- See Also
-
Links
- “Foundations for Transfer in Reinforcement Learning: A Taxonomy of Knowledge Modalities”, Wulfmeier et al 2023
- “PiRank: Learning To Rank via Differentiable Sorting”, Swezey et al 2020
- “Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment”, Talebi et al 2020
- “Deep Reinforcement Learning for Closed-Loop Blood Glucose Control”, Fox et al 2020
- “Multi-Task Learning With Deep Neural Networks: A Survey”, Crawshaw 2020
- “Algorithms With Predictions”, Mitzenmacher & Vassilvitskii 2020
- “Systems That Defy Detailed Understanding § Deep Reinforcement Learning”, Elhage 2020
- “Monte Carlo Gradient Estimation in Machine Learning”, Mohamed et al 2019
- “Evolving Super Stimuli for Real Neurons Using Deep Generative Networks”, Ponce et al 2019
- “An Overview of Multi-Task Learning in Deep Neural Networks”, Ruder 2017
- “On the Computability of Solomonoff Induction and AIXI”, Leike & Hutter 2017
- “Do Artificial Reinforcement-Learning Agents Matter Morally?”, Tomasik 2014
- “Advanced Forecasting Methods for Global Crisis Warning and Models of Intelligence”, Werbos 1977
- “Deep Reinforcement Learning Doesn'T Work Yet”
- “Reddit: Reinforcement Learning Subreddit”, Reddit 2024
- Wikipedia
- Miscellaneous
- Link Bibliography
See Also
Links
“Foundations for Transfer in Reinforcement Learning: A Taxonomy of Knowledge Modalities”, Wulfmeier et al 2023
Foundations for Transfer in Reinforcement Learning: A Taxonomy of Knowledge Modalities
“PiRank: Learning To Rank via Differentiable Sorting”, Swezey et al 2020
“Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment”, Talebi et al 2020
Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment
“Deep Reinforcement Learning for Closed-Loop Blood Glucose Control”, Fox et al 2020
Deep Reinforcement Learning for Closed-Loop Blood Glucose Control
“Multi-Task Learning With Deep Neural Networks: A Survey”, Crawshaw 2020
“Algorithms With Predictions”, Mitzenmacher & Vassilvitskii 2020
“Systems That Defy Detailed Understanding § Deep Reinforcement Learning”, Elhage 2020
Systems that defy detailed understanding § Deep reinforcement Learning
“Monte Carlo Gradient Estimation in Machine Learning”, Mohamed et al 2019
“Evolving Super Stimuli for Real Neurons Using Deep Generative Networks”, Ponce et al 2019
Evolving super stimuli for real neurons using deep generative networks
“An Overview of Multi-Task Learning in Deep Neural Networks”, Ruder 2017
“On the Computability of Solomonoff Induction and AIXI”, Leike & Hutter 2017
“Do Artificial Reinforcement-Learning Agents Matter Morally?”, Tomasik 2014
“Advanced Forecasting Methods for Global Crisis Warning and Models of Intelligence”, Werbos 1977
Advanced Forecasting Methods for Global Crisis Warning and Models of Intelligence:
“Deep Reinforcement Learning Doesn'T Work Yet”
“Reddit: Reinforcement Learning Subreddit”, Reddit 2024
Wikipedia
Miscellaneous
-
/doc/reinforcement-learning/2020-real-googlebrain-automlzero-populationperformanceevolution.mp4: -
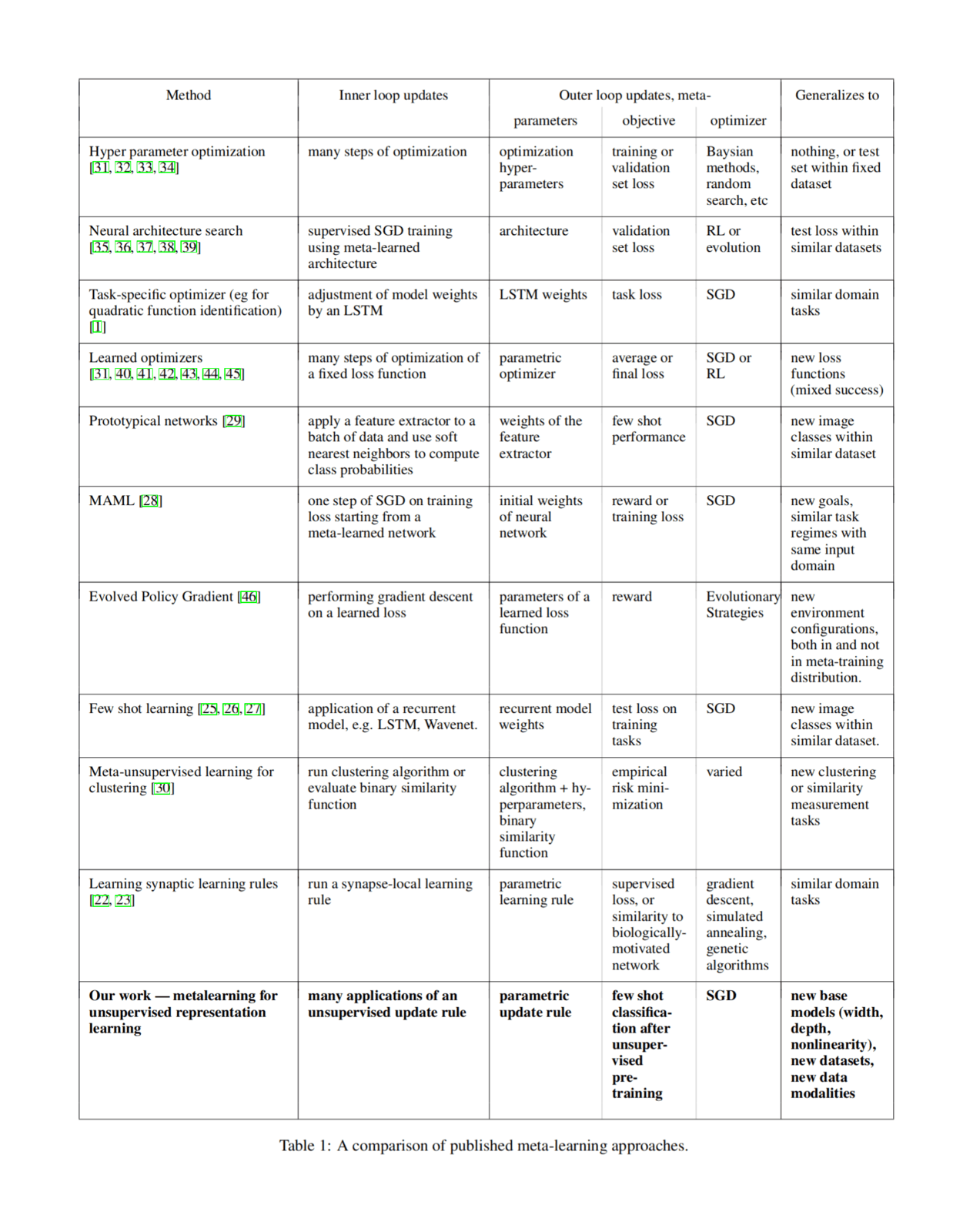
/doc/reinforcement-learning/2018-metz-table1-metalearningparadigms.png: -
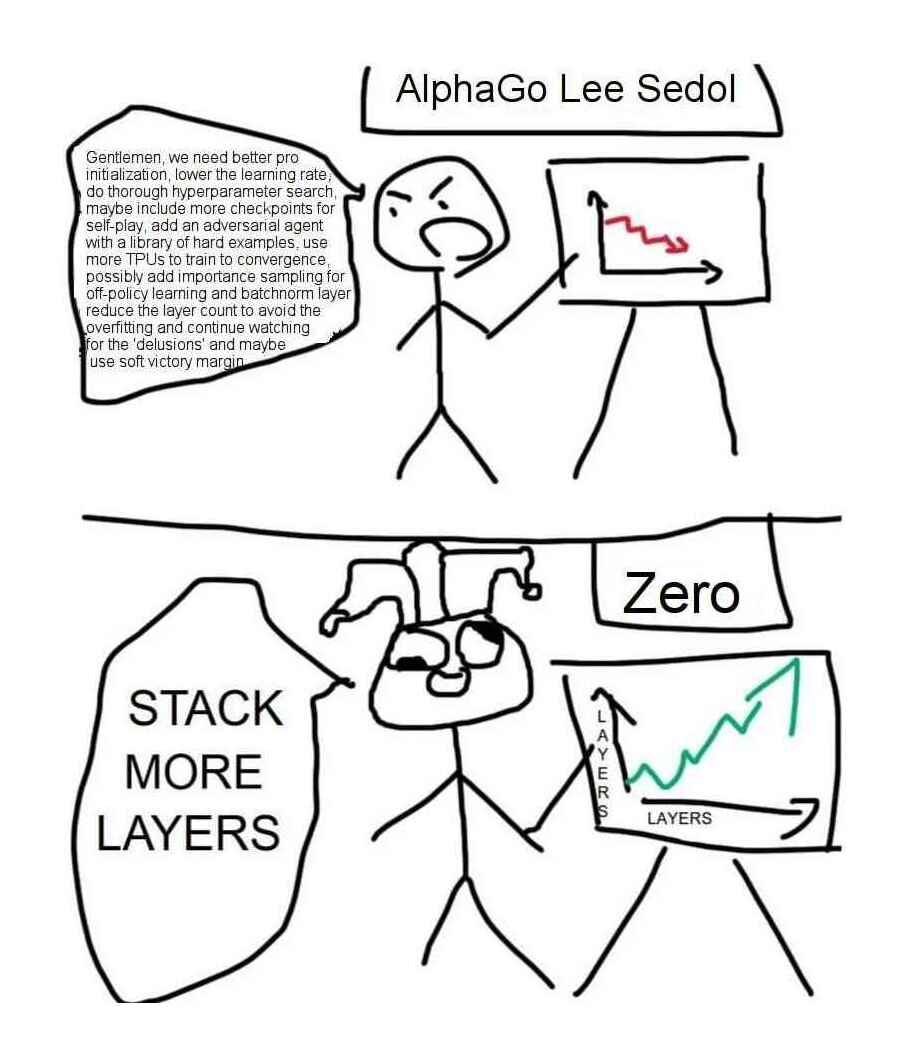
/doc/reinforcement-learning/2017-12-24-gwern-meme-nnlayers-alphagozero.jpg: -
/doc/reinforcement-learning/2004-cook-twoneuronbicycle.avi-poster.jpg: -
/doc/reinforcement-learning/1993-lin.pdf:View PDF:
-
/doc/statistics/decision/1960-howard-dynamicprogrammingmarkovprocesses.pdf -
https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research -
https://rll.berkeley.edu/deeprlcourse/docs/nuts-and-bolts.pdf: -
https://win-vector.com/2016/09/11/adversarial-machine-learning/ -
https://www.quantamagazine.org/in-new-math-proofs-artificial-intelligence-plays-to-win-20220307/
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://blog.nelhage.com/post/systems-that-defy-understanding/: “Systems That Defy Detailed Understanding § Deep Reinforcement Learning”, Nelson Elhage