‘CS/r’ directory
- See Also
- Gwern
- “How Many Shower Controls Are There?”, Gwern & Pro 2023
- “Anti-Spaced Repetition for Serendipity”, Gwern 2017
- “Oh Deer: Could Deer Evolve to Avoid Car Accidents?”, Gwern 2018
- “Visualizing Active Learning Sample-Efficiency”, Gwern 2022
- “Simulating ‘tail Collapse’ in R”, Gwern 2024
- “Website Colors: Red vs Blue”, Gwern 2024
- “Acne: a Good Quantified Self Topic”, Gwern 2019
- “Statistical Notes”, Gwern 2014
- “Gwern.net Website Traffic”, Gwern 2011
- “Archiving URLs”, Gwern 2011
- “Problem 14 Dynamic Programming Solutions”, Gwern et al 2022
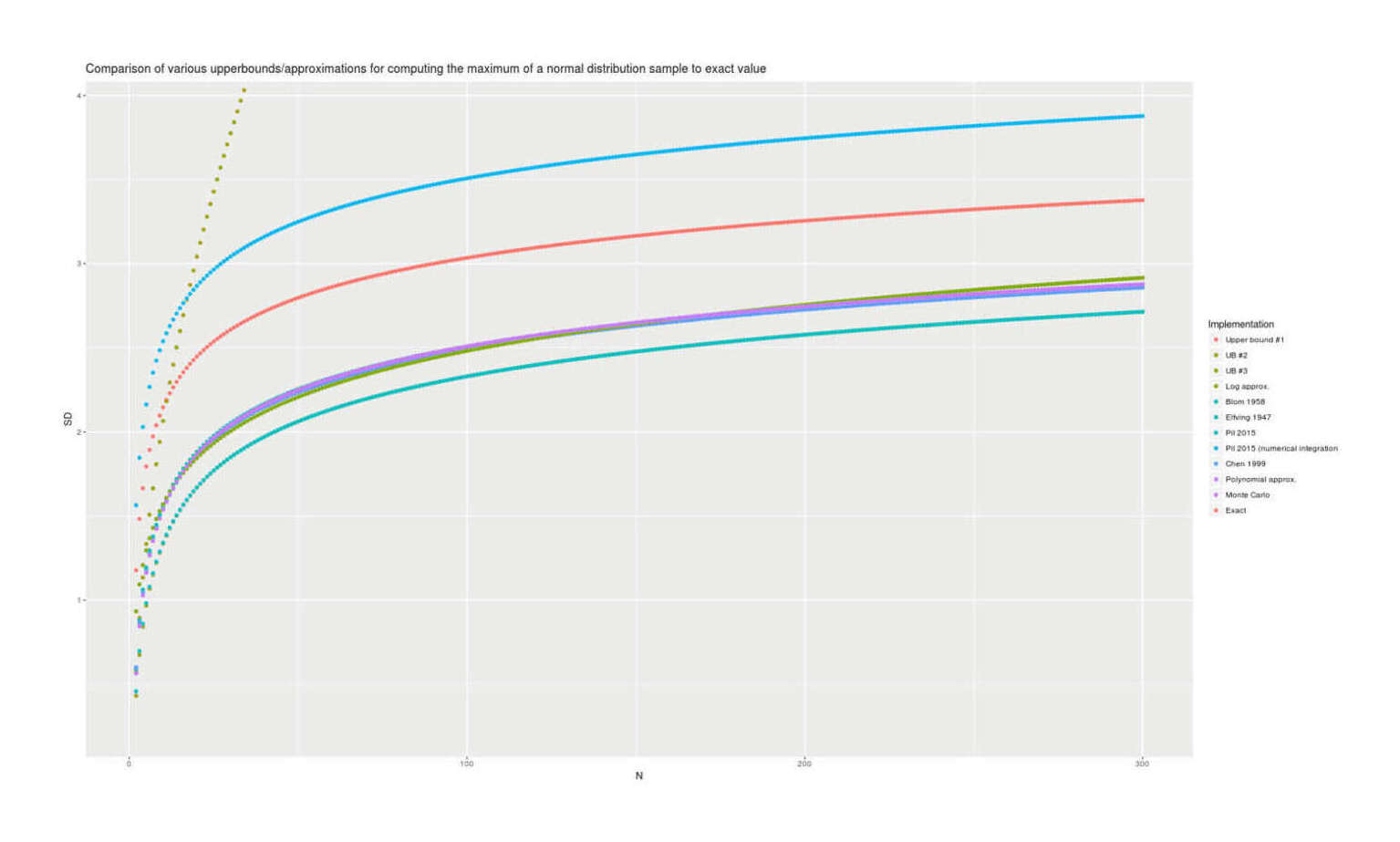
- “Calculating The Gaussian Expected Maximum”, Gwern 2016
- “A/B Testing Long-Form Readability on Gwern.net”, Gwern 2012
- “Dog Cloning For Special Forces: Breed All You Can Breed”, Gwern 2018
- “Creatine Cognition Meta-Analysis”, Gwern 2013
- “Common Selection Scenarios”, Gwern 2021
- “Darknet Market Archives (2013–2015)”, Gwern 2013
- “Banner Ads Considered Harmful”, Gwern 2017
- “Magnesium Self-Experiments”, Gwern 2013
- “Embryo Selection For Intelligence”, Gwern 2016
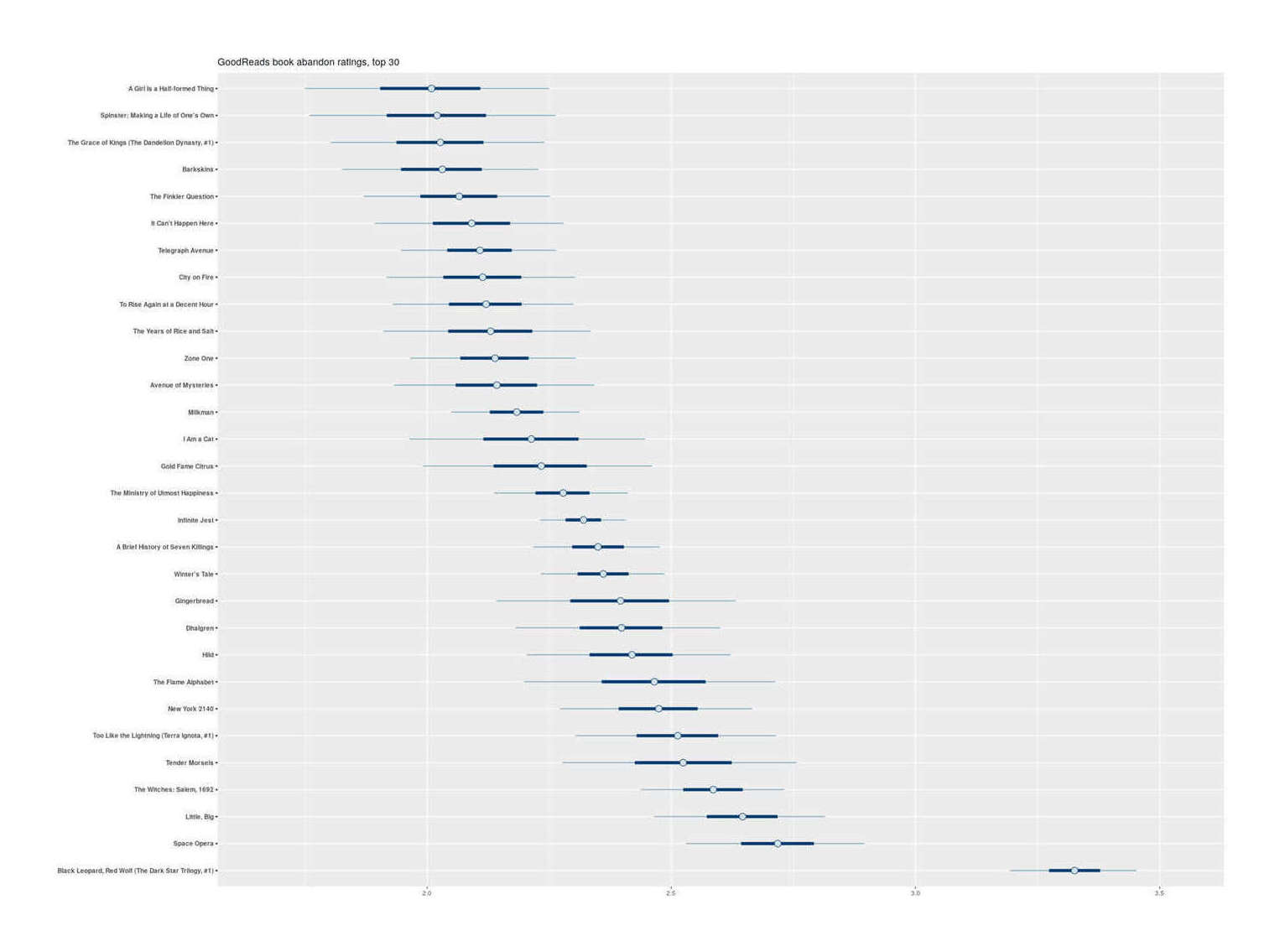
- “The Most ‘Abandoned’ Books on GoodReads”, Gwern 2019
- “Redshift Sleep Experiment”, Gwern 2012
- “The Power of Twins: The Scottish Milk Experiment”, Gwern 2016
- “Solving Pascal’s Mugging With Dynamic Programming”, Gwern 2019
- “Genius Revisited Revisited”, Gwern 2016
- “LSD Microdosing RCT”, Gwern 2012
- “Catnip Immunity and Alternatives”, Gwern 2015
- “Hafu Gender Ratios in Anime”, Gwern 2011
- “DNM-Related Arrests, 2011–2015”, Gwern 2012
- “Darknet Market Mortality Risks”, Gwern 2013
- “Embryo Editing for Intelligence”, Gwern 2016
- “Predicting Google Closures”, Gwern 2013
- “History of Iterated Embryo Selection”, Gwern 2019
- “The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
- “World Catnip Surveys”, Gwern 2015
- “Dual n-Back Meta-Analysis”, Gwern 2012
- “Life Extension Cost-Benefits”, Gwern 2015
- “Modafinil Community Survey”, Gwern 2015
- “Bacopa Quasi-Experiment”, Gwern 2014
- “ZMA Sleep Experiment”, Gwern 2017
- “Zeo Sleep Self-Experiments”, Gwern 2010
- “Long Bets As Charitable Giving Opportunity”, Gwern 2017
- “When Should I Check The Mail?”, Gwern 2015
- “CO2/ventilation Sleep Experiment”, Gwern 2016
- “Iodine and Adult IQ Meta-Analysis”, Gwern 2012
- “HP: Methods of Rationality Review Statistics”, Gwern 2012
- “Lunar Circadian Rhythms”, Gwern 2013
- “Internet WiFi Improvement”, Gwern 2016
- “Potassium Sleep Experiments”, Gwern 2012
- “Caffeine Wakeup Experiment”, Gwern 2013
- “Vitamin D Sleep Experiments”, Gwern 2012
- “Treadmill Desk Observations”, Gwern 2012
- “Candy Japan’s New Box A/B Test”, Gwern 2016
- “Bitter Melon for Blood Glucose”, Gwern 2015
- “Diet Variance: Soylent Study”, Gwern 2013
- “Who Wrote The Death Note Script?”, Gwern 2009
- “LessWrong and Cryonics”, Gwern 2013
- “Conscientiousness & Online Education”, Gwern 2012
- “Weather and My Productivity”, Gwern 2013
- “Hacker News Submission Analysis”, Gwern 2013
- “2013 LLLT Self-Experiment”, Gwern 2013
- “2012 Election Predictions”, Gwern 2012
- “Touhou Music by the Numbers”, Gwern 2013
- “2014 Spirulina Randomized Self-Experiment”, Gwern 2014
- “LW Anchoring Experiment”, Gwern 2012
- “Alerts Over Time”, Gwern 2013
- “2013 Lewis Meditation Results”, Gwern 2013
- “Resilient Haskell Software”, Gwern 2008
- Links
- “Estimating Distributional Models With Brms: Additive Distributional Models”, Bürkner 2019
- “Structural Equation Models As Computation Graphs”, Kesteren & Oberski 2019
- “Spearman’s Rho for the AMH Copula: a Beautiful Formula”, Machler 2014
- “Drugs 2.0 § Your Crack’s in the Post”, Power 2013
- “CRAN: Package BEST”
- “CRAN: Package BradleyTerry2”
- “CRAN: Package EnvStats”
- “CRAN: Package MASS”
- “CRAN: Package Abc”
- “CRAN: Package Animation”
- “CRAN: Package Bayesmeta”
- “Estimating Monotonic Effects With Brms”
- “CRAN: Package CensReg”
- “CRAN: Package Changepoint”
- “Introduction to Data.tree”
- “CRAN: Package Evd”
- “CRAN: Package Flexsurv”
- “CRAN: Package Insol”
- “CRAN: Package Lme4”
- “CRAN: Package Lmomco”
- “CRAN: Package MatrixStats”
- “
memoise” - “CRAN: Package Mice”
- “CRAN: Package Orderstats”
- “CRAN: Package Randcorr”
- “CRAN: Package RandomForest”
- “CRAN: Package RandomForestSRC”
- “CRAN: Package RandomSurvivalForest”
- “CRAN: Package
rgl” - “Package Survival”
- “CRAN: Package Txtplot”
- “Survival Analysis”
- “Create Elegant Data Visualizations Using the Grammar of Graphics”
- “Brms: an R Package for Bayesian Generalized Multivariate Non-Linear Multilevel Models Using Stan”, Bürkner 2026
- “3 Years of Daily Weight: What the Patterns Actually Are”
- Bayesian Data Analysis, Gelman et al 2026
- “Homepage”
- Miscellaneous
- Bibliography
See Also
Gwern
“How Many Shower Controls Are There?”, Gwern & Pro 2023
“Anti-Spaced Repetition for Serendipity”, Gwern 2017
“Oh Deer: Could Deer Evolve to Avoid Car Accidents?”, Gwern 2018
“Visualizing Active Learning Sample-Efficiency”, Gwern 2022
“Simulating ‘tail Collapse’ in R”, Gwern 2024
“Website Colors: Red vs Blue”, Gwern 2024
“Acne: a Good Quantified Self Topic”, Gwern 2019
“Statistical Notes”, Gwern 2014
“Gwern.net Website Traffic”, Gwern 2011
“Archiving URLs”, Gwern 2011
“Problem 14 Dynamic Programming Solutions”, Gwern et al 2022
“Calculating The Gaussian Expected Maximum”, Gwern 2016
“A/B Testing Long-Form Readability on Gwern.net”, Gwern 2012
“Dog Cloning For Special Forces: Breed All You Can Breed”, Gwern 2018
“Creatine Cognition Meta-Analysis”, Gwern 2013
“Common Selection Scenarios”, Gwern 2021
“Darknet Market Archives (2013–2015)”, Gwern 2013
“Magnesium Self-Experiments”, Gwern 2013
“Embryo Selection For Intelligence”, Gwern 2016
“The Most ‘Abandoned’ Books on GoodReads”, Gwern 2019
“Redshift Sleep Experiment”, Gwern 2012
“The Power of Twins: The Scottish Milk Experiment”, Gwern 2016
“Solving Pascal’s Mugging With Dynamic Programming”, Gwern 2019
“Genius Revisited Revisited”, Gwern 2016
“LSD Microdosing RCT”, Gwern 2012
“Catnip Immunity and Alternatives”, Gwern 2015
“Hafu Gender Ratios in Anime”, Gwern 2011
“DNM-Related Arrests, 2011–2015”, Gwern 2012
“Darknet Market Mortality Risks”, Gwern 2013
“Embryo Editing for Intelligence”, Gwern 2016
“Predicting Google Closures”, Gwern 2013
“History of Iterated Embryo Selection”, Gwern 2019
“The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
“World Catnip Surveys”, Gwern 2015
“Dual n-Back Meta-Analysis”, Gwern 2012
“Life Extension Cost-Benefits”, Gwern 2015
“Modafinil Community Survey”, Gwern 2015
“Bacopa Quasi-Experiment”, Gwern 2014
“ZMA Sleep Experiment”, Gwern 2017
“Zeo Sleep Self-Experiments”, Gwern 2010
“Long Bets As Charitable Giving Opportunity”, Gwern 2017
“When Should I Check The Mail?”, Gwern 2015
“CO2/ventilation Sleep Experiment”, Gwern 2016
“Iodine and Adult IQ Meta-Analysis”, Gwern 2012
“HP: Methods of Rationality Review Statistics”, Gwern 2012
“Lunar Circadian Rhythms”, Gwern 2013
“Internet WiFi Improvement”, Gwern 2016
“Potassium Sleep Experiments”, Gwern 2012
“Caffeine Wakeup Experiment”, Gwern 2013
“Vitamin D Sleep Experiments”, Gwern 2012
“Treadmill Desk Observations”, Gwern 2012
“Candy Japan’s New Box A/B Test”, Gwern 2016
“Bitter Melon for Blood Glucose”, Gwern 2015
“Diet Variance: Soylent Study”, Gwern 2013
“Who Wrote The Death Note Script?”, Gwern 2009
“LessWrong and Cryonics”, Gwern 2013
“Conscientiousness & Online Education”, Gwern 2012
“Weather and My Productivity”, Gwern 2013
“Hacker News Submission Analysis”, Gwern 2013
“2013 LLLT Self-Experiment”, Gwern 2013
“2012 Election Predictions”, Gwern 2012
“Touhou Music by the Numbers”, Gwern 2013
“2014 Spirulina Randomized Self-Experiment”, Gwern 2014
“LW Anchoring Experiment”, Gwern 2012
“Alerts Over Time”, Gwern 2013
“2013 Lewis Meditation Results”, Gwern 2013
“Resilient Haskell Software”, Gwern 2008
Links
“Estimating Distributional Models With Brms: Additive Distributional Models”, Bürkner 2019
Estimating Distributional Models with brms: Additive Distributional Models
“Structural Equation Models As Computation Graphs”, Kesteren & Oberski 2019
“Spearman’s Rho for the AMH Copula: a Beautiful Formula”, Machler 2014
“Drugs 2.0 § Your Crack’s in the Post”, Power 2013
“CRAN: Package BEST”
“CRAN: Package BradleyTerry2”
“CRAN: Package EnvStats”
“CRAN: Package MASS”
“CRAN: Package Abc”
“CRAN: Package Animation”
“CRAN: Package Bayesmeta”
“Estimating Monotonic Effects With Brms”
“CRAN: Package CensReg”
“CRAN: Package Changepoint”
“Introduction to Data.tree”
“CRAN: Package Evd”
“CRAN: Package Flexsurv”
“CRAN: Package Insol”
“CRAN: Package Lme4”
“CRAN: Package Lmomco”
“CRAN: Package MatrixStats”
“memoise”
“CRAN: Package Mice”
“CRAN: Package Orderstats”
“CRAN: Package Randcorr”
“CRAN: Package RandomForest”
“CRAN: Package RandomForestSRC”
“CRAN: Package RandomSurvivalForest”
“CRAN: Package rgl”
View External Link:
“Package Survival”
“CRAN: Package Txtplot”
“Survival Analysis”
“Create Elegant Data Visualizations Using the Grammar of Graphics”
Create Elegant Data Visualizations Using the Grammar of Graphics
“Brms: an R Package for Bayesian Generalized Multivariate Non-Linear Multilevel Models Using Stan”, Bürkner 2026
brms: an R package for Bayesian generalized multivariate non-linear multilevel models using Stan
“3 Years of Daily Weight: What the Patterns Actually Are”
Bayesian Data Analysis, Gelman et al 2026
“Homepage”
View PHP:
Miscellaneous
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
2013-power: “Drugs 2.0 § Your Crack’s in the Post”,