‘scientific bias’ directory
- See Also
- Gwern
- “The Difficulty of Psychometrics”, Gwern 2026
- “PDF Forgeries Are Surprisingly Rare”, Gwern 2022
- “Against Caring About Subtle Poisons”, Gwern 2023
- “The Existential Risk of Math Errors”, Gwern 2012
- “Feynman’s Maze-Running Story”, Gwern 2014
- “Open Questions”, Gwern 2018
- “How Often Does Correlation=Causality?”, Gwern 2014
- “One Man’s Modus Ponens”, Gwern 2012
- “Littlewood’s Law and the Global Media”, Gwern 2018
- “Does Mouse Utopia Exist?”, Gwern 2019
- “Leprechaun Hunting & Citogenesis”, Gwern 2014
- “A Replication and Methodological Critique of the Study ‘Evaluating Drug Trafficking on the Tor Network’”, Munksgaard et al 2016
- “Hydrocephalus and Intelligence: The Hollow Men”, Gwern 2015
- “Why Correlation Usually ≠ Causation”, Gwern 2014
- “The Replication Crisis: Flaws in Mainstream Science”, Gwern 2010
- “How Should We Critique Research?”, Gwern 2019
- “Dual n-Back Meta-Analysis”, Gwern 2012
- “Lunar Circadian Rhythms”, Gwern 2013
- Links
- “‘Nutrition Science’s Most Preposterous Result’ Is False”, Cremieux 2026
- “[How Peter Miller Manipulates the Manifold Prediction Market on COVID-19 Origins]”, Draaglom 2026
- “PaperBanana: Automating Academic Illustration for AI Scientists”, Zhu et al 2026
- “Generative AI and Wikipedia Editing: What We Learned in 2025”, Edu 2026
- “Did a Celebrated Researcher Obscure a Baby’s Poisoning? After a Newborn Died of Opioid Poisoning, a New Branch of Pediatrics Came into Being. But the Evidence Doesn’t Add Up”, Taub 2026
- “Inventing the ‘Methods’ Section: What the Evolution of Scientific Methods Says about Their Future”, Hunt 2026
- “Oliver Sacks Put Himself Into His Case Studies. What Was the Cost? The Scientist Was Famous for Linking Healing With Storytelling. Sometimes That Meant Reshaping Patients’ Reality”, Aviv 2025
- “Debunking When Prophecy Fails”, Kelly 2025
- “Why You Shouldn’t Trust Data Collected on MTurk”, Kay 2025
- “Harvard Sues Ex-HBS Professor Gino for Defamation, Accusing Her of Falsifying Evidence”
- “Fraudulent Publishing in the Mathematical Sciences”, Agricola et al 2025
- “Pitfalls in Evaluating Language Model Forecasters”, Paleka et al 2025
- “A Sting Inside a Papermill”
- “AI, Materials, and Fraud, Oh My! The Red Flags We Should Have Seen Earlier for a Too-Good-To-Be-True Paper on AI Tool Adoption at a Materials Research Firm”, Shindel 2025
- “That Survivorship Bias Plane: The Exact Backstory to That Picture of an Airplane With Red Dots on top of It”, Liu 2025
- “When ChatGPT Broke an Entire Field: An Oral History”, Pavlus 2025
- “Can We Trust Social Science Yet?”, Briggs 2025
- “The World Happiness Report Is a Sham: A Case Study in Elite Misinformation”, Mounk 2025
- “Super Nintendo Hardware Is Running Faster As It Ages”, Maiberg 2025
- “An Introduction To Forensic Metascience”, Heathers 2025
- “This Tiny Fish’s Mistaken Identity Halted a Dam’s Construction”
- “The Rise of the Science Sleuths”
- “The Global Pattern of Centenarians Highlights Deep Problems in Demography”, Newman 2024
- “Political Language In Economics”, Zubin et al 2024
- “The Composer Has No Clothes”, Brown 2024
- “Revisiting the Relationship between Economic Freedom and Development to Account for Statistical Deception by Autocratic Regimes”, Alvarez et al 2024
- “Questionable Practices in Machine Learning”, Leech et al 2024
- “Delving into ChatGPT Usage in Academic Writing through Excess Vocabulary”, Kobak et al 2024
- “For Chinese Students, the New Tactic Against AI Checks: More AI”, Qitong 2024
- “Paper Tiger? Chinese Science and Home Bias in Citations”, Qiu et al 2024
- “Research Misconduct in China: towards an Institutional Analysis”, Zhang & Wang 2024
- “Epigenetic Age Oscillates during the Day”, Koncevičius et al 2024
- “Is Economics Self-Correcting? Replications in the American Economic Review”, Ankel-Peters et al 2024
- “Maternal Mortality in the United States: Are the High and Rising Rates due to Changes in Obstetrical Factors, Maternal Medical Conditions, or Maternal Mortality Surveillance?”, Joseph et al 2024
- “Google Scholar Is Manipulable”, Ibrahim et al 2024
- “A Multilab Replication of the Induced-Compliance Paradigm of Cognitive Dissonance”, Vaidis et al 2024
- “Psychology Remains Marginally Valid”, Oktar 2024
- “Illusory Generalizability of Clinical Prediction Models”, Chekroud et al 2024
- “‘An Existential Crisis’ for Science”, Research 2024
- “Heresy, Witchcraft, Jean Gerson, Scepticism and the Use of Placebo Controls”, Kirakosian et al 2023
- “Prosocial Motives Underlie Scientific Censorship by Scientists: A Perspective and Research Agenda”, Clark et al 2023
- “Published Benefits of Ivermectin Use in Itajaí, Brazil for COVID-19 Infection, Hospitalization, and Mortality Are Entirely Explained by Statistical Artefacts”, Mills et al 2023
- “A Quantitative Study of Inappropriate Image Duplication in the Journal Toxicology Reports”, David 2023
- “Indoctrination in Introduction to Psychology”, Bartels 2023
- “Metascience Since 2012: A Personal History”, Buck 2023
- “The Garden of Forking Paths; An Evaluation of Joseph’s ‘A Reevaluation of the 1990 Minnesota Study of Twins Reared Apart IQ Study’”, Bouchard 2023
- “Replicability & Generalisability: A Guide to CEA Discounts”, Bettle 2023
- “Measuring Backsliding With Observables: Observable-To-Subjective Score Mapping (OSM)”, Weitzel et al 2023
- “Empirical Design in Reinforcement Learning”, Patterson et al 2023
- “Final Report of Investigation Committee Concerning Allegations against Professor Francesca Gino—Case RI21-001”, Amabile et al 2023
- “Homeopathy Can Offer Empirical Insights on Treatment Effects in a Null Field”, Sigurdson et al 2023
- “Positive Citation Bias and Over-Interpreted Results Lead to Misinformation on Common Mycorrhizal Networks in Forests”, Karst et al 2023
- “Raising the Value of Research Studies in Psychological Science by Increasing the Credibility of Research Reports: the Transparent Psi Project”, Kekecs et al 2023
- “A Discipline-Wide Investigation of the Replicability of Psychology Papers over the past Two Decades”, Youyou et al 2023
- “How Do Psychology Researchers Interpret the Results of Multiple Replication Studies?”, Akker et al 2023
- “Comparing Analysis Blinding With Preregistration in the Many-Analysts Religion Project”, Sarafoglou et al 2023
- “
#ReceptioGateand the (Absolute) State of Academia: The Numbers Game Has Incentivized Bad Behavior”, Gauthier 2023 - “A Spotlight on Bias in the Growth Mindset Intervention Literature: A Reply to Commentaries That Contextualize the Discussion (Oyserman 2023; Yan & Schuetze 2023) and Illustrate the Conclusion (Tipton Et Al 2023)”, Macnamara & Burgoyne 2023
- “Positive Single-Center Randomized Trials and Subsequent Multicenter Randomized Trials in Critically Ill Patients: a Systematic Review”, Kotani et al 2023
- “Medieval Manuscripts Provenance: The RECEPTIO-Rossi Affair IV: My ‘Accusations’”
- “Many Researchers Were Not Compliant With Their Published Data Sharing Statement: a Mixed-Methods Study”, Gabelica et al 2022
- “The Future Failed: No Evidence for Precognition in a Large Scale Replication Attempt of Bem 2011”, Muhmenthaler et al 2022
- “Are Most Published Criminological Research Findings Wrong? Taking Stock of Criminological Research Using a Bayesian Simulation Approach”, Niemeyer et al 2022
- “No Evidence That Mandatory Open Data Policies Increase Error Correction”, Berberi & Roche 2022
- “Inconvenient Truths and the Usefulness of Identifying Unknown Unknowns”, Gould & Georgiou 2022
- “Evaluating the Replicability of Social Priming Studies”, Giolla et al 2022
- “Effects of Randomized Treatment With Icosapent Ethyl and a Mineral Oil Comparator on Interleukin-1β, Interleukin-6, C-Reactive Protein, Oxidized Low-Density Lipoprotein Cholesterol, Homocysteine, Lipoprotein(A), and Lipoprotein-Associated Phospholipase A2: A REDUCE-IT Biomarker Substudy”, Ridker et al 2022
- “Is Psychological Science Self-Correcting? Citations Before and After Successful and Failed Replications”, Hippel 2022
- “Olfactory Exposure to Late-Pregnant and Lactating Mice Causes Stress-Induced Analgesia in Male Mice”, Rosen et al 2022
- “The Impact of Digital Media on Children’s Intelligence While Controlling for Genetic Differences in Cognition and Socioeconomic Background”, Sauce et al 2022
- “Do Multiple Experimenters Improve the Reproducibility of Animal Studies?”, Kortzfleisch et al 2022
- “Theoretical False Positive Psychology”, Wilson et al 2022
- “Does Democracy Matter?”, Gerring et al 2022
- “‘I Think I Discovered a Military Base in the Middle of the Ocean’—Null Island, the Most Real of Fictional Places”, Juhasz & Mooney 2022
- “The Dunning-Kruger Effect Is Autocorrelation”
- “Clinical Prediction Models in Psychiatry: a Systematic Review of Two Decades of Progress and Challenges”, Meehan et al 2022
- “Reproducible Brain-Wide Association Studies Require Thousands of Individuals”, Marek et al 2022
- “A 680,000-Person Megastudy of Nudges to Encourage Vaccination in Pharmacies”, Milkman et al 2022
- “The Backfire Effect After Correcting Misinformation Is Strongly Associated With Reliability”, Swire-Thompson et al 2022
- “Bullet Babies: The Repeating Nature of the Medical Hoax”, Herr 2022
- “Fooled by Beautiful Data: Visualization Esthetics Bias Trust in Science, News, and Social Media”, Lin & Thornton 2022
- “A Systematic Review and Meta-Analysis of the Success of Blinding in Antidepressant RCTs”, Scott et al 2022
- “Replication Crisis and Placebo Studies: Rebooting the Bioethical Debate”, Blease et al 2022
- “Reproducibility in the Social Sciences”, Moody et al 2022
- “The Efficacy of Psychotherapies and Pharmacotherapies for Mental Disorders in Adults: an Umbrella Review and Meta-Analytic Evaluation of Recent Meta-Analyses”, Leichsenring et al 2022
- “How Malleable Are Cognitive Abilities? A Critical Perspective on Popular Brief Interventions”, Moreau 2021
- “More Treatment but No Less Depression: The Treatment-Prevalence Paradox”, Ormel et al 2021
- “Megastudies Improve the Impact of Applied Behavioral Science”, Milkman et al 2021
- “No Strong Evidence of Stereotype Threat in Females: A Reassessment of the Meta-Analysis”, Warne 2021
- “Metformin Treatment of Diverse Caenorhabditis Species Reveals the Importance of Genetic Background in Longevity and Healthspan Extension Outcomes”, Onken et al 2021
- “The Psychophysiology of Political Ideology: Replications, Reanalyses, and Recommendations”, Osmundsen et al 2021
- “Predict Science to Improve Science”, DellaVigna et al 2021
- “The Predicament of Establishing Persistence: Slavery and Human Capital in Africa”, Malik & Bouaroudj 2021
- “The Implicit Association Test in Introductory Psychology Textbooks: Blind Spot for Controversy”, Bartels & Schoenrade 2021
- “A Pre-Registered, Multi-Lab Non-Replication of the Action-Sentence Compatibility Effect (ACE)”, Morey et al 2021
- “Are Conservatives More Rigid Than Liberals? A Meta-Analytic Test of the Rigidity-Of-The-Right Hypothesis”, Costello et al 2021
- “Empirical Audit and Review and an Assessment of Evidentiary Value in Research on the Psychological Consequences of Scarcity”, O’Donnell et al 2021
- “Effect Sizes Reported in Highly Cited Emotion Research Compared With Larger Studies and Meta-Analyses Addressing the Same Questions”, Cristea et al 2021
- “The Role of Human Fallibility in Psychological Research: A Survey of Mistakes in Data Management”, Kovacs et al 2021
- “On the Reliability of Published Findings Using the Regression Discontinuity Design in Political Science”, Stommes et al 2021
- “Is Coffee the Cause or the Cure? Conflicting Nutrition Messages in 2 Decades of Online New York Times’ Nutrition News Coverage”, Ihekweazu 2021
- “Causal and Associational Linking Language From Observational Research and Health Evaluation Literature in Practice: A Systematic Language Evaluation”, Haber et al 2021
- “TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands”, Shapiro et al 2021
- “Systematic Bias in the Progress of Research”, Rubin & Rubin 2021
- “Common Elective Orthopaedic Procedures and Their Clinical Effectiveness: Umbrella Review of Level 1 Evidence”, Blom et al 2021
- “Small Effects: The Indispensable Foundation for a Cumulative Psychological Science”, Götz et al 2021
- “The Revolution Will Be Hard to Evaluate: How Co-Occurring Policy Changes Affect Research on the Health Effects of Social Policies”, Matthay et al 2021
- “The Piranha Problem: Large Effects Swimming in a Small Pond”, Tosh et al 2021
- “Challenging the Link Between Early Childhood Television Exposure and Later Attention Problems: A Multiverse Approach”, McBee et al 2021
- “The Influence of Hidden Researcher Decisions in Applied Microeconomics”, Huntington-Klein et al 2021
- “Man-Bites-Dog Contagion: Disproportionate Diffusion of Information about Rare Categories of Events”, Jang & Shore 2021
- “Therapygenetic Effects of 5-HTTLPR on Cognitive-Behavioral Therapy in Anxiety Disorders: A Meta-Analysis”, Schiele et al 2021
- “Maximal Positive Controls: A Method for Estimating the Largest Plausible Effect Size”, Hilgard 2021
- “Putting the Self in Self-Correction: Findings From the Loss-Of-Confidence Project”, Rohrer et al 2021
- “Artificial Intelligence in Drug Discovery: What Is Realistic, What Are Illusions? Part 1: Ways to Make an Impact, and Why We Are Not There Yet: Quality Is More Important Than Speed and Cost in Drug Discovery”, Bender & Cortés-Ciriano 2021
- “When the Numbers Do Not Add Up: The Practical Limits of Stochastologicals for Soft Psychology”, Broers 2021
- “Honest Signaling in Academic Publishing”, Tiokhin et al 2021
- “So Useful As a Good Theory? The Practicality Crisis in (Social) Psychological Theory”, Berkman & Wilson 2021
- “Comment by Peter Norvig on "Being Good at Programming Competitions Correlates Negatively With Being Good on the Job"”, Norvig 2020
- “Has the Effect of the American Flag on Political Attitudes Declined Over Time? A Case Study of the Historical Context of American Flag Priming”, Carter et al 2020
- “The Statistical Properties of RCTs and a Proposal for Shrinkage”, Zwet et al 2020
- “Many Labs 5: Testing Pre-Data-Collection Peer Review As an Intervention to Increase Replicability”, Ebersole et al 2020
- “The Reproducibility of Statistical Results in Psychological Research: An Investigation Using Unpublished Raw Data”, Artner et al 2020
- “Psychological Measurement and the Replication Crisis: Four Sacred Cows”, Lilienfeld & Strother 2020
- “Cite Unseen: Theory and Evidence on the Effect of Open Access on Cites to Academic Articles Across the Quality Spectrum”, McCabe & Snyder 2020
- “False Individual Patient Data and Zombie Randomized Controlled Trials Submitted to Anesthesia”, Carlisle 2020
- “Heterogeneity in Direct Replications in Psychology and Its Association With Effect Size”, Olsson-Collentine et al 2020
- “A Replication Crisis in Methodological Research?”, Boulesteix et al 2020
- “The Small Effects of Political Advertising Are Small regardless of Context, Message, Sender, or Receiver: Evidence from 59 Real-Time Randomized Experiments”, Coppock et al 2020
- “Towards Reproducible Brain-Wide Association Studies”, Marek et al 2020
- “Laypeople Can Predict Which Social-Science Studies Will Be Replicated Successfully”, Hoogeveen et al 2020
- “Specification Curve Analysis”, Simonsohn et al 2020
- “Can Short Psychological Interventions Affect Educational Performance? Revisiting the Effect of Self-Affirmation Interventions”, Serra-Garcia et al 2020
- “The Multiverse of Methods: Extending the Multiverse Analysis to Address Data-Collection Decisions”, Harder 2020
- “How Do Scientific Views Change? Notes From an Extended Adversarial Collaboration”, Cowan et al 2020
- “What Is the Test-Retest Reliability of Common Task-Functional MRI Measures? New Empirical Evidence and a Meta-Analysis”, Elliott et al 2020
- “Health Recommendations and Selection in Health Behaviors”, Oster 2020
- “Variability in the Analysis of a Single Neuroimaging Dataset by Many Teams”, Botvinik-Nezer et al 2020
- “Supercentenarian and Remarkable Age Records Exhibit Patterns Indicative of Clerical Errors and Pension Fraud”, Newman 2020
- “Bilingualism Affords No General Cognitive Advantages: A Population Study of Executive Function in 11,000 People”, Nichols et al 2020
- “Statistics As Squid Ink: How Prominent Researchers Can Get Away With Misrepresenting Data”, Gelman & Guzey 2020
- “Ideological Diversity, Hostility, and Discrimination in Philosophy”, Peters et al 2020
- “On Attenuated Interactions, Measurement Error, and Statistical Power: Guidelines for Social and Personality Psychologists”, Blake & Gangestad 2020
- “A Controlled Trial for Reproducibility: For Three Years, Part of DARPA Has Funded Two Teams for Each Project: One for Research and One for Reproducibility. The Investment Is Paying Off.”, Raphael et al 2020
- “What Do Editors Maximize? Evidence from 4 Economics Journals”, Card & DellaVigna 2020
- “Foreign Language Learning in Older Age Does Not Improve Memory or Intelligence: Evidence from a Randomized Controlled Study”, Berggren et al 2020
- “The Stewart Retractions: A Quantitative and Qualitative Analysis”, Pickett 2020
- “Quantifying Independently Reproducible Machine Learning”, Raff 2020
- “Compliance With Legal Requirement to Report Clinical Trial Results on ClinicalTrials.gov: a Cohort Study”, DeVito et al 2020
- “Implications of Ideological Bias in Social Psychology on Clinical Practice”, Silander et al 2020
- “Cognitive and Academic Benefits of Music Training With Children: A Multilevel Meta-Analysis”, Sala & Gobet 2020
- “What Intellectual Progress Did I Make In The 2010s?”, Alexander 2020
- “Blinding to Remove Biases in Science and Society”, MacCoun 2020
- “Why the Increasing Use of Complex Causal Models Is a Problem: On the Danger Sophisticated Theoretical Narratives Pose to Truth”, Saylors & Trafimow 2020
- “Estimating the Deep Replicability of Scientific Findings Using Human and Artificial Intelligence”, Yang et al 2020
- “Lack of Evidence for Associative Learning in Pea Plants”, Markel 2020
- “Self-Reported Health without Clinically Measurable Benefits among Adult Users of Multivitamin and Multimineral Supplements: a Cross-Sectional Study”, Paranjpe et al 2020
- “Do Police Killings of Unarmed Persons Really Have Spillover Effects? Reanalyzing Bor Et Al 2018”, Nix & Lozada 2019
- “Catching Cheating Students”, Lin & Levitt 2019
- “Why We Sleep Data Manipulation: A Smoking Gun?”, Gelman 2019
- “Whassup With Why We Sleep?”, Gelman 2019
- “Comparing Meta-Analyses and Preregistered Multiple-Laboratory Replication Projects”, Kvarven et al 2019
- “Why We Sleep Update: Some Thoughts While We Wait for Matthew Walker to Respond to Alexey Guzey’s Criticisms”, Gelman 2019
- “Flexible yet Fair: Blinding Analyses in Experimental Psychology”, Dutilh et al 2019
- “Many Labs 2: Investigating Variation in Replicability Across Sample and Setting”, Klein et al 2019
- “Is Matthew Walker’s Why We Sleep Riddled With Scientific and Factual Errors?”, Gelman 2019
- “[Comment on Guzey Post]”, Kinkajoe 2019
- “Matthew Walker’s Why We Sleep Is Riddled With Scientific and Factual Errors”, Guzey 2019
- “Effect of Lower Versus Higher Red Meat Intake on Cardiometabolic and Cancer Outcomes: A Systematic Review of Randomized Trials”, Zeraatkar et al 2019
- “Anthropology’s Science Wars: Insights from a New Survey”, Horowitz et al 2019
- “A National Experiment Reveals Where a Growth Mindset Improves Achievement”, Yeager et al 2019
- “Debunking the Stanford Prison Experiment”, Texier 2019
- “The Architectural Bias in Current Biblical Archaeology”, Ben-Yosef 2019
- “The Maddening Saga of How an Alzheimer’s ‘Cabal’ Thwarted Progress toward a Cure for Decades”, Begley 2019
- “Exploring Research-Methods Blogs in Psychology: Who Posts What About Whom, and With What Effect?”, Nicolas et al 2019
- “Generalizable and Robust TV Advertising Effects”, Shapiro et al 2019
- “Meta-Research: A Comprehensive Review of Randomized Clinical Trials in Three Medical Journals Reveals 396 Medical Reversals”, Herrera-Perez et al 2019
- “6 Lessons for a Cogent Science of Implicit Bias and Its Criticism”, Gawronski 2019
- “The Hype Cycle of Working Memory Training”, Redick 2019
- “Statistical Methods for Replicability Assessment”, Hung & Fithian 2019
- “Rigorous Large-Scale Educational RCTs Are Often Uninformative: Should We Be Concerned?”, Lortie-Forgues & Inglis 2019
- “What Can We Learn from Many Labs Replications? 3. Can Replication Studies Detect Fraud?”, Stroebe 2019
- “Citogenesis: the Serious Circular Reporting Problem Wikipedians Are Fighting. Circular Reporting Is a Real Problem on Platforms like Wikipedia—And It’s Harder to Solve Than It Looks”, Harrison 2019
- “Inside the Secret Sting Operations to Expose Celebrity Psychics: Are Some Celebrity Mediums Fooling Their Audience Members by Reading Social Media Pages in Advance? A Group of Online Vigilantes Is out to Prove It”, Hitt 2019
- “Orchestrating False Beliefs about Gender Discrimination”, Pallesen 2019
- “On the Estimation of Treatment Effects With Endogenous Misreporting”, Nguimkeu et al 2019
- “The Blank Pages of History”, Chlopodo 2019
- “Large Teams Develop and Small Teams Disrupt Science and Technology”, Wu et al 2019
- “The Advantages of Bilingualism Debate”, Antoniou 2019
- “How Replicable Are Links Between Personality Traits and Consequential Life Outcomes? The Life Outcomes of Personality Replication Project”, Soto 2019
- “A Comprehensive Meta-Analysis of Money Priming”, Lodder et al 2019
- “No Support for Historical Candidate Gene or Candidate Gene-By-Interaction Hypotheses for Major Depression Across Multiple Large Samples”, Border et al 2019
- “Why Is Nonadherence to Cancer Screening Associated With Increased Mortality?”, Association 2018
- “Association of Non-Adherence to Cancer Screening Examinations With Mortality From Unrelated Causes: A Secondary Analysis of the PLCO Cancer Screening Trial”, Pierre-Victor & Pinsky 2018
- “Mesmerising Science: The Franklin Commission and the Modern Clinical Trial”, Laukaityte 2018
- “Generalizability of Heterogeneous Treatment Effect Estimates across Samples”, Coppock et al 2018
- “Predicting Replication Outcomes in the Many Labs 2 Study”, Forsell et al 2018
- “Deterministic Implementations for Reproducibility in Deep Reinforcement Learning”, Nagarajan et al 2018
- “Effects of the Tennessee Prekindergarten Program on Children’s Achievement and Behavior through Third Grade”, Lipsey et al 2018
- “Evaluating the Replicability of Social Science Experiments in Nature and Science 2010–2015”, Camerer et al 2018
- “Statistical Paradises and Paradoxes in Big Data (1): Law of Large Populations, Big Data Paradox, and the 2016 US Presidential Election”, Meng 2018
- “Disentangling Bias and Variance in Election Polls”, Shirani-Mehr et al 2018
- “Propagation of Mistakes in Papers”, Neumann 2018
- “Causal Language and Strength of Inference in Academic and Media Articles Shared in Social Media (CLAIMS): A Systematic Review”, Haber et al 2018
- “Acceptable Losses: the Debatable Origins of Loss Aversion”, Yechiam 2018
- “A Real-Life Lord of the Flies: the Troubling Legacy of the Robbers Cave Experiment; In the Early 1950s, the Psychologist Muzafer Sherif Brought Together a Group of Boys at a US Summer Camp—And Tried to Make Them Fight Each Other. Does His Work Teach Us Anything about Our Age of Resurgent Tribalism? [An Extract from The Lost Boys]”, Shariatmadari 2018
- “What Science Is like in North Korea: Isolated from the Rest of the World, North Korean Researchers Struggle to Balance Rigorous Scientific Work With the Demands of a Dictator”, Fiscutean 2018
- “Homogenous: The Political Affiliations of Elite Liberal Arts College Faculty”, Langbert 2018
- “"Are You Gonna Publish That?" Peer-Reviewed Publication Outcomes of Doctoral Dissertations in Psychology”, Evans et al 2018
- “Knowing What We Are Getting: Evaluating Scientific Research on the International Space Station”, Bianco & Schmidt 2017
- “The Prehistory of Biology Preprints: A Forgotten Experiment from the 1960s”, Cobb 2017
- “Percutaneous Coronary Intervention in Stable Angina (ORBITA): a Double-Blind, Randomized Controlled Trial”, Al-Lamee et al 2017
- “The Power of Bias in Economics Research”, Ioannidis et al 2017
- “Deep Reinforcement Learning That Matters”, Henderson et al 2017
- “Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents”, Machado et al 2017
- “Does Diversity Pay? A Replication of Herring 2009 [No]”, Stojmenovska et al 2017
- “Impossibly Hungry Judges”, Lakens 2017
- “How Gullible Are We? A Review of the Evidence from Psychology and Social Science”, Mercier 2017
- “Avoiding Erroneous Citations in Ecological Research: Read Before You Apply”, Šigut et al 2017
- “Coverage of Rosenhan’s ‘On Being Sane in Insane Places’ in Abnormal Psychology Textbooks”, Bartels & Peters 2017
- “Roosevelt Predicted to Win: Revisiting the 1936 Literary Digest Poll”, Lohr & Brick 2017
- “Laboratory Environmental Factors and Pain Behavior: the Relevance of Unknown Unknowns to Reproducibility and Translation”, Mogil 2017
- “Empirical Assessment of Published Effect Sizes and Power in the Recent Cognitive Neuroscience and Psychology Literature”, Szucs & Ioannidis 2017
- “Blind Analysis As a Correction for Confirmatory Bias in Physics and in Psychology”, MacCoun & Perlmutter 2017
- “When the Music’s Over. Does Music Skill Transfer to Children’s and Young Adolescents’ Cognitive and Academic Skills? A Meta-Analysis”, Sala & Gobet 2017
- “Meta-Assessment of Bias in Science”
- “Does Teaching Children How to Play Cognitively Demanding Games Improve Their Educational Attainment? Evidence from a Randomized Controlled Trial of Chess Instruction in England”, jerrim 2017
- “Potential Contribution of Lifestyle and Socioeconomic Factors to Healthy User Bias in Anti-Hypertensives and Lipid-Lowering Drugs”, Kinjo et al 2017
- “What Does Any of This Have To Do With Physics? Einstein and Feynman Ushered Me into Grad School, Reality Ushered Me Out”, Henderson 2016
- “Rational Judges, Not Extraneous Factors In Decisions”, Stafford 2016
- “Responses to Critiques on Machine Learning of Criminality Perceptions (Addendum of ArXiv:1611.04135)”, Wu & Zhang 2016
- “How Multiple Imputation Makes a Difference”, Lall 2016
- “Statistically Controlling for Confounding Constructs Is Harder Than You Think”, Westfall & Yarkoni 2016
- “Reading ‘The Baby Factory’ in Context”, Srivastava 2016
- “When Quality Beats Quantity: Decision Theory, Drug Discovery, and the Reproducibility Crisis”, Scannell & Bosley 2016
- “The Baby Factory: Difficult Research Objects, Disciplinary Standards, and the Production of Statistical-Significance”, Peterson 2016
- “Looking Across and Looking Beyond the Knowledge Frontier: Intellectual Distance, Novelty, and Resource Allocation in Science”, Boudreau et al 2016
- “The Missing 11th of the Month”, Hagen 2015
- “Estimating the Reproducibility of Psychological Science”, Collaboration 2015
- “The Economics of Reproducibility in Preclinical Research”, Freedman et al 2015
- “Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time”, Kaplan & Irvin 2015
- “Small Telescopes: Detectability and the Evaluation of Replication Results”, Simonsohn 2015
- “Scholarly Context Not Found: One in Five Articles Suffers from Reference Rot”, Klein et al 2014
- “The Corrupted Epidemiological Evidence Base of Psychiatry: A Key Driver of Over-Diagnosis”, Raven 2014
- “Association Between Analytic Strategy and Estimates of Treatment Outcomes in Meta-Analyses”, Dechartres et al 2014
- “Practice Does Not Make Perfect: No Causal Effect of Music Practice on Music Ability”, Mosing et al 2014
- “Deliberate Practice: Is That All It Takes to Become an Expert?”, Hambrick et al 2014
- “Olfactory Exposure to Males, including Men, Causes Stress and Related Analgesia in Rodents”, Sorge et al 2014
- “The Control Group Is Out Of Control”, Alexander 2014
- “Trap of Trends to Statistical-Significance: Likelihood of Near-Statistically-Significant p-Values Becoming More Statistically-Significant With Extra Data”, Wood et al 2014
- “The Chrysalis Effect: How Ugly Initial Results Metamorphosize Into Beautiful Articles”, O’Boyle et al 2014
- “Identifying The Effect Of Open Access On Citations Using A Panel Of Science Journals”, McCabe & Snyder 2014
- “p-Curve: A Key to the File-Drawer”, Simonsohn et al 2014
- “Open Access to Data: An Ideal Professed but Not Practised”, Andreoli-Versbach & Mueller-Langer 2014
- “Use of Placebo Controls in the Evaluation of Surgery: Systematic Review”, Wartolowska 2014
- “Too Much Success for Recent Groundbreaking Epigenetic Experiments”, Francis 2014
- “Predictors and Moderators of Agreement between Clinical and Research Diagnoses for Children and Adolescents”, Jensen-Doss et al 2014
- “The Availability of Research Data Declines Rapidly With Article Age”, Vines et al 2013
- “The Pervasive Problem With Placebos in Psychology: Why Active Control Groups Are Not Sufficient to Rule Out Placebo Effects”, Boot et al 2013
- “Researchers Finally Replicated Reinhart-Rogoff [GDP vs National Debt], and There Are Serious Problems”, Varghese 2013
- “Lizardman’s Constant Is 4%”, Alexander 2013
- “Investing in Preschool Programs”, Duncan & Magnuson 2013
- “A Survey on Data Reproducibility in Cancer Research Provides Insights into Our Limited Ability to Translate Findings from the Laboratory to the Clinic”, Mobley et al 2013
- “Star Wars: The Empirics Strike Back”, Brodeur et al 2013
- “Empirical Estimates Suggest Most Published Medical Research Is True”, Jager & Leek 2013
- “What’s to Know about the Credibility of Empirical Economics?”, Ioannidis & Doucouliagos 2013
- “The Garden of Forking Paths: Why Multiple Comparisons Can Be a Problem, Even When There Is No `fishing Expedition` or `p-Hacking` and the Research Hypothesis Was Posited ahead of Time”, Gelman & Loken 2013
- “Investigating Variation in Replicability: The `Many Labs` Replication Project”, Klein 2013
- “Randomized Controlled Trials Commissioned by the Institute of Education Sciences Since 2002: How Many Found Positive Versus Weak or No Effects?”, Policy 2013
- “A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices”, Prasad 2013
- “The Data Vigilante”
- “Flawed Science: The Fraudulent Research Practices of Social Psychologist Diederik Stapel”, Committee et al 2012
- “Scientific Misconduct and the Myth of Self-Correction in Science”, Stroebe et al 2012
- “A Peculiar Prevalence of p Values Just below 0.05”, Masicampo & Lalande 2012
- “The Iron Law Of Evaluation And Other Metallic Rules”, Rossi 2012
- “Depressive Realism: A Meta-Analytic Review”, Moore & Fresco 2012
- “Correlation and Causation in the Study of Personality”, Lee 2012
- “How Near-Miss Events Amplify or Attenuate Risky Decision Making”, Tinsley et al 2012
- “Measuring the Prevalence of Questionable Research Practices With Incentives for Truth-Telling”, John et al 2012
- “The Ironic Effect of Significant Results on the Credibility of Multiple-Study Articles”, Schimmack 2012
- “Chocolate Consumption, Cognitive Function, and Nobel Laureates”, Messerli 2012
- “Compliance With Mandatory Reporting of Clinical Trial Results on ClinicalTrials.gov: Cross Sectional Study”, Prayle 2012
- “Most Reported Genetic Associations With General Intelligence Are Probably False Positives”, Chabris et al 2012
- “Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results”, Wicherts et al 2011
- “Statistically-Significant Meta-Analyses of Clinical Trials Have Modest Credibility and Inflated Effects”, Pereira & Ioannidis 2011
- “Artifact and Recording Concepts in EEG”, Tatum et al 2011
- “Notes on a New Philosophy of Empirical Science”, Burfoot 2011
- “Epidemiology, Quality and Reporting Characteristics of Systematic Reviews of Traditional Chinese Medicine Interventions Published in Chinese Journals”, Ma et al 2011
- “Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect”, Bem 2011
- “Was There Really a Hawthorne Effect at the Hawthorne Plant? An Analysis of the Original Illumination Experiments”, Levitt & List 2011
- “BCR Fall 2011_full”, Garnier 2011
- “Excess Statistical-Significance Bias in the Literature on Brain Volume Abnormalities”, Ioannidis 2011
- “The Mismeasure of Science: Stephen Jay Gould versus Samuel George Morton on Skulls and Bias”, Lewis 2011
- “Erroneous Analyses of Interactions in Neuroscience: a Problem of Statistical-Significance”, Nieuwenhuis 2011
- “Peer-Review in a World With Rational Scientists: Toward Selection of the Average”, Thurner & Hanel 2010
- “Japan, Checking on Its Oldest, Finds Many Gone”
- “On Rustles, Wolf Interpretations, and Other Wild Speculations”, Navon 2010
- “‘Positive’ Results Increase Down the Hierarchy of the Sciences”, Fanelli 2010
- “Chinese Journal Finds 31% of Submissions Plagiarized”, Zhang 2010
- “Holiday Reading: Cigarette Smoking: an Underused Tool in High-Performance Endurance Training”, Myers 2010
- “Placebo Interventions for All Clinical Conditions”, Hróbjartsson & Gøtzsche 2010
- “Rewriting History”, Ljungqvist et al 2009
- “Large-Scale Assessment of the Effect of Popularity on the Reliability of Research”, Pfeiffer & Hoffmann 2009
- “How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data”, Fanelli 2009
- “When Superstars Flop: Public Status and Choking Under Pressure in International Soccer Penalty Shootouts”, Jordet 2009
- “Producing Wrong Data Without Doing Anything Obviously Wrong!”, Mytkowicz et al 2009
- “Statin Adherence and Risk of Accidents: a Cautionary Tale”, Dormuth et al 2009
- “Models for Potentially Biased Evidence in Meta-Analysis Using Empirically Based Priors”, Welton et al 2008
- “Killing For Their Country: A New Look at ‘Killology’”, Engen 2008
- “Probing the Improbable: Methodological Challenges for Risks With Low Probabilities and High Stakes”, Ord et al 2008
- “Figureheads, Ghost-Writers and Pseudonymous Quant Bloggers: The Recent Evolution of Authorship in Science Publishing”, Charlton 2008
- “Why Most Discovered True Associations Are Inflated”, Ioannidis 2008
- “The Allure of Equality: Uniformity in Probabilistic and Statistical Judgment”, Falk & Lann 2008
- “Lost in Publication: How Measurement Harms Science”, Lawrence 2008
- “Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): Explanation and Elaboration”, Vandenbroucke et al 2007
- “A Mathematical Theory of Citing”, Simkin & Roychowdhury 2007
- “Psychological Treatments That Cause Harm”, Lilienfeld 2007
- “Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments”, Rutter 2007
- “Meditation Practices for Health: State of the Research”, Center 2007
- “Testing Multiple Statistical Hypotheses Resulted in Spurious Associations: a Study of Astrological Signs and Health”, Austin et al 2006
- “Mechanisms of the Placebo Effect of Sweet Cough Syrups”, Eccles 2006
- “Lessons from the JMCB Archive”, McCullough et al 2006
- “Comparison of Evidence on Harms of Medical Interventions in Randomized and Nonrandomized Studies”, Papanikolaou et al 2006
- “Evidence of Bias in Estimates of Influenza Vaccine Effectiveness in Seniors”, Jackson et al 2005
- “Contradicted and Initially Stronger Effects in Highly Cited Clinical Research”, Ioannidis 2005
- “Blind Analysis In Nuclear And Particle Physics”, Klein & Roodman 2005
- “Experimenter Effects and the Remote Detection of Staring”, Wiseman & Schlitz 2005
- “An Alternative to Null-Hypothesis Statistical-Significance Tests”, Killeen 2005
- “When Is a Correlation between Non-Independent Variables ‘Spurious’?”, Brett 2004
- “S. L. A. Marshall’s Men against Fire: New Evidence regarding Fire Ratios”, II 2003
- “Does High Self-Esteem Cause Better Performance, Interpersonal Success, Happiness, Or Healthier Lifestyles?”, Baumeister et al 2003
- “Personal Reflections on Lessons Learned from Randomized Trials Involving Newborn Infants, 1951–1967”, Silverman 2003
- “C:/ncn/bre587”
- “Effects of Remote, Retroactive Intercessory Prayer on Outcomes in Patients With Bloodstream Infection: Randomized Controlled Trial”, Leibovici 2001
- “The Hazards of Predicting Divorce Without Crossvalidation”, Heyman & Slep 2001
- “Beleaguered Pygmalion: A History of the Controversy Over Claims That Teacher Expectancy Raises Intelligence”, Spitz 1999
- “Controlled Trials: the 1948 Watershed”, Doll 1998
- “Applications of Randomness in System Performance Measurement”, Blackwell 1998
- “The Unpredictability Paradox: Review of Empirical Comparisons of Randomized and Non-Randomized Clinical Trials”, Kunz & Oxman 1998
- “The Science of Murphy’s Law: Life’s Little Annoyances Are Not As Random As They Seem: the Awful Truth Is That the Universe Is against You”, Matthews 1997
- “Trends in Science Coverage: a Content Analysis of 3 US Newspapers”, Pellechia 1997
- “The Rise and Fall of Uncitedness”, Schwartz 1997
- “The T-Experiments: Errors in Scientific Software”, Hatton 1997
- “The ‘File Drawer Problem’ of Non-Significant Results: Does It Apply to Biological Research?”
- “The Social Misconstruction of Reality: Validity and Verification in the Scholarly Community”, Hamilton 1996
- “The Big Crunch”, Goodstein 1994
- “The Efficacy of Psychological, Educational, and Behavioral Treatment: Confirmation from Meta-Analysis”, Lipsey & Wilson 1993
- “The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality”, Koehler 1993
- “On Being a Whistleblower: The Needleman Case”, Ernhart et al 1993
- “How a Publicity Blitz Created The Myth of Subliminal Advertising”, Rogers 1992
- “Statistics As Rhetoric in Psychology”, John 1992
- “The Crisis in Measurement Literacy in Psychology and Education”, Lambert 1991
- “What’s Wrong With Psychology Anyway?”, Lykken 1991
- “Possible Inaccuracies Occurring in Citation Analysis”, Moed & Vriens 1989
- “Methods for Studying Coincidences”, Diaconis & Mosteller 1989
- “Walter Stewart: Fighting Fraud in Science (They Call Him the ‘terrorist of the Lab’, but This Self-Appointed Scourge of Scientific Fraud Has Reason to Suspect That As Much As 25% of All Research Papers May Be Intentionally Fudged) [Interview]”, Stewart & Stewart 1989
- “About Face: The Odyssey of an American Warrior § S. L. A. Marshall (SLAM)”, Hackworth & Sherman 1989 (page 37)
- “Informal Conceptions of Probability”
- “Statistical Procedures and the Justification of Knowledge in Psychological Science”, Rosnow & Rosenthal 1989
- “The Elusive Open Mind: 10 Years of Negative Research in Parapsychology”, Blackmore 1987
- “Assessing Uncertainty in Physical Constants”, Henrion & Fischhoff 1986
- Pasteur Et Le Choléra Des Poules: Révision Critique D’un Récit Historique, Cadeddu 1985
- “Magnitude of Teacher Expectancy Effects on Pupil IQ As a Function of the Credibility of Expectancy Induction: A Synthesis of Findings from 18 Experiments”, Raudenbush 1984
- “The Citation Bias: Fad and Fashion in the Judgment and Decision Literature”, Christensen-Szalanski & Beach 1984
- “An Investigation of the Validity of Bibliographic Citations”, Broadus 1983
- “Taboo, Constraint, and Responsibility in Educational Research”, Jensen 1983b
- “Fake!”, Hamblin 1981
- “Rating the Ratings: Assessing the Psychometric Quality of Rating Data”, Saal et al 1980
- “Reliability: A Review of Psychometric Basics and Recent Marketing Practices”, Peter 1979
- “Consumer Research: How Valid and Useful Are All Our Consumer Behavior Research Findings?: A State-Of-The-Art Review”, Jacoby 1978
- “What Is Not What in Statistics”, Guttman 1977
- Experimenter Effects in Behavioral Research: Enlarged Edition, Rosenthal 1976
- “Critical Analysis of the Statistical and Ethical Implications of Various Definitions of ‘Test Bias’”, Hunter & Schmidt 1976
- “Comparative Studies of Psychotherapies: Is It True That "Everyone Has Won and All Must Have Prizes"?”, Luborsky et al 1975
- “Editorial [EJP Editorial on Registered Reports]”, Johnson 1975b
- “Models of Control and Control of Bias”, Johnson 1975
- “Spurious Regressions in Econometrics”, Granger & Newbold 1974
- Social Sciences As Sorcery, Andreski 1973
- “Social Psychology As History”, Gergen 1973
- “Interpreting Regression toward the Mean in Developmental Research”, Furby 1973
- “Pygmalion Reconsidered: A Case Study in Statistical Inference: Reconsideration of the Rosenthal-Jacobson Data on Teacher Expectancy”, Elashoff & Snow 1971
- “Nuisance Variables and the Ex Post Facto Design”, Meehl 1970
- “Pygmalion In The Classroom: Teacher Expectation and Pupil’s Intellectual Development”, Rosenthal & Jacobson 1968
- “Theory-Testing in Psychology and Physics: A Methodological Paradox”, Meehl 1967
- “Control of Spurious Association and the Reliability of the Controlled Variable”, Kahneman 1965
- “Is the Scientific Paper Fraudulent? Yes; It Misrepresents Scientific Thought”, Medawar 1964
- “Responsibility for Raw Data”, Wolins 1962
- “Lysergic Acid Diethylamide (LSD-25): Xv. the Effects Produced By Substitution of a Tap Water Placebo”, Abramson et al 1955
- “Regression Fallacies in the Matched Groups Experiment”, Thorndike 1942
- “Evaluating the Effect of Inadequately Measured Variables in Partial Correlation Analysis”, Stouffer 1936
- “Halo Effect: A Constant Error in Psychological Ratings”, Thorndike 1920
- “The Impersonator: The Fake Data Were Coming From Inside the Lab”
- “Me versus the Entire Field of Fetish Research”, Aella 2026
- “After Century of Removing Appendixes, Docs Find Antibiotics Can Be Enough: In a Five-Year Follow-Up, Nearly Two-Thirds of Patients Never Needed Surgery”
- “The High Cost of Not Doing Experiments”
- “Metacritic Has A (File-Drawer) Problem”
- “Help, Doctor, I’ve Been Exposed to [Proprietary]!”
- “PaperBanana: Automating Academic Illustration for AI Scientists”
- “Assuring an Accurate Research Record [Aidan Toner-Rodgers’s AI Research Fraud]”
- “Alexey Guzey’s Homepage”, Guzey 2026
- “Open Science Challenges, Benefits and Tips in Early Career and Beyond”, Allen & Mehler 2026
- “The PRISMA Statement for Reporting Systematic Reviews and Meta-Analyses of Studies That Evaluate Health Care Interventions: Explanation and Elaboration”, Liberati et al 2026
- “Why Most Published Research Findings Are False”, Ioannidis 2026
- “Most Published Research Findings Are False—But a Little Replication Goes a Long Way”, Moonesinghe et al 2026
- “How to Make More Published Research True”, Ioannidis 2026
- “Does Far Transfer Exist? Negative Evidence From Chess, Music, and Working Memory Training”
- “The Journal of Scientific Integrity [Fraud in Honeybee Communication Research]”
- “WTH Is Cerebrolysin, Actually?”
- “Misconduct in Bioscience Research: a 40-Year Perspective”
- “Evaluating Extraordinary Claims: Mind Over Matter? Or Mind Over Mind?”
- “Replications of Marketing Studies”
- “Publication Bias in the Stereotype Threat Literature”
- “On the Science and Ethics of Ebola Treatments”
- “James Heathers. Scientist. Troublemaker. [Homepage]”, Heathers 2026
- “My IRB Nightmare”
- “Book Review: The 7 Principles For Making Marriage Work”
- “A Catastrophic Failure of Peer Review in Obstetrics and Gynaecology”
- “The Psychology of Parapsychology, or Why Good Researchers Publishing Good Articles in Good Journals Can Still Get It Totally Wrong”
- “Massive Lykos and MAPS Layoffs amid FDA Rejection Reactions; 3 MDMA Papers Retracted; and False Insights”
- “The Secret Of The Soldiers Who Didn’t Shoot”
- “[More on How Peter Miller Manipulates COVID-19 Origin Prediction Market]”
- “More Than 230,000 Japanese Centenarians ‘Missing’”
- “Here’s How Cornell Scientist Brian Wansink Turned Shoddy Data Into Viral Studies About How We Eat”
- “Surely You Can Be Serious”, Mastroianni 2026
- “Computational Analysis of Lifespan Experiment Reproducibility”
- “How Much Should We Trust Developing Country GDP? [Little]”
- “Inventing the Randomized Double-Blind Trial: The Nürnberg Salt Test of 1835”
- “Unregulated Peptides: Does BPC-157 Hold Its Promises?”
- “Does Pentagon Pizza Theory Work? [No]”
- “AI Tools Are Spotting Errors in Research Papers: inside a Growing Movement”
- “Wikipedia Shapes Language in Science Papers: Experiment Traces How Online Encyclopaedia Influences Research Write-Ups”
- “Diederik Stapel’s Audacious Academic Fraud”
- “A Primer on Why Microbiome Research Is Hard”
- “The Academic Culture of Fraud”
- “Pangram: an AI Text Detector That Actually Works”, Pangram 2026
- “How Many American Women Die From Causes Related to Pregnancy or Childbirth? No One Knows.”
- “Do Drugs Make Religious Experience Possible? They Did for James and for Other Philosopher-Mystics of His Day. James’s Experiments With Psychoactive Drugs Raise Difficult Questions about Belief and Its Conditions”
- “Do Life Hacks Work? The Truth Is, We’ll Never Know”
- “In a Blind Test, Audiophiles Couldn’t Tell the Difference between Audio Signals Sent through Copper Wire, a Banana, or Wet Mud—’The Mud Should Sound Perfectly Awful, but It Doesn’t’, Notes the Experiment Creator”
- “Cancer Studies Are Fatally Flawed. Meet the Young Billionaire [John Arnold] Who’s Exposing the Truth About Bad Science”
- NoahHaber
- razibkhan
- xiao_ted
- Sort By Magic
- Wikipedia (14)
- Miscellaneous
- Bibliography
See Also
Gwern
“The Difficulty of Psychometrics”, Gwern 2026
{kind=link}
“PDF Forgeries Are Surprisingly Rare”, Gwern 2022
“Against Caring About Subtle Poisons”, Gwern 2023
“The Existential Risk of Math Errors”, Gwern 2012
“Feynman’s Maze-Running Story”, Gwern 2014
“Open Questions”, Gwern 2018
“How Often Does Correlation=Causality?”, Gwern 2014
“One Man’s Modus Ponens”, Gwern 2012
“Littlewood’s Law and the Global Media”, Gwern 2018
“Does Mouse Utopia Exist?”, Gwern 2019
“Leprechaun Hunting & Citogenesis”, Gwern 2014
“A Replication and Methodological Critique of the Study ‘Evaluating Drug Trafficking on the Tor Network’”, Munksgaard et al 2016
“Hydrocephalus and Intelligence: The Hollow Men”, Gwern 2015
“Why Correlation Usually ≠ Causation”, Gwern 2014
“The Replication Crisis: Flaws in Mainstream Science”, Gwern 2010
“How Should We Critique Research?”, Gwern 2019
“Dual n-Back Meta-Analysis”, Gwern 2012
“Lunar Circadian Rhythms”, Gwern 2013
Links
“‘Nutrition Science’s Most Preposterous Result’ Is False”, Cremieux 2026
“[How Peter Miller Manipulates the Manifold Prediction Market on COVID-19 Origins]”, Draaglom 2026
[How Peter Miller manipulates the Manifold prediction market on COVID-19 origins]
“PaperBanana: Automating Academic Illustration for AI Scientists”, Zhu et al 2026
PaperBanana: Automating Academic Illustration for AI Scientists
“Generative AI and Wikipedia Editing: What We Learned in 2025”, Edu 2026
Generative AI and Wikipedia editing: What we learned in 2025
“Did a Celebrated Researcher Obscure a Baby’s Poisoning? After a Newborn Died of Opioid Poisoning, a New Branch of Pediatrics Came into Being. But the Evidence Doesn’t Add Up”, Taub 2026
“Inventing the ‘Methods’ Section: What the Evolution of Scientific Methods Says about Their Future”, Hunt 2026
Inventing the ‘Methods’ Section: What the evolution of scientific methods says about their future
“Oliver Sacks Put Himself Into His Case Studies. What Was the Cost? The Scientist Was Famous for Linking Healing With Storytelling. Sometimes That Meant Reshaping Patients’ Reality”, Aviv 2025
“Debunking When Prophecy Fails”, Kelly 2025
“Why You Shouldn’t Trust Data Collected on MTurk”, Kay 2025
“Harvard Sues Ex-HBS Professor Gino for Defamation, Accusing Her of Falsifying Evidence”
Harvard Sues Ex-HBS Professor Gino for Defamation, Accusing Her of Falsifying Evidence
“Fraudulent Publishing in the Mathematical Sciences”, Agricola et al 2025
“Pitfalls in Evaluating Language Model Forecasters”, Paleka et al 2025
“A Sting Inside a Papermill”
“AI, Materials, and Fraud, Oh My! The Red Flags We Should Have Seen Earlier for a Too-Good-To-Be-True Paper on AI Tool Adoption at a Materials Research Firm”, Shindel 2025
“That Survivorship Bias Plane: The Exact Backstory to That Picture of an Airplane With Red Dots on top of It”, Liu 2025
“When ChatGPT Broke an Entire Field: An Oral History”, Pavlus 2025
“Can We Trust Social Science Yet?”, Briggs 2025
“The World Happiness Report Is a Sham: A Case Study in Elite Misinformation”, Mounk 2025
The World Happiness Report Is a Sham: A case study in elite misinformation
“Super Nintendo Hardware Is Running Faster As It Ages”, Maiberg 2025
“An Introduction To Forensic Metascience”, Heathers 2025
“This Tiny Fish’s Mistaken Identity Halted a Dam’s Construction”
This Tiny Fish’s Mistaken Identity Halted a Dam’s Construction
“The Rise of the Science Sleuths”
“The Global Pattern of Centenarians Highlights Deep Problems in Demography”, Newman 2024
The global pattern of centenarians highlights deep problems in demography
“Political Language In Economics”, Zubin et al 2024
“The Composer Has No Clothes”, Brown 2024
“Revisiting the Relationship between Economic Freedom and Development to Account for Statistical Deception by Autocratic Regimes”, Alvarez et al 2024
“Questionable Practices in Machine Learning”, Leech et al 2024
“Delving into ChatGPT Usage in Academic Writing through Excess Vocabulary”, Kobak et al 2024
Delving into ChatGPT usage in academic writing through excess vocabulary
“For Chinese Students, the New Tactic Against AI Checks: More AI”, Qitong 2024
For Chinese Students, the New Tactic Against AI Checks: More AI
“Paper Tiger? Chinese Science and Home Bias in Citations”, Qiu et al 2024
“Research Misconduct in China: towards an Institutional Analysis”, Zhang & Wang 2024
Research misconduct in China: towards an institutional analysis
“Epigenetic Age Oscillates during the Day”, Koncevičius et al 2024
“Is Economics Self-Correcting? Replications in the American Economic Review”, Ankel-Peters et al 2024
Is economics self-correcting? Replications in the American Economic Review
“Maternal Mortality in the United States: Are the High and Rising Rates due to Changes in Obstetrical Factors, Maternal Medical Conditions, or Maternal Mortality Surveillance?”, Joseph et al 2024
“Google Scholar Is Manipulable”, Ibrahim et al 2024
“A Multilab Replication of the Induced-Compliance Paradigm of Cognitive Dissonance”, Vaidis et al 2024
A Multilab Replication of the Induced-Compliance Paradigm of Cognitive Dissonance
“Psychology Remains Marginally Valid”, Oktar 2024
Psychology remains marginally valid :
View PDF:
“Illusory Generalizability of Clinical Prediction Models”, Chekroud et al 2024
“‘An Existential Crisis’ for Science”, Research 2024
“Heresy, Witchcraft, Jean Gerson, Scepticism and the Use of Placebo Controls”, Kirakosian et al 2023
Heresy, witchcraft, Jean Gerson, scepticism and the use of placebo controls
“Prosocial Motives Underlie Scientific Censorship by Scientists: A Perspective and Research Agenda”, Clark et al 2023
Prosocial motives underlie scientific censorship by scientists: A perspective and research agenda
“Published Benefits of Ivermectin Use in Itajaí, Brazil for COVID-19 Infection, Hospitalization, and Mortality Are Entirely Explained by Statistical Artefacts”, Mills et al 2023
“A Quantitative Study of Inappropriate Image Duplication in the Journal Toxicology Reports”, David 2023
A Quantitative Study of Inappropriate Image Duplication in the Journal Toxicology Reports
“Indoctrination in Introduction to Psychology”, Bartels 2023
“Metascience Since 2012: A Personal History”, Buck 2023
“The Garden of Forking Paths; An Evaluation of Joseph’s ‘A Reevaluation of the 1990 Minnesota Study of Twins Reared Apart IQ Study’”, Bouchard 2023
“Replicability & Generalisability: A Guide to CEA Discounts”, Bettle 2023
“Measuring Backsliding With Observables: Observable-To-Subjective Score Mapping (OSM)”, Weitzel et al 2023
Measuring Backsliding with Observables: Observable-to-Subjective Score Mapping (OSM)
“Empirical Design in Reinforcement Learning”, Patterson et al 2023
“Final Report of Investigation Committee Concerning Allegations against Professor Francesca Gino—Case RI21-001”, Amabile et al 2023
View PDF (242MB):
“Homeopathy Can Offer Empirical Insights on Treatment Effects in a Null Field”, Sigurdson et al 2023
Homeopathy can offer empirical insights on treatment effects in a null field
“Positive Citation Bias and Over-Interpreted Results Lead to Misinformation on Common Mycorrhizal Networks in Forests”, Karst et al 2023
“Raising the Value of Research Studies in Psychological Science by Increasing the Credibility of Research Reports: the Transparent Psi Project”, Kekecs et al 2023
“A Discipline-Wide Investigation of the Replicability of Psychology Papers over the past Two Decades”, Youyou et al 2023
A discipline-wide investigation of the replicability of Psychology papers over the past two decades
“How Do Psychology Researchers Interpret the Results of Multiple Replication Studies?”, Akker et al 2023
How do psychology researchers interpret the results of multiple replication studies?
“Comparing Analysis Blinding With Preregistration in the Many-Analysts Religion Project”, Sarafoglou et al 2023
Comparing Analysis Blinding With Preregistration in the Many-Analysts Religion Project
“#ReceptioGate and the (Absolute) State of Academia: The Numbers Game Has Incentivized Bad Behavior”, Gauthier 2023
#ReceptioGate and the (absolute) state of academia: The numbers game has incentivized bad behavior
“A Spotlight on Bias in the Growth Mindset Intervention Literature: A Reply to Commentaries That Contextualize the Discussion (Oyserman 2023; Yan & Schuetze 2023) and Illustrate the Conclusion (Tipton Et Al 2023)”, Macnamara & Burgoyne 2023
“Positive Single-Center Randomized Trials and Subsequent Multicenter Randomized Trials in Critically Ill Patients: a Systematic Review”, Kotani et al 2023
“Medieval Manuscripts Provenance: The RECEPTIO-Rossi Affair IV: My ‘Accusations’”
Medieval Manuscripts Provenance: The RECEPTIO-Rossi Affair IV: My ‘Accusations’
“Many Researchers Were Not Compliant With Their Published Data Sharing Statement: a Mixed-Methods Study”, Gabelica et al 2022
“The Future Failed: No Evidence for Precognition in a Large Scale Replication Attempt of Bem 2011”, Muhmenthaler et al 2022
The Future Failed: No Evidence for Precognition in a Large Scale Replication Attempt of Bem 2011
“Are Most Published Criminological Research Findings Wrong? Taking Stock of Criminological Research Using a Bayesian Simulation Approach”, Niemeyer et al 2022
“No Evidence That Mandatory Open Data Policies Increase Error Correction”, Berberi & Roche 2022
No evidence that mandatory open data policies increase error correction
“Inconvenient Truths and the Usefulness of Identifying Unknown Unknowns”, Gould & Georgiou 2022
Inconvenient truths and the usefulness of identifying unknown unknowns
“Evaluating the Replicability of Social Priming Studies”, Giolla et al 2022
“Effects of Randomized Treatment With Icosapent Ethyl and a Mineral Oil Comparator on Interleukin-1β, Interleukin-6, C-Reactive Protein, Oxidized Low-Density Lipoprotein Cholesterol, Homocysteine, Lipoprotein(A), and Lipoprotein-Associated Phospholipase A2: A REDUCE-IT Biomarker Substudy”, Ridker et al 2022
“Is Psychological Science Self-Correcting? Citations Before and After Successful and Failed Replications”, Hippel 2022
“Olfactory Exposure to Late-Pregnant and Lactating Mice Causes Stress-Induced Analgesia in Male Mice”, Rosen et al 2022
Olfactory exposure to late-pregnant and lactating mice causes stress-induced analgesia in male mice
“The Impact of Digital Media on Children’s Intelligence While Controlling for Genetic Differences in Cognition and Socioeconomic Background”, Sauce et al 2022
“Do Multiple Experimenters Improve the Reproducibility of Animal Studies?”, Kortzfleisch et al 2022
Do multiple experimenters improve the reproducibility of animal studies?
“Theoretical False Positive Psychology”, Wilson et al 2022
“Does Democracy Matter?”, Gerring et al 2022
“‘I Think I Discovered a Military Base in the Middle of the Ocean’—Null Island, the Most Real of Fictional Places”, Juhasz & Mooney 2022
“The Dunning-Kruger Effect Is Autocorrelation”
“Clinical Prediction Models in Psychiatry: a Systematic Review of Two Decades of Progress and Challenges”, Meehan et al 2022
“Reproducible Brain-Wide Association Studies Require Thousands of Individuals”, Marek et al 2022
Reproducible brain-wide association studies require thousands of individuals
“A 680,000-Person Megastudy of Nudges to Encourage Vaccination in Pharmacies”, Milkman et al 2022
A 680,000-person megastudy of nudges to encourage vaccination in pharmacies
“The Backfire Effect After Correcting Misinformation Is Strongly Associated With Reliability”, Swire-Thompson et al 2022
The backfire effect after correcting misinformation is strongly associated with reliability
“Bullet Babies: The Repeating Nature of the Medical Hoax”, Herr 2022
“Fooled by Beautiful Data: Visualization Esthetics Bias Trust in Science, News, and Social Media”, Lin & Thornton 2022
Fooled by beautiful data: Visualization esthetics bias trust in science, news, and social media
“A Systematic Review and Meta-Analysis of the Success of Blinding in Antidepressant RCTs”, Scott et al 2022
A systematic review and meta-analysis of the success of blinding in antidepressant RCTs
“Replication Crisis and Placebo Studies: Rebooting the Bioethical Debate”, Blease et al 2022
Replication crisis and placebo studies: rebooting the bioethical debate
“Reproducibility in the Social Sciences”, Moody et al 2022
“The Efficacy of Psychotherapies and Pharmacotherapies for Mental Disorders in Adults: an Umbrella Review and Meta-Analytic Evaluation of Recent Meta-Analyses”, Leichsenring et al 2022
“How Malleable Are Cognitive Abilities? A Critical Perspective on Popular Brief Interventions”, Moreau 2021
How malleable are cognitive abilities? A critical perspective on popular brief interventions
“More Treatment but No Less Depression: The Treatment-Prevalence Paradox”, Ormel et al 2021
More treatment but no less depression: The Treatment-Prevalence Paradox
“Megastudies Improve the Impact of Applied Behavioral Science”, Milkman et al 2021
Megastudies improve the impact of applied behavioral science
“No Strong Evidence of Stereotype Threat in Females: A Reassessment of the Meta-Analysis”, Warne 2021
No Strong Evidence of Stereotype Threat in Females: A Reassessment of the Meta-Analysis
“Metformin Treatment of Diverse Caenorhabditis Species Reveals the Importance of Genetic Background in Longevity and Healthspan Extension Outcomes”, Onken et al 2021
“The Psychophysiology of Political Ideology: Replications, Reanalyses, and Recommendations”, Osmundsen et al 2021
The Psychophysiology of Political Ideology: Replications, Reanalyses, and Recommendations
“Predict Science to Improve Science”, DellaVigna et al 2021
“The Predicament of Establishing Persistence: Slavery and Human Capital in Africa”, Malik & Bouaroudj 2021
The Predicament of Establishing Persistence: Slavery and Human Capital in Africa
“The Implicit Association Test in Introductory Psychology Textbooks: Blind Spot for Controversy”, Bartels & Schoenrade 2021
The Implicit Association Test in Introductory Psychology Textbooks: Blind Spot for Controversy
“A Pre-Registered, Multi-Lab Non-Replication of the Action-Sentence Compatibility Effect (ACE)”, Morey et al 2021
A pre-registered, multi-lab non-replication of the action-sentence compatibility effect (ACE)
“Are Conservatives More Rigid Than Liberals? A Meta-Analytic Test of the Rigidity-Of-The-Right Hypothesis”, Costello et al 2021
“Empirical Audit and Review and an Assessment of Evidentiary Value in Research on the Psychological Consequences of Scarcity”, O’Donnell et al 2021
“Effect Sizes Reported in Highly Cited Emotion Research Compared With Larger Studies and Meta-Analyses Addressing the Same Questions”, Cristea et al 2021
“The Role of Human Fallibility in Psychological Research: A Survey of Mistakes in Data Management”, Kovacs et al 2021
The Role of Human Fallibility in Psychological Research: A Survey of Mistakes in Data Management
“On the Reliability of Published Findings Using the Regression Discontinuity Design in Political Science”, Stommes et al 2021
“Is Coffee the Cause or the Cure? Conflicting Nutrition Messages in 2 Decades of Online New York Times’ Nutrition News Coverage”, Ihekweazu 2021
“Causal and Associational Linking Language From Observational Research and Health Evaluation Literature in Practice: A Systematic Language Evaluation”, Haber et al 2021
“TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands”, Shapiro et al 2021
TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands
“Systematic Bias in the Progress of Research”, Rubin & Rubin 2021
“Common Elective Orthopaedic Procedures and Their Clinical Effectiveness: Umbrella Review of Level 1 Evidence”, Blom et al 2021
“Small Effects: The Indispensable Foundation for a Cumulative Psychological Science”, Götz et al 2021
Small Effects: The Indispensable Foundation for a Cumulative Psychological Science
“The Revolution Will Be Hard to Evaluate: How Co-Occurring Policy Changes Affect Research on the Health Effects of Social Policies”, Matthay et al 2021
“The Piranha Problem: Large Effects Swimming in a Small Pond”, Tosh et al 2021
“Challenging the Link Between Early Childhood Television Exposure and Later Attention Problems: A Multiverse Approach”, McBee et al 2021
“The Influence of Hidden Researcher Decisions in Applied Microeconomics”, Huntington-Klein et al 2021
The influence of hidden researcher decisions in applied microeconomics
“Man-Bites-Dog Contagion: Disproportionate Diffusion of Information about Rare Categories of Events”, Jang & Shore 2021
Man-Bites-Dog Contagion: Disproportionate Diffusion of Information about Rare Categories of Events
“Therapygenetic Effects of 5-HTTLPR on Cognitive-Behavioral Therapy in Anxiety Disorders: A Meta-Analysis”, Schiele et al 2021
“Maximal Positive Controls: A Method for Estimating the Largest Plausible Effect Size”, Hilgard 2021
Maximal positive controls: A method for estimating the largest plausible effect size
“Putting the Self in Self-Correction: Findings From the Loss-Of-Confidence Project”, Rohrer et al 2021
Putting the Self in Self-Correction: Findings From the Loss-of-Confidence Project
“Artificial Intelligence in Drug Discovery: What Is Realistic, What Are Illusions? Part 1: Ways to Make an Impact, and Why We Are Not There Yet: Quality Is More Important Than Speed and Cost in Drug Discovery”, Bender & Cortés-Ciriano 2021
“When the Numbers Do Not Add Up: The Practical Limits of Stochastologicals for Soft Psychology”, Broers 2021
When the Numbers Do Not Add Up: The Practical Limits of Stochastologicals for Soft Psychology
“Honest Signaling in Academic Publishing”, Tiokhin et al 2021
“So Useful As a Good Theory? The Practicality Crisis in (Social) Psychological Theory”, Berkman & Wilson 2021
So Useful as a Good Theory? The Practicality Crisis in (Social) Psychological Theory
“Comment by Peter Norvig on "Being Good at Programming Competitions Correlates Negatively With Being Good on the Job"”, Norvig 2020
“Has the Effect of the American Flag on Political Attitudes Declined Over Time? A Case Study of the Historical Context of American Flag Priming”, Carter et al 2020
“The Statistical Properties of RCTs and a Proposal for Shrinkage”, Zwet et al 2020
The statistical properties of RCTs and a proposal for shrinkage
“Many Labs 5: Testing Pre-Data-Collection Peer Review As an Intervention to Increase Replicability”, Ebersole et al 2020
Many Labs 5: Testing Pre-Data-Collection Peer Review as an Intervention to Increase Replicability
“The Reproducibility of Statistical Results in Psychological Research: An Investigation Using Unpublished Raw Data”, Artner et al 2020
“Psychological Measurement and the Replication Crisis: Four Sacred Cows”, Lilienfeld & Strother 2020
Psychological measurement and the replication crisis: Four sacred cows
“Cite Unseen: Theory and Evidence on the Effect of Open Access on Cites to Academic Articles Across the Quality Spectrum”, McCabe & Snyder 2020
“False Individual Patient Data and Zombie Randomized Controlled Trials Submitted to Anesthesia”, Carlisle 2020
False individual patient data and zombie randomized controlled trials submitted to Anesthesia
“Heterogeneity in Direct Replications in Psychology and Its Association With Effect Size”, Olsson-Collentine et al 2020
Heterogeneity in direct replications in psychology and its association with effect size
“A Replication Crisis in Methodological Research?”, Boulesteix et al 2020
“The Small Effects of Political Advertising Are Small regardless of Context, Message, Sender, or Receiver: Evidence from 59 Real-Time Randomized Experiments”, Coppock et al 2020
“Towards Reproducible Brain-Wide Association Studies”, Marek et al 2020
“Laypeople Can Predict Which Social-Science Studies Will Be Replicated Successfully”, Hoogeveen et al 2020
Laypeople Can Predict Which Social-Science Studies Will Be Replicated Successfully
“Specification Curve Analysis”, Simonsohn et al 2020
“Can Short Psychological Interventions Affect Educational Performance? Revisiting the Effect of Self-Affirmation Interventions”, Serra-Garcia et al 2020
“The Multiverse of Methods: Extending the Multiverse Analysis to Address Data-Collection Decisions”, Harder 2020
The Multiverse of Methods: Extending the Multiverse Analysis to Address Data-Collection Decisions
“How Do Scientific Views Change? Notes From an Extended Adversarial Collaboration”, Cowan et al 2020
How Do Scientific Views Change? Notes From an Extended Adversarial Collaboration
“What Is the Test-Retest Reliability of Common Task-Functional MRI Measures? New Empirical Evidence and a Meta-Analysis”, Elliott et al 2020
“Health Recommendations and Selection in Health Behaviors”, Oster 2020
“Variability in the Analysis of a Single Neuroimaging Dataset by Many Teams”, Botvinik-Nezer et al 2020
Variability in the analysis of a single neuroimaging dataset by many teams
“Supercentenarian and Remarkable Age Records Exhibit Patterns Indicative of Clerical Errors and Pension Fraud”, Newman 2020
“Bilingualism Affords No General Cognitive Advantages: A Population Study of Executive Function in 11,000 People”, Nichols et al 2020
“Statistics As Squid Ink: How Prominent Researchers Can Get Away With Misrepresenting Data”, Gelman & Guzey 2020
Statistics as Squid Ink: How Prominent Researchers Can Get Away with Misrepresenting Data :
View PDF:
“Ideological Diversity, Hostility, and Discrimination in Philosophy”, Peters et al 2020
Ideological diversity, hostility, and discrimination in philosophy
“On Attenuated Interactions, Measurement Error, and Statistical Power: Guidelines for Social and Personality Psychologists”, Blake & Gangestad 2020
“A Controlled Trial for Reproducibility: For Three Years, Part of DARPA Has Funded Two Teams for Each Project: One for Research and One for Reproducibility. The Investment Is Paying Off.”, Raphael et al 2020
“What Do Editors Maximize? Evidence from 4 Economics Journals”, Card & DellaVigna 2020
What Do Editors Maximize? Evidence from 4 Economics Journals
“Foreign Language Learning in Older Age Does Not Improve Memory or Intelligence: Evidence from a Randomized Controlled Study”, Berggren et al 2020
“The Stewart Retractions: A Quantitative and Qualitative Analysis”, Pickett 2020
The Stewart Retractions: A Quantitative and Qualitative Analysis
“Quantifying Independently Reproducible Machine Learning”, Raff 2020
“Compliance With Legal Requirement to Report Clinical Trial Results on ClinicalTrials.gov: a Cohort Study”, DeVito et al 2020
“Implications of Ideological Bias in Social Psychology on Clinical Practice”, Silander et al 2020
Implications of ideological bias in social psychology on clinical practice
“Cognitive and Academic Benefits of Music Training With Children: A Multilevel Meta-Analysis”, Sala & Gobet 2020
Cognitive and academic benefits of music training with children: A multilevel meta-analysis
“What Intellectual Progress Did I Make In The 2010s?”, Alexander 2020
“Blinding to Remove Biases in Science and Society”, MacCoun 2020
“Why the Increasing Use of Complex Causal Models Is a Problem: On the Danger Sophisticated Theoretical Narratives Pose to Truth”, Saylors & Trafimow 2020
“Estimating the Deep Replicability of Scientific Findings Using Human and Artificial Intelligence”, Yang et al 2020
Estimating the deep replicability of scientific findings using human and artificial intelligence
“Lack of Evidence for Associative Learning in Pea Plants”, Markel 2020
“Self-Reported Health without Clinically Measurable Benefits among Adult Users of Multivitamin and Multimineral Supplements: a Cross-Sectional Study”, Paranjpe et al 2020
“Do Police Killings of Unarmed Persons Really Have Spillover Effects? Reanalyzing Bor Et Al 2018”, Nix & Lozada 2019
Do police killings of unarmed persons really have spillover effects? Reanalyzing Bor et al 2018
“Catching Cheating Students”, Lin & Levitt 2019
“Why We Sleep Data Manipulation: A Smoking Gun?”, Gelman 2019
“Whassup With Why We Sleep?”, Gelman 2019
“Comparing Meta-Analyses and Preregistered Multiple-Laboratory Replication Projects”, Kvarven et al 2019
Comparing meta-analyses and preregistered multiple-laboratory replication projects
“Why We Sleep Update: Some Thoughts While We Wait for Matthew Walker to Respond to Alexey Guzey’s Criticisms”, Gelman 2019
“Flexible yet Fair: Blinding Analyses in Experimental Psychology”, Dutilh et al 2019
Flexible yet fair: blinding analyses in experimental psychology
“Many Labs 2: Investigating Variation in Replicability Across Sample and Setting”, Klein et al 2019
Many Labs 2: Investigating Variation in Replicability Across Sample and Setting
“Is Matthew Walker’s Why We Sleep Riddled With Scientific and Factual Errors?”, Gelman 2019
Is Matthew Walker’s Why We Sleep Riddled with Scientific and Factual Errors?
“[Comment on Guzey Post]”, Kinkajoe 2019
“Matthew Walker’s Why We Sleep Is Riddled With Scientific and Factual Errors”, Guzey 2019
Matthew Walker’s Why We Sleep Is Riddled with Scientific and Factual Errors
“Effect of Lower Versus Higher Red Meat Intake on Cardiometabolic and Cancer Outcomes: A Systematic Review of Randomized Trials”, Zeraatkar et al 2019
“Anthropology’s Science Wars: Insights from a New Survey”, Horowitz et al 2019
“A National Experiment Reveals Where a Growth Mindset Improves Achievement”, Yeager et al 2019
A national experiment reveals where a growth mindset improves achievement
“Debunking the Stanford Prison Experiment”, Texier 2019
“The Architectural Bias in Current Biblical Archaeology”, Ben-Yosef 2019
“The Maddening Saga of How an Alzheimer’s ‘Cabal’ Thwarted Progress toward a Cure for Decades”, Begley 2019
The maddening saga of how an Alzheimer’s ‘cabal’ thwarted progress toward a cure for decades
“Exploring Research-Methods Blogs in Psychology: Who Posts What About Whom, and With What Effect?”, Nicolas et al 2019
Exploring Research-Methods Blogs in Psychology: Who Posts What About Whom, and With What Effect?
“Generalizable and Robust TV Advertising Effects”, Shapiro et al 2019
“Meta-Research: A Comprehensive Review of Randomized Clinical Trials in Three Medical Journals Reveals 396 Medical Reversals”, Herrera-Perez et al 2019
“6 Lessons for a Cogent Science of Implicit Bias and Its Criticism”, Gawronski 2019
6 Lessons for a Cogent Science of Implicit Bias and Its Criticism
“The Hype Cycle of Working Memory Training”, Redick 2019
“Statistical Methods for Replicability Assessment”, Hung & Fithian 2019
“Rigorous Large-Scale Educational RCTs Are Often Uninformative: Should We Be Concerned?”, Lortie-Forgues & Inglis 2019
Rigorous Large-Scale Educational RCTs Are Often Uninformative: Should We Be Concerned?
“What Can We Learn from Many Labs Replications? 3. Can Replication Studies Detect Fraud?”, Stroebe 2019
What Can We Learn from Many Labs Replications? 3. Can replication studies detect fraud?
“Citogenesis: the Serious Circular Reporting Problem Wikipedians Are Fighting. Circular Reporting Is a Real Problem on Platforms like Wikipedia—And It’s Harder to Solve Than It Looks”, Harrison 2019
“Inside the Secret Sting Operations to Expose Celebrity Psychics: Are Some Celebrity Mediums Fooling Their Audience Members by Reading Social Media Pages in Advance? A Group of Online Vigilantes Is out to Prove It”, Hitt 2019
“Orchestrating False Beliefs about Gender Discrimination”, Pallesen 2019
“On the Estimation of Treatment Effects With Endogenous Misreporting”, Nguimkeu et al 2019
On the estimation of treatment effects with endogenous misreporting
“The Blank Pages of History”, Chlopodo 2019
“Large Teams Develop and Small Teams Disrupt Science and Technology”, Wu et al 2019
Large teams develop and small teams disrupt science and technology
“The Advantages of Bilingualism Debate”, Antoniou 2019
“How Replicable Are Links Between Personality Traits and Consequential Life Outcomes? The Life Outcomes of Personality Replication Project”, Soto 2019
“A Comprehensive Meta-Analysis of Money Priming”, Lodder et al 2019
“No Support for Historical Candidate Gene or Candidate Gene-By-Interaction Hypotheses for Major Depression Across Multiple Large Samples”, Border et al 2019
“Why Is Nonadherence to Cancer Screening Associated With Increased Mortality?”, Association 2018
Why Is Nonadherence to Cancer Screening Associated With Increased Mortality? :
View PDF:
“Association of Non-Adherence to Cancer Screening Examinations With Mortality From Unrelated Causes: A Secondary Analysis of the PLCO Cancer Screening Trial”, Pierre-Victor & Pinsky 2018
“Mesmerising Science: The Franklin Commission and the Modern Clinical Trial”, Laukaityte 2018
Mesmerising Science: The Franklin Commission and the Modern Clinical Trial
“Generalizability of Heterogeneous Treatment Effect Estimates across Samples”, Coppock et al 2018
Generalizability of heterogeneous treatment effect estimates across samples
“Predicting Replication Outcomes in the Many Labs 2 Study”, Forsell et al 2018
“Deterministic Implementations for Reproducibility in Deep Reinforcement Learning”, Nagarajan et al 2018
Deterministic Implementations for Reproducibility in Deep Reinforcement Learning
“Effects of the Tennessee Prekindergarten Program on Children’s Achievement and Behavior through Third Grade”, Lipsey et al 2018
“Evaluating the Replicability of Social Science Experiments in Nature and Science 2010–2015”, Camerer et al 2018
Evaluating the replicability of social science experiments in Nature and Science 2010–2015
“Statistical Paradises and Paradoxes in Big Data (1): Law of Large Populations, Big Data Paradox, and the 2016 US Presidential Election”, Meng 2018
“Disentangling Bias and Variance in Election Polls”, Shirani-Mehr et al 2018
“Propagation of Mistakes in Papers”, Neumann 2018
“Causal Language and Strength of Inference in Academic and Media Articles Shared in Social Media (CLAIMS): A Systematic Review”, Haber et al 2018
“Acceptable Losses: the Debatable Origins of Loss Aversion”, Yechiam 2018
“What Science Is like in North Korea: Isolated from the Rest of the World, North Korean Researchers Struggle to Balance Rigorous Scientific Work With the Demands of a Dictator”, Fiscutean 2018
“Homogenous: The Political Affiliations of Elite Liberal Arts College Faculty”, Langbert 2018
Homogenous: The Political Affiliations of Elite Liberal Arts College Faculty :
“"Are You Gonna Publish That?" Peer-Reviewed Publication Outcomes of Doctoral Dissertations in Psychology”, Evans et al 2018
“Knowing What We Are Getting: Evaluating Scientific Research on the International Space Station”, Bianco & Schmidt 2017
Knowing What We Are Getting: Evaluating Scientific Research on the International Space Station
“The Prehistory of Biology Preprints: A Forgotten Experiment from the 1960s”, Cobb 2017
The prehistory of biology preprints: A forgotten experiment from the 1960s
“Percutaneous Coronary Intervention in Stable Angina (ORBITA): a Double-Blind, Randomized Controlled Trial”, Al-Lamee et al 2017
“The Power of Bias in Economics Research”, Ioannidis et al 2017
“Deep Reinforcement Learning That Matters”, Henderson et al 2017
“Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents”, Machado et al 2017
“Does Diversity Pay? A Replication of Herring 2009 [No]”, Stojmenovska et al 2017
“Impossibly Hungry Judges”, Lakens 2017
“How Gullible Are We? A Review of the Evidence from Psychology and Social Science”, Mercier 2017
How Gullible are We? A Review of the Evidence from Psychology and Social Science
“Avoiding Erroneous Citations in Ecological Research: Read Before You Apply”, Šigut et al 2017
Avoiding erroneous citations in ecological research: read before you apply
“Coverage of Rosenhan’s ‘On Being Sane in Insane Places’ in Abnormal Psychology Textbooks”, Bartels & Peters 2017
Coverage of Rosenhan’s ‘On Being Sane in Insane Places’ in Abnormal Psychology Textbooks
“Roosevelt Predicted to Win: Revisiting the 1936 Literary Digest Poll”, Lohr & Brick 2017
Roosevelt Predicted to Win: Revisiting the 1936 Literary Digest Poll
“Laboratory Environmental Factors and Pain Behavior: the Relevance of Unknown Unknowns to Reproducibility and Translation”, Mogil 2017
“Empirical Assessment of Published Effect Sizes and Power in the Recent Cognitive Neuroscience and Psychology Literature”, Szucs & Ioannidis 2017
“Blind Analysis As a Correction for Confirmatory Bias in Physics and in Psychology”, MacCoun & Perlmutter 2017
Blind Analysis as a Correction for Confirmatory Bias in Physics and in Psychology
“When the Music’s Over. Does Music Skill Transfer to Children’s and Young Adolescents’ Cognitive and Academic Skills? A Meta-Analysis”, Sala & Gobet 2017
“Meta-Assessment of Bias in Science”
“Does Teaching Children How to Play Cognitively Demanding Games Improve Their Educational Attainment? Evidence from a Randomized Controlled Trial of Chess Instruction in England”, jerrim 2017
“Potential Contribution of Lifestyle and Socioeconomic Factors to Healthy User Bias in Anti-Hypertensives and Lipid-Lowering Drugs”, Kinjo et al 2017
“What Does Any of This Have To Do With Physics? Einstein and Feynman Ushered Me into Grad School, Reality Ushered Me Out”, Henderson 2016
“Rational Judges, Not Extraneous Factors In Decisions”, Stafford 2016
“Responses to Critiques on Machine Learning of Criminality Perceptions (Addendum of ArXiv:1611.04135)”, Wu & Zhang 2016
Responses to Critiques on Machine Learning of Criminality Perceptions (Addendum of arXiv:1611.04135)
“How Multiple Imputation Makes a Difference”, Lall 2016
“Statistically Controlling for Confounding Constructs Is Harder Than You Think”, Westfall & Yarkoni 2016
Statistically Controlling for Confounding Constructs Is Harder than You Think
“Reading ‘The Baby Factory’ in Context”, Srivastava 2016
Reading ‘The Baby Factory’ in context
View External Link:
https://thehardestscience.com/2016/02/12/reading-the-baby-factory-in-context/
“When Quality Beats Quantity: Decision Theory, Drug Discovery, and the Reproducibility Crisis”, Scannell & Bosley 2016
When Quality Beats Quantity: Decision Theory, Drug Discovery, and the Reproducibility Crisis
“The Baby Factory: Difficult Research Objects, Disciplinary Standards, and the Production of Statistical-Significance”, Peterson 2016
“Looking Across and Looking Beyond the Knowledge Frontier: Intellectual Distance, Novelty, and Resource Allocation in Science”, Boudreau et al 2016
“The Missing 11th of the Month”, Hagen 2015
“Estimating the Reproducibility of Psychological Science”, Collaboration 2015
“The Economics of Reproducibility in Preclinical Research”, Freedman et al 2015
“Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time”, Kaplan & Irvin 2015
Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time
“Small Telescopes: Detectability and the Evaluation of Replication Results”, Simonsohn 2015
Small Telescopes: Detectability and the Evaluation of Replication Results
“Scholarly Context Not Found: One in Five Articles Suffers from Reference Rot”, Klein et al 2014
Scholarly Context Not Found: One in Five Articles Suffers from Reference Rot
“The Corrupted Epidemiological Evidence Base of Psychiatry: A Key Driver of Over-Diagnosis”, Raven 2014
The Corrupted Epidemiological Evidence Base of Psychiatry: A Key Driver of Over-diagnosis :
View PDF:
“Association Between Analytic Strategy and Estimates of Treatment Outcomes in Meta-Analyses”, Dechartres et al 2014
Association Between Analytic Strategy and Estimates of Treatment Outcomes in Meta-analyses
“Practice Does Not Make Perfect: No Causal Effect of Music Practice on Music Ability”, Mosing et al 2014
Practice Does Not Make Perfect: No Causal Effect of Music Practice on Music Ability
“Deliberate Practice: Is That All It Takes to Become an Expert?”, Hambrick et al 2014
Deliberate practice: Is that all it takes to become an expert?
“Olfactory Exposure to Males, including Men, Causes Stress and Related Analgesia in Rodents”, Sorge et al 2014
Olfactory exposure to males, including men, causes stress and related analgesia in rodents
“The Control Group Is Out Of Control”, Alexander 2014
“Trap of Trends to Statistical-Significance: Likelihood of Near-Statistically-Significant p-Values Becoming More Statistically-Significant With Extra Data”, Wood et al 2014
“The Chrysalis Effect: How Ugly Initial Results Metamorphosize Into Beautiful Articles”, O’Boyle et al 2014
The Chrysalis Effect: How Ugly Initial Results Metamorphosize Into Beautiful Articles
“Identifying The Effect Of Open Access On Citations Using A Panel Of Science Journals”, McCabe & Snyder 2014
Identifying The Effect Of Open Access On Citations Using A Panel Of Science Journals
“p-Curve: A Key to the File-Drawer”, Simonsohn et al 2014
“Open Access to Data: An Ideal Professed but Not Practised”, Andreoli-Versbach & Mueller-Langer 2014
“Use of Placebo Controls in the Evaluation of Surgery: Systematic Review”, Wartolowska 2014
Use of placebo controls in the evaluation of surgery: systematic review
“Too Much Success for Recent Groundbreaking Epigenetic Experiments”, Francis 2014
Too much success for recent groundbreaking epigenetic experiments
“Predictors and Moderators of Agreement between Clinical and Research Diagnoses for Children and Adolescents”, Jensen-Doss et al 2014
“The Availability of Research Data Declines Rapidly With Article Age”, Vines et al 2013
The availability of research data declines rapidly with article age
“The Pervasive Problem With Placebos in Psychology: Why Active Control Groups Are Not Sufficient to Rule Out Placebo Effects”, Boot et al 2013
“Researchers Finally Replicated Reinhart-Rogoff [GDP vs National Debt], and There Are Serious Problems”, Varghese 2013
“Lizardman’s Constant Is 4%”, Alexander 2013
“Investing in Preschool Programs”, Duncan & Magnuson 2013
“A Survey on Data Reproducibility in Cancer Research Provides Insights into Our Limited Ability to Translate Findings from the Laboratory to the Clinic”, Mobley et al 2013
“Star Wars: The Empirics Strike Back”, Brodeur et al 2013
“Empirical Estimates Suggest Most Published Medical Research Is True”, Jager & Leek 2013
Empirical estimates suggest most published medical research is true
“What’s to Know about the Credibility of Empirical Economics?”, Ioannidis & Doucouliagos 2013
What’s to know about the credibility of empirical economics?
“The Garden of Forking Paths: Why Multiple Comparisons Can Be a Problem, Even When There Is No `fishing Expedition` or `p-Hacking` and the Research Hypothesis Was Posited ahead of Time”, Gelman & Loken 2013
“Investigating Variation in Replicability: The `Many Labs` Replication Project”, Klein 2013
Investigating variation in replicability: The `Many Labs` Replication Project
“Randomized Controlled Trials Commissioned by the Institute of Education Sciences Since 2002: How Many Found Positive Versus Weak or No Effects?”, Policy 2013
“A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices”, Prasad 2013
A Decade of Reversal: An Analysis of 146 Contradicted Medical Practices
“The Data Vigilante”
“Flawed Science: The Fraudulent Research Practices of Social Psychologist Diederik Stapel”, Committee et al 2012
Flawed science: The fraudulent research practices of social psychologist Diederik Stapel
“Scientific Misconduct and the Myth of Self-Correction in Science”, Stroebe et al 2012
Scientific Misconduct and the Myth of Self-Correction in Science
“A Peculiar Prevalence of p Values Just below 0.05”, Masicampo & Lalande 2012
“The Iron Law Of Evaluation And Other Metallic Rules”, Rossi 2012
“Depressive Realism: A Meta-Analytic Review”, Moore & Fresco 2012
“Correlation and Causation in the Study of Personality”, Lee 2012
“How Near-Miss Events Amplify or Attenuate Risky Decision Making”, Tinsley et al 2012
How Near-Miss Events Amplify or Attenuate Risky Decision Making
“Measuring the Prevalence of Questionable Research Practices With Incentives for Truth-Telling”, John et al 2012
Measuring the Prevalence of Questionable Research Practices with Incentives for Truth-Telling
“The Ironic Effect of Significant Results on the Credibility of Multiple-Study Articles”, Schimmack 2012
The Ironic Effect of Significant Results on the Credibility of Multiple-Study Articles
“Chocolate Consumption, Cognitive Function, and Nobel Laureates”, Messerli 2012
Chocolate Consumption, Cognitive Function, and Nobel Laureates
“Compliance With Mandatory Reporting of Clinical Trial Results on ClinicalTrials.gov: Cross Sectional Study”, Prayle 2012
“Most Reported Genetic Associations With General Intelligence Are Probably False Positives”, Chabris et al 2012
Most reported genetic associations with general intelligence are probably false positives
“Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results”, Wicherts et al 2011
“Statistically-Significant Meta-Analyses of Clinical Trials Have Modest Credibility and Inflated Effects”, Pereira & Ioannidis 2011
“Artifact and Recording Concepts in EEG”, Tatum et al 2011
“Notes on a New Philosophy of Empirical Science”, Burfoot 2011
“Epidemiology, Quality and Reporting Characteristics of Systematic Reviews of Traditional Chinese Medicine Interventions Published in Chinese Journals”, Ma et al 2011
“Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect”, Bem 2011
“Was There Really a Hawthorne Effect at the Hawthorne Plant? An Analysis of the Original Illumination Experiments”, Levitt & List 2011
“BCR Fall 2011_full”, Garnier 2011
View PDF:
“Excess Statistical-Significance Bias in the Literature on Brain Volume Abnormalities”, Ioannidis 2011
Excess Statistical-Significance Bias in the Literature on Brain Volume Abnormalities
“The Mismeasure of Science: Stephen Jay Gould versus Samuel George Morton on Skulls and Bias”, Lewis 2011
The Mismeasure of Science: Stephen Jay Gould versus Samuel George Morton on Skulls and Bias
“Erroneous Analyses of Interactions in Neuroscience: a Problem of Statistical-Significance”, Nieuwenhuis 2011
Erroneous analyses of interactions in neuroscience: a problem of statistical-significance :
“Peer-Review in a World With Rational Scientists: Toward Selection of the Average”, Thurner & Hanel 2010
Peer-review in a world with rational scientists: Toward selection of the average
“Japan, Checking on Its Oldest, Finds Many Gone”
“‘Positive’ Results Increase Down the Hierarchy of the Sciences”, Fanelli 2010
‘Positive’ Results Increase Down the Hierarchy of the Sciences
“Chinese Journal Finds 31% of Submissions Plagiarized”, Zhang 2010
Chinese journal finds 31% of submissions plagiarized :
View PDF:
“Holiday Reading: Cigarette Smoking: an Underused Tool in High-Performance Endurance Training”, Myers 2010
Holiday reading: Cigarette smoking: an underused tool in high-performance endurance training
“Placebo Interventions for All Clinical Conditions”, Hróbjartsson & Gøtzsche 2010
“Rewriting History”, Ljungqvist et al 2009
“Large-Scale Assessment of the Effect of Popularity on the Reliability of Research”, Pfeiffer & Hoffmann 2009
Large-Scale Assessment of the Effect of Popularity on the Reliability of Research
“How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data”, Fanelli 2009
“When Superstars Flop: Public Status and Choking Under Pressure in International Soccer Penalty Shootouts”, Jordet 2009
“Producing Wrong Data Without Doing Anything Obviously Wrong!”, Mytkowicz et al 2009
Producing Wrong Data Without Doing Anything Obviously Wrong!
“Statin Adherence and Risk of Accidents: a Cautionary Tale”, Dormuth et al 2009
“Models for Potentially Biased Evidence in Meta-Analysis Using Empirically Based Priors”, Welton et al 2008
Models for potentially biased evidence in meta-analysis using empirically based priors
“Killing For Their Country: A New Look at ‘Killology’”, Engen 2008
“Probing the Improbable: Methodological Challenges for Risks With Low Probabilities and High Stakes”, Ord et al 2008
Probing the Improbable: Methodological Challenges for Risks with Low Probabilities and High Stakes
“Figureheads, Ghost-Writers and Pseudonymous Quant Bloggers: The Recent Evolution of Authorship in Science Publishing”, Charlton 2008
View PDF:
“Why Most Discovered True Associations Are Inflated”, Ioannidis 2008
Why Most Discovered True Associations Are Inflated :
View PDF:
“The Allure of Equality: Uniformity in Probabilistic and Statistical Judgment”, Falk & Lann 2008
The allure of equality: Uniformity in probabilistic and statistical judgment :
View PDF:
“Lost in Publication: How Measurement Harms Science”, Lawrence 2008
“Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): Explanation and Elaboration”, Vandenbroucke et al 2007
“A Mathematical Theory of Citing”, Simkin & Roychowdhury 2007
“Psychological Treatments That Cause Harm”, Lilienfeld 2007
“Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments”, Rutter 2007
Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments
“Meditation Practices for Health: State of the Research”, Center 2007
“Testing Multiple Statistical Hypotheses Resulted in Spurious Associations: a Study of Astrological Signs and Health”, Austin et al 2006
“Mechanisms of the Placebo Effect of Sweet Cough Syrups”, Eccles 2006
“Lessons from the JMCB Archive”, McCullough et al 2006
“Comparison of Evidence on Harms of Medical Interventions in Randomized and Nonrandomized Studies”, Papanikolaou et al 2006
Comparison of evidence on harms of medical interventions in randomized and nonrandomized studies
“Evidence of Bias in Estimates of Influenza Vaccine Effectiveness in Seniors”, Jackson et al 2005
Evidence of bias in estimates of influenza vaccine effectiveness in seniors
“Contradicted and Initially Stronger Effects in Highly Cited Clinical Research”, Ioannidis 2005
Contradicted and Initially Stronger Effects in Highly Cited Clinical Research
“Blind Analysis In Nuclear And Particle Physics”, Klein & Roodman 2005
“Experimenter Effects and the Remote Detection of Staring”, Wiseman & Schlitz 2005
“An Alternative to Null-Hypothesis Statistical-Significance Tests”, Killeen 2005
An alternative to null-hypothesis statistical-significance tests
“When Is a Correlation between Non-Independent Variables ‘Spurious’?”, Brett 2004
When is a correlation between non-independent variables ‘spurious’?
“S. L. A. Marshall’s Men against Fire: New Evidence regarding Fire Ratios”, II 2003
S. L. A. Marshall’s men against fire: New evidence regarding fire ratios
“Does High Self-Esteem Cause Better Performance, Interpersonal Success, Happiness, Or Healthier Lifestyles?”, Baumeister et al 2003
“Personal Reflections on Lessons Learned from Randomized Trials Involving Newborn Infants, 1951–1967”, Silverman 2003
Personal reflections on lessons learned from randomized trials involving newborn infants, 1951–1967
“C:/ncn/bre587”
“Effects of Remote, Retroactive Intercessory Prayer on Outcomes in Patients With Bloodstream Infection: Randomized Controlled Trial”, Leibovici 2001
“The Hazards of Predicting Divorce Without Crossvalidation”, Heyman & Slep 2001
“Beleaguered Pygmalion: A History of the Controversy Over Claims That Teacher Expectancy Raises Intelligence”, Spitz 1999
“Controlled Trials: the 1948 Watershed”, Doll 1998
“Applications of Randomness in System Performance Measurement”, Blackwell 1998
Applications of Randomness in System Performance Measurement
“The Unpredictability Paradox: Review of Empirical Comparisons of Randomized and Non-Randomized Clinical Trials”, Kunz & Oxman 1998
“The Science of Murphy’s Law: Life’s Little Annoyances Are Not As Random As They Seem: the Awful Truth Is That the Universe Is against You”, Matthews 1997
“Trends in Science Coverage: a Content Analysis of 3 US Newspapers”, Pellechia 1997
Trends in science coverage: a content analysis of 3 US newspapers
“The Rise and Fall of Uncitedness”, Schwartz 1997
“The T-Experiments: Errors in Scientific Software”, Hatton 1997
“The ‘File Drawer Problem’ of Non-Significant Results: Does It Apply to Biological Research?”
The ‘File Drawer Problem’ of Non-Significant Results: Does It Apply to Biological Research? :
View PDF:
“The Social Misconstruction of Reality: Validity and Verification in the Scholarly Community”, Hamilton 1996
The Social Misconstruction of Reality: Validity and Verification in the Scholarly Community :
“The Big Crunch”, Goodstein 1994
“The Efficacy of Psychological, Educational, and Behavioral Treatment: Confirmation from Meta-Analysis”, Lipsey & Wilson 1993
“The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality”, Koehler 1993
The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality
“On Being a Whistleblower: The Needleman Case”, Ernhart et al 1993
“How a Publicity Blitz Created The Myth of Subliminal Advertising”, Rogers 1992
How a Publicity Blitz Created The Myth of Subliminal Advertising
“Statistics As Rhetoric in Psychology”, John 1992
“The Crisis in Measurement Literacy in Psychology and Education”, Lambert 1991
The Crisis in Measurement Literacy in Psychology and Education
“What’s Wrong With Psychology Anyway?”, Lykken 1991
“Possible Inaccuracies Occurring in Citation Analysis”, Moed & Vriens 1989
“Methods for Studying Coincidences”, Diaconis & Mosteller 1989
“Walter Stewart: Fighting Fraud in Science (They Call Him the ‘terrorist of the Lab’, but This Self-Appointed Scourge of Scientific Fraud Has Reason to Suspect That As Much As 25% of All Research Papers May Be Intentionally Fudged) [Interview]”, Stewart & Stewart 1989
“About Face: The Odyssey of an American Warrior § S. L. A. Marshall (SLAM)”, Hackworth & Sherman 1989 (page 37)
About Face: The Odyssey of an American Warrior § S. L. A. Marshall (SLAM) :
“Informal Conceptions of Probability”
“Statistical Procedures and the Justification of Knowledge in Psychological Science”, Rosnow & Rosenthal 1989
Statistical Procedures and the Justification of Knowledge in Psychological Science
“The Elusive Open Mind: 10 Years of Negative Research in Parapsychology”, Blackmore 1987
The Elusive Open Mind: 10 Years of Negative Research in Parapsychology
“Assessing Uncertainty in Physical Constants”, Henrion & Fischhoff 1986
Pasteur Et Le Choléra Des Poules: Révision Critique D’un Récit Historique, Cadeddu 1985
Pasteur et le choléra des poules: révision critique d’un récit historique
“Magnitude of Teacher Expectancy Effects on Pupil IQ As a Function of the Credibility of Expectancy Induction: A Synthesis of Findings from 18 Experiments”, Raudenbush 1984
“The Citation Bias: Fad and Fashion in the Judgment and Decision Literature”, Christensen-Szalanski & Beach 1984
The Citation Bias: Fad and Fashion in the Judgment and Decision Literature
“An Investigation of the Validity of Bibliographic Citations”, Broadus 1983
An investigation of the validity of bibliographic citations :
View PDF:
“Taboo, Constraint, and Responsibility in Educational Research”, Jensen 1983b
Taboo, constraint, and responsibility in educational research :
View PDF:
“Fake!”, Hamblin 1981
“Rating the Ratings: Assessing the Psychometric Quality of Rating Data”, Saal et al 1980
Rating the ratings: Assessing the psychometric quality of rating data
“Reliability: A Review of Psychometric Basics and Recent Marketing Practices”, Peter 1979
Reliability: A Review of Psychometric Basics and Recent Marketing Practices
“Consumer Research: How Valid and Useful Are All Our Consumer Behavior Research Findings?: A State-Of-The-Art Review”, Jacoby 1978
View PDF:
“What Is Not What in Statistics”, Guttman 1977
What is Not What in Statistics :
View PDF:
Experimenter Effects in Behavioral Research: Enlarged Edition, Rosenthal 1976
Experimenter Effects in Behavioral Research: Enlarged Edition
“Critical Analysis of the Statistical and Ethical Implications of Various Definitions of ‘Test Bias’”, Hunter & Schmidt 1976
Critical Analysis of the Statistical and Ethical Implications of Various Definitions of ‘Test Bias’
“Comparative Studies of Psychotherapies: Is It True That "Everyone Has Won and All Must Have Prizes"?”, Luborsky et al 1975
Comparative Studies of Psychotherapies: Is It True That "Everyone Has Won and All Must Have Prizes"?
“Editorial [EJP Editorial on Registered Reports]”, Johnson 1975b
“Models of Control and Control of Bias”, Johnson 1975
“Spurious Regressions in Econometrics”, Granger & Newbold 1974
Spurious regressions in econometrics :
View PDF:
Social Sciences As Sorcery, Andreski 1973
“Social Psychology As History”, Gergen 1973
“Interpreting Regression toward the Mean in Developmental Research”, Furby 1973
Interpreting regression toward the mean in developmental research
“Pygmalion Reconsidered: A Case Study in Statistical Inference: Reconsideration of the Rosenthal-Jacobson Data on Teacher Expectancy”, Elashoff & Snow 1971
“Nuisance Variables and the Ex Post Facto Design”, Meehl 1970
Nuisance Variables and the Ex Post Facto Design :
View PDF:
“Pygmalion In The Classroom: Teacher Expectation and Pupil’s Intellectual Development”, Rosenthal & Jacobson 1968
Pygmalion In The Classroom: Teacher Expectation and Pupil’s Intellectual Development
“Theory-Testing in Psychology and Physics: A Methodological Paradox”, Meehl 1967
Theory-Testing in Psychology and Physics: A Methodological Paradox
“Control of Spurious Association and the Reliability of the Controlled Variable”, Kahneman 1965
Control of spurious association and the reliability of the controlled variable
“Is the Scientific Paper Fraudulent? Yes; It Misrepresents Scientific Thought”, Medawar 1964
Is the Scientific Paper Fraudulent? Yes; It Misrepresents Scientific Thought
“Responsibility for Raw Data”, Wolins 1962
“Lysergic Acid Diethylamide (LSD-25): Xv. the Effects Produced By Substitution of a Tap Water Placebo”, Abramson et al 1955
Lysergic Acid Diethylamide (LSD-25): Xv. the Effects Produced By Substitution of a Tap Water Placebo
“Regression Fallacies in the Matched Groups Experiment”, Thorndike 1942
“Evaluating the Effect of Inadequately Measured Variables in Partial Correlation Analysis”, Stouffer 1936
Evaluating the Effect of Inadequately Measured Variables in Partial Correlation Analysis
“Halo Effect: A Constant Error in Psychological Ratings”, Thorndike 1920
“The Impersonator: The Fake Data Were Coming From Inside the Lab”
The Impersonator: The Fake Data Were Coming From Inside the Lab
“Me versus the Entire Field of Fetish Research”, Aella 2026
“After Century of Removing Appendixes, Docs Find Antibiotics Can Be Enough: In a Five-Year Follow-Up, Nearly Two-Thirds of Patients Never Needed Surgery”
“The High Cost of Not Doing Experiments”
“Metacritic Has A (File-Drawer) Problem”
Metacritic Has A (File-Drawer) Problem
View External Link:
“Help, Doctor, I’ve Been Exposed to [Proprietary]!”
“PaperBanana: Automating Academic Illustration for AI Scientists”
PaperBanana: Automating Academic Illustration for AI Scientists
“Assuring an Accurate Research Record [Aidan Toner-Rodgers’s AI Research Fraud]”
Assuring an accurate research record [Aidan Toner-Rodgers’s AI research fraud]
“Alexey Guzey’s Homepage”, Guzey 2026
“Open Science Challenges, Benefits and Tips in Early Career and Beyond”, Allen & Mehler 2026
Open science challenges, benefits and tips in early career and beyond
“The PRISMA Statement for Reporting Systematic Reviews and Meta-Analyses of Studies That Evaluate Health Care Interventions: Explanation and Elaboration”, Liberati et al 2026
“Why Most Published Research Findings Are False”, Ioannidis 2026
“Most Published Research Findings Are False—But a Little Replication Goes a Long Way”, Moonesinghe et al 2026
Most Published Research Findings Are False—But a Little Replication Goes a Long Way
“How to Make More Published Research True”, Ioannidis 2026
“Does Far Transfer Exist? Negative Evidence From Chess, Music, and Working Memory Training”
Does Far Transfer Exist? Negative Evidence From Chess, Music, and Working Memory Training
“The Journal of Scientific Integrity [Fraud in Honeybee Communication Research]”
The Journal of Scientific Integrity [fraud in honeybee communication research]
“WTH Is Cerebrolysin, Actually?”
“Misconduct in Bioscience Research: a 40-Year Perspective”
“Evaluating Extraordinary Claims: Mind Over Matter? Or Mind Over Mind?”
Evaluating Extraordinary Claims: Mind Over Matter? Or Mind Over Mind?
View HTML:
“Replications of Marketing Studies”
“Publication Bias in the Stereotype Threat Literature”
Publication Bias in the Stereotype Threat Literature
View External Link:
https://replicationindex.com/2022/02/15/rr22-stereotype-threat/
“On the Science and Ethics of Ebola Treatments”
“James Heathers. Scientist. Troublemaker. [Homepage]”, Heathers 2026
“My IRB Nightmare”
View External Link:
“Book Review: The 7 Principles For Making Marriage Work”
“A Catastrophic Failure of Peer Review in Obstetrics and Gynaecology”
A catastrophic failure of peer review in obstetrics and gynaecology
“The Psychology of Parapsychology, or Why Good Researchers Publishing Good Articles in Good Journals Can Still Get It Totally Wrong”
“Massive Lykos and MAPS Layoffs amid FDA Rejection Reactions; 3 MDMA Papers Retracted; and False Insights”
“The Secret Of The Soldiers Who Didn’t Shoot”
“[More on How Peter Miller Manipulates COVID-19 Origin Prediction Market]”
[More on how Peter Miller manipulates COVID-19 origin prediction market]
“More Than 230,000 Japanese Centenarians ‘Missing’”
“Here’s How Cornell Scientist Brian Wansink Turned Shoddy Data Into Viral Studies About How We Eat”
Here’s How Cornell Scientist Brian Wansink Turned Shoddy Data Into Viral Studies About How We Eat
“Surely You Can Be Serious”, Mastroianni 2026
“Computational Analysis of Lifespan Experiment Reproducibility”
Computational Analysis of Lifespan Experiment Reproducibility
“How Much Should We Trust Developing Country GDP? [Little]”
“Inventing the Randomized Double-Blind Trial: The Nürnberg Salt Test of 1835”
Inventing the randomized double-blind trial: The Nürnberg salt test of 1835
“Unregulated Peptides: Does BPC-157 Hold Its Promises?”
“Does Pentagon Pizza Theory Work? [No]”
“AI Tools Are Spotting Errors in Research Papers: inside a Growing Movement”
AI tools are spotting errors in research papers: inside a growing movement
“Wikipedia Shapes Language in Science Papers: Experiment Traces How Online Encyclopaedia Influences Research Write-Ups”
“Diederik Stapel’s Audacious Academic Fraud”
“A Primer on Why Microbiome Research Is Hard”
“The Academic Culture of Fraud”
View External Link:
https://www.palladiummag.com/2024/08/02/the-academic-culture-of-fraud/
“Pangram: an AI Text Detector That Actually Works”, Pangram 2026
“How Many American Women Die From Causes Related to Pregnancy or Childbirth? No One Knows.”
How Many American Women Die From Causes Related to Pregnancy or Childbirth? No One Knows.
“Do Drugs Make Religious Experience Possible? They Did for James and for Other Philosopher-Mystics of His Day. James’s Experiments With Psychoactive Drugs Raise Difficult Questions about Belief and Its Conditions”
“Do Life Hacks Work? The Truth Is, We’ll Never Know”
“In a Blind Test, Audiophiles Couldn’t Tell the Difference between Audio Signals Sent through Copper Wire, a Banana, or Wet Mud—’The Mud Should Sound Perfectly Awful, but It Doesn’t’, Notes the Experiment Creator”
“Cancer Studies Are Fatally Flawed. Meet the Young Billionaire [John Arnold] Who’s Exposing the Truth About Bad Science”
NoahHaber
razibkhan
xiao_ted
I’m curious how much overlap there is between ‘serious AI researchers’ and AI-adjacent subcultures
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
reproducibility-bias research-ecosystem availability-data citation-issues cognitive-bilingualism reproducibility-analysis
spurious-associations
research-integrity
Wikipedia (14)
Miscellaneous
/doc/statistics/bias/2023-sigurdson-figure2-effectsizesofhomeopathystudiesshowmeaneffectsize036.jpg/doc/statistics/bias/2023-youyou-figure2-replicabilityscoresbypsychologyfield.jpg/doc/statistics/bias/2022-brodeur-figure3-teststatisticsbypreregistrationstatusareequallybiased.jpg/doc/statistics/bias/2022-brodeur-figure6-teststatisticsfromprespecifiedanalysesarelessbiased.jpg/doc/statistics/bias/2022-giolla-figure2-originalprimingeffectsvsreplicationattempts.jpg/doc/statistics/bias/2021-bender-figure2-benefitsofcostimprovementstodrugpipeline.jpg/doc/statistics/bias/2021-morey-figure6-actioncompatibilityeffectmetaanalysisliftofftimes.jpg/doc/statistics/bias/2021-morey-figure7-actioncompatibilityeffectmetanalysismovetimes.jpg/doc/statistics/bias/2021-rubin-figure3-fallincitationspostjournalclosure.jpg/doc/statistics/bias/2019-guzey-whywesleep-tableofcontents.png/doc/statistics/bias/2019-schafer-figure1-preregisteredreporteffectsizesvsunpreregisteredstudies.jpg/doc/statistics/bias/2018-coppock-figure2-withinstudycomparisonofsurveyeffectsizes.jpg/doc/statistics/bias/2018-devries-figure1-publicationbiasflowchart.jpg/doc/statistics/bias/2015-krawczyk.pdf:View PDF:
/doc/statistics/bias/2013-button.pdf:View PDF:
/doc/statistics/bias/2013-duncan-figure2-metanalyticdeclineinearlychildcareeffectsovertime.jpg/doc/statistics/bias/2011-osherovich.pdf:View PDF:
/doc/statistics/bias/2011-simmons.pdf:View PDF:
/doc/statistics/bias/2011-tatum-eeg-figure2-compositeeeg.png/doc/statistics/bias/2009-anda.pdf:View PDF:
/doc/statistics/bias/2007-kyzas.pdf:View PDF:
/doc/statistics/bias/2003-krum.pdf:View PDF:
/doc/statistics/bias/1992-miller-researchfraudbehavioralmedicalsciences.pdf:/doc/statistics/bias/1988-utts.pdf:View PDF:
/doc/statistics/bias/1987-smith.pdf:View PDF:
/doc/statistics/bias/1986-henrion-figure1-historyofmeasurementofspeedoflight18751958.jpghttp://www.law.nyu.edu/sites/default/files/upload_documents/September%209%20Neil%20Malhotra.pdf:https://aeon.co/essays/my-paranormal-adventure-in-pursuit-of-life-after-deathhttps://asteriskmag.com/issues/2/my-primal-scream-of-rage-the-big-alcohol-study-that-didn-t-happenhttps://asteriskmag.com/issues/2/read-this-not-that-the-hidden-cost-of-nutrition-misinformationhttps://ctlj.colorado.edu/wp-content/uploads/2015/08/Meyer-final.pdf:-
View External Link:
https://doughanley.com/files/papers/thompson_hanley_wikipedia.pdfhttps://freakonomics.com/podcast/why-is-there-so-much-fraud-in-academia/https://goodscience.substack.com/p/weve-made-some-metascience-progresshttps://history.army.mil/html/books/070/70-64/cmhPub_70-64.pdf:https://openpsychometrics.org/info/survey-topic-participation-bias/https://reflectivedisequilibrium.blogspot.com/2014/05/what-do-null-fields-tell-us-about-fraud.htmlhttps://replicationindex.com/2020/12/30/a-meta-scientific-perspective-on-thinking-fast-and-slow/https://steamtraen.blogspot.com/2023/06/a-coda-to-wansink-story.htmlhttps://steamtraen.blogspot.com/2023/07/strange-numbers-in-dataset-of-zhang.htmlhttps://steamtraen.blogspot.com/2023/11/attack-of-50-foot-research-assistants.htmlhttps://undark.org/2023/05/25/where-the-wood-wide-web-narrative-went-wrong/https://undark.org/2023/06/21/in-a-tipsters-note-a-view-of-science-publishings-achilles-heel/https://web.archive.org/web/20100304165140/http://www.libertary.com/books/reconciliation-roadhttps://www.amazon.com/Ending-Medical-Reversal-Improving-Outcomes/dp/1421417723https://www.aporiamagazine.com/p/bias-is-often-unpredictablehttps://www.canadianmilitaryhistory.ca/wp-content/uploads/2012/03/4-Engen-Marshall-under-fire.pdf:https://www.chess.com/article/view/no-castling-chess-kramnik-alphazerohttps://www.chronicle.com/article/we-must-stop-the-avalanche-of-low-quality-research/https://www.cs.ucr.edu/~eamonn/Keogh_SIGKDD09_tutorial.pdf:https://www.demographic-research.org/volumes/vol40/29/40-29.pdf:https://www.demographic-research.org/volumes/vol49/27/49-27.pdf:https://www.economist.com/china/2024/02/22/why-fake-research-is-rampant-in-chinaView External Link:
https://www.economist.com/china/2024/02/22/why-fake-research-is-rampant-in-chinahttps://www.lesswrong.com/posts/9qCN6tRBtksSyXfHu/frequentist-statistics-are-frequently-subjectivehttps://www.newyorker.com/magazine/2023/10/09/they-studied-dishonesty-was-their-work-a-liehttps://www.newyorker.com/news/the-weekend-essay/the-hidden-harms-of-cprhttps://www.nytimes.com/2024/03/21/health/psychedelics-roland-griffiths-johns-hopkins.htmlhttps://www.reddit.com/r/LocalLLaMA/comments/1fuxw8d/just_for_kicks_i_looked_at_the_newly_released/https://www.science.org/content/blog-post/faked-beta-amyloid-data-what-does-it-meanhttps://www.the100.ci/2023/03/07/non-representative-samples-what-could-possibly-go-wrong/https://www.thecut.com/2016/10/inside-psychologys-methodological-terrorism-debate.htmlhttps://www.theguardian.com/lifeandstyle/2017/jun/03/quasi-religious-great-self-esteem-con
{kind=link}
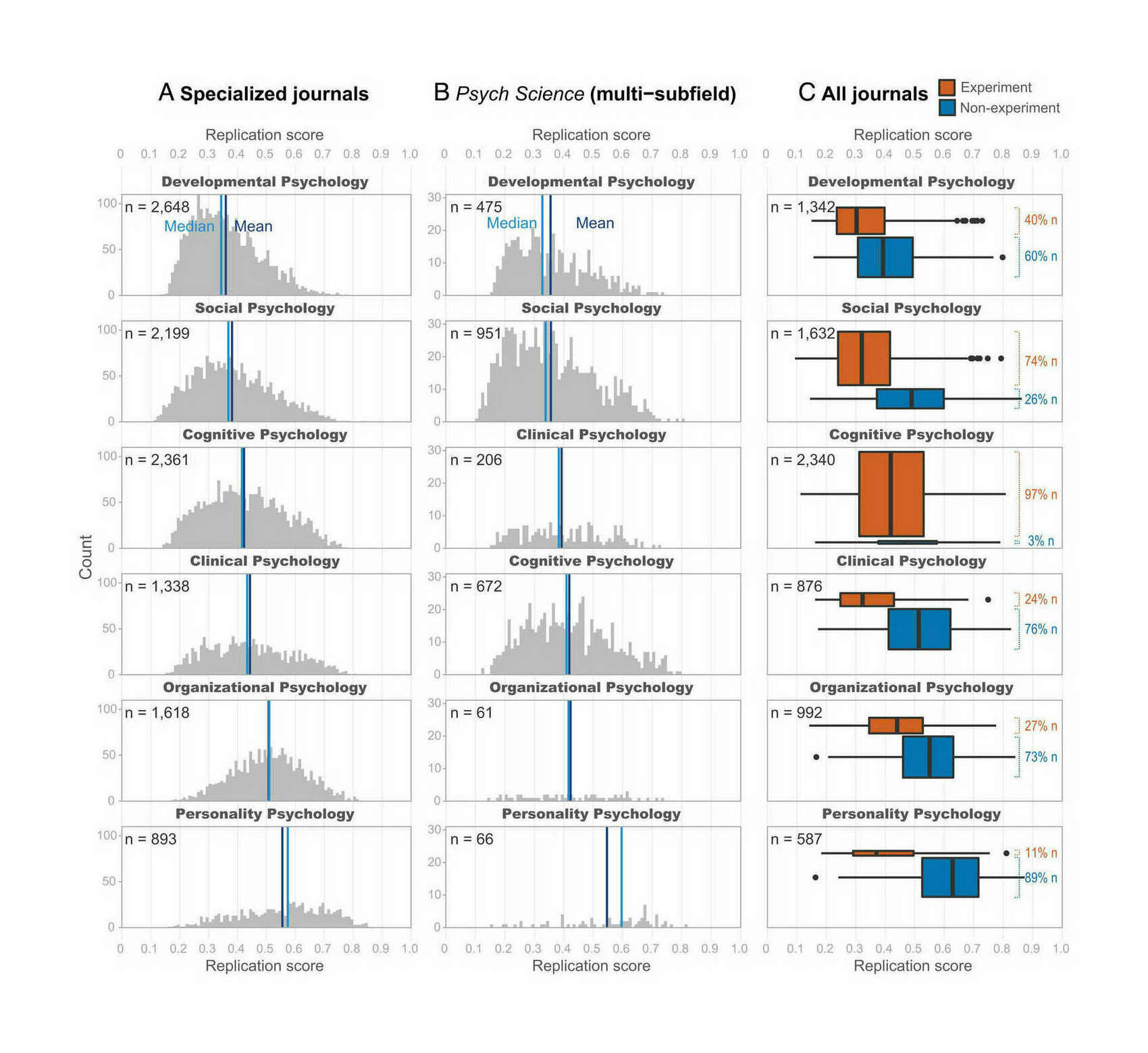{kind=link}
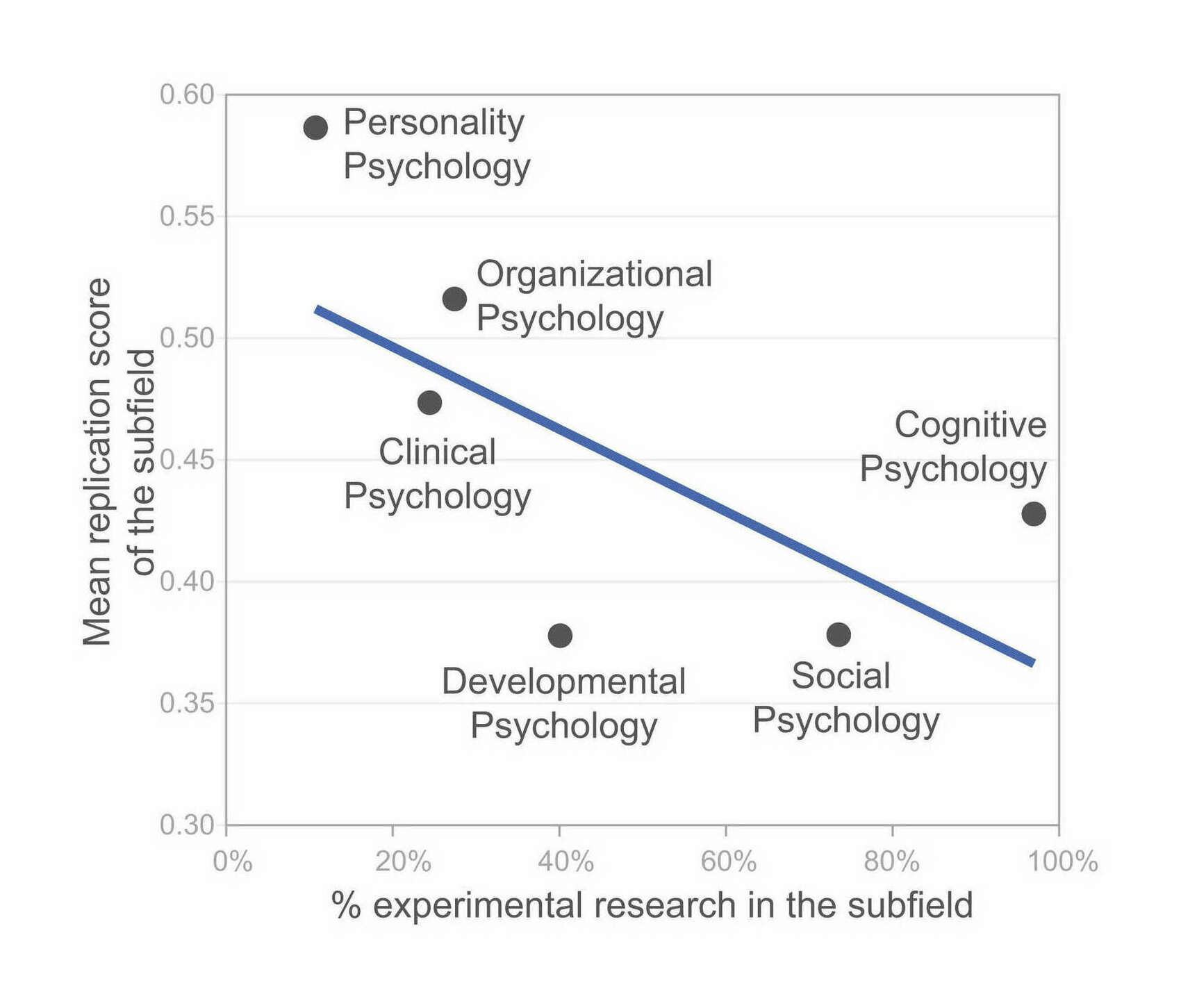{kind=link}
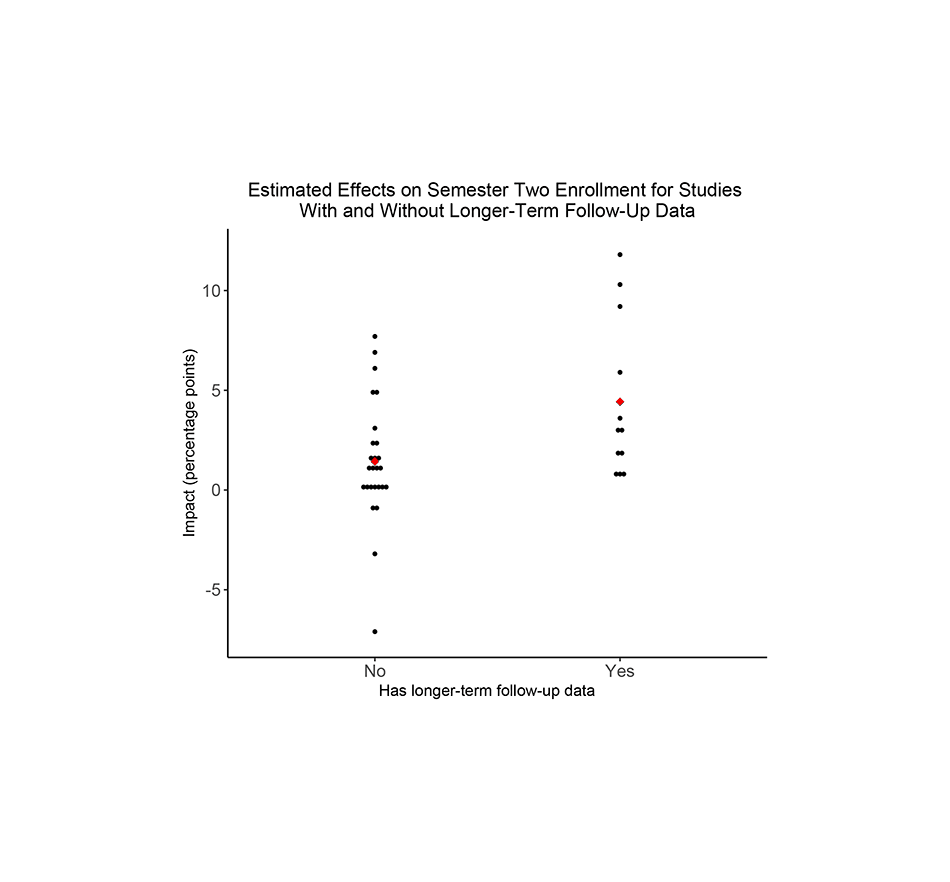{kind=link}
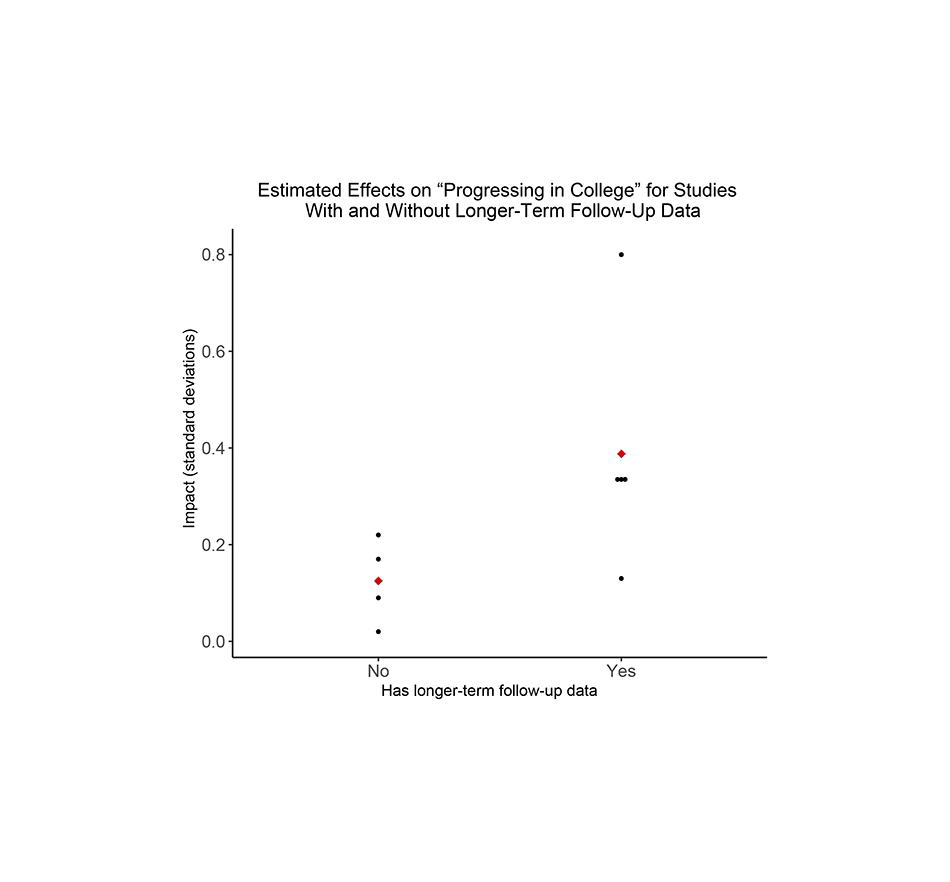{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
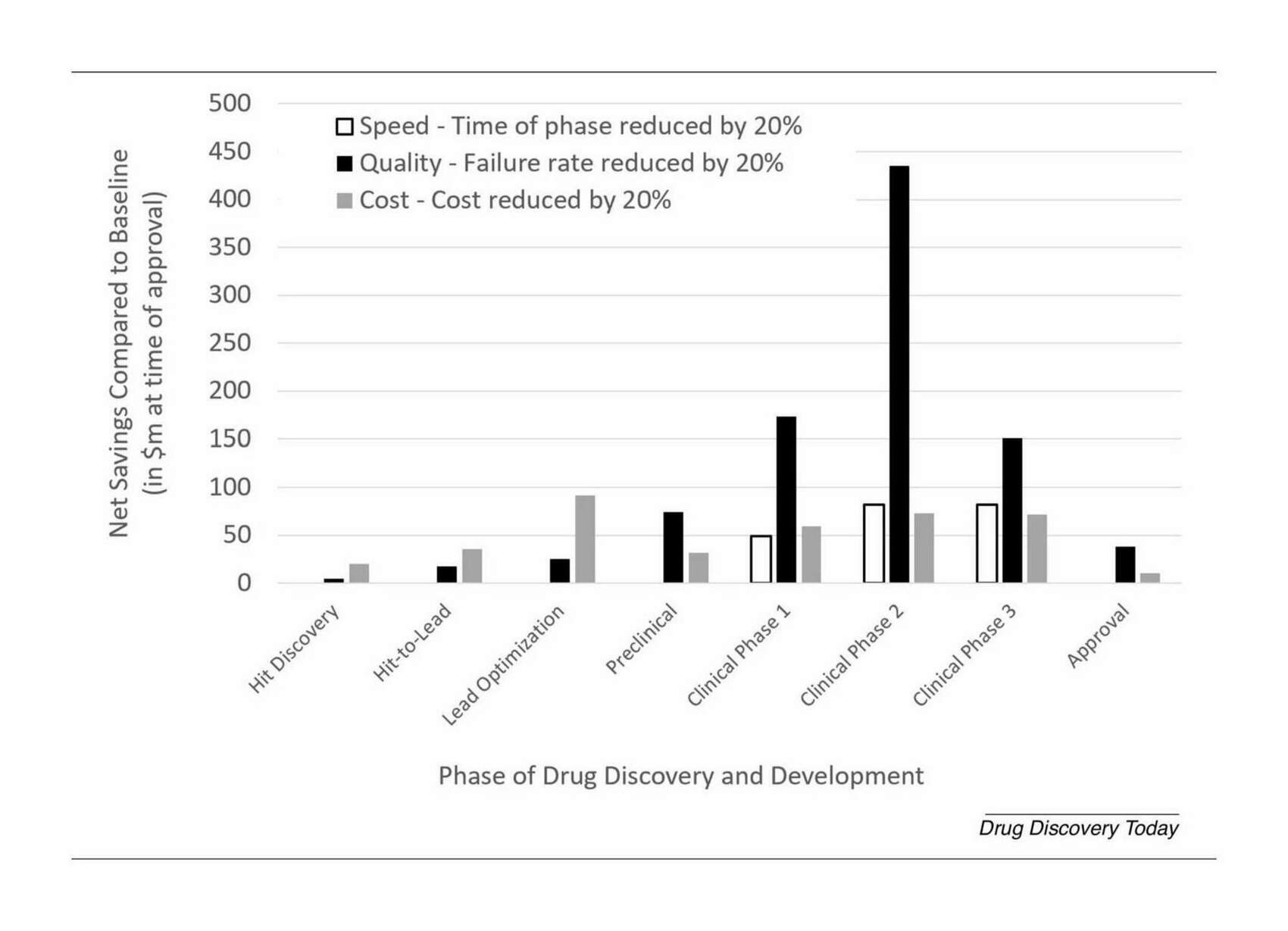{kind=link}
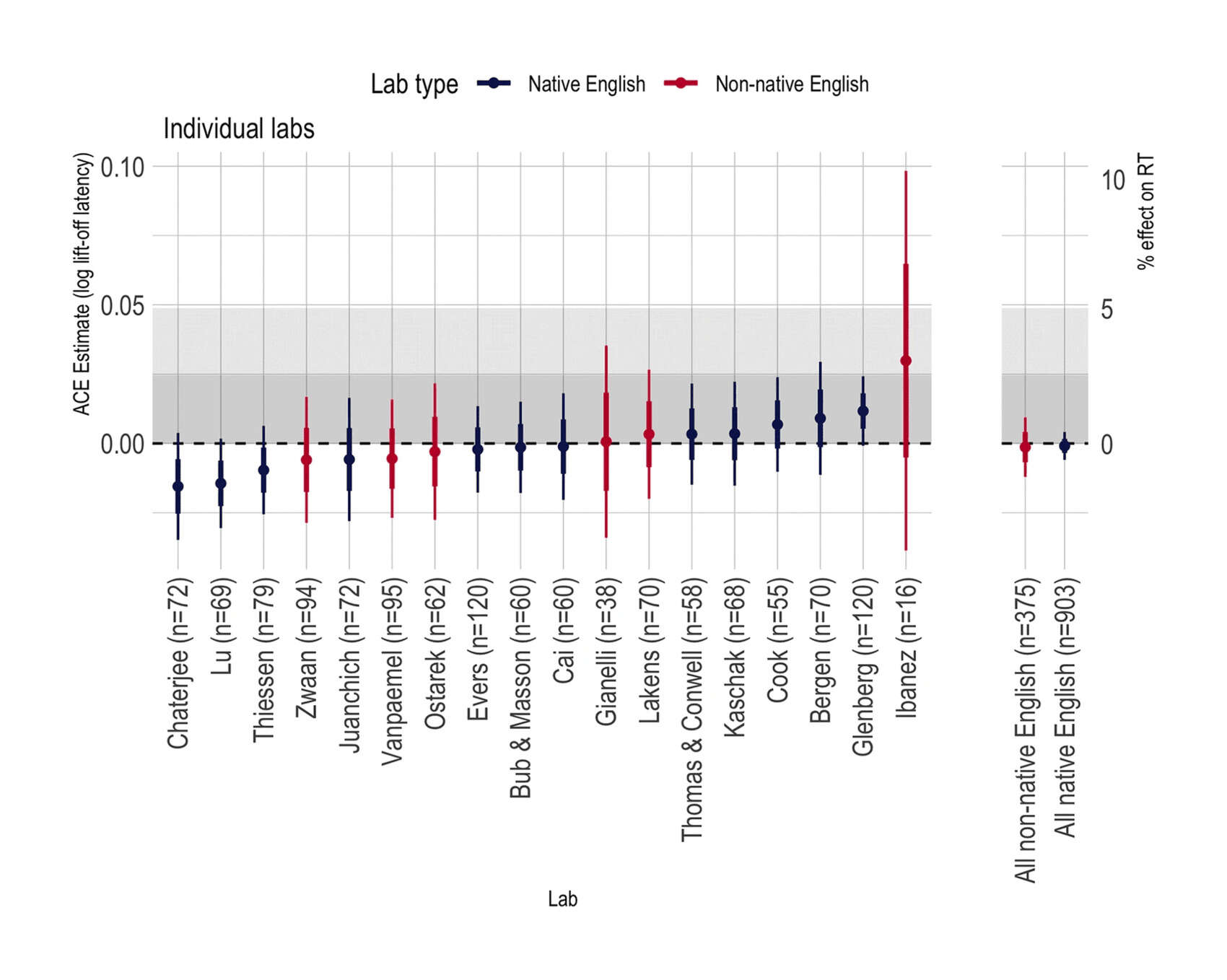{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
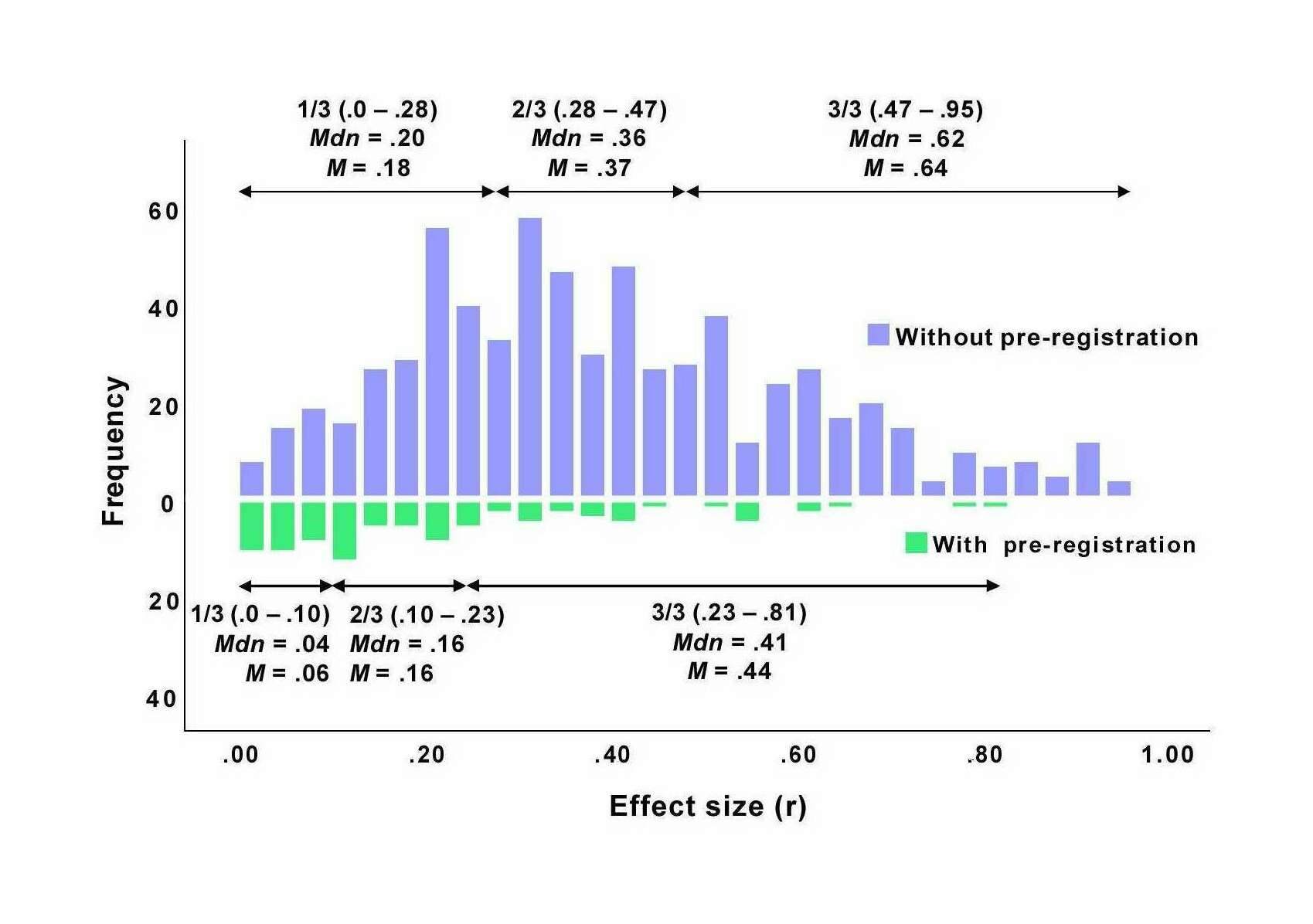{kind=link}
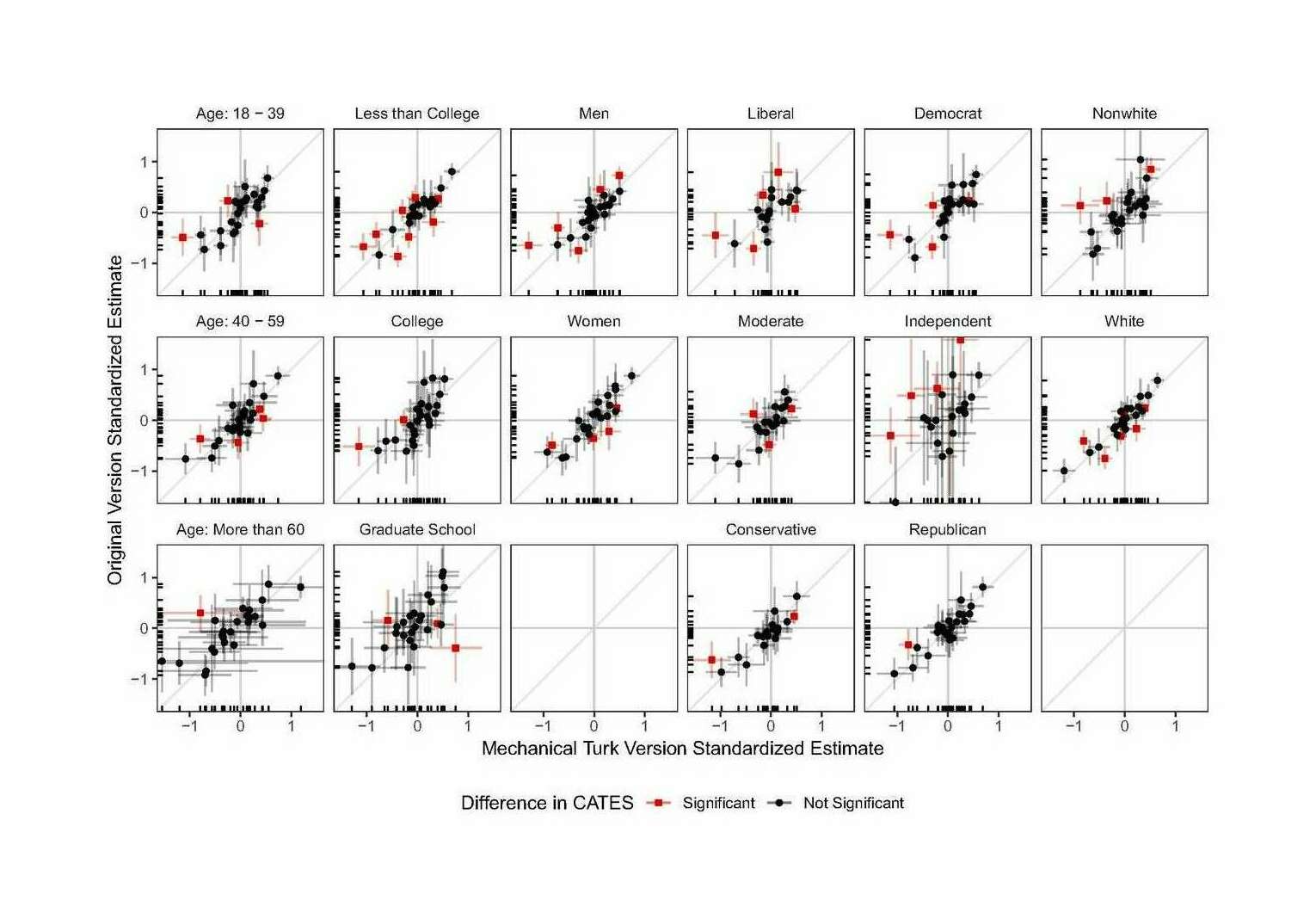{kind=link}
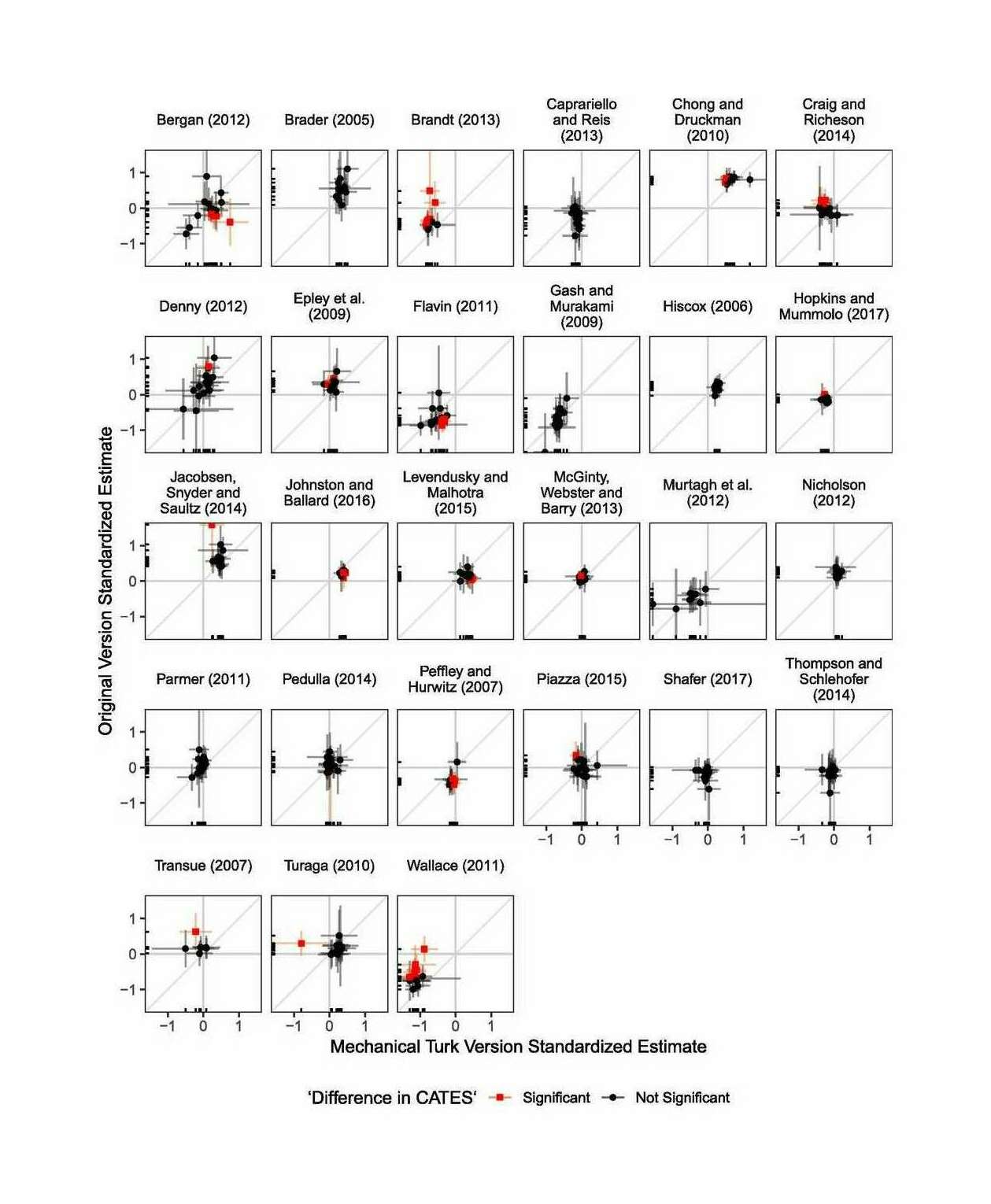{kind=link}
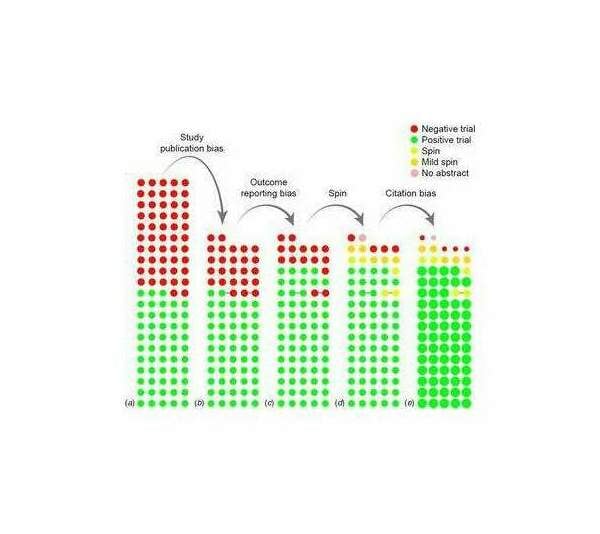{kind=link}
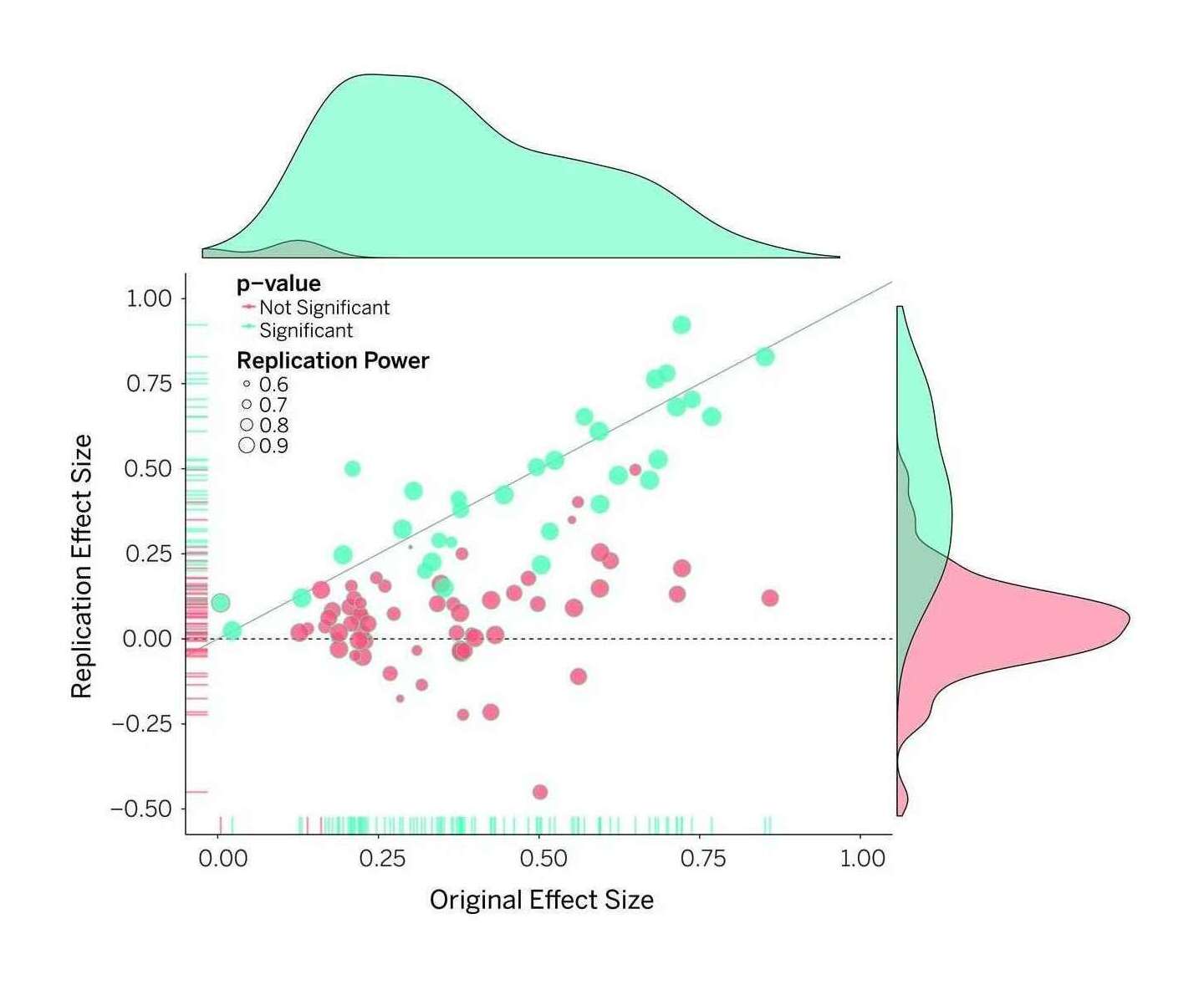{kind=link}
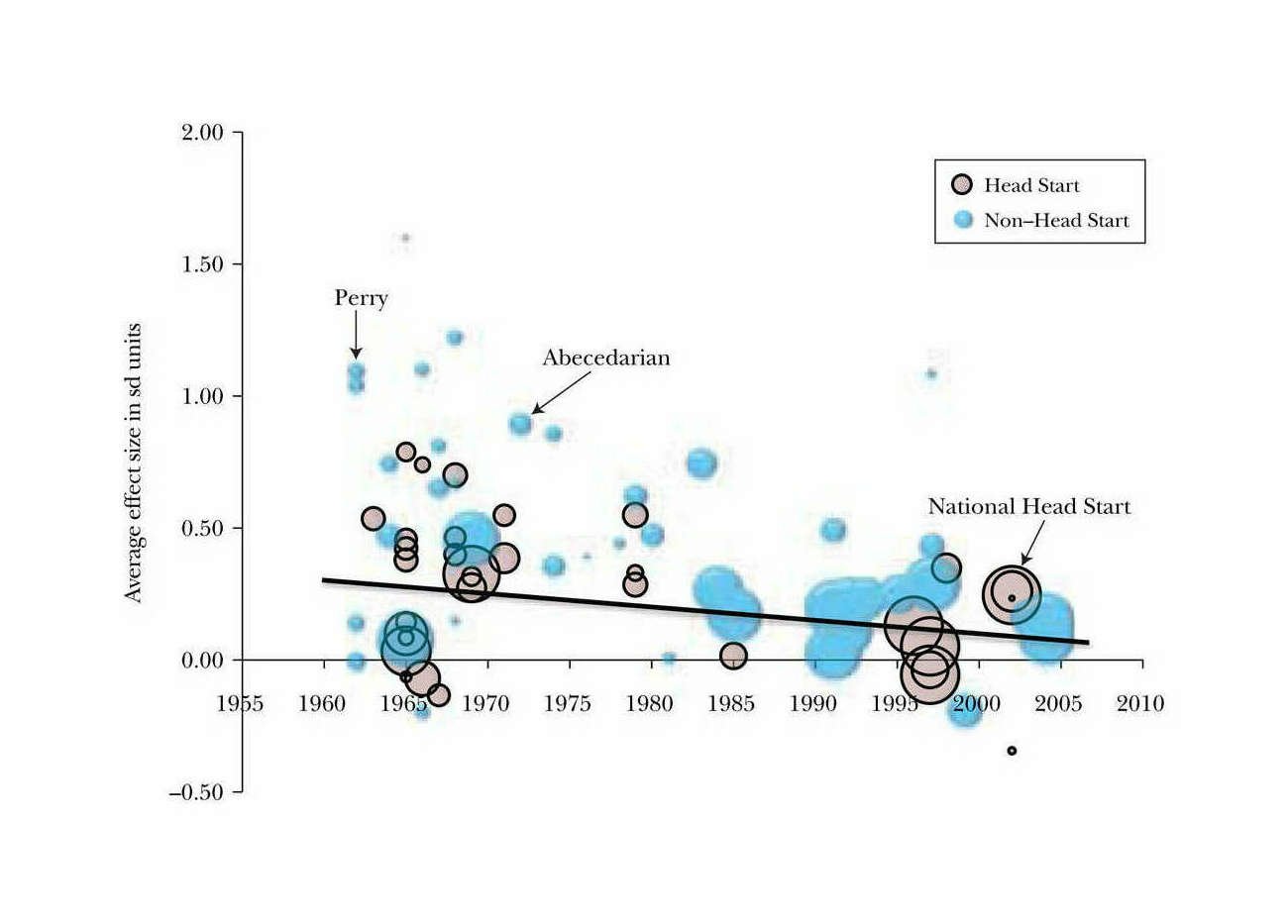{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
2025-kelly.pdf: “Debunking When Prophecy Fails”,2025-kay.pdf: “Why You Shouldn’t Trust Data Collected on MTurk”,https://jamesheathers.curve.space/: “An Introduction To Forensic Metascience”,https://journals.sagepub.com/doi/10.1177/17470161241247720: “Research Misconduct in China: towards an Institutional Analysis”,https://onlinelibrary.wiley.com/doi/full/10.1111/ecin.13222: “Is Economics Self-Correcting? Replications in the American Economic Review”,https://www.sciencedirect.com/science/article/pii/S000293782400005X: “Maternal Mortality in the United States: Are the High and Rising Rates due to Changes in Obstetrical Factors, Maternal Medical Conditions, or Maternal Mortality Surveillance?”,2023-kirakosian.pdf: “Heresy, Witchcraft, Jean Gerson, Scepticism and the Use of Placebo Controls”,https://osf.io/preprints/socarxiv/zpgdf/: “Measuring Backsliding With Observables: Observable-To-Subjective Score Mapping (OSM)”,https://royalsocietypublishing.org/rsos/article/10/2/191375/91837/Raising-the-value-of-research-studies-in: “Raising the Value of Research Studies in Psychological Science by Increasing the Credibility of Research Reports: the Transparent Psi Project”,https://www.pnas.org/doi/10.1073/pnas.2208863120: “A Discipline-Wide Investigation of the Replicability of Psychology Papers over the past Two Decades”,https://journals.sagepub.com/doi/full/10.1177/25152459221128319: “Comparing Analysis Blinding With Preregistration in the Many-Analysts Religion Project”,https://thecritic.co.uk/receptiogate-and-the-absolute-state-of-academia/: “#ReceptioGateand the (Absolute) State of Academia: The Numbers Game Has Incentivized Bad Behavior”,https://osf.io/mhv8f/: “Are Most Published Criminological Research Findings Wrong? Taking Stock of Criminological Research Using a Bayesian Simulation Approach”,https://www.nature.com/articles/s41559-022-01879-9: “No Evidence That Mandatory Open Data Policies Increase Error Correction”,2022-gould.pdf: “Inconvenient Truths and the Usefulness of Identifying Unknown Unknowns”,https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3001564: “Do Multiple Experimenters Improve the Reproducibility of Animal Studies?”,2022-wilson.pdf: “Theoretical False Positive Psychology”,2022-marek.pdf: “Reproducible Brain-Wide Association Studies Require Thousands of Individuals”,https://www.pnas.org/doi/10.1073/pnas.2115126119: “A 680,000-Person Megastudy of Nudges to Encourage Vaccination in Pharmacies”,2022-swirethompson.pdf: “The Backfire Effect After Correcting Misinformation Is Strongly Associated With Reliability”,https://osf.io/preprints/psyarxiv/dnr9s/: “Fooled by Beautiful Data: Visualization Esthetics Bias Trust in Science, News, and Social Media”,2022-scott.pdf: “A Systematic Review and Meta-Analysis of the Success of Blinding in Antidepressant RCTs”,2022-moody.pdf: “Reproducibility in the Social Sciences”,2021-milkman.pdf: “Megastudies Improve the Impact of Applied Behavioral Science”,2021-shapiro.pdf: “TV Advertising Effectiveness and Profitability: Generalizable Results From 288 Brands”,https://arxiv.org/abs/2105.13445: “The Piranha Problem: Large Effects Swimming in a Small Pond”,https://www.sciencedirect.com/science/article/pii/S1359644620305274#sec0010: “Artificial Intelligence in Drug Discovery: What Is Realistic, What Are Illusions? Part 1: Ways to Make an Impact, and Why We Are Not There Yet: Quality Is More Important Than Speed and Cost in Drug Discovery”,https://arxiv.org/abs/2011.15004: “The Statistical Properties of RCTs and a Proposal for Shrinkage”,https://associationofanaesthetists-publications.onlinelibrary.wiley.com/doi/10.1111/anae.15263: “False Individual Patient Data and Zombie Randomized Controlled Trials Submitted to Anesthesia”,2020-simonsohn.pdf: “Specification Curve Analysis”,https://statmodeling.stat.columbia.edu/2019/12/27/why-we-sleep-data-manipulation-a-smoking-gun/: “Why We Sleep Data Manipulation: A Smoking Gun?”,https://statmodeling.stat.columbia.edu/2019/12/26/whassup-with-why-we-sleep/: “Whassup With Why We Sleep?”,https://guzey.com/books/why-we-sleep/: “Matthew Walker’s Why We Sleep Is Riddled With Scientific and Factual Errors”,https://www.tandfonline.com/doi/full/10.1080/01973533.2019.1577736#section-heading-2: “What Can We Learn from Many Labs Replications? 3. Can Replication Studies Detect Fraud?”,https://www.sciencedirect.com/science/article/pii/S0885200618300279: “Effects of the Tennessee Prekindergarten Program on Children’s Achievement and Behavior through Third Grade”,https://databasearchitects.blogspot.com/2018/06/propagation-of-mistakes-in-papers.html: “Propagation of Mistakes in Papers”,2018-yechiam.pdf: “Acceptable Losses: the Debatable Origins of Loss Aversion”,2017-ioannidis.pdf: “The Power of Bias in Economics Research”,2017-mogil.pdf: “Laboratory Environmental Factors and Pain Behavior: the Relevance of Unknown Unknowns to Reproducibility and Translation”,https://jamanetwork.com/journals/jama/article-abstract/1895246: “Association Between Analytic Strategy and Estimates of Treatment Outcomes in Meta-Analyses”,2014-simonsohn.pdf: “p-Curve: A Key to the File-Drawer”,1987-rossi: “The Iron Law Of Evaluation And Other Metallic Rules”,2011-levitt.pdf: “Was There Really a Hawthorne Effect at the Hawthorne Plant? An Analysis of the Original Illumination Experiments”,2006-eccles.pdf: “Mechanisms of the Placebo Effect of Sweet Cough Syrups”,2006-mccullough.pdf: “Lessons from the JMCB Archive”,1992-john.pdf: “Statistics As Rhetoric in Psychology”,1980-saal.pdf: “Rating the Ratings: Assessing the Psychometric Quality of Rating Data”,https://guzey.com/: “Alexey Guzey’s Homepage”,