Computer Optimization: Your Computer Is Faster Than You Think
Compilation of links demonstrating that it is common to find order-of-magnitude speedups in software, especially when designed carefully for (extraordinarily powerful) contemporary computer hardware with end-to-end principled thinking.
You can have a second computer once you’ve shown you know how to use the first one.
“Welcome to the Jungle” (CPU design and Moore’s law; cf. “How Many Computers In Your Computer?”)
“There’s plenty of room at the Top: What will drive computer performance after Moore’s law?”, Leiserson et al 2020 (gains from End-To-End Principle-based systems design1)
“Scalability! But at what COST?”, McSherry et al 201511ya (when laptops > clusters: the importance of good baselines; “Big Data” doesn’t fit in a laptop); “Command-line Tools can be 235× Faster than your Hadoop Cluster”
“What it takes to run Stack Overflow”, Nick Craver; “We stand to save $7m over 5 years from our cloud exit”, David Heinemeier Hansson; “Production Twitter on One Machine? 100Gbps NICs and NVMe are fast”
“Anatomy of a hack: How crackers ransack passwords like
qeadzcwrsfxv1331; For Ars, 3 crackers have at 16,000+ hashed passcodes—with 90% success”; “Computing Adler32 Checksums at 41 GB/s”“Parsing Gigabytes of JSON per Second”, Langdale & Lemire 2019
59 GB/s FizzBuzz; “Modern storage is plenty fast. It is the APIs that are bad.”; “10M IOPS, one physical core.
#io_uring #linux”; “Achieving 11M IOPS & 66 GB/s IO on a Single ThreadRipper Workstation”“The C10K problem”, Kegel 200125ya; “Serving Netflix Video at 50 gigabyte/s on FreeBSD”, Gallatin 2021/“Serving Netflix Video Traffic at 100 gigabyte/s and Beyond”, Gallatin 2022
“Multicast and the Markets” (network optimization & mechanical sympathy in high-frequency trading)
Ultra-low bit-rate audio for tiny podcasts with Codec2 and WaveNet decoders (1 hour = 1MB)
“The computers are fast, but you don’t know it” (replacing slow pandas with 6,000× faster parallelized C++)
“Scaling SQLite to 4M QPS on a Single Server (EC2 vs Bare Metal)”, Expensify; “50% faster than 3.7.17” (“… We have achieved this by incorporating hundreds of micro-optimizations. Each micro-optimization might improve the performance by as little as 0.05%.”)
“Optimization story—quantum mechanics simulation speedup”; “14,000× Speedup a.k.a. Computer Science For the Win”
“Cutting The Pipe: Achieving Sub-Second Iteration Times”, Frykholm 201214ya (optimizing game development)
“How Michael Abrash doubled Quake’s framerate”, Fabien Sanglard 2026
“The Billion Row Challenge (1BRC): Step-by-step in Java from 71s to 1.7s” (and 4s in Go & 0.5s in C)
“GCC Compiler vs Human—119× Faster Assembly 💻🆚🧑💻”; “Python, C, Assembly—2,500× Faster Cosine Similarity 📐”; “Summing ASCII encoded integers on Haswell at almost the speed of memcpy” (“320× faster than the following naive C++ solution”)
“How to Speed up a Python Program 114,000×”, David Schachter 2012-12-04
“The Prospero Challenge” (rendering a vector graphic toy language; 15,000ms simple implementation → 3,750ms → 6.3ms → 3.9ms, total speedup: 3,800×)
“Optimizing a MOS 6502 CPU Apple image decoder, from 70 minutes to 1 minute”
“Minimal Boolean Formulas”, Russ Cox
-
“8088 Domination”: “how I created 8088 Domination, which is a program that displays fairly decent full-motion video on a 198145ya IBM PC”/part 2
“A Mind Is Born” (256 bytes; for comparison, this line of Markdown linking the demo is 194 bytes long, and the video several million bytes)
Casey Muratori: refterm v2, Witness pathing (summary)
-
“Algorithmic Progress in 6 Domains”, Grace 2013
“A Time Leap Challenge for SAT Solving”, Fichte et al 2020 (hardware overhang: ~2.5SAT solving since 200026ya, about equally due to software & hardware gains, although slightly more software—new software on old hardware beats old on new.)
“Measuring hardware overhang”, hippke (“with today’s algorithms, computers would have beat the world chess champion already in 199432ya on a contemporary desk computer”)
Memory Locality:
“What Every Programmer Should Know About Memory”, Drepper 2007
“You’re Doing It Wrong: Think you’ve mastered the art of server performance? Think again.”, Poul-Henning Kamp 201016ya (on using cache-oblivious B-heaps to optimize Varnish performance 10×)
“The LMAX Architecture”, Fowler 201115ya (TigerBeetle)
“In-place Superscalar Samplesort (IPS4o): Engineering In-place (Shared-memory) Sorting Algorithms”, Axtmann et al 2020; “Vectorized and performance-portable Quicksort”, Blacher et al 2022
“Fast approximate string matching with large edit distances in Big Data (201511ya)”
“ParPaRaw: Massively Parallel Parsing of [CSV] Delimiter-Separated Raw Data”, Stehl & Jacobsen 2019
“Scaling our Spreadsheet Engine from Thousands to Billions of Cells: From Maps To Arrays”, Lukas Köbis 2022
“Persistent RNNs: Stashing Recurrent Weights On-Chip”, Diamos et al 2016; “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”, Dao et al 2022
DL/Deep Reinforcement Learning:
Training A3C to solve Atari Pong in <4 minutes on the ARCHER supercomputer through brute parallelism
“
megastephelps you build 1-million FPS reinforcement learning environments on a single GPU”, Jones“The Mathematics of 2048: Optimal Play with Markov Decision Processes”
Bruteforcing Breakout (optimal play by depth-first search of an approximate MDP in an optimized C++ simulator for 6 CPU-years; crazy gameplay—like chess endgame tables, a glimpse of superintelligence)
“Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS with Asynchronous Reinforcement Learning”, Petrenko et al 2020; “Megaverse: Simulating Embodied Agents at One Million Experiences per Second”, Petrenko et al 2021; “Brax: A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, Freeman et al 2021; “Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning”, Makoviychuk et al 2021 (Rudin et al 2021); WarpDrive
“Large Batch Simulation for Deep Reinforcement Learning”, Shacklett et al 2021
“Scaling Scaling Laws with Board Games”, Jones 2021
“Mastering Real-Time Strategy Games with Deep Reinforcement Learning: Mere Mortal Edition”, Winter
“Scaling down Deep Learning”, Greydanus 2020
“Podracer architectures for scalable Reinforcement Learning”, Hessel et al 2021 (highly-efficient TPU pod use: eg. solving Pong in <1min at 43 million FPS on a TPU-2048); “Q-DAX: Accelerated Quality-Diversity for Robotics through Massive Parallelism”, Lim et al 2022; “EvoJAX: Hardware-Accelerated Neuroevolution”, Tang et al 2022; “JaxMARL: Multi-Agent RL Environments in JAX”, Rutherford et al 2023
“Training the Ant simulating at 1 million steps per second on CUDA (NVIDIA RTX 2080), using Tiny Differentiable Simulator and C++ Augmented Random Search.” (Erwin Coumans 2021)
“This Snake environment simulates 14M snakes and trains 1M snake steps per second.”
“TextWorldExpress: Simulating Text Games at One Million Steps Per Second”, Jansen & Côté 2022
“Getting the World Record in HATETRIS”, Dave & Filipe 2022
“Parallel Q-Learning (PQL): Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation”, Li et al 2023
Latency/UI:
“Transatlantic ping faster than sending a pixel to the screen?”
“Local-first software: You own your data, in spite of the cloud”/Kleppmann et al 2019
“Project Starline: A high-fidelity telepresence system”, Lawrence et al 2021
“Use GPT-3 incorrectly: reduce costs 40× and increase speed by 5×”, Pullen 2023
Organizations:
WhatsApp (201313ya: “50 staff members” for 200m users; 201511ya: 50 “engineers”, 900m users)
Craigslist (2017: ~50 employees)
Instagram (201214ya FB acquisition: 13 employees; architecture)
YouTube (200620ya Google acquisition: ~10 employees)
Reddit (201115ya: 4 engineers; 2021: ~700 total staff, >52m users)
Wikimedia Foundation (“Internet hosting” in 2021: $2.99$2.42021m)
Twitter: Musk acquisition cut up to 90% of employees+contractors; widespread confident assertions by ex-Twitter staff that the site would suffer crashes (possibly terminal crashes which could not be recovered from), within a month or two, turned out to be false.
See Also: “Some examples of people quickly accomplishing ambitious things together.”
A novice was trying to fix a broken Lisp machine by turning the power off and on.
Knight, seeing what the student was doing, spoke sternly: “You cannot fix a machine by just power-cycling it with no understanding of what is going wrong.”
Knight turned the machine off and on.
The machine worked.
“Tom Knight and the Lisp Machine”, AI Koans
AI scaling can continue even if semiconductors do not, particularly with self-optimizing stacks; John Carmack notes, apropos of Seymour Cray, that “Hyperscale data centers and even national supercomputers are loosely coupled things today, but if challenges demanded it, there is a world with a zetta[flops] scale, tightly integrated, low latency matrix dissipating a gigawatt in a swimming pool of circulating fluorinert.”↩︎
A relevant example is Amazon’s “best practices” for hosting a WordPress blog:
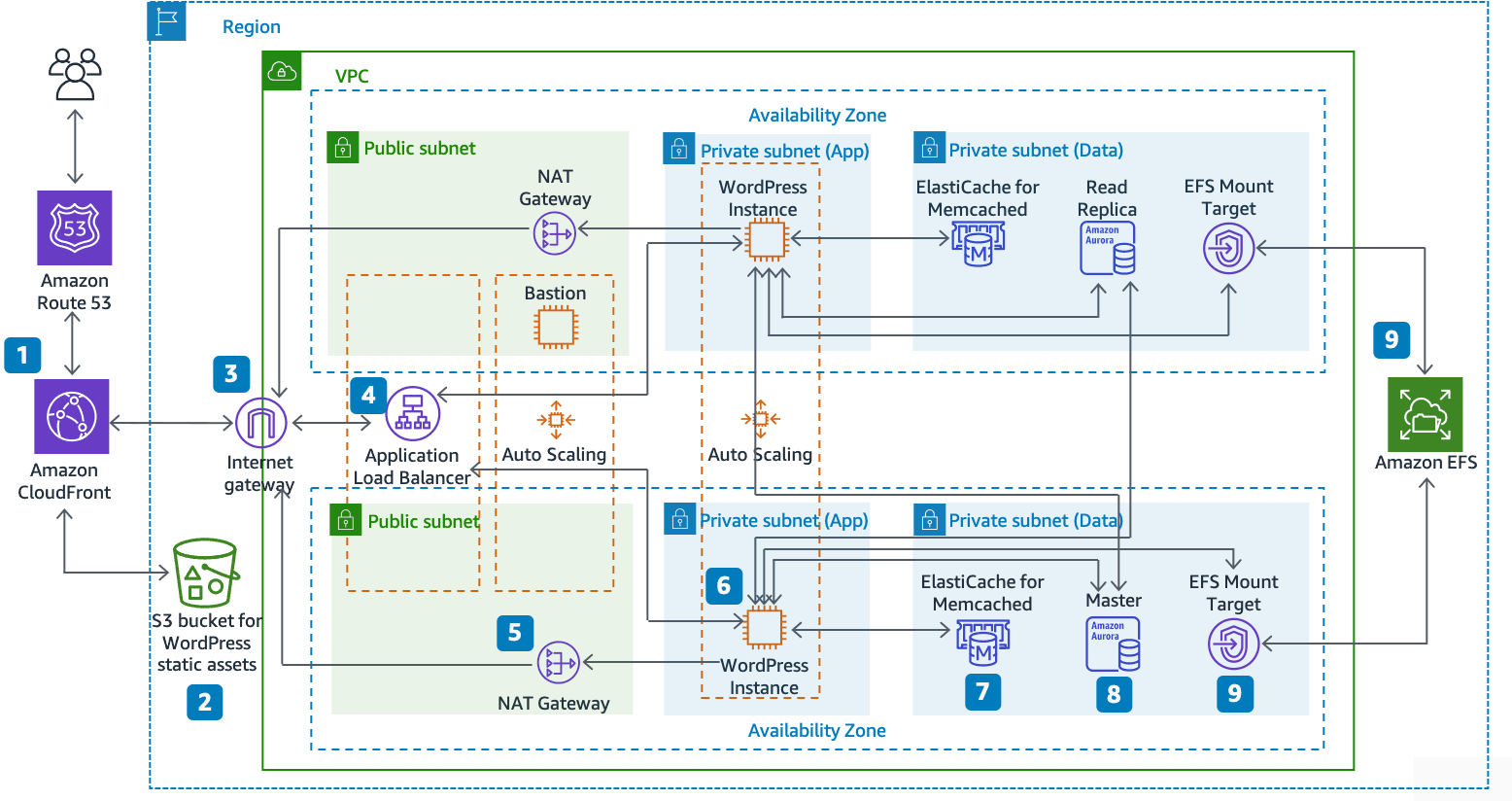
“Reference architecture for hosting WordPress on AWS: The Hosting WordPress on AWS reference architecture available on GitHub outlines best practices for deploying WordPress on AWS and includes a set of AWS CloudFormation templates to get you up and running quickly. The following architecture is based on that reference architecture. The rest of this section will review the reasons behind the architectural choices.”