‘DALL·E’ directory
- See Also
- Gwern
- Links
- “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
- “On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021
- “Decision Transformer: Reinforcement Learning via Sequence Modeling”, Chen et al 2021
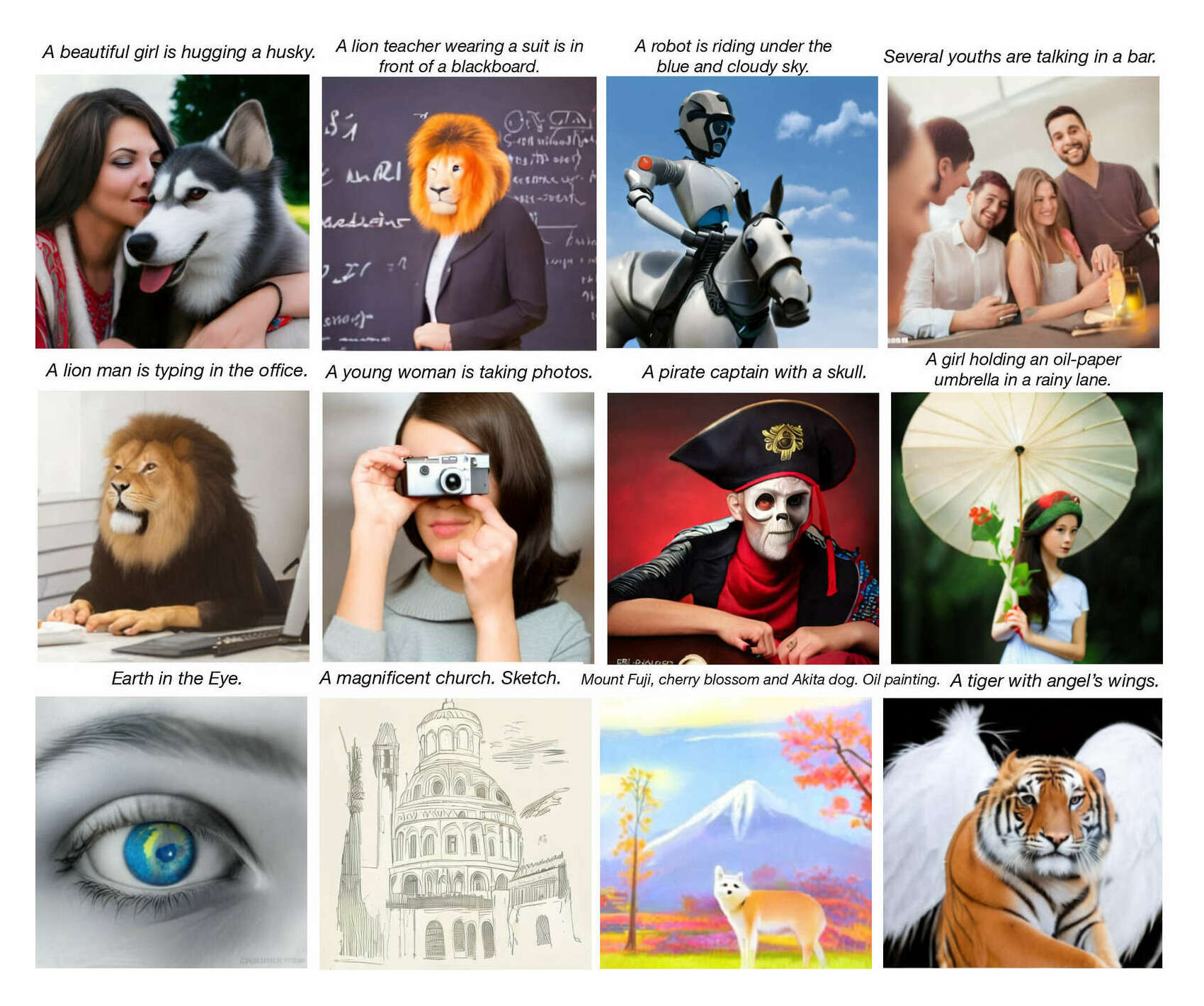
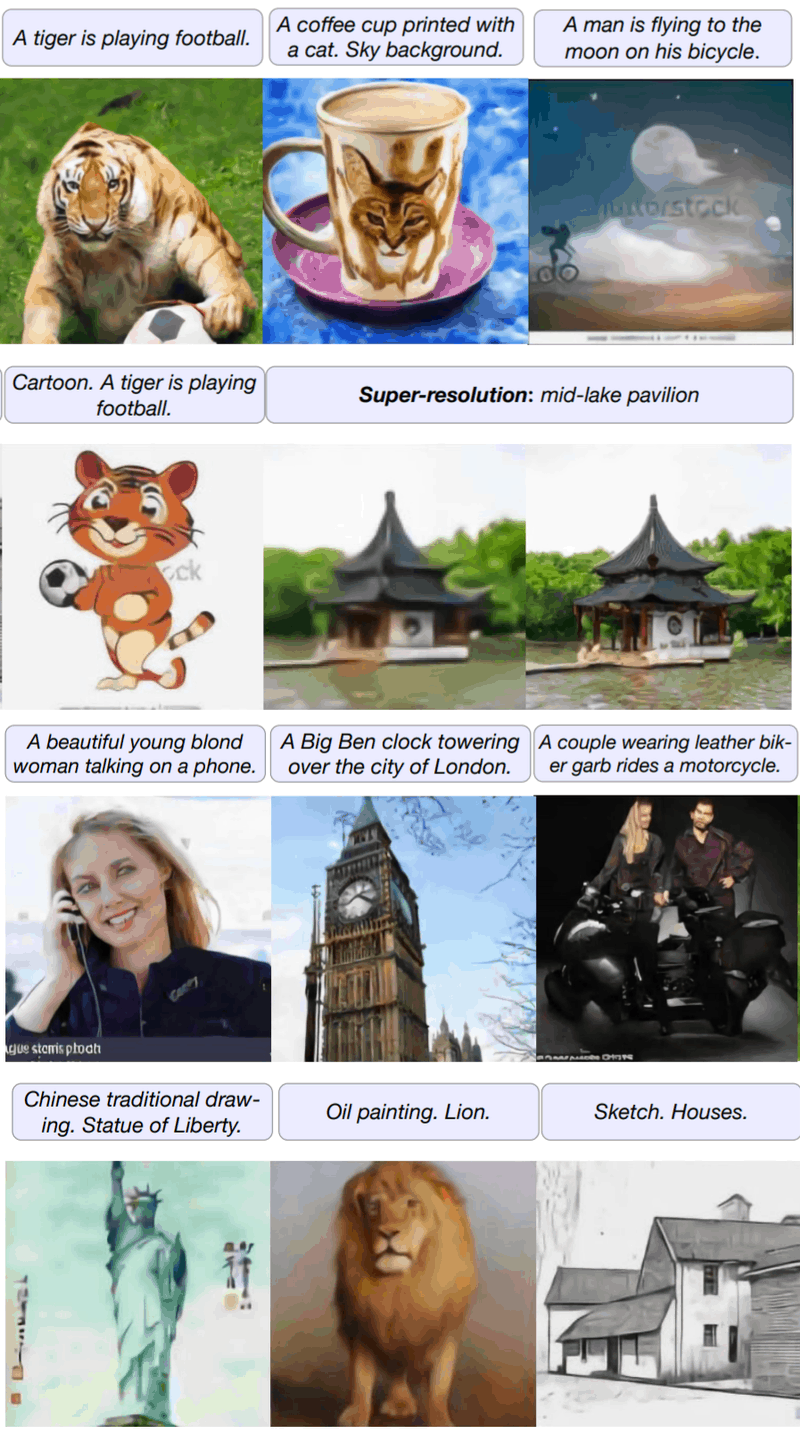
- “Zero-Shot Text-To-Image Generation”, Ramesh et al 2021
- “Ben Barry”
- “DALL·E 2: Emerging Content Category Breakdown”
- “DALL·E 2: Recombinant Art & Design”
- “DALL·E 2—Unofficial Natural Language Image Editing, Art Critique Survey”
- “Make-A-Scene: Scene-Based Text-To-Image Generation With Human Priors”
- “Open-AI’s DALL-E for Large Scale Training in Mesh-Tensorflow.”
- “Combination of OpenAI GLIDE and Latent Diffusion”
- “My-Colab-Experiments/Simple_ruDALLE_inference_[Supports_v1_0_0].ipynb”
- “Text-To-Image Generation. The Repo for NeurIPS 2021 Paper "CogView: Mastering Text-To-Image Generation via Transformers".”
- “CLIP Implementation for Russian Language”
- “Generate Images from Texts. In Russian”
- “RUDOLPH: One Hyper-Tasking Transformer Can Be Creative As DALL-E and GPT-3 and Smart As CLIP”
- “A Human-In-The-Loop Workflow for Creating HD Images from Text”
- “Kakaobrain/mindall-E: PyTorch Implementation of a 1.3B Text-To-Image Generation Model Trained on 14 Million Image-Text Pairs”
- “Minimaxir/ai-Generated-Pokemon-Rudalle: Python Script to Preprocess Images of All Pokémon to Finetune RuDALL-E”
- “Neonbjb/tortoise-Tts: A Multi-Voice TTS System Trained With an Emphasis on Quality”
- “Openai/DALL-E: PyTorch Package for the Discrete VAE Used for DALL”
- “Wordalle—A Hugging Face Space”
- “Imagen Video”
- “Pokemon AI: Gotta Create’Em All!”, Eloie 2026
- “Sentence Embeddings Have a Problem, the Reason Sometimes Dall-E2 Fails”
- “CogView 以文生图”
- “This Image Does Not Exist”
- “MASSIVE 💥 DALL·E 2 ANIME ⚡︎ KEYWORDS + MODIFIERS LIST ★ : Haaaaven”
- “The Daily Wrong”
- “A Guide To Asking Robots To Design Stained Glass Windows”, Alexander 2026
- “Kakao Brain Unveils Image-Generating AI Model”
- “What DALL·E 2 Can and Cannot Do”
- “My Deepfake DALL·E 2 Vacation Photos Passed the Turing Test”
- “We Asked 100 Humans to Draw the DALL”
- “AI Art, Explained”
- Wikipedia (2)
- Miscellaneous
- Bibliography
See Also
Gwern
“Research Ideas”, Gwern 2017
Links
“LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
“On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021
“Decision Transformer: Reinforcement Learning via Sequence Modeling”, Chen et al 2021
Decision Transformer: Reinforcement Learning via Sequence Modeling
“Zero-Shot Text-To-Image Generation”, Ramesh et al 2021
“Ben Barry”
View External Link:
“DALL·E 2: Emerging Content Category Breakdown”
“DALL·E 2: Recombinant Art & Design”
“DALL·E 2—Unofficial Natural Language Image Editing, Art Critique Survey”
DALL·E 2—Unofficial Natural Language Image Editing, Art Critique Survey
“Make-A-Scene: Scene-Based Text-To-Image Generation With Human Priors”
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
“Open-AI’s DALL-E for Large Scale Training in Mesh-Tensorflow.”
Open-AI’s DALL-E for large scale training in mesh-tensorflow.
“Combination of OpenAI GLIDE and Latent Diffusion”
“My-Colab-Experiments/Simple_ruDALLE_inference_[Supports_v1_0_0].ipynb”
my-colab-experiments/Simple_ruDALLE_inference_[supports_v1_0_0].ipynb
“Text-To-Image Generation. The Repo for NeurIPS 2021 Paper "CogView: Mastering Text-To-Image Generation via Transformers".”
“CLIP Implementation for Russian Language”
“Generate Images from Texts. In Russian”
“RUDOLPH: One Hyper-Tasking Transformer Can Be Creative As DALL-E and GPT-3 and Smart As CLIP”
RUDOLPH: One Hyper-Tasking Transformer can be creative as DALL-E and GPT-3 and smart as CLIP
“A Human-In-The-Loop Workflow for Creating HD Images from Text”
A Human-in-the-Loop workflow for creating HD images from text
“Kakaobrain/mindall-E: PyTorch Implementation of a 1.3B Text-To-Image Generation Model Trained on 14 Million Image-Text Pairs”
“Minimaxir/ai-Generated-Pokemon-Rudalle: Python Script to Preprocess Images of All Pokémon to Finetune RuDALL-E”
“Neonbjb/tortoise-Tts: A Multi-Voice TTS System Trained With an Emphasis on Quality”
neonbjb/tortoise-tts: A multi-voice TTS system trained with an emphasis on quality
“Openai/DALL-E: PyTorch Package for the Discrete VAE Used for DALL”
openai/DALL-E: PyTorch package for the discrete VAE used for DALL
“Wordalle—A Hugging Face Space”
“Imagen Video”
“Pokemon AI: Gotta Create’Em All!”, Eloie 2026
“Sentence Embeddings Have a Problem, the Reason Sometimes Dall-E2 Fails”
Sentence Embeddings have a problem, the reason sometimes Dall-E2 fails
“CogView 以文生图”
“This Image Does Not Exist”
“MASSIVE 💥 DALL·E 2 ANIME ⚡︎ KEYWORDS + MODIFIERS LIST ★ : Haaaaven”
MASSIVE 💥 DALL·E 2 ANIME ⚡︎ KEYWORDS + MODIFIERS LIST ★ : haaaaven
“The Daily Wrong”
View External Link:
https://web.archive.org/web/20230601024130/https://dailywrong.com/
“A Guide To Asking Robots To Design Stained Glass Windows”, Alexander 2026
“Kakao Brain Unveils Image-Generating AI Model”
“What DALL·E 2 Can and Cannot Do”
“My Deepfake DALL·E 2 Vacation Photos Passed the Turing Test”
“We Asked 100 Humans to Draw the DALL”
“AI Art, Explained”
Wikipedia (2)
Miscellaneous
/doc/ai/nn/transformer/gpt/dall-e/2022-ramesh-figure16-dalle2badtextsamplessayingdeeplearning.png/doc/ai/nn/transformer/gpt/dall-e/2021-ding-figure1-cogviewcherrypickedsamples.png/doc/ai/nn/transformer/gpt/dall-e/2021-ding-figure5-randomrankedcogviewsamples.png/doc/ai/nn/transformer/gpt/dall-e/2021-openai-dalle-textpromptexamples.png/doc/ai/nn/transformer/gpt/dall-e/2021-zhang-figure5-ernievilstyleexamples.png/doc/ai/nn/transformer/gpt/dall-e/2021-zhang-figure6-ernievilgchinesepoetrygeneratedimages.pnghttp://dallery.gallery/wp-content/uploads/2022/07/The-DALL%C2%B7E-2-prompt-book.pdfhttps://ai.meta.com/blog/greater-creative-control-for-ai-image-generation/https://colab.research.google.com/drive/1Gg7-c7LrUTNfQ-Fk-BVNCe9kvedZZsAhhttps://colab.research.google.com/drive/1Tb7J4PvvegWOybPfUubl5O7m5I24CBg5https://colab.research.google.com/github/ouhenio/minDALL-E_notebook/blob/main/minDALLE.ipynbhttps://jacobmartins.com/posts/how-i-used-dalle2-to-generate-the-logo-for-octosql/https://mirror.xyz/herndondryhurst.eth/eZG6mucl9fqU897XvJs0vUUMnm5OITpSWN8S-6KWamYhttps://ml.berkeley.edu/blog/posts/dalle2/View External Link:
https://ml.berkeley.edu/blog/posts/vq-vae/View External Link:
https://openai.com/blog/dall-e-api-now-available-in-public-beta/https://publicdomainreview.org/essay/chaos-bewitched-moby-dick-and-aihttps://www.reddit.com/r/AnimeResearch/comments/txvu3a/anime_x_dalle_2_thread/https://www.reddit.com/r/MachineLearning/comments/qmzy8a/rudalle_model_is_opensource_p/https://www.reddit.com/r/MachineLearning/comments/vx89nj/p_dalle_mini_mega_demo_and_production_api/https://www.reddit.com/r/MediaSynthesis/comments/rc9ft8/nsfw_rudalle_texttoimage_model_finetuned_to/https://www.reddit.com/r/MediaSynthesis/comments/rxpz4d/an_experiment_with_openais_glide_apples_in/https://www.reddit.com/r/bigsleep/comments/ql9n81/new_texttoimage_ai_models_rudalle_example_from/https://www.reddit.com/r/dalle2/comments/11oiqrb/classic_anime_characters_made_using_the_new/https://www.reddit.com/r/dalle2/comments/11zq37j/the_legend_of_zelda_made_using_experimental_dalle2/https://www.reddit.com/r/dalle2/comments/uwb3cz/the_first_image_in_this_video_was_created_from/https://www.reddit.com/r/dalle2/comments/v1swsh/how_to_use_edit_mode_aka_inpainting_to_change/https://www.reddit.com/r/pokemon/comments/rgmyxp/i_trained_an_ai_on_all_the_official_pokemon/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2111.02114#laion: “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”,https://arxiv.org/abs/2108.07258: “On the Opportunities and Risks of Foundation Models”,https://sites.google.com/berkeley.edu/decision-transformer: “Decision Transformer: Reinforcement Learning via Sequence Modeling”,