- See Also
-
Links
- “Generative Models: What Do They Know? Do They Know Things? Let’s Find Out!”, Du et al 2023
- “Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models”, Gandikota et al 2023
- “Rosetta Neurons: Mining the Common Units in a Model Zoo”, Dravid et al 2023
- “Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”, Stein et al 2023
- “Drag Your GAN (DragGAN): Interactive Point-Based Manipulation on the Generative Image Manifold”, Pan et al 2023
- “Realistic Face Reconstruction from Deep Embeddings”, Vendrow & Vendrow 2023
- “SAN: Inducing Metrizability of GAN With Discriminative Normalized Linear Layer”, Takida et al 2023
- “StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-To-Image Synthesis”, Sauer et al 2023
- “Brain2GAN: Reconstructing Perceived Faces from the Primate Brain via StyleGAN3”, Anonymous 2022
- “Fast Text2StyleGAN: Text-Free Learning of a Natural Language Interface for Pretrained Face Generators”, Du et al 2022
- “User-Controllable Latent Transformer for StyleGAN Image Layout Editing”, Endo 2022
- “Generator Knows What Discriminator Should Learn in Unconditional GANs”, Lee et al 2022
- “CelebV-HQ: A Large-Scale Video Facial Attributes Dataset”, Zhu et al 2022
- “InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images”, Li et al 2022
- “BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Lee et al 2022
- “Diffusion-GAN: Training GANs With Diffusion”, Wang et al 2022
- “StyleGAN-Human: A Data-Centric Odyssey of Human Generation”, Fu et al 2022
- “Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values”, Humayun et al 2022
- “State-Of-The-Art in the Architecture, Methods and Applications of StyleGAN”, Bermano et al 2022
- “AI-Synthesized Faces Are Indistinguishable from Real Faces and More Trustworthy”, Nightingale & Farid 2022
- “StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Sauer et al 2022
- “StyleGAN-V: A Continuous Video Generator With the Price, Image Quality and Perks of StyleGAN2”, Skorokhodov et al 2021
- “Efficient Geometry-Aware 3D Generative Adversarial Networks”, Chan et al 2021
- “CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions”, Abdal et al 2021
- “HyperStyle: StyleGAN Inversion With HyperNetworks for Real Image Editing”, Alaluf et al 2021
- “LAFITE: Towards Language-Free Training for Text-To-Image Generation”, Zhou et al 2021
- “Improving Visual Quality of Image Synthesis by A Token-Based Generator With Transformers”, Zeng et al 2021
- “StyleCLIPDraw: Coupling Content and Style in Text-To-Drawing Synthesis”, Schaldenbrand et al 2021
- “StyleAlign: Analysis and Applications of Aligned StyleGAN Models”, Wu et al 2021
- “Pose With Style: Detail-Preserving Pose-Guided Image Synthesis With Conditional StyleGAN”, AlBahar et al 2021
- “Controlled GAN-Based Creature Synthesis via a Challenging Game Art Dataset—Addressing the Noise-Latent Trade-Off”, Vavilala & Forsyth 2021
- “LARGE: Latent-Based Regression through GAN Semantics”, Nitzan et al 2021
- “Alias-Free Generative Adversarial Networks”, Karras et al 2021
- “Lazy, a Tool for Running Things in Idle Time”, nshepperd 2021
- “Exploiting Spatial Dimensions of Latent in GAN for Real-Time Image Editing”, Kim et al 2021
- “Explaining in Style: Training a GAN to Explain a Classifier in StyleSpace”, Lang et al 2021
- “DatasetGAN: Efficient Labeled Data Factory With Minimal Human Effort”, Zhang et al 2021
- “Labels4Free: Unsupervised Segmentation Using StyleGAN”, Abdal et al 2021
- “Repurposing GANs for One-Shot Semantic Part Segmentation”, Tritrong et al 2021
- “Generative Adversarial Transformers”, Hudson & Zitnick 2021
- “Generating Images from Caption and vice Versa via CLIP-Guided Generative Latent Space Search”, Galatolo et al 2021
- “Not-So-BigGAN: Generating High-Fidelity Images on Small Compute With Wavelet-Based Super-Resolution”, Han et al 2020
- “Rewriting a Deep Generative Model”, Bau et al 2020
- “Differentiable Augmentation for Data-Efficient GAN Training”, Zhao et al 2020
- “StyleGAN2-ADA: Training Generative Adversarial Networks With Limited Data”, Karras et al 2020
- “On Data Augmentation for GAN Training”, Tran et al 2020
- “Image Augmentations for GAN Training”, Zhao et al 2020
- “Ambigrammatic Figures: 55 Grotesque Ambigrams”, Levin & Huang 2020
- “Practical Aspects of StyleGAN2 Training”, l4rz 2020
- “GANSpace: Discovering Interpretable GAN Controls”, Härkönen et al 2020
- “Evolving Normalization-Activation Layers”, Liu et al 2020
- “Top-K Training of GANs: Improving GAN Performance by Throwing Away Bad Samples”, Sinha et al 2020
- “Unsupervised Discovery of Interpretable Directions in the GAN Latent Space”, Voynov & Babenko 2020
- “Conditional Image Generation and Manipulation for User-Specified Content § Pg3”, Stap 2020 (page 3)
- “Analyzing and Improving the Image Quality of StyleGAN”, Karras et al 2019
- “Detecting GAN Generated Errors”, Zhu et al 2019
- “Stabilizing Generative Adversarial Networks: A Survey”, Wiatrak et al 2019
- “Interpreting the Latent Space of GANs for Semantic Face Editing”, Shen et al 2019
- “On the "STeerability" of Generative Adversarial Networks”, Jahanian et al 2019
- “Style Generator Inversion for Image Enhancement and Animation”, Gabbay & Hoshen 2019
- “NoGAN: Decrappification, DeOldification, and Super Resolution”, Antic et al 2019
- “Improved Precision and Recall Metric for Assessing Generative Models”, Kynkäänniemi et al 2019
- “Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?”, Abdal et al 2019
- “The Machine As Author”, Gervais 2019
- “MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks”, Karnewar & Wang 2019
- “This Person Does Not Exist”, Wang 2019
- “FIGR: Few-Shot Image Generation With Reptile”, Clouâtre & Demers 2019
- “A Style-Based Generator Architecture for Generative Adversarial Networks”, Karras et al 2018
- “GAN Dissection: Visualizing and Understanding Generative Adversarial Networks”, Bau et al 2018
- “Discriminator Rejection Sampling”, Azadi et al 2018
- “On Self Modulation for Generative Adversarial Networks”, Chen et al 2018
- “Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow”, Peng et al 2018
- “Inverting The Generator Of A Generative Adversarial Network (II)”, Creswell & Bharath 2018
- “Megapixel Size Image Creation Using Generative Adversarial Networks”, Marchesi 2017
- “AdaIN: Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization”, Huang & Belongie 2017
- “StackGAN: Text to Photo-Realistic Image Synthesis With Stacked Generative Adversarial Networks”, Zhang et al 2016
- “Ukiyo-E Search”, Resig 2013
- “Generating New Watch Designs With StyleGAN”
- “This President Does Not Exist: Generating Artistic Portraits of Donald Trump Using StyleGAN Transfer Learning: Theory and Implementation in Tensorflow”
- “Network-Snapshot-057891.pkl”
- “TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs”, TRC 2024
- “StyleGAN for Evil: Trypophobia and Clockwork Oranging”
- “How I Learned to Stop Worrying and Love Transfer Learning”
- “Removing Blob Artifact from StyleGAN Generations without Retraining. Inspired by StyleGAN2”
- “I Trained a StyleGAN on Images of Butterflies from the Natural History Museum in London.”
- “Random Walk StyleGAN”
- Sort By Magic
- Miscellaneous
- Link Bibliography
See Also
Links
“Generative Models: What Do They Know? Do They Know Things? Let’s Find Out!”, Du et al 2023
Generative Models: What do they know? Do they know things? Let’s find out!
“Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models”, Gandikota et al 2023
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
“Rosetta Neurons: Mining the Common Units in a Model Zoo”, Dravid et al 2023
“Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”, Stein et al 2023
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
“Drag Your GAN (DragGAN): Interactive Point-Based Manipulation on the Generative Image Manifold”, Pan et al 2023
Drag Your GAN (DragGAN): Interactive Point-based Manipulation on the Generative Image Manifold
“Realistic Face Reconstruction from Deep Embeddings”, Vendrow & Vendrow 2023
“SAN: Inducing Metrizability of GAN With Discriminative Normalized Linear Layer”, Takida et al 2023
SAN: Inducing Metrizability of GAN with Discriminative Normalized Linear Layer
“StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-To-Image Synthesis”, Sauer et al 2023
StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
“Brain2GAN: Reconstructing Perceived Faces from the Primate Brain via StyleGAN3”, Anonymous 2022
Brain2GAN: Reconstructing perceived faces from the primate brain via StyleGAN3
“Fast Text2StyleGAN: Text-Free Learning of a Natural Language Interface for Pretrained Face Generators”, Du et al 2022
“User-Controllable Latent Transformer for StyleGAN Image Layout Editing”, Endo 2022
User-Controllable Latent Transformer for StyleGAN Image Layout Editing
“Generator Knows What Discriminator Should Learn in Unconditional GANs”, Lee et al 2022
Generator Knows What Discriminator Should Learn in Unconditional GANs
“CelebV-HQ: A Large-Scale Video Facial Attributes Dataset”, Zhu et al 2022
“InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images”, Li et al 2022
InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images
“BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Lee et al 2022
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
“Diffusion-GAN: Training GANs With Diffusion”, Wang et al 2022
“StyleGAN-Human: A Data-Centric Odyssey of Human Generation”, Fu et al 2022
“Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values”, Humayun et al 2022
“State-Of-The-Art in the Architecture, Methods and Applications of StyleGAN”, Bermano et al 2022
State-of-the-Art in the Architecture, Methods and Applications of StyleGAN
“AI-Synthesized Faces Are Indistinguishable from Real Faces and More Trustworthy”, Nightingale & Farid 2022
AI-synthesized faces are indistinguishable from real faces and more trustworthy
“StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Sauer et al 2022
“StyleGAN-V: A Continuous Video Generator With the Price, Image Quality and Perks of StyleGAN2”, Skorokhodov et al 2021
StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
“Efficient Geometry-Aware 3D Generative Adversarial Networks”, Chan et al 2021
“CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions”, Abdal et al 2021
CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
“HyperStyle: StyleGAN Inversion With HyperNetworks for Real Image Editing”, Alaluf et al 2021
HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
“LAFITE: Towards Language-Free Training for Text-To-Image Generation”, Zhou et al 2021
LAFITE: Towards Language-Free Training for Text-to-Image Generation
“Improving Visual Quality of Image Synthesis by A Token-Based Generator With Transformers”, Zeng et al 2021
Improving Visual Quality of Image Synthesis by A Token-based Generator with Transformers
“StyleCLIPDraw: Coupling Content and Style in Text-To-Drawing Synthesis”, Schaldenbrand et al 2021
StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
“StyleAlign: Analysis and Applications of Aligned StyleGAN Models”, Wu et al 2021
StyleAlign: Analysis and Applications of Aligned StyleGAN Models
“Pose With Style: Detail-Preserving Pose-Guided Image Synthesis With Conditional StyleGAN”, AlBahar et al 2021
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
“Controlled GAN-Based Creature Synthesis via a Challenging Game Art Dataset—Addressing the Noise-Latent Trade-Off”, Vavilala & Forsyth 2021
“LARGE: Latent-Based Regression through GAN Semantics”, Nitzan et al 2021
“Alias-Free Generative Adversarial Networks”, Karras et al 2021
“Lazy, a Tool for Running Things in Idle Time”, nshepperd 2021
“Exploiting Spatial Dimensions of Latent in GAN for Real-Time Image Editing”, Kim et al 2021
Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
“Explaining in Style: Training a GAN to Explain a Classifier in StyleSpace”, Lang et al 2021
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
“DatasetGAN: Efficient Labeled Data Factory With Minimal Human Effort”, Zhang et al 2021
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
“Labels4Free: Unsupervised Segmentation Using StyleGAN”, Abdal et al 2021
“Repurposing GANs for One-Shot Semantic Part Segmentation”, Tritrong et al 2021
“Generative Adversarial Transformers”, Hudson & Zitnick 2021
“Generating Images from Caption and vice Versa via CLIP-Guided Generative Latent Space Search”, Galatolo et al 2021
Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
“Not-So-BigGAN: Generating High-Fidelity Images on Small Compute With Wavelet-Based Super-Resolution”, Han et al 2020
not-so-BigGAN: Generating High-Fidelity Images on Small Compute with Wavelet-based Super-Resolution
“Rewriting a Deep Generative Model”, Bau et al 2020
“Differentiable Augmentation for Data-Efficient GAN Training”, Zhao et al 2020
“StyleGAN2-ADA: Training Generative Adversarial Networks With Limited Data”, Karras et al 2020
StyleGAN2-ADA: Training Generative Adversarial Networks with Limited Data
“On Data Augmentation for GAN Training”, Tran et al 2020
“Image Augmentations for GAN Training”, Zhao et al 2020
“Ambigrammatic Figures: 55 Grotesque Ambigrams”, Levin & Huang 2020
“Practical Aspects of StyleGAN2 Training”, l4rz 2020
“GANSpace: Discovering Interpretable GAN Controls”, Härkönen et al 2020
“Evolving Normalization-Activation Layers”, Liu et al 2020
“Top-K Training of GANs: Improving GAN Performance by Throwing Away Bad Samples”, Sinha et al 2020
Top-K Training of GANs: Improving GAN Performance by Throwing Away Bad Samples
“Unsupervised Discovery of Interpretable Directions in the GAN Latent Space”, Voynov & Babenko 2020
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
“Conditional Image Generation and Manipulation for User-Specified Content § Pg3”, Stap 2020 (page 3)
Conditional Image Generation and Manipulation for User-Specified Content § pg3:
“Analyzing and Improving the Image Quality of StyleGAN”, Karras et al 2019
“Detecting GAN Generated Errors”, Zhu et al 2019
“Stabilizing Generative Adversarial Networks: A Survey”, Wiatrak et al 2019
“Interpreting the Latent Space of GANs for Semantic Face Editing”, Shen et al 2019
Interpreting the Latent Space of GANs for Semantic Face Editing
“On the "STeerability" of Generative Adversarial Networks”, Jahanian et al 2019
“Style Generator Inversion for Image Enhancement and Animation”, Gabbay & Hoshen 2019
Style Generator Inversion for Image Enhancement and Animation
“NoGAN: Decrappification, DeOldification, and Super Resolution”, Antic et al 2019
NoGAN: Decrappification, DeOldification, and Super Resolution
“Improved Precision and Recall Metric for Assessing Generative Models”, Kynkäänniemi et al 2019
Improved Precision and Recall Metric for Assessing Generative Models
“Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?”, Abdal et al 2019
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?
“The Machine As Author”, Gervais 2019
“MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks”, Karnewar & Wang 2019
MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks
“This Person Does Not Exist”, Wang 2019
“FIGR: Few-Shot Image Generation With Reptile”, Clouâtre & Demers 2019
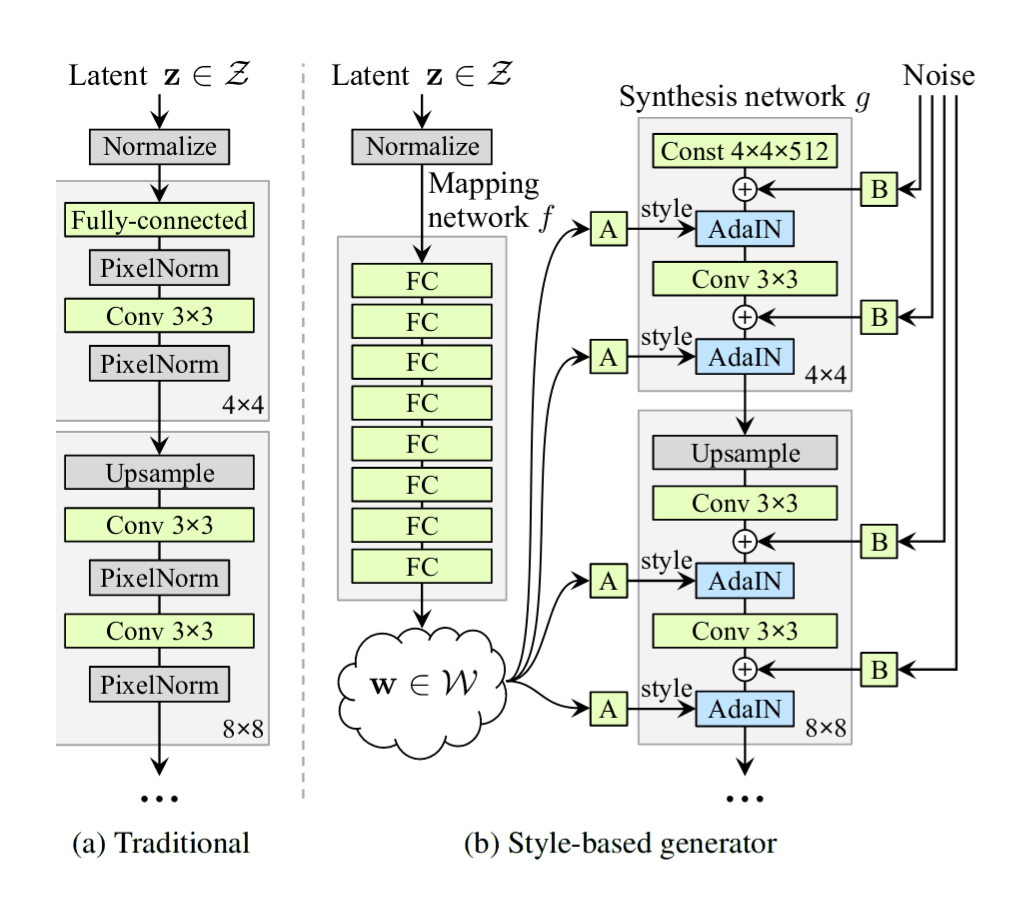
“A Style-Based Generator Architecture for Generative Adversarial Networks”, Karras et al 2018
A Style-Based Generator Architecture for Generative Adversarial Networks
“GAN Dissection: Visualizing and Understanding Generative Adversarial Networks”, Bau et al 2018
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
“Discriminator Rejection Sampling”, Azadi et al 2018
“On Self Modulation for Generative Adversarial Networks”, Chen et al 2018
“Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow”, Peng et al 2018
“Inverting The Generator Of A Generative Adversarial Network (II)”, Creswell & Bharath 2018
Inverting The Generator Of A Generative Adversarial Network (II)
“Megapixel Size Image Creation Using Generative Adversarial Networks”, Marchesi 2017
Megapixel Size Image Creation using Generative Adversarial Networks
“AdaIN: Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization”, Huang & Belongie 2017
AdaIN: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
“StackGAN: Text to Photo-Realistic Image Synthesis With Stacked Generative Adversarial Networks”, Zhang et al 2016
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
“Ukiyo-E Search”, Resig 2013
“Generating New Watch Designs With StyleGAN”
“This President Does Not Exist: Generating Artistic Portraits of Donald Trump Using StyleGAN Transfer Learning: Theory and Implementation in Tensorflow”
“Network-Snapshot-057891.pkl”
“TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs”, TRC 2024
“StyleGAN for Evil: Trypophobia and Clockwork Oranging”
“How I Learned to Stop Worrying and Love Transfer Learning”
“Removing Blob Artifact from StyleGAN Generations without Retraining. Inspired by StyleGAN2”
Removing blob artifact from StyleGAN generations without retraining. Inspired by StyleGAN2
“I Trained a StyleGAN on Images of Butterflies from the Natural History Museum in London.”
I trained a StyleGAN on images of butterflies from the Natural History Museum in London.
“Random Walk StyleGAN”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
generative-models
generative-synthesis
latent-control
scalable-gan
stylegan
latent-editing
Miscellaneous
-
/doc/ai/nn/gan/stylegan/2021-karras-aliasfreegan-afhq-3-interpolation.mp4: -
/doc/ai/nn/gan/stylegan/2020-05-05-levin-ambigrammaticfigures-combinedexamples.mp4: -
/doc/ai/nn/gan/stylegan/2020-05-05-tjukanov-mapdreameraicartography.html -
/doc/ai/nn/gan/stylegan/2020-03-26-shawnpresser-stylegan2-imagenet-run52-1394688-interpolation-7.mp4: -
/doc/ai/anime/danbooru/2019-02-11-stylegan-asuka-handselectedsamples.zip -
/doc/ai/anime/danbooru/2019-02-10-stylegan-holo-handselectedsamples.zip -
/doc/ai/anime/danbooru/2019-02-06-progan-danbooru2017-faces-randomsamples.tar -
/doc/ai/nn/gan/stylegan/2019-abdal-figure1-ffhqembeddingsartcatsdogscars.png: -
/doc/ai/anime/danbooru/2018-09-22-progan-holofaces-topdecile.tar.xz -
/doc/ai/nn/gan/stylegan/2018-karras-stylegan-figure1-styleganarchitecture.png -
/doc/ai/nn/gan/stylegan/2017-royer-cartoonset-randomsamples.png: -
http://www.highdimensionalcoconuts.com/Work/GenerativeImages/GenerativeFruit/generative_fruit.html -
https://blog.metaphysic.ai/the-road-to-realistic-full-body-deepfakes/ -
https://digital-thinking.de/watchgan-advancing-generated-watch-images-with-stylegans/ -
https://github.com/HighCWu/stylegan2-pytorch2paddle/blob/tadne/convert_weight.py -
https://github.com/NVlabs/stylegan/blob/master/generate_figures.py -
https://github.com/NVlabs/stylegan/blob/master/pretrained_example.py -
https://github.com/NVlabs/stylegan/blob/master/training/training_loop.py#L112 -
https://github.com/NVlabs/stylegan/blob/master/training/training_loop.py#L136 -
https://github.com/Puzer/stylegan-encoder-encoder/blob/master/Play_with_latent_directions.ipynb -
https://github.com/ak9250/stylegan-art/blob/master/styleganportraits.ipynb -
https://github.com/aydao/stylegan2-surgery/tree/model-release -
https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset -
https://github.com/halcy/stylegan/blob/master/Stylegan-Generate-Encode.ipynb -
https://github.com/martinarjovsky/WassersteinGAN/issues/2#issuecomment-278710552 -
https://github.com/taziksh/hayasaka.ai/blob/master/StyleGAN2_Tazik_25GB_RAM.ipynb -
https://github.com/xunings/styleganime2/blob/master/misc/ranker.py -
https://nyx-ai.github.io/stylegan2-flax-tpu/:View HTML (19MB):
/doc/www/nyx-ai.github.io/a95f4c42e4300722b1adcf0f494ac943437fcc56.html -
https://towardsdatascience.com/creating-new-scripts-with-stylegan-c16473a50fd0 -
https://twitter.com/RiversHaveWings/status/1516928082262650881 -
https://www.deviantart.com/caji9i/art/stylegan-neural-ahegao-842847987 -
https://www.kaggle.com/code/andy8744/generating-ganyu-from-trained-model/notebook -
https://www.kaggle.com/datasets/andy8744/rezero-rem-anime-faces-for-gan-training -
https://www.reddit.com/r/MachineLearning/comments/akbc11/p_tag_estimation_for_animestyle_girl_image/ -
https://www.reddit.com/r/MachineLearning/comments/apq4xu/p_stylegan_on_anime_faces/egf8pvt/ -
https://www.reddit.com/r/MachineLearning/comments/apq4xu/p_stylegan_on_anime_faces/egmyf60/ -
https://www.reddit.com/r/MachineLearning/comments/bkrn3i/p_stylegan_trained_on_album_covers/ -
https://www.reddit.com/r/MediaSynthesis/comments/tiil1b/xx_waifu_01_xx_loop_by_squaremusher/ -
https://www.reddit.com/r/computervision/comments/bfcnbj/p_stylegan_on_oxford_visual_geometry_group/ -
https://zlkj.in/tmp/stylegan/00051-sgan-danbooru-512px-1gpu-progan/
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://arxiv.org/abs/2311.12092: “Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models”, Rohit Gandikota, Joanna Materzynska, Tingrui Zhou, Antonio Torralba, David Bau -
https://arxiv.org/abs/2306.09346: “Rosetta Neurons: Mining the Common Units in a Model Zoo”, Amil Dravid, Yossi Gandelsman, Alexei A. Efros, Assaf Shocher -
https://arxiv.org/abs/2305.10973: “Drag Your GAN (DragGAN): Interactive Point-Based Manipulation on the Generative Image Manifold”, Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, Christian Theobalt -
https://arxiv.org/abs/2301.12811#sony: “SAN: Inducing Metrizability of GAN With Discriminative Normalized Linear Layer”, Yuhta Takida, Masaaki Imaizumi, Takashi Shibuya, Chieh-Hsin Lai, Toshimitsu Uesaka, Naoki Murata, Yuki Mitsufuji -
https://arxiv.org/abs/2301.09515#nvidia: “StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-To-Image Synthesis”, Axel Sauer, Tero Karras, Samuli Laine, Andreas Geiger, Timo Aila -
https://arxiv.org/abs/2209.03953: “Fast Text2StyleGAN: Text-Free Learning of a Natural Language Interface for Pretrained Face Generators”, Xiaodan Du, Raymond A. Yeh, Nicholas Kolkin, Eli Shechtman, Greg Shakhnarovich -
https://arxiv.org/abs/2208.12408: “User-Controllable Latent Transformer for StyleGAN Image Layout Editing”, Yuki Endo -
https://arxiv.org/abs/2206.04658#nvidia: “BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon -
https://arxiv.org/abs/2203.01993: “Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values”, Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk -
https://arxiv.org/abs/2202.00273: “StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Axel Sauer, Katja Schwarz, Andreas Geiger -
https://arxiv.org/abs/2112.14683: “StyleGAN-V: A Continuous Video Generator With the Price, Image Quality and Perks of StyleGAN2”, Ivan Skorokhodov, Sergey Tulyakov, Mohamed Elhoseiny -
https://arxiv.org/abs/2112.07945#nvidia: “Efficient Geometry-Aware 3D Generative Adversarial Networks”, -
https://arxiv.org/abs/2111.03133: “StyleCLIPDraw: Coupling Content and Style in Text-To-Drawing Synthesis”, Peter Schaldenbrand, Zhixuan Liu, Jean Oh -
https://arxiv.org/abs/2102.01645: “Generating Images from Caption and vice Versa via CLIP-Guided Generative Latent Space Search”, Federico A. Galatolo, Mario G. C. A. Cimino, Gigliola Vaglini -
https://arxiv.org/abs/2009.04433: “Not-So-BigGAN: Generating High-Fidelity Images on Small Compute With Wavelet-Based Super-Resolution”, Seungwook Han, Akash Srivastava, Cole Hurwitz, Prasanna Sattigeri, David D. Cox -
https://arxiv.org/abs/2006.10738: “Differentiable Augmentation for Data-Efficient GAN Training”, Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu, Song Han -
https://github.com/golanlevin/AmbigrammaticFigures: “Ambigrammatic Figures: 55 Grotesque Ambigrams”, Golan Levin, Lingdong Huang -
2019-abdal.pdf: “Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?”, Rameen Abdal, Yipeng Qin, Peter Wonka -
https://web.archive.org/web/20230101012202/https://thispersondoesnotexist.com/: “This Person Does Not Exist”, Phillip Wang -
https://sites.research.google/trc/: “TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs”, TRC