- See Also
-
Links
- “Towards Playing Full MOBA Games With Deep Reinforcement Learning”, Ye et al 2020
- “Mastering Complex Control in MOBA Games With Deep Reinforcement Learning”, Ye et al 2019
- “Dota 2 With Large Scale Deep Reinforcement Learning”, Berner et al 2019
- “OpenAI Five: 2016–2019”, OpenAI 2019
- “Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
- “Solving Rubik’s Cube With a Robot Hand [blog]”, OpenAI 2019
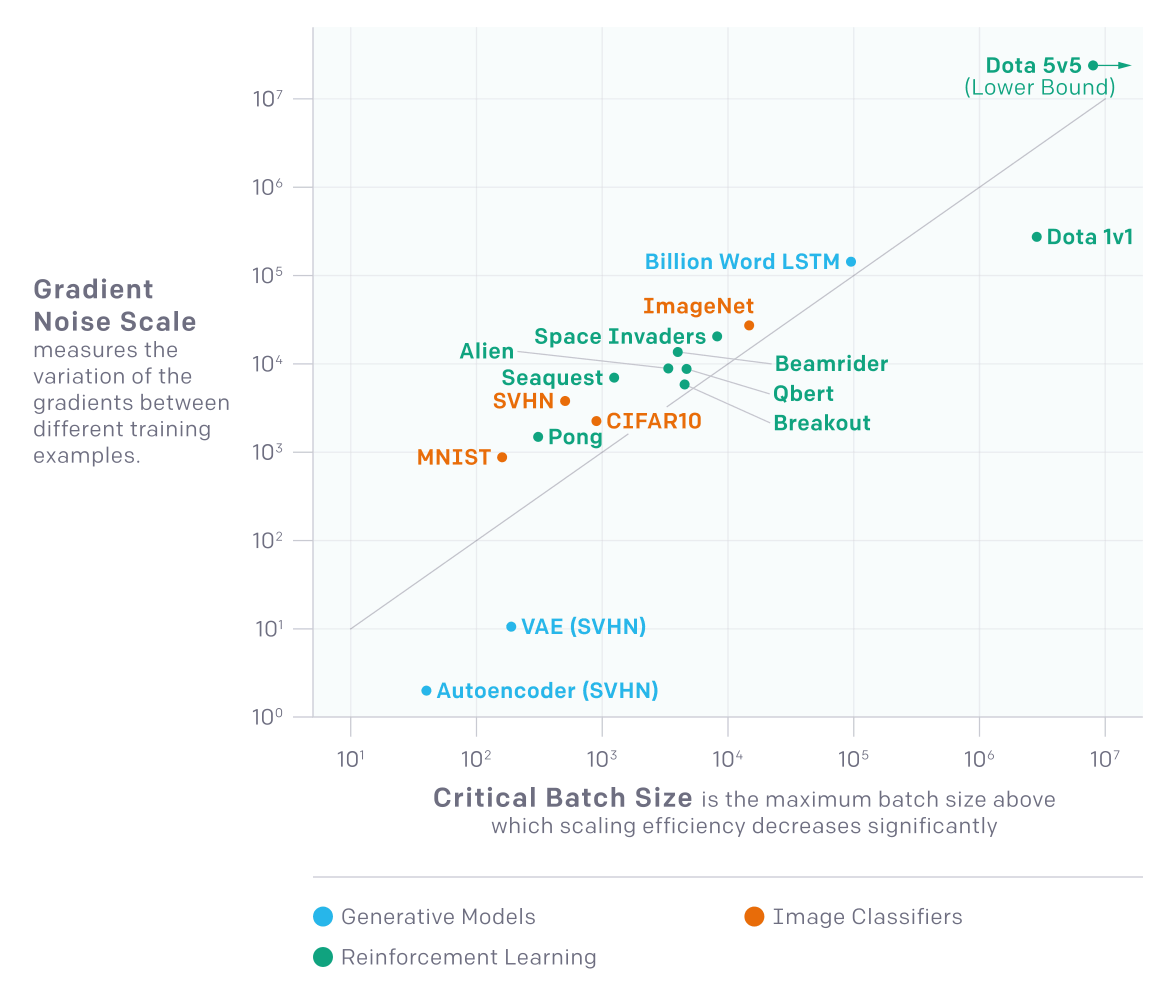
- “An Empirical Model of Large-Batch Training”, McCandlish et al 2018
- “How AI Training Scales”, McCandlish et al 2018
- “Emergent Complexity via Multi-Agent Competition”, Bansal et al 2017
- “Proximal Policy Optimization Algorithms”, Schulman et al 2017
- “Net2Net: Accelerating Learning via Knowledge Transfer”, Chen et al 2015
- “Dota 2 With Large Scale Deep Reinforcement Learning § Pg11”, Rerun 2024 (page 11 org openai)
- “If You Want to Solve a Hard Problem in Reinforcement Learning, You Just Scale. It's Just Gonna Work Just like Supervised Learning. It's the Same, the Same Story Exactly. It Was Kind of Hard to Believe That Supervised Learning Can Do All Those Things, but It's Not Just Vision, It's Everything and the Same Thing Seems to Hold for Reinforcement Learning Provided You Have a Lot of Experience.”
- Wikipedia
- Miscellaneous
- Link Bibliography
See Also
Links
“Towards Playing Full MOBA Games With Deep Reinforcement Learning”, Ye et al 2020
Towards Playing Full MOBA Games with Deep Reinforcement Learning
“Mastering Complex Control in MOBA Games With Deep Reinforcement Learning”, Ye et al 2019
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
“Dota 2 With Large Scale Deep Reinforcement Learning”, Berner et al 2019
“OpenAI Five: 2016–2019”, OpenAI 2019
“Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
“Solving Rubik’s Cube With a Robot Hand [blog]”, OpenAI 2019
“An Empirical Model of Large-Batch Training”, McCandlish et al 2018
“How AI Training Scales”, McCandlish et al 2018
“Emergent Complexity via Multi-Agent Competition”, Bansal et al 2017
“Proximal Policy Optimization Algorithms”, Schulman et al 2017
“Net2Net: Accelerating Learning via Knowledge Transfer”, Chen et al 2015
“Dota 2 With Large Scale Deep Reinforcement Learning § Pg11”, Rerun 2024 (page 11 org openai)
“If You Want to Solve a Hard Problem in Reinforcement Learning, You Just Scale. It's Just Gonna Work Just like Supervised Learning. It's the Same, the Same Story Exactly. It Was Kind of Hard to Believe That Supervised Learning Can Do All Those Things, but It's Not Just Vision, It's Everything and the Same Thing Seems to Hold for Reinforcement Learning Provided You Have a Lot of Experience.”
Wikipedia
Miscellaneous
-
https://medium.com/syncedreview/openais-long-pursuit-of-dota-2-mastery-1d3a861472bd -
https://web.archive.org/web/20210131091045/https://arena.openai.com/#/results: -
https://www.reddit.com/r/DotA2/comments/beyilz/openai_live_updates_thread_lessons_on_how_to_beat/ -
https://www.reddit.com/r/DotA2/comments/bf49yk/hello_were_the_dev_team_behind_openai_five_we/: -
https://www.youtube.com/watch?v=QyJGXc9WeNo&list=PLOXw6I10VTv9HODt7TFEL72K3Q6C4itG6&index=3
{kind=link}
{kind=link}
Link Bibliography
-
https://arxiv.org/abs/2011.12692#tencent: “Towards Playing Full MOBA Games With Deep Reinforcement Learning”, -
https://openai.com/research/how-ai-training-scales: “How AI Training Scales”, Sam McCandlish, Jared Kaplan, Dario Amodei