- See Also
-
Gwern
- “April 2014 News”, Gwern 2014
- “DNM-Related Arrests, 2011–2015”, Gwern 2012
- “Darknet Market Mortality Risks”, Gwern 2013
- “Prediction Markets”, Gwern 2009
- “Predicting Google Closures”, Gwern 2013
- “Life Extension Cost-Benefits”, Gwern 2015
- “When Should I Check The Mail?”, Gwern 2015
- “‘HP: Methods of Rationality’ Review Statistics”, Gwern 2012
- “Girl Scouts & Good Corporate Governance”, Gwern 2011
- “Alerts Over Time”, Gwern 2013
- “Wikipedia & Knol: Why Knol Already Failed”, Gwern 2009
-
Links
- “Published Benefits of Ivermectin Use in Itajaí, Brazil for COVID-19 Infection, Hospitalization, and Mortality Are Entirely Explained by Statistical Artefacts”, Mills et al 2023
- “The Lindy Effect”, Ord 2023
- “Mortality Postponement and Compression at Older Ages in Human Cohorts”, McCarthy & Wang 2023
- “A Hierarchical Process Model Links Behavioral Aging and Lifespan in C. Elegans”, Oswal et al 2022
- “An Explanation for Negligible Senescence in Animals”, Xia & Møller 2022
- “Forgotten Books: The Application of Unseen Species Models to the Survival of Culture”, Kestemont et al 2022
- “Supplementary Materials for Forgotten Books: The Application of Unseen Species Models to the Survival of Culture {Kestemont Et Al 2022}”, Kestemont 2022
- “Germline Mutation Rates in Young Adults Predict Longevity and Reproductive Lifespan”, Cawthon et al 2020
- “Statistical Reliability Analysis for a Most Dangerous Occupation: Roman Emperor”, Saleh 2019
- “Effect of Aspirin on Disability-Free Survival in the Healthy Elderly”, McNeil et al 2018
- “Epigenetic Prediction of Complex Traits and Death”, McCartney et al 2018
- “Relationship Foraging: Does Time Spent Searching Predict Relationship Length?”, Cohen & Todd 2018
- “Churn Prediction in Mobile Social Games: Towards a Complete Assessment Using Survival Ensembles”, Periáñez et al 2017
- “Statistical Inference for Data-Adaptive Doubly Robust Estimators With Survival Outcomes”, Díaz 2017
- “Heritability of Schizophrenia and Schizophrenia Spectrum Based on the Nationwide Danish Twin Register”, Hilker et al 2017
- “A Long Journey to Reproducible Results: Replicating Our Work Took Four Years and 100,000 Worms but Brought Surprising Discoveries”, Lithgow et al 2017
- “Machine Learning for Survival Analysis: A Survey”, Wang et al 2017
- “Revisiting the Risks of Bitcoin Currency Exchange Closure”, Moore et al 2016
- “Only the Bad Die Young: Restaurant Mortality in the Western US”, Luo & Stark 2014
- “The Caenorhabditis Elegans Lifespan Machine”, Stroustrup et al 2013
- “The Survival Time of Chocolates on Hospital Wards: Covert Observational Study”, Gajendragadkar et al 2013
- “Indefinite Survival through Backup Copies”, Sandberg & Armstrong 2012
- “File:Newbie Survival by Semester Rows.png”
- “How Fast Does the Grim Reaper Walk? Receiver Operating Characteristics Curve Analysis in Healthy Men Aged 70 and Over”, Stanaway et al 2011
- “Random Survival Forests”, Ishwaran et al 2008
- “Full Publication of Results Initially Presented in Abstracts”, Scherer et al 2007
- “The Case of the Disappearing Teaspoons: Longitudinal Cohort Study of the Displacement of Teaspoons in an Australian Research Institute”, Lim et al 2005
- “Statistics Review 12: Survival Analysis”, Bewick et al 2004
- “Brms: an R Package for Bayesian Generalized Multivariate Non-Linear Multilevel Models Using Stan”, Bürkner 2024
- Sort By Magic
- Wikipedia
- Miscellaneous
- Link Bibliography
See Also
Gwern
“DNM-Related Arrests, 2011–2015”, Gwern 2012
“Darknet Market Mortality Risks”, Gwern 2013
“Prediction Markets”, Gwern 2009
“Predicting Google Closures”, Gwern 2013
“Life Extension Cost-Benefits”, Gwern 2015
“When Should I Check The Mail?”, Gwern 2015
“‘HP: Methods of Rationality’ Review Statistics”, Gwern 2012
“Girl Scouts & Good Corporate Governance”, Gwern 2011
“Alerts Over Time”, Gwern 2013
“Wikipedia & Knol: Why Knol Already Failed”, Gwern 2009
Links
“Published Benefits of Ivermectin Use in Itajaí, Brazil for COVID-19 Infection, Hospitalization, and Mortality Are Entirely Explained by Statistical Artefacts”, Mills et al 2023
“The Lindy Effect”, Ord 2023
“Mortality Postponement and Compression at Older Ages in Human Cohorts”, McCarthy & Wang 2023
Mortality postponement and compression at older ages in human cohorts
“A Hierarchical Process Model Links Behavioral Aging and Lifespan in C. Elegans”, Oswal et al 2022
A hierarchical process model links behavioral aging and lifespan in C. elegans
“An Explanation for Negligible Senescence in Animals”, Xia & Møller 2022
“Forgotten Books: The Application of Unseen Species Models to the Survival of Culture”, Kestemont et al 2022
Forgotten books: The application of unseen species models to the survival of culture
“Supplementary Materials for Forgotten Books: The Application of Unseen Species Models to the Survival of Culture {Kestemont Et Al 2022}”, Kestemont 2022
“Germline Mutation Rates in Young Adults Predict Longevity and Reproductive Lifespan”, Cawthon et al 2020
Germline mutation rates in young adults predict longevity and reproductive lifespan
“Statistical Reliability Analysis for a Most Dangerous Occupation: Roman Emperor”, Saleh 2019
Statistical reliability analysis for a most dangerous occupation: Roman emperor
“Effect of Aspirin on Disability-Free Survival in the Healthy Elderly”, McNeil et al 2018
Effect of Aspirin on Disability-free Survival in the Healthy Elderly
“Epigenetic Prediction of Complex Traits and Death”, McCartney et al 2018
“Relationship Foraging: Does Time Spent Searching Predict Relationship Length?”, Cohen & Todd 2018
Relationship Foraging: Does time spent searching predict relationship length?
“Churn Prediction in Mobile Social Games: Towards a Complete Assessment Using Survival Ensembles”, Periáñez et al 2017
Churn Prediction in Mobile Social Games: Towards a Complete Assessment Using Survival Ensembles
“Statistical Inference for Data-Adaptive Doubly Robust Estimators With Survival Outcomes”, Díaz 2017
Statistical Inference for Data-adaptive Doubly Robust Estimators with Survival Outcomes
“Heritability of Schizophrenia and Schizophrenia Spectrum Based on the Nationwide Danish Twin Register”, Hilker et al 2017
“A Long Journey to Reproducible Results: Replicating Our Work Took Four Years and 100,000 Worms but Brought Surprising Discoveries”, Lithgow et al 2017
“Machine Learning for Survival Analysis: A Survey”, Wang et al 2017
“Revisiting the Risks of Bitcoin Currency Exchange Closure”, Moore et al 2016
“Only the Bad Die Young: Restaurant Mortality in the Western US”, Luo & Stark 2014
Only the Bad Die Young: Restaurant Mortality in the Western US
“The Caenorhabditis Elegans Lifespan Machine”, Stroustrup et al 2013
“The Survival Time of Chocolates on Hospital Wards: Covert Observational Study”, Gajendragadkar et al 2013
The survival time of chocolates on hospital wards: covert observational study
“Indefinite Survival through Backup Copies”, Sandberg & Armstrong 2012
“File:Newbie Survival by Semester Rows.png”
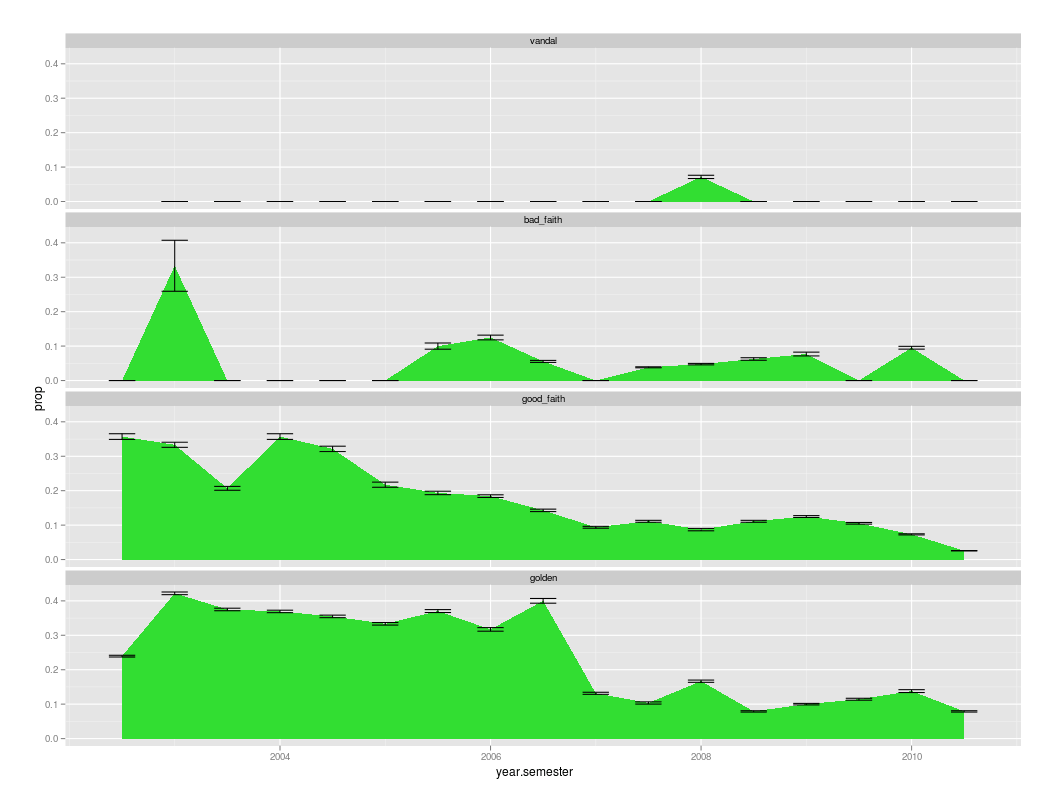{kind=link}
“How Fast Does the Grim Reaper Walk? Receiver Operating Characteristics Curve Analysis in Healthy Men Aged 70 and Over”, Stanaway et al 2011
“Random Survival Forests”, Ishwaran et al 2008
“Full Publication of Results Initially Presented in Abstracts”, Scherer et al 2007
Full publication of results initially presented in abstracts
“The Case of the Disappearing Teaspoons: Longitudinal Cohort Study of the Displacement of Teaspoons in an Australian Research Institute”, Lim et al 2005
“Statistics Review 12: Survival Analysis”, Bewick et al 2004
“Brms: an R Package for Bayesian Generalized Multivariate Non-Linear Multilevel Models Using Stan”, Bürkner 2024
brms: an R package for Bayesian generalized multivariate non-linear multilevel models using Stan
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
survival-trends
lifespan-research
biostatistics
Wikipedia
Miscellaneous
-
/doc/darknet-market/2013-05-05-moore-bitcoinexchangesurvivalanalysis-complianceamlcftwhole.csv -
/doc/darknet-market/2013-05-05-moore-bitcoinexchangesurvivalanalysis-sdatamodcc.csv -
/doc/darknet-market/2013-05-05-moore-bitcoinexchangesurvivalanalysis.R -
https://cran.r-project.org/web/packages/randomSurvivalForest/index.html -
https://livingstingy.blogspot.com/2010/08/bathtub-or-weibull-curve.html: -
https://www.amazon.com/Applied-Survival-Analysis-Regression-Probability/dp/0471754994/ -
https://www.sciencedirect.com/science/article/pii/S0047637419300181
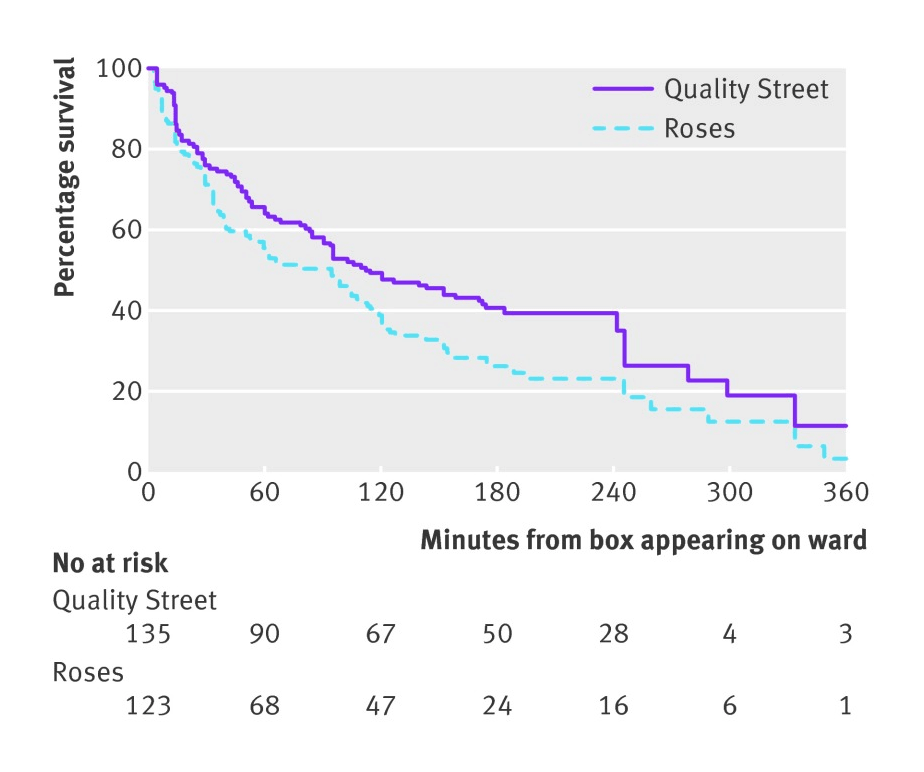{kind=link}