‘copyright’ directory
- See Also
- Gwern
- Links
- “Learnings from Paying Artists Royalties for AI-Generated Art: A Retrospective on Tess.Design, Our Attempt to Make an Ethical, Artist-Friendly AI Marketplace. We Launched Tess in May 2024 and Shut It down in January 2026”, Enthoven 2026
- “History LLMs: Information Hub for Our Project Training the Largest Possible Historical LLMs”, Göttlich et al 2025
- “Teaching AI [Blacklist/whitelist of Example Sources for Claude RLHF]”, Sheets 2025
- “Cloudflare Will Now Block AI Bots from Crawling Its Clients’ Websites by Default: The Company Will Also Introduce a ‘Pay-Per-Crawl’ System to Give Users More Fine-Grained Control over How AI Companies Can Access Their Sites”, Hall 2025
- “Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training”, Langlais et al 2025
- “How Sherlock Holmes Broke Copyright Law”
- “To Whom Does the World Belong? The Battle over Copyright in the Age of ChatGPT”, Hartley 2024
- “Newswire: A Large-Scale Structured Database of a Century of Historical News”, Silcock et al 2024
- “I Wish I Knew How to Force Quit You”, Life & Rich 2024
- “Scarlett Johansson Says She Is "Shocked, Angered" over New ChatGPT Voice”, Allyn 2024
- BobbyAllyn @ "2024-05-20"
- karpathy @ "2024-05-14"
- “ChatGPT Will Be Able to Talk to You like Scarlett Johansson in Her / Upgrades to ChatGPT’s Voice Mode Bring It Closer to the Vision of a Responsive AI Assistant—And Sam Altman Seems to Know It”, Robison 2024
- “OpenAI Destroyed a Trove of Books Used to Train AI Models. The Employees Who Collected the Data Are Gone.”, Rafieyan & Chowdhury 2024
- “How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta Ignored Corporate Policies, Altered Their Own Rules and Discussed Skirting Copyright Law As They Sought Online Information to Train Their Newest Artificial Intelligence Systems”, Metz et al 2024
- “Inside Big Tech’s Underground Race to Buy AI Training Data”, Paul & Tong 2024
- “Navigating the Challenges and Opportunities of Synthetic Voices: We’re Sharing Lessons from a Small Scale Preview of Voice Engine, a Model for Creating Custom Voices.”, OpenAI 2024
- “DE-COP: Detecting Copyrighted Content in Language Models Training Data”, Duarte et al 2024
- “Why a Chinese Court’s Landmark Decision Recognising the Copyright for an AI-Generated Image Benefits Creators in This Nascent Field”, Shen 2024
- “Databases in 2024: A Year in Review”
- “CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”, Gokaslan et al 2023
- “ChatGPT Can Talk Now, Threatening Alexa and Siri: OpenAI Is Rapidly Pushing out Updates to Its Products to Make Them More Accessible to More People, As Amazon Invests in a Leading Start-Up § Sky Voice”, Vynck 2023
- “Joint Submission of [Proposed] Consent Judgment and Permanent Injunction Subject to Reservation of Right of Appeal”
- “Patents and Regulatory Exclusivities on GLP-1 Receptor Agonists”, Alhiary et al 2023
- “Why YouTube Could Give Google an Edge in AI”, Victor 2023
- “Animator Supporters Project Posts Toshio Okada’s Criticisms of Production Committee System With English Subtitles”, Morrissy 2023
- “I Don’t Remember DRM Being Mentioned in All of the Ted Nelson Stuff I’ve Read…”
- “Meet the Archive Moles: There’s a Growing Band of People Digging through Library Stacks and Second-Hand Bookshops in Search of Lost Classics. I’m One of Them”, Scholes 2023
- “This Artist Is Dominating AI-Generated Art. And He’s Not Happy about It. Greg Rutkowski Is a More Popular Prompt Than Picasso”, Heikkilä 2022
- “Make Some Sense of Scent Trademarks: The United States Needs a Graphical Representation Requirement”, Brill 2022
- “Trademark Electronic Search System: Active Scent Trademarks [13 Results]”, USPTO 2022
- “Restricted Access: How the Internet Can Be Used to Promote Reading and Learning”, Derksen et al 2022
- “The Impact of Open Access Mandates on Invention”, Bryan & Ozcan 2021
- “Externalities in Knowledge Production: Evidence from a Randomized Field Experiment”, Hinnosaar et al 2021
- “Digitization and the Demand for Physical Works: Evidence from the Google Books Project”, Nagaraj & Reimers 2021
- “Roadblock to Innovation: The Role of Patent Litigation in Corporate R&D”, Mezzanotti 2021
- “How Is Science Clicked on Twitter? Click Metrics for Bitly Short Links to Scientific Publications”, Fang et al 2021
- “[IP Reform Won]”, Steve132 2020
- “‘It’s the Screams of the Damned!’ The Eerie AI World of Deepfake Music”
- “Shadow of the Great Firewall: The Impact of Google Blockade on Innovation in China”, Zheng & Wang 2020c
- “Internet Archive Offers 1.4 Million Copyrighted Books for Free Online”
- “BioRxiv: the Preprint Server for Biology”, Sever et al 2019
- “Of Coase and Copyrights: The Law and Economics of Literary Fan Art”, Guerra-Pujol 2019
- “The Effects of Internet Book Piracy: The Case of Comics”, Tanaka 2019 (page 2)
- “Wikipedia Matters”, Hinnosaar et al 2019
- “The Machine As Author”, Gervais 2019
- “Henry Darger’s ‘Realms Of The Unreal’—But Who In The Realm Is Kiyoko Lerner?”, Westby 2019
- “Clown Eggs”, Fagundes & Perzanowski 2019
- “Mickey Mouse Will Be Public Domain Soon—Here’s What That Means: The Internet Stopped Another Copyright Extension without Firing a Shot”, Lee 2019
- “Can Creative Firms Thrive Without Copyright? Value Generation And Capture From Private-Collective Innovation”, Erickson 2018b
- “What Is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use”, Erickson et al 2018
- “Bad Romance: To Cash in on Kindle Unlimited, a Cabal of Authors Gamed Amazon’s Algorithm”, Jeong 2018
- “Kindle Unlimited Book Stuffing Scam Earns Millions and Amazon Isn’t Stopping It: Book Stuffer Chance Carter Is Gone. But Readers Are Still Paying for Books That Are 90% Filler.”, Zetlin 2018
- “Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects”, Baltes & Diehl 2018
- “Why Mickey Mouse’s 1998 Copyright Extension Probably Won’t Happen Again: Copyrights from the 1920s Will Start Expiring next Year If Congress Doesn’t Act.”, Lee 2018
- “Examining Wikipedia With a Broader Lens: Quantifying the Value of Wikipedia’s Relationships With Other Large-Scale Online Communities”, Vincent 2018
- “The Prehistory of Biology Preprints: A Forgotten Experiment from the 1960s”, Cobb 2017
- “Creating a Last Twenty (L20) Collection: Implementing §108(H) in Libraries, Archives and Museums”, Gard 2017
- “Does Copyright Affect Reuse? Evidence from Google Books and Wikipedia”, Nagaraj 2017
- “Preprint Déjà Vu: an FAQ”, Ginsparg 2017
- “Public Record, Astronomical Price: Court Reporters Charge Outrageous Fees to Reproduce Trial Transcripts. That’s Bad for Defendants, Journalists, and Democracy.”, Eisenberg 2017
- “Experimental Studies on the Psychology of Property Rights”, Haji 2017
- “Yutaka Yamamoto, Toshio Okada Criticize Production Committee System”, Stimson 2017
- “When Nothing Ever Goes Out of Print: Maintaining Backlist Ebooks”, Elsey 2016
- Unsong, Alexander 2015
- “The Valuation of Unprotected Works: A Case Study of Public Domain Images on Wikipedia”, Heald et al 2015
- “How Copyright Keeps Works Disappeared”, Heald 2014
- “Why This Movie Perfectly Re-Created a Picasso, Destroyed It, and Mailed the Evidence to Picasso’s Estate”, Calautti 2014
- “The International Cognitive Ability Resource: Development and Initial Validation of a Public-Domain Measure”, Condon & Revelle 2014
- “Impact of Wikipedia on Market Information Environment: Evidence on Management Disclosure and Investor Reaction”, Xu & Zhang 2013
- “The Six Fingers of Time [Tragedy of the Anticommons]”, epiktistes 2013
- “Do Bad Things Happen When Works Enter the Public Domain?: Empirical Tests of Copyright Term Extension”, Buccafusco & Heald 2013
- “Did Plant Patents Create the American Rose?”, Moser & Rhode 2012
- “The Public Domain Review: About”, Review 2011
- “John Bruno Hare Obituary”
- “File Sharing and Copyright”, Oberholzer-Gee & Strumpf 2010
- “AMV Remix: Do-It-Yourself Anime Music Videos”, Knobel et al 2010
- “Colmcille and the Battle of the Book: Technology, Law and Access to Knowledge in 6th Century Ireland”, Corrigan 2007
- “Case Study: Anime Music Videos”, Milstein 2007
- “Strategizing Industry Structure: the Case of Open Systems in a Low-Tech Industry”, Lecocq & Demil 2006
- “The Command Line In 2004”, Stephenson & Birkel 2004
- “What Color Are Your Bits?”, Skala 2004
- “CC-0: Creative Commons Public Domain License”, Commons 2002
- “Piracy Is Progressive Taxation, and Other Thoughts on the Evolution of Online Distribution: Seven Lessons from Tim O’Reilly’s Experience As an Author and Publisher”, O’Reilly 2002
- “Piracy Is Progressive Taxation, and Other Thoughts on the Evolution of Online Distribution”, OReilly 2002
- “Web Precursor Xanadu Project Goes Open Source: A Brilliant Collection of Ideas That Was Never Going to Ship—So Is It Relevant?”, Lea 1999
- “University Presses: Balancing Academic and Market Values”, Case 1997
- “Stranger in Parodies: Weird Al and the Law of Musical Satire”, Sanders & Gordon 1990
- “The First Illustrations for Paradise Lost”, Shawcross 1975
- “Secrets by the Thousands”, Walker 1946
- “Thomas Jefferson to Isaac McPherson, 13 August 1813”, Jefferson 1813
- “Isaac McPherson to Thomas Jefferson, 3 August 1813”
- “Why Are Tech Companies Making Custom Typefaces?”
- “Music Industry Forces Widely Used Journalist Tool Offline”
- “TimeCapsuleLLM: An LLM Trained Only on Data from Certain Time Periods to Reduce Modern Bias”
- “Are We Running Out of Trademarks? An Empirical Study of Trademark Depletion and Congestion”
- “Copying Is the Way Design Works”
- “Postmortem: Every Frame a Painting”, Zhou 2026
- “Hackers and ‘Information Wants to Be Free’: The Most Famous Phrase in the Book Wasn’t Mine. And It Wasn’t in the Book.”
- “Class of 2020: New in the Public Domain Today!”
- “All Sound Recordings Prior to 1923 Will Enter the US Public Domain in 2022”
- “How Michael Jackson Bought The Beatles Catalogue And Turned It Into A Multi-Billion Dollar Music Empire”
- “A Children’s Classic, A 9-Year-Old-Boy And a Fateful Bequest—For Albert Clarke, the Rise Of Goodnight Moon Is No Storybook Romance—Broken Homes, Broken Noses”
- “Streaming Reaches Flood Stage: Does Spotify Stimulate or Depress Music Sales?”
- “Within The Context Of All Contexts: The Rewiring Of Our Relationship To Music”
- “Music Copyright After ‘Blurred Lines’: Experts Speak Out”
- “Batman Forever? The Role of Trademarks for Reuse in the US Comics Industry”
- “Torching the Modern-Day Library of Alexandria: ‘Somewhere at Google There Is a Database Containing 25 Million Books and Nobody Is Allowed to Read Them.’”
- “Who Owns Einstein? The Battle for the World’s Most Famous Face”
- “Metadata Is the Biggest Little Problem Plaguing the Music Industry”
- “Inside the Discord Where Thousands of Rogue Producers Are Making AI Music”
- “Dutch Pictures on Wikipedia: 500 times More”
- “Zoey Ellis Books”, Ellis 2026
- Sort By Magic
- Wikipedia (19)
- Miscellaneous
- Bibliography
See Also
Gwern
“Copyright & AI”, Gwern 2023
“Self-Funding Harberger Taxes”, Gwern 2024
Links
“Learnings from Paying Artists Royalties for AI-Generated Art: A Retrospective on Tess.Design, Our Attempt to Make an Ethical, Artist-Friendly AI Marketplace. We Launched Tess in May 2024 and Shut It down in January 2026”, Enthoven 2026
“History LLMs: Information Hub for Our Project Training the Largest Possible Historical LLMs”, Göttlich et al 2025
History LLMs: Information hub for our project training the largest possible historical LLMs
“Teaching AI [Blacklist/whitelist of Example Sources for Claude RLHF]”, Sheets 2025
Teaching AI [blacklist/whitelist of example sources for Claude RLHF]
“Cloudflare Will Now Block AI Bots from Crawling Its Clients’ Websites by Default: The Company Will Also Introduce a ‘Pay-Per-Crawl’ System to Give Users More Fine-Grained Control over How AI Companies Can Access Their Sites”, Hall 2025
“Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training”, Langlais et al 2025
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
“How Sherlock Holmes Broke Copyright Law”
“To Whom Does the World Belong? The Battle over Copyright in the Age of ChatGPT”, Hartley 2024
To Whom Does the World Belong? The battle over copyright in the age of ChatGPT
“Newswire: A Large-Scale Structured Database of a Century of Historical News”, Silcock et al 2024
Newswire: A Large-Scale Structured Database of a Century of Historical News
“I Wish I Knew How to Force Quit You”, Life & Rich 2024
“Scarlett Johansson Says She Is "Shocked, Angered" over New ChatGPT Voice”, Allyn 2024
Scarlett Johansson says she is "shocked, angered" over new ChatGPT voice
BobbyAllyn @ "2024-05-20"
Scarlett Johansson on suing OpenAI for personality/voice right infringement
karpathy @ "2024-05-14"
“ChatGPT Will Be Able to Talk to You like Scarlett Johansson in Her / Upgrades to ChatGPT’s Voice Mode Bring It Closer to the Vision of a Responsive AI Assistant—And Sam Altman Seems to Know It”, Robison 2024
“OpenAI Destroyed a Trove of Books Used to Train AI Models. The Employees Who Collected the Data Are Gone.”, Rafieyan & Chowdhury 2024
“How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta Ignored Corporate Policies, Altered Their Own Rules and Discussed Skirting Copyright Law As They Sought Online Information to Train Their Newest Artificial Intelligence Systems”, Metz et al 2024
“Inside Big Tech’s Underground Race to Buy AI Training Data”, Paul & Tong 2024
“Navigating the Challenges and Opportunities of Synthetic Voices: We’re Sharing Lessons from a Small Scale Preview of Voice Engine, a Model for Creating Custom Voices.”, OpenAI 2024
“DE-COP: Detecting Copyrighted Content in Language Models Training Data”, Duarte et al 2024
DE-COP: Detecting Copyrighted Content in Language Models Training Data
“Why a Chinese Court’s Landmark Decision Recognising the Copyright for an AI-Generated Image Benefits Creators in This Nascent Field”, Shen 2024
“Databases in 2024: A Year in Review”
“CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”, Gokaslan et al 2023
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
“ChatGPT Can Talk Now, Threatening Alexa and Siri: OpenAI Is Rapidly Pushing out Updates to Its Products to Make Them More Accessible to More People, As Amazon Invests in a Leading Start-Up § Sky Voice”, Vynck 2023
“Joint Submission of [Proposed] Consent Judgment and Permanent Injunction Subject to Reservation of Right of Appeal”
“Patents and Regulatory Exclusivities on GLP-1 Receptor Agonists”, Alhiary et al 2023
Patents and Regulatory Exclusivities on GLP-1 Receptor Agonists
“Why YouTube Could Give Google an Edge in AI”, Victor 2023
“Animator Supporters Project Posts Toshio Okada’s Criticisms of Production Committee System With English Subtitles”, Morrissy 2023
“I Don’t Remember DRM Being Mentioned in All of the Ted Nelson Stuff I’ve Read…”
I don’t remember DRM being mentioned in all of the Ted Nelson stuff I’ve read…
“Meet the Archive Moles: There’s a Growing Band of People Digging through Library Stacks and Second-Hand Bookshops in Search of Lost Classics. I’m One of Them”, Scholes 2023
“This Artist Is Dominating AI-Generated Art. And He’s Not Happy about It. Greg Rutkowski Is a More Popular Prompt Than Picasso”, Heikkilä 2022
“Make Some Sense of Scent Trademarks: The United States Needs a Graphical Representation Requirement”, Brill 2022
Make Some Sense of Scent Trademarks: The United States Needs a Graphical Representation Requirement
“Trademark Electronic Search System: Active Scent Trademarks [13 Results]”, USPTO 2022
Trademark Electronic Search System: active scent trademarks [13 results]
“Restricted Access: How the Internet Can Be Used to Promote Reading and Learning”, Derksen et al 2022
Restricted access: How the internet can be used to promote reading and learning
“The Impact of Open Access Mandates on Invention”, Bryan & Ozcan 2021
“Externalities in Knowledge Production: Evidence from a Randomized Field Experiment”, Hinnosaar et al 2021
Externalities in knowledge production: evidence from a randomized field experiment
“Digitization and the Demand for Physical Works: Evidence from the Google Books Project”, Nagaraj & Reimers 2021
Digitization and the Demand for Physical Works: Evidence from the Google Books Project
“Roadblock to Innovation: The Role of Patent Litigation in Corporate R&D”, Mezzanotti 2021
Roadblock to Innovation: The Role of Patent Litigation in Corporate R&D
“How Is Science Clicked on Twitter? Click Metrics for Bitly Short Links to Scientific Publications”, Fang et al 2021
How is science clicked on Twitter? Click metrics for Bitly short links to scientific publications
“[IP Reform Won]”, Steve132 2020
“‘It’s the Screams of the Damned!’ The Eerie AI World of Deepfake Music”
‘It’s the screams of the damned!’ The eerie AI world of deepfake music
“Shadow of the Great Firewall: The Impact of Google Blockade on Innovation in China”, Zheng & Wang 2020c
Shadow of the great firewall: The impact of Google blockade on innovation in China
“Internet Archive Offers 1.4 Million Copyrighted Books for Free Online”
Internet Archive offers 1.4 million copyrighted books for free online
“BioRxiv: the Preprint Server for Biology”, Sever et al 2019
“Of Coase and Copyrights: The Law and Economics of Literary Fan Art”, Guerra-Pujol 2019
Of Coase and Copyrights: The Law and Economics of Literary Fan Art
“The Effects of Internet Book Piracy: The Case of Comics”, Tanaka 2019 (page 2)
“Wikipedia Matters”, Hinnosaar et al 2019
“The Machine As Author”, Gervais 2019
“Henry Darger’s ‘Realms Of The Unreal’—But Who In The Realm Is Kiyoko Lerner?”, Westby 2019
Henry Darger’s ‘Realms Of The Unreal’—But Who In The Realm Is Kiyoko Lerner?
“Clown Eggs”, Fagundes & Perzanowski 2019
“Mickey Mouse Will Be Public Domain Soon—Here’s What That Means: The Internet Stopped Another Copyright Extension without Firing a Shot”, Lee 2019
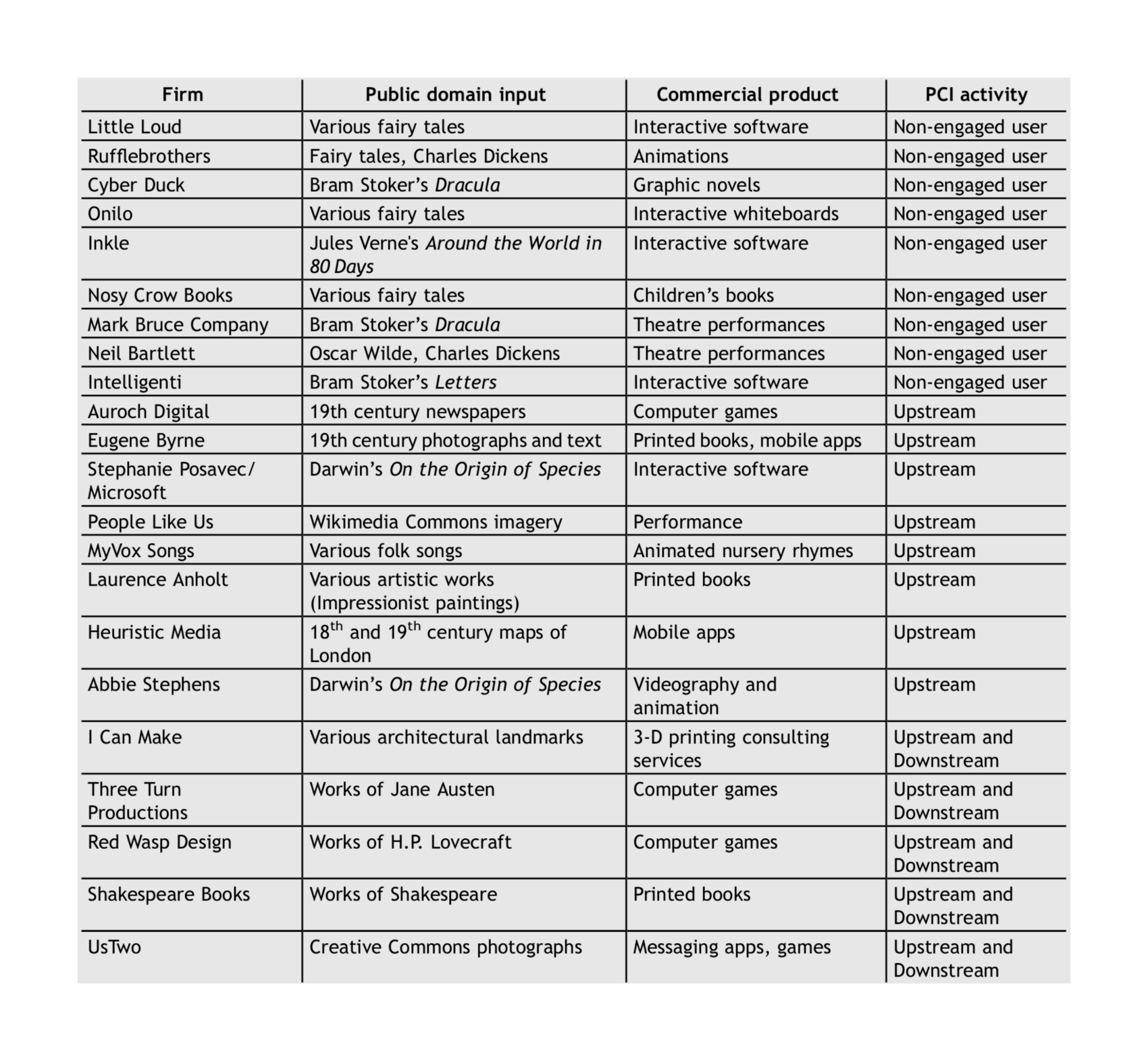
“Can Creative Firms Thrive Without Copyright? Value Generation And Capture From Private-Collective Innovation”, Erickson 2018b
“What Is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use”, Erickson et al 2018
What is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use
“Bad Romance: To Cash in on Kindle Unlimited, a Cabal of Authors Gamed Amazon’s Algorithm”, Jeong 2018
Bad romance: To cash in on Kindle Unlimited, a cabal of authors gamed Amazon’s algorithm
“Kindle Unlimited Book Stuffing Scam Earns Millions and Amazon Isn’t Stopping It: Book Stuffer Chance Carter Is Gone. But Readers Are Still Paying for Books That Are 90% Filler.”, Zetlin 2018
“Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects”, Baltes & Diehl 2018
Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects
“Why Mickey Mouse’s 1998 Copyright Extension Probably Won’t Happen Again: Copyrights from the 1920s Will Start Expiring next Year If Congress Doesn’t Act.”, Lee 2018
“Examining Wikipedia With a Broader Lens: Quantifying the Value of Wikipedia’s Relationships With Other Large-Scale Online Communities”, Vincent 2018
“The Prehistory of Biology Preprints: A Forgotten Experiment from the 1960s”, Cobb 2017
The prehistory of biology preprints: A forgotten experiment from the 1960s
“Creating a Last Twenty (L20) Collection: Implementing §108(H) in Libraries, Archives and Museums”, Gard 2017
Creating a Last Twenty (L20) Collection: Implementing §108(h) in Libraries, Archives and Museums
“Does Copyright Affect Reuse? Evidence from Google Books and Wikipedia”, Nagaraj 2017
Does Copyright Affect Reuse? Evidence from Google Books and Wikipedia
“Preprint Déjà Vu: an FAQ”, Ginsparg 2017
“Public Record, Astronomical Price: Court Reporters Charge Outrageous Fees to Reproduce Trial Transcripts. That’s Bad for Defendants, Journalists, and Democracy.”, Eisenberg 2017
“Experimental Studies on the Psychology of Property Rights”, Haji 2017
“Yutaka Yamamoto, Toshio Okada Criticize Production Committee System”, Stimson 2017
Yutaka Yamamoto, Toshio Okada Criticize Production Committee System
“When Nothing Ever Goes Out of Print: Maintaining Backlist Ebooks”, Elsey 2016
When Nothing Ever Goes Out of Print: Maintaining Backlist Ebooks
Unsong, Alexander 2015
“The Valuation of Unprotected Works: A Case Study of Public Domain Images on Wikipedia”, Heald et al 2015
The Valuation of Unprotected Works: A Case Study of Public Domain Images on Wikipedia
“How Copyright Keeps Works Disappeared”, Heald 2014
“Why This Movie Perfectly Re-Created a Picasso, Destroyed It, and Mailed the Evidence to Picasso’s Estate”, Calautti 2014
“The International Cognitive Ability Resource: Development and Initial Validation of a Public-Domain Measure”, Condon & Revelle 2014
“Impact of Wikipedia on Market Information Environment: Evidence on Management Disclosure and Investor Reaction”, Xu & Zhang 2013
“The Six Fingers of Time [Tragedy of the Anticommons]”, epiktistes 2013
“Do Bad Things Happen When Works Enter the Public Domain?: Empirical Tests of Copyright Term Extension”, Buccafusco & Heald 2013
“Did Plant Patents Create the American Rose?”, Moser & Rhode 2012
Did Plant Patents Create the American Rose? :
View PDF:
“The Public Domain Review: About”, Review 2011
“John Bruno Hare Obituary”
“File Sharing and Copyright”, Oberholzer-Gee & Strumpf 2010
“AMV Remix: Do-It-Yourself Anime Music Videos”, Knobel et al 2010
“Colmcille and the Battle of the Book: Technology, Law and Access to Knowledge in 6th Century Ireland”, Corrigan 2007
Colmcille and the Battle of the Book: Technology, Law and Access to Knowledge in 6th Century Ireland
“Case Study: Anime Music Videos”, Milstein 2007
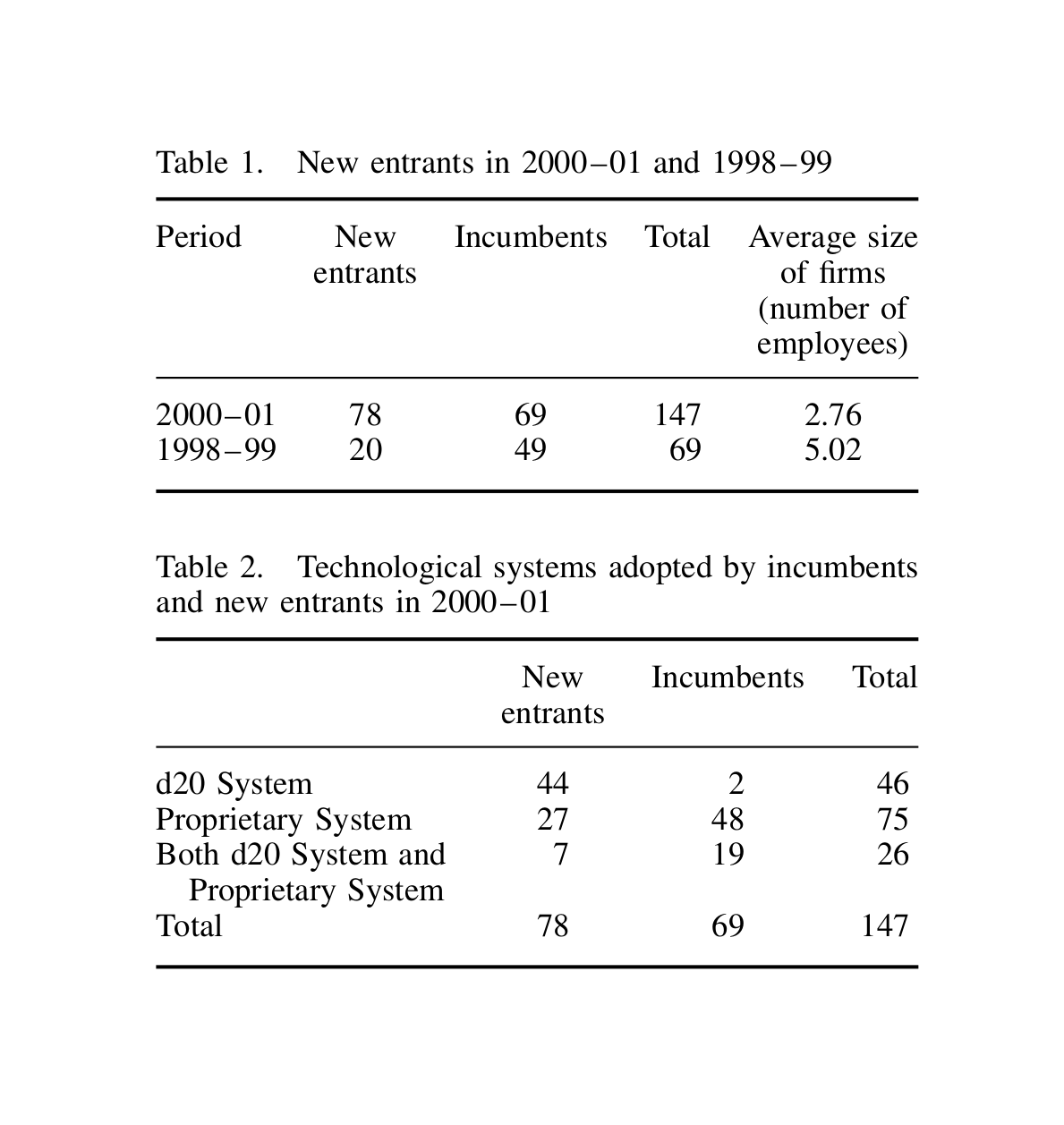
“Strategizing Industry Structure: the Case of Open Systems in a Low-Tech Industry”, Lecocq & Demil 2006
Strategizing industry structure: the case of open systems in a low-tech industry
“The Command Line In 2004”, Stephenson & Birkel 2004
“What Color Are Your Bits?”, Skala 2004
“CC-0: Creative Commons Public Domain License”, Commons 2002
“Piracy Is Progressive Taxation, and Other Thoughts on the Evolution of Online Distribution: Seven Lessons from Tim O’Reilly’s Experience As an Author and Publisher”, O’Reilly 2002
“Piracy Is Progressive Taxation, and Other Thoughts on the Evolution of Online Distribution”, OReilly 2002
Piracy is Progressive Taxation, and Other Thoughts on the Evolution of Online Distribution
“Web Precursor Xanadu Project Goes Open Source: A Brilliant Collection of Ideas That Was Never Going to Ship—So Is It Relevant?”, Lea 1999
“University Presses: Balancing Academic and Market Values”, Case 1997
University presses: balancing academic and market values :
View PDF:
“Stranger in Parodies: Weird Al and the Law of Musical Satire”, Sanders & Gordon 1990
Stranger in Parodies: Weird Al and the Law of Musical Satire
“The First Illustrations for Paradise Lost”, Shawcross 1975
“Secrets by the Thousands”, Walker 1946
“Thomas Jefferson to Isaac McPherson, 13 August 1813”, Jefferson 1813
“Isaac McPherson to Thomas Jefferson, 3 August 1813”
“Why Are Tech Companies Making Custom Typefaces?”
“Music Industry Forces Widely Used Journalist Tool Offline”
“TimeCapsuleLLM: An LLM Trained Only on Data from Certain Time Periods to Reduce Modern Bias”
TimeCapsuleLLM: An LLM trained only on data from certain time periods to reduce modern bias
“Are We Running Out of Trademarks? An Empirical Study of Trademark Depletion and Congestion”
Are We Running Out of Trademarks? An Empirical Study of Trademark Depletion and Congestion
“Copying Is the Way Design Works”
“Postmortem: Every Frame a Painting”, Zhou 2026
“Hackers and ‘Information Wants to Be Free’: The Most Famous Phrase in the Book Wasn’t Mine. And It Wasn’t in the Book.”
“Class of 2020: New in the Public Domain Today!”
“All Sound Recordings Prior to 1923 Will Enter the US Public Domain in 2022”
All Sound Recordings Prior to 1923 Will Enter the US Public Domain in 2022
“How Michael Jackson Bought The Beatles Catalogue And Turned It Into A Multi-Billion Dollar Music Empire”
“A Children’s Classic, A 9-Year-Old-Boy And a Fateful Bequest—For Albert Clarke, the Rise Of Goodnight Moon Is No Storybook Romance—Broken Homes, Broken Noses”
“Streaming Reaches Flood Stage: Does Spotify Stimulate or Depress Music Sales?”
Streaming Reaches Flood Stage: Does Spotify Stimulate or Depress Music Sales?
“Within The Context Of All Contexts: The Rewiring Of Our Relationship To Music”
Within The Context Of All Contexts: The Rewiring Of Our Relationship To Music
“Music Copyright After ‘Blurred Lines’: Experts Speak Out”
“Batman Forever? The Role of Trademarks for Reuse in the US Comics Industry”
Batman forever? The role of trademarks for reuse in the US comics industry
“Torching the Modern-Day Library of Alexandria: ‘Somewhere at Google There Is a Database Containing 25 Million Books and Nobody Is Allowed to Read Them.’”
“Who Owns Einstein? The Battle for the World’s Most Famous Face”
Who owns Einstein? The battle for the world’s most famous face
“Metadata Is the Biggest Little Problem Plaguing the Music Industry”
Metadata is the biggest little problem plaguing the music industry
“Inside the Discord Where Thousands of Rogue Producers Are Making AI Music”
Inside the Discord Where Thousands of Rogue Producers Are Making AI Music
“Dutch Pictures on Wikipedia: 500 times More”
Dutch pictures on Wikipedia: 500 times more
View External Link:
“Zoey Ellis Books”, Ellis 2026
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
copyright-implications
voice-rights
Wikipedia (19)
Miscellaneous
/doc/economics/copyright/2018-biasi.pdf:View PDF:
/doc/economics/copyright/2018-erickson-table1-openipusers.png/doc/economics/copyright/2006-lecocque-table12-rpgindustrycompanygrowth1998vs2000.pnghttps://archive.nytimes.com/opinionator.blogs.nytimes.com/2008/09/23/toms-essay/https://billwillingham.substack.com/p/willingham-sends-fables-into-thehttps://blog.twitch.tv/en/2020/11/11/music-related-copyright-claims-and-twitch/https://daily.jstor.org/the-daguerreotypes-famous-why-not-the-calotype/https://dash.harvard.edu/bitstream/handle/1/3693705/Kremer_PatentBuyouts.pdf?sequence=2#page=2https://journal.atp.art/the-next-rembrandt-who-holds-the-copyright-in-computer-generated-art/https://law.justia.com/cases/federal/district-courts/FSupp2/150/613/2468303/https://marginalrevolution.com/marginalrevolution/2023/01/ai-passes-law-and-economics-exam.htmlhttps://papers.ssrn.com/sol3/papers.cfm?abstract_id=4553431View External Link:
https://thehustle.co/the-company-that-has-a-monopoly-on-ice-cream-truck-music/https://web.archive.org/web/20110807132554/http://library.findlaw.com/1998/Oct/1/127402.htmlhttps://www.filfre.net/2023/11/a-digital-pornutopia-part-2-the-internet-is-for-porn/https://www.minnesotalawreview.org/wp-content/uploads/2012/01/Heald_FinalPDF.pdf#page=4:https://www.morselnewyork.com/foodart/2017/10/3/over-100-years-agohttps://www.newyorker.com/magazine/1993/01/11/the-flash-of-geniushttps://www.newyorker.com/magazine/2023/06/12/how-the-marvel-cinematic-universe-swallowed-hollywoodhttps://www.nytimes.com/2020/02/04/business/custom-urls.htmlhttps://www.reddit.com/r/aigamedev/comments/142j3yt/valve_is_not_willing_to_publish_games_with_ai/https://www.theguardian.com/books/2019/mar/19/francis-spufford-pens-unauthorised-narnia-novelhttps://www.thenation.com/article/culture/clip-art-desktop-publishing-stock-images/https://www.uspto.gov/sites/default/files/documents/OpenAI_RFC-84-FR-58141.pdf:https://www.wired.com/story/matthew-butterick-ai-copyright-lawsuits-openai-meta/
{kind=link}
{kind=link}
Bibliography
https://www.thisamericanlife.org/832/transcript#act2: “I Wish I Knew How to Force Quit You”,https://www.npr.org/2024/05/20/1252495087/openai-pulls-ai-voice-that-was-compared-to-scarlett-johansson-in-the-movie-her: “Scarlett Johansson Says She Is "Shocked, Angered" over New ChatGPT Voice”,https://x.com/BobbyAllyn/status/1792679435701014908: “Scarlett Johansson on Suing OpenAI for Personality/voice Right Infringement”,https://x.com/karpathy/status/1790373216537502106: “The Killer App of LLMs Is Scarlett Johansson.”,https://www.theverge.com/2024/5/13/24155652/chatgpt-voice-mode-gpt4o-upgrades: “ChatGPT Will Be Able to Talk to You like Scarlett Johansson in Her / Upgrades to ChatGPT’s Voice Mode Bring It Closer to the Vision of a Responsive AI Assistant—And Sam Altman Seems to Know It”,https://www.businessinsider.com/openai-destroyed-ai-training-datasets-lawsuit-authors-books-copyright-2024-5: “OpenAI Destroyed a Trove of Books Used to Train AI Models. The Employees Who Collected the Data Are Gone.”,https://www.nytimes.com/2024/04/06/technology/tech-giants-harvest-data-artificial-intelligence.html: “How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta Ignored Corporate Policies, Altered Their Own Rules and Discussed Skirting Copyright Law As They Sought Online Information to Train Their Newest Artificial Intelligence Systems”,https://www.reuters.com/technology/inside-big-techs-underground-race-buy-ai-training-data-2024-04-05/: “Inside Big Tech’s Underground Race to Buy AI Training Data”,https://arxiv.org/abs/2310.16825: “CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”,https://www.washingtonpost.com/technology/2023/09/25/chatgpt-voice-talk-assistant/: “ChatGPT Can Talk Now, Threatening Alexa and Siri: OpenAI Is Rapidly Pushing out Updates to Its Products to Make Them More Accessible to More People, As Amazon Invests in a Leading Start-Up § Sky Voice”,https://www.theinformation.com/articles/why-youtube-could-give-google-an-edge-in-ai: “Why YouTube Could Give Google an Edge in AI”,https://www.animenewsnetwork.com/interest/2023-03-02/animator-supporters-project-posts-toshio-okada-criticisms-of-production-committee-system-with-/.195481: “Animator Supporters Project Posts Toshio Okada’s Criticisms of Production Committee System With English Subtitles”,2022-brill.pdf: “Make Some Sense of Scent Trademarks: The United States Needs a Graphical Representation Requirement”,https://asistdl.onlinelibrary.wiley.com/doi/full/10.1002/asi.24458: “How Is Science Clicked on Twitter? Click Metrics for Bitly Short Links to Scientific Publications”,2020-zheng-3.pdf: “Shadow of the Great Firewall: The Impact of Google Blockade on Innovation in China”,2018-erickson.pdf: “What Is the Commons Worth? Estimating the Value of Wikimedia Imagery by Observing Downstream Use”,https://unsongbook.com/: Unsong,https://publicdomainreview.org/about/: “The Public Domain Review: About”,