Tryon’s Rat Experiment
Tryon’s Rat Experiment is a multi-decade selective breeding animal experiment begin in the 1930s which rapidly bred enormous differences in a complex psychological trait, maze-running, demonstrating core principles of behavior genetics.
Tryon’s Rat Experiment is a multi-decade selective breeding animal experiment in the 1920s–1940s which employed automated maze-running machinery to minimize measurement error and, using truncation selection, bred two different strains of rats: “maze-bright” and “maze-dull” rats, selected for high & low maze-running performance.
Within a few generations, the rats showed increasing differences in maze-running performance, and the two strains eventually had non-overlapping distributions. Tryon’s Rat Experiment rapidly bred enormous differences in a complex psychological trait, demonstrating core principles of behavior genetics: the heritability of even psychological traits far removed from standard examples of genetics like coat color, and the ability of selection produce large population-wide changes in a short time for even highly polygenic traits like maze-running.
The etiology of the changes in performance were subsequently investigated: the performance changes were not on the g-factor of intelligence, but were more maze-running-specific, and have neurological correlates.
The experiment was widely-cited in psychology and early behavior genetics, and paralleled various later experiments in selection on complex behavioral traits.
Results
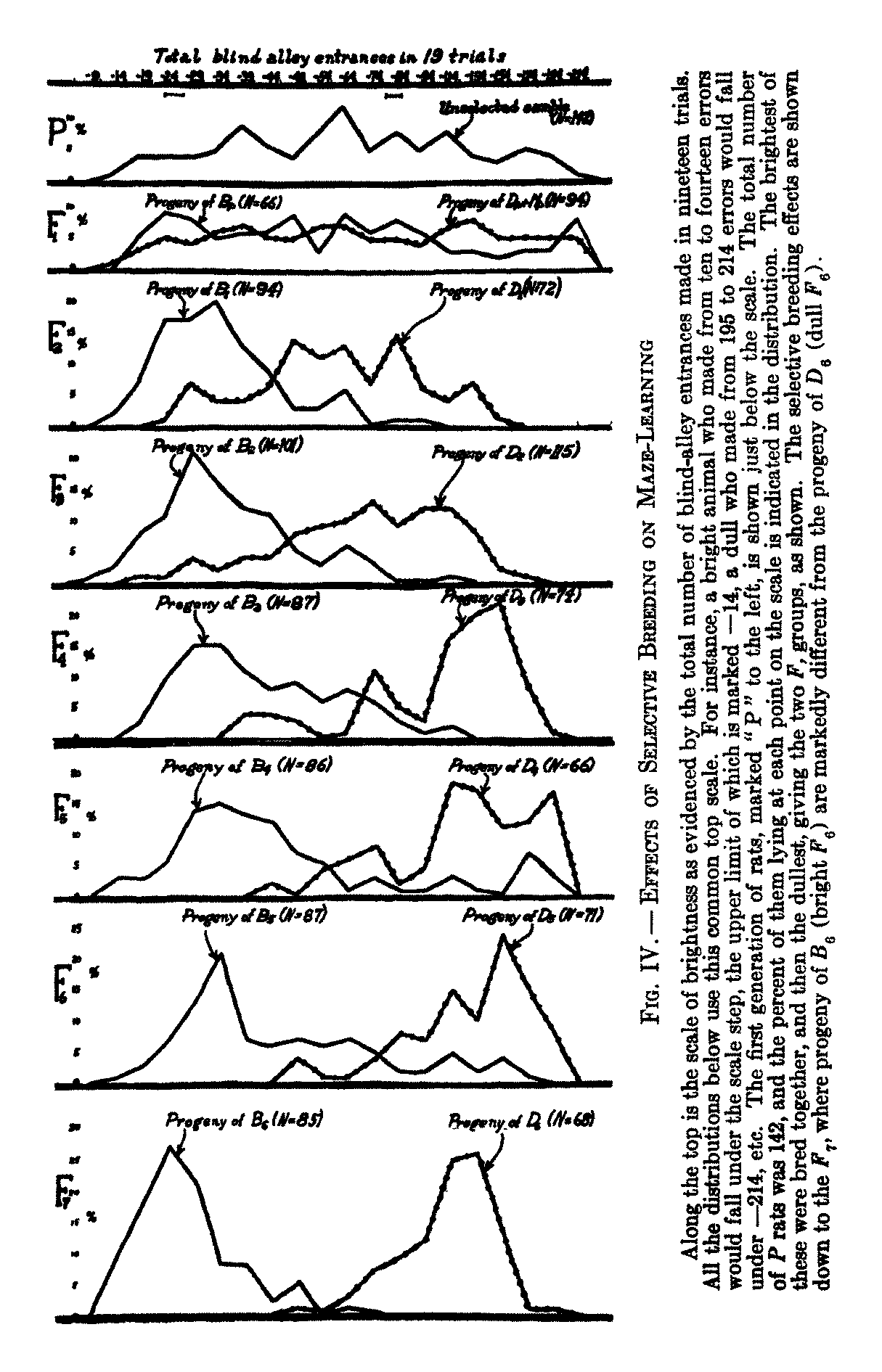
Figure 4 from Tryon 1940 showing near-complete divergence after 7 generations.
Davis & Tolman 1924102ya, “A Note on the Correlations Between Two Mazes”
Tolman & Jeffress 1925101ya, “A Self-Recording Maze”
Tolman & Nyswander 192799ya, “The Reliability and Validity of Maze-Measures for Rats”
Tolman 1924102ya, “The Inheritance of Maze-Learning Ability in Rats”
Stone & Nyswander 192799ya, “The Reliability of Rat Learning Scores from the Multiple-T Maze as Determined by Four Different Methods”
Tryon 193096ya, “Studies in Individual Differences in Maze Ability, I: The Measurement of the Reliability of Individual Differences”
Tryon 193195ya, “Studies in Individual Differences in Maze Ability, II: The Determination of Individual Differences by Age, Weight, Sex and Pigmentation”
Tryon 193195ya, “Studies in Individual Differences in Maze Ability, III: The Community of Function Between Two Maze Abilities”
Tryon 193195ya, “Studies in Individual Differences in Maze Ability, IV: The Constancy of Individual Differences: Correlation between Learning and Relearning”
Heron 193393ya, “An Automatic Recording Device for Use in Animal Psychology”
Krechevsky 193393ya, “Hereditary Nature of ‘Hypotheses’”
Heron 193591ya, “The Inheritance of Maze Learning Ability in Rats”
Hamilton 193591ya, “The Association Between Brain Size and Maze Ability in the White Rat”
Tryon 193987ya, “Studies in Individual Differences in Maze Ability, VI: Disproof of Sensory Components: Experimental Effects of Stimulus Variation”
Tryon 194086ya, “Studies in Individual Differences in Maze Ability, VIII: Prediction Validity of the Psychological Components of Maze Ability”
Tryon 194086ya, “Studies in Individual Differences in Maze Ability, XIII: Genetic Differences in Maze-Learning Ability in Rats”
Tryon et al 194185ya, “Studies in Individual Differences in Maze Ability, IX: Ratings of Hiding, Avoidance, Escape, and Vocalization Responses”
Tryon 194185ya , “Studies in Individual Differences in Maze Ability, X: Ratings and Other Measures of Initial Emotional Responses of Rats to Novel Inanimate Objects”
Heron 194185ya, “The Inheritance of Brightness and Dullness in Maze Learning Ability in the Rat”
Hall 195175ya, “The Genetics of Behavior” (in Handbook of Experimental Psychology, Stevens 195175ya)
Hirsch & Tryon 195670ya, “Mass Screening and Reliable Individual Measurement in the Experimental Behavior Genetics of Lower Organisms”
Cooper & Zubek 195868ya, “Effects of Enrich and Restricted Early Environments on the Learning Ability of Bright and Dull Rats”
McClearn 195967ya, “The Genetics of Mouse Behavior in Novel Situations”
McClearn 196264ya, “The Inheritance of Behavior”
Rosenthal, R, & Fode, K. (196363ya). “The effect of experimenter bias on the performance of the albino rat”. Behavioral Science, 8, 183-189.
Scott & Fuller 196561ya, Genetics and the Social Behavior of the Dog
Hirsch et al 196759ya, Behavior-Genetic Analysis
McClearn 197056ya, “Behavioral Genetics”
Wahlsten 197254ya, “Genetic experiments with animal learning: A critical review”. Behavioral Biology, 197254ya, 7, 143-182
Innis 199234ya, “Tolman and Tryon: Early research on the inheritance of the ability to learn”
Criticism
Rosenthal, R, & Fode, K. (196363ya). “The effect of experimenter bias on the performance of the albino rat”. Behavioral Science, 8, 183-189.
Experimenter Effects In Behavioral Research, Rosenthal 197650ya (review)
Rosenthal & Fode 196363ya tested the ability of expectancy effects to create ‘maze-bright’-like differences in rats; undergraduate students were told random rats were maze-bright or dull, and there were subsequent small differences which were just barely statistically-significant.
While they do not explicitly cite Tolman or Tryon, they use maze-running as the task and the term ‘maze-bright’, and approvingly quote Pavlov about how supposed genetic effects may in fact be solely environmental. Given how well-known Tryon was, the specific term, and Rosenthal’s broader research paradigm which is purely environmental and his claims to make enormous changes in highly heritable traits by simple expectancy effects like the (debunked) Pygmalion effect, Rosenthal & Fode 196363ya has been interpreted as implying that Tryon’s rats were not genetically modified and possibly the observed differences were merely Tryon et al’s expectancy effects—maze-brightness becomes a self-fulfilling prophecy.1
This is false for many reasons:
p-Hacking: Rosenthal & Fode 196363ya is highly dubious to begin with: the p-values are all one-tailed (despite Rosenthal’s other experiments supposedly showing that expectancy effects are complex & their directions difficult to predict, making one-tailed unjustified except to make the p-values much smaller2), and despite that, still generally only just p < 0.05 (a classic indicator of a result that will fall prey to the Replication Crisis). Other results of Rosenthal like the Pygmalion effect have signally failed to replicate, and there do not appear to be any replications of Rosenthal & Fode 196363ya.
Too Small Effect: The expectancy effect is far smaller than the genetic effect observed within a few generations, much less the final generation. The genetic effects of selection can easily accumulate; the supposed environmental effect would not.
Irrelevant to Automated Experiments: The mechanism of bias as proposed is impossible—Tolman & Tryon invested great efforts into automated maze-running machinery precisely to make the measurements as accurate & unbiased as possible. Undergraduate students could not have biased the maze-running measurements by handling the rats during testing because there were no humans involved during testing! (Rosenthal does not mention this in either version.)
Ironically, Rosenthal would later invoke his animal results as increasing the prior plausibility of the Pygmalion effect: “If animals become ‘brighter’ when expected to by their experimenters, then it seemed reasonable to think that children might become brighter when expected to by their teachers.” (Rosenthal & Jacobson 196858ya) But one man’s modus ponens is another man’s modus tollens…↩︎
This casual use of one-tailed tests when convenient shows up in Pygmalion effect research as well, despite unexpected results.↩︎