‘NN’ directory
- See Also
- Gwern
- “2019 News”, Gwern 2019
- “Regexps Used to Be AI”, Gwern 2024
- “Research Ideas”, Gwern 2017
- “The Neural Net Tank Urban Legend”, Gwern 2011
- “Surprisingly Turing-Complete”, Gwern 2012
- “Evolution As Backstop for Reinforcement Learning”, Gwern 2018
- “ARPA and SCI: Surfing AI”, Gwern 2018
- “Computer Optimization: Your Computer Is Faster Than You Think”, Gwern 2021
- “Timing Technology: Lessons From The Media Lab”, Gwern 2012
- Links
- “How to Win a Best Paper Award (Or, an Opinionated Take on How to Do Important Research)”, Carlini 2026
- “How The New York Times Uses a Custom AI Tool to Track the ‘Manosphere’”
- “Want a Fortell Hearing Aid? Well, Who Do You Know? AI-Powered Startup Fortell Has Become a Secret Handshake for the Privileged Hearing-Impaired Crowd Who Swear by the Product. Now, It Wants to Be in Your Ears”, Levy 2025
- “The Price of Progress: Algorithmic Efficiency and the Falling Cost of AI Inference”, Gundlach et al 2025
- “Computational Design of Superstable Proteins through Maximized Hydrogen Bonding”, Zheng et al 2025
- “Does the Light Novel Translation Process Need AI?”, Orsini 2025
- “Epistasis and Deep Learning in Quantitative Genetics: We Explore When Deep Learning (DL) Outperforms Linear Models in Predicting Complex Phenotypes. We Show That DL Requires at Least 20% As Many Samples As Possible Epistatic Interactions, and Benefits from Marker Feature Selection and Multi-Task Learning on Correlated Phenotypes”, Bell et al 2025
- “Subtitling Your Life: Hearing Aids and Cochlear Implants Have Been Getting Better for Years, but a New Type of Device—Eyeglasses That Display Real-Time Speech Transcription on Their Lenses—Are a Game-Changing Breakthrough”, Owen 2025
- “What Happened to Pathology AI Companies? [Automation As Colonization Wave]”, Mahajan 2025
- “Covering Cracks in Content Moderation: Delexicalized Distant Supervision for Illicit Drug Jargon Detection”, Song et al 2025
- “Estimating the Probability of Sampling a Trained Neural Network at Random”, Scherlis & Belrose 2025
- “Trusted Machine Learning Models Unlock Private Inference for Problems Currently Infeasible With Cryptography”, Shumailov et al 2025
- “Beyond Gradient Averaging in Parallel Optimization: Improved Robustness through Gradient Agreement Filtering”, Chaubard et al 2024
- “Muon: An Optimizer for Hidden Layers in Neural Networks”, Jordan 2024
- “Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World”, Kazdan et al 2024
- “Why Concepts Are (Probably) Vectors”, Piantadosi et al 2024
- “Robin Hanson: Prediction Markets, the Future of Civilization, and Polymathy—#66 § Opposition to DL”, Hanson & Hsu 2024
- “Memorization in Machine Learning: A Survey of Results”, Usynin et al 2024
- “Missed Causes and Ambiguous Effects: Counterfactuals Pose Challenges for Interpreting Neural Networks”, Mueller 2024
- “Simultaneous Linear Connectivity of Neural Networks modulo Permutation”, Sharma et al 2024
- “The Boundary of Neural Network Trainability Is Fractal”, Sohl-Dickstein 2024
- “Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility”, Weissburg et al 2024
- “Outliers With Opposing Signals Have an Outsized Effect on Neural Network Optimization”, Rosenfeld & Risteski 2023
- “Proving Linear Mode Connectivity of Neural Networks via Optimal Transport”, Ferbach et al 2023
- “How Deep Is the Brain? The Shallow Brain Hypothesis”, Suzuki et al 2023
- “Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture”, Fu et al 2023
- “Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition”, Chen et al 2023
- “Efficient Video and Audio Processing With Loihi 2”, Shrestha et al 2023
- “Latent State Models of Training Dynamics”, Hu et al 2023
- “Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity”, Zhou et al 2023
- “Combining Human Expertise With Artificial Intelligence: Experimental Evidence from Radiology”, Agarwal et al 2023
- “The Architecture of a Biologically Plausible Language Organ”, Mitropolsky & Papadimitriou 2023
- “Adam Accumulation to Reduce Memory Footprints of Both Activations and Gradients for Large-Scale DNN Training”, Zhang et al 2023
- “Neural Oscillators Are Universal”, Lanthaler et al 2023
- “Protecting Society from AI Misuse: When Are Restrictions on Capabilities Warranted?”, Anderljung & Hazell 2023
- “Symbolic Discovery of Optimization Algorithms”, Chen et al 2023
- “The Forward-Forward Algorithm: Some Preliminary Investigations”, Hinton 2022
- “Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability”, Damian et al 2022
- “Do Current Multi-Task Optimization Methods in Deep Learning Even Help?”, Xin et al 2022
- “Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Rakhmatulin et al 2022
- “Git Re-Basin: Merging Models modulo Permutation Symmetries”, Ainsworth et al 2022
- “Learning With Differentiable Algorithms”, Petersen 2022
- “Normalized Activation Function: Toward Better Convergence”, Peiwen & Changsheng 2022
- “Bugs in the Data: How ImageNet Misrepresents Biodiversity”, Luccioni & Rolnick 2022
- “The Value of Out-Of-Distribution Data”, Silva et al 2022
- “AniWho: A Quick and Accurate Way to Classify Anime Character Faces in Images”, Naftali et al 2022
- “Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training”, You et al 2022
- “Adaptive Gradient Methods at the Edge of Stability”, Cohen et al 2022
- “Learning With Combinatorial Optimization Layers: a Probabilistic Approach”, Dalle et al 2022
- “What Do We Maximize in Self-Supervised Learning?”, Shwartz-Ziv et al 2022
- “Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit”, Barak et al 2022
- “High-Performing Neural Network Models of Visual Cortex Benefit from High Latent Dimensionality”, Elmoznino & Bonner 2022
- “Perceptein: A Synthetic Protein-Level Neural Network in Mammalian Cells”, Chen et al 2022
- “Predicting Word Learning in Children from the Performance of Computer Vision Systems”, Rane et al 2022
- “Wav2Vec-Aug: Improved Self-Supervised Training With Limited Data”, Sriram et al 2022
- “The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon”, Thilak et al 2022
- “An Improved One Millisecond Mobile Backbone”, Vasu et al 2022
- “Greedy Bayesian Posterior Approximation With Deep Ensembles”, Tiulpin & Blaschko 2022
- “Generating Scientific Claims for Zero-Shot Scientific Fact Checking”, Wright et al 2022
- “On the Generalization Mystery in Deep Learning”, Chatterjee & Zielinski 2022
- “Deep Lexical Hypothesis: Identifying Personality Structure in Natural Language”, Cutler & Condon 2022
- “Gradients without Backpropagation”, Baydin et al 2022
- “Towards Scaling Difference Target Propagation by Learning Backprop Targets”, Ernoult et al 2022
- “M5 Accuracy Competition: Results, Findings, and Conclusions”, Makridakis et al 2022
- “Formal Analysis of Art: Proxy Learning of Visual Concepts from Style Through Language Models”, Kim et al 2022
- “Silent Bugs in Deep Learning Frameworks: An Empirical Study of Keras and TensorFlow”, Tambon et al 2021
- “Artificial Intelligence ‘Sees’ Split Electrons”, Perdew 2021
- “Pushing the Frontiers of Density Functionals by Solving the Fractional Electron Problem”, Kirkpatrick et al 2021
- Word Golf, Xia 2021
- “Deep Learning Enables Genetic Analysis of the Human Thoracic Aorta”, Pirruccello et al 2021
- “Why Do Self-Supervised Models Transfer? Investigating the Impact of Invariance on Downstream Tasks”, Ericsson et al 2021
- “Achieving Human Parity on Visual Question Answering”, Yan et al 2021
- “BC-Z: Zero-Shot Task Generalization With Robotic Imitation Learning”, Jang et al 2021
- “Learning in High Dimension Always Amounts to Extrapolation”, Balestriero et al 2021
- “The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks”, Entezari et al 2021
- “The Structure of Genotype-Phenotype Maps Makes Fitness Landscapes Navigable”, Greenbury et al 2021
- “Deep Neural Networks and Tabular Data: A Survey”, Borisov et al 2021
- “Learning through Atypical "Phase Transitions" in Overparameterized Neural Networks”, Baldassi et al 2021
- “RAFT: A Real-World Few-Shot Text Classification Benchmark”, Alex et al 2021
- “PPT: Pre-Trained Prompt Tuning for Few-Shot Learning”, Gu et al 2021
- “DART: Differentiable Prompt Makes Pre-Trained Language Models Better Few-Shot Learners”, Zhang et al 2021
- “ETA Prediction With Graph Neural Networks in Google Maps”, Derrow-Pinion et al 2021
- “Neural Operator: Learning Maps Between Function Spaces”, Kovachki et al 2021
- “Introducing Triton: Open-Source GPU Programming for Neural Networks”, Tillet 2021
- “Predictive Coding: a Theoretical and Experimental Review”, Millidge et al 2021
- “A Connectivity-Constrained Computational Account of Topographic Organization in Primate High-Level Visual Cortex”, Blauch et al 2021
- “A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers”, Miao et al 2021
- “Coarse-To-Fine Q-Attention: Efficient Learning for Visual Robotic Manipulation via Discretisation”, James et al 2021
- “Randomness In Neural Network Training: Characterizing The Impact of Tooling”, Zhuang et al 2021
- “Revisiting Deep Learning Models for Tabular Data”, Gorishniy et al 2021
- “BEiT: BERT Pre-Training of Image Transformers”, Bao et al 2021
- “Revisiting Model Stitching to Compare Neural Representations”, Bansal et al 2021
- “Artificial Intelligence in China’s Revolution in Military Affairs”, Kania 2021
- “The Geometry of Concept Learning”, Sorscher et al 2021
- “VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning”, Bardes et al 2021
- “The Modern Mathematics of Deep Learning”, Berner et al 2021
- “Understanding by Understanding Not: Modeling Negation in Language Models”, Hosseini et al 2021
- “Entailment As Few-Shot Learner”, Wang et al 2021
- “PAWS: Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments With Support Samples”, Assran et al 2021
- “Epistemic Autonomy: Self-Supervised Learning in the Mammalian Hippocampus”, Santos-Pata et al 2021
- “Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization”, Xie et al 2021
- “Contrasting Contrastive Self-Supervised Representation Learning Models”, Kotar et al 2021
- “Characterizing and Improving the Robustness of Self-Supervised Learning through Background Augmentations”, Ryali et al 2021
- “GWAS in Almost 195,000 Individuals Identifies 50 Previously Unidentified Genetic Loci for Eye Color”, Simcoe et al 2021
- “BERTese: Learning to Speak to BERT”, Haviv et al 2021
- “Predictive Coding Can Do Exact Backpropagation on Any Neural Network”, Salvatori et al 2021
- “Barlow Twins: Self-Supervised Learning via Redundancy Reduction”, Zbontar et al 2021
- “WIT: Wikipedia-Based Image Text Dataset for Multimodal Multilingual Machine Learning”, Srinivasan et al 2021
- “The Inverse Variance–flatness Relation in Stochastic Gradient Descent Is Critical for Finding Flat Minima”, Feng & Tu 2021
- “Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability”, Cohen et al 2021
- “Rip Van Winkle’s Razor: A Simple Estimate of Overfit to Test Data”, Arora & Zhang 2021
- “Image Completion via Inference in Deep Generative Models”, Harvey et al 2021
- “Differentiable Logic Machines”, Zimmer et al 2021
- “Contrastive Learning Inverts the Data Generating Process”, Zimmermann et al 2021
- “DirectPred: Understanding Self-Supervised Learning Dynamics without Contrastive Pairs”, Tian et al 2021
- “MLGO: a Machine Learning Guided Compiler Optimizations Framework”, Trofin et al 2021
- “Facial Recognition Technology Can Expose Political Orientation from Naturalistic Facial Images”, Kosinski 2021
- “Solving Mixed Integer Programs Using Neural Networks”, Nair et al 2020
- “Sixteen Facial Expressions Occur in Similar Contexts Worldwide”, Cowen 2020
- “PiRank: Learning To Rank via Differentiable Sorting”, Swezey et al 2020
- “Real-Time Synthesis of Imagined Speech Processes from Minimally Invasive Recordings of Neural Activity”, Angrick et al 2020
- “Generalization Bounds for Deep Learning”, Valle-Pérez & Louis 2020
- “Selective Eye-Gaze Augmentation To Enhance Imitation Learning In Atari Games”, Thammineni et al 2020
- “SimSiam: Exploring Simple Siamese Representation Learning”, Chen & He 2020
- “Recent Advances in Neurotechnologies With Broad Potential for Neuroscience Research”, Vázquez-Guardado et al 2020
- “Voting for Authorship Attribution Applied to Dark Web Data”, Samreen & Alalfi 2020
- “Twenty Years Beyond the Turing Test: Moving Beyond the Human Judges Too”, Hernández-Orallo 2020
- “Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding”, Roberts et al 2020
- “Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary With Width and Depth”, Nguyen et al 2020
- “Guys and Dolls”, Devlin & Locatelli 2020
- “Open-Domain Question Answering Goes Conversational via Question Rewriting”, Anantha et al 2020
- “Digital Voicing of Silent Speech”, Gaddy & Klein 2020
- “Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment”, Talebi et al 2020
- “Implicit Gradient Regularization”, Barrett & Dherin 2020
- “Learning Explanations That Are Hard to Vary”, Parascandolo et al 2020
- “Large Associative Memory Problem in Neurobiology and Machine Learning”, Krotov & Hopfield 2020
- “AdapterHub: A Framework for Adapting Transformers”, Pfeiffer et al 2020
- “Identifying Regulatory Elements via Deep Learning”, Barshai et al 2020
- “Is SGD a Bayesian Sampler? Well, Almost”, Mingard et al 2020
- “Bootstrap Your Own Latent (BYOL): A New Approach to Self-Supervised Learning”, Grill et al 2020
- “SCAN: Learning to Classify Images without Labels”, Gansbeke et al 2020
- “Politeness Transfer: A Tag and Generate Approach”, Madaan et al 2020
- “Supervised Contrastive Learning”, Khosla et al 2020
- “Backpropagation and the Brain”, Lillicrap et al 2020
- “Can You Put It All Together: Evaluating Conversational Agents’ Ability to Blend Skills”, Smith et al 2020
- “Topology of Deep Neural Networks”, Naitzat et al 2020
- “Improved Baselines With Momentum Contrastive Learning”, Chen et al 2020
- “The Large Learning Rate Phase of Deep Learning: the Catapult Mechanism”, Lewkowycz et al 2020
- “Fast Differentiable Sorting and Ranking”, Blondel et al 2020
- “The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence”, Marcus 2020
- “Quantifying Independently Reproducible Machine Learning”, Raff 2020
- “The Secret History of Facial Recognition: Sixty Years Ago, a Sharecropper’s Son Invented a Technology to Identify Faces. Then the Record of His Role All but Vanished. Who Was Woody Bledsoe, and Who Was He Working For?”, Raviv 2020
- “The Case for Bayesian Deep Learning”, Wilson 2020
- “Can the Brain Do Backpropagation? -Exact Implementation of Backpropagation in Predictive Coding Networks”, Song et al 2020
- “Learning Neural Activations”, Minhas & Asif 2019
- “2019 AI Alignment Literature Review and Charity Comparison”, Larks 2019
- “Libri-Light: A Benchmark for ASR With Limited or No Supervision”, Kahn et al 2019
- “Connecting Vision and Language With Localized Narratives”, Pont-Tuset et al 2019
- “12-In-1: Multi-Task Vision and Language Representation Learning”, Lu et al 2019
- “A Deep Learning Framework for Neuroscience”, Richards et al 2019
- “Machine Learning for Scent: Learning Generalizable Perceptual Representations of Small Molecules”, Sanchez-Lengeling et al 2019
- “KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition With Deep Learning”, Clanuwat et al 2019
- “Approximate Inference in Discrete Distributions With Monte Carlo Tree Search and Value Functions”, Buesing et al 2019
- “Best Practices for the Human Evaluation of Automatically Generated Text”, Lee et al 2019
- “RandAugment: Practical Automated Data Augmentation With a Reduced Search Space”, Cubuk et al 2019
- “Large-Scale Pretraining for Neural Machine Translation With Tens of Billions of Sentence Pairs”, Meng et al 2019
- “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations”, Lan et al 2019
- “Engineering a Less Artificial Intelligence”, Sinz et al 2019
- “Neural Networks Are a Priori Biased towards Boolean Functions With Low Entropy”, Mingard et al 2019
- “Simple, Scalable Adaptation for Neural Machine Translation”, Bapna et al 2019
- “Emergent Tool Use From Multi-Agent Autocurricula”, Baker et al 2019
- “A Step Toward Quantifying Independently Reproducible Machine Learning Research”, Raff 2019
- “Does Machine Translation Affect International Trade? Evidence from a Large Digital Platform”, Brynjolfsson et al 2019b
- “Can One Concurrently Record Electrical Spikes from Every Neuron in a Mammalian Brain?”, Kleinfeld et al 2019
- “Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges”, Arivazhagan et al 2019
- “Deep Set Prediction Networks”, Zhang et al 2019
- “Optimizing Color for Camouflage and Visibility Using Deep Learning: the Effects of the Environment and the Observer’s Visual System”, Fennell et al 2019
- “Speech2Face: Learning the Face Behind a Voice”, Oh et al 2019
- “Universal Approximation With Deep Narrow Networks”, Kidger & Lyons 2019
- “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”, Wang et al 2019
- “Universal Quantum Control through Deep Reinforcement Learning”, Niu et al 2019
- “Analysing Mathematical Reasoning Abilities of Neural Models”, Saxton et al 2019
- “Reinforcement Learning for Recommender Systems: A Case Study on Youtube”, Chen 2019
- “Stochastic Optimization of Sorting Networks via Continuous Relaxations”, Grover et al 2019
- “Surprises in High-Dimensional Ridgeless Least Squares Interpolation”, Hastie et al 2019
- “DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs”, Dua et al 2019
- “Theories of Error Back-Propagation in the Brain”, Whittington & Bogacz 2019
- “A Replication Study: Machine Learning Models Are Capable of Predicting Sexual Orientation From Facial Images”, Leuner 2019
- “Unmasking Clever Hans Predictors and Assessing What Machines Really Learn”, Lapuschkin et al 2019
- “What Makes a Good Conversation? How Controllable Attributes Affect Human Judgments”, See et al 2019
- “The Evolved Transformer”, So et al 2019
- “Forecasting Transformative AI: An Expert Survey”, Gruetzemacher et al 2019
- “Human Few-Shot Learning of Compositional Instructions”, Lake et al 2019
- “Evaluation and Accurate Diagnoses of Pediatric Diseases Using Artificial Intelligence”, Liang et al 2019
- “Why Is There No Successful Whole Brain Simulation (Yet)?”, Stiefel 2019
- “High-Performance Medicine: the Convergence of Human and Artificial Intelligence”, Topol 2019
- “Identifying Facial Phenotypes of Genetic Disorders Using Deep Learning”, Gurovich et al 2019
- “Reinventing the Wheel: Discovering the Optimal Rolling Shape With PyTorch”, Wiener 2019
- “James Zou Homepage [Machine Learning]”, Zou 2019
- “An Empirical Study of Example Forgetting during Deep Neural Network Learning”, Toneva et al 2018
- “CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge”, Talmor et al 2018
- “Depth With Nonlinearity Creates No Bad Local Minima in ResNets”, Kawaguchi & Bengio 2018
- “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding”, Devlin et al 2018
- “Interpretable Textual Neuron Representations for NLP”, Poerner et al 2018
- “Searching for Efficient Multi-Scale Architectures for Dense Image Prediction”, Chen et al 2018
- “Machine Learning to Predict Osteoporotic Fracture Risk from Genotypes”, Forgetta et al 2018
- “Accelerated Reinforcement Learning for Sentence Generation by Vocabulary Prediction”, Hashimoto & Tsuruoka 2018
- “Searching Toward Pareto-Optimal Device-Aware Neural Architectures”, Cheng et al 2018
- “A Study of Reinforcement Learning for Neural Machine Translation”, Wu et al 2018
- “Modeling Visual Context Is Key to Augmenting Object Detection Datasets”, Dvornik et al 2018
- “Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search”, Zela et al 2018
- “Automatically Composing Representation Transformations As a Means for Generalization”, Chang et al 2018
- “Differentiable Learning-To-Normalize via Switchable Normalization”, Luo et al 2018
- “On the Spectral Bias of Neural Networks”, Rahaman et al 2018
- “Neural Tangent Kernel: Convergence and Generalization in Neural Networks”, Jacot et al 2018
- “Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning”, Pang et al 2018
- “Do CIFAR-10 Classifiers Generalize to CIFAR-10?”, Recht et al 2018
- “Zero-Shot Dual Machine Translation”, Sestorain et al 2018
- “Do Better ImageNet Models Transfer Better?”, Kornblith et al 2018
- “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”, Wang et al 2018
- “Adafactor: Adaptive Learning Rates With Sublinear Memory Cost”, Shazeer & Stern 2018
- “Averaging Weights Leads to Wider Optima and Better Generalization”, Izmailov et al 2018
- “SentEval: An Evaluation Toolkit for Universal Sentence Representations”, Conneau & Kiela 2018
- “Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge”, Clark et al 2018
- “Analyzing Uncertainty in Neural Machine Translation”, Ott et al 2018
- “End-To-End Deep Image Reconstruction from Human Brain Activity”, Shen et al 2018
- “Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari”, Chrabaszcz et al 2018
- “SignSGD: Compressed Optimization for Non-Convex Problems”, Bernstein et al 2018
- “Differentiable Dynamic Programming for Structured Prediction and Attention”, Mensch & Blondel 2018
- “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction”, Lel et al 2018
- “Semantic Projection: Recovering Human Knowledge of Multiple, Distinct Object Features from Word Embeddings”, Grand et al 2018
- “Panoptic Segmentation”, Kirillov et al 2018
- “Clinically Applicable Deep Learning for Diagnosis and Referral in Retinal Disease”, Fauw et al 2018
- “Prediction of Cardiovascular Risk Factors from Retinal Fundus Photographs via Deep Learning”, Poplin et al 2018
- “Three-Dimensional Visualization and a Deep-Learning Model Reveal Complex Fungal Parasite Networks in Behaviorally Manipulated Ants”, Fredericksen et al 2017
- “Decoupled Weight Decay Regularization”, Loshchilov & Hutter 2017
- “Automatic Differentiation in PyTorch”, Paszke et al 2017
- “Rethinking Generalization Requires Revisiting Old Ideas: Statistical Mechanics Approaches and Complex Learning Behavior”, Martin & Mahoney 2017
- “Mixup: Beyond Empirical Risk Minimization”, Zhang et al 2017
- “Malware Detection by Eating a Whole EXE”, Raff et al 2017
- “AlphaGo Zero: Mastering the Game of Go without Human Knowledge”, Silver et al 2017
- “Swish: Searching for Activation Functions”, Ramachandran et al 2017
- “Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates”, Smith & Topin 2017
- “Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection”, Dwibedi et al 2017
- “Emergence of Locomotion Behaviors in Rich Environments”, Heess et al 2017
- “The Persistence and Transience of Memory”, Richards & Frankland 2017
- “Verb Physics: Relative Physical Knowledge of Actions and Objects”, Forbes & Choi 2017
- “Driver Identification Using Automobile Sensor Data from a Single Turn”, Hallac et al 2017
- “StreetStyle: Exploring World-Wide Clothing Styles from Millions of Photos”, Matzen et al 2017
- “Deep Voice 2: Multi-Speaker Neural Text-To-Speech”, Arik et al 2017
- “WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017
- “Inferring and Executing Programs for Visual Reasoning”, Johnson et al 2017
- “Visual Attribute Transfer through Deep Image Analogy”, Liao et al 2017
- “On Weight Initialization in Deep Neural Networks”, Kumar 2017
- “A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference”, Williams et al 2017
- “RACE: Large-Scale ReAding Comprehension Dataset From Examinations”, Lai et al 2017
- “Data-Efficient Deep Reinforcement Learning for Dexterous Manipulation”, Popov et al 2017
- “Prototypical Networks for Few-Shot Learning”, Snell et al 2017
- “Meta Networks”, Munkhdalai & Yu 2017
- “Understanding Synthetic Gradients and Decoupled Neural Interfaces”, Czarnecki et al 2017
- “Adaptive Neural Networks for Efficient Inference”, Bolukbasi et al 2017
- “Deep Voice: Real-Time Neural Text-To-Speech”, Arik et al 2017
- “Machine Learning Predicts Laboratory Earthquakes”, Bertr et al 2017
- “Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks”, Katz et al 2017
- “Dermatologist-Level Classification of Skin Cancer With Deep Neural Networks”, Esteva et al 2017
- “Child Machines”, Proudfoot 2017
- “Machine Learning for Systems and Systems for Machine Learning”, Dean 2017
- “Feedback Networks”, Zamir et al 2016
- “CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning”, Johnson et al 2016
- “Towards Information-Seeking Agents”, Bachman et al 2016
- “Spatially Adaptive Computation Time for Residual Networks”, Figurnov et al 2016
- “Deep Learning Reinvents the Hearing Aid: Finally, Wearers of Hearing Aids Can Pick out a Voice in a Crowded Room”, Wang 2016b
- “MS MARCO: A Human Generated MAchine Reading COmprehension Dataset”, Bajaj et al 2016
- “Learning to Reinforcement Learn”, Wang et al 2016
- “Lip Reading Sentences in the Wild”, Chung et al 2016
- “Could a Neuroscientist Understand a Microprocessor?”, Jonas & Kording 2016
- “A Neural Network Playground”, Smilkov & Carter 2016
- “Homotopy Analysis for Tensor PCA”, Anandkumar et al 2016
- “Why Does Deep and Cheap Learning Work so Well?”, Lin et al 2016
- “SGDR: Stochastic Gradient Descent With Warm Restarts”, Loshchilov & Hutter 2016
- “Concrete Problems in AI Safety”, Amodei et al 2016
- “SQuAD: 100,000+ Questions for Machine Comprehension of Text”, Rajpurkar et al 2016
- “Matching Networks for One Shot Learning”, Vinyals et al 2016
- “Convolutional Sketch Inversion”, Güçlütürk et al 2016
- “Unifying Count-Based Exploration and Intrinsic Motivation”, Bellemare et al 2016
- “Synthesizing the Preferred Inputs for Neurons in Neural Networks via Deep Generator Networks”, Nguyen et al 2016
- “Toward Deeper Understanding of Neural Networks: The Power of Initialization and a Dual View on Expressivity”, Daniely et al 2016
- “"Why Should I Trust You?": Explaining the Predictions of Any Classifier”, Ribeiro et al 2016
- “Mastering the Game of Go With Deep Neural Networks and Tree Search”, Silver et al 2016
- “Learning to Compose Neural Networks for Question Answering”, Andreas et al 2016
- “How a Japanese Cucumber Farmer Is Using Deep Learning and TensorFlow”, Sato 2016
- “Random Gradient-Free Minimization of Convex Functions”, Nesterov & Spokoiny 2015
- “Convergent Learning: Do Different Neural Networks Learn the Same Representations?”, Li et al 2015
- “Data-Dependent Initializations of Convolutional Neural Networks”, Krähenbühl et al 2015
- “Online Batch Selection for Faster Training of Neural Networks”, Loshchilov & Hutter 2015
- “Neural Module Networks”, Andreas et al 2015
- “Deep DPG (DDPG): Continuous Control With Deep Reinforcement Learning”, Lillicrap et al 2015
- “A Neural Algorithm of Artistic Style”, Gatys et al 2015
- “VQA: Visual Question Answering”, Agrawal et al 2015
- “Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks”, Weston et al 2015
- “Probabilistic Line Searches for Stochastic Optimization”, Mahsereci & Hennig 2015
- “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”, He et al 2015
- Neural Networks and Deep Learning, Nielsen 2015
- “Neural Networks and Deep Learning § Ch6 Deep Learning”, Nielsen 2015
- “Qualitatively Characterizing Neural Network Optimization Problems”, Goodfellow et al 2014
- “Freeze-Thaw Bayesian Optimization”, Swersky et al 2014
- “Microsoft COCO: Common Objects in Context”, Lin et al 2014
- “Deep Learning in Neural Networks: An Overview”, Schmidhuber 2014
- “Neural Networks, Manifolds, and Topology”, Olah 2014
- “Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks”, Saxe et al 2013
- “Distributed Representations of Words and Phrases and Their Compositionality”, Mikolov et al 2013
- “Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science”, Clark 2013
- “Deep Gaussian Processes”, Damianou & Lawrence 2012
- “Artist Agent: A Reinforcement Learning Approach to Automatic Stroke Generation in Oriental Ink Painting”, Xie et al 2012
- “HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent”, Niu et al 2011
- “Large-Scale Deep Unsupervised Learning Using Graphics Processors”, Raina et al 2009
- “A Free Energy Principle for the Brain”, Friston et al 2006
- “Some AI Koans § Http://www.catb.org/esr/jargon/html/koans.html#id3141241”, Raymond 2003
- “Some AI Koans”, Raymond 2003
- “Understanding the Nature of the General Factor of Intelligence: The Role of Individual Differences in Neural Plasticity As an Explanatory Mechanism”, Garlick 2002
- “Starfish § Bulrushes”, Watts 1999
- “Exponentiated Gradient versus Gradient Descent for Linear Predictors”, Kivinen & Warmuth 1997
- “Optimality in Biological and Artificial Networks?”, Levine & Elsberry 1997
- “A Sociological Study of the Official History of the Perceptrons Controversy”, Olazaran 1996
- “Turing Patterns in CNNs, I: Once over Lightly”, Goras et al 1995
- “Learning and Generalization in a Two-Layer Neural Network: The Role of the Vapnik-Chervonvenkis Dimension”, Opper 1994
- “A Sociological Study of the Official History of the Perceptrons Controversy [1993]”, Olazaran 1993
- “The Statistical Mechanics of Learning a Rule”, Watkin et al 1993
- “On Learning the Past Tenses of English Verbs”, Rumelhart & McClelland 1993
- “Statistical Mechanics of Learning from Examples”, Seung et al 1992
- “Memorization Without Generalization in a Multilayered Neural Network”, Hansel et al 1992
- “Symbolic and Neural Learning Algorithms: An Experimental Comparison”, Shavlik et al 1991
- “Backpropagation Learning For Multilayer Feed-Forward Neural Networks Using The Conjugate Gradient Method”, Johansson et al 1991
- “Artificial Neural Networks, Back Propagation, and the Kelley-Bryson Gradient Procedure”, Dreyfus 1990
- “Exhaustive Learning”, Schwartz et al 1990
- “International Joint Conference on Neural Networks, January 15–19, 1990: Volume 1: Theory Track, Neural and Cognitive Sciences Track”, Caudill 1990
- “International Joint Conference on Neural Networks, January 15–19, 1990: Volume 2: Applications Track”, Caudill 1990
- “Explanatory Coherence”, Thagard 1989
- “Parallel Distributed Processing: Implications for Cognition and Development”, McClelland 1989
- “Cellular Neural Networks: Theory”, Chua & Yang 1988b
- “Cellular Neural Networks: Applications”, Chua & Yang 1988
- “The Brain As Template”, Finkbeiner 1988
- “Observation of Phase Transitions in Spreading Activation Networks”, Shrager et al 1987
- “Learning Representations by Backpropagating Errors”, Rumelhart et al 1986b
- Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Volume 1: Foundations, Rumelhart et al 1986
- “Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural Networks”, Amit et al 1985
- “Learning-Logic: Casting the Cortex of the Human Brain in Silicon”, Parker 1985
- “Toward An Interactive Model Of Reading”, Rumelhart 1985
- “Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences”, Werbos 1974
- “Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms”, Rosenblatt 1962
- “Speculations on Perceptrons and Other Automata”, Good 1959
- “Pandemonium: A Paradigm for Learning”, Selfridge 1959
- “Representation of Events in Nerve Nets and Finite Automata”, Kleene 1951
- “A Logical Calculus of the Ideas Immanent in Nervous Activity”, McCulloch & Pitts 1943
- “The Age of Em, A Book”, Hanson 2026
- “
gsutil Config: Obtain Credentials and Create Configuration File”, Google 2026 - “Why Momentum Really Works”
- “Differentiable Finite State Machines”
- “About Sam Greydanus”, Greydanus 2026
- “Contrastive Representation Learning”
- “McCulloch and Pitts [Re-Evaluating Neuroscientifically]”
- “The Internet’s AI Slop Problem Is Only Going to Get Worse”
- “Glow: Better Reversible Generative Models”
- “Preetum Nakkiran”
- “Differentiable Programming from Scratch”
- “Deep Reinforcement Learning Doesn’t Work Yet”
- “[Commonsense Media Survey on US Generative Media Use]”
- “Gourmand Cat Fence”
- “Simple versus Short: Higher-Order Degeneracy and Error-Correction”
- “Inferring Neural Activity Before Plasticity As a Foundation for Learning beyond Backpropagation”
- “Reddit: Reinforcement Learning Subreddit”, Reddit 2026
- “AI and the Indian Election”, Schneier 2026
- “Lip Reading Sentences in the Wild [Video]”
- Wikipedia (13)
- Miscellaneous
- Bibliography
See Also
Gwern
“Regexps Used to Be AI”, Gwern 2024
“Research Ideas”, Gwern 2017
“The Neural Net Tank Urban Legend”, Gwern 2011
“Surprisingly Turing-Complete”, Gwern 2012
“Evolution As Backstop for Reinforcement Learning”, Gwern 2018
“ARPA and SCI: Surfing AI”, Gwern 2018
“Computer Optimization: Your Computer Is Faster Than You Think”, Gwern 2021
Computer Optimization: Your Computer Is Faster Than You Think
“Timing Technology: Lessons From The Media Lab”, Gwern 2012
Links
“How to Win a Best Paper Award (Or, an Opinionated Take on How to Do Important Research)”, Carlini 2026
How to win a best paper award (or, an opinionated take on how to do important research)
“How The New York Times Uses a Custom AI Tool to Track the ‘Manosphere’”
How The New York Times uses a custom AI tool to track the ‘manosphere’
“Want a Fortell Hearing Aid? Well, Who Do You Know? AI-Powered Startup Fortell Has Become a Secret Handshake for the Privileged Hearing-Impaired Crowd Who Swear by the Product. Now, It Wants to Be in Your Ears”, Levy 2025
“The Price of Progress: Algorithmic Efficiency and the Falling Cost of AI Inference”, Gundlach et al 2025
The Price of Progress: Algorithmic Efficiency and the Falling Cost of AI Inference
“Computational Design of Superstable Proteins through Maximized Hydrogen Bonding”, Zheng et al 2025
Computational design of superstable proteins through maximized hydrogen bonding
“Does the Light Novel Translation Process Need AI?”, Orsini 2025
“Epistasis and Deep Learning in Quantitative Genetics: We Explore When Deep Learning (DL) Outperforms Linear Models in Predicting Complex Phenotypes. We Show That DL Requires at Least 20% As Many Samples As Possible Epistatic Interactions, and Benefits from Marker Feature Selection and Multi-Task Learning on Correlated Phenotypes”, Bell et al 2025
“Subtitling Your Life: Hearing Aids and Cochlear Implants Have Been Getting Better for Years, but a New Type of Device—Eyeglasses That Display Real-Time Speech Transcription on Their Lenses—Are a Game-Changing Breakthrough”, Owen 2025
“What Happened to Pathology AI Companies? [Automation As Colonization Wave]”, Mahajan 2025
What happened to pathology AI companies? [automation as colonization wave]
“Covering Cracks in Content Moderation: Delexicalized Distant Supervision for Illicit Drug Jargon Detection”, Song et al 2025
“Estimating the Probability of Sampling a Trained Neural Network at Random”, Scherlis & Belrose 2025
Estimating the Probability of Sampling a Trained Neural Network at Random
“Trusted Machine Learning Models Unlock Private Inference for Problems Currently Infeasible With Cryptography”, Shumailov et al 2025
“Beyond Gradient Averaging in Parallel Optimization: Improved Robustness through Gradient Agreement Filtering”, Chaubard et al 2024
“Muon: An Optimizer for Hidden Layers in Neural Networks”, Jordan 2024
“Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World”, Kazdan et al 2024
Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World
“Why Concepts Are (Probably) Vectors”, Piantadosi et al 2024
“Robin Hanson: Prediction Markets, the Future of Civilization, and Polymathy—#66 § Opposition to DL”, Hanson & Hsu 2024
Robin Hanson: Prediction Markets, the Future of Civilization, and Polymathy—#66 § Opposition to DL
“Memorization in Machine Learning: A Survey of Results”, Usynin et al 2024
“Missed Causes and Ambiguous Effects: Counterfactuals Pose Challenges for Interpreting Neural Networks”, Mueller 2024
“The Boundary of Neural Network Trainability Is Fractal”, Sohl-Dickstein 2024
“Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility”, Weissburg et al 2024
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility
“Outliers With Opposing Signals Have an Outsized Effect on Neural Network Optimization”, Rosenfeld & Risteski 2023
Outliers with Opposing Signals Have an Outsized Effect on Neural Network Optimization
“Proving Linear Mode Connectivity of Neural Networks via Optimal Transport”, Ferbach et al 2023
Proving Linear Mode Connectivity of Neural Networks via Optimal Transport
“How Deep Is the Brain? The Shallow Brain Hypothesis”, Suzuki et al 2023
“Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture”, Fu et al 2023
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
“Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition”, Chen et al 2023
Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition
“Efficient Video and Audio Processing With Loihi 2”, Shrestha et al 2023
“Latent State Models of Training Dynamics”, Hu et al 2023
“Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity”, Zhou et al 2023
Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity
“Combining Human Expertise With Artificial Intelligence: Experimental Evidence from Radiology”, Agarwal et al 2023
Combining Human Expertise with Artificial Intelligence: Experimental Evidence from Radiology
“The Architecture of a Biologically Plausible Language Organ”, Mitropolsky & Papadimitriou 2023
“Adam Accumulation to Reduce Memory Footprints of Both Activations and Gradients for Large-Scale DNN Training”, Zhang et al 2023
“Neural Oscillators Are Universal”, Lanthaler et al 2023
“Protecting Society from AI Misuse: When Are Restrictions on Capabilities Warranted?”, Anderljung & Hazell 2023
Protecting Society from AI Misuse: When are Restrictions on Capabilities Warranted?
“Symbolic Discovery of Optimization Algorithms”, Chen et al 2023
“The Forward-Forward Algorithm: Some Preliminary Investigations”, Hinton 2022
The Forward-Forward Algorithm: Some Preliminary Investigations
“Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability”, Damian et al 2022
Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability
“Do Current Multi-Task Optimization Methods in Deep Learning Even Help?”, Xin et al 2022
Do Current Multi-Task Optimization Methods in Deep Learning Even Help?
“Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Rakhmatulin et al 2022
Selective neutralization and deterring of cockroaches with laser automated by machine vision
“Git Re-Basin: Merging Models modulo Permutation Symmetries”, Ainsworth et al 2022
“Learning With Differentiable Algorithms”, Petersen 2022
“Normalized Activation Function: Toward Better Convergence”, Peiwen & Changsheng 2022
“Bugs in the Data: How ImageNet Misrepresents Biodiversity”, Luccioni & Rolnick 2022
“The Value of Out-Of-Distribution Data”, Silva et al 2022
“AniWho: A Quick and Accurate Way to Classify Anime Character Faces in Images”, Naftali et al 2022
AniWho: A Quick and Accurate Way to Classify Anime Character Faces in Images
“Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training”, You et al 2022
Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training
“Adaptive Gradient Methods at the Edge of Stability”, Cohen et al 2022
“Learning With Combinatorial Optimization Layers: a Probabilistic Approach”, Dalle et al 2022
Learning with Combinatorial Optimization Layers: a Probabilistic Approach
“What Do We Maximize in Self-Supervised Learning?”, Shwartz-Ziv et al 2022
“Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit”, Barak et al 2022
Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit
“High-Performing Neural Network Models of Visual Cortex Benefit from High Latent Dimensionality”, Elmoznino & Bonner 2022
High-performing neural network models of visual cortex benefit from high latent dimensionality
“Perceptein: A Synthetic Protein-Level Neural Network in Mammalian Cells”, Chen et al 2022
Perceptein: A synthetic protein-level neural network in mammalian cells
“Predicting Word Learning in Children from the Performance of Computer Vision Systems”, Rane et al 2022
Predicting Word Learning in Children from the Performance of Computer Vision Systems
“Wav2Vec-Aug: Improved Self-Supervised Training With Limited Data”, Sriram et al 2022
Wav2Vec-Aug: Improved self-supervised training with limited data
“The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon”, Thilak et al 2022
The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon
“An Improved One Millisecond Mobile Backbone”, Vasu et al 2022
“Greedy Bayesian Posterior Approximation With Deep Ensembles”, Tiulpin & Blaschko 2022
“Generating Scientific Claims for Zero-Shot Scientific Fact Checking”, Wright et al 2022
Generating Scientific Claims for Zero-Shot Scientific Fact Checking
“On the Generalization Mystery in Deep Learning”, Chatterjee & Zielinski 2022
“Deep Lexical Hypothesis: Identifying Personality Structure in Natural Language”, Cutler & Condon 2022
Deep Lexical Hypothesis: Identifying personality structure in natural language
“Gradients without Backpropagation”, Baydin et al 2022
“Towards Scaling Difference Target Propagation by Learning Backprop Targets”, Ernoult et al 2022
Towards Scaling Difference Target Propagation by Learning Backprop Targets
“M5 Accuracy Competition: Results, Findings, and Conclusions”, Makridakis et al 2022
“Formal Analysis of Art: Proxy Learning of Visual Concepts from Style Through Language Models”, Kim et al 2022
Formal Analysis of Art: Proxy Learning of Visual Concepts from Style Through Language Models
“Silent Bugs in Deep Learning Frameworks: An Empirical Study of Keras and TensorFlow”, Tambon et al 2021
Silent Bugs in Deep Learning Frameworks: An Empirical Study of Keras and TensorFlow
“Artificial Intelligence ‘Sees’ Split Electrons”, Perdew 2021
“Pushing the Frontiers of Density Functionals by Solving the Fractional Electron Problem”, Kirkpatrick et al 2021
Pushing the frontiers of density functionals by solving the fractional electron problem
Word Golf, Xia 2021
“Deep Learning Enables Genetic Analysis of the Human Thoracic Aorta”, Pirruccello et al 2021
Deep learning enables genetic analysis of the human thoracic aorta
“Why Do Self-Supervised Models Transfer? Investigating the Impact of Invariance on Downstream Tasks”, Ericsson et al 2021
Why Do Self-Supervised Models Transfer? Investigating the Impact of Invariance on Downstream Tasks
“Achieving Human Parity on Visual Question Answering”, Yan et al 2021
“BC-Z: Zero-Shot Task Generalization With Robotic Imitation Learning”, Jang et al 2021
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
“Learning in High Dimension Always Amounts to Extrapolation”, Balestriero et al 2021
“The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks”, Entezari et al 2021
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks
“The Structure of Genotype-Phenotype Maps Makes Fitness Landscapes Navigable”, Greenbury et al 2021
The structure of genotype-phenotype maps makes fitness landscapes navigable
“Deep Neural Networks and Tabular Data: A Survey”, Borisov et al 2021
“Learning through Atypical "Phase Transitions" in Overparameterized Neural Networks”, Baldassi et al 2021
Learning through atypical "phase transitions" in overparameterized neural networks
“RAFT: A Real-World Few-Shot Text Classification Benchmark”, Alex et al 2021
“PPT: Pre-Trained Prompt Tuning for Few-Shot Learning”, Gu et al 2021
“DART: Differentiable Prompt Makes Pre-Trained Language Models Better Few-Shot Learners”, Zhang et al 2021
DART: Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
“ETA Prediction With Graph Neural Networks in Google Maps”, Derrow-Pinion et al 2021
“Neural Operator: Learning Maps Between Function Spaces”, Kovachki et al 2021
“Introducing Triton: Open-Source GPU Programming for Neural Networks”, Tillet 2021
Introducing Triton: Open-source GPU programming for neural networks
“Predictive Coding: a Theoretical and Experimental Review”, Millidge et al 2021
“A Connectivity-Constrained Computational Account of Topographic Organization in Primate High-Level Visual Cortex”, Blauch et al 2021
“A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers”, Miao et al 2021
A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers
“Coarse-To-Fine Q-Attention: Efficient Learning for Visual Robotic Manipulation via Discretisation”, James et al 2021
Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation
“Randomness In Neural Network Training: Characterizing The Impact of Tooling”, Zhuang et al 2021
Randomness In Neural Network Training: Characterizing The Impact of Tooling
“Revisiting Deep Learning Models for Tabular Data”, Gorishniy et al 2021
“BEiT: BERT Pre-Training of Image Transformers”, Bao et al 2021
“Revisiting Model Stitching to Compare Neural Representations”, Bansal et al 2021
Revisiting Model Stitching to Compare Neural Representations
“Artificial Intelligence in China’s Revolution in Military Affairs”, Kania 2021
Artificial intelligence in China’s revolution in military affairs
“The Geometry of Concept Learning”, Sorscher et al 2021
“VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning”, Bardes et al 2021
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
“The Modern Mathematics of Deep Learning”, Berner et al 2021
“Understanding by Understanding Not: Modeling Negation in Language Models”, Hosseini et al 2021
Understanding by Understanding Not: Modeling Negation in Language Models
“Entailment As Few-Shot Learner”, Wang et al 2021
“PAWS: Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments With Support Samples”, Assran et al 2021
“Epistemic Autonomy: Self-Supervised Learning in the Mammalian Hippocampus”, Santos-Pata et al 2021
Epistemic Autonomy: Self-supervised Learning in the Mammalian Hippocampus
“Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization”, Xie et al 2021
Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization
“Contrasting Contrastive Self-Supervised Representation Learning Models”, Kotar et al 2021
Contrasting Contrastive Self-Supervised Representation Learning Models
“Characterizing and Improving the Robustness of Self-Supervised Learning through Background Augmentations”, Ryali et al 2021
“GWAS in Almost 195,000 Individuals Identifies 50 Previously Unidentified Genetic Loci for Eye Color”, Simcoe et al 2021
GWAS in almost 195,000 individuals identifies 50 previously unidentified genetic loci for eye color
“BERTese: Learning to Speak to BERT”, Haviv et al 2021
“Predictive Coding Can Do Exact Backpropagation on Any Neural Network”, Salvatori et al 2021
Predictive Coding Can Do Exact Backpropagation on Any Neural Network
“Barlow Twins: Self-Supervised Learning via Redundancy Reduction”, Zbontar et al 2021
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
“WIT: Wikipedia-Based Image Text Dataset for Multimodal Multilingual Machine Learning”, Srinivasan et al 2021
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
“The Inverse Variance–flatness Relation in Stochastic Gradient Descent Is Critical for Finding Flat Minima”, Feng & Tu 2021
“Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability”, Cohen et al 2021
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
“Rip Van Winkle’s Razor: A Simple Estimate of Overfit to Test Data”, Arora & Zhang 2021
Rip van Winkle’s Razor: A Simple Estimate of Overfit to Test Data
“Image Completion via Inference in Deep Generative Models”, Harvey et al 2021
“Differentiable Logic Machines”, Zimmer et al 2021
“Contrastive Learning Inverts the Data Generating Process”, Zimmermann et al 2021
“DirectPred: Understanding Self-Supervised Learning Dynamics without Contrastive Pairs”, Tian et al 2021
DirectPred: Understanding self-supervised Learning Dynamics without Contrastive Pairs
“MLGO: a Machine Learning Guided Compiler Optimizations Framework”, Trofin et al 2021
MLGO: a Machine Learning Guided Compiler Optimizations Framework
“Facial Recognition Technology Can Expose Political Orientation from Naturalistic Facial Images”, Kosinski 2021
Facial recognition technology can expose political orientation from naturalistic facial images
“Solving Mixed Integer Programs Using Neural Networks”, Nair et al 2020
“Sixteen Facial Expressions Occur in Similar Contexts Worldwide”, Cowen 2020
Sixteen facial expressions occur in similar contexts worldwide
“PiRank: Learning To Rank via Differentiable Sorting”, Swezey et al 2020
“Real-Time Synthesis of Imagined Speech Processes from Minimally Invasive Recordings of Neural Activity”, Angrick et al 2020
“Generalization Bounds for Deep Learning”, Valle-Pérez & Louis 2020
“Selective Eye-Gaze Augmentation To Enhance Imitation Learning In Atari Games”, Thammineni et al 2020
Selective Eye-gaze Augmentation To Enhance Imitation Learning In Atari Games
“SimSiam: Exploring Simple Siamese Representation Learning”, Chen & He 2020
“Recent Advances in Neurotechnologies With Broad Potential for Neuroscience Research”, Vázquez-Guardado et al 2020
Recent advances in neurotechnologies with broad potential for neuroscience research
“Voting for Authorship Attribution Applied to Dark Web Data”, Samreen & Alalfi 2020
“Twenty Years Beyond the Turing Test: Moving Beyond the Human Judges Too”, Hernández-Orallo 2020
Twenty Years Beyond the Turing Test: Moving Beyond the Human Judges Too
“Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding”, Roberts et al 2020
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
“Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary With Width and Depth”, Nguyen et al 2020
“Guys and Dolls”, Devlin & Locatelli 2020
“Open-Domain Question Answering Goes Conversational via Question Rewriting”, Anantha et al 2020
Open-Domain Question Answering Goes Conversational via Question Rewriting
“Digital Voicing of Silent Speech”, Gaddy & Klein 2020
“Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment”, Talebi et al 2020
Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment
“Implicit Gradient Regularization”, Barrett & Dherin 2020
“Learning Explanations That Are Hard to Vary”, Parascandolo et al 2020
“Large Associative Memory Problem in Neurobiology and Machine Learning”, Krotov & Hopfield 2020
Large Associative Memory Problem in Neurobiology and Machine Learning
“AdapterHub: A Framework for Adapting Transformers”, Pfeiffer et al 2020
“Identifying Regulatory Elements via Deep Learning”, Barshai et al 2020
“Is SGD a Bayesian Sampler? Well, Almost”, Mingard et al 2020
“Bootstrap Your Own Latent (BYOL): A New Approach to Self-Supervised Learning”, Grill et al 2020
Bootstrap your own latent (BYOL): A new approach to self-supervised Learning
“SCAN: Learning to Classify Images without Labels”, Gansbeke et al 2020
“Politeness Transfer: A Tag and Generate Approach”, Madaan et al 2020
“Supervised Contrastive Learning”, Khosla et al 2020
“Backpropagation and the Brain”, Lillicrap et al 2020
“Can You Put It All Together: Evaluating Conversational Agents’ Ability to Blend Skills”, Smith et al 2020
Can You Put it All Together: Evaluating Conversational Agents’ Ability to Blend Skills
“Topology of Deep Neural Networks”, Naitzat et al 2020
“Improved Baselines With Momentum Contrastive Learning”, Chen et al 2020
“The Large Learning Rate Phase of Deep Learning: the Catapult Mechanism”, Lewkowycz et al 2020
The large learning rate phase of deep learning: the catapult mechanism
“Fast Differentiable Sorting and Ranking”, Blondel et al 2020
“The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence”, Marcus 2020
The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence
“Quantifying Independently Reproducible Machine Learning”, Raff 2020
“The Secret History of Facial Recognition: Sixty Years Ago, a Sharecropper’s Son Invented a Technology to Identify Faces. Then the Record of His Role All but Vanished. Who Was Woody Bledsoe, and Who Was He Working For?”, Raviv 2020
“The Case for Bayesian Deep Learning”, Wilson 2020
“Can the Brain Do Backpropagation? -Exact Implementation of Backpropagation in Predictive Coding Networks”, Song et al 2020
“Learning Neural Activations”, Minhas & Asif 2019
“2019 AI Alignment Literature Review and Charity Comparison”, Larks 2019
“Libri-Light: A Benchmark for ASR With Limited or No Supervision”, Kahn et al 2019
Libri-Light: A Benchmark for ASR with Limited or No Supervision
“Connecting Vision and Language With Localized Narratives”, Pont-Tuset et al 2019
“12-In-1: Multi-Task Vision and Language Representation Learning”, Lu et al 2019
12-in-1: Multi-Task Vision and Language Representation Learning
“A Deep Learning Framework for Neuroscience”, Richards et al 2019
A deep learning framework for neuroscience :
View PDF:
“Machine Learning for Scent: Learning Generalizable Perceptual Representations of Small Molecules”, Sanchez-Lengeling et al 2019
Machine Learning for Scent: Learning Generalizable Perceptual Representations of Small Molecules
“KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition With Deep Learning”, Clanuwat et al 2019
KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning
“Approximate Inference in Discrete Distributions With Monte Carlo Tree Search and Value Functions”, Buesing et al 2019
Approximate Inference in Discrete Distributions with Monte Carlo Tree Search and Value Functions
“Best Practices for the Human Evaluation of Automatically Generated Text”, Lee et al 2019
Best practices for the human evaluation of automatically generated text
“RandAugment: Practical Automated Data Augmentation With a Reduced Search Space”, Cubuk et al 2019
RandAugment: Practical automated data augmentation with a reduced search space
“Large-Scale Pretraining for Neural Machine Translation With Tens of Billions of Sentence Pairs”, Meng et al 2019
Large-scale Pretraining for Neural Machine Translation with Tens of Billions of Sentence Pairs
“ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations”, Lan et al 2019
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
“Engineering a Less Artificial Intelligence”, Sinz et al 2019
Engineering a Less Artificial Intelligence :
View PDF:
“Neural Networks Are a Priori Biased towards Boolean Functions With Low Entropy”, Mingard et al 2019
Neural networks are a priori biased towards Boolean functions with low entropy
“Simple, Scalable Adaptation for Neural Machine Translation”, Bapna et al 2019
“Emergent Tool Use From Multi-Agent Autocurricula”, Baker et al 2019
“A Step Toward Quantifying Independently Reproducible Machine Learning Research”, Raff 2019
A Step Toward Quantifying Independently Reproducible Machine Learning Research
“Does Machine Translation Affect International Trade? Evidence from a Large Digital Platform”, Brynjolfsson et al 2019b
Does Machine Translation Affect International Trade? Evidence from a Large Digital Platform
“Can One Concurrently Record Electrical Spikes from Every Neuron in a Mammalian Brain?”, Kleinfeld et al 2019
Can One Concurrently Record Electrical Spikes from Every Neuron in a Mammalian Brain?
“Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges”, Arivazhagan et al 2019
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
“Deep Set Prediction Networks”, Zhang et al 2019
“Optimizing Color for Camouflage and Visibility Using Deep Learning: the Effects of the Environment and the Observer’s Visual System”, Fennell et al 2019
“Speech2Face: Learning the Face Behind a Voice”, Oh et al 2019
“Universal Approximation With Deep Narrow Networks”, Kidger & Lyons 2019
“SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”, Wang et al 2019
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
“Universal Quantum Control through Deep Reinforcement Learning”, Niu et al 2019
Universal quantum control through deep reinforcement learning
“Analysing Mathematical Reasoning Abilities of Neural Models”, Saxton et al 2019
“Reinforcement Learning for Recommender Systems: A Case Study on Youtube”, Chen 2019
Reinforcement Learning for Recommender Systems: A Case Study on Youtube
“Stochastic Optimization of Sorting Networks via Continuous Relaxations”, Grover et al 2019
Stochastic Optimization of Sorting Networks via Continuous Relaxations
“Surprises in High-Dimensional Ridgeless Least Squares Interpolation”, Hastie et al 2019
Surprises in High-Dimensional Ridgeless Least Squares Interpolation
“DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs”, Dua et al 2019
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
“Theories of Error Back-Propagation in the Brain”, Whittington & Bogacz 2019
“A Replication Study: Machine Learning Models Are Capable of Predicting Sexual Orientation From Facial Images”, Leuner 2019
“Unmasking Clever Hans Predictors and Assessing What Machines Really Learn”, Lapuschkin et al 2019
Unmasking Clever Hans Predictors and Assessing What Machines Really Learn
“What Makes a Good Conversation? How Controllable Attributes Affect Human Judgments”, See et al 2019
What makes a good conversation? How controllable attributes affect human judgments
“The Evolved Transformer”, So et al 2019
“Forecasting Transformative AI: An Expert Survey”, Gruetzemacher et al 2019
“Human Few-Shot Learning of Compositional Instructions”, Lake et al 2019
“Evaluation and Accurate Diagnoses of Pediatric Diseases Using Artificial Intelligence”, Liang et al 2019
Evaluation and accurate diagnoses of pediatric diseases using artificial intelligence :
View PDF:
“Why Is There No Successful Whole Brain Simulation (Yet)?”, Stiefel 2019
Why is There No Successful Whole Brain Simulation (Yet)? :
View PDF:
“High-Performance Medicine: the Convergence of Human and Artificial Intelligence”, Topol 2019
High-performance medicine: the convergence of human and artificial intelligence :
View PDF:
“Identifying Facial Phenotypes of Genetic Disorders Using Deep Learning”, Gurovich et al 2019
Identifying facial phenotypes of genetic disorders using deep learning :
“Reinventing the Wheel: Discovering the Optimal Rolling Shape With PyTorch”, Wiener 2019
Reinventing the Wheel: Discovering the Optimal Rolling Shape with PyTorch
“James Zou Homepage [Machine Learning]”, Zou 2019
“An Empirical Study of Example Forgetting during Deep Neural Network Learning”, Toneva et al 2018
An Empirical Study of Example Forgetting during Deep Neural Network Learning
“CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge”, Talmor et al 2018
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
“Depth With Nonlinearity Creates No Bad Local Minima in ResNets”, Kawaguchi & Bengio 2018
Depth with Nonlinearity Creates No Bad Local Minima in ResNets
“BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding”, Devlin et al 2018
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
“Interpretable Textual Neuron Representations for NLP”, Poerner et al 2018
“Searching for Efficient Multi-Scale Architectures for Dense Image Prediction”, Chen et al 2018
Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
“Machine Learning to Predict Osteoporotic Fracture Risk from Genotypes”, Forgetta et al 2018
Machine Learning to Predict Osteoporotic Fracture Risk from Genotypes
“Accelerated Reinforcement Learning for Sentence Generation by Vocabulary Prediction”, Hashimoto & Tsuruoka 2018
Accelerated Reinforcement Learning for Sentence Generation by Vocabulary Prediction
“Searching Toward Pareto-Optimal Device-Aware Neural Architectures”, Cheng et al 2018
Searching Toward Pareto-Optimal Device-Aware Neural Architectures
“A Study of Reinforcement Learning for Neural Machine Translation”, Wu et al 2018
A Study of Reinforcement Learning for Neural Machine Translation
“Modeling Visual Context Is Key to Augmenting Object Detection Datasets”, Dvornik et al 2018
Modeling Visual Context is Key to Augmenting Object Detection Datasets
“Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search”, Zela et al 2018
Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search
“Automatically Composing Representation Transformations As a Means for Generalization”, Chang et al 2018
Automatically Composing Representation Transformations as a Means for Generalization
“Differentiable Learning-To-Normalize via Switchable Normalization”, Luo et al 2018
Differentiable Learning-to-Normalize via Switchable Normalization
“On the Spectral Bias of Neural Networks”, Rahaman et al 2018
“Neural Tangent Kernel: Convergence and Generalization in Neural Networks”, Jacot et al 2018
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
“Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning”, Pang et al 2018
Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning
“Do CIFAR-10 Classifiers Generalize to CIFAR-10?”, Recht et al 2018
“Zero-Shot Dual Machine Translation”, Sestorain et al 2018
“Do Better ImageNet Models Transfer Better?”, Kornblith et al 2018
“GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”, Wang et al 2018
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
“Adafactor: Adaptive Learning Rates With Sublinear Memory Cost”, Shazeer & Stern 2018
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
“Averaging Weights Leads to Wider Optima and Better Generalization”, Izmailov et al 2018
Averaging Weights Leads to Wider Optima and Better Generalization
“SentEval: An Evaluation Toolkit for Universal Sentence Representations”, Conneau & Kiela 2018
SentEval: An Evaluation Toolkit for Universal Sentence Representations
“Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge”, Clark et al 2018
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
“Analyzing Uncertainty in Neural Machine Translation”, Ott et al 2018
“End-To-End Deep Image Reconstruction from Human Brain Activity”, Shen et al 2018
End-to-end deep image reconstruction from human brain activity
“Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari”, Chrabaszcz et al 2018
Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari
“SignSGD: Compressed Optimization for Non-Convex Problems”, Bernstein et al 2018
“Differentiable Dynamic Programming for Structured Prediction and Attention”, Mensch & Blondel 2018
Differentiable Dynamic Programming for Structured Prediction and Attention
“UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction”, Lel et al 2018
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
“Semantic Projection: Recovering Human Knowledge of Multiple, Distinct Object Features from Word Embeddings”, Grand et al 2018
“Panoptic Segmentation”, Kirillov et al 2018
“Clinically Applicable Deep Learning for Diagnosis and Referral in Retinal Disease”, Fauw et al 2018
Clinically applicable deep learning for diagnosis and referral in retinal disease :
View PDF:
“Prediction of Cardiovascular Risk Factors from Retinal Fundus Photographs via Deep Learning”, Poplin et al 2018
Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning
“Three-Dimensional Visualization and a Deep-Learning Model Reveal Complex Fungal Parasite Networks in Behaviorally Manipulated Ants”, Fredericksen et al 2017
“Decoupled Weight Decay Regularization”, Loshchilov & Hutter 2017
“Automatic Differentiation in PyTorch”, Paszke et al 2017
“Rethinking Generalization Requires Revisiting Old Ideas: Statistical Mechanics Approaches and Complex Learning Behavior”, Martin & Mahoney 2017
“Mixup: Beyond Empirical Risk Minimization”, Zhang et al 2017
“Malware Detection by Eating a Whole EXE”, Raff et al 2017
“AlphaGo Zero: Mastering the Game of Go without Human Knowledge”, Silver et al 2017
AlphaGo Zero: Mastering the game of Go without human knowledge
“Swish: Searching for Activation Functions”, Ramachandran et al 2017
“Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates”, Smith & Topin 2017
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
“Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection”, Dwibedi et al 2017
Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection
“Emergence of Locomotion Behaviors in Rich Environments”, Heess et al 2017
“The Persistence and Transience of Memory”, Richards & Frankland 2017
“Verb Physics: Relative Physical Knowledge of Actions and Objects”, Forbes & Choi 2017
Verb Physics: Relative Physical Knowledge of Actions and Objects
“Driver Identification Using Automobile Sensor Data from a Single Turn”, Hallac et al 2017
Driver Identification Using Automobile Sensor Data from a Single Turn
“StreetStyle: Exploring World-Wide Clothing Styles from Millions of Photos”, Matzen et al 2017
StreetStyle: Exploring world-wide clothing styles from millions of photos
“Deep Voice 2: Multi-Speaker Neural Text-To-Speech”, Arik et al 2017
“WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017
WebVision Challenge: Visual Learning and Understanding With Web Data
“Inferring and Executing Programs for Visual Reasoning”, Johnson et al 2017
“Visual Attribute Transfer through Deep Image Analogy”, Liao et al 2017
“On Weight Initialization in Deep Neural Networks”, Kumar 2017
“A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference”, Williams et al 2017
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
“RACE: Large-Scale ReAding Comprehension Dataset From Examinations”, Lai et al 2017
RACE: Large-scale ReAding Comprehension Dataset From Examinations
“Data-Efficient Deep Reinforcement Learning for Dexterous Manipulation”, Popov et al 2017
Data-efficient Deep Reinforcement Learning for Dexterous Manipulation
“Prototypical Networks for Few-Shot Learning”, Snell et al 2017
“Meta Networks”, Munkhdalai & Yu 2017
“Understanding Synthetic Gradients and Decoupled Neural Interfaces”, Czarnecki et al 2017
Understanding Synthetic Gradients and Decoupled Neural Interfaces
“Adaptive Neural Networks for Efficient Inference”, Bolukbasi et al 2017
“Deep Voice: Real-Time Neural Text-To-Speech”, Arik et al 2017
“Machine Learning Predicts Laboratory Earthquakes”, Bertr et al 2017
“Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks”, Katz et al 2017
Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks
“Dermatologist-Level Classification of Skin Cancer With Deep Neural Networks”, Esteva et al 2017
Dermatologist-level classification of skin cancer with deep neural networks :
View PDF:
“Child Machines”, Proudfoot 2017
“Machine Learning for Systems and Systems for Machine Learning”, Dean 2017
Machine Learning for Systems and Systems for Machine Learning
“Feedback Networks”, Zamir et al 2016
“CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning”, Johnson et al 2016
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
“Towards Information-Seeking Agents”, Bachman et al 2016
“Spatially Adaptive Computation Time for Residual Networks”, Figurnov et al 2016
“Deep Learning Reinvents the Hearing Aid: Finally, Wearers of Hearing Aids Can Pick out a Voice in a Crowded Room”, Wang 2016b
“MS MARCO: A Human Generated MAchine Reading COmprehension Dataset”, Bajaj et al 2016
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
“Learning to Reinforcement Learn”, Wang et al 2016
“Lip Reading Sentences in the Wild”, Chung et al 2016
“Could a Neuroscientist Understand a Microprocessor?”, Jonas & Kording 2016
“A Neural Network Playground”, Smilkov & Carter 2016
“Homotopy Analysis for Tensor PCA”, Anandkumar et al 2016
“Why Does Deep and Cheap Learning Work so Well?”, Lin et al 2016
“SGDR: Stochastic Gradient Descent With Warm Restarts”, Loshchilov & Hutter 2016
“Concrete Problems in AI Safety”, Amodei et al 2016
“SQuAD: 100,000+ Questions for Machine Comprehension of Text”, Rajpurkar et al 2016
“Matching Networks for One Shot Learning”, Vinyals et al 2016
“Convolutional Sketch Inversion”, Güçlütürk et al 2016
“Unifying Count-Based Exploration and Intrinsic Motivation”, Bellemare et al 2016
“Synthesizing the Preferred Inputs for Neurons in Neural Networks via Deep Generator Networks”, Nguyen et al 2016
Synthesizing the preferred inputs for neurons in neural networks via deep generator networks
“Toward Deeper Understanding of Neural Networks: The Power of Initialization and a Dual View on Expressivity”, Daniely et al 2016
“"Why Should I Trust You?": Explaining the Predictions of Any Classifier”, Ribeiro et al 2016
"Why Should I Trust You?": Explaining the Predictions of Any Classifier
“Mastering the Game of Go With Deep Neural Networks and Tree Search”, Silver et al 2016
Mastering the game of Go with deep neural networks and tree search
“Learning to Compose Neural Networks for Question Answering”, Andreas et al 2016
“How a Japanese Cucumber Farmer Is Using Deep Learning and TensorFlow”, Sato 2016
How a Japanese cucumber farmer is using deep learning and TensorFlow
“Random Gradient-Free Minimization of Convex Functions”, Nesterov & Spokoiny 2015
“Convergent Learning: Do Different Neural Networks Learn the Same Representations?”, Li et al 2015
Convergent Learning: Do different neural networks learn the same representations?
“Data-Dependent Initializations of Convolutional Neural Networks”, Krähenbühl et al 2015
Data-dependent Initializations of Convolutional Neural Networks
“Online Batch Selection for Faster Training of Neural Networks”, Loshchilov & Hutter 2015
Online Batch Selection for Faster Training of Neural Networks
“Neural Module Networks”, Andreas et al 2015
“Deep DPG (DDPG): Continuous Control With Deep Reinforcement Learning”, Lillicrap et al 2015
Deep DPG (DDPG): Continuous control with deep reinforcement learning
“A Neural Algorithm of Artistic Style”, Gatys et al 2015
“VQA: Visual Question Answering”, Agrawal et al 2015
“Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks”, Weston et al 2015
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks
“Probabilistic Line Searches for Stochastic Optimization”, Mahsereci & Hennig 2015
“Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”, He et al 2015
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Neural Networks and Deep Learning, Nielsen 2015
“Neural Networks and Deep Learning § Ch6 Deep Learning”, Nielsen 2015
“Qualitatively Characterizing Neural Network Optimization Problems”, Goodfellow et al 2014
Qualitatively characterizing neural network optimization problems
“Freeze-Thaw Bayesian Optimization”, Swersky et al 2014
“Microsoft COCO: Common Objects in Context”, Lin et al 2014
“Deep Learning in Neural Networks: An Overview”, Schmidhuber 2014
“Neural Networks, Manifolds, and Topology”, Olah 2014
“Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks”, Saxe et al 2013
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
“Distributed Representations of Words and Phrases and Their Compositionality”, Mikolov et al 2013
Distributed Representations of Words and Phrases and their Compositionality
“Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science”, Clark 2013
Whatever next? Predictive brains, situated agents, and the future of cognitive science
“Deep Gaussian Processes”, Damianou & Lawrence 2012
“Artist Agent: A Reinforcement Learning Approach to Automatic Stroke Generation in Oriental Ink Painting”, Xie et al 2012
“HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent”, Niu et al 2011
HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
“Large-Scale Deep Unsupervised Learning Using Graphics Processors”, Raina et al 2009
Large-scale deep unsupervised learning using graphics processors
“A Free Energy Principle for the Brain”, Friston et al 2006
“Some AI Koans § Http://www.catb.org/esr/jargon/html/koans.html#id3141241”, Raymond 2003
Some AI Koans § http://www.catb.org/esr/jargon/html/koans.html#id3141241
“Some AI Koans”, Raymond 2003
“Understanding the Nature of the General Factor of Intelligence: The Role of Individual Differences in Neural Plasticity As an Explanatory Mechanism”, Garlick 2002
“Starfish § Bulrushes”, Watts 1999
“Exponentiated Gradient versus Gradient Descent for Linear Predictors”, Kivinen & Warmuth 1997
Exponentiated Gradient versus Gradient Descent for Linear Predictors
“Optimality in Biological and Artificial Networks?”, Levine & Elsberry 1997
“A Sociological Study of the Official History of the Perceptrons Controversy”, Olazaran 1996
A Sociological Study of the Official History of the Perceptrons Controversy
“Turing Patterns in CNNs, I: Once over Lightly”, Goras et al 1995
“Learning and Generalization in a Two-Layer Neural Network: The Role of the Vapnik-Chervonvenkis Dimension”, Opper 1994
“A Sociological Study of the Official History of the Perceptrons Controversy [1993]”, Olazaran 1993
A Sociological Study of the Official History of the Perceptrons Controversy [1993]
“The Statistical Mechanics of Learning a Rule”, Watkin et al 1993
“On Learning the Past Tenses of English Verbs”, Rumelhart & McClelland 1993
“Statistical Mechanics of Learning from Examples”, Seung et al 1992
“Memorization Without Generalization in a Multilayered Neural Network”, Hansel et al 1992
Memorization Without Generalization in a Multilayered Neural Network
“Symbolic and Neural Learning Algorithms: An Experimental Comparison”, Shavlik et al 1991
Symbolic and neural learning algorithms: An experimental comparison
“Backpropagation Learning For Multilayer Feed-Forward Neural Networks Using The Conjugate Gradient Method”, Johansson et al 1991
“Artificial Neural Networks, Back Propagation, and the Kelley-Bryson Gradient Procedure”, Dreyfus 1990
Artificial neural networks, back propagation, and the Kelley-Bryson gradient procedure :
View PDF:
“Exhaustive Learning”, Schwartz et al 1990
“International Joint Conference on Neural Networks, January 15–19, 1990: Volume 1: Theory Track, Neural and Cognitive Sciences Track”, Caudill 1990
“International Joint Conference on Neural Networks, January 15–19, 1990: Volume 2: Applications Track”, Caudill 1990
International Joint Conference on Neural Networks, January 15–19, 1990: Volume 2: Applications Track :
“Explanatory Coherence”, Thagard 1989
“Parallel Distributed Processing: Implications for Cognition and Development”, McClelland 1989
Parallel Distributed Processing: Implications for Cognition and Development
“Cellular Neural Networks: Theory”, Chua & Yang 1988b
“Cellular Neural Networks: Applications”, Chua & Yang 1988
“The Brain As Template”, Finkbeiner 1988
View PDF:
“Observation of Phase Transitions in Spreading Activation Networks”, Shrager et al 1987
Observation of Phase Transitions in Spreading Activation Networks
“Learning Representations by Backpropagating Errors”, Rumelhart et al 1986b
Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Volume 1: Foundations, Rumelhart et al 1986
View PDF (33MB):
“Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural Networks”, Amit et al 1985
Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural Networks
“Learning-Logic: Casting the Cortex of the Human Brain in Silicon”, Parker 1985
Learning-Logic: Casting the Cortex of the Human Brain in Silicon :
View PDF:
“Toward An Interactive Model Of Reading”, Rumelhart 1985
Toward An Interactive Model Of Reading :
View PDF:
“Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences”, Werbos 1974
Beyond regression: new tools for prediction and analysis in the behavioral sciences
“Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms”, Rosenblatt 1962
Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms :
View PDF (18MB):
“Speculations on Perceptrons and Other Automata”, Good 1959
“Pandemonium: A Paradigm for Learning”, Selfridge 1959
Pandemonium: A Paradigm for Learning :
View PDF:
“Representation of Events in Nerve Nets and Finite Automata”, Kleene 1951
Representation of Events in Nerve Nets and Finite Automata :
View PDF:
“A Logical Calculus of the Ideas Immanent in Nervous Activity”, McCulloch & Pitts 1943
A logical calculus of the ideas immanent in nervous activity
“The Age of Em, A Book”, Hanson 2026
“gsutil Config: Obtain Credentials and Create Configuration File”, Google 2026
gsutil config: Obtain credentials and create configuration file
“Why Momentum Really Works”
“Differentiable Finite State Machines”
“About Sam Greydanus”, Greydanus 2026
View External Link:
“Contrastive Representation Learning”
“McCulloch and Pitts [Re-Evaluating Neuroscientifically]”
“The Internet’s AI Slop Problem Is Only Going to Get Worse”
“Glow: Better Reversible Generative Models”
“Preetum Nakkiran”
“Differentiable Programming from Scratch”
“Deep Reinforcement Learning Doesn’t Work Yet”
“[Commonsense Media Survey on US Generative Media Use]”
“Gourmand Cat Fence”
“Simple versus Short: Higher-Order Degeneracy and Error-Correction”
Simple versus Short: Higher-order degeneracy and error-correction
“Inferring Neural Activity Before Plasticity As a Foundation for Learning beyond Backpropagation”
Inferring neural activity before plasticity as a foundation for learning beyond backpropagation
“Reddit: Reinforcement Learning Subreddit”, Reddit 2026
“AI and the Indian Election”, Schneier 2026
“Lip Reading Sentences in the Wild [Video]”
Wikipedia (13)
Miscellaneous
/doc/ai/nn/2022-12-02-gwern-meme-itsafraid-googlereluctancetoproductizedeeplearningresearch.jpg/doc/ai/nn/2021-santospata-figure1-hippocampusselfsupervisionlearning.jpg/doc/ai/nn/2000-cartwright-intelligentdataanalysisinscience.pdf:View PDF (22MB):
/doc/ai/nn/2000-cartwright-intelligentdataanalysisinscience.pdf/doc/ai/nn/1997-dhar-intelligentdecisionsupportmethods.pdf:View PDF (124MB):
/doc/ai/nn/1991-sethi-artificialneuralnetworksandstatisticalpatternrecognition.pdf:/doc/ai/nn/1977-agrawala-machinerecognitionofpatterns.pdf:View PDF (31MB):
http://unremediatedgender.space/2018/Jan/blame-me-for-trying/https://aleph.se/andart2/math/weird-probability-distributions/View External Link:
https://aleph.se/andart2/math/weird-probability-distributions/https://juretriglav.si/compressing-global-illumination-with-neural-networks/https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4553431View External Link:
https://people.idsia.ch/~juergen/DanNet-triggers-deep-CNN-revolution-2011.htmlhttps://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37648.pdfhttps://www.chinalawtranslate.com/overview-of-draft-measures-on-generative-ai/https://www.kaggle.com/code/andy8744/predict-anime-face-using-pre-trained-model/datahttps://www.lesswrong.com/posts/RKDQCB6smLWgs2Mhr/multi-component-learning-and-s-curveshttps://www.neelnanda.io/mechanistic-interpretability/favourite-papershttps://www.protocol.com/china/i-built-bytedance-censorship-machinehttps://www.quantamagazine.org/to-be-energy-efficient-brains-predict-their-perceptions-20211115/https://www.thelancet.com/journals/landig/article/PIIS2589-7500(24)00267-X/fulltexthttps://www.vox.com/future-perfect/23775650/ai-regulation-openai-gpt-anthropic-midjourney-stable
{kind=link}
{kind=link}
{kind=link}
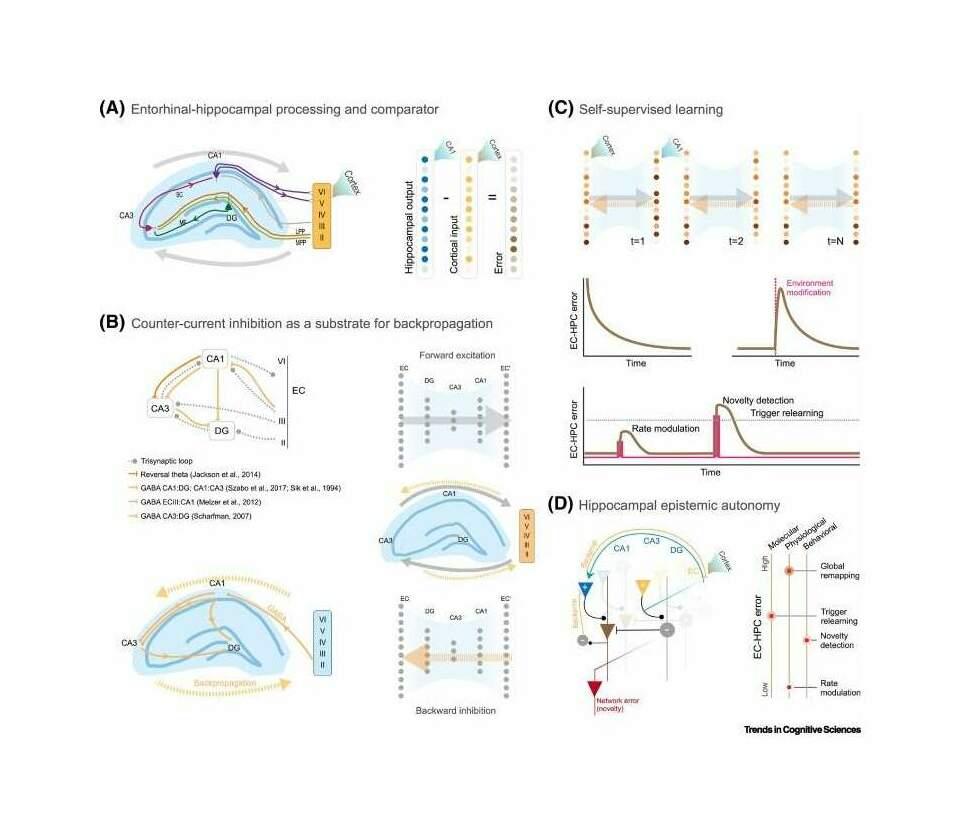{kind=link}
{kind=link}
Bibliography
https://research.arcadiascience.com/pub/result-gp-deep-learning-scaling/release/1/: “Epistasis and Deep Learning in Quantitative Genetics: We Explore When Deep Learning (DL) Outperforms Linear Models in Predicting Complex Phenotypes. We Show That DL Requires at Least 20% As Many Samples As Possible Epistatic Interactions, and Benefits from Marker Feature Selection and Multi-Task Learning on Correlated Phenotypes”,https://arxiv.org/abs/2310.12109: “Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture”,https://www.nber.org/papers/w31422: “Combining Human Expertise With Artificial Intelligence: Experimental Evidence from Radiology”,https://arxiv.org/abs/2302.06675#google: “Symbolic Discovery of Optimization Algorithms”,https://www.tandfonline.com/doi/full/10.1080/00305316.2022.2121777: “Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”,https://arxiv.org/abs/2208.11012: “AniWho: A Quick and Accurate Way to Classify Anime Character Faces in Images”,https://arxiv.org/abs/2201.13415: “Towards Scaling Difference Target Propagation by Learning Backprop Targets”,https://www.sciencedirect.com/science/article/pii/S0169207021001874: “M5 Accuracy Competition: Results, Findings, and Conclusions”,https://arxiv.org/abs/2112.13314: “Silent Bugs in Deep Learning Frameworks: An Empirical Study of Keras and TensorFlow”,2021-kirkpatrick.pdf#deepmind: “Pushing the Frontiers of Density Functionals by Solving the Fractional Electron Problem”,https://www.word.golf/: Word Golf,https://arxiv.org/abs/2110.00683: “Learning through Atypical "Phase Transitions" in Overparameterized Neural Networks”,https://arxiv.org/abs/2106.08254#microsoft: “BEiT: BERT Pre-Training of Image Transformers”,https://arxiv.org/abs/2104.13963#facebook: “PAWS: Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments With Support Samples”,https://arxiv.org/abs/2103.14005: “Contrasting Contrastive Self-Supervised Representation Learning Models”,https://arxiv.org/abs/2103.12719#facebook: “Characterizing and Improving the Robustness of Self-Supervised Learning through Background Augmentations”,https://arxiv.org/abs/2102.06810#facebook: “DirectPred: Understanding Self-Supervised Learning Dynamics without Contrastive Pairs”,https://arxiv.org/abs/2007.07779: “AdapterHub: A Framework for Adapting Transformers”,https://arxiv.org/abs/2006.07733#deepmind: “Bootstrap Your Own Latent (BYOL): A New Approach to Self-Supervised Learning”,https://arxiv.org/abs/2005.12320: “SCAN: Learning to Classify Images without Labels”,https://arxiv.org/abs/2004.11362#google: “Supervised Contrastive Learning”,https://www.lesswrong.com/posts/SmDziGM9hBjW9DKmf/2019-ai-alignment-literature-review-and-charity-comparison: “2019 AI Alignment Literature Review and Charity Comparison”,https://arxiv.org/abs/1912.03098#google: “Connecting Vision and Language With Localized Narratives”,https://arxiv.org/abs/1909.13719#google: “RandAugment: Practical Automated Data Augmentation With a Reduced Search Space”,https://arxiv.org/abs/1909.11942#google: “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations”,https://arxiv.org/abs/1905.00537: “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”,https://arxiv.org/abs/1810.04805#google: “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding”,https://arxiv.org/abs/1806.10779: “Differentiable Learning-To-Normalize via Switchable Normalization”,https://arxiv.org/abs/1803.05407: “Averaging Weights Leads to Wider Optima and Better Generalization”,https://arxiv.org/abs/1802.08842: “Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari”,2017-silver.pdf#deepmind: “AlphaGo Zero: Mastering the Game of Go without Human Knowledge”,https://arxiv.org/abs/1708.07120: “Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates”,https://www.sciencedirect.com/science/article/pii/S0896627317303653: “The Persistence and Transience of Memory”,https://arxiv.org/abs/1705.05640: “WebVision Challenge: Visual Learning and Understanding With Web Data”,https://arxiv.org/abs/1612.02297: “Spatially Adaptive Computation Time for Residual Networks”,2009-raina.pdf: “Large-Scale Deep Unsupervised Learning Using Graphics Processors”,1994-opper.pdf: “Learning and Generalization in a Two-Layer Neural Network: The Role of the Vapnik-Chervonvenkis Dimension”,1993-olazaran.pdf: “A Sociological Study of the Official History of the Perceptrons Controversy [1993]”,1992-seung.pdf: “Statistical Mechanics of Learning from Examples”,1992-hansel.pdf: “Memorization Without Generalization in a Multilayered Neural Network”,1989-mcclelland.pdf: “Parallel Distributed Processing: Implications for Cognition and Development”,1985-amit.pdf: “Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural Networks”,