- See Also
- Gwern
-
Links
- “Hierarchical Feature Warping and Blending for Talking Head Animation”, Zhang et al 2024
- “APISR: Anime Production Inspired Real-World Anime Super-Resolution”, Wang et al 2024
- “Re:Draw—Context Aware Translation As a Controllable Method for Artistic Production”, Cardoso et al 2024
- “MobileDiffusion: Subsecond Text-To-Image Generation on Mobile Devices”, Zhao et al 2023
- “Adversarial Diffusion Distillation”, Sauer et al 2023
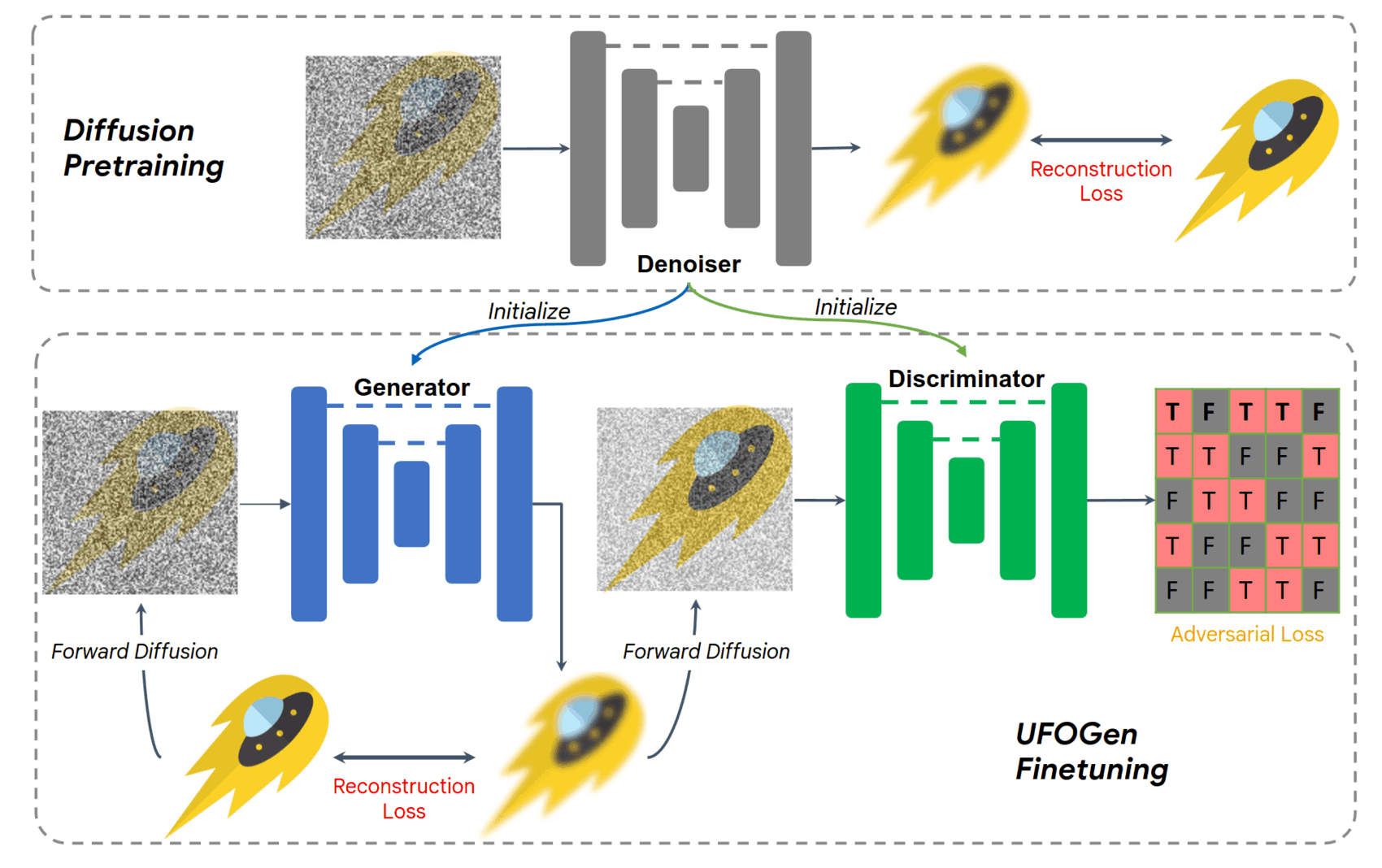
- “UFOGen: You Forward Once Large Scale Text-To-Image Generation via Diffusion GANs”, Xu et al 2023
- “Application of Generative Adversarial Networks in Color Art Image Shadow Generation”, Wu et al 2023
- “Region Assisted Sketch Colorization”, Wang et al 2023e
- “FlatGAN: A Holistic Approach for Robust Flat-Coloring in High-Definition With Understanding Line Discontinuity”, Kim et al 2023
- “Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion”, Kim et al 2023
- “The Colorization Based on Self-Attention Mechanism and GAN”, Sun et al 2023
- “Semi-Supervised Reference-Based Sketch Extraction Using a Contrastive Learning Framework”, Seo et al 2023
- “Semi-Implicit Denoising Diffusion Models (SIDDMs)”, Xu et al 2023
- “StyleTTS 2: Towards Human-Level Text-To-Speech through Style Diffusion and Adversarial Training With Large Speech Language Models”, Li et al 2023
- “High-Fidelity Audio Compression With Improved RVQGAN”, Kumar et al 2023
- “Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships”, Lan et al 2023
- “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
- “Thangka Sketch Colorization Based on Multi-Level Adaptive-Instance-Normalized Color Fusion and Skip Connection Attention”, Li et al 2023
- “Two-Step Training: Adjustable Sketch Colorization via Reference Image and Text Tag”, Yan et al 2023
- “Abstraction-Perception Preserving Cartoon Face Synthesis”, Ho et al 2023
- “GigaGAN: Scaling up GANs for Text-To-Image Synthesis”, Kang et al 2023
- “Overview of Cartoon Face Generation”, Shen et al 2023
- “Enhancing Image Representation in Conditional Image Synthesis”, Shim et al 2023
- “StencilTorch: An Iterative and User-Guided Framework for Anime Lineart Colorization”, Hati et al 2023
- “PMSGAN: Parallel Multistage GANs for Face Image Translation”, Liang et al 2023
- “FAEC-GAN: An Unsupervised Face-To-Anime Translation Based on Edge Enhancement and Coordinate Attention”, Lin et al 2023
- “A Survey on Text Generation Using Generative Adversarial Networks”, Rosa & Papa 2022
- “Appearance-Preserved Portrait-To-Anime Translation via Proxy-Guided Domain Adaptation”, Xiao et al 2022
- “Seeing a Rose in 5,000 Ways”, Zhang et al 2022
- “Reference Based Sketch Extraction via Attention Mechanism”, Ashtari et al 2022
- “Dr.3D: Adapting 3D GANs to Artistic Drawings”, Jin et al 2022
- “Null-Text Inversion for Editing Real Images Using Guided Diffusion Models”, Mokady et al 2022
- “An Analysis: Different Methods about Line Art Colorization”, Gao et al 2022b
- “Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization”, Cho et al 2022
- “High Fidelity Neural Audio Compression”, Défossez et al 2022
- “T2CI-GAN: Text to Compressed Image Generation Using Generative Adversarial Network”, Rajesh et al 2022
- “GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images”, Gao et al 2022
- “Musika! Fast Infinite Waveform Music Generation”, Pasini & Schlüter 2022
- “Using Generative Adversarial Networks for Conditional Creation of Anime Posters”, Sankalpa et al 2022
- “AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos”, Wu et al 2022
- “Learning to Generate Artistic Character Line Drawing”, Fang et al 2022
- “Cascaded Video Generation for Videos In-The-Wild”, Castrejon et al 2022
- “StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-To-Speech Synthesis”, Li et al 2022
- “Why GANs Are Overkill for NLP”, Alvarez-Melis et al 2022
- “VQGAN-CLIP: Open Domain Image Generation and Editing With Natural Language Guidance”, Crowson et al 2022
- “Imitating, Fast and Slow: Robust Learning from Demonstrations via Decision-Time Planning”, Qi et al 2022
- “TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer”, Ge et al 2022
- “MaxViT: Multi-Axis Vision Transformer”, Tu et al 2022
- “Vector-Quantized Image Modeling With Improved VQGAN”, Yu et al 2022
- “Truncated Diffusion Probabilistic Models and Diffusion-Based Adversarial Auto-Encoders”, Zheng et al 2022
- “Do GANs Learn the Distribution? Some Theory and Empirics”, Arora et al 2022
- “Using Constant Learning Rate of Two Time-Scale Update Rule for Training Generative Adversarial Networks”, Sato & Iiduka 2022
- “Microdosing: Knowledge Distillation for GAN Based Compression”, Helminger et al 2022
- “An Unsupervised Font Style Transfer Model Based on Generative Adversarial Networks”, Zeng & Pan 2021
- “Multimodal Conditional Image Synthesis With Product-Of-Experts GANs”, Huang et al 2021
- “TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems”, Doan et al 2021
- “Compositional Transformers for Scene Generation”, Hudson & Zitnick 2021
- “Tackling the Generative Learning Trilemma With Denoising Diffusion GANs”, Xiao et al 2021
- “EditGAN: High-Precision Semantic Image Editing”, Ling et al 2021
- “Projected GANs Converge Faster”, Sauer et al 2021
- “STransGAN: An Empirical Study on Transformer in GANs”, Xu et al 2021
- “MSMT-GAN: Multi-Tailed, Multi-Headed, Spatial Dynamic Memory Refined Text-To-Image Synthesis”, Seshadri & Ravindran 2021
- “Unpaired Font Family Synthesis Using Conditional Generative Adversarial Networks”, Hassan et al 2021
- “Fake It Till You Make It: Face Analysis in the Wild Using Synthetic Data Alone”, Wood et al 2021
- “ViTGAN: Training GANs With Vision Transformers”, Lee et al 2021
- “MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021
- “HiT: Improved Transformer for High-Resolution GANs”, Zhao et al 2021
- “GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for Videos Too!)”, Chong & Forsyth 2021
- “MixerGAN: An MLP-Based Architecture for Unpaired Image-To-Image Translation”, Cazenavette & Guevara 2021
- “EigenGAN: Layer-Wise Eigen-Learning for GANs”, He et al 2021
- “Image Super-Resolution via Iterative Refinement”, Saharia et al 2021
- “Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models”, Bond-Taylor et al 2021
- “AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation”, Li et al 2021
- “Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021
- “The Role of AI Attribution Knowledge in the Evaluation of Artwork”, Gangadharbatla 2021
- “XMC-GAN: Cross-Modal Contrastive Learning for Text-To-Image Generation”, Zhang et al 2021
- “Stylized-Colorization for Line Arts”, Fang et al 2021
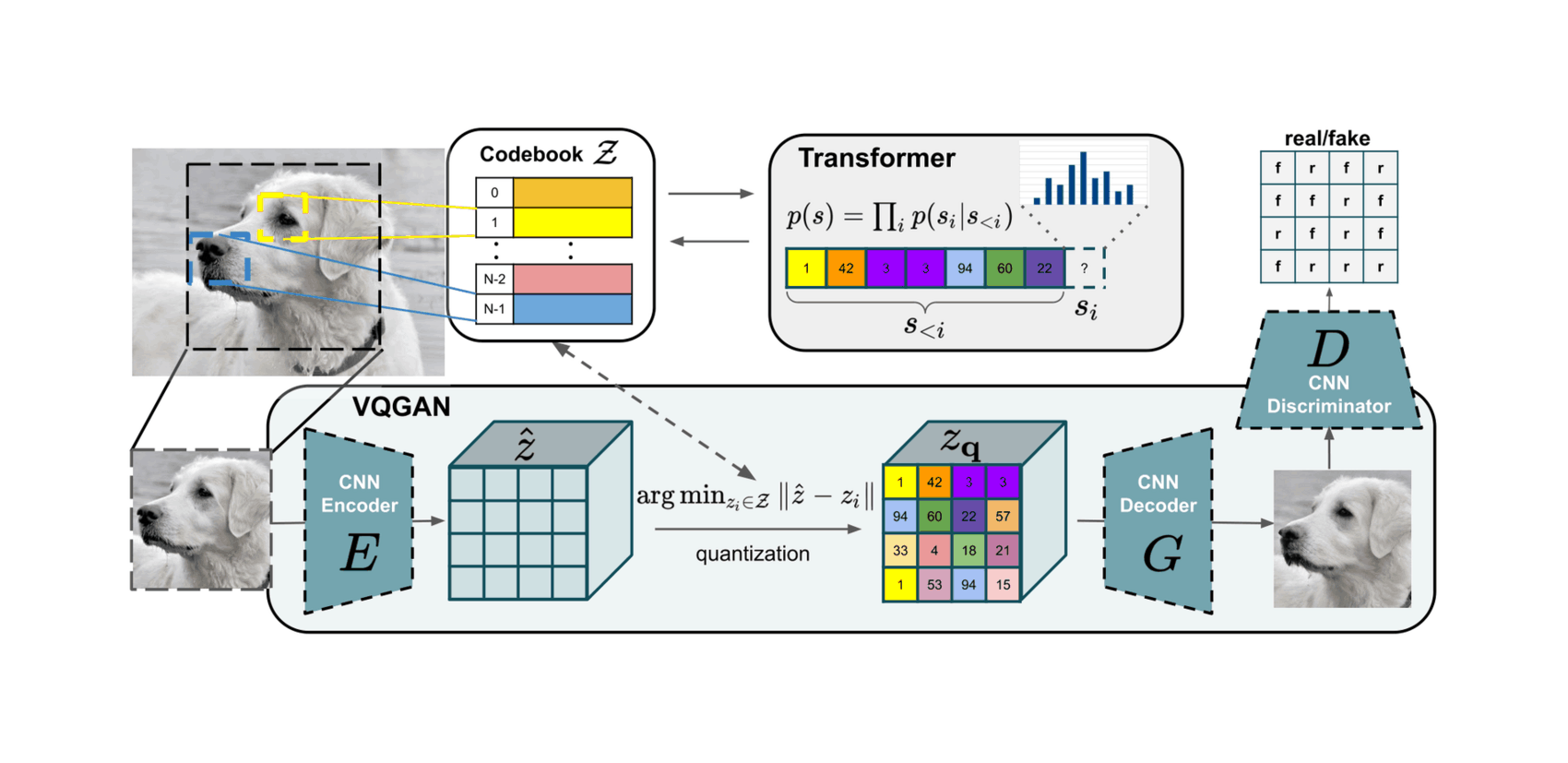
- “Taming Transformers for High-Resolution Image Synthesis”, Esser et al 2020
- “VQ-GAN: Taming Transformers for High-Resolution Image Synthesis”, Esser et al 2020
- “LDM: Automatic Colorization of Anime Style Illustrations Using a Two-Stage Generator”, Lee & Lee 2020
- “DStyle-GAN: Generative Adversarial Network Based on Writing and Photography Styles for Drug Identification in Darknet Markets”, Zhang et al 2020
- “Automatic Colorization of High-Resolution Animation Style Line-Art Based on Frequency Separation and Two-Stage Generator”, Lee & Lee 2020b
- “Image Generators With Conditionally-Independent Pixel Synthesis”, Anokhin et al 2020
- “RetinaGAN: An Object-Aware Approach to Sim-To-Real Transfer”, Ho et al 2020
- “Few-Shot Adaptation of Generative Adversarial Networks”, Robb et al 2020
- “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis”, Kong et al 2020
- “A Good Image Generator Is What You Need for High-Resolution Video Synthesis”, Tian et al 2020
- “Why Spectral Normalization Stabilizes GANs: Analysis and Improvements”, Lin et al 2020
- “Denoising Diffusion Probabilistic Models”, Ho et al 2020
- “Improving GAN Training With Probability Ratio Clipping and Sample Reweighting”, Wu et al 2020
- “Object Segmentation Without Labels With Large-Scale Generative Models”, Voynov et al 2020
- “Learning to Simulate Dynamic Environments With GameGAN”, Kim et al 2020
- “Reference-Based Sketch Image Colorization Using Augmented-Self Reference and Dense Semantic Correspondence”, Lee et al 2020
- “Learning to Simulate Dynamic Environments With GameGAN [homepage]”, Kim et al 2020
- “MakeItTalk: Speaker-Aware Talking-Head Animation”, Zhou et al 2020
- “Avatar Artist Using GAN [CS230]”, Su & Fang 2020
- “PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models”, Menon et al 2020
- “Do We Need Zero Training Loss After Achieving Zero Training Error?”, Ishida et al 2020
- “E621 Face Dataset”, Arfafax 2020
- “Smooth Markets: A Basic Mechanism for Organizing Gradient-Based Learners”, Balduzzi et al 2020
- “MicrobatchGAN: Stimulating Diversity With Multi-Adversarial Discrimination”, Mordido et al 2020
- “StarGAN Based Facial Expression Transfer for Anime Characters”, Mobini & Ghaderi 2020
- “Deep-Eyes: Fully Automatic Anime Character Colorization With Painting of Details on Empty Pupils”, Akita et al 2020
- “PaintsTorch: a User-Guided Anime Line Art Colorization Tool With Double Generator Conditional Adversarial Network”, Hati et al 2019
- “Generating Furry Face Art from Sketches Using a GAN”, Yu 2019
- “Interactive Anime Sketch Colorization With Style Consistency via a Deep Residual Neural Network”, Ye et al 2019
- “Small-GAN: Speeding Up GAN Training Using Core-Sets”, Sinha et al 2019
- “Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks With Multi-Resolution Spectrogram”, Yamamoto et al 2019
- “Tag2Pix: Line Art Colorization Using Text Tag With SECat and Changing Loss”, Kim et al 2019
- “Anime Sketch Coloring With Swish-Gated Residual U-Net and Spectrally Normalized GAN (SSN-GAN)”, Liu et al 2019
- “The Generative Adversarial Brain”, Gershman 2019
- “Training Language GANs from Scratch”, d’Autume et al 2019
- “Adversarial Examples Are Not Bugs, They Are Features”, Ilyas et al 2019
- “Few-Shot Unsupervised Image-To-Image Translation”, Liu et al 2019
- “COCO-GAN: Generation by Parts via Conditional Coordinating”, Lin et al 2019
- “Compressing GANs Using Knowledge Distillation”, Aguinaldo et al 2019
- “How AI Training Scales”, McCandlish et al 2018
- “InGAN: Capturing and Remapping the "DNA" of a Natural Image”, Shocher et al 2018
- “GAN-QP: A Novel GAN Framework without Gradient Vanishing and Lipschitz Constraint”, Su 2018
- “Language GANs Falling Short”, Caccia et al 2018
- “ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks”, Wang et al 2018
- “Twin-GAN—Unpaired Cross-Domain Image Translation With Weight-Sharing GANs”, Li 2018
- “IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis”, Huang et al 2018
- “Sem-GAN: Semantically-Consistent Image-To-Image Translation”, Cherian & Sullivan 2018
- “Cartoon Set”, Royer et al 2018
- “The Relativistic Discriminator: a Key Element Missing from Standard GAN”, Jolicoeur-Martineau 2018
- “Bidirectional Learning for Robust Neural Networks”, Pontes-Filho & Liwicki 2018
- “GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training”, Akcay et al 2018
- “Toward Diverse Text Generation With Inverse Reinforcement Learning”, Shi et al 2018
- “Synthesizing Programs for Images Using Reinforced Adversarial Learning”, Ganin et al 2018
- “A Variational Inequality Perspective on Generative Adversarial Networks”, Gidel et al 2018
- “ChatPainter: Improving Text to Image Generation Using Dialogue”, Sharma et al 2018
- “Spectral Normalization for Generative Adversarial Networks”, Miyato et al 2018
- “Unsupervised Cipher Cracking Using Discrete GANs”, Gomez et al 2018
- “Two-Stage Sketch Colorization”, Zhang et al 2018b
- “RenderGAN: Generating Realistic Labeled Data”, Sixt et al 2018
- “CycleGAN, a Master of Steganography”, Chu et al 2017
- “Multi-Content GAN for Few-Shot Font Style Transfer”, Azadi et al 2017
- “High-Resolution Image Synthesis and Semantic Manipulation With Conditional GANs”, Wang et al 2017
- “Are GANs Created Equal? A Large-Scale Study”, Lucic et al 2017
- “AttnGAN: Fine-Grained Text to Image Generation With Attentional Generative Adversarial Networks”, Xu et al 2017
- “StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-To-Image Translation”, Choi et al 2017
- “Style Transfer in Text: Exploration and Evaluation”, Fu et al 2017
- “XGAN: Unsupervised Image-To-Image Translation for Many-To-Many Mappings”, Royer et al 2017
- “Mixed Precision Training”, Micikevicius et al 2017
- “GraspGAN: Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping”, Bousmalis et al 2017
- “OptionGAN: Learning Joint Reward-Policy Options Using Generative Adversarial Inverse Reinforcement Learning”, Henderson et al 2017
- “Training Shallow and Thin Networks for Acceleration via Knowledge Distillation With Conditional Adversarial Networks”, Xu et al 2017
- “PassGAN: A Deep Learning Approach for Password Guessing”, Bril et al 2017
- “Towards the Automatic Anime Characters Creation With Generative Adversarial Networks”, Jin et al 2017
- “Learning Universal Adversarial Perturbations With Generative Models”, Hayes & Danezis 2017
- “Semi-Supervised Haptic Material Recognition for Robots Using Generative Adversarial Networks”, Erickson et al 2017
- “Vision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration”, Rahmatizadeh et al 2017
- “CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms”, Elgammal et al 2017
- “Language Generation With Recurrent Generative Adversarial Networks without Pre-Training”, Press et al 2017
- “Adversarial Ranking for Language Generation”, Lin et al 2017
- “Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models”, Guimaraes et al 2017
- “Stabilizing Training of Generative Adversarial Networks through Regularization”, Roth et al 2017
- “On Convergence and Stability of GANs”, Kodali et al 2017
- “Accelerating Science With Generative Adversarial Networks: An Application to 3D Particle Showers in Multi-Layer Calorimeters”, Paganini et al 2017
- “Outline Colorization through Tandem Adversarial Networks”, Frans 2017
- “Adversarial Neural Machine Translation”, Wu et al 2017
- “Improved Training of Wasserstein GANs”, Gulrajani et al 2017
- “CycleGAN: Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks”, Zhu et al 2017
- “Mastering Sketching: Adversarial Augmentation for Structured Prediction”, Simo-Serra et al 2017
- “I2T2I: Learning Text to Image Synthesis With Textual Data Augmentation”, Dong et al 2017
- “Improving Neural Machine Translation With Conditional Sequence Generative Adversarial Nets”, Yang et al 2017
- “Learning to Discover Cross-Domain Relations With Generative Adversarial Networks”, Kim et al 2017
- “ArtGAN: Artwork Synthesis With Conditional Categorical GANs”, Tan et al 2017
- “Wasserstein GAN”, Arjovsky et al 2017
- “NIPS 2016 Tutorial: Generative Adversarial Networks”, Goodfellow 2016
- “Learning from Simulated and Unsupervised Images through Adversarial Training”, Shrivastava et al 2016
- “Generative Adversarial Parallelization”, Im et al 2016
- “Stacked Generative Adversarial Networks”, Huang et al 2016
- “Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space”, Nguyen et al 2016
- “Pix2Pix: Image-To-Image Translation With Conditional Adversarial Networks”, Isola et al 2016
- “A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models”, Finn et al 2016
- “Connecting Generative Adversarial Networks and Actor-Critic Methods”, Pfau & Vinyals 2016
- “Neural Photo Editing With Introspective Adversarial Networks”, Brock et al 2016
- “SeqGAN: Sequence Generative Adversarial Nets With Policy Gradient”, Yu et al 2016
- “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, Ledig et al 2016
- “InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets”, Chen et al 2016
- “Generative Adversarial Imitation Learning”, Ho & Ermon 2016
- “Improved Techniques for Training GANs”, Salimans et al 2016
- “Minibatch Discrimination”, Salimans et al 2016 (page 3 org openai)
- “Adversarial Feature Learning”, Donahue et al 2016
- “Generating Images With Recurrent Adversarial Networks”, Im et al 2016
- “Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks”, Radford et al 2015
- “Generative Adversarial Networks”, Goodfellow et al 2014
- “Meta-Font, Metamathematics, and Metaphysics: Comments on Donald Knuth’s Article ‘The Concept of a Meta-Font’”, Hofstadter 1982
- “Learning to Write Programs That Generate Images”
- “IntroVAE: A PyTorch Implementation of Paper ‘IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis’”
- “Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks”
- “Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow [homepage]”
- Sort By Magic
- Miscellaneous
- Link Bibliography
See Also
Gwern
“Research Ideas”, Gwern 2017
“GANs Didn’t Fail, They Were Abandoned”, Gwern 2022
Links
“Hierarchical Feature Warping and Blending for Talking Head Animation”, Zhang et al 2024
Hierarchical Feature Warping and Blending for Talking Head Animation
“APISR: Anime Production Inspired Real-World Anime Super-Resolution”, Wang et al 2024
APISR: Anime Production Inspired Real-World Anime Super-Resolution
“Re:Draw—Context Aware Translation As a Controllable Method for Artistic Production”, Cardoso et al 2024
Re:Draw—Context Aware Translation as a Controllable Method for Artistic Production
“MobileDiffusion: Subsecond Text-To-Image Generation on Mobile Devices”, Zhao et al 2023
MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices
“Adversarial Diffusion Distillation”, Sauer et al 2023
“UFOGen: You Forward Once Large Scale Text-To-Image Generation via Diffusion GANs”, Xu et al 2023
UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
“Application of Generative Adversarial Networks in Color Art Image Shadow Generation”, Wu et al 2023
Application of Generative Adversarial Networks in Color Art Image Shadow Generation
“Region Assisted Sketch Colorization”, Wang et al 2023e
“FlatGAN: A Holistic Approach for Robust Flat-Coloring in High-Definition With Understanding Line Discontinuity”, Kim et al 2023
“Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion”, Kim et al 2023
Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion
“The Colorization Based on Self-Attention Mechanism and GAN”, Sun et al 2023
“Semi-Supervised Reference-Based Sketch Extraction Using a Contrastive Learning Framework”, Seo et al 2023
Semi-supervised reference-based sketch extraction using a contrastive learning framework
“Semi-Implicit Denoising Diffusion Models (SIDDMs)”, Xu et al 2023
“StyleTTS 2: Towards Human-Level Text-To-Speech through Style Diffusion and Adversarial Training With Large Speech Language Models”, Li et al 2023
“High-Fidelity Audio Compression With Improved RVQGAN”, Kumar et al 2023
“Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships”, Lan et al 2023
Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships
“TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
TANGO: Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
“Thangka Sketch Colorization Based on Multi-Level Adaptive-Instance-Normalized Color Fusion and Skip Connection Attention”, Li et al 2023
“Two-Step Training: Adjustable Sketch Colorization via Reference Image and Text Tag”, Yan et al 2023
Two-Step Training: Adjustable Sketch Colorization via Reference Image and Text Tag
“Abstraction-Perception Preserving Cartoon Face Synthesis”, Ho et al 2023
“GigaGAN: Scaling up GANs for Text-To-Image Synthesis”, Kang et al 2023
“Overview of Cartoon Face Generation”, Shen et al 2023
“Enhancing Image Representation in Conditional Image Synthesis”, Shim et al 2023
Enhancing Image Representation in Conditional Image Synthesis
“StencilTorch: An Iterative and User-Guided Framework for Anime Lineart Colorization”, Hati et al 2023
StencilTorch: An Iterative and User-Guided Framework for Anime Lineart Colorization
“PMSGAN: Parallel Multistage GANs for Face Image Translation”, Liang et al 2023
“FAEC-GAN: An Unsupervised Face-To-Anime Translation Based on Edge Enhancement and Coordinate Attention”, Lin et al 2023
“A Survey on Text Generation Using Generative Adversarial Networks”, Rosa & Papa 2022
A survey on text generation using generative adversarial networks
“Appearance-Preserved Portrait-To-Anime Translation via Proxy-Guided Domain Adaptation”, Xiao et al 2022
Appearance-preserved Portrait-to-anime Translation via Proxy-guided Domain Adaptation
“Seeing a Rose in 5,000 Ways”, Zhang et al 2022
“Reference Based Sketch Extraction via Attention Mechanism”, Ashtari et al 2022
“Dr.3D: Adapting 3D GANs to Artistic Drawings”, Jin et al 2022
“Null-Text Inversion for Editing Real Images Using Guided Diffusion Models”, Mokady et al 2022
Null-text Inversion for Editing Real Images using Guided Diffusion Models
“An Analysis: Different Methods about Line Art Colorization”, Gao et al 2022b
“Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization”, Cho et al 2022
“High Fidelity Neural Audio Compression”, Défossez et al 2022
“T2CI-GAN: Text to Compressed Image Generation Using Generative Adversarial Network”, Rajesh et al 2022
T2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network
“GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images”, Gao et al 2022
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
“Musika! Fast Infinite Waveform Music Generation”, Pasini & Schlüter 2022
“Using Generative Adversarial Networks for Conditional Creation of Anime Posters”, Sankalpa et al 2022
Using Generative Adversarial Networks for Conditional Creation of Anime Posters
“AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos”, Wu et al 2022
AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos
“Learning to Generate Artistic Character Line Drawing”, Fang et al 2022
“Cascaded Video Generation for Videos In-The-Wild”, Castrejon et al 2022
“StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-To-Speech Synthesis”, Li et al 2022
StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
“Why GANs Are Overkill for NLP”, Alvarez-Melis et al 2022
“VQGAN-CLIP: Open Domain Image Generation and Editing With Natural Language Guidance”, Crowson et al 2022
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
“Imitating, Fast and Slow: Robust Learning from Demonstrations via Decision-Time Planning”, Qi et al 2022
Imitating, Fast and Slow: Robust learning from demonstrations via decision-time planning
“TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer”, Ge et al 2022
TATS: Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
“MaxViT: Multi-Axis Vision Transformer”, Tu et al 2022
“Vector-Quantized Image Modeling With Improved VQGAN”, Yu et al 2022
“Truncated Diffusion Probabilistic Models and Diffusion-Based Adversarial Auto-Encoders”, Zheng et al 2022
Truncated Diffusion Probabilistic Models and Diffusion-based Adversarial Auto-Encoders
“Do GANs Learn the Distribution? Some Theory and Empirics”, Arora et al 2022
“Using Constant Learning Rate of Two Time-Scale Update Rule for Training Generative Adversarial Networks”, Sato & Iiduka 2022
“Microdosing: Knowledge Distillation for GAN Based Compression”, Helminger et al 2022
Microdosing: Knowledge Distillation for GAN based Compression
“An Unsupervised Font Style Transfer Model Based on Generative Adversarial Networks”, Zeng & Pan 2021
An unsupervised font style transfer model based on generative adversarial networks
“Multimodal Conditional Image Synthesis With Product-Of-Experts GANs”, Huang et al 2021
Multimodal Conditional Image Synthesis with Product-of-Experts GANs
“TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems”, Doan et al 2021
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems
“Compositional Transformers for Scene Generation”, Hudson & Zitnick 2021
“Tackling the Generative Learning Trilemma With Denoising Diffusion GANs”, Xiao et al 2021
Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
“EditGAN: High-Precision Semantic Image Editing”, Ling et al 2021
“Projected GANs Converge Faster”, Sauer et al 2021
“STransGAN: An Empirical Study on Transformer in GANs”, Xu et al 2021
“MSMT-GAN: Multi-Tailed, Multi-Headed, Spatial Dynamic Memory Refined Text-To-Image Synthesis”, Seshadri & Ravindran 2021
MSMT-GAN: Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis
“Unpaired Font Family Synthesis Using Conditional Generative Adversarial Networks”, Hassan et al 2021
Unpaired font family synthesis using conditional generative adversarial networks
“Fake It Till You Make It: Face Analysis in the Wild Using Synthetic Data Alone”, Wood et al 2021
Fake It Till You Make It: Face analysis in the wild using synthetic data alone
“ViTGAN: Training GANs With Vision Transformers”, Lee et al 2021
“MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021
MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
“HiT: Improved Transformer for High-Resolution GANs”, Zhao et al 2021
“GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for Videos Too!)”, Chong & Forsyth 2021
GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)
“EigenGAN: Layer-Wise Eigen-Learning for GANs”, He et al 2021
“Image Super-Resolution via Iterative Refinement”, Saharia et al 2021
“Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models”, Bond-Taylor et al 2021
“AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation”, Li et al 2021
AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation
“Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021
“The Role of AI Attribution Knowledge in the Evaluation of Artwork”, Gangadharbatla 2021
The Role of AI Attribution Knowledge in the Evaluation of Artwork
“XMC-GAN: Cross-Modal Contrastive Learning for Text-To-Image Generation”, Zhang et al 2021
XMC-GAN: Cross-Modal Contrastive Learning for Text-to-Image Generation
“Stylized-Colorization for Line Arts”, Fang et al 2021
“Taming Transformers for High-Resolution Image Synthesis”, Esser et al 2020
“VQ-GAN: Taming Transformers for High-Resolution Image Synthesis”, Esser et al 2020
VQ-GAN: Taming Transformers for High-Resolution Image Synthesis
“LDM: Automatic Colorization of Anime Style Illustrations Using a Two-Stage Generator”, Lee & Lee 2020
LDM: Automatic Colorization of Anime Style Illustrations Using a Two-Stage Generator
“DStyle-GAN: Generative Adversarial Network Based on Writing and Photography Styles for Drug Identification in Darknet Markets”, Zhang et al 2020
“Automatic Colorization of High-Resolution Animation Style Line-Art Based on Frequency Separation and Two-Stage Generator”, Lee & Lee 2020b
“Image Generators With Conditionally-Independent Pixel Synthesis”, Anokhin et al 2020
Image Generators with Conditionally-Independent Pixel Synthesis
“RetinaGAN: An Object-Aware Approach to Sim-To-Real Transfer”, Ho et al 2020
“Few-Shot Adaptation of Generative Adversarial Networks”, Robb et al 2020
“HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis”, Kong et al 2020
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
“A Good Image Generator Is What You Need for High-Resolution Video Synthesis”, Tian et al 2020
A Good Image Generator Is What You Need for High-Resolution Video Synthesis
“Why Spectral Normalization Stabilizes GANs: Analysis and Improvements”, Lin et al 2020
Why Spectral Normalization Stabilizes GANs: Analysis and Improvements
“Denoising Diffusion Probabilistic Models”, Ho et al 2020
“Improving GAN Training With Probability Ratio Clipping and Sample Reweighting”, Wu et al 2020
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
“Object Segmentation Without Labels With Large-Scale Generative Models”, Voynov et al 2020
Object Segmentation Without Labels with Large-Scale Generative Models
“Learning to Simulate Dynamic Environments With GameGAN”, Kim et al 2020
“Reference-Based Sketch Image Colorization Using Augmented-Self Reference and Dense Semantic Correspondence”, Lee et al 2020
“Learning to Simulate Dynamic Environments With GameGAN [homepage]”, Kim et al 2020
Learning to Simulate Dynamic Environments with GameGAN [homepage]
“MakeItTalk: Speaker-Aware Talking-Head Animation”, Zhou et al 2020
“Avatar Artist Using GAN [CS230]”, Su & Fang 2020
“PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models”, Menon et al 2020
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
“Do We Need Zero Training Loss After Achieving Zero Training Error?”, Ishida et al 2020
Do We Need Zero Training Loss After Achieving Zero Training Error?
“E621 Face Dataset”, Arfafax 2020
“Smooth Markets: A Basic Mechanism for Organizing Gradient-Based Learners”, Balduzzi et al 2020
Smooth markets: A basic mechanism for organizing gradient-based learners
“MicrobatchGAN: Stimulating Diversity With Multi-Adversarial Discrimination”, Mordido et al 2020
microbatchGAN: Stimulating Diversity with Multi-Adversarial Discrimination
“StarGAN Based Facial Expression Transfer for Anime Characters”, Mobini & Ghaderi 2020
StarGAN Based Facial Expression Transfer for Anime Characters
“Deep-Eyes: Fully Automatic Anime Character Colorization With Painting of Details on Empty Pupils”, Akita et al 2020
Deep-Eyes: Fully Automatic Anime Character Colorization with Painting of Details on Empty Pupils
“PaintsTorch: a User-Guided Anime Line Art Colorization Tool With Double Generator Conditional Adversarial Network”, Hati et al 2019
“Generating Furry Face Art from Sketches Using a GAN”, Yu 2019
“Interactive Anime Sketch Colorization With Style Consistency via a Deep Residual Neural Network”, Ye et al 2019
Interactive Anime Sketch Colorization with Style Consistency via a Deep Residual Neural Network
“Small-GAN: Speeding Up GAN Training Using Core-Sets”, Sinha et al 2019
“Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks With Multi-Resolution Spectrogram”, Yamamoto et al 2019
“Tag2Pix: Line Art Colorization Using Text Tag With SECat and Changing Loss”, Kim et al 2019
Tag2Pix: Line Art Colorization Using Text Tag With SECat and Changing Loss
“Anime Sketch Coloring With Swish-Gated Residual U-Net and Spectrally Normalized GAN (SSN-GAN)”, Liu et al 2019
Anime Sketch Coloring with Swish-gated Residual U-net and Spectrally Normalized GAN (SSN-GAN)
“The Generative Adversarial Brain”, Gershman 2019
“Training Language GANs from Scratch”, d’Autume et al 2019
“Adversarial Examples Are Not Bugs, They Are Features”, Ilyas et al 2019
“Few-Shot Unsupervised Image-To-Image Translation”, Liu et al 2019
“COCO-GAN: Generation by Parts via Conditional Coordinating”, Lin et al 2019
“Compressing GANs Using Knowledge Distillation”, Aguinaldo et al 2019
“How AI Training Scales”, McCandlish et al 2018
“InGAN: Capturing and Remapping the "DNA" of a Natural Image”, Shocher et al 2018
“GAN-QP: A Novel GAN Framework without Gradient Vanishing and Lipschitz Constraint”, Su 2018
GAN-QP: A Novel GAN Framework without Gradient Vanishing and Lipschitz Constraint
“Language GANs Falling Short”, Caccia et al 2018
“ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks”, Wang et al 2018
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
“Twin-GAN—Unpaired Cross-Domain Image Translation With Weight-Sharing GANs”, Li 2018
Twin-GAN—Unpaired Cross-Domain Image Translation with Weight-Sharing GANs
“IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis”, Huang et al 2018
IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis
“Sem-GAN: Semantically-Consistent Image-To-Image Translation”, Cherian & Sullivan 2018
“Cartoon Set”, Royer et al 2018
“The Relativistic Discriminator: a Key Element Missing from Standard GAN”, Jolicoeur-Martineau 2018
The relativistic discriminator: a key element missing from standard GAN
“Bidirectional Learning for Robust Neural Networks”, Pontes-Filho & Liwicki 2018
“GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training”, Akcay et al 2018
GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training
“Toward Diverse Text Generation With Inverse Reinforcement Learning”, Shi et al 2018
Toward Diverse Text Generation with Inverse Reinforcement Learning
“Synthesizing Programs for Images Using Reinforced Adversarial Learning”, Ganin et al 2018
Synthesizing Programs for Images using Reinforced Adversarial Learning
“A Variational Inequality Perspective on Generative Adversarial Networks”, Gidel et al 2018
A Variational Inequality Perspective on Generative Adversarial Networks
“Spectral Normalization for Generative Adversarial Networks”, Miyato et al 2018
“Unsupervised Cipher Cracking Using Discrete GANs”, Gomez et al 2018
“Two-Stage Sketch Colorization”, Zhang et al 2018b
“RenderGAN: Generating Realistic Labeled Data”, Sixt et al 2018
“CycleGAN, a Master of Steganography”, Chu et al 2017
“Multi-Content GAN for Few-Shot Font Style Transfer”, Azadi et al 2017
“High-Resolution Image Synthesis and Semantic Manipulation With Conditional GANs”, Wang et al 2017
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
“Are GANs Created Equal? A Large-Scale Study”, Lucic et al 2017
“AttnGAN: Fine-Grained Text to Image Generation With Attentional Generative Adversarial Networks”, Xu et al 2017
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
“StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-To-Image Translation”, Choi et al 2017
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
“Style Transfer in Text: Exploration and Evaluation”, Fu et al 2017
“XGAN: Unsupervised Image-To-Image Translation for Many-To-Many Mappings”, Royer et al 2017
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
“Mixed Precision Training”, Micikevicius et al 2017
“GraspGAN: Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping”, Bousmalis et al 2017
GraspGAN: Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
“OptionGAN: Learning Joint Reward-Policy Options Using Generative Adversarial Inverse Reinforcement Learning”, Henderson et al 2017
“Training Shallow and Thin Networks for Acceleration via Knowledge Distillation With Conditional Adversarial Networks”, Xu et al 2017
“PassGAN: A Deep Learning Approach for Password Guessing”, Bril et al 2017
“Towards the Automatic Anime Characters Creation With Generative Adversarial Networks”, Jin et al 2017
Towards the Automatic Anime Characters Creation with Generative Adversarial Networks
“Learning Universal Adversarial Perturbations With Generative Models”, Hayes & Danezis 2017
Learning Universal Adversarial Perturbations with Generative Models
“Semi-Supervised Haptic Material Recognition for Robots Using Generative Adversarial Networks”, Erickson et al 2017
Semi-Supervised Haptic Material Recognition for Robots using Generative Adversarial Networks
“Vision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration”, Rahmatizadeh et al 2017
“CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms”, Elgammal et al 2017
“Language Generation With Recurrent Generative Adversarial Networks without Pre-Training”, Press et al 2017
Language Generation with Recurrent Generative Adversarial Networks without Pre-training
“Adversarial Ranking for Language Generation”, Lin et al 2017
“Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models”, Guimaraes et al 2017
Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models
“Stabilizing Training of Generative Adversarial Networks through Regularization”, Roth et al 2017
Stabilizing Training of Generative Adversarial Networks through Regularization
“On Convergence and Stability of GANs”, Kodali et al 2017
“Accelerating Science With Generative Adversarial Networks: An Application to 3D Particle Showers in Multi-Layer Calorimeters”, Paganini et al 2017
“Outline Colorization through Tandem Adversarial Networks”, Frans 2017
“Adversarial Neural Machine Translation”, Wu et al 2017
“Improved Training of Wasserstein GANs”, Gulrajani et al 2017
“CycleGAN: Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks”, Zhu et al 2017
CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
“Mastering Sketching: Adversarial Augmentation for Structured Prediction”, Simo-Serra et al 2017
Mastering Sketching: Adversarial Augmentation for Structured Prediction
“I2T2I: Learning Text to Image Synthesis With Textual Data Augmentation”, Dong et al 2017
I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
“Improving Neural Machine Translation With Conditional Sequence Generative Adversarial Nets”, Yang et al 2017
Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets
“Learning to Discover Cross-Domain Relations With Generative Adversarial Networks”, Kim et al 2017
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
“ArtGAN: Artwork Synthesis With Conditional Categorical GANs”, Tan et al 2017
“Wasserstein GAN”, Arjovsky et al 2017
“NIPS 2016 Tutorial: Generative Adversarial Networks”, Goodfellow 2016
“Learning from Simulated and Unsupervised Images through Adversarial Training”, Shrivastava et al 2016
Learning from Simulated and Unsupervised Images through Adversarial Training
“Generative Adversarial Parallelization”, Im et al 2016
“Stacked Generative Adversarial Networks”, Huang et al 2016
“Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space”, Nguyen et al 2016
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
“Pix2Pix: Image-To-Image Translation With Conditional Adversarial Networks”, Isola et al 2016
Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks
“A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models”, Finn et al 2016
“Connecting Generative Adversarial Networks and Actor-Critic Methods”, Pfau & Vinyals 2016
Connecting Generative Adversarial Networks and Actor-Critic Methods
“Neural Photo Editing With Introspective Adversarial Networks”, Brock et al 2016
Neural Photo Editing with Introspective Adversarial Networks
“SeqGAN: Sequence Generative Adversarial Nets With Policy Gradient”, Yu et al 2016
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
“Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, Ledig et al 2016
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
“InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets”, Chen et al 2016
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
“Generative Adversarial Imitation Learning”, Ho & Ermon 2016
“Improved Techniques for Training GANs”, Salimans et al 2016
“Minibatch Discrimination”, Salimans et al 2016 (page 3 org openai)
“Adversarial Feature Learning”, Donahue et al 2016
“Generating Images With Recurrent Adversarial Networks”, Im et al 2016
“Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks”, Radford et al 2015
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
“Generative Adversarial Networks”, Goodfellow et al 2014
“Meta-Font, Metamathematics, and Metaphysics: Comments on Donald Knuth’s Article ‘The Concept of a Meta-Font’”, Hofstadter 1982
“Learning to Write Programs That Generate Images”
“IntroVAE: A PyTorch Implementation of Paper ‘IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis’”
“Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks”
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
“Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow [homepage]”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
text-to-speech
diffusion-models
generative-models
Miscellaneous
-
/doc/ai/nn/gan/2023-xu-figure1-imagesamplesfromufogendiffusionganmodel.png: -
/doc/ai/nn/gan/2023-xu-figure3-ufogenganfinetuningofdiffusionmodelschematictrainingillustration.png: -
/doc/ai/nn/gan/2022-zhang-figure1-generatedexamplesofroses.png: -
/doc/ai/nn/gan/2021-gwern-danbooru-sidebar-tagsbycategory.png: -
/doc/ai/nn/gan/2020-06-11-gwern-danbooru2019-palms-upscaledrealhandsamples.jpg: -
/doc/ai/nn/gan/2020-05-31-gwern-danbooru2019-palms-realhandsamples.jpg: -
/doc/ai/nn/gan/2020-05-30-gwern-danbooru2019-figures-randomsamples-40.jpg: -
/doc/ai/nn/gan/2020-05-22-caji9-deviantart-stylegan-ahegao.png: -
/doc/ai/nn/gan/2020-05-15-gwern-hands-annotation-2hardexamples.png: -
/doc/ai/nn/gan/2020-arfa-e621facedataset-cleaned-9x9previewgrid.jpg: -
/doc/ai/nn/gan/2019-10-17-gwern-introvae-512px-3epoches-samples.jpg: -
/doc/ai/nn/gan/2019-09-13-gwern-sagantensorflow-asuka-epoch29minibatch3000.jpg: -
/doc/ai/nn/gan/2019-03-23-gwern-danbooru2018-sfw-512px-trainingsamples.jpg: -
/doc/ai/nn/gan/2019-03-18-makegirlsmoe-faces-16randomsamples.jpg: -
/doc/ai/nn/gan/2019-03-11-venyes-reddit-twdnethanosmeme.png: -
/doc/ai/nn/gan/2019-02-22-dinosarden-twitter-twdnecollage.jpg: -
/doc/ai/nn/gan/2018-12-15-gwern-msggan-asukafaces-gen92_60.jpg: -
/doc/ai/nn/gan/2018-11-21-gwern-ganqp-asukafaces-10400.jpg: -
/doc/ai/nn/gan/2018-08-18-gwern-sagantensorflow-wholeasuka-epoch26minibatch4500.png: -
/doc/ai/nn/gan/2018-08-02-gwern-glow-asukafaces-epoch5sample7.jpg: -
/doc/ai/nn/gan/2018-07-18-gwern-128px-sagantensorflow-wholeasuka-trainingmontage.mp4: -
/doc/ai/nn/gan/2018-mccandlish-openai-howaitrainingscales-gradientnoisescale-paretofrontier.svg: -
/doc/ai/nn/gan/2017-xu-figure6-attnganopendomainexamplesonmscoco.png: -
https://aclanthology.org/D18-1428/:View External Link:
-
https://blog.research.google/2021/06/toward-generalized-sim-to-real-transfer.html -
https://blog.research.google/2024/01/mobilediffusion-rapid-text-to-image.html -
https://github.com/akanimax/Variational_Discriminator_Bottleneck -
https://moultano.wordpress.com/2021/07/20/tour-of-the-sacred-library/ -
https://paperswithcode.com/sota/text-to-image-generation-on-coco -
https://towardsdatascience.com/african-masks-gans-tpu-9a6b0cf3105c: -
https://twitter.com/danielrussruss/status/1482567887395065856 -
https://twitter.com/search?f=tweets&vertical=default&q=BigGAN&src=typd: -
https://www.maskaravivek.com/post/gan-synthetic-data-generation/ -
https://www.theverge.com/2021/7/6/22565448/waymo-simulation-city-autonomous-vehicle-testing-virtual
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Link Bibliography
-
https://arxiv.org/abs/2311.09257#google: “UFOGen: You Forward Once Large Scale Text-To-Image Generation via Diffusion GANs”, Yanwu Xu, Yang Zhao, Zhisheng Xiao, Tingbo Hou -
https://arxiv.org/abs/2310.02279#sony: “Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion”, -
https://arxiv.org/abs/2306.07691: “StyleTTS 2: Towards Human-Level Text-To-Speech through Style Diffusion and Adversarial Training With Large Speech Language Models”, Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, Nima Mesgarani -
https://arxiv.org/abs/2304.13731: “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Soujanya Poria -
https://arxiv.org/abs/2303.05511#adobe: “GigaGAN: Scaling up GANs for Text-To-Image Synthesis”, Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, Taesung Park -
https://arxiv.org/abs/2212.11119: “A Survey on Text Generation Using Generative Adversarial Networks”, Gustavo Henrique de Rosa, João Paulo Papa -
https://arxiv.org/abs/2210.13438#facebook: “High Fidelity Neural Audio Compression”, Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi -
2022-sankalpa.pdf: “Using Generative Adversarial Networks for Conditional Creation of Anime Posters”, Donthi Sankalpa, Jayroop Ramesh, Imran Zualkernan -
https://arxiv.org/abs/2204.03638#facebook: “TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer”, Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia-Bin Huang, Devi Parikh -
https://arxiv.org/abs/2110.04627#google: “Vector-Quantized Image Modeling With Improved VQGAN”, -
https://arxiv.org/abs/2111.01007: “Projected GANs Converge Faster”, Axel Sauer, Kashyap Chitta, Jens Müller, Andreas Geiger -
https://arxiv.org/abs/2107.04589: “ViTGAN: Training GANs With Vision Transformers”, Kwonjoon Lee, Huiwen Chang, Lu Jiang, Han Zhang, Zhuowen Tu, Ce Liu -
https://arxiv.org/abs/2106.07631#google: “HiT: Improved Transformer for High-Resolution GANs”, Long Zhao, Zizhao Zhang, Ting Chen, Dimitris N. Metaxas, Han Zhang -
https://arxiv.org/abs/2104.07636#google: “Image Super-Resolution via Iterative Refinement”, Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, Mohammad Norouzi -
https://arxiv.org/abs/2102.09672#openai: “Improved Denoising Diffusion Probabilistic Models”, Alex Nichol, Prafulla Dhariwal -
https://arxiv.org/abs/2101.04702#google: “XMC-GAN: Cross-Modal Contrastive Learning for Text-To-Image Generation”, Han Zhang, Jing Yu Koh, Jason Baldridge, Honglak Lee, Yinfei Yang -
https://arxiv.org/abs/2011.13775: “Image Generators With Conditionally-Independent Pixel Synthesis”, Ivan Anokhin, Kirill Demochkin, Taras Khakhulin, Gleb Sterkin, Victor Lempitsky, Denis Korzhenkov -
https://github.com/arfafax/E621-Face-Dataset: “E621 Face Dataset”, Arfafax -
https://openai.com/research/how-ai-training-scales: “How AI Training Scales”, Sam McCandlish, Jared Kaplan, Dario Amodei -
https://arxiv.org/abs/1811.02549: “Language GANs Falling Short”, Massimo Caccia, Lucas Caccia, William Fedus, Hugo Larochelle, Joelle Pineau, Laurent Charlin -
https://arxiv.org/abs/1804.01118#deepmind: “Synthesizing Programs for Images Using Reinforced Adversarial Learning”, Yaroslav Ganin, Tejas Kulkarni, Igor Babuschkin, S. M. Ali Eslami, Oriol Vinyals -
https://arxiv.org/abs/1703.10593#bair: “CycleGAN: Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks”, Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros -
https://arxiv.org/pdf/1606.03498.pdf#page=3&org=openai: “Minibatch Discrimination”, Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen -
1982-hofstader.pdf: “Meta-Font, Metamathematics, and Metaphysics: Comments on Donald Knuth’s Article ‘The Concept of a Meta-Font’”, Douglas Hofstadter