- See Also
- Gwern
-
Links
- “A Peter Thiel-Backed AI Startup, Cognition Labs, Seeks $2 Billion Valuation: Funding round Could Increase Startup’s Valuation Nearly Sixfold in a Matter of Weeks, Reflecting AI Frenzy”, Jin 2024
- “Vulnerability Detection With Code Language Models: How Far Are We?”, Ding et al 2024
- “Gold-Medalist Coders Build an AI That Can Do Their Job for Them: A New Startup Called Cognition AI Can Turn a User’s Prompt into a Website or Video Game”, Vance 2024
- “TestGen-LLM: Automated Unit Test Improvement Using Large Language Models at Meta”, Alshahwan et al 2024
- “The Impact of AI Tool on Engineering at ANZ Bank: An Empirical Study on GitHub Copilot Within a Corporate Environment”, Chatterjee et al 2024
- “Coding on Copilot: 2023 Data Shows Downward Pressure on Code Quality, Plus Projections for 2024”, Harding & Kloster 2024
- “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
- “Leveraging Large Language Models to Boost Dafny’s Developers Productivity”, Silva et al 2024
- “WaveCoder: Widespread And Versatile Enhanced Instruction Tuning With Refined Data Generation”, Yu et al 2023
- “StarVector: Generating Scalable Vector Graphics Code from Images”, Rodriguez et al 2023
- “Universal Self-Consistency for Large Language Model Generation”, Chen et al 2023
- “LLM-Assisted Code Cleaning For Training Accurate Code Generators”, Jain et al 2023
- “ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
- “CodeFusion: A Pre-Trained Diffusion Model for Code Generation”, Singh et al 2023
- “Eureka: Human-Level Reward Design via Coding Large Language Models”, Ma et al 2023
- “Data Contamination Through the Lens of Time”, Roberts et al 2023
- “SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?”, Jimenez et al 2023
- “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Zhou et al 2023
- “Solving Challenging Math Word Problems Using GPT-4 Code Interpreter With Code-Based Self-Verification”, Zhou et al 2023
- “Testing GPT-4 With Wolfram Alpha and Code Interpreter Plug-Ins on Math and Science Problems”, Davis & Aaronson 2023
- “Insights into Stack Overflow’s Traffic: We’re Setting the Record Straight”, Darilek 2023
- “Are Large Language Models a Threat to Digital Public Goods? Evidence from Activity on Stack Overflow”, Rio-Chanona et al 2023
- “Explaining Competitive-Level Programming Solutions Using LLMs”, Li et al 2023
- “AI Is a Lot of Work: As the Technology Becomes Ubiquitous, a Vast Tasker Underclass Is Emerging—And Not Going Anywhere”, Dzieza 2023
- “When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)”, Mozannar et al 2023
- “CodeCompose: A Large-Scale Industrial Deployment of AI-Assisted Code Authoring”, Murali et al 2023
- “Chatting With GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing”, Liu et al 2023
- “Large Language Model Programs”, Schlag et al 2023
- “StarCoder: May the Source Be With You!”, Li et al 2023
- “Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding”, Xie et al 2023
- “LLM+P: Empowering Large Language Models With Optimal Planning Proficiency”, Liu et al 2023
- “Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes”, Arora et al 2023
- “How Secure Is Code Generated by ChatGPT?”, Khoury et al 2023
- “Today Was the First Day That I Could Definitively Say That GPT-4 Has Saved Me a Substantial Amount of Tedious Work”, Tao 2023
- “Language Models Can Solve Computer Tasks”, Kim et al 2023
- “Introducing Microsoft 365 Copilot—Your Copilot for Work”, Spataro 2023
- “Large Language Models and Simple, Stupid Bugs”, Jesse et al 2023
- “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Azerbayev et al 2023
- “CodeBERTScore: Evaluating Code Generation With Pretrained Models of Code”, Zhou et al 2023
- “Faithful Chain-Of-Thought Reasoning”, Lyu et al 2023
- “Large Language Models Are Versatile Decomposers: Decompose Evidence and Questions for Table-Based Reasoning”, Ye et al 2023
- “Google Is Asking Employees to Test Potential ChatGPT Competitors, including a Chatbot Called 'Apprentice Bard'”, Elias 2023
- “An Analysis of the Automatic Bug Fixing Performance of ChatGPT”, Sobania et al 2023
- “Connor Leahy on Aliens, Ethics, Economics, Memetics, and Education § GPT-4”, Leahy 2023
- “General Availability of Azure OpenAI Service Expands Access to Large, Advanced AI Models With Added Enterprise Benefits”, Boyd 2023
- “SantaCoder: Don’t Reach for the Stars!”, Allal et al 2023
- “TrojanPuzzle: Covertly Poisoning Code-Suggestion Models”, Aghakhani et al 2023
- “ERNIE-Code: Beyond English-Centric Cross-Lingual Pretraining for Programming Languages”, Chai et al 2022
- “The Stack: 3 TB of Permissively Licensed Source Code”, Kocetkov et al 2022
- “PAL: Program-Aided Language Models”, Gao et al 2022
- “Do Users Write More Insecure Code With AI Assistants?”, Perry et al 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “Programming Possibility: Kevin Scott on AI’s Impact on Cognitive Work”, Hoffman & Scott 2022
- “Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, Suzgun et al 2022
- “Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners”, Su et al 2022
- “Repair Is Nearly Generation: Multilingual Program Repair With LLMs”, Joshi et al 2022
- “Limitations of Language Models in Arithmetic and Symbolic Induction”, Qian et al 2022
- “Language Models Can Teach Themselves to Program Better”, Haluptzok et al 2022
- “PanGu-Coder: Program Synthesis With Function-Level Language Modeling”, Christopoulou et al 2022
- “CodeT: Code Generation With Generated Tests”, Chen et al 2022
- “Can Large Language Models Reason about Medical Questions?”, Liévin et al 2022
- “Craft an Iron Sword: Dynamically Generating Interactive Game Characters by Prompting Large Language Models Tuned on Code”, Volum et al 2022
- “Code Translation With Compiler Representations”, Szafraniec et al 2022
- “Repository-Level Prompt Generation for Large Language Models of Code”, Shrivastava et al 2022
- “Learning to Model Editing Processes”, Reid & Neubig 2022
- “Productivity Assessment of Neural Code Completion”, Ziegler et al 2022
- “End-To-End Symbolic Regression With Transformers”, Kamienny et al 2022
- “InCoder: A Generative Model for Code Infilling and Synthesis”, Fried et al 2022
- “PaLM: Scaling Language Modeling With Pathways”, Chowdhery et al 2022
- “A Conversational Paradigm for Program Synthesis”, Nijkamp et al 2022
- “Evaluating the Text-To-SQL Capabilities of Large Language Models”, Rajkumar et al 2022
- “Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models”, Vaithilingam et al 2022
- “PolyCoder: A Systematic Evaluation of Large Language Models of Code”, Xu et al 2022
- “Pop Quiz! Can a Large Language Model Help With Reverse Engineering?”, Pearce et al 2022
- “Text and Code Embeddings by Contrastive Pre-Training”, Neelakantan et al 2022
- “Neural Language Models Are Effective Plagiarists”, Biderman & Raff 2022
- “Deep Symbolic Regression for Recurrent Sequences”, d’Ascoli et al 2022
- “Discovering the Syntax and Strategies of Natural Language Programming With Generative Language Models”, Jiang et al 2022
- “A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More”, Drori et al 2021
- “Few-Shot Semantic Parsing With Language Models Trained On Code”, Shin & Durme 2021
- “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
- “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
- “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
- “Jigsaw: Large Language Models Meet Program Synthesis”, Jain et al 2021
- “Can Pre-Trained Language Models Be Used to Resolve Textual and Semantic Merge Conflicts?”, Zhang et al 2021
- “Solving Linear Algebra by Program Synthesis”, Drori & Verma 2021
- “Solving Probability and Statistics Problems by Program Synthesis”, Tang et al 2021
- “Automatic Program Repair With OpenAI’s Codex: Evaluating QuixBugs”, Prenner & Robbes 2021
- “GenLine and GenForm: Two Tools for Interacting With Generative Language Models in a Code Editor”, Jiang et al 2021b
- “An Empirical Cybersecurity Evaluation of GitHub Copilot’s Code Contributions”, Pearce et al 2021
- “Learning C to X86 Translation: An Experiment in Neural Compilation”, Armengol-Estapé & O’Boyle 2021
- “Program Synthesis With Large Language Models”, Austin et al 2021
- “TAPEX: Table Pre-Training via Learning a Neural SQL Executor”, Liu et al 2021
- “Evaluating Large Language Models Trained on Code”, Chen et al 2021
- “Research Recitation: A First Look at Rote Learning in GitHub Copilot Suggestions”, Ziegler 2021
- “Microsoft and OpenAI Have a New AI Tool That Will Give Coding Suggestions to Software Developers”, Novet 2021
- “SymbolicGPT: A Generative Transformer Model for Symbolic Regression”, Valipour et al 2021
- “Measuring Coding Challenge Competence With APPS”, Hendrycks et al 2021
- “Improving Code Autocompletion With Transfer Learning”, Zhou et al 2021
- “LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning”, Wu et al 2021
- “Learning Autocompletion from Real-World Datasets”, Aye et al 2020
- “GraphCodeBERT: Pre-Training Code Representations With Data Flow”, Guo et al 2020
- “CoCoNuT: Combining Context-Aware Neural Translation Models Using Ensemble for Program Repair”, Lutellier et al 2020
- “TransCoder: Unsupervised Translation of Programming Languages”, Lachaux et al 2020
- “GPT-3 Random Sample Dump: JavaScript Tutorial”, GPT-3 2020
- “IJON: Exploring Deep State Spaces via Fuzzing”, Aschermann et al 2020
- “IntelliCode Compose: Code Generation Using Transformer”, Svyatkovskiy et al 2020
- “Deep Learning for Symbolic Mathematics”, Lample & Charton 2019
- “CodeSearchNet Challenge: Evaluating the State of Semantic Code Search”, Husain et al 2019
- “BERTScore: Evaluating Text Generation With BERT”, Zhang et al 2019
- “Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning”, Zhong et al 2017
- “Learning to Superoptimize Programs”, Bunel et al 2017
- “DeepCoder: Learning to Write Programs”, Balog et al 2016
- “Neural Programmer-Interpreters”, Reed & Freitas 2015
- “OpenAI API Alchemy: Smart Formatting and Code Creation”
- spolu
- “Transformer-VAE for Program Synthesis”
- Sort By Magic
- Wikipedia
- Miscellaneous
- Link Bibliography
See Also
Gwern
“CQK Is The First Unused TLA”, Gwern 2023
Links
“A Peter Thiel-Backed AI Startup, Cognition Labs, Seeks $2 Billion Valuation: Funding round Could Increase Startup’s Valuation Nearly Sixfold in a Matter of Weeks, Reflecting AI Frenzy”, Jin 2024
“Vulnerability Detection With Code Language Models: How Far Are We?”, Ding et al 2024
Vulnerability Detection with Code Language Models: How Far Are We?
“Gold-Medalist Coders Build an AI That Can Do Their Job for Them: A New Startup Called Cognition AI Can Turn a User’s Prompt into a Website or Video Game”, Vance 2024
“TestGen-LLM: Automated Unit Test Improvement Using Large Language Models at Meta”, Alshahwan et al 2024
TestGen-LLM: Automated Unit Test Improvement using Large Language Models at Meta
“The Impact of AI Tool on Engineering at ANZ Bank: An Empirical Study on GitHub Copilot Within a Corporate Environment”, Chatterjee et al 2024
“Coding on Copilot: 2023 Data Shows Downward Pressure on Code Quality, Plus Projections for 2024”, Harding & Kloster 2024
Coding on Copilot: 2023 Data Shows Downward Pressure on Code Quality, Plus Projections for 2024
“Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
“Leveraging Large Language Models to Boost Dafny’s Developers Productivity”, Silva et al 2024
Leveraging Large Language Models to Boost Dafny’s Developers Productivity
“WaveCoder: Widespread And Versatile Enhanced Instruction Tuning With Refined Data Generation”, Yu et al 2023
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
“StarVector: Generating Scalable Vector Graphics Code from Images”, Rodriguez et al 2023
StarVector: Generating Scalable Vector Graphics Code from Images
“Universal Self-Consistency for Large Language Model Generation”, Chen et al 2023
Universal Self-Consistency for Large Language Model Generation
“LLM-Assisted Code Cleaning For Training Accurate Code Generators”, Jain et al 2023
LLM-Assisted Code Cleaning For Training Accurate Code Generators
“ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
“CodeFusion: A Pre-Trained Diffusion Model for Code Generation”, Singh et al 2023
CodeFusion: A Pre-trained Diffusion Model for Code Generation
“Eureka: Human-Level Reward Design via Coding Large Language Models”, Ma et al 2023
Eureka: Human-Level Reward Design via Coding Large Language Models
“Data Contamination Through the Lens of Time”, Roberts et al 2023
“SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?”, Jimenez et al 2023
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
“Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Zhou et al 2023
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
“Solving Challenging Math Word Problems Using GPT-4 Code Interpreter With Code-Based Self-Verification”, Zhou et al 2023
“Testing GPT-4 With Wolfram Alpha and Code Interpreter Plug-Ins on Math and Science Problems”, Davis & Aaronson 2023
Testing GPT-4 with Wolfram Alpha and Code Interpreter plug-ins on math and science problems
“Insights into Stack Overflow’s Traffic: We’re Setting the Record Straight”, Darilek 2023
Insights into Stack Overflow’s traffic: We’re setting the record straight
“Are Large Language Models a Threat to Digital Public Goods? Evidence from Activity on Stack Overflow”, Rio-Chanona et al 2023
Are Large Language Models a Threat to Digital Public Goods? Evidence from Activity on Stack Overflow
“Explaining Competitive-Level Programming Solutions Using LLMs”, Li et al 2023
Explaining Competitive-Level Programming Solutions using LLMs
“AI Is a Lot of Work: As the Technology Becomes Ubiquitous, a Vast Tasker Underclass Is Emerging—And Not Going Anywhere”, Dzieza 2023
“When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)”, Mozannar et al 2023
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)
“CodeCompose: A Large-Scale Industrial Deployment of AI-Assisted Code Authoring”, Murali et al 2023
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
“Chatting With GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing”, Liu et al 2023
Chatting with GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing
“Large Language Model Programs”, Schlag et al 2023
“StarCoder: May the Source Be With You!”, Li et al 2023
“Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding”, Xie et al 2023
Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding
“LLM+P: Empowering Large Language Models With Optimal Planning Proficiency”, Liu et al 2023
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
“Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes”, Arora et al 2023
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
“How Secure Is Code Generated by ChatGPT?”, Khoury et al 2023
“Today Was the First Day That I Could Definitively Say That GPT-4 Has Saved Me a Substantial Amount of Tedious Work”, Tao 2023
“Language Models Can Solve Computer Tasks”, Kim et al 2023
“Introducing Microsoft 365 Copilot—Your Copilot for Work”, Spataro 2023
“Large Language Models and Simple, Stupid Bugs”, Jesse et al 2023
“ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Azerbayev et al 2023
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics
“CodeBERTScore: Evaluating Code Generation With Pretrained Models of Code”, Zhou et al 2023
CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code
“Faithful Chain-Of-Thought Reasoning”, Lyu et al 2023
“Large Language Models Are Versatile Decomposers: Decompose Evidence and Questions for Table-Based Reasoning”, Ye et al 2023
“Google Is Asking Employees to Test Potential ChatGPT Competitors, including a Chatbot Called 'Apprentice Bard'”, Elias 2023
“An Analysis of the Automatic Bug Fixing Performance of ChatGPT”, Sobania et al 2023
An Analysis of the Automatic Bug Fixing Performance of ChatGPT
“Connor Leahy on Aliens, Ethics, Economics, Memetics, and Education § GPT-4”, Leahy 2023
Connor Leahy on Aliens, Ethics, Economics, Memetics, and Education § GPT-4
“General Availability of Azure OpenAI Service Expands Access to Large, Advanced AI Models With Added Enterprise Benefits”, Boyd 2023
“SantaCoder: Don’t Reach for the Stars!”, Allal et al 2023
“TrojanPuzzle: Covertly Poisoning Code-Suggestion Models”, Aghakhani et al 2023
“ERNIE-Code: Beyond English-Centric Cross-Lingual Pretraining for Programming Languages”, Chai et al 2022
ERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages
“The Stack: 3 TB of Permissively Licensed Source Code”, Kocetkov et al 2022
“PAL: Program-Aided Language Models”, Gao et al 2022
“Do Users Write More Insecure Code With AI Assistants?”, Perry et al 2022
“Broken Neural Scaling Laws”, Caballero et al 2022
“Programming Possibility: Kevin Scott on AI’s Impact on Cognitive Work”, Hoffman & Scott 2022
Programming Possibility: Kevin Scott on AI’s Impact on Cognitive Work
“Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, Suzgun et al 2022
Challenging BIG-Bench Tasks (BBH) and Whether Chain-of-Thought Can Solve Them
“Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners”, Su et al 2022
Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners
“Repair Is Nearly Generation: Multilingual Program Repair With LLMs”, Joshi et al 2022
Repair Is Nearly Generation: Multilingual Program Repair with LLMs
“Limitations of Language Models in Arithmetic and Symbolic Induction”, Qian et al 2022
Limitations of Language Models in Arithmetic and Symbolic Induction
“Language Models Can Teach Themselves to Program Better”, Haluptzok et al 2022
“PanGu-Coder: Program Synthesis With Function-Level Language Modeling”, Christopoulou et al 2022
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
“CodeT: Code Generation With Generated Tests”, Chen et al 2022
“Can Large Language Models Reason about Medical Questions?”, Liévin et al 2022
“Craft an Iron Sword: Dynamically Generating Interactive Game Characters by Prompting Large Language Models Tuned on Code”, Volum et al 2022
“Code Translation With Compiler Representations”, Szafraniec et al 2022
“Repository-Level Prompt Generation for Large Language Models of Code”, Shrivastava et al 2022
Repository-Level Prompt Generation for Large Language Models of Code
“Learning to Model Editing Processes”, Reid & Neubig 2022
“Productivity Assessment of Neural Code Completion”, Ziegler et al 2022
“End-To-End Symbolic Regression With Transformers”, Kamienny et al 2022
“InCoder: A Generative Model for Code Infilling and Synthesis”, Fried et al 2022
InCoder: A Generative Model for Code Infilling and Synthesis
“PaLM: Scaling Language Modeling With Pathways”, Chowdhery et al 2022
“A Conversational Paradigm for Program Synthesis”, Nijkamp et al 2022
“Evaluating the Text-To-SQL Capabilities of Large Language Models”, Rajkumar et al 2022
Evaluating the Text-to-SQL Capabilities of Large Language Models
“Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models”, Vaithilingam et al 2022
“PolyCoder: A Systematic Evaluation of Large Language Models of Code”, Xu et al 2022
PolyCoder: A Systematic Evaluation of Large Language Models of Code
“Pop Quiz! Can a Large Language Model Help With Reverse Engineering?”, Pearce et al 2022
Pop Quiz! Can a Large Language Model Help With Reverse Engineering?
“Text and Code Embeddings by Contrastive Pre-Training”, Neelakantan et al 2022
“Neural Language Models Are Effective Plagiarists”, Biderman & Raff 2022
“Deep Symbolic Regression for Recurrent Sequences”, d’Ascoli et al 2022
“Discovering the Syntax and Strategies of Natural Language Programming With Generative Language Models”, Jiang et al 2022
“A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More”, Drori et al 2021
“Few-Shot Semantic Parsing With Language Models Trained On Code”, Shin & Durme 2021
Few-Shot Semantic Parsing with Language Models Trained On Code
“WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
WebGPT: Browser-assisted question-answering with human feedback
“WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
WebGPT: Improving the factual accuracy of language models through web browsing
“Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
“Jigsaw: Large Language Models Meet Program Synthesis”, Jain et al 2021
“Can Pre-Trained Language Models Be Used to Resolve Textual and Semantic Merge Conflicts?”, Zhang et al 2021
Can Pre-trained Language Models be Used to Resolve Textual and Semantic Merge Conflicts?
“Solving Linear Algebra by Program Synthesis”, Drori & Verma 2021
“Solving Probability and Statistics Problems by Program Synthesis”, Tang et al 2021
Solving Probability and Statistics Problems by Program Synthesis
“Automatic Program Repair With OpenAI’s Codex: Evaluating QuixBugs”, Prenner & Robbes 2021
Automatic Program Repair with OpenAI’s Codex: Evaluating QuixBugs
“GenLine and GenForm: Two Tools for Interacting With Generative Language Models in a Code Editor”, Jiang et al 2021b
GenLine and GenForm: Two Tools for Interacting with Generative Language Models in a Code Editor
“An Empirical Cybersecurity Evaluation of GitHub Copilot’s Code Contributions”, Pearce et al 2021
An Empirical Cybersecurity Evaluation of GitHub Copilot’s Code Contributions
“Learning C to X86 Translation: An Experiment in Neural Compilation”, Armengol-Estapé & O’Boyle 2021
Learning C to x86 Translation: An Experiment in Neural Compilation
“Program Synthesis With Large Language Models”, Austin et al 2021
“TAPEX: Table Pre-Training via Learning a Neural SQL Executor”, Liu et al 2021
TAPEX: Table Pre-training via Learning a Neural SQL Executor
“Evaluating Large Language Models Trained on Code”, Chen et al 2021
“Research Recitation: A First Look at Rote Learning in GitHub Copilot Suggestions”, Ziegler 2021
Research recitation: A first look at rote learning in GitHub Copilot suggestions
“Microsoft and OpenAI Have a New AI Tool That Will Give Coding Suggestions to Software Developers”, Novet 2021
Microsoft and OpenAI have a new AI tool that will give coding suggestions to software developers
“SymbolicGPT: A Generative Transformer Model for Symbolic Regression”, Valipour et al 2021
SymbolicGPT: A Generative Transformer Model for Symbolic Regression
“Measuring Coding Challenge Competence With APPS”, Hendrycks et al 2021
“Improving Code Autocompletion With Transfer Learning”, Zhou et al 2021
“LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning”, Wu et al 2021
LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning
“Learning Autocompletion from Real-World Datasets”, Aye et al 2020
“GraphCodeBERT: Pre-Training Code Representations With Data Flow”, Guo et al 2020
GraphCodeBERT: Pre-training Code Representations with Data Flow
“CoCoNuT: Combining Context-Aware Neural Translation Models Using Ensemble for Program Repair”, Lutellier et al 2020
CoCoNuT: Combining Context-Aware Neural Translation Models using Ensemble for Program Repair
“TransCoder: Unsupervised Translation of Programming Languages”, Lachaux et al 2020
TransCoder: Unsupervised Translation of Programming Languages
“GPT-3 Random Sample Dump: JavaScript Tutorial”, GPT-3 2020
“IJON: Exploring Deep State Spaces via Fuzzing”, Aschermann et al 2020
“IntelliCode Compose: Code Generation Using Transformer”, Svyatkovskiy et al 2020
“Deep Learning for Symbolic Mathematics”, Lample & Charton 2019
“CodeSearchNet Challenge: Evaluating the State of Semantic Code Search”, Husain et al 2019
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
“BERTScore: Evaluating Text Generation With BERT”, Zhang et al 2019
“Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning”, Zhong et al 2017
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
“Learning to Superoptimize Programs”, Bunel et al 2017
“DeepCoder: Learning to Write Programs”, Balog et al 2016
“Neural Programmer-Interpreters”, Reed & Freitas 2015
“OpenAI API Alchemy: Smart Formatting and Code Creation”
spolu
“Transformer-VAE for Program Synthesis”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
ai-research
interactive-ai
language-assist
code-generation
Wikipedia
Miscellaneous
-
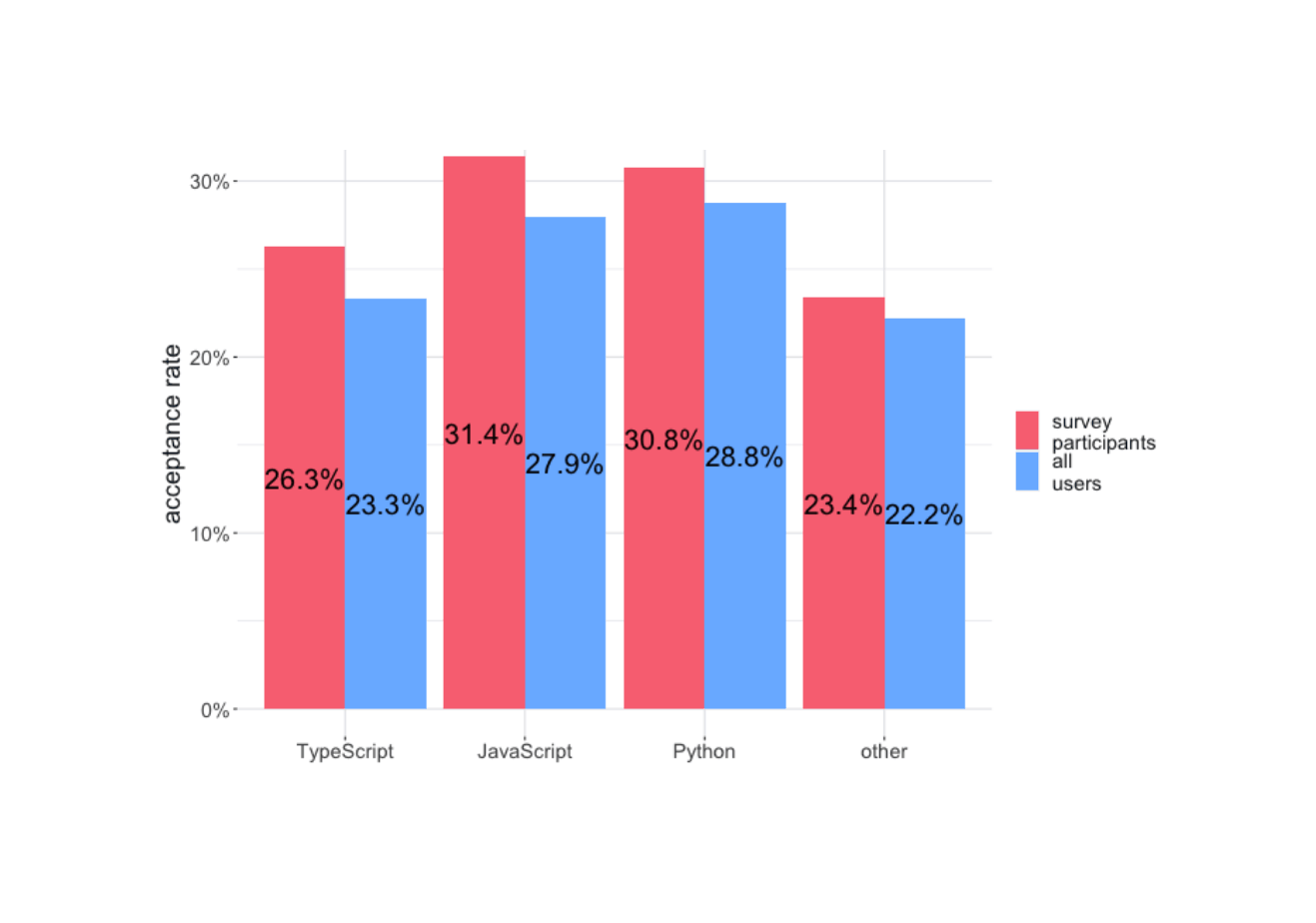
/doc/ai/nn/transformer/gpt/codex/2024-03-07-inflection-inflection25benchmarks.svg -
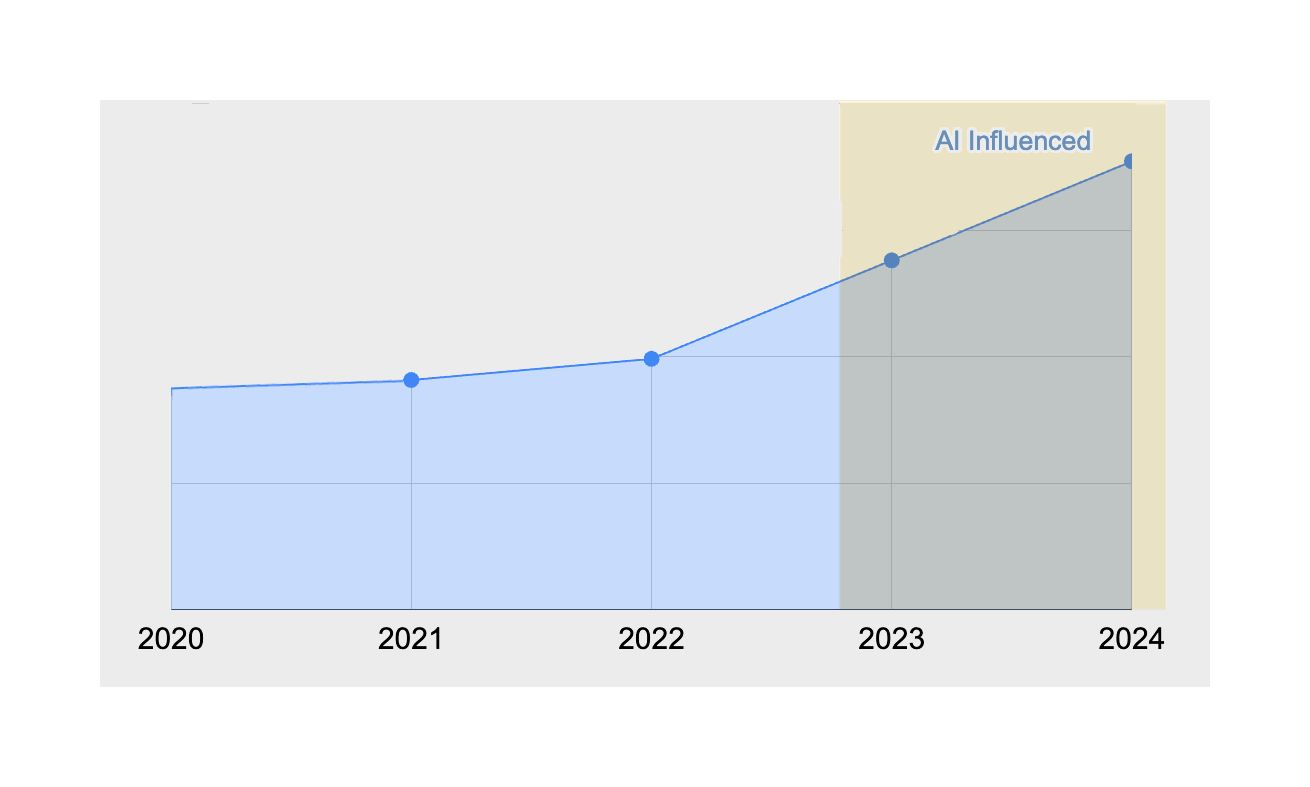
/doc/ai/nn/transformer/gpt/codex/2024-harding-figure1-codechurnincreasefrom2020to2023.png: -
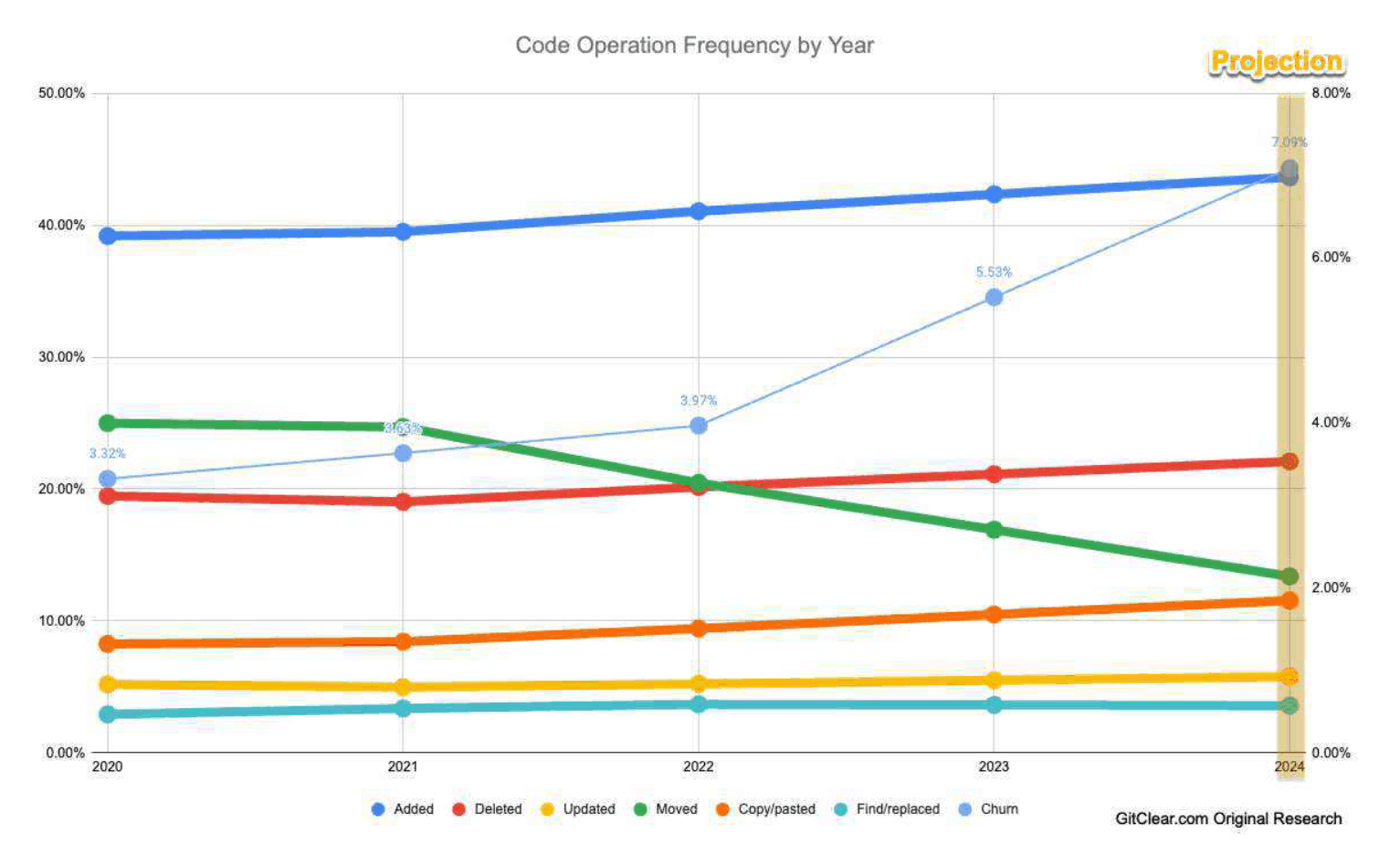
/doc/ai/nn/transformer/gpt/codex/2024-harding-figure2-gitcodemodificationsbytypeovertime.png: -
/doc/ai/nn/transformer/gpt/codex/2023-01-16-microsoft-timelineofairesearchandproducts.png: -
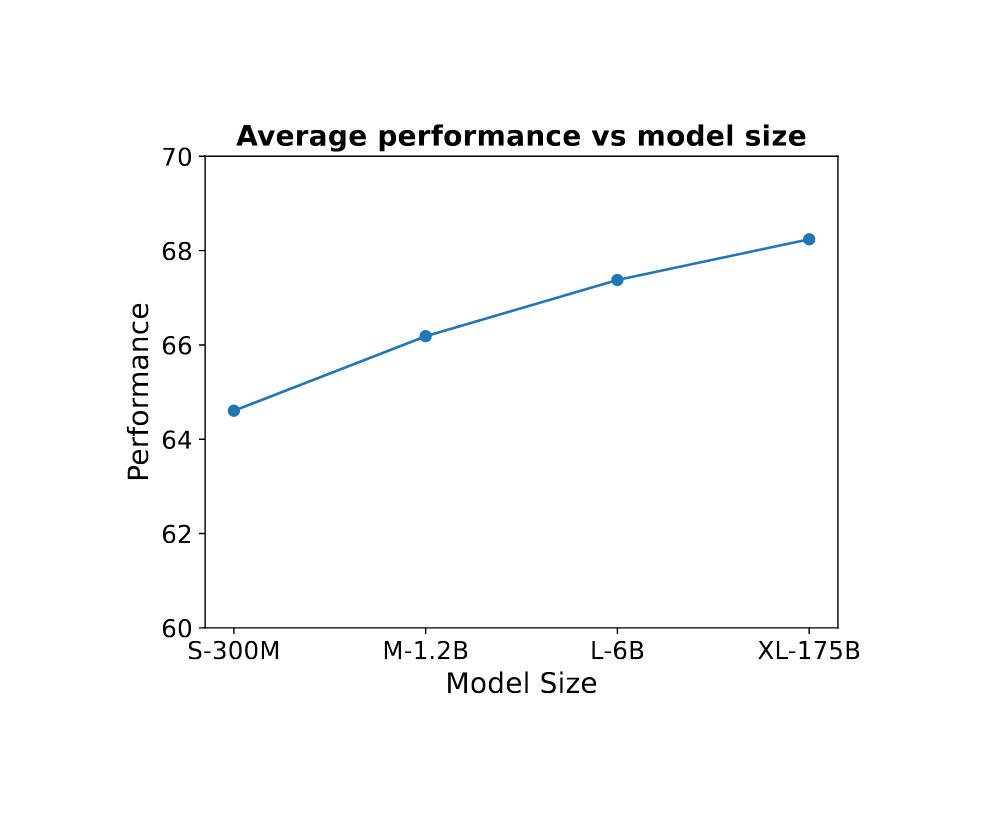
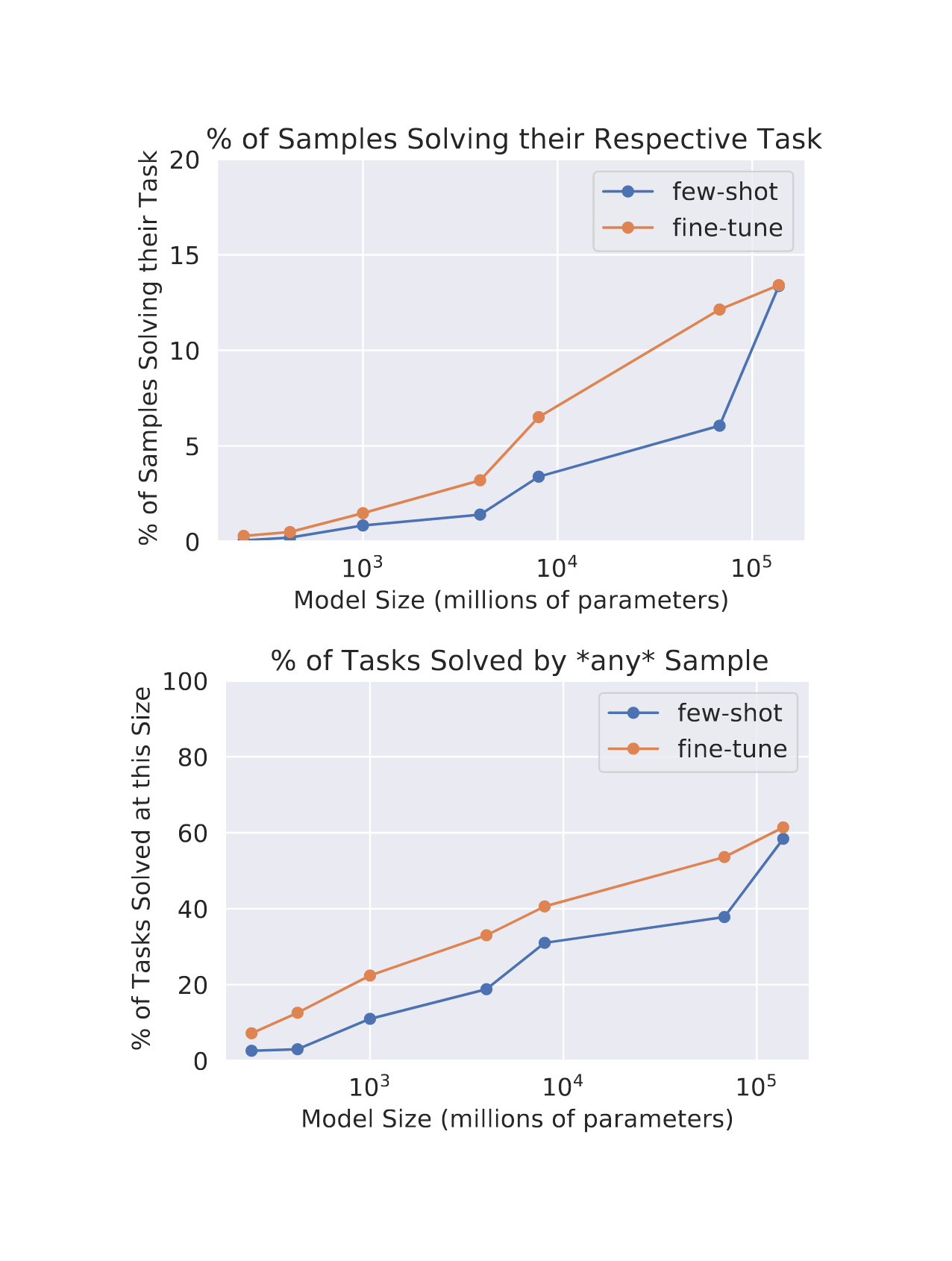
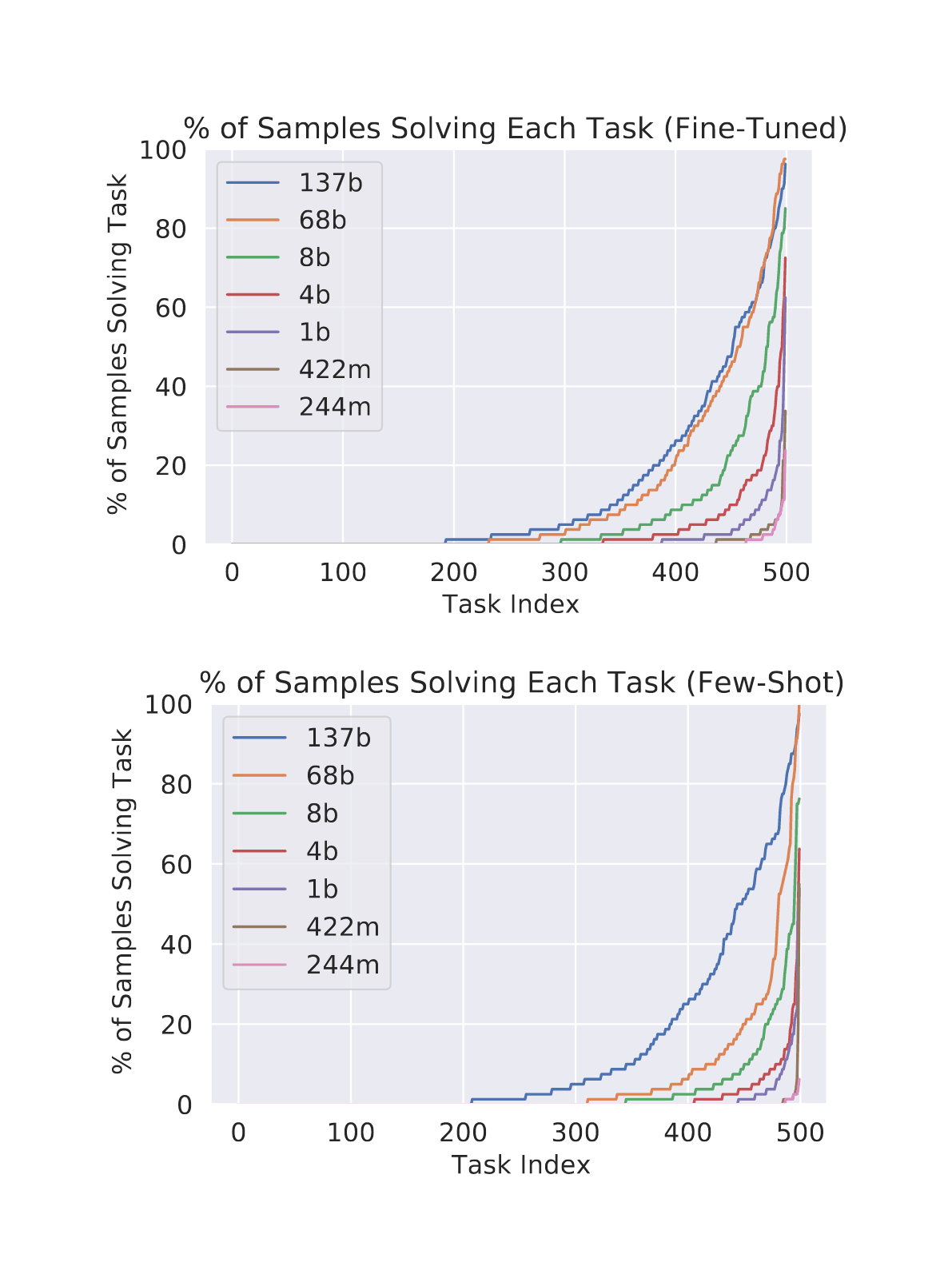
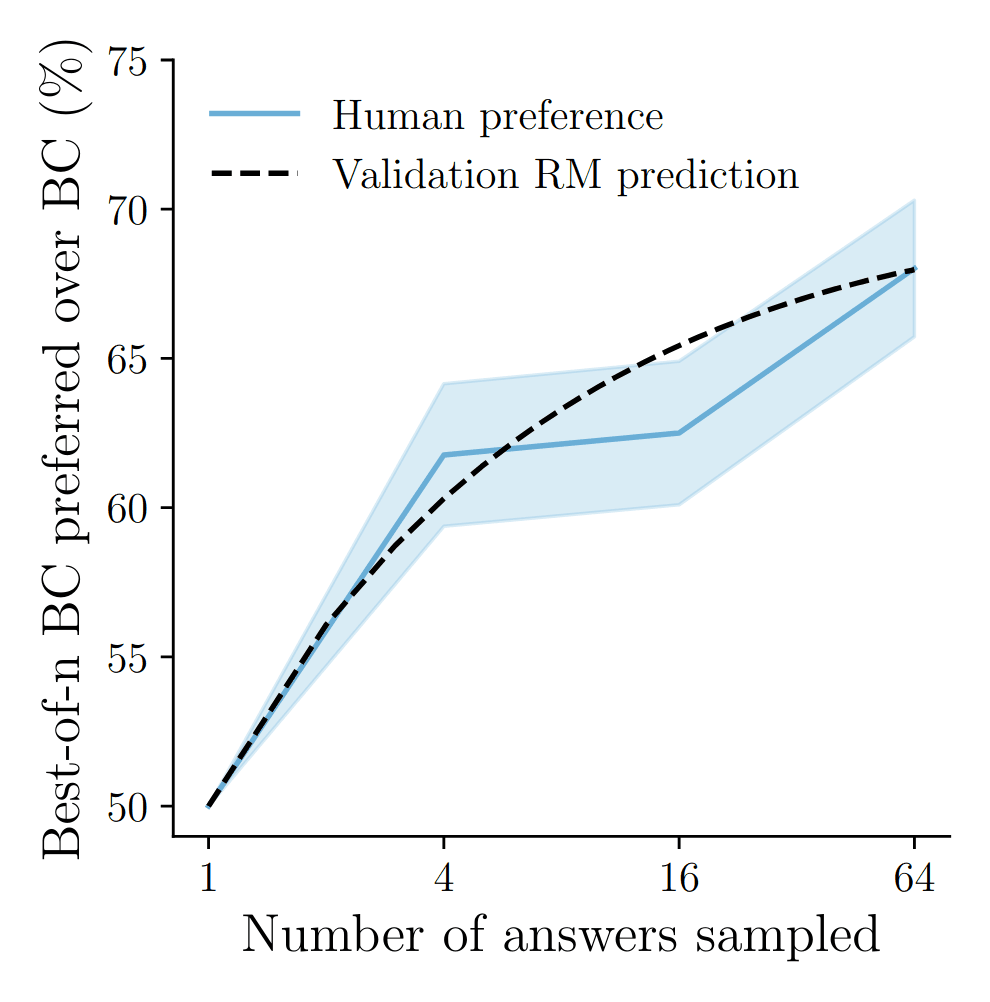
/doc/ai/nn/transformer/gpt/codex/2021-austin-figure3-lamdaprogrammingperformancevsmodelscaling.png: -
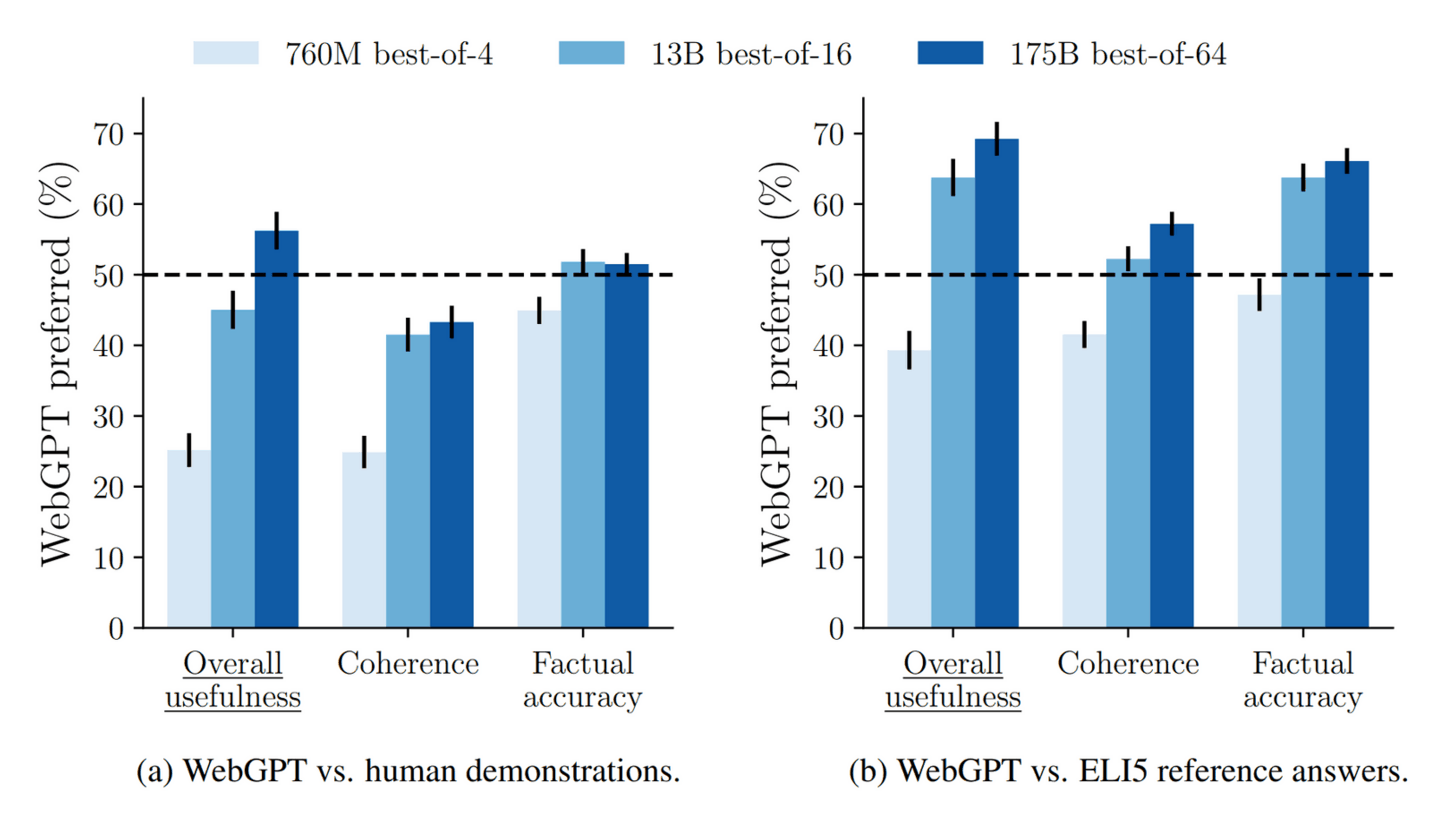
/doc/ai/nn/transformer/gpt/codex/2021-nakano-figure1-gpt3textbrowserenvironmentobservations.png: -
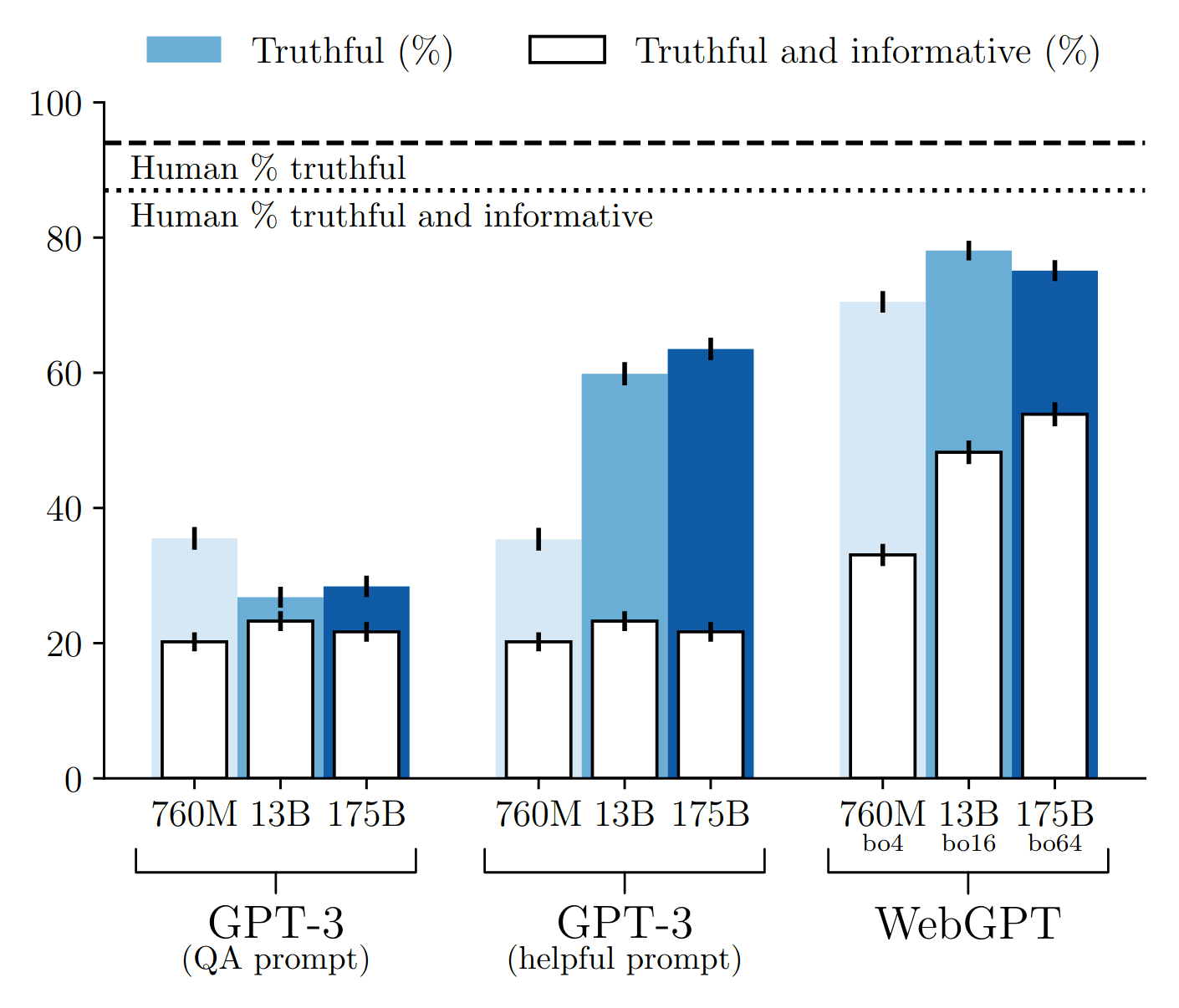
/doc/ai/nn/transformer/gpt/codex/2021-nakano-figure3-truthfulqaresultsbyscaling.png: -
/doc/ai/nn/transformer/gpt/codex/2021-nakano-figure7-bestfnscalingbyflopsandanswerssampled.png: -
https://andrewmayne.com/2023/03/23/chatgpt-code-interpreter-magic/:View External Link:
https://andrewmayne.com/2023/03/23/chatgpt-code-interpreter-magic/ -
https://blog.mentat.ai/benchmarking-gpt-4-turbo-a-cautionary-tale -
https://borretti.me/article/astronomical-calculations-for-hard-sf-common-lisp -
https://builtin.com/job/customer-success/expert-ai-teacher-contract/1267315 -
https://docs.parea.ai/blog/benchmarking-anthropic-beta-tool-use -
https://finedataproducts.com/posts/2024-03-10-tax-scenarios-with-ai/ -
https://gist.github.com/harryaskham/68a611bef777525991790bca2f2d324d -
https://github.blog/2023-02-14-github-copilot-for-business-is-now-available/ -
https://github.com/E-xyza/Exonerate/blob/master/bench/reports/gpt-bench.md -
https://github.com/aiwebb/treenav-bench#interesting-findings -
https://github.com/jujumilk3/leaked-system-prompts/blob/main/github-copilot-chat_20230513.md: -
https://kenkantzer.com/lessons-after-a-half-billion-gpt-tokens/ -
https://koenvangilst.nl/blog/keeping-code-complexity-in-check -
https://lemire.me/blog/2023/03/22/can-gpt-pass-my-programming-courses/ -
https://medium.com/tenable-techblog/g-3po-a-protocol-droid-for-ghidra-4b46fa72f1ff -
https://micahflee.com/2023/04/capturing-the-flag-with-gpt-4/ -
https://nickarner.com/notes/llm-powered-assistants-for-complex-interfaces-february-26-2023/ -
https://old.reddit.com/r/singularity/comments/1atjz9v/ive_put_a_complex_codebase_into_a_single/ -
https://openai.com/blog/function-calling-and-other-api-updates#function-calling -
https://openai.com/blog/introducing-text-and-code-embeddings/ -
https://platform.openai.com/docs/guides/embeddings/code-search-using-embeddings: -
https://platform.openai.com/docs/guides/embeddings/use-cases -
https://research.checkpoint.com/2023/opwnai-cybercriminals-starting-to-use-chatgpt/ -
https://simonwillison.net/2022/Dec/5/rust-chatgpt-copilot/: -
https://stability.ai/blog/stablecode-llm-generative-ai-coding -
https://statmodeling.stat.columbia.edu/2023/04/18/chatgpt4-writes-stan-code-so-i-dont-have-to/ -
https://statmodeling.stat.columbia.edu/2023/08/20/bob-carpenter-thinks-gpt-4-is-awesome/ -
https://tagide.com/education/writing-a-tokenizer-with-chatgpt/: -
https://towardsdatascience.com/can-chatgpt-write-better-sql-than-a-data-analyst-f079518efab2: -
https://towardsdatascience.com/codex-by-openai-in-action-83529c0076cc: -
https://twitter.com/AlexKontorovich/status/1678772963183820801 -
https://twitter.com/AlexKontorovich/status/1678772964836397056 -
https://twitter.com/DaveMonlander/status/1612802240582135809 -
https://twitter.com/GabriellaG439/status/1561007332267421696 -
https://twitter.com/ItalyPaleAle/status/1409890404615409671: -
https://twitter.com/PerksPlus0001/status/1631372820709253120: -
https://twitter.com/ThePrimeagen/status/1628047727866126336: -
https://twitter.com/ThomasMiconi/status/1569408502447374336: -
https://twitter.com/amanrsanger/status/1631029716550549504: -
https://twitter.com/andrewwhite01/status/1616933106786738176 -
https://twitter.com/atlantis__labs/status/1677782219937525760 -
https://twitter.com/fabianstelzer/status/1572571003804614657: -
https://twitter.com/francoisfleuret/status/1699117856779075949 -
https://twitter.com/jamesbrandecon/status/1639709460762624001: -
https://twitter.com/jeremyphoward/status/1688793283034779648 -
https://twitter.com/jeremyphoward/status/1765529891343339804 -
https://twitter.com/jeremyphoward/status/1779311134656671872 -
https://twitter.com/kenshinsamurai9/status/1662510532585291779 -
https://twitter.com/marvinvonhagen/status/1657060506371346432 -
https://twitter.com/mathemagic1an/status/1636121914849792000 -
https://twitter.com/mattshumer_/status/1782468402293903662: -
https://twitter.com/maxkriegers/status/1663372146696138752: -
https://twitter.com/moreisdifferent/status/1612489352105365511: -
https://twitter.com/patrickmineault/status/1591874392279351297: -
https://twitter.com/perrymetzger/status/1632004276883947520: -
https://twitter.com/philhawksworth/status/1720106515300860230 -
https://twitter.com/scottleibrand/status/1430753899460194310: -
https://twitter.com/sergeykarayev/status/1569377881440276481: -
https://twitter.com/sergeykarayev/status/1569571367833714688: -
https://twitter.com/sharifshameem/status/1672852345259180037: -
https://twitter.com/thisiswrenn/status/1523182708385452032: -
https://twitter.com/yoheinakajima/status/1670557048743010305 -
https://verse.systems/blog/post/2024-03-09-using-llms-to-generate-fuzz-generators/ -
https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/ -
https://www.chargebackstop.com/blog/card-networks-exploitation -
https://www.engraved.blog/building-a-virtual-machine-inside/ -
https://www.honeycomb.io/blog/hard-stuff-nobody-talks-about-llm -
https://www.kite.com/blog/product/kite-launches-ai-powered-javascript-completions/ -
https://www.lesswrong.com/posts/KSroBnxCHodGmPPJ8/jailbreaking-gpt-4-s-code-interpreter -
https://www.lesswrong.com/posts/ib9bfyJiz4FLuHDQs/openai-codex-first-impressions:View External Link:
https://www.lesswrong.com/posts/ib9bfyJiz4FLuHDQs/openai-codex-first-impressions -
https://www.lesswrong.com/posts/ukTLGe5CQq9w8FMne/inducing-unprompted-misalignment-in-llms -
https://www.lesswrong.com/posts/ux93sLHcqmBfsRTvg/gpt-can-write-quines-now-gpt-4:View External Link:
https://www.lesswrong.com/posts/ux93sLHcqmBfsRTvg/gpt-can-write-quines-now-gpt-4 -
https://www.nytimes.com/2021/09/09/technology/codex-artificial-intelligence-coding.html -
https://www.oneusefulthing.org/p/it-is-starting-to-get-strange -
https://www.patterns.app/blog/2023/01/18/crunchbot-sql-analyst-gpt/ -
https://www.reddit.com/r/ChatGPT/comments/12a0ajb/i_gave_gpt4_persistent_memory_and_the_ability_to/ -
https://www.reddit.com/r/GPT3/comments/106t5gv/compressing_prompt_text_with_lossless_compression/: -
https://www.reddit.com/r/OpenAI/comments/1bm305k/what_the_hell_claud_3_opus_is_a_straight/ -
https://www.reddit.com/r/singularity/comments/1atjz9v/ive_put_a_complex_codebase_into_a_single/ -
https://www.samdickie.me/writing/experiment-1-creating-a-landing-page-using-ai-tools-no-code -
https://www.shawnmatthewcrawford.com/balloons-the-balloon-clicker-game.html: -
https://www.theverge.com/2021/8/10/22618128/openai-codex-natural-language-into-code-api-beta-access -
https://www.zdnet.com/article/microsoft-has-over-a-million-paying-github-copilot-users-ceo-nadella/ -
https://xenaproject.wordpress.com/2022/09/12/beyond-the-liquid-tensor-experiment/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://www.wsj.com/tech/ai/a-peter-thiel-backed-ai-startup-cognition-labs-seeks-2-billion-valuation-998fa39d: “A Peter Thiel-Backed AI Startup, Cognition Labs, Seeks $2 Billion Valuation: Funding round Could Increase Startup’s Valuation Nearly Sixfold in a Matter of Weeks, Reflecting AI Frenzy”, Berber Jin -
https://arxiv.org/abs/2403.18624: “Vulnerability Detection With Code Language Models: How Far Are We?”, -
https://www.bloomberg.com/news/articles/2024-03-12/cognition-ai-is-a-peter-thiel-backed-coding-assistant: “Gold-Medalist Coders Build an AI That Can Do Their Job for Them: A New Startup Called Cognition AI Can Turn a User’s Prompt into a Website or Video Game”, Ashlee Vance -
2024-harding.pdf: “Coding on Copilot: 2023 Data Shows Downward Pressure on Code Quality, Plus Projections for 2024”, William Harding, Matthew Kloster -
https://arxiv.org/abs/2401.05566#anthropic: “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, -
https://arxiv.org/abs/2312.11556: “StarVector: Generating Scalable Vector Graphics Code from Images”, Juan A. Rodriguez, Shubham Agarwal, Issam H. Laradji, Pau Rodriguez, David Vazquez, Christopher Pal, Marco Pedersoli -
https://arxiv.org/abs/2310.04406: “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, Yu-Xiong Wang -
https://arxiv.org/abs/2308.07921: “Solving Challenging Math Word Problems Using GPT-4 Code Interpreter With Code-Based Self-Verification”, -
https://www.theverge.com/features/23764584/ai-artificial-intelligence-data-notation-labor-scale-surge-remotasks-openai-chatbots: “AI Is a Lot of Work: As the Technology Becomes Ubiquitous, a Vast Tasker Underclass Is Emerging—And Not Going Anywhere”, Josh Dzieza -
https://arxiv.org/abs/2306.04930#microsoft: “When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)”, Hussein Mozannar, Gagan Bansal, Adam Fourney, Eric Horvitz -
https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/: “Introducing Microsoft 365 Copilot—Your Copilot for Work”, Jared Spataro -
https://arxiv.org/abs/2303.11455: “Large Language Models and Simple, Stupid Bugs”, Kevin Jesse, Toufique Ahmed, Premkumar T. Devanbu, Emily Morgan -
https://arxiv.org/abs/2302.12433: “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, Jeremy Avigad -
https://www.cnbc.com/2023/01/31/google-testing-chatgpt-like-chatbot-apprentice-bard-with-employees.html: “Google Is Asking Employees to Test Potential ChatGPT Competitors, including a Chatbot Called 'Apprentice Bard'”, Jennifer Elias -
https://arxiv.org/abs/2301.08653: “An Analysis of the Automatic Bug Fixing Performance of ChatGPT”, Dominik Sobania, Martin Briesch, Carol Hanna, Justyna Petke -
https://azure.microsoft.com/en-us/blog/general-availability-of-azure-openai-service-expands-access-to-large-advanced-ai-models-with-added-enterprise-benefits/: “General Availability of Azure OpenAI Service Expands Access to Large, Advanced AI Models With Added Enterprise Benefits”, Eric Boyd -
https://arxiv.org/abs/2211.15533: “The Stack: 3 TB of Permissively Licensed Source Code”, -
https://greylock.com/greymatter/kevin-scott-ai-programming-possibility/: “Programming Possibility: Kevin Scott on AI’s Impact on Cognitive Work”, Reid Hoffman, Kevin Scott -
https://arxiv.org/abs/2210.09261#google: “Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, -
https://arxiv.org/abs/2209.01975: “Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners”, -
https://arxiv.org/abs/2207.08143: “Can Large Language Models Reason about Medical Questions?”, Valentin Liévin, Christoffer Egeberg Hother, Ole Winther -
https://arxiv.org/abs/2205.06537#github: “Productivity Assessment of Neural Code Completion”, -
https://arxiv.org/abs/2204.05999#facebook: “InCoder: A Generative Model for Code Infilling and Synthesis”, -
https://arxiv.org/abs/2204.02311#google: “PaLM: Scaling Language Modeling With Pathways”, -
2022-vaithilingam.pdf: “Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models”, Priyan Vaithilingam, Tianyi Zhang, Elena Glassman -
https://arxiv.org/abs/2201.10005#openai: “Text and Code Embeddings by Contrastive Pre-Training”, -
https://arxiv.org/abs/2112.09332#openai: “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, -
https://openai.com/research/webgpt: “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Jacob Hilton, Suchir Balaji, Reiichiro Nakano, John Schulman -
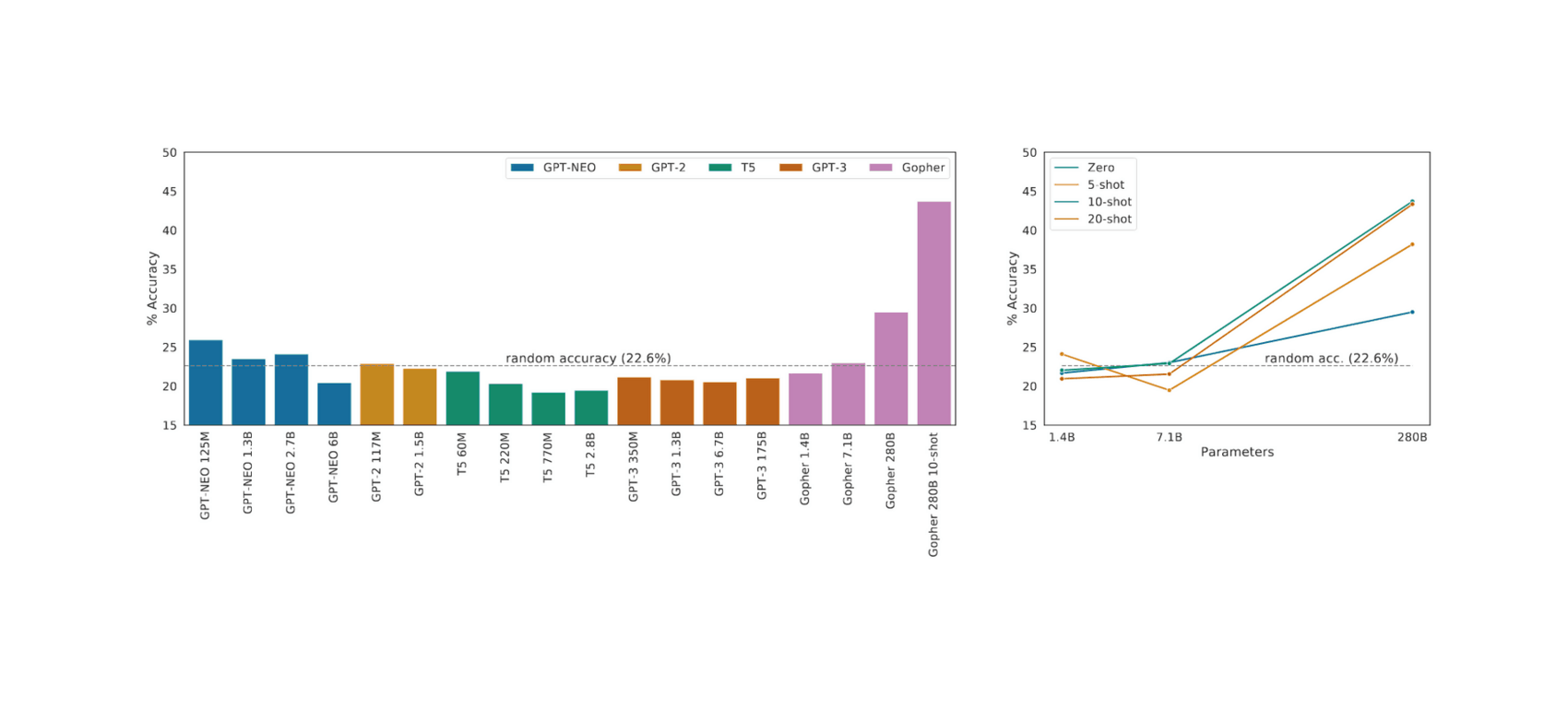
https://arxiv.org/abs/2112.11446#deepmind: “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, -
https://arxiv.org/abs/2111.11904#microsoft: “Can Pre-Trained Language Models Be Used to Resolve Textual and Semantic Merge Conflicts?”, Jialu Zhang, Todd Mytkowicz, Mike Kaufman, Ruzica Piskac, Shuvendu K. Lahiri -
https://arxiv.org/abs/2111.08267: “Solving Probability and Statistics Problems by Program Synthesis”, Leonard Tang, Elizabeth Ke, Nikhil Singh, Nakul Verma, Iddo Drori -
2021-jiang-2.pdf: “GenLine and GenForm: Two Tools for Interacting With Generative Language Models in a Code Editor”, Ellen Jiang, Edwin Toh, Alejandra Molina, Aaron Donsbach, Carrie Cai, Michael Terry