Which books on GoodReads are most difficult to finish? Estimating proportions in December 2019 gives an entirely different result than absolute counts.
What books are hardest for a reader who starts them to finish, and most likely to be abandoned? I scrape a crowdsourced tag,
abandoned, from the GoodReads book social network on 2019-12-09 to estimate conditional probability of being abandoned.The default GoodReads tag interface presents only raw counts of tags, not counts divided by total ratings (=reads). This conflates popularity with probability of being abandoned: a popular but rarely-abandoned book may have more
abandonedtags than a less popular but often-abandoned book. There is also residual error from the winner’s curse where books with fewer ratings are more mis-estimated than popular books. I fix that to see what more correct rankings look like.Correcting for both changes the top-5 ranking completely, from (raw counts):
to (shrunken posterior proportions):
I also consider a model adjusting for covariates (author/average-rating/year), to see what books are most surprisingly often-abandoned given their pedigrees & rating etc. Abandon rates increase the newer a book is, and the lower the average rating.
Adjusting for those, the top-5 are:
The Casual Vacancy, J. K. Rowling
Books at the top of the adjusted list appear to reflect a mix of highly-popular authors changing genres, and ‘prestige’ books which are highly-rated but a slog to read.
These results are interesting for how they highlight how people read books for many reasons (such as marketing campaigns, literary prestige, or following a popular author), and this is reflected in their decision whether to continue reading or to abandon a book.
The book review website/social network GoodReads (2006–) is probably the single largest book-focused website in the Anglosphere—it is almost as widely used by authors, who as much as they may despise it, can’t live without it. (I was surprised when, reading writer interviews to learn about preferred writing times, how many have given interviews to GoodReads over the years.) I do not recommend GoodReads as it is extremely slow, largely unmaintained post-acquisition, and user-hostile (eg. eliminating the API access which allowed users to escape to better book websites like LibraryThing); nevertheless, it remains the largest book website and some interesting data can be extracted from it. Its functionality is limited, but GoodReads does support user-set tags on books in the form of ‘bookshelves’; one such tag is the GR “abandoned” bookshelf1, which lets people record which books they couldn’t finish reading.2 A (former) GoodReads user myself, I came across that tag and thought to myself that the results were amusing—take that, both highschool English class & J. K. Rowling!—but also totally misleading, since the bookshelf page only shows books sorted by total tags per book.
Little recent data. There aren’t many similar sources for people dropping books. Amazon’s Kindle has allowed for similar inferences by indirectly gauging reader attrition through the distribution of ‘highlights’ (user-made excerpts/notes), under the assumption that highlight-worthy material is uniformly distributed & thus absence of evidence (of highlighting) is evidence of absence (of reading), which Jordan Ellenberg in 2014 to facetiously estimate that Thomas Piketty’s Capital in the Twenty-First Century was the most abandoned book of 2014. That hasn’t seemed to be updated recently, even though Amazon surely has detailed analytics and knows exactly what books have highest abandonment rates (to address Kindle Unlimited fraud & cabals if nothing else), so GoodReads offers a useful alternative despite all the flaws of haphazardly-collected social media data.
Problems in Ranking by Raw Count
Popularity ≠ Unreadability. It’s no surprise that J. K. Rowling’s The Casual Vacancy or Catch-22 are at the top of the list, because they are read so often. A really abandonable-book probably would never become popular enough to get enough abandoned-tags to crack the list. (There are only two kinds of books: those people complain about reading, and those people don’t read.)
So as it is, a simple sort-by-count tells us nothing more than a lot of people have read these books. It’d be more interesting to look at something like what books have the highest percentage of abandoned tags versus total reads. GoodReads, as it happens, provides the number of ‘reads’ as recorded by GR users, so that’s good.
Low counts mean sampling error. However, the abandoned counts are also low in an absolute sense: GR displays only the top 25 pages (so we can’t look at least abandoned books), and to make the cutoff requires just 40 tags. In comparison, the most-read book on the list has 6,238,667 reads. The average percentage abandoned of reads is ~0.13%, which is extremely rare (1 in 769); I am certain that books are abandoned at a much higher rate than that, because I know I abandon books more frequently than 1 in every 769 books despite finishing books being a point of pride for me3, implying that the tags are not necessarily unbiased either.
Bayesian correction for flukes. So we have potentially unstable estimates of percentages: we have a lot (n = 1250) of entries, which we know ought to be similar, but with highly noisy estimates as we try to estimate what is a tiny & rare event (read → abandoned), which will exaggerate differences & mislead us due to winner’s curse/regression to the mean, particularly when we look at the extremes like top/bottom. This makes it a good fit for Bayesian multilevel modeling: we can treat each book as a random effect, and get shrinkage back to a common mean, reducing the damage done by the sampling error.
From a Bayesian multi-level model, we can then extract reasonably stable proportions, rank, and get out a more meaningful list of books by ‘abandon’ rates. Sounds good to me, and the result should be amusing.
Data
Scraping
No API or CLI, so manual extraction. Despite the GoodReads API (which has since been removed), scraping the data turned out to be a nuisance. The GoodReads API appears to only support exporting your particular data, and not scraping arbitrary tags or lists: it doesn’t even hint at the necessary functionality, and searching didn’t turn up any hints. (Perhaps unsurprisingly given GR’s neglect by Amazon since its acquisition.) The data appears on the web interface in HTML form, so I settled for scraping that. (If I wanted the reviews themselves, I would encounter even more horrifying limitations: GoodReads restricts every reader to seeing a maximum of 300 reviews for a book, no matter how many there actually are—one can see additional sets of 300 by choosing different sorting options, but one can never browse anything close to all of them. This means that a review which falls below the top 300 becomes invisible, and the top reviews become a self-reinforcing echo chamber.)
GR lies to bots.4
At first, I thought I could simply use my usual elinks -dump trick and iterate through the 25 pages GR allows.5 This failed because GR only shows you the other pages when you are logged in; if you are logged out, every page request returns the first page (!) and it’s no good. If there were more pages than 25, I’d look further into exporting cookies from Firefox to elinks or using a TagSoup-like library to parse it, but it’s not worth it for so little.
Instead, I copy-pasted each page’s text by hand, and did Emacs macro & regexp search-and-replaces to turn it into a usable CSV. I kept the provided metadata of author/average-GR-rating (1–5 Likert scale)/publication-year.
Preprocessing
Transforming to normality. Reads/Abandoned are highly right-skewed, as one would expect, and a log-transform helps. Year is tricky, because it ranges from 750BC to 2019, but is so left-skewed to books published in the 20th & especially 21st century that the usual transforms like square/cube-rooting do nothing (which will be a problem if we want to use it as a covariate to look at temporal trends in abandon-rates); I settled for transforming years into percentiles. And we’ll want an Abandon rate in addition to the raw Abandoned count.
Reading the CSV of tag data in & transforming:
gr <- read.csv("https://gwern.net/doc/culture/2019-12-09-goodreads-bookshelf-abandoned.csv",
colClasses=c("factor", "factor", "integer", "numeric", "integer", "integer"))
## Raw data:
head(gr)
# Title Author Abandoned Rating Reads Year
# 1 The Casual Vacancy J. K. Rowling 763 3.30 288511 2012
# 2 Catch-22 (Catch-22, #1) Joseph Heller 685 3.98 679887 1961
# 3 American Gods (American Gods, #1) Neil Gaiman 663 4.11 693316 2001
# 4 A Game of Thrones (A Song of Ice and Fire, #1) George R. R. Martin 655 4.45 1833563 1996
# 5 The Book Thief Markus Zusak 608 4.37 1644846 2005
# 6 Outlander (Outlander, #1) Diana Gabaldon 572 4.22 744288 1991
## Transforms:
gr$Reads.log <- log(gr$Reads)
gr$Abandoned.log <- log(gr$Abandoned)
perc.rank <- function(x) trunc(rank(x))/length(x)
gr$Year.percentile <- perc.rank(gr$Year)
gr$Abandoned.rate <- gr$Abandoned / gr$Reads
gr$Abandoned.rate.log <- log(gr$Abandoned.rate)Description
Describing basic statistics:
library(skimr)
skim(gr) ## n = 50 books per page * 25 pages = 1250
# Skim summary statistics
# n obs: 1250
# n variables: 11
#
# ── Variable type:factor ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
# variable missing complete n n_unique top_counts ordered
# Author 0 1250 1250 835 Ste: 12, Nei: 9, Nea: 8, Chu: 6 FALSE
# Title 0 1250 1250 1248 Lie: 2, The: 2, 'Su: 1, 10%: 1 FALSE
#
# ── Variable type:integer ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
# variable missing complete n mean sd p0 p25 p50 p75 p100 hist
# Abandoned 0 1250 1250 104.95 84.51 43 53 74 124.75 763 ▇▂▁▁▁▁▁▁
# Reads 0 1250 1250 264410.29 491210.21 4837 48771.25 108093.5 263805.75 6238667 ▇▁▁▁▁▁▁▁
# Year 0 1250 1250 1982.6 162.45 -750 1995 2009 2013 2019 ▁▁▁▁▁▁▁▇
#
# ── Variable type:numeric ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
# variable missing complete n mean sd p0 p25 p50 p75 p100 hist
# Abandoned.log 0 1250 1250 4.45 0.58 3.76 3.97 4.3 4.83 6.64 ▇▅▃▂▂▁▁▁
# Abandoned.rate 0 1250 1250 0.0013 0.0015 1.7e-05 0.00035 0.00079 0.0016 0.02 ▇▁▁▁▁▁▁▁
# Abandoned.rate.log 0 1250 1250 -7.21 1.09 -10.97 -7.95 -7.14 -6.43 -3.89 ▁▁▃▆▇▅▂▁
# Rating 0 1250 1250 3.92 0.28 2.69 3.76 3.94 4.11 4.65 ▁▁▁▃▆▇▃▁
# Reads.log 0 1250 1250 11.66 1.25 8.48 10.79 11.59 12.48 15.65 ▁▃▆▇▆▃▁▁
# Year.percentile 0 1250 1250 0.5 0.29 8e-04 0.25 0.51 0.72 1 ▇▇▆▇▇▇▆▇
round(digits=2, cor(subset(gr, select=c("Abandoned.log", "Reads.log", "Rating", "Year.percentile", "Abandoned.rate.log"))))
# Abandoned.log Reads.log Rating Year.percentile Abandoned.rate.log
# Abandoned.log 1.00
# Reads.log 0.49 1.00
# Rating 0.08 0.42 1.00
# Year.percentile -0.09 -0.36 -0.18 1.00
# Abandoned.rate.log -0.03 -0.89 -0.44 0.36 1.00Newer/lower-rated = worse. As expected, read count correlates strongly with abandon count, and also as makes sense, being a more recent book correlates with fewer reads (less time for people to have read it). Abandoned rates mechanically correlate with abandoned/read counts, of course, since it’s derived from them; more interesting is that higher ratings predict much lower abandon rates, and being older also predicts lower abandon rates. The further correlation of average rating with year percentile is interesting, as it suggests more recent books both have worse ratings and are otherwise more likely to be abandoned—you’d think people would avoid new books with lower ratings, but I guess novelty & marketing are enough to convince people to waste their time.
Analysis
Simple Proportions
So the data looks sensible. What do the raw abandon rates look like when we look at the worst (largest) abandon rates?
gr$Rank.raw <- 1:nrow(gr)
gr <- gr[order(gr$Abandoned.rate, decreasing=TRUE),]
gr$Rank.proportion <- 1:nrow(gr)
cor(gr$Rank.raw, gr$Rank.proportion, method = "spearman")
# [1] -0.0406028435
gr[1:30,c(13, 12, 1, 2, 10)]
# Rank.proportion Rank.raw Title Author Abandoned.rate
# 1 117 Black Leopard, Red Wolf (The Dark Star Trilogy, #1) Marlon James 0.0204
# 2 482 Space Opera Catherynne M. Valente 0.0114
# 3 411 Little, Big John Crowley 0.0106
# 4 256 The Witches: Salem, 1692 Stacy Schiff 0.0099
# 5 982 Tender Morsels Margo Lanagan 0.0096
# 6 663 Too Like the Lightning (Terra Ignota, #1) Ada Palmer 0.0093
# 7 1212 The Flame Alphabet Ben Marcus 0.0091
# 8 592 New York 2140 Kim Stanley Robinson 0.0090
# 9 690 Hild Nicola Griffith 0.0085
# 10 1039 Gingerbread Helen Oyeyemi 0.0084
# 11 701 Dhalgren Samuel R. Delany 0.0083
# 12 114 Winter's Tale Mark Helprin 0.0078
# 13 134 A Brief History of Seven Killings Marlon James 0.0078
# 14 10 Infinite Jest David Foster Wallace 0.0075
# 15 184 The Ministry of Utmost Happiness Arundhati Roy 0.0072
# 16 962 Gold Fame Citrus Claire Vaye Watkins 0.0071
# 17 1007 I Am a Cat Natsume Sōseki 0.0070
# 18 159 Milkman Anna Burns 0.0066
# 19 689 Avenue of Mysteries John Irving 0.0064
# 20 718 The Years of Rice and Salt Kim Stanley Robinson 0.0064
# 21 371 Zone One Colson Whitehead 0.0063
# 22 522 To Rise Again at a Decent Hour Joshua Ferris 0.0063
# 23 565 City on Fire Garth Risk Hallberg 0.0062
# 24 330 Telegraph Avenue Michael Chabon 0.0061
# 25 576 It Can’t Happen Here Sinclair Lewis 0.0061
# 26 568 The Finkler Question Howard Jacobson 0.0059
# 27 1128 Spinster: Making a Life of One's Own Kate Bolick 0.0058
# 28 771 The Grace of Kings (The Dandelion Dynasty, #1) Ken Liu 0.0058
# 29 645 Barkskins Annie Proulx 0.0057
# 30 1134 A Girl Is a Half-formed Thing Eimear McBride 0.0057The ranking by rate looks completely different from ranking by count: The Casual Vacancy, Catch-22, American Gods, A Game of Thrones6 etc have all vanished and been replaced by an almost disjoint set. (In fact, the two rankings are uncorrelated: ρ = −0.04.)
Proportion rankings look right. These rankings look much more sensible to me as estimates of most-likely-to-be-abandoned: I did in fact abandon Dhalgren in disgust, and while I enjoyed Natsume Sōseki’s satires of post-Meiji Japan & academia in I Am a Cat, I understand why readers might drop it. I’m unfamiliar with Black Leopard, Red Wolf which tops the ranking, but on looking into it further, that makes sense: it is set in Africa & attempts to Africanize American superhero pop culture, has been hailed by the literary press & given awards, somewhat politicized, is over 600 pages long, and even its fans concede that it is difficult to read7. So Black Leopard, Red Wolf topping the ranking may not be flattering, but may be fair.
Bayesian Modeling
Implementing Bayesian correction… However—that brings us back to sampling error. Black Leopard, Red Wolf just came out in 2019 and hardly anyone has read it. In several cases, a member of the top 50 approaches the cut-off for not being in the list at all by having <40 abandon count (eg. Spinster or The Flame Alphabet). Is it really plausible that they have the highest abandon rates? This smacks of the winner’s curse, where measurement error/small noisy datapoints dominate the extremes of an analysis without actually being extreme (just numerous & poorly estimated).
So the next step is Bayesian modeling to account for the uncertainty caused by small n for these most-abandonable books. Using brms, we estimate a simple Bayesian binomial model, with a random effect for a given book’s abandon rate, and add a semi-informative prior expressing our opinion that all books are somewhat similar in abandon rate & there are not wacky huge differences in log odds.
Results:
library(brms)
gbSimple <- brm(Abandoned|trials(Reads) ~ (1|Title), family=binomial,
prior=c(prior(student_t(3,0,0.5), class="sd", group="Title")), data=gr, chains=30)
gbSimple
# Formula: Abandoned | trials(Reads) ~ (1 | Title)
# Data: gr (Number of observations: 1250)
# Samples: 30 chains, each with iter = 2000; warmup = 1000; thin = 1;
# total post-warmup samples = 30000
#
# Group-Level Effects:
# ~Title (Number of levels: 1248)
# Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
# sd(Intercept) 1.08 0.02 1.04 1.13 751 1.04
#
# Population-Level Effects:
# Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
# Intercept -7.21 0.03 -7.27 -7.15 363 1.09
rgbs <- as.data.frame(ranef(gbSimple)$Title)
rgbs <- rgbs[order(rgbs$Estimate.Intercept, decreasing=TRUE),]
## Combine with original GR dataset to examine full rankings at leisure:
rgbs$Title <- rownames(rgbs)
grShrunk <- merge(rgbs, gr, all=TRUE)
grShrunk <- grShrunk[order(grShrunk$Estimate.Intercept, decreasing=TRUE),]
write.csv(grShrunk, row.names=FALSE,
file="2020-01-05-goodreads-bookshelf-abandoned-posteriorproportions.csv")
## https://gwern.net/doc/culture/2020-01-05-goodreads-bookshelf-abandoned-posteriorproportions.csvhead(rgbs, n=30)
Estimate.Intercept Est.Error.Intercept Q2.5.Intercept Q97.5.Intercept
# Black Leopard, Red Wolf (The Dark Star Trilogy, #1) 3.32379864 0.0790607148 3.16589591 3.47735486
# Space Opera 2.71627444 0.1112760421 2.49346320 2.92865256
# Little, Big 2.64442569 0.1059941782 2.43214091 2.84849322
# The Witches: Salem, 1692 2.58375600 0.0899676079 2.40497914 2.75670092
# Tender Morsels 2.52059267 0.1430103435 2.23171890 2.79277487
# Too Like the Lightning (Terra Ignota, #1) 2.51037552 0.1248071384 2.26078544 2.74843195
# New York 2140 2.47210718 0.1191486878 2.23275007 2.69988279
# The Flame Alphabet 2.46184114 0.1554327209 2.15012868 2.75649392
# Hild 2.41661420 0.1280633539 2.15894924 2.66063531
# Dhalgren 2.39653706 0.1279221591 2.14009601 2.64025458
# Gingerbread 2.39249509 0.1477781116 2.09432888 2.67215550
# Winter's Tale 2.35943852 0.0792310629 2.20259365 2.51172500
# A Brief History of Seven Killings 2.34778502 0.0787129413 2.19104704 2.49958076
# Infinite Jest 2.31906968 0.0539429921 2.21314673 2.42519239
# The Ministry of Utmost Happiness 2.27664588 0.0827673701 2.11245754 2.43835817
# Gold Fame Citrus 2.23087746 0.1436343235 1.94186387 2.50264489
# I Am a Cat 2.21057738 0.1455388602 1.91550434 2.48521722
# Milkman 2.18260216 0.0814159601 2.01950559 2.33876916
# Avenue of Mysteries 2.13978963 0.1272281207 1.88351811 2.38285098
# Zone One 2.13680900 0.1028742023 1.93089374 2.33295611
# The Years of Rice and Salt 2.12679705 0.1265444209 1.87263437 2.36955658
# To Rise Again at a Decent Hour 2.11845577 0.1129727195 1.89144903 2.33461408
# City on Fire 2.11101764 0.1169914835 1.87395603 2.33317581
# Telegraph Avenue 2.10574358 0.0969163720 1.91411544 2.29259053
# It Can’t Happen Here 2.08954687 0.1167404830 1.85544344 2.31284728
# The Finkler Question 2.06326071 0.1174026491 1.82910415 2.28826845
# Barkskins 2.02841842 0.1217175555 1.78412138 2.26053102
# The Grace of Kings (The Dandelion Dynasty, #1) 2.02389635 0.1315723831 1.75779024 2.27784518
# Spinster: Making a Life of One's Own 2.01611353 0.1538652622 1.70673329 2.30803729
# A Girl Is a Half-formed Thing 2.00585364 0.1538617892 1.69349463 2.29740124
titles <- sapply(gsub(" ", ".", row.names(rgbs)[1:30]),
function(t) { paste0("r_Title[", t, ",Intercept]") } )
stanplot(gbSimple, pars=titles, exact_match=TRUE) + scale_y_discrete(labels =row.names(rgbs)[1:30]) +
labs(title="GoodReads book abandon ratings, top 30")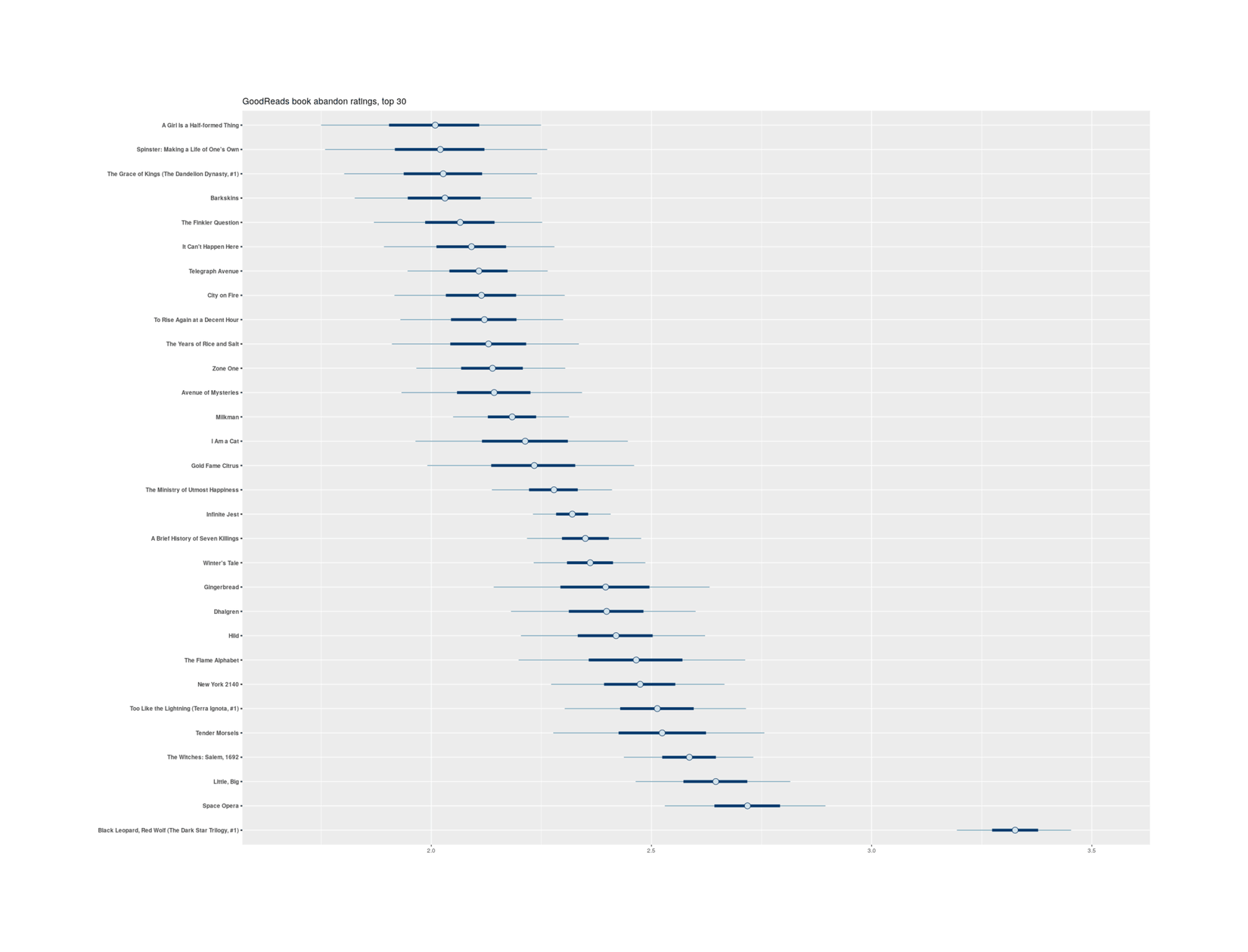
Black Leopard, Red Wolf does not enjoy any reprieve here, and to my annoyance, the top ranking changes little from raw proportion to shrunken proportion:
raw <- as.character(gr[order(gr$Abandoned.rate, decreasing=TRUE),]$Title)[1:30]
adjusted <- rownames(rgbs)[1:30]
rawDf <- data.frame(Title=raw, Ranking.raw=1:30)
adjustedDf <- data.frame(Title=adjusted, Ranking.adjusted=1:30)
comparisonDf <- merge(adjustedDf, rawDf, all=TRUE)
comparisonDf$Difference <- comparisonDf$Ranking.raw - comparisonDf$Ranking.adjusted
comparisonDf <- comparisonDf[order(comparisonDf$Ranking.raw),]; comparisonDf
# Title Ranking.adjusted Ranking.raw Difference
# 5 Black Leopard, Red Wolf (The Dark Star Trilogy, #1) 1 1 0
# 17 Space Opera 2 2 0
# 14 Little, Big 3 3 0
# 25 The Witches: Salem, 1692 4 4 0
# 20 Tender Morsels 5 5 0
# 28 Too Like the Lightning (Terra Ignota, #1) 6 6 0
# 22 The Flame Alphabet 8 7 -1
# 16 New York 2140 7 8 1
# 10 Hild 9 9 0
# 8 Gingerbread 11 10 -1
# 7 Dhalgren 10 11 1
# 29 Winter's Tale 12 12 0
# 1 A Brief History of Seven Killings 13 13 0
# 12 Infinite Jest 14 14 0
# 24 The Ministry of Utmost Happiness 15 15 0
# 9 Gold Fame Citrus 16 16 0
# 11 I Am a Cat 17 17 0
# 15 Milkman 18 18 0
# 3 Avenue of Mysteries 19 19 0
# 26 The Years of Rice and Salt 21 20 -1
# 30 Zone One 20 21 1
# 27 To Rise Again at a Decent Hour 22 22 0
# 6 City on Fire 23 23 0
# 19 Telegraph Avenue 24 24 0
# 13 It Can’t Happen Here 25 25 0
# 21 The Finkler Question 26 26 0
# 18 Spinster: Making a Life of One's Own 29 27 -2
# 23 The Grace of Kings (The Dandelion Dynasty, #1) 28 28 0
# 4 Barkskins 27 29 2
# 2 A Girl Is a Half-formed Thing 30 30 0…turns out to be unnecessary. Ah well! Apparently the restriction to >40 “abandoned” counts, while unfortunate for many reasons, actually does take care of much of the winner’s-curse bias in looking at raw proportions: the Bayesian model can’t adjust it much based on the available data.
Least Abandoned
Top-30 addictive books. On a more positive note, of the books which are included in the dataset, which 30 have the lowest abandon rates? I find the results entirely plausible8:
grShrunk[1220:1250,c(1, 6)]
# Title Author
# The Kite Runner Khaled Hosseini
# The Return of the King (The Lord of the Rings, #3) J. R. R. Tolkien
# The Old Man and the Sea Ernest Hemingway
# The Stranger Albert Camus
# The Da Vinci Code (Robert Langdon, #2) Dan Brown
# The Help Kathryn Stockett
# Mockingjay (The Hunger Games, #3) Suzanne Collins
# The Lightning Thief (Percy Jackson and the Olympians, #1) Rick Riordan
# Tuesdays with Morrie Mitch Albom
# A Thousand Splendid Suns Khaled Hosseini
# Twilight (Twilight, #1) Stephenie Meyer
# Bridget Jones's Diary (Bridget Jones, #1) Helen Fielding
# The Great Gatsby F. Scott Fitzgerald
# Memoirs of a Geisha Arthur Golden
# The Secret Garden Frances Hodgson Burnett
# The Secret Life of Bees Sue Monk Kidd
# My Sister's Keeper Jodi Picoult
# The Fault in Our Stars John Green
# The Diary of a Young Girl Anne Frank
# The Notebook (The Notebook, #1) Nicholas Sparks
# Catching Fire (The Hunger Games, #2) Suzanne Collins
# New Moon (Twilight, #2) Stephenie Meyer
# Eclipse (Twilight, #3) Stephenie Meyer
# To Kill a Mockingbird (To Kill a Mockingbird, #1) Harper Lee
# Angels & Demons (Robert Langdon, #1) Dan Brown
# The Giver (The Giver, #1) Lois Lowry
# Harry Potter and the Order of the Phoenix (Harry Potter, #5) J. K. Rowling
# The Hunger Games (The Hunger Games, #1) Suzanne Collins
# Animal Farm George Orwell
# Harry Potter and the Chamber of Secrets (Harry Potter, #2) J. K. Rowling
# Harry Potter and the Sorcerer's Stone (Harry Potter, #1) J. K. RowlingAfter all, whatever else you might think of books like The Da Vinci Code or Twilight, they did hook their readers; and before Harry Potter was a movie franchise juggernaut, it was the delight & despair of school/public librarians attempting to cater to suddenly-ravenous children.
Full Rankings
The full n = 1250 posterior proportion rankings in descending order as a table (click to uncollapse):
|
Rank |
Title |
Author |
Year |
Rating |
Abandonment |
|---|---|---|---|---|---|
|
1 |
Black Leopard, Red Wolf (The Dark Star Trilogy, #1) |
Marlon James |
2019 |
3.49 |
3.323 |
|
2 |
Space Opera |
Catherynne M. Valente |
2018 |
3.50 |
2.714 |
|
3 |
Little, Big |
John Crowley |
1981 |
3.83 |
2.643 |
|
4 |
The Witches: Salem, 1692 |
Stacy Schiff |
2015 |
3.17 |
2.582 |
|
5 |
Tender Morsels |
Margo Lanagan |
2007 |
3.56 |
2.520 |
|
6 |
Too Like the Lightning (Terra Ignota, #1) |
Ada Palmer |
2016 |
3.82 |
2.508 |
|
7 |
New York 2140 |
Kim Stanley Robinson |
2017 |
3.55 |
2.472 |
|
8 |
The Flame Alphabet |
Ben Marcus |
2012 |
2.88 |
2.459 |
|
9 |
Hild |
Nicola Griffith |
2013 |
3.78 |
2.415 |
|
10 |
Dhalgren |
Samuel R. Delany |
1975 |
3.78 |
2.394 |
|
11 |
Gingerbread |
Helen Oyeyemi |
2019 |
3.07 |
2.391 |
|
12 |
Winter’s Tale |
Mark Helprin |
1983 |
3.50 |
2.359 |
|
13 |
A Brief History of Seven Killings |
Marlon James |
2014 |
3.87 |
2.347 |
|
14 |
Infinite Jest |
David Foster Wallace |
1996 |
4.29 |
2.317 |
|
15 |
The Ministry of Utmost Happiness |
Arundhati Roy |
2017 |
3.47 |
2.275 |
|
16 |
Gold Fame Citrus |
Claire Vaye Watkins |
2015 |
3.30 |
2.228 |
|
17 |
I Am a Cat |
Natsume Sōseki |
1905 |
3.71 |
2.208 |
|
18 |
Milkman |
Anna Burns |
2018 |
3.60 |
2.181 |
|
19 |
Avenue of Mysteries |
John Irving |
2015 |
3.23 |
2.139 |
|
20 |
Zone One |
Colson Whitehead |
2011 |
3.26 |
2.135 |
|
21 |
The Years of Rice and Salt |
Kim Stanley Robinson |
2002 |
3.73 |
2.125 |
|
22 |
To Rise Again at a Decent Hour |
Joshua Ferris |
2014 |
3.08 |
2.118 |
|
23 |
City on Fire |
Garth Risk Hallberg |
2015 |
3.41 |
2.109 |
|
24 |
Telegraph Avenue |
Michael Chabon |
2012 |
3.38 |
2.104 |
|
25 |
It Can’t Happen Here |
Sinclair Lewis |
1935 |
3.76 |
2.089 |
|
26 |
The Finkler Question |
Howard Jacobson |
2010 |
2.78 |
2.062 |
|
27 |
Barkskins |
Annie Proulx |
2016 |
3.77 |
2.026 |
|
28 |
The Grace of Kings (The Dandelion Dynasty, #1) |
Ken Liu |
2015 |
3.73 |
2.022 |
|
29 |
Spinster: Making a Life of One’s Own |
Kate Bolick |
2015 |
3.45 |
2.014 |
|
30 |
A Girl Is a Half-formed Thing |
Eimear McBride |
2013 |
3.47 |
2.003 |
|
31 |
Jane, Unlimited |
Kristin Cashore |
2017 |
3.36 |
1.990 |
|
32 |
Do Not Say We Have Nothing |
Madeleine Thien |
2016 |
3.90 |
1.942 |
|
33 |
The Map of Time |
Félix J. Palma |
2008 |
3.38 |
1.936 |
|
34 |
The Quick |
Lauren Owen |
2014 |
3.24 |
1.922 |
|
35 |
The Queen of the Night |
Alexander Chee |
2016 |
3.43 |
1.912 |
|
36 |
What is Not Yours is Not Yours |
Helen Oyeyemi |
2016 |
3.64 |
1.902 |
|
37 |
Frog Music |
Emma Donoghue |
2014 |
3.15 |
1.897 |
|
38 |
Bridge of Clay |
Markus Zusak |
2018 |
3.80 |
1.890 |
|
39 |
The Good Neighbor: The Life and Work of Fred Rogers |
Maxwell King |
2018 |
4.01 |
1.875 |
|
40 |
The Prague Cemetery |
Umberto Eco |
2010 |
3.43 |
1.874 |
|
41 |
4 3 2 1 |
Paul Auster |
2017 |
3.84 |
1.869 |
|
42 |
The Luminaries |
Eleanor Catton |
2013 |
3.72 |
1.864 |
|
43 |
Two Years Eight Months and Twenty-Eight Nights |
Salman Rushdie |
2015 |
3.38 |
1.853 |
|
44 |
The Children’s Book |
A. S. Byatt |
2009 |
3.67 |
1.848 |
|
45 |
The Unconsoled |
Kazuo Ishiguro |
1995 |
3.53 |
1.827 |
|
46 |
How to Live Safely in a Science Fictional Universe |
Charles Yu |
2010 |
3.38 |
1.819 |
|
47 |
The Golden Notebook |
Doris Lessing |
1962 |
3.76 |
1.816 |
|
48 |
The Gone-Away World |
Nick Harkaway |
2008 |
4.12 |
1.812 |
|
49 |
The Wangs vs. the World |
Jade Chang |
2016 |
3.31 |
1.811 |
|
50 |
The Mermaid and Mrs. Hancock |
Imogen Hermes Gowar |
2018 |
3.61 |
1.811 |
|
51 |
Reservoir 13 |
Jon McGregor |
2017 |
3.59 |
1.810 |
|
52 |
Bleeding Edge |
Thomas Pynchon |
2013 |
3.57 |
1.800 |
|
53 |
After Alice |
Gregory Maguire |
2015 |
2.79 |
1.797 |
|
54 |
Deathless (Leningrad Diptych, #1) |
Catherynne M. Valente |
2011 |
4.01 |
1.785 |
|
55 |
White Trash: The 400-Year Untold History of Class in America |
Nancy Isenberg |
2016 |
3.74 |
1.775 |
|
56 |
2312 |
Kim Stanley Robinson |
2012 |
3.45 |
1.771 |
|
57 |
On Such a Full Sea |
Chang-rae Lee |
2014 |
3.48 |
1.766 |
|
58 |
Open City |
Teju Cole |
2011 |
3.50 |
1.754 |
|
59 |
Harry Potter and the Methods of Rationality |
Eliezer Yudkowsky |
2015 |
4.39 |
1.754 |
|
60 |
Titus Groan (Gormenghast, #1) |
Mervyn Peake |
1946 |
3.91 |
1.736 |
|
61 |
Kraken |
China Miéville |
2010 |
3.60 |
1.728 |
|
62 |
Moonglow |
Michael Chabon |
2016 |
3.81 |
1.727 |
|
63 |
Wildwood (Wildwood Chronicles, #1) |
Colin Meloy |
2011 |
3.65 |
1.706 |
|
64 |
Gravity’s Rainbow |
Thomas Pynchon |
1973 |
4.01 |
1.698 |
|
65 |
Flat Broke with Two Goats: A Memoir of Appalachia |
Jennifer McGaha |
2018 |
3.24 |
1.695 |
|
66 |
Skippy Dies |
Paul Murray |
2010 |
3.72 |
1.695 |
|
67 |
Quicksilver (The Baroque Cycle, #1) |
Neal Stephenson |
2003 |
3.93 |
1.693 |
|
68 |
The Sellout |
Paul Beatty |
2015 |
3.77 |
1.683 |
|
69 |
Super Sad True Love Story |
Gary Shteyngart |
2010 |
3.45 |
1.681 |
|
70 |
2666 |
Roberto Bolaño |
2004 |
4.21 |
1.680 |
|
71 |
The Secret Chord |
Geraldine Brooks |
2015 |
3.58 |
1.679 |
|
72 |
Swamplandia! |
Karen Russell |
2011 |
3.23 |
1.673 |
|
73 |
Lincoln in the Bardo |
George Saunders |
2017 |
3.76 |
1.670 |
|
74 |
A Manual for Cleaning Women: Selected Stories |
Lucia Berlin |
2015 |
4.18 |
1.658 |
|
75 |
S. |
J. J. Abrams |
2013 |
3.84 |
1.646 |
|
76 |
Liar, Temptress, Soldier, Spy: Four Women Undercover in the Civil War |
Karen Abbott |
2014 |
3.75 |
1.641 |
|
77 |
The Empathy Exams |
Leslie Jamison |
2014 |
3.64 |
1.640 |
|
78 |
The Red House |
Mark Haddon |
2012 |
2.94 |
1.636 |
|
79 |
The Pox Party (The Astonishing Life of Octavian Nothing, Traitor to the Nation, #1) |
M. T. Anderson |
2006 |
3.50 |
1.635 |
|
80 |
Uncommon Type |
Tom Hanks |
2017 |
3.44 |
1.631 |
|
81 |
Welcome to Night Vale (Welcome to Night Vale, #1) |
Joseph Fink |
2015 |
3.84 |
1.622 |
|
82 |
The Girl Who Circumnavigated Fairyland in a Ship of Her Own Making (Fairyland, #1) |
Catherynne M. Valente |
2011 |
3.96 |
1.584 |
|
83 |
How Not to Be Wrong: The Power of Mathematical Thinking |
Jordan Ellenberg |
2014 |
3.96 |
1.573 |
|
84 |
The Favorite Sister |
Jessica Knoll |
2018 |
3.09 |
1.569 |
|
85 |
The Rise and Fall of D.O.D.O. |
Neal Stephenson |
2017 |
3.87 |
1.551 |
|
86 |
Theft by Finding: Diaries 1977–2002 |
David Sedaris |
2015 |
3.93 |
1.549 |
|
87 |
Wolf Hall (Thomas Cromwell #1) |
Hilary Mantel |
2009 |
3.86 |
1.545 |
|
88 |
The Good Lord Bird |
James McBride |
2013 |
3.77 |
1.542 |
|
89 |
The Savage Detectives |
Roberto Bolaño |
1998 |
4.12 |
1.534 |
|
90 |
Unsheltered |
Barbara Kingsolver (Author, Narrator) |
2018 |
3.61 |
1.527 |
|
91 |
How to Be Both |
Ali Smith |
2014 |
3.65 |
1.518 |
|
92 |
Capital in the Twenty-First Century |
Thomas Piketty |
2013 |
4.04 |
1.516 |
|
93 |
NW |
Zadie Smith |
2012 |
3.44 |
1.501 |
|
94 |
The Post-Birthday World |
Lionel Shriver |
2007 |
3.54 |
1.500 |
|
95 |
My Absolute Darling |
Gabriel Tallent |
2017 |
3.63 |
1.496 |
|
96 |
How to Read a Book: The Classic Guide to Intelligent Reading |
Mortimer J. Adler |
1940 |
4.01 |
1.492 |
|
97 |
A Murder in Time (Kendra Donovan, #1) |
Julie McElwain |
2016 |
3.75 |
1.490 |
|
98 |
The Windup Girl |
Paolo Bacigalupi |
2009 |
3.75 |
1.488 |
|
99 |
The Lonely Polygamist |
Brady Udall |
2010 |
3.51 |
1.484 |
|
100 |
We Are Never Meeting In Real Life |
Samantha Irby |
2017 |
3.92 |
1.479 |
|
101 |
The High Mountains of Portugal |
Yann Martel |
2016 |
3.38 |
1.472 |
|
102 |
The Bees |
Laline Paull |
2014 |
3.70 |
1.469 |
|
103 |
The Better Angels of Our Nature: Why Violence Has Declined |
Steven Pinker |
2010 |
4.18 |
1.463 |
|
104 |
The People in the Trees |
Hanya Yanagihara |
2013 |
3.69 |
1.458 |
|
105 |
H is for Hawk |
Helen Macdonald |
2014 |
3.73 |
1.458 |
|
106 |
The Flamethrowers |
Rachel Kushner |
2013 |
3.48 |
1.457 |
|
107 |
Then We Came to the End |
Joshua Ferris |
2007 |
3.46 |
1.442 |
|
108 |
The Pale King |
David Foster Wallace |
2011 |
3.95 |
1.438 |
|
109 |
The Buried Giant |
Kazuo Ishiguro |
2015 |
3.49 |
1.434 |
|
110 |
Gödel, Escher, Bach: An Eternal Golden Braid |
Douglas R. Hofstadter |
1979 |
4.29 |
1.432 |
|
111 |
The Peripheral |
William Gibson |
2014 |
3.94 |
1.432 |
|
112 |
The Essex Serpent |
Sarah Perry |
2016 |
3.60 |
1.428 |
|
113 |
The Monstrumologist (The Monstrumologist, #1) |
Rick Yancey |
2009 |
3.88 |
1.421 |
|
114 |
Imagine Me Gone |
Adam Haslett |
2016 |
3.69 |
1.410 |
|
115 |
The Little Paris Bookshop |
Nina George |
2013 |
3.50 |
1.410 |
|
116 |
Idaho |
Emily Ruskovich |
2017 |
3.52 |
1.402 |
|
117 |
Descent |
Tim Johnston |
2015 |
3.60 |
1.397 |
|
118 |
James Potter and the Hall of Elders’ Crossing (James Potter, #1) |
G. Norman Lippert |
2007 |
3.77 |
1.396 |
|
119 |
American War |
Omar El Akkad |
2017 |
3.79 |
1.385 |
|
120 |
The Little Friend |
Donna Tartt |
2002 |
3.46 |
1.381 |
|
121 |
Some Luck (Last Hundred Years: A Family Saga, #1) |
Jane Smiley |
2014 |
3.61 |
1.369 |
|
122 |
Underworld |
Don DeLillo |
1997 |
3.92 |
1.359 |
|
123 |
All the Birds in the Sky |
Charlie Jane Anders |
2016 |
3.58 |
1.354 |
|
124 |
Fire and Fury: Inside the Trump White House |
Michael Wolff |
2018 |
3.44 |
1.351 |
|
125 |
The Water Knife |
Paolo Bacigalupi |
2015 |
3.83 |
1.350 |
|
126 |
Accelerando |
Charles Stross |
2005 |
3.88 |
1.346 |
|
127 |
Jonathan Strange & Mr Norrell |
Susanna Clarke |
2004 |
3.82 |
1.341 |
|
128 |
Perdido Street Station (New Crobuzon, #1) |
China Miéville |
2000 |
3.97 |
1.333 |
|
129 |
The Road to Character |
David Brooks |
2015 |
3.66 |
1.327 |
|
130 |
The Zookeeper’s Wife |
Diane Ackerman |
2007 |
3.46 |
1.320 |
|
131 |
Meddling Kids |
Edgar Cantero |
2017 |
3.56 |
1.319 |
|
132 |
The Sympathizer |
Viet Thanh Nguyen |
2015 |
4.00 |
1.319 |
|
133 |
Dark Money: The Hidden History of the Billionaires Behind the Rise of the Radical Right |
Jane Mayer |
2016 |
4.34 |
1.317 |
|
134 |
Night Train to Lisbon |
Pascal Mercier |
2004 |
3.72 |
1.307 |
|
135 |
Fates and Furies |
Lauren Groff |
2015 |
3.57 |
1.304 |
|
136 |
Ulysses |
James Joyce |
1922 |
3.73 |
1.304 |
|
137 |
Nexus (Nexus, #1) |
Ramez Naam |
2012 |
4.05 |
1.293 |
|
138 |
John Dies at the End (John Dies at the End, #1) |
David Wong |
2007 |
3.90 |
1.290 |
|
139 |
Warlight |
Michael Ondaatje |
2018 |
3.64 |
1.286 |
|
140 |
Once Upon a River |
Diane Setterfield |
2018 |
3.99 |
1.284 |
|
141 |
The Yiddish Policemen’s Union |
Michael Chabon |
2007 |
3.71 |
1.279 |
|
142 |
The Library at Mount Char |
Scott Hawkins |
2015 |
4.09 |
1.279 |
|
143 |
The Casual Vacancy |
J. K. Rowling |
2012 |
3.30 |
1.276 |
|
144 |
Vampires in the Lemon Grove |
Karen Russell |
2013 |
3.68 |
1.275 |
|
145 |
The Satanic Verses |
Salman Rushdie |
1988 |
3.71 |
1.273 |
|
146 |
California |
Edan Lepucki |
2014 |
3.23 |
1.264 |
|
147 |
Snow |
Orhan Pamuk |
2002 |
3.58 |
1.258 |
|
148 |
The Hidden Life of Trees: What They Feel, How They Communicate – Discoveries from a Secret World |
Peter Wohlleben |
2015 |
4.06 |
1.256 |
|
149 |
We Are Not Ourselves |
Matthew Thomas |
2014 |
3.70 |
1.253 |
|
150 |
Here I Am |
Jonathan Safran Foer |
2016 |
3.64 |
1.253 |
|
151 |
The Paying Guests |
Sarah Waters |
2014 |
3.41 |
1.241 |
|
152 |
Gilead (Gilead, #1) |
Marilynne Robinson |
2004 |
3.85 |
1.239 |
|
153 |
The Bone Clocks |
David Mitchell |
2014 |
3.83 |
1.233 |
|
154 |
Lab Girl |
Hope Jahren |
2016 |
4.02 |
1.230 |
|
155 |
Sex at Dawn: The Prehistoric Origins of Modern Sexuality |
Christopher Ryan |
2010 |
4.02 |
1.226 |
|
156 |
Antifragile: Things That Gain from Disorder |
Nassim Nicholas Taleb |
2012 |
4.09 |
1.225 |
|
157 |
The Overstory |
Richard Powers |
2018 |
4.19 |
1.225 |
|
158 |
The Readers of Broken Wheel Recommend |
Katarina Bivald |
2013 |
3.55 |
1.224 |
|
159 |
Ancillary Justice (Imperial Radch #1) |
Ann Leckie |
2013 |
3.98 |
1.219 |
|
160 |
LaRose |
Louise Erdrich |
2016 |
3.87 |
1.217 |
|
161 |
Time and Again (Time, #1) |
Jack Finney |
1970 |
3.96 |
1.211 |
|
162 |
The Almost Moon |
Alice Sebold |
2007 |
2.69 |
1.209 |
|
163 |
The Book of Disquiet: The Complete Edition |
Fernando Pessoa |
1982 |
4.46 |
1.207 |
|
164 |
Hidden Figures |
Margot Lee Shetterly |
2016 |
3.97 |
1.206 |
|
165 |
Seating Arrangements |
Maggie Shipstead |
2012 |
3.03 |
1.205 |
|
166 |
A Constellation of Vital Phenomena |
Anthony Marra |
2013 |
4.13 |
1.201 |
|
167 |
The City of Brass (The Daevabad Trilogy, #1) |
S. A. Chakraborty |
2017 |
4.15 |
1.198 |
|
168 |
Outline |
Rachel Cusk |
2014 |
3.62 |
1.197 |
|
169 |
In the Unlikely Event |
Judy Blume |
2015 |
3.52 |
1.192 |
|
170 |
Min kamp 1 (Min kamp #1) |
Karl Ove Knausgård |
2009 |
4.08 |
1.189 |
|
171 |
Boneshaker (The Clockwork Century, #1) |
Cherie Priest |
2009 |
3.50 |
1.184 |
|
172 |
My Name Is Red |
Orhan Pamuk |
1998 |
3.85 |
1.184 |
|
173 |
The Gathering |
Anne Enright |
2007 |
3.07 |
1.178 |
|
174 |
The Lacuna |
Barbara Kingsolver |
2009 |
3.79 |
1.178 |
|
175 |
The First Fifteen Lives of Harry August |
Claire North |
2014 |
4.04 |
1.171 |
|
176 |
Going Bovine |
Libba Bray |
2009 |
3.65 |
1.170 |
|
177 |
In One Person |
John Irving |
2012 |
3.67 |
1.170 |
|
178 |
The Elegance of the Hedgehog |
Muriel Barbery |
2006 |
3.76 |
1.168 |
|
179 |
Dear Life |
Alice Munro |
2012 |
3.75 |
1.167 |
|
180 |
Challenger Deep |
Neal Shusterman |
2015 |
4.14 |
1.157 |
|
181 |
Swing Time |
Zadie Smith |
2016 |
3.56 |
1.157 |
|
182 |
Less |
Andrew Sean Greer |
2017 |
3.71 |
1.157 |
|
183 |
Paddle Your Own Canoe: One Man’s Fundamentals for Delicious Living |
Nick Offerman |
2013 |
3.68 |
1.152 |
|
184 |
Er ist wieder da |
Timur Vermes |
2012 |
3.44 |
1.147 |
|
185 |
Seveneves |
Neal Stephenson |
2015 |
3.99 |
1.144 |
|
186 |
Fleishman Is in Trouble |
Taffy Brodesser-Akner |
2019 |
3.77 |
1.143 |
|
187 |
Special Topics in Calamity Physics |
Marisha Pessl |
2006 |
3.71 |
1.140 |
|
188 |
Blackout (All Clear, #1) |
Connie Willis |
2010 |
3.83 |
1.132 |
|
189 |
The Emperor’s Children |
Claire Messud |
2006 |
2.95 |
1.126 |
|
190 |
Arcadia |
Lauren Groff |
2012 |
3.67 |
1.124 |
|
191 |
Tinkers |
Paul Harding |
2008 |
3.38 |
1.122 |
|
192 |
Afterworlds (Afterworlds #1) |
Scott Westerfeld |
2014 |
3.73 |
1.120 |
|
193 |
Tangerine |
Christine Mangan |
2018 |
3.21 |
1.118 |
|
194 |
Pygmy |
Chuck Palahniuk |
2009 |
2.97 |
1.117 |
|
195 |
The Invisible Library (The Invisible Library, #1) |
Genevieve Cogman |
2015 |
3.73 |
1.114 |
|
196 |
Swann’s Way (In Search of Lost Time, #1) |
Marcel Proust |
1913 |
4.14 |
1.108 |
|
197 |
The Road to Little Dribbling: Adventures of an American in Britain |
Bill Bryson |
2015 |
3.71 |
1.106 |
|
198 |
The Summer Before the War |
Helen Simonson |
2016 |
3.78 |
1.099 |
|
199 |
Sweetbitter |
Stephanie Danler |
2016 |
3.28 |
1.091 |
|
200 |
Women Who Run With the Wolves: Myths and Stories of the Wild Woman Archetype |
Clarissa Pinkola Estés |
1992 |
4.15 |
1.087 |
|
201 |
House of Leaves |
Mark Z. Danielewski |
2000 |
4.10 |
1.086 |
|
202 |
Possession |
A. S. Byatt |
1990 |
3.89 |
1.079 |
|
203 |
Fear: Trump in the White House |
Bob Woodward |
2018 |
3.91 |
1.078 |
|
204 |
The Girls of Atomic City: The Untold Story of the Women Who Helped Win World War II |
Denise Kiernan |
2013 |
3.68 |
1.068 |
|
205 |
The Narrow Road to the Deep North |
Richard Flanagan |
2013 |
4.01 |
1.066 |
|
206 |
Red Mars (Mars Trilogy, #1) |
Kim Stanley Robinson |
1992 |
3.85 |
1.054 |
|
207 |
Five Days at Memorial: Life and Death in a Storm-Ravaged Hospital |
Sheri Fink |
2013 |
3.90 |
1.053 |
|
208 |
An Instance of the Fingerpost |
Iain Pears |
1997 |
3.94 |
1.053 |
|
209 |
My Brilliant Friend (The Neapolitan Novels, #1) |
2011 |
3.94 |
1.048 |
|
|
210 |
12 Rules for Life: An Antidote to Chaos |
Jordan B. Peterson |
2018 |
3.96 |
1.040 |
|
211 |
Transcription |
Kate Atkinson |
2018 |
3.50 |
1.034 |
|
212 |
One More Thing: Stories and Other Stories |
B. J. Novak |
2014 |
3.67 |
1.027 |
|
213 |
The Library Book |
Susan Orlean |
2018 |
3.95 |
1.018 |
|
214 |
The 7½ Deaths of Evelyn Hardcastle |
Stuart Turton |
2018 |
3.92 |
1.017 |
|
215 |
1Q84 |
Haruki Murakami |
2009 |
3.92 |
1.016 |
|
216 |
The Glass Bead Game |
Hermann Hesse |
1943 |
4.11 |
1.011 |
|
217 |
The Book of Strange New Things |
Michel Faber |
2014 |
3.66 |
1.008 |
|
218 |
The Terror |
Dan Simmons |
2007 |
4.06 |
1.008 |
|
219 |
Sea of Poppies (Ibis Trilogy, #1) |
Amitav Ghosh |
2008 |
3.95 |
1.003 |
|
220 |
Blindsight (Firefall, #1) |
Peter Watts |
2006 |
4.01 |
1.002 |
|
221 |
The Valley of Amazement |
Amy Tan |
2013 |
3.63 |
0.997 |
|
222 |
Code Name Verity |
Elizabeth E. Wein |
2012 |
4.05 |
0.997 |
|
223 |
The Slap |
Christos Tsiolkas |
2008 |
3.19 |
0.995 |
|
224 |
The Goblin Emperor (The Goblin Emperor, #1) |
Katherine Addison |
2014 |
4.04 |
0.995 |
|
225 |
Purity |
Jonathan Franzen |
2015 |
3.61 |
0.994 |
|
226 |
Midnight’s Children |
Salman Rushdie |
1981 |
3.98 |
0.990 |
|
227 |
The Mars Room |
Rachel Kushner |
2018 |
3.49 |
0.986 |
|
228 |
Inherent Vice |
Thomas Pynchon |
2009 |
3.74 |
0.983 |
|
229 |
A God in Ruins (Todd Family, #2) |
Kate Atkinson |
2015 |
3.94 |
0.981 |
|
230 |
Mrs. Lincoln’s Dressmaker |
Jennifer Chiaverini |
2013 |
3.46 |
0.975 |
|
231 |
Boy, Snow, Bird |
Helen Oyeyemi |
2013 |
3.35 |
0.972 |
|
232 |
Cryptonomicon |
Neal Stephenson |
1999 |
4.25 |
0.964 |
|
233 |
The Witch Elm |
Tana French |
2018 |
3.54 |
0.963 |
|
234 |
Beauty Queens |
Libba Bray |
2011 |
3.62 |
0.959 |
|
235 |
To Say Nothing of the Dog (Oxford Time Travel, #2) |
Connie Willis |
1998 |
4.13 |
0.957 |
|
236 |
The Design of Everyday Things |
Donald A. Norman |
1988 |
4.18 |
0.956 |
|
237 |
Life After Life (Todd Family, #1) |
Kate Atkinson |
2013 |
3.76 |
0.954 |
|
238 |
The Highly Sensitive Person: How to Thrive When the World Overwhelms You |
Elaine N. Aron |
1996 |
3.87 |
0.949 |
|
239 |
Blood Meridian, or the Evening Redness in the West |
Cormac McCarthy |
1985 |
4.17 |
0.944 |
|
240 |
Fire & Blood (A Targaryen History, #1) |
George R. R. Martin |
2018 |
3.89 |
0.940 |
|
241 |
The Cat’s Table |
Michael Ondaatje |
2011 |
3.60 |
0.936 |
|
242 |
Embassytown |
China Miéville |
2011 |
3.88 |
0.935 |
|
243 |
Mein Kampf |
Adolf Hitler |
1925 |
3.16 |
0.926 |
|
244 |
Cloud Atlas |
David Mitchell |
2004 |
4.01 |
0.924 |
|
245 |
The Known World |
Edward P. Jones |
2003 |
3.83 |
0.917 |
|
246 |
The Tiger’s Wife |
Téa Obreht |
2011 |
3.39 |
0.911 |
|
247 |
Furiously Happy: A Funny Book About Horrible Things |
Jenny Lawson |
2015 |
3.92 |
0.911 |
|
248 |
A Place for Us |
Fatima Farheen Mirza |
2018 |
4.15 |
0.910 |
|
249 |
Pure (Pure, #1) |
Julianna Baggott |
2012 |
3.74 |
0.907 |
|
250 |
The Hero With a Thousand Faces |
Joseph Campbell |
1949 |
4.20 |
0.907 |
|
251 |
SPQR: A History of Ancient Rome |
Mary Beard |
2015 |
4.07 |
0.905 |
|
252 |
The Magic Mountain |
Thomas Mann |
1924 |
4.14 |
0.903 |
|
253 |
A Tale for the Time Being |
Ruth Ozeki |
2013 |
4.00 |
0.900 |
|
254 |
The Rook (The Checquy Files, #1) |
Daniel O’Malley |
2012 |
4.12 |
0.896 |
|
255 |
Anathem |
Neal Stephenson |
2008 |
4.18 |
0.893 |
|
256 |
Girl Waits with Gun (Kopp Sisters, #1) |
Amy Stewart |
2015 |
3.76 |
0.892 |
|
257 |
The Gene: An Intimate History |
Siddhartha Mukherjee |
2016 |
4.37 |
0.892 |
|
258 |
Today Will Be Different |
Maria Semple |
2016 |
3.18 |
0.892 |
|
259 |
The Righteous Mind: Why Good People Are Divided by Politics and Religion |
Jonathan Haidt |
2012 |
4.22 |
0.888 |
|
260 |
Aftermath (Star Wars: Aftermath, #1) |
Chuck Wendig |
2015 |
3.21 |
0.887 |
|
261 |
Zen and the Art of Motorcycle Maintenance: An Inquiry Into Values |
Robert M. Pirsig |
1974 |
3.77 |
0.884 |
|
262 |
Lily and the Octopus |
Steven Rowley |
2016 |
3.71 |
0.883 |
|
263 |
Better Than Before: Mastering the Habits of Our Everyday Lives |
Gretchen Rubin |
2015 |
3.84 |
0.881 |
|
264 |
The Nix |
Nathan Hill |
2016 |
4.09 |
0.879 |
|
265 |
The Magicians (The Magicians, #1) |
Lev Grossman |
2009 |
3.51 |
0.879 |
|
266 |
Hopscotch |
Julio Cortázar |
1963 |
4.24 |
0.876 |
|
267 |
The Waves |
Virginia Woolf |
1931 |
4.14 |
0.874 |
|
268 |
Gardens of the Moon (Malazan Book of the Fallen, #1) |
Steven Erikson |
1999 |
3.88 |
0.872 |
|
269 |
Children of Blood and Bone (Legacy of Orïsha, #1) |
Tomi Adeyemi |
2018 |
4.16 |
0.870 |
|
270 |
The Orphan Master’s Son |
Adam Johnson |
2012 |
4.07 |
0.867 |
|
271 |
Salt: A World History |
Mark Kurlansky |
2002 |
3.74 |
0.867 |
|
272 |
Kushiel’s Dart (Phèdre’s Trilogy, #1) |
Jacqueline Carey |
2001 |
4.03 |
0.863 |
|
273 |
Everyone Brave is Forgiven |
Chris Cleave |
2016 |
3.78 |
0.861 |
|
274 |
The Wolf of Wall Street (The Wolf of Wall Street, #1) |
Jordan Belfort |
2007 |
3.71 |
0.857 |
|
275 |
If on a Winter’s Night a Traveler |
Italo Calvino |
1979 |
4.05 |
0.856 |
|
276 |
Feed (Newsflesh Trilogy, #1) |
Mira Grant |
2010 |
3.85 |
0.855 |
|
277 |
Going Clear: Scientology, Hollywood, and the Prison of Belief |
Lawrence Wright |
2013 |
4.04 |
0.854 |
|
278 |
Why We Broke Up |
Daniel Handler |
2011 |
3.48 |
0.852 |
|
279 |
The Other Einstein |
Marie Benedict |
2016 |
3.74 |
0.852 |
|
280 |
Foucault’s Pendulum |
Umberto Eco |
1988 |
3.89 |
0.851 |
|
281 |
Sweet Tooth |
Ian McEwan |
2012 |
3.41 |
0.848 |
|
282 |
Longbourn |
Jo Baker |
2013 |
3.63 |
0.847 |
|
283 |
A Little Life |
Hanya Yanagihara |
2015 |
4.30 |
0.846 |
|
284 |
Dorothy Must Die (Dorothy Must Die, #1) |
Danielle Paige |
2014 |
3.83 |
0.844 |
|
285 |
The Interestings |
Meg Wolitzer |
2013 |
3.57 |
0.844 |
|
286 |
The Dante Club (The Dante Club #1) |
Matthew Pearl |
2003 |
3.38 |
0.831 |
|
287 |
The Clockmaker’s Daughter |
Kate Morton |
2018 |
3.73 |
0.831 |
|
288 |
The Happiness Project |
Gretchen Rubin |
2009 |
3.61 |
0.827 |
|
289 |
The Female Persuasion |
Meg Wolitzer |
2018 |
3.60 |
0.827 |
|
290 |
The Reality Dysfunction (Night’s Dawn, #1) |
Peter F. Hamilton |
1996 |
4.14 |
0.824 |
|
291 |
How to Change Your Mind: What the New Science of Psychedelics Teaches Us About Consciousness, Dying, Addiction, Depression, and Transcendence |
Michael Pollan |
2018 |
4.28 |
0.821 |
|
292 |
The Hare With Amber Eyes: A Family’s Century of Art and Loss |
Edmund de Waal |
2009 |
3.87 |
0.820 |
|
293 |
Eileen |
Ottessa Moshfegh |
2015 |
3.49 |
0.819 |
|
294 |
Pride and Prejudice and Zombies (Pride and Prejudice and Zombies, #1) |
Seth Grahame-Smith |
2009 |
3.29 |
0.817 |
|
295 |
The Marriage Plot |
Jeffrey Eugenides |
2011 |
3.44 |
0.814 |
|
296 |
The World Without Us |
Alan Weisman |
2007 |
3.80 |
0.814 |
|
297 |
The Fifth Season (The Broken Earth, #1) |
N. K. Jemisin |
2015 |
4.31 |
0.813 |
|
298 |
The Shining Girls |
Lauren Beukes |
2013 |
3.50 |
0.812 |
|
299 |
The Passage (The Passage, #1) |
Justin Cronin |
2010 |
4.04 |
0.809 |
|
300 |
Shades of Grey (Shades of Grey, #1) |
Jasper Fforde |
2009 |
4.14 |
0.801 |
|
301 |
The Fireman |
Joe Hill |
2016 |
3.89 |
0.799 |
|
302 |
Flight Behavior |
Barbara Kingsolver |
2012 |
3.78 |
0.798 |
|
303 |
Salvage the Bones |
Jesmyn Ward |
2011 |
3.92 |
0.797 |
|
304 |
Her Body and Other Parties |
Carmen Maria Machado |
2017 |
3.91 |
0.794 |
|
305 |
The Dog Stars |
Peter Heller |
2012 |
3.92 |
0.793 |
|
306 |
Bad Feminist |
Roxane Gay |
2014 |
3.94 |
0.784 |
|
307 |
Mythos: The Greek Myths Retold |
Stephen Fry |
2017 |
4.24 |
0.783 |
|
308 |
And I Darken (The Conqueror’s Saga, #1) |
Kiersten White |
2016 |
3.87 |
0.782 |
|
309 |
The Inheritance of Loss |
Kiran Desai |
2005 |
3.42 |
0.781 |
|
310 |
Reading Lolita in Tehran: A Memoir in Books |
Azar Nafisi |
2003 |
3.60 |
0.781 |
|
311 |
Doomsday Book (Oxford Time Travel, #1) |
Connie Willis |
1992 |
4.03 |
0.768 |
|
312 |
Master and Commander (Aubrey & Maturin, #1) |
Patrick O’Brian |
1970 |
4.10 |
0.766 |
|
313 |
The Thousand Autumns of Jacob de Zoet |
David Mitchell |
2010 |
4.03 |
0.759 |
|
314 |
A Suitable Boy (A Suitable Boy, #1) |
Vikram Seth |
1993 |
4.11 |
0.749 |
|
315 |
The City & the City |
China Miéville |
2009 |
3.91 |
0.747 |
|
316 |
Death Comes to Pemberley |
P. D. James |
2011 |
3.25 |
0.746 |
|
317 |
Labyrinth (Languedoc, #1) |
Kate Mosse |
2005 |
3.57 |
0.743 |
|
318 |
The Disappearing Spoon: And Other True Tales of Madness, Love, and the History of the World from the Periodic Table of the Elements |
Sam Kean |
2010 |
3.91 |
0.737 |
|
319 |
The Bone Season (The Bone Season, #1) |
Samantha Shannon |
2013 |
3.76 |
0.737 |
|
320 |
The Dovekeepers |
Alice Hoffman |
2011 |
4.04 |
0.735 |
|
321 |
The Signal and the Noise: Why So Many Predictions Fail—But Some Don’t |
Nate Silver |
2012 |
3.98 |
0.734 |
|
322 |
The Book of Speculation |
Erika Swyler |
2015 |
3.60 |
0.732 |
|
323 |
Housekeeping |
Marilynne Robinson |
1980 |
3.82 |
0.727 |
|
324 |
The Long Earth (The Long Earth, #1) |
Terry Pratchett |
2012 |
3.76 |
0.725 |
|
325 |
Consider Phlebas |
Iain M. Banks |
1987 |
3.86 |
0.724 |
|
326 |
Trigger Warning: Short Fictions and Disturbances |
Neil Gaiman |
2015 |
3.93 |
0.724 |
|
327 |
The Leavers |
Lisa Ko |
2017 |
3.87 |
0.722 |
|
328 |
How to Build a Girl |
Caitlin Moran |
2014 |
3.71 |
0.719 |
|
329 |
Sacré Bleu |
Christopher Moore |
2012 |
3.78 |
0.715 |
|
330 |
Altered Carbon (Takeshi Kovacs, #1) |
Richard K. Morgan |
2002 |
4.05 |
0.709 |
|
331 |
The Three-Body Problem (Remembrance of Earth’s Past #1) |
Liu Cixin |
2008 |
4.06 |
0.704 |
|
332 |
White Teeth |
Zadie Smith |
2000 |
3.76 |
0.700 |
|
333 |
Manhattan Beach |
Jennifer Egan |
2017 |
3.62 |
0.699 |
|
334 |
Naked Lunch |
William S. Burroughs |
1959 |
3.46 |
0.699 |
|
335 |
The Hangman’s Daughter (The Hangman’s Daughter, #1) |
Oliver Pötzsch |
2008 |
3.73 |
0.693 |
|
336 |
Reamde |
Neal Stephenson |
2011 |
3.97 |
0.691 |
|
337 |
On the Jellicoe Road |
Melina Marchetta |
2006 |
4.13 |
0.690 |
|
338 |
Serena |
Ron Rash |
2008 |
3.53 |
0.687 |
|
339 |
A Gentleman in Moscow |
Amor Towles |
2016 |
4.36 |
0.682 |
|
340 |
The Power |
Naomi Alderman |
2016 |
3.84 |
0.682 |
|
341 |
My Grandmother Asked Me to Tell You She’s Sorry |
Fredrik Backman |
2013 |
4.05 |
0.678 |
|
342 |
The Monuments Men: Allied Heroes, Nazi Thieves, and the Greatest Treasure Hunt in History |
Robert M. Edsel |
2009 |
3.76 |
0.673 |
|
343 |
Finnikin of the Rock (Lumatere Chronicles, #1) |
Melina Marchetta |
2008 |
3.91 |
0.669 |
|
344 |
Authority (Southern Reach, #2) |
Jeff VanderMeer |
2014 |
3.51 |
0.667 |
|
345 |
The End of Your Life Book Club |
Will Schwalbe |
2012 |
3.81 |
0.664 |
|
346 |
The Golem and the Jinni (The Golem and the Jinni, #1) |
Helene Wecker |
2013 |
4.11 |
0.664 |
|
347 |
Rabbit, Run |
John Updike |
1960 |
3.58 |
0.661 |
|
348 |
Present Over Perfect: Leaving Behind Frantic for a Simpler, More Soulful Way of Living |
Shauna Niequist |
2016 |
3.85 |
0.660 |
|
349 |
The Crimson Petal and the White |
Michel Faber |
2002 |
3.88 |
0.646 |
|
350 |
The Bear and the Nightingale (Winternight Trilogy, #1) |
Katherine Arden |
2017 |
4.12 |
0.643 |
|
351 |
Lord Foul’s Bane (The Chronicles of Thomas Covenant the Unbeliever, #1) |
Stephen R. Donaldson |
1977 |
3.72 |
0.640 |
|
352 |
Flatland: A Romance of Many Dimensions |
Edwin A. Abbott |
1884 |
3.82 |
0.639 |
|
353 |
The Hundred Thousand Kingdoms (Inheritance, #1) |
N. K. Jemisin |
2010 |
3.85 |
0.637 |
|
354 |
A Spool of Blue Thread |
Anne Tyler |
2015 |
3.41 |
0.636 |
|
355 |
Eligible (The Austen Project, #4) |
Curtis Sittenfeld |
2016 |
3.61 |
0.635 |
|
356 |
The Chemist |
Stephenie Meyer |
2016 |
3.71 |
0.634 |
|
357 |
Thinking, Fast and Slow |
Daniel Kahneman |
2011 |
4.14 |
0.632 |
|
358 |
Tenth of December |
George Saunders |
2013 |
3.97 |
0.632 |
|
359 |
The Sword of Shannara (The Original Shannara Trilogy, #1) |
Terry Brooks |
1977 |
3.76 |
0.632 |
|
360 |
Incarceron (Incarceron, #1) |
Catherine Fisher |
2007 |
3.64 |
0.630 |
|
361 |
Metro 2033 (Metro, #1) |
Dmitry Glukhovsky |
2005 |
3.99 |
0.629 |
|
362 |
Tropic of Cancer |
Henry Miller |
1934 |
3.68 |
0.627 |
|
363 |
Consider the Lobster and Other Essays |
David Foster Wallace |
2005 |
4.24 |
0.624 |
|
364 |
Gulp: Adventures on the Alimentary Canal |
Mary Roach |
2013 |
3.93 |
0.624 |
|
365 |
The Little Stranger |
Sarah Waters |
2009 |
3.54 |
0.621 |
|
366 |
A Confederacy of Dunces |
John Kennedy Toole |
1980 |
3.88 |
0.614 |
|
367 |
The Hundred-Year-Old Man Who Climbed Out of the Window and Disappeared (The Hundred-Year-Old Man, #1) |
Jonas Jonasson |
2009 |
3.83 |
0.613 |
|
368 |
The Left Hand of Darkness (Hainish Cycle #4) |
Ursula K. Le Guin |
1969 |
4.06 |
0.613 |
|
369 |
Shantaram |
Gregory David Roberts |
2003 |
4.27 |
0.613 |
|
370 |
The Idiot |
Elif Batuman |
2017 |
3.63 |
0.606 |
|
371 |
The Idiot |
Fyodor Dostoyevsky |
1869 |
4.18 |
0.606 |
|
372 |
At Home: A Short History of Private Life |
Bill Bryson |
2010 |
3.97 |
0.606 |
|
373 |
Let’s Pretend This Never Happened: A Mostly True Memoir |
Jenny Lawson |
2012 |
3.90 |
0.601 |
|
374 |
The Heart Goes Last |
Margaret Atwood |
2015 |
3.37 |
0.601 |
|
375 |
The Postmistress |
Sarah Blake |
2009 |
3.33 |
0.595 |
|
376 |
Cleopatra: A Life |
Stacy Schiff |
2010 |
3.66 |
0.594 |
|
377 |
Red Sparrow (Red Sparrow Trilogy, #1) |
Jason Matthews |
2013 |
3.95 |
0.594 |
|
378 |
Etiquette & Espionage (Finishing School, #1) |
Gail Carriger |
2013 |
3.81 |
0.592 |
|
379 |
How to Be a Woman |
Caitlin Moran |
2011 |
3.73 |
0.589 |
|
380 |
The Royal We |
Heather Cocks |
2015 |
3.80 |
0.589 |
|
381 |
The Diviners (The Diviners, #1) |
Libba Bray |
2012 |
3.97 |
0.588 |
|
382 |
The Museum of Extraordinary Things |
Alice Hoffman |
2014 |
3.74 |
0.586 |
|
383 |
The Black Company (The Chronicles of the Black Company, #1) |
Glen Cook |
1984 |
3.94 |
0.583 |
|
384 |
Astrophysics for People in a Hurry |
Neil deGrasse Tyson |
2017 |
4.10 |
0.583 |
|
385 |
The Long Way to a Small, Angry Planet (Wayfarers, #1) |
Becky Chambers |
2014 |
4.16 |
0.582 |
|
386 |
The Wedding Date (The Wedding Date, #1) |
Jasmine Guillory |
2018 |
3.54 |
0.581 |
|
387 |
Alexander Hamilton |
Ron Chernow |
2004 |
4.23 |
0.570 |
|
388 |
The Atlantis Gene (The Origin Mystery, #1) |
A. G. Riddle |
2013 |
3.72 |
0.566 |
|
389 |
American Pastoral (The American Trilogy, #1) |
Philip Roth |
1997 |
3.92 |
0.566 |
|
390 |
Truthwitch (The Witchlands, #1) |
Susan Dennard |
2016 |
3.89 |
0.565 |
|
391 |
Behind the Beautiful Forevers: Life, Death, and Hope in a Mumbai Undercity |
Katherine Boo |
2012 |
3.98 |
0.564 |
|
392 |
Night Film |
Marisha Pessl |
2013 |
3.78 |
0.564 |
|
393 |
The Lies of Locke Lamora (Gentleman Bastard, #1) |
Scott Lynch |
2006 |
4.30 |
0.563 |
|
394 |
A Visit from the Goon Squad |
Jennifer Egan |
2010 |
3.66 |
0.557 |
|
395 |
Suite Française |
Irène Némirovsky |
2004 |
3.84 |
0.555 |
|
396 |
The Twelve Tribes of Hattie |
Ayana Mathis |
2012 |
3.48 |
0.554 |
|
397 |
The Warmth of Other Suns: The Epic Story of America’s Great Migration |
Isabel Wilkerson |
2010 |
4.36 |
0.554 |
|
398 |
The Weird Sisters |
Eleanor Brown |
2011 |
3.36 |
0.553 |
|
399 |
The Aeronaut’s Windlass (The Cinder Spires, #1) |
Jim Butcher |
2015 |
4.18 |
0.549 |
|
400 |
The Eyre Affair (Thursday Next, #1) |
Jasper Fforde |
2001 |
3.91 |
0.542 |
|
401 |
Tigana |
Guy Gavriel Kay |
1990 |
4.10 |
0.542 |
|
402 |
Armada |
Ernest Cline |
2015 |
3.52 |
0.534 |
|
403 |
Red Rising (Red Rising, #1) |
Pierce Brown |
2014 |
4.27 |
0.526 |
|
404 |
The Burgess Boys |
Elizabeth Strout |
2013 |
3.57 |
0.523 |
|
405 |
The Coldest Girl in Coldtown |
Holly Black |
2013 |
3.85 |
0.522 |
|
406 |
The Knife of Never Letting Go (Chaos Walking, #1) |
Patrick Ness |
2008 |
3.98 |
0.520 |
|
407 |
The Story of Edgar Sawtelle |
David Wroblewski |
2008 |
3.62 |
0.520 |
|
408 |
The Emperor of All Maladies: A Biography of Cancer |
Siddhartha Mukherjee |
2010 |
4.31 |
0.517 |
|
409 |
Geek Love |
Katherine Dunn |
1989 |
3.97 |
0.517 |
|
410 |
The Particular Sadness of Lemon Cake |
Aimee Bender |
2010 |
3.21 |
0.515 |
|
411 |
The Leftovers |
Tom Perrotta |
2011 |
3.40 |
0.511 |
|
412 |
The Black Swan: The Impact of the Highly Improbable |
Nassim Nicholas Taleb |
2007 |
3.92 |
0.511 |
|
413 |
Don Quixote |
Miguel de Cervantes Saavedra |
1615 |
3.87 |
0.508 |
|
414 |
A Heartbreaking Work of Staggering Genius |
Dave Eggers |
2000 |
3.68 |
0.505 |
|
415 |
Damned (Damned, #1) |
Chuck Palahniuk |
2011 |
3.38 |
0.503 |
|
416 |
My Year of Rest and Relaxation |
Ottessa Moshfegh |
2018 |
3.67 |
0.496 |
|
417 |
Sleeping Beauties |
Stephen King |
2017 |
3.73 |
0.492 |
|
418 |
The Corrections |
Jonathan Franzen |
2001 |
3.79 |
0.491 |
|
419 |
The Tin Drum |
Günter Grass |
1959 |
3.96 |
0.490 |
|
420 |
The Girls |
Emma Cline |
2016 |
3.47 |
0.489 |
|
421 |
The Wonder |
Emma Donoghue |
2016 |
3.62 |
0.486 |
|
422 |
To the Lighthouse |
Virginia Woolf |
1927 |
3.77 |
0.482 |
|
423 |
Let the Great World Spin |
Colum McCann |
2009 |
3.95 |
0.475 |
|
424 |
The Heart’s Invisible Furies |
John Boyne |
2017 |
4.47 |
0.472 |
|
425 |
The Orchardist |
Amanda Coplin |
2012 |
3.77 |
0.471 |
|
426 |
Acceptance (Southern Reach, #3) |
Jeff VanderMeer |
2014 |
3.57 |
0.470 |
|
427 |
A Fire Upon the Deep (Zones of Thought, #1) |
Vernor Vinge |
1992 |
4.14 |
0.468 |
|
428 |
The Untethered Soul: The Journey Beyond Yourself |
Michael A. Singer |
2007 |
4.25 |
0.467 |
|
429 |
The Radium Girls: The Dark Story of America’s Shining Women |
Kate Moore |
2017 |
4.16 |
0.466 |
|
430 |
Three Men in a Boat (Three Men, #1) |
Jerome K. Jerome |
1889 |
3.89 |
0.464 |
|
431 |
Angle of Repose |
Wallace Stegner |
1971 |
4.27 |
0.463 |
|
432 |
The New Jim Crow: Mass Incarceration in the Age of Colorblindness |
Michelle Alexander |
2010 |
4.50 |
0.459 |
|
433 |
The Imperfectionists |
Tom Rachman |
2010 |
3.54 |
0.457 |
|
434 |
What Happened |
Hillary Rodham Clinton |
2017 |
3.97 |
0.456 |
|
435 |
The Undoing Project: A Friendship That Changed Our Minds |
Michael Lewis |
2016 |
3.99 |
0.447 |
|
436 |
A Discovery of Witches (All Souls Trilogy, #1) |
Deborah Harkness |
2011 |
4.00 |
0.445 |
|
437 |
The Gargoyle |
Andrew Davidson |
2008 |
3.96 |
0.440 |
|
438 |
Mad About the Boy (Bridget Jones, #3) |
Helen Fielding |
2013 |
3.35 |
0.440 |
|
439 |
Girl, Wash Your Face: Stop Believing the Lies about Who You Are So You Can Become Who You Were Meant to Be |
Rachel Hollis |
2018 |
3.76 |
0.439 |
|
440 |
Pale Fire |
Vladimir Nabokov |
1962 |
4.15 |
0.433 |
|
441 |
The Girl Who Drank the Moon |
Kelly Barnhill |
2016 |
4.18 |
0.428 |
|
442 |
Splintered (Splintered, #1) |
A. G. Howard |
2013 |
3.94 |
0.425 |
|
443 |
Revelation Space (Revelation Space, #1) |
Alastair Reynolds |
2000 |
3.98 |
0.421 |
|
444 |
Sing, Unburied, Sing |
Jesmyn Ward |
2017 |
4.02 |
0.418 |
|
445 |
The Sweetness at the Bottom of the Pie (Flavia de Luce, #1) |
Alan Bradley |
2009 |
3.81 |
0.416 |
|
446 |
Evicted: Poverty and Profit in the American City |
Matthew Desmond |
2016 |
4.48 |
0.415 |
|
447 |
The Immortalists |
Chloe Benjamin |
2018 |
3.72 |
0.414 |
|
448 |
There There |
Tommy Orange |
2018 |
3.98 |
0.412 |
|
449 |
The Brief Wondrous Life of Oscar Wao |
Junot Díaz |
2007 |
3.90 |
0.410 |
|
450 |
The Nest |
Cynthia D’Aprix Sweeney |
2016 |
3.42 |
0.408 |
|
451 |
Carve the Mark (Carve the Mark, #1) |
Veronica Roth |
2017 |
3.78 |
0.404 |
|
452 |
Pandora’s Star |
Peter F. Hamilton |
2004 |
4.24 |
0.404 |
|
453 |
Middlemarch |
George Eliot |
1871 |
3.96 |
0.402 |
|
454 |
Tiger’s Curse (The Tiger Saga, #1) |
Colleen Houck |
2011 |
4.06 |
0.398 |
|
455 |
Quiet: The Power of Introverts in a World That Can’t Stop Talking |
Susan Cain |
2012 |
4.06 |
0.395 |
|
456 |
The Girl Who Saved the King of Sweden |
Jonas Jonasson |
2013 |
3.76 |
0.395 |
|
457 |
Feed |
M. T. Anderson |
2002 |
3.54 |
0.393 |
|
458 |
Leviathan (Leviathan, #1) |
Scott Westerfeld |
2009 |
3.91 |
0.388 |
|
459 |
The Hazel Wood (The Hazel Wood, #1) |
Melissa Albert |
2018 |
3.59 |
0.387 |
|
460 |
The Crying of Lot 49 |
Thomas Pynchon |
1966 |
3.69 |
0.385 |
|
461 |
The Blind Assassin |
Margaret Atwood |
2000 |
3.95 |
0.383 |
|
462 |
We Need to Talk About Kevin |
Lionel Shriver |
2003 |
4.07 |
0.382 |
|
463 |
The Man in the High Castle |
1962 |
3.62 |
0.376 |
|
|
464 |
Autobiography of a Yogi |
Paramahansa Yogananda |
1946 |
4.23 |
0.375 |
|
465 |
Collapse: How Societies Choose to Fail or Succeed |
Jared Diamond |
2004 |
3.93 |
0.373 |
|
466 |
Dandelion Wine |
Ray Bradbury |
1957 |
4.09 |
0.371 |
|
467 |
Little Brother (Little Brother, #1) |
Cory Doctorow |
2008 |
3.93 |
0.370 |
|
468 |
The Once and Future King (The Once and Future King, #1–4) |
T. H. White |
1958 |
4.08 |
0.369 |
|
469 |
Mr. Penumbra’s 24-Hour Bookstore (Mr. Penumbra’s 24-Hour Bookstore, #1) |
Robin Sloan |
2012 |
3.75 |
0.367 |
|
470 |
Orlando |
Virginia Woolf |
1928 |
3.87 |
0.355 |
|
471 |
The Girl with the Lower Back Tattoo |
Amy Schumer |
2016 |
3.73 |
0.355 |
|
472 |
On the Road |
Jack Kerouac |
1957 |
3.63 |
0.353 |
|
473 |
Tinker, Tailor, Soldier, Spy |
John le Carré |
1974 |
4.05 |
0.352 |
|
474 |
Walden |
Henry David Thoreau |
1854 |
3.79 |
0.350 |
|
475 |
Uprooted |
Naomi Novik |
2015 |
4.09 |
0.349 |
|
476 |
Getting Things Done: The Art of Stress-Free Productivity |
David Allen |
2001 |
3.99 |
0.347 |
|
477 |
Essentialism: The Disciplined Pursuit of Less |
Greg McKeown |
2011 |
4.03 |
0.344 |
|
478 |
The Magus |
John Fowles |
1965 |
4.05 |
0.344 |
|
479 |
Seraphina (Seraphina, #1) |
Rachel Hartman |
2012 |
3.96 |
0.343 |
|
480 |
The Worst Hard Time: The Untold Story of Those Who Survived the Great American Dust Bowl |
Timothy Egan |
2005 |
4.04 |
0.338 |
|
481 |
Tiny Beautiful Things: Advice on Love and Life from Dear Sugar |
Cheryl Strayed |
2012 |
4.31 |
0.336 |
|
482 |
The Historian |
Elizabeth Kostova |
2005 |
3.78 |
0.333 |
|
483 |
In the Garden of Beasts: Love, Terror, and an American Family in Hitler’s Berlin |
Erik Larson |
2011 |
3.83 |
0.330 |
|
484 |
Committed: A Skeptic Makes Peace with Marriage |
Elizabeth Gilbert |
2009 |
3.41 |
0.326 |
|
485 |
On Beauty |
Zadie Smith |
2005 |
3.72 |
0.324 |
|
486 |
Musicophilia: Tales of Music and the Brain |
Oliver Sacks |
2007 |
3.91 |
0.322 |
|
487 |
The Signature of All Things |
Elizabeth Gilbert |
2013 |
3.84 |
0.317 |
|
488 |
Prince of Thorns (The Broken Empire, #1) |
Mark Lawrence |
2011 |
3.86 |
0.317 |
|
489 |
The Kiss Quotient (The Kiss Quotient, #1) |
Helen Hoang |
2018 |
3.90 |
0.316 |
|
490 |
Partials (Partials Sequence, #1) |
Dan Wells |
2012 |
3.94 |
0.312 |
|
491 |
The Life-Changing Magic of Tidying Up: The Japanese Art of Decluttering and Organizing |
Marie Kondō |
2011 |
3.83 |
0.311 |
|
492 |
Catch-22 (Catch-22, #1) |
Joseph Heller |
1961 |
3.98 |
0.310 |
|
493 |
NOS4A2 |
Joe Hill |
2013 |
4.07 |
0.310 |
|
494 |
Lies My Teacher Told Me: Everything Your American History Textbook Got Wrong |
James W. Loewen |
1995 |
3.97 |
0.309 |
|
495 |
Everything Is Illuminated |
Jonathan Safran Foer |
2002 |
3.90 |
0.307 |
|
496 |
The Women in the Castle |
Jessica Shattuck |
2017 |
3.86 |
0.307 |
|
497 |
Someday, Someday, Maybe |
Lauren Graham |
2013 |
3.51 |
0.306 |
|
498 |
The Amazing Adventures of Kavalier & Clay |
Michael Chabon |
2000 |
4.18 |
0.305 |
|
499 |
Dad Is Fat |
Jim Gaffigan |
2013 |
3.78 |
0.304 |
|
500 |
Daring Greatly: How the Courage to Be Vulnerable Transforms the Way We Live, Love, Parent, and Lead |
Brené Brown |
2012 |
4.27 |
0.304 |
|
501 |
The Dark Forest (Remembrance of Earth’s Past, #2) |
Liu Cixin |
2008 |
4.41 |
0.302 |
|
502 |
Killers of the Flower Moon: The Osage Murders and the Birth of the FBI |
David Grann |
2017 |
4.09 |
0.301 |
|
503 |
Dead Wake: The Last Crossing of the Lusitania |
Erik Larson |
2015 |
4.08 |
0.299 |
|
504 |
Next Year in Havana |
Chanel Cleeton |
2018 |
3.95 |
0.299 |
|
505 |
A Darker Shade of Magic (Shades of Magic, #1) |
V. E. Schwab (pseudonym) |
2015 |
4.09 |
0.298 |
|
506 |
Meditations |
Marcus Aurelius |
180 |
4.23 |
0.297 |
|
507 |
An Absolutely Remarkable Thing (An Absolutely Remarkable Thing, #1) |
Hank Green |
2018 |
4.03 |
0.294 |
|
508 |
Bury My Heart at Wounded Knee: An Indian History of the American West |
Dee Brown |
1970 |
4.23 |
0.294 |
|
509 |
Lady Chatterley’s Lover |
D. H. Lawrence |
1928 |
3.50 |
0.290 |
|
510 |
You Are a Badass: How to Stop Doubting Your Greatness and Start Living an Awesome Life |
Jen Sincero |
2013 |
3.96 |
0.290 |
|
511 |
How to Stop Time |
Matt Haig |
2017 |
3.85 |
0.287 |
|
512 |
Bonk: The Curious Coupling of Science and Sex |
Mary Roach |
2008 |
3.84 |
0.285 |
|
513 |
Thus Spoke Zarathustra |
Friedrich Nietzsche |
1883 |
4.06 |
0.283 |
|
514 |
March |
Geraldine Brooks |
2005 |
3.75 |
0.278 |
|
515 |
Falling Kingdoms (Falling Kingdoms, #1) |
Morgan Rhodes |
2012 |
3.80 |
0.272 |
|
516 |
This Side of Paradise |
F. Scott Fitzgerald |
1920 |
3.67 |
0.267 |
|
517 |
Strange the Dreamer (Strange the Dreamer, #1) |
Laini Taylor |
2017 |
4.33 |
0.267 |
|
518 |
The New York Trilogy |
Paul Auster |
1987 |
3.89 |
0.261 |
|
519 |
Lamb: The Gospel According to Biff, Christ’s Childhood Pal |
Christopher Moore |
2002 |
4.25 |
0.261 |
|
520 |
The Book of Lost Things |
John Connolly |
2006 |
3.98 |
0.260 |
|
521 |
Modern Romance |
Aziz Ansari |
2015 |
3.83 |
0.260 |
|
522 |
The Dragonbone Chair (Memory, Sorrow, and Thorn, #1) |
Tad Williams |
1988 |
3.95 |
0.259 |
|
523 |
American Gods (American Gods, #1) |
Neil Gaiman |
2001 |
4.11 |
0.258 |
|
524 |
Freedom |
Jonathan Franzen |
2010 |
3.75 |
0.254 |
|
525 |
Even Cowgirls Get the Blues |
Tom Robbins |
1976 |
3.76 |
0.250 |
|
526 |
Artemis |
Andy Weir |
2017 |
3.67 |
0.247 |
|
527 |
Stories of Your Life and Others |
Ted Chiang |
2002 |
4.26 |
0.242 |
|
528 |
Neuromancer (Sprawl, #1) |
William Gibson |
1984 |
3.89 |
0.240 |
|
529 |
Beautiful Ruins |
Jess Walter |
2012 |
3.68 |
0.235 |
|
530 |
Something Wicked This Way Comes (Green Town, #2) |
Ray Bradbury |
1962 |
3.94 |
0.232 |
|
531 |
Moonwalking with Einstein: The Art and Science of Remembering Everything |
Joshua Foer |
2011 |
3.87 |
0.229 |
|
532 |
Crazy Rich Asians (Crazy Rich Asians, #1) |
Kevin Kwan |
2013 |
3.84 |
0.227 |
|
533 |
A Canticle for Leibowitz (St. Leibowitz, #1) |
Walter M. Miller Junior |
1959 |
3.98 |
0.226 |
|
534 |
Year One (Chronicles of The One, #1) |
Nora Roberts |
2017 |
4.04 |
0.224 |
|
535 |
Sophie’s World |
Jostein Gaarder |
1991 |
3.92 |
0.223 |
|
536 |
Bring Up the Bodies (Thomas Cromwell, #2) |
Hilary Mantel |
2012 |
4.28 |
0.222 |
|
537 |
Mrs. Dalloway |
Virginia Woolf |
1925 |
3.79 |
0.217 |
|
538 |
The Red and the Black |
Stendhal |
1830 |
3.87 |
0.216 |
|
539 |
Braving the Wilderness: The Quest for True Belonging and the Courage to Stand Alone |
Brené Brown |
2017 |
4.16 |
0.215 |
|
540 |
The Rules of Magic (Practical Magic, #0) |
Alice Hoffman |
2017 |
3.96 |
0.215 |
|
541 |
Atlas Shrugged |
Ayn Rand |
1957 |
3.69 |
0.215 |
|
542 |
Spinning Silver |
Naomi Novik |
2018 |
4.25 |
0.211 |
|
543 |
Villette |
Charlotte Brontë |
1853 |
3.76 |
0.210 |
|
544 |
The One & Only |
Emily Giffin |
2014 |
3.15 |
0.209 |
|
545 |
The Goldfinch |
Donna Tartt |
2013 |
3.91 |
0.207 |
|
546 |
The Circle |
Dave Eggers |
2013 |
3.43 |
0.205 |
|
547 |
The Distant Hours |
Kate Morton |
2010 |
3.88 |
0.204 |
|
548 |
Britt-Marie Was Here |
Fredrik Backman |
2014 |
4.07 |
0.203 |
|
549 |
The Queen of the Tearling (The Queen of the Tearling, #1) |
Erika Johansen |
2014 |
4.01 |
0.201 |
|
550 |
The Liars’ Club |
Mary Karr |
1995 |
3.93 |
0.200 |
|
551 |
The Dispossessed |
Ursula K. Le Guin |
1974 |
4.21 |
0.193 |
|
552 |
Blood Red Road (Dust Lands, #1) |
Moira Young |
2011 |
3.92 |
0.190 |
|
553 |
Beartown (Beartown, #1) |
Fredrik Backman |
2016 |
4.26 |
0.190 |
|
554 |
The Sparrow (The Sparrow, #1) |
Mary Doria Russell |
1996 |
4.16 |
0.190 |
|
555 |
You (You, #1) |
Caroline Kepnes |
2014 |
3.90 |
0.190 |
|
556 |
The Master and Margarita |
Mikhail Bulgakov |
1967 |
4.30 |
0.188 |
|
557 |
Creativity, Inc.: Overcoming the Unseen Forces That Stand in the Way of True Inspiration |
Ed Catmull |
2009 |
4.20 |
0.184 |
|
558 |
The Heart Is a Lonely Hunter |
Carson McCullers |
1940 |
3.98 |
0.182 |
|
559 |
Saturday |
Ian McEwan |
2005 |
3.63 |
0.181 |
|
560 |
The Mists of Avalon (Avalon, #1) |
Marion Zimmer Bradley |
1982 |
4.12 |
0.177 |
|
561 |
Blindness |
José Saramago |
1995 |
4.11 |
0.177 |
|
562 |
Zealot: The Life and Times of Jesus of Nazareth |
Reza Aslan |
2013 |
3.84 |
0.175 |
|
563 |
Sleeping Giants (Themis Files, #1) |
Sylvain Neuvel |
2016 |
3.84 |
0.170 |
|
564 |
The Guns of August |
Barbara W. Tuchman |
1962 |
4.18 |
0.170 |
|
565 |
Go Set a Watchman (To Kill a Mockingbird, #2) |
Harper Lee |
2015 |
3.31 |
0.165 |
|
566 |
A Spark of Light |
Jodi Picoult |
2018 |
3.68 |
0.163 |
|
567 |
The 48 Laws of Power |
Robert Greene |
1998 |
4.18 |
0.163 |
|
568 |
The Hour I First Believed |
Wally Lamb |
2007 |
3.81 |
0.161 |
|
569 |
The Paper Magician |
Charlie N. Holmberg |
2014 |
3.65 |
0.152 |
|
570 |
The Girl With All the Gifts (The Girl With All the Gifts, #1) |
M. R. Carey |
2014 |
3.94 |
0.152 |
|
571 |
Heart-Shaped Box |
Joe Hill |
2007 |
3.83 |
0.151 |
|
572 |
Illuminae (The Illuminae Files, #1) |
Amie Kaufman |
2015 |
4.30 |
0.151 |
|
573 |
The Wind-Up Bird Chronicle |
Haruki Murakami |
1994 |
4.17 |
0.151 |
|
574 |
The Portrait of a Lady |
Henry James |
1881 |
3.77 |
0.150 |
|
575 |
Three Dark Crowns (Three Dark Crowns, #1) |
Kendare Blake |
2016 |
3.86 |
0.148 |
|
576 |
The Diamond Age: Or, A Young Lady’s Illustrated Primer |
Neal Stephenson |
1995 |
4.19 |
0.144 |
|
577 |
The Jane Austen Book Club |
Karen Joy Fowler |
2004 |
3.08 |
0.140 |
|
578 |
Haunted |
Chuck Palahniuk |
2005 |
3.59 |
0.137 |
|
579 |
Mindset: The New Psychology of Success |
Carol S. Dweck |
2006 |
4.07 |
0.133 |
|
580 |
Tender Is the Night |
F. Scott Fitzgerald |
1934 |
3.82 |
0.132 |
|
581 |
The Sisters Brothers |
Patrick deWitt |
2011 |
3.85 |
0.129 |
|
582 |
The Blade Itself (The First Law, #1) |
Joe Abercrombie |
2006 |
4.16 |
0.127 |
|
583 |
The God of Small Things |
Arundhati Roy |
1997 |
3.93 |
0.125 |
|
584 |
Notes from a Small Island |
Bill Bryson |
1995 |
3.92 |
0.124 |
|
585 |
The Secret History |
Donna Tartt |
1992 |
4.09 |
0.118 |
|
586 |
Animal, Vegetable, Miracle: A Year of Food Life |
Barbara Kingsolver |
2007 |
4.04 |
0.114 |
|
587 |
Burial Rites |
Hannah Kent |
2013 |
4.03 |
0.114 |
|
588 |
This Is How You Lose Her |
Junot Díaz |
2010 |
3.75 |
0.113 |
|
589 |
The Silmarillion (Middle-Earth Universe) |
J. R. R. Tolkien |
1977 |
3.92 |
0.111 |
|
590 |
1491: New Revelations of the Americas Before Columbus |
Charles C. Mann |
2005 |
4.02 |
0.106 |
|
591 |
Fragile Things: Short Fictions and Wonders |
Neil Gaiman |
2006 |
4.00 |
0.105 |
|
592 |
The Underground Railroad |
Colson Whitehead |
2016 |
4.02 |
0.105 |
|
593 |
The Beekeeper’s Apprentice (Mary Russell and Sherlock Holmes, #1) |
Laurie R. King |
1994 |
4.07 |
0.104 |
|
594 |
The Slow Regard of Silent Things (The Kingkiller Chronicle, #2.5) |
Patrick Rothfuss |
2014 |
3.91 |
0.103 |
|
595 |
The Forest of Hands and Teeth (The Forest of Hands and Teeth, #1) |
Carrie Ryan |
2009 |
3.59 |
0.099 |
|
596 |
The Brothers Karamazov |
Fyodor Dostoyevsky |
1879 |
4.32 |
0.099 |
|
597 |
Heartless |
Marissa Meyer |
2016 |
4.05 |
0.098 |
|
598 |
Guns, Germs, and Steel: The Fates of Human Societies |
Jared Diamond |
1997 |
4.03 |
0.098 |
|
599 |
The Japanese Lover |
Isabel Allende |
2015 |
3.81 |
0.096 |
|
600 |
The History of Love |
Nicole Krauss |
2005 |
3.92 |
0.091 |
|
601 |
One Hundred Years of Solitude |
Gabriel García Márquez |
1967 |
4.06 |
0.087 |
|
602 |
Her Fearful Symmetry |
Audrey Niffenegger |
2009 |
3.24 |
0.087 |
|
603 |
The Rosie Effect (Don Tillman, #2) |
Graeme Simsion |
2014 |
3.59 |
0.085 |
|
604 |
The Vegetarian |
Han Kang |
2007 |
3.58 |
0.082 |
|
605 |
Soulless (Parasol Protectorate, #1) |
Gail Carriger |
2009 |
3.91 |
0.082 |
|
606 |
The Lost City of Z: A Tale of Deadly Obsession in the Amazon |
David Grann |
2009 |
3.87 |
0.081 |
|
607 |
10% Happier: How I Tamed the Voice in My Head, Reduced Stress Without Losing My Edge, and Found Self-Help That Actually Works |
Dan Harris |
2014 |
3.92 |
0.080 |
|
608 |
Circe |
Madeline Miller |
2018 |
4.28 |
0.080 |
|
609 |
Doctor Zhivago |
Boris Pasternak |
1957 |
4.03 |
0.078 |
|
610 |
City of Girls |
Elizabeth Gilbert |
2019 |
4.07 |
0.077 |
|
611 |
Vanity Fair |
William Makepeace Thackeray |
1847 |
3.78 |
0.076 |
|
612 |
Oryx and Crake (MaddAddam, #1) |
Margaret Atwood |
2003 |
4.01 |
0.073 |
|
613 |
The Scorpio Races |
Maggie Stiefvater |
2011 |
4.09 |
0.073 |
|
614 |
A Portrait of the Artist as a Young Man |
James Joyce |
1916 |
3.61 |
0.073 |
|
615 |
Snow Crash |
Neal Stephenson |
1992 |
4.03 |
0.072 |
|
616 |
Wicked: The Life and Times of the Wicked Witch of the West (The Wicked Years, #1) |
Gregory Maguire |
1995 |
3.53 |
0.070 |
|
617 |
The Sound and the Fury |
William Faulkner |
1929 |
3.86 |
0.069 |
|
618 |
We Are All Completely Beside Ourselves |
Karen Joy Fowler |
2013 |
3.72 |
0.067 |
|
619 |
Commonwealth |
Ann Patchett |
2016 |
3.81 |
0.067 |
|
620 |
Not That Kind of Girl: A Young Woman Tells You What She’s Learned |
Lena Dunham |
2014 |
3.30 |
0.067 |
|
621 |
Bird by Bird: Some Instructions on Writing and Life |
Anne Lamott |
1994 |
4.24 |
0.066 |
|
622 |
Abraham Lincoln: Vampire Hunter (Abraham Lincoln: Vampire Hunter, #1) |
Seth Grahame-Smith |
2010 |
3.70 |
0.064 |
|
623 |
Maisie Dobbs (Maisie Dobbs, #1) |
Jacqueline Winspear |
2003 |
3.91 |
0.062 |
|
624 |
The God Delusion |
Richard Dawkins |
2006 |
3.90 |
0.059 |
|
625 |
The Omnivore’s Dilemma: A Natural History of Four Meals |
Michael Pollan |
2006 |
4.18 |
0.057 |
|
626 |
The Thief (The Queen’s Thief, #1) |
Megan Whalen Turner |
1996 |
3.88 |
0.057 |
|
627 |
Homo Deus: A History of Tomorrow |
Yuval Noah Harari |
2015 |
4.27 |
0.055 |
|
628 |
Love Letters to the Dead |
Ava Dellaira |
2014 |
3.81 |
0.055 |
|
629 |
The Power of Now: A Guide to Spiritual Enlightenment |
Eckhart Tolle |
1997 |
4.13 |
0.053 |
|
630 |
Practical Magic (Practical Magic #1) |
Alice Hoffman |
1995 |
3.78 |
0.051 |
|
631 |
Caleb’s Crossing |
Geraldine Brooks |
2011 |
3.82 |
0.050 |
|
632 |
Luckiest Girl Alive |
Jessica Knoll |
2015 |
3.49 |
0.048 |
|
633 |
Bleak House |
Charles Dickens |
1853 |
4.01 |
0.047 |
|
634 |
The Name of the Rose |
Umberto Eco |
1980 |
4.12 |
0.046 |
|
635 |
The Divine Comedy |
Dante Alighieri |
1320 |
4.07 |
0.042 |
|
636 |
Half of a Yellow Sun |
Chimamanda Ngozi Adichie |
2006 |
4.31 |
0.042 |
|
637 |
The Night Circus |
Erin Morgenstern |
2011 |
4.04 |
0.042 |
|
638 |
Outlander (Outlander, #1) |
Diana Gabaldon |
1991 |
4.22 |
0.040 |
|
639 |
Into the Water |
Paula Hawkins |
2017 |
3.56 |
0.036 |
|
640 |
The Magician King (The Magicians, #2) |
Lev Grossman |
2011 |
3.92 |
0.034 |
|
641 |
Moby-Dick, or, the Whale |
Herman Melville |
1851 |
3.49 |
0.025 |
|
642 |
White Noise |
Don DeLillo |
1985 |
3.86 |
0.023 |
|
643 |
Lisey’s Story |
Stephen King |
2006 |
3.67 |
0.022 |
|
644 |
A Reliable Wife |
Robert Goolrick |
2009 |
3.26 |
0.022 |
|
645 |
What the Dog Saw and Other Adventures |
Malcolm Gladwell |
2009 |
3.85 |
0.016 |
|
646 |
The President Is Missing |
Bill Clinton |
2018 |
3.83 |
0.015 |
|
647 |
Eating Animals |
Jonathan Safran Foer |
2009 |
4.20 |
0.015 |
|
648 |
A People’s History of the United States |
Howard Zinn |
1980 |
4.08 |
0.014 |
|
649 |
All the Pretty Horses (The Border Trilogy, #1) |
Cormac McCarthy |
1992 |
3.99 |
0.013 |
|
650 |
The Alchemyst (The Secrets of the Immortal Nicholas Flamel, #1) |
Michael Scott |
2007 |
3.84 |
0.012 |
|
651 |
What Is the What |
Dave Eggers |
2006 |
4.16 |
0.012 |
|
652 |
The Mysterious Benedict Society (The Mysterious Benedict Society, #1) |
Trenton Lee Stewart |
2007 |
4.16 |
0.012 |
|
653 |
The Song of Achilles |
Madeline Miller |
2011 |
4.33 |
0.004 |
|
654 |
Rivers of London (Peter Grant, #1) |
Ben Aaronovitch |
2011 |
3.91 |
−0.002 |
|
655 |
War and Peace |
Leo Tolstoy |
1867 |
4.11 |
−0.005 |
|
656 |
The Black Prism (Lightbringer, #1) |
Brent Weeks |
2010 |
4.24 |
−0.006 |
|
657 |
Olive Kitteridge (Olive Kitteridge, #1) |
Elizabeth Strout |
2008 |
3.82 |
−0.010 |
|
658 |
The Round House |
Louise Erdrich |
2012 |
3.93 |
−0.013 |
|
659 |
The Girl of Fire and Thorns (Fire and Thorns, #1) |
Rae Carson |
2011 |
3.79 |
−0.014 |
|
660 |
Big Magic: Creative Living Beyond Fear |
Elizabeth Gilbert |
2015 |
3.92 |
−0.017 |
|
661 |
Homegoing |
Yaa Gyasi |
2016 |
4.42 |
−0.018 |
|
662 |
A Short History of Nearly Everything |
Bill Bryson |
2003 |
4.21 |
−0.018 |
|
663 |
Americanah |
Chimamanda Ngozi Adichie |
2013 |
4.30 |
−0.020 |
|
664 |
The Shadow of the Wind (The Cemetery of Forgotten Books, #1) |
Carlos Ruiz Zafón |
2001 |
4.26 |
−0.021 |
|
665 |
Alias Grace |
Margaret Atwood |
1996 |
4.03 |
−0.022 |
|
666 |
The Dinner |
Herman Koch |
2009 |
3.22 |
−0.022 |
|
667 |
I’ll Be Gone in the Dark: One Woman’s Obsessive Search for the Golden State Killer |
Michelle McNamara |
2018 |
4.15 |
−0.023 |
|
668 |
The Artist’s Way |
Julia Cameron |
1992 |
3.91 |
−0.025 |
|
669 |
Hyperion (Hyperion Cantos, #1) |
Dan Simmons |
1989 |
4.24 |
−0.025 |
|
670 |
The Man Who Mistook His Wife for a Hat and Other Clinical Tales |
Oliver Sacks |
1985 |
4.06 |
−0.026 |
|
671 |
The Miniaturist |
Jessie Burton |
2014 |
3.59 |
−0.027 |
|
672 |
First Grave on the Right (Charley Davidson, #1) |
Darynda Jones |
2011 |
4.05 |
−0.027 |
|
673 |
The Devil in the White City: Murder, Magic, and Madness at the Fair That Changed America |
Erik Larson |
2003 |
3.99 |
−0.030 |
|
674 |
We |
Yevgeny Zamyatin |
1921 |
3.94 |
−0.031 |
|
675 |
A Prayer for Owen Meany |
John Irving |
1989 |
4.23 |
−0.032 |
|
676 |
Wool Omnibus (Silo, #1) |
Hugh Howey |
2012 |
4.23 |
−0.032 |
|
677 |
The Alienist (Dr. Laszlo Kreizler, #1) |
Caleb Carr |
1994 |
4.06 |
−0.032 |
|
678 |
The English Patient |
Michael Ondaatje |
1992 |
3.88 |
−0.037 |
|
679 |
Gone (Gone, #1) |
Michael Grant |
2008 |
3.86 |
−0.041 |
|
680 |
American Psycho |
Bret Easton Ellis |
1991 |
3.82 |
−0.044 |
|
681 |
A Passage to India |
E. M. Forster |
1924 |
3.68 |
−0.046 |
|
682 |
I Am Pilgrim |
Terry Hayes |
2013 |
4.24 |
−0.054 |
|
683 |
Grave Mercy (His Fair Assassin, #1) |
Robin LaFevers |
2012 |
3.90 |
−0.058 |
|
684 |
Jitterbug Perfume |
Tom Robbins |
1984 |
4.25 |
−0.060 |
|
685 |
The Gentleman’s Guide to Vice and Virtue (Montague Siblings, #1) |
Mackenzi Lee |
2017 |
4.14 |
−0.060 |
|
686 |
Love in the Time of Cholera |
Gabriel García Márquez |
1985 |
3.91 |
−0.061 |
|
687 |
The Year of Magical Thinking |
Joan Didion |
2005 |
3.89 |
−0.061 |
|
688 |
Exit West |
Mohsin Hamid |
2017 |
3.79 |
−0.065 |
|
689 |
Let’s Explore Diabetes with Owls |
David Sedaris |
2013 |
3.82 |
−0.065 |
|
690 |
Annihilation (Southern Reach, #1) |
Jeff VanderMeer |
2014 |
3.68 |
−0.069 |
|
691 |
Sapiens: A Brief History of Humankind |
Yuval Noah Harari |
2011 |
4.44 |
−0.070 |
|
692 |
At the Water’s Edge |
Sara Gruen |
2015 |
3.66 |
−0.071 |
|
693 |
Shadow of Night (All Souls Trilogy, #2) |
Deborah Harkness |
2012 |
4.06 |
−0.078 |
|
694 |
Major Pettigrew’s Last Stand |
Helen Simonson |
2010 |
3.89 |
−0.092 |
|
695 |
The Keeper of Lost Things |
Ruth Hogan |
2017 |
3.82 |
−0.096 |
|
696 |
Landline |
Rainbow Rowell |
2014 |
3.55 |
−0.097 |
|
697 |
Station Eleven |
Emily St. John Mandel |
2014 |
4.03 |
−0.099 |
|
698 |
Cutting for Stone |
Abraham Verghese |
2009 |
4.29 |
−0.102 |
|
699 |
What If?: Serious Scientific Answers to Absurd Hypothetical Questions |
Randall Munroe |
2014 |
4.16 |
−0.107 |
|
700 |
Truly Madly Guilty |
Liane Moriarty |
2016 |
3.57 |
−0.111 |
|
701 |
Hounded (The Iron Druid Chronicles, #1) |
Kevin Hearne |
2011 |
4.11 |
−0.111 |
|
702 |
_The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good Life_ |
Mark Manson |
2016 |
3.97 |
−0.115 |
|
703 |
Flaggermusmannen (Harry Hole, #1) |
Jo Nesbø |
1997 |
3.54 |
−0.117 |
|
704 |
Stiff: The Curious Lives of Human Cadavers |
Mary Roach |
2003 |
4.06 |
−0.119 |
|
705 |
Before the Fall |
Noah Hawley |
2016 |
3.73 |
−0.122 |
|
706 |
Hillbilly Elegy: A Memoir of a Family and Culture in Crisis |
J. D. Vance |
2016 |
3.93 |
−0.122 |
|
707 |
The Strain (The Strain Trilogy, #1) |
Guillermo del Toro |
2009 |
3.78 |
−0.122 |
|
708 |
Anna Karenina |
Leo Tolstoy |
1877 |
4.04 |
−0.124 |
|
709 |
Under the Banner of Heaven: A Story of Violent Faith |
Jon Krakauer |
2003 |
4.00 |
−0.126 |
|
710 |
I Capture the Castle |
Dodie Smith |
1948 |
4.00 |
−0.127 |
|
711 |
The Origin of Species |
Charles Darwin |
1859 |
3.98 |
−0.132 |
|
712 |
People of the Book |
Geraldine Brooks |
2008 |
4.02 |
−0.136 |
|
713 |
Loving Frank |
Nancy Horan |
2007 |
3.75 |
−0.137 |
|
714 |
Lilac Girls (Lilac Girls, #1) |
Martha Hall Kelly |
2016 |
4.29 |
−0.140 |
|
715 |
World War Z: An Oral History of the Zombie War |
Max Brooks |
2006 |
4.01 |
−0.142 |
|
716 |
Good Omens: The Nice and Accurate Prophecies of Agnes Nutter, Witch |
Terry Pratchett |
1990 |
4.25 |
−0.142 |
|
717 |
The Raven Boys (The Raven Cycle, #1) |
Maggie Stiefvater |
2012 |
4.06 |
−0.143 |
|
718 |
The Shipping News |
Annie Proulx |
1993 |
3.86 |
−0.144 |
|
719 |
Stranger in a Strange Land |
Robert A. Heinlein |
1961 |
3.92 |
−0.145 |
|
720 |
The Young Elites (The Young Elites, #1) |
Marie Lu |
2014 |
3.90 |
−0.145 |
|
721 |
Lolita |
Vladimir Nabokov |
1955 |
3.89 |
−0.161 |
|
722 |
The Girl in the Spider’s Web (Millennium, #4) |
David Lagercrantz |
2015 |
3.76 |
−0.165 |
|
723 |
The Twelve (The Passage, #2) |
Justin Cronin |
2012 |
4.00 |
−0.167 |
|
724 |
Bel Canto |
Ann Patchett |
2001 |
3.93 |
−0.168 |
|
725 |
The Witching Hour (Lives of the Mayfair Witches, #1) |
Anne Rice |
1990 |
4.11 |
−0.168 |
|
726 |
The 4-Hour Workweek |
Timothy Ferriss |
2007 |
3.87 |
−0.169 |
|
727 |
La Vérité sur l’affaire Harry Quebert |
Joël Dicker |
2012 |
4.03 |
−0.170 |
|
728 |
The Paris Wife |
Paula McLain |
2011 |
3.81 |
−0.172 |
|
729 |
Life |
Keith Richards |
2010 |
3.86 |
−0.173 |
|
730 |
The Snow Child |
Eowyn Ivey |
2012 |
3.97 |
−0.174 |
|
731 |
God Is Not Great: How Religion Poisons Everything |
Christopher Hitchens |
2007 |
3.97 |
−0.175 |
|
732 |
Carry On (Simon Snow, #1) |
Rainbow Rowell |
2015 |
4.24 |
−0.175 |
|
733 |
A Scanner Darkly |
Philip K. Dick |
1977 |
4.02 |
−0.180 |
|
734 |
The Lake House |
Kate Morton |
2015 |
4.05 |
−0.186 |
|
735 |
Vicious (Villains, #1) |
V. E. Schwab |
2013 |
4.24 |
−0.187 |
|
736 |
Peace Like a River |
Leif Enger |
2001 |
4.00 |
−0.189 |
|
737 |
Nausea |
Jean-Paul Sartre |
1938 |
3.92 |
−0.191 |
|
738 |
Revolutionary Road |
Richard Yates |
1961 |
3.91 |
−0.193 |
|
739 |
The Moon is a Harsh Mistress |
Robert A. Heinlein |
1966 |
4.17 |
−0.193 |
|
740 |
The Kiss of Deception (The Remnant Chronicles, #1) |
Mary E. Pearson |
2014 |
4.02 |
−0.193 |
|
741 |
Ishmael |
Daniel Quinn |
1992 |
3.99 |
−0.199 |
|
742 |
Extremely Loud and Incredibly Close |
Jonathan Safran Foer |
2005 |
3.98 |
−0.199 |
|
743 |
A Great and Terrible Beauty (Gemma Doyle #1) |
Libba Bray |
2003 |
3.79 |
−0.201 |
|
744 |
The Turn of the Screw |
Henry James |
1898 |
3.43 |
−0.208 |
|
745 |
The Wishing Spell (The Land of Stories, #1) |
Chris Colfer |
2012 |
4.23 |
−0.209 |
|
746 |
Furies of Calderon (Codex Alera, #1) |
Jim Butcher |
2004 |
4.12 |
−0.210 |
|
747 |
As I Lay Dying |
William Faulkner |
1930 |
3.71 |
−0.211 |
|
748 |
The Gifts of Imperfection |
Brené Brown |
2010 |
4.21 |
−0.212 |
|
749 |
Hard-Boiled Wonderland and the End of the World |
Haruki Murakami |
1985 |
4.15 |
−0.213 |
|
750 |
The Wrath and the Dawn (The Wrath and the Dawn, #1) |
Renée Ahdieh |
2015 |
4.15 |
−0.214 |
|
751 |
Horns |
Joe Hill |
2009 |
3.92 |
−0.214 |
|
752 |
The Cuckoo’s Calling (Cormoran Strike, #1) |
Robert Galbraith (Pseudonym) |
2013 |
3.86 |
−0.216 |
|
753 |
The Art of Fielding |
Chad Harbach |
2011 |
3.99 |
−0.221 |
|
754 |
Small Great Things |
Jodi Picoult |
2016 |
4.34 |
−0.224 |
|
755 |
Glass Sword (Red Queen, #2) |
Victoria Aveyard |
2016 |
3.91 |
−0.227 |
|
756 |
The Unlikely Pilgrimage of Harold Fry (Harold Fry, #1) |
Rachel Joyce |
2012 |
3.91 |
−0.231 |
|
757 |
Case Histories (Jackson Brodie #1) |
Kate Atkinson |
2004 |
3.83 |
−0.240 |
|
758 |
Madame Bovary |
Gustave Flaubert |
1856 |
3.66 |
−0.241 |
|
759 |
Corelli’s Mandolin |
Louis de Bernières |
1994 |
3.98 |
−0.243 |
|
760 |
Invisible Man |
Ralph Ellison |
1952 |
3.86 |
−0.245 |
|
761 |
Under the Dome |
Stephen King |
2009 |
3.90 |
−0.249 |
|
762 |
My Name Is Lucy Barton |
Elizabeth Strout |
2016 |
3.51 |
−0.249 |
|
763 |
The Death of Mrs. Westaway |
Ruth Ware |
2018 |
3.81 |
−0.257 |
|
764 |
Magic Bites (Kate Daniels, #1) |
Ilona Andrews |
2007 |
4.07 |
−0.260 |
|
765 |
Paradise Lost |
John Milton |
1667 |
3.81 |
−0.267 |
|
766 |
The House of Mirth |
Edith Wharton |
1905 |
3.95 |
−0.270 |
|
767 |
Neverwhere (London Below, #1) |
Neil Gaiman |
1996 |
4.17 |
−0.271 |
|
768 |
The Professor and the Madman: A Tale of Murder, Insanity and the Making of the Oxford English Dictionary |
Simon Winchester |
1998 |
3.84 |
−0.272 |
|
769 |
Orange Is the New Black |
Piper Kerman |
2010 |
3.71 |
−0.272 |
|
770 |
Six of Crows (Six of Crows, #1) |
Leigh Bardugo |
2015 |
4.46 |
−0.276 |
|
771 |
We Were the Mulvaneys |
Joyce Carol Oates |
1996 |
3.72 |
−0.277 |
|
772 |
The Selfish Gene |
Richard Dawkins |
1976 |
4.13 |
−0.278 |
|
773 |
Nine Perfect Strangers |
Liane Moriarty |
2018 |
3.50 |
−0.280 |
|
774 |
Still Life (Chief Inspector Armand Gamache, #1) |
Louise Penny |
2005 |
3.88 |
−0.285 |
|
775 |
The Trial |
Franz Kafka |
1925 |
3.97 |
−0.289 |
|
776 |
Norse Mythology |
Neil Gaiman |
2017 |
4.09 |
−0.292 |
|
777 |
Leviathan Wakes (The Expanse, #1) |
James S. A. Corey |
2011 |
4.25 |
−0.294 |
|
778 |
The Woman in White |
Wilkie Collins |
1859 |
3.99 |
−0.295 |
|
779 |
Across the Universe (Across the Universe, #1) |
Beth Revis |
2011 |
3.77 |
−0.296 |
|
780 |
The Darkest Minds (The Darkest Minds, #1) |
Alexandra Bracken |
2012 |
4.20 |
−0.298 |
|
781 |
Dead Witch Walking (The Hollows, #1) |
Kim Harrison |
2004 |
4.04 |
−0.301 |
|
782 |
The World Is Flat: A Brief History of the Twenty-first Century |
Thomas L. Friedman |
2005 |
3.68 |
−0.303 |
|
783 |
Ringworld (Ringworld, #1) |
Larry Niven |
1970 |
3.96 |
−0.305 |
|
784 |
The Age of Miracles |
Karen Thompson Walker |
2012 |
3.65 |
−0.308 |
|
785 |
The Last of the Mohicans (The Leatherstocking Tales #2) |
James Fenimore Cooper |
1826 |
3.70 |
−0.310 |
|
786 |
Sabriel (Abhorsen, #1) |
Garth Nix |
1995 |
4.17 |
−0.312 |
|
787 |
Let the Right One In |
John Ajvide Lindqvist |
2004 |
4.06 |
−0.313 |
|
788 |
Normal People |
Sally Rooney |
2018 |
3.89 |
−0.313 |
|
789 |
A Connecticut Yankee in King Arthur’s Court |
Mark Twain |
1889 |
3.77 |
−0.319 |
|
790 |
Start with Why: How Great Leaders Inspire Everyone to Take Action |
Simon Sinek |
2009 |
4.07 |
−0.320 |
|
791 |
Three Cups of Tea: One Man’s Mission to Promote Peace … One School at a Time |
Greg Mortenson |
2006 |
3.65 |
−0.321 |
|
792 |
The Year of the Flood (MaddAddam, #2) |
Margaret Atwood |
2009 |
4.07 |
−0.325 |
|
793 |
American Sniper: The Autobiography of the Most Lethal Sniper in U.S. Military History |
Chris Kyle |
2012 |
4.00 |
−0.326 |
|
794 |
Bitten (Otherworld, #1) |
Kelley Armstrong |
2001 |
4.05 |
−0.330 |
|
795 |
Brideshead Revisited |
Evelyn Waugh |
1945 |
4.00 |
−0.332 |
|
796 |
A Man Called Ove |
Fredrik Backman |
2012 |
4.36 |
−0.333 |
|
797 |
Call Me By Your Name (Call Me By Your Name, #1) |
André Aciman |
2007 |
4.27 |
−0.336 |
|
798 |
Between the World and Me |
Ta-Nehisi Coates |
2015 |
4.40 |
−0.342 |
|
799 |
Shiver (The Wolves of Mercy Falls, #1) |
Maggie Stiefvater |
2009 |
3.77 |
−0.348 |
|
800 |
Tell the Wolves I’m Home |
Carol Rifka Brunt |
2012 |
4.04 |
−0.348 |
|
801 |
The 5th Wave (The 5th Wave, #1) |
Rick Yancey |
2013 |
4.06 |
−0.353 |
|
802 |
Shatter Me (Shatter Me, #1) |
Tahereh Mafi |
2011 |
3.97 |
−0.356 |
|
803 |
Far From the Madding Crowd |
Thomas Hardy |
1874 |
3.94 |
−0.358 |
|
804 |
The Color of Magic (Discworld, #1; Rincewind, #1) |
Terry Pratchett |
1983 |
3.99 |
−0.367 |
|
805 |
11/22/63 |
Stephen King |
2011 |
4.31 |
−0.368 |
|
806 |
Pachinko |
Min Jin Lee |
2017 |
4.26 |
−0.369 |
|
807 |
A Dirty Job (Grim Reaper, #1) |
Christopher Moore |
2006 |
4.07 |
−0.372 |
|
808 |
Daughter of Smoke & Bone (Daughter of Smoke & Bone, #1) |
Laini Taylor |
2011 |
4.03 |
−0.373 |
|
809 |
Magyk (Septimus Heap, #1) |
Angie Sage |
2005 |
3.82 |
−0.378 |
|
810 |
The Last Wish (The Witcher, #0.5) |
Andrzej Sapkowski |
1993 |
4.19 |
−0.379 |
|
811 |
The Way of Shadows (Night Angel, #1) |
Brent Weeks |
2008 |
4.15 |
−0.380 |
|
812 |
Caraval (Caraval, #1) |
Stephanie Garber |
2017 |
3.95 |
−0.383 |
|
813 |
The Winner’s Curse (The Winner’s Trilogy, #1) |
Marie Rutkoski |
2014 |
4.00 |
−0.385 |
|
814 |
The Alice Network |
Kate Quinn |
2017 |
4.26 |
−0.392 |
|
815 |
Yes Please |
Amy Poehler |
2014 |
3.82 |
−0.393 |
|
816 |
An American Marriage |
Tayari Jones |
2018 |
3.97 |
−0.394 |
|
817 |
The Pillars of the Earth (Kingsbridge, #1) |
Ken Follett |
1989 |
4.31 |
−0.394 |
|
818 |
The Unbearable Lightness of Being |
Milan Kundera |
1984 |
4.10 |
−0.399 |
|
819 |
Since You’ve Been Gone |
Morgan Matson |
2014 |
4.14 |
−0.401 |
|
820 |
The Secret Keeper |
Kate Morton |
2012 |
4.14 |
−0.401 |
|
821 |
Atonement |
Ian McEwan |
2001 |
3.90 |
−0.402 |
|
822 |
Dragonfly in Amber (Outlander, #2) |
Diana Gabaldon |
1992 |
4.32 |
−0.402 |
|
823 |
The Name of the Wind (The Kingkiller Chronicle, #1) |
Patrick Rothfuss |
2007 |
4.54 |
−0.406 |
|
824 |
Me and Earl and the Dying Girl |
Jesse Andrews |
2012 |
3.56 |
−0.408 |
|
825 |
Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation |
Lynne Truss |
2003 |
3.87 |
−0.408 |
|
826 |
An Abundance of Katherines |
John Green |
2006 |
3.59 |
−0.410 |
|
827 |
Anna Dressed in Blood (Anna, #1) |
Kendare Blake |
2011 |
3.94 |
−0.412 |
|
828 |
‘Surely You’re Joking, Mr. Feynman!’: Adventures of a Curious Character |
Richard P. Feynman |
1985 |
4.28 |
−0.417 |
|
829 |
Daisy Jones & The Six |
Taylor Jenkins Reid |
2019 |
4.22 |
−0.423 |
|
830 |
Steppenwolf |
Hermann Hesse |
1927 |
4.12 |
−0.437 |
|
831 |
Under the Never Sky (Under the Never Sky, #1) |
Veronica Rossi |
2011 |
4.00 |
−0.438 |
|
832 |
The Eye of the World (The Wheel of Time, #1) |
Robert Jordan |
1990 |
4.19 |
−0.440 |
|
833 |
All the Light We Cannot See |
Anthony Doerr |
2014 |
4.33 |
−0.441 |
|
834 |
One Day |
David Nicholls |
2009 |
3.78 |
−0.443 |
|
835 |
Dubliners |
James Joyce |
1914 |
3.85 |
−0.446 |
|
836 |
The Age of Innocence |
Edith Wharton |
1920 |
3.94 |
−0.450 |
|
837 |
Three Wishes |
Liane Moriarty |
2003 |
3.78 |
−0.452 |
|
838 |
The Plague |
Albert Camus |
1947 |
3.98 |
−0.459 |
|
839 |
The House at Riverton |
Kate Morton |
2006 |
3.95 |
−0.461 |
|
840 |
Never Let Me Go |
Kazuo Ishiguro |
2005 |
3.82 |
−0.461 |
|
841 |
The Remains of the Day |
Kazuo Ishiguro |
1989 |
4.12 |
−0.462 |
|
842 |
One Day in December |
Josie Silver |
2018 |
4.00 |
−0.463 |
|
843 |
The Angel’s Game (El cementerio de los libros olvidados #2) |
Carlos Ruiz Zafón |
2008 |
3.91 |
−0.465 |
|
844 |
The Kill Order (The Maze Runner, #0.5) |
James Dashner |
2012 |
3.72 |
−0.465 |
|
845 |
A Fine Balance |
Rohinton Mistry |
1995 |
4.36 |
−0.467 |
|
846 |
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics |
Daniel James Brown |
2013 |
4.35 |
−0.475 |
|
847 |
Gulliver’s Travels |
Jonathan Swift |
1726 |
3.56 |
−0.476 |
|
848 |
The Iron King (The Iron Fey, #1) |
Julie Kagawa |
2010 |
3.91 |
−0.479 |
|
849 |
Moloka’i (Moloka’i #1) |
Alan Brennert |
2003 |
4.17 |
−0.482 |
|
850 |
In Defense of Food: An Eater’s Manifesto |
Michael Pollan |
2008 |
4.08 |
−0.488 |
|
851 |
Rules of Civility |
Amor Towles |
2011 |
4.04 |
−0.498 |
|
852 |
Attachments |
Rainbow Rowell |
2011 |
3.92 |
−0.504 |
|
853 |
Beautiful Darkness (Caster Chronicles, #2) |
Kami Garcia |
2010 |
3.84 |
−0.507 |
|
854 |
Lean In: Women, Work, and the Will to Lead |
Sheryl Sandberg |
2013 |
3.95 |
−0.508 |
|
855 |
The Shack |
William Paul Young |
2007 |
3.76 |
−0.509 |
|
856 |
Life As We Knew It (Last Survivors, #1) |
Susan Beth Pfeffer |
2006 |
3.89 |
−0.514 |
|
857 |
The Big Sleep (Philip Marlowe, #1) |
Raymond Chandler |
1939 |
4.01 |
−0.516 |
|
858 |
The Thirteenth Tale |
Diane Setterfield |
2006 |
3.96 |
−0.516 |
|
859 |
Dark Matter |
Blake Crouch |
2016 |
4.10 |
−0.517 |
|
860 |
I Am the Messenger |
Markus Zusak |
2002 |
4.07 |
−0.521 |
|
861 |
Julie and Julia: 365 Days, 524 Recipes, 1 Tiny Apartment Kitchen |
Julie Powell |
2005 |
3.70 |
−0.521 |
|
862 |
Crossed (Matched, #2) |
Ally Condie |
2011 |
3.52 |
−0.525 |
|
863 |
The Likeness (Dublin Murder Squad, #2) |
Tana French |
2008 |
4.06 |
−0.525 |
|
864 |
Watership Down (Watership Down, #1) |
Richard Adams |
1972 |
4.05 |
−0.525 |
|
865 |
Born to Run: A Hidden Tribe, Superathletes, and the Greatest Race the World Has Never Seen |
Christopher McDougall |
2009 |
4.29 |
−0.526 |
|
866 |
The Jungle |
Upton Sinclair |
1906 |
3.74 |
−0.527 |
|
867 |
Hollow City (Miss Peregrine’s Peculiar Children, #2) |
Ransom Riggs |
2014 |
4.07 |
−0.530 |
|
868 |
One Thousand White Women: The Journals of May Dodd (One Thousand White Women, #1) |
Jim Fergus |
1998 |
3.88 |
−0.532 |
|
869 |
The White Tiger |
Aravind Adiga |
2008 |
3.73 |
−0.541 |
|
870 |
Twenty Thousand Leagues Under the Sea (Extraordinary Voyages, #6) |
Jules Verne |
1869 |
3.88 |
−0.541 |
|
871 |
The Light Between Oceans |
M. L. Stedman |
2012 |
4.02 |
−0.544 |
|
872 |
State of Wonder |
Ann Patchett |
2011 |
3.87 |
−0.546 |
|
873 |
Beloved |
Toni Morrison |
1987 |
3.82 |
−0.552 |
|
874 |
Days of Blood & Starlight (Daughter of Smoke & Bone, #2) |
Laini Taylor |
2012 |
4.18 |
−0.555 |
|
875 |
The Power of Habit: Why We Do What We Do in Life and Business |
Charles Duhigg |
2012 |
4.09 |
−0.556 |
|
876 |
Unwind (Unwind, #1) |
Neal Shusterman |
2007 |
4.18 |
−0.561 |
|
877 |
The Way of Kings (The Stormlight Archive, #1) |
Brandon Sanderson |
2010 |
4.65 |
−0.561 |
|
878 |
In the Woods (Dublin Murder Squad, #1) |
Tana French |
2007 |
3.76 |
−0.567 |
|
879 |
Inkheart (Inkworld, #1) |
Cornelia Funke |
2003 |
3.88 |
−0.570 |
|
880 |
The Martian |
Andy Weir |
2012 |
4.40 |
−0.578 |
|
881 |
A Brief History of Time |
Stephen Hawking |
1988 |
4.17 |
−0.578 |
|
882 |
The Forgotten Garden |
Kate Morton |
2008 |
4.14 |
−0.581 |
|
883 |
The Fountainhead |
Ayn Rand |
1943 |
3.86 |
−0.582 |
|
884 |
Fall of Giants (The Century Trilogy, #1) |
Ken Follett |
2010 |
4.29 |
−0.585 |
|
885 |
The Forever War (The Forever War, #1) |
Joe Haldeman |
1974 |
4.15 |
−0.586 |
|
886 |
I’ll Give You the Sun |
Jandy Nelson |
2014 |
4.13 |
−0.590 |
|
887 |
Invisible Monsters |
Chuck Palahniuk |
1999 |
4.00 |
−0.599 |
|
888 |
Lonesome Dove |
Larry McMurtry |
1985 |
4.49 |
−0.604 |
|
889 |
The Cruel Prince (The Folk of the Air, #1) |
Holly Black |
2018 |
4.16 |
−0.605 |
|
890 |
The Stand |
Stephen King |
1978 |
4.34 |
−0.606 |
|
891 |
Dune (Dune, #1) |
Frank Herbert |
1965 |
4.22 |
−0.606 |
|
892 |
Shōgun (Asian Saga, #1) |
James Clavell |
1975 |
4.39 |
−0.607 |
|
893 |
Everything I Never Told You |
Celeste Ng |
2014 |
3.85 |
−0.609 |
|
894 |
Reached (Matched, #3) |
Ally Condie |
2012 |
3.56 |
−0.612 |
|
895 |
Ready Player One (Ready Player One, #1) |
Ernest Cline |
2011 |
4.27 |
−0.612 |
|
896 |
For Whom the Bell Tolls |
Ernest Hemingway |
1940 |
3.96 |
−0.614 |
|
897 |
Steelheart (The Reckoners, #1) |
Brandon Sanderson |
2013 |
4.16 |
−0.625 |
|
898 |
Bad Blood: Secrets and Lies in a Silicon Valley Startup |
2018 |
4.45 |
−0.629 |
|
|
899 |
Delirium (Delirium, #1) |
Lauren Oliver |
2011 |
3.98 |
−0.629 |
|
900 |
Wild: From Lost to Found on the Pacific Crest Trail |
Cheryl Strayed |
2012 |
4.00 |
−0.631 |
|
901 |
Darkfever (Fever, #1) |
Karen Marie Moning |
2006 |
4.11 |
−0.640 |
|
902 |
North and South |
Elizabeth Gaskell |
1854 |
4.14 |
−0.644 |
|
903 |
The Ocean at the End of the Lane |
Neil Gaiman |
2013 |
4.00 |
−0.648 |
|
904 |
The Gunslinger (The Dark Tower, #1) |
Stephen King |
1982 |
3.96 |
−0.656 |
|
905 |
Graceling (Graceling Realm, #1) |
Kristin Cashore |
2008 |
4.09 |
−0.662 |
|
906 |
Heart of Darkness |
Joseph Conrad |
1902 |
3.42 |
−0.662 |
|
907 |
An Ember in the Ashes (An Ember in the Ashes, #1) |
Sabaa Tahir |
2015 |
4.30 |
−0.668 |
|
908 |
All the Bright Places |
Jennifer Niven |
2015 |
4.17 |
−0.670 |
|
909 |
Kafka on the Shore |
Haruki Murakami |
2002 |
4.13 |
−0.682 |
|
910 |
Why Not Me? |
Mindy Kaling |
2015 |
3.90 |
−0.683 |
|
911 |
This is Where I Leave You |
Jonathan Tropper |
2009 |
3.89 |
−0.684 |
|
912 |
Team of Rivals: The Political Genius of Abraham Lincoln |
Doris Kearns Goodwin |
2005 |
4.28 |
−0.686 |
|
913 |
The Final Empire (Mistborn, #1) |
Brandon Sanderson |
2006 |
4.45 |
−0.686 |
|
914 |
Uglies (Uglies, #1) |
Scott Westerfeld |
2005 |
3.86 |
−0.687 |
|
915 |
The Book Thief |
Markus Zusak |
2005 |
4.37 |
−0.691 |
|
916 |
Middlesex |
Jeffrey Eugenides |
2002 |
4.00 |
−0.695 |
|
917 |
The White Queen (The Plantagenet and Tudor Novels, #2; The Cousins War #1) |
Philippa Gregory |
2009 |
3.92 |
−0.695 |
|
918 |
Miss Peregrine’s Home for Peculiar Children (Miss Peregrine’s Peculiar Children, #1) |
Ransom Riggs |
2011 |
3.91 |
−0.696 |
|
919 |
Beautiful Creatures (Caster Chronicles, #1) |
Kami Garcia |
2009 |
3.76 |
−0.697 |
|
920 |
Gabriel’s Inferno (Gabriel’s Inferno, #1) |
Sylvain Reynard |
2011 |
4.01 |
−0.699 |
|
921 |
Storm Front (The Dresden Files, #1) |
Jim Butcher |
2000 |
4.01 |
−0.702 |
|
922 |
The Hours |
Michael Cunningham |
1998 |
3.93 |
−0.704 |
|
923 |
Inferno (The Divine Comedy #1) |
Dante Alighieri |
1320 |
4.00 |
−0.707 |
|
924 |
Crime and Punishment |
Fyodor Dostoyevsky |
1866 |
4.21 |
−0.709 |
|
925 |
I’d Tell You I Love You, But Then I’d Have to Kill You (Gallagher Girls, #1) |
Ally Carter |
2006 |
3.83 |
−0.709 |
|
926 |
I Am Malala: The Story of the Girl Who Stood Up for Education and Was Shot by the Taliban |
Malala Yousafzai |
2012 |
4.11 |
−0.712 |
|
927 |
Midnight in the Garden of Good and Evil |
John Berendt |
1994 |
3.92 |
−0.713 |
|
928 |
The Woman in Cabin 10 |
Ruth Ware |
2016 |
3.69 |
−0.713 |
|
929 |
The Three Musketeers (The D’Artagnan Romances, #1) |
Alexandre Dumas |
1844 |
4.07 |
−0.718 |
|
930 |
A Wizard of Earthsea |
Ursula K. Le Guin |
1968 |
4.00 |
−0.718 |
|
931 |
A New Earth: Awakening to Your Life’s Purpose |
Eckhart Tolle |
2005 |
4.07 |
−0.721 |
|
932 |
Think and Grow Rich |
Napoleon Hill |
1937 |
4.18 |
−0.721 |
|
933 |
The Haunting of Hill House |
Shirley Jackson |
1959 |
3.84 |
−0.722 |
|
934 |
Tess of the D’Urbervilles |
Thomas Hardy |
1891 |
3.79 |
−0.722 |
|
935 |
A Game of Thrones (A Song of Ice and Fire, #1) |
George R. R. Martin |
1996 |
4.45 |
−0.726 |
|
936 |
Little Bee |
Chris Cleave |
2008 |
3.71 |
−0.731 |
|
937 |
The Seven Husbands of Evelyn Hugo |
Taylor Jenkins Reid |
2017 |
4.32 |
−0.733 |
|
938 |
The Cider House Rules |
John Irving |
1985 |
4.12 |
−0.734 |
|
939 |
Eleanor Oliphant is Completely Fine |
Gail Honeyman |
2017 |
4.31 |
−0.740 |
|
940 |
The Fiery Cross (Outlander, #5) |
Diana Gabaldon |
2001 |
4.27 |
−0.742 |
|
941 |
Uncle Tom’s Cabin |
Harriet Beecher Stowe |
1852 |
3.86 |
−0.744 |
|
942 |
Fire (Graceling Realm, #2) |
Kristin Cashore |
2009 |
4.11 |
−0.745 |
|
943 |
David and Goliath: Underdogs, Misfits, and the Art of Battling Giants |
Malcolm Gladwell |
2009 |
3.94 |
−0.745 |
|
944 |
Just Kids |
Patti Smith |
2010 |
4.14 |
−0.755 |
|
945 |
The Wind in the Willows |
Kenneth Grahame |
1908 |
3.99 |
−0.762 |
|
946 |
David Copperfield |
Charles Dickens |
1849 |
3.98 |
−0.768 |
|
947 |
The 7 Habits of Highly Effective People: Powerful Lessons in Personal Change |
Stephen R. Covey |
1989 |
4.10 |
−0.768 |
|
948 |
Where’d You Go, Bernadette |
Maria Semple |
2012 |
3.90 |
−0.770 |
|
949 |
Men Are from Mars, Women Are from Venus |
John Gray |
1992 |
3.55 |
−0.770 |
|
950 |
Kitchen Confidential: Adventures in the Culinary Underbelly |
Anthony Bourdain |
2000 |
4.07 |
−0.775 |
|
951 |
Red Queen (Red Queen, #1) |
Victoria Aveyard |
2015 |
4.06 |
−0.775 |
|
952 |
The Immortal Life of Henrietta Lacks |
Rebecca Skloot |
2010 |
4.06 |
−0.781 |
|
953 |
Matched (Matched, #1) |
Ally Condie |
2010 |
3.67 |
−0.783 |
|
954 |
A Room with a View |
E. M. Forster |
1908 |
3.91 |
−0.785 |
|
955 |
Wizard’s First Rule (Sword of Truth, #1) |
Terry Goodkind |
1994 |
4.13 |
−0.785 |
|
956 |
And the Mountains Echoed |
Khaled Hosseini |
2012 |
4.05 |
−0.785 |
|
957 |
Grey (Fifty Shades as Told by Christian, #1) |
E. L. James |
2015 |
3.78 |
−0.785 |
|
958 |
The Guernsey Literary and Potato Peel Pie Society |
Mary Ann Shaffer |
2008 |
4.16 |
−0.787 |
|
959 |
The Prince |
Niccolò Machiavelli |
1513 |
3.81 |
−0.799 |
|
960 |
Wicked Lovely (Wicked Lovely, #1) |
Melissa Marr |
2007 |
3.69 |
−0.799 |
|
961 |
Hotel on the Corner of Bitter and Sweet |
Jamie Ford |
2009 |
4.01 |
−0.807 |
|
962 |
The Westing Game |
Ellen Raskin |
1978 |
4.02 |
−0.807 |
|
963 |
A Clockwork Orange |
Anthony Burgess |
1962 |
3.99 |
−0.814 |
|
964 |
A Farewell to Arms |
Ernest Hemingway |
1929 |
3.80 |
−0.815 |
|
965 |
The Virgin Suicides |
Jeffrey Eugenides |
1993 |
3.84 |
−0.816 |
|
966 |
The Clan of the Cave Bear (Earth’s Children, #1) |
Jean M. Auel |
1980 |
4.04 |
−0.826 |
|
967 |
Anansi Boys |
Neil Gaiman |
2005 |
4.02 |
−0.829 |
|
968 |
Interview with the Vampire (The Vampire Chronicles, #1) |
Anne Rice |
1976 |
3.99 |
−0.832 |
|
969 |
The Ultimate Hitchhiker’s Guide to the Galaxy (Hitchhiker’s Guide to the Galaxy, #1–5) |
Douglas Adams |
1996 |
4.38 |
−0.835 |
|
970 |
Fifty Shades of Grey (Fifty Shades, #1) |
E. L. James |
2011 |
3.67 |
−0.836 |
|
971 |
The House of the Spirits |
Isabel Allende |
1982 |
4.22 |
−0.837 |
|
972 |
Les Misérables |
Victor Hugo |
1862 |
4.16 |
−0.839 |
|
973 |
Life of Pi |
Yann Martel |
2001 |
3.90 |
−0.840 |
|
974 |
A Tree Grows in Brooklyn |
Betty Smith |
1943 |
4.26 |
−0.844 |
|
975 |
Mr. Mercedes (Bill Hodges Trilogy, #1) |
Stephen King |
2014 |
3.96 |
−0.846 |
|
976 |
The Nightingale |
Kristin Hannah |
2015 |
4.57 |
−0.849 |
|
977 |
Inferno (Robert Langdon, #4) |
Dan Brown |
2013 |
3.84 |
−0.850 |
|
978 |
The Red Pyramid (The Kane Chronicles, #1) |
Rick Riordan |
2010 |
4.08 |
−0.850 |
|
979 |
Robinson Crusoe |
Daniel Defoe |
1719 |
3.67 |
−0.852 |
|
980 |
The Sun Is Also a Star |
Nicola Yoon |
2016 |
4.09 |
−0.854 |
|
981 |
Eat, Pray, Love |
Elizabeth Gilbert |
2006 |
3.55 |
−0.855 |
|
982 |
The No. 1 Ladies’ Detective Agency (No. 1 Ladies’ Detective Agency #1) |
Alexander McCall Smith |
1998 |
3.78 |
−0.857 |
|
983 |
The Host (The Host, #1) |
Stephenie Meyer |
2008 |
3.84 |
−0.858 |
|
984 |
A Million Little Pieces |
James Frey |
2003 |
3.64 |
−0.863 |
|
985 |
Norwegian Wood |
Haruki Murakami |
1987 |
4.03 |
−0.864 |
|
986 |
Choke |
Chuck Palahniuk |
2001 |
3.69 |
−0.872 |
|
987 |
After You (Me Before You, #2) |
Jojo Moyes |
2015 |
3.72 |
−0.874 |
|
988 |
Pretty Girls |
Karin Slaughter |
2015 |
3.99 |
−0.876 |
|
989 |
Becoming |
Michelle Obama |
2018 |
4.58 |
−0.884 |
|
990 |
I Am Number Four (Lorien Legacies, #1) |
Pittacus Lore |
2010 |
3.94 |
−0.885 |
|
991 |
Turtles All the Way Down |
John Green |
2017 |
3.98 |
−0.885 |
|
992 |
The Unbecoming of Mara Dyer (Mara Dyer, #1) |
Michelle Hodkin |
2011 |
4.07 |
−0.886 |
|
993 |
Will Grayson, Will Grayson |
John Green |
2010 |
3.79 |
−0.887 |
|
994 |
Beneath a Scarlet Sky |
Mark T. Sullivan |
2017 |
4.42 |
−0.892 |
|
995 |
The Road |
Cormac McCarthy |
2006 |
3.96 |
−0.895 |
|
996 |
The Hate U Give |
Angie Thomas |
2017 |
4.52 |
−0.897 |
|
997 |
Foundation (Foundation #1) |
Isaac Asimov |
1951 |
4.16 |
−0.901 |
|
998 |
Doctor Sleep (The Shining, #2) |
Stephen King |
2013 |
4.12 |
−0.903 |
|
999 |
Veronika Decides to Die |
Paulo Coelho |
1998 |
3.70 |
−0.904 |
|
1000 |
Allegiant (Divergent, #3) |
Veronica Roth |
2013 |
3.63 |
−0.906 |
|
1001 |
Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic Future |
Ashlee Vance |
2015 |
4.23 |
−0.909 |
|
1002 |
The Kitchen House |
Kathleen Grissom |
2010 |
4.19 |
−0.917 |
|
1003 |
The Republic |
Plato |
−380 |
3.93 |
−0.920 |
|
1004 |
The Graveyard Book |
Neil Gaiman |
2008 |
4.13 |
−0.927 |
|
1005 |
The World According to Garp |
John Irving |
1978 |
4.08 |
−0.929 |
|
1006 |
Aristotle and Dante Discover the Secrets of the Universe |
Benjamin Alire Sáenz |
2012 |
4.34 |
−0.931 |
|
1007 |
Their Eyes Were Watching God |
Zora Neale Hurston |
1937 |
3.91 |
−0.931 |
|
1008 |
Before We Were Yours |
Lisa Wingate |
2017 |
4.37 |
−0.931 |
|
1009 |
The Storyteller |
Jodi Picoult |
2013 |
4.28 |
−0.935 |
|
1010 |
A Dance with Dragons (A Song of Ice and Fire, #5) |
George R. R. Martin |
2011 |
4.33 |
−0.935 |
|
1011 |
The Picture of Dorian Gray |
Oscar Wilde |
1890 |
4.07 |
−0.942 |
|
1012 |
A Court of Thorns and Roses (A Court of Thorns and Roses, #1) |
Sarah J. Maas |
2015 |
4.25 |
−0.944 |
|
1013 |
The Hunchback of Notre-Dame |
Victor Hugo |
1831 |
3.99 |
−0.945 |
|
1014 |
Little Fires Everywhere |
Celeste Ng |
2017 |
4.11 |
−0.946 |
|
1015 |
Firefly Lane (Firefly Lane, #1) |
Kristin Hannah |
2008 |
4.07 |
−0.947 |
|
1016 |
It |
Stephen King |
1986 |
4.24 |
−0.951 |
|
1017 |
Dreams from My Father: A Story of Race and Inheritance |
Barack Obama |
1995 |
3.87 |
−0.953 |
|
1018 |
Throne of Glass (Throne of Glass, #1) |
Sarah J. Maas |
2012 |
4.22 |
−0.955 |
|
1019 |
Before I Fall |
Lauren Oliver |
2010 |
3.91 |
−0.955 |
|
1020 |
Great Expectations |
Charles Dickens |
1861 |
3.77 |
−0.955 |
|
1021 |
A Clash of Kings (A Song of Ice and Fire, #2) |
George R. R. Martin |
1998 |
4.41 |
−0.957 |
|
1022 |
The Good Girl |
Mary Kubica |
2014 |
3.81 |
−0.957 |
|
1023 |
The Great Alone |
Kristin Hannah |
2018 |
4.32 |
−0.960 |
|
1024 |
Wallbanger (Cocktail, #1) |
Alice Clayton |
2012 |
4.07 |
−0.971 |
|
1025 |
The Sun Also Rises |
Ernest Hemingway |
1926 |
3.82 |
−0.974 |
|
1026 |
Assassin’s Apprentice (Farseer Trilogy, #1) |
Robin Hobb |
1995 |
4.15 |
−0.977 |
|
1027 |
Wuthering Heights |
Emily Brontë |
1847 |
3.85 |
−0.979 |
|
1028 |
The Complete Sherlock Holmes (Sherlock Holmes) |
Arthur Conan Doyle |
1927 |
4.51 |
−0.982 |
|
1029 |
The Silkworm (Cormoran Strike, #2) |
Robert Galbraith (Pseudonym) |
2014 |
4.04 |
−0.984 |
|
1030 |
The War of the Worlds |
H. G. Wells |
1897 |
3.82 |
−0.984 |
|
1031 |
Hyperbole and a Half: Unfortunate Situations, Flawed Coping Mechanisms, Mayhem, and Other Things That Happened |
Allie Brosh |
2013 |
4.18 |
−0.986 |
|
1032 |
The Adventures of Sherlock Holmes (Sherlock Holmes, #3) |
Arthur Conan Doyle |
1892 |
4.31 |
−0.986 |
|
1033 |
Specials (Uglies, #3) |
Scott Westerfeld |
2006 |
3.77 |
−0.991 |
|
1034 |
Running with Scissors |
Augusten Burroughs |
2002 |
3.72 |
−0.994 |
|
1035 |
Breakfast of Champions |
Kurt Vonnegut |
1973 |
4.07 |
−1.000 |
|
1036 |
Room |
Emma Donoghue |
2010 |
4.05 |
−1.005 |
|
1037 |
The Woman in the Window |
A. J. Finn |
2018 |
3.93 |
−1.016 |
|
1038 |
Is Everyone Hanging Out Without Me? (And Other Concerns) |
Mindy Kaling |
2011 |
3.85 |
−1.026 |
|
1039 |
In Cold Blood |
Truman Capote |
1965 |
4.07 |
−1.028 |
|
1040 |
The Angel Experiment (Maximum Ride, #1) |
James Patterson |
2005 |
4.08 |
−1.028 |
|
1041 |
Cold Mountain |
Charles Frazier |
1997 |
3.85 |
−1.033 |
|
1042 |
When You Are Engulfed in Flames |
David Sedaris |
2008 |
4.06 |
−1.041 |
|
1043 |
The Handmaid’s Tale (The Handmaid’s Tale, #1) |
Margaret Atwood |
1985 |
4.10 |
−1.057 |
|
1044 |
The Iliad |
Homer |
−750 |
3.85 |
−1.058 |
|
1045 |
The Count of Monte Cristo |
Alexandre Dumas |
1844 |
4.24 |
−1.065 |
|
1046 |
Things Fall Apart (The African Trilogy, #1) |
Chinua Achebe |
1959 |
3.65 |
−1.069 |
|
1047 |
Oliver Twist |
Charles Dickens |
1838 |
3.86 |
−1.072 |
|
1048 |
Cell |
Stephen King |
2006 |
3.65 |
−1.072 |
|
1049 |
The Heir (The Selection, #4) |
Kiera Cass |
2015 |
3.81 |
−1.081 |
|
1050 |
Cat’s Cradle |
Kurt Vonnegut |
1963 |
4.16 |
−1.089 |
|
1051 |
The Well of Ascension (Mistborn, #2) |
Brandon Sanderson |
2007 |
4.37 |
−1.090 |
|
1052 |
East of Eden |
John Steinbeck |
1952 |
4.37 |
−1.092 |
|
1053 |
On Writing: A Memoir of the Craft |
Stephen King |
2000 |
4.33 |
−1.092 |
|
1054 |
World Without End (Kingsbridge, #2) |
Ken Follett |
2007 |
4.26 |
−1.093 |
|
1055 |
The Scorch Trials (The Maze Runner, #2) |
James Dashner |
2010 |
3.92 |
−1.098 |
|
1056 |
The Invention of Wings |
Sue Monk Kidd |
2014 |
4.24 |
−1.103 |
|
1057 |
The Maze Runner (The Maze Runner, #1) |
James Dashner |
2009 |
4.02 |
−1.109 |
|
1058 |
Fear and Loathing in Las Vegas |
Hunter S. Thompson |
1972 |
4.08 |
−1.109 |
|
1059 |
A Tale of Two Cities |
Charles Dickens |
1859 |
3.83 |
−1.110 |
|
1060 |
The Art of War |
Sun Tzu |
−500 |
3.97 |
−1.114 |
|
1061 |
The Martian Chronicles |
Ray Bradbury |
1949 |
4.14 |
−1.116 |
|
1062 |
The Things They Carried |
Tim O’Brien |
1990 |
4.13 |
−1.116 |
|
1063 |
Speaker for the Dead (Ender’s Saga, #2) |
Orson Scott Card |
1986 |
4.07 |
−1.121 |
|
1064 |
Dark Lover (Black Dagger Brotherhood, #1) |
J. R. Ward |
2005 |
4.20 |
−1.122 |
|
1065 |
The Secret (The Secret, #1) |
Rhonda Byrne |
2006 |
3.66 |
−1.123 |
|
1066 |
Shadow and Bone (The Shadow and Bone Trilogy, #1) |
Leigh Bardugo |
2012 |
4.03 |
−1.137 |
|
1067 |
Fallen (Fallen, #1) |
Lauren Kate |
2009 |
3.73 |
−1.140 |
|
1068 |
Artemis Fowl (Artemis Fowl #1) |
Eoin Colfer |
2001 |
3.84 |
−1.145 |
|
1069 |
The Bell Jar |
Sylvia Plath |
1963 |
4.00 |
−1.148 |
|
1070 |
Stardust |
Neil Gaiman |
1998 |
4.08 |
−1.150 |
|
1071 |
The Rosie Project (Don Tillman, #1) |
Graeme Simsion |
2013 |
4.02 |
−1.151 |
|
1072 |
Perfume: The Story of a Murderer |
Patrick Süskind |
1985 |
4.02 |
−1.157 |
|
1073 |
Fangirl |
Rainbow Rowell |
2013 |
4.08 |
−1.164 |
|
1074 |
Bossypants |
Tina Fey |
2011 |
3.95 |
−1.171 |
|
1075 |
Killing Floor (Jack Reacher, #1) |
Lee Child |
1997 |
4.05 |
−1.171 |
|
1076 |
The Phantom Tollbooth |
Norton Juster |
1961 |
4.21 |
−1.172 |
|
1077 |
Emma |
Jane Austen |
1815 |
4.00 |
−1.189 |
|
1078 |
The Red Tent |
Anita Diamant |
1997 |
4.17 |
−1.189 |
|
1079 |
Origin (Robert Langdon, #5) |
Dan Brown |
2015 |
3.85 |
−1.191 |
|
1080 |
Legend (Legend, #1) |
Marie Lu |
2011 |
4.18 |
−1.191 |
|
1081 |
A Walk in the Woods: Rediscovering America on the Appalachian Trail |
Bill Bryson |
1997 |
4.06 |
−1.216 |
|
1082 |
Behind Closed Doors |
B. A. Paris |
2016 |
3.95 |
−1.218 |
|
1083 |
The Lord of the Rings (The Lord of the Rings, #1–3) |
J. R. R. Tolkien |
1955 |
4.49 |
−1.223 |
|
1084 |
Me Talk Pretty One Day |
David Sedaris |
2000 |
3.98 |
−1.226 |
|
1085 |
The Time Traveler’s Wife |
Audrey Niffenegger |
2003 |
3.97 |
−1.234 |
|
1086 |
The Wise Man’s Fear (The Kingkiller Chronicle, #2) |
Patrick Rothfuss |
2011 |
4.57 |
−1.236 |
|
1087 |
We Were Liars |
E. Lockhart |
2014 |
3.84 |
−1.238 |
|
1088 |
City of Bones (The Mortal Instruments, #1) |
Cassandra Clare |
2007 |
4.11 |
−1.239 |
|
1089 |
Eleanor & Park |
Rainbow Rowell |
2012 |
4.08 |
−1.240 |
|
1090 |
The Poisonwood Bible |
Barbara Kingsolver |
1998 |
4.05 |
−1.243 |
|
1091 |
The City of Ember |
Jeanne DuPrau |
2003 |
3.86 |
−1.247 |
|
1092 |
Rebecca |
Daphne du Maurier |
1938 |
4.22 |
−1.251 |
|
1093 |
Insurgent (Divergent, #2) |
Veronica Roth |
2012 |
4.04 |
−1.254 |
|
1094 |
Harry Potter and the Cursed Child: Parts One and Two (Harry Potter, #8) |
John Tiffany (Adaptation) |
2016 |
3.66 |
−1.254 |
|
1095 |
Dracula |
Bram Stoker |
1897 |
3.99 |
−1.266 |
|
1096 |
Eldest (The Inheritance Cycle, #2) |
Christopher Paolini |
2005 |
3.98 |
−1.271 |
|
1097 |
Blink: The Power of Thinking Without Thinking |
Malcolm Gladwell |
2005 |
3.92 |
−1.272 |
|
1098 |
The Art of Racing in the Rain |
Garth Stein |
2008 |
4.21 |
−1.285 |
|
1099 |
The Memory Keeper’s Daughter |
Kim Edwards |
2005 |
3.66 |
−1.293 |
|
1100 |
Educated |
Tara Westover |
2018 |
4.48 |
−1.293 |
|
1101 |
The Hitchhiker’s Guide to the Galaxy (Hitchhiker’s Guide to the Galaxy, #1) |
Douglas Adams |
1979 |
4.22 |
−1.297 |
|
1102 |
Cinder (The Lunar Chronicles, #1) |
Marissa Meyer |
2012 |
4.15 |
−1.298 |
|
1103 |
To All the Boys I’ve Loved Before (To All the Boys I’ve Loved Before, #1) |
Jenny Han |
2014 |
4.16 |
−1.299 |
|
1104 |
The Screwtape Letters |
C.S. Lewis |
1942 |
4.22 |
−1.301 |
|
1105 |
Where the Crawdads Sing |
Delia Owens |
2018 |
4.50 |
−1.302 |
|
1106 |
Mansfield Park |
Jane Austen |
1814 |
3.85 |
−1.315 |
|
1107 |
How to Win Friends and Influence People |
Dale Carnegie |
1936 |
4.19 |
−1.333 |
|
1108 |
Do Androids Dream of Electric Sheep? |
Philip K. Dick |
1968 |
4.08 |
−1.338 |
|
1109 |
Northanger Abbey |
Jane Austen |
1818 |
3.81 |
−1.339 |
|
1110 |
A Feast for Crows (A Song of Ice and Fire, #4) |
George R. R. Martin |
2005 |
4.13 |
−1.339 |
|
1111 |
The Tattooist of Auschwitz (The Tattooist of Auschwitz, #1) |
Heather Morris |
2018 |
4.27 |
−1.344 |
|
1112 |
Under the Tuscan Sun |
Frances Mayes |
1996 |
3.75 |
−1.352 |
|
1113 |
The Husband’s Secret |
Liane Moriarty |
2013 |
3.94 |
−1.360 |
|
1114 |
Evermore (The Immortals, #1) |
Alyson Noel |
2009 |
3.59 |
−1.362 |
|
1115 |
Milk and Honey |
Rupi Kaur |
2014 |
4.11 |
−1.367 |
|
1116 |
Brisingr (The Inheritance Cycle, #3) |
Christopher Paolini |
2008 |
4.05 |
−1.368 |
|
1117 |
Unbroken: A World War II Story of Survival, Resilience and Redemption |
Laura Hillenbrand |
2010 |
4.38 |
−1.371 |
|
1118 |
Dark Places |
Gillian Flynn |
2009 |
3.93 |
−1.377 |
|
1119 |
The Girl with the Dragon Tattoo (Millennium, #1) |
Stieg Larsson |
2005 |
4.13 |
−1.403 |
|
1120 |
She’s Come Undone |
Wally Lamb |
1992 |
3.87 |
−1.404 |
|
1121 |
Slaughterhouse-Five |
Kurt Vonnegut |
1969 |
4.07 |
−1.406 |
|
1122 |
The Amber Spyglass (His Dark Materials, #3) |
Philip Pullman |
2000 |
4.09 |
−1.408 |
|
1123 |
The Scarlet Letter |
Nathaniel Hawthorne |
1850 |
3.40 |
−1.415 |
|
1124 |
Gone Girl |
Gillian Flynn |
2012 |
4.06 |
−1.419 |
|
1125 |
The Bourne Identity (Jason Bourne, #1) |
Robert Ludlum |
1980 |
4.01 |
−1.424 |
|
1126 |
One Flew Over the Cuckoo’s Nest |
Ken Kesey |
1962 |
4.19 |
−1.425 |
|
1127 |
I, Robot (Robot, #0.1) |
Isaac Asimov |
1950 |
4.19 |
−1.426 |
|
1128 |
A Wrinkle in Time (Time Quintet, #1) |
Madeleine L’Engle |
1962 |
4.00 |
−1.437 |
|
1129 |
The Girl on the Train |
Paula Hawkins |
2015 |
3.91 |
−1.444 |
|
1130 |
Crown of Midnight (Throne of Glass, #2) |
Sarah J. Maas |
2013 |
4.45 |
−1.448 |
|
1131 |
The Grapes of Wrath |
John Steinbeck |
1939 |
3.96 |
−1.449 |
|
1132 |
Mere Christianity |
C.S. Lewis |
1952 |
4.32 |
−1.451 |
|
1133 |
Beautiful Disaster (Beautiful, #1) |
Jamie McGuire |
2011 |
4.12 |
−1.467 |
|
1134 |
Murder on the Orient Express (Hercule Poirot, #10) |
Agatha Christie |
1934 |
4.17 |
−1.477 |
|
1135 |
Paper Towns |
John Green |
2008 |
3.83 |
−1.500 |
|
1136 |
Vampire Academy (Vampire Academy, #1) |
Richelle Mead |
2007 |
4.13 |
−1.502 |
|
1137 |
Angela’s Ashes (Frank McCourt, #1) |
Frank McCourt |
1996 |
4.10 |
−1.509 |
|
1138 |
The Girl Who Kicked the Hornet’s Nest (Millennium, #3) |
Stieg Larsson |
2007 |
4.22 |
−1.521 |
|
1139 |
Steve Jobs |
Walter Isaacson |
2011 |
4.13 |
−1.526 |
|
1140 |
I Know This Much Is True |
Wally Lamb |
1998 |
4.18 |
−1.526 |
|
1141 |
Dead Until Dark (Sookie Stackhouse, #1) |
Charlaine Harris |
2001 |
3.96 |
−1.529 |
|
1142 |
I Know Why the Caged Bird Sings (Maya Angelou’s Autobiography, #1) |
Maya Angelou |
1969 |
4.23 |
−1.529 |
|
1143 |
Treasure Island |
Robert Louis Stevenson |
1882 |
3.83 |
−1.530 |
|
1144 |
Thirteen Reasons Why |
Jay Asher |
2007 |
3.95 |
−1.533 |
|
1145 |
Looking for Alaska |
John Green |
2005 |
4.04 |
−1.534 |
|
1146 |
Fight Club |
Chuck Palahniuk |
1996 |
4.19 |
−1.541 |
|
1147 |
Scarlet (The Lunar Chronicles, #2) |
Marissa Meyer |
2013 |
4.29 |
−1.543 |
|
1148 |
Fifty Shades Darker (Fifty Shades, #2) |
E. L. James |
2011 |
3.85 |
−1.545 |
|
1149 |
Man’s Search for Meaning |
Viktor E. Frankl |
1946 |
4.36 |
−1.551 |
|
1150 |
Frankenstein |
Mary Wollstonecraft Shelley |
1818 |
3.79 |
−1.559 |
|
1151 |
The Lost Symbol (Robert Langdon, #3) |
Dan Brown |
2009 |
3.70 |
−1.564 |
|
1152 |
Marked (House of Night, #1) |
P. C. Cast |
2007 |
3.80 |
−1.568 |
|
1153 |
Anna and the French Kiss (Anna and the French Kiss, #1) |
Stephanie Perkins |
2010 |
4.02 |
−1.569 |
|
1154 |
Sarah’s Key |
Tatiana de Rosnay |
2006 |
4.16 |
−1.572 |
|
1155 |
Big Little Lies |
Liane Moriarty |
2014 |
4.26 |
−1.573 |
|
1156 |
The Death Cure (The Maze Runner, #3) |
James Dashner |
2011 |
3.77 |
−1.584 |
|
1157 |
Eragon (The Inheritance Cycle, #1) |
Christopher Paolini |
2002 |
3.89 |
−1.585 |
|
1158 |
The Thorn Birds |
Colleen McCullough |
1977 |
4.23 |
−1.587 |
|
1159 |
If I Stay (If I Stay, #1) |
Gayle Forman |
2009 |
3.95 |
−1.587 |
|
1160 |
Hush, Hush (Hush, Hush, #1) |
Becca Fitzpatrick |
2009 |
3.98 |
−1.591 |
|
1161 |
Brave New World |
Aldous Huxley |
1932 |
3.98 |
−1.596 |
|
1162 |
A Storm of Swords (A Song of Ice and Fire, #3) |
George R. R. Martin |
2000 |
4.54 |
−1.599 |
|
1163 |
What Alice Forgot |
Liane Moriarty |
2009 |
4.08 |
−1.606 |
|
1164 |
Watchmen |
Alan Moore |
1987 |
4.36 |
−1.615 |
|
1165 |
Fifty Shades Freed (Fifty Shades, #3) |
E. L. James |
2012 |
3.86 |
−1.616 |
|
1166 |
Snow Flower and the Secret Fan |
Lisa See |
2005 |
4.07 |
−1.616 |
|
1167 |
Water for Elephants |
Sara Gruen |
2006 |
4.08 |
−1.621 |
|
1168 |
The Perks of Being a Wallflower |
Stephen Chbosky |
1999 |
4.20 |
−1.623 |
|
1169 |
Siddhartha |
Hermann Hesse |
1922 |
4.02 |
−1.624 |
|
1170 |
Clockwork Angel (The Infernal Devices, #1) |
Cassandra Clare |
2010 |
4.33 |
−1.625 |
|
1171 |
Persuasion |
Jane Austen |
1818 |
4.14 |
−1.629 |
|
1172 |
The Golden Compass (His Dark Materials, #1) |
Philip Pullman |
1995 |
3.97 |
−1.655 |
|
1173 |
Outliers: The Story of Success |
Malcolm Gladwell |
2008 |
4.14 |
−1.658 |
|
1174 |
Freakonomics: A Rogue Economist Explores the Hidden Side of Everything |
Steven D. Levitt |
2005 |
3.96 |
−1.676 |
|
1175 |
Alice’s Adventures in Wonderland & Through the Looking-Glass |
Lewis Carroll |
1871 |
4.07 |
−1.686 |
|
1176 |
Pride and Prejudice |
Jane Austen |
1813 |
4.26 |
−1.705 |
|
1177 |
The Tipping Point: How Little Things Can Make a Big Difference |
Malcolm Gladwell |
2000 |
3.96 |
−1.711 |
|
1178 |
The Alchemist |
Paulo Coelho |
1988 |
3.86 |
−1.721 |
|
1179 |
The Other Boleyn Girl (The Plantagenet and Tudor Novels, #9) |
Philippa Gregory |
2001 |
4.06 |
−1.721 |
|
1180 |
The Princess Bride |
William Goldman |
1973 |
4.26 |
−1.726 |
|
1181 |
The Two Towers (The Lord of the Rings, #2) |
J. R. R. Tolkien |
1954 |
4.44 |
−1.733 |
|
1182 |
Sharp Objects |
Gillian Flynn |
2006 |
3.96 |
−1.734 |
|
1183 |
Little Women |
Louisa May Alcott |
1869 |
4.06 |
−1.747 |
|
1184 |
The Chronicles of Narnia (Chronicles of Narnia, #1–7) |
C.S. Lewis |
1956 |
4.26 |
−1.754 |
|
1185 |
The Girl Who Played with Fire (Millennium, #2) |
Stieg Larsson |
2006 |
4.24 |
−1.769 |
|
1186 |
The Bad Beginning (A Series of Unfortunate Events, #1) |
Lemony Snicket |
1999 |
3.94 |
−1.774 |
|
1187 |
The Lovely Bones |
Alice Sebold |
2002 |
3.80 |
−1.775 |
|
1188 |
The Glass Castle |
Jeannette Walls |
2005 |
4.27 |
−1.779 |
|
1189 |
The Curious Incident of the Dog in the Night-Time |
Mark Haddon |
2003 |
3.87 |
−1.790 |
|
1190 |
City of Lost Souls (The Mortal Instruments, #5) |
Cassandra Clare |
2012 |
4.28 |
−1.804 |
|
1191 |
Ender’s Game (Ender’s Saga, #1) |
Orson Scott Card |
1985 |
4.30 |
−1.806 |
|
1192 |
1984 |
George Orwell |
1949 |
4.18 |
−1.831 |
|
1193 |
Fahrenheit 451 |
Ray Bradbury |
1953 |
3.98 |
−1.850 |
|
1194 |
Me Before You (Me Before You, #1) |
Jojo Moyes |
2012 |
4.26 |
−1.872 |
|
1195 |
The Color Purple |
Alice Walker |
1982 |
4.20 |
−1.903 |
|
1196 |
The Fellowship of the Ring (The Lord of the Rings, #1) |
J. R. R. Tolkien |
1954 |
4.36 |
−1.910 |
|
1197 |
Jane Eyre |
Charlotte Brontë |
1847 |
4.12 |
−1.920 |
|
1198 |
Wonder |
R. J. Palacio |
2012 |
4.45 |
−1.929 |
|
1199 |
Sense and Sensibility |
Jane Austen |
1811 |
4.07 |
−1.932 |
|
1200 |
The Hobbit, or There and Back Again |
J. R. R. Tolkien |
1937 |
4.27 |
−1.936 |
|
1201 |
Anne of Green Gables (Anne of Green Gables, #1) |
L. M. Montgomery |
1908 |
4.25 |
−1.947 |
|
1202 |
The Selection (The Selection, #1) |
Kiera Cass |
2012 |
4.14 |
−1.976 |
|
1203 |
The Odyssey |
Homer |
−700 |
3.75 |
−1.979 |
|
1204 |
The Catcher in the Rye |
J. D. Salinger |
1951 |
3.80 |
−1.992 |
|
1205 |
One for the Money (Stephanie Plum, #1) |
Janet Evanovich |
1994 |
4.04 |
−2.013 |
|
1206 |
City of Ashes (The Mortal Instruments, #2) |
Cassandra Clare |
2008 |
4.19 |
−2.038 |
|
1207 |
The Shining (The Shining, #1) |
Stephen King |
1977 |
4.21 |
−2.043 |
|
1208 |
Divergent (Divergent, #1) |
Veronica Roth |
2011 |
4.20 |
−2.050 |
|
1209 |
Gone with the Wind |
Margaret Mitchell |
1936 |
4.29 |
−2.053 |
|
1210 |
The Adventures of Tom Sawyer |
Mark Twain |
1875 |
3.91 |
−2.056 |
|
1211 |
Lord of the Flies |
William Golding |
1954 |
3.68 |
−2.061 |
|
1212 |
The Adventures of Huckleberry Finn |
Mark Twain |
1884 |
3.81 |
−2.097 |
|
1213 |
Confessions of a Shopaholic (Shopaholic, #1) |
Sophie Kinsella |
2000 |
3.64 |
−2.098 |
|
1214 |
Digital Fortress |
Dan Brown |
1998 |
3.64 |
−2.148 |
|
1215 |
The Devil Wears Prada (The Devil Wears Prada, #1) |
Lauren Weisberger |
2003 |
3.73 |
−2.155 |
|
1216 |
Into the Wild |
Jon Krakauer |
1996 |
3.97 |
−2.166 |
|
1217 |
Breaking Dawn (Twilight, #4) |
Stephenie Meyer |
2008 |
3.69 |
−2.180 |
|
1218 |
The Lost Hero (The Heroes of Olympus, #1) |
Rick Riordan |
2010 |
4.35 |
−2.218 |
|
1219 |
The Kite Runner |
Khaled Hosseini |
2003 |
4.29 |
−2.222 |
|
1220 |
The Return of the King (The Lord of the Rings, #3) |
J. R. R. Tolkien |
1955 |
4.53 |
−2.257 |
|
1221 |
The Old Man and the Sea |
Ernest Hemingway |
1952 |
3.76 |
−2.269 |
|
1222 |
The Stranger |
Albert Camus |
1942 |
3.97 |
−2.270 |
|
1223 |
The Da Vinci Code (Robert Langdon, #2) |
Dan Brown |
2003 |
3.83 |
−2.273 |
|
1224 |
The Help |
Kathryn Stockett |
2009 |
4.47 |
−2.276 |
|
1225 |
Mockingjay (The Hunger Games, #3) |
Suzanne Collins |
2010 |
4.03 |
−2.293 |
|
1226 |
The Lightning Thief (Percy Jackson and the Olympians, #1) |
Rick Riordan |
2005 |
4.25 |
−2.316 |
|
1227 |
Tuesdays with Morrie |
Mitch Albom |
1997 |
4.10 |
−2.324 |
|
1228 |
A Thousand Splendid Suns |
Khaled Hosseini |
2007 |
4.36 |
−2.417 |
|
1229 |
Twilight (Twilight, #1) |
Stephenie Meyer |
2005 |
3.59 |
−2.421 |
|
1230 |
Bridget Jones’s Diary (Bridget Jones, #1) |
Helen Fielding |
1996 |
3.77 |
−2.437 |
|
1231 |
The Great Gatsby |
F. Scott Fitzgerald |
1925 |
3.91 |
−2.443 |
|
1232 |
Memoirs of a Geisha |
Arthur Golden |
1997 |
4.11 |
−2.529 |
|
1233 |
The Secret Garden |
Frances Hodgson Burnett |
1910 |
4.13 |
−2.537 |
|
1234 |
The Secret Life of Bees |
Sue Monk Kidd |
2001 |
4.04 |
−2.554 |
|
1235 |
My Sister’s Keeper |
Jodi Picoult |
2004 |
4.07 |
−2.596 |
|
1236 |
The Fault in Our Stars |
John Green |
2012 |
4.23 |
−2.610 |
|
1237 |
The Diary of a Young Girl |
Anne Frank |
1947 |
4.13 |
−2.651 |
|
1238 |
The Notebook (The Notebook, #1) |
Nicholas Sparks |
1996 |
4.09 |
−2.811 |
|
1239 |
Catching Fire (The Hunger Games, #2) |
Suzanne Collins |
2009 |
4.29 |
−2.866 |
|
1240 |
New Moon (Twilight, #2) |
Stephenie Meyer |
2006 |
3.53 |
−2.867 |
|
1241 |
Eclipse (Twilight, #3) |
Stephenie Meyer |
2007 |
3.69 |
−2.880 |
|
1242 |
To Kill a Mockingbird (To Kill a Mockingbird, #1) |
Harper Lee |
1960 |
4.27 |
−2.957 |
|
1243 |
Angels & Demons (Robert Langdon, #1) |
Dan Brown |
2000 |
3.89 |
−2.970 |
|
1244 |
The Giver (The Giver, #1) |
Lois Lowry |
1993 |
4.13 |
−3.061 |
|
1245 |
Harry Potter and the Order of the Phoenix (Harry Potter, #5) |
J. K. Rowling |
2003 |
4.49 |
−3.414 |
|
1246 |
The Hunger Games (The Hunger Games, #1) |
Suzanne Collins |
2008 |
4.33 |
−3.432 |
|
1247 |
Animal Farm |
George Orwell |
1945 |
3.92 |
−3.466 |
|
1248 |
Harry Potter and the Chamber of Secrets (Harry Potter, #2) |
J. K. Rowling |
1998 |
4.41 |
−3.664 |
|
1249 |
Harry Potter and the Sorcerer’s Stone (Harry Potter, #1) |
J. K. Rowling |
1997 |
4.47 |
−3.737 |
Modeling With Covariates
‘Controlling for’ other variables. What else can we do? The scrape includes some basic metadata, so we can fit a model with them as covariates and get out new coefficients for each book as before—it’s all there, just toss some more variables into the formula.
“Controlling For”?
But it’s worth taking a moment to think about what it would mean to go beyond estimating proportions to fitting a model with covariates like Abandoned ~ Author + Year + Rating + Title.
If we just wanted to rank titles, we have already done that. If you want to know which title has the most readers who then go on to label it ‘abandoned’, there’s not much you can do aside from correcting for sampling error; count the numbers, divide, and sort. The ranking is what it is. Just look at it above! If we add in additional covariates, the meaning of the coefficient numbers change, even if the names like Title do not. So what would the number mean for Title if we added in those other variables?
What does ‘controlling for’ mean? Well, we are looking at an algorithm which tries to minimize its prediction error, by combining multiple variables into a prediction, and the final coefficient number is the marginal effect conditional on the others; this reduces to just ranking for titles alone when there are no others, but when we add the others in, what our new ranking by title coefficient will translate to is something like “what titles were surprisingly likely/unlikely to be abandoned after factoring in how often books published this year, by that author, with those average ratings?”
Perhaps something like “unexpectedly abandoned given what we’d predict”? So Rowling might have a low abandonment rate in general (since the Harry Potter books are so sticky) and her Casual Vacancy rated highly with a minor penalty for being a recently-published book, but then her Casual Vacancy is unexpectedly frequently abandoned (because her legions of fans discover it is really not what they expected nor hoped for), and so its marginal coefficient is extremely high (even as its concrete, absolute, raw abandonment rate is low); this reflects that Casual Vacancy is quite anomalous among J. K. Rowling’s book (which it is), and not necessarily that it is a ‘bad’ book. On the other hand, another book might be by an obscure struggling author with high abandonment rates and rated mediocrely, but is a bit more compelling than expected for such a mediocrity, and so somewhat surprisingly not abandoned too often, and it’ll get ranked quite low; not because it is necessarily better in any way than Casual Vacancy but simply because it is anomalous (in a good way) for its covariates. (If this is confusing, don’t feel bad; think of all the researchers who casually “control for education & SES” or “control for BMI & self-reported diet” and things like that.)
Fitting
Flexibly modeling the covariates with splines. Anyway! With those caveats in mind, let’s fit a baroque model. The binomial & prior & Title are all as before. Author must be treated like Title, as a random effects, because most authors are represented only once and are uninformative. Rating could be treated as just a regular additive variable, but ratings websites tend to have odd distributions of Likert scales, giving ‘J-shaped’ ratings, so I will instead exploit brms’s fancy spline feature to let ratings be modeled as some sort of smooth curve like a quadratic curve, or if no curves turn out to be justified by the data, it’ll fall back to a regular old line/additive variable. Similarly, for Year.percentile: we could treat it as a regular additive variable, but there’s no good reason to think the relationship between publication year & abandonment is linear, so we’ll let the spline figure it out. Finally, because the Author adds in 835 levels, and we have 2 new spline variables, this model will be substantially harder to fit to convergence, and will need to run for much longer; I ran it overnight on my AMD Threadripper.
Results:
library(brms)
gb <- brm(Abandoned|trials(Reads) ~ s(Year.percentile) + s(Rating) + (1|Author) + (1|Title),
prior=c(prior(student_t(3,0,1), class="sd", group="Title")), family=binomial, data=gr, chains=30, iter=10000)
gb
## Plot the possibly nonlinear effects of Year/Rating:
marginal_effects(gb)
## Rank books by coefficient:
rgb <- as.data.frame(ranef(gb)$Title)
rgb <- rgb[order(rgb$Estimate.Intercept, decreasing=TRUE),]
head(rgb, n=50)
# Estimate.Intercept Est.Error.Intercept Q2.5.Intercept Q97.5.Intercept
# The Casual Vacancy 1.741876609 0.281476983 1.19001267649 2.30289577
# The Chemist 1.587266441 0.250780279 1.07036085240 2.06884029
# Infinite Jest 1.449431926 0.305558801 0.84629547789 2.04348551
# The Glass Bead Game 1.344537965 0.307995293 0.74003704574 1.95158587
# Theft by Finding: Diaries 1977-2002 1.256870674 0.278197570 0.71059050369 1.80099836
# Gravity’s Rainbow 1.165383010 0.276765364 0.62329326315 1.69933120
# Blood Meridian, or the Evening Redness in the West 1.156560985 0.300233089 0.56855843405 1.74681282
# The Unconsoled 1.095660050 0.287313105 0.53636629027 1.66013999
# Ulysses 1.048522494 0.297841824 0.46765972763 1.63793080
# The Host (The Host, #1) 1.014493672 0.230310063 0.55312203415 1.46168229
# Little, Big 1.012476536 0.448363994 0.12090276666 1.88812074
# The Monstrumologist (The Monstrumologist, #1) 0.988457042 0.355105336 0.27806260365 1.67888621
# Dandelion Wine 0.975103599 0.280633476 0.42510571471 1.52494322
# Quicksilver (The Baroque Cycle, #1) 0.963443821 0.211581044 0.55036451966 1.37662957
# American Gods (American Gods, #1) 0.941171033 0.189903539 0.56971175875 1.30850397
# Bleak House 0.936355723 0.253714907 0.44327736503 1.43655797
# Underworld 0.914496144 0.351775206 0.22000323756 1.60774910
# The Years of Rice and Salt 0.904524932 0.279030303 0.35647211675 1.45513845
# Dhalgren 0.900008923 0.440174328 0.03641451487 1.77439496
# I Am a Cat 0.883040852 0.444432162 0.01238843445 1.76210642
# The Silmarillion (Middle-Earth Universe) 0.861654737 0.247010783 0.38291861129 1.36739720
# Under the Banner of Heaven: A Story of Violent Faith 0.846854948 0.352070453 0.15594807111 1.52565917
# It Can’t Happen Here 0.838745403 0.442892564 -0.01990111314 1.70470050
# A Connecticut Yankee in King Arthur’s Court 0.829646511 0.311586812 0.22130511478 1.43963893
# The Gone-Away World 0.827484825 0.442804235 -0.03667923383 1.69096191
# The Waves 0.820727828 0.285890675 0.26132158033 1.37930626
# Gödel, Escher, Bach: An Eternal Golden Braid 0.816626681 0.437128163 -0.04353752831 1.67540809
# The Book of Disquiet: The Complete Edition 0.809341905 0.441578311 -0.05697029017 1.68484471
# Tender Morsels 0.784969319 0.441631533 -0.10498169773 1.65195379
# Titus Groan (Gormenghast, #1) 0.777043249 0.437648826 -0.08284551560 1.63911701
# 1Q84 0.776369266 0.244856092 0.29537586773 1.25094910
# The Lacuna 0.759484402 0.272298402 0.22625747544 1.28831931
# How to Read a Book: The Classic Guide to Intelligent Reading 0.747111449 0.442452171 -0.11125431192 1.62098481
# Barkskins 0.744000502 0.350624236 0.05288160822 1.43224617
# Bridge of Clay 0.737458793 0.311989629 0.12101640247 1.33840941
# Hild 0.726140501 0.441738217 -0.14334736809 1.57580440
# Harry Potter and the Methods of Rationality 0.725682599 0.443761467 -0.13334026501 1.59044401
# Tender Is the Night 0.725508879 0.307743065 0.12441375362 1.32282931
# Swann's Way (In Search of Lost Time, #1) 0.714724806 0.438353277 -0.14725016691 1.57008149
# Winter's Tale 0.713598568 0.439409311 -0.14859480091 1.57056254
# Perdido Street Station (New Crobuzon, #1) 0.707905742 0.272161167 0.17611553854 1.24237051
# Zone One 0.699312934 0.352195479 0.00570113601 1.39064540
# Villette 0.698141817 0.350428018 0.00946856345 1.38295155
# The Dovekeepers 0.695801671 0.275740994 0.15586008712 1.23671725
# The Golden Notebook 0.695319765 0.439303760 -0.16519743865 1.54446027
# Three Wishes 0.691457342 0.260047140 0.19221973319 1.19709825
# What the Dog Saw and Other Adventures 0.688134160 0.264350162 0.15641277774 1.20366679
# The Stand 0.685553475 0.184846308 0.31377846354 1.04337187
# Cryptonomicon 0.684769185 0.209651679 0.28237060226 1.09454115
# Wolf Hall (Thomas Cromwell #1) 0.683110921 0.352403909 -0.03925119519 1.37325692Interpreting Covariate-Adjusted Rankings
Anomaly explanations: mismatch, fads, slogs, & niche. As warned, the rankings are different from the regular rankings, because it’s estimating something different and not some ‘corrected’ version: these are better thought of as ‘surprisingly often-abandoned given their author/rating’. This could reflect a book being critically overrated, or some phenomena causing serious mismatch between a book & readers. With this in mind, some examples are interesting and make sense:
-
Wrong Audience: The Casual Vacancy shows up again: from what I’ve read about it, I think that is simply due to Harry Potter readers picking it up because J. K. Rowling wrote it, and discovering it was nothing like Harry Potter.
Meyer’s The Chemist may be a similar case—instead of a supernatural romance like her Twilight series, it’s an action-thriller potboiler about an ex-government agent on the run etc.
-
Overrated Prestige: Dhalgren shows up, and I’d consider that one probably due to being critically overrated—Delany was a critical darling because he was ‘black’ and ‘gay’ and ‘transgressive’, but I do not award books points for those traits & was deeply unimpressed by what I read of Dhalgren (& the man himself when I went to his panels at SF conventions), and I appear to not be alone in this.
-
Highly Rated But Difficult: I suspect I Am A Cat & The Silmarillion mix those two explanations: few would read The Silmarillion if that was all Tolkien had written, but it’s also genuinely difficult, despite its rewards.
-
Polarizing: The presence of a few like A Connecticut Yankee in King Arthur’s Court, Harry Potter and the Methods of Rationality, Perdido Street Station, and Cryptonomicon are a little more puzzling: none of those are hard to read, and they aren’t really pushed on school curriculums or radically different from the author’s other work, nor are they critically vaunted (3 of the 4 are much more likely to be harshly insulted by literary professors & critics as problematic).
I suspect for those, it’s neither being critically overrated nor reaching the wrong argument, but being intrinsically polarizing and ‘love it or hate it’—they appeal to a niche of readers. I greatly enjoyed A Connecticut Yankee because I like worldbuilding and development and proto-steampunk, and the plot being silly and the economics/technology tremendously overly-optimistic didn’t bother me; but I could easily imagine someone else who hates it like poison and being unable to finish it. Similarly, Cryptonomicon: discussion of how to implement cryptography with a deck of cards? Bring. It. On. (But for other people maybe not so much.)
This is consistent with the average rating results: polarizing books may get lower reviews/ratings, as extreme as being abandoned, but they still earn high average ratings from those who like it (and the latter will tend to self-select into reading them).
Perhaps polarizing books are an example of what one should strive for? Find something & do it well—aiming for the moon instead of mediocrity. In the contemporary world, as Tim O’Reilly noted all the way back in 2002, “Obscurity is a far greater threat to authors and creative artists than piracy.”. The downside is relatively bounded—it’s hard for a book to do worse than simply vanish into ignominious obscurity—and the upside is nigh-unlimited, but the average book is simply a failure. I’m reminded of an OKCupid dating photo analysis which argued that it’s more important to have profile photos that stand out from the crowd & polarize the opposite-sex, perhaps by appealing to niches (like having tattoos) than ones which are uncontroversially ‘pretty’.
See Also
External Links
Appendix
Abandoned: “List of Books Voted Most Abandoned”
GoodReads also has a list for voting on frequently-abandoned books, but after looking at it, the data seems to be garbage and deeply unrepresentative of GoodReads readers in general, so I abandoned any further analysis of it.
I noticed while looking for API help that there was a similar list, but constructed using voting: “The Most Begun ‘Read but Unfinished’ (Initiated) book ever”. GR users can vote on books (either casting a vote from a book or, default, not voting on it), and add new books to the list. The list page reports that it covers 2,329 books, and has votes from 12,525 voters.
With the idea of perhaps combining the two datasets in a latent variable factor analysis to get a more accurate measure of abandonment, I extracted the data from it, same as with the tag.
Loading the CSV up, counting shows it has recorded 47,897 votes or ~20 votes per book on the list. The data is, however, so skewed as to be borderline useless:
gv <- read.csv("https://gwern.net/doc/culture/2019-12-09-goodreads-votinglist-abandoned.csv",
colClasses=c("factor", "factor", "numeric", "integer", "integer"))
skim(gv)
# Skim summary statistics
# n obs: 2327
# n variables: 5
#
# ── Variable type:factor ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
# variable missing complete n n_unique top_counts ordered
# Author 0 2327 2327 1707 Ste: 23, Ann: 14, Cha: 10, Mic: 10 FALSE
# Title 0 2327 2327 2317 Ali: 2, And: 2, Aut: 2, Bri: 2 FALSE
#
# ── Variable type:integer ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
# variable missing complete n mean sd p0 p25 p50 p75 p100 hist
# Reads 0 2327 2327 130479.28 385056.57 1 2036.5 14864 84767 6239642 ▇▁▁▁▁▁▁▁
# Votes 0 2327 2327 20.58 104.76 1 1 1 3 1991 ▇▁▁▁▁▁▁▁
#
# ── Variable type:numeric ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
# variable missing complete n mean sd p0 p25 p50 p75 p100 hist
# Rating 0 2327 2327 3.84 0.35 0 3.67 3.88 4.06 5 ▁▁▁▁▁▃▇▁Effectively, aside from the top 300 books, books have only 1 or 2 votes. Still, I gave it a chance, albeit with heavier regularization:
bgv <- brm(Votes|trials(Reads) ~ (1|Title), prior=c(prior(student_t(3,0,0.5), class="sd", group="Title")),
family=binomial, data=gv, chains=30)
bgv
# Formula: Votes | trials(Reads) ~ (1 | Title)
# Data: gv (Number of observations: 2327)
# Samples: 30 chains, each with iter = 2000; warmup = 1000; thin = 1;
# total post-warmup samples = 30000
#
# Group-Level Effects:
# ~Title (Number of levels: 2317)
# Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
# sd(Intercept) 1.93 0.04 1.85 2.00 1356 1.02
#
# Population-Level Effects:
# Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
# Intercept -8.90 0.04 -8.99 -8.81 975 1.03
bgvr <- as.data.frame(ranef(bgv)$Title); bgvr <- bgvr[order(bgvr$Estimate.Intercept, decreasing=TRUE),]head(bgvr, n=30)
# Estimate.Intercept Est.Error.Intercept Q2.5.Intercept Q97.5.Intercept
# How to Read a Page: A Cours... 5.38204009 1.2305407158 2.6889175683 7.46299219
# Finnegans Wake 5.09604001 0.0784560406 4.9395880468 5.24884339
# Adept (The Wiccan Diaries #3) 4.98646278 1.1811990071 2.3623513076 6.96201323
# Who Moved My Bone: A Guide ... 4.95494745 1.1611594828 2.3886414505 6.89145803
# The Scarlet Letter and Othe... 4.74029863 0.1680566097 4.3998550261 5.06238828
# Ulysses 4.73227532 0.0508705552 4.6333361209 4.83198213
# Gravity’s Rainbow 4.60794433 0.0651088164 4.4806395498 4.73529781
# Obras completas 4.37501582 0.7559132531 2.7108179987 5.64226480
# Dianetics: The Modern Scien... 4.27649757 0.1979955275 3.8732683273 4.64355668
# Neophyte (The Wiccan Diarie...) 4.15909507 1.0569860403 1.7519603753 5.91731061
# Realmgolds (The Gryphon Cle...) 4.10459375 1.0194113326 1.8366736192 5.78690229
# Infinite Jest 4.03234211 0.0619999259 3.9111099731 4.15344818
# American Junk 3.87078182 0.9922211213 1.6522260087 5.52190577
# The Satanic Verses 3.82457833 0.0718885158 3.6828805976 3.96392974
# The American Heritage Dicti... 3.80920846 0.7108850861 2.2099731437 5.00493848
# Holy Bible: King James Version 3.77235163 0.0526127709 3.6691860039 3.87512458
# The Wiccan Diaries (The Wic...) 3.74341315 0.9991628239 1.5006262229 5.40201310
# The Journal of Joyce Carol ... 3.65267531 0.7142768009 2.0675646812 4.86252960
# The Art of Interior Design:... 3.64215451 1.8634692814 -0.1039907607 7.22634805
# Prague and Bohemia: Medieva... 3.64105168 1.8494993932 -0.0422548391 7.19596699
# Alphabets Sublime: Contempo... 3.63497694 1.8612179073 -0.0378189700 7.19803265
# Swann's Way (In Search of L...) 3.63054368 0.0829307061 3.4682225579 3.79141887
# Murphy Blue 3.62759642 1.8880145651 -0.1063323453 7.28576732
# In Search of Lost Time (6 V...) 3.62753180 0.1515961350 3.3232938116 3.91714796
# Spies and Saucers 3.56821959 1.8299110410 -0.1192548224 7.04941588
# Quantum Gods: Creation Cha... 3.54662054 0.9733951263 1.3588060829 5.16892444
# Kobrin in There with the Kids 3.52129542 1.7882763228 -0.0855424774 6.8839114
# [Arabic book]... 3.51498925 1.8135874144 -0.1436548668 6.90342934
# Parkway 3.48491516 1.7801420369 -0.1339575798 6.80541442
# Mason & Dixon 3.47998067 0.1664473049 3.1457974255 3.79687113The results, while not totally absurd (Infinite Jest still shows up), are too idiosyncratic to take seriously. The American Heritage Dictionary, really? An Arabic book? And the voters seem to have something against The Wiccan Diaries…
This hardly even overlaps with the tag dataset, and so I abandoned the idea of trying to pool them.
-
Two alternative tags, “couldn’t finish”/“didn’t finish”, are much less popular, but after I did this analysis, I learned of “dnf” (did not finish), which is noticeably more popular than “abandoned”. In hindsight, that might’ve been better to analyze. (On the other hand, “dnf” is hard to find and the list seems heavy on genre fiction, so I wonder if it’s used by a niche group of readers and much more unrepresentative of GR than ‘abandoned’?)↩︎
-
!Margin: Fixing GoodReads.↩︎
-
Yes, I did finish (and enjoy) Infinite Jest. The trick was keeping a finger or bookmark at the last endnote, so flipping back and forth wasn’t too much of a hassle.↩︎
-
!Margin: GR sits on a throne of lies.↩︎
-
Example Bash script:
↩︎## eg. https://www.goodreads.com/shelf/show/abandoned?page=1 (for i in {1..25}; do elinks -dump "https://www.goodreads.com/shelf/show/abandoned?page=$i" \ | grep -E --before=3 --after=1 "shelved .* times as abandoned" sleep 2s done) > gr-abandoned.txt -
Yes, yes, ‘and even the author abandoned it!’ You are very clever.↩︎
-
Vox’s (otherwise highly complimentary) reviewer admits:
↩︎But while I may respect James’s choice as a critic, as a reader, I found much of Black Leopard to be a slog. It’s difficult to push through page after page of beautiful sentences—and James’s sentences really are stunning—that are organized specifically to avoid telling you who is doing what or why and why you should care. Sure, truth is unstable, stories don’t need resolution, the gods are dead, etc. etc., but would it kill this book to give me a single concrete arc to hang onto? It’s 620 pages long! Cut a girl a break!
-
Although again I will note that low abandon-rates don’t necessarily mean high-quality—it simply means those readers who chose to start them tended to finish them, for whatever reason.↩︎