January 2020 News
January 2020 Gwern.net newsletter with 5 writeups, and links on AI scaling, videos-for-cats, and art; 1 book and 1 opera review.
January 2020’s Gwern.net newsletter is now out; previous, December 2019/2019 round-up (archives). This is a collation of links and summary of major changes, overlapping with my Changelog; brought to you by my donors on Patreon.
Writings
“Danbooru2019: A Large-Scale Crowdsourced & Tagged Anime Illustration Dataset”
This Waifu Does Not Existv3: 100k StyleGAN 2 anime portrait samples
Gwern.net: margin notes are now inlined on mobile
Media
Links
Genetics:
Everything Is Heritable:
Recent Evolution:
“The Exposome in Human Evolution: From Dust to Diesel”, Trumble & Finch 2019 (media; previously, Hubbard et al 2016)
Engineering:
“Utility and First Clinical Application of Screening Embryos for Polygenic Disease Risk Reduction”, Treff et al 2019 (Genomic Prediction)
AI:
“2019 AI Alignment Literature Review and Charity Comparison”, Larks
Matters Of Scale:
“Scaling Laws for Neural Language Models”, Kaplan et al 2020 (NN LMs appear to be nowhere near saturation nor training infeasibility as larger models show predictable gains and are both more compute-efficient & data-efficient (!)—onwards to GPT-3?)
“Big Transfer (BiT): Large Scale Learning of General Visual Representations for Transfer”, Kolesnikov et al 2019 (blog; JFT-300M showing larger=better: large benchmark gains, transfer everywhere, much more robust representations, more plausible errors, etc.)
“DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, Wijmans et al 2019 (blog; “Mishkin et al 2019 benchmarked classical (mapping + planning) and learning-based methods…and showed that classical methods outperform learning-based. However, they trained for ‘only’ 5 million steps…Savva et al 2019 then scaled this training to 75 million steps and found that this trend reverses…Fig. 1 shows an agent does not saturate before 1 billion steps, suggesting that previous studies were incomplete by 1–2 orders of magnitude.”)
“Meena: Towards a Human-like Open-Domain Chatbot”, Adiwardana et al 2020 (blog; 2.6b parameters trained on 341GB text, although Kaplan et al 2020 suggests they’d’ve done better to go much bigger & trained much less than 164 epochs; likelihood loss near identical with human-rated performance? Likelihood loss seems ultimately a flawed metric, but maybe we’re still far from hitting its limits…)
“A Very Unlikely Chess Game” (GPT-2-1.5b shenanigans; rival implementation)
Statistics/Meta-Science:
“Compliance with legal requirement to report clinical trial results on ClinicalTrials.gov: a cohort study”, DeVito et al 2020; “FDA and NIH let clinical trial sponsors keep results secret and break the law”, Science
“A national experiment reveals where a growth mindset improves achievement”, Yeager et al 2019 (the incredible shrinking ‘growth mindset’ effect & the Stainless Steel Law)
“Backlash Over Meat Dietary Recommendations Raises Questions About Corporate Ties to Nutrition Scientists”, Rubin 2019 (criticizing the critics of Carroll & Doherty 2019 / Zeraatkar et al 2019a / Han et al 2019 / Vernooij et al 2019 / Zeraatkar et al 2019b / Valli et al 2019 / Johnston et al 2019—“what’s sauce for the goose is sauce for the gander”)
“Follow-up: I found two identical packs of Skittles, among 468 packs with a total of 27,740 Skittles” (empirically verifying the birthday paradox in Skittles bags)
Politics/religion:
“The rape of men: the darkest secret of war” (case study: Libya)
“Statistical Reliability Analysis For A Most Dangerous Occupation: Roman Emperor”, Saleh 2019
“Parachuting For Charity: Is It Worth The Money? A 5-Year Audit Of Parachute Injuries In Tayside And The Cost To The NHS”, Lee et al 1999
“What’s in a Font?: Ideological Perceptions of Typography”, Haenschen & Tamul 2019 (‘Sunrise is the future liberals want’)
Psychology/biology:
“A Meta-Analysis of Procedures to Change Implicit Measures”, Forscher et al 2019
“Attention And Awareness In Stage Magic: Turning Tricks Into Research”, Macknik et al 2008
“A World Without Pain: Does hurting make us human?” (cf. my essay on pain)
“What Intellectual Progress Did I Make In The 2010s?”, Scott Alexander (a look back on how his ideas/beliefs evolved over the past decade of psychiatry blogging)
“Three cases of giant panda attack on humans at Beijing Zoo”, Zhang et al 201412ya (graphic images)
Technology:
“Cats, Once YouTube Stars, Are Now an ‘Emerging Audience’: They’re addicted to channels like Little Kitty & Family, Handsome Nature, and Videos for Your Cat—provided their owners switch on the iPad first” (After reading this, I gave videos-for-cats another try with my cat, since he gets stir-crazy in winter. I full-screened it, in landscape mode; he continued resolutely ignoring the screen as always, until I left my earphones out and he heard the birds chirping—he went nuts, convinced a bird had gotten into the apartment, until he finally noticed the screen, and I could see the instant the lightbulb went on and he was hooked. He’ll watch videos like Paul Dinning’s “8 Hour Bird Bonanza” for as many hours as I’ll leave it on, hunting behind the monitor for the birds, and makes a nuisance of himself sitting in front of it, waiting for the birds to come back—which he is doing as I try to write this! These are truly superstimuli: cats would never see these many birds this close up so unsuspecting in the wild.)
Economics:
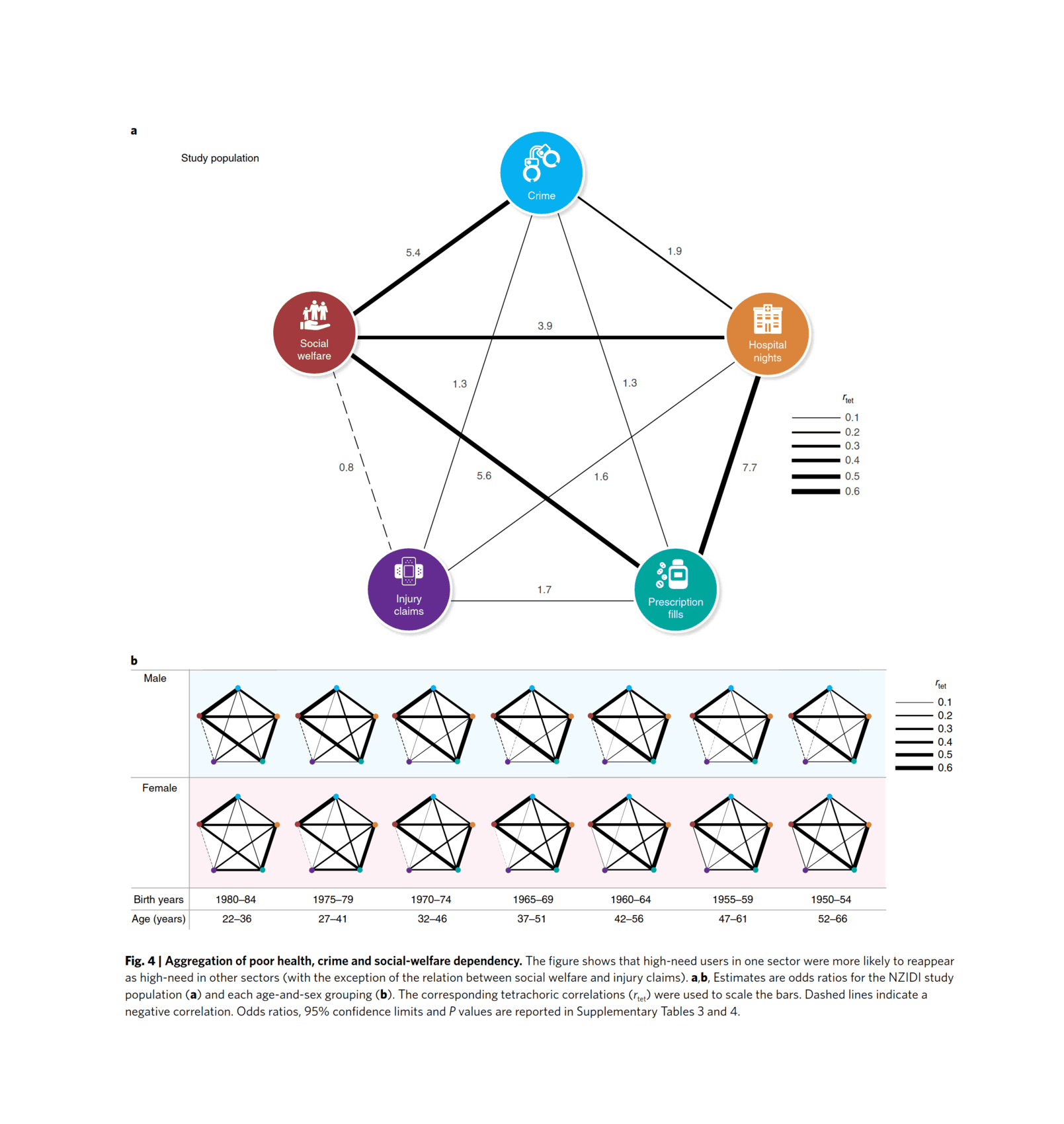
“Clustering of health, crime and social-welfare inequality in 4 million citizens from two nations”, Richmond-Rakerd et al 2020 (everything is correlated: “Figure 4: Aggregation of poor health, crime and social-welfare dependency”; previously, Belsky et al 2016 & Caspi et al 2016)
“The Exquisitely English (and Amazingly Lucrative) World of London Clerks”
{kind=link}
Philosophy:
Fiction:
“Behind the Sensationalism: Images of a Decaying Corpse in Japanese Buddhist Art”, Kanda 200521ya (on kusozu, cf. Maraṇasati; graphic images; famous examples: Body of a Courtesan in 9 stages, Kobayashi Eitaku c. 1870s, and The Death Of A Noble Lady And The Decay Of Her Body, c. 1700s)
“Having Had No Predecessor to Imitate, He Had No Successor Capable of Imitating Him”, Alvaro de Menard (summary of the Homeric Question, resolved by Parry 1933; also worth reading: Borges on the literary merits of different translations of Homer & The Thousand and One Nights)
“Choose Your Own Adventure: One Book, Many Readings”, Christian Swinehart 200917ya (visualizing paths through the classic CYOA gamebooks; see also: “These Maps Reveal the Hidden Structures of Choose Your Own Adventure Books: If you decide to see more, click on this story”, Atlas Obscura 2017)
“Master of Orion”, Jimmy Maher (review of the seminal 4X strategy game)
Misc:
Books
Nonfiction:
An Introduction to Japanese Court Poetry, Miner 196858ya (review)
Film/TV
Live-action: