Orchestrating false beliefs about gender discrimination
[Edit: I wrote a more succinct and updated version of this post here. Probably read that instead.]
In this article from the New York Times, they claim that there is extreme gender discrimination in tech:
In a 2016 experiment conducted by the tech recruiting firm Speak With a Geek, 5,000 résumés with identical information were submitted to firms. When identifying details were removed from the résumés, 54 percent of the women received interview offers; when gendered names and other biographical information were given, only 5 percent of them did.
This turned out to be fake. (Twitter thread with details). The study doesn’t actually exist. It was also ridiculous. If you know anything about plausible effect sizes, or interview processes, or the real world, you would immediately see that a disparity of this magnitude was fully implausible.
What about other studies regarding gender discrimination? For example, there is that study about classical orchestras, where blind auditions massively increased the chance of women to get hired.
Here is The Guardian about this study:
Even when the screen is only used for the preliminary round, it has a powerful impact; researchers have determined that this step alone makes it 50% more likely that a woman will advance to the finals
This study has 1388 citations. It has also been featured on Freakonomics, TED talks, Reddit, Slate, New York Times, Wikipedia, and I’m sure countless other mediums. I hear about it in frequently in real life when gender discrimination is discussed. Active mentioning of it on Twitter can be seen in this search.
I have not once heard anything skeptical said about that study, and it is published in a fine journal. So one would think it is a solid result. But let’s try to look into the paper. It is publically available here. (Statistics follow, scroll down for conclusion.)
Table 4 presents the first results comparing success in blind auditions vs non-blind auditions.

The value for relative female success is the proportion of women that are successful in the audition process minus the proportion of men that are successful. The values for non-blind auditions are positive, meaning a larger proportion of women are successful, whereas the values for blind auditions are negative, meaning a larger proportion of men are successful. So, this table unambiguously shows that men are doing comparatively better in blind auditions than in non-blind auditions. The exact opposite of what is claimed.
Now, of course this measure could be confounded. It is possible that the group of people who apply to blind auditions is not identical to the group of people who apply to non-blind auditions. Perhaps women (mistakenly as it turns out) think that more of them succeed in blind auditions, and thus more women apply to those, resulting in the average skill level among the female applicants decreasing, which affects the results.
There is some data in which the same people have applied to both orchestras using blind auditions and orchestras using non-blind auditions, which is presented in table 5:
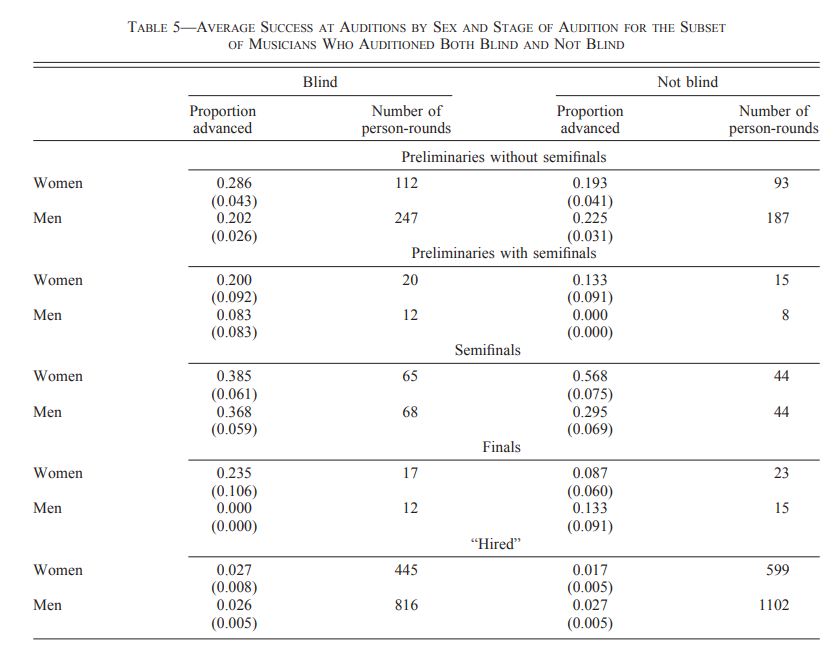
Here we see that the proportion of women advanced is higher in blind auditions in the hired, finals, and preliminaries categories, but lower in the semifinals category. However, it is highly doubtful that we can conclude anything from this table.
- The sample sizes are small, and the proportions vary wildly, indicating that the results are not significant. No standard errors or p values of the difference in proportions are listed in the table. I calculated a Fisher’s exact test for the largest category (hired) and got a p-value of 0.28.
- The analysis is limited by having only 1–3 orchestras of the blind / non-blind type depending on the category. So even if there was clear discrimination, this could be caused by very few people.
In the next table they instead address the issue by regression analysis. Here they can include covariates such as number of auditions attended, year, etc, hopefully correcting for the sample composition problems mentioned above. Such analyses should always be viewed critically, since the results can vary a lot depending on which covariates you include. They list the results in table 6:
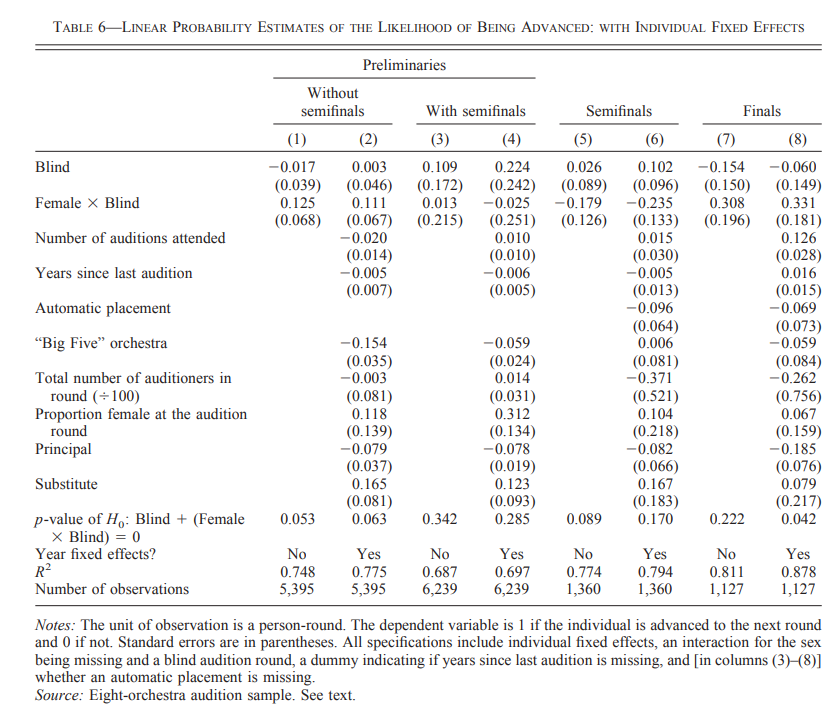
This is a somewhat complicated regression table. Again the values fluctuate wildly, with the proportion of women advanced in blind auditions being higher in the finals, and the proportion of men advanced being higher in the semifinals. But again, the sample sizes are too small, the p-values are not significant, and nothing can be concluded from this. There is one p-value (0.042) that is nominally significant at 0.05. However, given that at least 8 tests are performed in this table, we should adjust for multiple testing, which with the Bonferroni correction gives us a p-value of 0.33.
The paper also looks at the issue from another angle: How do blind auditions impact the likelihood of a woman ending up being hired? The results in this section (even after a statistically questionable data split) are not significant, as they state in the paper:
Women are about 5 percentage points more likely to be hired than are men in a completely blind audition, although the effect is not statistically significant. The effect is nil, however, when there is a semifinal round, perhaps as a result of the unusual effects of the semifinal round. The impact for all rounds [columns (5) and (6)] is about 1 percentage point, although the standard errors are large and thus the effect is not statistically significant.
So, in conclusion, this study presents no statistically significant evidence that blind auditions increase the chances of female applicants. In my reading, the unadjusted results seem to weakly indicate the opposite, that male applicants have a slightly increased chance in blind auditions; but this advantage disappears with controls.













