‘economics’ directory
- See Also
- Gwern
- “King Pin”, Gwern et al 2026
- “Long-Run Trends in US Total Factor Productivity”, Gwern & Images-2.0 2026
- “The Efficient Market Hypothesis in Action”, Gwern 2025
- “Why So Few Matt Levines?”, Gwern 2024
- “Startup Ideas”, Gwern 2017
- “Who Buys Fonts?”, Gwern 2021
- “Open Questions”, Gwern 2018
- “My Ordinary Life: Improvements Since the 1990s”, Gwern 2018
- “How Often Does Correlation=Causality?”, Gwern 2014
- “What Is The Collecting Mindset?”, Gwern 2021
- “Laws of Tech: Commoditize Your Complement”, Gwern 2018
- “Ordinary Incompetence”, Gwern 2021
- “Progress In Beauty”, Gwern 2016
- “Fashion Cycles”, Gwern 2021
- “Review Of 𝑇𝘩𝑒 𝐶𝑢𝑙𝑡𝑢𝑟𝑎𝑙 𝑅𝑒𝑣𝑜𝑙𝑢𝑡𝑖𝑜𝑛, Dikötter 2016”, Gwern 2019
- “How Many Computers Are In Your Computer?”, Gwern 2010
- “Local Optima & Greedy Choices”, Gwern 2021
- “InflationAdjuster”, Gwern 2019
- “Technology Holy Wars Are Coordination Problems”, Gwern 2020
- “Embryo Selection For Intelligence”, Gwern 2016
- “Timing Technology: Lessons From The Media Lab”, Gwern 2012
- “Are Sunk Costs Fallacies?”, Gwern 2012
- “Darknet Market Mortality Risks”, Gwern 2013
- “Prediction Markets”, Gwern 2009
- “The Narrowing Circle”, Gwern 2012
- “History of Iterated Embryo Selection”, Gwern 2019
- “Long Bets As Charitable Giving Opportunity”, Gwern 2017
- “Slowing Moore’s Law: How It Could Happen”, Gwern 2012
- “Charity Is Not about Helping”, Gwern 2011
- “Girl Scouts & Good Corporate Governance”, Gwern 2011
- “Scientific Stagnation”, Gwern 2012
- “Evolutionary Software Licenses”, Gwern 2009
- “Wikipedia & Knol: Why Knol Already Failed”, Gwern 2009
- “Life Contracts”, Gwern 2009
- “Wikipedia and Other Wikis”, Gwern 2009
- “Console Insurance Is A Ripoff”, Gwern 2009
- “Barratry”, Gwern 2009
- Links
- “Why Kinship Societies Kill Their Old: The Economic Logic of Modern-Day Witch Killings”, Oks 2026
- “Why China Got Rich, and India Didn’t”, Oks 2026
- “The Nepo Theory of Vibecession: The Under-Discussed Variable behind Number Go Up Economics Being Such a Downer”, Hill 2026
- “The Southern Poverty Law Center Indictment”, Tabarrok 2026
- “Notes on a Non-Profit [Southern Poverty Law Center] Indicted for Bank Fraud”, McKenzie 2026
- “Consequences of the Black Sea Slave Trade: Long-Run Development in Eastern Europe”, Charnysh & Lall 2026
- “New Orleans’s Car-Crash Conspiracy: High-Speed Accidents, Crooked Lawyers, and Poor People Desperate for Cash—It Was the Kind of Scheme That Could Have Been Cooked up Only in the Big Easy”
- “The Impact of Dating Apps on Young Adults: Evidence from Tinder”, Büyükeren et al 2026
- “Are Prediction Markets Good for Anything? We All Know They’re Casinos. It’s Time to Look at the Data behind the Froth”, Schwarz 2026
- “Why Your Egg Prices Are so Much Lower Than Last Year”
- “Is It Really Impossible to Make a Living As an Animator in Japan?”
- “Anime in 2025: Is the Crunchyroll Cage Real?”
- “The Returns to Education: A Meta-Study”, Clark & Nielsen 2026
- “Fraud Investigation Is Believing Your Lying Eyes”, McKenzie 2026
- “Highway to Hitler”, Voigtländer & Voth 2026
- “Gatekeepers of Law: Inside the Westlaw and LexisNexis Duopoly; Ever Since a Spate of Mergers in the 1990s, Westlaw and LexisNexis Have Dominated Legal Research. And That Might Be Why Searching Legal Cases Is so Costly, Even in the Age of AI”, Blakely 2025
- “The $140K Question: Cost Changes Over Time”
- “How Getting Richer Made Teenagers Less Free: We Value Children More Than Ever. But We’re Suffocating Them”, Piper 2025
- “Marginal Returns to Public Universities”, Mountjoy 2025
- magnushambleton @ "2025-12-01"
- “Mr. Roberts Goes to Hollywood, Part 2: The Producer [How a Poorly Designed German Tax Loophole Funded 2000s Hollywood]”, Maher 2025
- “Looks and Gaming: Who and Why?”, Chung et al 2025
- “Don’t Let People Buy Credit With Borrowed Funds”, Habryka 2025
- “Toward an Agentic Theory of Outsider Outliers: The Case of Carlos Ghosn”, Cooper & Ewing 2025
- “Digital Distractions With Peer Influence: The Impact of Mobile App Usage on Academic and Labor Market Outcomes”, Jia et al 2025
- “Reasons for Discontinuation of Obesity Pharmacotherapy With Semaglutide or Tirzepatide in Clinical Practice”, Gasoyan et al 2025
- “Greenland Is A Beautiful Nightmare”, Duggan 2025
- “What If NIH Had Been 40% Smaller?”, Azoulay et al 2025
- “Discontinuation of Semaglutide Among Older Adults With Diabetes in the US and Japan”, Inoue et al 2025
- “Why Chainsaw Man Is Going Theatrical With MAPPA President Manabu Ohtsuka, Vice President Hiroya Hasegawa”, Chik et al 2025
- “How Kentucky Bourbon Went from Boom to Bust”, King 2025
- “The Long-Run Effects of Government Spending”, Antolin-Diaz & Surico 2025
- “How GLP-1s Are Breaking Life Insurance: Patients Look Healthy on Paper. Two Years Later, They’re High-Risk Again”, Sharma 2025
- “Corporate Discount Rates”, Gormsen & Huber 2025
- “Comprehension in Economic Games”, Koppel et al 2025
- “The Grugbrained CEO”, Rodriques 2025
- “Semen and Semantics: Understanding Porn With Language Embeddings”, future_detective 2025
- “Revealing Economic Facts: LLMs Know More Than They Say”, Buckmann et al 2025
- “China’s Superstition Boom in a Godless State § DeepSeek’s Occult Tech Boom”, Li 2025
- “Ambulance Taxis: The Impact of Regulation and Litigation on Health-Care Fraud”, Eliason et al 2025
- “When Did Growth Begin? New Estimates of Productivity Growth in England 1250–1870”, Bouscasse et al 2025
- “The Growth Consequences of Socialism”, Bergh et al 2025
- “Not That Norfolk! Mislabeled Shipments Led to Trump Tariffs on Uninhabited Islands and Remote Outposts With No US Trade”
- “Journey of a Pill”, Kaur et al 2025
- “No Evidence of Effects of Testosterone on Economic Preferences: Results From a Large (n = 1,000) Double-Blind Randomized Controlled Study”
- “The (Heterogeneous) Economic Effects of Private Equity Buyouts”, Davis et al 2025
- “Effects of Family Socioeconomic Status on Educational Outcomes in Primary and Secondary Education: A Systematic Review of the Causal Evidence”, Song et al 2025
- “Surprising Trends in Lego Pricing: Managing a Strong Brand for the Long Term [Deflation]”, Hodge 2025
- “Two Americas, One Bank Branch, and $50,000 Cash”, McKenzie 2025
- “The Aggregate and Distributional Effects of Immigration Restrictions: The 1920s Quota Acts and the Great Black Migration”, Xie 2025b
- “Project Play Survey: Family Spending on Youth Sports Rises 46% over 5 Years”, Play 2025
- “AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society”, Piao et al 2025
- “Wind Turbines, Shadow Flicker, and Real Estate Values”, Andersen & Hener 2025
- “The Time I Joined Peace Corps and Worked With An African HIV Program for Sex Workers in Eswatini: Part 1”, Laurenson 2025
- “Decisions under Risk Are Decisions under Complexity: Comment”, Banki et al 2025
- “What Will AI Do to pre-Research/research? AI Makes Doing and Communicating Research Much Easier. Will There Be Any Point to It?”, Gans 2025
- “The Efficient Market Hypothesis When Time Travel Is Possible”, Gans & o1-pro 2025
- “Discontinuation and Reinitiation of Dual-Labeled GLP-1 Receptor Agonists Among US Adults With Overweight or Obesity”, Rodriguez et al 2025
- “The Impact of the Chinese Exclusion Act on the Economic Development of the Western United States: Reduced the Male Labor Supply of Chinese and White Workers in the West”, Long et al 2025
- “A Marriage Proposal Spoken Entirely in Office Jargon”, Barber 2025
- “Dying or Lying? For-Profit Hospices and End-Of-Life Care”, Gruber et al 2025
- “Sources of Market Power in Web Search: Evidence from a Field Experiment”, Allcott et al 2025
- “The Effects Of Medical Debt Relief: Evidence From Two Randomized Experiments”, Raymond et al 2024
- “Market Response to Court Rejection of California’s Board Diversity Laws”, Klick 2024
- “The Emergence of Strategic Reasoning of Large Language Models”, Lee & Kader 2024
- “Decisions under Risk Are Decisions under Complexity”, Oprea 2024
- “Everybody Loves FRED: How America Fell for a Data Tool”
- “LLMs Learn to Collaborate and Reason: December 2024 Update to ‘Generative AI for Economic Research: Use Cases and Implications for Economists’, Published in the Journal of Economic Literature 61(4)”, Korinek 2024
- “Territory Flows and Trade Flows, 1870–2008”, Hu et al 2024
- “The Global Race For Talent: Brain Drain, Knowledge Transfer, And Growth”, Marta 2024
- “Y Combinator Often Backs Startups That Duplicate Other YC Companies, Data Shows—Not Just AI Code Editors”
- “Why Businesses Fail: Underadoption of Improved Practices by Brazilian Micro-Enterprises”, Oliveira 2024
- “How Do You Say Your Name? Difficult-To-Pronounce Names and Labor Market Outcomes”, Ge & Wu 2024
- “Optimal Resilience In Multitier Supply Chains”, M. et al 2024
- “Data and Code For: "Dying or Lying? For-Profit Hospices and End of Life Care"”, Gruber et al 2024
- “Personality Profiles of 263 Occupations”, Anni et al 2024
- “Picking Uncle Sam’s Pockets, With Jetson Leder-Luis § A $10 Billion Asterisk: Ambulances for Dialysis Patients”, McKenzie & Leder-Luis 2024
- “Picking Uncle Sam’s Pockets, With Jetson Leder-Luis § Hospice Fraud; Potentially Saved Money”, McKenzie & Leder-Luis 2024
- “An Intuitive Explanation of Black-Scholes: I Explain the Black-Scholes Formula Using Only Basic Probability Theory and Calculus, With a Focus on the Big Picture and Intuition over Technical Details”, Gundersen 2024
- “Getting Down to Business: Chain Ownership and Fertility Clinic Performance”, Forgia & Bodner 2024
- “Matt Levine, Bloomberg Opinion Columnist”, Levine 2024
- “The Economic Way of Thinking in a Pandemic”, Tabarrok 2024
- “Entrepreneurship Changed the Way I Think”, Handmer 2024
- “On the UBI Paper”, Mowshowitz 2024
- “Founder Mode”, Graham 2024
- “The Relationship Between Team Diversity and Team Performance: Reconciling Promise and Reality Through a Comprehensive Meta-Analysis Registered Report”, Wallrich et al 2024
- “Causal Inference on Human Behaviour”, Bailey et al 2024
- “The Untold Story Behind a Meteoric Rise: The Early Days of Valve from a Woman Inside”, Harrington 2024
- “The Lifetime Costs of Bad Health”, Nardi et al 2024
- “Political Language In Economics”, Zubin et al 2024
- “Revisiting the Relationship between Economic Freedom and Development to Account for Statistical Deception by Autocratic Regimes”, Alvarez et al 2024
- “Using Grocery Data for Credit Decisions”, Lee et al 2024b
- “Navigating Corporate Giants: Jeffrey Snover and the Making of PowerShell”, Snover & Bell 2024
- “Health Care Centralization: The Health Impacts of Obstetric Unit Closures in the United States”, Fischer et al 2024
- “FDI Technology Spillovers in Chinese Supplier-Customer Networks”, Li et al 2024b
- “Is Socially Responsible Capitalism Truly Polarizing?”, Stone & Lees 2024
- “Income Inequality in the United States: Using Tax Data to Measure Long-Term Trends”, Auten & Splinter 2024
- “Are Older People Aware of Their Cognitive Decline? Misperception and Financial Decision-Making”, Mazzonna & Peracchi 2024
- “Subjective Job Insecurity and the Rise of the Precariat: Evidence from the United Kingdom, Germany, and the United States”, Manning & Mazeine 2024
- “Creating the ‘American Way’ of Business: Evidence from WWII in the United States”, Giorcelli 2024
- “Examining the Effects of Weather on Online Shopping Cart Abandonment: Evidence from an Online Retailing Platform”, Li et al 2024
- “The Ant And The Grasshopper: Seasonality And The Invention Of Agriculture”, Matranga 2024
- “Is Economics Self-Correcting? Replications in the American Economic Review”, Ankel-Peters et al 2024
- “What’s Behind Her Smile? Health, Looks, and Self-Esteem”, Gallego et al 2024
- “Covid-19 Is (Probably) Not an Exogenous Shock or Valid Instrument”, Clement 2024
- “The Long-Run Impacts of Adolescent Drinking: Evidence from Zero Tolerance Laws”, Abboud et al 2024
- “The Psychology Of Poverty: Where Do We Stand?”, Haushofer & Salicath 2024
- “Behavioral Responses to State Income Taxation of High Earners: Evidence from California”, Rauh & Shyu 2024
- “E-Cigarette Flavor Restrictions’ Effects on Tobacco Product Sales”, Friedman et al 2024
- “How Beautiful People See the World: Cooperativeness Judgments of and by Beautiful People”, Zylbersztejn et al 2024
- “Causal Assessment of Income Inequality on Self-Rated Health and All-Cause Mortality: A Systematic Review and Meta-Analysis”, Shimonovich et al 2024
- “Lay Economic Reasoning: An Integrative Review and Call to Action”, Bhattacharjee & Dana 2024
- “Acutely Precarious? Detecting Objective Precarity in Journalism”, Jana 2024
- “School Closures during the 1918 Flu Pandemic”, Ager et al 2024
- “Workplace Aggression and Employee Performance: A Meta-Analytic Investigation of Mediating Mechanisms and Cultural Contingencies”, Zhong et al 2024
- “The Economic Impact of Depression Treatment in India: Evidence from Community-Based Provision of Pharmacotherapy”, Angelucci & Bennett 2024
- “Inconsistent Definitions of GDP: Implications for Estimates of Decoupling”, Semieniuk 2024
- “Writing Matters”, Feld et al 2024
- “Does Trade Reform Promote Economic Growth? A Review of Recent Evidence”, Irwin 2024
- “The Gender Gap in Confidence: Expected but Not Accounted For”, Exley & Nielsen 2024
- “Associations between Common Genetic Variants and Income Provide Insights about the Socio-Economic Health Gradient”
- “Solar Eclipses and the Origins of Critical Thinking and Complexity”, Litina & Fernández 2023
- “The Long Shadow of Checks § Check Settlement in the Pre-Computer-Era”, McKenzie 2023
- “Lord of the Roths: How Tech Mogul Peter Thiel Turned a Retirement Account for the Middle Class Into a $5 Billion Tax-Free Piggy Bank”
- “Cultural Values and Productivity”, Ek 2023
- “Strategic CEO Activism in Polarized Markets”, Homroy & Gangopadhyay 2023
- “America, Jump-Started: World War II R&D and the Takeoff of the US Innovation System”, Gross & Sampat 2023
- “Intergenerational Mobility in American History: Accounting for Race and Measurement Error”, Ward 2023
- “The Possibility of Making $138,000 from Shredded Banknote Pieces Using Computer Vision”, Kong 2023
- “Economic Inequality Fosters the Belief That Success Is Zero-Sum”, Davidai 2023
- “A Challenge to Orthodoxy in Psychology: Thomas Sowell and Social Justice”, O’Donohue et al 2023
- “After 50 Years, Health Professional Shortage Areas Had No Significant Impact On Mortality Or Physician Density”, Markowski et al 2023
- “Macroevolutionary Origins of Comparative Development”, Riahi 2023
- “Can GPT Models Be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on Mock CFA Exams”, Callanan et al 2023
- “Do Looks Matter for an Academic Career in Economics?”, Hale et al 2023
- “Does Alleviating Poverty Increase Cognitive Performance? Short-Term & Long-Term Evidence from a Randomized Controlled Trial”, Szaszi et al 2023
- “Ozempic Is Making People Buy Less Food, Walmart Says”, Case & Banjo 2023
- “An Evolutionary Model of Personality Traits Related to Cooperative Behavior Using a Large Language Model”, Suzuki & Arita 2023
- “The Economic Origins of Government”, Allen et al 2023
- “Quantifying Racial Discrimination in the 1944 G.I. Bill”, Eden 2023
- “Beauty and Stock Market Participation”, Gan et al 2023
- “Public Policy toward Professional Sports Stadiums: A Review”, Bradbury et al 2023
- “Monitoring for Waste: Evidence from Medicare Audits”, Shi 2023
- “Microsoft Says Apple Used Bing Offer As Google ‘Bargaining Chip’”, Nylen 2023
- “Expert Opinions and Negative Externalities Do Not Decrease Support for Anti-Price Gouging Policies”, Klofstad & Uscinski 2023
- “Congestion on the Information Superhighway: Inefficiencies in Economics Working Papers: Online Appendix: Additional Tables and Figures”, Lusher et al 2023
- “To Pay for Weight Loss Drugs, Some Take Second Jobs, Ring Up Credit Card Debts: Some People Pay More Than $10,000 a Year Out-Of-Pocket for Ozempic and Mounjaro”, Armour 2023
- “Congestion on the Information Superhighway § Figure 1: Time Series of Number of Working Paper Releases”, Lusher et al 2023
- “Congestion on the Information Superhighway: Inefficiencies in Economics Working Papers”, Lusher et al 2023
- “How Well Do Laboratory-Derived Estimates of Time Preference Predict Real-World Behaviors? Comparisons to Four Benchmarks”, Bartels et al 2023
- “Increasing the External Validity of Social Preference Games by Reducing Measurement Error”, Wang & Navarro-Martinez 2023
- “We Do Not Know the Population of Every Country in the World for the Past Two Thousand Years”, Guinnane 2023
- “How Much Do EAGs Cost (And Why)?”, Eli_Nathan 2023
- “OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax?”, Blair-Stanek et al 2023
- “A Systematic Review and Meta-Analysis of the Relationship between Economic Inequality and Prosocial Behavior”, Yang & Konrath 2023c
- “Behavioral Genetics of Temporal Framing: Heritability of Time Perspective and Its Common Genetic Bases With Major Personality Traits”, Stolarski et al 2023
- “Google Maps Has Become an Eyesore § Comments”, Cory 2023
- “What Happened to US Business Dynamism?”, Akcigit & Ates 2023
- “The Consequences of Job Search Monitoring for the Long-Term Unemployed: Disability instead of Employment?”, Brouwer et al 2023
- “The Lion’s Share: Evidence from Federal Contracts on the Value of Political Connections”, Ağca & Igan 2023
- “The Long-Run Relationship between per Capita Incomes and Population Size”, Eden & Kuruc 2023
- “Supplement: Gender-Based Pricing in Consumer Packaged Goods: A Pink Tax?”, Moshary et al 2023
- “Gender-Based Pricing in Consumer Packaged Goods: A Pink Tax?”, Moshary et al 2023
- “The Heterogeneous Earnings Impact of Job Loss Across Workers, Establishments, and Markets”, Athey et al 2023
- “Cognitive Biases: Mistakes or Missing Stakes?”, Enke et al 2023
- “School Quality and the Return to Schooling in Britain: New Evidence from a Large-Scale Compulsory Schooling Reform”, Clark 2023
- “Income and Inequality in the Aztec Empire on the Eve of the Spanish Conquest”, Alfani & Carballo 2023
- “Rebel, Remain, or Resign? Military Elites’ Decision-Making at the Onset of the American Civil War”, White 2023
- “Pareto-Improving Optimal Capital and Labor Taxes”, Greulich et al 2023
- “Using Sequences of Life-Events to Predict Human Lives”, Savcisens et al 2023
- “Increasing Pressure on US Men for Income in order to Find a Spouse”, Fieder & Huber 2023
- “National and Global Impacts of Genetically Modified Crops”, Hansen & Wingender 2023
- “The Psychology of Zero-Sum Beliefs”, Davidai & Tepper 2023b
- “Does Access to Citizenship Confer Socio-Economic Returns? Evidence from a Randomized Control Design”, Hainmueller et al 2023
- “Economic Consequences of Kinship: Evidence From US Bans on Cousin Marriage”, Ghosh et al 2023
- “Bilateral Trade Imbalances”, Cuñat & Zymek 2023
- “The Mainstreaming of Marx: Measuring the Effect of the Russian Revolution on Karl Marx’s Influence”, Magness & Makovi 2023
- “Is Beauty-Based Inequality Gendered? A Systematic Review of Gender Differences in Socioeconomic Outcomes of Physical Attractiveness in Labor Markets”, Kukkonen et al 2023
- “Saving Time and Money in Biomedical Publishing: the Case for Free-Format Submissions With Minimal Requirements”, Clotworthy et al 2023
- “College Quality As Revealed by Willingness-To-Pay for College Graduates”, Green & Swepston 2023
- “Do Financial Incentives Encourage Women to Apply for a Tech Job? Evidence from a Natural Field Experiment”, Feld et al 2023
- “Founder Personality and Entrepreneurial Outcomes: A Large-Scale Field Study of Technology Startups”, Freiberg & Matz 2023
- “Taxing Uber”, Agrawal & Zhao 2023
- “The Shadow of Peasant Past: Seven Generations of Inequality Persistence in Northern Sweden”, Hällsten & Kolk 2023
- “Business-Size Bias in Moral Concern: People Are More Dishonest Against Big Than Small Organizations”, Martuza et al 2023
- “Effectiveness of an Over-The-Counter Self-Fitting Hearing Aid Compared With an Audiologist-Fitted Hearing Aid: A Randomized Clinical Trial”, Sousa et al 2023
- “Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games”
- “Invisible Hurdles: Gender and Institutional Differences in the Evaluation of Economics Papers”, Ersoy & Pate 2023
- “Energy Saving May Kill: Evidence from the Fukushima Nuclear Accident”, He & Tanaka 2023
- “Managers and Productivity in Retail”, Metcalfe et al 2023
- “BloombergGPT: A Large Language Model for Finance”, Wu et al 2023
- “Arm Seeks to Raise Prices ahead of Hotly Anticipated IPO: SoftBank-Owned Group Aims to Charge More for Each Chip Design in Radical Shake-Up of Business Model”, Gross et al 2023
- “Ride-Hailing and Transit Accessibility considering the Trade-Off between Time and Money”, Pereira et al 2023
- “Does Information Affect Homophily?”, Gallen & Wasserman 2023
- “The Myth of Wartime Prosperity: Evidence from the Canadian Experience”, Geloso & Pender 2023
- “Conscientiousness and Labor Market Returns: Evidence from a Field Experiment in West Africa-Author=Mathias Allemand, Martina Kirchberger, Sveta Milusheva, Carol Newman, Brent Roberts, Vincent Thorne”, Group 2023 (page 3)
- “Evidence on Economies of Scale in Local Public Service Provision: A Meta-Analysis”, Gómez-Reino et al 2023
- “Fortunate Families? The Effects of Wealth on Marriage and Fertility”, Cesarini et al 2023
- “Personality Differences and Investment Decision-Making”, Jiang et al 2023
- “The Unintended Effects of Minimum Wage Increases on Crime”, Fone et al 2023
- “Unexpected Interruptions, Idle Time, and Creativity: Evidence from a Natural Experiment”, Schweisfurth & Greul 2023
- “Do Firms Value Court Enforceability of Noncompete Agreements? A Revealed Preference Approach”, Hiraiwa et al 2023
- “A 12-Gene Pharmacogenetic Panel to Prevent Adverse Drug Reactions: an Open-Label, Multicenter, Controlled, Cluster-Randomized Crossover Implementation Study (PREPARE)”, Swen et al 2023
- “Consumption and Income Inequality in the United States Since the 1960s”, Meyer & Sullivan 2023b
- “Status and Mortality: Is There a Whitehall Effect in the United States?”, Nicholas 2023
- “Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”, Nay 2023
- “Islam and Human Capital in Historical Spain”, Cinnirella et al 2023
- “Google Wants RISC-V to Be a ‘tier-1’ Android Architecture: Google’s Keynote at the RISC-V Summit Promises Official, Polished Support”, Amadeo 2023
- “Holiday Gift Giving in Retreat”, Waldfogel 2023
- “Variation in Hospitalization Costs, Charges, and Lengths of Hospital Stay for Coronavirus Disease 2019 Patients Treated With Venovenous Extracorporeal Membrane Oxygenation in the United States: A Cohort Study”, Mazzeffi et al 2023
- “More Than a Penny’s Worth: Left-Digit Bias and Firm Pricing”, Strulov-Shlain 2022
- “Measuring and Improving Stakeholder Welfare Is Easier Said Than Done”, Gurun et al 2022
- “The Mechanics of the Industrial Revolution”, Kelly et al 2022b
- “Linux, Amazon, Meta, and Microsoft Want to Break the Google Maps Monopoly: Overture Maps Foundation Wants to End the Oppressive Rule of the Google Maps API”, Amadeo 2022
- “An Economic Analysis of Crime Costs Associated With Psychopathic Personality Disorder and Violence Risk”, Gatner et al 2022b
- “The Effect of Financial Resources on Fertility: Evidence from Administrative Data on Lottery Winners”, Tsai et al 2022
- “Advancing Antivenom: Snakebites Kill 80–140,000 People Every Year. Better Antivenom Should Be a High Priority—Thankfully New Technology Can Help”, Bonde 2022
- “Hideous but worth It: Distinctive Ugliness As a Signal of Luxury”, Cesareo et al 2022
- “Social Economic Decision-Making and Psychopathy: A Systematic Review and Meta-Analysis”, Gunschera et al 2022
- “Are Ideas Being Fished Out?”, Klüppel & Knott 2022
- “Quantifying the Causal Impact of Biological Risk Factors on Healthcare Costs”, Lee et al 2022
- “Facial Attractiveness and CEO Compensation: Evidence from the Banking Industry”, Ahmed et al 2022
- “When a Town Wins the Lottery: Evidence from Spain”, Kent & Martínez-Marquina 2022
- “Too Much Efficiency Makes Everything Worse: Overfitting and the Strong Version of Goodhart’s Law”
- “Within-Firm Productivity Dispersion: Estimates and Implications”, Orr 2022
- “Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation”, Mulligan 2022
- “Sophisticated Deviants: Intelligence and Radical Economic Attitudes”, Lin & Bates 2022
- “The Paradox of Wealthy Nations’ Low Adolescent Life Satisfaction”, Rudolf & Bethmann 2022
- “Why Is Europe More Equal Than the United States?”, Blanchet et al 2022
- “Religious Festivals and Economic Development: Evidence from the Timing of Mexican Saint Day Festivals”, Montero & Yang 2022
- “Scaring or Scarring? Labor Market Effects of Criminal Victimization”, Bindler & Ketel 2022
- “The Delusive Economy: How Information and Affect Color Perceptions of National Economic Performance”, Linsi et al 2022
- “Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning”, Anonymous 2022
- “A Causal Test of the Strength of Weak Ties”, Rajkumar et al 2022
- “Does the Dream of Home Ownership Rest Upon Biased Beliefs? A Test Based on Predicted and Realized Life Satisfaction”, Odermatt & Stutzer 2022
- “The Political Economy of Populism”, Guriev & Papaioannou 2022
- “Visual Studio Code Is Designed to Fracture”, Huntley 2022
- “Using Large Language Models to Simulate Multiple Humans”, Aher et al 2022
- “Competition for Attention in the ETF Space”, Ben-David et al 2022
- “Losing Sight of Piecemeal Progress: People Lump and Dismiss Improvement Efforts That Fall Short of Categorical Change—Despite Improving”, O’Brien 2022
- “Do Pre-Registration and Pre-Analysis Plans Reduce p-Hacking and Publication Bias?”, Brodeur et al 2022
- “Understanding Jane Street: Strong Language”, Hobart 2022
- “The Signaling Value of University Rankings: Evidence from Top 14 Law Schools”, Naven & Whalen 2022
- “Cost-Effectiveness of Polygenic Risk Scores to Guide Statin Therapy for Cardiovascular Disease Prevention”, Kiflen et al 2022
- “The Moralization of Effort”, Celniker et al 2022
- “Turn 800 Marks into 115,000 Euros: the Tenant Gets the Deposit Back: A Plaintiff Has Fought in Court to Get Back a Rent Deposit Paid by Her Parents More Than 60 Years Ago. The Amount Has Grown Enormously Since Then”, Berliner 2022
- “The Age of the Superyacht”
- “Taxing Top Incomes in a World of Ideas”, Jones 2022
- “Do Doctors Improve the Health Care of Their Parents? Evidence from Admission Lotteries”, Artmann et al 2022
- “Robust Incentives for Teams”, Dai & Toikka 2022
- “Assortative Matching at the Top of the Distribution: Evidence from the World’s Most Exclusive Marriage Market”, Goñi 2022
- “A Pay Change and Its Long-Term Consequences”, Krueger & Friebel 2022
- “This Is Air: The ‘Non-Health’ Effects of Air Pollution”, Aguilar-Gomez et al 2022
- “If I Could Do It, So Can They: Among the Rich, Those With Humbler Origins Are Less Sensitive to the Difficulties of the Poor”, Koo et al 2022
- “Army Service in the All-Volunteer Era”, Greenberg et al 2022b
- “Collaborations and Innovation in Partitioned Industries: An Analysis of US Feature Film Coproductions”, Jia et al 2022
- “Essays on Technology and Work”, Tuhkuri 2022
- “‘Beauty Too Rich for Use’: Billionaires’ Assets and Attractiveness”, Hamermesh & Leigh 2022
- “Sweet Unbinding: Sugarcane Cultivation and the Demise of Foot-Binding”, Cheng et al 2022
- “Clans and Calamity: How Social Capital Saved Lives during China’s Great Famine”, Cao et al 2022
- “The Doctor Prescribed an Obesity Drug. Her Insurer Called It ‘Vanity.’ Many Insurance Companies Refuse to Cover New Weight Loss Drugs That Their Doctors Deem Medically Necessary”, Kolata 2022
- “The Null Result Penalty”, Chopra et al 2022 (page 3)
- “Schizophrenia Polygenic Risk Score and Long-Term Success in the Labour Market: A Cohort Study”, Viinikainen et al 2022
- “A Golden Opportunity: The Gold Rush, Entrepreneurship and Culture”, Stuetzer et al 2022
- “Emergent Bartering Behavior in Multi-Agent Reinforcement Learning”, Johanson et al 2022
- “What Determines Consumer Financial Distress? Place-Based and Person-Based Factors”, Keys et al 2022
- “Reputation Inflation”, Filippas et al 2022
- “Soft Skills in the Youth Labor Market”, Heller & Kessler 2022c
- “Understanding of Trade”, Stantcheva 2022 (page 2)
- “When Scale and Replication Work: Learning from Summer Youth Employment Experiments”, Heller 2022b
- “Rent Seeking and the Decline of the Florentine School”, Piano & Hardy 2022
- “How Much Does That Cost? Examining the Economic Costs of Crime in North America Attributable to People With Psychopathic Personality Disorder”, Gatner et al 2022
- “A Meta-Analysis of the Effects of Electronic Performance Monitoring on Work Outcomes”, Ravid et al 2022
- “Risks and Global Supply Chains: What We Know and What We Need to Know”, Baldwin & Freeman 2022b
- “The LGBTQ+ Gap: Recent Estimates for Young Adults in the United States”, Folch 2022
- “Launching With a Parachute: The Gig Economy and New Business Formation”, Barrios et al 2022
- “Will Studying Economics Make You Rich? A Regression Discontinuity Analysis of the Returns to College Major”, Bleemer & Mehta 2022
- “Sibling Similarity in Income: A Life Course Perspective”, Grätz & Kolk 2022
- “Residual Confounding in Health Plan Performance Assessments: Evidence From Randomization in Medicaid”, Wallace et al 2022
- “Scientific Grant Funding”, Goolsbee & Jones 2022
- “Burden of Covid-19 Restrictions: National, Regional and Global Estimates”, Fink et al 2022
- “Demand for Rarity: Evidence from a Collectible Good”, Hughes 2022
- “Why Do Women Earn Less Than Men? Evidence from Bus and Train Operators”, Bolotnyy & Emanuel 2022
- “Criminalizing Poverty: The Consequences of Court Fees in a Randomized Experiment”, Pager et al 2022
- “The Road Not Taken: Technological Uncertainty and the Evaluation of Innovations”, Tan 2022
- “Darwinian Rational Expectations”, Finestone 2022
- “Each Is to Count for One and None for More Than One: Predictors of Support for Economic Redistribution”, Lin & Bates 2022
- “National Development Delivers: And How! And How?”, Pritchett 2022
- “The Economic Effects of the English Parliamentary Enclosures”, Heldring et al 2022
- “For Want of a Cup: The Rise of Tea in England and the Impact of Water Quality on Mortality”, Antman 2022
- “The Gender Gap in Self-Promotion”, Exley & Kessler 2022
- “Niche Diversity Predicts Personality Structure Across 115 Nations”, Durkee et al 2022
- “Global Evidence on the Selfish Rich Inequality Hypothesis”, Almås et al 2022
- “Pandemic Recession and Helicopter Money: Venice, 1629–1631”, Masciandaro et al 2022
- “Gender Preference Gaps and Voting for Redistribution”, Ranehill & Weber 2022
- “Elite Capture of Foreign Aid: Evidence from Offshore Bank Accounts”, Andersen et al 2022
- “Hobo Economicus”, Leeson et al 2022
- “Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning”, Curry et al 2022
- “‘The Best Country in the World’: The Surprising Social Mobility of New York’s Irish-Famine Immigrants”, Anbinder et al 2022
- “Can Information Reduce Ethnic Discrimination? Evidence from Airbnb”, Laouénan & Rathelot 2022
- “Labor Market Returns to Vocational Secondary Education”, Silliman & Virtanen 2022
- “Familial Resemblance, Citizenship, and Counterproductive Work Behavior: A Combined Twin, Adoption, Parent-Offspring, and Spouse Approach”, Anderson et al 2022b
- “Bronze Age Long-Distance Exchange, Secret Societies, Rock Art, and the Supra Regional Interaction Hypothesis”, Ling et al 2022
- “Privacy and Information Avoidance: An Experiment on Data-Sharing Preferences”, Svirsky 2022
- “Opportunity Neglect: An Aversion to Low-Probability Gains”, Prinsloo et al 2022
- “Social Mobility and Political Regimes: Intergenerational Mobility in Hungary, 1949–2017”, Bukowski et al 2022
- “Total Meat Intake Is Associated With Life Expectancy: A Cross-Sectional Data Analysis of 175 Contemporary Populations”, You et al 2022
- “Intelligence, Errors, and Cooperation in Repeated Interactions”, Proto et al 2021
- “Parents Think—Incorrectly—That Teaching Their Children That the World Is a Bad Place Is Likely Best for Them”, Clifton & Meindl 2021
- “The CEO Beauty Premium: Founder CEO Attractiveness and Firm Valuation in Initial Coin Offerings”, Colombo et al 2021
- “Displacement, Diversity, and Mobility: Career Impacts of Japanese American Internment”, Arellano-Bover 2021
- “Silver Coins, Wooden Tallies and Parchment Rolls in Henry III’s Exchequer”, Cassidy 2021
- “Improving Real-Time Rendering of Dynamic Digital Characters in Cycles”, Dietrich 2021
- “Marriage, Quarrels, and Lovemaking”, Silva & Cordeiro 2021
- “Long-Term Effects of the Targeting the Ultra Poor Program”, Banerjee et al 2021
- “Post-Materialism and Economic Growth: Cultural Backlash, 1981–2019”, Kafka & Kostis 2021
- “Out of the Dark: The Effect of Law Enforcement Actions on Cryptocurrency Market Prices”, Abramova & Bohme 2021
- “Occupational Characteristics Moderate Personality-Performance Relations in Major Occupational Groups”, Wilmot & Ones 2021
- “Patience and Comparative Development”, Sunde et al 2021
- “Steam Deck Won’t Have Any Exclusive Games, Valve Confirms”, Palumbo 2021
- “Promoting to Opportunity: Evidence and Implications from the US Submarine Service”, Suandi 2021
- “The Predicament of Establishing Persistence: Slavery and Human Capital in Africa”, Malik & Bouaroudj 2021
- “What Drives Racial Diversity on US Corporate Boards?”, Bogan et al 2021
- “Does the Mafia Hire Good Accountants?”, Bianchi et al 2021
- “Forced Entrepreneurs”, Hacamo & Kleiner 2021
- “Intelligence Disclosure and Cooperation in Repeated Interactions”, Lambrecht et al 2021
- “Returning Actionable Genomic Results in a Research Biobank: Analytic Validity, Clinical Implementation, and Resource Usage”, Zawatsky et al 2021
- “One Flew Over the Cuckoo’s Clock: Selling Exclusivity Through Conspicuous Goods on Evolution”, Oosterman & Angelini 2021
- “Protective State Policies and the Employment of Fathers With Criminal Records”, Emory 2021
- “Trait/Financial Information of Potential Male Mate Eliminates Mate-Choice Copying by Women: Trade-Off Between Social Information and Personal Information in Mate Selection”, Liu et al 2021b
- “Should Subscription-Based Content Creators Display Their Earnings on Crowdfunding Platforms? Evidence from Patreon”, Crosby & McKenzie 2021
- “Personal Relative Deprivation and the Belief That Economic Success Is Zero-Sum”, Ongis & Davidai 2021
- “The Aggregate Cost of Crime in the United States”, Anderson 2021b
- “Keeping It in the Family: Female Inheritance, Inmarriage, and the Status of Women”, Bahrami-Rad 2021
- “The Intergenerational Effects of a Large Wealth Shock: White Southerners After the Civil War”, Ager et al 2021
- “Opportunity Unraveled: Private Information and the Missing Markets for Financing Human Capital”, Herbst & Hendren 2021
- “Market Expectations of a Warming Climate”, Schlenker & Taylor 2021
- “Gender Quotas and Company Financial Performance: A Systematic Review”, Yu & Madison 2021
- “Individualistic CEO and Corporate Innovation: Evidence from US Frontier Culture”, Gao et al 2021
- “Big Five Personality Traits and Performance: A Quantitative Synthesis of 50+ Meta-Analyses”, Zell & Lesick 2021b
- “Gender Identity, Coworking Spouses and Relative Income within Households”, Zinovyeva & Tverdostup 2021
- “Neural Autopilot and Context-Sensitivity of Habits”, Camerer & Li 2021
- “Personality Traits and Reasons for Residential Mobility: Longitudinal Data from United Kingdom, Germany, and Australia”, Jokela 2021
- “The Real Effects of Monetary Expansions: Evidence from a Large-Scale Historical Experiment”, Palma 2021
- “Geography and Agricultural Productivity: Cross-Country Evidence from Micro Plot-Level Data”, Adamopoulos & Restuccia 2021
- “The Institutional Foundations of Surf Break Governance in Atlantic Europe”, Rode 2021
- “Personality Psychology”, Roberts & Yoon 2021
- “Playlisting Favorites: Measuring Platform Bias in the Music Industry”, Aguiar et al 2021
- “The Children of the Missed Pill”, Rau et al 2021
- “High Income Men Have High Value As Long-Term Mates in the US: Personal Income and the Probability of Marriage, Divorce, and Childbearing in the US”, Hopcroft 2021
- “Using Genes to Explore the Effects of Cognitive and Non-Cognitive Skills on Education and Labor Market Outcomes”, Buser et al 2021 (page 3)
- “Consumers Believe That Products Work Better for Others”, Polman et al 2021
- “Relationship between Rice Farming and Polygenic Scores Potentially Linked to Agriculture in China”, Zhu et al 2021
- “Win-Win Denial: The Psychological Underpinnings of Zero-Sum Thinking”, Johnson et al 2021c
- “On the Economic Design of Stablecoins”, Catalini & Gortari 2021
- “Are Black Restaurant Servers Tipped Less Than White Servers? 3 Experimental Tests of Server Race Effects Customers’ Tipping Behaviors”, Brewster et al 2021
- “The Wild Card: Colonial Paper Money in French North America, 1685–1719”, Cutsinger et al 2021
- “The Econometrics of Early Childhood Human Capital and Investments”, Cunha et al 2021
- “Two Blades of Grass: The Impact of the Green Revolution”, Gollin et al 2021
- “Who Is High Income, Anyway? Social Comparison, Subjective Group Identification, and Preferences over Progressive Taxation”, Cansunar 2021
- “Founding Teams and Startup Performance”, Choi et al 2021
- “Greenland Bans All Oil Exploration: Arctic Nation Has No Active Oil Fields but US Estimates There Could Be 17.5 Billion Barrels Undiscovered”, Press 2021
- “Does Transportation Mean Transplantation? Impact of New Airline Routes on Sharing of Cadaveric Kidneys”, Wang et al 2021b
- “Walrasian Equilibrium Behavior in Nature”, Loch-Temzelides 2021
- “Beholding Inequality: Race, Gender, and Returns to Physical Attractiveness in the United States”, Monk et al 2021
- “Steps of Reasoning in Children and Adolescents”, Brocas & Carrillo 2021
- “Career Effects of Mental Health”, Biasi et al 2021 (page 2)
- “Government Grants, Donors, and Nonprofit Performance”, Coupet & Schehl 2021
- “Peers, Buccaneers and Downton Abbey: An Economic Analysis of 19th Century British Aristocratic Marriages”, Taylor 2021
- “Alienation Is Not ‘Bullshit’: An Empirical Critique of Graeber’s Theory of BS Jobs”, Soffia et al 2021
- “Does Biology Drive Child Penalties? Evidence from Biological and Adoptive Families”, Kleven et al 2021
- “Of Forking Paths and Tied Hands: Selective Publication of Findings, and What Economists Should Do about It”, Kasy 2021
- “Everything You Might Want to Know about Whaling”, Lakeman 2021
- “Local Effects of Large New Apartment Buildings in Low-Income Areas”, Asquith et al 2021
- “Why Some Blame Politics for Their Personal Problems”, Baird & Wolak 2021
- “Union Reform, Performance Pay, and New Teacher Supply: Evidence from Wisconsin’s Act 10”, Baron 2021
- “Does Insecure Land Tenure Deter Investment? Evidence from a Randomized Controlled Trial”, Huntington & Shenoy 2021
- “The Long-Term Causal Effect of US Bombing Missions on Economic Development: Evidence from the Ho Chi Minh Trail and Xieng Khouang Province in Lao P.D.R”, Yamada & Yamada 2021
- “It’s Trust or Risk? Chemosensory Anxiety Signals Affect Bargaining in Women”, Meister & Pause 2021
- “Competition in the Black Market: Estimating the Causal Effect of Gangs in Chicago”, Bruhn 2021
- “Rent Seeking for Madness: the Political Economy of Mental Asylums in the United States, 1870–1910”, Geloso & March 2021
- “Death Toll of Price Limits and Protectionism in the Russian Pharmaceutical Market”, Khvan & Yakovlev 2021
- “Lehman’s Lemons: Do Career Disruptions Matter for the Top 5%?”, Fedyk & Hodson 2021
- “Employee Responses to Compensation Changes: Evidence from a Sales Firm”, Sandvik et al 2021
- “Are CEOs Different?”, Kaplan & Sorensen 2021
- “Oil Import Portfolio Risk and Spillover Volatility”, Bigerna et al 2021
- “The Congestion Costs of Uber and Lyft”, Tarduno 2021
- “Informational Herding, Optimal Experimentation, and Contrarianism”, Smith et al 2021
- “Care to Wager Again? An Appraisal of Paul Ehrlich’s Counterbet Offer to Julian Simon, Part 2: Critical Analysis”, Desrochers et al 2021b
- “Care to Wager Again? An Appraisal of Paul Ehrlich’s Counterbet Offer to Julian Simon, Part 1: Outcomes”, Desrochers et al 2021
- “Why Do Wealthy Parents Have Wealthy Children?”, Fagereng et al 2021
- “Intergenerational Mobility of Immigrants in the United States over Two Centuries”, Abramitzky et al 2021
- “Folklore”, Michalopoulos & Xue 2021
- “Instrumental Use Erodes Sacred Values”, Ruttan & Nordgren 2021
- “Lifting Growth Barriers for New Firms: Evidence from an Entrepreneurship Training Experiment With Two Million Online Businesses”, Jin & Sun 2021
- “Financial Institutions and the British Industrial Revolution: Did Financial Underdevelopment Hold Back Growth?”, Hodgson 2021
- “The Cultural Dynamics of Declining Residential Mobility”, Buttrick & Oishi 2021
- “People Management Skills, Employee Attrition, and Manager Rewards: An Empirical Analysis”, Hoffman & Tadelis 2021
- “College Quality and Attendance Patterns: A Long-Run View”, Hendricks et al 2021
- “The Link between Income, Income Inequality, and Prosocial Behavior around the World: A Multiverse Approach”, Macchia & Whillans 2021
- “The Semiconductor Supply Chain: Assessing National Competitiveness”, Khan et al 2021
- “Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail”, Jones 2021
- “Ten Facts on Declining Business Dynamism and Lessons from Endogenous Growth Theory”, Akcigit & Ates 2021
- “Debasement of Silver throughout the Late Bronze-Iron Age Transition in the Southern Levant: Analytical and Cultural Implications”, Eshel et al 2021
- “Will NASDAQ’s Diversity Rules Harm Investors?”, Fried 2021
- “The Use and Misuse of Income Data and Extreme Poverty in the United States”, Meyer et al 2021
- “Racial Bias in the Sharing Economy and the Role of Trust and Self-Congruence”, Nødtvedt et al 2021
- “The Psychology of Asymmetric Zero-Sum Beliefs”, Roberts & Davidai 2021
- “Natural Selection in Contemporary Humans Is Linked to Income and Substitution Effects”, Hugh-Jones & Abdellaoui 2021
- “Economic Implications of Access to Daylight and Views in Office Buildings from Improved Productivity”, MacNaughton 2021
- “Non-Replicable Publications Are Cited More Than Replicable Ones”, Serra-Garcia & Gneezy 2021
- “How War Changes Land: Soil Fertility, Unexploded Bombs, and the Underdevelopment of Cambodia”, Lin 2020b
- “A Global Decline in Research Productivity? Evidence from China and Germany”, Boeing & Hünermund 2020
- “The Airbnbs”, Graham 2020
- “Why Is Productivity Correlated With Competition?”, Backus 2020
- “Does Building New Housing Cause Displacement? The Supply and Demand Effects of Construction in San Francisco”, Pennington 2020
- “Intergenerational Mobility in the Very Long Run: Florence (1427–2011)”, Barone & Mocetti 2020
- “What Matters More for Entrepreneurship Success? A Meta-Analysis Comparing General Mental Ability and Emotional Intelligence in Entrepreneurial Settings”, Allen et al 2020
- “Predicting Mid-Life Capital Formation With Pre-School Delay of Gratification and Life-Course Measures of Self-Regulation”, Benjamin et al 2020
- “The Daily Grind: Before Millstones Were Invented, the Preparation of Flour for Food Was an Arduous Task Largely Carried out by Women for Hours Every Day. How Did It Affect Their Lives and Why Does It Remain a Tradition in Some Places Even Today?”, Laudan 2020
- “The Death of a Technical Skill”, Horton & Tambe 2020
- “Are Inventors or Firms the Engines of Innovation?”, Bhaskarabhatla et al 2020
- “The Micro-Evidence for the Malthusian System: France, 1670–1840”, Cummins 2020
- “The Elasticity of Science”, Myers 2020
- “Writing a Book: Is It worth It? [Yes, With Luck and Marketing]”, Kleppmann 2020
- “Information Frictions and Entrepreneurship”, Hegde & Tumlinson 2020
- “The Gift of Moving: Intergenerational Consequences of a Mobility Shock”, Nakamura et al 2020
- “The Perfection Premium”, Isaac & Spangenberg 2020
- “The Washington Consensus Works: Causal Effects of Reform, 1970–2015”, Grier & Grier 2020
- “Does Education Matter? Tests from Extensions of Compulsory Schooling in England and Wales 1919-22, 1947, and 1972”, Clark & Cummins 2020
- “Collider Bias in Economic History Research”, Schneider 2020b
- “Does It Matter Where You Came From? Ancestry Composition and Economic Performance of US Counties, 1850–2010”, Fulford et al 2020
- “Learning Is Not Enough: Diminishing Marginal Revenues and Increasing Abatement Costs of Wind and Solar”, Das et al 2020b
- “Molecular Genetics, Risk Aversion, Return Perceptions, and Stock Market Participation”, Sias et al 2020 (page 2)
- “The Return of the $70 Video Game Has Been a Long Time Coming: Top-End Game Pricing Has Never Been Lower When Measured in Constant Dollars”, Orland 2020
- “Lessons from Investing in 483 Companies”, O’Shaughnessy & Songhurst 2020
- “The Rise and Fall of Adobe Flash: Before Flash Player Sunsets This December, We Talk Its Legacy With Those Who Built It”, Moss 2020
- “Prestige Matters: Wage Premium and Value Addition in Elite Colleges”, Sekhri 2020
- “Randomizing Religion: the Impact of Protestant Evangelism on Economic Outcomes”, Bryan et al 2020
- “When Corporate Social Responsibility Backfires: Evidence from a Natural Field Experiment”, List & Momeni 2020
- “Happy Lottery Winners and Lottery-Ticket Bias”, Kim & Oswald 2020
- “Heads or Tails: The Impact of a Coin Toss on Major Life Decisions and Subsequent Happiness”, Levitt 2020
- “Replicating Patterns of Prospect Theory for Decision under Risk”, Ruggeri et al 2020
- “SoftBank Vision Fund Posts $17.7 Billion Loss on WeWork, Uber”, Alpeyev 2020
- “Optimal Smart Contracts With Costly Verification”, Mamageishvili & Schlegel 2020
- “Theory of the Nudnik: The Future of Consumer Activism and What We Can Do to Stop It”, Arbel & Shapira 2020
- “Progress Studies for Aspiring Young Scholars: An Online Summer Program in the History of Technology for High School Students”, Scholars 2020
- “An Attempt at Explaining, Blaming, and Being Very Slightly Sympathetic Toward Enron”, Lakeman 2020
- “Are Tariffs Bad for Growth? Yes, Say 5 Decades of Data from 150 Countries”, Furceri et al 2020
- “In Ohio, the Amish Take On the Coronavirus: A Famously Traditional Community Has Mobilized to Help Hospitals With Medical Supplies, Even As It Struggles With Reconciling Its Communal Way of Life With the Dictates of Social Distancing.”, Williamson 2020
- “Genetic Endowments and Wealth Inequality”, Barth et al 2020
- “Do Management Interventions Last? Evidence from India”, Bloom et al 2020b
- “Are Ideas Getting Harder to Find?”, Bloom et al 2020
- “The Effects of Income Transparency on Well-Being: Evidence from a Natural Experiment”, Perez-Truglia 2020
- “Open Source Fonts Are Love Letters to the Design Community: Typefaces That Be Freely Used and Modified Give Others a Chance to Hone Their Craft—And Share Valuable Feedback”, Finley 2020
- “How Cameo Turned D-List Celebs Into a Monetization Machine: Inside the Surreal and Lucrative Two-Sided Marketplace of Mediocre Famous People”, Sauer 2020
- “Npm Is Joining GitHub”, Friedman 2020
- “Stay True to Your Roots? Category Distance, Hierarchy, and the Performance of New Entrants in the Music Industry”, Younkin & Kashkooli 2020
- “The Lasting Effects of the 1918 Influenza Pandemic”, Tabarrok 2020
- “What Remains of Cross-Country Convergence”, Johnson & Papageorgiou 2020b
- “Liberalizing Art. Evidence on the Impressionists at the End of the Paris Salon”, Etro et al 2020
- “What Do Editors Maximize? Evidence from 4 Economics Journals”, Card & DellaVigna 2020
- “Recalibrating Global Data Center Energy-Use Estimates”, Masanet et al 2020
- “Slavery and Anglo-American Capitalism Revisited”, Wright 2020
- “The College Admissions Contribution to the Labor Market Beauty Premium”, On 2020
- “Reputation Transferability across Contexts: Maintaining Cooperation among Anonymous Cryptomarket Actors When Moving between Markets”, Norbutas et al 2020
- “Nothing Ventured, Nothing Gained: Parasite Infection Is Associated With Entrepreneurial Initiation, Engagement, and Performance”, Lerner et al 2020
- “Clustering of Health, Crime and Social-Welfare Inequality in 4 Million Citizens from Two Nations”, Richmond-Rakerd et al 2020
- “The Gender Cliff in the Relative Contribution to the Household Income: Insights from Modeling Marriage Markets in 27 European Countries”, Grow & Bavel 2020
- “Understanding Contemporary Forms of Exploitation: Attributions of Passion Serve to Legitimize the Poor Treatment of Workers”, Kim et al 2020b
- “The Changing Structure of American Innovation: Some Cautionary Remarks for Economic Growth”, Arora et al 2020
- “Consumer Debt and Satisfaction in Life”, Greenberg & Mogilner 2020
- “The Signal Quality of Earnings Announcements: Evidence from an Informed Trading Cartel”, Xie 2020
- “Beneath the Radar: Exploring the Economics of Business Fraud via Underground Markets”, Gãnán et al 2020
- “Persistence Despite Revolutions”, Alesina et al 2020
- “Destructive Creation at Work: How Financial Distress Spurs Entrepreneurship”, Babina 2020
- “Social Media-Predicted Personality Traits and Values Can Help Match People to Their Ideal Jobs”, Kern et al 2019
- “CEO Selection and Executive Appearance”, Cook & Mobbs 2019
- “Non-Cognitive Skills: How Much Do They Matter for Earnings in Canada?”, McLean et al 2019
- “This Is Why Your Holiday Travel Is Awful: The Long, Sordid History of New York’s Penn Station Shows How Progressives Have Made It Too Hard for the Government to Do Big Things—And Why, Believe It or Not, Robert Caro Is to Blame”, Dunkelman 2019
- “The Social Subsidy of Angel Investing”, Danco 2019
- “Collective Dynamics of Dark Web Marketplaces”, ElBahrawy et al 2019
- “A Century of Research on Conscientiousness at Work”, Wilmot & Ones 2019
- “The Origins of Firm Strategy: Learning by Economic Experimentation and Strategic Pivots in the Early Automobile Industry”, Pillai et al 2019
- “Predicting Entrepreneurial Success Is Hard: Evidence from a Business Plan Competition in Nigeria”, McKenzie & Sansone 2019
- “Be Cautious With the Precautionary Principle: Evidence from Fukushima Daiichi Nuclear Accident”, Neidell 2019
- “Why Underachievers Dominate Secret Police Organizations: Evidence from Autocratic Argentina”, Scharpf & Gläßel 2019
- “The Economic Effects of Facebook”, Mosquera et al 2019
- “Polygenic Score Analysis Of Educational Achievement And Intergenerational Mobility”, Rustichini et al 2019
- “Measuring ‘Schmeduling’”, Rees-Jones & Taubinsky 2019
- “Progress by Consent: Adam Smith As Development Economist”, Easterly 2019
- “Mismatches in the Marriage Market”, Lichter et al 2019
- “The Impact of the 2018 Tariffs on Prices and Welfare”, Amiti et al 2019
- “Let’s (Not) Make a Deal: Geopolitics and Greenland”, Rahbek-Clemmensen 2019
- “A Scientific Approach to Entrepreneurial Decision Making: Evidence from a Randomized Control Trial”, Camuffo et al 2019
- “Lee Kuan Yew Review, Part Four: The Pathway to Power”, TracingWoodgrains 2019
- “Is the Rate of Scientific Progress Slowing Down?”, Cowen & Southwood 2019
- “Can You Indemnify Against Dick Pics? The Rise of Scandal Insurance in Hollywood”, Kachka 2019
- “Universal Basic Income in the United States and Advanced Countries”, Hoynes & Rothstein 2019
- “Reviving American Entrepreneurship? Tax Reform and Business Dynamism”, Sedlacek & Sterk 2019
- “On the Resilience of the Dark Net Market Ecosystem to Law Enforcement Intervention”, Bradley 2019
- “Lee Kuan Yew Review, Part Three: Race, Language, and Uncomfortable Questions”, TracingWoodgrains 2019
- “The Macroeconomic Impact of Microeconomic Shocks: Beyond Hulten’s Theorem”, Baqaee & Farhi 2019
- “Lee Kuan Yew Review, Part Two: "You Are Free to Agree"”, TracingWoodgrains 2019
- “Book Review: From Third World to First, by Lee Kuan Yew [PART ONE]”, TracingWoodgrains 2019
- “The Promise and Price of Cellular Therapies: New ‘Living Drugs’—Made from a Patient’s Own Cells—Can Cure Once Incurable Cancers. But Can We Afford Them?”, Mukherjee 2019
- “Moving off the Map: How Knowledge of Organizational Operations Empowers and Alienates”, Huising 2019
- “Squaring Venture Capital Valuations With Reality”, Gornall & Strebulaev 2019
- “Time Use and Happiness of Millionaires: Evidence From the Netherlands”, Smeets et al 2019
- “Judge Judy Is Still Judging You: For More Than 20 Years, Judith Sheindlin Has Dominated Daytime Ratings—By Making Justice in a Complicated World Look Easy”, Hughes 2019
- “Does Management Training Help Entrepreneurs Grow New Ventures? Field Experimental Evidence from Singapore”, Kotha et al 2019
- “Food Deserts and the Causes of Nutritional Inequality”, Allcott et al 2019
- “Corporate Editors in the Evolving Landscape of OpenStreetMap”, Anderson et al 2019
- “Heritability of Lifetime Earnings”, Hyytinen et al 2019
- “Using Randomized Controlled Trials to Estimate Long-Run Impacts in Development Economics”, Bouguen et al 2019
- “The Utterly Dysfunctional Belt and Road”, Greer 2019
- “1960: The Year The Singularity Was Cancelled”, Alexander 2019
- “Antitrust As Allocator of Coordination Rights”, Paul 2019
- “Predicting Individual-Level Income from Facebook Profiles”, Matz et al 2019
- “Your Order, Their Labor: An Exploration of Algorithms and Laboring on Food Delivery Platforms in China”, Ping 2019
- “The Arrival of Fast Internet and Employment in Africa”, Hjort & Poulsen 2019
- “Scaling of Atypical Knowledge Combinations in American Metropolitan Areas from 1836–2010”, Mewes 2019
- “Squeezing the Bears: Cornering Risk and Limits on Arbitrage during the ‘British Bicycle Mania’, 1896–1898”, Quinn 2019
- “How the next Recession Could save Lives: Death Rates Have Dropped during past Economic Downturns, Even As Many Health Trends Have Worsened. Researchers Are Scrambling to Decipher Lessons Before the next Big Recession”, Peeples 2019
- “Repurposing Large Health Insurance Claims Data to Estimate Genetic and Environmental Contributions in 560 Phenotypes”, Lakhani et al 2019
- “‘Crowds’ of Amateurs & Professional Entrepreneurs in Marketplaces”, Boudreau 2019
- “GDP-B: Accounting for the Value of New and Free Goods in the Digital Economy”, Brynjolfsson et al 2019
- “Entrepreneurial Uncertainty and Expert Evaluation: An Empirical Analysis”, Scott et al 2019
- “Can Psychological Traits Be Inferred From Spending? Evidence From Transaction Data”, Gladstone et al 2019
- “The Deadweight Loss Of Social Recognition”, Butera et al 2019
- “My Stepdad’s Huge Data Set: Welcome to the Age of Data-Driven Porn”, Turner 2019
- “Farewell to Confucianism: The Modernizing Effect of Dismantling China’s Imperial Examination System”, Bai 2019b
- “Health and Wealth in the Roman Empire”, Jongman 2019
- “Can Psychological Traits Be Inferred From Spending? Evidence From Transaction Data § Table S3: The 5 Spending Categories Most Positively and Negatively Correlated With Each of the Psychological Traits”, Gladstone et al 2019 (page 12)
- “The Ties That Bind: Implicit Contracts and Management Practices in Family-Run Firms”, Lemos 2019
- “Mycorrhizal Fungi Respond to Resource Inequality by Moving Phosphorus from Rich to Poor Patches across Networks”, Whiteside et al 2019
- “The Politics of Zero-Sum Thinking: The Relationship between Political Ideology and the Belief That Life Is a Zero-Sum Game”, Davidai & Ongis 2019
- “Accounting Theory As a Bayesian Discipline”, Johnstone 2018
- “Buffett’s Alpha”, Frazzini et al 2018
- “Do Economists Swing for the Fences After Tenure?”, Brogaard et al 2018
- “The Rich are Different: Unravelling the Perceived and Self-Reported Personality Profiles of High-Net-Worth Individuals”, Leckelt et al 2018
- “Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs”, Broockman et al 2018
- “Replication Data For: ‘Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs’”, Broockman et al 2018
- “Are CEOs Born Leaders? Lessons from Traits of a Million Individuals”, Adams et al 2018
- “Shall We Serve the Dark Lords? A Meta-Analytic Review of Psychopathy and Leadership”, Landay et al 2018
- “Dark Motives and Elective Use of Brainteaser Interview Questions”, Highhouse et al 2018
- “Knitting Community: Human and Social Capital in the Transition to Entrepreneurship”, Kim 2018
- “Newton’s Financial Misadventures in the South Sea Bubble”, Odlyzko 2018
- “Notes on the Dynamics of Human Civilization: The Growth Revolution”, Greer 2018
- “Effects of Non-Normal Performance Distributions on the Accuracy of Utility Analysis”, Aguinis et al 2018
- “Blockchain-Based Solution for Proof of Delivery of Physical Assets”, Hasan & Salah 2018
- “Solving the Buyer and Seller’s Dilemma: A Dual-Deposit Escrow Smart Contract for Provably Cheat-Proof Delivery and Payment for a Digital Good without a Trusted Mediator”, Asgaonkar & Krishnamachari 2018
- “Do High School Sports Build or Reveal Character? Bounding Causal Estimates of Sports Participation”, Ransom & Ransom 2018
- “The Geography of Family Differences and Intergenerational Mobility”, Gallagher et al 2018
- “The Prevalence and Co-Occurrence of Psychiatric Conditions among Entrepreneurs and Their Families”, Freeman et al 2018
- “Is There a Startup Wage Premium? Evidence from MIT Graduates”, Kim 2018b
- “Categorizing Variants of Goodhart’s Law”, Manheim & Garrabrant 2018
- “The Impact of Consulting Services on Small and Medium Enterprises: Evidence from a Randomized Trial in Mexico”, Bruhn et al 2018
- “CEO Traits and Firm Outcomes: Do Early Childhood Experiences Matter?”, Henderson & Hutton 2018
- “Are Resettled Oustees from the Sardar Sarovar Dam Project Better off Today Than Their Former Neighbors Who Were Not Ousted?”, times 2018
- “Funding Breakthrough Research: Promises and Challenges of the ‘ARPA Model’”, Azoulay et al 2018
- “Pursuing Sustainable Productivity With Millions of Smallholder Farmers”, Cui et al 2018
- “Misperceiving Inequality”, Gimpelson & Treisman 2018
- “Relative Education and the Advantage of a College Degree”, Horowitz 2018
- “Why Do Academics Oppose the Market? A Test of Nozick’s Hypothesis”, Magni-Berton & Ríos 2018
- “Why The Business Case for Diversity Is Wrong”, Maitland 2018
- “A Survey of Empirical Evidence on Patents and Innovation”, Sampat 2018
- “Having a Creative Day: Understanding Entrepreneurs’ Daily Idea Generation through a Recovery Lens”, Weinberger et al 2018
- “Algorithmic Entities”, LoPucki 2018
- “Domestic Round-Trip Fares and Fees: Average Domestic Round-Trip Airfare: Nominal & Real 2018”, America 2018
- “Competing for Love: Applying Sexual Economics Theory to Mating Contests”, Baumeister et al 2017
- “A French Migrant Business Network in the Period of Export-Led Growth (ELG) in Mexico: The Case of the Barcelonnettes”, Galindo 2017
- “Adaptability and Survival in Small & Medium-Sized Firms”, Hodgson et al 2017
- “Birth Order and College Major in Sweden”, Barclay et al 2017
- “Early Industrial Roots of Green Chemistry and the History of the BHC Ibuprofen Process Invention and Its Quality Connection”, Murphy 2017
- “The Power of Bias in Economics Research”, Ioannidis et al 2017
- “Management As a Technology?”, Bloom et al 2017b
- “Labour Repression & the Indo-Japanese Divergence”, Pseudoerasmus 2017
- “Is Individual Job Performance Distributed According to a Power Law? A Review of Methods for Comparing Heavy-Tailed Distributions”, Spain et al 2017
- “The Transmission of Inequality Across Multiple Generations: Testing Recent Theories With Evidence from Germany”, Braun & Stuhler 2017
- “15+ Ways a Venture Capitalist Says ‘No’”, Allen 2017
- “Does Diversity Pay? A Replication of Herring 2009 [No]”, Stojmenovska et al 2017
- “The Most Senseless Environmental Crime of the 20th Century: Fifty Years Ago 180,000 Whales Disappeared from the Oceans without a Trace, and Researchers Are Still Trying to Make Sense of Why. Inside the Most Irrational Environmental Crime of the Century.”, Homans 2017
- “The Exquisitely English (And Amazingly Lucrative) World of London Clerks: It’s a Dickensian Profession That Can Still Pay Upwards of $650,000 per Year”, Akam 2017
- “Kim Cavitt Public Comment on FTC Hearing Aid Legislation [2017]”, Cavitt 2017
- “50 Years Of Growth In American Consumption, Income, And Wages”, Sacerdote 2017
- “Genetic Predisposition to Obesity and Medicare Expenditures”, Wehby et al 2017
- “Smart and Illicit: Who Becomes an Entrepreneur and Do They Earn More?”, Levine & Rubinstein 2017
- “2016 Letter to Shareholders”, Bezos 2017
- “Pricing the Future in the 17th Century: Calculating Technologies in Competition”, Deringer 2017
- “Migration, Population Composition and Long Run Economic Development: Evidence from Settlements in the Pampas”, Droller 2017
- “Better Babblers”, Hanson 2017
- “Dissecting Ponzi Schemes on Ethereum: Identification, Analysis, and Impact”, Bartoletti et al 2017
- “Surveying the Forest: A Meta-Analysis, Moderator Investigation, and Future-Oriented Discussion of the Antecedents of Voluntary Employee Turnover”, Rubenstein et al 2017
- “Potterian Economics”, Levy & Snir 2017
- “Years of Potential Life Lost and Life Expectancy in Schizophrenia: a Systematic Review and Meta-Analysis”, Hjorthøj et al 2017
- “Industrial Espionage and Productivity”, Glitz & Meyersson 2017
- “Creative Destruction: Barriers to Urban Growth and the Great Boston Fire of 1872”, Hornbeck & Keniston 2017
- “Export of Plastic Debris by Rivers into the Sea”, Schmidt et al 2017b
- “Birkin Demand: A Sage & Stylish Investment”, Newsom 2016
- “KopperCoin—A Distributed File Storage With Financial Incentives”, Kopp et al 2016
- “Overconfidence in Personnel Selection: When and Why Unstructured Interview Information Can Hurt Hiring Decisions”, Kausel et al 2016
- “Evaluating Indicators of Job Performance: Distributions and Types of Analyses”, Chambers 2016
- “The Causal Effects of Education on Health, Mortality, Cognition, Well-Being, and Income in the UK Biobank”, Davies et al 2016
- “Evidence for a Conserved Quantity in Human Mobility”, Alessandretti et al 2016
- “The View from Above: Applications of Satellite Data in Economics”, Donaldson & Storeygard 2016
- “Resetting the Urban Network: 117–2012”, Michaels & Rauch 2016
- “Human Collective Intelligence As Distributed Bayesian Inference”, Krafft et al 2016
- “The Genetics of Success: How Single-Nucleotide Polymorphisms Associated With Educational Attainment Relate to Life-Course Development”, Belsky et al 2016
- “The Implications of Modern Business-Entity Law for the Regulation of Autonomous Systems”, Bayern 2016
- “Preparing for the Worst: The Space Insurance Market’s Realistic Disaster Scenarios”, Gubby et al 2016
- “Safeguarding the Future: The Story of How Singapore Has Managed Its Reserves and the Founding of GIC”, Orchard 2016
- “Valuing the Human Health Damage Caused by the Fraud of Volkswagen”, Oldenkamp et al 2016
- “Molecular Genetic Contributions to Social Deprivation and Household Income in UK Biobank (n = 112,151)”, Hill et al 2016
- “Wealth, Health, and Child Development: Evidence from Administrative Data on Swedish Lottery Players”, Cesarini et al 2016
- “Does Academic Research Destroy Stock Return Predictability?”, McLean & Pontiff 2016
- “Adapting to Climate Change: The Remarkable Decline in the US Temperature-Mortality Relationship over the Twentieth Century”, Barreca et al 2016
- “Equality Under Threat by the Talented: Evidence from Worker-Managed Firms”, Burdín 2016
- “Going for the Gold: The Economics of the Olympics”, Baade & Matheson 2016
- “Religiosity and Income: a Panel Cointegration and Causality Analysis”, Herzer & Strulik 2016
- “Book Review of Ryan Patrick Hanley, Ed. 2016, Adam Smith: His Life, Thought, and Legacy”, Howes 2016
- “The Contractual Nature of the City”, Lu 2016
- “Overweight Trends among Polish Schoolchildren Before and After the Transition from Communism to Capitalism”, Gomula et al 2015
- “Genes, Legitimacy And Hypergamy: Another Look At The Economics Of Marriage”, Saint-Paul 2015
- “Validation of Decentralised Smart Contracts Through Game Theory and Formal Methods”, Bigi et al 2015
- “The Institutional Causes of China’s Great Famine, 1959–1961”, Meng et al 2015
- “What Makes Uber Run: The Transportation Service Has Become a Global Brand, an Economic Force, and a Cultural Lightning Rod”, Chafkin 2015
- “Ironing Out Deficiencies: Evidence from the United States on the Economic Effects of Iron Deficiency”, Niemesh 2015
- “Non-Cognitive Deficits and Young Adult Outcomes: The Long-Run Impacts of a Universal Child Care Program”, Baker et al 2015
- “Do Pharmacists Buy Bayer? Informed Shoppers and the Brand Premium”, Bronnenberg et al 2015
- “Signaling and Productivity in the Private Financial Returns to Schooling”, Bingley et al 2015
- “The Economics of Reproducibility in Preclinical Research”, Freedman et al 2015
- “A Swedish National Twin Study of Criminal Behavior and Its Violent, White-Collar and Property Subtypes”, Kendler et al 2015
- “Bankruptcy Rates among NFL Players With Short-Lived Income Spikes”, Carlson et al 2015
- “How Those Plush Easter Bunnies Got so Cuddly”, Postrel 2015
- “To Apply or Not to Apply: A Survey Analysis of Grant Writing Costs and Benefits”, Hippel & Hippel 2015
- “Competition, Work Rules and Productivity”, Bridgman 2015
- “Manic Tendencies Are Not Related to Being an Entrepreneur, Intending to Become an Entrepreneur, or Succeeding As an Entrepreneur”, Johnson et al 2015b
- “Gender Identity and Relative Income within Households”, Bertrand et al 2015
- “Rational Theory of Warrant Pricing”, Samuelson 2015
- “The Financing of Jihadi Terrorist Cells in Europe”, Oftedal 2015
- “The Burden of Health Care Costs for Patients With Dementia in the Last 5 Years of Life”, Kelley et al 2015
- “Only the Bad Die Young: Restaurant Mortality in the Western US”, Luo & Stark 2014
- “Discounting Behavior: A Reconsideration”, Andersen et al 2014
- “Harvard Innovation Lab Visualizes the Evolution of the Desk”, Azzarello 2014
- “Intergenerational Wealth Mobility in England, 1858–2012: Surnames and Social Mobility”, Clark & Cummins 2014
- “The Stock Market Speaks: How Dr. Alchian Learned to Build the Bomb”, Newhard 2014
- “The Summer’s Most Unread Book Is… A Simple Index Drawn from E-Books Shows Which Best Sellers Are Going Unread (We’re Looking at You, Piketty)”, Ellenberg 2014
- “Default Tips”, Haggag & Paci 2014
- “The Political Economy of Special Economic Zones”, Moberg 2014
- “Two Party Double Deposit Trustless Escrow in Cryptographic Networks and Bitcoin [BitHalo]”, Zimbeck 2014
- “I Don’t Want to Hire Women”, Anonymous 2014
- “Field Experiments of Success-Breeds-Success Dynamics”, Rijt et al 2014
- “Slavery, Statehood, and Economic Development in Sub-Saharan Africa”, Bezemer et al 2014
- “Executive Summary of Phase 3 of the Bayer Veterinary Care Usage Study”, Volk et al 2014
- “Managing an Iconic Old Luxury Brand in a New Luxury Economy: Hermès Handbags in the US Market”, Lewis & Haas 2014
- “Taxes, Lawyers, and the Decline of Witch Trials in France”, Johnson & Koyama 2014
- “Everything from 1991 Radio Shack Ad I Now Do With My Phone”, Cichon 2014
- “A Few Goodmen: Surname-Sharing Economist Coauthors”, Goodman et al 2014
- Quaker Capitalism: Lessons for Today, Turnbull 2014
- “Corporate Governance Without Shareholders: A Cautionary Lesson from Non-Profit Organizations”, Dent 2014
- “Killing Time: Dracula and Social Discoordination”, Robbins 2014
- “The Brand Personality of Rocks: A Critical Evaluation of a Brand Personality Scale”, Avis et al 2013
- “Systematic Review of the Hawthorne Effect: New Concepts Are Needed to Study Research Participation Effects”, McCambridge et al 2013
- “Growing up in a Recession”, Giuliano & Spilimbergo 2013
- “Catalyzing Strategies and Efficient Tie Formation: How Entrepreneurial Firms Obtain Investment Ties”, Hallen & Eisenhardt 2013
- “20 Years of Bitext”, Brown et al 2013
- “On the Distribution of Job Performance: The Role of Measurement Characteristics in Observed Departures from Normality”, Beck et al 2013
- “PET-PEESE: Meta-Regression Approximations to Reduce Publication Selection Bias”, Stanley & Doucouliagos 2013
- “Belief in the Unstructured Interview: The Persistence of an Illusion”, Dana et al 2013
- “Star Performers in 21st Century Organizations”, Aguinis & O’Boyle 2013
- “The Origins of Scaling in Cities”, Bettencourt 2013
- “Inflated Applicants: Attribution Errors in Performance Evaluation by Professionals”, Swift et al 2013
- “Family, Education, and Sources of Wealth among the Richest Americans, 1982–2012”, Kaplan & Rauh 2013
- “Researchers Finally Replicated Reinhart-Rogoff [GDP vs National Debt], and There Are Serious Problems”, Varghese 2013
- “The Business of Phish”, Dhar 2013
- “Do Labor Market Policies Have Displacement Effects? Evidence from a Clustered Randomized Experiment”, Crépon et al 2013
- “Comparing Ecological Sustainability in Autocracies and Democracies”, Wurster 2013
- “Your Right Arm For A Publication In AER?”, Attema et al 2013
- “Survival of the Unfittest: Why the Worst Infrastructure Gets Built, And What We Can Do about It”, Flyvbjerg 2013
- “Does the John Bates Clark Medal Boost Subsequent Productivity and Citation Success?”, Chan et al 2013
- “The Black Arts of SaaS Pricing”, McKenzie 2013
- “Credit Suisse Global Investment Returns Yearbook 2013”, Dimson et al 2013
- “The Moral Consequences of Economic Growth: An Empirical Investigation”, Davis & Knauss 2013
- “Market Research, Wireframing, and Design”, Srinivasan 2013
- “What’s to Know about the Credibility of Empirical Economics?”, Ioannidis & Doucouliagos 2013
- “The Global Decline of the Labor Share”, Karabarbounis & Neiman 2013
- “Prevented Mortality and Greenhouse Gas Emissions from Historical and Projected Nuclear Power”, Karecha & Hansen 2013
- “On the Time Spent Preparing Grant Proposals: an Observational Study of Australian Researchers”, Herbert et al 2013
- “Does Management Matter? Evidence from India”, Bloom et al 2012
- “The Nixon Shock After Forty Years: the Import Surcharge Revisited”, Irwin 2012
- “People and Process, Suits and Innovators: the Role of Individuals in Firm Performance”, Mollick 2012
- “The Collapse of the Soviet Union and the Productivity of American Mathematicians”, Borjas & Doran 2012
- “Judicial Biases in Ottoman Istanbul: Islamic Justice and Its Compatibility With Modern Economic Life”, Kuran & Lustig 2012
- “On a Tiny Caribbean Island, Hermit Crabs Form Sophisticated Social Networks [Video]: Hermit Crabs Have Evolved Sophisticated Social Strategies to Exchange Resources so That Everyone Benefits”, Jabr 2012
- “Why Do Nigerian Scammers Say They Are from Nigeria?”, Herley 2012
- “Are Women Overinvesting in Education? Evidence from the Medical Profession”, Chen & Chevalier 2012
- “Gains from Trade When Firms Matter”, Melitz & Trefler 2012
- “The Best And The Rest: Revisiting The Norm Of Normality Of Individual Performance”, O’Boyle & Aguinis 2012
- “Salary Negotiation: Make More Money, Be More Valued”, McKenzie 2012
- “The Short-Term & Long-Term Career Effects of Graduating in a Recession”, Oreopoulos et al 2012
- “American Incomes 1774–1860”, Lindhart & Williamson 2012
- “The Marginal External Cost of Obesity in the United States”, Parks 2012
- “Executive Summary of Phase 2 of the Bayer Veterinary Care Usage Study”, Volk et al 2011
- “Reality at Odds With Perceptions: Narcissistic Leaders and Group Performance”, Nevicka et al 2011
- “Shining New Light on the Hawthorne Illumination Experiments”, Izawa et al 2011
- “A Simple Decomposition of the Variance of Output Growth across Countries”, Reicher 2011
- “The Causal Effect of Parents’ Schooling on Children’s Schooling: A Comparison of Estimation Methods”, Holmlund et al 2011
- “The Long-Run Impact of Bombing Vietnam”, Miguel & Roland 2011
- “Do Interest Groups Affect US Immigration Policy?”, Facchini et al 2011
- “Coups, Corporations, and Classified Information”, Dube et al 2011
- “Incentive-Compatible Escrow Mechanisms”, Witkowski et al 2011
- “Agricultural Prices (May 2011)”, Board 2011
- “Cognitive Capitalism: The Effect of Cognitive Ability on Wealth, As Mediated Through Scientific Achievement and Economic Freedom”, Rindermann & Thompson 2011
- “The Magic Washing Machine”
- “Tanpin Kanri: Retail Practice at Seven-Eleven Japan”, Lal & Han 2011
- “Travelers’ Types”, Brãnas-Garza et al 2011
- “The Mathematics Of Beauty”, Rudder 2011
- “Was There Really a Hawthorne Effect at the Hawthorne Plant? An Analysis of the Original Illumination Experiments”, Levitt & List 2011
- “The Soviet Problem With Two ‘Unknowns’: How an American Architect and a Soviet Negotiator Jump-Started the Industrialization of Russia, Part II: Saul Bron”, Melnikova-Raich 2011
- “Abnormal Returns From the Common Stock Investments of Members of the US House of Representatives”, Ziobrowski et al 2011
- “The Time Resolution of the St Petersburg Paradox”, Peters 2011
- “Why Do Management Practices Differ across Firms and Countries?”, Bloom & Reenen 2010
- “Direct versus Indirect Colonial Rule in India: Long-Term Consequences”, Iyer 2010
- “The Economic Argument”, Munroe 2010
- “Urban Scaling and Its Deviations: Revealing the Structure of Wealth, Innovation and Crime across Cities”, Bettencourt et al 2010
- “The Theory Of Interstellar Trade”, Krugman 2010
- “Who Gains and Who Loses from Credit Card Payments? Theory and Calibrations”, Schuh et al 2010
- “Career Trajectories of Dutch Pop Musicians: A Longitudinal Study”, Zwaan et al 2010
- “Can Openness Mitigate the Effects of Weather Shocks? Evidence from India’s Famine Era”, Burgess & Donaldson 2010
- “Corporate Psychopathy: Talking the Walk”, Babiak et al 2010
- “Social Context of Shell Acquisition in Coenobita Clypeatus Hermit Crabs”, Rotjan et al 2010
- “Performance Persistence in Entrepreneurship”, Gompers et al 2010
- “The Employment Retention and Advancement Project: How Effective Are Different Approaches Aiming to Increase Employment Retention and Advancement? Final Impacts for 12 Models”, Hendra et al 2010
- “The Economic Value of Teeth”, Glied & Neidell 2010
- “The Optimal Taxation of Height: A Case Study of Utilitarian Income Redistribution”, Mankiw & Weinzierl 2010
- “The Corporate Governance of Benedictine Abbeys”, Rost et al 2010
- “The New Kaldor Facts: Ideas, Institutions, Population, and Human Capital”, Jones & Romer 2010
- “The Soviet Problem With Two ‘Unknowns’: How an American Architect and a Soviet Negotiator Jump-Started the Industrialization of Russia, Part I: Albert Kahn”, Melnikova-Raich 2010
- “Systematic Review: the Costs of Ulcerative Colitis in Western Countries”
- “The Normalization of Deviance in Healthcare Delivery”, Banja 2010
- “The Cost of Crime to Society: New Crime-Specific Estimates for Policy and Program Evaluation”, McCollister et al 2010
- “Long-Term Economic Costs of Psychological Problems during Childhood”, Smith & Smith 2010
- “An Economic Analysis of the Financial Records of Al-Qa’ida in Iraq”, Bahney et al 2010
- “The Elves Leave Middle Earth: Sodas Are No Longer Free”, Blank 2009
- “Victorian Pioneers of Corporate Sustainability”, Desrochers 2009
- “Occupational Feminization and Pay: Assessing Causal Dynamics Using 1950–2000 US Census Data”, Levanon et al 2009
- “Education, Aspirations and Life Satisfaction”, Ferrante 2009
- “So Long, and No Thanks for the Externalities: the Rational Rejection of Security Advice by Users”, Herley 2009
- “A Theory of the Pre-Modern British Aristocracy”, Allen 2009
- “Founder-CEOs, Investment Decisions, and Stock Market Performance”, Fahlenbrach 2009
- “The Aid Effectiveness Literature: The Sad Results Of 40 Years Of Research”, Doucouliagos & Paldam 2009
- “So You Want to Be a Rock-N-Roll Star? Career Success of Pop Musicians in the Netherlands”, Zwaan et al 2009
- “Anatomy of a Scare: Yellow Peril Politics in America, 1980–1993”, Heale 2009
- “How To Successfully Compete With Open Source Software”, McKenzie 2009
- “Frank Ramsey’s Notes on Saving and Taxation”, Ramsey & Duarte 2009
- “Field Experiments in Economics: The Past, the Present, and the Future”, Levitt & List 2009
- “The Age of Reason: Financial Decisions over the Life Cycle and Implications for Regulation”, Agarwal et al 2009
- “Japan’s Phillips Curve Looks Like Japan”, Smith 2008
- “The Optimistic Thought Experiment”, Thiel 2008
- “Showing That You Care: The Evolution of Health Altruism”, Hanson 2008
- “Why Do the Poor Live in Cities? The Role of Public Transportation”, Glaeser et al 2008
- “Staffing 21st-Century Organizations”, Cascio & Aguinis 2008
- “The Ocean’s Hot Dog: The Development of the Fish Stick”, Josephson 2008
- “Marketing Actions Can Modulate Neural Representations of Experienced Pleasantness”, Plassman 2008
- “Stress That Doesn’t Pay: The Commuting Paradox”, Stutzer 2008
- “Does Price Matter in Charitable Giving? Evidence from a Large-Scale Natural Field Experiment”, Karlan & List 2007
- “Underfunding in Terrorist Organizations”, Shapiro & Siegel 2007
- “The Guidelines Manual—Chapter 8: Incorporating Health Economics in Guidelines and Assessing Resource Impact”, NICE 2007
- “So You Discovered an Anomaly…Gonna Publish It? An Investigation Into the Rationality of Publishing a Market Anomaly”, Doran & Wright 2007
- “Gibbon Was Right: The Decline and Fall of the Roman Economy”, Jongman 2007
- “To Leave or Not to Leave: The Distribution of Bequest Motives”, Kopczuk & Lupton 2007
- “Catṡlechta and Other Medieval Legal Material Relating to Cats”, Murray 2007
- “The Cambist and Lord Iron: A Fairy Tale of Economics”, Abraham 2007
- “Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments”, Rutter 2007
- “Cognition and Behavior in Two-Person Guessing Games: An Experimental Study”, Costa-Gomes & Crawford 2006
- “Jacks of All Trades and Masters of None: Audiences’ Reactions to Spanning Genres in Feature Film Production”, Hsu 2006
- “Is Economics Performative? Option Theory and the Construction of Derivatives Markets”, Mackenzie 2006
- “Superman or the Fantastic Four? Knowledge Combination and Experience in Innovative Teams”, Taylor & Greve 2006
- “IQ in the Ramsey Model: A Naïve Calibration”, Jones 2006
- “Lessons from the JMCB Archive”, McCullough et al 2006
- “Asset Float and Speculative Bubbles”, Hong et al 2006
- “Investing in the Unknown and Unknowable”, Zeckhauser 2006
- “Guard Labor”, Jayadev & Bowles 2006
- “No Booze? You May Lose: Why Drinkers Earn More Money Than Nondrinkers”, Peters & Stringham 2006
- “The Effects of Attention-Deficit/hyperactivity Disorder on Employment and Household Income”, Biederman et al 2006
- “Modeling Bursts and Heavy Tails in Human Dynamics”, Vazquez et al 2005
- “Turnpike Trusts and the Transportation Revolution in 18th Century England”, Bogart 2005
- “The Paradox Of Beneficial Retirement”, Smilansky 2005
- “The Great Leap Forward: Anatomy of a Central Planning Disaster”, Li & Yang 2005
- “Slavery and the Intergenerational Transmission of Human Capital”, Sacerdote 2005
- “Temperament Profiles in Physicians, Lawyers, Managers, Industrialists, Architects, Journalists, and Artists: a Study in Psychiatric Outpatients”, Akiskal et al 2005
- “Salt, Salt Making, and the Rise of Cheshire”, Gittins 2005
- “A126_jun05Hirschfeld_S85toS90”, Charlie 2005
- “What Determines Productivity? Lessons from the Dramatic Recovery of the US and Canadian Iron Ore Industries Following Their Early 1980s Crisis”, Schmitz 2005
- “The Economic Burden of Schizophrenia in the United States in 2002”, Wu 2005
- “Return the ‘Sunk Costs Are Sunk’ Concept to Principles of Economics Textbooks”, Davis 2005
- “Mania and Dysregulation in Goal Pursuit: a Review”, Johnson 2005
- “What I Love about Scrooge: In Praise of Misers”, Landsburg 2004
- “Abnormal Returns from the Common Stock Investments of the US Senate”, Ziobrowski et al 2004
- “Bow Ties, Metabolism and Disease”, Csete & Doyle 2004
- “The Worldly Philosophers and the War Economy”, Galbraith 2004
- “Product Substitutability and Productivity Dispersion”, Syverson 2004
- “Suicide: An Economic Approach”, Becker & Posner 2004
- “The Tragicomedy of the Surfers’ Commons”, Nazer 2004
- “The Global Costs of Schizophrenia”, Knapp 2004
- “A Market-Induced Mechanism for Stock Pinning”, Avellaneda & Lipkin 2003
- “Economic Production As Chemistry”, Padgett et al 2003
- “Good times Make You Sick”, Ruhm 2003
- “The Village Full Budget”, Mercer & Freedlun 2003
- “Assessing the Impact of the Green Revolution, 1960–2000”, Evenson & Gollin 2003
- “Work Ethics and the Collapse of the Soviet System”, Pereira & Pereira 2003
- “MDRC’s The Higher Education Randomized Controlled Trials Restricted Access File (THE-RCT RAF), United States, 2003–2019”, MDRC 2003
- “Privacy, Economics, and Price Discrimination on the Internet”, Odlyzko 2003
- “Estimating the Payoff to Attending a More Selective College: An Application of Selection on Observables and Unobservables”, Dale & Krueger 2002
- “Do Natural Disasters Promote Long-Run Growth?”, Skidmore & Toya 2002
- “Joel on Software: Strategy Letter V”, Spolsky 2002
- “Causes of Repressed Inflation in the Soviet Consumer Market, 1965–1989: Retail Price Subsidies, the Siphoning Effect, and the Budget Deficit”, Kim 2002
- “Stung by Security Flaws, Microsoft Makes Software Safety a Top Goal”, Markoff 2002
- “Decisions and Revisions: The Affective Forecasting of Changeable Outcomes”, Gilbert & Ebert 2002
- “Price Behavior in Ancient Babylon”, Temin 2002
- “This Is Your Father’s IBM, Only Smarter: How a Former Has-Been Kicked Its Old Habits, Got Open-Source Religion, and Regained Its Status As One of the Biggest, Baddest Tech Companies on Earth.”
- “It Pays to Be Ignorant: A Simple Political Economy of Rigorous Program Evaluation”, Pritchett 2002
- “The Wheel of Reincarnation”, Hardy 2002
- “Can Nonexperimental Comparison Group Methods Match the Findings from a Random Assignment Evaluation of Mandatory Welfare-To-Work Programs? MDRC Working Papers on Research Methodology”, Bloom et al 2002
- “Estimating Real Income in the United States 1888–1994: Correcting CPI Bias Using Engel Curves”, Costa 2001
- “How Dangerous Are Drinking Drivers?”, Levitt & Porter 2001
- “Do Incentive Contracts Crowd Out Voluntary Cooperation?”, Fehr & Gächter 2001
- “Nobody Ever Gets Credit for Fixing Problems That Never Happened: Creating and Sustaining Process Improvement”, Repenning & Sterman 2001
- “Cultural Entrepreneurship: Stories, Legitimacy, and the Acquisition of Resources”, Lounsbury & Glynn 2001
- “Prescription Drug Prices: Why Do Some Pay More Than Others Do?”, Frank 2001
- “The Personal Discount Rate: Evidence from Military Downsizing Programs”, Warner & Pleeter 2001
- “The Bench Burner: How Did a Judge With Such Subversive Ideas Become a Leading Influence on American Legal Opinion?”, MacFarquhar 2001
- From Third World to First: The Singapore Story—1965–2000, Yew 2000
- “An Economic Theory of Avant-Garde and Popular Art, or High and Low Culture”, Cowen & Tabarrok 2000
- “Pay Enough Or Don’t Pay At All”, Gneezy & Rustichini 2000
- “A Meta-Analysis of Antecedents and Correlates of Employee Turnover: Update, Moderator Tests, and Research Implications for the Next Millennium”, Griffeth et al 2000
- “Interview With Ryan Dancey: D20 System and Open Gaming Movement”, Dancey 2000
- “Cornucopia: The Pace of Economic Growth in the 20th Century”, DeLong 2000
- “The Importance of Slavery and the Slave Trade to Industrializing Britain”, Eltis & Engerman 2000
- “How Taxing Is Corruption on International Investors?”, Wei 2000
- “The Redesign of the Matching Market for American Physicians: Some Engineering Aspects of Economic Design”, Roth & Peranson 1999
- “Why Do Some Countries Produce So Much More Output Per Worker Than Others?”, Hall & Jones 1999
- “Medieval and Early Modern Coinage and Its Problems”, Kohn 1999
- “Hayek: A Critique”, Benoist 1998
- Information Rules: A Strategic Guide to the Network Economy, Shapiro & Varian 1998
- “Scholarly Restraints? ABA Accreditation and Legal Education”, Shepherd & Shepherd 1998
- “Operations of "Unfettered" Labor Markets: Exit and Voice in American Labor Markets at the Turn of the Century”, Fishback 1998
- “The True Cost of Living: 1974–1991”, Hamilton 1998
- “Entrepreneurs’ Perceived Chances for Success”, Cooper et al 1998
- “Estimates of World GDP, One Million BC–Present”, DeLong 1998
- “Introduction to the Economics of Religion”, Iannaccone 1998
- “Research, Patenting, and Technological Change”, Kortum 1997
- “There’s Money in the Air: the CFC Ban and DuPont’s Regulatory Strategy”, Maxwell & Briscoe 1997
- “Dimensions of Brand Personality”, Aaker 1997
- “Why Are Worker Cooperatives So Rare?”, Kremer 1997
- “Why Do People Dislike Inflation?”, Shiller 1997
- “High-Tech R&D Subsidies Estimating the Effects of Sematech”, Irwin & Klenow 1996
- “Individual Differences and Behavior in Organizations”, Murphy et al 1996
- “Taxi Industry Regulation, Deregulation, and Reregulation: The Paradox of Market Failure”, Dempsey 1996
- “The Role of Premarket Factors in Black-White Wage Differences”, Neal & Johnson 1996
- “The Great Wars, the Great Crash, and Steady State Growth: Some New Evidence about an Old Stylized Fact”, Ben-David & Papell 1995
- “Stability in the Absence of Deposit Insurance: The Canadian Banking System, 1890–1966”, Carr et al 1995
- “Employee Turnover”, Hom & Griffeth 1995
- “Usage Heterogeneity and Extended Warranties”
- “An Economic Evaluation of Manic-Depressive Illness—1991”, Wyatt & Henter 1995
- “New Data on Air Pollution in the Former Soviet Union”, Shahgedanova & Burt 1994
- “Anthropological Invariants in Travel Behavior”, Marchetti 1994 (page 6)
- “The Incidence of Mandated Maternity Benefits”, Gruber 1994
- “The Role Of The CIA In Economic And Technological Intelligence”, Foley 1994
- “Where Is There Consensus Among American Economic Historians? The Results of a Survey on Forty Propositions”, Whaples 1994
- “Leadership Style and Incentives”, Rotemberg & Saloner 1993
- “Population Growth and Technological Change: One Million B.C. to 1990”, Kremer 1993
- “Measuring Asset Values for Cash Settlement in Derivative Markets: Hedonic Repeated Measures Indices and Perpetual Futures”, Shiller 1993
- “Egalitarian Behavior and Reverse Dominance Hierarchy [And Comments and Reply]”, Boehm et al 1993
- Manual on Free Zones, Kelleher 1993
- Towards A New Socialism
- “Agricultural Prices (December 1992)”, Board 1992
- “Was There a Hawthorne Effect?”, Jones 1992
- “A Politician’s Dream Is a Businessman’s Nightmare”, McGovern 1992
- “Retrospective Capital Gains Taxation”, Auerbach 1991
- “Organizations and Markets”, Simon 1991
- “The Big Five Personality Dimensions And Job Performance: A Meta-Analysis”, Barrick & Mount 1991
- “Universal Portfolios”, Cover 1991
- “Multitask Principal-Agent Analyses: Incentive Contracts, Asset Ownership, and Job Design”, Holmström & Milgrom 1991
- “Millers and Grinders: Technology and Household Economy in Meso-America”, Bauer 1990
- “Noise Trader Risk in Financial Markets”, Long et al 1990
- “L. V. Kantorovich: The Price Implications of Optimal Planning”, Gardner 1990
- “Real Wages, Employment, and the Phillips Curve”, Sumner & Silver 1989
- “From Here to There; Or, If Cooperative Ownership Is So Desirable, Why Are There So Few Cooperatives?”, Elster 1989
- “A Theory of Rational Addiction”, Becker & Murphy 1988
- “Diplomacy and Domestic Politics: The Logic of Two-Level Games”, Putnam 1988
- “Undated Futures Markets”, Gehr 1988
- “Political Cleavages and Changing Exposure to Trade”, Rogowski 1987
- “Henry Adams, the Second Law of Thermodynamics, and the Course of History”, Burich 1987
- “The Empirical Renaissance in Industrial Economics: An Overview”, Bresnahan & Schmalensee 1987
- “Experts and Servants: The National Council on Household Employment and the Decline of Domestic Service in the Twentieth Century”, Dudden 1986
- “Is Time Travel Impossible? A Financial Proof”, Reinganum 1986
- “Evaluating the Econometric Evaluations of Training Programs With Experimental Data”, LaLonde 1986
- “Noise”, Black 1986
- “Management Training: Justify Costs or Say Goodbye”, Urban et al 1985
- “A Research Note on Deriving the Square-Cube Law of Formal Organizations from the Theory of Time-Minimization”, Stephan 1983
- “Let’s Take the Con Out of Econometrics”, Leamer 1983
- “Rival Interpretations of Market Society: Civilizing, Destructive, or Feeble?”, Hirschman 1982
- “Christmas Gifts and Kin Networks”, Caplow 1982
- “On Number Numbness”, Hofstadter 1982b
- “Rank-Order Tournaments As Optimum Labor Contracts”, Lazear & Rosen 1981
- “Reflections on Optimal Punishment, Or: Should the Rich Pay Higher Fines?”, Friedman 1981
- “A Theory of Primitive Society, With Special Reference to Law”, Posner 1980
- “The Cultivation of the Soil As a Moral Directive: Population Growth, Family Ties, and the Maintenance of Community Among the Old Order Amish”, Ericksen et al 1980
- “Rating the Ratings: Assessing the Psychometric Quality of Rating Data”, Saal et al 1980
- “Paperwork and Bureaucracy”, Bennett & Johnson 1979
- “Prospect Theory: An Analysis of Decision under Risk”, Kahneman & Tversky 1979
- “Derivation of Some Social-Demographic Regularities from the Theory of Time-Minimization”, Stephan 1979
- “Impact of Valid Selection Procedures on Work-Force Productivity”, Schmidt et al 1979
- “Theory of the Firm: Managerial Behavior, Agency Costs, and Ownership Structure”, Jensen & Meckling 1979c
- “Foreign-Trained Physicians and Health Care in the United States”, Svorny 1979
- “Moral Hazard and Observability”, Holmström 1979
- “Growth Accounting With Intermediate Inputs”, Hulten 1978
- “The Hawthorne Experiments: First Statistical Interpretation”, Franke & Kaul 1978
- “The Economics of the Baby Shortage”, Landes & Posner 1978
- “The Gains and Losses from Industrial Concentration”, Peltzman 1977
- “Double Loop Learning in Organizations”, Argyris 1977
- “The Effects of the Rural Income Maintenance Experiment on the School Performance of Children”
- “The Economics of Safety Legislation in Underground Coal Mining”, Henderson 1977
- “The Fishers of Men: The Profits of the Slave Trade”, Thomas & Bean 1974
- “Spurious Regressions in Econometrics”, Granger & Newbold 1974
- “Portfolio Turnpike Theorems for Constant Policies”, Ross 1974
- “Unemployment Compensation: Adverse Incentives And Distributional Anomalies”, Feldstein 1974
- “Economics of Petrodollars”, Oweiss 1974
- “The Society of Arts & Government 1754–1800: Public Encouragement of Arts, Manufactures, and Commerce in 18th-Century England”, Allan 1974
- “The General Impossibility of Normative Accounting Standards”, Demski 1973
- “An Evaluation of Consumer Protection Legislation: The 1962 Drug Amendments”, Peltzman 1973
- Mitsui: 3 Centuries of Japanese Business, Roberts 1973
- “A Study of the Effects of Competition in the Tax-Exempt Bond Market”, Kessel 1971
- “Suppression of Inventions”, Hirshleifer 1971
- “The Achieving Society”, McClelland 1971
- “Banking and Interest Rates in a World Without Money: The Effects of Uncontrolled Banking”, Black 1970
- “Statistical Theories of Success”, Zener 1970
- “East Indian Cane Workers In Jamaica”, Ehrlich 1969
- “The Performance of Mutual Funds in the Period 1945–1964”, Jensen 1968
- “An Analysis Of Scientific Productivity”, Zener 1968
- “British Imperial Policy and the Economic Interpretation of the American Revolution”
- “Soviet Reality Sans Potemkin: The Amenities of Moscow from the Native Point of View”, Schroeder 1968
- The Economics of Knowledge and the Knowledge of Economics, Boulding 1966b
- “The Dollars and Sense of Continuing Education”, Jones 1966
- “The Economics of the Coming Spaceship Earth”, Boulding 1966
- “On the Geometry of Organizations”, McWhinney 1965
- “A Quantitative Approach to the Study of the Effects of British Imperial Policy upon Colonial Welfare: Some Preliminary Findings”
- “Measuring Utility by a Single-Response Sequential Method”, Becker et al 1964
- “Testing a Model for Organizational Growth”, Draper & Strother 1963
- “Exploration of a Biological Model of Industrial Organization”, Levy & Donhowe 1962
- “Probability, Statistical Decision Theory, and Accounting”, Bierman 1962
- “Distributions of Correlation Coefficients in Economic Time Series”, Ames & Reiter 1961
- “The Economics of Invention: A Survey of the Literature”, Nelson 1959
- “The Structure and Growth of Soviet Industry: A Comparison With the United States”, Nutter 1959
- Probability and Statistics for Business Decisions: An Introduction to Managerial Economics Under Uncertainty, Schlaifer 1959
- “Predatory Price Cutting: The Standard Oil (New Jersey) Case”, McGee 1958
- “The True Story of Russia’s Weakness [Stifled by Bad Planning, Bureaucratic Inefficiency, and Lack of Any Real Incentive]”, Nutter 1957
- “Rational Decision Making in Portfolio Management”, Latané 1957
- Patterns of Industrial Bureaucracy: a Case Study of Modern Factory Administration, Gouldner 1954
- “Non-Cooperative Games”, Nash 1951
- “What Price Speed? Specific Power Required for Propulsion of Vehicles”, Gabrielli & Kármán 1950
- “Uncertainty, Evolution, and Economic Theory”, Alchian 1950
- “William Shipley And The Royal Society Of Arts: The History of an Idea”, Luckhurst 1949
- “Economic Calculation in the Socialist Society”, Hoff 1949
- “Charles Dickens [His Ideology/ethics]”, Orwell 1940
- “Averaging of Income for Income-Tax Purposes”, Vickrey 1939
- “The Soviet Economy in Danger”, Trotsky 1932
- “F. P. Ramsey [Obituary]”, Keynes 1930
- “Stability in Competition”, Hotelling 1929
- “A Mathematical Theory of Saving”, Ramsey 1928
- “A Contribution to the Theory of Taxation”, Ramsey 1927b
- “London Labour and the London Poor; a Cyclopaedia of the Condition and Earnings of Those That Will Work, Those That Cannot Work, and Those That Will Not Work: Volume 1: The London Street-Folk § Of Cats’-Meat & Dogs’-Meat Dealers”, Mayhew 1851
- Confusion of Confusions, Vega & Kellenbenz 1688
- “The Cat’s Meat Man”
- “The Value of Health and Longevity”
- “All That Is Solid Bursts into Flame: Capitalism and Fire in the 19th-Century United States”
- “Making Is Show Business Now”
- Paris Anecdote, d’Anglemont 2026
- Paris Inconnu, d’Anglemont et al 2026
- “Double Deposit Escrow”
- “Bithalo”
- “2015.11.20: Break a Dozen Secret Keys, Get a Million More for Free”
- “Can AI Do Replications? GPT-5.2 vs GPT-5.4 vs Refine.ink”, Wiebe 2026
- “Moretti Replication Published in AER”, Wiebe 2026
- “Risk Management and Sounding Crazy”
- “An Amazing Journey With Claude 3.5 and ChatGPT-4o Who Helped Me Backwards Engineer an Econometrics Theory Paper and Taught Me a Lot More in the Process”
- “Millennium Cohort Study (UK)”
- “The Games People Play With Cash Flow”
- “The Untold Story of SQLite With Richard Hipp”
- “How Funerals Keep Africa Poor”
- “Crystal Ball Trading Challenge”, Wealth 2026
- “Multi-Signature”
- “How Not to Bomb Your Offer Negotiation”
- “The Hardest Chess Problem in the World?”
- “Hledger Homepage”
- “A Meta-Analysis of Work Sample Test Validity: Updating and Integrating Some Classic Literature”
- “VTSAX: Vanguard Total Stock Market Index Fund Admiral Shares”, Vanguard 2026
- “1,000 True Fans”, Kelly 2026
- “Underutilized Fixed Assets”
- “The New Economics of Chess”
- “Claude, Read the Chevron PDF”, Cowen & Claude-3 2026
- “Claude Sonnet 3.5, Economist”
- “Deep Research for Short Economics Papers”, Cowen 2026
- “Rob Wiblin Interviews Tyler on Stubborn Attachments (BONUS)”
- “The Relentless Misery of 1.6 Gallons”
- “Nintil”, Ricon 2026
- “Parents’ Beliefs in the ‘American Dream’ Affect Parental Investments in Children: Evidence from an Experiment”
- “How to Pay to Change the Law”
- “Albert Millican’s Travels and Adventures of an Orchid Hunter”
- “Mrs Giacometti Prodgers, the Cabman’s Nemesis”
- “From Fire Hazards to Family Trees: The Sanborn Fire Insurance Maps”
- “The Art of Making Debts: Accounting for an Obsession in 19th-Century France”
- “Red Markets”
- “Meditations on Moloch”
- “Book Review: Legal Systems Very Different From Ours”
- “How Record Rentals Helped Save Japan’s Music Industry”
- “6-Year-Old Stares Down Bottomless Abyss Of Formal Schooling”
- “The Hazy Economy of Cannabis”
- “Growing One’s Consulting Business”, McKenzie 2026
- “Flight Simulators for Management Education”
- “Against the Survival of the Prettiest”
- “Why Ireland’s Housing Bubble Burst”
- “Why Skyscrapers Are so Short”
- “The Rise of Niche Consumption”
- “The Public Thinks the Average Company Makes a 36% Profit Margin, Which Is About 5× Too High”
- “Playing to Win”
- “Project Vend: Can Claude Run a Small Shop? (And Why Does That Matter?)”
- “First Year of Candy Japan”
- “How I Decided the Price for My Japanese Candy Subscription Service”
- “How Credit Cards Make Money”
- “Working Title (Real Estate Insurance)”, McKenzie 2026
- “Japanese Anime Studio Khara Moving to Blender”
- “Kitty Litter’s Invention Spawned Pet Cat Industry”
- “Duration of Unemployment in the CPS”, Statistics 2026
- “CPI Inflation Calculator”, Statistics 2026
- “The Life of American Workers in 1915”
- “A Forensic Examination of China’s National Accounts”
- “Marc Andreessen Says The 1990s Dot-Com Bubble Startups Were ‘All Right But Just Early’”
- “Inside The Global ‘Club’ That Helps Executives Escape Their Crimes”
- “Refugees from Dust and Shrinking Land: Tracking the Dust Bowl Migrants”
- “Candy Japan Crosses $10,000 MRR”
- “How Candy Japan Got Credit Card Fraud Somewhat under Control”
- “Results from Candy Japan Box Design A/B Test”
- “How China Is Like the 19th Century US”, Potter 2026
- “What Do Criminal Records Tell Us about Adam Smith and the Industrial Revolution?”
- “Chapter 31, ‘On Machinery’, On the Principles of Political Economy and Taxation”
- “Switzerland’s ‘Silicon Valley of Smell’ Prospers in Age of Big Data”
- “How Much Should We Trust Developing Country GDP? [Little]”
- “Raising a Stink”
- “The Roentgen Standard”, Niven 2026
- “‘The Cambist and Lord Iron: A Fairy Tale of Economics’ Discussion”
- “Normal Cryonics”
- “The Cambist and Lord Iron: A Fairy Tale of Economics [Lightspeed Magazine Mirror]”
- “The Law of Small Numbers in Financial Markets: Theory and Evidence”
- “Sovereign Haircuts: 200 Years of Creditor Losses”
- “The Most Popular Chess Streamer on Twitch”
- “How Driscoll’s Reinvented the Strawberry”
- “Suzy Batiz’s Empire of Odor”
- “What Are You Paying For in a $300 Chess Set? Mostly the Knights”
- “How Magnus Carlsen Turned Chess Skill Into a Business Empire”
- “How Costco Won In Japan”
- “How Madagascar’s Farmers Spend Money from the Vanilla Boom”
- The Diff, Hobart 2026
- “Anti-Anxiety Pill Travels 52,000 Kilometres to Get to Canadian Shelves, Study Shows”
- “The Complete History of How SoundScan Changed Popular Music Forever”
- “Is Spotify’s Model Wiping Out Music’s Middle Class?”
- “Plant-Based Meat like Beyond and Impossible Burgers Get Their Beefy Taste from Flavorists”
- “Inside a Startup’s Plan to Turn a Swarm of DIY Satellites Into an All-Seeing Eye”
- “Why Big Data Has Been (Mostly) Good for Music”
- “You’ve Never Heard of China’s Greatest Sci-Fi Novel”
- “Why British Nuclear Flopped”
- “2 Years Ago, India Lacked Fast, Cheap Internet—One Billionaire Changed All That: Mukesh Ambani’s National 4G Network for Reliance Jio, Which Charges Pennies for Data, Is Bringing Hundreds of Millions Online for the First Time”
- “Who Controls Diners’ Data? OpenTable Moves to Assert Control: Some Restaurateurs Say Booking Service Is Trying to Squeeze Rival SevenRooms; OpenTable Says It Is Protecting User Privacy”
- “Why Anime Is on the Rise Even Though the Industry Is so Poor”
- richgel999
- Sort By Magic
healthcare-costscritique-analysisexclusive-contentdeposit-recoverygeopolitical-economicstheatrical-releaseprogress-studiesbehavioral-economicstipping-behaviorhealth-impacttransplant-marketbusiness-strategycommunity-economicsdevelopment-economicssmart-contractssocial-networksobesity-policyorganizational-performancebeauty-premium
- Wikipedia (27)
- Miscellaneous
- Bibliography
See Also
Gwern
“King Pin”, Gwern et al 2026
{kind=link}
“Long-Run Trends in US Total Factor Productivity”, Gwern & Images-2.0 2026
{kind=link}
“The Efficient Market Hypothesis in Action”, Gwern 2025
{kind=link}
“Why So Few Matt Levines?”, Gwern 2024
“Startup Ideas”, Gwern 2017
“Who Buys Fonts?”, Gwern 2021
“Open Questions”, Gwern 2018
“My Ordinary Life: Improvements Since the 1990s”, Gwern 2018
“How Often Does Correlation=Causality?”, Gwern 2014
“What Is The Collecting Mindset?”, Gwern 2021
“Laws of Tech: Commoditize Your Complement”, Gwern 2018
“Ordinary Incompetence”, Gwern 2021
“Progress In Beauty”, Gwern 2016
“Fashion Cycles”, Gwern 2021
“Review Of 𝑇𝘩𝑒 𝐶𝑢𝑙𝑡𝑢𝑟𝑎𝑙 𝑅𝑒𝑣𝑜𝑙𝑢𝑡𝑖𝑜𝑛, Dikötter 2016”, Gwern 2019
“How Many Computers Are In Your Computer?”, Gwern 2010
“Local Optima & Greedy Choices”, Gwern 2021
“InflationAdjuster”, Gwern 2019
“Technology Holy Wars Are Coordination Problems”, Gwern 2020
“Embryo Selection For Intelligence”, Gwern 2016
“Timing Technology: Lessons From The Media Lab”, Gwern 2012
“Are Sunk Costs Fallacies?”, Gwern 2012
“Darknet Market Mortality Risks”, Gwern 2013
“Prediction Markets”, Gwern 2009
“The Narrowing Circle”, Gwern 2012
“History of Iterated Embryo Selection”, Gwern 2019
“Long Bets As Charitable Giving Opportunity”, Gwern 2017
“Slowing Moore’s Law: How It Could Happen”, Gwern 2012
“Charity Is Not about Helping”, Gwern 2011
“Girl Scouts & Good Corporate Governance”, Gwern 2011
“Scientific Stagnation”, Gwern 2012
“Evolutionary Software Licenses”, Gwern 2009
“Wikipedia & Knol: Why Knol Already Failed”, Gwern 2009
“Life Contracts”, Gwern 2009
“Wikipedia and Other Wikis”, Gwern 2009
“Console Insurance Is A Ripoff”, Gwern 2009
“Barratry”, Gwern 2009
Links
“Why Kinship Societies Kill Their Old: The Economic Logic of Modern-Day Witch Killings”, Oks 2026
Why kinship societies kill their old: The economic logic of modern-day witch killings
“Why China Got Rich, and India Didn’t”, Oks 2026
“The Nepo Theory of Vibecession: The Under-Discussed Variable behind Number Go Up Economics Being Such a Downer”, Hill 2026
“The Southern Poverty Law Center Indictment”, Tabarrok 2026
“Notes on a Non-Profit [Southern Poverty Law Center] Indicted for Bank Fraud”, McKenzie 2026
Notes on a non-profit [Southern Poverty Law Center] indicted for bank fraud
“Consequences of the Black Sea Slave Trade: Long-Run Development in Eastern Europe”, Charnysh & Lall 2026
Consequences of the Black Sea Slave Trade: Long-Run Development in Eastern Europe
“New Orleans’s Car-Crash Conspiracy: High-Speed Accidents, Crooked Lawyers, and Poor People Desperate for Cash—It Was the Kind of Scheme That Could Have Been Cooked up Only in the Big Easy”
“The Impact of Dating Apps on Young Adults: Evidence from Tinder”, Büyükeren et al 2026
The Impact of Dating Apps on Young Adults: Evidence from Tinder
“Are Prediction Markets Good for Anything? We All Know They’re Casinos. It’s Time to Look at the Data behind the Froth”, Schwarz 2026
“Why Your Egg Prices Are so Much Lower Than Last Year”
Why your egg prices are so much lower than last year
View External Link:
https://www.npr.org/2026/03/13/nx-s1-5745075/egg-prices-avian-flu
“Is It Really Impossible to Make a Living As an Animator in Japan?”
Is it Really Impossible to Make a Living as an Animator in Japan?
“Anime in 2025: Is the Crunchyroll Cage Real?”
“The Returns to Education: A Meta-Study”, Clark & Nielsen 2026
“Fraud Investigation Is Believing Your Lying Eyes”, McKenzie 2026
“Highway to Hitler”, Voigtländer & Voth 2026
“Gatekeepers of Law: Inside the Westlaw and LexisNexis Duopoly; Ever Since a Spate of Mergers in the 1990s, Westlaw and LexisNexis Have Dominated Legal Research. And That Might Be Why Searching Legal Cases Is so Costly, Even in the Age of AI”, Blakely 2025
“The $140K Question: Cost Changes Over Time”
“How Getting Richer Made Teenagers Less Free: We Value Children More Than Ever. But We’re Suffocating Them”, Piper 2025
“Marginal Returns to Public Universities”, Mountjoy 2025
magnushambleton @ "2025-12-01"
“Mr. Roberts Goes to Hollywood, Part 2: The Producer [How a Poorly Designed German Tax Loophole Funded 2000s Hollywood]”, Maher 2025
“Looks and Gaming: Who and Why?”, Chung et al 2025
“Don’t Let People Buy Credit With Borrowed Funds”, Habryka 2025
“Toward an Agentic Theory of Outsider Outliers: The Case of Carlos Ghosn”, Cooper & Ewing 2025
Toward an Agentic Theory of Outsider Outliers: The Case of Carlos Ghosn
“Digital Distractions With Peer Influence: The Impact of Mobile App Usage on Academic and Labor Market Outcomes”, Jia et al 2025
“Reasons for Discontinuation of Obesity Pharmacotherapy With Semaglutide or Tirzepatide in Clinical Practice”, Gasoyan et al 2025
“Greenland Is A Beautiful Nightmare”, Duggan 2025
“What If NIH Had Been 40% Smaller?”, Azoulay et al 2025
“Discontinuation of Semaglutide Among Older Adults With Diabetes in the US and Japan”, Inoue et al 2025
Discontinuation of Semaglutide Among Older Adults With Diabetes in the US and Japan
“Why Chainsaw Man Is Going Theatrical With MAPPA President Manabu Ohtsuka, Vice President Hiroya Hasegawa”, Chik et al 2025
“How Kentucky Bourbon Went from Boom to Bust”, King 2025
“The Long-Run Effects of Government Spending”, Antolin-Diaz & Surico 2025
“Corporate Discount Rates”, Gormsen & Huber 2025
“Comprehension in Economic Games”, Koppel et al 2025
“The Grugbrained CEO”, Rodriques 2025
“Semen and Semantics: Understanding Porn With Language Embeddings”, future_detective 2025
Semen and Semantics: Understanding Porn with Language Embeddings
“Revealing Economic Facts: LLMs Know More Than They Say”, Buckmann et al 2025
“China’s Superstition Boom in a Godless State § DeepSeek’s Occult Tech Boom”, Li 2025
China’s Superstition Boom in a Godless State § DeepSeek’s Occult Tech Boom
“Ambulance Taxis: The Impact of Regulation and Litigation on Health-Care Fraud”, Eliason et al 2025
Ambulance Taxis: The Impact of Regulation and Litigation on Health-Care Fraud
“When Did Growth Begin? New Estimates of Productivity Growth in England 1250–1870”, Bouscasse et al 2025
When Did Growth Begin? New Estimates of Productivity Growth in England 1250–1870
“The Growth Consequences of Socialism”, Bergh et al 2025
“Not That Norfolk! Mislabeled Shipments Led to Trump Tariffs on Uninhabited Islands and Remote Outposts With No US Trade”
“Journey of a Pill”, Kaur et al 2025
“No Evidence of Effects of Testosterone on Economic Preferences: Results From a Large (n = 1,000) Double-Blind Randomized Controlled Study”
View External Link:
“The (Heterogeneous) Economic Effects of Private Equity Buyouts”, Davis et al 2025
The (Heterogeneous) Economic Effects of Private Equity Buyouts
“Effects of Family Socioeconomic Status on Educational Outcomes in Primary and Secondary Education: A Systematic Review of the Causal Evidence”, Song et al 2025
“Surprising Trends in Lego Pricing: Managing a Strong Brand for the Long Term [Deflation]”, Hodge 2025
Surprising Trends in Lego Pricing: Managing a Strong Brand for the Long Term [deflation]
“Two Americas, One Bank Branch, and $50,000 Cash”, McKenzie 2025
“The Aggregate and Distributional Effects of Immigration Restrictions: The 1920s Quota Acts and the Great Black Migration”, Xie 2025b
“Project Play Survey: Family Spending on Youth Sports Rises 46% over 5 Years”, Play 2025
Project Play survey: Family spending on youth sports rises 46% over 5 years
“AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society”, Piao et al 2025
“Wind Turbines, Shadow Flicker, and Real Estate Values”, Andersen & Hener 2025
“The Time I Joined Peace Corps and Worked With An African HIV Program for Sex Workers in Eswatini: Part 1”, Laurenson 2025
“Decisions under Risk Are Decisions under Complexity: Comment”, Banki et al 2025
Decisions under Risk Are Decisions under Complexity: Comment
“What Will AI Do to pre-Research/research? AI Makes Doing and Communicating Research Much Easier. Will There Be Any Point to It?”, Gans 2025
“The Efficient Market Hypothesis When Time Travel Is Possible”, Gans & o1-pro 2025
The efficient market hypothesis when time travel is possible
“Discontinuation and Reinitiation of Dual-Labeled GLP-1 Receptor Agonists Among US Adults With Overweight or Obesity”, Rodriguez et al 2025
“The Impact of the Chinese Exclusion Act on the Economic Development of the Western United States: Reduced the Male Labor Supply of Chinese and White Workers in the West”, Long et al 2025
“A Marriage Proposal Spoken Entirely in Office Jargon”, Barber 2025
“Dying or Lying? For-Profit Hospices and End-Of-Life Care”, Gruber et al 2025
“Sources of Market Power in Web Search: Evidence from a Field Experiment”, Allcott et al 2025
Sources of Market Power in Web Search: Evidence from a Field Experiment
“The Effects Of Medical Debt Relief: Evidence From Two Randomized Experiments”, Raymond et al 2024
The Effects Of Medical Debt Relief: Evidence From Two Randomized Experiments
“Market Response to Court Rejection of California’s Board Diversity Laws”, Klick 2024
Market Response to Court Rejection of California’s Board Diversity Laws
“The Emergence of Strategic Reasoning of Large Language Models”, Lee & Kader 2024
The Emergence of Strategic Reasoning of Large Language Models
“Decisions under Risk Are Decisions under Complexity”, Oprea 2024
“Everybody Loves FRED: How America Fell for a Data Tool”
“LLMs Learn to Collaborate and Reason: December 2024 Update to ‘Generative AI for Economic Research: Use Cases and Implications for Economists’, Published in the Journal of Economic Literature 61(4)”, Korinek 2024
“Territory Flows and Trade Flows, 1870–2008”, Hu et al 2024
“The Global Race For Talent: Brain Drain, Knowledge Transfer, And Growth”, Marta 2024
The Global Race For Talent: Brain Drain, Knowledge Transfer, And Growth
“Y Combinator Often Backs Startups That Duplicate Other YC Companies, Data Shows—Not Just AI Code Editors”
“Why Businesses Fail: Underadoption of Improved Practices by Brazilian Micro-Enterprises”, Oliveira 2024
Why Businesses Fail: Underadoption of Improved Practices by Brazilian Micro-Enterprises
“How Do You Say Your Name? Difficult-To-Pronounce Names and Labor Market Outcomes”, Ge & Wu 2024
How Do You Say Your Name? Difficult-to-Pronounce Names and Labor Market Outcomes
“Optimal Resilience In Multitier Supply Chains”, M. et al 2024
“Data and Code For: "Dying or Lying? For-Profit Hospices and End of Life Care"”, Gruber et al 2024
Data and Code for: "Dying or Lying? For-Profit Hospices and End of Life Care"
“Personality Profiles of 263 Occupations”, Anni et al 2024
“Picking Uncle Sam’s Pockets, With Jetson Leder-Luis § A $10 Billion Asterisk: Ambulances for Dialysis Patients”, McKenzie & Leder-Luis 2024
“Picking Uncle Sam’s Pockets, With Jetson Leder-Luis § Hospice Fraud; Potentially Saved Money”, McKenzie & Leder-Luis 2024
Picking Uncle Sam’s pockets, with Jetson Leder-Luis § Hospice fraud; potentially saved money
“An Intuitive Explanation of Black-Scholes: I Explain the Black-Scholes Formula Using Only Basic Probability Theory and Calculus, With a Focus on the Big Picture and Intuition over Technical Details”, Gundersen 2024
“Getting Down to Business: Chain Ownership and Fertility Clinic Performance”, Forgia & Bodner 2024
Getting Down to Business: Chain Ownership and Fertility Clinic Performance
“Matt Levine, Bloomberg Opinion Columnist”, Levine 2024
“The Economic Way of Thinking in a Pandemic”, Tabarrok 2024
“Entrepreneurship Changed the Way I Think”, Handmer 2024
“On the UBI Paper”, Mowshowitz 2024
“Founder Mode”, Graham 2024
“The Relationship Between Team Diversity and Team Performance: Reconciling Promise and Reality Through a Comprehensive Meta-Analysis Registered Report”, Wallrich et al 2024
“Causal Inference on Human Behaviour”, Bailey et al 2024
“The Untold Story Behind a Meteoric Rise: The Early Days of Valve from a Woman Inside”, Harrington 2024
The Untold Story Behind a Meteoric Rise: The Early Days of Valve from a Woman Inside
“The Lifetime Costs of Bad Health”, Nardi et al 2024
“Political Language In Economics”, Zubin et al 2024
“Revisiting the Relationship between Economic Freedom and Development to Account for Statistical Deception by Autocratic Regimes”, Alvarez et al 2024
“Using Grocery Data for Credit Decisions”, Lee et al 2024b
“Navigating Corporate Giants: Jeffrey Snover and the Making of PowerShell”, Snover & Bell 2024
Navigating Corporate Giants: Jeffrey Snover and the Making of PowerShell
“Health Care Centralization: The Health Impacts of Obstetric Unit Closures in the United States”, Fischer et al 2024
Health Care Centralization: The Health Impacts of Obstetric Unit Closures in the United States
“FDI Technology Spillovers in Chinese Supplier-Customer Networks”, Li et al 2024b
FDI technology spillovers in Chinese supplier-customer networks
“Is Socially Responsible Capitalism Truly Polarizing?”, Stone & Lees 2024
“Income Inequality in the United States: Using Tax Data to Measure Long-Term Trends”, Auten & Splinter 2024
Income Inequality in the United States: Using Tax Data to Measure Long-Term Trends
“Are Older People Aware of Their Cognitive Decline? Misperception and Financial Decision-Making”, Mazzonna & Peracchi 2024
Are Older People Aware of Their Cognitive Decline? Misperception and Financial Decision-Making
“Subjective Job Insecurity and the Rise of the Precariat: Evidence from the United Kingdom, Germany, and the United States”, Manning & Mazeine 2024
“Creating the ‘American Way’ of Business: Evidence from WWII in the United States”, Giorcelli 2024
Creating the ‘American Way’ of Business: Evidence from WWII in the United States
“Examining the Effects of Weather on Online Shopping Cart Abandonment: Evidence from an Online Retailing Platform”, Li et al 2024
“The Ant And The Grasshopper: Seasonality And The Invention Of Agriculture”, Matranga 2024
The Ant And The Grasshopper: Seasonality And The Invention Of Agriculture
“Is Economics Self-Correcting? Replications in the American Economic Review”, Ankel-Peters et al 2024
Is economics self-correcting? Replications in the American Economic Review
“What’s Behind Her Smile? Health, Looks, and Self-Esteem”, Gallego et al 2024
“Covid-19 Is (Probably) Not an Exogenous Shock or Valid Instrument”, Clement 2024
Covid-19 is (Probably) Not an Exogenous Shock or Valid Instrument
“The Long-Run Impacts of Adolescent Drinking: Evidence from Zero Tolerance Laws”, Abboud et al 2024
The long-run impacts of adolescent drinking: Evidence from Zero Tolerance Laws
“The Psychology Of Poverty: Where Do We Stand?”, Haushofer & Salicath 2024
“Behavioral Responses to State Income Taxation of High Earners: Evidence from California”, Rauh & Shyu 2024
Behavioral Responses to State Income Taxation of High Earners: Evidence from California
“E-Cigarette Flavor Restrictions’ Effects on Tobacco Product Sales”, Friedman et al 2024
E-cigarette Flavor Restrictions’ Effects on Tobacco Product Sales
“How Beautiful People See the World: Cooperativeness Judgments of and by Beautiful People”, Zylbersztejn et al 2024
How beautiful people see the world: Cooperativeness judgments of and by beautiful people
“Causal Assessment of Income Inequality on Self-Rated Health and All-Cause Mortality: A Systematic Review and Meta-Analysis”, Shimonovich et al 2024
“Lay Economic Reasoning: An Integrative Review and Call to Action”, Bhattacharjee & Dana 2024
Lay economic reasoning: An integrative review and call to action
“Acutely Precarious? Detecting Objective Precarity in Journalism”, Jana 2024
Acutely Precarious? Detecting Objective Precarity in Journalism
“School Closures during the 1918 Flu Pandemic”, Ager et al 2024
“Workplace Aggression and Employee Performance: A Meta-Analytic Investigation of Mediating Mechanisms and Cultural Contingencies”, Zhong et al 2024
“The Economic Impact of Depression Treatment in India: Evidence from Community-Based Provision of Pharmacotherapy”, Angelucci & Bennett 2024
“Inconsistent Definitions of GDP: Implications for Estimates of Decoupling”, Semieniuk 2024
Inconsistent definitions of GDP: Implications for estimates of decoupling
“Writing Matters”, Feld et al 2024
“Does Trade Reform Promote Economic Growth? A Review of Recent Evidence”, Irwin 2024
Does Trade Reform Promote Economic Growth? A Review of Recent Evidence
“The Gender Gap in Confidence: Expected but Not Accounted For”, Exley & Nielsen 2024
The Gender Gap in Confidence: Expected but Not Accounted For
“Associations between Common Genetic Variants and Income Provide Insights about the Socio-Economic Health Gradient”
“Solar Eclipses and the Origins of Critical Thinking and Complexity”, Litina & Fernández 2023
Solar Eclipses and the Origins of Critical Thinking and Complexity
“The Long Shadow of Checks § Check Settlement in the Pre-Computer-Era”, McKenzie 2023
The Long Shadow of Checks § check settlement in the pre-computer-era
“Lord of the Roths: How Tech Mogul Peter Thiel Turned a Retirement Account for the Middle Class Into a $5 Billion Tax-Free Piggy Bank”
“Cultural Values and Productivity”, Ek 2023
“Strategic CEO Activism in Polarized Markets”, Homroy & Gangopadhyay 2023
“America, Jump-Started: World War II R&D and the Takeoff of the US Innovation System”, Gross & Sampat 2023
America, Jump-Started: World War II R&D and the Takeoff of the US Innovation System
“Intergenerational Mobility in American History: Accounting for Race and Measurement Error”, Ward 2023
Intergenerational Mobility in American History: Accounting for Race and Measurement Error
“The Possibility of Making $138,000 from Shredded Banknote Pieces Using Computer Vision”, Kong 2023
The possibility of making $138,000 from shredded banknote pieces using computer vision
“Economic Inequality Fosters the Belief That Success Is Zero-Sum”, Davidai 2023
Economic Inequality Fosters the Belief That Success Is Zero-Sum
“A Challenge to Orthodoxy in Psychology: Thomas Sowell and Social Justice”, O’Donohue et al 2023
A Challenge to Orthodoxy in Psychology: Thomas Sowell and Social Justice
“After 50 Years, Health Professional Shortage Areas Had No Significant Impact On Mortality Or Physician Density”, Markowski et al 2023
“Macroevolutionary Origins of Comparative Development”, Riahi 2023
“Can GPT Models Be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on Mock CFA Exams”, Callanan et al 2023
Can GPT models be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on mock CFA Exams
“Do Looks Matter for an Academic Career in Economics?”, Hale et al 2023
“Does Alleviating Poverty Increase Cognitive Performance? Short-Term & Long-Term Evidence from a Randomized Controlled Trial”, Szaszi et al 2023
“Ozempic Is Making People Buy Less Food, Walmart Says”, Case & Banjo 2023
“An Evolutionary Model of Personality Traits Related to Cooperative Behavior Using a Large Language Model”, Suzuki & Arita 2023
“The Economic Origins of Government”, Allen et al 2023
“Quantifying Racial Discrimination in the 1944 G.I. Bill”, Eden 2023
“Beauty and Stock Market Participation”, Gan et al 2023
“Public Policy toward Professional Sports Stadiums: A Review”, Bradbury et al 2023
“Monitoring for Waste: Evidence from Medicare Audits”, Shi 2023
“Microsoft Says Apple Used Bing Offer As Google ‘Bargaining Chip’”, Nylen 2023
Microsoft Says Apple Used Bing Offer as Google ‘Bargaining Chip’
“Expert Opinions and Negative Externalities Do Not Decrease Support for Anti-Price Gouging Policies”, Klofstad & Uscinski 2023
Expert opinions and negative externalities do not decrease support for anti-price gouging policies
“Congestion on the Information Superhighway: Inefficiencies in Economics Working Papers: Online Appendix: Additional Tables and Figures”, Lusher et al 2023
“To Pay for Weight Loss Drugs, Some Take Second Jobs, Ring Up Credit Card Debts: Some People Pay More Than $10,000 a Year Out-Of-Pocket for Ozempic and Mounjaro”, Armour 2023
“Congestion on the Information Superhighway § Figure 1: Time Series of Number of Working Paper Releases”, Lusher et al 2023
{kind=link}
“Congestion on the Information Superhighway: Inefficiencies in Economics Working Papers”, Lusher et al 2023
Congestion on the information superhighway: Inefficiencies in economics working papers
“How Well Do Laboratory-Derived Estimates of Time Preference Predict Real-World Behaviors? Comparisons to Four Benchmarks”, Bartels et al 2023
“We Do Not Know the Population of Every Country in the World for the Past Two Thousand Years”, Guinnane 2023
We Do Not Know the Population of Every Country in the World for the Past Two Thousand Years
“How Much Do EAGs Cost (And Why)?”, Eli_Nathan 2023
“OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax?”, Blair-Stanek et al 2023
OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax?
“A Systematic Review and Meta-Analysis of the Relationship between Economic Inequality and Prosocial Behavior”, Yang & Konrath 2023c
“Behavioral Genetics of Temporal Framing: Heritability of Time Perspective and Its Common Genetic Bases With Major Personality Traits”, Stolarski et al 2023
“Google Maps Has Become an Eyesore § Comments”, Cory 2023
“What Happened to US Business Dynamism?”, Akcigit & Ates 2023
“The Consequences of Job Search Monitoring for the Long-Term Unemployed: Disability instead of Employment?”, Brouwer et al 2023
“The Lion’s Share: Evidence from Federal Contracts on the Value of Political Connections”, Ağca & Igan 2023
The Lion’s Share: Evidence from Federal Contracts on the Value of Political Connections
“The Long-Run Relationship between per Capita Incomes and Population Size”, Eden & Kuruc 2023
The long-run relationship between per capita incomes and population size
“Supplement: Gender-Based Pricing in Consumer Packaged Goods: A Pink Tax?”, Moshary et al 2023
Supplement: Gender-Based Pricing in Consumer Packaged Goods: A Pink Tax?
“Gender-Based Pricing in Consumer Packaged Goods: A Pink Tax?”, Moshary et al 2023
Gender-Based Pricing in Consumer Packaged Goods: A Pink Tax?
“The Heterogeneous Earnings Impact of Job Loss Across Workers, Establishments, and Markets”, Athey et al 2023
The Heterogeneous Earnings Impact of Job Loss Across Workers, Establishments, and Markets
“Cognitive Biases: Mistakes or Missing Stakes?”, Enke et al 2023
“School Quality and the Return to Schooling in Britain: New Evidence from a Large-Scale Compulsory Schooling Reform”, Clark 2023
“Income and Inequality in the Aztec Empire on the Eve of the Spanish Conquest”, Alfani & Carballo 2023
Income and inequality in the Aztec Empire on the eve of the Spanish conquest
“Rebel, Remain, or Resign? Military Elites’ Decision-Making at the Onset of the American Civil War”, White 2023
Rebel, Remain, or Resign? Military Elites’ Decision-Making at the Onset of the American Civil War
“Pareto-Improving Optimal Capital and Labor Taxes”, Greulich et al 2023
“Using Sequences of Life-Events to Predict Human Lives”, Savcisens et al 2023
“Increasing Pressure on US Men for Income in order to Find a Spouse”, Fieder & Huber 2023
Increasing pressure on US men for income in order to find a spouse
“National and Global Impacts of Genetically Modified Crops”, Hansen & Wingender 2023
“The Psychology of Zero-Sum Beliefs”, Davidai & Tepper 2023b
“Does Access to Citizenship Confer Socio-Economic Returns? Evidence from a Randomized Control Design”, Hainmueller et al 2023
Does Access to Citizenship Confer Socio-Economic Returns? Evidence from a Randomized Control Design
“Economic Consequences of Kinship: Evidence From US Bans on Cousin Marriage”, Ghosh et al 2023
Economic Consequences of Kinship: Evidence From US Bans on Cousin Marriage
“Bilateral Trade Imbalances”, Cuñat & Zymek 2023
“The Mainstreaming of Marx: Measuring the Effect of the Russian Revolution on Karl Marx’s Influence”, Magness & Makovi 2023
The Mainstreaming of Marx: Measuring the Effect of the Russian Revolution on Karl Marx’s Influence
“Is Beauty-Based Inequality Gendered? A Systematic Review of Gender Differences in Socioeconomic Outcomes of Physical Attractiveness in Labor Markets”, Kukkonen et al 2023
“Saving Time and Money in Biomedical Publishing: the Case for Free-Format Submissions With Minimal Requirements”, Clotworthy et al 2023
“College Quality As Revealed by Willingness-To-Pay for College Graduates”, Green & Swepston 2023
College quality as revealed by willingness-to-pay for college graduates
“Do Financial Incentives Encourage Women to Apply for a Tech Job? Evidence from a Natural Field Experiment”, Feld et al 2023
“Founder Personality and Entrepreneurial Outcomes: A Large-Scale Field Study of Technology Startups”, Freiberg & Matz 2023
Founder personality and entrepreneurial outcomes: A large-scale field study of technology startups
“Taxing Uber”, Agrawal & Zhao 2023
“The Shadow of Peasant Past: Seven Generations of Inequality Persistence in Northern Sweden”, Hällsten & Kolk 2023
The Shadow of Peasant Past: Seven Generations of Inequality Persistence in Northern Sweden
“Business-Size Bias in Moral Concern: People Are More Dishonest Against Big Than Small Organizations”, Martuza et al 2023
Business-Size Bias in Moral Concern: People are More Dishonest Against Big than Small Organizations
“Effectiveness of an Over-The-Counter Self-Fitting Hearing Aid Compared With an Audiologist-Fitted Hearing Aid: A Randomized Clinical Trial”, Sousa et al 2023
“Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games”
Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games
“Invisible Hurdles: Gender and Institutional Differences in the Evaluation of Economics Papers”, Ersoy & Pate 2023
Invisible hurdles: Gender and institutional differences in the evaluation of economics papers
“Energy Saving May Kill: Evidence from the Fukushima Nuclear Accident”, He & Tanaka 2023
Energy Saving May Kill: Evidence from the Fukushima Nuclear Accident
“Managers and Productivity in Retail”, Metcalfe et al 2023
“BloombergGPT: A Large Language Model for Finance”, Wu et al 2023
“Arm Seeks to Raise Prices ahead of Hotly Anticipated IPO: SoftBank-Owned Group Aims to Charge More for Each Chip Design in Radical Shake-Up of Business Model”, Gross et al 2023
“Ride-Hailing and Transit Accessibility considering the Trade-Off between Time and Money”, Pereira et al 2023
Ride-hailing and transit accessibility considering the trade-off between time and money
“Does Information Affect Homophily?”, Gallen & Wasserman 2023
“The Myth of Wartime Prosperity: Evidence from the Canadian Experience”, Geloso & Pender 2023
The myth of wartime prosperity: Evidence from the Canadian experience
“Conscientiousness and Labor Market Returns: Evidence from a Field Experiment in West Africa-Author=Mathias Allemand, Martina Kirchberger, Sveta Milusheva, Carol Newman, Brent Roberts, Vincent Thorne”, Group 2023 (page 3)
“Evidence on Economies of Scale in Local Public Service Provision: A Meta-Analysis”, Gómez-Reino et al 2023
Evidence on economies of scale in local public service provision: A meta-analysis
“Fortunate Families? The Effects of Wealth on Marriage and Fertility”, Cesarini et al 2023
Fortunate Families? The Effects of Wealth on Marriage and Fertility
“Personality Differences and Investment Decision-Making”, Jiang et al 2023
“The Unintended Effects of Minimum Wage Increases on Crime”, Fone et al 2023
“Unexpected Interruptions, Idle Time, and Creativity: Evidence from a Natural Experiment”, Schweisfurth & Greul 2023
Unexpected Interruptions, Idle Time, and Creativity: Evidence from a Natural Experiment
“Do Firms Value Court Enforceability of Noncompete Agreements? A Revealed Preference Approach”, Hiraiwa et al 2023
Do Firms Value Court Enforceability of Noncompete Agreements? A Revealed Preference Approach
“A 12-Gene Pharmacogenetic Panel to Prevent Adverse Drug Reactions: an Open-Label, Multicenter, Controlled, Cluster-Randomized Crossover Implementation Study (PREPARE)”, Swen et al 2023
“Consumption and Income Inequality in the United States Since the 1960s”, Meyer & Sullivan 2023b
Consumption and Income Inequality in the United States since the 1960s
“Status and Mortality: Is There a Whitehall Effect in the United States?”, Nicholas 2023
Status and mortality: Is there a Whitehall effect in the United States?
“Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”, Nay 2023
“Islam and Human Capital in Historical Spain”, Cinnirella et al 2023
“Google Wants RISC-V to Be a ‘tier-1’ Android Architecture: Google’s Keynote at the RISC-V Summit Promises Official, Polished Support”, Amadeo 2023
“Holiday Gift Giving in Retreat”, Waldfogel 2023
“Variation in Hospitalization Costs, Charges, and Lengths of Hospital Stay for Coronavirus Disease 2019 Patients Treated With Venovenous Extracorporeal Membrane Oxygenation in the United States: A Cohort Study”, Mazzeffi et al 2023
“More Than a Penny’s Worth: Left-Digit Bias and Firm Pricing”, Strulov-Shlain 2022
“Measuring and Improving Stakeholder Welfare Is Easier Said Than Done”, Gurun et al 2022
Measuring and Improving Stakeholder Welfare Is Easier Said than Done
“The Mechanics of the Industrial Revolution”, Kelly et al 2022b
“Linux, Amazon, Meta, and Microsoft Want to Break the Google Maps Monopoly: Overture Maps Foundation Wants to End the Oppressive Rule of the Google Maps API”, Amadeo 2022
“An Economic Analysis of Crime Costs Associated With Psychopathic Personality Disorder and Violence Risk”, Gatner et al 2022b
“The Effect of Financial Resources on Fertility: Evidence from Administrative Data on Lottery Winners”, Tsai et al 2022
The Effect of Financial Resources on Fertility: Evidence from Administrative Data on Lottery Winners
“Advancing Antivenom: Snakebites Kill 80–140,000 People Every Year. Better Antivenom Should Be a High Priority—Thankfully New Technology Can Help”, Bonde 2022
“Hideous but worth It: Distinctive Ugliness As a Signal of Luxury”, Cesareo et al 2022
Hideous but worth it: distinctive ugliness as a signal of luxury
“Social Economic Decision-Making and Psychopathy: A Systematic Review and Meta-Analysis”, Gunschera et al 2022
Social economic decision-making and psychopathy: A systematic review and meta-analysis
“Are Ideas Being Fished Out?”, Klüppel & Knott 2022
“Quantifying the Causal Impact of Biological Risk Factors on Healthcare Costs”, Lee et al 2022
Quantifying the causal impact of biological risk factors on healthcare costs
“Facial Attractiveness and CEO Compensation: Evidence from the Banking Industry”, Ahmed et al 2022
Facial attractiveness and CEO compensation: Evidence from the banking industry
“When a Town Wins the Lottery: Evidence from Spain”, Kent & Martínez-Marquina 2022
“Too Much Efficiency Makes Everything Worse: Overfitting and the Strong Version of Goodhart’s Law”
Too much efficiency makes everything worse: overfitting and the strong version of Goodhart’s law
“Within-Firm Productivity Dispersion: Estimates and Implications”, Orr 2022
Within-Firm Productivity Dispersion: Estimates and Implications
“Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation”, Mulligan 2022
Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation
“Sophisticated Deviants: Intelligence and Radical Economic Attitudes”, Lin & Bates 2022
Sophisticated deviants: Intelligence and radical economic attitudes
“The Paradox of Wealthy Nations’ Low Adolescent Life Satisfaction”, Rudolf & Bethmann 2022
The Paradox of Wealthy Nations’ Low Adolescent Life Satisfaction
“Why Is Europe More Equal Than the United States?”, Blanchet et al 2022
“Religious Festivals and Economic Development: Evidence from the Timing of Mexican Saint Day Festivals”, Montero & Yang 2022
“Scaring or Scarring? Labor Market Effects of Criminal Victimization”, Bindler & Ketel 2022
Scaring or Scarring? Labor Market Effects of Criminal Victimization
“The Delusive Economy: How Information and Affect Color Perceptions of National Economic Performance”, Linsi et al 2022
The delusive economy: how information and affect color perceptions of national economic performance
“Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning”, Anonymous 2022
“A Causal Test of the Strength of Weak Ties”, Rajkumar et al 2022
“Does the Dream of Home Ownership Rest Upon Biased Beliefs? A Test Based on Predicted and Realized Life Satisfaction”, Odermatt & Stutzer 2022
“The Political Economy of Populism”, Guriev & Papaioannou 2022
“Visual Studio Code Is Designed to Fracture”, Huntley 2022
“Using Large Language Models to Simulate Multiple Humans”, Aher et al 2022
“Competition for Attention in the ETF Space”, Ben-David et al 2022
“Losing Sight of Piecemeal Progress: People Lump and Dismiss Improvement Efforts That Fall Short of Categorical Change—Despite Improving”, O’Brien 2022
“Do Pre-Registration and Pre-Analysis Plans Reduce p-Hacking and Publication Bias?”, Brodeur et al 2022
Do Pre-Registration and Pre-Analysis Plans Reduce p-Hacking and Publication Bias?
“Understanding Jane Street: Strong Language”, Hobart 2022
“Cost-Effectiveness of Polygenic Risk Scores to Guide Statin Therapy for Cardiovascular Disease Prevention”, Kiflen et al 2022
“The Moralization of Effort”, Celniker et al 2022
“Turn 800 Marks into 115,000 Euros: the Tenant Gets the Deposit Back: A Plaintiff Has Fought in Court to Get Back a Rent Deposit Paid by Her Parents More Than 60 Years Ago. The Amount Has Grown Enormously Since Then”, Berliner 2022
“The Age of the Superyacht”
“Taxing Top Incomes in a World of Ideas”, Jones 2022
“Do Doctors Improve the Health Care of Their Parents? Evidence from Admission Lotteries”, Artmann et al 2022
Do Doctors Improve the Health Care of Their Parents? Evidence from Admission Lotteries
“Robust Incentives for Teams”, Dai & Toikka 2022
“Assortative Matching at the Top of the Distribution: Evidence from the World’s Most Exclusive Marriage Market”, Goñi 2022
“A Pay Change and Its Long-Term Consequences”, Krueger & Friebel 2022
“This Is Air: The ‘Non-Health’ Effects of Air Pollution”, Aguilar-Gomez et al 2022
“If I Could Do It, So Can They: Among the Rich, Those With Humbler Origins Are Less Sensitive to the Difficulties of the Poor”, Koo et al 2022
“Army Service in the All-Volunteer Era”, Greenberg et al 2022b
“Collaborations and Innovation in Partitioned Industries: An Analysis of US Feature Film Coproductions”, Jia et al 2022
“Essays on Technology and Work”, Tuhkuri 2022
“‘Beauty Too Rich for Use’: Billionaires’ Assets and Attractiveness”, Hamermesh & Leigh 2022
‘Beauty too rich for use’: Billionaires’ assets and attractiveness
“Sweet Unbinding: Sugarcane Cultivation and the Demise of Foot-Binding”, Cheng et al 2022
Sweet unbinding: Sugarcane cultivation and the demise of foot-binding
“Clans and Calamity: How Social Capital Saved Lives during China’s Great Famine”, Cao et al 2022
Clans and calamity: How social capital saved lives during China’s Great Famine
“The Doctor Prescribed an Obesity Drug. Her Insurer Called It ‘Vanity.’ Many Insurance Companies Refuse to Cover New Weight Loss Drugs That Their Doctors Deem Medically Necessary”, Kolata 2022
“The Null Result Penalty”, Chopra et al 2022 (page 3)
“Schizophrenia Polygenic Risk Score and Long-Term Success in the Labour Market: A Cohort Study”, Viinikainen et al 2022
Schizophrenia polygenic risk score and long-term success in the labour market: A cohort study
“A Golden Opportunity: The Gold Rush, Entrepreneurship and Culture”, Stuetzer et al 2022
A Golden Opportunity: The Gold Rush, Entrepreneurship and Culture
“Emergent Bartering Behavior in Multi-Agent Reinforcement Learning”, Johanson et al 2022
Emergent Bartering Behavior in Multi-Agent Reinforcement Learning
“What Determines Consumer Financial Distress? Place-Based and Person-Based Factors”, Keys et al 2022
What Determines Consumer Financial Distress? Place-Based and Person-Based Factors
“Reputation Inflation”, Filippas et al 2022
“Soft Skills in the Youth Labor Market”, Heller & Kessler 2022c
“Understanding of Trade”, Stantcheva 2022 (page 2)
“When Scale and Replication Work: Learning from Summer Youth Employment Experiments”, Heller 2022b
When scale and replication work: Learning from summer youth employment experiments
“Rent Seeking and the Decline of the Florentine School”, Piano & Hardy 2022
“How Much Does That Cost? Examining the Economic Costs of Crime in North America Attributable to People With Psychopathic Personality Disorder”, Gatner et al 2022
“A Meta-Analysis of the Effects of Electronic Performance Monitoring on Work Outcomes”, Ravid et al 2022
A meta-analysis of the effects of electronic performance monitoring on work outcomes
“Risks and Global Supply Chains: What We Know and What We Need to Know”, Baldwin & Freeman 2022b
Risks and Global Supply Chains: What We Know and What We Need to Know
“The LGBTQ+ Gap: Recent Estimates for Young Adults in the United States”, Folch 2022
The LGBTQ+ Gap: Recent Estimates for Young Adults in the United States
“Launching With a Parachute: The Gig Economy and New Business Formation”, Barrios et al 2022
Launching with a parachute: The gig economy and new business formation
“Will Studying Economics Make You Rich? A Regression Discontinuity Analysis of the Returns to College Major”, Bleemer & Mehta 2022
“Sibling Similarity in Income: A Life Course Perspective”, Grätz & Kolk 2022
“Residual Confounding in Health Plan Performance Assessments: Evidence From Randomization in Medicaid”, Wallace et al 2022
Residual Confounding in Health Plan Performance Assessments: Evidence From Randomization in Medicaid
“Scientific Grant Funding”, Goolsbee & Jones 2022
“Burden of Covid-19 Restrictions: National, Regional and Global Estimates”, Fink et al 2022
Burden of Covid-19 restrictions: National, regional and global estimates
“Demand for Rarity: Evidence from a Collectible Good”, Hughes 2022
“Why Do Women Earn Less Than Men? Evidence from Bus and Train Operators”, Bolotnyy & Emanuel 2022
Why Do Women Earn Less than Men? Evidence from Bus and Train Operators
“Criminalizing Poverty: The Consequences of Court Fees in a Randomized Experiment”, Pager et al 2022
Criminalizing Poverty: The Consequences of Court Fees in a Randomized Experiment
“The Road Not Taken: Technological Uncertainty and the Evaluation of Innovations”, Tan 2022
The Road Not Taken: Technological Uncertainty and the Evaluation of Innovations
“Darwinian Rational Expectations”, Finestone 2022
“Each Is to Count for One and None for More Than One: Predictors of Support for Economic Redistribution”, Lin & Bates 2022
“National Development Delivers: And How! And How?”, Pritchett 2022
“The Economic Effects of the English Parliamentary Enclosures”, Heldring et al 2022
The Economic Effects of the English Parliamentary Enclosures
“For Want of a Cup: The Rise of Tea in England and the Impact of Water Quality on Mortality”, Antman 2022
For Want of a Cup: The Rise of Tea in England and the Impact of Water Quality on Mortality
“The Gender Gap in Self-Promotion”, Exley & Kessler 2022
“Niche Diversity Predicts Personality Structure Across 115 Nations”, Durkee et al 2022
Niche Diversity Predicts Personality Structure Across 115 Nations
“Global Evidence on the Selfish Rich Inequality Hypothesis”, Almås et al 2022
“Pandemic Recession and Helicopter Money: Venice, 1629–1631”, Masciandaro et al 2022
“Gender Preference Gaps and Voting for Redistribution”, Ranehill & Weber 2022
“Elite Capture of Foreign Aid: Evidence from Offshore Bank Accounts”, Andersen et al 2022
Elite Capture of Foreign Aid: Evidence from Offshore Bank Accounts
“Hobo Economicus”, Leeson et al 2022
“Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning”, Curry et al 2022
Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning
“‘The Best Country in the World’: The Surprising Social Mobility of New York’s Irish-Famine Immigrants”, Anbinder et al 2022
“Can Information Reduce Ethnic Discrimination? Evidence from Airbnb”, Laouénan & Rathelot 2022
Can Information Reduce Ethnic Discrimination? Evidence from Airbnb
“Labor Market Returns to Vocational Secondary Education”, Silliman & Virtanen 2022
“Familial Resemblance, Citizenship, and Counterproductive Work Behavior: A Combined Twin, Adoption, Parent-Offspring, and Spouse Approach”, Anderson et al 2022b
“Bronze Age Long-Distance Exchange, Secret Societies, Rock Art, and the Supra Regional Interaction Hypothesis”, Ling et al 2022
“Privacy and Information Avoidance: An Experiment on Data-Sharing Preferences”, Svirsky 2022
Privacy and Information Avoidance: An Experiment on Data-Sharing Preferences
“Opportunity Neglect: An Aversion to Low-Probability Gains”, Prinsloo et al 2022
“Social Mobility and Political Regimes: Intergenerational Mobility in Hungary, 1949–2017”, Bukowski et al 2022
Social Mobility and Political Regimes: Intergenerational Mobility in Hungary, 1949–2017
“Total Meat Intake Is Associated With Life Expectancy: A Cross-Sectional Data Analysis of 175 Contemporary Populations”, You et al 2022
“Intelligence, Errors, and Cooperation in Repeated Interactions”, Proto et al 2021
Intelligence, Errors, and Cooperation in Repeated Interactions
“Parents Think—Incorrectly—That Teaching Their Children That the World Is a Bad Place Is Likely Best for Them”, Clifton & Meindl 2021
“The CEO Beauty Premium: Founder CEO Attractiveness and Firm Valuation in Initial Coin Offerings”, Colombo et al 2021
The CEO beauty premium: Founder CEO attractiveness and firm valuation in initial coin offerings
“Displacement, Diversity, and Mobility: Career Impacts of Japanese American Internment”, Arellano-Bover 2021
Displacement, Diversity, and Mobility: Career Impacts of Japanese American Internment
“Silver Coins, Wooden Tallies and Parchment Rolls in Henry III’s Exchequer”, Cassidy 2021
Silver coins, wooden tallies and parchment rolls in Henry III’s Exchequer
“Improving Real-Time Rendering of Dynamic Digital Characters in Cycles”, Dietrich 2021
Improving Real-time Rendering of Dynamic Digital Characters in Cycles
“Marriage, Quarrels, and Lovemaking”, Silva & Cordeiro 2021
“Long-Term Effects of the Targeting the Ultra Poor Program”, Banerjee et al 2021
“Post-Materialism and Economic Growth: Cultural Backlash, 1981–2019”, Kafka & Kostis 2021
Post-materialism and economic growth: Cultural backlash, 1981–2019
“Out of the Dark: The Effect of Law Enforcement Actions on Cryptocurrency Market Prices”, Abramova & Bohme 2021
Out of the Dark: The Effect of Law Enforcement Actions on Cryptocurrency Market Prices
“Occupational Characteristics Moderate Personality-Performance Relations in Major Occupational Groups”, Wilmot & Ones 2021
Occupational characteristics moderate personality-performance relations in major occupational groups
“Patience and Comparative Development”, Sunde et al 2021
“Steam Deck Won’t Have Any Exclusive Games, Valve Confirms”, Palumbo 2021
“Promoting to Opportunity: Evidence and Implications from the US Submarine Service”, Suandi 2021
Promoting to Opportunity: Evidence and Implications from the US Submarine Service
“The Predicament of Establishing Persistence: Slavery and Human Capital in Africa”, Malik & Bouaroudj 2021
The Predicament of Establishing Persistence: Slavery and Human Capital in Africa
“What Drives Racial Diversity on US Corporate Boards?”, Bogan et al 2021
“Does the Mafia Hire Good Accountants?”, Bianchi et al 2021
“Forced Entrepreneurs”, Hacamo & Kleiner 2021
“Intelligence Disclosure and Cooperation in Repeated Interactions”, Lambrecht et al 2021
Intelligence Disclosure and Cooperation in Repeated Interactions
“Returning Actionable Genomic Results in a Research Biobank: Analytic Validity, Clinical Implementation, and Resource Usage”, Zawatsky et al 2021
“One Flew Over the Cuckoo’s Clock: Selling Exclusivity Through Conspicuous Goods on Evolution”, Oosterman & Angelini 2021
One Flew Over the Cuckoo’s Clock: Selling Exclusivity Through Conspicuous Goods on Evolution
“Protective State Policies and the Employment of Fathers With Criminal Records”, Emory 2021
Protective State Policies and the Employment of Fathers with Criminal Records
“Trait/Financial Information of Potential Male Mate Eliminates Mate-Choice Copying by Women: Trade-Off Between Social Information and Personal Information in Mate Selection”, Liu et al 2021b
“Should Subscription-Based Content Creators Display Their Earnings on Crowdfunding Platforms? Evidence from Patreon”, Crosby & McKenzie 2021
“Personal Relative Deprivation and the Belief That Economic Success Is Zero-Sum”, Ongis & Davidai 2021
Personal relative deprivation and the belief that economic success is zero-sum
“The Aggregate Cost of Crime in the United States”, Anderson 2021b
“Keeping It in the Family: Female Inheritance, Inmarriage, and the Status of Women”, Bahrami-Rad 2021
Keeping it in the family: Female inheritance, inmarriage, and the status of women
“The Intergenerational Effects of a Large Wealth Shock: White Southerners After the Civil War”, Ager et al 2021
The Intergenerational Effects of a Large Wealth Shock: White Southerners after the Civil War
“Opportunity Unraveled: Private Information and the Missing Markets for Financing Human Capital”, Herbst & Hendren 2021
Opportunity Unraveled: Private Information and the Missing Markets for Financing Human Capital
“Market Expectations of a Warming Climate”, Schlenker & Taylor 2021
“Gender Quotas and Company Financial Performance: A Systematic Review”, Yu & Madison 2021
Gender quotas and company financial performance: A systematic review
“Individualistic CEO and Corporate Innovation: Evidence from US Frontier Culture”, Gao et al 2021
Individualistic CEO and Corporate Innovation: Evidence from US Frontier Culture
“Big Five Personality Traits and Performance: A Quantitative Synthesis of 50+ Meta-Analyses”, Zell & Lesick 2021b
Big Five personality traits and performance: A quantitative synthesis of 50+ meta-analyses
“Gender Identity, Coworking Spouses and Relative Income within Households”, Zinovyeva & Tverdostup 2021
Gender Identity, Coworking Spouses and Relative Income within Households
“Neural Autopilot and Context-Sensitivity of Habits”, Camerer & Li 2021
“Personality Traits and Reasons for Residential Mobility: Longitudinal Data from United Kingdom, Germany, and Australia”, Jokela 2021
“The Real Effects of Monetary Expansions: Evidence from a Large-Scale Historical Experiment”, Palma 2021
The Real Effects of Monetary Expansions: Evidence from a Large-scale Historical Experiment
“Geography and Agricultural Productivity: Cross-Country Evidence from Micro Plot-Level Data”, Adamopoulos & Restuccia 2021
Geography and Agricultural Productivity: Cross-Country Evidence from Micro Plot-Level Data
“The Institutional Foundations of Surf Break Governance in Atlantic Europe”, Rode 2021
The institutional foundations of surf break governance in Atlantic Europe
“Personality Psychology”, Roberts & Yoon 2021
“Playlisting Favorites: Measuring Platform Bias in the Music Industry”, Aguiar et al 2021
Playlisting favorites: Measuring platform bias in the music industry
“The Children of the Missed Pill”, Rau et al 2021
“High Income Men Have High Value As Long-Term Mates in the US: Personal Income and the Probability of Marriage, Divorce, and Childbearing in the US”, Hopcroft 2021
“Using Genes to Explore the Effects of Cognitive and Non-Cognitive Skills on Education and Labor Market Outcomes”, Buser et al 2021 (page 3)
“Consumers Believe That Products Work Better for Others”, Polman et al 2021
“Relationship between Rice Farming and Polygenic Scores Potentially Linked to Agriculture in China”, Zhu et al 2021
Relationship between rice farming and polygenic scores potentially linked to agriculture in China
“Win-Win Denial: The Psychological Underpinnings of Zero-Sum Thinking”, Johnson et al 2021c
Win-win denial: The psychological underpinnings of zero-sum thinking
“On the Economic Design of Stablecoins”, Catalini & Gortari 2021
“Are Black Restaurant Servers Tipped Less Than White Servers? 3 Experimental Tests of Server Race Effects Customers’ Tipping Behaviors”, Brewster et al 2021
“The Wild Card: Colonial Paper Money in French North America, 1685–1719”, Cutsinger et al 2021
The wild card: colonial paper money in French North America, 1685–1719
“The Econometrics of Early Childhood Human Capital and Investments”, Cunha et al 2021
The Econometrics of Early Childhood Human Capital and Investments
“Two Blades of Grass: The Impact of the Green Revolution”, Gollin et al 2021
“Who Is High Income, Anyway? Social Comparison, Subjective Group Identification, and Preferences over Progressive Taxation”, Cansunar 2021
“Founding Teams and Startup Performance”, Choi et al 2021
“Greenland Bans All Oil Exploration: Arctic Nation Has No Active Oil Fields but US Estimates There Could Be 17.5 Billion Barrels Undiscovered”, Press 2021
“Does Transportation Mean Transplantation? Impact of New Airline Routes on Sharing of Cadaveric Kidneys”, Wang et al 2021b
“Walrasian Equilibrium Behavior in Nature”, Loch-Temzelides 2021
“Beholding Inequality: Race, Gender, and Returns to Physical Attractiveness in the United States”, Monk et al 2021
Beholding Inequality: Race, Gender, and Returns to Physical Attractiveness in the United States
“Steps of Reasoning in Children and Adolescents”, Brocas & Carrillo 2021
“Career Effects of Mental Health”, Biasi et al 2021 (page 2)
“Government Grants, Donors, and Nonprofit Performance”, Coupet & Schehl 2021
“Peers, Buccaneers and Downton Abbey: An Economic Analysis of 19th Century British Aristocratic Marriages”, Taylor 2021
“Alienation Is Not ‘Bullshit’: An Empirical Critique of Graeber’s Theory of BS Jobs”, Soffia et al 2021
Alienation Is Not ‘Bullshit’: An Empirical Critique of Graeber’s Theory of BS Jobs
“Does Biology Drive Child Penalties? Evidence from Biological and Adoptive Families”, Kleven et al 2021
Does Biology Drive Child Penalties? Evidence from Biological and Adoptive Families
“Of Forking Paths and Tied Hands: Selective Publication of Findings, and What Economists Should Do about It”, Kasy 2021
“Everything You Might Want to Know about Whaling”, Lakeman 2021
“Local Effects of Large New Apartment Buildings in Low-Income Areas”, Asquith et al 2021
Local Effects of Large New Apartment Buildings in Low-Income Areas
“Why Some Blame Politics for Their Personal Problems”, Baird & Wolak 2021
“Union Reform, Performance Pay, and New Teacher Supply: Evidence from Wisconsin’s Act 10”, Baron 2021
Union Reform, Performance Pay, and New Teacher Supply: Evidence from Wisconsin’s Act 10
“Does Insecure Land Tenure Deter Investment? Evidence from a Randomized Controlled Trial”, Huntington & Shenoy 2021
Does insecure land tenure deter investment? Evidence from a randomized controlled trial
“The Long-Term Causal Effect of US Bombing Missions on Economic Development: Evidence from the Ho Chi Minh Trail and Xieng Khouang Province in Lao P.D.R”, Yamada & Yamada 2021
“It’s Trust or Risk? Chemosensory Anxiety Signals Affect Bargaining in Women”, Meister & Pause 2021
It’s trust or risk? Chemosensory anxiety signals affect bargaining in women
“Competition in the Black Market: Estimating the Causal Effect of Gangs in Chicago”, Bruhn 2021
Competition in the Black Market: Estimating the Causal Effect of Gangs in Chicago
“Rent Seeking for Madness: the Political Economy of Mental Asylums in the United States, 1870–1910”, Geloso & March 2021
Rent seeking for madness: the political economy of mental asylums in the United States, 1870–1910
“Death Toll of Price Limits and Protectionism in the Russian Pharmaceutical Market”, Khvan & Yakovlev 2021
Death Toll of Price Limits and Protectionism in the Russian Pharmaceutical Market
“Lehman’s Lemons: Do Career Disruptions Matter for the Top 5%?”, Fedyk & Hodson 2021
Lehman’s Lemons: Do Career Disruptions Matter for the Top 5%?
“Employee Responses to Compensation Changes: Evidence from a Sales Firm”, Sandvik et al 2021
Employee Responses to Compensation Changes: Evidence from a Sales Firm
“Are CEOs Different?”, Kaplan & Sorensen 2021
“Oil Import Portfolio Risk and Spillover Volatility”, Bigerna et al 2021
“The Congestion Costs of Uber and Lyft”, Tarduno 2021
“Informational Herding, Optimal Experimentation, and Contrarianism”, Smith et al 2021
Informational Herding, Optimal Experimentation, and Contrarianism
“Care to Wager Again? An Appraisal of Paul Ehrlich’s Counterbet Offer to Julian Simon, Part 2: Critical Analysis”, Desrochers et al 2021b
“Care to Wager Again? An Appraisal of Paul Ehrlich’s Counterbet Offer to Julian Simon, Part 1: Outcomes”, Desrochers et al 2021
“Why Do Wealthy Parents Have Wealthy Children?”, Fagereng et al 2021
“Intergenerational Mobility of Immigrants in the United States over Two Centuries”, Abramitzky et al 2021
Intergenerational Mobility of Immigrants in the United States over Two Centuries
“Folklore”, Michalopoulos & Xue 2021
“Instrumental Use Erodes Sacred Values”, Ruttan & Nordgren 2021
“Lifting Growth Barriers for New Firms: Evidence from an Entrepreneurship Training Experiment With Two Million Online Businesses”, Jin & Sun 2021
“Financial Institutions and the British Industrial Revolution: Did Financial Underdevelopment Hold Back Growth?”, Hodgson 2021
“The Cultural Dynamics of Declining Residential Mobility”, Buttrick & Oishi 2021
“People Management Skills, Employee Attrition, and Manager Rewards: An Empirical Analysis”, Hoffman & Tadelis 2021
People Management Skills, Employee Attrition, and Manager Rewards: An Empirical Analysis
“College Quality and Attendance Patterns: A Long-Run View”, Hendricks et al 2021
“The Link between Income, Income Inequality, and Prosocial Behavior around the World: A Multiverse Approach”, Macchia & Whillans 2021
“The Semiconductor Supply Chain: Assessing National Competitiveness”, Khan et al 2021
The Semiconductor Supply Chain: Assessing National Competitiveness
“Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail”, Jones 2021
Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail
“Ten Facts on Declining Business Dynamism and Lessons from Endogenous Growth Theory”, Akcigit & Ates 2021
Ten Facts on Declining Business Dynamism and Lessons from Endogenous Growth Theory
“Debasement of Silver throughout the Late Bronze-Iron Age Transition in the Southern Levant: Analytical and Cultural Implications”, Eshel et al 2021
“Will NASDAQ’s Diversity Rules Harm Investors?”, Fried 2021
“The Use and Misuse of Income Data and Extreme Poverty in the United States”, Meyer et al 2021
The Use and Misuse of Income Data and Extreme Poverty in the United States
“Racial Bias in the Sharing Economy and the Role of Trust and Self-Congruence”, Nødtvedt et al 2021
Racial Bias in the Sharing Economy and the Role of Trust and Self-Congruence
“The Psychology of Asymmetric Zero-Sum Beliefs”, Roberts & Davidai 2021
“Natural Selection in Contemporary Humans Is Linked to Income and Substitution Effects”, Hugh-Jones & Abdellaoui 2021
Natural Selection in Contemporary Humans is Linked to Income and Substitution Effects
“Economic Implications of Access to Daylight and Views in Office Buildings from Improved Productivity”, MacNaughton 2021
Economic implications of access to daylight and views in office buildings from improved productivity
“Non-Replicable Publications Are Cited More Than Replicable Ones”, Serra-Garcia & Gneezy 2021
Non-replicable publications are cited more than replicable ones
“How War Changes Land: Soil Fertility, Unexploded Bombs, and the Underdevelopment of Cambodia”, Lin 2020b
How War Changes Land: Soil Fertility, Unexploded Bombs, and the Underdevelopment of Cambodia
“A Global Decline in Research Productivity? Evidence from China and Germany”, Boeing & Hünermund 2020
A global decline in research productivity? Evidence from China and Germany
“The Airbnbs”, Graham 2020
“Why Is Productivity Correlated With Competition?”, Backus 2020
“Does Building New Housing Cause Displacement? The Supply and Demand Effects of Construction in San Francisco”, Pennington 2020
“Intergenerational Mobility in the Very Long Run: Florence (1427–2011)”, Barone & Mocetti 2020
Intergenerational Mobility in the Very Long Run: Florence (1427–2011)
“What Matters More for Entrepreneurship Success? A Meta-Analysis Comparing General Mental Ability and Emotional Intelligence in Entrepreneurial Settings”, Allen et al 2020
“Predicting Mid-Life Capital Formation With Pre-School Delay of Gratification and Life-Course Measures of Self-Regulation”, Benjamin et al 2020
“The Daily Grind: Before Millstones Were Invented, the Preparation of Flour for Food Was an Arduous Task Largely Carried out by Women for Hours Every Day. How Did It Affect Their Lives and Why Does It Remain a Tradition in Some Places Even Today?”, Laudan 2020
“The Death of a Technical Skill”, Horton & Tambe 2020
“Are Inventors or Firms the Engines of Innovation?”, Bhaskarabhatla et al 2020
“The Micro-Evidence for the Malthusian System: France, 1670–1840”, Cummins 2020
The micro-evidence for the Malthusian system: France, 1670–1840
“The Elasticity of Science”, Myers 2020
“Writing a Book: Is It worth It? [Yes, With Luck and Marketing]”, Kleppmann 2020
Writing a book: is it worth it? [yes, with luck and marketing]
“Information Frictions and Entrepreneurship”, Hegde & Tumlinson 2020
“The Gift of Moving: Intergenerational Consequences of a Mobility Shock”, Nakamura et al 2020
The Gift of Moving: Intergenerational Consequences of a Mobility Shock
“The Perfection Premium”, Isaac & Spangenberg 2020
“The Washington Consensus Works: Causal Effects of Reform, 1970–2015”, Grier & Grier 2020
The Washington Consensus Works: Causal Effects of Reform, 1970–2015
“Does Education Matter? Tests from Extensions of Compulsory Schooling in England and Wales 1919-22, 1947, and 1972”, Clark & Cummins 2020
“Collider Bias in Economic History Research”, Schneider 2020b
“Does It Matter Where You Came From? Ancestry Composition and Economic Performance of US Counties, 1850–2010”, Fulford et al 2020
“Learning Is Not Enough: Diminishing Marginal Revenues and Increasing Abatement Costs of Wind and Solar”, Das et al 2020b
“Molecular Genetics, Risk Aversion, Return Perceptions, and Stock Market Participation”, Sias et al 2020 (page 2)
Molecular Genetics, Risk Aversion, Return Perceptions, and Stock Market Participation
“The Return of the $70 Video Game Has Been a Long Time Coming: Top-End Game Pricing Has Never Been Lower When Measured in Constant Dollars”, Orland 2020
“Lessons from Investing in 483 Companies”, O’Shaughnessy & Songhurst 2020
“The Rise and Fall of Adobe Flash: Before Flash Player Sunsets This December, We Talk Its Legacy With Those Who Built It”, Moss 2020
“Prestige Matters: Wage Premium and Value Addition in Elite Colleges”, Sekhri 2020
Prestige Matters: Wage Premium and Value Addition in Elite Colleges
“Randomizing Religion: the Impact of Protestant Evangelism on Economic Outcomes”, Bryan et al 2020
Randomizing Religion: the Impact of Protestant Evangelism on Economic Outcomes
“When Corporate Social Responsibility Backfires: Evidence from a Natural Field Experiment”, List & Momeni 2020
When Corporate Social Responsibility Backfires: Evidence from a Natural Field Experiment
“Happy Lottery Winners and Lottery-Ticket Bias”, Kim & Oswald 2020
“Heads or Tails: The Impact of a Coin Toss on Major Life Decisions and Subsequent Happiness”, Levitt 2020
Heads or Tails: The Impact of a Coin Toss on Major Life Decisions and Subsequent Happiness
“Replicating Patterns of Prospect Theory for Decision under Risk”, Ruggeri et al 2020
Replicating patterns of prospect theory for decision under risk
“SoftBank Vision Fund Posts $17.7 Billion Loss on WeWork, Uber”, Alpeyev 2020
SoftBank Vision Fund Posts $17.7 Billion Loss on WeWork, Uber
“Optimal Smart Contracts With Costly Verification”, Mamageishvili & Schlegel 2020
“Theory of the Nudnik: The Future of Consumer Activism and What We Can Do to Stop It”, Arbel & Shapira 2020
Theory of the Nudnik: The Future of Consumer Activism and What We Can Do to Stop It
“Progress Studies for Aspiring Young Scholars: An Online Summer Program in the History of Technology for High School Students”, Scholars 2020
“An Attempt at Explaining, Blaming, and Being Very Slightly Sympathetic Toward Enron”, Lakeman 2020
An Attempt at Explaining, Blaming, and Being Very Slightly Sympathetic Toward Enron
“Are Tariffs Bad for Growth? Yes, Say 5 Decades of Data from 150 Countries”, Furceri et al 2020
Are tariffs bad for growth? Yes, say 5 decades of data from 150 countries
“In Ohio, the Amish Take On the Coronavirus: A Famously Traditional Community Has Mobilized to Help Hospitals With Medical Supplies, Even As It Struggles With Reconciling Its Communal Way of Life With the Dictates of Social Distancing.”, Williamson 2020
“Genetic Endowments and Wealth Inequality”, Barth et al 2020
“Do Management Interventions Last? Evidence from India”, Bloom et al 2020b
“Are Ideas Getting Harder to Find?”, Bloom et al 2020
“The Effects of Income Transparency on Well-Being: Evidence from a Natural Experiment”, Perez-Truglia 2020
The Effects of Income Transparency on Well-Being: Evidence from a Natural Experiment
“Open Source Fonts Are Love Letters to the Design Community: Typefaces That Be Freely Used and Modified Give Others a Chance to Hone Their Craft—And Share Valuable Feedback”, Finley 2020
“How Cameo Turned D-List Celebs Into a Monetization Machine: Inside the Surreal and Lucrative Two-Sided Marketplace of Mediocre Famous People”, Sauer 2020
“Npm Is Joining GitHub”, Friedman 2020
“Stay True to Your Roots? Category Distance, Hierarchy, and the Performance of New Entrants in the Music Industry”, Younkin & Kashkooli 2020
“The Lasting Effects of the 1918 Influenza Pandemic”, Tabarrok 2020
“What Remains of Cross-Country Convergence”, Johnson & Papageorgiou 2020b
“Liberalizing Art. Evidence on the Impressionists at the End of the Paris Salon”, Etro et al 2020
Liberalizing art. Evidence on the Impressionists at the end of the Paris Salon
“What Do Editors Maximize? Evidence from 4 Economics Journals”, Card & DellaVigna 2020
What Do Editors Maximize? Evidence from 4 Economics Journals
“Recalibrating Global Data Center Energy-Use Estimates”, Masanet et al 2020
“Slavery and Anglo-American Capitalism Revisited”, Wright 2020
“The College Admissions Contribution to the Labor Market Beauty Premium”, On 2020
The College Admissions Contribution to the Labor Market Beauty Premium
“Reputation Transferability across Contexts: Maintaining Cooperation among Anonymous Cryptomarket Actors When Moving between Markets”, Norbutas et al 2020
“Nothing Ventured, Nothing Gained: Parasite Infection Is Associated With Entrepreneurial Initiation, Engagement, and Performance”, Lerner et al 2020
“Clustering of Health, Crime and Social-Welfare Inequality in 4 Million Citizens from Two Nations”, Richmond-Rakerd et al 2020
Clustering of health, crime and social-welfare inequality in 4 million citizens from two nations
“The Gender Cliff in the Relative Contribution to the Household Income: Insights from Modeling Marriage Markets in 27 European Countries”, Grow & Bavel 2020
“Understanding Contemporary Forms of Exploitation: Attributions of Passion Serve to Legitimize the Poor Treatment of Workers”, Kim et al 2020b
“The Changing Structure of American Innovation: Some Cautionary Remarks for Economic Growth”, Arora et al 2020
The Changing Structure of American Innovation: Some Cautionary Remarks for Economic Growth
“Consumer Debt and Satisfaction in Life”, Greenberg & Mogilner 2020
“The Signal Quality of Earnings Announcements: Evidence from an Informed Trading Cartel”, Xie 2020
The signal quality of earnings announcements: evidence from an informed trading cartel
“Beneath the Radar: Exploring the Economics of Business Fraud via Underground Markets”, Gãnán et al 2020
Beneath the radar: Exploring the economics of business fraud via underground markets
“Persistence Despite Revolutions”, Alesina et al 2020
“Destructive Creation at Work: How Financial Distress Spurs Entrepreneurship”, Babina 2020
Destructive Creation at Work: How Financial Distress Spurs Entrepreneurship
“Social Media-Predicted Personality Traits and Values Can Help Match People to Their Ideal Jobs”, Kern et al 2019
Social media-predicted personality traits and values can help match people to their ideal jobs
“CEO Selection and Executive Appearance”, Cook & Mobbs 2019
“Non-Cognitive Skills: How Much Do They Matter for Earnings in Canada?”, McLean et al 2019
Non-Cognitive Skills: How Much Do They Matter for Earnings in Canada?
“This Is Why Your Holiday Travel Is Awful: The Long, Sordid History of New York’s Penn Station Shows How Progressives Have Made It Too Hard for the Government to Do Big Things—And Why, Believe It or Not, Robert Caro Is to Blame”, Dunkelman 2019
“The Social Subsidy of Angel Investing”, Danco 2019
“Collective Dynamics of Dark Web Marketplaces”, ElBahrawy et al 2019
“A Century of Research on Conscientiousness at Work”, Wilmot & Ones 2019
“The Origins of Firm Strategy: Learning by Economic Experimentation and Strategic Pivots in the Early Automobile Industry”, Pillai et al 2019
“Predicting Entrepreneurial Success Is Hard: Evidence from a Business Plan Competition in Nigeria”, McKenzie & Sansone 2019
Predicting entrepreneurial success is hard: Evidence from a business plan competition in Nigeria
“Be Cautious With the Precautionary Principle: Evidence from Fukushima Daiichi Nuclear Accident”, Neidell 2019
Be Cautious with the Precautionary Principle: Evidence from Fukushima Daiichi Nuclear Accident
“Why Underachievers Dominate Secret Police Organizations: Evidence from Autocratic Argentina”, Scharpf & Gläßel 2019
Why Underachievers Dominate Secret Police Organizations: Evidence from Autocratic Argentina
“The Economic Effects of Facebook”, Mosquera et al 2019
“Polygenic Score Analysis Of Educational Achievement And Intergenerational Mobility”, Rustichini et al 2019
Polygenic Score Analysis Of Educational Achievement And Intergenerational Mobility
“Measuring ‘Schmeduling’”, Rees-Jones & Taubinsky 2019
“Progress by Consent: Adam Smith As Development Economist”, Easterly 2019
“Mismatches in the Marriage Market”, Lichter et al 2019
“The Impact of the 2018 Tariffs on Prices and Welfare”, Amiti et al 2019
“Let’s (Not) Make a Deal: Geopolitics and Greenland”, Rahbek-Clemmensen 2019
“A Scientific Approach to Entrepreneurial Decision Making: Evidence from a Randomized Control Trial”, Camuffo et al 2019
A Scientific Approach to Entrepreneurial Decision Making: Evidence from a Randomized Control Trial
“Lee Kuan Yew Review, Part Four: The Pathway to Power”, TracingWoodgrains 2019
“Is the Rate of Scientific Progress Slowing Down?”, Cowen & Southwood 2019
“Can You Indemnify Against Dick Pics? The Rise of Scandal Insurance in Hollywood”, Kachka 2019
Can You Indemnify Against Dick Pics? The rise of scandal insurance in Hollywood
“Universal Basic Income in the United States and Advanced Countries”, Hoynes & Rothstein 2019
Universal Basic Income in the United States and Advanced Countries
“Reviving American Entrepreneurship? Tax Reform and Business Dynamism”, Sedlacek & Sterk 2019
Reviving American entrepreneurship? tax reform and business dynamism
“On the Resilience of the Dark Net Market Ecosystem to Law Enforcement Intervention”, Bradley 2019
On the Resilience of the Dark Net Market Ecosystem to Law Enforcement Intervention
“Lee Kuan Yew Review, Part Three: Race, Language, and Uncomfortable Questions”, TracingWoodgrains 2019
Lee Kuan Yew Review, Part Three: Race, Language, and Uncomfortable Questions
“The Macroeconomic Impact of Microeconomic Shocks: Beyond Hulten’s Theorem”, Baqaee & Farhi 2019
The Macroeconomic Impact of Microeconomic Shocks: Beyond Hulten’s Theorem
“Lee Kuan Yew Review, Part Two: "You Are Free to Agree"”, TracingWoodgrains 2019
“Book Review: From Third World to First, by Lee Kuan Yew [PART ONE]”, TracingWoodgrains 2019
Book Review: From Third World to First, by Lee Kuan Yew [PART ONE]
“The Promise and Price of Cellular Therapies: New ‘Living Drugs’—Made from a Patient’s Own Cells—Can Cure Once Incurable Cancers. But Can We Afford Them?”, Mukherjee 2019
“Moving off the Map: How Knowledge of Organizational Operations Empowers and Alienates”, Huising 2019
Moving off the Map: How Knowledge of Organizational Operations Empowers and Alienates
“Squaring Venture Capital Valuations With Reality”, Gornall & Strebulaev 2019
“Time Use and Happiness of Millionaires: Evidence From the Netherlands”, Smeets et al 2019
Time Use and Happiness of Millionaires: Evidence From the Netherlands
“Judge Judy Is Still Judging You: For More Than 20 Years, Judith Sheindlin Has Dominated Daytime Ratings—By Making Justice in a Complicated World Look Easy”, Hughes 2019
“Does Management Training Help Entrepreneurs Grow New Ventures? Field Experimental Evidence from Singapore”, Kotha et al 2019
“Food Deserts and the Causes of Nutritional Inequality”, Allcott et al 2019
“Corporate Editors in the Evolving Landscape of OpenStreetMap”, Anderson et al 2019
Corporate Editors in the Evolving Landscape of OpenStreetMap
“Heritability of Lifetime Earnings”, Hyytinen et al 2019
“Using Randomized Controlled Trials to Estimate Long-Run Impacts in Development Economics”, Bouguen et al 2019
Using Randomized Controlled Trials to Estimate Long-Run Impacts in Development Economics
“The Utterly Dysfunctional Belt and Road”, Greer 2019
“1960: The Year The Singularity Was Cancelled”, Alexander 2019
“Antitrust As Allocator of Coordination Rights”, Paul 2019
“Predicting Individual-Level Income from Facebook Profiles”, Matz et al 2019
“Your Order, Their Labor: An Exploration of Algorithms and Laboring on Food Delivery Platforms in China”, Ping 2019
“The Arrival of Fast Internet and Employment in Africa”, Hjort & Poulsen 2019
“Scaling of Atypical Knowledge Combinations in American Metropolitan Areas from 1836–2010”, Mewes 2019
Scaling of Atypical Knowledge Combinations in American Metropolitan Areas from 1836–2010
“Squeezing the Bears: Cornering Risk and Limits on Arbitrage during the ‘British Bicycle Mania’, 1896–1898”, Quinn 2019
“How the next Recession Could save Lives: Death Rates Have Dropped during past Economic Downturns, Even As Many Health Trends Have Worsened. Researchers Are Scrambling to Decipher Lessons Before the next Big Recession”, Peeples 2019
“Repurposing Large Health Insurance Claims Data to Estimate Genetic and Environmental Contributions in 560 Phenotypes”, Lakhani et al 2019
“‘Crowds’ of Amateurs & Professional Entrepreneurs in Marketplaces”, Boudreau 2019
‘Crowds’ of Amateurs & Professional Entrepreneurs in Marketplaces
“GDP-B: Accounting for the Value of New and Free Goods in the Digital Economy”, Brynjolfsson et al 2019
GDP-B: Accounting for the Value of New and Free Goods in the Digital Economy
“Entrepreneurial Uncertainty and Expert Evaluation: An Empirical Analysis”, Scott et al 2019
Entrepreneurial Uncertainty and Expert Evaluation: An Empirical Analysis
“Can Psychological Traits Be Inferred From Spending? Evidence From Transaction Data”, Gladstone et al 2019
Can Psychological Traits Be Inferred From Spending? Evidence From Transaction Data
“The Deadweight Loss Of Social Recognition”, Butera et al 2019
“My Stepdad’s Huge Data Set: Welcome to the Age of Data-Driven Porn”, Turner 2019
My Stepdad’s Huge Data Set: Welcome to the age of data-driven porn
“Farewell to Confucianism: The Modernizing Effect of Dismantling China’s Imperial Examination System”, Bai 2019b
Farewell to Confucianism: The modernizing effect of dismantling China’s imperial examination system
“Health and Wealth in the Roman Empire”, Jongman 2019
“Can Psychological Traits Be Inferred From Spending? Evidence From Transaction Data § Table S3: The 5 Spending Categories Most Positively and Negatively Correlated With Each of the Psychological Traits”, Gladstone et al 2019 (page 12)
“The Ties That Bind: Implicit Contracts and Management Practices in Family-Run Firms”, Lemos 2019
The ties that bind: implicit contracts and management practices in family-run firms
“Mycorrhizal Fungi Respond to Resource Inequality by Moving Phosphorus from Rich to Poor Patches across Networks”, Whiteside et al 2019
“The Politics of Zero-Sum Thinking: The Relationship between Political Ideology and the Belief That Life Is a Zero-Sum Game”, Davidai & Ongis 2019
“Accounting Theory As a Bayesian Discipline”, Johnstone 2018
“Buffett’s Alpha”, Frazzini et al 2018
“Do Economists Swing for the Fences After Tenure?”, Brogaard et al 2018
“The Rich are Different: Unravelling the Perceived and Self-Reported Personality Profiles of High-Net-Worth Individuals”, Leckelt et al 2018
“Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs”, Broockman et al 2018
“Replication Data For: ‘Predispositions and the Political Behavior of American Economic Elites: Evidence from Technology Entrepreneurs’”, Broockman et al 2018
“Are CEOs Born Leaders? Lessons from Traits of a Million Individuals”, Adams et al 2018
Are CEOs Born Leaders? Lessons from Traits of a Million Individuals
“Shall We Serve the Dark Lords? A Meta-Analytic Review of Psychopathy and Leadership”, Landay et al 2018
Shall we serve the dark lords? A meta-analytic review of psychopathy and leadership
“Dark Motives and Elective Use of Brainteaser Interview Questions”, Highhouse et al 2018
Dark Motives and Elective Use of Brainteaser Interview Questions
“Knitting Community: Human and Social Capital in the Transition to Entrepreneurship”, Kim 2018
Knitting Community: Human and Social Capital in the Transition to Entrepreneurship
“Newton’s Financial Misadventures in the South Sea Bubble”, Odlyzko 2018
“Notes on the Dynamics of Human Civilization: The Growth Revolution”, Greer 2018
Notes on the Dynamics of Human Civilization: The Growth Revolution
“Effects of Non-Normal Performance Distributions on the Accuracy of Utility Analysis”, Aguinis et al 2018
Effects of Non-normal Performance Distributions on the Accuracy of Utility Analysis
“Blockchain-Based Solution for Proof of Delivery of Physical Assets”, Hasan & Salah 2018
Blockchain-Based Solution for Proof of Delivery of Physical Assets
“Solving the Buyer and Seller’s Dilemma: A Dual-Deposit Escrow Smart Contract for Provably Cheat-Proof Delivery and Payment for a Digital Good without a Trusted Mediator”, Asgaonkar & Krishnamachari 2018
“Do High School Sports Build or Reveal Character? Bounding Causal Estimates of Sports Participation”, Ransom & Ransom 2018
Do high school sports build or reveal character? Bounding causal estimates of sports participation
“The Geography of Family Differences and Intergenerational Mobility”, Gallagher et al 2018
The geography of family differences and intergenerational mobility
“The Prevalence and Co-Occurrence of Psychiatric Conditions among Entrepreneurs and Their Families”, Freeman et al 2018
The prevalence and co-occurrence of psychiatric conditions among entrepreneurs and their families
“Is There a Startup Wage Premium? Evidence from MIT Graduates”, Kim 2018b
Is there a startup wage premium? Evidence from MIT graduates
“Categorizing Variants of Goodhart’s Law”, Manheim & Garrabrant 2018
“The Impact of Consulting Services on Small and Medium Enterprises: Evidence from a Randomized Trial in Mexico”, Bruhn et al 2018
“CEO Traits and Firm Outcomes: Do Early Childhood Experiences Matter?”, Henderson & Hutton 2018
CEO Traits and Firm Outcomes: Do Early Childhood Experiences Matter?
“Are Resettled Oustees from the Sardar Sarovar Dam Project Better off Today Than Their Former Neighbors Who Were Not Ousted?”, times 2018
“Funding Breakthrough Research: Promises and Challenges of the ‘ARPA Model’”, Azoulay et al 2018
Funding Breakthrough Research: Promises and Challenges of the ‘ARPA Model’
“Pursuing Sustainable Productivity With Millions of Smallholder Farmers”, Cui et al 2018
Pursuing sustainable productivity with millions of smallholder farmers
“Misperceiving Inequality”, Gimpelson & Treisman 2018
“Relative Education and the Advantage of a College Degree”, Horowitz 2018
“Why Do Academics Oppose the Market? A Test of Nozick’s Hypothesis”, Magni-Berton & Ríos 2018
Why do academics oppose the market? A test of Nozick’s hypothesis
“Why The Business Case for Diversity Is Wrong”, Maitland 2018
“A Survey of Empirical Evidence on Patents and Innovation”, Sampat 2018
“Having a Creative Day: Understanding Entrepreneurs’ Daily Idea Generation through a Recovery Lens”, Weinberger et al 2018
Having a creative day: Understanding entrepreneurs’ daily idea generation through a recovery lens
“Algorithmic Entities”, LoPucki 2018
“Domestic Round-Trip Fares and Fees: Average Domestic Round-Trip Airfare: Nominal & Real 2018”, America 2018
Domestic Round-Trip Fares and Fees: Average Domestic Round-Trip Airfare: Nominal & Real 2018
“Competing for Love: Applying Sexual Economics Theory to Mating Contests”, Baumeister et al 2017
Competing for love: Applying sexual economics theory to mating contests
“A French Migrant Business Network in the Period of Export-Led Growth (ELG) in Mexico: The Case of the Barcelonnettes”, Galindo 2017
“Adaptability and Survival in Small & Medium-Sized Firms”, Hodgson et al 2017
“Birth Order and College Major in Sweden”, Barclay et al 2017
“Early Industrial Roots of Green Chemistry and the History of the BHC Ibuprofen Process Invention and Its Quality Connection”, Murphy 2017
“The Power of Bias in Economics Research”, Ioannidis et al 2017
“Management As a Technology?”, Bloom et al 2017b
“Labour Repression & the Indo-Japanese Divergence”, Pseudoerasmus 2017
“Is Individual Job Performance Distributed According to a Power Law? A Review of Methods for Comparing Heavy-Tailed Distributions”, Spain et al 2017
“The Transmission of Inequality Across Multiple Generations: Testing Recent Theories With Evidence from Germany”, Braun & Stuhler 2017
“15+ Ways a Venture Capitalist Says ‘No’”, Allen 2017
“Does Diversity Pay? A Replication of Herring 2009 [No]”, Stojmenovska et al 2017
“The Most Senseless Environmental Crime of the 20th Century: Fifty Years Ago 180,000 Whales Disappeared from the Oceans without a Trace, and Researchers Are Still Trying to Make Sense of Why. Inside the Most Irrational Environmental Crime of the Century.”, Homans 2017
“The Exquisitely English (And Amazingly Lucrative) World of London Clerks: It’s a Dickensian Profession That Can Still Pay Upwards of $650,000 per Year”, Akam 2017
“Kim Cavitt Public Comment on FTC Hearing Aid Legislation [2017]”, Cavitt 2017
Kim Cavitt public comment on FTC hearing aid legislation [2017]
“50 Years Of Growth In American Consumption, Income, And Wages”, Sacerdote 2017
50 Years Of Growth In American Consumption, Income, And Wages
“Genetic Predisposition to Obesity and Medicare Expenditures”, Wehby et al 2017
“Smart and Illicit: Who Becomes an Entrepreneur and Do They Earn More?”, Levine & Rubinstein 2017
Smart and Illicit: Who Becomes an Entrepreneur and Do They Earn More?
“2016 Letter to Shareholders”, Bezos 2017
“Pricing the Future in the 17th Century: Calculating Technologies in Competition”, Deringer 2017
Pricing the Future in the 17th Century: Calculating Technologies in Competition
“Migration, Population Composition and Long Run Economic Development: Evidence from Settlements in the Pampas”, Droller 2017
“Better Babblers”, Hanson 2017
“Dissecting Ponzi Schemes on Ethereum: Identification, Analysis, and Impact”, Bartoletti et al 2017
Dissecting Ponzi schemes on Ethereum: identification, analysis, and impact
“Surveying the Forest: A Meta-Analysis, Moderator Investigation, and Future-Oriented Discussion of the Antecedents of Voluntary Employee Turnover”, Rubenstein et al 2017
“Potterian Economics”, Levy & Snir 2017
“Years of Potential Life Lost and Life Expectancy in Schizophrenia: a Systematic Review and Meta-Analysis”, Hjorthøj et al 2017
“Industrial Espionage and Productivity”, Glitz & Meyersson 2017
“Creative Destruction: Barriers to Urban Growth and the Great Boston Fire of 1872”, Hornbeck & Keniston 2017
Creative Destruction: Barriers to Urban Growth and the Great Boston Fire of 1872
“Export of Plastic Debris by Rivers into the Sea”, Schmidt et al 2017b
“Birkin Demand: A Sage & Stylish Investment”, Newsom 2016
“KopperCoin—A Distributed File Storage With Financial Incentives”, Kopp et al 2016
KopperCoin—A Distributed File Storage with Financial Incentives
“Overconfidence in Personnel Selection: When and Why Unstructured Interview Information Can Hurt Hiring Decisions”, Kausel et al 2016
“Evaluating Indicators of Job Performance: Distributions and Types of Analyses”, Chambers 2016
Evaluating indicators of job performance: Distributions and types of analyses
“The Causal Effects of Education on Health, Mortality, Cognition, Well-Being, and Income in the UK Biobank”, Davies et al 2016
“Evidence for a Conserved Quantity in Human Mobility”, Alessandretti et al 2016
“The View from Above: Applications of Satellite Data in Economics”, Donaldson & Storeygard 2016
The View from Above: Applications of Satellite Data in Economics
“Resetting the Urban Network: 117–2012”, Michaels & Rauch 2016
“Human Collective Intelligence As Distributed Bayesian Inference”, Krafft et al 2016
Human collective intelligence as distributed Bayesian inference
“The Genetics of Success: How Single-Nucleotide Polymorphisms Associated With Educational Attainment Relate to Life-Course Development”, Belsky et al 2016
“The Implications of Modern Business-Entity Law for the Regulation of Autonomous Systems”, Bayern 2016
The Implications of Modern Business-Entity Law for the Regulation of Autonomous Systems
“Preparing for the Worst: The Space Insurance Market’s Realistic Disaster Scenarios”, Gubby et al 2016
Preparing for the Worst: The Space Insurance Market’s Realistic Disaster Scenarios
“Safeguarding the Future: The Story of How Singapore Has Managed Its Reserves and the Founding of GIC”, Orchard 2016
Safeguarding the Future: The Story of How Singapore Has Managed Its Reserves and the Founding of GIC
“Valuing the Human Health Damage Caused by the Fraud of Volkswagen”, Oldenkamp et al 2016
Valuing the human health damage caused by the fraud of Volkswagen
“Molecular Genetic Contributions to Social Deprivation and Household Income in UK Biobank (n = 112,151)”, Hill et al 2016
“Wealth, Health, and Child Development: Evidence from Administrative Data on Swedish Lottery Players”, Cesarini et al 2016
Wealth, Health, and Child Development: Evidence from Administrative Data on Swedish Lottery Players
“Does Academic Research Destroy Stock Return Predictability?”, McLean & Pontiff 2016
“Adapting to Climate Change: The Remarkable Decline in the US Temperature-Mortality Relationship over the Twentieth Century”, Barreca et al 2016
“Equality Under Threat by the Talented: Evidence from Worker-Managed Firms”, Burdín 2016
Equality Under Threat by the Talented: Evidence from Worker-Managed Firms
“Going for the Gold: The Economics of the Olympics”, Baade & Matheson 2016
“Religiosity and Income: a Panel Cointegration and Causality Analysis”, Herzer & Strulik 2016
Religiosity and income: a panel cointegration and causality analysis
“Book Review of Ryan Patrick Hanley, Ed. 2016, Adam Smith: His Life, Thought, and Legacy”, Howes 2016
Book review of Ryan Patrick Hanley, ed. 2016, Adam Smith: His Life, Thought, and Legacy
“The Contractual Nature of the City”, Lu 2016
“Overweight Trends among Polish Schoolchildren Before and After the Transition from Communism to Capitalism”, Gomula et al 2015
“Genes, Legitimacy And Hypergamy: Another Look At The Economics Of Marriage”, Saint-Paul 2015
Genes, Legitimacy And Hypergamy: Another Look At The Economics Of Marriage
“Validation of Decentralised Smart Contracts Through Game Theory and Formal Methods”, Bigi et al 2015
Validation of Decentralised Smart Contracts Through Game Theory and Formal Methods
“The Institutional Causes of China’s Great Famine, 1959–1961”, Meng et al 2015
“What Makes Uber Run: The Transportation Service Has Become a Global Brand, an Economic Force, and a Cultural Lightning Rod”, Chafkin 2015
“Ironing Out Deficiencies: Evidence from the United States on the Economic Effects of Iron Deficiency”, Niemesh 2015
Ironing Out Deficiencies: Evidence from the United States on the Economic Effects of Iron Deficiency
“Non-Cognitive Deficits and Young Adult Outcomes: The Long-Run Impacts of a Universal Child Care Program”, Baker et al 2015
“Do Pharmacists Buy Bayer? Informed Shoppers and the Brand Premium”, Bronnenberg et al 2015
Do Pharmacists Buy Bayer? Informed Shoppers and the Brand Premium
“Signaling and Productivity in the Private Financial Returns to Schooling”, Bingley et al 2015
Signaling and Productivity in the Private Financial Returns to Schooling
“The Economics of Reproducibility in Preclinical Research”, Freedman et al 2015
“A Swedish National Twin Study of Criminal Behavior and Its Violent, White-Collar and Property Subtypes”, Kendler et al 2015
“Bankruptcy Rates among NFL Players With Short-Lived Income Spikes”, Carlson et al 2015
Bankruptcy Rates among NFL Players with Short-Lived Income Spikes
“How Those Plush Easter Bunnies Got so Cuddly”, Postrel 2015
“To Apply or Not to Apply: A Survey Analysis of Grant Writing Costs and Benefits”, Hippel & Hippel 2015
To Apply or Not to Apply: A Survey Analysis of Grant Writing Costs and Benefits
“Competition, Work Rules and Productivity”, Bridgman 2015
“Manic Tendencies Are Not Related to Being an Entrepreneur, Intending to Become an Entrepreneur, or Succeeding As an Entrepreneur”, Johnson et al 2015b
“Gender Identity and Relative Income within Households”, Bertrand et al 2015
“Rational Theory of Warrant Pricing”, Samuelson 2015
“The Financing of Jihadi Terrorist Cells in Europe”, Oftedal 2015
“The Burden of Health Care Costs for Patients With Dementia in the Last 5 Years of Life”, Kelley et al 2015
The burden of health care costs for patients with dementia in the last 5 years of life
“Only the Bad Die Young: Restaurant Mortality in the Western US”, Luo & Stark 2014
Only the Bad Die Young: Restaurant Mortality in the Western US
“Discounting Behavior: A Reconsideration”, Andersen et al 2014
“Harvard Innovation Lab Visualizes the Evolution of the Desk”, Azzarello 2014
“Intergenerational Wealth Mobility in England, 1858–2012: Surnames and Social Mobility”, Clark & Cummins 2014
Intergenerational Wealth Mobility in England, 1858–2012: Surnames and Social Mobility
“The Stock Market Speaks: How Dr. Alchian Learned to Build the Bomb”, Newhard 2014
The stock market speaks: How Dr. Alchian learned to build the bomb
“The Summer’s Most Unread Book Is… A Simple Index Drawn from E-Books Shows Which Best Sellers Are Going Unread (We’re Looking at You, Piketty)”, Ellenberg 2014
“Default Tips”, Haggag & Paci 2014
“The Political Economy of Special Economic Zones”, Moberg 2014
“Two Party Double Deposit Trustless Escrow in Cryptographic Networks and Bitcoin [BitHalo]”, Zimbeck 2014
Two Party double deposit trustless escrow in cryptographic networks and Bitcoin [BitHalo]
“I Don’t Want to Hire Women”, Anonymous 2014
“Field Experiments of Success-Breeds-Success Dynamics”, Rijt et al 2014
“Slavery, Statehood, and Economic Development in Sub-Saharan Africa”, Bezemer et al 2014
Slavery, Statehood, and Economic Development in Sub-Saharan Africa
“Executive Summary of Phase 3 of the Bayer Veterinary Care Usage Study”, Volk et al 2014
Executive summary of phase 3 of the Bayer veterinary care usage study
“Managing an Iconic Old Luxury Brand in a New Luxury Economy: Hermès Handbags in the US Market”, Lewis & Haas 2014
Managing an iconic old luxury brand in a new luxury economy: Hermès handbags in the US market
“Taxes, Lawyers, and the Decline of Witch Trials in France”, Johnson & Koyama 2014
“Everything from 1991 Radio Shack Ad I Now Do With My Phone”, Cichon 2014
“A Few Goodmen: Surname-Sharing Economist Coauthors”, Goodman et al 2014
Quaker Capitalism: Lessons for Today, Turnbull 2014
“Corporate Governance Without Shareholders: A Cautionary Lesson from Non-Profit Organizations”, Dent 2014
Corporate Governance Without Shareholders: A Cautionary Lesson from Non-Profit Organizations
“Killing Time: Dracula and Social Discoordination”, Robbins 2014
“The Brand Personality of Rocks: A Critical Evaluation of a Brand Personality Scale”, Avis et al 2013
The brand personality of rocks: A critical evaluation of a brand personality scale
“Systematic Review of the Hawthorne Effect: New Concepts Are Needed to Study Research Participation Effects”, McCambridge et al 2013
“Growing up in a Recession”, Giuliano & Spilimbergo 2013
“Catalyzing Strategies and Efficient Tie Formation: How Entrepreneurial Firms Obtain Investment Ties”, Hallen & Eisenhardt 2013
Catalyzing Strategies and Efficient Tie Formation: How Entrepreneurial Firms Obtain Investment Ties
“20 Years of Bitext”, Brown et al 2013
“On the Distribution of Job Performance: The Role of Measurement Characteristics in Observed Departures from Normality”, Beck et al 2013
“PET-PEESE: Meta-Regression Approximations to Reduce Publication Selection Bias”, Stanley & Doucouliagos 2013
PET-PEESE: Meta-regression approximations to reduce publication selection bias
“Belief in the Unstructured Interview: The Persistence of an Illusion”, Dana et al 2013
Belief in the unstructured interview: The persistence of an illusion
“Star Performers in 21st Century Organizations”, Aguinis & O’Boyle 2013
“The Origins of Scaling in Cities”, Bettencourt 2013
“Inflated Applicants: Attribution Errors in Performance Evaluation by Professionals”, Swift et al 2013
Inflated Applicants: Attribution Errors in Performance Evaluation by Professionals
“Family, Education, and Sources of Wealth among the Richest Americans, 1982–2012”, Kaplan & Rauh 2013
Family, Education, and Sources of Wealth among the Richest Americans, 1982–2012
“Researchers Finally Replicated Reinhart-Rogoff [GDP vs National Debt], and There Are Serious Problems”, Varghese 2013
“The Business of Phish”, Dhar 2013
“Do Labor Market Policies Have Displacement Effects? Evidence from a Clustered Randomized Experiment”, Crépon et al 2013
Do Labor Market Policies have Displacement Effects? Evidence from a Clustered Randomized Experiment
“Comparing Ecological Sustainability in Autocracies and Democracies”, Wurster 2013
Comparing ecological sustainability in autocracies and democracies
“Your Right Arm For A Publication In AER?”, Attema et al 2013
“Survival of the Unfittest: Why the Worst Infrastructure Gets Built, And What We Can Do about It”, Flyvbjerg 2013
Survival of the Unfittest: Why the Worst Infrastructure Gets Built, And What We Can Do about It
“Does the John Bates Clark Medal Boost Subsequent Productivity and Citation Success?”, Chan et al 2013
Does the John Bates Clark Medal Boost Subsequent Productivity and Citation Success?
“The Black Arts of SaaS Pricing”, McKenzie 2013
“Credit Suisse Global Investment Returns Yearbook 2013”, Dimson et al 2013
“The Moral Consequences of Economic Growth: An Empirical Investigation”, Davis & Knauss 2013
The moral consequences of economic growth: An empirical investigation
“Market Research, Wireframing, and Design”, Srinivasan 2013
“What’s to Know about the Credibility of Empirical Economics?”, Ioannidis & Doucouliagos 2013
What’s to know about the credibility of empirical economics?
“The Global Decline of the Labor Share”, Karabarbounis & Neiman 2013
“Prevented Mortality and Greenhouse Gas Emissions from Historical and Projected Nuclear Power”, Karecha & Hansen 2013
Prevented mortality and greenhouse gas emissions from historical and projected nuclear power
“On the Time Spent Preparing Grant Proposals: an Observational Study of Australian Researchers”, Herbert et al 2013
On the time spent preparing grant proposals: an observational study of Australian researchers
“Does Management Matter? Evidence from India”, Bloom et al 2012
“The Nixon Shock After Forty Years: the Import Surcharge Revisited”, Irwin 2012
The Nixon shock after forty years: the import surcharge revisited
“People and Process, Suits and Innovators: the Role of Individuals in Firm Performance”, Mollick 2012
People and process, suits and innovators: the role of individuals in firm performance
“The Collapse of the Soviet Union and the Productivity of American Mathematicians”, Borjas & Doran 2012
The Collapse of the Soviet Union and the Productivity of American Mathematicians
“Judicial Biases in Ottoman Istanbul: Islamic Justice and Its Compatibility With Modern Economic Life”, Kuran & Lustig 2012
Judicial Biases in Ottoman Istanbul: Islamic Justice and Its Compatibility with Modern Economic Life
“On a Tiny Caribbean Island, Hermit Crabs Form Sophisticated Social Networks [Video]: Hermit Crabs Have Evolved Sophisticated Social Strategies to Exchange Resources so That Everyone Benefits”, Jabr 2012
“Why Do Nigerian Scammers Say They Are from Nigeria?”, Herley 2012
“Are Women Overinvesting in Education? Evidence from the Medical Profession”, Chen & Chevalier 2012
Are Women Overinvesting in Education? Evidence from the Medical Profession
“Gains from Trade When Firms Matter”, Melitz & Trefler 2012
“The Best And The Rest: Revisiting The Norm Of Normality Of Individual Performance”, O’Boyle & Aguinis 2012
The Best And The Rest: Revisiting The Norm Of Normality Of Individual Performance
“Salary Negotiation: Make More Money, Be More Valued”, McKenzie 2012
“The Short-Term & Long-Term Career Effects of Graduating in a Recession”, Oreopoulos et al 2012
The short-term & long-term career effects of graduating in a recession
“American Incomes 1774–1860”, Lindhart & Williamson 2012
“The Marginal External Cost of Obesity in the United States”, Parks 2012
“Executive Summary of Phase 2 of the Bayer Veterinary Care Usage Study”, Volk et al 2011
Executive summary of phase 2 of the Bayer veterinary care usage study
“Reality at Odds With Perceptions: Narcissistic Leaders and Group Performance”, Nevicka et al 2011
Reality at Odds With Perceptions: Narcissistic Leaders and Group Performance
“Shining New Light on the Hawthorne Illumination Experiments”, Izawa et al 2011
“A Simple Decomposition of the Variance of Output Growth across Countries”, Reicher 2011
A simple decomposition of the variance of output growth across countries
“The Causal Effect of Parents’ Schooling on Children’s Schooling: A Comparison of Estimation Methods”, Holmlund et al 2011
The Causal Effect of Parents’ Schooling on Children’s Schooling: A Comparison of Estimation Methods
“The Long-Run Impact of Bombing Vietnam”, Miguel & Roland 2011
“Do Interest Groups Affect US Immigration Policy?”, Facchini et al 2011
“Coups, Corporations, and Classified Information”, Dube et al 2011
“Incentive-Compatible Escrow Mechanisms”, Witkowski et al 2011
“Agricultural Prices (May 2011)”, Board 2011
“Cognitive Capitalism: The Effect of Cognitive Ability on Wealth, As Mediated Through Scientific Achievement and Economic Freedom”, Rindermann & Thompson 2011
“The Magic Washing Machine”
“Tanpin Kanri: Retail Practice at Seven-Eleven Japan”, Lal & Han 2011
“Travelers’ Types”, Brãnas-Garza et al 2011
“The Mathematics Of Beauty”, Rudder 2011
“Was There Really a Hawthorne Effect at the Hawthorne Plant? An Analysis of the Original Illumination Experiments”, Levitt & List 2011
“The Soviet Problem With Two ‘Unknowns’: How an American Architect and a Soviet Negotiator Jump-Started the Industrialization of Russia, Part II: Saul Bron”, Melnikova-Raich 2011
“Abnormal Returns From the Common Stock Investments of Members of the US House of Representatives”, Ziobrowski et al 2011
Abnormal Returns From the Common Stock Investments of Members of the US House of Representatives
“The Time Resolution of the St Petersburg Paradox”, Peters 2011
“Why Do Management Practices Differ across Firms and Countries?”, Bloom & Reenen 2010
Why Do Management Practices Differ across Firms and Countries?
“Direct versus Indirect Colonial Rule in India: Long-Term Consequences”, Iyer 2010
Direct versus Indirect Colonial Rule in India: Long-Term Consequences
“The Economic Argument”, Munroe 2010
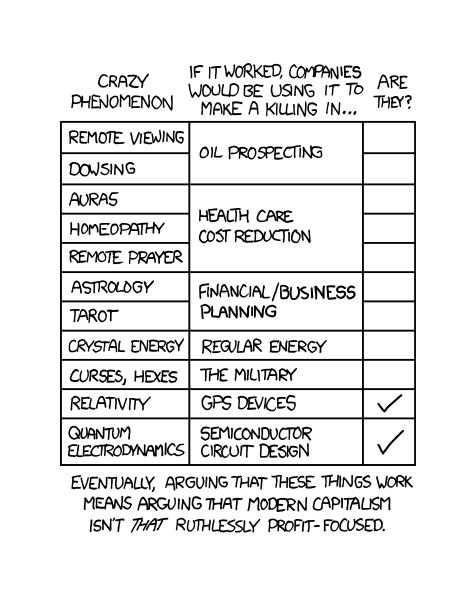{kind=link}
“Urban Scaling and Its Deviations: Revealing the Structure of Wealth, Innovation and Crime across Cities”, Bettencourt et al 2010
“The Theory Of Interstellar Trade”, Krugman 2010
“Who Gains and Who Loses from Credit Card Payments? Theory and Calibrations”, Schuh et al 2010
Who Gains and Who Loses from Credit Card Payments? Theory and Calibrations
“Career Trajectories of Dutch Pop Musicians: A Longitudinal Study”, Zwaan et al 2010
Career trajectories of Dutch pop musicians: A longitudinal study
“Can Openness Mitigate the Effects of Weather Shocks? Evidence from India’s Famine Era”, Burgess & Donaldson 2010
Can Openness Mitigate the Effects of Weather Shocks? Evidence from India’s Famine Era
“Corporate Psychopathy: Talking the Walk”, Babiak et al 2010
“Social Context of Shell Acquisition in Coenobita Clypeatus Hermit Crabs”, Rotjan et al 2010
Social context of shell acquisition in Coenobita clypeatus hermit crabs
“Performance Persistence in Entrepreneurship”, Gompers et al 2010
“The Employment Retention and Advancement Project: How Effective Are Different Approaches Aiming to Increase Employment Retention and Advancement? Final Impacts for 12 Models”, Hendra et al 2010
“The Economic Value of Teeth”, Glied & Neidell 2010
“The Optimal Taxation of Height: A Case Study of Utilitarian Income Redistribution”, Mankiw & Weinzierl 2010
The Optimal Taxation of Height: A Case Study of Utilitarian Income Redistribution
“The Corporate Governance of Benedictine Abbeys”, Rost et al 2010
“The New Kaldor Facts: Ideas, Institutions, Population, and Human Capital”, Jones & Romer 2010
The New Kaldor Facts: Ideas, Institutions, Population, and Human Capital
“The Soviet Problem With Two ‘Unknowns’: How an American Architect and a Soviet Negotiator Jump-Started the Industrialization of Russia, Part I: Albert Kahn”, Melnikova-Raich 2010
“Systematic Review: the Costs of Ulcerative Colitis in Western Countries”
Systematic review: the costs of ulcerative colitis in Western countries
“The Normalization of Deviance in Healthcare Delivery”, Banja 2010
“The Cost of Crime to Society: New Crime-Specific Estimates for Policy and Program Evaluation”, McCollister et al 2010
The cost of crime to society: new crime-specific estimates for policy and program evaluation
“Long-Term Economic Costs of Psychological Problems during Childhood”, Smith & Smith 2010
Long-term economic costs of psychological problems during childhood
“An Economic Analysis of the Financial Records of Al-Qa’ida in Iraq”, Bahney et al 2010
An Economic Analysis of the Financial Records of al-Qa’ida in Iraq
“The Elves Leave Middle Earth: Sodas Are No Longer Free”, Blank 2009
“Victorian Pioneers of Corporate Sustainability”, Desrochers 2009
“Occupational Feminization and Pay: Assessing Causal Dynamics Using 1950–2000 US Census Data”, Levanon et al 2009
Occupational Feminization and Pay: Assessing Causal Dynamics Using 1950–2000 US Census Data
“Education, Aspirations and Life Satisfaction”, Ferrante 2009
“So Long, and No Thanks for the Externalities: the Rational Rejection of Security Advice by Users”, Herley 2009
So long, and no thanks for the externalities: the rational rejection of security advice by users
“A Theory of the Pre-Modern British Aristocracy”, Allen 2009
“Founder-CEOs, Investment Decisions, and Stock Market Performance”, Fahlenbrach 2009
Founder-CEOs, Investment Decisions, and Stock Market Performance
“The Aid Effectiveness Literature: The Sad Results Of 40 Years Of Research”, Doucouliagos & Paldam 2009
The Aid Effectiveness Literature: The Sad Results Of 40 Years Of Research
“So You Want to Be a Rock-N-Roll Star? Career Success of Pop Musicians in the Netherlands”, Zwaan et al 2009
So you want to be a Rock-n-Roll star? Career success of pop musicians in the Netherlands
“Anatomy of a Scare: Yellow Peril Politics in America, 1980–1993”, Heale 2009
Anatomy of a Scare: Yellow Peril Politics in America, 1980–1993
“How To Successfully Compete With Open Source Software”, McKenzie 2009
“Frank Ramsey’s Notes on Saving and Taxation”, Ramsey & Duarte 2009
“Field Experiments in Economics: The Past, the Present, and the Future”, Levitt & List 2009
Field experiments in economics: The past, the present, and the future
“The Age of Reason: Financial Decisions over the Life Cycle and Implications for Regulation”, Agarwal et al 2009
The Age of Reason: Financial Decisions over the Life Cycle and Implications for Regulation
“Japan’s Phillips Curve Looks Like Japan”, Smith 2008
“The Optimistic Thought Experiment”, Thiel 2008
“Showing That You Care: The Evolution of Health Altruism”, Hanson 2008
“Why Do the Poor Live in Cities? The Role of Public Transportation”, Glaeser et al 2008
Why do the poor live in cities? The role of public transportation
“Staffing 21st-Century Organizations”, Cascio & Aguinis 2008
“The Ocean’s Hot Dog: The Development of the Fish Stick”, Josephson 2008
“Marketing Actions Can Modulate Neural Representations of Experienced Pleasantness”, Plassman 2008
Marketing actions can modulate neural representations of experienced pleasantness
“Stress That Doesn’t Pay: The Commuting Paradox”, Stutzer 2008
“Does Price Matter in Charitable Giving? Evidence from a Large-Scale Natural Field Experiment”, Karlan & List 2007
Does Price Matter in Charitable Giving? Evidence from a Large-Scale Natural Field Experiment
“Underfunding in Terrorist Organizations”, Shapiro & Siegel 2007
“The Guidelines Manual—Chapter 8: Incorporating Health Economics in Guidelines and Assessing Resource Impact”, NICE 2007
“So You Discovered an Anomaly…Gonna Publish It? An Investigation Into the Rationality of Publishing a Market Anomaly”, Doran & Wright 2007
“Gibbon Was Right: The Decline and Fall of the Roman Economy”, Jongman 2007
“To Leave or Not to Leave: The Distribution of Bequest Motives”, Kopczuk & Lupton 2007
To Leave or Not to Leave: The Distribution of Bequest Motives
“Catṡlechta and Other Medieval Legal Material Relating to Cats”, Murray 2007
Catṡlechta and other medieval legal material relating to cats
“The Cambist and Lord Iron: A Fairy Tale of Economics”, Abraham 2007
“Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments”, Rutter 2007
Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments
“Cognition and Behavior in Two-Person Guessing Games: An Experimental Study”, Costa-Gomes & Crawford 2006
Cognition and Behavior in Two-Person Guessing Games: An Experimental Study
“Jacks of All Trades and Masters of None: Audiences’ Reactions to Spanning Genres in Feature Film Production”, Hsu 2006
“Is Economics Performative? Option Theory and the Construction of Derivatives Markets”, Mackenzie 2006
Is economics performative? Option theory and the construction of derivatives markets
“Superman or the Fantastic Four? Knowledge Combination and Experience in Innovative Teams”, Taylor & Greve 2006
Superman or the Fantastic Four? Knowledge Combination and Experience in Innovative Teams
“IQ in the Ramsey Model: A Naïve Calibration”, Jones 2006
“Lessons from the JMCB Archive”, McCullough et al 2006
“Asset Float and Speculative Bubbles”, Hong et al 2006
“Investing in the Unknown and Unknowable”, Zeckhauser 2006
“Guard Labor”, Jayadev & Bowles 2006
“No Booze? You May Lose: Why Drinkers Earn More Money Than Nondrinkers”, Peters & Stringham 2006
No Booze? You May Lose: Why Drinkers Earn More Money Than Nondrinkers
“The Effects of Attention-Deficit/hyperactivity Disorder on Employment and Household Income”, Biederman et al 2006
The effects of attention-deficit/hyperactivity disorder on employment and household income
“Modeling Bursts and Heavy Tails in Human Dynamics”, Vazquez et al 2005
“Turnpike Trusts and the Transportation Revolution in 18th Century England”, Bogart 2005
Turnpike trusts and the transportation revolution in 18th century England
“The Paradox Of Beneficial Retirement”, Smilansky 2005
“The Great Leap Forward: Anatomy of a Central Planning Disaster”, Li & Yang 2005
The Great Leap Forward: Anatomy of a Central Planning Disaster
“Slavery and the Intergenerational Transmission of Human Capital”, Sacerdote 2005
Slavery and the Intergenerational Transmission of Human Capital
“Temperament Profiles in Physicians, Lawyers, Managers, Industrialists, Architects, Journalists, and Artists: a Study in Psychiatric Outpatients”, Akiskal et al 2005
“Salt, Salt Making, and the Rise of Cheshire”, Gittins 2005
“A126_jun05Hirschfeld_S85toS90”, Charlie 2005
“What Determines Productivity? Lessons from the Dramatic Recovery of the US and Canadian Iron Ore Industries Following Their Early 1980s Crisis”, Schmitz 2005
“The Economic Burden of Schizophrenia in the United States in 2002”, Wu 2005
The Economic Burden of Schizophrenia in the United States in 2002
“Return the ‘Sunk Costs Are Sunk’ Concept to Principles of Economics Textbooks”, Davis 2005
Return the ‘Sunk Costs Are Sunk’ Concept to Principles of Economics Textbooks
“Mania and Dysregulation in Goal Pursuit: a Review”, Johnson 2005
“What I Love about Scrooge: In Praise of Misers”, Landsburg 2004
“Abnormal Returns from the Common Stock Investments of the US Senate”, Ziobrowski et al 2004
Abnormal Returns from the Common Stock Investments of the US Senate
“Bow Ties, Metabolism and Disease”, Csete & Doyle 2004
“The Worldly Philosophers and the War Economy”, Galbraith 2004
“Product Substitutability and Productivity Dispersion”, Syverson 2004
“Suicide: An Economic Approach”, Becker & Posner 2004
“The Tragicomedy of the Surfers’ Commons”, Nazer 2004
“The Global Costs of Schizophrenia”, Knapp 2004
“A Market-Induced Mechanism for Stock Pinning”, Avellaneda & Lipkin 2003
“Economic Production As Chemistry”, Padgett et al 2003
“Good times Make You Sick”, Ruhm 2003
“The Village Full Budget”, Mercer & Freedlun 2003
“Assessing the Impact of the Green Revolution, 1960–2000”, Evenson & Gollin 2003
“Work Ethics and the Collapse of the Soviet System”, Pereira & Pereira 2003
“MDRC’s The Higher Education Randomized Controlled Trials Restricted Access File (THE-RCT RAF), United States, 2003–2019”, MDRC 2003
“Privacy, Economics, and Price Discrimination on the Internet”, Odlyzko 2003
Privacy, Economics, and Price Discrimination on the Internet
“Estimating the Payoff to Attending a More Selective College: An Application of Selection on Observables and Unobservables”, Dale & Krueger 2002
“Do Natural Disasters Promote Long-Run Growth?”, Skidmore & Toya 2002
“Joel on Software: Strategy Letter V”, Spolsky 2002
“Causes of Repressed Inflation in the Soviet Consumer Market, 1965–1989: Retail Price Subsidies, the Siphoning Effect, and the Budget Deficit”, Kim 2002
“Stung by Security Flaws, Microsoft Makes Software Safety a Top Goal”, Markoff 2002
Stung by Security Flaws, Microsoft Makes Software Safety a Top Goal
“Decisions and Revisions: The Affective Forecasting of Changeable Outcomes”, Gilbert & Ebert 2002
Decisions and revisions: The affective forecasting of changeable outcomes
“Price Behavior in Ancient Babylon”, Temin 2002
“This Is Your Father’s IBM, Only Smarter: How a Former Has-Been Kicked Its Old Habits, Got Open-Source Religion, and Regained Its Status As One of the Biggest, Baddest Tech Companies on Earth.”
“It Pays to Be Ignorant: A Simple Political Economy of Rigorous Program Evaluation”, Pritchett 2002
It pays to be ignorant: A simple political economy of rigorous program evaluation
“The Wheel of Reincarnation”, Hardy 2002
“Can Nonexperimental Comparison Group Methods Match the Findings from a Random Assignment Evaluation of Mandatory Welfare-To-Work Programs? MDRC Working Papers on Research Methodology”, Bloom et al 2002
“Estimating Real Income in the United States 1888–1994: Correcting CPI Bias Using Engel Curves”, Costa 2001
Estimating Real Income in the United States 1888–1994: Correcting CPI Bias Using Engel Curves
“How Dangerous Are Drinking Drivers?”, Levitt & Porter 2001
“Do Incentive Contracts Crowd Out Voluntary Cooperation?”, Fehr & Gächter 2001
“Nobody Ever Gets Credit for Fixing Problems That Never Happened: Creating and Sustaining Process Improvement”, Repenning & Sterman 2001
“Cultural Entrepreneurship: Stories, Legitimacy, and the Acquisition of Resources”, Lounsbury & Glynn 2001
Cultural entrepreneurship: stories, legitimacy, and the acquisition of resources
“Prescription Drug Prices: Why Do Some Pay More Than Others Do?”, Frank 2001
Prescription Drug Prices: Why Do Some Pay More Than Others Do?
“The Personal Discount Rate: Evidence from Military Downsizing Programs”, Warner & Pleeter 2001
The Personal Discount Rate: Evidence from Military Downsizing Programs
“The Bench Burner: How Did a Judge With Such Subversive Ideas Become a Leading Influence on American Legal Opinion?”, MacFarquhar 2001
From Third World to First: The Singapore Story—1965–2000, Yew 2000
“An Economic Theory of Avant-Garde and Popular Art, or High and Low Culture”, Cowen & Tabarrok 2000
An Economic Theory of Avant-Garde and Popular Art, or High and Low Culture
“Pay Enough Or Don’t Pay At All”, Gneezy & Rustichini 2000
“A Meta-Analysis of Antecedents and Correlates of Employee Turnover: Update, Moderator Tests, and Research Implications for the Next Millennium”, Griffeth et al 2000
“Interview With Ryan Dancey: D20 System and Open Gaming Movement”, Dancey 2000
Interview with Ryan Dancey: D20 System and Open Gaming Movement
“Cornucopia: The Pace of Economic Growth in the 20th Century”, DeLong 2000
“The Importance of Slavery and the Slave Trade to Industrializing Britain”, Eltis & Engerman 2000
The Importance of Slavery and the Slave Trade to Industrializing Britain
“How Taxing Is Corruption on International Investors?”, Wei 2000
“The Redesign of the Matching Market for American Physicians: Some Engineering Aspects of Economic Design”, Roth & Peranson 1999
“Why Do Some Countries Produce So Much More Output Per Worker Than Others?”, Hall & Jones 1999
Why do Some Countries Produce So Much More Output Per Worker than Others?
“Medieval and Early Modern Coinage and Its Problems”, Kohn 1999
“Hayek: A Critique”, Benoist 1998
Information Rules: A Strategic Guide to the Network Economy, Shapiro & Varian 1998
“Scholarly Restraints? ABA Accreditation and Legal Education”, Shepherd & Shepherd 1998
“Operations of "Unfettered" Labor Markets: Exit and Voice in American Labor Markets at the Turn of the Century”, Fishback 1998
“The True Cost of Living: 1974–1991”, Hamilton 1998
“Entrepreneurs’ Perceived Chances for Success”, Cooper et al 1998
“Estimates of World GDP, One Million BC–Present”, DeLong 1998
“Introduction to the Economics of Religion”, Iannaccone 1998
“Research, Patenting, and Technological Change”, Kortum 1997
“There’s Money in the Air: the CFC Ban and DuPont’s Regulatory Strategy”, Maxwell & Briscoe 1997
There’s money in the air: the CFC ban and DuPont’s regulatory strategy
“Dimensions of Brand Personality”, Aaker 1997
“Why Are Worker Cooperatives So Rare?”, Kremer 1997
“Why Do People Dislike Inflation?”, Shiller 1997
“High-Tech R&D Subsidies Estimating the Effects of Sematech”, Irwin & Klenow 1996
“Individual Differences and Behavior in Organizations”, Murphy et al 1996
“Taxi Industry Regulation, Deregulation, and Reregulation: The Paradox of Market Failure”, Dempsey 1996
Taxi Industry Regulation, Deregulation, and Reregulation: The Paradox of Market Failure
“The Role of Premarket Factors in Black-White Wage Differences”, Neal & Johnson 1996
The Role of Premarket Factors in Black-White Wage Differences
“The Great Wars, the Great Crash, and Steady State Growth: Some New Evidence about an Old Stylized Fact”, Ben-David & Papell 1995
“Stability in the Absence of Deposit Insurance: The Canadian Banking System, 1890–1966”, Carr et al 1995
Stability in the Absence of Deposit Insurance: The Canadian Banking System, 1890–1966
“Employee Turnover”, Hom & Griffeth 1995
“Usage Heterogeneity and Extended Warranties”
“An Economic Evaluation of Manic-Depressive Illness—1991”, Wyatt & Henter 1995
“New Data on Air Pollution in the Former Soviet Union”, Shahgedanova & Burt 1994
“Anthropological Invariants in Travel Behavior”, Marchetti 1994 (page 6)
“The Incidence of Mandated Maternity Benefits”, Gruber 1994
“The Role Of The CIA In Economic And Technological Intelligence”, Foley 1994
The Role Of The CIA In Economic And Technological Intelligence
“Where Is There Consensus Among American Economic Historians? The Results of a Survey on Forty Propositions”, Whaples 1994
“Leadership Style and Incentives”, Rotemberg & Saloner 1993
“Population Growth and Technological Change: One Million B.C. to 1990”, Kremer 1993
Population Growth and Technological Change: One Million B.C. to 1990
“Measuring Asset Values for Cash Settlement in Derivative Markets: Hedonic Repeated Measures Indices and Perpetual Futures”, Shiller 1993
“Egalitarian Behavior and Reverse Dominance Hierarchy [And Comments and Reply]”, Boehm et al 1993
Egalitarian Behavior and Reverse Dominance Hierarchy [and Comments and Reply]
Manual on Free Zones, Kelleher 1993
Towards A New Socialism
“Agricultural Prices (December 1992)”, Board 1992
“Was There a Hawthorne Effect?”, Jones 1992
“A Politician’s Dream Is a Businessman’s Nightmare”, McGovern 1992
“Retrospective Capital Gains Taxation”, Auerbach 1991
“Organizations and Markets”, Simon 1991
“The Big Five Personality Dimensions And Job Performance: A Meta-Analysis”, Barrick & Mount 1991
The Big Five Personality Dimensions And Job Performance: A Meta-Analysis
“Universal Portfolios”, Cover 1991
“Multitask Principal-Agent Analyses: Incentive Contracts, Asset Ownership, and Job Design”, Holmström & Milgrom 1991
Multitask principal-agent analyses: Incentive contracts, asset ownership, and job design
“Millers and Grinders: Technology and Household Economy in Meso-America”, Bauer 1990
Millers and Grinders: Technology and Household Economy in Meso-America
“Noise Trader Risk in Financial Markets”, Long et al 1990
“L. V. Kantorovich: The Price Implications of Optimal Planning”, Gardner 1990
L. V. Kantorovich: The Price Implications of Optimal Planning
“Real Wages, Employment, and the Phillips Curve”, Sumner & Silver 1989
“From Here to There; Or, If Cooperative Ownership Is So Desirable, Why Are There So Few Cooperatives?”, Elster 1989
From Here to There; or, If Cooperative Ownership Is So Desirable, Why are There So Few Cooperatives?
“A Theory of Rational Addiction”, Becker & Murphy 1988
“Diplomacy and Domestic Politics: The Logic of Two-Level Games”, Putnam 1988
Diplomacy and Domestic Politics: The Logic of Two-Level Games
“Undated Futures Markets”, Gehr 1988
“Political Cleavages and Changing Exposure to Trade”, Rogowski 1987
“Henry Adams, the Second Law of Thermodynamics, and the Course of History”, Burich 1987
Henry Adams, the Second Law of Thermodynamics, and the Course of History
“The Empirical Renaissance in Industrial Economics: An Overview”, Bresnahan & Schmalensee 1987
The Empirical Renaissance in Industrial Economics: An Overview
“Experts and Servants: The National Council on Household Employment and the Decline of Domestic Service in the Twentieth Century”, Dudden 1986
“Is Time Travel Impossible? A Financial Proof”, Reinganum 1986
“Evaluating the Econometric Evaluations of Training Programs With Experimental Data”, LaLonde 1986
Evaluating the Econometric Evaluations of Training Programs with Experimental Data
“Noise”, Black 1986
“Management Training: Justify Costs or Say Goodbye”, Urban et al 1985
“A Research Note on Deriving the Square-Cube Law of Formal Organizations from the Theory of Time-Minimization”, Stephan 1983
“Let’s Take the Con Out of Econometrics”, Leamer 1983
“Rival Interpretations of Market Society: Civilizing, Destructive, or Feeble?”, Hirschman 1982
Rival Interpretations of Market Society: Civilizing, Destructive, or Feeble?
“Christmas Gifts and Kin Networks”, Caplow 1982
“On Number Numbness”, Hofstadter 1982b
“Rank-Order Tournaments As Optimum Labor Contracts”, Lazear & Rosen 1981
“Reflections on Optimal Punishment, Or: Should the Rich Pay Higher Fines?”, Friedman 1981
Reflections on Optimal Punishment, or: Should the Rich Pay Higher Fines?
“A Theory of Primitive Society, With Special Reference to Law”, Posner 1980
A Theory of Primitive Society, with Special Reference to Law
“The Cultivation of the Soil As a Moral Directive: Population Growth, Family Ties, and the Maintenance of Community Among the Old Order Amish”, Ericksen et al 1980
“Rating the Ratings: Assessing the Psychometric Quality of Rating Data”, Saal et al 1980
Rating the ratings: Assessing the psychometric quality of rating data
“Paperwork and Bureaucracy”, Bennett & Johnson 1979
“Prospect Theory: An Analysis of Decision under Risk”, Kahneman & Tversky 1979
“Derivation of Some Social-Demographic Regularities from the Theory of Time-Minimization”, Stephan 1979
Derivation of Some Social-Demographic Regularities from the Theory of Time-Minimization
“Impact of Valid Selection Procedures on Work-Force Productivity”, Schmidt et al 1979
Impact of valid selection procedures on work-force productivity
“Theory of the Firm: Managerial Behavior, Agency Costs, and Ownership Structure”, Jensen & Meckling 1979c
Theory of the Firm: Managerial Behavior, Agency Costs, and Ownership Structure
“Foreign-Trained Physicians and Health Care in the United States”, Svorny 1979
Foreign-Trained Physicians and Health Care in the United States
“Moral Hazard and Observability”, Holmström 1979
“Growth Accounting With Intermediate Inputs”, Hulten 1978
“The Hawthorne Experiments: First Statistical Interpretation”, Franke & Kaul 1978
“The Economics of the Baby Shortage”, Landes & Posner 1978
“The Gains and Losses from Industrial Concentration”, Peltzman 1977
“Double Loop Learning in Organizations”, Argyris 1977
“The Effects of the Rural Income Maintenance Experiment on the School Performance of Children”
The Effects of the Rural Income Maintenance Experiment on the School Performance of Children
“The Economics of Safety Legislation in Underground Coal Mining”, Henderson 1977
The Economics of Safety Legislation in Underground Coal Mining
“The Fishers of Men: The Profits of the Slave Trade”, Thomas & Bean 1974
“Spurious Regressions in Econometrics”, Granger & Newbold 1974
“Portfolio Turnpike Theorems for Constant Policies”, Ross 1974
“Unemployment Compensation: Adverse Incentives And Distributional Anomalies”, Feldstein 1974
Unemployment Compensation: Adverse Incentives And Distributional Anomalies
“Economics of Petrodollars”, Oweiss 1974
“The Society of Arts & Government 1754–1800: Public Encouragement of Arts, Manufactures, and Commerce in 18th-Century England”, Allan 1974
“The General Impossibility of Normative Accounting Standards”, Demski 1973
“An Evaluation of Consumer Protection Legislation: The 1962 Drug Amendments”, Peltzman 1973
An Evaluation of Consumer Protection Legislation: The 1962 Drug Amendments
Mitsui: 3 Centuries of Japanese Business, Roberts 1973
“A Study of the Effects of Competition in the Tax-Exempt Bond Market”, Kessel 1971
A Study of the Effects of Competition in the Tax-Exempt Bond Market
“Suppression of Inventions”, Hirshleifer 1971
“The Achieving Society”, McClelland 1971
“Banking and Interest Rates in a World Without Money: The Effects of Uncontrolled Banking”, Black 1970
Banking and Interest Rates in a World Without Money: The Effects of Uncontrolled Banking
“Statistical Theories of Success”, Zener 1970
“East Indian Cane Workers In Jamaica”, Ehrlich 1969
“The Performance of Mutual Funds in the Period 1945–1964”, Jensen 1968
“An Analysis Of Scientific Productivity”, Zener 1968
“British Imperial Policy and the Economic Interpretation of the American Revolution”
British Imperial Policy and the Economic Interpretation of the American Revolution
“Soviet Reality Sans Potemkin: The Amenities of Moscow from the Native Point of View”, Schroeder 1968
Soviet Reality Sans Potemkin: The amenities of Moscow from the native point of view
The Economics of Knowledge and the Knowledge of Economics, Boulding 1966b
“The Dollars and Sense of Continuing Education”, Jones 1966
“The Economics of the Coming Spaceship Earth”, Boulding 1966
“On the Geometry of Organizations”, McWhinney 1965
“A Quantitative Approach to the Study of the Effects of British Imperial Policy upon Colonial Welfare: Some Preliminary Findings”
“Measuring Utility by a Single-Response Sequential Method”, Becker et al 1964
“Testing a Model for Organizational Growth”, Draper & Strother 1963
“Exploration of a Biological Model of Industrial Organization”, Levy & Donhowe 1962
Exploration of a Biological Model of Industrial Organization
“Probability, Statistical Decision Theory, and Accounting”, Bierman 1962
“Distributions of Correlation Coefficients in Economic Time Series”, Ames & Reiter 1961
Distributions of Correlation Coefficients in Economic Time Series
“The Economics of Invention: A Survey of the Literature”, Nelson 1959
“The Structure and Growth of Soviet Industry: A Comparison With the United States”, Nutter 1959
The Structure and Growth of Soviet Industry: A Comparison with the United States
Probability and Statistics for Business Decisions: An Introduction to Managerial Economics Under Uncertainty, Schlaifer 1959
“Predatory Price Cutting: The Standard Oil (New Jersey) Case”, McGee 1958
“The True Story of Russia’s Weakness [Stifled by Bad Planning, Bureaucratic Inefficiency, and Lack of Any Real Incentive]”, Nutter 1957
“Rational Decision Making in Portfolio Management”, Latané 1957
Patterns of Industrial Bureaucracy: a Case Study of Modern Factory Administration, Gouldner 1954
Patterns of Industrial Bureaucracy: a case study of modern factory administration
“Non-Cooperative Games”, Nash 1951
“What Price Speed? Specific Power Required for Propulsion of Vehicles”, Gabrielli & Kármán 1950
What price speed? Specific power required for propulsion of vehicles
“Uncertainty, Evolution, and Economic Theory”, Alchian 1950
“William Shipley And The Royal Society Of Arts: The History of an Idea”, Luckhurst 1949
William Shipley And The Royal Society Of Arts: The History of an Idea
“Economic Calculation in the Socialist Society”, Hoff 1949
“Charles Dickens [His Ideology/ethics]”, Orwell 1940
“Averaging of Income for Income-Tax Purposes”, Vickrey 1939
“The Soviet Economy in Danger”, Trotsky 1932
“F. P. Ramsey [Obituary]”, Keynes 1930
“Stability in Competition”, Hotelling 1929
“A Mathematical Theory of Saving”, Ramsey 1928
“A Contribution to the Theory of Taxation”, Ramsey 1927b
“London Labour and the London Poor; a Cyclopaedia of the Condition and Earnings of Those That Will Work, Those That Cannot Work, and Those That Will Not Work: Volume 1: The London Street-Folk § Of Cats’-Meat & Dogs’-Meat Dealers”, Mayhew 1851
Confusion of Confusions, Vega & Kellenbenz 1688
“The Cat’s Meat Man”
“The Value of Health and Longevity”
“All That Is Solid Bursts into Flame: Capitalism and Fire in the 19th-Century United States”
All That Is Solid Bursts into Flame: Capitalism and Fire in the 19th-Century United States
“Making Is Show Business Now”
Paris Anecdote, d’Anglemont 2026
Paris Inconnu, d’Anglemont et al 2026
“Double Deposit Escrow”
“Bithalo”
“2015.11.20: Break a Dozen Secret Keys, Get a Million More for Free”
2015.11.20: Break a dozen secret keys, get a million more for free
“Can AI Do Replications? GPT-5.2 vs GPT-5.4 vs Refine.ink”, Wiebe 2026
“Moretti Replication Published in AER”, Wiebe 2026
“Risk Management and Sounding Crazy”
“An Amazing Journey With Claude 3.5 and ChatGPT-4o Who Helped Me Backwards Engineer an Econometrics Theory Paper and Taught Me a Lot More in the Process”
“Millennium Cohort Study (UK)”
“The Games People Play With Cash Flow”
“The Untold Story of SQLite With Richard Hipp”
“How Funerals Keep Africa Poor”
“Crystal Ball Trading Challenge”, Wealth 2026
“Multi-Signature”
“How Not to Bomb Your Offer Negotiation”
“The Hardest Chess Problem in the World?”
“Hledger Homepage”
“A Meta-Analysis of Work Sample Test Validity: Updating and Integrating Some Classic Literature”
A Meta-analysis of work sample test validity: Updating and integrating some classic literature
“VTSAX: Vanguard Total Stock Market Index Fund Admiral Shares”, Vanguard 2026
VTSAX: Vanguard Total Stock Market Index Fund Admiral Shares
“1,000 True Fans”, Kelly 2026
“Underutilized Fixed Assets”
“The New Economics of Chess”
“Claude, Read the Chevron PDF”, Cowen & Claude-3 2026
“Claude Sonnet 3.5, Economist”
“Deep Research for Short Economics Papers”, Cowen 2026
“Rob Wiblin Interviews Tyler on Stubborn Attachments (BONUS)”
“The Relentless Misery of 1.6 Gallons”
“Nintil”, Ricon 2026
“Parents’ Beliefs in the ‘American Dream’ Affect Parental Investments in Children: Evidence from an Experiment”
View External Link:
“How to Pay to Change the Law”
“Albert Millican’s Travels and Adventures of an Orchid Hunter”
Albert Millican’s Travels and Adventures of an Orchid Hunter
“Mrs Giacometti Prodgers, the Cabman’s Nemesis”
“From Fire Hazards to Family Trees: The Sanborn Fire Insurance Maps”
From Fire Hazards to Family Trees: The Sanborn Fire Insurance Maps
“The Art of Making Debts: Accounting for an Obsession in 19th-Century France”
The Art of Making Debts: Accounting for an Obsession in 19th-Century France
“Red Markets”
“Meditations on Moloch”
“Book Review: Legal Systems Very Different From Ours”
“How Record Rentals Helped Save Japan’s Music Industry”
“6-Year-Old Stares Down Bottomless Abyss Of Formal Schooling”
“The Hazy Economy of Cannabis”
“Growing One’s Consulting Business”, McKenzie 2026
Growing One’s Consulting Business
View External Link:
https://training.kalzumeus.com/newsletters/archive/consulting_1
“Flight Simulators for Management Education”
“Against the Survival of the Prettiest”
“Why Ireland’s Housing Bubble Burst”
“Why Skyscrapers Are so Short”
“The Rise of Niche Consumption”
“The Public Thinks the Average Company Makes a 36% Profit Margin, Which Is About 5× Too High”
The Public Thinks the Average Company Makes a 36% Profit Margin, Which Is About 5× Too High
“Playing to Win”
“Project Vend: Can Claude Run a Small Shop? (And Why Does That Matter?)”
Project Vend: Can Claude run a small shop? (And why does that matter?)
“First Year of Candy Japan”
“How I Decided the Price for My Japanese Candy Subscription Service”
How I decided the price for my Japanese candy subscription service
“How Credit Cards Make Money”
View External Link:
https://www.bitsaboutmoney.com/archive/how-credit-cards-make-money/
“Working Title (Real Estate Insurance)”, McKenzie 2026
“Japanese Anime Studio Khara Moving to Blender”
“Kitty Litter’s Invention Spawned Pet Cat Industry”
“Duration of Unemployment in the CPS”, Statistics 2026
“CPI Inflation Calculator”, Statistics 2026
“The Life of American Workers in 1915”
“A Forensic Examination of China’s National Accounts”
“Marc Andreessen Says The 1990s Dot-Com Bubble Startups Were ‘All Right But Just Early’”
Marc Andreessen Says The 1990s Dot-Com Bubble Startups Were ‘All Right But Just Early’
“Inside The Global ‘Club’ That Helps Executives Escape Their Crimes”
Inside The Global ‘Club’ That Helps Executives Escape Their Crimes
“Refugees from Dust and Shrinking Land: Tracking the Dust Bowl Migrants”
Refugees from Dust and Shrinking Land: Tracking the Dust Bowl Migrants
“Candy Japan Crosses $10,000 MRR”
“How Candy Japan Got Credit Card Fraud Somewhat under Control”
How Candy Japan got credit card fraud somewhat under control
“Results from Candy Japan Box Design A/B Test”
“How China Is Like the 19th Century US”, Potter 2026
“What Do Criminal Records Tell Us about Adam Smith and the Industrial Revolution?”
What do criminal records tell us about Adam Smith and the Industrial Revolution?
“Chapter 31, ‘On Machinery’, On the Principles of Political Economy and Taxation”
Chapter 31, ‘On Machinery’, On the Principles of Political Economy and Taxation
“Switzerland’s ‘Silicon Valley of Smell’ Prospers in Age of Big Data”
Switzerland’s ‘Silicon Valley of smell’ prospers in age of big data
“How Much Should We Trust Developing Country GDP? [Little]”
“Raising a Stink”
“The Roentgen Standard”, Niven 2026
“‘The Cambist and Lord Iron: A Fairy Tale of Economics’ Discussion”
‘The Cambist and Lord Iron: A Fairy Tale of Economics’ discussion
“Normal Cryonics”
View External Link:
https://www.lesswrong.com/posts/hiDkhLyN5S2MEjrSE/normal-cryonics1hmp
“The Cambist and Lord Iron: A Fairy Tale of Economics [Lightspeed Magazine Mirror]”
The Cambist and Lord Iron: A Fairy Tale of Economics [Lightspeed Magazine mirror]
“The Law of Small Numbers in Financial Markets: Theory and Evidence”
The Law of Small Numbers in Financial Markets: Theory and Evidence
“Sovereign Haircuts: 200 Years of Creditor Losses”
“The Most Popular Chess Streamer on Twitch”
“How Driscoll’s Reinvented the Strawberry”
“Suzy Batiz’s Empire of Odor”
“What Are You Paying For in a $300 Chess Set? Mostly the Knights”
What Are You Paying For in a $300 Chess Set? Mostly the Knights
“How Magnus Carlsen Turned Chess Skill Into a Business Empire”
How Magnus Carlsen Turned Chess Skill Into a Business Empire
“How Costco Won In Japan”
“How Madagascar’s Farmers Spend Money from the Vanilla Boom”
The Diff, Hobart 2026
“Anti-Anxiety Pill Travels 52,000 Kilometres to Get to Canadian Shelves, Study Shows”
Anti-anxiety pill travels 52,000 kilometres to get to Canadian shelves, study shows
“The Complete History of How SoundScan Changed Popular Music Forever”
The Complete History of How SoundScan Changed Popular Music Forever
“Is Spotify’s Model Wiping Out Music’s Middle Class?”
“Plant-Based Meat like Beyond and Impossible Burgers Get Their Beefy Taste from Flavorists”
Plant-based meat like Beyond and Impossible burgers get their beefy taste from flavorists
“Inside a Startup’s Plan to Turn a Swarm of DIY Satellites Into an All-Seeing Eye”
Inside a Startup’s Plan to Turn a Swarm of DIY Satellites Into an All-Seeing Eye
View External Link:
“Why Big Data Has Been (Mostly) Good for Music”
“You’ve Never Heard of China’s Greatest Sci-Fi Novel”
“Why British Nuclear Flopped”
“2 Years Ago, India Lacked Fast, Cheap Internet—One Billionaire Changed All That: Mukesh Ambani’s National 4G Network for Reliance Jio, Which Charges Pennies for Data, Is Bringing Hundreds of Millions Online for the First Time”
“Who Controls Diners’ Data? OpenTable Moves to Assert Control: Some Restaurateurs Say Booking Service Is Trying to Squeeze Rival SevenRooms; OpenTable Says It Is Protecting User Privacy”
“Why Anime Is on the Rise Even Though the Industry Is so Poor”
Why Anime Is on the Rise Even Though the Industry Is so Poor
richgel999
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
healthcare-costs
critique-analysis
exclusive-content
deposit-recovery
geopolitical-economics
theatrical-release
progress-studies
behavioral-economics
tipping-behavior
health-impact
transplant-market
business-strategy
community-economics
development-economics
smart-contracts
obesity-policy
organizational-performance
Wikipedia (27)
Miscellaneous
/doc/economics/2023-debrouwer-figure2-survivalanalysisofunemploymentinsuranceapplicantsinbelgium.jpghttps://acoup.blog/2022/02/11/collections-rome-decline-and-fall-part-iii-things//doc/economics/2021-cummissionme-furrycommissionstreetad.jpg/doc/economics/2021-gollin-figure1-wheatyieldbystaggeredrollout.jpg/doc/economics/2021-gollin-figure4-economicgrowthduetothegreenrevolution.jpg/doc/economics/2021-zinovyeva-figure2-simulationsofdifferentnonbiasgendercliffexplanations.png/doc/economics/2021-zinovyeva-figure3-probabilityofcoupleseparationbyfemaleincome.png/doc/economics/2021-zinovyeva-figure4-relativearningsoffemalesbycoworkingstatus.jpg/doc/economics/2020-sekhri-figure2-rddexitexamscorebyexamscore.jpg/doc/psychology/collecting/2019-08-22-kevinlynagh-pricingnicheproducts.html/doc/economics/2019-mewes-figure1-technologicaldiversitybypopulation.png/doc/economics/2019-mewes-figure3-technologicaldiversityscalingovertime.jpg/doc/economics/2019-mewes-figure5-technologicaldiversityscalingbypopulationovertime.jpg/doc/economics/2019-quinn-figure1-bicyclemania-indexvsdividendsbubble.jpg/doc/economics/2017-rubenstein-figure1-summaryofjobturnoverpredictors.png/doc/economics/2014-designboom-evolutionofthedesk-beforeafter.jpg/doc/economics/2014-soll-thevanishedgrandeurofaccounting.html/doc/economics/2013-adkison-wizardsofthecostequitydistribution.html/doc/economics/2011-census-19472003uspopulationeducationalattainment.png/doc/economics/2010-04-01-shirky-thecollapseofcomplexbusinessmodels.html/doc/economics/2008-katz-relativefractionuscollegenocollege.jpg/doc/economics/2006-mackenzie-figure2-1976-05-25-black-optionpricingservice.png/doc/economics/2002-05-01-notesonline-socialismwhathappenedwhatnow.html/doc/economics/2002-temin-figure1-thepriceofbarleyinbabylonia417to72bc.jpg/doc/economics/2002-temin-figure2-thepriceofwoolinbabylonia417to72bc.jpg/doc/economics/2000-eltis-table1-britishcarribeaneconomybysector.jpg/doc/economics/1986-lalonde-table5-correlationalvscausalestimatesofeffectoflabortrainingprogram.png/doc/economics/1984-axelrod-theevolutionofcooperation-ch4-theliveandletlivesysteminwwi.html/doc/economics/1969-brooks-businessadventures-ch7-noncommunicationge.pdf/doc/economics/1957-04-mechanixillustrated-pg99-clowncopyrighteggs-stanbultkingofeggheads.jpg/doc/economics/mooreslaw-backblaze-2017-costpergbharddrive.jpghttps://betonit.substack.com/p/chatgpt-takes-my-midterm-and-getshttps://capitalismandfreedom.substack.com/p/episode-28-steven-d-levitt-freakonomicshttps://clarifycapital.com/the-future-of-investment-pitchinghttps://classic.esquire.com/article/share/58ff278a-21da-4ee4-a446-b7f451b90275https://danluu.com/nothing-works/View External Link:
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/PGFOXWhttps://economicsociology.org/2017/08/29/economics-to-sociology-phrasebook/https://emilkirkegaard.dk/en/2023/07/gdp-problems-but-what-solutions/View External Link:
https://emilkirkegaard.dk/en/2023/07/gdp-problems-but-what-solutions/https://erikgahner.dk/2023/twenty-years-of-marginal-revolution/https://finedataproducts.com/posts/2024-03-10-tax-scenarios-with-ai/https://forum.effectivealtruism.org/posts/cPDptuFTiCLr8XXkL/cause-exploration-prizes-crime-reductionhttps://github.com/chenandrewy/Prompts-to-Paper/blob/master/READMEhttps://interviewing.io/blog/voice-modulation-gender-technical-interviewshttps://marginalrevolution.com/marginalrevolution/2024/08/claude-reviews-you.htmlhttps://matthewbarnett.substack.com/p/gpt-4-takes-bryan-caplans-midtermhttps://mattsclancy.substack.com/p/the-size-of-firms-and-the-naturehttps://mauricio-romero.com/pdfs/papers/Factorial%20Designs%20(Current%20WP).pdfhttps://outsidetheasylum.blog/the-economics-of-organized-play/https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4333314View External Link:
https://research.google/blog/robust-online-allocation-with-dual-mirror-descent/https://thelampmagazine.com/issues/issue-17/shadow-on-the-sunhttps://thezvi.wordpress.com/2020/05/23/mazes-sequence-summary/https://undark.org/2023/07/19/the-vice-of-spice-confronting-lead-tainted-turmeric/https://warontherocks.com/2021/11/feeding-the-bear-a-closer-look-at-russian-army-logistics/https://www.acf.hhs.gov/opre/project/employment-retention-and-advancement-project-era-1998-2011https://www.ageofinvention.xyz/p/age-of-invention-the-second-soulhttps://www.animallaw.info/article/detailed-discussion-legal-rights-and-duties-lost-pet-disputeshttps://www.astralcodexten.com/p/the-buying-things-from-a-store-faqhttps://www.atlasobscura.com/articles/medieval-eel-rent-map-englandhttps://www.bitsaboutmoney.com/archive/seeing-like-a-bank/View External Link:
https://www.fortressofdoors.com/the-future-of-games-is-an-instant-flash-to-the-past/https://www.ft.com/content/968ae6cd-2485-4ab0-b0d1-eb206f59884aView External Link:
https://www.ft.com/content/968ae6cd-2485-4ab0-b0d1-eb206f59884ahttps://www.instyle.com/celebrity/britney-spears-perfume-billion-dollar-businesshttps://www.laweekly.com/ticketmaster-and-servants-bands-get-cut-of-service-fee/https://www.lesswrong.com/posts/EbFABnst8LsidYs5Y/goodhart-taxonomyhttps://www.newyorker.com/magazine/2023/06/05/how-to-hire-a-pop-star-for-your-private-partyhttps://www.newyorker.com/science/annals-of-medicine/how-ecmo-is-redefining-deathhttps://www.nytimes.com/2024/04/08/science/rip-medical-debt.htmlhttps://www.openphilanthropy.org/research/south-asian-air-quality/https://www.overcomingbias.com/p/one-pill-to-break-us-allhtmlhttps://www.protocol.com/chess-streaming-twitch-hikaru-botezhttps://www.ribbonfarm.com/2009/10/07/the-gervais-principle-or-the-office-according-to-the-office/https://www.sciencedirect.com/science/article/pii/S0169207024001079https://www.sciencedirect.com/science/article/pii/S0749597823000560https://www.theatlantic.com/ideas/archive/2023/12/great-resignation-myth-polls/676189/https://www.thebigquestions.com/2023/04/05/gpt-4-fails-economics/https://www.theonion.com/corporation-reaches-goal-shuts-down-1819566365https://www.wired.com/2014/10/a-spreadsheet-way-of-knowledge/-
View External Link:
-
View External Link:
{kind=link}
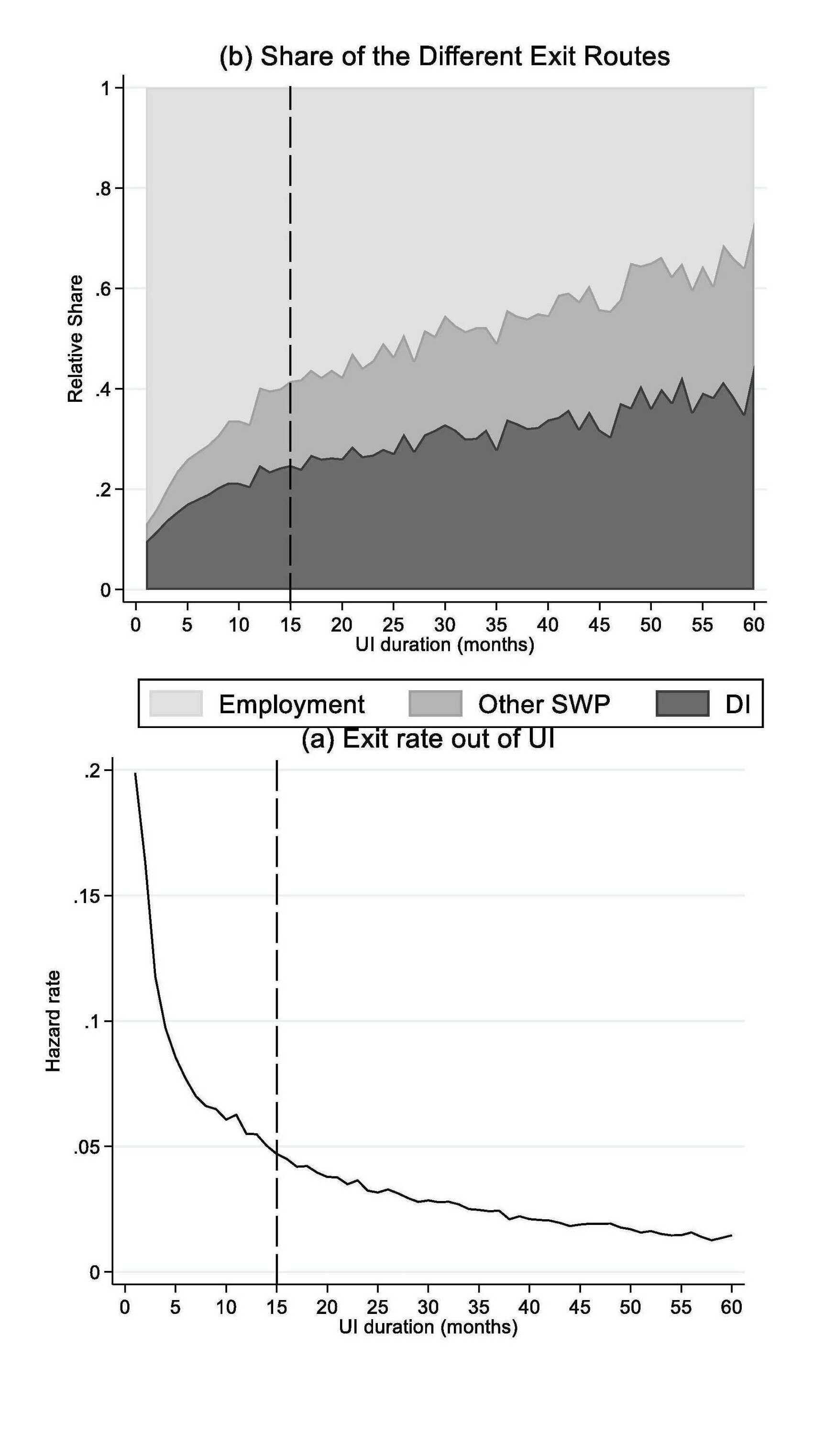{kind=link}
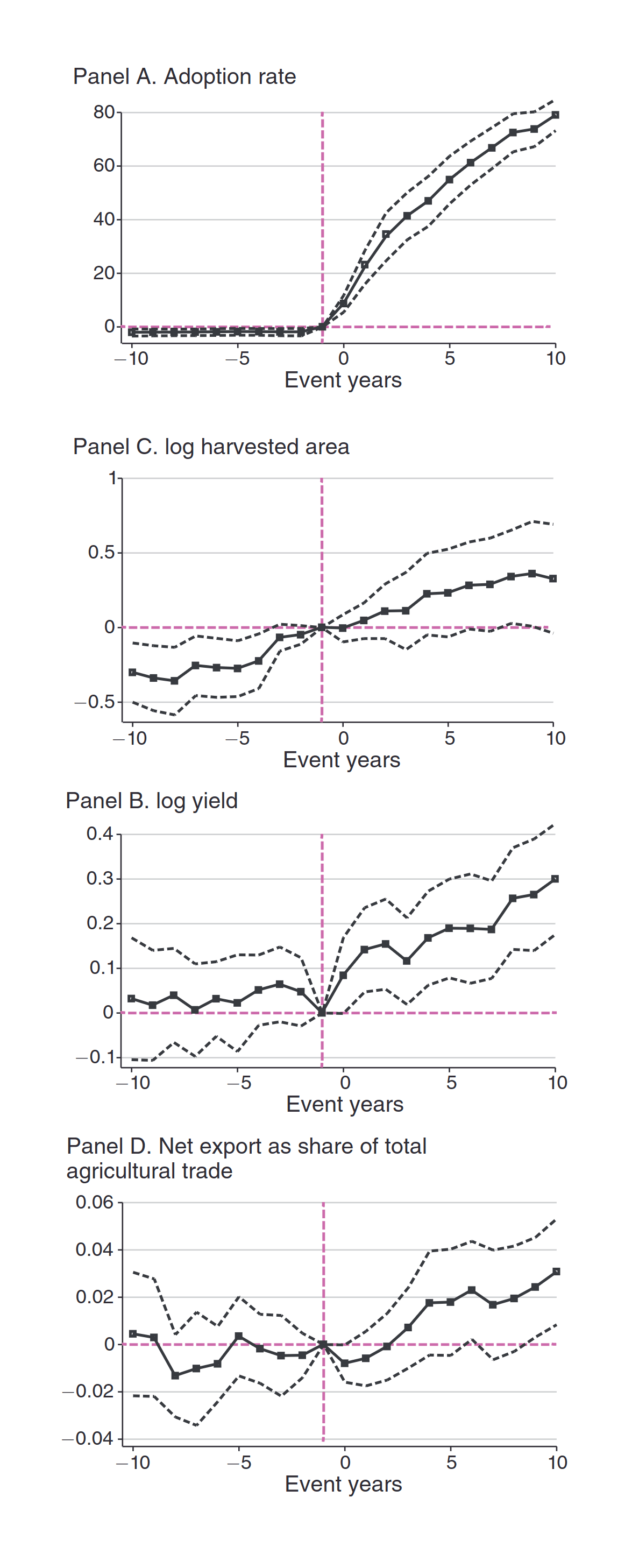{kind=link}
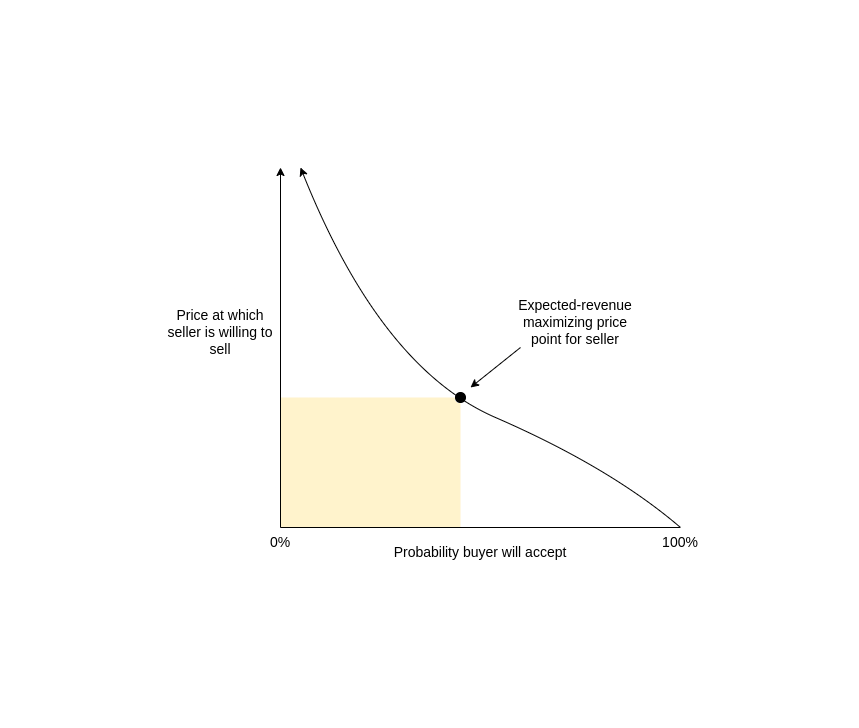{kind=link}
{kind=link}
{kind=link}
{kind=link}
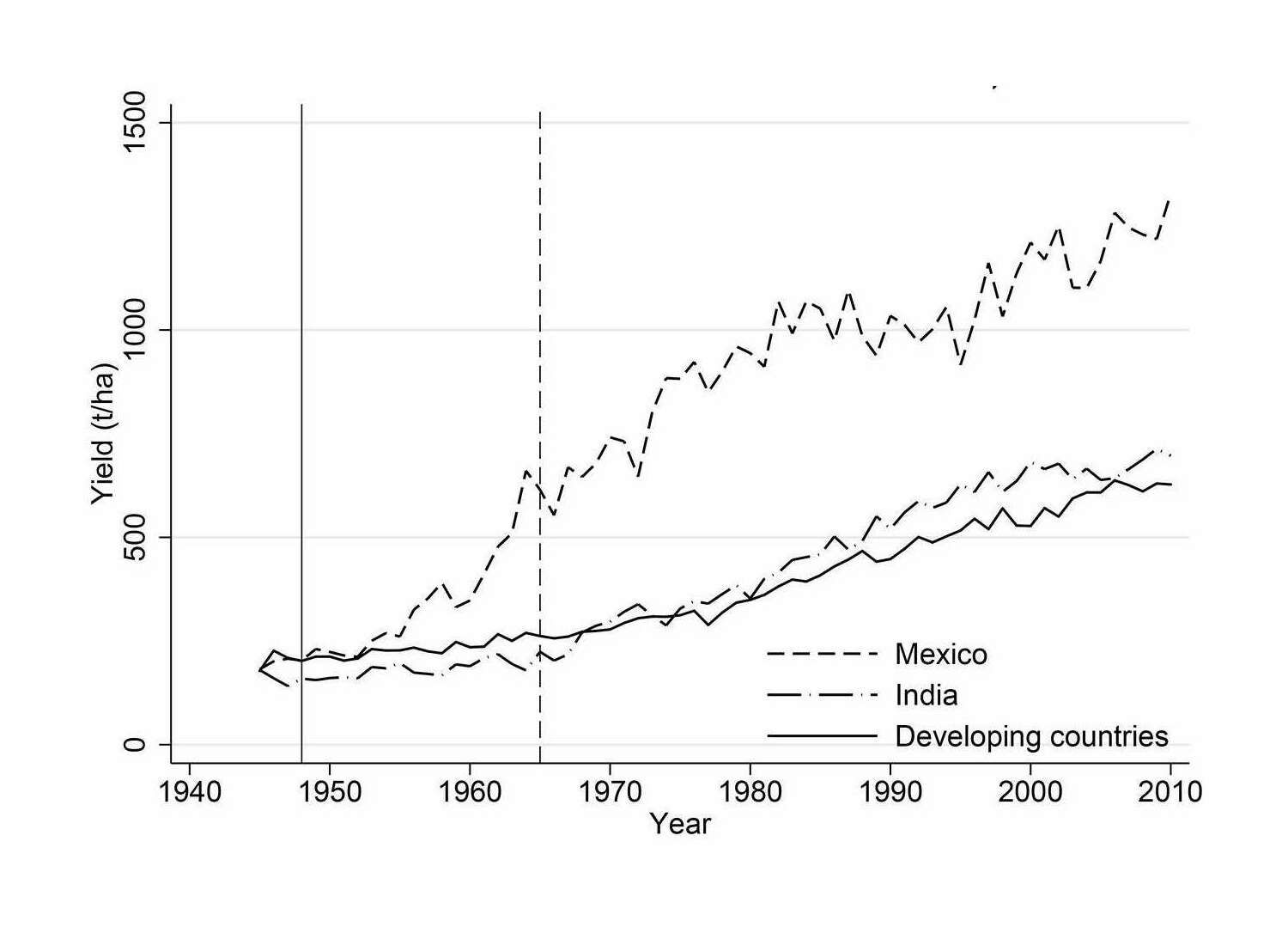{kind=link}
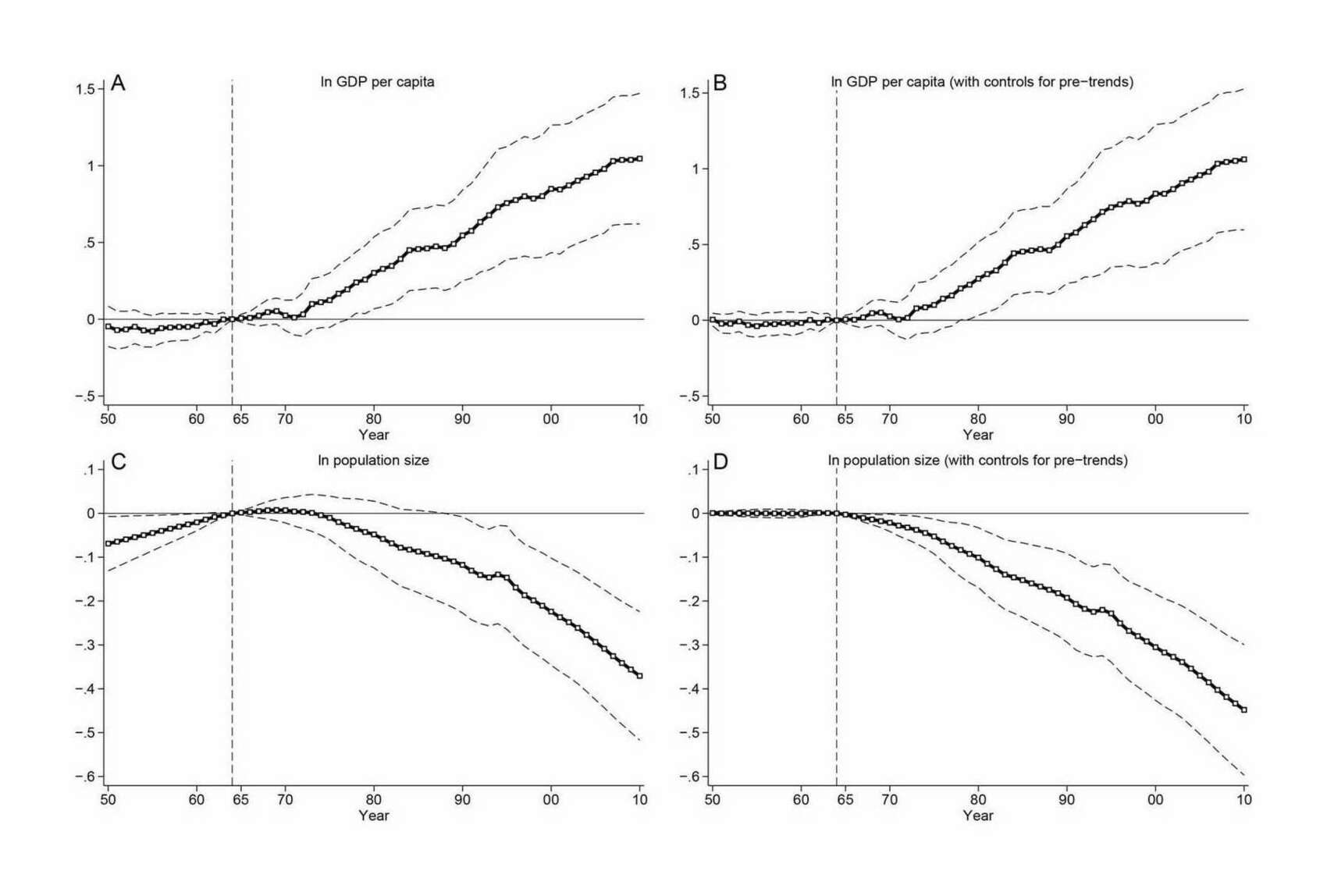{kind=link}
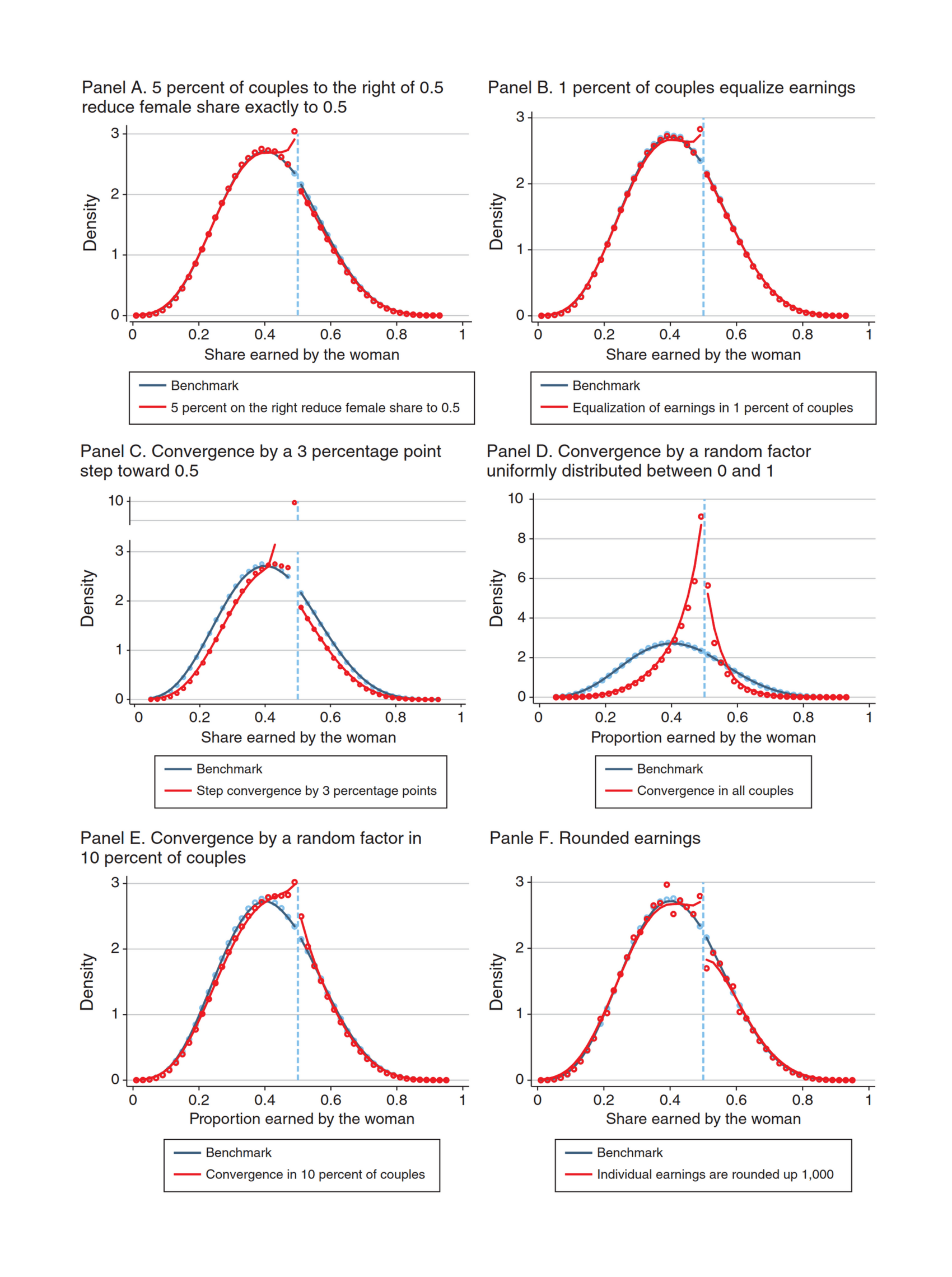{kind=link}
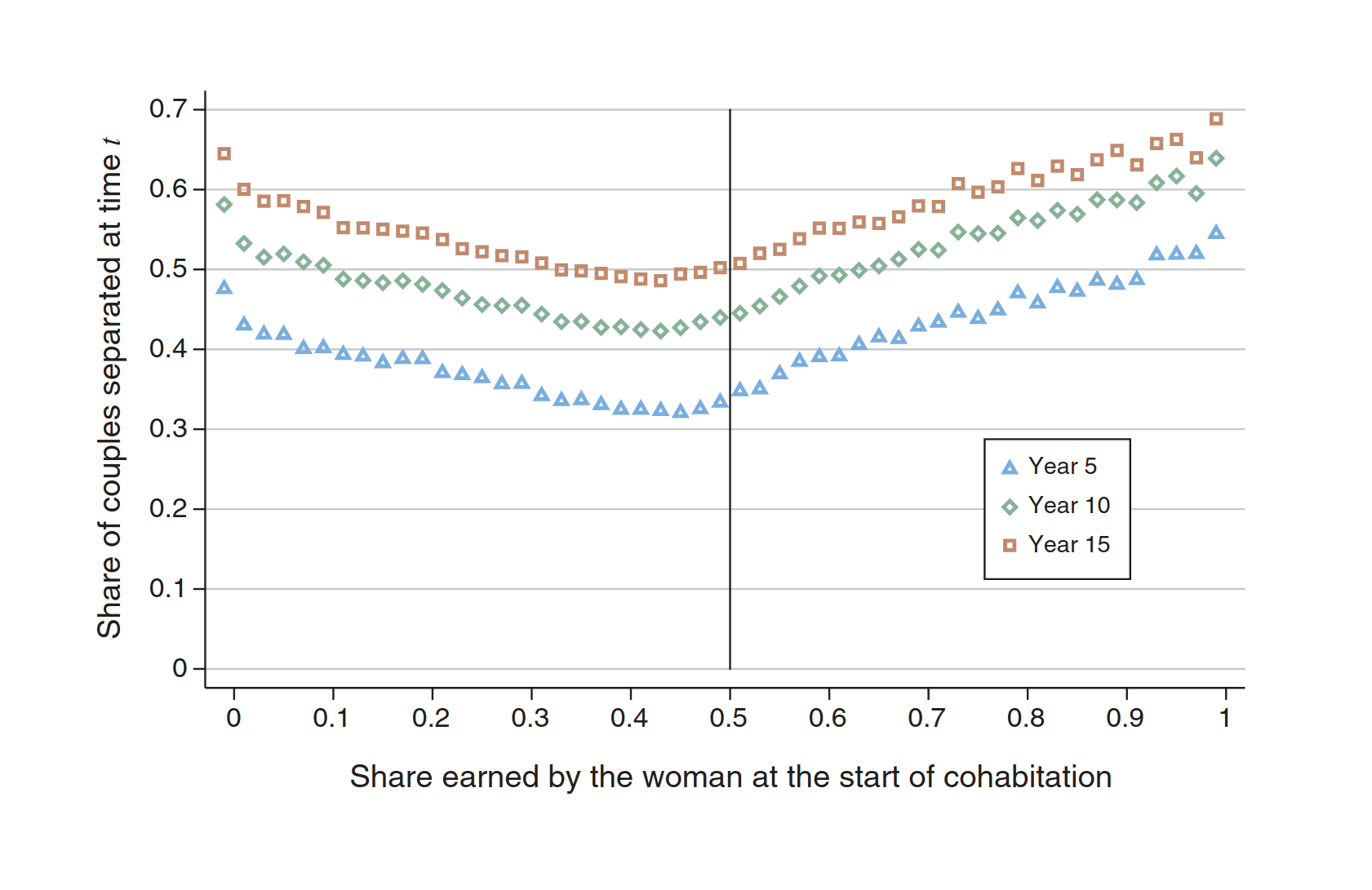{kind=link}
{kind=link}
{kind=link}
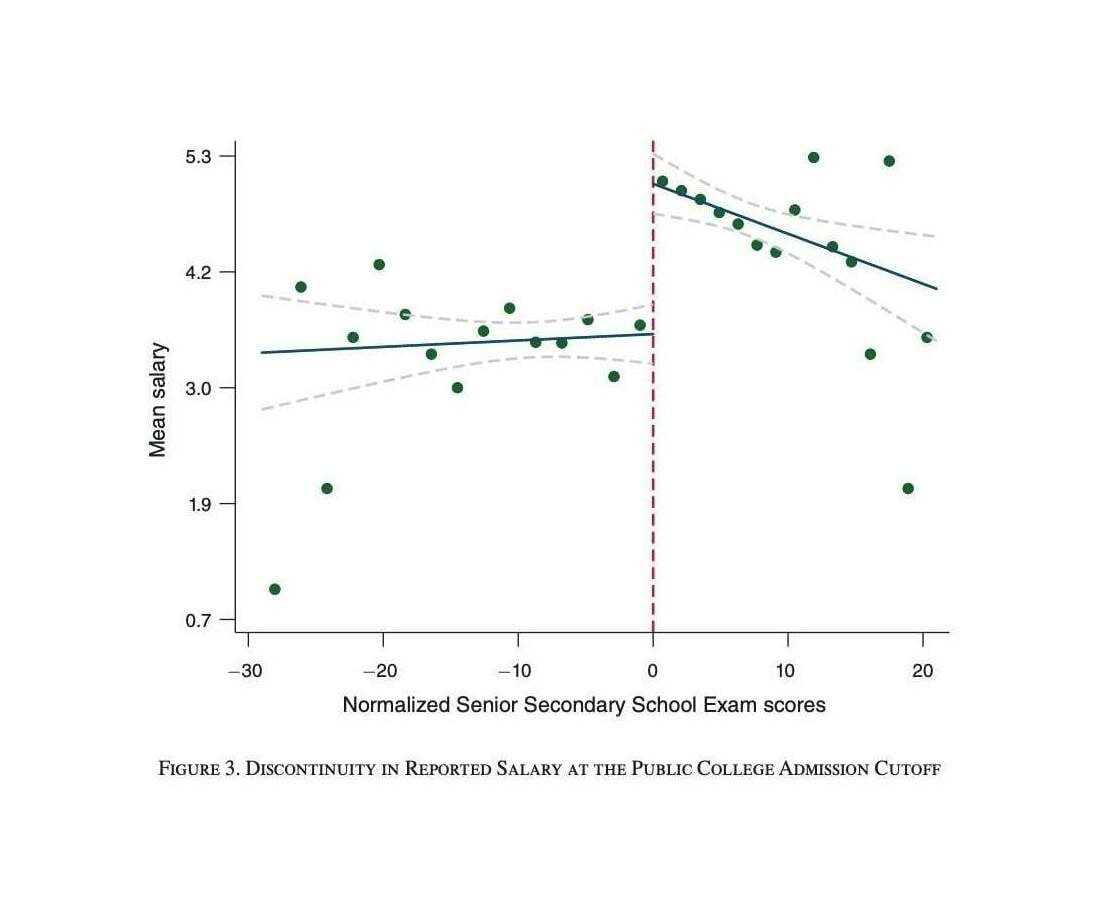{kind=link}
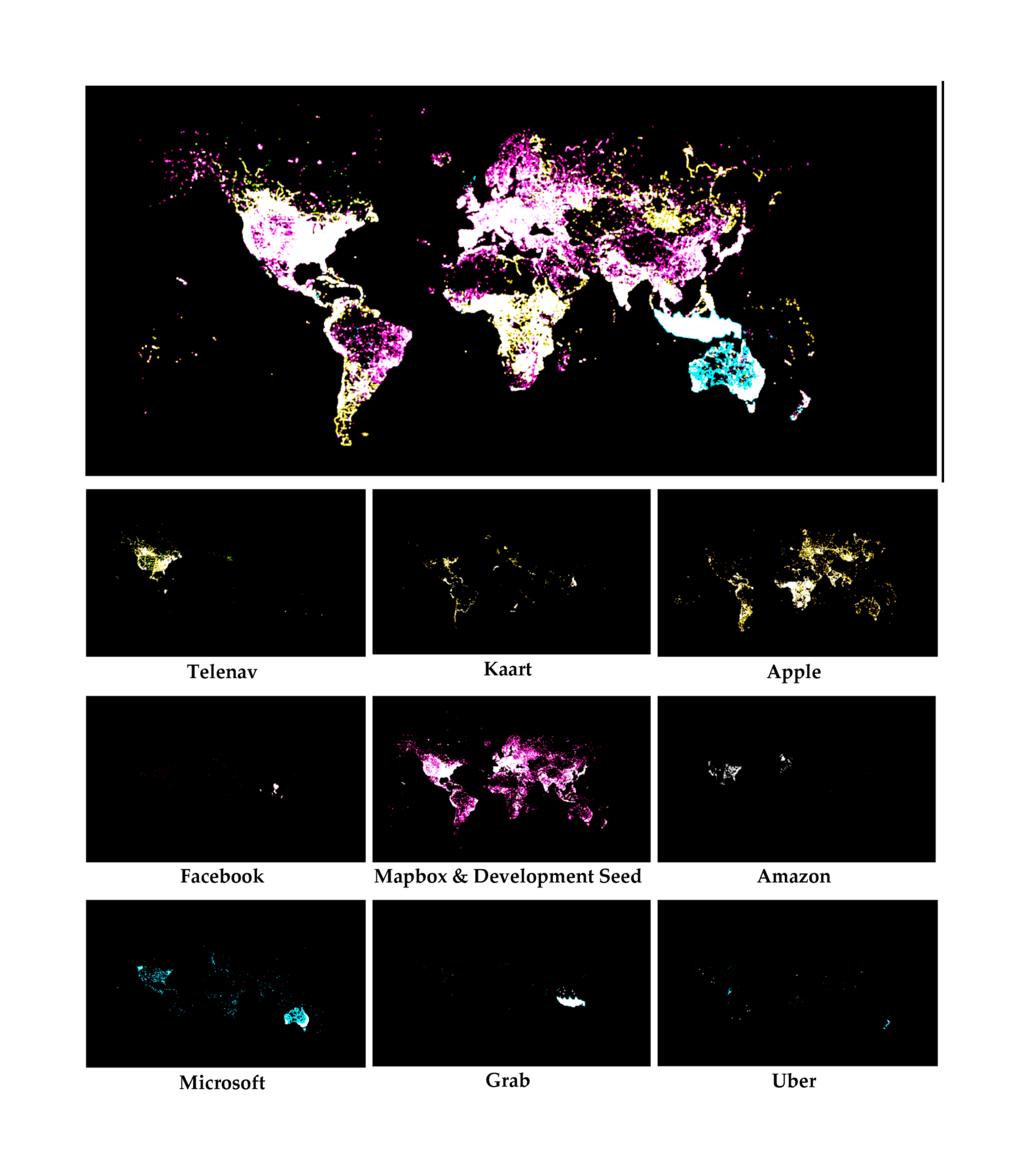{kind=link}
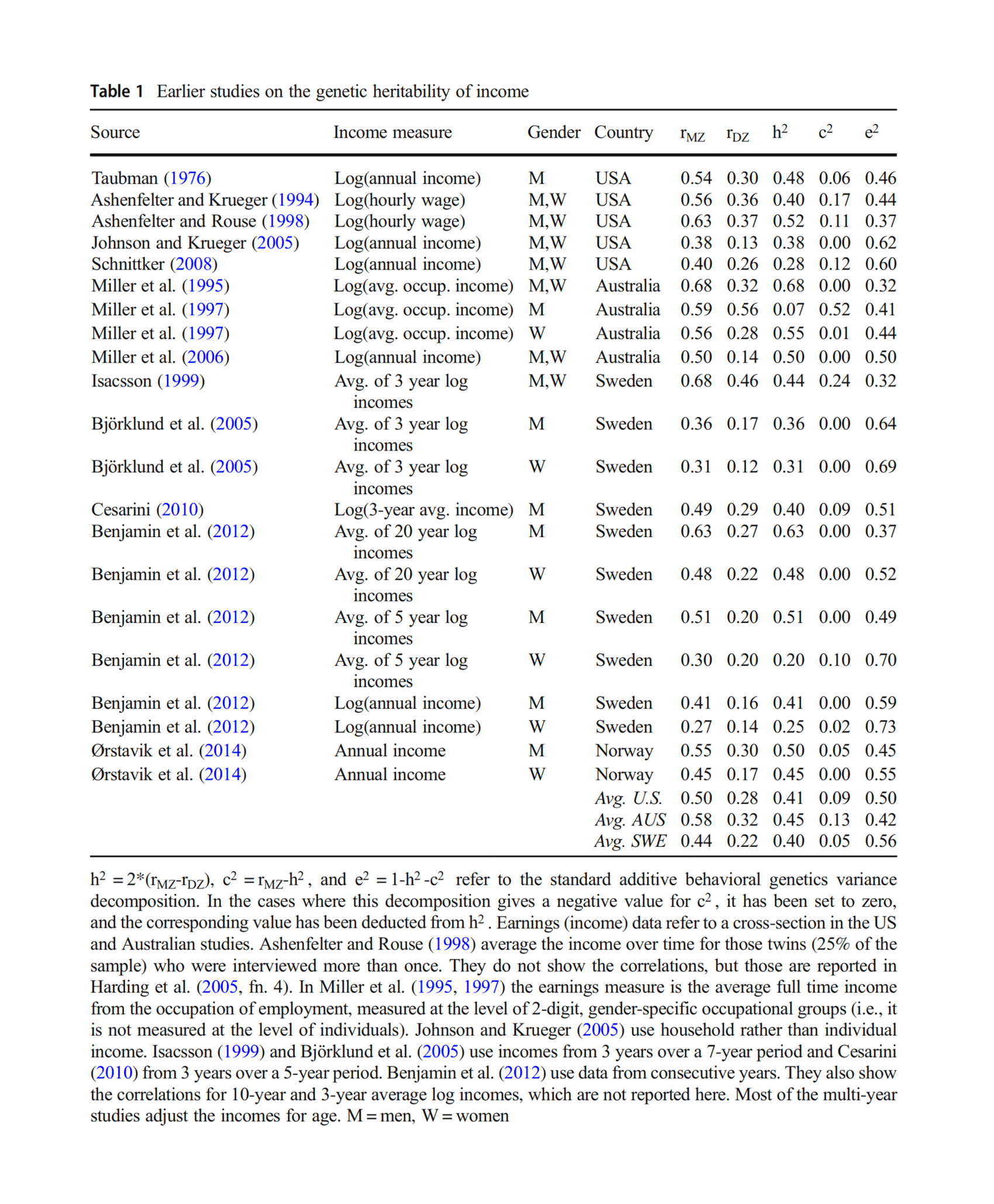{kind=link}
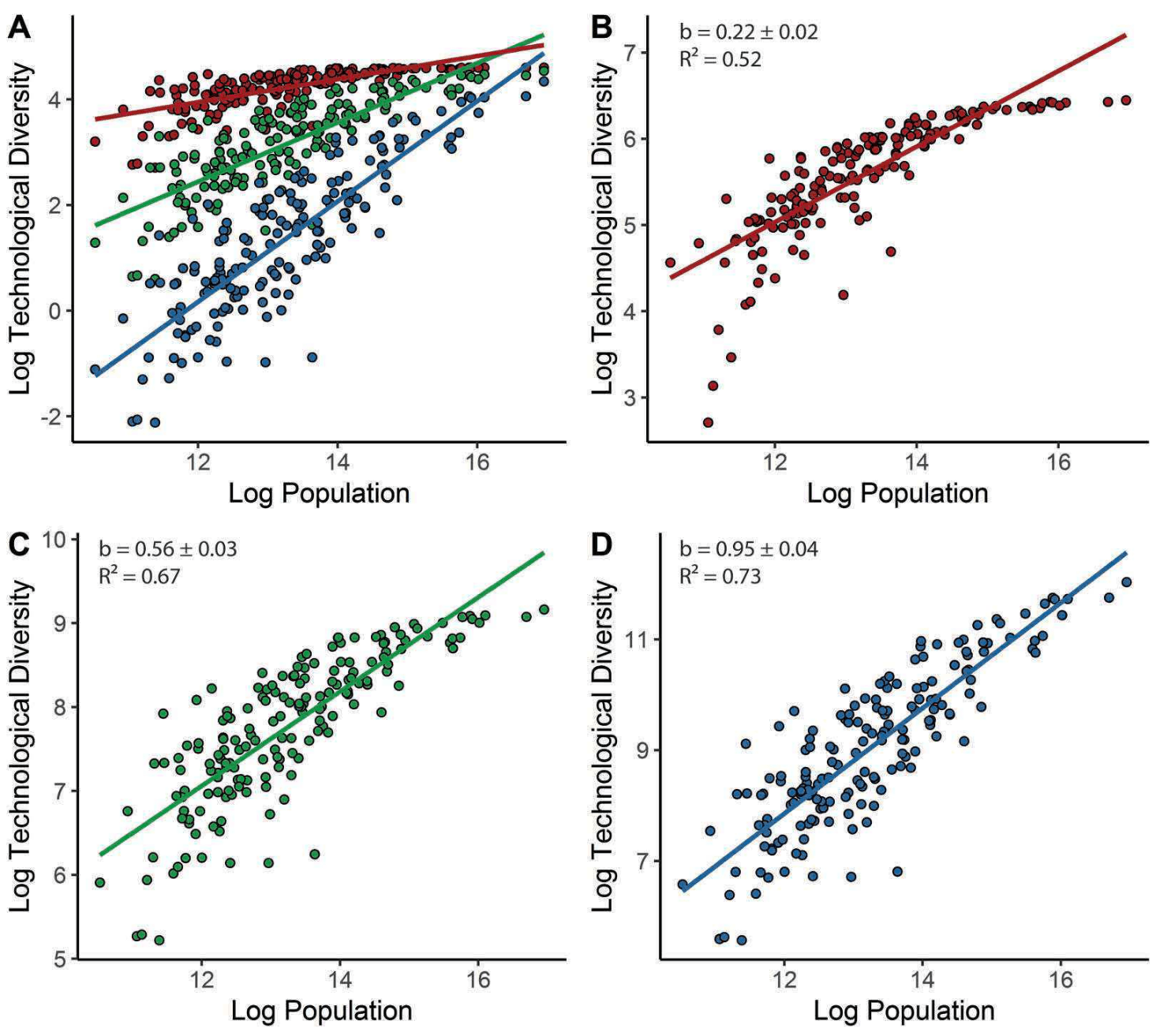{kind=link}
{kind=link}
{kind=link}
{kind=link}
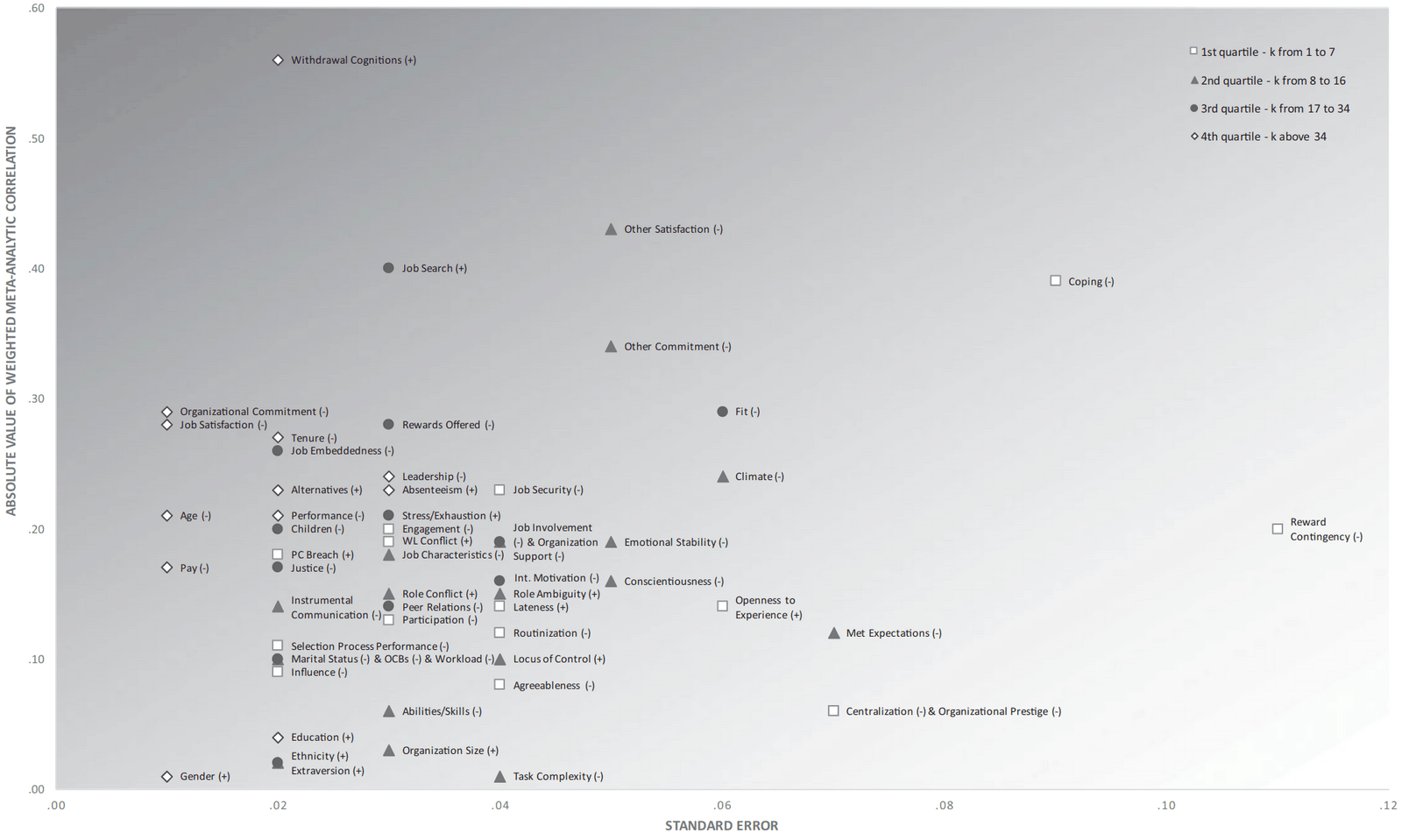{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
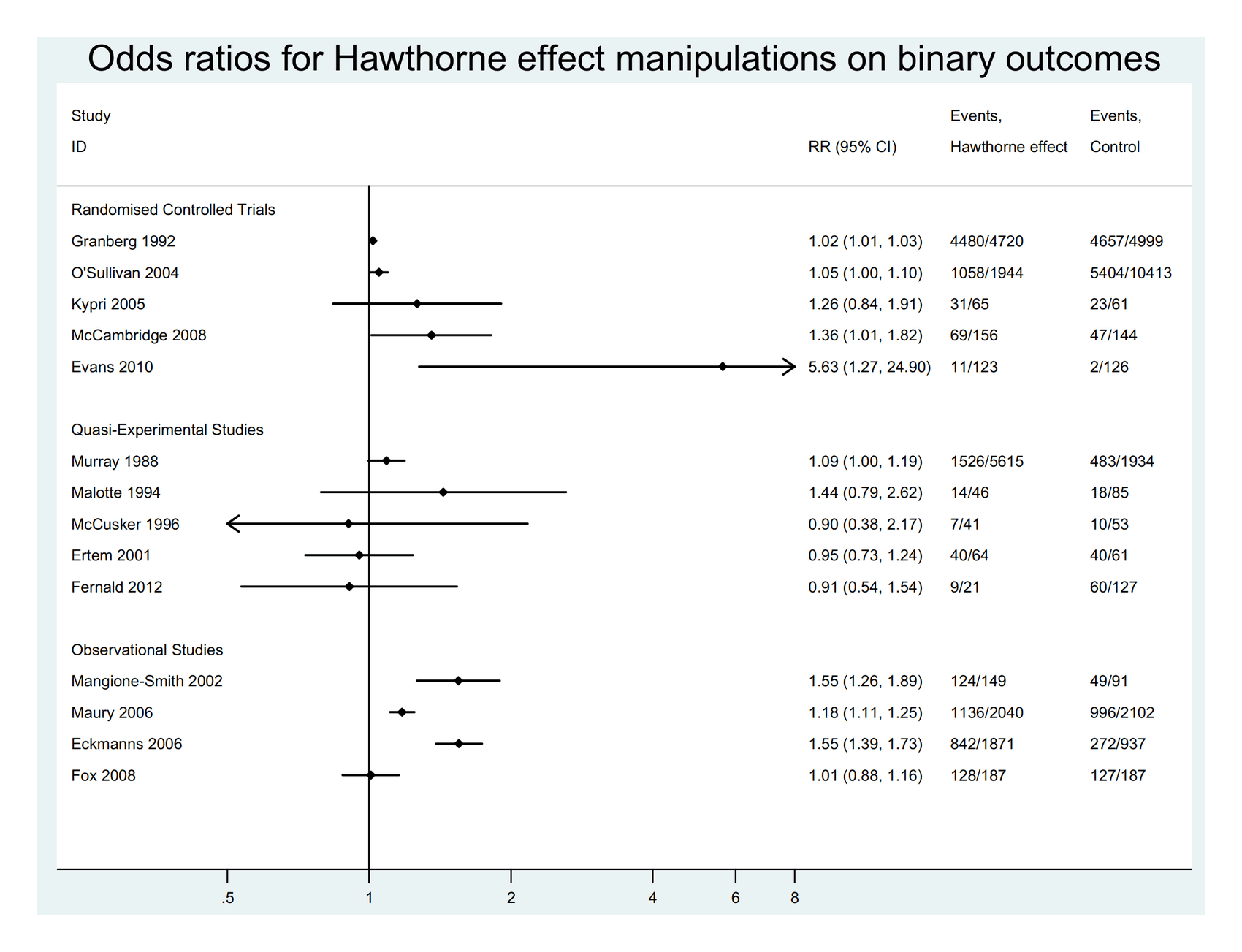{kind=link}
{kind=link}
{kind=link}
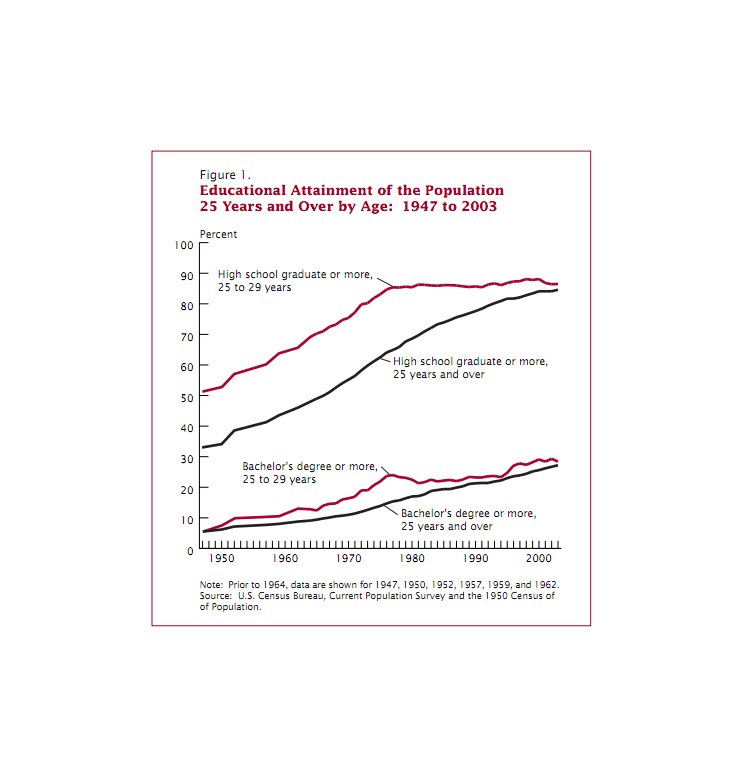{kind=link}
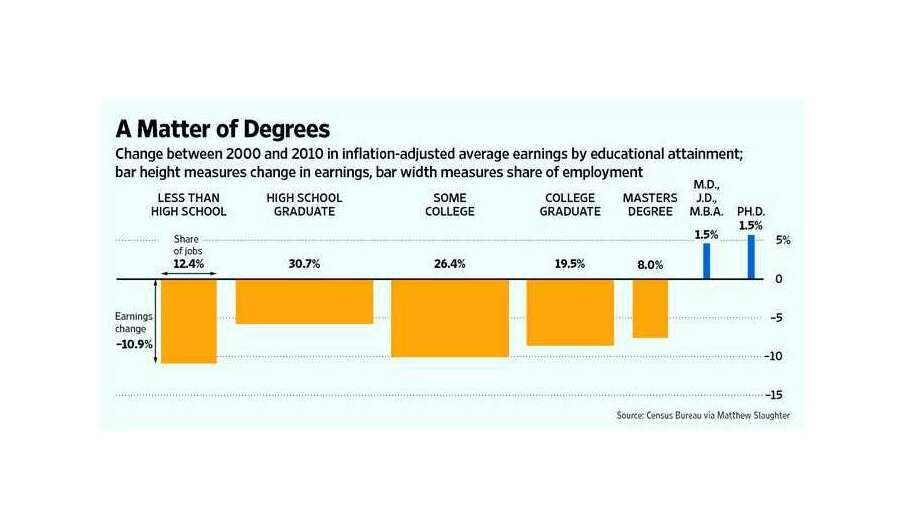{kind=link}
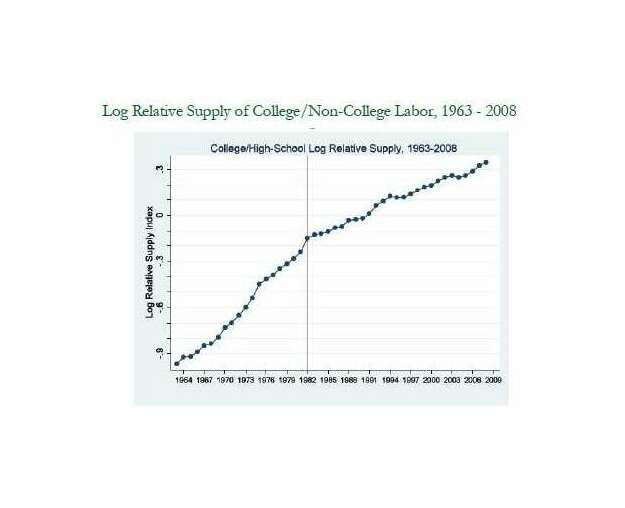{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
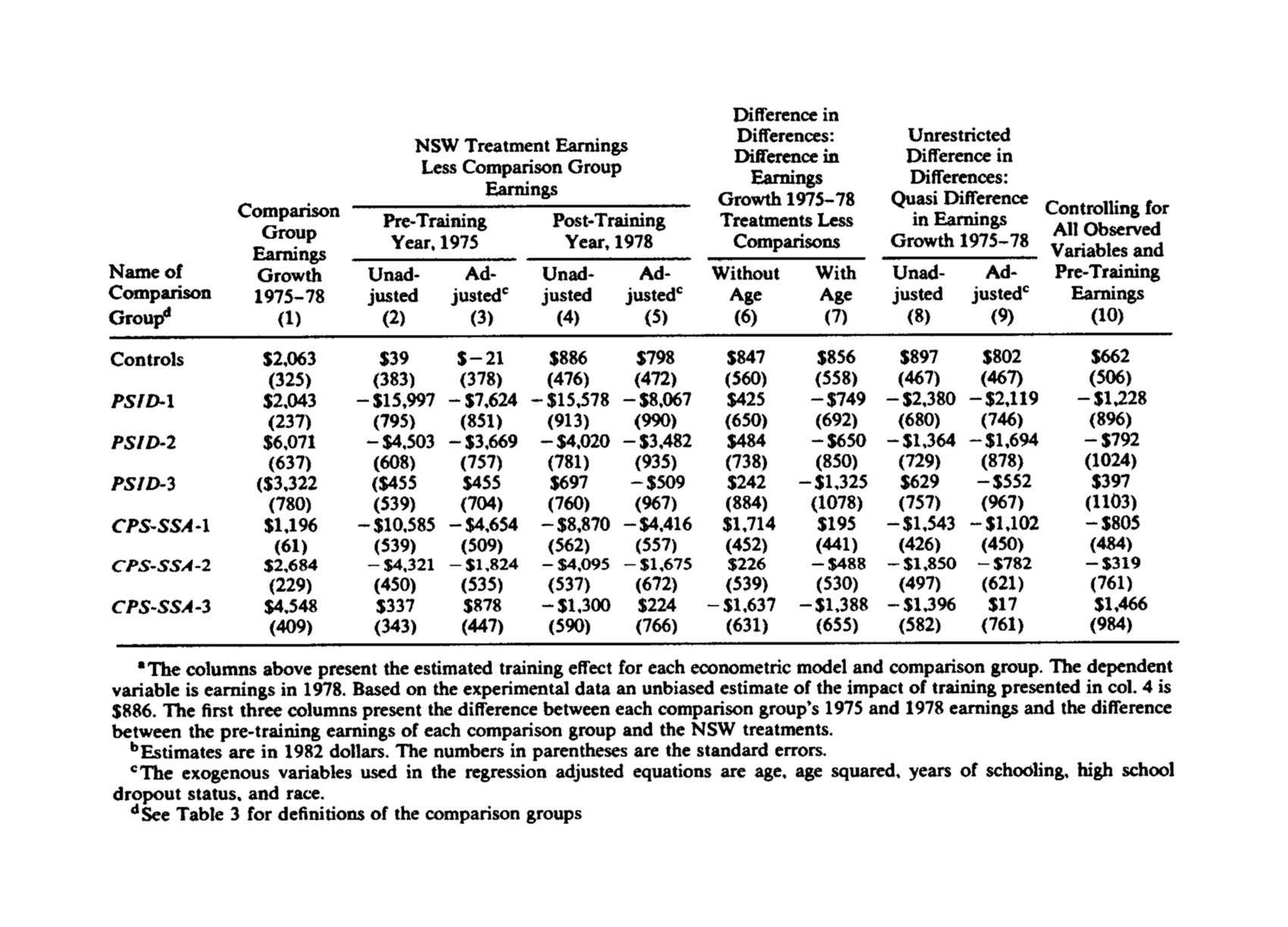{kind=link}
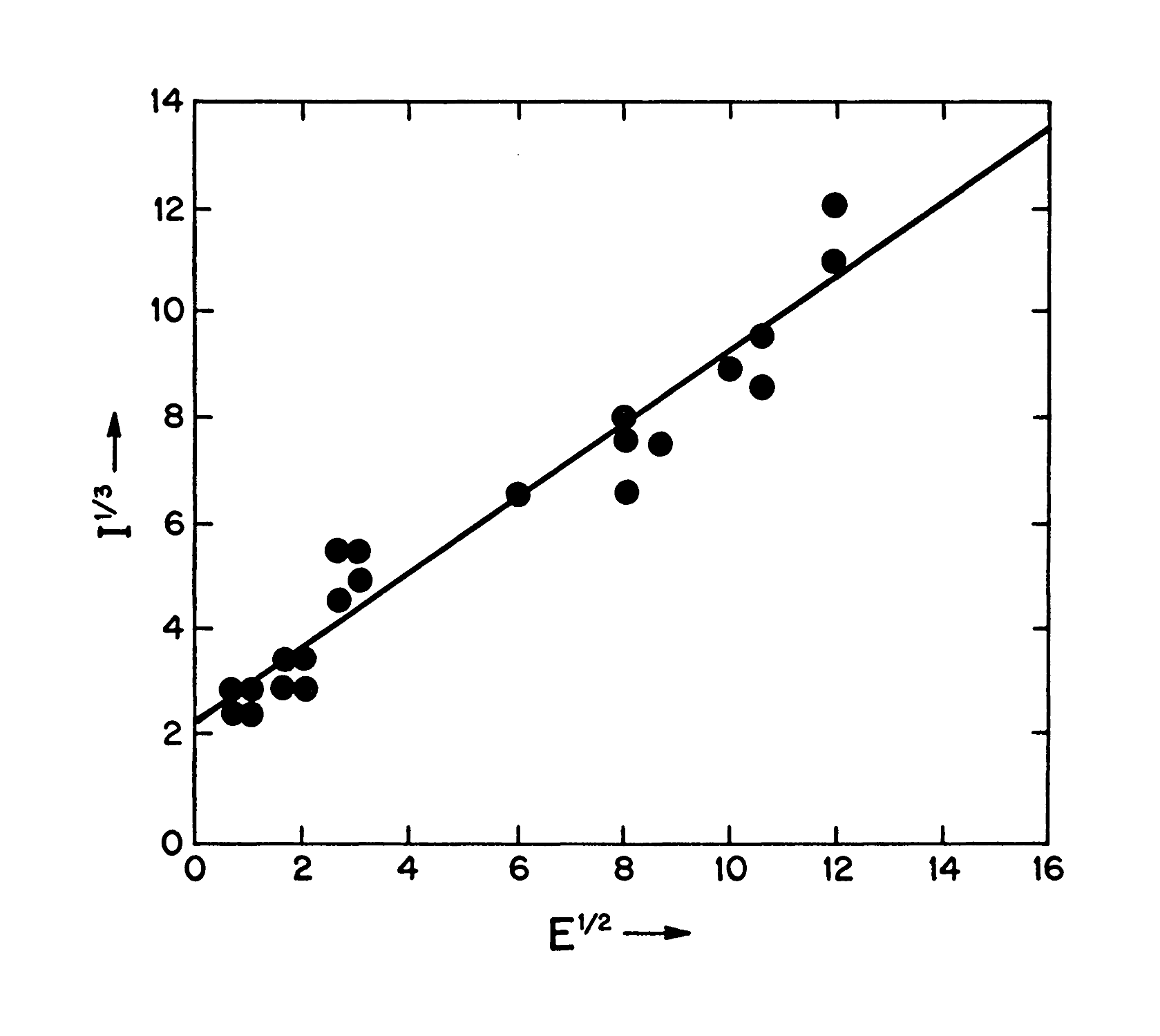{kind=link}
{kind=link}
{kind=link}
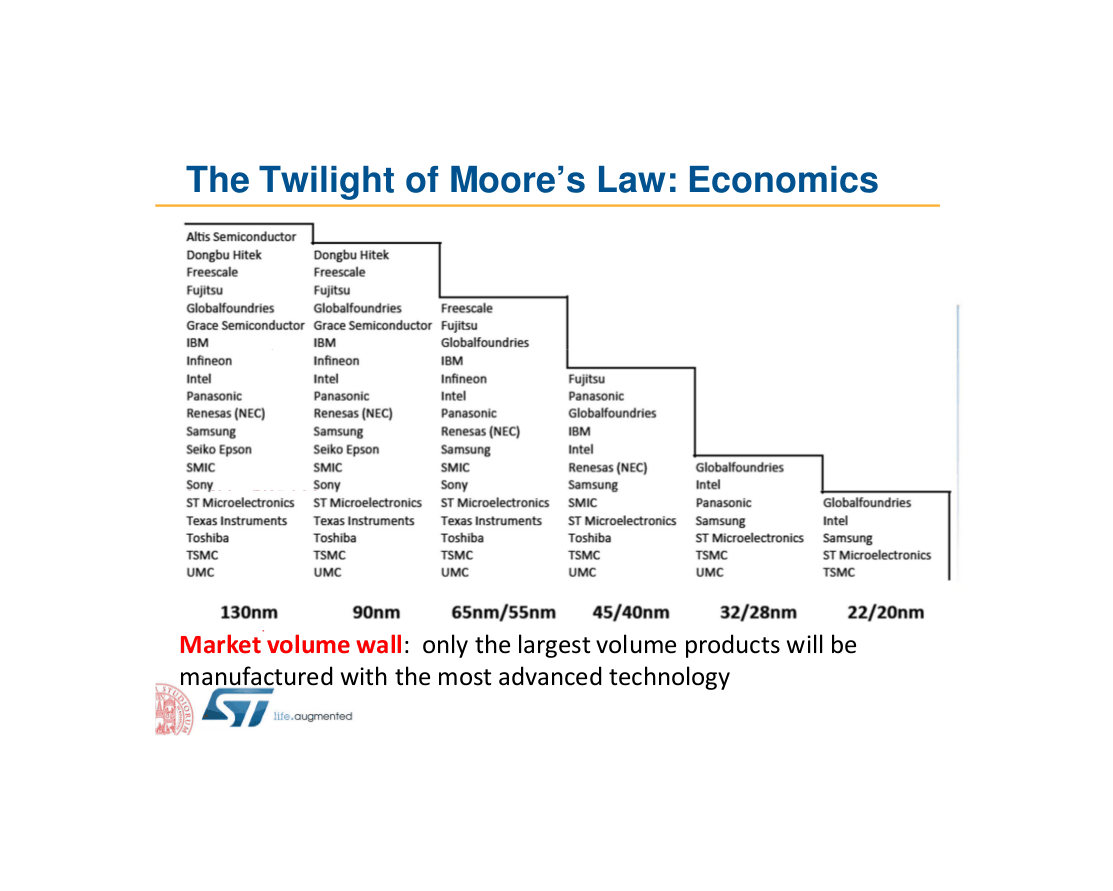{kind=link}
{kind=link}
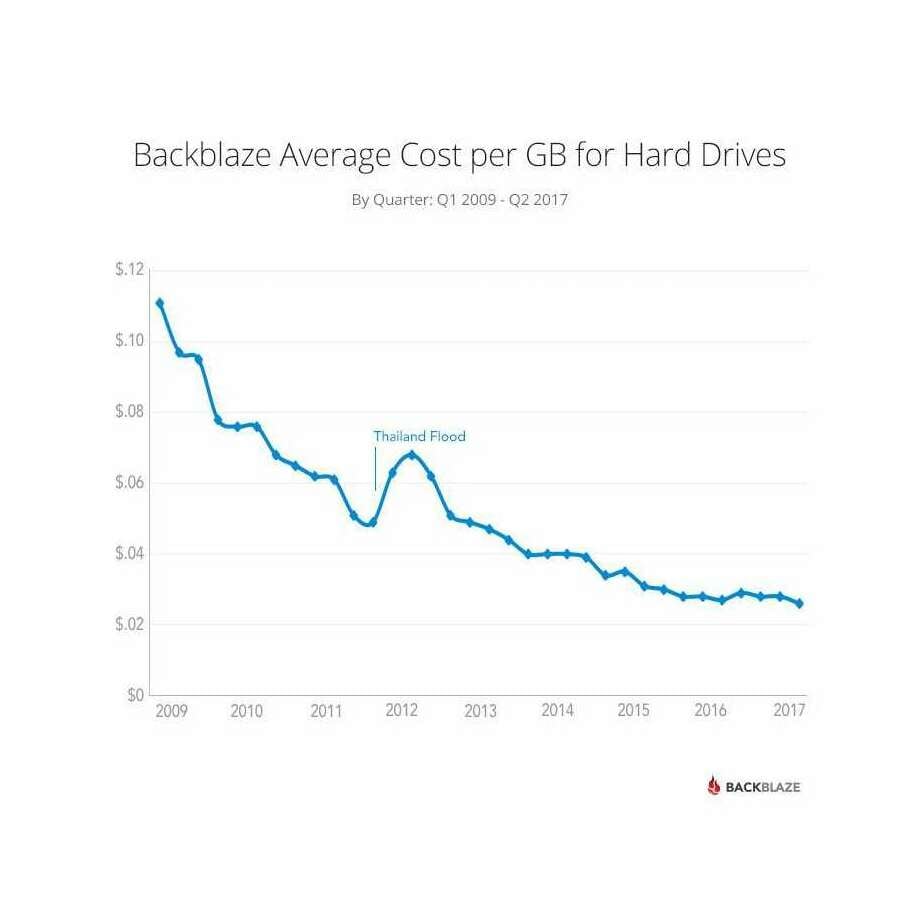{kind=link}
Bibliography
2026-buyukeren.pdf: “The Impact of Dating Apps on Young Adults: Evidence from Tinder”,https://sinopsis.cz/en/chinas-superstition-boom-in-a-godless-state/: “China’s Superstition Boom in a Godless State § DeepSeek’s Occult Tech Boom”,https://joshuagans.substack.com/p/what-will-ai-do-to-presearch: “What Will AI Do to pre-Research/research? AI Makes Doing and Communicating Research Much Easier. Will There Be Any Point to It?”,https://www.sciencedirect.com/science/article/pii/S0165176525000461: “The Efficient Market Hypothesis When Time Travel Is Possible”,2024-oprea.pdf: “Decisions under Risk Are Decisions under Complexity”,2024-tabarrok.pdf: “The Economic Way of Thinking in a Pandemic”,2024-wallrich.pdf: “The Relationship Between Team Diversity and Team Performance: Reconciling Promise and Reality Through a Comprehensive Meta-Analysis Registered Report”,https://onlinelibrary.wiley.com/doi/full/10.1111/ecin.13222: “Is Economics Self-Correcting? Replications in the American Economic Review”,2024-gallego.pdf: “What’s Behind Her Smile? Health, Looks, and Self-Esteem”,https://www.cambridge.org/core/journals/social-philosophy-and-policy/article/psychology-of-poverty-where-do-we-stand/0EE340EA852D6F3688C27F03024FA4DF: “The Psychology Of Poverty: Where Do We Stand?”,2024-bhattacharjee.pdf: “Lay Economic Reasoning: An Integrative Review and Call to Action”,2023-litina.pdf: “Solar Eclipses and the Origins of Critical Thinking and Complexity”,2023-homroy.pdf: “Strategic CEO Activism in Polarized Markets”,2023-davidai.pdf: “Economic Inequality Fosters the Belief That Success Is Zero-Sum”,https://arxiv.org/abs/2310.08678: “Can GPT Models Be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on Mock CFA Exams”,2023-hale.pdf: “Do Looks Matter for an Academic Career in Economics?”,https://journals.sagepub.com/doi/full/10.1177/20531680231194805: “Expert Opinions and Negative Externalities Do Not Decrease Support for Anti-Price Gouging Policies”,https://www.wsj.com/health/healthcare/ozempic-mounjaro-weight-loss-drug-cost-32fc3555: “To Pay for Weight Loss Drugs, Some Take Second Jobs, Ring Up Credit Card Debts: Some People Pay More Than $10,000 a Year Out-Of-Pocket for Ozempic and Mounjaro”,https://psycnet.apa.org/fulltext/2023-75190-001.html: “How Well Do Laboratory-Derived Estimates of Time Preference Predict Real-World Behaviors? Comparisons to Four Benchmarks”,2023-akcigit.pdf: “What Happened to US Business Dynamism?”,2023-agca.pdf: “The Lion’s Share: Evidence from Federal Contracts on the Value of Political Connections”,2023-alfani.pdf: “Income and Inequality in the Aztec Empire on the Eve of the Spanish Conquest”,https://www.tandfonline.com/doi/full/10.1080/19485565.2023.2220950: “Increasing Pressure on US Men for Income in order to Find a Spouse”,2023-hansen.pdf: “National and Global Impacts of Genetically Modified Crops”,2023-davidai-2.pdf: “The Psychology of Zero-Sum Beliefs”,https://www.pnas.org/doi/10.1073/pnas.2215829120: “Founder Personality and Entrepreneurial Outcomes: A Large-Scale Field Study of Technology Startups”,2023-agrawal.pdf: “Taxing Uber”,2023-hallsten.pdf: “The Shadow of Peasant Past: Seven Generations of Inequality Persistence in Northern Sweden”,https://onlinelibrary.wiley.com/doi/full/10.1111/ecin.13145: “Invisible Hurdles: Gender and Institutional Differences in the Evaluation of Economics Papers”,https://www.nber.org/papers/w31192: “Managers and Productivity in Retail”,2023-gomezreino.pdf: “Evidence on Economies of Scale in Local Public Service Provision: A Meta-Analysis”,https://www.nber.org/papers/w31041: “Personality Differences and Investment Decision-Making”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4335945: “Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”,2023-cinnirella.pdf: “Islam and Human Capital in Historical Spain”,https://arstechnica.com/gadgets/2023/01/google-announces-official-android-support-for-risc-v/: “Google Wants RISC-V to Be a ‘tier-1’ Android Architecture: Google’s Keynote at the RISC-V Summit Promises Official, Polished Support”,2022-kelly-2.pdf: “The Mechanics of the Industrial Revolution”,https://arstechnica.com/gadgets/2022/12/linux-amazon-meta-and-microsoft-want-to-break-the-google-maps-monopoly/: “Linux, Amazon, Meta, and Microsoft Want to Break the Google Maps Monopoly: Overture Maps Foundation Wants to End the Oppressive Rule of the Google Maps API”,2022-cesareo.pdf: “Hideous but worth It: Distinctive Ugliness As a Signal of Luxury”,https://www.sciencedirect.com/science/article/pii/S0148619522000510: “Facial Attractiveness and CEO Compensation: Evidence from the Banking Industry”,2022-kent.pdf: “When a Town Wins the Lottery: Evidence from Spain”,2022-orr.pdf: “Within-Firm Productivity Dispersion: Estimates and Implications”,2022-mulligan.pdf: “Peltzman Revisited: Quantifying 21st-Century Opportunity Costs of FDA Regulation”,https://www.journals.uchicago.edu/doi/10.1086/718515: “Scaring or Scarring? Labor Market Effects of Criminal Victimization”,https://link.springer.com/article/10.1057/s41269-022-00258-3: “The Delusive Economy: How Information and Affect Color Perceptions of National Economic Performance”,https://openreview.net/forum?id=DY1pMrmDkm: “Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4180594: “Do Pre-Registration and Pre-Analysis Plans Reduce p-Hacking and Publication Bias?”,2022-naven.pdf: “The Signaling Value of University Rankings: Evidence from Top 14 Law Schools”,2022-goni.pdf: “Assortative Matching at the Top of the Distribution: Evidence from the World’s Most Exclusive Marriage Market”,2022-krueger.pdf: “A Pay Change and Its Long-Term Consequences”,2022-tuhkuri.pdf: “Essays on Technology and Work”,2022-cheng.pdf: “Sweet Unbinding: Sugarcane Cultivation and the Demise of Foot-Binding”,https://www.sciencedirect.com/science/article/pii/S0304387822000396: “Clans and Calamity: How Social Capital Saved Lives during China’s Great Famine”,https://www.cesifo.org/DocDL/cesifo1_wp9776.pdf#page=3: “The Null Result Penalty”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4114397: “A Golden Opportunity: The Gold Rush, Entrepreneurship and Culture”,2022-piano.pdf: “Rent Seeking and the Decline of the Florentine School”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4072893: “The LGBTQ+ Gap: Recent Estimates for Young Adults in the United States”,2022-barrios.pdf: “Launching With a Parachute: The Gig Economy and New Business Formation”,2022-pager.pdf: “Criminalizing Poverty: The Consequences of Court Fees in a Randomized Experiment”,2022-pritchett.pdf: “National Development Delivers: And How! And How?”,https://www.nber.org/papers/w29772: “The Economic Effects of the English Parliamentary Enclosures”,2022-ling.pdf: “Bronze Age Long-Distance Exchange, Secret Societies, Rock Art, and the Supra Regional Interaction Hypothesis”,2021-clifton.pdf: “Parents Think—Incorrectly—That Teaching Their Children That the World Is a Bad Place Is Likely Best for Them”,https://onlinelibrary.wiley.com/doi/full/10.1002/sej.1417: “The CEO Beauty Premium: Founder CEO Attractiveness and Firm Valuation in Initial Coin Offerings”,https://code.blender.org/2021/12/improving-real-time-rendering-of-dynamic-digital-characters-in-cycles/: “Improving Real-Time Rendering of Dynamic Digital Characters in Cycles”,https://academic.oup.com/restud/article/89/5/2806/6447525: “Patience and Comparative Development”,2021-suandi.pdf: “Promoting to Opportunity: Evidence and Implications from the US Submarine Service”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3957650: “Does the Mafia Hire Good Accountants?”,2021-ongis.pdf: “Personal Relative Deprivation and the Belief That Economic Success Is Zero-Sum”,2021-anderson-2.pdf: “The Aggregate Cost of Crime in the United States”,2021-zinovyeva.pdf: “Gender Identity, Coworking Spouses and Relative Income within Households”,2022-roberts.pdf: “Personality Psychology”,2021-aguiar.pdf: “Playlisting Favorites: Measuring Platform Bias in the Music Industry”,https://papers.tinbergen.nl/21088.pdf#page=3: “Using Genes to Explore the Effects of Cognitive and Non-Cognitive Skills on Education and Labor Market Outcomes”,2021-johnson-3.pdf: “Win-Win Denial: The Psychological Underpinnings of Zero-Sum Thinking”,2021-cansunar.pdf: “Who Is High Income, Anyway? Social Comparison, Subjective Group Identification, and Preferences over Progressive Taxation”,2021-brocas.pdf: “Steps of Reasoning in Children and Adolescents”,https://journals.sagepub.com/doi/full/10.1177/09500170211015067: “Alienation Is Not ‘Bullshit’: An Empirical Critique of Graeber’s Theory of BS Jobs”,https://mattlakeman.org/2021/06/01/everything-you-might-want-to-know-about-whaling/: “Everything You Might Want to Know about Whaling”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3821615: “Death Toll of Price Limits and Protectionism in the Russian Pharmaceutical Market”,2021-kaplan.pdf: “Are CEOs Different?”,2021-macchia.pdf: “The Link between Income, Income Inequality, and Prosocial Behavior around the World: A Multiverse Approach”,https://www.nber.org/system/files/working_papers/w28340/w28340.pdf: “Recipes and Economic Growth: A Combinatorial March Down an Exponential Tail”,2021-fried.pdf: “Will NASDAQ’s Diversity Rules Harm Investors?”,https://ideas.repec.org/p/uea/ueaeco/2021-02.html: “Natural Selection in Contemporary Humans Is Linked to Income and Substitution Effects”,https://www.sciencedirect.com/science/article/pii/S0167268119302641: “Predicting Mid-Life Capital Formation With Pre-School Delay of Gratification and Life-Course Measures of Self-Regulation”,https://worksinprogress.co/issue/the-daily-grind/: “The Daily Grind: Before Millstones Were Invented, the Preparation of Flour for Food Was an Arduous Task Largely Carried out by Women for Hours Every Day. How Did It Affect Their Lives and Why Does It Remain a Tradition in Some Places Even Today?”,2020-clark.pdf: “Does Education Matter? Tests from Extensions of Compulsory Schooling in England and Wales 1919-22, 1947, and 1972”,2020-sias.pdf#page=2: “Molecular Genetics, Risk Aversion, Return Perceptions, and Stock Market Participation”,https://onlinelibrary.wiley.com/doi/full/10.1111/roiw.12469: “Happy Lottery Winners and Lottery-Ticket Bias”,2020-arbel.pdf: “Theory of the Nudnik: The Future of Consumer Activism and What We Can Do to Stop It”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3521798: “The College Admissions Contribution to the Labor Market Beauty Premium”,https://ideas.repec.org/p/nbr/nberwo/27053.html: “Persistence Despite Revolutions”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2379577: “CEO Selection and Executive Appearance”,2019-mosquera.pdf: “The Economic Effects of Facebook”,https://journals.sagepub.com/doi/full/10.1177/1948550619854751: “Time Use and Happiness of Millionaires: Evidence From the Netherlands”,2019-hyytinen.pdf: “Heritability of Lifetime Earnings”,2018-kim.pdf: “Knitting Community: Human and Social Capital in the Transition to Entrepreneurship”,https://journals.aom.org/doi/abs/10.5465/AMBPP.2018.12279abstract: “Effects of Non-Normal Performance Distributions on the Accuracy of Utility Analysis”,2018-ransom.pdf: “Do High School Sports Build or Reveal Character? Bounding Causal Estimates of Sports Participation”,https://link.springer.com/article/10.1007/s10698-017-9300-9: “Early Industrial Roots of Green Chemistry and the History of the BHC Ibuprofen Process Invention and Its Quality Connection”,2017-ioannidis.pdf: “The Power of Bias in Economics Research”,https://pseudoerasmus.com/2017/10/02/ijd/: “Labour Repression & the Indo-Japanese Divergence”,2017-spain.pdf: “Is Individual Job Performance Distributed According to a Power Law? A Review of Methods for Comparing Heavy-Tailed Distributions”,2017-braun.pdf: “The Transmission of Inequality Across Multiple Generations: Testing Recent Theories With Evidence from Germany”,https://digitalcommons.sia.edu/cgi/viewcontent.cgi?article=1007&context=stu_proj#pdf: “Birkin Demand: A Sage & Stylish Investment”,2016-chambers.pdf: “Evaluating Indicators of Job Performance: Distributions and Types of Analyses”,https://academic.oup.com/qje/article/131/2/687/2606947: “Wealth, Health, and Child Development: Evidence from Administrative Data on Swedish Lottery Players”,2015-baker.pdf: “Non-Cognitive Deficits and Young Adult Outcomes: The Long-Run Impacts of a Universal Child Care Program”,https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0118494: “To Apply or Not to Apply: A Survey Analysis of Grant Writing Costs and Benefits”,2014-clark.pdf: “Intergenerational Wealth Mobility in England, 1858–2012: Surnames and Social Mobility”,2014-bezemer.pdf: “Slavery, Statehood, and Economic Development in Sub-Saharan Africa”,https://www.trendingbuffalo.com/life/uncle-steves-buffalo/everything-from-1991-radio-shack-ad-now/: “Everything from 1991 Radio Shack Ad I Now Do With My Phone”,2013-stanley.pdf: “PET-PEESE: Meta-Regression Approximations to Reduce Publication Selection Bias”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2216732: “Does the John Bates Clark Medal Boost Subsequent Productivity and Citation Success?”,2012-kuran.pdf: “Judicial Biases in Ottoman Istanbul: Islamic Justice and Its Compatibility With Modern Economic Life”,2011-levitt.pdf: “Was There Really a Hawthorne Effect at the Hawthorne Plant? An Analysis of the Original Illumination Experiments”,2011-melnikovaraich.pdf: “The Soviet Problem With Two ‘Unknowns’: How an American Architect and a Soviet Negotiator Jump-Started the Industrialization of Russia, Part II: Saul Bron”,2010-bloom.pdf: “Why Do Management Practices Differ across Firms and Countries?”,2010-zwaan.pdf: “Career Trajectories of Dutch Pop Musicians: A Longitudinal Study”,2010-babiak.pdf: “Corporate Psychopathy: Talking the Walk”,2010-melnikovaraich.pdf: “The Soviet Problem With Two ‘Unknowns’: How an American Architect and a Soviet Negotiator Jump-Started the Industrialization of Russia, Part I: Albert Kahn”,https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2821100/: “The Normalization of Deviance in Healthcare Delivery”,2009-desrochers.pdf: “Victorian Pioneers of Corporate Sustainability”,2009-allen.pdf: “A Theory of the Pre-Modern British Aristocracy”,2009-zwaan.pdf: “So You Want to Be a Rock-N-Roll Star? Career Success of Pop Musicians in the Netherlands”,2007-murray.pdf: “Catṡlechta and Other Medieval Legal Material Relating to Cats”,2007-abraham.pdf: “The Cambist and Lord Iron: A Fairy Tale of Economics”,2006-mccullough.pdf: “Lessons from the JMCB Archive”,https://arxiv.org/abs/physics/0510117: “Modeling Bursts and Heavy Tails in Human Dynamics”,2004-csete.pdf: “Bow Ties, Metabolism and Disease”,2004-syverson.pdf: “Product Substitutability and Productivity Dispersion”,http://www.cap-lore.com/Hardware/Wheel.html: “The Wheel of Reincarnation”,2000-eltis.pdf: “The Importance of Slavery and the Slave Trade to Industrializing Britain”,1999-hall.pdf: “Why Do Some Countries Produce So Much More Output Per Worker Than Others?”,https://www.amazon.com/Information-Rules-Strategic-Network-Economy-ebook/dp/B004OC07FI/: Information Rules: A Strategic Guide to the Network Economy,1998-shepherd.pdf: “Scholarly Restraints? ABA Accreditation and Legal Education”,1997-kortoum.pdf: “Research, Patenting, and Technological Change”,1994-shahgedanova.pdf: “New Data on Air Pollution in the Former Soviet Union”,1994-gruber.pdf: “The Incidence of Mandated Maternity Benefits”,1993-kremer.pdf: “Population Growth and Technological Change: One Million B.C. to 1990”,1993-boehm.pdf: “Egalitarian Behavior and Reverse Dominance Hierarchy [And Comments and Reply]”,1991-holmstrom.pdf: “Multitask Principal-Agent Analyses: Incentive Contracts, Asset Ownership, and Job Design”,1989-elster.pdf: “From Here to There; Or, If Cooperative Ownership Is So Desirable, Why Are There So Few Cooperatives?”,1988-becker.pdf: “A Theory of Rational Addiction”,1986-lalonde.pdf: “Evaluating the Econometric Evaluations of Training Programs With Experimental Data”,1983-stephan.pdf: “A Research Note on Deriving the Square-Cube Law of Formal Organizations from the Theory of Time-Minimization”,1980-saal.pdf: “Rating the Ratings: Assessing the Psychometric Quality of Rating Data”,1979-jensen-3.pdf: “Theory of the Firm: Managerial Behavior, Agency Costs, and Ownership Structure”,1966-jones.pdf: “The Dollars and Sense of Continuing Education”,1965-mcwhinney.pdf: “On the Geometry of Organizations”,1950-gabrielli.pdf: “What Price Speed? Specific Power Required for Propulsion of Vehicles”,
social-networks[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]
[see previous entry]