- See Also
- Gwern
-
Links
- “Universal Chemical Programming Language for Robotic Synthesis Repeatability”, Rauschen et al 2024
- “Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles”, Kusano et al 2023
- “ReCoRe: Regularized Contrastive Representation Learning of World Model”, Poudel et al 2023
- “Eureka: Human-Level Reward Design via Coding Large Language Models”, Ma et al 2023
- “Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions”, Chebotar et al 2023
- “Deep RL at Scale: Sorting Waste in Office Buildings With a Fleet of Mobile Manipulators”, Herzog et al 2023
- “Learning Agile Soccer Skills for a Bipedal Robot With Deep Reinforcement Learning”, Haarnoja et al 2023
- “ACT: Learning Fine-Grained Bimanual Manipulation With Low-Cost Hardware”, Zhao et al 2023
- “LLM+P: Empowering Large Language Models With Optimal Planning Proficiency”, Liu et al 2023
- “Bubble-Based Microrobots With Rapid Circular Motions for Epithelial Pinning and Drug Delivery”, Lee et al 2023
- “ChemCrow: Augmenting Large-Language Models With Chemistry Tools”, Bran et al 2023
- “Learning Humanoid Locomotion With Transformers”, Radosavovic et al 2023
- “The Characteristics and Geographic Distribution of Robot Hubs in U.S. Manufacturing Establishments”, Brynjolfsson et al 2023
- “MimicPlay: Long-Horizon Imitation Learning by Watching Human Play”, Wang et al 2023
- “Faithful Chain-Of-Thought Reasoning”, Lyu et al 2023
- “Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula”, Bronstein et al 2022
- “Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes”, Kumar et al 2022
- “Token Turing Machines”, Ryoo et al 2022
- “Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Agarwal et al 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “Creating a Dynamic Quadrupedal Robotic Goalkeeper With Reinforcement Learning”, Huang et al 2022
- “DALL·E-Bot: Introducing Web-Scale Diffusion Models to Robotics”, Kapelyukh et al 2022
- “Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Rakhmatulin et al 2022
- “Versatile Articulated Aerial Robot DRAGON: Aerial Manipulation and Grasping by Vectorable Thrust Control”, Zhao et al 2022
- “LaTTe: Language Trajectory TransformEr”, Bucker et al 2022
- “PI-ARS: Accelerating Evolution-Learned Visual-Locomotion With Predictive Information Representations”, Lee et al 2022
- “Semantic Abstraction (SemAbs): Open-World 3D Scene Understanding from 2D Vision-Language Models”, Ha & Song 2022
- “Inner Monologue: Embodied Reasoning through Planning With Language Models”, Huang et al 2022
- “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
- “Watch and Match: Supercharging Imitation With Regularized Optimal Transport”, Haldar et al 2022
- “Fleet-DAgger: Interactive Robot Fleet Learning With Scalable Human Supervision”, Hoque et al 2022
- “DayDreamer: World Models for Physical Robot Learning”, Wu et al 2022
- “ADAPT: Vision-Language Navigation With Modality-Aligned Action Prompts”, Lin et al 2022
- “Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
- “Gato: A Generalist Agent”, Reed et al 2022
- “Rapid Locomotion via Reinforcement Learning”, Margolis et al 2022
- “Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?”, Cui et al 2022
- “Semantic Exploration from Language Abstractions and Pretrained Representations”, Tam et al 2022
- “Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale”, Ramrakhya et al 2022
- “Demonstrate Once, Imitate Immediately (DOME): Learning Visual Servoing for One-Shot Imitation Learning”, Valassakis et al 2022
- “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
- “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
- “CLIP on Wheels (CoW): Zero-Shot Object Navigation As Object Localization and Exploration”, Gadre et al 2022
- “Robot Peels Banana With Goal-Conditioned Dual-Action Deep Imitation Learning”, Kim et al 2022
- “SURF: Semi-Supervised Reward Learning With Data Augmentation for Feedback-Efficient Preference-Based Reinforcement Learning”, Park et al 2022
- “The Unsurprising Effectiveness of Pre-Trained Vision Models for Control”, Parisi et al 2022
- “VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning”, Borja-Diaz et al 2022
- “Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion”, Ji et al 2022
- “LID: Pre-Trained Language Models for Interactive Decision-Making”, Li et al 2022
- “Accelerated Quality-Diversity for Robotics through Massive Parallelism”, Lim et al 2022
- “Surprisingly Robust In-Hand Manipulation: An Empirical Study”, Bhatt et al 2022
- “Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots”, Bhatia et al 2022
- “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Miki et al 2022
- “Language Models As Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, Huang et al 2022
- “Robots and Firm Investment”, Benmelech & Zator 2022
- “Agile Locomotion via Model-Free Learning”, Margolis 2022
- “Gastrointestinal Interoception in Eating Disorders: Charting a New Path”, Khalsa et al 2022
- “Simple but Effective: CLIP Embeddings for Embodied AI”, Khandelwal et al 2021
- “AW-Opt: Learning Robotic Skills With Imitation and Reinforcement at Scale”, Lu et al 2021
- “BC-Z: Zero-Shot Task Generalization With Robotic Imitation Learning”, Jang et al 2021
- “Learning Behaviors through Physics-Driven Latent Imagination”, Richard et al 2021
- “Discovering and Achieving Goals via World Models”, Mendonca et al 2021
- “Beyond Pick-And-Place: Tackling Robotic Stacking of Diverse Shapes”, Lee et al 2021
- “Legged Robots That Keep on Learning: Fine-Tuning Locomotion Policies in the Real World”, Smith et al 2021
- “Skill Induction and Planning With Latent Language”, Sharma et al 2021
- “Bridge Data: Boosting Generalization of Robotic Skills With Cross-Domain Datasets”, Ebert et al 2021
- “Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning”, Rudin et al 2021
- “CLIPort: What and Where Pathways for Robotic Manipulation”, Shridhar et al 2021
- “A Workflow for Offline Model-Free Robotic Reinforcement Learning”, Kumar et al 2021
- “Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks”, Wu et al 2021
- “Learning to Navigate Sidewalks in Outdoor Environments”, Sorokin et al 2021
- “PlaTe: Visually-Grounded Planning With Transformers in Procedural Tasks”, Sun et al 2021
- “Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation”, Nair et al 2021
- “Implicit Behavioral Cloning”, Florence et al 2021
- “Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning”, Makoviychuk et al 2021
- “On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021
- “DexMV: Imitation Learning for Dexterous Manipulation from Human Videos”, Qin et al 2021
- “Language Grounding With 3D Objects”, Thomason et al 2021
- “Time-Optimal Planning for Quadrotor Waypoint Flight”, Foehn et al 2021
- “RMA: Rapid Motor Adaptation for Legged Robots”, Kumar et al 2021
- “Learning to See Before Learning to Act: Visual Pre-Training for Manipulation”, Yen-Chen et al 2021
- “Coarse-To-Fine Q-Attention: Efficient Learning for Visual Robotic Manipulation via Discretisation”, James et al 2021
- “The Rise of Intelligent Matter”, Kaspar et al 2021
- “Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments”, Riviere et al 2021
- “Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain”, Scanlon et al 2021
- “Latent Imagination Facilitates Zero-Shot Transfer in Autonomous Racing”, Brunnbauer et al 2021
- “Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo 2021
- “Asymmetric Self-Play for Automatic Goal Discovery in Robotic Manipulation”, OpenAI et al 2021
- “Go-Explore: First Return, Then Explore”, Ecoffet et al 2021
- “Unlocking Pixels for Reinforcement Learning via Implicit Attention”, Choromanski et al 2021
- “Regenerating Soft Robots through Neural Cellular Automata”, Horibe et al 2021
- “MAP-Elites Enables Powerful Stepping Stones and Diversity for Modular Robotics”, Nordmoen et al 2021
- “ViNG: Learning Open-World Navigation With Visual Goals”, Shah et al 2020
- “Learning Accurate Long-Term Dynamics for Model-Based Reinforcement Learning”, Lambert et al 2020
- “A Framework for Efficient Robotic Manipulation”, Zhan et al 2020
- “Imitating Interactive Intelligence”, Abramson et al 2020
- “Autonomous Navigation of Stratospheric Balloons Using Reinforcement Learning”, Bellemare et al 2020
- “A Recurrent Vision-And-Language BERT for Navigation”, Hong et al 2020
- “MoGaze: A Dataset of Full-Body Motions That Includes Workspace Geometry and Eye-Gaze”, Kratzer et al 2020
- “Multimodal Dynamics Modeling for Off-Road Autonomous Vehicles”, Tremblay et al 2020
- “The Robot Household Marathon Experiment”, Kazhoyan et al 2020
- “RetinaGAN: An Object-Aware Approach to Sim-To-Real Transfer”, Ho et al 2020
- “Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding”, Roberts et al 2020
- “MELD: Meta-Reinforcement Learning from Images via Latent State Models”, Zhao et al 2020
- “Guys and Dolls”, Devlin & Locatelli 2020
- “DreamerV2: Mastering Atari With Discrete World Models”, Hafner et al 2020
- “An Adaptive Deep Reinforcement Learning Framework Enables Curling Robots With Human-Like Performance in Real-World Conditions”, Won et al 2020
- “Meta-Learning through Hebbian Plasticity in Random Networks”, Najarro & Risi 2020
- “Dm_control: Software and Tasks for Continuous Control”, Tassa et al 2020
- “Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS With Asynchronous Reinforcement Learning”, Petrenko et al 2020
- “Active Preference-Based Gaussian Process Regression for Reward Learning”, Bıyık et al 2020
- “VLN-BERT: Improving Vision-And-Language Navigation With Image-Text Pairs from the Web”, Majumdar et al 2020
- “First Return, Then Explore”, Ecoffet et al 2020
- “AI-Powered Rat Could Be a Valuable New Tool for Neuroscience: Researchers from DeepMind and Harvard Are Using a Virtual Rat to See What Neural Networks Can Teach Us about Biology”, Gent 2020
- “Never Stop Learning: The Effectiveness of Fine-Tuning in Robotic Reinforcement Learning”, Julian et al 2020
- “Learning Agile Robotic Locomotion Skills by Imitating Animals”, Peng et al 2020
- “Learning to Fly via Deep Model-Based Reinforcement Learning”, Becker-Ehmck et al 2020
- “Deep Neuroethology of a Virtual Rodent”, Merel et al 2020
- “Learning to Walk in the Real World With Minimal Human Effort”, Ha et al 2020
- “In the 1970s, the CIA Created a Robot Dragonfly Spy. Now We Know How It Works. Newly Released Documents Show How the CIA Created One of the World’s First Examples of Insect Robotics.”, Hambling 2020
- “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
- “Remote-Controlled Insect Navigation Using Plasmonic Nanotattoos”, Tadepalli et al 2020
- “AI Helps Warehouse Robots Pick Up New Tricks: Backed by Machine Learning Luminaries, Covariant.ai’s Bots Can Handle Jobs Previously Needing a Human Touch”, Knight 2020
- “First-In-Human Evaluation of a Hand-Held Automated Venipuncture Device for Rapid Venous Blood Draws”, Leipheimer et al 2020
- “Near-Perfect Point-Goal Navigation from 2.5 Billion Frames of Experience”, Wijmans & Kadian 2020
- “Reinforcement Learning Upside Down: Don’t Predict Rewards—Just Map Them to Actions”, Schmidhuber 2019
- “Increasing Generality in Machine Learning through Procedural Content Generation”, Risi & Togelius 2019
- “SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms”, Tsykunov et al 2019
- “Scaling Robot Supervision to Hundreds of Hours With RoboTurk: Robotic Manipulation Dataset through Human Reasoning and Dexterity”, Mandlekar et al 2019
- “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, Wijmans et al 2019
- “Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning”, Yu et al 2019
- “Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
- “Solving Rubik’s Cube With a Robot Hand [blog]”, OpenAI 2019
- “Scaling Data-Driven Robotics With Reward Sketching and Batch Reinforcement Learning”, Cabi et al 2019
- “Learning to Seek: Autonomous Source Seeking With Deep Reinforcement Learning Onboard a Nano Drone Microcontroller”, Duisterhof et al 2019
- “ROBEL: Robotics Benchmarks for Learning With Low-Cost Robots”, Ahn et al 2019
- “TuneNet: One-Shot Residual Tuning for System Identification and Sim-To-Real Robot Task Transfer”, Allevato et al 2019
- “The Robot Revolution: Managerial and Employment Consequences for Firms”, Dixon et al 2019
- “An Application of Reinforcement Learning to Aerobatic Helicopter Flight”, Abbeel et al 2019
- “AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
- “Adversarial Policies: Attacking Deep Reinforcement Learning”, Gleave et al 2019
- “End-To-End Robotic Reinforcement Learning without Reward Engineering”, Singh et al 2019
- “Habitat: A Platform for Embodied AI Research”, Savva et al 2019
- “Long-Range Indoor Navigation With PRM-RL”, Francis et al 2019
- “Learning Agile and Dynamic Motor Skills for Legged Robots”, Hwangbo et al 2019
- “The RobotriX: An EXtremely Photorealistic and Very-Large-Scale Indoor Dataset of Sequences With Robot Trajectories and Interactions”, Garcia-Garcia et al 2019
- “Living With Harmony: A Personal Companion System by Realbotix™”, Coursey et al 2019
- “Sim-To-Real via Sim-To-Sim: Data-Efficient Robotic Grasping via Randomized-To-Canonical Adaptation Networks”, James et al 2018
- “ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst”, Bansal et al 2018
- “Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control”, Ebert et al 2018
- “An Introduction to Deep Reinforcement Learning”, Francois-Lavet et al 2018
- “Organic Synthesis in a Modular Robotic System Driven by a Chemical Programming Language”, Steiner et al 2018
- “Neural Probabilistic Motor Primitives for Humanoid Control”, Merel et al 2018
- “Deep Reinforcement Learning”, Li 2018
- “Learning Navigation Behaviors End-To-End With AutoRL”, Chiang et al 2018
- “Benchmarking Reinforcement Learning Algorithms on Real-World Robots”, Mahmood et al 2018
- “Fully Distributed Multi-Robot Collision Avoidance via Deep Reinforcement Learning for Safe and Efficient Navigation in Complex Scenarios”, Fan et al 2018
- “Learning Dexterous In-Hand Manipulation”, OpenAI et al 2018
- “Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias”, Gupta et al 2018
- “Visual Reinforcement Learning With Imagined Goals”, Nair et al 2018
- “QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation”, Kalashnikov et al 2018
- “Adversarial Active Exploration for Inverse Dynamics Model Learning”, Hong et al 2018
- “More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch”, Calandra et al 2018
- “Learning Real-World Robot Policies by Dreaming”, Piergiovanni et al 2018
- “Synthesizing Programs for Images Using Reinforced Adversarial Learning”, Ganin et al 2018
- “One Big Net For Everything”, Schmidhuber 2018
- “One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”, Yu et al 2018
- “Neural Network Based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction”, Lathuilière et al 2017
- “The Signature of Robot Action Success in EEG Signals of a Human Observer: Decoding and Visualization Using Deep Convolutional Neural Networks”, Behncke et al 2017
- “Sim-To-Real Transfer of Robotic Control With Dynamics Randomization”, Peng et al 2017
- “Flow: A Modular Learning Framework for Mixed Autonomy Traffic”, Wu et al 2017
- “PRM-RL: Long-Range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-Based Planning”, Faust et al 2017
- “GraspGAN: Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping”, Bousmalis et al 2017
- “Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics”, Chatzilygeroudis & Mouret 2017
- “One-Shot Visual Imitation Learning via Meta-Learning”, Finn et al 2017
- “Brain Responses During Robot-Error Observation”, Welke et al 2017
- “Deep Learning in Robotics: A Review of Recent Research”, Pierson & Gashler 2017
- “Proximal Policy Optimization Algorithms”, Schulman et al 2017
- “The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously”, Cabi et al 2017
- “Semi-Supervised Haptic Material Recognition for Robots Using Generative Adversarial Networks”, Erickson et al 2017
- “Vision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration”, Rahmatizadeh et al 2017
- “Deep Q-Learning from Demonstrations”, Hester et al 2017
- “Data-Efficient Deep Reinforcement Learning for Dexterous Manipulation”, Popov et al 2017
- “Black-Box Data-Efficient Policy Search for Robotics”, Chatzilygeroudis et al 2017
- “One-Shot Imitation Learning”, Duan et al 2017
- “Enabling Robots to Communicate Their Objectives”, Huang et al 2017
- “Sim-To-Real Robot Learning from Pixels With Progressive Nets”, Rusu et al 2016
- “Supervision via Competition: Robot Adversaries for Learning Tasks”, Pinto et al 2016
- “Deep Reinforcement Learning for Robotic Manipulation With Asynchronous Off-Policy Updates”, Gu et al 2016
- “Deep Visual Foresight for Planning Robot Motion”, Finn & Levine 2016
- “Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning”, Zhu et al 2016
- “Learning Hand-Eye Coordination for Robotic Grasping With Deep Learning and Large-Scale Data Collection”, Levine et al 2016
- “Optimization-Based Locomotion Planning, Estimation, and Control Design for the Atlas Humanoid Robot”, Kuindersma et al 2015
- “MAP-Elites: Illuminating Search Spaces by Mapping Elites”, Mouret & Clune 2015
- “End-To-End Training of Deep Visuomotor Policies”, Levine et al 2015
- “An Invitation to Imitation”, Bagnell 2015
- “Gaussian Processes for Data-Efficient Learning in Robotics and Control”, Deisenroth et al 2015
- “Robots That Can Adapt like Animals”, Cully et al 2014
- “PILCO: A Model-Based and Data-Efficient Approach to Policy Search”, Deisenroth & Rasmussen 2011
- “Motion Planning for Dynamic Folding of a Cloth With Two High-Speed Robot Hands and Two High-Speed Sliders”, Yamakawa et al 2011
- “Towards Insect Cyborgs: Interfacing Microtechnologies With Metamorphic Development”, Bozkurt 2010 (page 4)
- “Motion Planning for Dynamic Knotting of a Flexible Rope With a High-Speed Robot Arm”, Yamakawa et al 2010
- “Insect-Machine Interface Based Neurocybernetics”, Bozkurt et al 2009
- “Weldon’s Dice, Automated”, Labby 2009
- “Resilient Machines Through Continuous Self-Modeling”, Bongard et al 2006
- “Robot Predictions Evolution”, Moravec 2004
- “Spatio-Temporal Prediction Modulates the Perception of Self-Produced Stimuli”, Blakemore et al 1999
- “When Will Computer Hardware Match the Human Brain?”, Moravec 1998
- “Evolving 3D Morphology and Behavior by Competition”, Sims 1994
- “The Stanford Cart and the CMU Rover”, Moravec 1990
- “How Robots Can Acquire New Skills from Their Shared Experience”
- “Learning to Write Programs That Generate Images”
- “Learning Dexterity”
- “Scale: The Data Platform for AI; High Quality Training and Validation Data for AI Applications”, AI 2024
- “Forget about Drones, Forget about Dystopian Sci-Fi—A Terrifying New Generation of Autonomous Weapons Is Already Here. Meet the Small Band of Dedicated Optimists Battling Nefarious Governments and Bureaucratic Tedium to Stop the Proliferation of Killer Robots And, Just Maybe, save Humanity from Itself.”
- “Japan Nuclear Plant Gets Help from US Robots: Obama Administration Sends Shipment of Robots to Help Regain Control over Stricken Fukushima Nuclear Plant”
- “The Robots Are Coming for Garment Workers. That’s Good for the U.S., Bad for Poor Countries: Automation Is Reaching into Trades That Once Seemed Immune, Transforming Sweatshops in Places like Bangladesh and Bringing Production back to America”
- “48:44—Tesla Vision · 1:13:12—Planning and Control · 1:24:35—Manual Labeling · 1:28:11—Auto Labeling · 1:35:15—Simulation · 1:42:10—Hardware Integration · 1:45:40—Dojo”
- “Robot Peels Banana With Deep Learning, UT ISI Lab”
- “Supplementary Video for Do As I Can, Not As I Say: Grounding Language in Robotic Affordances”
- “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild [video]”
- Sort By Magic
- Wikipedia
- Miscellaneous
- Link Bibliography
See Also
Gwern
“Research Ideas”, Gwern 2017
“Free-Play Periods for RL Agents”, Gwern 2023
“ARPA and SCI: Surfing AI”, Gwern 2018
Links
“Universal Chemical Programming Language for Robotic Synthesis Repeatability”, Rauschen et al 2024
Universal chemical programming language for robotic synthesis repeatability
“Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles”, Kusano et al 2023
Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles
“ReCoRe: Regularized Contrastive Representation Learning of World Model”, Poudel et al 2023
ReCoRe: Regularized Contrastive Representation Learning of World Model
“Eureka: Human-Level Reward Design via Coding Large Language Models”, Ma et al 2023
Eureka: Human-Level Reward Design via Coding Large Language Models
“Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions”, Chebotar et al 2023
Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
“Deep RL at Scale: Sorting Waste in Office Buildings With a Fleet of Mobile Manipulators”, Herzog et al 2023
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
“Learning Agile Soccer Skills for a Bipedal Robot With Deep Reinforcement Learning”, Haarnoja et al 2023
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
“ACT: Learning Fine-Grained Bimanual Manipulation With Low-Cost Hardware”, Zhao et al 2023
ACT: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
“LLM+P: Empowering Large Language Models With Optimal Planning Proficiency”, Liu et al 2023
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
“Bubble-Based Microrobots With Rapid Circular Motions for Epithelial Pinning and Drug Delivery”, Lee et al 2023
Bubble-Based Microrobots with Rapid Circular Motions for Epithelial Pinning and Drug Delivery
“ChemCrow: Augmenting Large-Language Models With Chemistry Tools”, Bran et al 2023
ChemCrow: Augmenting large-language models with chemistry tools
“Learning Humanoid Locomotion With Transformers”, Radosavovic et al 2023
“The Characteristics and Geographic Distribution of Robot Hubs in U.S. Manufacturing Establishments”, Brynjolfsson et al 2023
The Characteristics and Geographic Distribution of Robot Hubs in U.S. Manufacturing Establishments
“MimicPlay: Long-Horizon Imitation Learning by Watching Human Play”, Wang et al 2023
MimicPlay: Long-Horizon Imitation Learning by Watching Human Play
“Faithful Chain-Of-Thought Reasoning”, Lyu et al 2023
“Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula”, Bronstein et al 2022
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
“Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes”, Kumar et al 2022
Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes
“Token Turing Machines”, Ryoo et al 2022
“Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Agarwal et al 2022
Legged Locomotion in Challenging Terrains using Egocentric Vision
“Broken Neural Scaling Laws”, Caballero et al 2022
“Creating a Dynamic Quadrupedal Robotic Goalkeeper With Reinforcement Learning”, Huang et al 2022
Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
“DALL·E-Bot: Introducing Web-Scale Diffusion Models to Robotics”, Kapelyukh et al 2022
DALL·E-Bot: Introducing Web-Scale Diffusion Models to Robotics
“Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Rakhmatulin et al 2022
Selective neutralization and deterring of cockroaches with laser automated by machine vision
“Versatile Articulated Aerial Robot DRAGON: Aerial Manipulation and Grasping by Vectorable Thrust Control”, Zhao et al 2022
“LaTTe: Language Trajectory TransformEr”, Bucker et al 2022
“PI-ARS: Accelerating Evolution-Learned Visual-Locomotion With Predictive Information Representations”, Lee et al 2022
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
“Semantic Abstraction (SemAbs): Open-World 3D Scene Understanding from 2D Vision-Language Models”, Ha & Song 2022
Semantic Abstraction (SemAbs): Open-World 3D Scene Understanding from 2D Vision-Language Models
“Inner Monologue: Embodied Reasoning through Planning With Language Models”, Huang et al 2022
Inner Monologue: Embodied Reasoning through Planning with Language Models
“LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
“Watch and Match: Supercharging Imitation With Regularized Optimal Transport”, Haldar et al 2022
Watch and Match: Supercharging Imitation with Regularized Optimal Transport
“Fleet-DAgger: Interactive Robot Fleet Learning With Scalable Human Supervision”, Hoque et al 2022
Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
“DayDreamer: World Models for Physical Robot Learning”, Wu et al 2022
“ADAPT: Vision-Language Navigation With Modality-Aligned Action Prompts”, Lin et al 2022
ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts
“Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
Housekeep: Tidying Virtual Households using Commonsense Reasoning
“Gato: A Generalist Agent”, Reed et al 2022
“Rapid Locomotion via Reinforcement Learning”, Margolis et al 2022
“Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?”, Cui et al 2022
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
“Semantic Exploration from Language Abstractions and Pretrained Representations”, Tam et al 2022
Semantic Exploration from Language Abstractions and Pretrained Representations
“Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale”, Ramrakhya et al 2022
Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale
“Demonstrate Once, Imitate Immediately (DOME): Learning Visual Servoing for One-Shot Imitation Learning”, Valassakis et al 2022
“Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances
“Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
“CLIP on Wheels (CoW): Zero-Shot Object Navigation As Object Localization and Exploration”, Gadre et al 2022
CLIP on Wheels (CoW): Zero-Shot Object Navigation as Object Localization and Exploration
“Robot Peels Banana With Goal-Conditioned Dual-Action Deep Imitation Learning”, Kim et al 2022
Robot peels banana with goal-conditioned dual-action deep imitation learning
“SURF: Semi-Supervised Reward Learning With Data Augmentation for Feedback-Efficient Preference-Based Reinforcement Learning”, Park et al 2022
“The Unsurprising Effectiveness of Pre-Trained Vision Models for Control”, Parisi et al 2022
The Unsurprising Effectiveness of Pre-Trained Vision Models for Control
“VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning”, Borja-Diaz et al 2022
VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning
“Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion”, Ji et al 2022
“LID: Pre-Trained Language Models for Interactive Decision-Making”, Li et al 2022
LID: Pre-Trained Language Models for Interactive Decision-Making
“Accelerated Quality-Diversity for Robotics through Massive Parallelism”, Lim et al 2022
Accelerated Quality-Diversity for Robotics through Massive Parallelism
“Surprisingly Robust In-Hand Manipulation: An Empirical Study”, Bhatt et al 2022
Surprisingly Robust In-Hand Manipulation: An Empirical Study
“Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots”, Bhatia et al 2022
Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots
“Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Miki et al 2022
Learning robust perceptive locomotion for quadrupedal robots in the wild
“Language Models As Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, Huang et al 2022
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
“Robots and Firm Investment”, Benmelech & Zator 2022
“Agile Locomotion via Model-Free Learning”, Margolis 2022
“Gastrointestinal Interoception in Eating Disorders: Charting a New Path”, Khalsa et al 2022
Gastrointestinal Interoception in Eating Disorders: Charting a New Path
“Simple but Effective: CLIP Embeddings for Embodied AI”, Khandelwal et al 2021
“AW-Opt: Learning Robotic Skills With Imitation and Reinforcement at Scale”, Lu et al 2021
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
“BC-Z: Zero-Shot Task Generalization With Robotic Imitation Learning”, Jang et al 2021
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
“Learning Behaviors through Physics-Driven Latent Imagination”, Richard et al 2021
Learning Behaviors through Physics-driven Latent Imagination
“Discovering and Achieving Goals via World Models”, Mendonca et al 2021
“Beyond Pick-And-Place: Tackling Robotic Stacking of Diverse Shapes”, Lee et al 2021
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
“Legged Robots That Keep on Learning: Fine-Tuning Locomotion Policies in the Real World”, Smith et al 2021
Legged Robots that Keep on Learning: Fine-Tuning Locomotion Policies in the Real World
“Bridge Data: Boosting Generalization of Robotic Skills With Cross-Domain Datasets”, Ebert et al 2021
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
“Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning”, Rudin et al 2021
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
“CLIPort: What and Where Pathways for Robotic Manipulation”, Shridhar et al 2021
“A Workflow for Offline Model-Free Robotic Reinforcement Learning”, Kumar et al 2021
A Workflow for Offline Model-Free Robotic Reinforcement Learning
“Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks”, Wu et al 2021
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
“Learning to Navigate Sidewalks in Outdoor Environments”, Sorokin et al 2021
“PlaTe: Visually-Grounded Planning With Transformers in Procedural Tasks”, Sun et al 2021
PlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks
“Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation”, Nair et al 2021
Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation
“Implicit Behavioral Cloning”, Florence et al 2021
“Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning”, Makoviychuk et al 2021
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
“On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021
“DexMV: Imitation Learning for Dexterous Manipulation from Human Videos”, Qin et al 2021
DexMV: Imitation Learning for Dexterous Manipulation from Human Videos
“Language Grounding With 3D Objects”, Thomason et al 2021
“Time-Optimal Planning for Quadrotor Waypoint Flight”, Foehn et al 2021
“RMA: Rapid Motor Adaptation for Legged Robots”, Kumar et al 2021
“Learning to See Before Learning to Act: Visual Pre-Training for Manipulation”, Yen-Chen et al 2021
Learning to See before Learning to Act: Visual Pre-training for Manipulation
“Coarse-To-Fine Q-Attention: Efficient Learning for Visual Robotic Manipulation via Discretisation”, James et al 2021
Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation
“The Rise of Intelligent Matter”, Kaspar et al 2021
“Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments”, Riviere et al 2021
Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments
“Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain”, Scanlon et al 2021
“Latent Imagination Facilitates Zero-Shot Transfer in Autonomous Racing”, Brunnbauer et al 2021
Latent Imagination Facilitates Zero-Shot Transfer in Autonomous Racing
“Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo 2021
Replaying real life: how the Waymo Driver avoids fatal human crashes
“Asymmetric Self-Play for Automatic Goal Discovery in Robotic Manipulation”, OpenAI et al 2021
Asymmetric self-play for automatic goal discovery in robotic manipulation
“Go-Explore: First Return, Then Explore”, Ecoffet et al 2021
“Unlocking Pixels for Reinforcement Learning via Implicit Attention”, Choromanski et al 2021
Unlocking Pixels for Reinforcement Learning via Implicit Attention
“Regenerating Soft Robots through Neural Cellular Automata”, Horibe et al 2021
“MAP-Elites Enables Powerful Stepping Stones and Diversity for Modular Robotics”, Nordmoen et al 2021
MAP-Elites Enables Powerful Stepping Stones and Diversity for Modular Robotics
“ViNG: Learning Open-World Navigation With Visual Goals”, Shah et al 2020
“Learning Accurate Long-Term Dynamics for Model-Based Reinforcement Learning”, Lambert et al 2020
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
“A Framework for Efficient Robotic Manipulation”, Zhan et al 2020
“Imitating Interactive Intelligence”, Abramson et al 2020
“Autonomous Navigation of Stratospheric Balloons Using Reinforcement Learning”, Bellemare et al 2020
Autonomous navigation of stratospheric balloons using reinforcement learning
“A Recurrent Vision-And-Language BERT for Navigation”, Hong et al 2020
“MoGaze: A Dataset of Full-Body Motions That Includes Workspace Geometry and Eye-Gaze”, Kratzer et al 2020
MoGaze: A Dataset of Full-Body Motions that Includes Workspace Geometry and Eye-Gaze
“Multimodal Dynamics Modeling for Off-Road Autonomous Vehicles”, Tremblay et al 2020
Multimodal dynamics modeling for off-road autonomous vehicles
“The Robot Household Marathon Experiment”, Kazhoyan et al 2020
“RetinaGAN: An Object-Aware Approach to Sim-To-Real Transfer”, Ho et al 2020
“Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding”, Roberts et al 2020
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
“MELD: Meta-Reinforcement Learning from Images via Latent State Models”, Zhao et al 2020
MELD: Meta-Reinforcement Learning from Images via Latent State Models
“Guys and Dolls”, Devlin & Locatelli 2020
“DreamerV2: Mastering Atari With Discrete World Models”, Hafner et al 2020
“An Adaptive Deep Reinforcement Learning Framework Enables Curling Robots With Human-Like Performance in Real-World Conditions”, Won et al 2020
“Meta-Learning through Hebbian Plasticity in Random Networks”, Najarro & Risi 2020
“Dm_control: Software and Tasks for Continuous Control”, Tassa et al 2020
“Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS With Asynchronous Reinforcement Learning”, Petrenko et al 2020
“Active Preference-Based Gaussian Process Regression for Reward Learning”, Bıyık et al 2020
Active Preference-Based Gaussian Process Regression for Reward Learning
“VLN-BERT: Improving Vision-And-Language Navigation With Image-Text Pairs from the Web”, Majumdar et al 2020
VLN-BERT: Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
“First Return, Then Explore”, Ecoffet et al 2020
“AI-Powered Rat Could Be a Valuable New Tool for Neuroscience: Researchers from DeepMind and Harvard Are Using a Virtual Rat to See What Neural Networks Can Teach Us about Biology”, Gent 2020
“Never Stop Learning: The Effectiveness of Fine-Tuning in Robotic Reinforcement Learning”, Julian et al 2020
Never Stop Learning: The Effectiveness of Fine-Tuning in Robotic Reinforcement Learning
“Learning Agile Robotic Locomotion Skills by Imitating Animals”, Peng et al 2020
Learning Agile Robotic Locomotion Skills by Imitating Animals
“Learning to Fly via Deep Model-Based Reinforcement Learning”, Becker-Ehmck et al 2020
“Deep Neuroethology of a Virtual Rodent”, Merel et al 2020
“Learning to Walk in the Real World With Minimal Human Effort”, Ha et al 2020
Learning to Walk in the Real World with Minimal Human Effort
“In the 1970s, the CIA Created a Robot Dragonfly Spy. Now We Know How It Works. Newly Released Documents Show How the CIA Created One of the World’s First Examples of Insect Robotics.”, Hambling 2020
“The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
“Remote-Controlled Insect Navigation Using Plasmonic Nanotattoos”, Tadepalli et al 2020
Remote-controlled insect navigation using plasmonic nanotattoos
“AI Helps Warehouse Robots Pick Up New Tricks: Backed by Machine Learning Luminaries, Covariant.ai’s Bots Can Handle Jobs Previously Needing a Human Touch”, Knight 2020
“First-In-Human Evaluation of a Hand-Held Automated Venipuncture Device for Rapid Venous Blood Draws”, Leipheimer et al 2020
First-in-human evaluation of a hand-held automated venipuncture device for rapid venous blood draws
“Near-Perfect Point-Goal Navigation from 2.5 Billion Frames of Experience”, Wijmans & Kadian 2020
Near-perfect point-goal navigation from 2.5 billion frames of experience
“Reinforcement Learning Upside Down: Don’t Predict Rewards—Just Map Them to Actions”, Schmidhuber 2019
Reinforcement Learning Upside Down: Don’t Predict Rewards—Just Map Them to Actions
“Increasing Generality in Machine Learning through Procedural Content Generation”, Risi & Togelius 2019
Increasing Generality in Machine Learning through Procedural Content Generation
“SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms”, Tsykunov et al 2019
SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms
“Scaling Robot Supervision to Hundreds of Hours With RoboTurk: Robotic Manipulation Dataset through Human Reasoning and Dexterity”, Mandlekar et al 2019
“DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, Wijmans et al 2019
DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames
“Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning”, Yu et al 2019
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
“Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
“Solving Rubik’s Cube With a Robot Hand [blog]”, OpenAI 2019
“Scaling Data-Driven Robotics With Reward Sketching and Batch Reinforcement Learning”, Cabi et al 2019
Scaling data-driven robotics with reward sketching and batch reinforcement learning
“Learning to Seek: Autonomous Source Seeking With Deep Reinforcement Learning Onboard a Nano Drone Microcontroller”, Duisterhof et al 2019
“ROBEL: Robotics Benchmarks for Learning With Low-Cost Robots”, Ahn et al 2019
ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots
“TuneNet: One-Shot Residual Tuning for System Identification and Sim-To-Real Robot Task Transfer”, Allevato et al 2019
TuneNet: One-Shot Residual Tuning for System Identification and Sim-to-Real Robot Task Transfer
“The Robot Revolution: Managerial and Employment Consequences for Firms”, Dixon et al 2019
The Robot Revolution: Managerial and Employment Consequences for Firms
“An Application of Reinforcement Learning to Aerobatic Helicopter Flight”, Abbeel et al 2019
An Application of Reinforcement Learning to Aerobatic Helicopter Flight
“AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
“Adversarial Policies: Attacking Deep Reinforcement Learning”, Gleave et al 2019
“End-To-End Robotic Reinforcement Learning without Reward Engineering”, Singh et al 2019
End-to-End Robotic Reinforcement Learning without Reward Engineering
“Habitat: A Platform for Embodied AI Research”, Savva et al 2019
“Long-Range Indoor Navigation With PRM-RL”, Francis et al 2019
“Learning Agile and Dynamic Motor Skills for Legged Robots”, Hwangbo et al 2019
“The RobotriX: An EXtremely Photorealistic and Very-Large-Scale Indoor Dataset of Sequences With Robot Trajectories and Interactions”, Garcia-Garcia et al 2019
“Living With Harmony: A Personal Companion System by Realbotix™”, Coursey et al 2019
Living with Harmony: A Personal Companion System by Realbotix™
“Sim-To-Real via Sim-To-Sim: Data-Efficient Robotic Grasping via Randomized-To-Canonical Adaptation Networks”, James et al 2018
“ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst”, Bansal et al 2018
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst
“Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control”, Ebert et al 2018
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
“An Introduction to Deep Reinforcement Learning”, Francois-Lavet et al 2018
“Organic Synthesis in a Modular Robotic System Driven by a Chemical Programming Language”, Steiner et al 2018
Organic synthesis in a modular robotic system driven by a chemical programming language
“Neural Probabilistic Motor Primitives for Humanoid Control”, Merel et al 2018
“Deep Reinforcement Learning”, Li 2018
“Learning Navigation Behaviors End-To-End With AutoRL”, Chiang et al 2018
“Benchmarking Reinforcement Learning Algorithms on Real-World Robots”, Mahmood et al 2018
Benchmarking Reinforcement Learning Algorithms on Real-World Robots
“Fully Distributed Multi-Robot Collision Avoidance via Deep Reinforcement Learning for Safe and Efficient Navigation in Complex Scenarios”, Fan et al 2018
“Learning Dexterous In-Hand Manipulation”, OpenAI et al 2018
“Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias”, Gupta et al 2018
Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias
“Visual Reinforcement Learning With Imagined Goals”, Nair et al 2018
“QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation”, Kalashnikov et al 2018
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
“Adversarial Active Exploration for Inverse Dynamics Model Learning”, Hong et al 2018
Adversarial Active Exploration for Inverse Dynamics Model Learning
“More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch”, Calandra et al 2018
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
“Learning Real-World Robot Policies by Dreaming”, Piergiovanni et al 2018
“Synthesizing Programs for Images Using Reinforced Adversarial Learning”, Ganin et al 2018
Synthesizing Programs for Images using Reinforced Adversarial Learning
“One Big Net For Everything”, Schmidhuber 2018
“One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”, Yu et al 2018
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
“Neural Network Based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction”, Lathuilière et al 2017
Neural Network Based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction
“The Signature of Robot Action Success in EEG Signals of a Human Observer: Decoding and Visualization Using Deep Convolutional Neural Networks”, Behncke et al 2017
“Sim-To-Real Transfer of Robotic Control With Dynamics Randomization”, Peng et al 2017
Sim-to-Real Transfer of Robotic Control with Dynamics Randomization
“Flow: A Modular Learning Framework for Mixed Autonomy Traffic”, Wu et al 2017
Flow: A Modular Learning Framework for Mixed Autonomy Traffic
“PRM-RL: Long-Range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-Based Planning”, Faust et al 2017
“GraspGAN: Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping”, Bousmalis et al 2017
GraspGAN: Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
“Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics”, Chatzilygeroudis & Mouret 2017
Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics
“One-Shot Visual Imitation Learning via Meta-Learning”, Finn et al 2017
“Brain Responses During Robot-Error Observation”, Welke et al 2017
“Deep Learning in Robotics: A Review of Recent Research”, Pierson & Gashler 2017
“Proximal Policy Optimization Algorithms”, Schulman et al 2017
“The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously”, Cabi et al 2017
The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously
“Semi-Supervised Haptic Material Recognition for Robots Using Generative Adversarial Networks”, Erickson et al 2017
Semi-Supervised Haptic Material Recognition for Robots using Generative Adversarial Networks
“Vision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration”, Rahmatizadeh et al 2017
“Deep Q-Learning from Demonstrations”, Hester et al 2017
“Data-Efficient Deep Reinforcement Learning for Dexterous Manipulation”, Popov et al 2017
Data-efficient Deep Reinforcement Learning for Dexterous Manipulation
“Black-Box Data-Efficient Policy Search for Robotics”, Chatzilygeroudis et al 2017
“One-Shot Imitation Learning”, Duan et al 2017
“Enabling Robots to Communicate Their Objectives”, Huang et al 2017
“Sim-To-Real Robot Learning from Pixels With Progressive Nets”, Rusu et al 2016
Sim-to-Real Robot Learning from Pixels with Progressive Nets
“Supervision via Competition: Robot Adversaries for Learning Tasks”, Pinto et al 2016
Supervision via Competition: Robot Adversaries for Learning Tasks
“Deep Reinforcement Learning for Robotic Manipulation With Asynchronous Off-Policy Updates”, Gu et al 2016
Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
“Deep Visual Foresight for Planning Robot Motion”, Finn & Levine 2016
“Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning”, Zhu et al 2016
Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning
“Learning Hand-Eye Coordination for Robotic Grasping With Deep Learning and Large-Scale Data Collection”, Levine et al 2016
“Optimization-Based Locomotion Planning, Estimation, and Control Design for the Atlas Humanoid Robot”, Kuindersma et al 2015
Optimization-based locomotion planning, estimation, and control design for the atlas humanoid robot
“MAP-Elites: Illuminating Search Spaces by Mapping Elites”, Mouret & Clune 2015
“End-To-End Training of Deep Visuomotor Policies”, Levine et al 2015
“An Invitation to Imitation”, Bagnell 2015
“Gaussian Processes for Data-Efficient Learning in Robotics and Control”, Deisenroth et al 2015
Gaussian Processes for Data-Efficient Learning in Robotics and Control
“Robots That Can Adapt like Animals”, Cully et al 2014
“PILCO: A Model-Based and Data-Efficient Approach to Policy Search”, Deisenroth & Rasmussen 2011
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
“Motion Planning for Dynamic Folding of a Cloth With Two High-Speed Robot Hands and Two High-Speed Sliders”, Yamakawa et al 2011
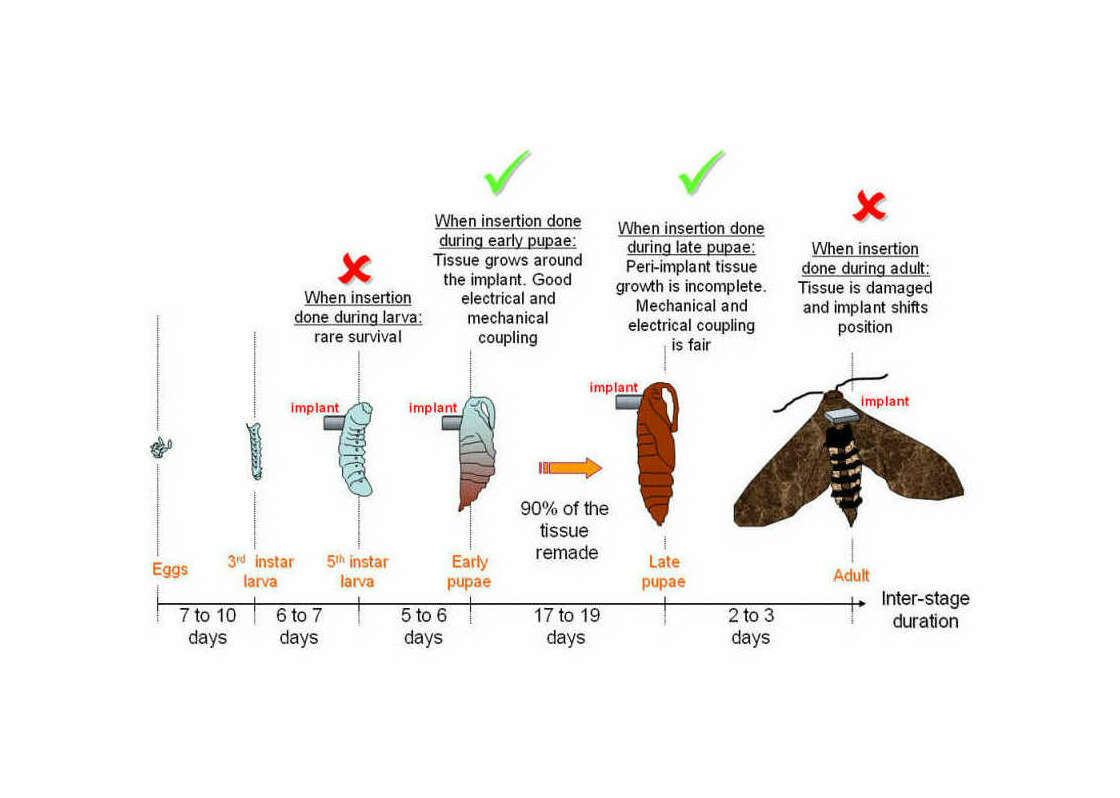
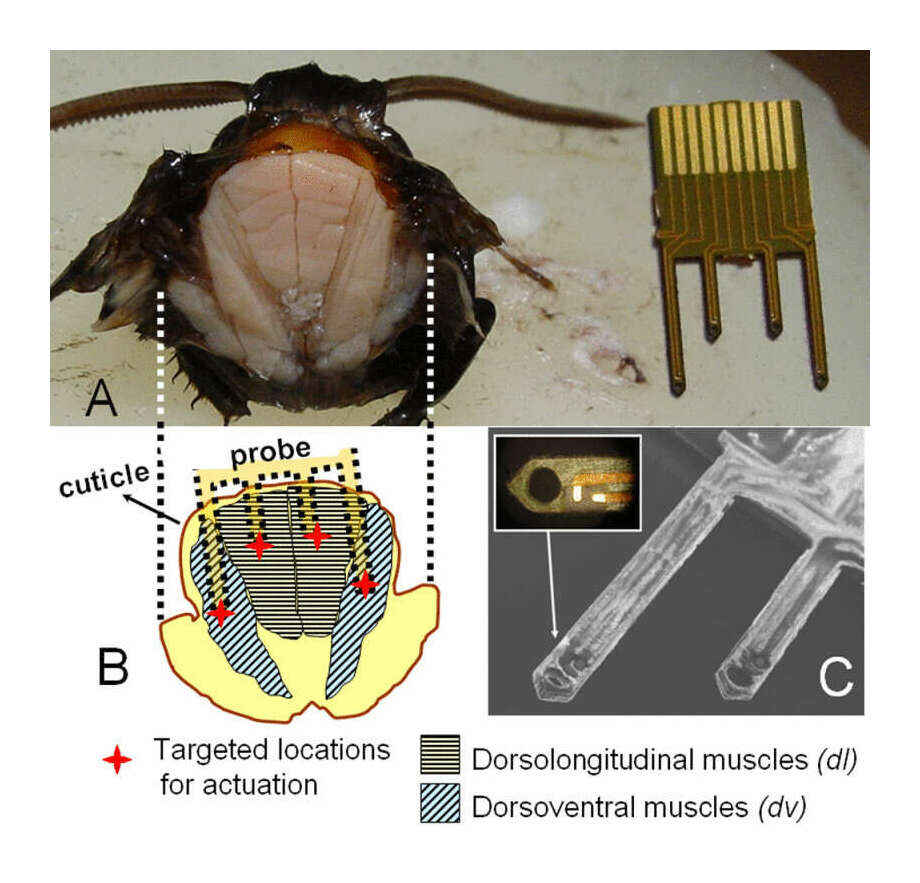
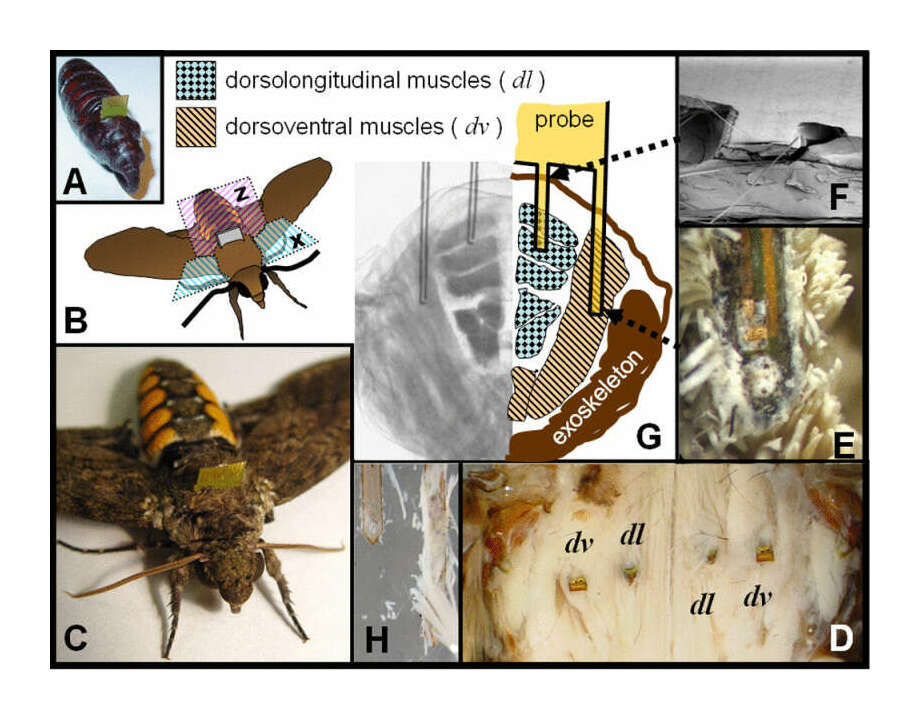
“Towards Insect Cyborgs: Interfacing Microtechnologies With Metamorphic Development”, Bozkurt 2010 (page 4)
Towards Insect Cyborgs: Interfacing Microtechnologies With Metamorphic Development
“Motion Planning for Dynamic Knotting of a Flexible Rope With a High-Speed Robot Arm”, Yamakawa et al 2010
Motion Planning for Dynamic Knotting of a Flexible Rope with a High-speed Robot Arm
“Insect-Machine Interface Based Neurocybernetics”, Bozkurt et al 2009
“Weldon’s Dice, Automated”, Labby 2009
“Resilient Machines Through Continuous Self-Modeling”, Bongard et al 2006
“Robot Predictions Evolution”, Moravec 2004
“Spatio-Temporal Prediction Modulates the Perception of Self-Produced Stimuli”, Blakemore et al 1999
Spatio-Temporal Prediction Modulates the Perception of Self-Produced Stimuli
“When Will Computer Hardware Match the Human Brain?”, Moravec 1998
“Evolving 3D Morphology and Behavior by Competition”, Sims 1994
“The Stanford Cart and the CMU Rover”, Moravec 1990
“How Robots Can Acquire New Skills from Their Shared Experience”
How Robots Can Acquire New Skills from Their Shared Experience:
“Learning to Write Programs That Generate Images”
“Learning Dexterity”
“Scale: The Data Platform for AI; High Quality Training and Validation Data for AI Applications”, AI 2024
Scale: The Data Platform for AI; High quality training and validation data for AI applications
“Forget about Drones, Forget about Dystopian Sci-Fi—A Terrifying New Generation of Autonomous Weapons Is Already Here. Meet the Small Band of Dedicated Optimists Battling Nefarious Governments and Bureaucratic Tedium to Stop the Proliferation of Killer Robots And, Just Maybe, save Humanity from Itself.”
“Japan Nuclear Plant Gets Help from US Robots: Obama Administration Sends Shipment of Robots to Help Regain Control over Stricken Fukushima Nuclear Plant”
“The Robots Are Coming for Garment Workers. That’s Good for the U.S., Bad for Poor Countries: Automation Is Reaching into Trades That Once Seemed Immune, Transforming Sweatshops in Places like Bangladesh and Bringing Production back to America”
“48:44—Tesla Vision · 1:13:12—Planning and Control · 1:24:35—Manual Labeling · 1:28:11—Auto Labeling · 1:35:15—Simulation · 1:42:10—Hardware Integration · 1:45:40—Dojo”
“Robot Peels Banana With Deep Learning, UT ISI Lab”
“Supplementary Video for Do As I Can, Not As I Say: Grounding Language in Robotic Affordances”
Supplementary video for Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
“Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild [video]”
Learning robust perceptive locomotion for quadrupedal robots in the wild [video]
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
eating-disorders
cognitive-robots
robotic-control
Wikipedia
-
View External Link:
-
View External Link:
-
View External Link:
-
View External Link:
Miscellaneous
-
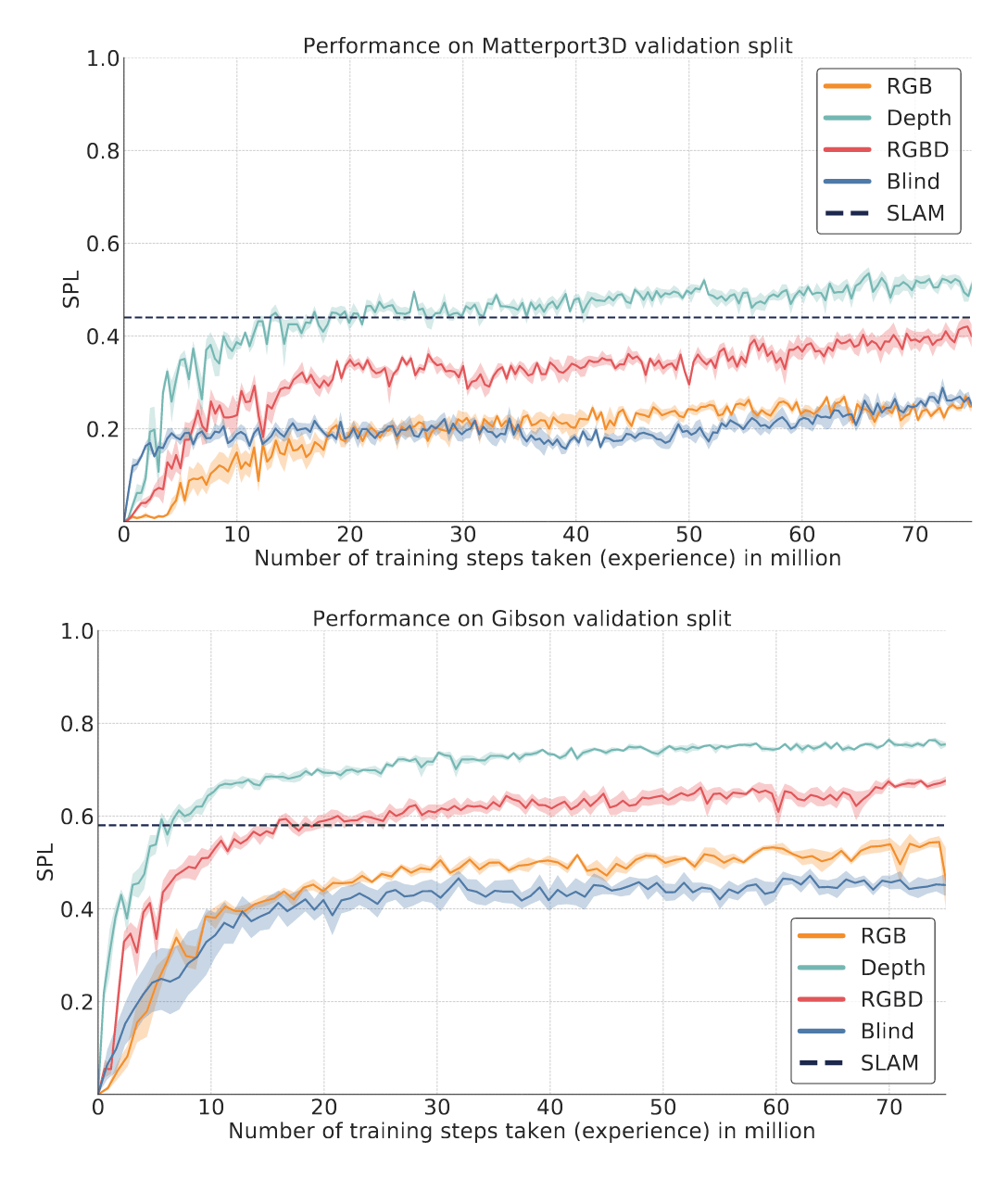
/doc/reinforcement-learning/robot/2019-savva-figure3-cnnroboticsscalesbetterthanslam.png: -
https://ai.facebook.com/blog/teaching-robots-to-perceive-understand-and-interact-through-touch/ -
https://austinvernon.site/blog/powerprojectionineastasia.html: -
https://bair.berkeley.edu/blog/2018/11/30/visual-rl/:View External Link:
-
https://bair.berkeley.edu/blog/2019/05/20/solar/:View HTML (93MB):
/doc/www/bair.berkeley.edu/ec8ce42605eee859c84e06d7284f7dd367cdd843.html -
https://bair.berkeley.edu/blog/2019/05/28/end-to-end/:View HTML (73MB):
/doc/www/bair.berkeley.edu/33a0dd4fa133e6bc28cc3d45535466dc6cb635de.html -
https://blog.research.google/2018/06/scalable-deep-reinforcement-learning.html -
https://blog.research.google/2019/02/long-range-robotic-navigation-via.html: -
https://blog.research.google/2021/06/the-importance-of-ab-testing-in-robotics.html: -
https://blog.research.google/2021/06/toward-generalized-sim-to-real-transfer.html -
https://blog.research.google/2022/02/can-robots-follow-instructions-for-new.html: -
https://blog.x.company/1-million-hours-of-stratospheric-flight-f7af7ae728ac -
https://daily.jstor.org/the-marvelous-automata-of-antiquity/ -
https://medium.com/@paulmorrishill/building-a-string-art-machine-eeee386a38db -
https://medium.com/aurora-blog/auroras-approach-to-development-5e42fec2ee4b -
https://medium.com/cruise/cruise-continuous-learning-machine-30d60f4c691b -
https://publicdomainreview.org/essay/wonder-and-pleasure-in-the-oude-doolhof-of-amsterdam#p-8-1 -
https://spectrum.ieee.org/ai-guided-robots-are-ready-to-sort-your-recyclables -
https://spectrum.ieee.org/automaton/robotics/home-robots/hello-robots-stretch-mobile-manipulator -
https://spectrum.ieee.org/hard-for-robots-autonomous-household-chores: -
https://spectrum.ieee.org/how-boston-dynamics-taught-its-robots-to-dance -
https://spectrum.ieee.org/roomba-inventor-joe-jones-on-weed-killing-robot -
https://techcrunch.com/2021/07/27/robotic-ai-firm-covariant-raises-another-80-million/ -
https://techcrunch.com/2023/12/29/china-robotaxi-apply-the-brakes/ -
https://twitter.com/olivercameron/status/1622802466470514688 -
https://twitter.com/pulkitology/status/1602707244470177792: -
https://twitter.com/rowancheung/status/1718298946819268980: -
https://venturebeat.com/business/openai-disbands-its-robotics-research-team/ -
https://waymo.com/blog/2023/09/waymos-autonomous-vehicles-are.html?hl=it_IT:View HTML (16MB):
/doc/www/waymo.com/26a176ab933b472c9eba11d74306b50da31e12bd.html -
https://www.construction-physics.com/p/where-are-the-robotic-bricklayers -
https://www.newyorker.com/magazine/2022/01/24/the-rise-of-ai-fighter-pilots -
https://www.nytimes.com/2018/03/15/business/self-driving-cars-remote-control.html -
https://www.nytimes.com/2019/03/26/technology/google-robotics-lab.html -
https://www.nytimes.com/2021/04/30/technology/robot-surgery-surgeon.html -
https://www.nytimes.com/2021/12/07/science/robots-pancake-jump.html -
https://www.quantamagazine.org/ai-makes-strides-in-virtual-worlds-more-like-our-own-20220624/ -
https://www.reddit.com/r/reinforcementlearning/search?q=flair%3ARobot&sort=top&restrict_sr=on&t=year: -
https://www.technologyreview.com/2021/08/06/1030802/ai-robots-take-over-warehouses/ -
https://www.theverge.com/2021/7/6/22565448/waymo-simulation-city-autonomous-vehicle-testing-virtual -
https://www.theverge.com/2021/9/9/22660467/irobot-roomba-ai-dog-poop-avoidance-j7-specs-price -
https://www.understandingai.org/p/driverless-cars-may-already-be-safer -
https://www.wired.com/story/ai-powered-totally-autonomous-future-of-war-is-here/ -
https://www.wired.com/story/autonomous-drones-could-soon-run-the-uks-energy-grid/: -
https://www.wired.com/story/can-robots-evolve-into-machines-of-loving-grace/gw:View External Link:
https://www.wired.com/story/can-robots-evolve-into-machines-of-loving-grace/gw -
https://www.wired.com/story/darpa-grand-challenge-2004-oral-history/ -
https://www.wired.com/story/elusive-hunt-robot-pick-ripe-strawberry/:View External Link:
https://www.wired.com/story/elusive-hunt-robot-pick-ripe-strawberry/ -
https://www.wired.com/story/fast-forward-humanoid-robots-are-coming-of-age/:View External Link:
https://www.wired.com/story/fast-forward-humanoid-robots-are-coming-of-age/ -
https://www.wired.com/story/parents-dementia-robots-warm-technology/ -
https://www.wired.com/story/this-brain-controlled-robotic-arm-can-twist-grasp-and-feel/ -
https://www.wired.com/story/why-scientists-love-making-robots-build-ikea-furniture/: -
https://www.wsj.com/business/meet-the-robots-slicing-your-barbecue-ribs-338a7794 -
https://www.youtube.com/watch?v=QyJGXc9WeNo&list=PLOXw6I10VTv9HODt7TFEL72K3Q6C4itG6&index=3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://arxiv.org/abs/2304.13653#deepmind: “Learning Agile Soccer Skills for a Bipedal Robot With Deep Reinforcement Learning”, -
https://arxiv.org/abs/2304.13705: “ACT: Learning Fine-Grained Bimanual Manipulation With Low-Cost Hardware”, Tony Z. Zhao, Vikash Kumar, Sergey Levine, Chelsea Finn -
2023-lee.pdf: “Bubble-Based Microrobots With Rapid Circular Motions for Epithelial Pinning and Drug Delivery”, -
https://arxiv.org/abs/2211.07638: “Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Ananye Agarwal, Ashish Kumar, Jitendra Malik, Deepak Pathak -
https://www.tandfonline.com/doi/full/10.1080/00305316.2022.2121777: “Selective Neutralization and Deterring of Cockroaches With Laser Automated by Machine Vision”, Ildar Rakhmatulin, Mathieu Lihoreau, Jose Pueyo -
https://arxiv.org/abs/2207.05608#google: “Inner Monologue: Embodied Reasoning through Planning With Language Models”, -
https://arxiv.org/abs/2207.04429: “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Dhruv Shah, Blazej Osinski, Brian Ichter, Sergey Levine -
https://arxiv.org/abs/2206.14349: “Fleet-DAgger: Interactive Robot Fleet Learning With Scalable Human Supervision”, -
https://arxiv.org/abs/2206.14176: “DayDreamer: World Models for Physical Robot Learning”, Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, Pieter Abbeel -
https://arxiv.org/abs/2205.06175#deepmind: “Gato: A Generalist Agent”, -
https://arxiv.org/abs/2204.05080#deepmind: “Semantic Exploration from Language Abstractions and Pretrained Representations”, -
https://arxiv.org/abs/2204.03514#facebook: “Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale”, Ram Ramrakhya, Eric Undersander, Dhruv Batra, Abhishek Das -
https://arxiv.org/abs/2204.01691#google: “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, -
https://arxiv.org/abs/2204.00598#google: “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, -
2022-miki.pdf: “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, Marco Hutter -
https://arxiv.org/abs/2108.07258: “On the Opportunities and Risks of Foundation Models”, -
https://waymo.com/blog/2021/03/replaying-real-life.html: “Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo -
2021-ecoffet.pdf#uber: “Go-Explore: First Return, Then Explore”, Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, Jeff Clune -
https://arxiv.org/abs/2012.05672#deepmind: “Imitating Interactive Intelligence”, -
https://arxiv.org/abs/2006.12983#deepmind: “Dm_control: Software and Tasks for Continuous Control”, -
https://openreview.net/forum?id=SyxrxR4KPS#deepmind: “Deep Neuroethology of a Virtual Rodent”, Josh Merel, Diego Aldarondo, Jesse Marshall, Yuval Tassa, Greg Wayne, Bence Olveczky (DM/Harvard) -
https://www.technologyreview.com/2020/02/17/844721/ai-openai-moonshot-elon-musk-sam-altman-greg-brockman-messy-secretive-reality/: “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Karen Hao -
https://arxiv.org/abs/1911.00357#facebook: “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, Dhruv Batra -
https://arxiv.org/abs/1904.01201#facebook: “Habitat: A Platform for Embodied AI Research”, -
https://arxiv.org/abs/1804.01118#deepmind: “Synthesizing Programs for Images Using Reinforced Adversarial Learning”, Yaroslav Ganin, Tejas Kulkarni, Igor Babuschkin, S. M. Ali Eslami, Oriol Vinyals -
2010-bozkurt.pdf#page=4: “Towards Insect Cyborgs: Interfacing Microtechnologies With Metamorphic Development”, Alper Bozkurt -
2010-yamakawa.pdf: “Motion Planning for Dynamic Knotting of a Flexible Rope With a High-Speed Robot Arm”, Yuji Yamakawa, Akio Namiki, Masatoshi Ishikawa -
2009-bozkurt.pdf: “Insect-Machine Interface Based Neurocybernetics”, Alper Bozkurt, Robert F. Gilmour, Ayesa Sinha, David Stern, Amit Lal -
https://web.archive.org/web/20230718144747/https://frc.ri.cmu.edu/~hpm/project.archive/robot.papers/2004/Predictions.html: “Robot Predictions Evolution”, Hans Moravec