- See Also
-
Gwern
- “CQK Is The First Unused TLA”, Gwern 2023
- “Prediction Markets”, Gwern 2009
- “In Defense of Inclusionism”, Gwern 2009
- “Writing a Wikipedia Link Archive Bot”, Gwern 2008
- “Wikipedia Résumé”, Gwern 2010
- “Wikipedia & YouTube”, Gwern 2009
- “Wikipedia & Knol: Why Knol Already Failed”, Gwern 2009
- “Wikipedia and Dark Side Editing”, Gwern 2009
- “Writing a Wikipedia RSS Link Archive Bot”, Gwern 2009
- “Wikipedia and Other Wikis”, Gwern 2009
-
Links
- “GoodWiki”, Choi 2023
- “WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
- “The Dirty Secrets of a Smear Campaign: Rumors Destroyed Hazim Nada’s Company. Then Hackers Handed Him Terabytes of Files Exposing a Covert Campaign against Him—And the Culprit Wasn’t a Rival but an Entire Country”, Kirkpatrick 2023
- “What Determines Hindsight Bias in Written Work? One Field and Three Experimental Studies in the Context of Wikipedia”, Meuer et al 2022
- “Trial by Internet: A Randomized Field Experiment on Wikipedia’s Influence on Judges’ Legal Reasoning”, Thompson et al 2022
- “How Wikipedia Influences Judicial Behavior”, Gordon 2022
- “Learning to Model Editing Processes”, Reid & Neubig 2022
- “Restricted Access: How the Internet Can Be Used to Promote Reading and Learning”, Derksen et al 2022
- “A Large-Scale Characterization of How Readers Browse Wikipedia”, Piccardi et al 2021
- “FRUIT: Faithfully Reflecting Updated Information in Text”, IV et al 2021
- “Externalities in Knowledge Production: Evidence from a Randomized Field Experiment”, Hinnosaar et al 2021
- “Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
- “Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
- “WIT: Wikipedia-Based Image Text Dataset for Multimodal Multilingual Machine Learning”, Srinivasan et al 2021
- “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, Gao et al 2021
- “TAPAS: Weakly Supervised Table Parsing via Pre-Training”, Herzig et al 2020
- “The Intrepid Mother and Son Who Unraveled a Geographic Hoax: Atlas Obscura Had a Page for Something Called Moose Boulder, Until Fan Roger Dickey Called Us on It.”, Taub 2020
- “REALM: Retrieval-Augmented Language Model Pre-Training”, Guu et al 2020
-
“
popups.js”, Achmiz 2019 -
“
wikipedia-Popups.js”, Achmiz 2019 - “Wikipedia Matters”, Hinnosaar et al 2019
- “The Wisdom of Polarized Crowds”, Shi 2019
- “Inside the Secret Sting Operations to Expose Celebrity Psychics: Are Some Celebrity Mediums Fooling Their Audience Members by Reading Social Media Pages in Advance? A Group of Online Vigilantes Is out to Prove It”, Hitt 2019
- “What Is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use”, Erickson et al 2018
- “Generating Wikipedia by Summarizing Long Sequences”, Liu et al 2018
- “Revisiting ‘The Rise and Decline’ in a Population of Peer Production Projects”, TeBlunthuis et al 2018
- “Examining Wikipedia With a Broader Lens: Quantifying the Value of Wikipedia’s Relationships With Other Large-Scale Online Communities”, Vincent 2018
- “Learning to Organize Knowledge and Answer Questions With N-Gram Machines”, Yang et al 2017
- “Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning”, Zhong et al 2017
- “Does Copyright Affect Reuse? Evidence from Google Books and Wikipedia”, Nagaraj 2017
- “Biases in the Production and Reception of Collective Knowledge: the Case of Hindsight Bias in Wikipedia”, Oeberst et al 2017
- “The Valuation of Unprotected Works: A Case Study of Public Domain Images on Wikipedia”, Heald et al 2015
- “Impact of Wikipedia on Market Information Environment: Evidence on Management Disclosure and Investor Reaction”, Xu & Zhang 2013
- “Wikimedia UK Board Meeting, London”, Gardner 2011
- “Circadian Patterns of Wikipedia Editorial Activity: A Demographic Analysis”, Yasseri et al 2011
- “File:Newbie Survival by Semester Rows.png”
- “Beware Trivial Inconveniences”, Alexander 2009
- “Wikipedia Over DNS”
- “He Says, She Says: Conflict and Coordination in Wikipedia”, Kittur et al 2007
- “What Is Popular on Wikipedia and Why?”, Spoerri 2007
- “A Group Is Its Own Worst Enemy”, Shirky 2005
- “Do Incentive Contracts Crowd Out Voluntary Cooperation?”, Fehr & Gächter 2001
- “Wikipedia Shapes Language in Science Papers: Experiment Traces How Online Encyclopaedia Influences Research Write-Ups”
- Sort By Magic
- Wikipedia
- Miscellaneous
- Link Bibliography
See Also
Gwern
“CQK Is The First Unused TLA”, Gwern 2023
“Prediction Markets”, Gwern 2009
“In Defense of Inclusionism”, Gwern 2009
“Writing a Wikipedia Link Archive Bot”, Gwern 2008
“Wikipedia Résumé”, Gwern 2010
“Wikipedia & YouTube”, Gwern 2009
“Wikipedia & Knol: Why Knol Already Failed”, Gwern 2009
“Wikipedia and Dark Side Editing”, Gwern 2009
“Writing a Wikipedia RSS Link Archive Bot”, Gwern 2009
“Wikipedia and Other Wikis”, Gwern 2009
Links
“GoodWiki”, Choi 2023
“WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
“The Dirty Secrets of a Smear Campaign: Rumors Destroyed Hazim Nada’s Company. Then Hackers Handed Him Terabytes of Files Exposing a Covert Campaign against Him—And the Culprit Wasn’t a Rival but an Entire Country”, Kirkpatrick 2023
“What Determines Hindsight Bias in Written Work? One Field and Three Experimental Studies in the Context of Wikipedia”, Meuer et al 2022
“Trial by Internet: A Randomized Field Experiment on Wikipedia’s Influence on Judges’ Legal Reasoning”, Thompson et al 2022
Trial by Internet: A Randomized Field Experiment on Wikipedia’s Influence on Judges’ Legal Reasoning
“How Wikipedia Influences Judicial Behavior”, Gordon 2022
“Learning to Model Editing Processes”, Reid & Neubig 2022
“Restricted Access: How the Internet Can Be Used to Promote Reading and Learning”, Derksen et al 2022
Restricted access: How the internet can be used to promote reading and learning
“A Large-Scale Characterization of How Readers Browse Wikipedia”, Piccardi et al 2021
A Large-Scale Characterization of How Readers Browse Wikipedia
“FRUIT: Faithfully Reflecting Updated Information in Text”, IV et al 2021
“Externalities in Knowledge Production: Evidence from a Randomized Field Experiment”, Hinnosaar et al 2021
Externalities in knowledge production: evidence from a randomized field experiment
“Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
“Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (VitaminC)
“WIT: Wikipedia-Based Image Text Dataset for Multimodal Multilingual Machine Learning”, Srinivasan et al 2021
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
“The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, Gao et al 2021
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
“TAPAS: Weakly Supervised Table Parsing via Pre-Training”, Herzig et al 2020
“The Intrepid Mother and Son Who Unraveled a Geographic Hoax: Atlas Obscura Had a Page for Something Called Moose Boulder, Until Fan Roger Dickey Called Us on It.”, Taub 2020
“REALM: Retrieval-Augmented Language Model Pre-Training”, Guu et al 2020
“popups.js”, Achmiz 2019
“wikipedia-Popups.js”, Achmiz 2019
“Wikipedia Matters”, Hinnosaar et al 2019
“The Wisdom of Polarized Crowds”, Shi 2019
“Inside the Secret Sting Operations to Expose Celebrity Psychics: Are Some Celebrity Mediums Fooling Their Audience Members by Reading Social Media Pages in Advance? A Group of Online Vigilantes Is out to Prove It”, Hitt 2019
“What Is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use”, Erickson et al 2018
What is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use
“Generating Wikipedia by Summarizing Long Sequences”, Liu et al 2018
“Revisiting ‘The Rise and Decline’ in a Population of Peer Production Projects”, TeBlunthuis et al 2018
Revisiting ‘The Rise and Decline’ in a Population of Peer Production Projects
“Examining Wikipedia With a Broader Lens: Quantifying the Value of Wikipedia’s Relationships With Other Large-Scale Online Communities”, Vincent 2018
“Learning to Organize Knowledge and Answer Questions With N-Gram Machines”, Yang et al 2017
Learning to Organize Knowledge and Answer Questions with N-Gram Machines
“Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning”, Zhong et al 2017
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
“Does Copyright Affect Reuse? Evidence from Google Books and Wikipedia”, Nagaraj 2017
Does Copyright Affect Reuse? Evidence from Google Books and Wikipedia
“Biases in the Production and Reception of Collective Knowledge: the Case of Hindsight Bias in Wikipedia”, Oeberst et al 2017
“The Valuation of Unprotected Works: A Case Study of Public Domain Images on Wikipedia”, Heald et al 2015
The Valuation of Unprotected Works: A Case Study of Public Domain Images on Wikipedia
“Impact of Wikipedia on Market Information Environment: Evidence on Management Disclosure and Investor Reaction”, Xu & Zhang 2013
“Wikimedia UK Board Meeting, London”, Gardner 2011
“Circadian Patterns of Wikipedia Editorial Activity: A Demographic Analysis”, Yasseri et al 2011
Circadian patterns of Wikipedia editorial activity: A demographic analysis
“File:Newbie Survival by Semester Rows.png”
{kind=link}
“Beware Trivial Inconveniences”, Alexander 2009
“Wikipedia Over DNS”
“He Says, She Says: Conflict and Coordination in Wikipedia”, Kittur et al 2007
“What Is Popular on Wikipedia and Why?”, Spoerri 2007
“A Group Is Its Own Worst Enemy”, Shirky 2005
“Do Incentive Contracts Crowd Out Voluntary Cooperation?”, Fehr & Gächter 2001
“Wikipedia Shapes Language in Science Papers: Experiment Traces How Online Encyclopaedia Influences Research Write-Ups”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
fact-checking
wikiresearch
wiki-learning
Wikipedia
Miscellaneous
-
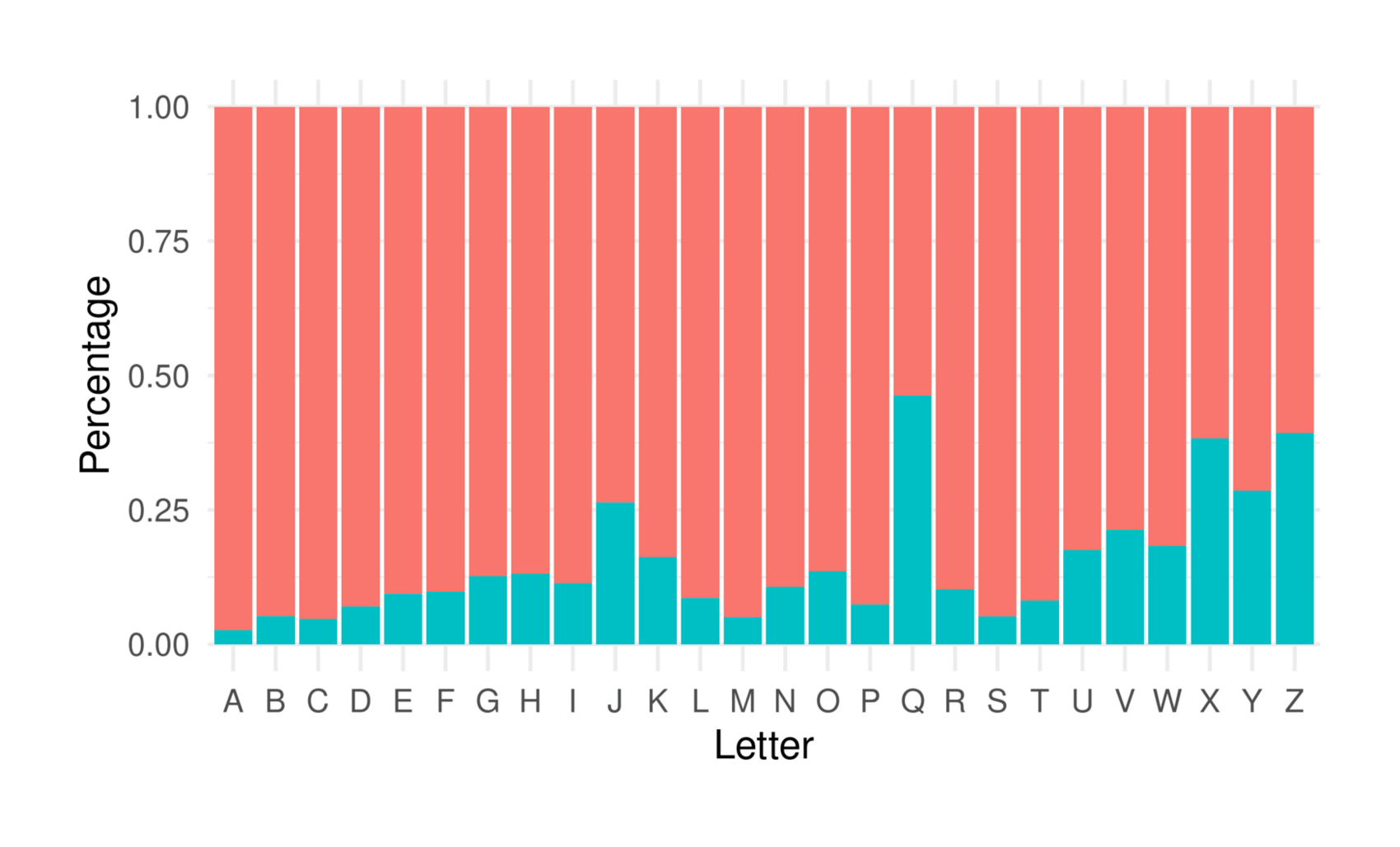
/doc/wikipedia/2023-10-01-gwern-tla-lettervsunusedtlaswiththatletterpercentageoverthealphabet.png: -
/doc/wikipedia/2023-10-01-gwern-wikipedia-unusedacronyms-alphanumerical1to3lettertlas.txt -
/doc/wikipedia/2023-10-01-gwern-wikipedia-unusedacronyms-processeddata.csv.xz: -
/doc/wikipedia/2023-09-30-gwern-wikipedia-unusedacronyms-threeletterandfourletter.txt -
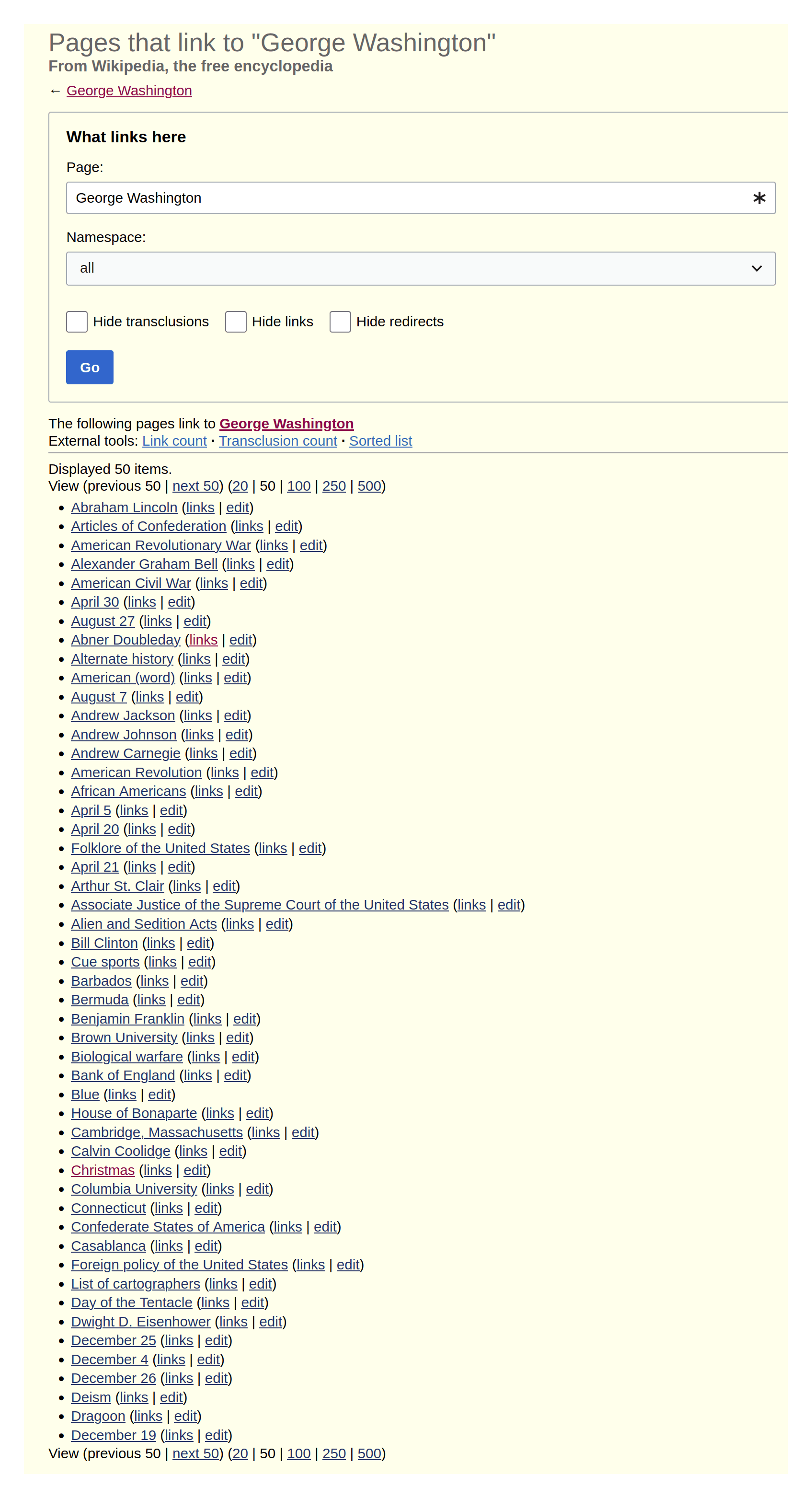
/doc/wikipedia/2023-04-18-mediawiki-englishwikipedia-georgewashington-whatlinkshere.png -
/doc/wikipedia/2017-09-29-gwern-wikipedia-humordeletion.jpg: -
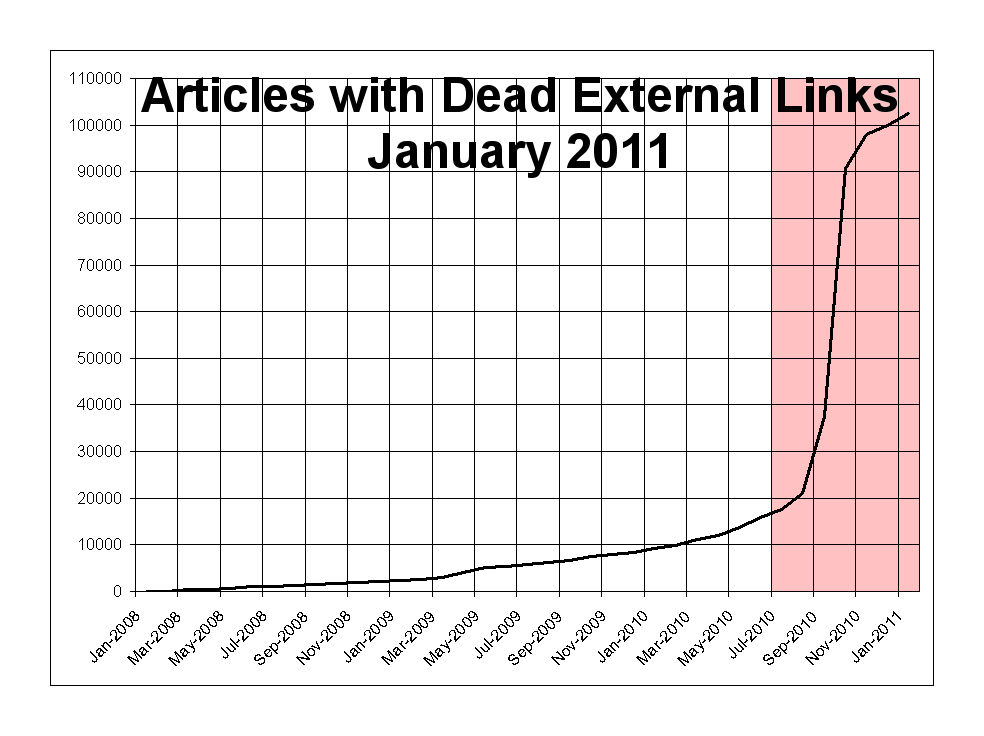
/doc/wikipedia/2011-01-wikipedia-articleswithdeadexternallinks.png -
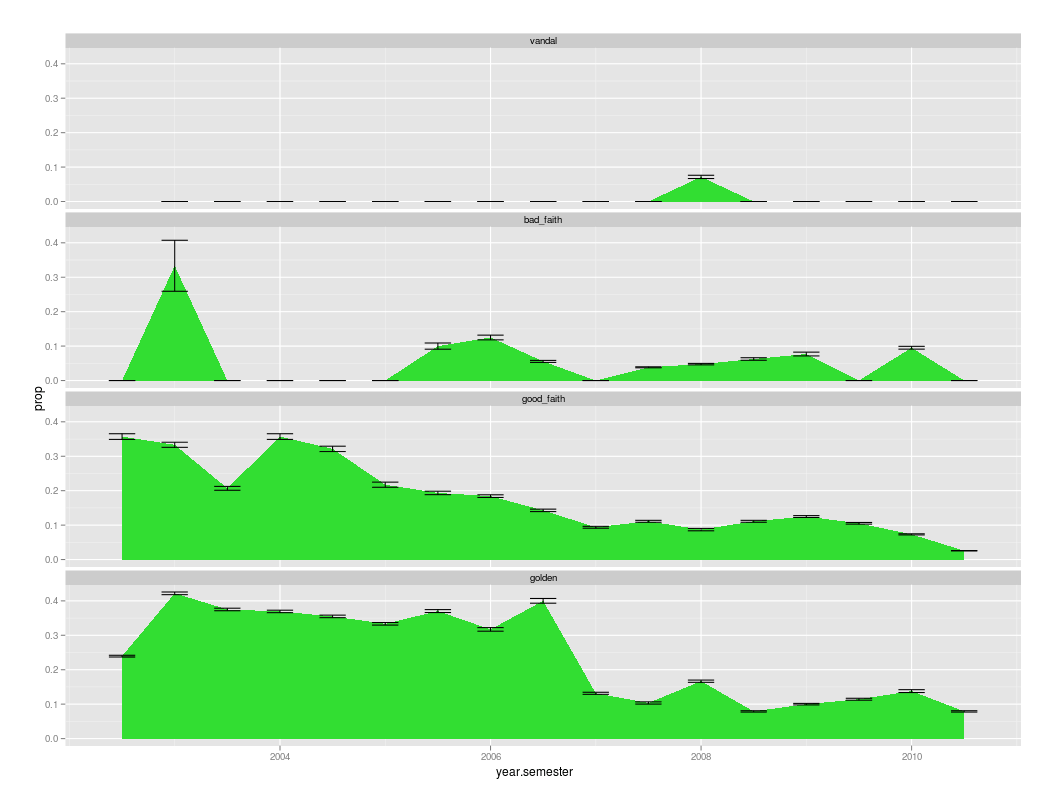
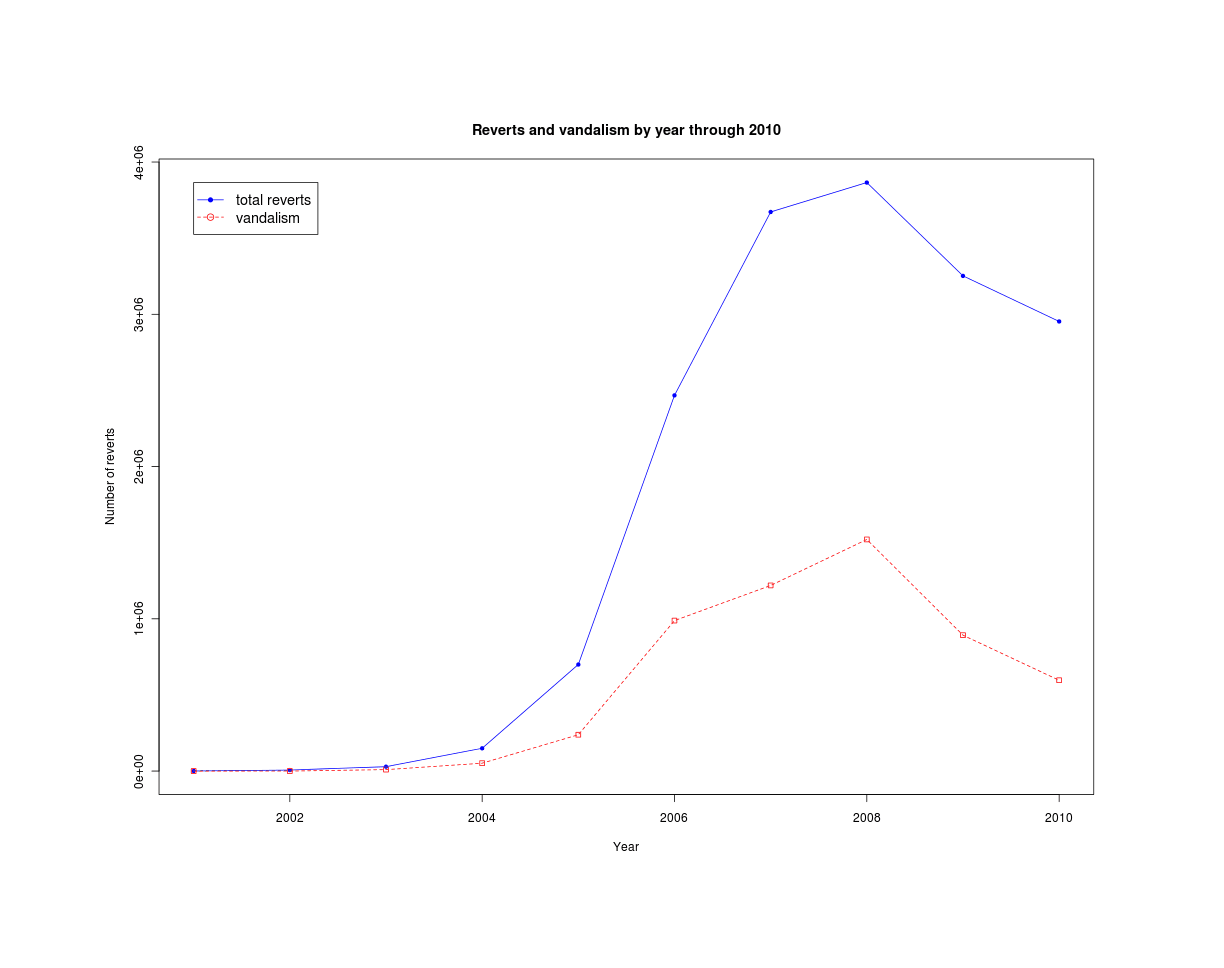
/doc/wikipedia/2011-wikipedia-vandalreverttrendbyyear20022010.png -
/doc/cs/algorithm/2006-jared-wikimediaprovesgreenspunstenthlaw.html -
http://slightlynew.blogspot.com/2011/05/who-writes-wikipedia-information.html -
https://colinmorris.github.io/blog/unpopular-wiki-articles:View External Link:
-
https://doughanley.com/files/papers/thompson_hanley_wikipedia.pdf -
https://getpocket.com/explore/item/one-woman-s-mission-to-rewrite-nazi-history-on-wikipedia -
https://meta.wikimedia.org/wiki/International_logo_contest/Logos_1-25 -
https://tedgioia.substack.com/p/how-a-prominent-composer-lost-his -
https://twitter.com/depthsofwiki/status/1735800801455419697: -
https://uxdesign.cc/design-notes-on-the-2023-wikipedia-redesign-d6573b9af28d -
https://www.koopatv.org/2022/10/why-people-dont-like-fandom-wikis.html -
https://www.smashingmagazine.com/2023/06/behind-curtains-wikipedia-redesign/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4174200: “Trial by Internet: A Randomized Field Experiment on Wikipedia’s Influence on Judges’ Legal Reasoning”, Neil Thompson, Brian Flanagan, Edana Richardson, Brian McKenzie, Xueyun Luo -
https://arxiv.org/abs/2112.11848: “A Large-Scale Characterization of How Readers Browse Wikipedia”, Tiziano Piccardi, Martin Gerlach, Akhil Arora, Robert West -
https://arxiv.org/abs/2107.01294#allen: “Scarecrow: A Framework for Scrutinizing Machine Text”, Yao Dou, Maxwell Forbes, Rik Koncel-Kedziorski, <a href=https://nasmith.github.io/>N. A. Smith</a>, Yejin Choi -
https://arxiv.org/abs/2101.00027#eleutherai: “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”,