- See Also
-
Links
- “AudioLM: a Language Modeling Approach to Audio Generation”, Borsos et al 2022
- “Goodbye WaveNet—A Language Model for Raw Audio With Context of 1⁄2 Million Samples”, Verma 2022
- “Codified Audio Language Modeling Learns Useful Representations for Music Information Retrieval”, Castellon et al 2021
- “VideoGPT: Video Generation Using VQ-VAE and Transformers”, Yan et al 2021
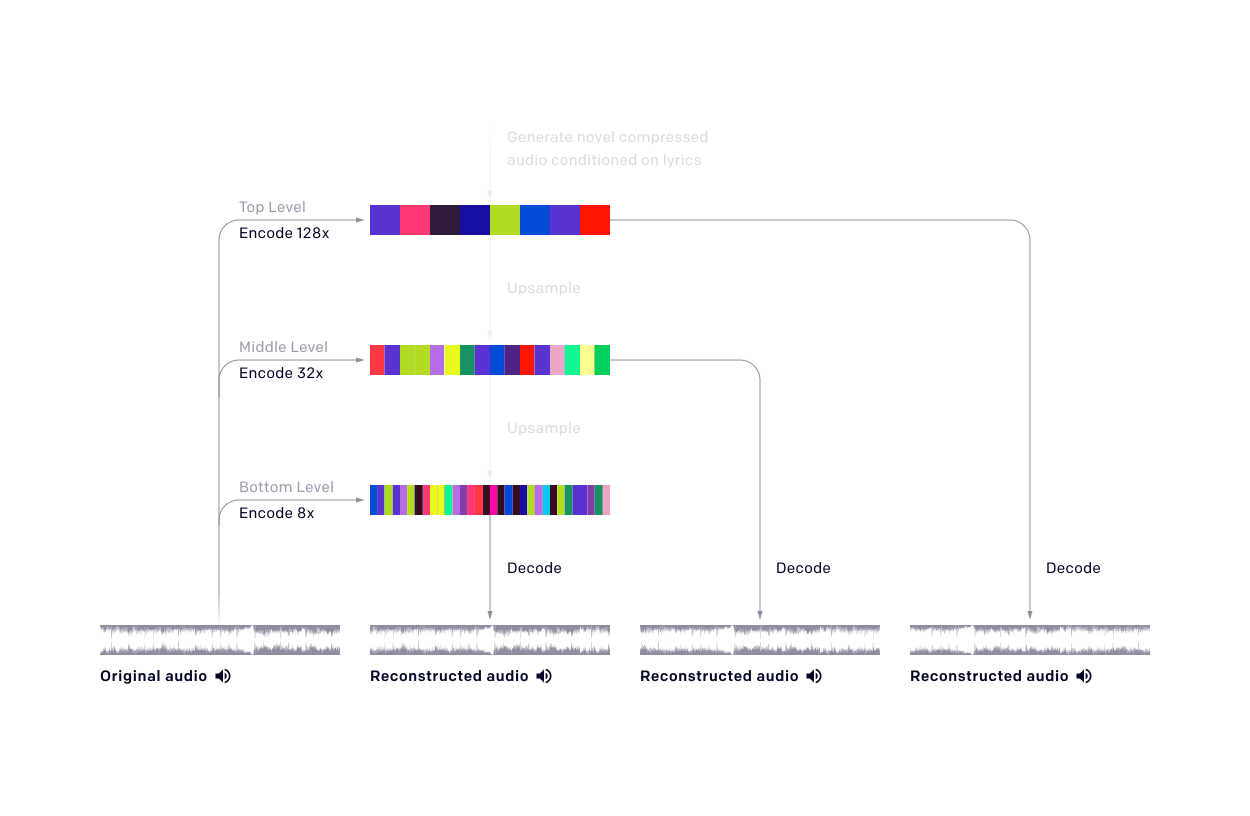
- “Jukebox: A Generative Model for Music”, Dhariwal et al 2020
- “Jukebox Sample Explorer”, OpenAI 2020
- “Jukebox: We’re Introducing Jukebox, a Neural Net That Generates Music, including Rudimentary Singing, As Raw Audio in a Variety of Genres and Artist Styles. We’re Releasing the Model Weights and Code, along With a Tool to Explore the Generated Samples.”, Dhariwal et al 2020
- “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
- “Generating Diverse High-Fidelity Images With VQ-VAE-2”, Razavi et al 2019
- “Generating Long Sequences With Sparse Transformers”, Child et al 2019
- “Code for ‘Jukebox: A Generative Model for Music’”
- “Making This Album With AI ‘Felt like Wandering in an Enormous Labyrinth’: Shadow Planet Is the Result of a Three-Way Collaboration between Humans and AI”
- Miscellaneous
- Link Bibliography
See Also
Links
“AudioLM: a Language Modeling Approach to Audio Generation”, Borsos et al 2022
“Goodbye WaveNet—A Language Model for Raw Audio With Context of 1⁄2 Million Samples”, Verma 2022
Goodbye WaveNet—A Language Model for Raw Audio with Context of 1⁄2 Million Samples
“Codified Audio Language Modeling Learns Useful Representations for Music Information Retrieval”, Castellon et al 2021
Codified audio language modeling learns useful representations for music information retrieval
“VideoGPT: Video Generation Using VQ-VAE and Transformers”, Yan et al 2021
“Jukebox: A Generative Model for Music”, Dhariwal et al 2020
“Jukebox Sample Explorer”, OpenAI 2020
“Jukebox: We’re Introducing Jukebox, a Neural Net That Generates Music, including Rudimentary Singing, As Raw Audio in a Variety of Genres and Artist Styles. We’re Releasing the Model Weights and Code, along With a Tool to Explore the Generated Samples.”, Dhariwal et al 2020
“The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
“Generating Diverse High-Fidelity Images With VQ-VAE-2”, Razavi et al 2019
“Generating Long Sequences With Sparse Transformers”, Child et al 2019
“Code for ‘Jukebox: A Generative Model for Music’”
“Making This Album With AI ‘Felt like Wandering in an Enormous Labyrinth’: Shadow Planet Is the Result of a Three-Way Collaboration between Humans and AI”
Miscellaneous
-
/doc/ai/music/2020-07-07-nshepperd-openaijukebox-gpt3-theuniverseisaglitch.mp3 -
/doc/ai/nn/transformer/gpt/jukebox/2020-05-02-gwern-meme-claspedarms-jukebox.png: -
/doc/ai/nn/transformer/gpt/jukebox/2020-dhariwal-openai-jukebox-vqvaetransformerarchitecture.png: -
/doc/ai/nn/transformer/gpt/jukebox/2020-dhariwal-openai-jukebox-vqvaetransformerarchitecture.svg: -
https://colab.research.google.com/drive/1ZrF6fJFMUaqloHJP1PqJTxMSJxKd-BVg -
https://colab.research.google.com/drive/1fQ6SXdO8fIMQ2c8t-ziAJIrAhJxcZT9O -
https://onezero.medium.com/co-writing-an-album-with-an-ai-880317103476: -
https://ooo.ghostbows.ooo/about/:View External Link:
-
https://www.youtube.com/watch?v=YESuww3zU2I&list=PLaa32nLgVvrkyveSU8rtD4l02eYQtRlWA&index=2:
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://arxiv.org/abs/2206.08297: “Goodbye WaveNet—A Language Model for Raw Audio With Context of 1⁄2 Million Samples”, Prateek Verma -
https://arxiv.org/abs/2104.10157: “VideoGPT: Video Generation Using VQ-VAE and Transformers”, Wilson Yan, Yunzhi Zhang, Pieter Abbeel, Aravind Srinivas -
https://cdn.openai.com/papers/jukebox.pdf: “Jukebox: A Generative Model for Music”, Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever -
https://openai.com/research/jukebox: “Jukebox: We’re Introducing Jukebox, a Neural Net That Generates Music, including Rudimentary Singing, As Raw Audio in a Variety of Genres and Artist Styles. We’re Releasing the Model Weights and Code, along With a Tool to Explore the Generated Samples.”, Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever -
https://www.technologyreview.com/2020/02/17/844721/ai-openai-moonshot-elon-musk-sam-altman-greg-brockman-messy-secretive-reality/: “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Karen Hao