GAN Explorations 012: Aesop’s Fables Woodcut Illustrations
February 6, 2020: What does it look like for a computer create art informed by 15th-century woodcut illustrations? In these examples, images were scanned by Brady Baltezore from Aesop: Five Centuries of Illustrated Fables, published in 1964 by the Metropolitan Museum of Art.
The book:



Sample book imagery:






Generated Images:
The model trained on the Aesop Images was transfer trained from my own WikiArt dataset.


Results Interpolation Video:
A 1-minute animated loop exploring the woodcut results.
Additional Generated Images:








Original StyleGAN Version with Blob Artifacts:
I originally attempted training with this dataset in November, 2019 before StyleGAN2 was released. The blob artifacts made the results unusable:

GAN Explorations 011: StyleGAN2 + Stochastic Weight Averaging
January 29, 2020: Explorations using Peter Baylie’s stochastic weight averaging script. A new, average model is created from two source models. The sources in this case are based on WikiArt imagery and Beeple’s art. Each source is transfer-learned from a common original source.
Basically, it’s a fast way to blend between two StyleGAN models!
Left Image: WikiArt
Middle Image: Average
Right Image: Beeple











GAN Explorations 010: StyleGAN2
January 6, 2020: Some still images from the StyleGAN2 implementation of #BeepleGAN.





GAN Explorations 009: StyleGAN2
December 14, 2019: Nvidia released StyleGAN2. The blobs are gone! Here are some early results of training with Beeple’s everyday imagery.
First a video:

Some generated stills:




GAN Explorations 008: Qrion Album Art
November 26, 2019: Created generative visualizer videos for the release of Qrion’s Sine Wave Party EP out on Anjunadeep. The artist, Momiji Tsukada, curated a set of images she associates with the music. I took these and created audio-reactive, generative videos. These are some of my favorite still images I created during the training process:








GAN Explorations 007: Embedding Imagery
November 5, 2019: Building upon BeepleGAN HQ, here is an exploration of embedding intentional imagery (the number “5”) into the output of the model. In this way, I’m able to control and specify what the output looks like rather than just taking whatever random output the model produces.
Results video:

Still frames:
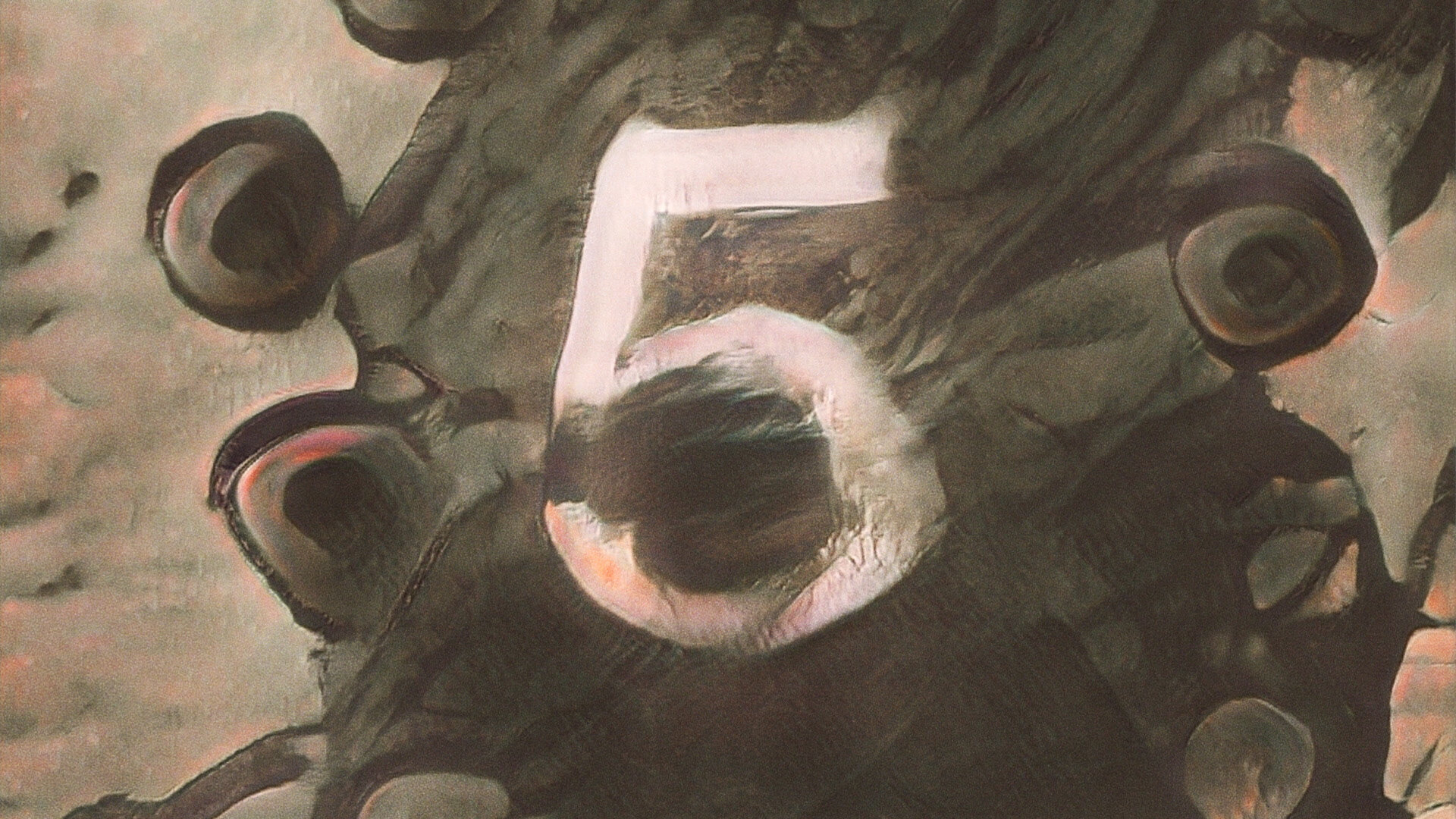

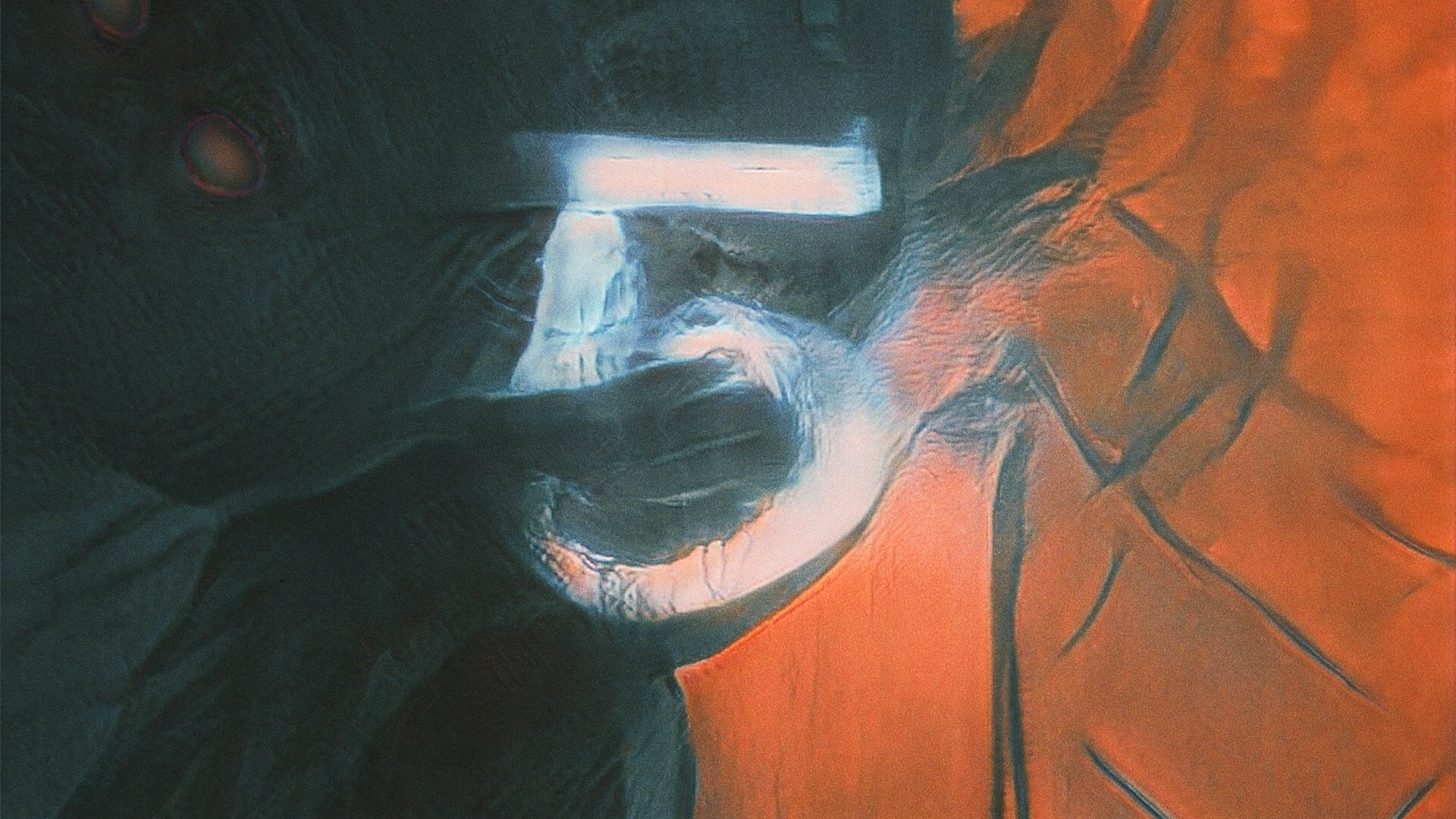
GAN Explorations 006: BeepleGAN HQ
October 28, 2019: BeepleGAN goes HD. 1024x1024. Holy moly.




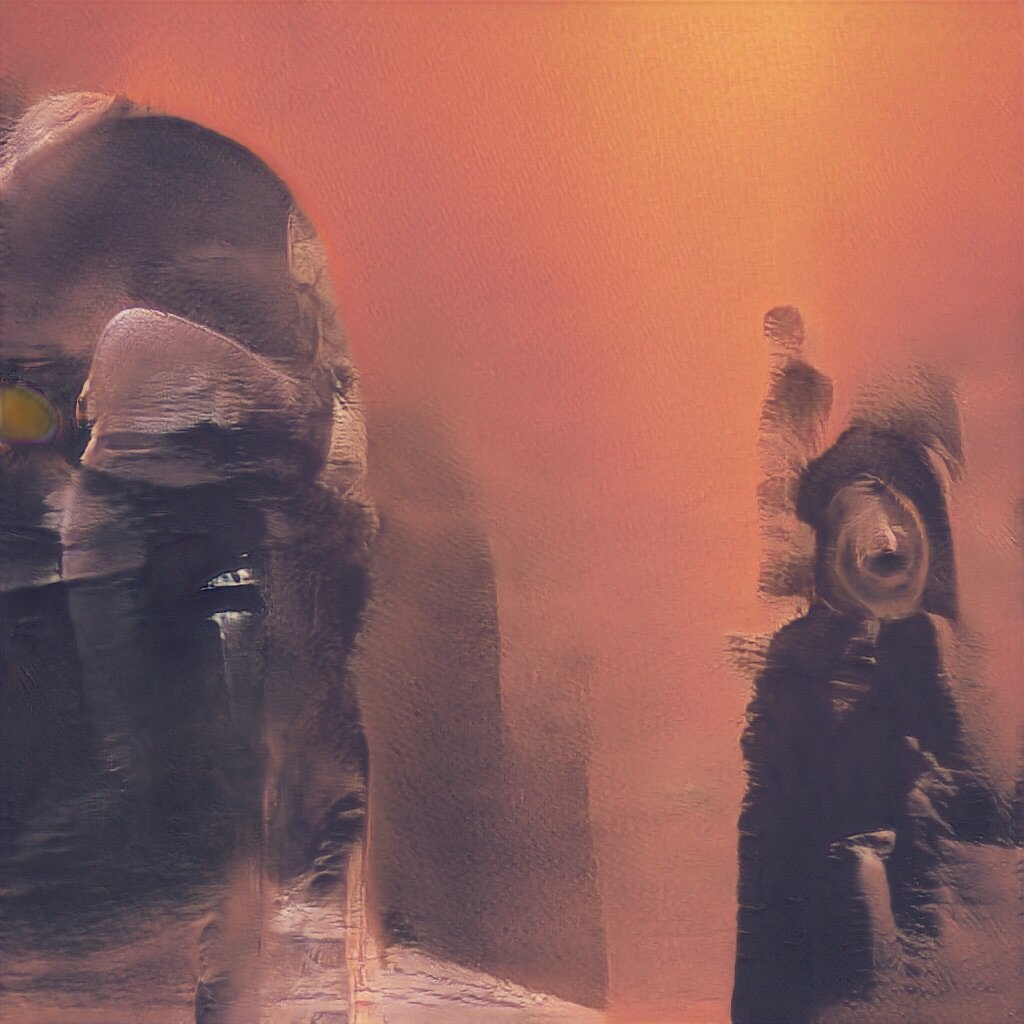





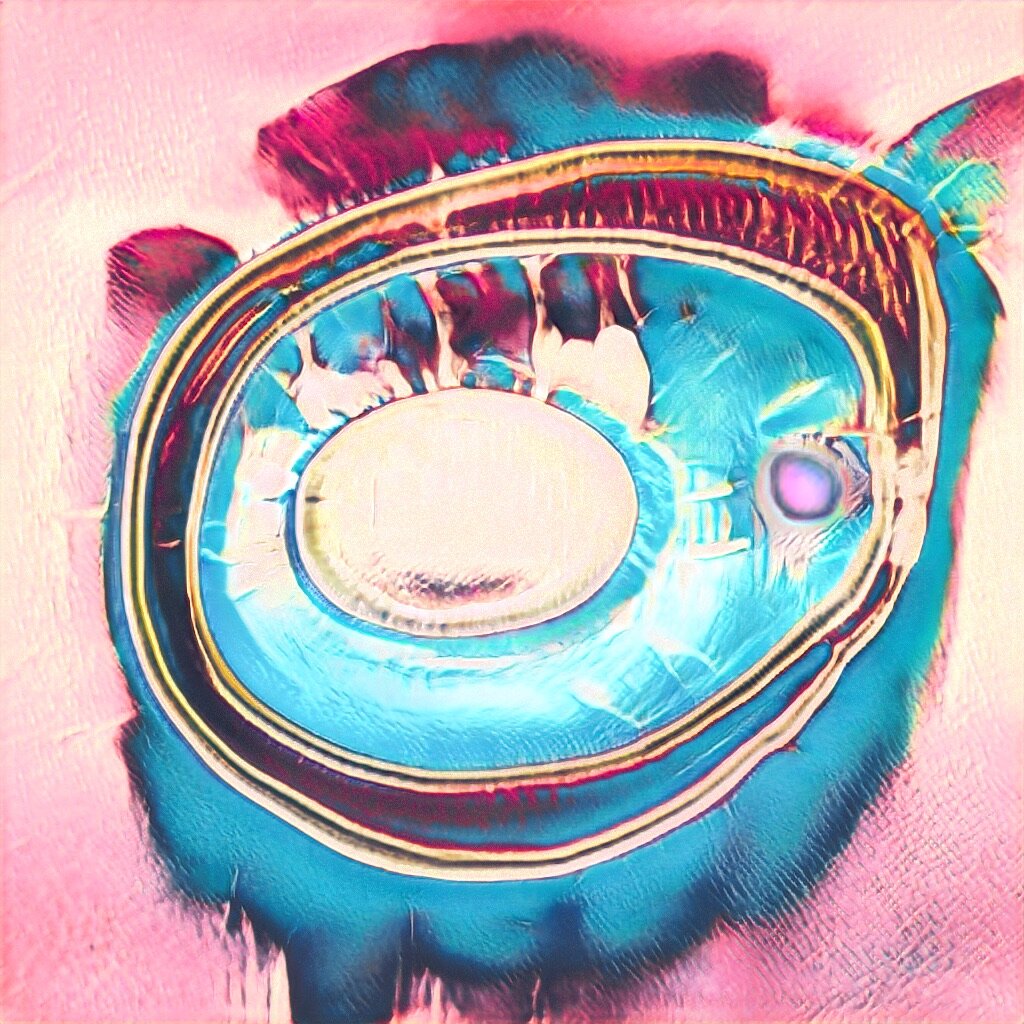



GAN Explorations 005: BeepleGAN
October 25, 2019: Learning from Beeple’s Everydays.








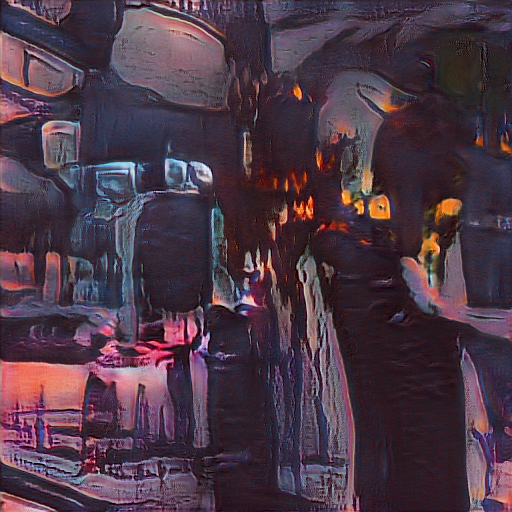








GAN Explorations 004: Cubism Transfer Learning
October 24, 2019: Image on the left is generated by /u/_C0D32_’s WikiArt.org model.
Image on the right shows that same latent vector after being trained on a custom dataset of cubist imagery.

A generated image versus it’s Cubist representation in the parallel model, followed by more examples:




GAN Explorations 003: PopArtGAN
October 21, 2019: Results of training StyleGAN from scratch on a custom dataset of Pop Art imagery.
A video:

A selection of stills:

GAN Explorations 002: Figure Drawing / Pop Art Diptychs
October 17, 2019: Results of transfer learning a model trained on WikiArt.org (from /u/_C0D32_) with both figure drawings and pop art. Diptychs feature the same random vector interpolation through the two parallel models.
Video:

Stills:





GAN Explorations 001: Figure drawings + the history of art as understood by a neural network.
October 16, 2019: Results of combining two StyleGAN neural networks - the first trained on a broad sampling of art (WikiArt.org), and the second a transfer learning from a small, custom dataset of figure drawings.
Video:

Sample images from varying truncation Ψ:








Acknowledgments and Inspiration
Thanks go to:
Gwern Branwen for their incredible guide to working with StyleGAN.
Reddit user /u/_C0D32_ for sharing their work with WIkiArt imagery and StyleGAN.
Josh Urban Davis for inspiration and guidance.
Maryam Ashoori for transfer learning inspiration.
Memo Akten for inspiration with his project, Deep Meditations.
Code modified from NVIDIA Research Projects official StyleGAN GitHub repo.