
Despite the buzz around GPT-3, it is, in and of itself, not AGI. In many ways, this makes it similar to AlphaGo or Deep Blue; while approaching human ability in one domain (playing Chess/Go, or writing really impressively), it doesn’t really seem like it will do Scary AGI Things™ any more than AlphaGo is going to be turning the Earth into paperclips anytime soon. While its writings are impressive at emulating humans, GPT-3 (or any potential future GPT-x) has no memory of past interactions, nor is it able to follow goals or maximize utility. However, language modelling has one crucial difference from Chess or Go or image classification. Natural language essentially encodes information about the world—the entire world, not just the world of the Goban, in a much more expressive way than any other modality ever could.[1] By harnessing the world model embedded in the language model, it may be possible to build a proto-AGI.
World Modelling
The explicit goal of a language model is only to maximize likelihood of the model on natural language data. In the autoregressive formulation that GPT-3 uses, this means being able to predict the next word as well as possible. However, this objective places much more weight on large, text-scale differences like grammar and spelling than fine, subtle differences in semantic meaning and logical coherency, which reflect as very subtle shifts in distribution. Once the former are near-perfect, though, the only place left to keep improving is the latter.
At the extreme, any model whose loss reaches the Shannon entropy of natural language—the theoretical lowest loss a language model can possibly achieve, due to the inherent randomness of language—will be completely indistinguishable from writings by a real human in every way, and the closer we get to it, the more abstract the effect on quality of each bit of improvement in loss. Or, said differently, stringing words together using Markov chain generators gets you 50% of the way there, figuring out grammar gets you another 50% of the remaining distance, staying on topic across paragraphs gets you another 50% of the remaining distance, being logically consistent gets you another 50% of the remaining distance, and so on.[2]
Shannon Entropy: the number of bits necessary, on average to specify one piece of text.
Why? Because if you have a coherent-but-not-logically consistent model, becoming more logically consistent helps you predict language better. Having a model of human behavior helps you predict language better. Having a model of the world helps you predict language better. As the low-hanging fruits of grammar and basic logical coherence are taken, the only place left for the model to keep improving the loss is a world model. Predicting text is equivalent to AI.
The thing about GPT-3 that makes it so important is that it provides evidence that as long as we keep increasing the model size, we can keep driving down the loss, possibly right up until it hits the Shannon entropy of text. No need for clever architectures or complex handcrafted heuristics. Just by scaling it up we can get a better language model, and a better language model entails a better world model.
But how do we use this language model if it’s buried implicitly-represented inside GPT-x, though? Well, we can literally just ask it, in natural language, what it thinks will happen next given a sequence of events, and its output distribution will approximate the distribution of what the average human thinks would happen next after those events. Great—we’ve got ourselves a usable world model.
“But wait!” you say, “Various experiments have shown that GPT-3 often fails at world modelling, and just conjecturing that adding more parameters will fix the problem is a massive leap!” If you’re thinking this, you’re absolutely correct. The biggest and most likely to be wrong assumption that I’m making is that larger models will develop better world models. Since as loss approaches the Shannon entropy its world modelling ability has to become about as good than the average human on the internet[3], this boils down to two questions: “Will we really make models whose loss gets close enough to the Shannon entropy?” and “How close is close enough, in order to have the world modelling capabilities to make all this practical?”
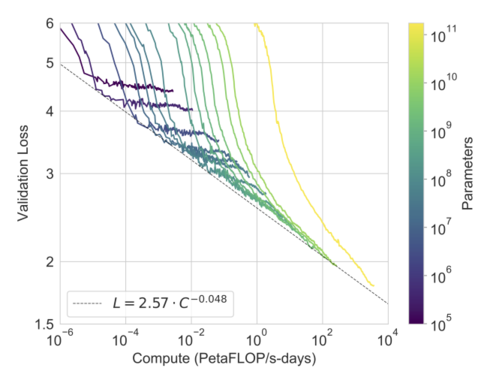 Loss keeps going down with more parameters and compute. (Source)
Loss keeps going down with more parameters and compute. (Source)
The answer to the first question is “most likely”—that’s the main takeaway of GPT-3. The answer to the second question is… nobody knows. Some have demonstrated ways of making GPT-3 better at world modelling, but this alone is probably not sufficient. When models with 1 trillion, then 10 trillion, then 100 trillion parameters become available, we will have empirical evidence to see whether this assumption is correct. If GPT-x demonstrates uncanny ability to predict outcomes in the real world, then this just might work.
Putting the pieces together
A world model alone does not an agent make, though.[4] So what does it take to make a world model into an agent? Well, first off we need a goal, such as “maximize number of paperclips”. Then, we just ask the world model “What action can I take to maximize the number of paperclips I have?” Simple, right? Actually, not quite. The problem is that our world model probably won’t be able to consider all the possible things that could happen next well enough to make a reasonable answer.
 GPT-3 considers mesa-optimization. (Source: OpenAI API)
GPT-3 considers mesa-optimization. (Source: OpenAI API)
So what can we do instead? Well, asking the world model for a list of things you could do in a given world state would probably not be outside the capabilities of a sufficiently powerful language model (think: “I am in situation xyz. Here is a list of things I could do:”). Similarly, asking the world model how much reward you’d get in some hypothetical world where you took a sequence of actions would probably be possible too—imagine asking something along the lines of “I go to ebay. I look up paperclips, sorted by price ascending. I spend $100 on the first item on the list. How many paperclips will I have?”[5] This will let us figure out what actions the agent can take in any given step (policy function), as well as how much reward each sequence of steps will net the agent (value function).
So now, to estimate the state-action value of any action, we can simply do Monte Carlo Tree Search to estimate the state-action values! Starting from a given agent state, we can roll out sequences of actions using the world model. By integrating over all rollouts, we can know how much future expected reward the agent can expect to get for each action it considers. Then, we can simply use, for example, a greedy policy with that state-action value function, to decide on actions to take.
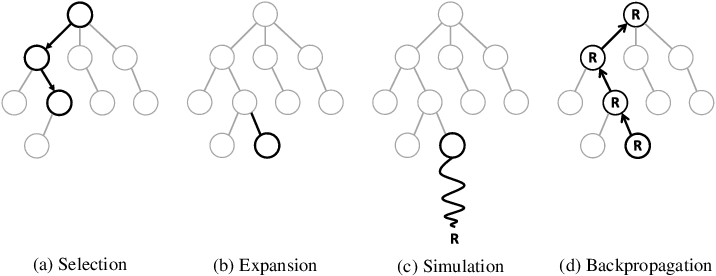 Monte Carlo Tree Search visualized (Source)
Monte Carlo Tree Search visualized (Source)
Each of these actions is likely to be very high level, such as “figure out the cheapest way to buy paperclips”, but thanks to the flexibility of language we can describe very complex ideas with short sequences of tokens. To actually execute these abstract actions once the agent decides on an action, that action can be broken down using the language model into smaller sub-goals such as “figure out the cheapest paperclips on Amazon”, similar to Hierarchical Reinforcement Learning. Possibly even just breaking actions down into a detailed list of instructions would be feasible, depending on the capabilities of the model and how abstract the actions are.
We can represent the agent state as natural language, too. Since the agent state is just a compressed representation of the observations, we can ask the language model to summarize the important information of any observations for its own internal world state. The language model could be used to periodically prune (i.e forget) the information inside its state, too, to make room for more observations.
Altogether, this gets us a system where we can pass observations from the outside world in, spend some time thinking about what to do, and output an action in natural language.
To handle input, you could have an input module that turns various modalities of observations into summarized text with respect to the current agent state. For instance, you could use something like iGPT to input camera images or screenshots, or raw HTML from webpages that the agent requests. How exactly this is done is tangential to the point; all that matters is that somehow the inputs are all converted to text and added to the agent state. The examples I have provided are just to convince you that it’s absolutely not insurmountable.
Finally, to get the model to actually act in the world, you could again use the language model to translate natural language into code that is then executed, or shell commands, or sequences of keypresses, or any of a number of other possible ways. Like input, there are an infinitude of different ways to solve the output problem, and which one turns out to be the best is entirely irrelevant to our discussion; all that matters is that it’s possible to get various modalities in and out of the text-only agent.[6]
 An example of an input module taking a screenshot input combined with the current agent state to give an observation with the information needed by the agent.
An example of an input module taking a screenshot input combined with the current agent state to give an observation with the information needed by the agent.
Conclusion
This is more a thought experiment than something that’s actually going to happen tomorrow; GPT-3 today just isn’t good enough at world modelling. Also, this method depends heavily on at least one major assumption—that bigger future models will have much better world modelling capabilities—and a bunch of other smaller implicit assumptions. However, this might be the closest thing we ever get to a chance to sound the fire alarm for AGI: there’s now a concrete path to proto-AGI that has a non-negligible chance of working.
Thanks to zitterbewegung, realmeatyhuman, and Shawn Presser for taking the time to provide feedback on the draft of this blog post!
To cite:
1 | @article{lg2020agilms, |
Images aren’t nearly as good as text for encoding unambiguous, complex ideas, unless you put text in images, but at that point that’s just language modelling with extra steps. Also, images can encode complex ideas, but in a much less information-dense manner; I have no doubt that a sufficiently large image model could also learn such information about the world through images, but most likely at multiple orders of magnitude higher cost than an equivalent-world-modelling-capability language model. ↩︎
Another way to look at this is at cherrypicking. Most impressive demos of GPT-3 where it displays impressive knowledge of the world are cherrypicked, but what that tells us is that the model needs to improve by approx bits, where N and L are the number of cherrypickings necessary and the length of the generations in consideration, respectively, to reach that level of quality. In other words, cherrypicking provides a window into how good future models could be; and typically, cherrypicked samples are much more logically coherent.
↩︎A Markov chain text generator trained on a small corpus represents a huge leap over randomness: instead of having to generate countless quadrillions of samples, one might only have to generate millions of samples to get a few coherent pages; this can be improved to hundreds or tens of thousands by increasing the depth of the n of its n-grams. […] But for GPT-3, once the prompt is dialed in, the ratio appears to have dropped to closer to 1:5—maybe even as low as 1:3! gwern
Which, despite what the all-too-common snide remarks about the intelligence of the average internet user would have you believe, is actually not that bad! ↩︎
A pure world model is in a lot of ways similar to the idea of Oracle AIs, specifically Predictors. Whether these LM-based world models will be powerful enough to model the impact of their own outputs is yet to be seen. ↩︎
A more involved way we could do this is by finetuning the model, or steering it using a smaller model, etc. to get the model to output the kinds of things we need, if just asking nicely and providing examples, like, how GPT-3 is used today, turns out to not be good enough. ↩︎
Given a strong enough agent, it might not even be necessary to give it the ability to actually act in the real world. LM-based agents probably (hopefully?) won’t get this strong, though. ↩︎