‘statistics’ directory
- See Also
- Gwern
- “Fake Journal Club: Teaching Critical Reading”, Gwern 2022
- “Rare Greek Variables”, Gwern 2021
- “Origin of ‘Littlewood’s Law of Miracles’”, Gwern 2019
- “GPT-2 Folk Music”, Gwern & Presser 2019
- “Hafu Gender Ratios in Anime”, Gwern 2011
- “LWer Effective Altruism Donations, 2013–2014”, Gwern 2015
- “CO2/ventilation Sleep Experiment”, Gwern 2016
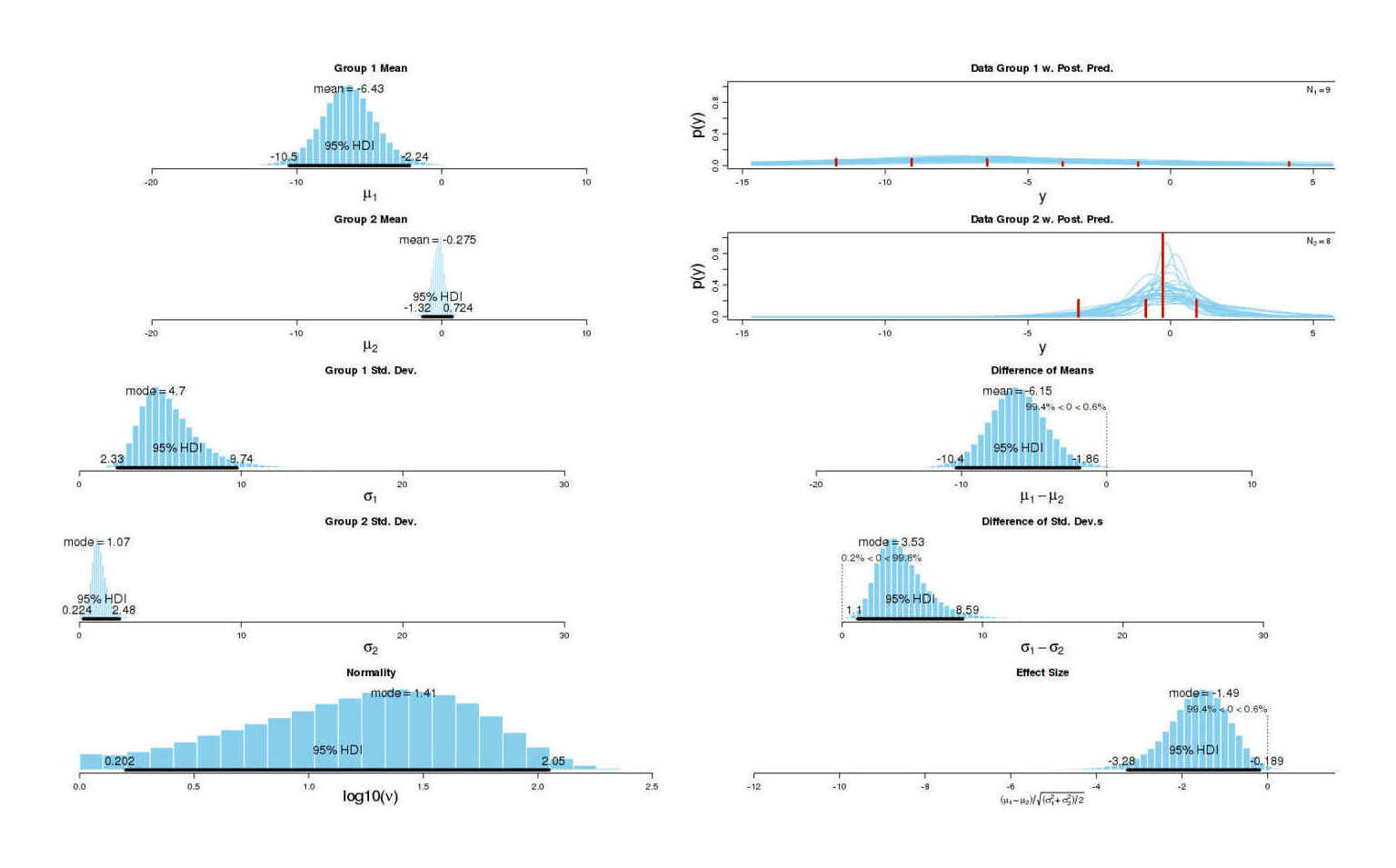
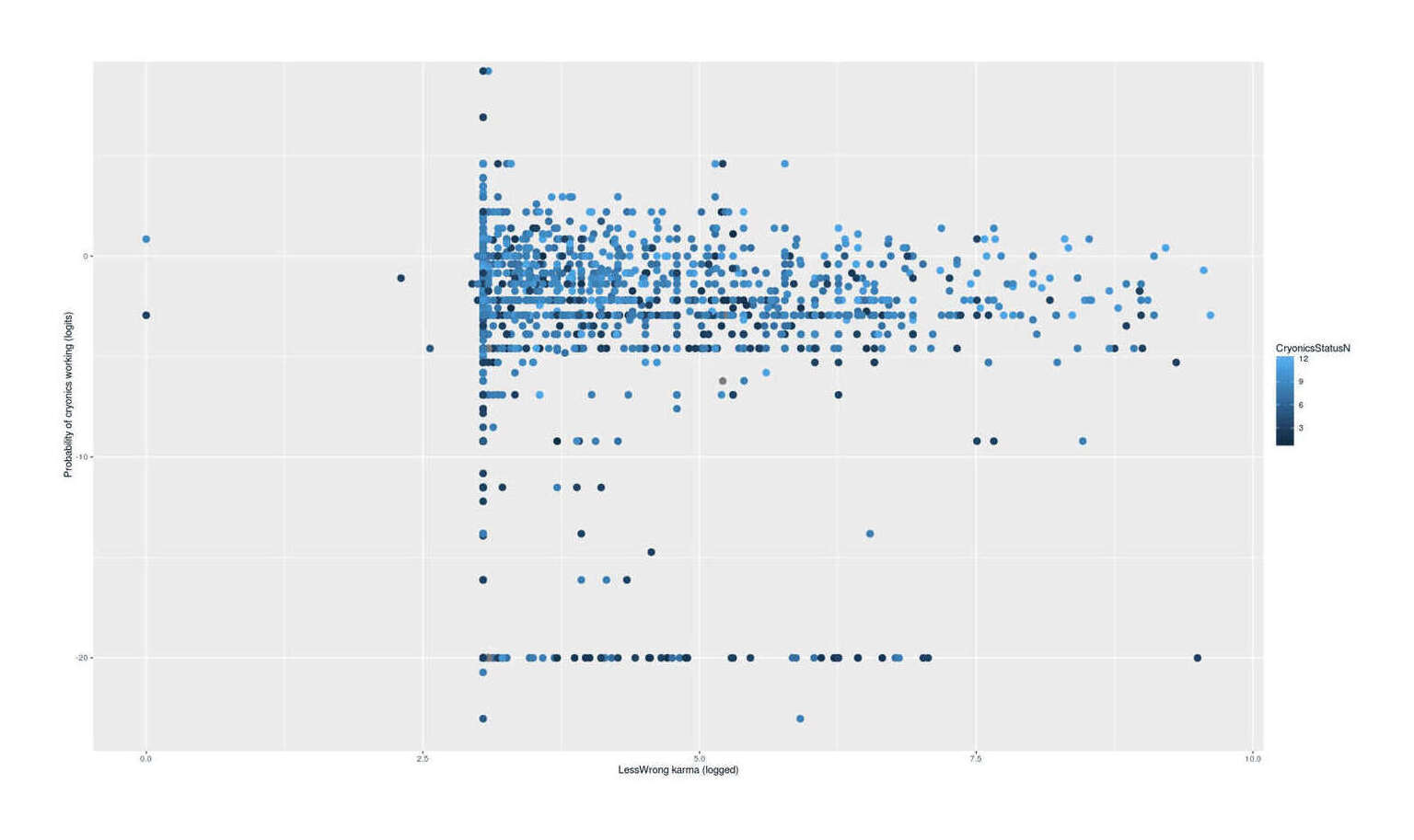
- “LessWrong and Cryonics”, Gwern 2013
- “Hacker News Submission Analysis”, Gwern 2013
- “2013 LLLT Self-Experiment”, Gwern 2013
- “𝑇𝑜𝑢𝘩𝑜𝑢 Music by the Numbers”, Gwern 2013
- “Bitcoin Donations on The Pirate Bay”, Gwern 2014
- “2014 Spirulina Randomized Self-Experiment”, Gwern 2014
- “LW Anchoring Experiment”, Gwern 2012
- “2013 Lewis Meditation Results”, Gwern 2013
- Links
- “Not That Norfolk! Mislabeled Shipments Led to Trump Tariffs on Uninhabited Islands and Remote Outposts With No US Trade”
- “A Tutorial on Teaching Data Analytics With Generative AI”, Bray 2024
- “Rapid and Accurate Multi-Phenotype Imputation for Millions of Individuals”, Gu et al 2023
- “Multivariate BWAS Can Be Replicable With Moderate Sample Sizes”, Spisak et al 2023
- “The Mechanics of the Industrial Revolution”, Kelly et al 2022b
- “Implementing Distributed Practice in Statistics Courses: Benefits for Retention and Transfer”, Ebersbach & Nazari 2020
- “A Fast and Scalable Framework for Large-Scale and Ultrahigh-Dimensional Sparse Regression With Application to the UK Biobank”, Qian et al 2020
- “The Dunning-Kruger Effect Is (Mostly) a Statistical Artefact: Valid Approaches to Testing the Hypothesis With Individual Differences Data”, Gignac & Zajenkowski 2020
- “Randomized Experiments in Education, With Implications for Multilevel Causal Inference”, Raudenbush & Schwartz 2020
- “Visual Model Fit Estimation in Scatterplots and Distribution of Attention: Influence of Slope and Noise Level”, Reimann et al 2020
- “Do GRE Scores Help Predict Getting a Physics Ph.D.? A Comment on a Paper by Miller Et Al”, Weissman 2019
- “Bifactor and Hierarchical Models: Specification, Inference, and Interpretation”, Markon 2019
- “Raincloud Plots: a Multi-Platform Tool for Robust Data Visualization”, Allen et al 2018
- “The Simple but Ingenious System Taiwan Uses to Crowdsource Its Laws: VTaiwan Is a Promising Experiment in Participatory Governance. But Politics Is Blocking It from Getting Greater Traction”, Horton 2018
- “We Are Not Alone! (At Least, Most of Us): Homonymy in Large Scale Social Groups”, Charpentier & Coulmont 2017
- “Generalized Network Psychometrics: Combining Network and Latent Variable Models”, Epskamp et al 2016
- “Exploring Factor Model Parameters across Continuous Variables With Local Structural Equation Models”, Hildebrandt et al 2016
- “Do Scholars Follow Betteridge’s Law? The Use of Questions in Journal Article Titles”, Cook & Plourde 2016
- “Reflections on How Designers Design With Data”, Bigelow et al 2014
- “Past, Present, and Future of Statistical Science [COPSS 50th Anniversary Anthology]”, Lin et al 2014
- “Psychological Measurement and Methodological Realism”, Hood 2013
- “Confidence Intervals for the Weighted Sum of Two Independent Binomial Proportions”, Decrouez & Robinson 2012
- “When Graphics Improve Liking but Not Learning from Online Lessons”, Sung & Mayer 2012
- “The Changing History of Robustness”, Stigler 2010
- “Using N-Of-1 Trials to Improve Patient Management and save Costs”, Scuffham et al 2010
- “The Life and Labors of Francis Galton: A Review of 4 Recent Books About the Father of Behavioral Statistics”, Clauser 2007
- “Value-Affirmative and Value-Protective Processing of Alcohol Education Messages That Include Statistical Evidence or Anecdotes”
- “Error Rates in Quadratic Discrimination With Constraints on the Covariance Matrices”, Flury et al 1994
- “Information and the Accuracy Attainable in the Estimation of Statistical Parameters”, Rao 1992
- “Transcending General Linear Reality”, Abbott 1988
- “On the Madness in His Method: R. B. Cattell’s Contributions to Structural Equation Modeling”, McArdle 1984
- “Statistics in Britain 1865–1930: The Social Construction of Scientific Knowledge”, MacKenzie 1981
- “Theoretical Risks and Tabular Asterisks: Sir Karl, Sir Ronald, and the Slow Progress of Soft Psychology”, Meehl 1978
- “On Rereading R. A. Fisher [Fisher Memorial Lecture, With Comments]”, Savage et al 1976
- “Social Statistics”, Blalock 1960
- “‘Student’ and Small Sample Theory”, Welch 1958
- “The Development of Hierarchical Factor Solutions”, Schid & Leiman 1957
- “Multiple Range and Multiple F Tests”
- “Large Sample Tests of Statistical Hypotheses concerning Several Parameters With Applications to Problems of Estimation”, Rao 1948
- “On the Non-Existence of Tests of ‘Student's’ Hypothesis Having Power Functions Independent of Σ”, Dantzig 1940
- “Professor Ronald Aylmer Fisher [Profile]”, Mahalanobis 1938
- “The Method of Path Coefficients”, Wright 1934
- “Some Experimental Results in the Correlation of Mental Abilities”, Brown 1910
- “Correlation Calculated from Faulty Data”, Spearman 1910
- “The Proof and Measurement of Association between Two Things”, Spearman 1904
- “David Gros Homepage”, Gros 2026
- “Sam’s Internet Home”
- Sort By Magic
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Gwern
“Fake Journal Club: Teaching Critical Reading”, Gwern 2022
“Rare Greek Variables”, Gwern 2021
“Origin of ‘Littlewood’s Law of Miracles’”, Gwern 2019
“GPT-2 Folk Music”, Gwern & Presser 2019
“Hafu Gender Ratios in Anime”, Gwern 2011
“LWer Effective Altruism Donations, 2013–2014”, Gwern 2015
“CO2/ventilation Sleep Experiment”, Gwern 2016
“LessWrong and Cryonics”, Gwern 2013
“Hacker News Submission Analysis”, Gwern 2013
“2013 LLLT Self-Experiment”, Gwern 2013
“𝑇𝑜𝑢𝘩𝑜𝑢 Music by the Numbers”, Gwern 2013
“Bitcoin Donations on The Pirate Bay”, Gwern 2014
“2014 Spirulina Randomized Self-Experiment”, Gwern 2014
“LW Anchoring Experiment”, Gwern 2012
“2013 Lewis Meditation Results”, Gwern 2013
Links
“Not That Norfolk! Mislabeled Shipments Led to Trump Tariffs on Uninhabited Islands and Remote Outposts With No US Trade”
“A Tutorial on Teaching Data Analytics With Generative AI”, Bray 2024
“Rapid and Accurate Multi-Phenotype Imputation for Millions of Individuals”, Gu et al 2023
Rapid and accurate multi-phenotype imputation for millions of individuals
“Multivariate BWAS Can Be Replicable With Moderate Sample Sizes”, Spisak et al 2023
Multivariate BWAS can be replicable with moderate sample sizes
“The Mechanics of the Industrial Revolution”, Kelly et al 2022b
“Implementing Distributed Practice in Statistics Courses: Benefits for Retention and Transfer”, Ebersbach & Nazari 2020
Implementing Distributed Practice in Statistics Courses: Benefits for Retention and Transfer
“A Fast and Scalable Framework for Large-Scale and Ultrahigh-Dimensional Sparse Regression With Application to the UK Biobank”, Qian et al 2020
“The Dunning-Kruger Effect Is (Mostly) a Statistical Artefact: Valid Approaches to Testing the Hypothesis With Individual Differences Data”, Gignac & Zajenkowski 2020
“Randomized Experiments in Education, With Implications for Multilevel Causal Inference”, Raudenbush & Schwartz 2020
Randomized Experiments in Education, with Implications for Multilevel Causal Inference
“Visual Model Fit Estimation in Scatterplots and Distribution of Attention: Influence of Slope and Noise Level”, Reimann et al 2020
“Do GRE Scores Help Predict Getting a Physics Ph.D.? A Comment on a Paper by Miller Et Al”, Weissman 2019
Do GRE scores help predict getting a physics Ph.D.? A comment on a paper by Miller et al
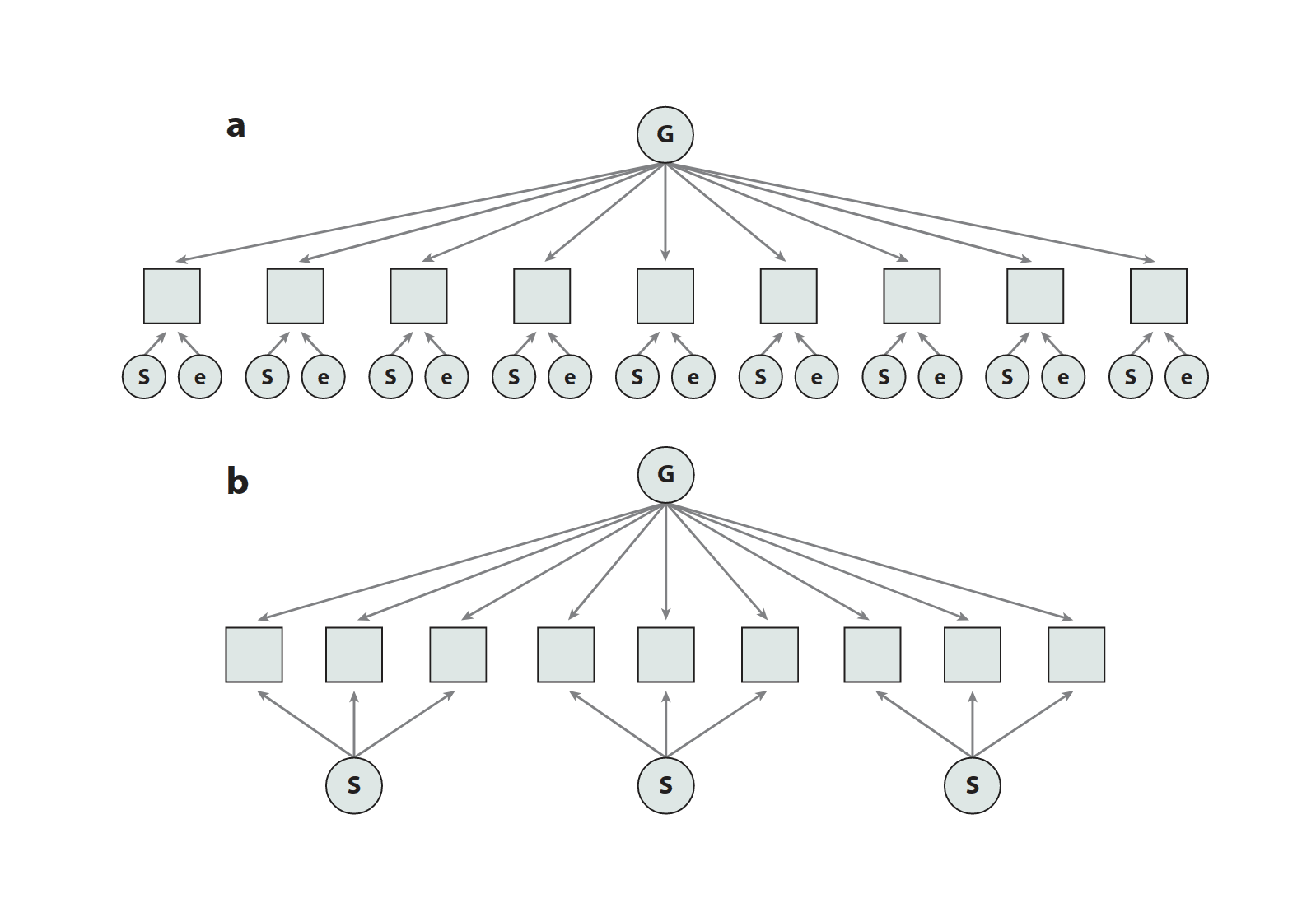
“Bifactor and Hierarchical Models: Specification, Inference, and Interpretation”, Markon 2019
Bifactor and Hierarchical Models: Specification, Inference, and Interpretation
“Raincloud Plots: a Multi-Platform Tool for Robust Data Visualization”, Allen et al 2018
Raincloud plots: a multi-platform tool for robust data visualization
“The Simple but Ingenious System Taiwan Uses to Crowdsource Its Laws: VTaiwan Is a Promising Experiment in Participatory Governance. But Politics Is Blocking It from Getting Greater Traction”, Horton 2018
“We Are Not Alone! (At Least, Most of Us): Homonymy in Large Scale Social Groups”, Charpentier & Coulmont 2017
We are not alone! (at least, most of us): Homonymy in large scale social groups
“Generalized Network Psychometrics: Combining Network and Latent Variable Models”, Epskamp et al 2016
Generalized Network Psychometrics: Combining Network and Latent Variable Models
“Exploring Factor Model Parameters across Continuous Variables With Local Structural Equation Models”, Hildebrandt et al 2016
Exploring Factor Model Parameters across Continuous Variables with Local Structural Equation Models
“Do Scholars Follow Betteridge’s Law? The Use of Questions in Journal Article Titles”, Cook & Plourde 2016
Do scholars follow Betteridge’s Law? The use of questions in journal article titles
“Reflections on How Designers Design With Data”, Bigelow et al 2014
“Past, Present, and Future of Statistical Science [COPSS 50th Anniversary Anthology]”, Lin et al 2014
Past, Present, and Future of Statistical Science [COPSS 50th anniversary anthology]
“Psychological Measurement and Methodological Realism”, Hood 2013
“Confidence Intervals for the Weighted Sum of Two Independent Binomial Proportions”, Decrouez & Robinson 2012
Confidence Intervals for the Weighted Sum of Two Independent Binomial Proportions
“When Graphics Improve Liking but Not Learning from Online Lessons”, Sung & Mayer 2012
When graphics improve liking but not learning from online lessons
“The Changing History of Robustness”, Stigler 2010
“Using N-Of-1 Trials to Improve Patient Management and save Costs”, Scuffham et al 2010
Using N-of-1 trials to improve patient management and save costs
“The Life and Labors of Francis Galton: A Review of 4 Recent Books About the Father of Behavioral Statistics”, Clauser 2007
“Value-Affirmative and Value-Protective Processing of Alcohol Education Messages That Include Statistical Evidence or Anecdotes”
“Error Rates in Quadratic Discrimination With Constraints on the Covariance Matrices”, Flury et al 1994
Error rates in quadratic discrimination with constraints on the covariance matrices
“Information and the Accuracy Attainable in the Estimation of Statistical Parameters”, Rao 1992
Information and the Accuracy Attainable in the Estimation of Statistical Parameters
“Transcending General Linear Reality”, Abbott 1988
“On the Madness in His Method: R. B. Cattell’s Contributions to Structural Equation Modeling”, McArdle 1984
On the Madness in His Method: R. B. Cattell’s Contributions to Structural Equation Modeling
“Statistics in Britain 1865–1930: The Social Construction of Scientific Knowledge”, MacKenzie 1981
Statistics in Britain 1865–1930: The Social Construction of Scientific Knowledge
“Theoretical Risks and Tabular Asterisks: Sir Karl, Sir Ronald, and the Slow Progress of Soft Psychology”, Meehl 1978
“On Rereading R. A. Fisher [Fisher Memorial Lecture, With Comments]”, Savage et al 1976
On Rereading R. A. Fisher [Fisher Memorial lecture, with comments]
“Social Statistics”, Blalock 1960
“‘Student’ and Small Sample Theory”, Welch 1958
“The Development of Hierarchical Factor Solutions”, Schid & Leiman 1957
“Multiple Range and Multiple F Tests”
“Large Sample Tests of Statistical Hypotheses concerning Several Parameters With Applications to Problems of Estimation”, Rao 1948
“On the Non-Existence of Tests of ‘Student's’ Hypothesis Having Power Functions Independent of Σ”, Dantzig 1940
On the Non-Existence of Tests of ‘Student's’ Hypothesis Having Power Functions Independent of σ
“Professor Ronald Aylmer Fisher [Profile]”, Mahalanobis 1938
“The Method of Path Coefficients”, Wright 1934
“Some Experimental Results in the Correlation of Mental Abilities”, Brown 1910
Some Experimental Results in the Correlation of Mental Abilities
“Correlation Calculated from Faulty Data”, Spearman 1910
“The Proof and Measurement of Association between Two Things”, Spearman 1904
“David Gros Homepage”, Gros 2026
“Sam’s Internet Home”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
biostatistics data-imputation sparse-regression reproducibility data-analytics participatory-governance
distributed-practice
causal-inference
Wikipedia (1)
Miscellaneous
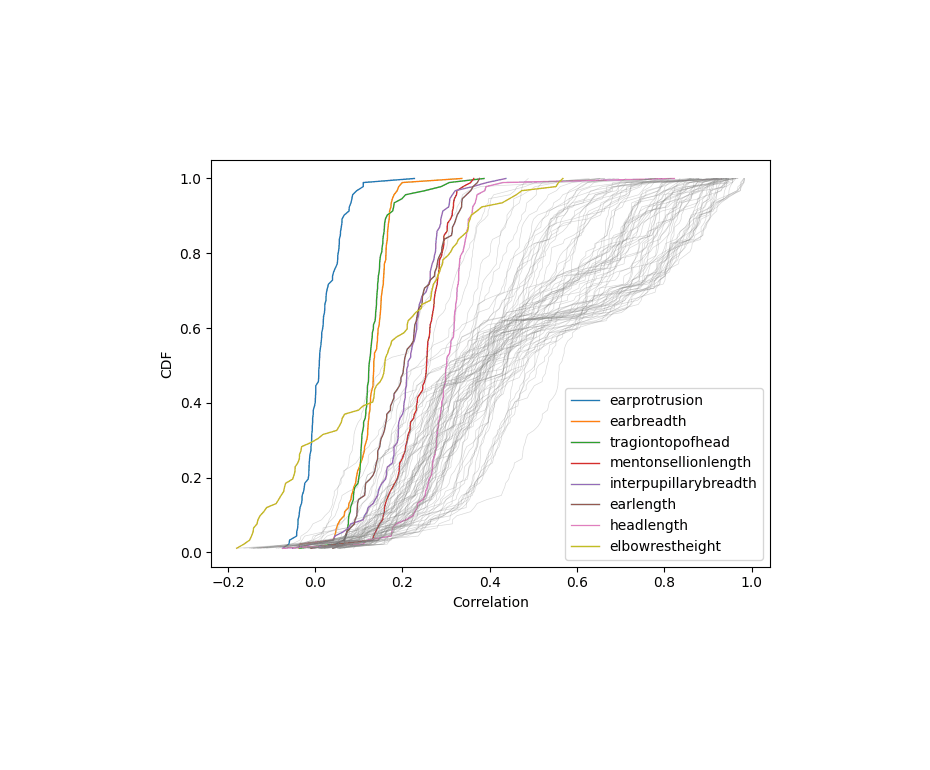
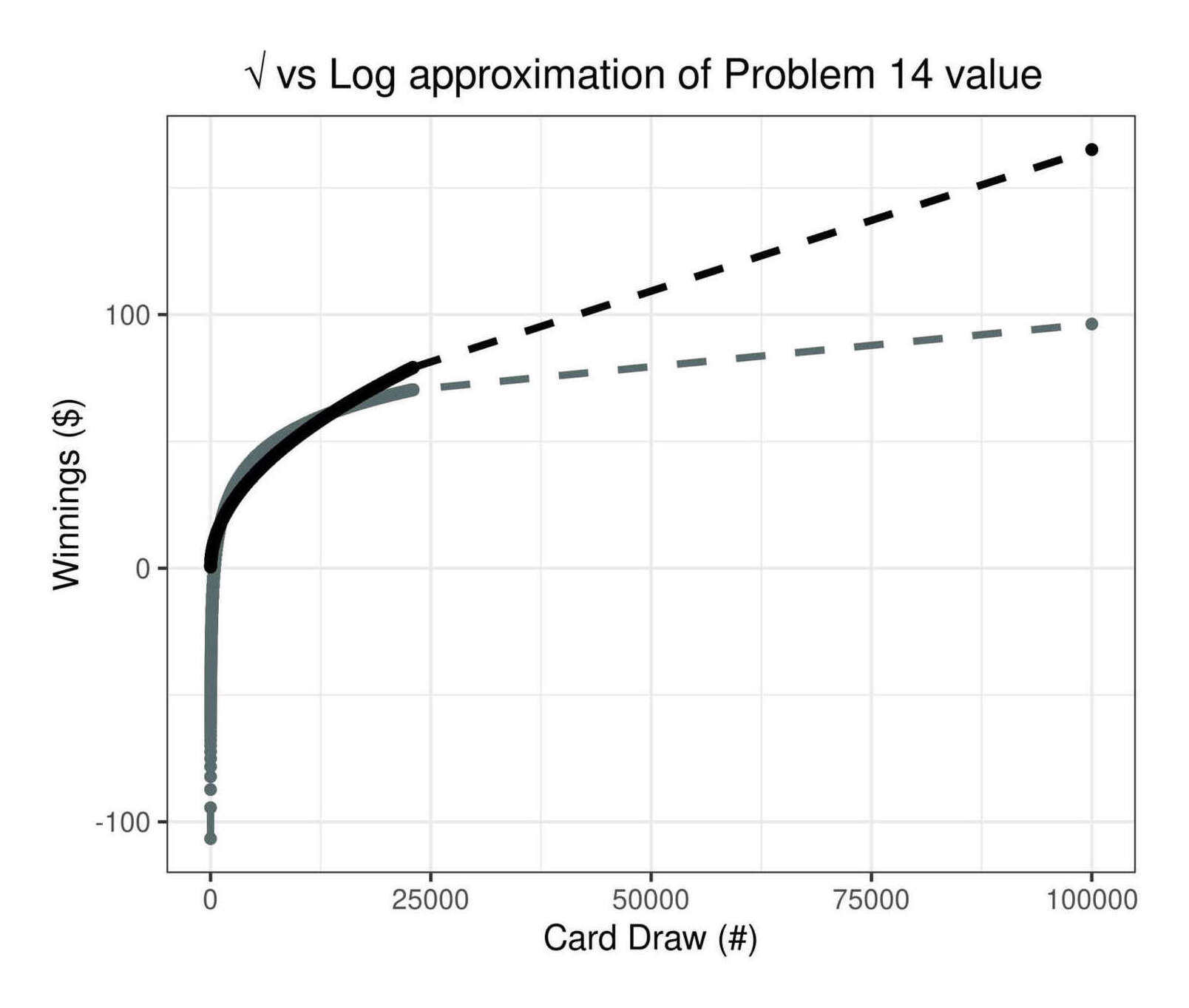
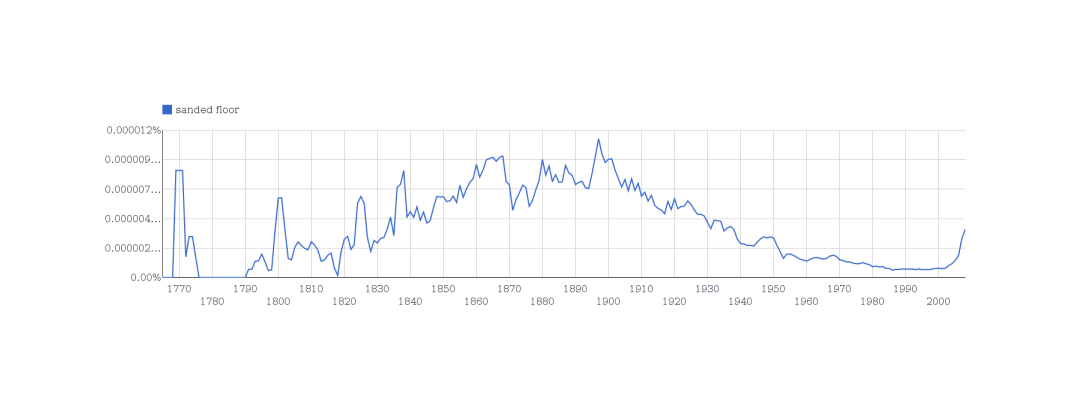
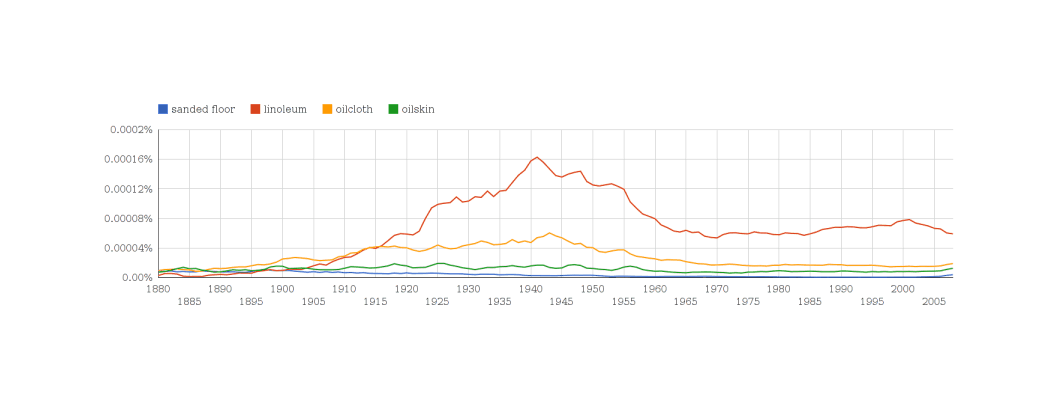
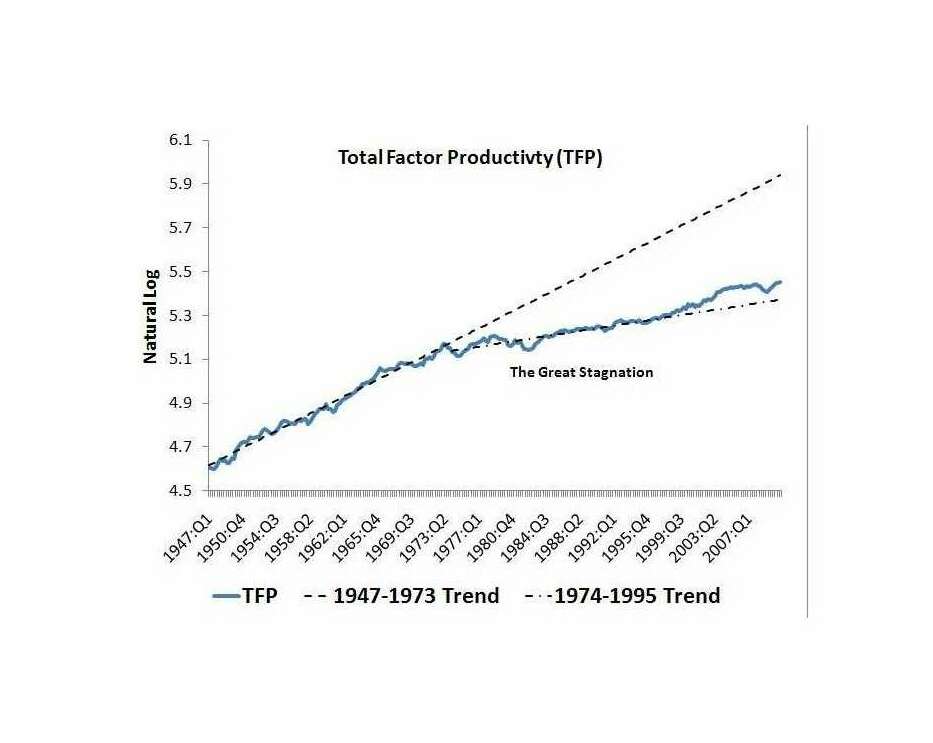
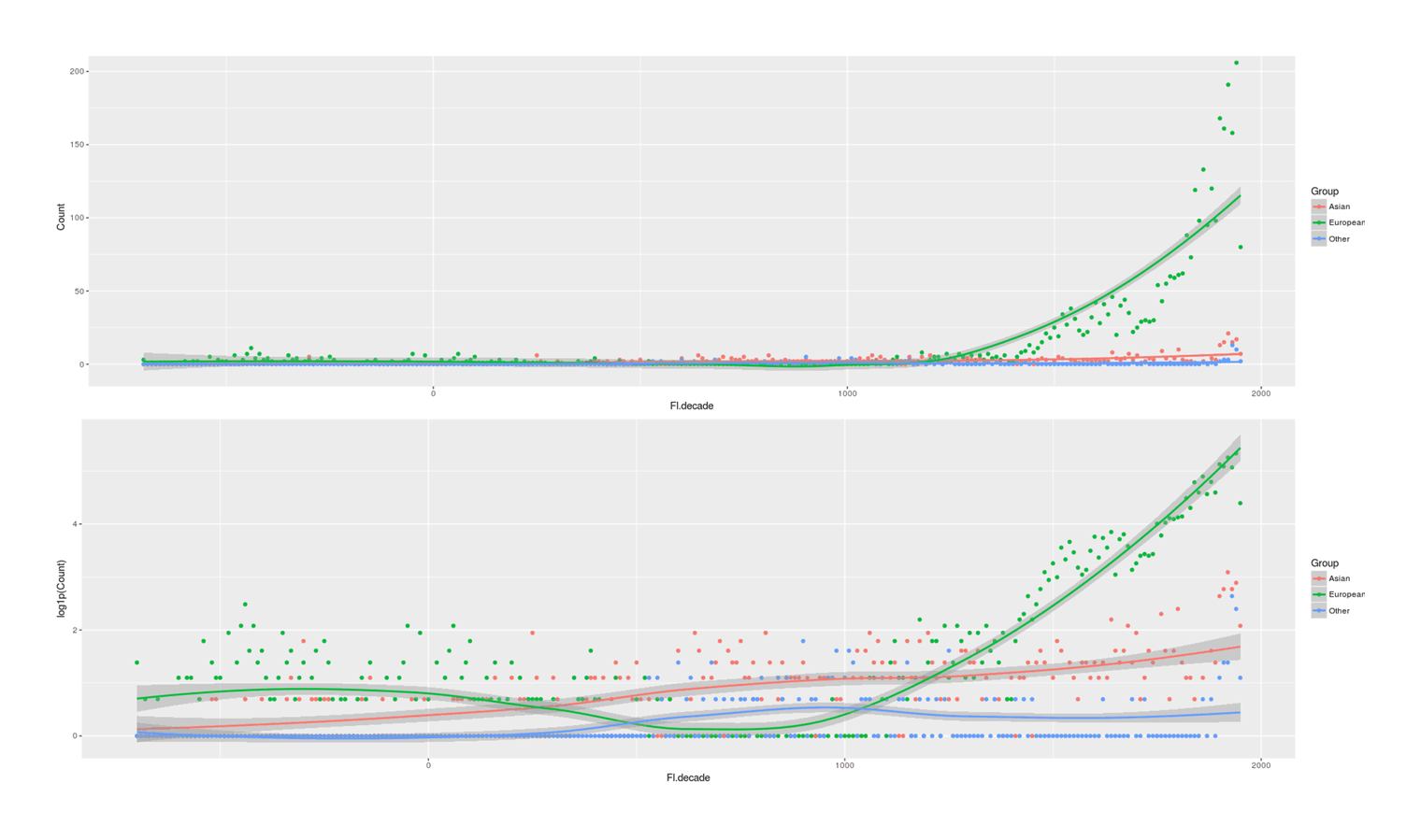
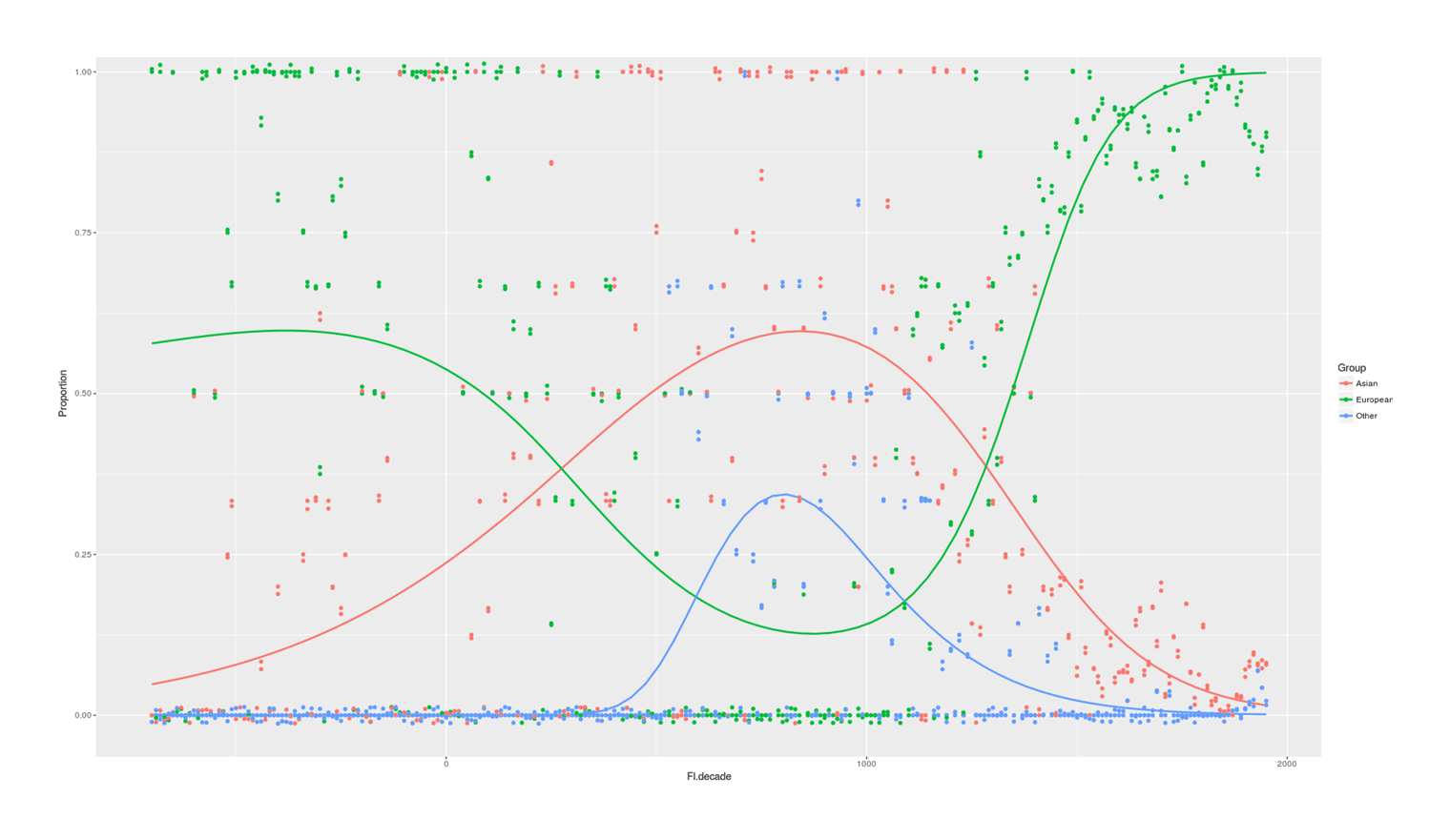
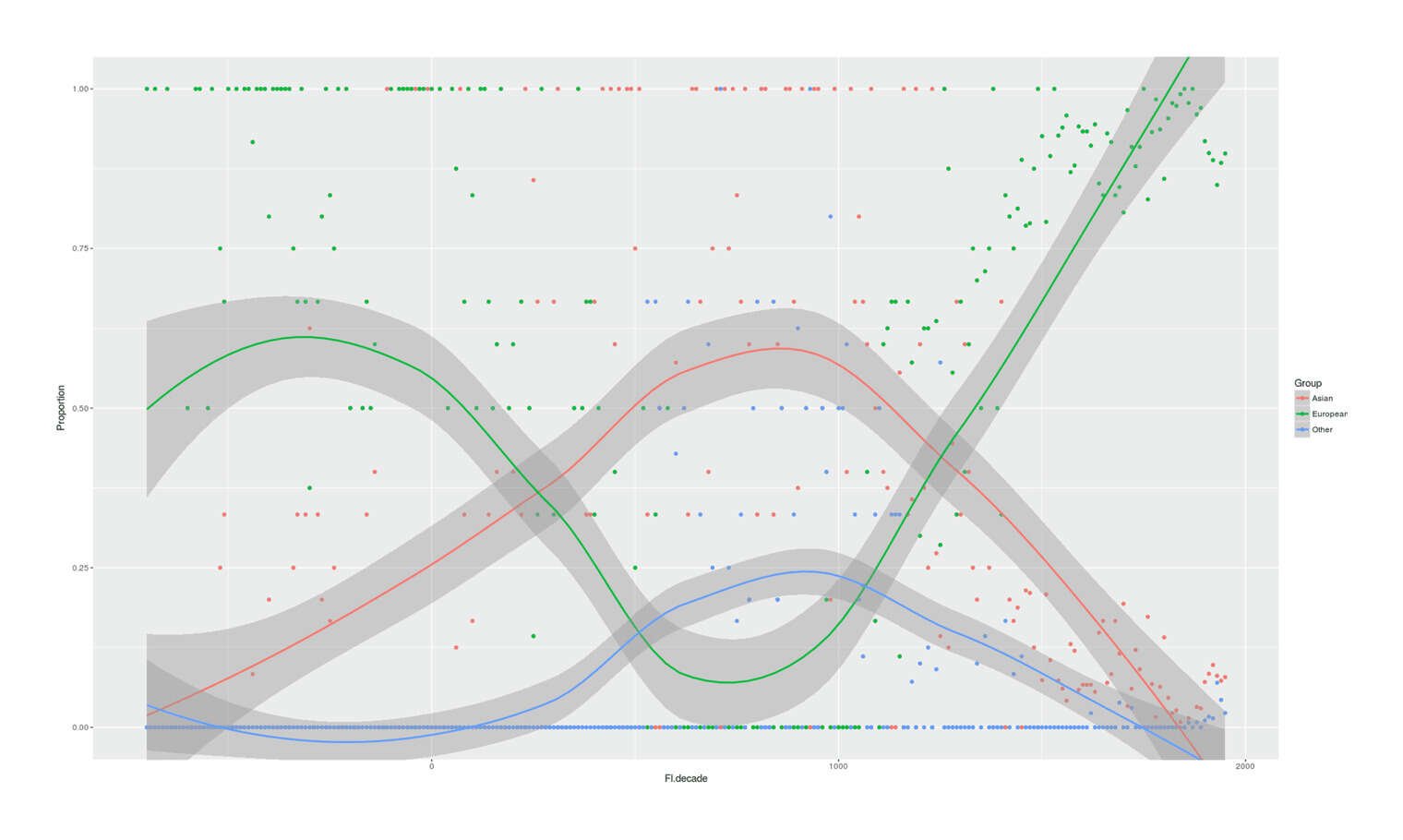
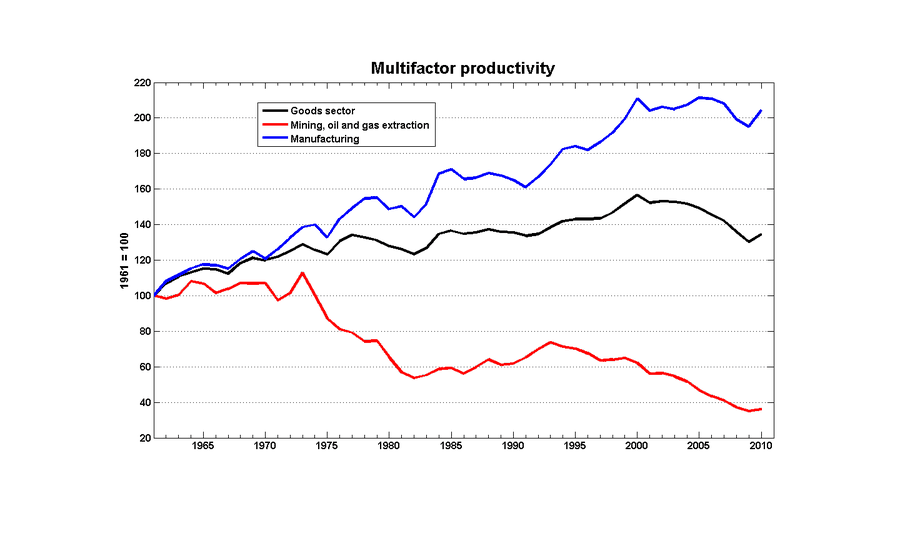
/doc/statistics/2022-10-11-problem14-squarerootvslogapproximationerror.jpg/doc/statistics/2021-haber-figure5-strengthofcorrelationiscausationbyexpertraters.jpg/doc/statistics/2020-06-30-gwern-meme-expandingbrain-statisticalpower.jpg/doc/statistics/2019-couvyduchesne-figure1-morphometricity.jpg/doc/statistics/2019-markon-figure1-bifactorvshierarchicalmodelfactoranalysis.png/doc/statistics/2016-gordon-figure7-propensityscoringresults.png/doc/statistics/2013-gwern-ngram-sandstoneoilskinlinoleum.png/doc/statistics/2012-silver-thesignalandthenoise-excerpts.pdf/doc/statistics/2008-sffed-johnfernald-americaquarterlytfp19472007.jpg/doc/statistics/2006-starbuck-websterstarbuck1988-figure26-managementsciencecorrelations.jpg/doc/statistics/2003-gwern-murray-humanaccomplishment-region-arima-forecast.jpg/doc/statistics/2003-gwern-murray-humanaccomplishment-region-bayes.png/doc/statistics/2003-gwern-murray-humanaccomplishment-region-counts.png/doc/statistics/2003-gwern-murray-humanaccomplishment-region-proportions-binomialspline.png/doc/statistics/2003-gwern-murray-humanaccomplishment-region-proportions-bootstrap.webm/doc/statistics/2003-gwern-murray-humanaccomplishment-region-proportions.jpg/doc/statistics/2001-08-canadianmultifactorproductivity19612010.png/doc/statistics/2001-francesrichard-obsessivegeneroustowardadiagramofmarklombardi.html/doc/statistics/gwern-selection-successrpredictor-twostep.pnghttps://kieranhealy.org/blog/archives/2023/06/19/the-naming-of-stats/https://www.oneusefulthing.org/p/it-is-starting-to-get-strange
{kind=link}
{kind=link}
{kind=link}
{kind=link}
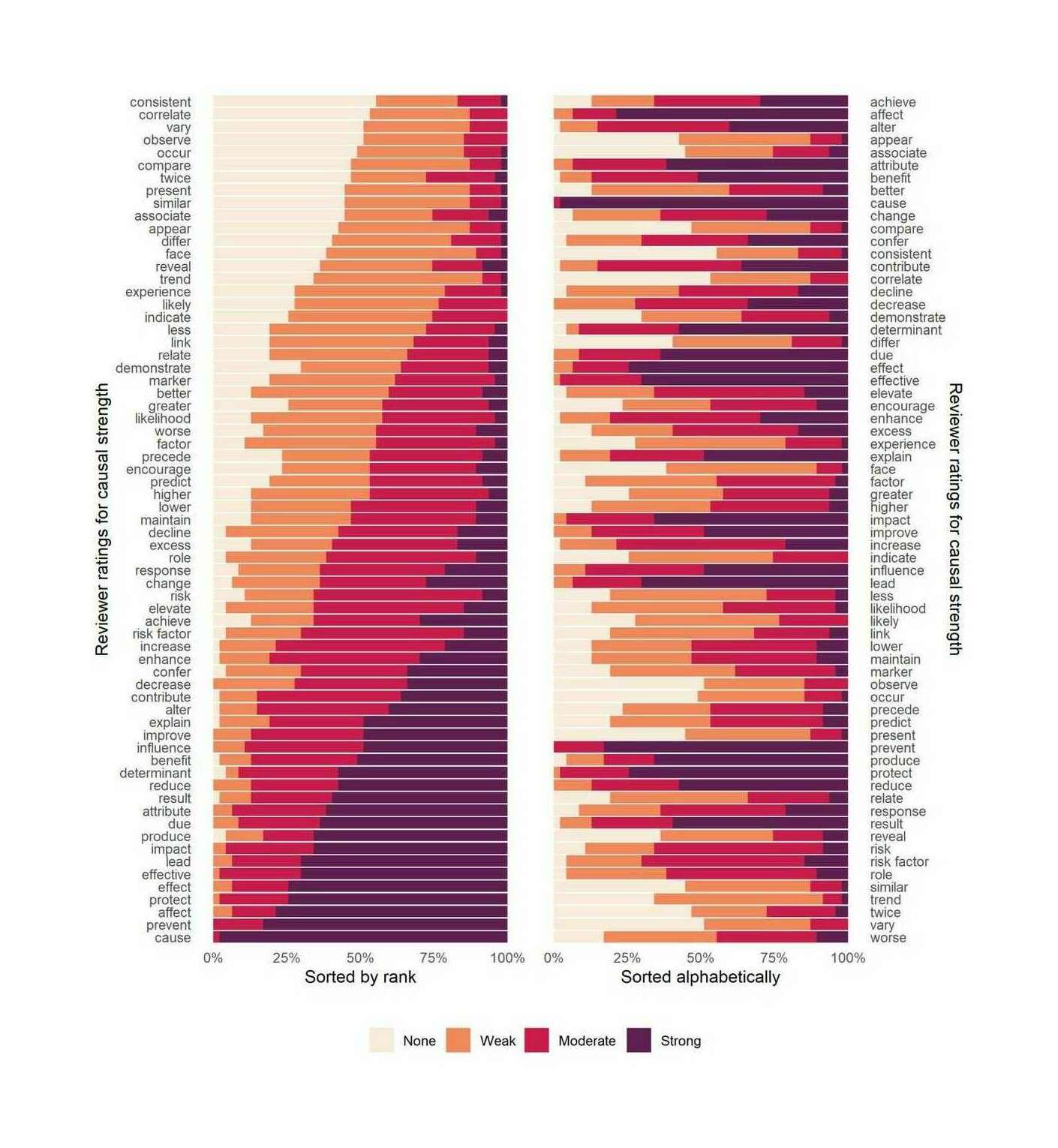{kind=link}
{kind=link}
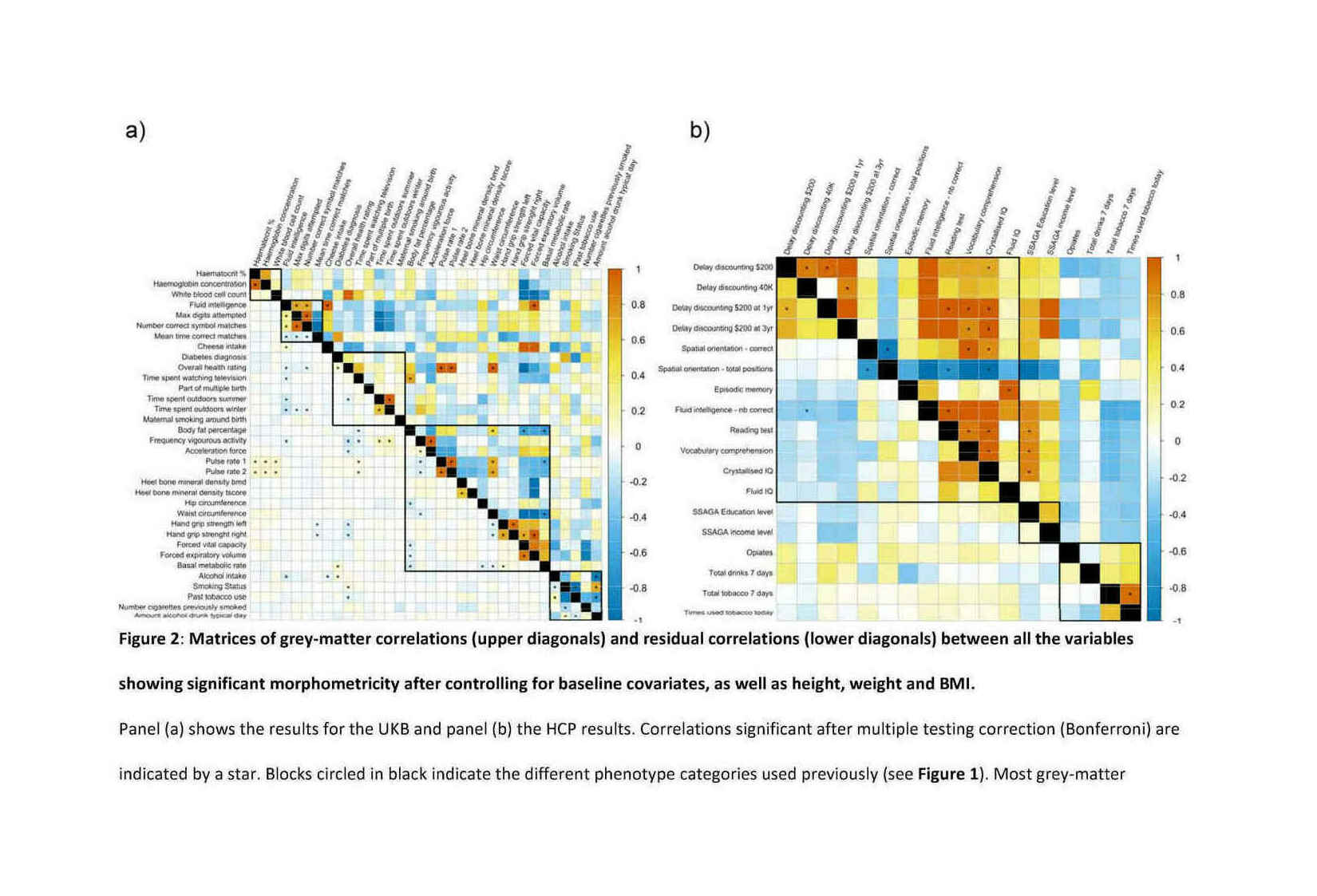{kind=link}
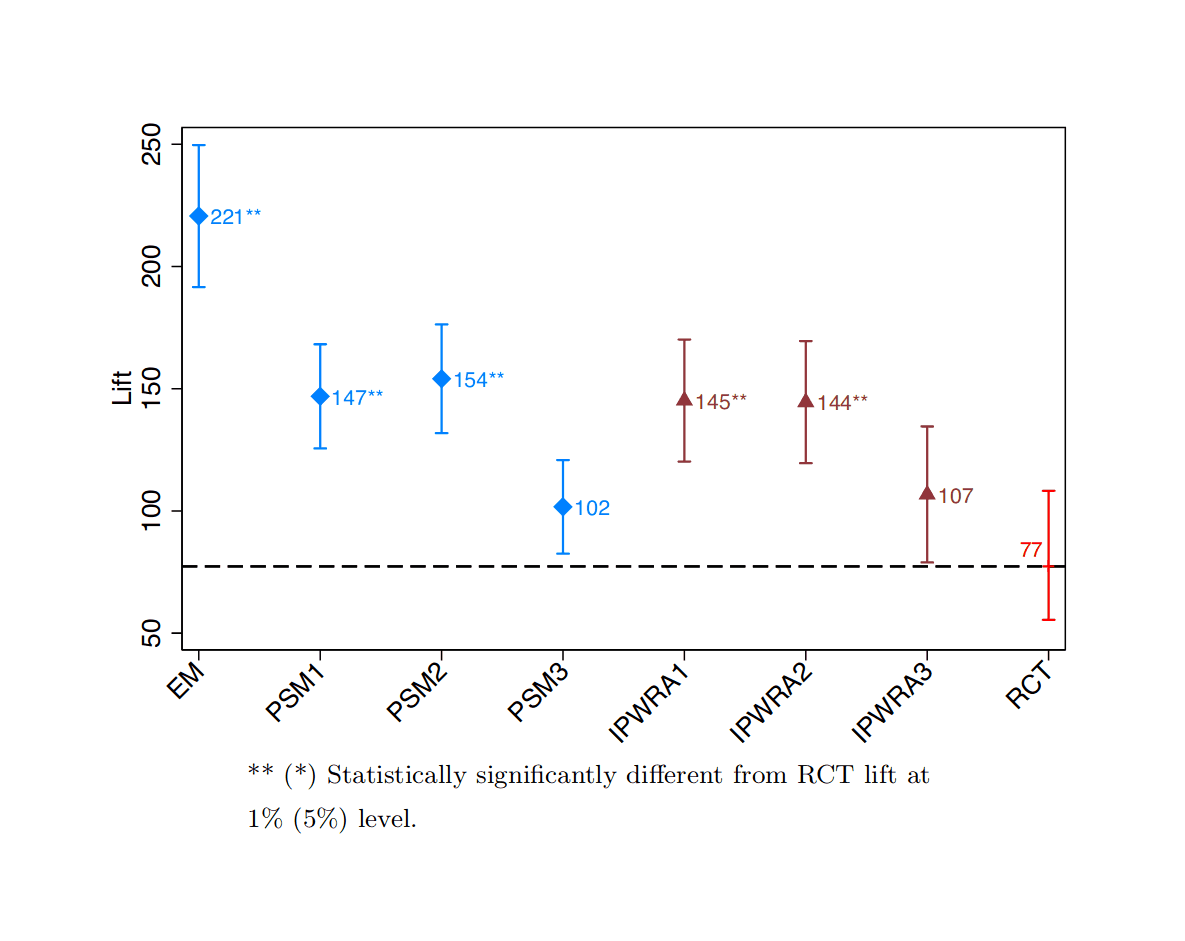
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://www.nature.com/articles/s41586-023-05745-x: “Multivariate BWAS Can Be Replicable With Moderate Sample Sizes”,2022-kelly-2.pdf: “The Mechanics of the Industrial Revolution”,2019-markon.pdf: “Bifactor and Hierarchical Models: Specification, Inference, and Interpretation”,https://www.technologyreview.com/2018/08/21/240284/the-simple-but-ingenious-system-taiwan-uses-to-crowdsource-its-laws/: “The Simple but Ingenious System Taiwan Uses to Crowdsource Its Laws: VTaiwan Is a Promising Experiment in Participatory Governance. But Politics Is Blocking It from Getting Greater Traction”,1984-mcardle.pdf: “On the Madness in His Method: R. B. Cattell’s Contributions to Structural Equation Modeling”,