, fluid intelligence (gf) requires abstract problem solving abilities, whereas crystallized intelligence (Gc) involves the mental manipulation of cultural knowledge. gf was measured by screening versions (odd numbered items and even numbered items for the pretest and posttest evaluations, respectively) of the Raven Advanced Progressive Matrices Test (RAPM), the abstract reasoning subtest from the Differential Aptitude Test (DAT-AR), and the inductive reasoning subtest from the Primary Mental Abilities Battery (PMA-R). Gc was measured by screening versions (odd numbered items and even numbered items for the pretest and posttest evaluations, respectively) of the verbal reasoning subtest from the DAT (DAT-VR), the numerical reasoning subtest from the DAT (DAT-NR), and the vocabulary subtest from the PMA (PMA-V). gf and Gc were measured by tests with (PMA subtests) and without (RAPM and DAT subtests) highly speeded constraints.
The framework for the cognitive training program followed the guidelines reported by Jaeggi et al 200818ya but it was re-programmed for Visual Basic (200818ya Version). Nevertheless, there were some differences: (a) the training began with four sessions (weeks 1 and 2) with a visual adaptive n-back version and four sessions (weeks 3 and 4) with an auditory adaptive n-back version before facing the sixteen sessions of the adaptive n-back dual program (weeks 5 to 12), and (b) while the training program is usually completed in one month, here we extended the training period to three months (12 weeks). There were two training sessions per week lasting around 30 min each and they took place under strict supervision in the laboratory. Participants worked within individual cabins and the experimenter was always available for attending any request they might have. Data were analyzed every week for checking their progress at both the individual and the group level. Participants received systematic feedback regarding their performance. Furthermore, every two weeks participants completed a motivation questionnaire asking for their (a) involvement with the task, (b) perceived difficulty level, (c) perceived challenging of the task levels, and (d) expectations for future achievement. At the end of the training period participants were asked with respect to their general evaluation of the program. Using a rating scale 0–10, average values were (a) 8.1 (range 8.0 to 8.2 across sessions), (b) 7.9 (range 7.4 to 8.5 across sessions), (c) 8.0 (range 7.8 to 8.2 across sessions), and (d) 7 (range 6.5 to 7.7 across sessions). [12 weeks * 2 sessions * 30 minutes = 720 minutes]
The control group was passive. After the recruitment process, members of this no-contact control group were invited to follow their normal life as university students. As reasoned in some of our previous research reports addressing the potential effect of cognitive training, and according to the main theoretical framework, we were not interested in comparing different types of training, but in the comparison between a specific cognitive training and doing nothing beyond regular life.
Four out of six intelligence tests were applied without severe time constraints. For the RAPM there was more than one minute per item (20 minutes for 18 items). For DAT-AR DAT-NR and DAT-VR, there were approximately 30 seconds per item (10 minutes for 20 items). For the speeded tests (PMA-R and PMA-V) there were between 5 and 12 seconds per item (PMA-R: 3 minutes for 15 items and PMA-V: 2 min for 25 items.)
posttest: training, n=28 RAPM: 37.25 (6.23) control n=28 RAPM: 35.46 (8.26)
DAT-AR PMA-R
Mean differences between the odd and even items were significant (p < 0.001 for all the tests, excluding the DAT-VR) which implies that pretest (odd) and posttest (even) scores must not be directly compared. –>
Burki Et Al 2014
“Individual differences in cognitive plasticity: an investigation of training curves in younger and older adults”, Burki et al 2014
To date, cognitive intervention research has provided mixed but nevertheless promising evidence with respect to the effects of cognitive training on untrained tasks (transfer). However, the mechanisms behind learning, training effects and their predictors are not fully understood. Moreover, individual differences, which may constitute an important factor impacting training outcome, are usually neglected. We suggest investigating individual training performance across training sessions in order to gain finer-grained knowledge of training gains, on the one hand, and assessing the potential impact of predictors such as age and fluid intelligence on learning rate, on the other hand. To this aim, we propose to model individual learning curves to examine the intra-individual change in training as well as inter-individual differences in intra-individual change. We recommend introducing a latent growth curve model (LGCM) analysis, a method frequently applied to learning data but rarely used in cognitive training research. Such advanced analyses of the training phase allow identifying factors to be respected when designing effective tailor-made training interventions. To illustrate the proposed approach, a LGCM analysis using data of a 10-day working memory training study in younger and older adults is reported.
Republication of a thesis.
Pugin Et Al 2014
“Working memory training shows immediate and long-term effects on cognitive performance in children and adolescents”, Pugin et al 201412ya:
Working memory is important for mental reasoning and learning processes. Several studies in adults and school-age children have shown performance improvement in cognitive tests after working memory training. Our aim was to examine not only immediate but also long-term effects of intensive working memory training on cognitive performance tests in children and adolescents. Fourteen healthy male subjects between 10 and 16 years trained a visuospatial n-back task over 3 weeks (30 min daily), while 15 individuals of the same age range served as a passive control group. Significant differences in immediate (after 3 weeks of training) and long-term effects (after 2-6 months) in an auditory n-back task were observed compared to controls (2.5 fold immediate and 4.7 fold long-term increase in the training group compared to the controls). The improvement was more pronounced in subjects who improved their performance during the training. Other cognitive functions (matrices test and Stroop task) did not change when comparing the training group to the control group. We conclude that spatial working memory training in children and adolescents boosts performance in similar memory tasks such as the auditory n-back task. The sustained performance improvement several months after the training supports the effectiveness of the training.
Heffernan 2014
“The Generalizability of Dual n-Back Training in Younger Adults”, Heffernan 201412ya (Halifax, Nova Scotia; Canada):
Introduction: The popularity of cognitive training has increased in recent years. Accumulating evidence shows that training can sometimes improve trained and non-trained cognitive functions, and these improvements may be related to individual differences in initial capacity and performance on the training task. The current study assessed the effectiveness of a custom-designed n-back task (the N-IGMA) versus an active control task (Blockmaster) at improving various forms of working memory capacity, attention, and fluid intelligence. Three measures of working memory capacity were considered: verbal, visuospatial and observed action. Methods: Outcome measures were assessed pre- and post-training. Nineteen healthy young adults (19-30 years of age) trained at-home for 30 minutes per day, five days a week for three weeks with either the N-IGMA (n=9) or Blockmaster (n=10) at-home games. Results: Pre-post changes were observed for some outcome measures and these were equal for the N-IGMA and active control group. Outcome improvements could be due to simple test/re-test benefits or alternatively the N-IGMA and Blockmaster tasks may produce equivalent training effects. Improvements in the training tasks did not correlate with the changes in the outcome measures, suggesting improvements in the outcome measures might not be attributable to transfer of learning. For verbal working memory only, participants with higher (versus lower) initial fluid intelligence demonstrated larger improvements on the outcome measures suggesting that in future research training tasks might need to be tailored to the individual participant. Pre-assessment but not change scores were related for observed action and visuospatial working memory, consistent with some overlap between content domains. Conclusion: Despite specifically targeting working memory, the N-IGMA was not better than a visuospatial control game at improving a variety of cognitive outcome measures in this small sample. Results suggest that the individual’s initial cognitive capacity might need to be considered in future training studies. Caution should be used in extrapolating the results of this study to other populations of interest (eg. older adults or individuals with cognitive deficits) since the present investigation included relatively high functioning individuals.
Hancock 2013
“Processing speed and working memory training in Multiple Sclerosis: a blinded randomized controlled trial”, Hancock 2013
Between 40-65% of patients with multiple sclerosis (MS) experience cognitive deficits associated with the disease. The two most common areas affected are information processing speed and working memory. Information processing speed has been posited as a core cognitive deficit in MS, and working memory has been shown to impact performance on a wide variety of domains for MS patients. Currently, clinicians have few reliable options for addressing cognitive deficits in MS. The current study aimed to investigate the effect of computerized, home-based cognitive training focused specifically on improving information processing speed and working memory for MS patients. Participants were recruited and randomized into either the Active Training or Sham Training group, tested with a neurocognitive battery at baseline, completed six weeks of training, and then were again tested with a neurocognitive battery at follow-up. After correcting for multiple comparisons, results indicated that the Active Training group scored higher on the Paced Auditory Serial Addition Test (a test of information processing speed and attention) following cognitive training, and data trended toward significance on the Controlled Oral Word Associations Task (a test of executive functioning), Letter Number Sequencing (a test of working memory), Brief Visuospatial Memory Test (a test of visual memory), and the Conners’ Continuous Performance Test (a test of attention). Results provide preliminary evidence that cognitive training with MS patients may produce moderate improvement in select areas of cognitive functioning. Follow-up studies with larger samples should be conducted to determine whether these results can be replicated, and also to determine the functional outcome of improvements on neurocognitive tests.
Waris Et Al 2015
“Transfer after Working Memory Updating Training”, Waris et al 2015
During the past decade, working memory training has attracted much interest. However, the training outcomes have varied between studies and methodological problems have hampered the interpretation of results. The current study examined transfer after working memory updating training by employing an extensive battery of pre-post cognitive measures with a focus on near transfer. Thirty-one healthy Finnish young adults were randomized into either a working memory training group or an active control group. The working memory training group practiced with three working memory tasks, while the control group trained with three commercial computer games with a low working memory load. The participants trained thrice a week for five weeks, with one training session lasting about 45 minutes. Compared to the control group, the working memory training group showed strongest transfer to an n-back task, followed by working memory updating, which in turn was followed by active working memory capacity. Our results support the view that working memory training produces near transfer effects, and that the degree of transfer depends on the cognitive overlap between the training and transfer measures.
Baniqued Et Al 2015
“Working Memory, Reasoning, and Task Switching Training: Transfer Effects, Limitations, and Great Expectations?”, Baniqued et al 201511ya:
Although some studies have shown that cognitive training can produce improvements to untrained cognitive domains (far transfer), many others fail to show these effects, especially when it comes to improving fluid intelligence. The current study was designed to overcome several limitations of previous training studies by incorporating training expectancy assessments, an active control group, and “Mind Frontiers,” a video game-based mobile program comprised of six adaptive, cognitively demanding training tasks that have been found to lead to increased scores in fluid intelligence (gf) tests. We hypothesize that such integrated training may lead to broad improvements in cognitive abilities by targeting aspects of working memory, executive function, reasoning, and problem solving. Ninety participants completed 20 hour-and-a-half long training sessions over four to five weeks, 45 of whom played Mind Frontiers and 45 of whom completed visual search and change detection tasks (active control). After training, the Mind Frontiers group improved in working memory n-back tests, a composite measure of perceptual speed, and a composite measure of reaction time in reasoning tests. No training-related improvements were found in reasoning accuracy or other working memory tests, nor in composite measures of episodic memory, selective attention, divided attention, and multi-tasking. Perceived self-improvement in the tested abilities did not differ between groups. A general expectancy difference in problem-solving was observed between groups, but this perceived benefit did not correlate with training-related improvement. In summary, although these findings provide modest evidence regarding the efficacy of an integrated cognitive training program, more research is needed to determine the utility of Mind Frontiers as a cognitive training tool.
Kuper & Karbach 2015
N-back training has recently come under intense scientific scrutiny due to reports of training-related improvements in general fluid intelligence. As of yet, relatively little is known about the effects of short-term n-back training interventions, however. In a pretest-training-posttest design, we compared brief dual and single n-back training regimen in terms of training gains and transfer effects relative to a passive control group. Transfer effects indicated that, in the short-term, single n-back training may be the more effective training task: At the short training duration we employed, training group showed far transfer to specific task switch costs, Stroop inhibition or matrix reasoning indexing fluid intelligence. Yet, both types of training resulted in a reduction of general task switch costs indicating improved cognitive control during the sustained maintenance of competing task sets. Single but not dual n-back training additionally yielded near transfer to an untrained working memory updating task.
Lindeløv Et Al 2016
“Training and transfer effects of N-back training for brain-injured and healthy subjects”, Lindeløv et al 2016:
Working memory impairments are prevalent among patients with acquired brain injury (ABI). Computerised training targeting working memory has been researched extensively using samples from healthy populations but this field remains isolated from similar research in ABI patients. We report the results of an actively controlled randomized controlled trial in which 17 patients and 18 healthy subjects completed training on an N-back task. The healthy group had superior improvements on both training tasks (SMD = 6.1 and 3.3) whereas the ABI group improved much less (SMD = 0.5 and 1.1). Neither group demonstrated transfer to untrained tasks. We conclude that computerised training facilitates improvement of specific skills rather than high-level cognition in healthy and ABI subjects alike. The acquisition of these specific skills seems to be impaired by brain injury. The most effective use of computer-based cognitive training may be to make the task resemble the targeted behavior(s) closely in order to exploit the stimulus-specificity of learning.
Schwarb Et Al 2015
“Working memory training improves visual short-term memory capacity”, Schwarb et al 2015
Lawlor-Savage & Goghari 2016
“Dual n-Back Working Memory Training in Healthy Adults: A Randomized Comparison to Processing Speed Training”, Lawlor-Savage & Goghari 2016:
Enhancing cognitive ability is an attractive concept, particularly for middle-aged adults interested in maintaining cognitive functioning and preventing age-related declines. Computerized working memory training has been investigated as a safe method of cognitive enhancement in younger and older adults, although few studies have considered the potential impact of working memory training on middle-aged adults. This study investigated dual n-back working memory training in healthy adults aged 30-60. Fifty-seven adults completed measures of working memory, processing speed, and fluid intelligence before and after a 5-week web-based dual n-back or active control (processing speed) training program. Results: Repeated measures multivariate analysis of variance failed to identify improvements across the three cognitive composites, working memory, processing speed, and fluid intelligence, after training. Follow-up Bayesian analyses supported null findings for training effects for each individual composite. Findings suggest that dual n-back working memory training may not benefit working memory or fluid intelligence in healthy adults. Further investigation is necessary to clarify if other forms of working memory training may be beneficial, and what factors impact training-related benefits, should they occur, in this population.
Studer-Luethi Et Al 2015
“Working memory training in children: Effectiveness depends on temperament”, Studer-Luethi et al 201511ya:
Studies revealing transfer effects of working memory (WM) training on non-trained cognitive performance of children hold promising implications for scholastic learning. However, the results of existing training studies are not consistent and provoke debates about the potential and limitations of cognitive enhancement. To examine the influence of individual differences on training outcomes is a promising approach for finding causes for such inconsistencies. In this study, we implemented WM training in an elementary school setting. The aim was to investigate near and far transfer effects on cognitive abilities and academic achievement and to examine the moderating effects of a dispositional and a regulative temperament factor, neuroticism and effortful control. Ninety-nine second-graders were randomly assigned to 20 sessions of computer-based adaptive WM training, computer-based reading training, or a no-contact control group. For the WM training group, our analyses reveal near transfer on a visual WM task, far transfer on a vocabulary task as a proxy for crystallized intelligence, and increased academic achievement in reading and math by trend. Considering individual differences in temperament, we found that effortful control predicts larger training mean and gain scores and that there is a moderation effect of both temperament factors on post-training improvement: WM training condition predicted higher post-training gains compared to both control conditions only in children with high effortful control or low neuroticism. Our results suggest that a short but intensive WM training program can enhance cognitive abilities in children, but that sufficient self-regulative abilities and emotional stability are necessary for WM training to be effective….We found no significant training group interaction on the performance in the Raven’s Progressive Matrices (F(2,92) = 1.57, p = .22, ηp2 = .004)…We found no significant long-term effects in the variables memory span, cognitive control, gf. Gc, and scholastic tests (all T < 1.4).
Minear Et Al 2016
“A simultaneous examination of two forms of working memory training: Evidence for near transfer only”, Minear et al 2016
The efficacy of working-memory training is a topic of considerable debate, with some studies showing transfer to measures such as fluid intelligence while others have not. We report the results of a study designed to examine two forms of working-memory training, one using a spatial n-back and the other a verbal complex span. Thirty-one undergraduates completed 4 weeks of n-back training and 32 completed 4 weeks of verbal complex span training. We also included two active control groups. One group trained on a non-adaptive version of n-back and the other trained on a real-time strategy video game. All participants completed pre- and post-training measures of a large battery of transfer tasks used to create composite measures of short-term and working memory in both verbal and visuospatial domains as well as verbal reasoning and fluid intelligence. We only found clear evidence for near transfer from the spatial n-back training to new forms of n-back, and this was the case for both adaptive and non-adaptive n-back.
Studer-Luethi Et Al 2016
“Working memory training in children: Effectiveness depends on temperament”, Studer-Luethi et al 2016:
Studies revealing transfer effects of working memory (WM) training on non-trained cognitive performance of children hold promising implications for scholastic learning. However, the results of existing training studies are not consistent and provoke debates about the potential and limitations of cognitive enhancement. To examine the influence of individual differences on training outcomes is a promising approach for finding causes for such inconsistencies. In this study, we implemented WM training in an elementary school setting. The aim was to investigate near and far transfer effects on cognitive abilities and academic achievement and to examine the moderating effects of a dispositional and a regulative temperament factor, neuroticism and effortful control. Ninety-nine second-graders were randomly assigned to 20 sessions of computer-based adaptive WM training, computer-based reading training, or a no-contact control group. For the WM training group, our analyses reveal near transfer on a visual WM task, far transfer on a vocabulary task as a proxy for crystallized intelligence, and increased academic achievement in reading and math by trend. Considering individual differences in temperament, we found that effortful control predicts larger training mean and gain scores and that there is a moderation effect of both temperament factors on post-training improvement: WM training condition predicted higher post-training gains compared to both control conditions only in children with high effortful control or low neuroticism. Our results suggest that a short but intensive WM training program can enhance cognitive abilities in children, but that sufficient self-regulative abilities and emotional stability are necessary for WM training to be effective.
…Fluid intelligence was assessed using either the even or odd items of Raven’s Progressive Matrices in counterbalanced order (RPM, 30 items; Raven, 199828ya). After two practice trials, children were allowed to work for 10 min and cross the right solution for each task. The number of correct solutions provided in this time limit was used as the dependent variable.
…We found no significant training group interaction on the performance in the Raven’s Progressive Matrices (F(2,92) = 1.57, p = .22, ηp2 = .004).
Meta-Analysis
I construct a meta-analysis of the >19 studies which measure IQ after an n-back intervention, confirming that there is a gain of small-to-medium effect size. I also investigate several n-back claims, criticisms, and indicators of bias, finding:
active vs passive control groups criticism: found, and it accounts for half the total effect size (similar to Zehdner et al 2009 & Melby-Lervåg & Hulme 2013)
dose-response relationship of n-back training time & IQ gains claim: not found
payment reducing performance claim: not found
kind of n-back matters: not found
publication bias criticism: not found
speeding of IQ tests criticism: not found
Due to its length and technical detail, my meta-analysis has been moved to a separate page.
Does It Really Work?
N-Back Improves Working Memory
There are quite a few studies showing significant increases in working memory: WM is something that can be trained. See for example “Changes in cortical activity after training of working memory - a single-subject analysis.” or “Increased prefrontal and parietal activity after training of working memory”.
There are a few studies showing that DNB training enhances gf; see the support section. There is also a study showing that WM training (not DNB) enhances Gc68.
IQ Tests
Measuring
Because N-back is supposed to improve your pure ‘fluid intelligence’ (gf), and not, say, your English vocabulary, the most accurate tests for seeing whether N-back has done anything are going to be ones that avoid vocabulary or literature or tests of subject-area knowledge. That is, ‘culture-neutral’ IQ tests. (A non-neutral test focuses more on your ‘crystallized intelligence’, while N-back is supposed to affect ‘fluid intelligence’; they do affect each other a little but it’s better to test fluid intelligence with a fluid intelligence test.)
As one ML member writes:
The WAIS test involves crystallized intelligence and is unsuitable for judging fluid intelligence. High working memory will not spawn the ability to solve complex mathematical and verbal problems on its own, you have to put your extended capacity to learning. All very-high-level IQ tests are largely crystallized IQ tests, therefore working memory gains will not be immediately apparent by their measure.ref
Available Tests
The gold-standard of culture-neutral IQ tests is Raven’s progressive matrices. Unfortunately, Raven’s is not available for free online, but there are a number of clones one can use - bearing in mind their likely inaccuracy and the fact that many of them do not randomize their questions. It’s a very good idea, if you plan to n-back for a long time, to take an IQ test before and an IQ test after, both to find out whether you improved and so you can tell the rest of us. But the interval has to be a long one: if you are testing at the beginning and end of your training there is probably going to be a practice effect which will distort your second score upwards69; it’s strongly recommended you take a particular test only once, or with intervals on the order of months (and preferably years).
The tests are:
iqtest.dk (interpret scores with caution: it seems that the maintainer renormed it on the population of online test-takers (!), which means it will be low. Many people report that their scores are much lower on it than standardized tests, and few report higher.)
“Culture Fair Numerical & Spatial Exam” -(formerly used by high-IQ societies)
Jouve-Cerebrals test of induction (formerly “Tri 52”)
High IQ Society Online Test (includes eCMA)
RAPM (for fee)
https://iqtest.com/ (for fee)
Raven-style matrix tests can be mechanically generated by the Sandia Generated Matrix Tool; the generated matrix test scores statistically look very similar to SPM test scores according to the paper, “Recreating Raven’s: Software for systematically generating large numbers of Raven-like matrix problems with normed properties”.
If Raven-style tests bore you or you’ve gone through the previous ones, there are a wealth of difficult tests at Miyaguchi’s “Uncommonly Difficult IQ Tests”, and a five-factor personality test, the IPIP-NEO, is free (although the connection to IQ is minimal).
Other tests that might be useful include digit-span tests: they provide a non-dual-N-back method of measuring WM before one begins training and then after. There is also Cogtest suite of spans and attention tasks or the https://cognitivefun.net/ site (which implements many tasks). The Automated Operation Span (OSPAN) Task could be used as well.
IQ Test Results
Reports of IQ tests have been mixed. Some results have been stunning, others have shown nothing.
Improvement
LSaul posted about his apparent rise in IQ back in October. From what I remember, he had recently failed to qualify for MENSA, which requires a score of about 131 (98th percentile). He then got a 151 (99.97th percentile) on a professionally administered IQ test (WAIS) three months later, after 2 months of regular dual-n-back use. –MR
(A >20 point gain sounds very impressive. But possible confounding factors here are that LSaul apparently took 2 different IQ tests; besides the general incomparability of different IQ tests, it sounds as if the first test was a culture-neutral one, while the WAIS has components such as verbal tests - the second might well be ‘easier’ for LSaul than the first.)
Mike L. writes:
Empirically speaking, however: I took a WAIS-IV IQ test (administered professionally) around a year ago and got a 110. I took a derivative of the same test recently (mind you, after about 20 days of DNB training) and got a score of 121.
The blogger of “Inhuman Experiment”, who played for ~22 days and went from ~2.6-back to ~4-back, reports:
The other test proved to be quite good (you can find it here). In this one, the questions vary, the difficulty is adjusted on the go depending on whether you answer them correctly, and there’s a time limit of 45 seconds per question, which makes this test better suited for re-taking. My first test, taken before playing the game, gave me a score of 126; my second test, taken yesterday, gave me a score of 132 (an increase of about 5%)….As you can see, it’s kind of difficult to draw any meaningful conclusions from this. Yes, there was a slight increase in my score, but I would say a similar increase could’ve been possible even without playing the game. I think the variation in the IQ test questions reduces the “learning by heart” effect, but that’s impossible to say without a control group.
Pontus Granström writes that
I scored 133 on www.mensa.dk/iqtest.swf today. I have never scored that high before I really feel the “DNB thinking” kicking in.
(He apparently took that test about a year ago, and avers that his original score on it ‘was 122. Well below 130.’)
Pheonexia writes:
Approximately three years ago I took the “European IQ Test.” It was posted on some message board and the author of the thread said the test was credible. At that time, I scored 126.
I’ve been n-backing since early February, so I figured I’d try it again today. I googled “European IQ Test” and clicked the first result, a test from Nanyang Technological University in Singapore. I don’t recall any of the exact questions for the first one I took three years ago, but the format of this test seemed almost identical. Today I scored 144, 18 points higher than before. https://www3.ntu.edu.sg/czzhao/iq/test.htm
To me, this is anecdotal evidence that n-backing does increase intelligence. I’ll try again for another three months and take a completely different test. I will admit, however, that I recognized one of the first questions as the Fibonacci sequence, so I attribute that to crystallized, not fluid intelligence. The highest score this test allows for is 171, meaning you got ZERO questions wrong. I got 6 wrong and 3 half questions wrong where it requires two answers (that was my worst section), so either 7.5 or 9 out of 33 questions wrong.
I took one of the IQ tests I did previously [previously linked as “High IQ Society Online Test”] and scored 109 on, I just took it again and scored 116…I don’t know about retest effect, but all the questions were different.
Toto writes in “TNB(PIA) may improve intelligence”:
While DNB proved ineffective for me (at least it didn’t increase my IQ, though it improved memory) TNB may have made a difference. I took 2 high-range tests during the last 2 months and the results were higher than I expected - my IQ was somewhere between 130 and 135 on good online tests, I scored 132 on a supervised test (Raven’s SM). My results on CFNSE https://etienne.se/cfnse/ and GET-γ https://www.epiqsociety.net/get were approximately 10 points higher - 6 on CFNSE (8 on my second attempt) and 21 on G.E.T . It could be because of a flaw of these tests, or they may not test the same ability as timed tests (though the correlation between them and famous supervised timed tests is said to be very high), it may be for some other reason as well, but it could be because of TNB. I had tried CFNSE long ago and scored 0 (but I probably didn’t try hard enough then).
christopher lines reports:
I did a couple of the online IQ tests after about 10 days (scored 126 in one of them [iqtest.dk] and 106 [iqout.com] in another); I repeated the same tests about a month later (about 1 month ago) and scored (133 and 109). I have no idea why the tests gave such big differences in scores but I definately [sic] think its easier the second time you do the tests because I remembered the strategies for solving the problems which took some time to figure out when I first did the tests. I am kind of against keep re-doing the tests because of learning effects and a bit truobled [sic] that different test produce such different results.
Tofu writes:
I’ve purposely not been doing anything to practice for the tests or anything else I thought could increase my score so I wouldn’t have to factor other things into an improvement in iq, which makes improvements more likely attributable to dual n-back. Before I took the test I scored at 117, a score about 1 in about 8 people can get (7.78 to be exact), and yesterday I scored at 127 (a score that 1 in 28 people would get). Its a pretty big difference I would say.
After a year of N-backing, Tofu has 3 sets of IQ test results using Self-Scoring IQ Tests (Victor Serebriakoff). To summarize:
0 months (D3B; ~71%): 27,25 = 117 IQ
3 (T4B; ~76%): 37,4070 = 128
12 (Q6B; ~47%): 34,42 = 128
Other relevant tests for Tofu:
As a sidenote- after 6 months I took a practice LSAT without any studying and got a 146, roughly 30th percentile, and I took an IQ test from https://iqtest.dk/main.swf after 1 year which I scored a 115 on. Also, in high school I took a professionally administered IQ test and got a 137 which may have been high because they took my age into account in the scoring like the old school IQ tests used to do, but I’m not sure if they actually did that.
Last year I scored 123 in www.iqtest.dk and today I made 140. If you eliminate statistic deviations, even if it’s just 5-10 points it’s very good IMO.
I do actually have gains to report on the “Advanced Culture Fair Test” found on iqcomparisonsite.com that I just took today. Facts: I scored 29 raw (out of 36) IQ 146 or 99.9%ile, compared to my 130 or 98%ile raw 21 that I scored when I took the test over a year ago.
…For comparison to other fluid measures, this result is 3 points higher than my Get-gamma score and 2 points higher than my GIGI certified and 13 points higher than my iqtestdk result which lands in the same place every time I take it (last time I took it was less than a month ago). My current DNB level averages 8+ over multiple (10-20) sessions.
milestones later reported:
Last night I retook the iqtest.org.uk and scored higher on a second try than I did a few months ago—145 up from 133. This could be due to 1. consistent quad back practice 2. being back on creatine as I have been for the last month 3. Omega 3/epa/fish oil 4. just a normal swing in scores due to other factors, including familiarity with the items. Or, of course, maybe some combination of the above
Hey guys I’ve been using brain workshop (Dual N back) for about 2 months now and would like to report an increase in IQ 124 → 132 (on professionally administered IQ tests that were supervised) The IQ tests were separated by a period of about a year as well.
(It’s a little unclear whether this was an improvement or not; the second score was on the Cattell Culture Fair III test, but Lachlan hasn’t said what the first one was. Since different tests have different norms and what not, Lachlan’s scores could actually be the same or declining.)
2008/06 DNB for cca 1 month, 1 - 2 hours a day, 5 times a week; after 2 weeks probably gain +8 points IQ (I think it was Wechsler IQ 140 administered by school psychologist and after 5 months Raven IQ 148 administered by some Mensa guy). No problems at all. Better dream recall.
Argumzio comments on Jan:
The difference between (what I assume both are) WAIS-III and RAPM is fairly significant; the former is about 2.667 sigma (FSIQ), and the latter is just over 3 sigma. For those who wish to know, both are set with a standard deviation of 15.
Keep in mind, however, that with WAIS-III you get the full treatment while with RAPM your fluid ability is assessed as in the original Jaeggi study, so Jan’s performance on other factors may have depressed and concealed his (already) high gf. or performance, capabilities. That’s why it is paramount to use the same test, or a test that is essentially of the same design.
MugginBuns (gains may’ve been from practice, or from a ‘feature selection’-based game MugginBuns is developing):
“https://www.iqtest.dk/main.swf - 126 3 months ago
https://www.gigiassessment.com/shop/index.php - 126 3 months ago
https://www.iqtest.dk/main.swf - 140 2 weeks ago
http://www.cerebrals.org/wp/?page_id=44 - 137 yesterday”
Previously I had a RAPM IQ test result was 112 by certified psychologist. In 200917ya August I practiced DNB 2.5 hours a day for 20 days with time off two days, Saturday and Sunday. After 20 days I took RAPM test in my university by certified psychologist. I got IQ gain was 12.1 points. In the test i was only able to answer more questions that related to changes in position of objects in the test (RAPM).
At 201016ya/04/12 I started SNB(single N-Back, visual modality) with training time was same as on DNB training time for 20 days. IQ gain by RAPM test was no change.That time i also was able to answer more questions that related to changes in position of objects in the RAPM test.
Colin Dickerman in the thread “IQ test in one month!”:
I took a free android IQ test (I’m computerless) and scored 123 about 4 months ago. I’ve started n-backing again and after 4 weeks of consistent effort, I average around 70% at dual 5 back…Okay, I jumped the gun a little bit and retook the test a day early. I scored 126…[My] N-back level stagnated in the mid 60% at 6-back.
Ok, so a few months ago the most i could get on the http://mensa.dk/iqtest/ was about 95,115-126. Well now its 136….with the standard deviation 24 of course…I got to admit that score was on one of my bad days, and I wasn’t really focused, plus I didn’t spend much time on the questions. Probably 2 months ago the highest was 126.
Before n-backing, my IQ lay in the region between 109 and 120 (most online tests always put me in the 113-120 range, but the MENSA test only gave me a result of 109). I’ve probably completed 10 IQ tests over the last 3 years and my scores seem to be relatively consistent….So, I’ve spent about one and a half months on dual-n-back. I did the https://www.iqtest.dk/main.swf test and got an IQ of 123.
iqtest.dk (English) I first attempted this test more than 2 years ago where I obtained a score of between 110-115. I attempted this test again today where I achieved a score of 138.
N-level: Well, as most of you may know, overtime I’ve very much just been rolling around in the mud of what BW has to offer, so because I haven’t stayed in one country long enough to call it home, it’s pretty much impossible for me to attribute my new ‘world view’ to one particular mode or another…DNB: 4-back - 8-back = Time taken to reach level, 10+ months Quad-n-back: 2-back - 6-back = Time taken to reach level, between 6-8 months Variable-arithmetic n-back: 3-back - 7-back = Time taken to reach level, between 3-4 months… [description of daily routine]
I’ve done about 40 half-hour sessions of dual n back and have made gains within the task-ie higher n-back score. Personally I don’t feel much smarter but I’ve noticed I read faster and can comprehend what I am reading at a faster speed as well. Previously I scored a 109, then after 40 sessions I scored at 122 on the Denmark Mensa IQ test. https://www.iqtest.dk/main.swf. My concern is that this supposed gain has not made a noticable improvement in my real-world intelligence, and that the Denmark IQ test is unreliable…I recently took a Mensa puzzle brain-teaser and scored a 18/30, which seems fairly mediocre? I don’t know..I was pretty stumped by some of the questions. Didn’t make me feel too smart….Update: I took the same IQ test(Denmark Mensa) again and I scored a 126, 4 points higher than my previous score of 122. Between taking the tests I had practiced dual n back for about 14 half hour sessions.
I liked IQ tests, especially the iqtest.dk. I did it for the last time between 1-2 years ago. My score was 110, I’m pretty sure. I scored never higher than 110, but also not much lower than 110. Guess i had just average intelligence and i was feeling that way too. On the Wechsler test i did 3-4 years ago i scored 107. so if i formulate it correctly my fluid intelligence was in line with my general intelligence. Now i do it for 11 consequent days, just 25 minutes a day and mostly at this point 2-3-4 back. But after the third day i felt much more clarity and better ability to formulate things, because my memory seemed so much better. Take note that I’m really an extremely sensitive person, so that is probably the reason i felt it so quickly. Today i decided to do the iqtest.dk test again, because i was excited to do it and not wait till the 19th day. My expectation was an iq in the 110-115 range, but guess what i scored 126…A few minutes ago i ended the iqtest.dk again and scored 122. This means for me I’m approximately as smart as 12 days before, furthermore i think i shouldn’t be any differences in raw intelligence.
He later reported additional results:
i did the full wais-iii 12-13 months ago. i scored 111 on the POI, which i think is the best measure for gf (although not a pure measure, but more comprehensive than just matrices) This where the scores within the POI:
Picture completion 11
Block Design 10
Matrix Reasoning 15
I trained 2.5 months from February to April 201214ya. Note that i am 21 years old (intelligence is in some degree malleable till 22/23 years old, right?) Well, i did the wais-iii again and have the results since a week. My POI is now 125 and this is how it looks:
Picture completion 8 (-3)
Block Design 18 (+8)
Matrix reasoning 16 (+1)
I started dual n backing about 5months ago.After training for first 2 months, I took an IQ test and Iqtest.dk. My score was in low 120s.(took the test multiple times and got almost the same score each and every time)
For the next 3 months apart from n backing, I included meditation, image streaming and juggling into my schedule. Yesterday I took the same test at iqtest.dk and got the score as 133.
I first started playing DNB some 3 years ago, trying to play three rounds everyday (skipped at most 20% of the total days), regardless of the n-back level.
2 years ago (highest consistent DNB: 4), I took my first MENSA test - and scored 130 (SD 24), top 10%.
2 weeks ago (highest consistent DNB: 7), I took my second MENSA test - and scored 156 (SD 24), top 1%, so I am joining.
EC:
I’ve been doing n-back since June of 201115ya and I’m averaging now between 8.0 and 8.25. I lay off for as long as six months at a time but get back to where I ended just two days after resuming. Before I started I toke iqtest.dk and scored 105. After six months and regularly scoring above 6 I retook the same test and scored 115. After one year and scoring above 7 I scored 127 IQ points. I retook the test just now and I scored 115.
No Improvement
Some have not:
I took the Online Denmark IQ test again [after N-back training] and I got 140 (the same result) I took a standardized (and charged) online IQ test from iqtest.com and I got 134 (though it may be a bit higher because English is not my mother tongue) –Crypto
jttoto reports a null result:
6 months ago I posted my IQ on this site after taking the Mensa Norway test… [see IQ tests section] I scored a 135. After 6 months of dual n-back, triple n-back, and quad n-back training, I took the same exact test. I scored exactly the same, 135. Granted, I took 7 less minutes to complete the test, but this was due to familiarity of some of the questions. That being said, I have been seeing significant increases in my digit span and other WM gains, so while my aptitude on questions like the Raven’s may not have increased, my memory has.
(It’s worth noting that Jttoto’s experience doesn’t rule out an IQ increase of some sort, as the original 135 score was from an IQ test he took after at least 10 hours of n-backing over 5 days, according to an earlier email; what it shows is that Jttoto didn’t benefit or the benefits happened early on, or there’s some other confounding factor. Test results can be very difficult to interpret.)
moe writes:
“After 6 months of training I decided to take the tri 52 again and there has been no improvement in intelligence (or should I say abstract reasoning ability), I’m still at 144 sd15 on that test. My digit span has gone up a bit from 9 forward 8 reverse to between 10-12 forward and reverse depending on how I’m feeling. I’m still not sure if the improvements in digit span are genuine memory improvements or increased skill at chunking.”
Jttoto further wrote in response to moe:
“Yes, I’ve continued to train QnB myself (about 3-4 times a week). Based on the iqout.com test, if anything, I’ve gone down a little!. This is not surprising and probably not attributed to n-backing. I’m at the age where cognitive decline begins and I was depressed that day. At the same time, one would think I would see measurable gains by now.”
“I’ve had pretty unimpressive findings. I’ve used Brain Workshop 4.4 for about four months, with about a half-hours use 4-6 days a week. I used Denmark IQ test and scored a 112 and after DNB I scored a 110.
My max DNB level was 11. Hours and hours and no gain in iq.”
Mike:
“…here they are (in order of test taking): 119, 125, 125, 107, 153, 131, (and I would say between 125 and 131 was my real iq) from different online tests almost 2 years ago before starting n-backing. after two years (I took the same bunch of online iq tests 3 weeks ago before trying faster trials) I got: 126, 135, 124, 125. so there wasn’t much of a change. but I had been playing n-back softly for a long time. I expected my iq to jump at least by 5 to 10 points, from what I felt in my life. then after my week of faster trials, I did this iq test: and I got 149. if anyone who already knows his iq wants to try it, I’d be curious to know if they also score higher than expected, at first try of course. I thought the 153 I once got was pure chance, but maybe it wasn’t completely, and that would be cool.”
“Been training for about 5 weeks now, 30 mins a day and made very quick progress initially, and now shuttling between n=7 and n=8 and occasionally reaching n=9 (when I set out, I begin with n=2 and the value of N for the next round depends on my performance in the round I just finished)…I took a few intelligence tests (mostly culture insensitive), and the scores have actually”DROPPED” some 3-4 percent. Although I guess that doesn’t mean much because I took those tests towards the end of the day at work and was somewhat exhausted, but it sure as hell means that there is no increase in my intelligence either!!”
Eggs:
“I have used dual, single and combination n back regularly for almost 2 years and no positive results come from it. I have the exact same IQ as I have according to Denmark IQ test. Not even a couple of points higher….Just to clarify, I have used n back, seen no improvement based on IQ tests or real-life benefits.”
Keep in mind, that if IQ is improved, that doesn’t necessarily mean anything unless one employs it to some end. It would be a shame to boost one’s IQ through N-back, but never use it because one was too busy playing!
Other Effects
Between 200818ya and 201115ya, I collected a number of anecdotal reports about the effects of n-backing; there are many other anecdotes out there, but the following are a good representation—for what they’re worth.
Besides these collected reports, there was a group survey: spreadsheet results.
Benefits
To be taken with salt71:
Ashirgo: “To be honest, I do not feel any obvious difference. There are moments in which I perceive a significant improvement, though, as well as particulars task which are much easier now.”
“I have also experienced better dream recalling, with all these reveries and other hallucinations included. I am more happier now than ever. I did doubt it would be ever possible! I am also more prone to get excited…Now people in my motherland are just boring to listen to. They speak too slow and seem as though it took them pains to express anything. I did not notice that after I had done my first ninety days of n-back, but now (after 2.5 months) it is just conspicuous.”ref
“My change of opinion72 can be easily attributed to the improvement of mood, in coincidence with the mere fact that the winter days have passed and now there is a bright and sunny Spring in my country”; when asked if the previous means Ashirgo attributes all the improvement to the weather, Ashirgo replied: “Fortunately, I can attribute many changes to n-back, I can now handle various tasks with little effort and it takes me much less time in comparison with others (especially when I know what to do). Nevertheless, the main problem for me is that I am also occupied with few things that I suppose to be able to test my newly acquired potential, therefore I cannot say that ‘changes’ are explicit everywhere.
On the other hand, I am starting to believe that any improvements (that one can expect) so smoothly and swiftly become a natural part of one’s capabilities that it makes them hardly noticeable until some tests/measures are taken.”
chinmi04: “For me, it definitely has taught me how to focus. But I’m still not sure whether that has something to do with merely coming to realize the importance of focusing, or whether the program has really physically rewired my brain to focus better. In any case, it appears that I’m now faster at mental reasoning, creative thinking and speaking fluency. But again, the effects are not so clear as to completely eliminate any doubt regarding the connection with the n-back program.”
“I have been maintaining a personal blog on WordPress since 3 years ago. Average post per month: a little over 1. Then I started with dual-n-back at the end of November… number of posts in January: 7! (none are about n-back)”
ArseneLupin: “Not much, yet, but I feel that I can easier get a hold of a discussion. The feeling is the same as when I am mastering a certain n-back in the game (a bit hard to explain).”
John: “I feel much sharper since I started in the middle of last November…My productivity is much higher these days. I’m a non-fiction writer, so having a higher working memory and fluid intelligence directly leads to better (and faster) performance. It’s amazing to see the stuff I produce today and compare it to before I began the Dual n-Back training. Also, I am simultaneously learning German, French and Spanish, and I’m certain this is helping me learn those languages faster.”
Ginkgo: “DN-Back has probably helped me with one of my hobbies.”
BamaDoc: “I note a subjective difference in recall. There might be some increase in attention, but I certainly do notice a difference in recall. It might be placebo, but I am convinced enough that I continue to find time to use the program.”ref
karnautrahl: “Since November however, I began to read the Neuroscience book in more detail. I mentioned late December I think that I was finding I could understand more stuff. I’ve spent about £1000 on books since November. The large majority are books on the brain, source from Amazon reviews, reading lists and out of my own pirate list when I liked a book. I stopped Dual n Back in December, early. The benefits have stayed however. I tested this the other day, very easily going to 3 n back, which was mostly where I was before. I guess in a way I’m trying to say that for me, whilst the focus may have been on G increase and IQ etc., now the focus is on—what’s really happened and what can I do with it. What I can do with it is choose to concentrate long enough to genuinely understand fairly technical in depth chapters on subjects often new to me.”ref Karnautrahl writes more on his self-improvements in his thread “Second lot of training started-and long term experience overall.”, and describes an incident in which though he stopped using DNB 3 months previously, he still dealt with a technical issue much faster and more effectively than he feels he would’ve before.
negatron: “One perhaps coincidental thing I noticed is that dream recollection went up substantially. A good while after I stopped I developed an odd curiosity for what I previously considered unpleasant material, such as advanced mathematics. Never imagined I’d consider the thought of advanced calculus exciting. I began reading up on such subjects far more frequently than I used to. This was well after I’ve long forgotten about dual n-back so I find it hard to attribute it to a placebo effect, believing that I’m more adapted to this material. On the other hand I don’t recall reading anything about motivational benefits to dual n-back training so I still consider this conjecture and perhaps an eventful coincidence just the same.”ref
sutur: “i didn’t really notice any concrete changes in my thinking process, which probably, if existent, are rather hard to detect reliably anyway. one thing i did notice however is an increased sense of calmness. i used to move my legs around an awful lot while sitting which i now don’t feel the urge to anymore. but of course this could be placebo or something else entirely. i also seem to be able to read text (in books or on screen) more fluently now with less danger of distraction. however, personally i am quite skeptic when people describe the changes they notice. changes in cognitive capacity are probably quite subtle, build up slowly and are hard to notice through introspection.”ref
astriaos: “By ‘robust’, I mean practically everything I do is qualitatively different from how I did things 30 days previous to the dual n-back training. For instance, in physics class I went from vaguely understanding most of the concepts covered in class to a mastery thorough enough that now my questions usually transcend the scope of the in-class and textbook material, routinely stupefying my physics teacher into longer-than-average pauses. It’s the same experience for all of my classes. Somehow, I’ve learned more-than-I usually learn of physics/government/ etc. (all of my classes, and any topic in general) information from sources outside of class, and without what I consider significant effort. I feel like my learning speed has gone up by some factor greater than 1; I can follow longer arguments with greater precision; my vocabulary has improved; I can pay attention longer; my problem solving skills are significantly better… Really, it’s amazing how much cognition depends on attention!”ref
flashquartermaster reports N-back cured his chronic fatigue syndrome?
UOChris1: “Harry Kahne was said to have developed the ability to perform several tasks at one time involving no less the 16 different areas of the brain….Surprisingly, I am slowly developing the ability simultaneously perform quad combination 3-back while reciting the alphabet backwards. The practice is very difficult and requires loads of concentration but I am experiencing perceivable gains in clarity of thought from one day of practice to the next whereas my gains from Brain Workshop alone were not perceivable on a daily basis.” UOChris1 wrote of another mode: “Triple-N-Back at .5sec intervals and piano notes instead of letters has greatly improved my subjectively perceived fluidity of thought. I am much more engaged in class, can read much quicker, and am coming up with many more creative solutions now than ever before. I didn’t notice the improvements as much when I was using slower intervals—I feel I make more decision cycles in a given amount of time before coming to a solution.”
Pontus Granström “I certainly feel calmer happier and more motivated after doing DNB, it has to do with the increase of dopamine receptors no doubt!”
Chris Warren summarizes the results of his intensive practice (covered above): “For those that are curious, I noticed the largest change in my thought processes on Wednesday. My abilities were noticeably different, to the extent that, at some points, it was, well, startling. I’ve started getting used to the feeling, so I can’t really compare my intelligence now versus Wednesday. However, I’m completely confident that I’ve become smarter. Under the kind of stress I’ve put my brain through, I can’t imagine a scenario where that wouldn’t happen.”
“After the first couple days of training, I experienced a very rapid increase in intelligence. It suddenly became easier to think. I can’t give you any hard evidence, since I didn’t bother to take any tests before I started. However, I can give you this: when I woke up Wednesday morning, I felt the same as I did after the first time I tried n-back. Except the feeling was 10 times stronger, and my thinking was noticeably faster and more comprehensive.”
Raman reports an initial null result: “19 days with n-back are over… no subjective benefits as such. But I am aware at what point I am comfortable or not. eg. y’day playing the game was effortless, and today my brain felt sort of sticky, the sequence was just not sticking in my brain. very strange what a few hours can do.”
iwan tulijef says that “Long time ago I was diagnosed Adhd [sic] and for long time I took meds and this training helped me to reduce my meds nearly to zero, compared with the doses I took before. Unfortunately this haven’t fixed the whole thing. But what I noticed was, hmm… those things are very difficult to describe…. that time by time I got more control about my mental life. Obvious effects in social matters were eg. that I could follow conversations better and behave more naturally. In my education matters, eg. that I understood maths proofs better. There are a lot of details. Interesting was, as these issues are, to understate it a bit, not unimportant for me, that in the beginning when I remarked changes, I got a bit euphoric, so the first effects of n-back feeled like the strongest.” and warns us that “It’s very difficult and very questionable to take objective informations out of subjective self evaluation.” (Iwan trained for 3-4 months, 20 rounds a day in the morning & evening.)
jttoto saw no gain on an IQ test, but thinks he’s benefited anyway: “My friends have always called me inattentive and absent-minded, but since playing n-back no one has called me that for a while. I now never forget where I park my car, when I used to do that nearly every other day. I feel more attentive. Even if my ability to solve problems hasn’t improved, the gains in my memory are real and measurable.”
reece: “Not that I’ve noticed [an improvement in lateral thinking]. I have noticed an improvement in my working memory however—seems easier to juggle a few ideas in my head at the same time which presumably the quad-n-back has helped with.” “I recently noticed that it appears to have made me better at playing ping pong and tetris. Oddly enough however, it doesn’t appear to have improved my reaction time…Working memory has improved, however other things I’ve always struggled with such as uncued long term memory recall have not… I’m still very absent-minded and believe n-back has made me more easily distractable (lowered latent inhibition?), although to be fair, I may have brought this on myself by playing quad n-back and this was not something I noticed when only playing dual n-back. I seem to be able to get by on about one hour less sleep per night and perform better cognitively when sleep deprived. Dream recall has increased significantly as has lucid dreaming. I do take a few nootropics, however I’ve been taking the same ones for years…Verbal fluency appears to have improved, proper spelling and punctuation are things I’ve always struggled with and do not appear to have ameliorated resultant from n-back training.” (Poll) “In my experience with dual and multimodal n-back, the benefits I’ve most observed have been increased multitasking ability and increased concentration in the presence of distractions. For me, the benefits of n-back training are most apparent on days I don’t take my ADHD medication. I have been training DNB with position-sound and color-image modes lately. I used QNB for several months in the past, however I (subjectively) believe DNB is giving me the most benefit.” (ADHD thread)
Michael Campbell: “Something very minor to some, but was good for me; I’m able to concentrate while reading a lot more than I have been able to in the past.”
exigentsky: “I’ve seen improvements in executive function and motivation. After DNB, I am more inclined to study and complete long pending items. However, there is a confounding variable. I don’t usually do DNB when in an unhealthy state of mind (for example, with little sleep and extremely high stress). Still, I believe that I can attribute some of the effects only to DNB.
In terms of working memory and other cognitive measures, I’m not sure. I don’t notice anything dramatic but also haven’t stuck to a DNB regime for more than a few weeks.”
cev: “I think I’ve put my finger on a particular benefit of dnb training: it seems to help my brain’s ‘internal clock’ - I am better able to order my thoughts in time.
DNB has also helped my foosball (!) playing: at a high level the game involves complex strings of motor movements and since I’ve been training, I’ve found that my coordination of these movements has greatly improved despite no longer practising.”
erm: “I can rely on this to drastically reduce anxiety, flightiness, improve concentration. It also seems to whet my appetite for intellectual work and increase purposefulness across the board.”
Tofu, after a year of n-backing: “N-back training may have somehow improved my verbal intelligence, but since verbal intelligence is a form of crystallized intelligence and training working memory is supposed to primarily improve fluid intelligence, it probably didn’t. My score on the verbal subtest went up and then down which would make no sense if it did have any influence…Since my IQ score increased from the first test to the second test, and stayed the same from the second test to the third test it could be possibly that working memory only contributes to IQ up to a certain point. All in all, I feel more inclined to say that n-back training has only a little if any effect on IQ though which is why reason I’m probably going to stop doing the n-back training.
On a more positive note, since I started n-back training I have noticed better concentration which I had a serious problem with before. In general, I feel like I think more clearly and I at least feel like I’ve become smarter too. I’ve reached a pretty high level in n-back and any gains I’ve made in the last month or two have been small, so I think I’ve reached a long-term plateau which is another reason for me to stop the training. From my experience when I stop the n-back training for a month or two and return to n-back training I still perform at the same level anyway. It seems like the effects from training are going to last a while which is also good news. Overall, I feel like the n-back training was worth it but if I had it to do over I would have probably stopped after a couple of months.”
kriegerlie: “i’ve defnitely had some benefit, like pontus said, dunno about being smarter, but my focus is incredible now. I can do what i thought I could never do, purely because I can focus more. Placebo or not. It’s a definite effect.”
Rotem: “DNB works, It’s one of the best investments I made in my life. I have much less anxiety ( I suffered from GAD my life was a nightmare), more confidence and I guarantee more intelligence - I can feel it…”
chortly: “For a while I imagined that my working memory muscles were indeed strengthening, the main sensation being that I could retain the various threads of a complicated conversation better as they dangled and were forgotten by the other conversationalists. But that was probably just wishful thinking. Because it’s boring and difficult, I haven’t stuck with it, though I keep intending to.”
JHarris: “I’ve been working with the dual n-back program for a bit of time now. Improvement is slow, but seems to be happening; I just had a 68% run at dual 3-back. Observations like this are not really scientific and hellishly subject to bias, but I think I may be noticing it slightly easier to think effectively.”
Neurohacker (in a thread on ADHD): “I’m definitely finding it helpful, even if it’s just giving me some practice at focusing…as a complementary strategy [to medication], it’s certainly working wonders.”
iwan tulijef: “n-Back helped me a lot. Especially in the beginning when I started with DNB, the effect was astounding. I got much faster in understanding written and spoken words.In the beginning I think the function of my working memory was really bad. What then happened is that I got habituated to the effect and the increases were smaller, so noticing improvements got more difficult.”
Arkanj3l: “On a side, I really enjoy the lucid feeling I get after an hour of n-back. I start to look at things and ideas seem to flow into my head very vividly (I’ve made some of my best Lego creations after an n-back session :p).”
Michael Logan: “…and learned very, very quickly that I had a short term memory and attention issue. The dual n back task laughed at me, but I vowed to overcome my inattention and short term memory issues, and within a few practices, I noticed an improvement not only in my scores on the computerized game, but in session with my clients….So Mind Sparke does provide that kind of novel learning challenge. I have not taken an IQ test, but I do believe the use of the tool is helping me build cognitive reserve for the later stages of my life.”
milestones: “I’m grateful for the gains I seemed to have received from training dual n back. I used to be extremely forgetful with remembering where I put things and now it’s very easy to retrace steps and recall where I placed xyz item. As far as IQ tests go, I did see a gain on a well designed (untimed) culture fair test of about 1 standard deviation after training one DNB on and off for close 2 years. (Other tests with lower ceilings, however, showed no or marginal gains).” A later post: “The gains I’m seeing are: faster encoding speed; faster and more accurate retrieval of data from long term memory; as well as an increase in data-sequencing speed (the latter is a relative weakness of mine that now seems to have been helped by consistent quad-back training—-though I’ve not tested any transfer so this is subjective). Also, though my fluid intelligence has probably ceased gaining, it seems I’m functioning at higher bands of ability far more regularly—even when I’m tired or sluggish.”
Lachlan Jones wrote, after a before/after IQ report, “The most significant real word application for me has been improvements in my piano playing. I am a pianist and can report significant improvements in my sight reading and the rate at which I learn new pieces.”
unfunf: “While I haven’t taken an IQ test to see if it has garnered any IQ improvement, I can say I started off at dual 4-back only 2 weeks ago and I am now nearing dual 6-back. I can also attest to a pretty large working memory improvement, beyond what I would call placebo (the effects of which I am very well aware). Even if it is not very effective, I still say this game is fun.”
NeuroGuy: “Dual-N-Back has subjectively done more for me in less then two weeks than any single nootropic, can hardly imagine it combined with spaced-repepition.”
TeCNoYoTTa: “I also want to report that after training on DNB I found that I am dreaming almost every day…by the way I remember that this effect was not directly after training…unfortunately I stopped using DNB from about 2 months or something like that and now I dream less”
dimecoin: “I make no claims, other than anecdotal - in that it seems to relax me and able to handle stress better when I do it regularly.”
Arbo Arba: “I did find a lot of changes come to my brain and personality, but I’m not sure if it’s from improving WM or if it’s just from spending a lot of time in an alpha-wave dominant state. I think it’s being in a prolonged alpha-brain wave dominant state, tbh, because I found that when I was younger and took up heavy reading projects I felt the same improvements—that is, having more focus, being able to ‘hear’ myself think very distinctly to the point where I could compose poems/emails in my head without effort. I don’t know why this is, but it happens so much with me that I can’t doubt that there is a real effect on my personality and default mental state when I’m doing ‘intellectual’ things.”
Akiyama Shinichi: “I train 3 times a day and every sesion last about 20 minutes. After a month a went to my chess club and completely crash players who was at completely different level. I chose one of the strongest player (at my level of course), because he was able to tell me if I’ve realy improved. Then I had to reveal my secret, and after month I tell how it works for them. I notice that I improve not only in chess. I’m a piano player and it’s really challenging. I was learning very slowly, but yesterday my teacher told me that in two weeks I learnt much more than in the last 2 months. He was even suspecting me that I take lectures from other teacher, not only from him. And that’s not all. I’m a student and one a month every of us have to prepare presentation on some topic. A few days ago was my turn. I didn’t notice it by myself, but one of my friend told me that I was very well-prepared, because I stopped making that annoying sound like”umm”, “yyyy” when I was thinking what to say. When I was performing my presentation I don’t have to think what to say next because I’d already know and didn’t have to think about it much.”
whoisbambam: “My mind feels faster. I also seem to have less mental fatigue during studying, n-backing, etc. I am more confident. I am confident that my memory has improved independent of n-backing (what they call ‘far transfer’ effect). I am not saying it is a HUGE difference. I can not say the same is true for any supplement i have taken other than possibly some small effect with magnesium l-threonate which also seems to make me ‘less mentally tired’ in particular, interestingly.”
Christopher Działo: “I’ve trained with n-back for several months and have noticed a profound ability to sight read music and locate the notes, my speed and overall dexterity has drastically increased and I shall continue to n-back and grow my musical talent.”
No Benefits
Confuzedd: “[asked if felt ‘sharper’]: Nothing.”
Chris: “One thing I have noticed is the recollection of a number of very unpleasant images in dreams. Specifically, images of bodily disease, mutilation, injury and post-mortem decomposition. I find it difficult to believe it’s just a coincidence, because I can’t remember when I last had such a dream, and I’ve had maybe half a dozen since I started dual n-back. But perhaps it’s simply owing to better recall.”ref
Pheonexia: “now I’m at 6-back and am consistently between 50 and 80% accurate….All that said, I have NOT noticed any differences in my mental capacity, intelligence, daily life, or even ability to remember things that just happened. I still sometimes forget people’s names right after they tell me them. I’m going to keep training though, because just because I haven’t consciously noticed these things, I have faith in scientific studies, so with enough training hopefully I’ll yield some positive benefits.”
TheQ17 reports little to no benefit: “At any rate, I don’t feel studying is any easier although it wasn’t really difficult to begin with for me. Perhaps I’ll give it another go over break and report back. My goal originally was to get to P5B before adding a second sound stimulus making a Sextuple Nback but I don’t know if Shamanu made an updated version to make that any easier. I’m also kind of on the fence about the effect on the depth of training. It may have been more beneficial to do higher N levels instead of more stimuli.”
Jonathan Graehl: “I can do dual 4-back with 95%+ accuracy and 5-back with 60%, and I’ve likely plateaued (naturally, my skill rapidly improved at first). I enjoy it as”practice focusing on something”, but haven’t noticed any evidence of any general improvement in memory or other mental abilities.”
Will Newsome: “After doing 100 trials of dual N back stretched over a week (mostly 4 back) I noticed that I felt slightly more conscious: my emotions were more salient, I enjoyed simple things more, and I just felt generally more alive. There were tons of free variables for me, though, so I doubt causation.”
steven0461: “I did maybe 10-15 half-hour sessions of mostly D5B-D6B last year over the course of a few weeks and didn’t notice any effects.”
EggplantWizard (D3B->D10B): “I would say that there has been some form of improvement—though it’s not clear if the improvement is task-specific. I haven’t noticed any significant difference in my day to day life, but (to be immodest in the name of efficiency for a moment) I had a very good memory to begin with, and I would say strong fluid intelligence. It’s possible that people starting from positions of lower fluid intelligence would see a more pronounced benefit.”
Matt: “…I’ve certainly improved at n-back type tasks, I can’t say that I’ve noticed any improvement while handling real life problems. I think the effects do generalize - I’m quite good at highly g-loaded tasks like the PASAT now, even without much practice - but the range of tasks which are subject to improvement from n-backing seems limited. I’m better at tasks involving mental updating, but my short term memory has only slightly improved, if at all. I don’t have an accurate way of measuring my change in gf (or g), as most of the fluid reasoning tasks available online use the same/similar rule patterns or aren’t accurately normed, but as I said before, my real life problem solving abilities have not subjectively improved…”
Jelani Sims: “I’ve been doing DNB since the group started, I haven’t noticed anything out of the ordinary in terms of cognition. But I never took a before and after IQ test and I haven’t really done anything that I found mentally difficult before. So it’s very hard for me to gauge mental improvements with nothing for me to base it on. I also changed my diet, started mindfulness meditation and exercising around the same time I started DNB, in an overall attempt to delay brain decline. Making it even more difficult to attribute anything directly to DNB. What I can say is I have been stuck on 12 for 4 months now, each level was increasingly more difficult to pass and 12 seems to be some sort of temporary plateau.”
argumzio: “I’ve seen no net benefit. Compared to improved nutrition, exercise, sleeping, and the occasional nootropic (eg. Piracetam, Alpha GPC, CDP Citicoline, Resveratrol, Kre-Alkalyn & Creatine Monohydrate, etc.), DNB did nothing. However, in terms of subjectively improved focus (counting the near-certain possibility that the aforementioned changes also influenced it), QNB* did the most for me, that is, allowing me to absorb information for longer periods of time and maintain this effort much later into the evening while mitigating the deleterious effects of fatigue and allowing me to feel rested after unusually shorter periods of sleep.”
Creativity
One of the worries occasionally cited is that DNB training mostly serves to increase one’s focus on the task one is thinking about. Which is great in most contexts but, the fear goes, the ability to focus on one thing is the ability to exclude (‘inhibit’) thoughts on all other topics - which is crucial to creativity. Working memory and ability to shift attention has a strong correlation with being able to solve insight problems with lateral thinking, but as with the WM-IQ link, that doesn’t say what happens when one intervenes on one side of the correlation (correlation is not causation):
Individuals may have difficulty in keeping in mind alternatives because multiple possibilities can exceed their working memory capacity (Byrne 200521ya; Johnson-Laird & Byrne 199135ya, Johnson-Laird & Byrne 200224ya). They also need to be able to switch their attention between the alternative possibilities to reach a solution. On this account, key component skills required in insight problem solving include attention switching and working memory skills….Attention and working memory may be crucial for different aspects of successful insight problem solving. Planning a number of moves in advance may be important to solve insight problems such as the well-known nine-dot problem (Chronicle et al 200125ya). Attention may play a role in helping people to decide what elements of a problem to focus on or in helping them to direct the search for relevant information internally and externally.
…Individuals who are good at solving insight problems are also good at switching attention. Correct performance on the insight problems was associated with correct performance on the visual elevator task (r=.515, p<.01). Correct performance on the insight problems was associated with correct performance on the plus-minus problems (r=-.511, n=32, p<.001)…Consistent with this account individuals who are better at storing and processing information in working memory are better at solving insight problems. [correlation with problem score: r=.39 for digit span, r=.511 for sentence span] 73
The major piece of experimental evidence is Takeuchi 2011 & Vartanian 201313ya, treated at length in the following subsection and well worth consideration; the rest of this section will discuss other lines of evidence.
Dopamine is related to changes caused by n-backing (see the McNab receptor study & for a general review, Söderqvist et al 2011), and increase in dopamine has been shown to cause a narrowing of focus/associations in priming tasks74. There are other related correlations on this; for example, Cassimjee 201075 report that “…the temperament dimension of Novelty Seeking was inversely related to performance accuracy on the LNB2 (Letter-N-Back).” But as ever, correlation is not causation; this result might not mean anything about someone deliberately increasing performance accuracy by practice - we might take it to mean just that narrow uninterested people had a small advantage at n-backing when they first began. Cassimjee 201016ya cites 2 other studies suggesting what this correlation means: “…participants with higher impulsivity may lack the attentional resources to retain critical information and inhibit irrelevant information. The activation of reactive control, which is a system that monitors, modulates and regulates reactive aspects of temperament, is inhibited in individuals high in novelty seeking…” This suggests the performance difference is a weakness that can be strengthened, not to a fundamental trade-off.
Reports from n-backers are mixed. One negative report is from john21012101:
I’ve done the dual n-back task avidly for over a month and while I find it makes me mentally sharper, that comes a high cost - the loss of creativity and lateral thinking. In fact, I experience what is called as severe directed attention fatigue (see
www.troutfoot.com/attn/dafintro.html).…and even short booster sessions severely impair creativity to the point that one becomes very mentally flat, single-minded, and I’d even say zombie-ish.
Ashirgo, chinmi04, & putomayo begged to differ in the same thread, with biped plumping for a null result.
There are some theoretical reasons to believe DNB isn’t causing gains at the expense of creativity, as there is that Jaeggi study showing gf gains, and gf is mildly correlated with creativity, according to exigentsky:
“Furthermore, if the preliminary results hold and dual-n-back actually increased gf. it should actually contribute to creativity for most people. After all, studies have shown that creativity (according to standard tests) and IQ are significantly correlated to a certain point (~120 on most). While both tests are imperfect and incomplete, they do give a general picture.
I have not felt a decrease in my creativity and am skeptical of the idea that dual-n-back harms it. If the purported mechanism is increasing latent inhibition, that would be an even bigger breakthrough than increasing IQ. The former is still largely considered immutable.”
Vlad has some more details on those correlations:
“Last but not least, there was this research”Relationship of intelligence and creativity in gifted and non-gifted students”, which I studied because of this today, and they found positive correlation IQ vs verbal and figural creative processes (fluency, flexibility, object designing, specific traits, insight…). And this mild correlation (of 0.3 - 0.5), did not differ for different IQ levels (higher IQs had mild higher creativity, lower IQs had mild lower creativity - always mild relationship, so exceptions too, but in general more IQ meant more creativity).”
On the other hand, Vlad also points out that:
“…there are few theories how WM works, and one of the most explaining is, that WM and attention are tied closely together (Ash always emphasizes this and he is right :). This should work through the fact, that higher WM means more sources for inhibition of distraction. So, the more WM, the better you can concentrate. They tested this with cocktail party effect: in general, only 33% of persons catch their name from irrelevant background noise, while concentrating on some task. Now they found, that only 20% of high WM people caught their name, but 65% of low WM. On the other side, contemporary researches sometimes differ between WM, STM, primary / secondary WM, even LTM… But the point is, attention works at least partly as a filter, and it gets better with higher WM.
Now the issue with creativity. I find this interesting, because I think somebody here worried already about being subjectively less creative than before BW training, and I got this feeling few times too.
…Every creator must deeply concentrate on his work. Maybe there are different kinds of creativity: “ADHD” creativity, meaningful creativity, brainstorming creativity, appreciation of art, and so on.
Btw after training dnb, I got this interest in art - I downloaded lots of classical and other artistic pictures (never before), and really enjoyed choosing which I like. Or have you ever seen “the hours”? I fell in love with that movie and even started to read things from virginia woolf”
As well, Pheonexia points out that McNab 2008 & McNab 200917ya demonstrated increases in various things related to dopamine because of DNB, and that there is one study that “Dopamine agonists disrupt visual latent inhibition in normal males using a within-subject paradigm”.
Takeuchi 2011
“Working Memory Training Using Mental Calculation Impacts Regional Gray Matter of the Frontal and Parietal Regions”, Takeuchi et al 201115ya:
Training working memory (WM) improves performance on untrained cognitive tasks and alters functional activity. However, WM training’s effects on gray matter morphology and a wide range of cognitive tasks are still unknown. We investigated this issue using voxel-based morphometry (VBM), various psychological measures, such as non-trained WM tasks and a creativity task, and intensive adaptive training of WM using mental calculations (IATWMMC), all of which are typical WM tasks. IATWMMC was associated with reduced regional gray matter volume in the bilateral fronto-parietal regions and the left superior temporal gyrus. It improved verbal letter span and complex arithmetic ability, but deteriorated creativity. These results confirm the training-induced plasticity in psychological mechanisms and the plasticity of gray matter structures in regions that have been assumed to be under strong genetic control.
Takeuchi 201115ya has many points of interest:
these subjects are really high quality students and grad students - which is why a number of them hit the RAPM ceiling (!); and it’s implied they are all Tohoku University students. Tohoku isn’t Tokyo U, but it’s still really good, Wikipedia telling me “It is the third oldest Imperial University in Japan and is a member of the National Seven Universities. It is considered as one of the top universities in Japan, and one of the top 50 universities in the world.”
While high quality, there aren’t that many of them; Jaeggi 200818ya had 35 subjects doing WM training, while this one has 18 doing the adaptive and another 18 doing non-adaptive, and the last of the 55 were pure control. So a little more than half as many; this is reflected in some of the weak results, so while rather disturbing, this isn’t a definitive refutation or anything.
the WM task subjects did not see any relative IQ gains, or much of a gain at all; the IATWMMC (adaptive arithmetic) group went from 27.3±1 to 31.3±0.7, and the placebo group (non-adaptive arithmetic) went from 29.1±0.9 to 32.0±0.8. This doesn’t show any noticeable difference, the authors describing the IQ as ‘probably void’.
20 hours of training is more than twice as much training as Jaeggi 2008’s longest group76, so one should not dismiss this solely on the grounds ‘if only they had trained more’
adaptive arithmetic doesn’t seem like much of a WM task; they did do some n-backing (mentioned briefly) during the fMRI pre/post, but not clear why they chose arithmetic over n-back. On the other hand, don’t many n-backers use the arithmetic modes…?
the adaptiveness is really important; they say the group doing non-adaptive arithmetic was the same as the no-intervention group on every measure! Including ‘a complex arithmetic task’
one of the key quotes:
Behavioral results comparing the combined control group, and the IATWMMC group showed a significantly larger pre- to post- test increase for performance of a complex arithmetic task (P = 0.049), for performance of the letter span task (P = 0.002), and for reverse Stroop interference (P = 0.008) in the IATWMMC group. The IATWMMC group showed a significantly larger pre- to post- test decrease in creativity test performance (P = 0.007) (for all the results of the psychological measures, see Table 1). Also the IATWMMC group showed a statistical trend of increase in the mental rotation task (P = 0.064).
About the only good news for n-backers is that the results were not huge enough to easily survive multiple-comparison correction
We performed several psychological tests and did not correct for the number of comparisons between statistical tests, as is almost always the case with this kind of study. When corrected using the Bonferroni correction, even after removing the probably void tests (RAPM and WAIS arithmetic), the statistical value for the effect of IATWMMC on the creativity tests marginally surpassed the threshold of P = 0.05 (P = 0.06). Thus, the results should be interpreted with caution until replicated.
Vartanian 2013
“Working Memory Training Is Associated with Lower Prefrontal Cortex Activation in a Divergent Thinking Task”; emphasis added:
Working memory (WM) training has been shown to lead to improvements in WM capacity and fluid intelligence. Given that divergent thinking loads on WM and fluid intelligence, we tested the hypothesis that WM training would improve performance and moderate neural function in the Alternate Uses Task (AUT)-a classic test of divergent thinking. We tested this hypothesis by administering the AUT in the functional magnetic resonance imaging scanner following a short regimen of WM training (experimental condition), or engagement in a choice reaction time task not expected to engage WM (active control condition). Participants in the experimental group exhibited significant improvement in performance in the WM task as a function of training, as well as a significant gain in fluid intelligence. Although the two groups did not differ in their performance on the AUT, activation was significantly lower in the experimental group in ventrolateral prefrontal and dorsolateral prefrontal cortex-two brain regions known to play dissociable and critical roles in divergent thinking. Furthermore, gain in fluid intelligence mediated the effect of training on brain activation in ventrolateral prefrontal cortex. These results indicate that a short regimen of WM training is associated with lower prefrontal activation - a marker of neural efficiency - in divergent thinking.
Non-IQ or Non-DNB Gains
This section is for studies that tested non-DNB WM interventions on IQ, or DNB interventions on non-IQ properties, and miscellaneous.
Chein 2010
“Expanding the mind’s workspace: Training and transfer effects with a complex working memory span task” (FLOSS implementation); from the introduction:
In the present study, a novel working memory (WM) training paradigm was used to test the malleability of WM capacity and to determine the extent to which the benefits of this training could be transferred to other cognitive skills. Training involved verbal and spatial versions of a complex WM span task designed to emphasize simultaneous storage and processing requirements. Participants who completed 4 weeks of WM training demonstrated significant improvements on measures of temporary memory. These WM training benefits generalized to performance on the Stroop task and, in a novel finding, promoted significant increases in reading comprehension. The results are discussed in relation to the hypothesis that WM training affects domain-general attention control mechanisms and can thereby elicit far-reaching cognitive benefits. Implications include the use of WM training as a general tool for enhancing important cognitive skills.
While WM training yielded many valuable benefits such as increased reading comprehension, it did not improve IQ as measured by an unspeeded Advanced Progressive Matrices (APM) IQ test;
However, such power limitations do not readily account for our failure to replicate a transfer of WM training benefits to measures of fluid intelligence (as was observed by Jaeggi et al 200818ya), since we did not find even a trend for improvement in trained participants on Raven’s APM. Beyond statistical explanations, differences in the training paradigms used for the two studies may explain the differences in transfer effects. The training program used by Jaeggi et al 200818ya involved 400 trials per training session, with a dual n-back training paradigm designed to emphasize binding processes and task management. Conversely, our training paradigm included only 32 trials per session and more heavily emphasized maintenance in the face of distraction. Finally, the seemingly conflicting results may be due to differences in intelligence test administration. As was pointed out in a recent critique (Moody, 200917ya), Jaeggi et al 200818ya used atypical speeded procedures in administering their tests of fluid intelligence, and these alterations may have confounded the apparent effect of WM training on intelligence.
Colom 2010
“Improvement in working memory is not related to increased intelligence scores” trained 173 students on WM tasks (such as the reading span task) with randomized difficulties, and found no linked IQ improvement; the IQ tests were “the Advanced Progressive Matrices Test (APM) along with the abstract reasoning (DAT-AR), verbal reasoning (DAT-VR), and spatial relations (DAT-SR) subtests from the Differential Aptitude Test Battery”. None were speeded as in Jaeggi 200818ya. Abstract:
The acknowledged high relationship between working memory and intelligence suggests common underlying cognitive mechanisms and, perhaps, shared biological substrates. If this is the case, improvement in working memory by repeated exposure to challenging span tasks might be reflected in increased intelligence scores. Here we report a study in which 288 university undergraduates completed the odd numbered items of four intelligence tests on time 1 and the even numbered items of the same tests one month later (time 2). In between, 173 participants completed three sessions, separated by exactly one week, comprising verbal, numerical, and spatial short-term memory (STM) and working memory (WMC) tasks imposing high processing demands (STM-WMC group). 115 participants also completed three sessions, separated by exactly one week, but comprising verbal, numerical, and spatial simple speed tasks (processing speed, PS, and attention, ATT) with very low processing demands (PS-ATT group). The main finding reveals increased scores from the pre-test to the post-test intelligence session (more than half a standard deviation on average). However, there was no differential improvement on intelligence between the STM-WMC and PS-ATT groups.
Commentators on the ML discussion criticized the study for:
Not using DNB itself
apparently little training time on the WM tasks (3 sessions over weeks, each of unclear duration)
the randomization of difficulty (as opposed to DNB’s adaptiveness)
the large increase in scores on the WM tasks over the 3 sessions (suggesting growing familiarity than real challenge & growth)
and the statistical observation that if IQ gains were linear with training and started small then 173 participants is not enough to observe with confidence any improvements.
Loosli Et Al 2011
“Working memory training improves reading processes in typically developing children”, Loosli, Buschkuehl, Perrig, and Jaeggi:
The goal of this study was to investigate whether a brief cognitive training intervention results in a specific performance increase in the trained task, and whether there are transfer effects to other nontrained measures. A computerized, adaptive working memory intervention was conducted with 9- to 11-year-old typically developing children. The children considerably improved their performance in the trained working memory task. Additionally, compared to a matched control group, the experimental group significantly enhanced their reading performance after training, providing further evidence for shared processes between working memory and reading.
This is showing connection to useful tasks, but not for showing any gain to IQ. The difference in score improvement between groups was small, half a point, and the training period fairly short; the authors write:
Due to the short training time, we did not expect large effects on gf (cf. Jaeggi et al 200818ya), also since two other studies that trained ADHD children observed transfer effects on gf only after 5 weeks involving sessions of 40 minutes each (Klingberg et al 200224ya, 200521ya).
In addition, the same group failed to show transfer on gf with a shorter training (Thorell et al 200818ya). Thus, considering that our training intervention was merely 10 sessions long, our lack of transfer to gf is hardly surprising; although there is now recent evidence that transfer to gf is possible with very little training time (Karbach & Kray 2009; poster). Our results, however, are comparable to those of Chein & Morrison 201016ya, who also trained their participants on a complex WM task and found no transfer to gf.
(Similar studies have also found improvement in reading skills after WM training, eg. Dahlin 2011 and Shiran & Breznitz 2011, but I do not believe others used n-back or looked for possible IQ gains.)
Nutley 2011
“Gains in fluid intelligence after training non-verbal reasoning in 4-year-old children: a controlled, randomized study”, Sissela Bergman Nutley et al:
Fluid intelligence (gf) predicts performance on a wide range of cognitive activities, and children with impaired gf often experience academic difficulties. Previous attempts to improve gf have been hampered by poor control conditions and single outcome measures77. It is thus still an open question whether gf can be improved by training. This study included 4-year-old children (n = 101) who performed computerized training (15 min/day for 25 days) of either non-verbal reasoning, working memory, a combination of both, or a placebo version of the combined training. Compared to the placebo group, the non-verbal reasoning training group improved significantly on gf when analysed as a latent variable of several reasoning tasks. Smaller gains on problem solving tests were seen in the combination training group. The group training working memory improved on measures of working memory, but not on problem solving tests. This study shows that it is possible to improve gf with training, which could have implications for early interventions in children.
Points:
The WM tasks were not n-back:
“The WM training was the same as described in Thorell et al 2009 developed by Cogmed Systems Inc. There were seven different versions of visuo-spatial WM tasks, out of which three were trained every day on a rotating schedule. Briefly, the tasks all consisted of a number of animated figures presented in different settings (eg. swimming in a pool, riding on a rollercoaster). Some of the figures (starting with two figures and then increasing in number depending on the child’s performance) made a sound and changed color during a short time period. The task then consisted of remembering which figures had changed color and in what order this had occurred.”
The magnitude of gf increase was not suspiciously large:
“The NVR training group showed transfer both when this was estimated with single tests, as well as when gf was measured as a latent variable. The magnitude of this improvement was approximately 8% (compared to the placebo group) which is comparable with previously reported gains of gf of 5-13.5% (Hamers et al 1998; Jaeggi et al 2008; Klauer & Willmes, 2002; Stankov, 1986).”
There are some possible counter-arguments to generalizing the lack of gf gains in the WM-only group, mostly related to the young age:
“This could mean that WM is not a limiting factor for 4-year-old children solving reasoning problems such as Raven’s CPM and Block Design. The moderate correlations between the Grid Task and the reasoning tests (between 0.3 and 0.6, see Table 1) point to the somewhat counterintuitive conclusion that correlation between two underlying abilities is not a sufficient predictor to determine amount of transfer of training effects between these abilities. A similar conclusion was drawn after the lack of training effects on WM after training inhibitory functions (Thorell et al 200917ya). In that study WM capacity correlated with performance on the inhibitory tasks at baseline (R = 0.3). An imaging study also showed that performance on a WM grid task and inhibitory tasks activate overlapping parts of the cortex (McNab, Leroux, Strand, Thorell, Bergman & Klingberg, 2008). Inhibitory training improved performance on the trained tasks, yet there was no transfer seen on WM tasks. The principles governing the type of cognitive training that will transfer are still unclear and pose an important question for future studies.
One way to find these principles may be through understanding the neural mechanisms of training. For example, WM training in 4-year-olds might have a more pronounced effect on the parietal lobe, compared to the less mature frontal lobe. If the transfer to gf is dependent on prefrontal functions, it may explain the lack of transfer from WM training to gf in 4-year-olds. In other words, transfer effects may differ with the progression of development.”
Zhao Et Al 2011
“Effect of updating training on fluid intelligence in children”, Chinese Science Bulletin:
Recent studies have indicated that working memory (WM) training can improve fluid intelligence. However, these earlier studies confused the impact of WM storage and central executive function on the effects of training. The current study used the running memory task to train the updating ability of [33] 9-11 year-old children using a double-blind controlled design. The results revealed that children’s fluid intelligence was significantly improved by memory-updating training. Overall, our findings suggest that the increase in fluid intelligence achieved with WM training is related to improving central executive function.
Roughan & Hadwin 2011
“The impact of working memory training in young people with social, emotional and behavioral difficulties”, Laura Roughan & Julie A. Hadwin 201115ya:
This study examined the impact of a working memory (WM) training programme on measures of WM, IQ, behavioral inhibition, self-report test and trait anxiety and teacher reported emotional and behavioral difficulties and attentional control before and after WM training and at a 3 month follow-up. The WM training group (N=7) showed significantly better post-training on measures of IQ, inhibition, test anxiety and teacher-reported behavior, attention and emotional symptoms, compared with a non-intervention passive control group (N=8). Group differences in WM were also evident at follow-up. The results indicated that WM training has some potential to be used to reduce the development of school related difficulties and associated mental health problems in young people. Further research using larger sample sizes and monitoring over a longer time period is needed to replicate and extend these results.
The WM training was done using Cogmed; it’s unclear whether the Cogmed tasks use DNB or not (they seem to have similar tasks available in it, at least), but the study did find IQ gains:
Considering T1 T2 IQ difference scores, the analysis revealed a significant group effect with a large ES (F(1,14) = 10.37, p < 0.01, n = 0.44); the intervention group showed increased IQ difference scores (N = 7, mean=5.36, SD = 6.52, range= -2.5 to 17.5) compared with the control group (N = 7, mean=-6.35, SD = 7.21, range = -15 to 5). T1 T3 analyses indicated that the T1 T3 difference was not significant (see Fig. 1).
Note the means as compared with the standard deviation; these are very troubled young people.
Brehmer Et Al 2012
“Working-memory training in younger and older adults: training gains, transfer, and maintenance”:
Working memory (WM), a key determinant of many higher-order cognitive functions, declines in old age. Current research attempts to develop process-specific WM training procedures, which may lead to general cognitive improvement. Adaptivity of the training as well as the comparison of training gains to performance changes of an active control group are key factors in evaluating the effectiveness of a specific training program. In the present study, 55 younger adults (20-30 years of age) and 45 older adults (60-70 years of age) received 5 weeks of computerized training on various spatial and verbal WM tasks. Half of the sample received adaptive training (ie. individually adjusted task difficulty), whereas the other half-worked on the same task material but on a low task difficulty level (active controls). Performance was assessed using criterion, near-transfer, and far-transfer tasks before training, after 5 weeks of intervention, as well as after a 3-month follow-up interval. Results indicate that (a) adaptive training generally led to larger training gains t/han low-level practice, (b) training and transfer gains were somewhat greater for younger than for older adults in some tasks, but comparable across age groups in other tasks, (c) far-transfer was observed to a test on sustained attention and for a self-rating scale on cognitive functioning in daily life for both young and old, and (d) training gains and transfer effects were maintained across the 3-month follow-up interval across age.
Used Cogmed, which Jaeggi says is not dual n-back.
Saccading
One fascinating psychology result is that strongly right-handed people can improve their memory (and possibly N-back performance) by simply taking 30 seconds and flicking (“saccading”) their eyes left and right (for a summary, see “A quick eye-exercise can improve your performance on memory tests (but only if you’re right-handed)”).
Version 4.5 of Brain Workshop introduced a saccading feature: a dot alternates sides of the screen and one is to follow it with one’s eyes. You activate it by pressing ‘e’ while in fullscreen mode (setting WINDOW_FULLSCREEN = True in the configuration file). It may or may not a bad idea to alternate rounds of N-back with rounds of saccading. At my request, saccading logs are now kept by BW so at some point in the future, it should be possible to request logs from users and see whether saccading in general correlates with N-back performance; I personally randomized use of saccading, but saw no benefits (see next section).
Ashirgo writes that her previous advice encompasses this eye-movement result; Pheonexia reports that after trying the saccading before a BW session, he “performed better than I ever have before”.
The most recent study on this effect seems to be “Eye movements enhance memory for individuals who are strongly right-handed and harm it for individuals who are not”. It says:
Subjects who make repetitive saccadic eye movements before a memory test subsequently exhibit superior retrieval in comparison with subjects who do not move their eyes. It has been proposed that eye movements enhance retrieval by increasing interaction of the left and right cerebral hemispheres. To test this, we compared the effect of eye movements on subsequent recall (Experiment1) and recognition (Experiment2) in two groups thought to differ in baseline degree of hemispheric interaction-individuals who are strongly right-handed (SR) and individuals who are not (nSR). For SR subjects, who naturally may experience less hemispheric interaction than nSR subjects, eye movements enhanced retrieval. In contrast, depending on the measure, eye movements were either inconsequential or even detrimental for nSR subjects. These results partially support the hemispheric interaction account, but demand an amendment to explain the harmful effects of eye movements for nSR individuals.
(Note that very important caveat: this is a useful technique only for strongly right-handed people; weak righties and lefties are outright harmed by this technique.)
See also “Interhemispheric Interaction and Saccadic Horizontal Eye Movements: Implications for Episodic Memory, EMDR, and PTSD”; “The efficacy and psychophysiological correlates of dual-attention tasks in eye movement desensitization and reprocessing (EMDR)”; “Horizontal saccadic eye movements enhance the retrieval of landmark shape and location information”; “Reduced misinformation effects following saccadic bilateral eye movements”; “Is saccade-induced retrieval enhancement a potential means of improving eyewitness evidence?”
Self-Experiment
Brain Workshop now has logging of saccading implemented; this was added at my request to make experimenting with saccading easier, since you can’t compare scores unless you know when you were saccading or not. After this was added (thanks Jonathan etc.), I began to randomize each day to saccading or not-saccading before rounds with a coin flip. Blinding is impossible, so I did nothing about that. After 158 rounds over roughly 35 days between 10 September and 2012-11-05, the result is: no difference. Not even close. So apparently though I am strongly right-handed as the original study’s memory effect required, saccading makes no difference to my n-back performance.
Analysis
My BW data had to be parsed by hand and some Emacs macros because I couldn’t figure out a nice clean programmatic way to parse it and spit out scores divvied by whether they were on a saccade on or off day (so if you want to replicate my analysis, you’ll have to do that yourself). The analysis78 using BEST reveals a difference of less than 1% right (+0.4%) per round, and the estimates of effect size are negative almost as often as they are positive:
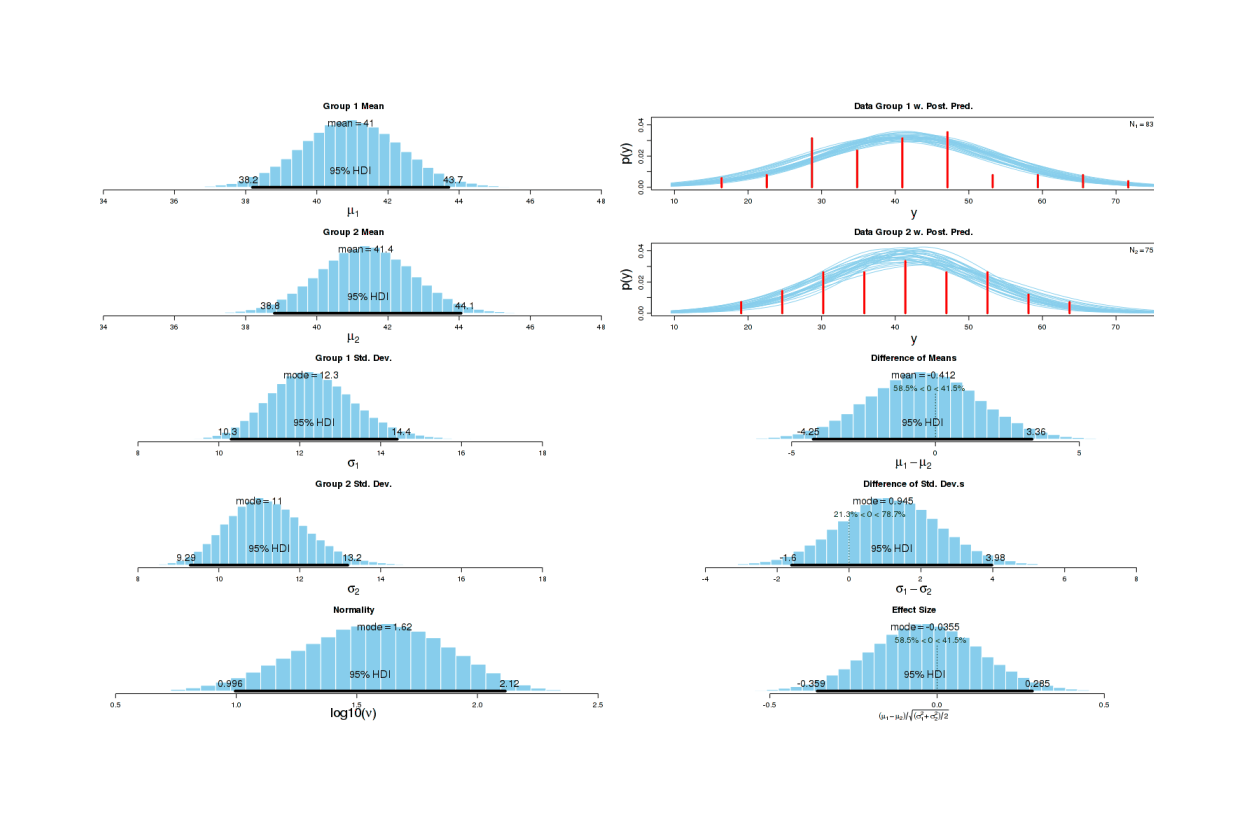
Bayesian MCMC estimates of difference in saccading and non-saccading scores
Since there’s hardly any evidence even though this looks like plenty of data, I think I’ll stop doing saccading. I can only speak for myself, so I would be pleased if other right-handed n-backers could adopt a similar procedure and see whether perhaps I am an exception.
Sleep
“Sleep Accelerates the Improvement in Working Memory Performance”, Kuriyama 200818ya:
Working memory (WM) performance, which is an important factor for determining problem-solving and reasoning ability, has been firmly believed to be constant. However, recent findings have demonstrated that WM performance has the potential to be improved by repetitive training. Although various skills are reported to be improved by sleep, the beneficial effect of sleep on WM performance has not been clarified. Here, we show that improvement in WM performance is facilitated by posttraining naturalistic sleep. A spatial variant of the n-back WM task was performed by 29 healthy young adults who were assigned randomly to three different experimental groups that had different time schedules of repetitive n-back WM task sessions, with or without intervening sleep. Intergroup and intersession comparisons of WM performance (accuracy and response time) profiles showed that n-back accuracy after posttraining sleep was significantly improved compared with that after the same period of wakefulness, independent of sleep timing, subject’s vigilance level, or circadian influences. On the other hand, response time was not influenced by sleep or repetitive training schedules. The present study indicates that improvement in n-back accuracy, which could reflect WM capacity, essentially benefits from posttraining sleep.
(In this test, the baseline/unpracticed performance of the two groups was the same; but the schedule in which subjects trained at 10 PM and went to bed resulted in greater improvements in performance than schedules in which subjects trained when they got up at 8 AM and went to bed ~10 PM.)
Lucid Dreaming
Stephen LaBerge, pioneer of lucid dreaming writes79
Why then is CNS activation necessary for lucid dreaming? Evidently the high level of cognitive function involved in lucid dreaming requires a correspondingly high level of neuronal activation. In terms of Antrobus 1986’s adaptation of Anderson 1983’s ACT* model of cognition to dreaming, working memory capacity is proportional to cognitive activation, which in turn is proportional to cortical activation. Becoming lucid requires an adequate level of working memory to active the presleep intention to recognize that one is dreaming. This level of activation is apparently not always available during sleep but normally only during phasic REM.
Allan Hobson has apparently speculated80 that WM and the prefrontal cortex is partially de-activated during REM sleep and this is why dreamers do not realize they are dreaming—they lose the critical thinking that would help them notice dream-world anomalies like their hands not looking right, pavement being aligned wrong, books not having text written in them, waking up in the wrong time (eg. back in school) or the wrong place.81 This is also the same regions that fluid intelligence and WM tasks like n-back tasks will activate.82 The suggestion then goes that n-back training will enable greater dream recognition & recall, which are crucial skills for any would-be lucid dreamer. A number of people have reported only dreams and lucid dreams as the result of n-back training (eg. Boris & Michael).
On the other hand, I have seen anecdotal reports that any intense mental exercise or learning causes increased dreaming, even if the exercise is domain-specific (eg. the famous Tetris effect) or just memorization (as in use of Mnemosyne for spaced repetition), and LaBerge also remarks (pg165 of Exploring the World of Lucid Dreaming):
Most people assume that a major function of sleeping and dreaming is rest and recuperation. This popular conception has been upheld by research. Thus, for humans, physical exercise leads to more sleep, especially delta sleep. Growth hormone, which triggers growth in children and the repair of stressed tissues, is released in delta sleep. On the other hand, mental exercise or emotional stress appears to result in increases in REM sleep and dreaming.
Aging
General cognitive factors like working memory and processing speed (& perceptual processing83) are traits that peak in early adult hood and then decline over a lifetime; the following image was adapted by Gizmodo from a study of age-related decline, “Models of visuospatial and verbal memory across the adult life span”84. The units are z-scores, units of standard deviations (so for the 80 year olds to be two full units below the 20 year olds indicates a profound fall in the averages85); the first image is from Park et al 2002:
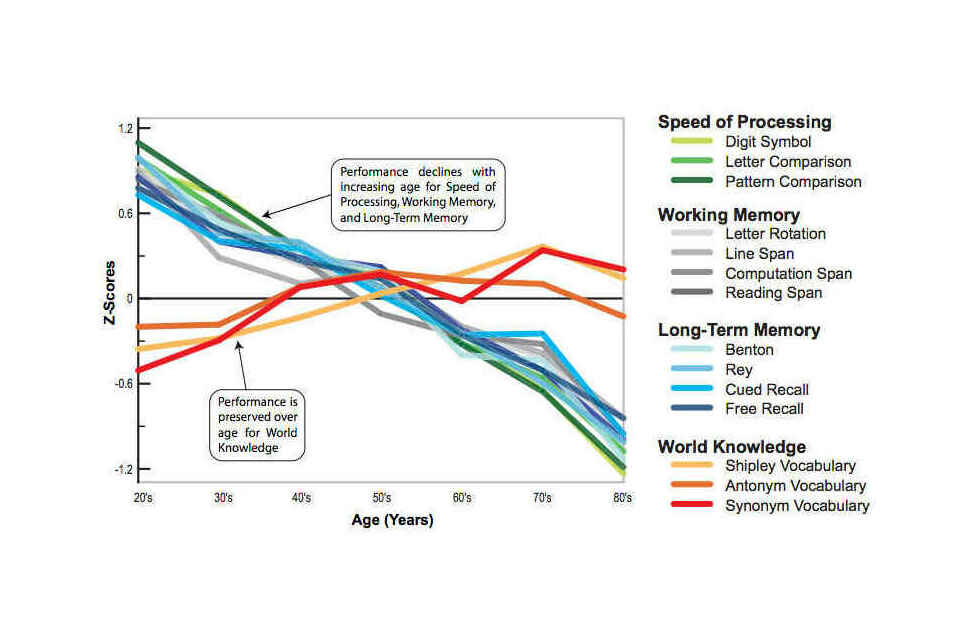
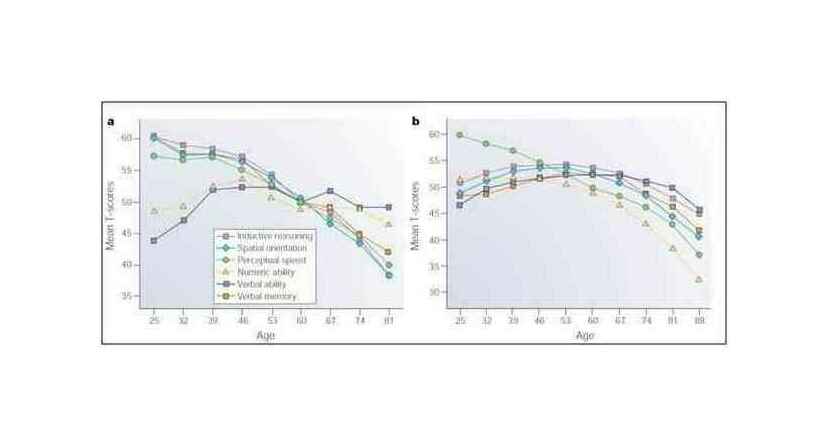
A cross-section of thousands of participants in the Cambridge brain-training study found “Age, was by far the most significant predictor of performance, with the mean scores of individuals in their 60s ~1.7 SDs below those in their early 20s (Figure 4a). (Note, in intelligence testing, 1 SD is equivalent to 15 IQ points).” These declines in reasoning affect valuable real-world activities like personal finance86, and simple everyday questions:

from Agarwal et al 200917ya, “The Age of Reason: Financial Decisions over the Life-Cycle with Implications for Regulation”
These results may be surprising because some studies did not find such dramatic declines, but apparently part of the decline can be hidden by practice effects87, and they are consistent with other results like the lifelong changes in Big Five personality traits (decreases in Extraversion & Openness to experience88, the latter decline possibly ameliorated by cognitive exercise). Longitudinal studies are pessimistic, finding declines early on, in one’s 40s (Sing-Manoux et al 2011). The degradation of white matter and its effects on episodic memory retrieval have been observed physically using fractional anisotropy. Another 201115ya study testing 200026ya individuals between 18 and 60 found that “Top performances in some of the tests were accomplished at the age of 22. A notable decline in certain measures of abstract reasoning, brain speed and in puzzle-solving became apparent at 27.”89 (Of course, like the previous study, a correlation over many individuals of varying ages is not as good as having a series of performance measurements for one aging individual. But time will cure that fault, hopefully.) The abstract of this Salthouse study says:
…Results from three methods of estimating retest effects in this project, together with results from studies comparing non-human animals raised in constant environments and from studies examining neurobiological variables not susceptible to retest effects, converge on a conclusion that some aspects of age-related cognitive decline begin in healthy educated adults when they are in their 20s and 30s.
From the optimistic perspective, Salthouse tested Fortune 500 CEOs and found that their membership by average age didn’t start dropping until their 60s, suggesting that they remained reasonably mentally sharp or were, in practice, compensating for the many insults of age;90 this way of thinking has obvious flaws for the rest of us.
There are a number of results indicating that the elderly, perhaps because they have so much severer cognitive deficits than the young, respond better to treatment. (This is common in nootropics, finding that something does not work in the young but does in the elderly: eg. creatine.) IQ gains in young adults are difficult and minimal even in Jaeggi 2008, but older adults improve about as much as young adults in Brehmer et al 2012 and instructing older adults to think aloud during an IQ test boosts scores (yet not younger adults)91, and training >65-year olds in one adaptive WM task similar to SNB lead to gains of ~6 IQ points on the Cattell Culture Fair IQ Test which were still present 8 months later; “Working Memory Training in Older Adults: Evidence of Transfer and Maintenance Effects” & Carretti et al 2012 makes for interesting reading92:
Few studies have examined working memory (WM) training-related gains and their transfer and maintenance effects in older adults. This present research investigates the efficacy of a verbal WM training program in adults aged 65-75 years, considering specific training gains on a verbal WM (criterion) task as well as transfer effects on measures of visuospatial WM, short-term memory, inhibition, processing speed, and fluid intelligence. Maintenance of training benefits was evaluated at 8-month follow-up. Trained older adults showed higher performance than did controls on the criterion task and maintained this benefit after 8 months. Substantial general transfer effects were found for the trained group, but not for the control one. Transfer maintenance gains were found at follow-up, but only for fluid intelligence and processing speed tasks. The results are discussed in terms of cognitive plasticity in older adults.
For more on aging and the brain, Mike Darwin recommends reading
Hedden T, Gabrieli JD. Nat Rev Neuroscience. 200422ya Feb;5(2):87-96. ‘Insights into the aging mind: a view from cognitive neuroscience’. PMID 14735112, which is available as full text from this link: https://brainybehavior.com/blog/wp-content/uploads/200719ya/11/agingbrain.pdf. I cannot recommend this paper highly enough. Additionally, the Salt Cognitive Aging Laboratory, which oversees the Virginia Cognitive Aging Project (VCAP) at the University of Virginia, is the premier facility in the US (and arguably the world) undertaking active, longitudinal studies of aging. The VCAP study has done comprehensive cognitive assessments in adults ranging 18–98 years of age. Approximately 3,800 adults have participated in their three-session (6-8 hour) assessment at least once, with about 1,600 participating at least twice, and about 450 of them participating three or more times. The data from this project have served as the basis for a veritable cornucopia of scientific publications which are available in the Resources Section of their website https://uva.theopenscholar.com/vcap/publications. Nearly 200 papers on the cognitive impact of aging are available free of charge on their website. It is necessary to register with your name and email address to access the papers, but it is well worth it.
TODO
Others to follow up on:
McNab F, Klingberg T (200818ya) Prefrontal cortex and basal ganglia control access to working memory. Nat Neurosci 11:103-107.
Colom et al. “Memory Span and General Intelligence: A Latent-Variable Approach”; Intelligence, v33 n6 p623-642 Nov-Dec 2005
There are several studies showing that working memory and intelligence are strongly related. However, working memory tasks require simultaneous processing and storage, so the causes of their relationship with intelligence are currently a matter of discussion. The present study examined the simultaneous relationships among short-term memory (STM), working memory (WM), and general intelligence (g). Two hundred and eight participants performed six verbal, quantitative, and spatial STM tasks, six verbal, quantitative, and spatial WM tasks, and eight tests measuring fluid, crystallized, spatial, and quantitative intelligence. Especial care is taken to avoid misrepresenting the relations among the constructs being studied because of specific task variance. Structural equation modeling (SEM) results revealed that (a) WM and g are (almost) isomorphic constructs, (b) the isomorphism vanishes when the storage component of WM is partialed out, and (c) STM and WM (with its storage component partialed out) predict g.
Colom et al. “General intelligence and memory span: Evidence for a common neuroanatomic framework”; Cognitive Neuropsychology, Volume 24, Issue 2007-12-08 , pages 867 - 878
General intelligence (g) is highly correlated with working-memory capacity (WMC). It has been argued that these central psychological constructs should share common neural systems. The present study examines this hypothesis using structural magnetic resonance imaging to determine any overlap in brain areas where regional grey matter volumes are correlated to measures of general intelligence and to memory span. In normal volunteers (n = 48) the results (p < .05, corrected for multiple comparisons) indicate that a common anatomic framework for these constructs implicates mainly frontal grey matter regions belonging to Brodmann area (BA) 10 (right superior frontal gyrus and left middle frontal gyrus) and, to a lesser degree, the right inferior parietal lobule (BA 40). These findings support the nuclear role of a discrete parieto-frontal network.
Software
Online
Most of the below implementations are obsolete or bitrotten.
There are many free implementations in Flash etc. online:
https://www.cogtest.com/tests/cognitive_int/db.html (Single N-back only)
Paid:
Desktop
Free:
Brain Workshop (Free Software/FLOSS).
BW is the standard implementation used by members of the DNB ML; it is Free, featureful, and well-supported.
hback (FLOSS)
Paid:
Brain Twister (the ‘official’ DNB program, used in the Jaeggi studies)
Mobile
Android
See also Lucas Charles’s August 201115ya review of 6 Android DNB apps.
Free:
Brain N Back (Quazar)
Brain N-Back (Phuc Nguyen)
Dual n-Back (Polytech Marseille)
IQ Boost (the free version)
N-Back (Piotr Wieczorek)
Paid:
N-Back Maestro (Urbian)
NBack (waterdev)
Brainturk (?)
IPhone
Free:
Paid:
Offline N-Back
You can play N-back in the real world, without a computer, if you like. See the ML thread “Non-electronic game version of N-back task” and the SnapBack rules. Jonathan Toomim points out that N-back can be easily done with a deck of cards alone, and the FAQ’s author suggests a simple mental arithmetic routine suitable for meditation that is much like SNB.
What Else Can I Do?
tDCS may increase WM, although it remains unclear whether the performance gains persist afterwards. See Boggio et al 2005, Fregni et al 2005, Ohn et al 2007, Boggio et al 2008, Jo et al 2009, Andrews et al 2011, Zaehle et al 2011, Berryhill & Jones 2012, Tseng et al 2012, Martin et al 2014, Matzen & Trumbo 2014, Carvalho et al 2014, Moreno et al 2015, Jones et al 2015, de Putter et al 2015, Choe et al 2016 (but also Marshall et al 2005, Steenbergen et al 2015, Hoy et al 2015, van Wessel et al 2015, Rethans et al 2015, Nilsson et al 2015, Nilsson et al 2017, Nikolin et al 2017, an informal incomplete tDCS-DNB experiment, and the meta-analysis Hill et al 2015).
Forum members have recommended a number of other things for general mental fitness:
Spaced repetition programs such as Mnemosyne are very useful for exploiting the spacing effect in order to memorize & remember things
Buddhist-style meditation has been recommended (there is a good Vipassana textbook available online; see Mindfulness in Plain English, and the https://openfocus.com/ website has been mentioned). Meditation has been well-studied and shown to induce physical changes and improve executive function & WM, S2B performance (local copy of Zeidan 2010), attention93, and cardiovascular health94 among many other results.
One study claims that spatial ability is trainable and that there is transfer (from trained tasks to novel ones)95. Suggested games include 4-D Rubik’s Cube, mental rotation, 3-D variants of Tetris, the VZ-2 paper folding test, and the Cambridge Brain Sciences suite of games/tasks.
neurofeedback can be similar to meditation and has been linked to physical changes in the brain;96 binaural beats have also been discussed.
Crypto recommends Win Wenger’s “image streaming” as another mental exercise
UOchris1 reports very positive results while working through a mental exercise regimen developed by an American performer from the 1920s who specialized in doing multiple mental tasks simultaneously; he is using a Stand Magazine article on Harry Kahne and Kahne’s “The Multiple Mentality Course” as resources.
Exercise is right up there with nutrition and sleep! See previous discussion.
I personally believe that the habit of listening to music - pervasive among students and especially university students - is deeply harmful to any serious thinking or learning. I’ve noticed my DNB scores seem damaged by my favorite music, although I have not done any experiments to test this theory. The existing research seems to agree with me in finding enjoyable music a distraction.
Supplements
Nootropics (see Nootropics for the author’s own experiences with them), may help boost performance. The relation of caffeine to learning & memory is complicated; for now, see the thread on it or my Nootropics page.
Piracetam
A useful pharmaceutical is piracetam; TheQ17 mentions that “Personally, I have found piracetam be quite useful in helping me stay alert and focused during long study hours or doing redundant tasks.” Other members also swear by piracetam+choline.
The author of this FAQ reports that piracetam and choline helped reduced mental fatigue and gave a small (~10%) increase in his D4B score.
Huperzine
Reece writes
I’ve tried huperzine [a chemical extracted from an herb] (actually been using it for about a year now) and it is quite effective for both lucid dreaming and increasing dream recall if taken shortly before bed, not to mention the other benefits you’d expect from a potent acetylcholinesterase inhibitor. I haven’t had anything in the way of negative side effects when I’ve stuck to a 5 day/week dosage of 200mcg.
I’ve never tried piracetam, however oxiracetam felt like a placebo when compared to the benefits I’ve received from huperzine A. At larger doses, I’ve found huperzine A to be far more powerful than any nootropic I’ve ever tried (haven’t tried any prescription meds such as deprenyl), however the side effects such as blurry vision and light-headedness weren’t something I could tolerate.
He further compared their effects:
I found Oxiracetam to have a somewhat “speedy” effect—you would certainly know you took something if someone slipped that in your drink! As for effects, Oxiracetam seemed to help most with verbal fluency (auditory working memory?) and creativity. Huperzine helped more with working memory although it didn’t have some of the interesting effects Oxiracetam had on creativity, nor the speedy rush that sometimes seemed like a powerful motivator to get work done.
(Reece did not take the oxiracetam with any choline supplements, which is usually recommended.)
Creatine
In the realm of unusual supplements to n-backing, we can include creatine possibly increasing intelligence, but the evidence is too weak to say much.
See Also
The author’s own Brain Workshop statistics can be found here
Appendix
Flaws in Mainstream Science (And Psychology)
By IQ, I mean fluid intelligence, not crystallized intelligence, since it’s unlikely that any generic training would teach you Latinate vocabulary terms or middle-school geometry. For those who object to the entire idea, please see Wikipedia or for a balanced overview of what IQ can predict and the exceptions, see Sternberg et al’s 200125ya review, “The Predictive Value of IQ”.↩︎
After a large amount of training, a task may become learned and cease to stress the bottleneck: eg. “Virtually Perfect Time Sharing in Dual-task Performance: Uncorking the Central Cognitive Bottleneck”.↩︎
See for example “Do working memory and susceptibility to interference predict individual differences in fluid intelligence?”, Borella 200620ya; WM predicts IQ better than strong focus/attention, with the correlation coming mostly from focus with only a small loading on executive control (Chuderski & Necka 2012).↩︎
“Brain networks for working memory and factors of intelligence assessed in males and females with fMRI and DTI”, Tang 201016ya; it found that “individual differences in activation during the n-back task were correlated to the general intelligence factor (g), as well as to distilled estimates (removing g) of speed of reasoning, numerical ability, and spatial ability, but not to memory”.
A more recent result is the fMRI study Chein 2011, “Domain-general mechanisms of complex working memory span”, which abstract says “For both verbal and spatial versions of the task, complex working memory span performance increased the activity in lateral prefrontal, anterior cingulate, and parietal cortices during the Encoding, Maintenance, and Coordination phase of task performance. Meanwhile, overlapping activity in anterior prefrontal and medial temporal lobe regions was associated with both verbal and spatial recall from working memory.”↩︎
eg. “Reasoning=working memory ≠ attention”, Buehner & Krummb & Pick 200521ya; more background is available on pg10/92 of “Working memory, fluid intelligence, and science learning”. But see the meta-analyses in Ackerman et al 2005 which find that WM ≠ IQ.↩︎
from Jaeggi et al 2010:
↩︎The findings of Study 1 confirm other findings from the literature (Jaeggi, Buschkuehl, Perrig, & Meier, 201016ya; Kane, Conway, Miura, & Colflesh, 200719ya): Consistent with our hypotheses, both n-back task variants were highly correlated, and both were best predicted by gf.
In general, matrix reasoning tasks seem to be better predictors for both the single and the dual n-back tasks than a measure of working memory capacity. As the reliability estimates were appropriate for the n-back tasks, the lack of correlation between the n-back tasks and the measure of working memory capacity cannot be attributed to insufficient reliability (Jaeggi, Buschkuehl, Perrig, & Meier, 201016ya). Rather, it seems that performance for the two tasks relies on different sources of variance, which might result from the different memory processes that are involved in the two tasks: whereas the n-back task relies on passive recognition processes, performance in working memory capacity tasks requires active and strategic recall processes (Kane, Conway, Miura, & Colflesh, 200719ya).
“Working memory capacity and fluid abilities: Examining the correlation between Operation Span and Raven”, Unsworth, Intelligence 200521ya:
↩︎However, as shown in Fig. 2, the correlations between solution accuracy for each item and Ospan, although fluctuating widely, does not appear to increase in any systematic manner as difficulty increases. Indeed, the correlation between Ospan and accuracy on the first problem was as high as with problem 24 (ie. problem 1 r=0.26, problem 24 r=0.26). These results are strikingly similar to those of Salthouse (199333ya) who showed roughly the same pattern of correlations between solution accuracy and a WM composite. Both sets of results suggest that there is not a clear relationship between item variations in difficulty on Raven and measures of WM.
…Although there seems to be adequate variability for quartile 4, this low correlation is probably due to the fact that not as many subjects attempted these problems. Indeed, 80% of participants attempted the first 27 problems, but only 47% of participants finished the test. Thus, only quartiles 1-3 should be interpreted. With this in mind, the results demonstrate that the correlation between solution accuracy and Ospan does not increase as difficulty increases but instead remains fairly constant across increasing levels of difficulty.
…One reviewer was concerned that only high working memory capacity individuals would finish the test. However, of those participants classified as high working memory (one standard deviation above the mean on Ospan), only 25% of them actually finished the test, whereas 71% of those classified as low working memory (one standard deviation below the mean on Ospan) finished the test. This results in somewhat lower scores for these 76 individuals on the two measures as compared the full sample (ie. M Ospan=11.12, S.D.=5.90; M Raven=17.50, S.D.=7.59).
“Does working memory training generalize?”, Shipstead et al 201016ya; abstract:
↩︎Recently, attempts have been made to alter the capacity of working memory (WMC) through extensive practice on adaptive working memory tasks that adjust difficulty in response to user performance. We discuss the design criteria required to claim validity as well as generalizability and how recent studies do or do not satisfy those criteria. It is concluded that, as of yet, the results are inconsistent and this is likely driven by inadequate controls and ineffective measurement of the cognitive abilities of interest.
See Minear & Shah 2008:
↩︎Performance on task switching, a paradigm commonly used to measure executive function, has been shown to improve with practice. However, no study has tested whether these benefits are specific to the tasks learned or are transferable to new situations. We report evidence of transferable improvement in a cued, randomly switching paradigm as measured by mixing cost, but we report no consistent improvement for switch cost. Improvement in mixing costs arises from a relative reduction in time to perform both switch and nonswitch trials that immediately follow switch trials, implicating the ability to recover from unexpected switches as the source of improvement. These results add to a growing number of studies demonstrating generalizable improvement with training on executive processing.
“Guest Column: Can We Increase Our Intelligence?”; Sam Wang & Sandra Aamodt; The New York Times
Differences in working memory capacity account for 50-70% of individual differences in fluid intelligence (abstract reasoning ability) in various meta-analyses, suggesting that it is one of the major building blocks of I.Q. (Ackerman et al; Kane et al; Süss et al 2002) This idea is intriguing because working memory can be improved by training.
See also the 201214ya NYT followup, “Can You Make Yourself Smarter?”↩︎
Is this right? I have no idea. But it is a curious collection of studies and an interesting proposed model: Hatton 1997:
↩︎For years I subscribed to such a principle: that modularization, or structural decomposition, is a good design concept and therefore always improves systems. This belief is so widespread as to be almost unchallengeable. It is responsible for the important programming language concept of compilation models-which are either separate, with guaranteed interface consistency (such as C++, Ada, and Modula-2), or independent, whereby a system is built in pieces and glued together later (C and Fortran, for example). It is a very attractive concept with strong roots in the “divide and conquer” principle of traditional engineering. However, this conventional wisdom may be wrong. Only those components that fit best into human short-term memory cache seem to use it effectively, thereby producing the lowest fault densities. Bigger and smaller average component sizes appear to degrade reliability.
…It is easy to get the impression from these case histories that developing software systems with low fault densities is exceedingly difficult. In fact, analysis of the literature reveals graphs such as that dependent faults per KLOC will approach an asymptote as time increases. In reality, only this asymptote makes sense for comparing the reliability of different systems. So, given that the asymptote can never be reached, the faults per KLOC and the rate of change of this value are required to compare such systems effectively. Of course, real systems are subject to continual noncorrective change, so things become rather more complex. No notion of rate of change of faults per KLOC was available for any of the data in this study, although both mature and immature systems were present, with the same behavior observed. This would suggest that the observed defect behavior is present through the life cycle, supporting even further the conjecture that it is a macroscopic property. If only immature systems had been present in the studies, it could have been argued that smaller components may get exercised more. This does not seem to be the case.
A further related point, also observed in the NAG library study, is that when component fault densities are plotted as a function of size, the usage of each component must be taken into account. The models discussed in this article are essentially asymptotic, and the fault densities they predict are therefore an envelope to which component fault densities will tend only as they are used sufficiently to begin to flush out faults. An unused component has complexity but no faults, by definition. The literature reports apparently near-zero-defect systems that have turned out on closer inspection to have been unused. shown in Figure 2. This data was compiled from NASA Goddard data by the University of Maryland’s Software Engineering Laboratory, as quoted in the December 199135ya special edition of Business Week. First of all, in spite of NASA’s enormous resources and talent pool, the average was still five to six faults per KLOC. Other studies have reported similar fault densities.4,8 More telling is the observation that in Figure 2, improvement has been achieved mostly by improving the bad processes, not the good ones. This fact suggests that consistency, a process issue, has improved much more than actual fault density, a product issue. The simple conclusion is that the average across many languages and development efforts for “good” software is around six faults per KLOC, and that with our best techniques, we can achieve 0.5-1 fault per KLOC. Perfection will always elude us, of course, but the intractability of achieving systematically better fault densities than have been achieved so far also suggests that some other limitation may be at work.
THE PROPOSED MODEL …Recovery code scrambling is an important factor in my proposed model. The evidence suggests that anything that fits in a short-term or cache memory is easier to understand and less fault-prone; pieces that are too large overflow, involving use of the more error-prone recovery code mechanism used for long-term storage. Thus, if a programmer is working with a component of complexity Ω, and that component fits entirely into the cache or short-term memory, which in turn can be manipulated without recourse to back-up or long-term memory, the incremental increase in bugs or disorder dE due to an incremental increase of complexity of dΩ is simply dE = (1/Ω) dΩ.
This resembles the argument leading to Boltzmann’s law relating entropy to complexity, where the analogue of equipartition of energy in a physical system is mirrored by the apparently equal distribution of rehearsal activity in the short-term memory. In other words, because no part of the cache is favored and the cache accurately manipulates symbols, the incremental increase in disorder is inversely proportional to the existing complexity, making the ideal case when pieces just fit into cache. It is assumed without loss of generality that both E and Ω are continuously valued variables. What happens when we encounter complexity greater than Ω′ (the complexity which will just fit into the cache)? The increase in disorder will correspond to the complexity in the (now-full) cache contents, plus a contribution proportional to the number of times the cache memory must be reloaded from the long-term memory. In other words, dE = (1/2Ω)’ (1 + Ω/Ω’) * dΩ
The factor of 1⁄2 matches Equation 1 when Ω = Ω′, that is, when the complexity of the program is about to overflow the cache memory. The second term is directly proportional to the cache overflow effect and mimics the scrambling of the recovery codes. Integrating Equations 1 and 2 suggests that E = log Ω for Ω ≤ Ω′ and E = 1⁄2 * (Ω/Ω’ + Ω^2/2*Ω’^2) for Ω > Ω’
…The Ada data and the assembly and macro-assembly data provide strong empirical support for this behavior, with about 200 to 400 lines corresponding to the complexity Ω′ at which cache memory overflows into long-term memory. That such disparate languages can produce approximately the same transition point from logarithmic to quadratic behavior supports the view that Ω is not the underlying algorithmic complexity but the symbolic complexity of the language implementation, given that a line of Ada would be expected to generate five or more lines of assembly. This is directly analogous to the observation that it is fit, rather than the actual information content of the cache that is relevant.9
…To summarize, if a system is decomposed into pieces much smaller than the short-term memory cache, the cache is used inefficiently because the interface of such a component with its neighbors is not “rehearsed” explicitly into the cache in the same way, and the resulting components tend to exhibit higher defect densities. If components exceed the cache size, they are less comprehensible because the recovery codes connecting comprehension with long-term memory break down. Only those components that match the cache size well use it effectively, thereby producing the lowest fault densities.
…Suppose that a particular functionality requires 1,000 “lines” to implement, where a “line” is some measure of complexity. The immediate implication of the earlier discussion is that, to be reliable, we should implement it as five 200-line components (each fitting in cache) rather than as 50 20-line components. The former would lead to perhaps 5 log_10(200) = 25 bugs while the latter would lead to 50 × log_10(20) = 150 bugs. This apparently inescapable but unpleasant conclusion runs completely counter to conventional wisdom. …The additional unreliability caused by splitting up the system might be due to simple interface inconsistencies. The Basili-Perricone study considered this a possible explanation, as did Moller-Paulish. However, it was not a factor in the Hatton-Hopkins study, since the internally reusable components in the NAG library (largely externally used reusable components) had high interface consistency. Furthermore, it is unlikely to explain the Compton-Withrow data because Ada mandates interface consistency in language implementations. (This may be responsible for the difference in small components in Figure 4.)
Jeff Atwood; “Multiple Monitors and Productivity”, “The Programmer’s Bill of Rights”, “Joining the Prestigious Three Monitor Club”, “Does More Than One Monitor Improve Productivity?” etc.↩︎
See citation roundup at the Skeptics StackExchange.↩︎
Jeff Atwood, “The Large Display Paradox”↩︎
See his blog posts, primarily “Programming’s Dirtiest Little Secret”. One dissenting viewpoint is John D. Cook’s “How much does typing speed matter?”, which takes an Amdahl’s law perspective—since typing speeds don’t vary by more than an order of magnitude or two or take up much time for the most part, you can’t expect the overall productivity boost of faster typing to be too big (though it could still be well worth your while). Nevertheless, I think the most compelling argument for learning typing well or using a good input device in general is to simply spend some time using a keyboard with a broken key or a worn-out mouse/trackball which once in a while misclicks: even an objectively ‘small’ error rate is enough to drive one batty and destroy ‘flow’. I’m reminded of Dan Luu’s articles on latency: specifically, web bloat & input & terminal latency.↩︎
Page 457, Coders at Work:
↩︎Seibel: “Is there anything you would have done differently about learning to program? Do you have any regrets about the sort of path you took or do you wish you had done anything earlier?”
Ken Thompson: “Oh, sure, sure. In high school I wish I’d taken typing. I suffer from poor typing yet today, but who knew. I didn’t plan anything or do anything. I have no discipline. I did what I wanted to do next, period, all the time. If I had some foresight or planning or something, there are things, like typing, I would have done when I had the chance.”
When I was younger, I reasoned that early in life is the best time to learn to read fast since one reaps the greatest gains over the longest possible period (I still agree with my former reasoning) and so did a great deal of reading on speed-reading and the related academic literature, and spent more than a few hours working with tachistocopic-style software. My ultimate conclusion was that it was a good use of my time as it bumped my WPM up to ~400-500 WPM from the ordinary 300 WPM, but the techniques were not going to give any useful ability beyond that as greater speed becomes an indication one is reading too easy material or one should be using more sophisticated search capabilities. In particular, tachistoscopes weren’t very useful for non-practice reading and were least useful on deep or heavily-hyperlinked content. “Photoreading”, however, is simply a scam or very shallow skimming. Unfortunately, I omitted to take notes on specific studies or programs, though, being too young to care about being able to explain & defend my beliefs later - but that is just as well since by now, all the websites would be gone, programs bitrotten, and links broken. Readers will just have to do their own research on the topic if they care (much easier in this age of Wikipedia). One starting point: Scott Young.↩︎
From the interview anthology Coders at Work (200917ya), pg114:
Peter Seibel: “Do you think that programming is at all biased toward being young?”
Douglas Crockford: “I used to think so. A few years ago I had sleep apnea, but I didn’t know it. I thought I was just getting tired and old, and I got to the point where it was so difficult to concentrate that I couldn’t program anymore because I just couldn’t keep enough stuff in my head. A lot of programming is you keep stuff in your head until you can get it written down and structured properly. And I just couldn’t do it.
I had lost that ability and I thought it was just because I was getting older. Fortunately, I got better and it came back and so I’m programming again. I’m doing it well and maybe a little bit better now because I’ve learned how not to depend so much on my memory. I’m better at documenting my code now than I used to be because I’m less confident that I’ll remember next week why I did this. In fact, sometimes I’ll be going through my stuff and I’m amazed at stuff that I had written: I don’t remember having done it and it’s either really either awful or brilliant. I had no idea I was capable of that.”
From pg154:
Seibel: “How do you design code?”
Brendan Eich: “A lot of prototyping. I used to do sort of high-level pseudocode, and then I’d start filling in bottom up. I do less of the high-level pseudocode because I can usually hold it in my head and just do bottom-up until it joins.
Often I’m working with existing pieces of code adding some new subsystem or something on the side and I can almost do it bottom-up. When I get in trouble in the middle I do still write pseudo-code and just start working bottom up until I can complete it. I try not to let that take too long because you’ve got to be able to test it; you’ve got to be able to see it run and step through it and make sure it’s doing what it’s supposed to be doing.”
From pg202, a cogent reminder that ’tis a good wind that blows no ill (and that as William T. Powers wrote somewhere on the CSGNet ML, “Some people revel in complexity, and what’s worse, they have the brain power to deal with vast systems of arcane equations. This ability can be a handicap because it leads to overlooking simple solutions.”):
Seibel: “Speaking of writing intricate code, I’ve noticed that people who are too smart, in a certain dimension anyway, make the worst code. Because they can actually fit the whole thing in their head they can write these great reams of spaghetti code.”
Joshua Bloch: “I agree with you that people who are both smart enough to cope with enormous complexity and lack empathy with the rest of us may fall prey to that. They think, ‘I can understand this and I can use it, so it has to be good.’”
From pg236:
Joe Armstrong: “I read somewhere, that you have to have a good memory to be a reasonable programmer. I believe that to be true.”
Seibel: “Bill Gates once claimed that he could still go to a blackboard and write out big chunks of the code to the BASIC that he written for the Altair, a decade or so after he had originally written it. Do you think you can remember your old code that way?”
Armstrong: “Yeah. Well, I could reconstruct something. Sometimes I’ve just completely lost some old code and it doesn’t worry me in the slightest.”
From page 246:
Simon Peyton Jones: “Yeah, that’s right. So essentially we wrote out our types by drawing them on large sheets of papers with arrows. That was our type system. That was a pretty large program—in fact it was over ambitious; we never completed it.”
Seibel: “Do you think you learned any lessons from that failure?”
Peyton Jones: “That was probably when I first became aware that writing a really big program you could end up with problems of scale—you couldn’t keep enough of it in your head at the same time. Previously all the things I had written, you could keep the whole thing in your head without any trouble. So it was probably the first time I’d done any serious attempt at long-standing documentation.”
Seibel: “But even that wasn’t enough, in this case…”
From page 440:
↩︎[David Deutsch:] “The second reason I like Python is that-and maybe this is just the way my brain has changed over the years-I can’t keep as much stuff in my head as I used to. It’s more important for me to have stuff in front of my face. So the fact that in Smalltalk you effectively cannot put more than one method on the screen at a time drives me nuts. As far as I’m concerned the fact that I edit Python programs with Emacs is an advantage because I can see more than ten lines’ worth at a time.”
From an interview given by Donald Knuth to Dikran Karagueuzian, the director of CSLI Publications:
↩︎I couldn’t keep up with all my teaching at Stanford though, I’m not on sabbatical but I found that doing software was much, was much harder than writing books and doing research papers. It takes another level of commitment that you have to have so much in your head at the time when you’re doing software, that, that I had to take leave of absence from Stanford from my, from my ordinary teaching for several quarters during this period.
The best programmers seem to suffer few distractions and the worst had many, although it is hard to infer causality from this striking correlation. From “The Rise of the New Groupthink”, Susan Cain, The New York Times (drawing on the 198739ya book Peopleware: Productive Projects and Teams or perhaps the related excerpts “Why Measure Performance”):
↩︎Privacy also makes us productive. In a fascinating study known as the Coding War Games, consultants Tom DeMarco and Timothy Lister compared the work of more than 600 computer programmers at 92 companies. They found that people from the same companies performed at roughly the same level - but that there was an enormous performance gap between organizations. What distinguished programmers at the top-performing companies wasn’t greater experience or better pay. It was how much privacy, personal workspace and freedom from interruption they enjoyed. 62% of the best performers said their workspace was sufficiently private compared with only 19% of the worst performers. 76% of the worst programmers but only 38% of the best said that they were often interrupted needlessly.
“Who is Likely to Acquire Programming Skills?”, Shute 199135ya; Shute measured WM for students learning Pascal and of course found that higher WM correlated with faster learning, but despite using the g-loaded ASVAB, unfortunately she apparently did not measure against IQ directly, so possibly it’s just IQ correlating with the programming skill:
↩︎Following instruction, an online battery of criterion tests was administered measuring programming knowledge and skills acquired from the tutor. Results showed that a large amount (68%) of the outcome variance could be predicted by a working-memory factor, specific word problem solving abilities (ie. problem identification and sequencing of elements) and some learning style measures (ie. asking for hints and running programs).
In “Why Angry Birds is so successful and popular: a cognitive teardown of the user experience”, ergonomics writer Charles L. Mauro singles out selective stressing of working memory as key to Angry Birds’s management of the difficulty of its puzzles:
↩︎It is a well-known fact of cognitive science that human short-term memory (SM), when compared to other attributes of our memory systems, is exceedingly limited….Where things get interesting is the point where poor user interface design impacts the demand placed on SM. For example, a user interface design solution that requires the user to view information on one screen, store it in short-term memory, and then reenter that same information in a data field on another screen seems like a trivial task. Research shows that it is difficult to do accurately, especially if some other form of stimulus flows between the memorization of the data from the first screen and before the user enters the data in the second. This disruptive data flow can be in almost any form, but as a general rule, anything that is engaging, such as conversation, noise, motion, or worst of all, a combination of all three, is likely to totally erase SM. When you encounter this type of data flow before you complete transfer of data using short-term memory, chances are very good that when you go back to retrieve important information from short-term memory, it is gone!
…Angry Birds is a surprisingly smart manager of the player’s short-term memory.
By simple manipulation of the user interface, Angry Birds designers created significant short-term memory loss, which in turn increases game play complexity but in a way that is not perceived by the player as negative and adds to the addictive nature of the game itself. The subtle, yet powerful concept employed in Angry Birds is to bend short-term memory but not to actually break it. If you do break SM, make sure you give the user a very simple, fast way to accurately reload. There are many examples in the Angry Birds game model of this principle in action….
One of the main benefits of playing Angry Birds on the iPad [rather than the smaller iPhone] is the ability to pinch down the window size so you can keep the entire game space (birds & pigs in houses) in full view all the time. Keeping all aspects of the game’s interface in full view prevents short-term memory loss and improves the rate at which you acquire skills necessary to move up to a higher game level. Side note: If you want the ultimate Angry Birds experience use a POGO pen on the iPad with the display pinched down to view the entire game space. This gives you finer control, better targeting and rapidly changing game play. The net impact in cognitive terms is a vastly superior skill acquisition profile. However, you will also find that the game is less interesting to play over extended periods. Why does this happen?
“Reexamining the Fault Density-Component Size Connection”, Les Hatton (extended excerpts):
↩︎For years I subscribed to such a principle: that modularization, or structural decomposition, is a good design concept and therefore always improves systems. This belief is so widespread as to be almost unchallengeable. It is responsible for the important programming language concept of compilation models-which are either separate, with guaranteed interface consistency (such as C++, Ada, and Modula-2), or independent, whereby a system is built in pieces and glued together later (C and Fortran, for example). It is a very attractive concept with strong roots in the “divide and conquer” principle of traditional engineering. However, this conventional wisdom may be wrong. Only those components that fit best into human short-term memory cache seem to use it effectively, thereby producing the lowest fault densities. Bigger and smaller average component sizes appear to degrade reliability.
…The Ada data and the assembly and macro-assembly data provide strong empirical support for this behavior, with about 200 to 400 lines corresponding to the complexity Ω′ at which cache memory overflows into long-term memory. That such disparate languages can produce approximately the same transition point from logarithmic to quadratic behavior supports the view that Ω is not the underlying algorithmic complexity but the symbolic complexity of the language implementation, given that a line of Ada would be expected to generate five or more lines of assembly. This is directly analogous to the observation that it is fit, rather than the actual information content of the cache that is relevant.9
…To summarize, if a system is decomposed into pieces much smaller than the short-term memory cache, the cache is used inefficiently because the interface of such a component with its neighbors is not “rehearsed” explicitly into the cache in the same way, and the resulting components tend to exhibit higher defect densities. If components exceed the cache size, they are less comprehensible because the recovery codes connecting comprehension with long-term memory break down. Only those components that match the cache size well use it effectively, thereby producing the lowest fault densities.
…Suppose that a particular functionality requires 1,000 “lines” to implement, where a “line” is some measure of complexity. The immediate implication of the earlier discussion is that, to be reliable, we should implement it as five 200-line components (each fitting in cache) rather than as 50 20-line components. The former would lead to perhaps bugs while the latter would lead to bugs. This apparently inescapable but unpleasant conclusion runs completely counter to conventional wisdom. …The additional unreliability caused by splitting up the system might be due to simple interface inconsistencies. The Basili-Perricone study considered this a possible explanation, as did Moller-Paulish. However, it was not a factor in the Hatton-Hopkins study, since the internally reusable components in the NAG library (largely externally used reusable components) had high interface consistency. Furthermore, it is unlikely to explain the Compton-Withrow data because Ada mandates interface consistency in language implementations. (This may be responsible for the difference in small components in Figure 4.)
“Walking is free, but Americans spent $13 million on brain-fitness software and games last year [2009]…”; from Newsweek↩︎
See for example Nature’s coverage of the Cambridge study, “No gain from brain training: Computerized mental workouts don’t boost mental skills, study claims”; or Discover’s blog discussion.↩︎
-
↩︎Training your memory, reasoning, or speed of processing improves that skill, found a large government-sponsored study called Active. Unfortunately, there is no transfer: improving processing speed does not improve memory, and improving memory does not improve reasoning. Similarly, doing crossword puzzles will improve your ability to…do crosswords. “The research so far suggests that cognitive training benefits only the task used in training and does not generalize to other tasks,” says Columbia’s Stern.
-
↩︎Doing crossword puzzles would seem to be ideal brain exercise since avid puzzlers do them daily and say it keeps them mentally sharp, especially with vocabulary and memory. But this may be confusing cause and effect. It is mostly people who are good at figuring out “Dole’s running mate” who do crosswords regularly; those who aren’t, don’t. In a recent study, Salt-house and colleagues found “no evidence” that people who do crosswords have “a slower rate of age-related decline in reasoning.” As he put it in a 200620ya analysis, there is “little scientific evidence that engagement in mentally stimulating activities alters the rate of mental aging,” an idea that is “more of an optimistic hope than an empirical reality.” (P.S.: Bob Dole’s 199630ya VP choice was Jack Kemp.)
Music correlates with increased SAT scores, which has been cited as a justification for teaching students music, but it exhibit a common pattern for claims of far transfer: it appears in simple analyses, disappears in randomized experiments (eg. Mehr et al 2013), and finally a thorough analysis including a wide range of covariates like Elpus 201313ya finds the correlation disappears because it was due to some confound like the higher-performing students also being wealthier. The background for music:
↩︎An entire special issue of the Journal of Aesthetic Education (JAE) in 200026ya, titled “The Arts and Academic Achievement: What the Evidence Shows”, was dedicated to examining the academic performance of arts and non-arts students. In that volume, Winner & Cooper 2000 meta-analyzed some 31 published and unpublished studies, yielding 66 separate effect sizes examining the general research question of whether arts education, broadly defined, positively influenced academic achievement. Results of the meta-analysis showed that arts education was moderately positively associated with higher achievement in math, verbal, and composite math-verbal outcomes. In the same journal issue, Vaughan & Winner 2000 sought to analyze the link between arts course work and SAT scores specifically. Using data from 12 years of national SAT means reported by the College Board in the annual Profiles of College Bound Seniors report, Vaughan and Winner found that students who self-reported on the SAT’s Student Descriptive Questionnaire that they had pursued arts course work outscored students who reported they had not taken any arts course work. Meta-analyses of music students’ performance on verbal (Butzlaff, 2000) and mathematical (Vaughan, 200026ya) standardized tests were somewhat inconclusive: Although positive associations were found in the correlational research literature, meta-analyses of results from the few experimental studies located in the literature showed little to no influence of music on verbal or math test scores…In British Columbia, Canada (Gouzouasis, Guhn, & Kishor, 2007), results of an observational study indicated an association between music enrollment and higher subject-area standardized test scores among high school students. The results of a randomized experiment in Montreal, Canada, showed no effects of piano instruction on subject-area standardized tests among elementary school children from low socioeconomic backgrounds (Costa-Giomi, 2004).
A specific example: Schneider et al 1993—chess-playing had superior chessboard recall than adults, but adults still had better recall of numbers. Exactly as expected from training with no transfer.↩︎
National memory champion Tatiana Cooley: “I’m incredibly absent-minded. I live by Post-its.” Or the Washington Post, reviewing Joshua Foer’s 201115ya Moonwalking With Einstein:
↩︎Foer sets out to meet the legendary “Brainman,” who learned Spanish in a single weekend, could instantly tell if any number up to 10,000 was prime, and saw digits in colors and shapes, enabling him to hold long lists of them in memory. The author also tracks down “Rain Man” Kim Peek, the famous savant whose astonishing ability to recite all of Shakespeare’s works, reproduce scores from a vast canon of classical music and retain the contents of 9,000 books was immortalized in the Hollywood movie starring Dustin Hoffman. When Foer is told that the Rain Man had an IQ of merely 87 - that he was actually missing a part of his brain; that memory champions have no more intelligence than you or I; that building a memory is a matter of dedication and training - he decides to try for the U.S. memory championship himself. Here is where the book veers sharply from science journalism to a memoir of a singular adventure.
“Getting a Grip on Drinking Behavior: Training Working Memory to Reduce Alcohol Abuse”, Houben et al 201115ya:
↩︎Alcohol abuse disrupts core executive functions, including working memory (WM)-the ability to maintain and manipulate goal-relevant information. When executive functions like WM are weakened, drinking behavior gets out of control and is guided more strongly by automatic impulses. This study investigated whether training WM restores control over drinking behavior. Forty-eight problem drinkers performed WM training tasks or control tasks during 25 sessions over at least 25 days. Before and after training, we measured WM and drinking behavior. Training WM improved WM and reduced alcohol intake for more than 1 month after the training. Further, the indirect effect of training on alcohol use through improved WM was moderated by participants’ levels of automatic impulses: Increased WM reduced alcohol consumption in participants with relatively strong automatic preferences for alcohol. These findings are consistent with the theoretical framework and demonstrate that training WM may be an effective strategy to reduce alcohol use by increasing control over automatic impulses to drink alcohol.
“Remember the Future: Working Memory Training Decreases Delay Discounting Among Stimulant Addicts”, Bickel et al 201115ya; WM tasks were digit span, reverse digit span, and a list-of-words-matching task. Decreasing their discount rate does not actually show any reduced drug abuse or better odds of rehabilitation, but it is hopeful.↩︎
“Self-Discipline Outdoes IQ in Predicting Academic Performance of Adolescents”, Duckworth 200620ya; abstract:
↩︎In a longitudinal study of 140 eighth-grade students, self-discipline measured by self-report, parent report, teacher report, and monetary choice questionnaires in the fall predicted final grades, school attendance, standardized achievement-test scores, and selection into a competitive high school program the following spring. In a replication with 164 eighth graders, a behavioral delay-of-gratification task, a questionnaire on study habits, and a group-administered IQ test were added. Self-discipline measured in the fall accounted for more than twice as much variance as IQ in final grades, high school selection, school attendance, hours spent doing homework, hours spent watching television (inversely), and the time of day students began their homework. The effect of self-discipline on final grades held even when controlling for first-marking-period grades, achievement-test scores, and measured IQ. These findings suggest a major reason for students falling short of their intellectual potential: their failure to exercise self-discipline.
This is probably not surprising, since even in adults, those with higher WMs are better at controlling their emotions when asked to do so; abstract of “Working memory capacity and spontaneous emotion regulation: High capacity predicts self-enhancement in response to negative feedback”:
↩︎Although previous evidence suggests that working memory capacity (WMC) is important for success at emotion regulation, that evidence may reveal simply that people with higher WMC follow instructions better than those with lower WMC. The present study tested the hypothesis that people with higher WMC more effectively engage in spontaneous emotion regulation following negative feedback, relative to those with lower WMC. Participants were randomly assigned to receive either no feedback or negative feedback about their emotional intelligence. They then completed a disguised measure of self-enhancement and a self-report measure of affect. Experimental condition and WMC interacted such that higher WMC predicted more self-enhancement and less negative affect following negative feedback. This research provides novel insight into the consequences of individual differences in WMC and illustrates that cognitive capacity may facilitate the spontaneous self-regulation of emotion.
“Investigating the predictive roles of working memory and IQ in academic attainment”, Alloway 201016ya:
…The findings indicate that children’s working memory skills at 5 years of age were the best predictor of literacy and numeracy 6 years later. IQ, in contrast, accounted for a smaller portion of unique variance to these learning outcomes. The results demonstrate that working memory is not a proxy for IQ but rather represents a dissociable cognitive skill with unique links to academic attainment. Critically, we find that working memory at the start of formal education is a more powerful predictor of subsequent academic success than IQ….
Less striking but still relevant is “Working Memory, but Not IQ, Predicts Subsequent Learning in Children with Learning Difficulties”, Alloway 200917ya:
↩︎The purpose of the present study was to compare the predictive power of working memory and IQ in children identified as having learning difficulties…Children aged between 7 and 11 years were tested at Time 1 on measures of working memory, IQ, and learning. They were then retested 2 years later on the learning measures. The findings indicated that working-memory capacity and domain-specific knowledge at Time 1, but not IQ, were significant predictors of learning at Time 2.
“Computerized Training of Working Memory in Children With ADHD - A Randomized, Controlled Trial”, Klingberg et al 200521ya; abstract:
…For the span-board task, there was a significant treatment effect both post-intervention and at follow-up. In addition, there were significant effects for secondary outcome tasks measuring verbal WM, response inhibition, and complex reasoning. Parent ratings showed significant reduction in symptoms of inattention and hyperactivity/impulsivity, both post-intervention and at follow-up. Conclusions:This study shows that WM can be improved by training in children with ADHD. This training also improved response inhibition and reasoning and resulted in a reduction of the parent-rated inattentive symptoms of ADHD.
See also Green et al 2012.↩︎
“Training and transfer effects of executive functions in preschool children”, Thorell et al 2009↩︎
“Differential effects of reasoning and speed training in children” (the list of reasoning games, page 5, does not seem to include any direct analogues to n-back):
↩︎The goal of this study was to determine whether intensive training can ameliorate cognitive skills in children. Children aged 7 to 9 from low socioeconomic backgrounds participated in one of two cognitive training programs for 60 minutes ⧸ day and 2 days ⧸ week, for a total of 8 weeks. Both training programs consisted of commercially available computerized and non- computerized games. Reasoning training emphasized planning and relational integration; speed training emphasized rapid visual detection and rapid motor responses. Standard assessments of reasoning ability - the Test of Non-Verbal Intelligence (TONI-3) and cognitive speed (Coding B from WISC IV) - were administered to all children before and after training. Neither group was exposed to these standardized tests during training. Children in the reasoning group improved substantially on TONI (Cohen’s d = 1.51), exhibiting an average increase of 10 points in Performance IQ, but did not improve on Coding. By contrast, children in the speed group improved substantially on Coding (d = 1.15), but did not improve on TONI. Counter to widespread belief, these results indicate that both fluid reasoning and processing speed are modifiable by training.
See again Sternberg et al’s 200125ya review, “The Predictive Value of IQ”:
Evidence from studies of the natural course of development: Some get more intelligent, others get less intelligent. The Berkeley Guidance Study (Honzik, Macfarlane, & Allen, 194878ya) investigated the stability of IQ test performance over 12 years. The authors reported that nearly 60% of the sample changed by 15 IQ points or more 6–18 years of age. A similar result was found in the Fels study (Sontag, Baker, & Nelson, 195868ya): Nearly two thirds of the children changed more than 15 IQ points from age 3 to age 10. Researchers also investigated the so-called intelligence lability score, which is a child’s standard deviation from his or her own grand mean IQ. Bayley (194977ya), in the Berkeley Growth study, detected very large individual differences in lability across the span of 18 years. Rees & Palmer 197056ya combined the data from five large-scale longitudinal studies, selecting those participants who had scores at both age 6 and age 12 or at both age 12 and age 17. They found that about 30% of the selected participants changed by 10 or more IQ points.
Sternberg et al also discusses the dramatic IQ gains possible during infancy when adoptees moving from a bad environment (Third or Second World orphanages) to good ones (First World homes), but also the discouraging examples of early intervention programs in the USA where initial IQ gains often fade away over the years.↩︎
See “Verbal and non-verbal intelligence changes in the teenage brain” (media coverage: “IQ Isn’t Set In Stone, Suggests Study That Finds Big Jumps, Dips In Teens”);
Neuroimaging allows us to test whether unexpected longitudinal fluctuations in measured IQ are related to brain development. Here we show that verbal and non-verbal IQ can rise or fall in the teenage years, with these changes in performance validated by their close correlation with changes in local brain structure. A combination of structural and functional imaging showed that verbal IQ changed with grey matter in a region that was activated by speech, whereas non-verbal IQ changed with grey matter in a region that was activated by finger movements. By using longitudinal assessments of the same individuals, we obviated the many sources of variation in brain structure that confound cross-sectional studies. This allowed us to dissociate neural markers for the two types of IQ and to show that general verbal and non-verbal abilities are closely linked to the sensorimotor skills involved in learning.
It’s worth noting that substantial changes in the brain continue to take place towards the end of adolescence and early adulthood, and at least some are about reducing one’s mental flexibility; from National Geographic, “Beautiful Brains: Moody. Impulsive. Maddening. Why do teenagers act the way they do? Viewed through the eyes of evolution, their most exasperating traits may be the key to success as adults”:
↩︎Meanwhile, in times of doubt, take inspiration in one last distinction of the teen brain-a final key to both its clumsiness and its remarkable adaptability. This is the prolonged plasticity of those late-developing frontal areas as they slowly mature. As noted earlier, these areas are the last to lay down the fatty myelin insulation-the brain’s white matter-that speeds transmission. And at first glance this seems like bad news: If we need these areas for the complex task of entering the world, why aren’t they running at full speed when the challenges are most daunting?
The answer is that speed comes at the price of flexibility. While a myelin coating greatly accelerates an axon’s bandwidth, it also inhibits the growth of new branches from the axon. According to Douglas Fields, an NIH neuroscientist who has spent years studying myelin, “This makes the period when a brain area lays down myelin a sort of crucial period of learning-the wiring is getting upgraded, but once that’s done, it’s harder to change.”
The window in which experience can best rewire those connections is highly specific to each brain area. Thus the brain’s language centers acquire their insulation most heavily in the first 13 years, when a child is learning language. The completed insulation consolidates those gains-but makes further gains, such as second languages, far harder to come by. So it is with the forebrain’s myelination during the late teens and early 20s. This delayed completion-a withholding of readiness-heightens flexibility just as we confront and enter the world that we will face as adults.
Jaeggi, S. M., Seewer, R., Nirkko, A. C., Eckstein, D., Schroth, G., Groner, R., et al, (200323ya). “Does excessive memory load attenuate activation in the prefrontal cortex? Load-dependent processing in single and dual tasks: functional magnetic resonance imaging study”, Neuroimage 19(2) 210-225.↩︎
22 = 4; 4-1 = 3. For DNB, the 3 responses are:
audio match
visual match
audio & visual matches
or 23 - 1↩︎
or 24 - 1↩︎
or 25 - 1↩︎
Spreading one’s efforts over a variety of activities is not necessarily a good thing, and can be sub-optimal; consider the charity example (“Giving Your All”, Steven E. Landsburg):
↩︎People constantly ignore my good advice by contributing to the American Heart Association, the American Cancer Society, CARE, and public radio all in the same year—as if they were thinking, “OK, I think I’ve pretty much wrapped up the problem of heart disease; now let’s see what I can do about cancer.”
I’m not the only one to notice this. ‘y offs et’ mentions during a discussion of TNB that:
↩︎It’s interesting how doing n-back proves that time is relative and based upon our perception of its passing
When I’m doing well, the next instance comes with metronome exactness as expected from a machine. When I’m resetting after a tricky double-back, the next instance always comes way too quickly, as if a second had been removed. The same perception happens on an upped level, and it is so persistent. It’s like some time had vanished.
For the longest time I thought the program had a bug, being the mere human.
Sleep affects IQ, not just vigilance or energy: “Adolescent sleep and fluid intelligence performance”, Johnstone et al 201016ya; abstract:
Fluid intelligence involves novel problem-solving and may be susceptible to poor sleep. This study examined relationships between adolescent sleep, fluid intelligence, and academic achievement. Participants were 217 adolescents (42% male) aged 13 to 18 years (mean age, 14.9 years; SD = 1.0) in grades 9-11. Fluid intelligence was predicted to mediate the relationship between adolescent sleep and academic achievement. Students completed online questionnaires of self-reported sleep, fluid intelligence (Letter Sets and Number Series), and self-reported grades. Total sleep time was not significantly related to fluid intelligence nor academic achievement (both p > 0.05); however, sleep difficulty (eg. difficulty initiating sleep, unrefreshing sleep) was related to both (P < 0.05)…
Further, we can easily delude ourselves about our own mental states:
↩︎Still, while it’s tempting to believe we can train ourselves to be among the five-hour group - we can’t, Dinges says - or that we are naturally those five-hour sleepers, consider a key finding from Van Dongen and Dinges’s study: after just a few days, the four- and six-hour group reported that, yes, they were slightly sleepy. But they insisted they had adjusted to their new state. Even 14 days into the study, they said sleepiness was not affecting them. In fact, their performance had tanked. In other words, the sleep-deprived among us are lousy judges of our own sleep needs.
“NASA Naps: NASA-supported sleep researchers are learning new and surprising things about naps.”, 2005-06-03:
↩︎“To our amazement, working memory performance benefited from the naps, [but] vigilance and basic alertness did not benefit very much,” says Dinges.
Aerobic exercise has been shown to improve mental fitness. One small study with old diabetics found improvement in working memory/executive function caused by an aerobic exercise regimen, and another found increased brain volume and increased hippocampal volume & BDNF secretion in healthy old people; a Cochrane Collaboration found benefits in 8 of 11 aerobic interventions in the elderly. And exercise improves working memory (or at least correlated with intelligence & education in twins), and there is some suggestive evidence that strength training or resistance training may help as well. One possible mechanism (in rats, anyway) is increases in chemical energy storage in the brain. For further reading, see the review & reviews cited in “Exercise and Children’s Intelligence, Cognition, and Academic Achievement” and Wikipedia.↩︎
See for example “Zinc status and cognitive function of pregnant women in Southern Ethiopia” or “Zinc supplementation improved cognitive performance and taste acuity in Indian adolescent girls”↩︎
“Acute hypoglycemia impairs nonverbal intelligence: importance of avoiding ceiling effects in cognitive function testing.”. While we’re at it, blood sugar seems to be closely linked to attention/self-control/self-discipline (see LW discussions: “The Physiology of Willpower”, “Willpower: not a limited resource?”, “What would you do if blood glucose theory of willpower was true?”, Vladimir/ Golovin, and “Superstimuli and the Collapse of Western Civilization”). For a roundup of all the research, read Baumeister & Tierney’s 201115ya book Willpower.
But see also the severe criticisms & failures to replicate which have battered the paradigm since 201115ya.↩︎
Quotes from “Do You Suffer From Decision Fatigue?”, NYT, itself quoting from Baumeister & Tierney 201115ya:
↩︎Once you’re mentally depleted, you become reluctant to make trade-offs, which involve a particularly advanced and taxing form of decision making. In the rest of the animal kingdom, there aren’t a lot of protracted negotiations between predators and prey. To compromise is a complex human ability and therefore one of the first to decline when willpower is depleted. You become what researchers call a cognitive miser, hoarding your energy. If you’re shopping, you’re liable to look at only one dimension, like price: just give me the cheapest. Or you indulge yourself by looking at quality: I want the very best (an especially easy strategy if someone else is paying). Decision fatigue leaves you vulnerable to marketers who know how to time their sales, as Jonathan Levav, the Stanford professor, demonstrated in experiments involving tailored suits and new cars.
Most of us in America won’t spend a lot of time agonizing over whether we can afford to buy soap, but it can be a depleting choice in rural India. Dean Spears, an economist at Princeton, offered people in 20 villages in Rajasthan in northwestern India the chance to buy a couple of bars of brand-name soap for the equivalent of less than 20 cents. It was a steep discount off the regular price, yet even that sum was a strain for the people in the 10 poorest villages. Whether or not they bought the soap, the act of making the decision left them with less willpower, as measured afterward in a test of how long they could squeeze a hand grip. In the slightly more affluent villages, people’s willpower wasn’t affected significantly…To establish cause and effect, researchers at Baumeister’s lab tried refueling the brain in a series of experiments involving lemonade mixed either with sugar or with a diet sweetener. The sugary lemonade provided a burst of glucose, the effects of which could be observed right away in the lab; the sugarless variety tasted quite similar without providing the same burst of glucose. Again and again, the sugar restored willpower, but the artificial sweetener had no effect. The glucose would at least mitigate the ego depletion and sometimes completely reverse it. The restored willpower improved people’s self-control as well as the quality of their decisions: they resisted irrational bias when making choices, and when asked to make financial decisions, they were more likely to choose the better long-term strategy instead of going for a quick payoff. The ego-depletion effect was even demonstrated with dogs in two studies by Holly Miller and Nathan DeWall at the University of Kentucky. After obeying sit and stay commands for 10 minutes, the dogs performed worse on self-control tests and were also more likely to make the dangerous decision to challenge another dog’s turf. But a dose of glucose restored their willpower. The results of the experiment were announced in January, during Heatherton’s speech accepting the leadership of the Society for Personality and Social Psychology, the world’s largest group of social psychologists. In his presidential address at the annual meeting in San Antonio, Heatherton reported that administering glucose completely reversed the brain changes wrought by depletion - a finding, he said, that thoroughly surprised him. Heatherton’s results did much more than provide additional confirmation that glucose is a vital part of willpower; they helped solve the puzzle over how glucose could work without global changes in the brain’s total energy use. Apparently ego depletion causes activity to rise in some parts of the brain and to decline in others. Your brain does not stop working when glucose is low. It stops doing some things and starts doing others. It responds more strongly to immediate rewards and pays less attention to long-term prospects.
…The psychologists gave preprogrammed BlackBerrys to more than 200 people going about their daily routines for a week. The phones went off at random intervals, prompting the people to report whether they were currently experiencing some sort of desire or had recently felt a desire. The painstaking study, led by Wilhelm Hofmann, then at the University of Würzburg, collected more than 10,000 momentary reports from morning until midnight.
Desire turned out to be the norm, not the exception. Half the people were feeling some desire when their phones went off - to snack, to goof off, to express their true feelings to their bosses - and another quarter said they had felt a desire in the past half-hour. Many of these desires were ones that the men and women were trying to resist, and the more willpower people expended, the more likely they became to yield to the next temptation that came along. When faced with a new desire that produced some I-want-to-but-I-really-shouldn’t sort of inner conflict, they gave in more readily if they had already fended off earlier temptations, particularly if the new temptation came soon after a previously reported one. The results suggested that people spend between three and four hours a day resisting desire. Put another way, if you tapped four or five people at any random moment of the day, one of them would be using willpower to resist a desire. The most commonly resisted desires in the phone study were the urges to eat and sleep, followed by the urge for leisure, like taking a break from work by doing a puzzle or playing a game instead of writing a memo. Sexual urges were next on the list of most-resisted desires, a little ahead of urges for other kinds of interactions, like checking Facebook. To ward off temptation, people reported using various strategies. The most popular was to look for a distraction or to undertake a new activity, although sometimes they tried suppressing it directly or simply toughing their way through it. Their success was decidedly mixed. They were pretty good at avoiding sleep, sex and the urge to spend money, but not so good at resisting the lure of television or the Web or the general temptation to relax instead of work.
…‘Good decision making is not a trait of the person, in the sense that it’s always there,’ Baumeister says. ‘It’s a state that fluctuates.’ His studies show that people with the best self-control are the ones who structure their lives so as to conserve willpower. They don’t schedule endless back-to-back meetings. They avoid temptations like all-you-can-eat buffets, and they establish habits that eliminate the mental effort of making choices. Instead of deciding every morning whether or not to force themselves to exercise, they set up regular appointments to work out with a friend. Instead of counting on willpower to remain robust all day, they conserve it so that it’s available for emergencies and important decisions….’Even the wisest people won’t make good choices when they’re not rested and their glucose is low,’ Baumeister points out. That’s why the truly wise don’t restructure the company at 4 p.m. They don’t make major commitments during the cocktail hour. And if a decision must be made late in the day, they know not to do it on an empty stomach. ‘The best decision makers,’ Baumeister says, ‘are the ones who know when not to trust themselves.’
Although that said, note that the blood sugar paradigm appears to have fallen victim to the Replication Crisis: “An opportunity cost model of subjective effort and task performance”, Kurzban et al 201313ya; “A Meta-Analysis of Blood Glucose Effects on Human Decision Making”, Orquin & Kurzban 2016; “Is Ego-Depletion a Replicable Effect? A Forensic Meta-Analysis of 165 Ego Depletion Articles”.↩︎
See “Effects of prior light exposure on early evening performance, subjective sleepiness, and hormonal secretion” (coverage), Münch et al 201214ya:
↩︎…For cognitive performance we found a significant interaction between light conditions, mental load (2- or 3-back task) and the order of light administration. On their first evening, subjects performed with similar accuracy after both light conditions, but on their second evening, subjects performed significantly more accurately after the DL in both n-back versions and committed fewer false alarms in the 2-back task compared to the AL group. Lower sleepiness in the evening was significantly correlated with better cognitive performance (p < .05).
“With regards to changes in n-back level, I went up about 1 solid level on all the tasks that I trained. That is, I went 7 → 8 for dual, 6 to 7 for position-sound-color, 6 to 7 for position-sound-shape, and 4 to 5 on quad. I don’t use any strategies.”↩︎
“Training of Working Memory Impacts Structural Connectivity”, Takeuchi 201016ya in Journal of Neuroscience.↩︎
New Humanist, “Lies, Damn Lies, and Chinese Science: The People’s Republic is becoming a technological superpower, but who’s checking the facts? Sam Geall seeks out the Chinese science cops” (see also Lancet, Nature, NYT, Joe Hilgard):
This publish-or-perish culture has led to unrealistic targets at Chinese universities - and as a predictable consequence, rampant plagiarism. In January, the peer-reviewed international journal Acta Crystallographica Section E announced the retraction of more than 70 papers by Chinese scientists who had falsified data. Three months later, the same publication announced the removal of another 39 articles “as a result of problems with the data sets or incorrect atom assignments”, 37 of which were entirely produced in Chinese universities. The New Jersey-based Centenary College closed its affiliated Chinese business school programme in July after a review “revealed evidence of widespread plagiarism, among other issues, at a level that ordinarily would have resulted in students’ immediate dismissal from the college.” A government study, cited by Nature, found that about one-third of over 6,000 scientists surveyed at six top Chinese institutions had practised “plagiarism, falsification or fabrication”. But it’s not only the emphasis on quantity that damages scientific quality in China. Publication bias - the tendency to privilege the results of studies that show a significant finding, rather than inconclusive results - is notoriously pervasive. One systematic review of acupuncture studies from 199828ya, published in Controlled Clinical Trials, found that every single clinical trial originating in China was positive - in other words, no trial published in China had found a treatment to be ineffective.
Crystallography: 1, 2 Science News, “Traditional Chinese medicine: Big questions: Journal reports of benefits often lack methodological rigor or details”:
↩︎Their new paper focuses exclusively on reports published since 199927ya in Chinese academic journals, roughly half of which were specialty publications. Clinicians authored half of the papers. Almost 85% of the reports focused on herbal remedies - anything from bulk herbs or pills to “decoctions”. Most of the remaining reviews assessed the value of acupuncture, although about 1% of the reports dealt with Tuina massage…The papers were reviews, or what are typically referred to in Western journals as meta-analyses…Many of the papers were incomplete, roughly one-third contained statistical errors and others provided data or comparisons that the authors termed misleading. Fewer than half of the surveyed papers described how the data they were presenting had been collected, how those data had been analyzed or how a decision had been made about which studies to compare. The majority of papers also did not assess the risk of bias across studies or offer any information on potential conflict-of-interest factors (such as who funded or otherwise offered support for the research being reviewed)….Overall, “the quality of these reviews is troubling,” the Lanzhou researchers conclude in the May 25 PLoS One.
“Plagiarism Plague Hinders China’s Scientific Ambition”, NPR:
In 200818ya, when her scientific publication, the Journal of Zhejiang University-Science, became the first in China to use CrossCheck text analysis software to spot plagiarism, Zhang was pleased to be a trailblazer. But when the first set of results came in, she was upset and horrified. “In almost 2 years, we find about 31% of papers with unreasonable copy[ing] and plagiarism,” she says, shaking her head. “This is true.” For computer science and life science papers, that figure went up to almost 40 percent…Despite the outpouring of Chinese papers, Chinese research isn’t that influential globally. Thomson Reuters’ Science Watch website notes that China isn’t even in the top 20 when measuring the number of times a paper is cited on a national basis. ScienceNet’s Zhao says he fears Chinese research is still about quantity rather than quality….However, China’s leaders have committed to fighting scientific fraud. And Zhang, the journal editor, says that one year on, plagiarism at her publication has fallen noticeably, to 24% of all submissions.
“China’s academic scandal: call toll-free hotlines to get your name published”; “Looks good on paper: A flawed system for judging research is leading to academic fraud”; “SAGE Publications busts ‘peer review and citation ring’, 60 papers retracted”; outsourced meta-analysis writing.
Pouring more money in seems to not be helping (“Fraud Scandals Sap China’s Dream of Becoming a Science Superpower”), and the fox is in charge of the hen house.↩︎
Abstract:
↩︎We investigated whether and how individual differences in personality determine cognitive training outcomes. 47 participants were either trained on a single or on a dual n-back task for a period of 4 weeks. 52 additional participants did not receive any training and served as a no-contact control group. We assessed neuroticism and conscientiousness as personality traits as well as performance in near and far transfer measures. The results indicated a significant interaction of neuroticism and intervention in terms of training efficacy. Whereas dual n-back training was more effective for participants low in neuroticism, single n-back training was more effective for participants high in neuroticism. Conscientiousness was associated with high training scores in the single n-back and improvement in near transfer measures, but lower far transfer performance, suggesting that subjects scoring high in this trait developed task-specific skills preventing generalizing effects. We conclude by proposing that individual differences in personality should be considered in future cognitive intervention studies to optimize the efficacy of training.
Research programmer Jonathan Graehl writes on the LW discussion of Jaeggi 201115ya:
↩︎…If you separated the “active control” group into high and low improvers post-hoc just like was done for the n-back group, you might see that the active control “high improvers” are even smarter than the n-back “high improvers”. We should expect some 8-9 year olds to improve in intelligence or motivation over the course of a month or two, without any intervention. Basically, this result sucks, because of the artificial post-hoc division into high- and low- responders to n-back training, needed to show a strong “effect”. I’m not certain that the effect is artificial; I’d have to spend a lot of time doing some kind of sampling to show how well the data is explained by my alternative hypothesis.
The DNB groups gain ~1 point (question), and the control group falls ~2 points after starting off ~2 points higher. In other words, if the control group had not fallen so much, the DNB groups would at no point have scored higher!
↩︎Replicating their results, we found a statistically-significant gain in gf scores in the training group over and above gains on the digit span task F(1, 26) = 3.00, p = 0.05, ηp2 = 0.10. In contrast, the control group showed a non-statistically-significant decrease in gf. F<1, and the critical group by time interaction was statistically-significant, F(1, 40) = 7.47, p = 0.01, ηp2 = 0.16. As can be seen in Figure 3, there was a trend toward a statistically-significant group difference in gf (RPM scores) at pre-training, p≤0.10. This raises the possibility that the relative gains in gf in the training versus control groups may be to some extent an artefact of baseline differences. However, the interactive effect of transfer as a function of group remained statistically-significant even after more closely matching the training and control groups for pre-training RPM scores (by removing the highest scoring controls) F(1, 30) = 3.66, p = 0.032, ηp2 = 0.10. The adjusted means (standard deviations) for the control and training groups were now 27.20 (1.93), 26.63 (2.60) at pre-training (t(43) = 1.29, P>0.05) and 26.50 (4.50), 27.07 (2.16) at post-training, respectively. Moreover, there was a trend for the gain in gf to be positively correlated with improvements in n-back performance across training r(29) = 0.36 at p = 0.057, suggesting that such gains were indeed a function of training…Although the gf transferable gains we found appear to be somewhat related to training gains and the effects remain when we trim the groups to provide a better match for pre-training gf. it is important to note that some degree of regression to the mean may be influencing the results.
At least, they seem to administer the whole thing with no mention of such a variation:
↩︎We assessed gf with the Raven’s Progressive Matrices (RPM; Guide to the standard progressive matrices, Raven 196066ya)—a standard measure in the literature. Each RPM item presented participants with a matrix of visual patterns with one pattern missing. The participant chose how the matrix should be completed by selecting a pattern from a series of alternatives. We used parallel versions of the RPM (even and uneven numbered pages), which we counterbalanced across participants and pre- and post-training. The RPM is scored on a scale from 0-30, with each correct matrix earning participants one point.
From the paper:
The figure depicts a block of the emotional version of the dual n-back task (training task) where n = 1. The top row shows the sequence across trials (A, B, C, D, etc.) of visually presented stimuli in a 4×4 grid (the visual stimuli were presented on a standard 1280×1024 pixel computer display). A picture of a face appeared in one of the 16 possible grid positions on each trial. Simultaneously, with the presentation of these visual stimuli on the computer display, participants heard words over headphones (second row in the figure). Participants were required to indicate, by button press, whether the trial was a ‘target trial’ or not. Targets could be visual or auditory. In the example here, Trial C is a visual target. That is, the face in Trial C is presented in the same location as the face in Trial B (ie. n = 1 positions back). Note, the faces are of different actors. For visual stimuli participants were asked to ignore the content of the image and solely attend to the location in which the images were presented. In the current example, Trial D was an auditory target trial because ‘Evil’ is the same word as the word presented in Trial C - n positions back (where n = 1). Each block consisted of 20+n trials.
(If you look at Figure 1, example stimuli words are ‘dead’, ‘hate’, ‘evil’, ‘rape’, ‘slum’, and a picture of a very angry male face.)↩︎
The difference doesn’t seem to change progress on n-back in either group, which is good since if there were differences, that would be troubling eg. if the affective n-back group didn’t increase as many levels, that would make any following results more dubious:
Performance of the two n-back groups pre- to post- training did not differ significantly on either the neutral F(1, 27) = 1.02, P>0.05 or affective F (1, 27)<1 n-back tasks. Similarly, the control group showed a significantly greater pre- to post-training improvement on the feature match task they trained on, compared with the n-back groups F(1, 42) = 41.09, P<0.001, ηp2 = 0.67.
And as one would hope, both DNB groups increased their WM scores:
↩︎As predicted, participants in the training group showed a significant improvement on digit span F(1, 28) = 33.96, p < 0.001, ηp2 = 0.55. However, this was not true of controls F(1, 15) = 1.89, p = 0.19, ηp2 = 0.11, and the gain was significantly greater in the training group participants compared to controls F(1,43) = 5.92, p = 0.02, ηp2 = 0.12.
Alloway 200917ya, “The efficacy of working memory training in improving crystallized intelligence” (PDF) 7 children with learning disabilities received the training for 8 weeks; Gc was measured using the vocabulary & math sections of the Wechsler IQ test.↩︎
The practice effect can last for many years. “Influence of Age on Practice Effects in Longitudinal Neurocognitive Change”, Salthouse 201016ya:
↩︎Longitudinal comparisons of neurocognitive functioning often reveal stability or age-related increases in performance among adults under about 60 years of age. Because nearly monotonic declines with increasing age are typically evident in cross-sectional comparisons, there is a discrepancy in the inferred age trends based on the two types of comparisons….Increased age was associated with significantly more negative longitudinal changes with each ability. All of the estimated practice effects were positive, but they varied in magnitude across neurocognitive abilities and as a function of age. After adjusting for practice effects the longitudinal changes were less positive at younger ages and slightly less negative at older ages. Conclusions: It was concluded that some, but not all, of the discrepancy between cross-sectional and longitudinal age trends in neurocognitive functioning is attributable to practice effects positively biasing the longitudinal trends.
Tofu: “I should also add, my score on the number test jumped dramatically from the first test to the second test probably because I taught myself how to do long division before the second test (which was the only studying I did for all 3 tests).”↩︎
Shipstead et al 2012 mention an amusing study I hadn’t heard of before:
↩︎Greenwald et al 1991 provided a useful demonstration of the problems associated with subjective reports. Participants in this study received commercially produced audiotapes that contained subliminal messages intended to improve either self-esteem or memory. Unknown to the participants, half of the tapes that were designed to improve memory were relabeled “self-esteem” and vice versa. At a 5-week posttest, participants’ scores on several standard measures of self-esteem and memory were improved, but this change was independent of the message and the label on the audiotape (ie. participants showed across the board improvement). However, in response to simple questions regarding perceived effects, roughly 50% of participants reported experiencing improvements that were consistent with the label on the audiotape, while only 15% reported improvements in the opposite domain. The self-report measures were neither related to actual improvements in transfer task performance nor related to the content of the intervention. Instead, they were attributable to expectation of outcome.
from at 90 days seeing little effect, to 2.5 months later producing the second testament↩︎
“Attention and Working Memory in Insight Problem-Solving”, Murray 201115ya. The study does not seem to have controlled for IQ, so it’s hard to say whether the WM/attention are responsible for increased performance or not.↩︎
From Sanderberg/Bostrom 200620ya:
↩︎Giving L-dopa, a dopamine precursor, to healthy volunteers did not affect direct semantic priming (faster recognition of words directly semantically related to a previous word, such as “black-white”) but did inhibit indirect priming (faster recognition of more semantically distant words, such as “summer-snow”) (Kischka et al 199630ya). This was interpreted by the authors of the study as dopamine inhibiting the spread of activation within the semantic network, that is, a focusing on the task.
“Temperament and character correlates of neuropsychological performance”, June 201016ya, Psychological Society of South Africa↩︎
Jaeggi 2008’s notes say the daily training was ~25 minutes; the longest group was 19 days; hours.↩︎
See the critical review of WM training research, “Does working memory training generalize?” (Shipstead et al 201016ya).↩︎
The R code:
on <- c(35,31,27,66,25,38,35,43,60,47,38,58,50,23,50,45,60,37,22,28,50,20,41,42,47,55,47,42,35, 40,44,40,33,44,19,58,38,41,52,41,33,47,45,45,55,20,31,42,53,27,45,50,65,33,33,30,52,36, 28,43,55,40,31,30,45,45,60,37,22,38,45,64,50,44,38) off <- c(17,43,46,50,36,31,38,33,66,30,68,42,40,29,69,40,41,45,37,18,44,60,31,46,46,45,27,35,45, 30,29,47,56,37,50,33,40,47,41,25,50,20,25,30,70,45,50,27,29,55,47,47,42,40,35,36,54,64, 25,28,31,15,47,64,35,33,60,38,28,60,50,42,31,50,30,35,61,56,30,44,37,43,38) length(c(on,off)) # [1] 158 source("BEST.R") mcmcChain = BESTmcmc(off, on) postInfo = BESTplot(off, on, mcmcChain) # image postInfo # SUMMARY.INFO # PARAMETER mean median mode HDIlow HDIhigh pcgtZero # mu1 40.96178 40.95536 40.93523 38.1887 43.7104 NA # mu2 41.37400 41.37365 41.39874 38.8068 44.0550 NA # muDiff -0.41222 -0.41368 -0.45968 -4.2497 3.3593 41.54 # sigma1 12.32844 12.27614 12.28283 10.3024 14.4116 NA # sigma2 11.21408 11.15464 10.99812 9.2924 13.1895 NA # sigmaDiff 1.11436 1.10736 0.94511 -1.6011 3.9756 78.73 # nu 45.65240 37.49245 22.16426 5.3586 108.1555 NA # nuLog10 1.56504 1.57394 1.61572 0.9956 2.1157 NA # effSz -0.03528 -0.03519 -0.03547 -0.3588 0.2851 41.54For those who prefer a regular two-sample test:
↩︎wilcox.test(off,on) # # Wilcoxon rank sum test with continuity correction # # data: off and on # W = 3004, p-value = 0.7066 # alternative hypothesis: true location shift is not equal to 0“The Psychophysiology of Lucid Dreaming”, collected in Conscious Mind, Sleeping Brain.↩︎
pg97 of his book The Dream Drugstore, Hobson 200125ya.↩︎
For example, one indicator of my false awakening dreams is that I wake up in the bed of my childhood home, where I have not lived in many years; there, the wall was to the left of my bed, but where I sleep now, the wall is to the right of my bed. Further, sometimes the false-awakening dream will get confused and put my new bed in my new room in the corner where the old bed was in my old room, even though my new bed has never been located in that spot.↩︎
-
↩︎Functional neuroimaging studies carried out on healthy volunteers while performing different n-back tasks have shown a common pattern of bilateral frontoparietal activation, especially of the dorsolateral prefrontal cortex (DLPFC). Our objective was to use functional magnetic resonance imaging (fMRI) to compare the pattern of brain activation while performing two similar n-back tasks which differed in their presentation modality. Thirteen healthy volunteers completed a verbal 2-back task presenting auditory stimuli, and a similar 2-back task presenting visual stimuli. A conjunction analysis showed bilateral activation of frontoparietal areas including the DLPFC. The left DLPFC and the superior temporal gyrus showed a greater activation in the auditory than in the visual condition, whereas posterior brain regions and the anterior cingulate showed a greater activation during the visual than during the auditory task. Thus, brain areas involved in the visual and auditory versions of the n-back task showed an important overlap between them, reflecting the supramodal characteristics of working memory. However, the differences found between the two modalities should be considered in order to select the most appropriate task for future clinical studies.
Schneider, B, Pichora-Fuller, MK. “Implications of perceptual deterioration for cognitive aging Research”. In: Craik, FI, Salthouse, TA, editors. The handbook of aging and cognition, Psychology Press, 200026ya. ISBN-10: 080585990X↩︎
Abstract: “The authors investigated the distinctiveness and interrelationships among visuospatial and verbal memory processes in short-term, working, and long-term memories in 345 adults. Beginning in the 20s, a continuous, regular decline occurs for processing-intensive tasks (eg. speed of processing, working memory, and long-term memory), whereas verbal knowledge increases across the life span [Besides Salthouse, for the verbal fluency claim see Schaie, K. W. Intellectual Development in Adulthood: The Seattle Longitudinal Study. Cambridge University Press, 199630ya]. There is little differentiation in the cognitive architecture of memory across the life span. Visuospatial and verbal working memory are distinct but highly interrelated systems with domain-specific short-term memory subsystems. In contrast to recent neuroimaging data, there is little evidence for dedifferentiation of function at the behavioral level in old compared with young adults.” That the neuroimaging shows no change in general locations of activity is probably interpretable as the lower performance being due to general low-level problems and inefficiencies of age, and not the elderly’s brains starting to ‘unlearn’ specific tasks.↩︎
“The Z-score represents the age-contingent mean, measured in units of standard deviation relative to the population mean. More precisely, the Z-score is (age-contingent mean minus population mean) / (population standard deviation).” –Agarwal et al 2009↩︎
“The Age of Reason: Financial Decisions over the Life-Cycle with Implications for Regulation”, Agarwal et al 200917ya (slides):
↩︎…The prevalence of dementia explodes after age 60, doubling with every 5 years of age.5 In the cohort above age 85, the prevalence of dementia exceeds 30%. Moreover, many older adults without a strict diagnosis of dementia, still experience substantial cognitive impairment. For example, the prevalence of the diagnosis “cognitive impairment without dementia” is nearly 30% between ages 80 and 89.6 Drawing these facts together, among the population between ages 80 and 89, about half of the population either has a diagnosis of dementia or cognitive impairment without dementia.
6: Plassman et al 2008. They define cognitive impairment without dementia as a Dementia Severity Rating Scale score of 6 to 11
…Third, using a new dataset, we document a link between age and the quality of financial decision-making in debt markets. In a cross-section of prime borrowers, middle-aged adults borrow at lower interest rates and pay fewer fees relative to younger and older adults. Averaging across ten credit markets, fee and interest payments are minimized around age 53. The measured effects are not explained by observed risk characteristics. Combining multiple data sets we do not find evidence that selection effects and cohort effects explain our results. The leading explanation for the patterns that we observe is that experience rises with age, but analytical abilities decline with it.
…Neurological pathologies represent one important pathway for age effects in older adults. For instance, dementia is primarily attributable to Alzheimer’s Disease (60%) and vascular disease (25%). The prevalence of dementia doubles with every five additional years of lifecycle age (Ferri et al 200620ya; Fratiglioni, De Ronchi, and Agüero-Torres, 1999).10 For example, Table 1 reports that the prevalence of dementia in North America rises from 3.3% for adults ages 70–74, to 6.5% for adults ages 75–79, to 12.8% for adults ages 80–84, to 30.1% for adults at least 85 years of age (Ferri et al 200620ya). Many older adults also suffer from a less severe form of cognitive impairment, which is diagnosed as “cognitive impairment without dementia.” For example, the prevalence of this diagnosis rises from 16.0% for adults ages 71-79, to 29.2% for adults ages 80-89.
10: There is also growing literature that identifies age-related changes in the nature of cognition (see Park and Schwarz, 199927ya [Cognitive Aging: A Primer]; and Denburg, Tranel, and Bechara 2005). Mather & Carstensen 2005 and Carstensen (200620ya) identify age-variation in cognitive preferences. Subjects with short time horizons or older ages attend to negative information relatively less than subjects with long time horizons or younger ages.
…Figure 4d plots naive and control performance in the Telephone Interview of Cognitive Status (TICS) task. This task asks the respondent ten trivial questions and assigns one point for each correct answer: What is the current year? Month? Day? Day of the week? What do you usually use to cut paper? What do you call the kind of prickly plant that grows in the desert? Who is the current president? Vice president? Count backwards from twenty to ten (twice). At age 63, the average score is 9.2 out of 10. By age 90, the average (control) score is 7.5. Finally, we present two measures of practical numeracy. 4e plots naive and control performance in response to the question: If the chance of getting a disease is 10 percent, how many people out of 1,000 would be expected to get the disease? At age 53, 79% answer correctly. By age 90, 50% answer correctly. Figure 4f plots naive and control performance in response to the question: If 5 people all have the winning numbers in the lottery and the prize is two million dollars, how much will each of them get? We believe that this question is imprecisely posed, since the logical answer could be either $2,000,000 or $400,000. However, the results are still interesting, since the fraction answering $400,000 (the official correct answer) drops precipitously. At age 53, 52% answer $400,000. By age 90, 10% give this answer.
…For the 198937ya, 199828ya, 200125ya, and 200422ya surveys, we compute the ratios of income, education, and net worth for borrowers to the population as a whole, by age group; results are presented in the online appendix. We find that within age groups, borrowers almost always have higher levels of income and education than the population as a whole, and often have higher levels of net worth. Moreover, older borrowers appear to have relatively higher levels of income and education relative to their peers than middle-aged borrowers do. Hence these data suggest that selection effects by age go in the opposite direction: older borrowers appear to be a better pool than middle-aged borrowers. We present additional results in the online appendix showing that borrowing by age does not appear to vary by race, and that older borrowers do not appear to have disproportionately lower incomes, FICO score, or higher debt levels. None of these analyses lend support to the idea that sample selection effects contribute to the U-shape patterns that we see in the data.
…The effects we find have a wide range of dollar magnitudes, reported in Table 4. We estimate that, for home-equity lines of credit, 75-year-olds pay about $265 more each year than 50-year-olds, and 25-year-olds pay about $295 more. For other quantities, say, credit card fees, the implied age differentials are small - roughly $10-$20 per year for each kind of fee. The importance of the U-shaped effects we estimate goes beyond the economic significance of each individual choice, however: it lies in the fact that the appearance of a U-shaped pattern of costs in such a wide variety of circumstances points to a phenomenon that might apply to many areas.
The practice effect can last for many years. “Influence of Age on Practice Effects in Longitudinal Neurocognitive Change”, Salthouse 201016ya:
↩︎Longitudinal comparisons of neurocognitive functioning often reveal stability or age-related increases in performance among adults under about 60 years of age. Because nearly monotonic declines with increasing age are typically evident in cross-sectional comparisons, there is a discrepancy in the inferred age trends based on the two types of comparisons….Increased age was associated with significantly more negative longitudinal changes with each ability. All of the estimated practice effects were positive, but they varied in magnitude across neurocognitive abilities and as a function of age. After adjusting for practice effects the longitudinal changes were less positive at younger ages and slightly less negative at older ages. Conclusions: It was concluded that some, but not all, of the discrepancy between cross-sectional and longitudinal age trends in neurocognitive functioning is attributable to practice effects positively biasing the longitudinal trends.
Perhaps surprisingly, the common wisdom that people adopt conservative attitudes as part of the aging process may not be correct, and the observed conservatism of old people due to their coming from a more conservative time (ie. the past, as the 20th century saw a grand sweep of liberal beliefs through First World societies); “Population Aging, Intracohort Aging, and Sociopolitical Attitudes”, Danigelis et al 2007’s abstract (excerpts):
↩︎Prevailing stereotypes of older people hold that their attitudes are inflexible or that aging tends to promote increasing conservatism in sociopolitical outlook. In spite of mounting scientific evidence demonstrating that learning, adaptation, and reassessment are behaviors in which older people can and do engage, the stereotype persists. We use U.S. General Social Survey data from 25 surveys between 197254ya and 200422ya to formally assess the magnitude and direction of changes in attitudes that occur within cohorts at different stages of the life course. We decompose changes in sociopolitical attitudes into the proportions attributable to cohort succession and intracohort aging for three categories of items: attitudes toward historically subordinate groups, civil liberties, and privacy. We find that significant intracohort change in attitudes occurs in cohorts-in-later-stages (age 60 and older) as well as cohorts-in-earlier-stages (ages 18 to 39), that the change for cohorts-in-later-stages is frequently greater than that for cohorts-in-earlier-stages, and that the direction of change is most often toward increased tolerance rather than increased conservatism. These findings are discussed within the context of population aging and development.
“Cognitive Decline Begins In Late 20s, Study Suggests”, Science Daily↩︎
-
↩︎The [Salthouse] graph shows two roller-coastering lines. One represents the proportion of people of each age who are in the top 25% on a standard lab test of reasoning ability-thinking. The other shows the proportion of CEOs of Fortune 500 companies of each age. Reasoning ability peaks at about age 28 and then plummets, tracing that well-known plunge that makes those older than 30 (OK, fine, 40) cringe: only 6% of top scorers are in their 50s, and only 4% are in their 60s. But the age distribution of CEOs is an almost perfect mirror image: it peaks just before age 60. About half are older than 55. And the number under 40 is about zero.
…Salt-house deduces more counterintuitive, and hopeful, lessons. The first is that in real life, rather than in psych labs, people rely on mental abilities that stand up very well to age and discover work-arounds for the mental skills that do fade.
“How to Gain Eleven IQ Points in Ten Minutes: Thinking Aloud Improves Raven’s Matrices Performance in Older Adults”, Fox et al 2009↩︎
Some relevant excerpts:
↩︎Buschkuehl et al 200818ya proposed an adaptive visual WM training program to old-old adults: Their results showed substantial gains in the WM trained tasks. Short and long-term transfer effects were found only for tasks with the same stimuli content. Similarly, Li et al 200818ya found in young and older adults specific improvement in the task practiced-a spatial 2 n-back WM task-that involved two conditions: one standard, one more demanding. Transfer effects were found on a more demanding 3 n-back visual task as well as on numerical n-back tasks. Although near transfer effects to the same (visual) and also different (numerical) modality were shown, no far transfer effects to more complex WM tasks (operation and rotation span tests) were found. With regard to maintenance effects, Buschkuehl et al 200818ya failed to find any maintenance 1 year after completion of training, in comparison with pretest. In contrast, Li et al 200818ya showed a maintenance of practice gains and of near-transfer effects at 3-month follow-up; nonetheless, in contrast with young adults, older participants showed a performance decrement from postpractice to follow-up.
…Common measures used in cognitive aging research, and theoretically related to WM, were chosen: short-term memory, fluid intelligence, inhibition, and processing speed (Craik & Salthouse, 200026ya; Verhaeghen, Steitz, Sliwinski, & Cerella, 200323ya). For nearest-transfer effects, a visuospatial WM task (Dot Matrix task; adapted from Miyake, Friedman, Rettinger, Shah, & Hegarty, 200125ya) was included. This task involves processes (elaboration and processing phase) similar to the one practiced. However, the nature of the material and the secondary requirement are different from those of the trained task. The Forward and Backward Digit Span tests were used to assess near-transfer effects because they are part of the general memory factor, but the task requests were different from those of the WM tasks (see Bopp & Verhaeghen, 200521ya). Because these tasks measure the same narrow or same broad ability, we expect transfer effects onto them. To determine the presence of far transfer effects, we chose classic tasks: the Cattell task to measure nonverbal reasoning ability; the Stroop Color test to index inhibition-related mechanisms; and the Pattern Comparison test to assess processing speed. The transfer abilities were chosen with consideration of their relationship to WM processes. Working memory impairment in older adults is generally attributed to general mechanisms such as inhibition and processing speed (Borella et al 200818ya). Furthermore, WM is frequently advanced as one of the mechanisms that also accounts for age-related differences in intelligence tasks (de Ribaupierre & Lecerf, 200620ya; Rabbitt & Lowe, 200026ya; Schaie & Hertzog, 198640ya)…
The Categorization Working Memory Span task (CWMS; Borella et al 200818ya; De Beni, Borella, Carretti, Marigo, & Nava, 200818ya) is similar to the classic WM tasks, such as the Listening Span test (Borella et al 200818ya), the only difference being that it involves processing lists of words rather than sentences, limiting the role of semantic processing. The materials consisted of 10 sets of words, each set comprising 20 lists of words, which were organized in series of word lists of different lengths (2–6). Each list contained 5 words of high-medium frequency. Furthermore, the lists contained zero, one, or two animal nouns, present in any position, including last. An example list is house, mother, dog, word, night. Of the total number of words (200) in the task, 28% were animal words. Participants listened to the lists of words audiorecorded presented at a rate of 1 s per word and had to tap their hand on the table whenever they heard an animal noun (processing phase). The interval between series of word lists was 2 s (the presentation was thus paced by the experimenter). At the end of the series, participants recalled the last word of each string in serial order (maintenance phase). Two practice trials of 2-word length were given before the experiment started. Words recalled were written down by the experimenter on a prepared form. The total number of correctly recalled words was used as the measure of WM performance (maximum score 20). This score has been demonstrated to show large correlations with visuospatial (Jigsaw Puzzle test) and verbal (Listening Span test) WM tasks (Borella et al 200818ya), and measures of fluid intelligence (Borella et al 200620ya).
…Culture Fair test, Scale 3 (Cattell & Cattell, 196363ya). Scale 3 of the Cattell test consists of two parallel forms (A and B), each containing four subtests to be completed in 2.5 to 4 min, depending on the subtest. In the first subtest, Series, participants saw an incomplete series of abstract shapes and figures and had to choose from six alternatives that best completed the series. In the second subtest, Classifications, participants saw 14 problems comprising abstract shapes and figures and had to choose which 2 of the 5 differed from the other 3. In the third subtest, Matrices, participants were presented with 13 incomplete matrices containing four to nine boxes of abstract figures and shapes plus an empty box and six choices: Their task was to select the answer that correctly completed each matrix. In the final subtest, Conditions, participants were presented with 10 sets of abstract figures, lines, and a single dot, along with five alternatives: Their task was to assess the relationship among the dot, figures, and lines, then choose the alternative in which a dot could be positioned in the same relationship. The dependent variable was the number of correctly solved items across the four subsets (maximum score of 50). One of the two parallel forms (A or B) was administered at pretest, the other at posttest in counterbalanced fashion across testing sessions.
…Far-transfer effect. For the Cattell test, results indicated that trained participants performed significantly better than did controls (Mdiff ϭ 3.22, p Ͻ .001). Posttest and follow-up performances were significantly better than on pretest (Mdiff ϭ 3.40, p Ͻ .001, and Mdiff ϭ 2.75, p Ͻ .001, respectively). No significant difference was found between posttest and follow-up. Post hoc comparisons revealed that only the trained group showed significant improvement in performance between pretest and both posttest ( p Ͻ .001) and follow-up ( p Ͻ .001), although posttest performance was not different from that of follow-up. By contrast, no significant difference was found for the control group. The trained group performed better at both posttest and follow-up than did the control group ( p Ͻ .001).
…First, the participants involved in our study were young-old (mean age of 69 years), whereas in Buschkuehl et al.’s (200818ya) study as well as that of Li et al 200818ya, they were old-old adults (mean age of 80.1 and 74.5 years, respectively). In the context of episodic memory, the meta-analysis by Verhaeghen et al 199234ya has pointed out that the benefit of interventions is negatively related to participant age (see also Singer, Lindenberger, & Baltes, 200323ya). It has been shown that cognitive plasticity is reduced over the adult life span (Jones et al 200620ya), with young-old exhibiting larger training-related gains than old-old (Singer et al 200323ya). The importance of participant age is evident from considering the results of training focused on executive control tasks-for example, task-switching (Buchler, Hoyer, & Cerella, 200818ya; Karbach & Kray, 200917ya; Kramer, Hahn, & Gopher, 199927ya), dual tasks (Bherer et al 200521ya, 200818ya), or general executive functions (Basak et al 200818ya)-for which transfer effects emerged with a sample comprising young-old (age range between 60 and 75 years, mean age between 65 and 71 years; Basak et al 200818ya; Bherer et al 200521ya, 200818ya; Karbach & Kray, 200917ya; Kramer et al 199531ya). The question of whether transfer effects of WM training can also be determined by participant age range is of interest and should be addressed in further research.
Second, as is mentioned at the beginning of this section, the task and the procedure used to train participants can be considered an important source of difference. For example, Buschkuehl et al 200818ya reported that trained participants claimed to have generated task-specific strategies in one of the variants of the WM task in which they were trained, leading to greater training gains (62%) with respect to the other two variants (44% and 15%, respectively). The difficulty of transferring the gains obtained in a specific task to other tasks suggests that the WM training by Buschkuehl et al. did not foster an increase in flexibility, but simply the tendency to find a strategy to recall as many items as possible but in the context of each WM task. In the case of Li et al 200818ya, the modest transfer effects to the WM task can be explained by reflecting on the nature of the trained task: n-back task, which involves the manipulation and maintenance of information as well as updating of temporal order and contextual information and binding processes between stimuli and certain representation (Oberauer, 200521ya). Although the n-back shares common processing mechanisms with complex span tasks, the underlying mechanisms of the n-back are not completely understood (Schmiedek, Hildebrandt, Lövden, Wilhelm, & Lindenberger, 200917ya). Moreover, the few studies that used it with other WM tasks- complex span tasks- have shown variable correlations (from very low or null-Kane, Conway, Miura, & Colflesh, 200719ya; Roberts & Gibson, 2002-to large-Schmiedek et al 200917ya; Shamosh et al 200818ya).
Specifically, performance on attentional blink; see “Mental Training Affects Distribution of Limited Brain Resources” (Slagter 200719ya); cf. “Study Suggests Meditation Can Help Train Attention” (New York Times).↩︎
“Can Meditation Curb Heart Attacks?” (New York Times)↩︎
Psychonomic Bulletin & Review 200818ya Aug;15(4):763-71. “Training generalized spatial skills.” Wright R, Thompson WL, Ganis G, Newcombe NS, Kosslyn SM.
↩︎…The present study investigated whether intensive long-term practice leads to change that transcends stimulus and task parameters. Thirty-one participants (14 male, 17 female) were tested on three cognitive tasks: a computerized version of the Shepard-Metzler (197155ya) mental rotation task (MRT), a mental paper-folding task (MPFT), and a verbal analogies task (VAT). Each individual then participated in daily practice sessions with the MRT or the MPFT over 21 days. Postpractice comparisons revealed transfer of practice gains to novel stimuli for the practiced task, as well as transfer to the other, nonpracticed spatial task. Thus, practice effects were process based, not instance based. Improvement in the nonpracticed spatial task was greater than that in the VAT; thus, improvement was not merely due to greater ease with computerized testing.
[A previous version of this footnote discussed methodological problems & transferrability of animal research; this has been moved elsewhere.] “First Direct Evidence of Neuroplastic Changes Following Brainwave Training” & “Mindfulness Meditation Training Changes Brain Structure in Eight Weeks”, Science Daily↩︎