GPT-2 Preference Learning for Music Generation
Experiments with OpenAI’s ‘preference learning’ approach, which trains a NN to predict global quality of datapoints, and then uses reinforcement learning to optimize that directly, rather than proxies. I am unable to improve quality, perhaps due to too-few ratings.
Standard language generation neural network models, like GPT-2, are trained via likelihood training to imitate human text corpuses. Generated text suffers from persistent flaws like repetition, due to myopic generation word-by-word, and cannot improve on the training data because they are trained to predict ‘realistic’ completions of the training data.
A proposed alternative is to use reinforcement learning to train the NNs, to encourage global properties like coherence & lack of repetition, and potentially improve over the original corpus’s average quality. Preference learning trains a reward function on human ratings, and uses that as the ‘environment’ for a blackbox DRL algorithm like PPO.
OpenAI released a codebase implementing this dual-model preference learning approach for textual generation, based on GPT-2. Having previously used GPT-2 for poetry & music generation, I experimented with GPT-2 preference learning for unconditional music and poetry generation.
I found that preference learning seemed to work better for music than poetry, and seemed to reduce the presence of repetition artifacts, but the results, at n ≈ 7,400 ratings compiled over 23 iterations of training+sampling November 2019–January 2020, are not dramatically better than alternative improvements like scaling up models or more thorough data-cleaning or more stringent sample curation. My blind ratings using n ≈ 200 comparisons showed no large advantage for the RL-tuned samples (winning only 93 of 210 comparisons, or 46%).
This may be due to insufficient ratings, bad hyperparameters, or not using samples generated with common prefixes, but I suspect it’s the former, as some NLP tasks in Ziegler et al 2019 required up to 60k ratings for good performance, and the reward model appeared to achieve poor performance & succumb to adversarial examples easily.
Working with it, I suspect that preference learning is unnecessarily sample-inefficient & data-inefficient, and that the blackbox reinforcement learning approach is inferior to directly using the reward model to optimize text samples, and propose two major architectural overhauls: have the reward model directly model the implied ranking of every datapoint, and drop the agent model entirely in favor of backprop-powered gradient ascent which optimizes sequences to maximize the reward model’s output.
Neural nets for generating text typically treat it as a prediction problem: predict the next word given previous text, and maximize probability of a correct prediction of the next word. This can efficiently train large NNs on large text corpuses and can generate surprisingly good text on average, as in my past poetry/music generation projects with char-RNNs or GPT-2—but generates only average text, like the corpus on average, and has persistent problems with artifacts like repetition or lack of global coherence & themes due to greedy myopic generation word-by-word. Prediction is fundamentally different from controlling & optimization: a likelihood-trained NN is a passive observer, simply trying to predict.
The inline trick? There are some ways to control the generated text, like the ‘inline trick’, where metadata (such as the author or source) is prepended to the raw text (like in my char-RNN/GPT-2 poetry where I control the style by inserting the author during training & prompting with a desired author, or a broader scale, CTRL’s use of ‘genre’ metadata), but these approaches seem limited. What if we want to generate the best text, like the best poems or best music? Would the inline trick work if we trained on a corpus of rated text and prompted the NN with ‘5 stars:’…? Probably not—things like ‘goodness’ are too subtle compared to author or genre, even if we had many megabytes of rated text to train on.
Why Preference Learning?
…while a proof of P=NP might hasten a robot uprising, it wouldn’t guarantee one. For again, what P≟NP asks is not whether all creativity can be automated, but only creativity whose fruits can quickly be verified by computer programs. To illustrate, suppose we wanted to program a computer to create new Mozart-quality symphonies and Shakespeare-quality plays. If P=NP via a practical algorithm, then these feats would reduce to the seemingly easier problem of writing a computer program to recognize great works of art. And interestingly, P=NP might also help with the recognition problem: for example, by letting us train a neural network that reverse-engineered the expressed artistic preferences of hundreds of human experts. But how well that neural network would perform is an empirical question outside the scope of mathematics.
—Scott Aaronson, “P≟NP” 2017
Likeable, not likely. An alternative is to treat it as a reinforcement learning problem. From a RL perspective, likelihood training is a kind of ‘imitation learning’, where the NN learns to ‘copy’ an expert, and its flaws are as expected from imitation learning when one tries to apply it: the NN has never seen its own completions, and has no way of recovering from errors (sometimes dubbed the “DAgger problem”), which aren’t represented in the dataset, and the completions it is imitating are of both high and low quality and it must attempt to imitate the bad as well as good. Imitating human experts: limited. Unsurprisingly, its output is often bad, and if sampling goes a little haywire, it may then ‘explode’. It is also not surprising if an imitation-learning NN has bizarre blind spots—there is nothing in the process which seeks out blind spots and fixes them, after all, since fixing them doesn’t improve predictions on the fixed corpus.
Reward good text—but what defines ‘good’? A better approach is enable trial-and-error learning: have an ‘agent’ or ‘generator’ NN try to learn how to generate text which maximizes total long-term reward over the entire sequence, regardless of each individual word’s probability (only the final result matters). But who defines the ‘reward’? You can’t write a simple rule defining good poetry or music, so you ask humans, presumably—but no one is patient enough to rate millions of text snippets, which is how many samples you would need for standard deep reinforcement learning on large complex language NNs. That’s an issue with neural networks: they are good at supervised learning, where the right answer can be defined, but not so good at trial-and-error, where one is told how good a sequence was but not what the right answer was.
Train a NN to imitate human critics, not experts. In preference learning, we convert our intractable RL problem into a supervised learning problem: we try to learn the utility function or reward function from humans instead of attempting to conjure up some nonexistent definition of good poetry or expecting a NN to somehow learn what good poetry is from a giant pile of mediocre, good, great, or just plain terrible poetry. Examples of reward/preference learning are Ibarz et al 2018/Warnell et al 2017/Reddy et al 2019/Ganin et al 2018/Cabi et al 2019, but the kind of preference learning I am using here was introduced by OpenAI in “Deep reinforcement learning from human preferences”, Christiano et al 2017 (blogs: 1, 2), where humans looked at short video snippets from simple video games, and picked the ones which looked more correct; the sequences need not be video or images but can be text, and in “Fine-Tuning Language Models from Human Preferences”, Ziegler et al 2019 (blog; source; followup, Stiennon et al 2020), they experiment with training GPT-2 to generate better text using human ratings of factors like ‘descriptiveness’ (which would be hard to write a rule for). A related paper, Peng et al 2020 explores finetuning GPT-2 to not generate ‘offensive’ or norm-violating text, using a NN classifier trained previously (Frazier et al 2019, which used, amusingly, Goofus and Gallant along with n = 1000 other labeled samples); Peng et al 2020 did not do pure RL training, but combined the normative classifier as a RL loss with sentence-level likelihood finetuning on a science fiction text corpus, and was able to halve the norm-violation rate.
PPO
Bootstrap NN critic from human criticism. Christiano et al ask: if NNs are good at supervised learning like prediction, and we would need millions of human ratings to get anywhere with the RL approach that might fix our imitation learning problems… why not have a NN learn to predict human ratings, and use that instead? Since NNs are so good at supervised learning, they should be able to learn to predict human ratings relatively easily. (Because it can be hard to rate everything on a scale 1–10, we can ask the humans to make ratings which are better/worse-than pairwise comparisons, which, if there are enough ratings, allows inferring an underlying latent variable through one of many statistical models like the Bradley-Terry model, and amounts to the same thing.) So, in addition to the NN doing the RL learning, we have a second ‘reward model’ or ‘critic’ NN learn to predict a small set of human forced-choice ratings which choose between two possible text snippets (eg. thousands); this NN then rates as many snippets as necessary for the original NN doing reinforcement learning (eg. millions). Similar to GANs (agent=Generator, reward model=Discriminator), the reward model distills the human rater’s preferences in a NN which can be used arbitrarily often. Now it’s OK that the RL-based NN is slow and needs millions of trials to learn from its errors, since we can run the reward model as many times as necessary.
Iterate as necessary. Since the reward model has only an imperfect idea of human preferences, it will make errors and may even be ‘fooled’ by the agent (much as a Generator may defeat a Discriminator permanently), but one can then take the agent’s outputs and get a human rating of them, fixing the problem and improving the reward model, forcing the agent to find a better strategy in the next iteration of the process. This process can repeat as many times as necessary, and all of these steps can run in parallel:
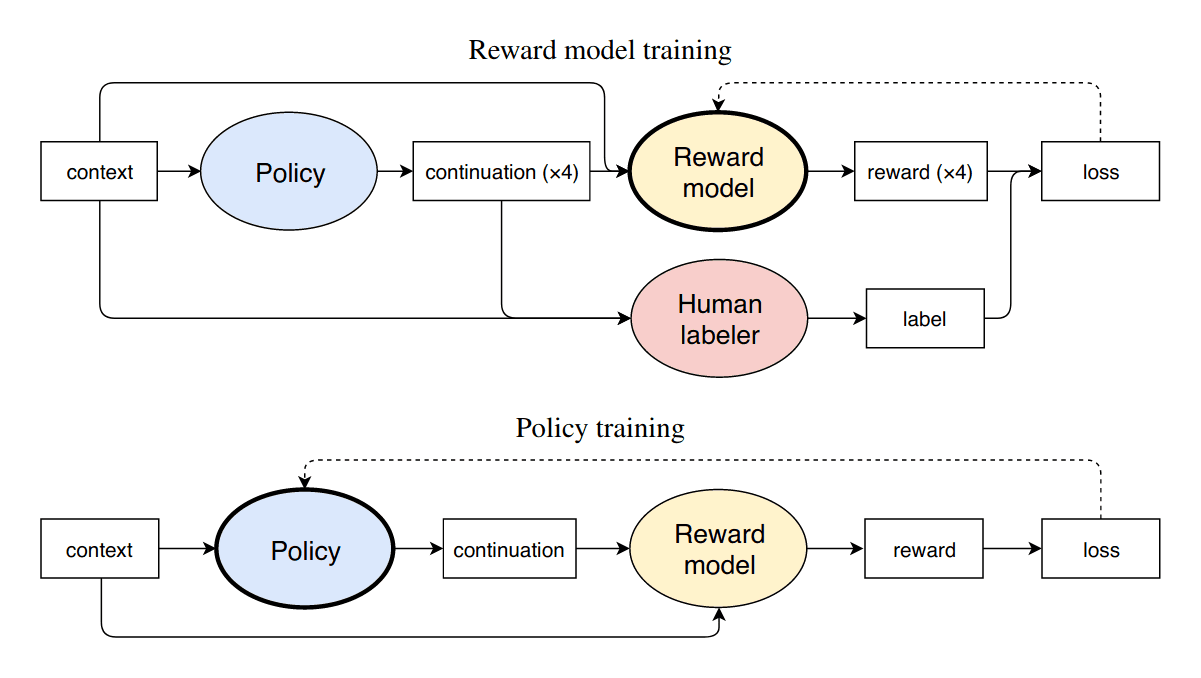
Ziegler et 2019: “Figure 1: Our training processes for reward model and policy. In the online case, the processes are interleaved.”
For Music or Poetry
Greedy generation. Christiano’s preference learning seems like it could help in generating natural language types which have proven tricky, due to global properties where word-by-word imitation is flawed.
Problem: repetition. Language generation models trained by maximum likelihood have long had serious problems with falling into repetitions, and with having any kind of ‘theme’ or ‘message’ or even just basic consistency. The stereotypical neural text sample from a char-RNN or Transformer model is made up of individual sentences which are flawlessly spelled, perfectly grammatical, a little confusingly obtuse, and completely unrelated to 10 sentences previously, reminiscent of schizophrenic ‘word salad’—and degenerating after a few pages into endless repetition of “the the the”.
How can NNs be so good & so bad? The repetition is particularly perplexing, because highly sophisticated char-RNN or Transformer models appear to encode all sorts of semantics and knowledge about the world and achieve difficult tasks, and yet fall prey to a pathology the humblest n-grams or Mad Libs-style template algorithm manages to avoid, and which still has no good solution. Unlike supervised seq2seq tasks, more sophisticated decoding search strategies like beam search help only a little in language generation, and can make things much worse by triggering repetition faster. (The recent nucleus sampling is a patch, and one can still induce repetition with low top-p settings; unlikelihood training appears to be better, but it is unknown if it’s a full solution.) But because it is so simple, a reward model should be able to detect it easily—how hard could it be to penalize using a BPE 20 times in a row?
Global coherency and themes are harder, but it is still something one expects a reward model to be able to pick up on eventually and notice when a sample has wandered off course in an illogical way: even if each individual word is a reasonably likely next word, the ending will be highly unlikely given the beginning, and a model looking at the big picture can detect that inconsistency.
Training
The Ziegler et al 2019 codebase, models, and datasets (but not the rating tools) were released by OpenAI in September 2019 for public use, and I began working on adapting it to poetry & music.
Installation
The OA source code can be downloaded from Github as usual:
git clone 'https://github.com/openai/lm-human-preferences' && cd ./lm-human-preferences/The necessary Python 3 packages are listed in the Pipfile.
One unusual requirement is gsutil: the OA datasets are stored on a Google Cloud Platform storage bucket. This bucket is public, but must be accessed through special credentials—if you are getting invalid_grant: Bad Request errors, you are running into this issue, and you need to get special credentials, perhaps via gcloud auth login.
At least in theory, if you have your Google credential ducks in a row and correctly pip installed all the dependencies, you should be able to run the combined-run example from their README:
experiment=descriptiveness
experiment_name=testdesc-$(date +%y%m%d%H%M)
./launch.py train_policy $experiment $experiment_nameThis will automatically download GPT-2-124M1 & the ‘descriptiveness’ dataset (as defined in launch.py), which uses snippets from BookCorpus, to train a reward model using 8 GPUs (OA used 8×V100s) on best-of-4 comparisons of book passage completions based on how physically descriptive or evocative of the scene they are for 1 epoch; and then attempt to train a PPO for ~2k steps/iterations to optimize fiction generation for descriptiveness.
Configuration
The OA codebase user ought to be aware of a few things before running on a generic new dataset:
GCP permissions: as discussed above, the OA datasets may not download unless one has the correct
gsutilcredentials generatedPython/Parallelism Issues: I ran into 2 errors which ultimately terminated at a call to
mpiexec.Python 2 vs 3: The first was a Python interpreter version error, where it was somehow calling a Python 2 interpreter even though my
virtualenvwas set to Python 3, and runninglaunch.pyexplicitly withpython3didn’t help, so I patched the source code as follows to force Python 3:diff --git a/lm_human_preferences/utils/launch.py b/lm_human_preferences/utils/launch.py index 30f3440..62f4fe3 100644 --- a/lm_human_preferences/utils/launch.py +++ b/lm_human_preferences/utils/launch.py @@ -11,7 +11,7 @@ def launch(name, f, *, namespace='safety', mode='local', mpi=1) -> None: with open('/tmp/pickle_fn', 'wb') as file: cloudpickle.dump(f, file) - subprocess.check_call(['mpiexec', '-n', str(mpi), 'python', '-c', 'import sys; import pickle; \ pickle.loads(open("/tmp/pickle_fn", "rb").read())()']) + subprocess.check_call(['mpiexec', '-n', str(mpi), 'python3', '-c', 'import sys; import pickle; \ pickle.loads(open("/tmp/pickle_fn", "rb").read())()']) return raise Exception('Other modes unimplemented!')Failing on 1 GPU: The README claims that running on 1 GPU should be possible, but when I tried running on 1 GPU (so I could keep finetuning GPT-2 on my other GPU),
mpiexecalways failed.I suspect that the call may need to be removed entirely. I avoided it by always running on both GPUs, and doing finetuning in the gaps between iterations, when I was busy with ratings or other things.
Disabling GCP: the OpenAI GCP bucket is hardwired, and aside from that, it’d be a pain to set up a GCP bucket, set its permissions, and work with it when training locally rather than on a cloud GPU instance.
The loading can be fixed by editing
launch.pyto specify local file paths. To disable saving to GCP, I did another edit:diff --git a/lm_human_preferences/language/trained_models.py b/lm_human_preferences/language/trained_models.py index f149a0c..99827fa 100644 --- a/lm_human_preferences/language/trained_models.py +++ b/lm_human_preferences/language/trained_models.py @@ -10,7 +10,7 @@ class TrainedModel(): def __init__(self, name, *, savedir=None, scope=None): self.name = name self.scope = scope - self.savedir = savedir if savedir else os.path.join('gs://gpt-2/models/', name) + self.savedir = savedir if savedir else name if name == 'test': self.encoding = encodings.Test else:JSON encoding of BPEs: once you can load a local dataset, you need to create said dataset, of course. Unfortunately, the codebase doesn’t make life easy for you, as the dataset must follow strict length limits & already be BPE encoded. Rating is complicated enough to require a separate section.
Hardwired English Heuristic Loss:
The single most frustrating bug I encountered in this code is due to a ‘clever’ hand-engineered feature added to try to filter out bad samples early2. The code by default looks for a period (
.) within the first n BPEs, and if there is not one, the sample is automatically penalized −1!I didn’t notice this in the poetry runs, but when I switched over to music, it became a huge problem with ABC samples—as it turns out, ABC does not require use of periods and most ABC music samples will have no periods. So every single sample was automatically rated −1, rendering training impossible. This turns out to be mentioned briefly in the paper but I had completely overlooked the implications until I reread it trying to understand how the ABC (but not poetry) reward model could be so badly mistaken:
To make the labeling task more natural, we select excerpts that start and end with a period. When sampling continuations that will be presented to humans, we use rejection sampling to ensure there is a period between tokens 16 and 24 and then truncate at that period. [This is a crude approximation for “end of sentence.” We chose it because it is easy to integrate into the RL loop, and even a crude approximation is sufficient for the intended purpose of making the human evaluation task somewhat easier.] During the RL finetuning, we penalize continuations that don’t have such a period by giving them a fixed reward of −1.
This ‘feature’ is specified in
launch.pyat the beginning but it’s unclear how to disable it entirely. To guarantee that it cannot interfere, I patched it out:diff --git a/lm_human_preferences/train_policy.py b/lm_human_preferences/train_policy.py @@ -398,7 +399,7 @@ def make_score_fn(hparams, score_model): def score_fn(queries, responses): responses = postprocess(responses) - score = penalize(responses, unpenalized_score_fn(queries, responses)) + score = unpenalized_score_fn(queries, responses) return score, responses, dict(score=score) score_fn.stat_schemas = dict(score=Schema(tf.float32, (None,))) return score_fnsymlink model directory: since I was retraining the baseline models as I went, particularly to fix the space problems in the ABC music model, it’s convenient to symlink over to the regular GPT-2 repo’s model directory, instead of dealing with copying over fresh checkpoints. (Saves disk space too.) Something like
ln -s ../gpt-2/models/irish-nospaces3/ 117M-irishworks.launch.pyconfig changes: all data-related parameters are hardwired, and must be manually set.The length of prefixes/queries/conditioning and the length of all samples must be exactly right; further, the size of the dataset (the n of ratings) must be manually specified, and even further, the specified n must be an exact multiple of the reward model’s minibatch size (it can, however, be lower than the actual n inside the dataset, so one doesn’t need to delete ratings if one has rated a few more than an exact multiple).
So for example, if one is training the reward model with a minibatch of n = 8 and one has n = 11,203 total ratings, that is not an exact multiple of 8 (11,203/8 = 1400.375) and one would instead specify n = 11,200 (which is both ≤ 11203 & an exact multiple: 8 × 1400).
Zombie processes:
Make sure GPU is GCed
OOM crashes are not uncommon during reward model training, puzzlingly, and one will typically kill a diverged process with
Control-c; however, these may leave zombie processes tying up GPU VRAM! Particularly if you are tinkering with settings like length or minibatch, this is a great danger—you may make a change, get an OOM crash (which leaves zombies), and any subsequent change you make will look like a failure. This caused me great trouble at least twice, as I began trying to debug which (harmless) config change now triggered instant OOMs.To avoid this, I suggest getting in the habit of always running
nvidia-smiafter a training run so you can check thatlaunch.pyhas not left any orphans (and if so, you can put them out of their misery).
ABC Music Configuration
Config by source editing. All of the hyperparameters & dataset metadata is defined in launch.py; there are no relevant CLI options. It is structured in two parts, for the reward model and then the agent; the configuration is a cascade of increasingly-specialized objects. So for the reward model for the descriptive experiment, the books_task object is specialized by _books_task, which is further specialized by descriptiveness; and likewise for the agent/PPO training.
Hijacking existing config. For my ABC music, instead of defining a new cascade, I simply hijacked the descriptiveness-related variables. I begin with the reward model in books_task, by cutting the conditioning down to the minimum which causes the code to not crash, 2, and expanding the response length considerably to cover entire ABC music pieces, and I change the base model name to the ABC GPT-2 I trained normally:
books_task = combos(
- bind('query_length', 64),
+ bind('query_length', 2), # must be a minimum of 2 (but why?)
bind('query_dataset', 'books'),
- bind('response_length', 24),
- bind('start_text', '.'), # Start the context at the beginning of a sentence
+ bind('response_length', 256),
+ bind('start_text', ''), # no conditioning aside from 'X:' in sample.py
bind('end_text', '.'), # End the context at the end of a sentence.
bind('truncate_token', 13), # Encoding of '.' -- end completions at the end of a sentence.
bind('truncate_after', 16), # Make sure completions are at least 16 tokens long.
- bind('policy.temperature', 0.7),
- bind('policy.initial_model', '124M'),
+ bind('policy.temperature', 1.0),
+ bind('policy.initial_model', '117M-irish'),
)The training code needs to be modified for the rating data type (pairwise) and for my limited compute resources (2×1080ti instead of OA’s 8×V100)—I have to cut down minibatch size & rollout batch size:
def get_train_reward_experiments():
_shared = combos(
- bind('labels.type', 'best_of_4'),
+ bind('labels.type', 'best_of_2'),
bind('normalize_after', True),
bind('normalize_before', True),
bind('normalize_samples', 256),
@@ -58,9 +58,9 @@ def get_train_reward_experiments():
_books_task = combos(
bind_nested('task', books_task),
_shared,
- bind('batch_size', 32),
- bind('rollout_batch_size', 512),
+ bind('batch_size', 10),
+ bind('rollout_batch_size', 226),
)Finally, I specify my local dataset & manually specify its corpus size as a multiple of the minibatch size (this must be updated every time I add ratings or they won’t be trained on):
@@ -75,8 +75,8 @@ def get_train_reward_experiments():
descriptiveness = combos(
_books_task,
- bind('labels.source', 'gs://lm-human-preferences/labels/descriptiveness/offline_5k.json'),
- bind('labels.num_train', 4_992),
+ bind('labels.source', 'irish.json'),
+ bind('labels.num_train', 16900),
bind('run.seed', 1)
)The agent model is easier to configure because I need only to adjust for compute:
def get_experiments():
train_reward_experiments = get_train_reward_experiments()
_books_task = combos(
bind_nested('task', books_task),
- bind('ppo.lr', 1e-5),
- bind('ppo.total_episodes', 1_000_000),
- bind('ppo.batch_size', 512),
+ bind('ppo.lr', 1e-6), # original: 5e-5
+ bind('ppo.total_episodes', 1_000_000),
+ # original: 1_000_000; note, this is *episodes*, not *steps*; each step consists of _n_ episodes
+ bind('ppo.batch_size', 18), # original: 512
)I also change the KL-regularization3 as it appears to far too harshly punish divergence from the baseline mode for ABC music and effectively disables exploration:
@@ -139,9 +138,9 @@ def get_experiments():
descriptiveness = combos(
_books_task,
- bind('rewards.kl_coef', 0.15),
+ bind('rewards.kl_coef', 0.02),
bind('rewards.adaptive_kl', 'on'),
- bind('rewards.adaptive_kl.target', 6.0),
+ bind('rewards.adaptive_kl.target', 25.0),For ABC music specifically, I made some further changes to the rest of the code:
train_policy.py: conditioning onX:for generating ABC music during training: all ABC music samples must start withX:followed by an integer, as an ID. I figured that if I had to condition on at least 2 BPEs, I might as well specify theX:and make it more likely that samples will be valid:diff --git a/lm_human_preferences/train_policy.py b/lm_human_preferences/train_policy.py index db02c98..b349717 100644 --- a/lm_human_preferences/train_policy.py +++ b/lm_human_preferences/train_policy.py @@ -282,6 +282,7 @@ class PPOTrainer(): step_started_at = time.time() queries = self.sample_queries() + queries = np.tile([55,25], (queries.shape[0],1)) # Irish ABC prefix: 'X:' (ie. for the initial numeric ID) rollouts = self.policy.respond(queries, length=self.hparams.task.response_length) responses = rollouts['responses']sample.py: in regular generation of samples from a trained agent/policy model, the default settings are a temperature of 1 & top-k = 40; the latter is fine but the former is too high, and I lower it to 0.8. (The code claims to support nucleus sampling, with atop_pargument, but when I changed that, it simply broke.) The diff:diff --git a/lm_human_preferences/language/sample.py b/lm_human_preferences/language/sample.py index 96e56e9..76e56a3 100644 --- a/lm_human_preferences/language/sample.py +++ b/lm_human_preferences/language/sample.py @@ -5,7 +5,7 @@ from lm_human_preferences.utils import core as utils def sample_sequence(*, step, model_hparams, length, batch_size=None, context=None, - temperature=1, top_k=0, top_p=1.0, extra_outputs={}, cond=None): + temperature=0.8, top_k=40, top_p=1.0, extra_outputs={}, cond=None): """ Sampling from an autoregressive sequence model.
My full diff/patch for running ABC music training is available to look at in case there is any ambiguity.
Running
./launch.py train_policy descriptiveness irish-combined-20191222.17 --mpi 2 ; sleep 4s; nvidia-smiRemember to check the nvidia-smi output after a crash or interrupt to make sure your GPU VRAM has been released & the zombie processes aren’t eating it.
Rating
The OA codebase comes with no built-in support for doing ratings; they used a data-labeling service which exposes an API and presumably felt there was not much point in providing the glue code. So, I rolled my own.
Data Formatting
The JSON schema. The input data format is JSON: it is an array of hashmap objects with, in the simplest case of best-of-two/pairwise ratings4, 4 fields (the first 3 of which are not strings but integer arrays, where each integer is assumed to be a BPE): the conditioning text query, the first candidate string sample0, the second candidate string sample1, and the rating best which is a single integer where 0 = first sample won / 1 = second sample and so on. How does this handle ties? Ties don’t seem to be expressed as the integer 3 as one would guess. For ties, I simply encode it as two ratings with each sample winning once, which should be roughly equivalent.
Hardwired n
The integer array lengths must be the length defined in the launch.py config, and so if a sample is too long or short, it must be truncated or padded to fit.
Record dubious samples. The JSON parser code here appears to not be strict, so you can append additional fields if you want. Because of issues with adversarial samples or ABC samples being syntactically invalid & not compiling to MIDI, and my concerns about what inclusion of them might do to training dynamics (perhaps they should be excluded entirely?), I add a field, broken, to allow filtering blacklisted samples out and distinguishing their ratings from my hand-ratings.
So, a full and complete example of a valid JSON ratings dataset with n = 1 pairwise ratings for ABC music would look like this:
[
{"query": [0,0],
"sample0": [ 27, 91, 437, 1659, 5239, 91, 29, 55, 25,23349, 198, 51,
25,14874, 1252,25308,22495, 198, 44, 25, 17, 14, 19, 198,
43, 25, 16, 14, 23, 198, 42, 25, 34, 198, 38, 535,
33, 91, 32, 17, 32, 17, 91, 38, 4339, 33, 91, 66,
17, 89, 17, 91, 38, 535, 33, 91, 32, 17, 32, 17,
91, 38, 4339, 33, 91, 66, 17, 32, 17, 91, 198, 38,
4339, 33, 91, 66, 17, 32, 17, 91, 38, 4339, 33, 91,
66, 17, 32, 17, 91, 38, 4339, 33, 91, 66, 17, 32,
17, 91, 38, 4339, 33, 91, 66, 17, 32, 17,15886, 59,
77, 27, 91, 437, 1659, 5239, 91, 29, 198, 27, 91, 437,
1659, 5239, 91, 29, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27],
"sample1": [ 27, 91, 437, 1659, 5239, 91, 29, 55, 25,14208, 2816, 198,
51, 25, 47,13218,34831, 338, 198, 44, 25, 19, 14, 19,
198, 43, 25, 16, 14, 23, 198, 42, 25, 35, 76, 1228,
198, 91, 25, 33, 198, 91, 93, 32, 17, 67, 32, 61,
38, 6242, 67, 91, 7, 18, 32, 4339, 37, 2782, 33, 66,
32, 91,12473, 93, 36, 17, 38, 18, 32, 91, 33, 67,
70, 5036, 17,36077, 91, 198, 93, 32, 17, 67, 32, 61,
38, 6242, 67, 91, 7, 18, 32, 4339, 37, 2782, 33, 66,
32, 91, 33, 67, 93, 67, 17, 276, 33, 67, 91, 8579,
38, 1961, 18, 25, 91, 198, 91, 25, 32, 91, 67, 17,
69, 9395,16344, 91, 2782, 69, 2934, 17,36077, 91, 93, 67,
17, 69, 9395,16344, 91, 70, 69, 891, 67, 17,36077, 91,
198, 93, 32, 17, 69, 9395,16344, 91, 2782, 69, 2934, 17,
36077, 91, 93, 70, 18,19082, 33, 67, 91, 8579, 38, 1961,
18, 25, 91, 59, 77, 27, 91, 437, 1659, 5239, 91, 29,
198, 27, 91, 437, 1659, 5239, 91, 29, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27],
"best": 1,
"broken": 1}
]Dissecting JSON example. In this ABC music example, it appears that sample0 is invalid for some reason: it either couldn’t be compiled to MIDI by abc2midi, Timidity couldn’t compile the MIDI to WAV, or it contained a string that violated the manual blacklist compiled from diverged adversarial samples. So, sample0 was automatically marked as the loser and sample1 won. Both samples have been padded out with the BPE 27. Checking the BPE encoding (which can be done conveniently with jq . encoder.json), BPE 0 is !, and the BPE encoding has odd handling of spaces so it’s unclear how to pad with spaces. 27 was chosen arbitrarily.
For scripting purposes, we’d like a CLI filter which takes text and prints out the BPE encoding. I hacked up the encode.py from the nshepperd codebase to make encode2.py, which reads from stdin, converts, and pads to our target length of 256:
#!/usr/bin/env python3
import argparse
import numpy as np
import sys
import encoder
from load_dataset import load_dataset
parser = argparse.ArgumentParser(
description='Pre-encode text files into tokenized training set.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--model_name', metavar='MODEL', type=str, default='117M', help='Pretrained model name')
parser.add_argument('--combine', metavar='CHARS', type=int, default=50000, help='Concatenate files with <|endoftext|> separator into chunks of this minimum size')
parser.add_argument('in_text', metavar='PATH', type=str, help='Input file, directory, or glob pattern (utf-8 text).')
target_length = 256
def main():
args = parser.parse_args()
enc = encoder.get_encoder(args.model_name)
chunks = load_dataset(enc, args.in_text, args.combine)
with np.printoptions(threshold=sys.maxsize):
result = chunks[0][0:target_length] # np.zeros(24)
if len(result) != target_length:
padding = [27] * target_length
result = np.concatenate((result, padding))
result = result[0:target_length]
print(np.array2string(result, separator=','))
if __name__ == '__main__':
main()Interactive Rating
For both poetry and ABC music, there is no need for a GUI or web interface. A Bash script suffices.
Parallelize & pre-compile the ABC. For a rating script, we want to minimize latency, and avoid doing any processing in the main thread, so all rated files are precompiled to WAVs before rating begins. All stages of the generated files are left in /tmp/ for easier debugging or picking out good pieces. The original text version of the ratings are saved to an additional text file for reference, since BPEs are hard to read.
To avoid repeatedly evaluating the same piece, which would happen occasionally with random samples, I shuffle the samples, store in an array, and proceed in a pairwise fashion to evaluate #1 vs n⧸2+1 (where n is the list length) etc., so no comparison overlaps or duplicates another.
Auto-fail broken samples. While rating, each music piece is automatically checked (auto-rated) for validity as a WAV (no WAV with a meaningful filesize = failed sample), and its ABC against a hand-written blacklist of adversarial examples. (I considered including ‘compressibility’ as a criteria—pipe samples into gzip and fail samples which compress too much—since I noticed bad samples were typically highly repetitive aside from their metadata block, but didn’t get around to it.) If both pieces in a comparison fail one of the checks, they are judged to be a tie (which is implemented as a pair of ratings). This saves an enormous amount of time & effort when extracting ratings from throughout a run, as many will be either broken or adversarial.
I print out the ABC pieces as well as play them—I find it helpful to see them while listening. The ABC pieces are played at slightly higher speed than normal, for ~10s each. (Because the generation is autoregressive, a piece which starts off badly probably isn’t going to wind up being stellar, so there’s no point in rating 3–4× fewer pieces by insisting on listening to entire pieces before rating. It’s more important to get through a lot of ratings than make each rating perfect.)
My rating script music-rater.sh requires encode2.py, parallel, abc2midi, timidity, & mpv to be installed. The script is less than elegant but (mostly) works:
#!/usr/bin/env bash
set +o posix
## $ bash music-rater.sh 1000 irish-samples-1.txt irish-1
N="$1" ## currently needs to be a multiple of 8
CORPUS="$2" ## "/home/gwern/wiki/doc/ai/2019-03-06-gpt2-poetry-1000samples.txt"
JSON="$3"
encode() {
TMP_FILE=$(mktemp /tmp/XXXXXX.txt)
echo "$@" >> $TMP_FILE
ENCODED=$(PYTHONPATH=src python3 encode2.py --model_name 117M $TMP_FILE)
echo "$ENCODED"; rm "$TMP_FILE"; }
export -f encode
generateJson() {
echo "{\"query\": [0,0], \"sample0\": $2, \"sample1\": $3, \"best\": $1}," >> $JSON-encoded.json;
### Store a backup copy of the plain text for easier consultation
echo "{\"query\": [0,0], \"sample0\": $4, \"sample1\": $5, \"best\": $1}," >> $JSON-text.json;
}
generateJsonBroken() {
echo "{\"query\": [0,0], \"sample0\": $2, \"sample1\": $3, \"best\": $1, \"broken\": 1}," >> $JSON-encoded.json;
echo "{\"query\": [0,0], \"sample0\": $4, \"sample1\": $5, \"best\": $1, \"broken\": 1}," >> $JSON-text.json;
}
rm -rf /tmp/music-samples/; mkdir /tmp/music-samples/
cat "$CORPUS" | sed -e 's/===.*/<|endoftext|>/g' -e 's/⏎/\n/g' | \
csplit --quiet --elide-empty-files --suppress-matched --prefix /tmp/music-samples/sample- - '/<|endoftext|>/' '{*}'
## Pre-compute all versions for speed; this also helps debugging since all stages can be inspected on disk in /tmp/music-samples/
generateEncoded() {
POEM="$@"
echo "Starting encoding: $@"
FIRST=$(cat $POEM)
encode "<|endoftext|>$FIRST\n<|endoftext|>" >> $POEMencoded
abc2midi "$POEM" -o $POEM.midi -Q 130
timidity -A125 -G5-20 $POEM.midi -Ow -o $POEM.wav; }
export -f generateEncoded
ls /tmp/music-samples/sample-* | shuf | head -$1 | parallel generateEncoded
filterMusic () { # }
## Snippets from many adversarial examples which automatically get marked as 'bad'; note the striking
## extent of repetition-trap-like samples, and the apparent inability of the small GPT-2 reward model to
## 'observe' the broader pattern of exact repetition = bad.
grep -F -i -e "2D2|G2D2G2D2|G2" -e "=e'|=e'=a'=a'=a'=g'=e'|=e'" -e "a' a' a' a'" -e "a=g|=f=g=a=c'=a=g|=f" \
-e "|=c'=d'=c'=c'=a=g|=c'=d'=c'=c'=a=g|" -e "|=c=e=g=c'=g=e|=c=e=g=c'=g=e|" -e "|=d=c'=a=g=d=e|=d=c'=a=g=d=e|=d" \
-e '(3B)(3B)(3B)(3B)(3B)' -e ',2B,2B,2|B,2B,2B,2|' -e ',C,C,C,C,C,C,C,C,C,C,C,C,C,' -e ',G,|G,A,B,G,A,B,G,|' \
-e ',|G,2A,2G,2G,A,|G,2A,2G,2A' -e '-ghhathan-ghhathan-ghhathan' -e '////////////' \
-e '/2B/2B/2B/2B/2B/2B/2B' -e '/g/g/g/g/g/g/g/g/g' -e '222222222' -e '2A2A2A2A2G2A2A2A2G2A2A2A2' \
-e '2A2G2A2G2A2A2' -e '2D2D2D2D2D2D2D2D2' -e '2F2A2G2A2A2G2A2A2' -e '2G,|G,2G,A,2G,A,2G,|C2G' \
-e '2G2E2|C2G2A2G2E2|' -e '2G2G2G2G2G2G2G2G2' -e '2c/2c/2c/2c/2c/2c/' -e '2d/2d/2d/2d/2d/2d/2d/2d/' \
-e '2g/2g/2g/2g/2g/2g/2g/2g/' -e '2|G2G2G2G2|' -e '4g/4a/4g/4a/4g/4a/4g' -e '=A|=c=A=A2=c=A=G=A|=c=A=A2=c=A=G=A|' \
-e '=D2=D2|=D2=D2=D2|' -e '=E=F=G=F=F=F=F=F=E=F' -e '=G,|=G,=A,=A,=A,=G,=G,|=G,' -e '=G2|=G2=G2=G2=G2=G2|=G2' \
-e '=G2|=G2=G2=G2|=G2' -e '=G=G=G=G=G=G=G=G=G=G' -e '=G|=A=c=A=A2=G|=A=c=A=A2=G|=A' -e '=G|=G=G=G=G=G=G=G|=G' \
-e '=G|=G=G=G=G=G=G|' -e '=a=a=a=a=a=a=a' -e '=b=d=b=d=b=d=b=d=b=d' -e '=c|=d=c=A=c=A=c|=d=c=A=c=d=d|' \
-e '=e=d=g=d=e=d=g=d|=e=d=g' -e '=g|=a=f=a=g=e=g|=a' -e '=g|=d=f=f=f=f=g|=d=f=f=f=f=g|=' -e 'A2G2A2G2A2G2A2G2A2A2G2A2G2A' \
-e 'A2|=A2G2A2|=A' -e 'AcAcAcAcAcAcAcA' -e 'B,B,B,B,B,B,B' -e 'B/B/B/B/B/B/B/B' -e 'B=G=A|=B=c=d=B=c=B=G=A|=B=c=d' \
-e 'BcB|BcBcBcB|BcB' -e 'CA,CA,CA,CA,CA,CA,CA,CA,CA,' -e 'D2|=D2=D2=C2|=C2=D2=D2|' -e 'DADDADDADDA' \
-e 'D|EGE|G2D|EGE|G2D|EGE' -e 'D|GDDD=FDDD|GDDD=FDDD|G' -e 'E2EDECCD|E2EDECCD|E' -e 'EBEBEBEBEBEBEBEBEBEBEB' \
-e 'EDEDEDEDEDE' -e 'EDEDEDEDEDED' -e 'EDEDEDEDEDEDEDEDEDEDEDED' -e 'ED{ED{ED{ED{ED{' \ # }}}}}
-e 'EGGAGEDC|EGGAGACD|E' -e 'G,G,G,G,G,G,G' -e 'G,G,G,G,G,G,G,G' -e 'G,G,G,G,G,G,G,G,G,G,' \
-e 'G,|G,2G,G,|G,2G,G,|G' -e 'G,|G,G,G,|G,G,G,|' -e 'G/G/G/G/G/G/G/G/' -e 'G2|G2G2G2|G2' \
-e 'G=A=c=G=A=c=G=A=c=G=A=c=G=A' -e 'G|=G=A=G=G2=G|=G=A=G=G2=G|' -e 'G|=G=G=G=G=G=G=G=G|' \
-e '\n\n\n' -e '\n|\n|\n|\n|\n|' -e '^A|^A^A^A^A^A^A^A^A|^' -e '^D|^D^D^D^D^D^D^D|^' \
-e '^f=f=f^f=f^f=f^d=f^f=f^' -e '^g|^g=f=f^d^d^c^c^g|^g=f' -e 'a a a a' -e 'a=a|=a=a=a=a=a=a|=' \
-e 'aaeaaeaaeaaeaaeaaea' -e 'abbabbaba' -e 'b b b b' -e 'b=a=g|=b=a=g=b=a=g|=b=a' -e 'c/2c/2c/2c/2c/2c/2c/' \
-e 'c/c/c/c/c/c/c/c/c/c/c' -e 'cccccccccccccccccc' -e 'e/e/e/e/e/e/e/e/e/e' -e 'f=a=a|=c=e=e=f=a=a|=c=e' \
-e 'f=e|=f=g=f=e=g=f=e=g=f' -e 'fBfBfBfBfBfBfBfBfBfB' -e 'f^d|^c^d^f^g^f^d|^c' -e 'g g g g g' \
-e 'g=e=g|=a=e=e=a=a=g=e=g|=a=e=' -e 'g=g^g|^g^g=g^g=g^g=g^g|' -e 'g=g|=a=g=f=e=g=g|=d' \
-e 'g=g|=d=g=g=d=g=g|' -e 'g|=d=g=g=b=g=g|=d=g=g=b=g=g|=d' -e '|(3DDDD2(3DDDD2|(3DDDD2(3DDDD2|' -e '|(G,G,G,G,G' \
-e '|=A=F=A=F=A=F=A=F|=A=F=A' -e '|=A=G=A=C2=G|=A=G=A=C2=G|=A=G=A=C2=G|' -e '|=E=G=G=E=F=A=A=F|=E=G=G=E=F=A=A=F|' \
-e '|=E=G=G=E=G=A=G=F|=E=G=G=E=G=A=G=F|' -e '|=G,2=G,2=G,2|=G,2' -e '|=G=A=G=c=G=G|=G=A=G=c=A=G|' \
-e '|=G=E=E=G=A=B=c=A|' -e '|=G=E=E=G=G=E=G=E|=G=E=' -e '|=G=G=G=G=G=G=G=G|' -e '|=G=G=G=G=G=G=G|=G=G=G=G=G=G=G|' \
-e '|=G=G=G=G|=G=G=G=G|' -e '|=a=f=a=a=f=a|=a=f=a=a=f=a|' -e '|=a=g=f=e=g=g|=d=g=g=d=g=g|=a=g=' -e '|=a=g=g=g=f=e|=d=g=g=e=g=g|' \
-e '|=b=a=g=b=a=g|' -e '|=c=c=c=g=c=e=c=g=c|=c' -e '|=c=d=c=B=c=d=e=d|=c=d=c=B=c=d=e=d|' -e '|=c=g=e=g=c=g=e=g|=c=g=e=g=c=g=e=g|' \
-e '|=d=c=e=d=c=e|=d=c=e=d=c=e|=d' -e '|=d=f=g=f=g=f=d=c|=d=f=g=f=g=f=d=c|' -e '|=d=g=g=d=g=g|=a=g=f=e=g=g|=d=g=g=d=g=g|' \
-e '|=d=g=g=d=g=g|=a=g=f=e=g=g|=d=g=g=d=g=g|=a=g=g=g=f=e|' -e '|=d=g=g=d=g=g|=a=g=g=g=f=e|=d=g=g=d' -e '|=d=g=g=d=g=g|=d=g=g=d=g=g' \
-e '|=d=g=g=d=g=g|=d=g=g=d=g=g|' -e '|=d=g=g=d=g=g|=d=g=g=d=g=g|' -e '|=d=g=g=d=g=g|=d=g=g=d=g=g|=d' \
-e '|=e=d=e=d=e=d=e=d|=e=d=e=d=e=d=e=d|' -e '|=e>=f=g>=e=d>=c=c>=d|=e>=' -e '|=g=e=g=g=e=g|=g=e=g=g=e=g|' \
-e '|=g=f=e=d=c=d=e=f|=g=f=e=d=c=d=e=f|' -e '|A,A,A,A,A,A,A,|A,A' -e '|C2CD2E|C2CD2E|C' \
-e '|C2ED2E|C2ED2E|' -e '|D2D2D2|D2D2D2|D2D2D2|' -e '|D2E2D2D2|D2E2D2D2|D2' -e '|D2E2D2|E2D2C2|D2E2D2|' \
-e '|D=ED=ED=ED2|D=ED=ED=ED2|D=ED' -e '|E2D2|E2D2|E2D2|' -e '|ECEECECECECECECECECECECECE' -e '|EDDDED|EDDDED|' \
-e '|EDDD|EDDD|EDDD|' -e '|EDEEDE|EDEEDE|EDEDED|' -e '|G,2G,2G,2|G,' -e '|G,A,A,A,A,2G,G,|G,A,A' \
-e '|G,A,G,A,G,A,G,A,|G,A,G,A,' -e '|G,B,CDDB,|G,B,CDDB,|G,B,CDDB,|' -e '|G,ED|EG,G,|G,ED|' \
-e '|G,EEEDEGG2|G,EEEDEGG2|G' -e '|G,G,A,G,A,G,F,G,|G,G,A,G,A,G,F,' -e '|G2A2A2G2A2|G2A2G2A2G2' \
-e '|G2G2A2|G2G2A2|G' -e '|G2G2G2G2G2G2|' -e '|G2G2G2G2|G2A2G2A2|G2A2G2A2|' -e '|GB\n|GB\n|GB\n|GB\n|GB\n|GB\n|' \
-e '|GGGGGGGGGGGGGGGGGGGG|' -e '|^A=c^c^A^G=F|^A=c^c^A^G=F|' -e '|^G^A^G^G2^G|^G^A^G^G2^G|' \
-e '|^G^G^G^G^G^G^G^G^G|' -e '|^c2^A2^A^G^A=c|^c2^A2^A^G^A=c|' -e '|^g=f^d^c^a^a|^g=f^' \
-e '|^g^a^a^a^g=f|^g^a^a^a^g=f|' -e '|^g^f^g^f^d^d|^g^f^g^f^d^d|' -e '|f/a/g/f/e/d/|f/a/g/f/e/d/|f/a/g/f/e/d/|f/a/g' \
-e '|gggggg|gggggg|'
}
echo "[" >> $JSON-encoded.json; echo "[" >> $JSON-text.json; # ]]
## should we simply auto-rate all pieces where possible (skipping pairs where both are valid) and not ask for any manual ratings?
SKIP_ALL=""
## to avoid duplicate comparisons, we split the set of items in half and select from the top & bottom half in each loop;
## if there are 100 shuffled items, we compare #1 & #51, then #2 & #52 etc.; thus, every item will be used once and only once
i=0
POEMS=()
for file in $(ls /tmp/music-samples/encoded | sed -e 's/encoded//' | shuf)
do
if [[ -f $file ]]; then
POEMS[$i]=$file
i=$(($i+1))
fi
done
I=0
LENGTH=$((${#POEMS[@]} / 2))
for ITERATION in `seq $I $LENGTH`; do
echo "ITERATION: $ITERATION"
echo "POEM: ${POEMS[I]}"
POEM=${POEMS[I]}
FIRST=$(cat $POEM)
FIRST_ENCODED=$(cat $POEMencoded)
J=$((I+LENGTH))
POEM2=${POEMS[$J]}
SECOND=$(cat $POEM2)
SECOND_ENCODED=$(cat $POEM2encoded)
## if first but not second is broken, second is the winner; if second but not first is broken, first wins;
## and if both are broken, then we insert a pair where both win to tell the model that they are equally bad.
## The check is a >100kb WAV file; if the ABC file is syntactically broken or too short to bother rating or
## something goes wrong with abc2midi/timidity, then there will be no or small WAV files, so this checks most
## errors. The other major error case is long repetitive degenerate ABC pieces generated by the model, so we
## have a 'filterMusic' blacklist for snippets which show up in degenerate pieces.
if [ ! $(wc -c < $POEM.wav) -ge 100000 ] || [[ -n $(echo "$FIRST" | filterMusic) ]]; then
generateJsonBroken 1 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
elif [ ! $(wc -c < $POEM2.wav) -ge 100000 ] || [[ -n $(echo "$SECOND" | filterMusic) ]]; then
generateJsonBroken 0 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
elif [ ! $(wc -c < $POEM.wav) -ge 100000 ] || [[ -n $(echo "$FIRST" | filterMusic) ]] && \
([ ! $(wc -c < $POEM2.wav) -ge 100000 ] || [[ -n $(echo "$SECOND" | filterMusic) ]]); then
generateJson 1 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
generateJson 0 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
else
if [ -z "$SKIP_ALL" ]; then
echo -e "\n\e[1m--------------------------------------------\e[0m"
echo "$FIRST"
timeout 10s mpv --af=scaletempo=scale=1.1:speed=pitch $POEM.wav
sleep 1s
echo "============================================="
echo "$SECOND"
timeout 9s mpv --af=scaletempo=scale=1.1:speed=pitch $POEM2.wav
echo ## print a newline to make output easier to read and divide from the foregoing
echo -e "[$I] 1: \e[1mFirst\e[0m wins | 2: \e[1mSecond\e[0m wins | 3: Equal | \
r: stop & auto-Rate Rest | x: e\e[1mX\e[0mit immediately"
read -N 1 RATING
case "$RATING" in
$'\n')
## skip
;;
1)
generateJson 0 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
;;
2)
generateJson 1 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
;;
3)
generateJson 0 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
generateJson 1 "$FIRST_ENCODED" "$SECOND_ENCODED" "$FIRST" "$SECOND"
;;
r)
SKIP_ALL="true"
;;
x)
break
;;
esac
fi
fi
I=$((I+1))
done
echo "]" >> $JSON-text.json; echo "]" >> $JSON-encoded.jsonWhen I run the PPO in a screen session, I can extract the full terminal history, with all printed out samples, to rate (C-a C-[ C-Space, PgUp to beginning of run, then C-space C-> to save terminal transcript to /tmp/screen-exchange), and filter out the samples and select only unique (important with divergence) samples with 42 characters or more for ratings:
TARGET="rlsamples-abc-01.txt"
ITERATION="abc-01";
grep -F -v -e ppo -e 'k =' -e 'score =' -e 'kl =' -e 'total =' /tmp/screen-exchange | \
sed -e 's/^X:$//' | sort --unique | sed -e 's/^/X:/' | sed -e 's/<|endoftext|>/\n/g' | \
sed -r '/^.{,42}$/d' | sed -e 's/^/<|endoftext|>\n===================\n/g' -e 's/⏎/\n/g'| \
grep -E -v "^$" > $TARGET
bash music-rater.sh 5000 $TARGET $ITERATION
## add the newly-encoded JSON ratings to the master dataset, remembering to close brackets:
emacs -nw abc-01-encoded.json irish.json
## update `launch.py` with the new dataset ## of ratings, or else they won't be used
grep -F 'best' irish.json | wc --lines
# 16901
emacs -nw launch.pyAlternately, I could generate samples from a checkpoint (assuming it’s not too far diverged):
./sample.py sample --mpi 2 --save_dir /tmp/save/train_policy/irish-combined-20191223.18/ --savescope policy \
--temperature 0.9 --nsamples 2000 --batch_size 30 | tee --append rlsamples-combinedabc-06.txtResults
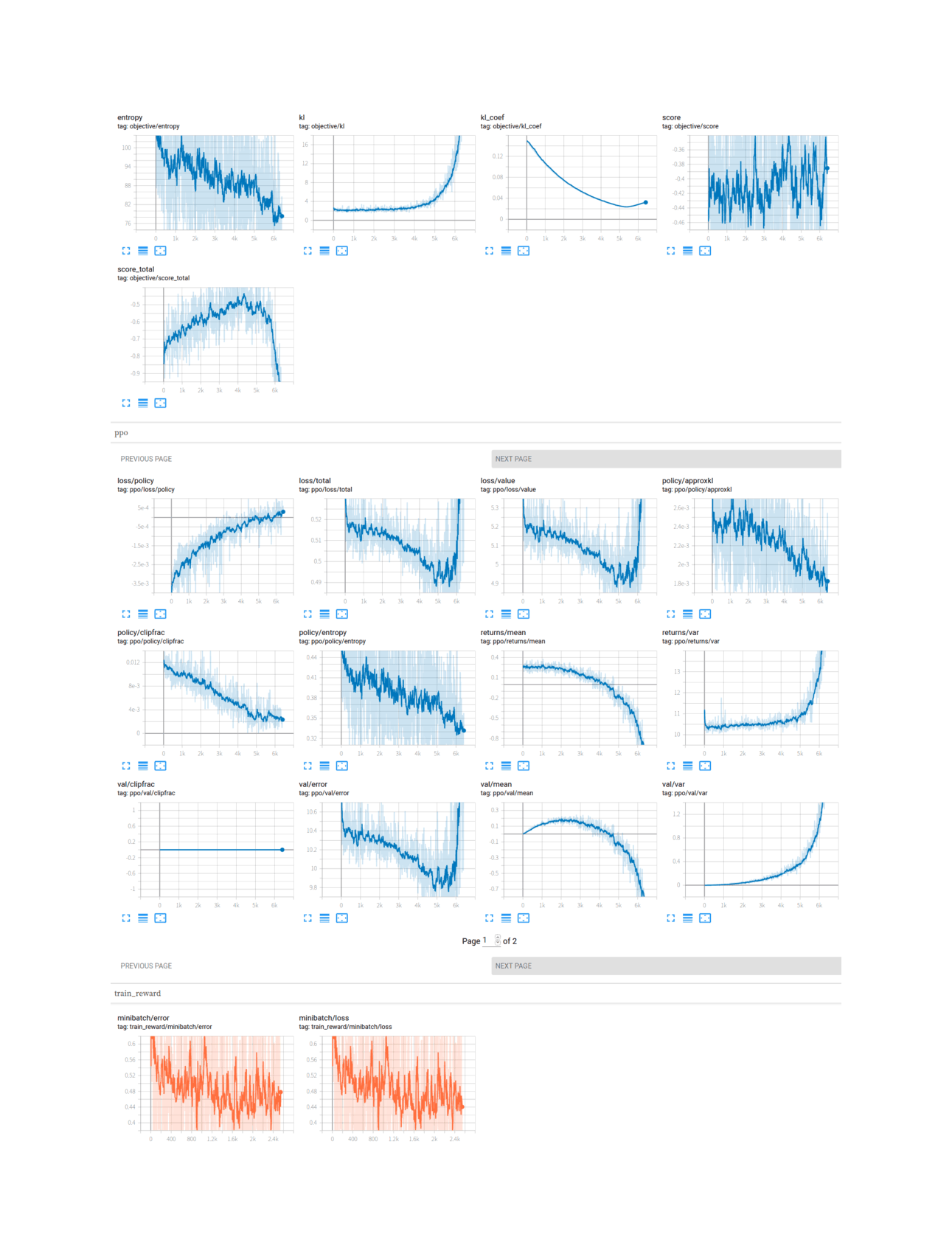
~1 day iterations. Early on, each iteration required a few hours at most on my 2×1080ti (a few minutes for the reward model then hours for PPO), and the PPO would diverge within ~3k iterations. As ratings accumulated, training the reward model began taking up to an hour (occasionally crashing with random OOMs at the end), and PPO began taking up to 24h, sometimes diverging as late as 9k iterations.

Example terminal output of an ABC music (combined model) PPO run, at 8,000 steps (~30 wallclock hours/60 GPU-hours)

Example TensorBoard logs of an ABC music (combined model) PPO run, in the process of diverging after two ‘bounces’ (full screenshot of an example divergence).
{kind=link}
n = 7k ratings / 40 hours. I ran ~23 iterations of training and then rating samples; not all iterations diverged, because they crashed or I accidentally killed them or I decided they were showing signs of divergence (like a collapse in the entropy of the policy). Excluding ‘broken’ auto-ratings, I rated n = 7,429 pairs of ABC music (this is an overestimate of the actual ratings, due to my implementing ties as double-samples); including auto-ratings, I had n = 25,508. I found I was able to get through ~200 ratings per session (~1h) before my skull began leaking out my ears, so I sometimes had to take breaks. Since each sample takes ~20s total (~10s per sample), this required a total of >40 hours of concentrated rating. (I initially tried doing other things while rating to lessen the time burden, but quickly discovered it was impossible to remember the first musical piece to compare it to the second piece if I was doing anything at all like reading.)
Divergences. The constant divergence created a lot of problems, and I tried to deal with them by automatically blacklisting examples with pathological patterns, but this did not help. Since the OA paper did not report any divergence issues, I tried going back to the OA setup by increasing the KL regularization, but while this generated different dynamics (instead of a gradual ‘double bounce’, there is a long steady state followed by a single abrupt collapse), it did not fix the issue:

Example TensorBoard of the combined model, diverging in a single bounce despite full KL regularization
Diverged examples:
X:
1⏎T:Portsmouth⏎M:4/4⏎L:1/4⏎K:C⏎c/c/|c/c/c/c/c/c/c/c/|c/c/c/c/c/c/c/c/c/|c/c/c/c/c/c/c/c/c/c/c/c/c/c/c/c/c/g/e/c/c/g/e/c/g/e/e/c/g/e/e/c/g/e/e/c/g/e/e/c/g/e/e/c/g/e/g/e/e/g/g/g/g/a/g/g/a/g/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a/g/a
X:
1⏎T:MollyRankin's⏎M:4/4⏎L:1/4⏎K:d/d/aae/d/|^cA(B/^c/)(d/B/)|⏎|:c/B/c/d/c/d/d/d/|c/d/e/c/d/f/d/f/|c/d/e/c/d/f/d/a/g/|a/a/e/c/d/f/d/^c/|d/e/f/d/e/f/d/e/|f/d/e/c/d/f/e/c/|d/e/f/d/e/f/e/c/|d/e/f/d/e/f/e/c/|d/e/f/d/e/f/e/c/|d/e/f/d/e/f/e/c/|d/e/f/d/e/f/e/c/|d/e/f/d/e/f/e/
X:
1⏎T:MollyBan⏎M:4/4⏎L:1/4⏎K:C⏎c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c'/2c'/2c'/2c'/2c'/2c'//2c'//2c'/2c'//2c'//2c'//2c'//2c'//2c'//c'//e////f/gab/c'/c'/g/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c'/c
X:
1⏎T:Ballydesmond⏎M:2/4⏎L:1/4⏎K:C⏎c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|e/2c/2d/2c/2d/2|⏎e2d2c2|A2A2A2|B2A2G2|A2A2A2|B2A2G2|A2A2A2|⏎|A2A2A2|A2A2A2|B2A2A2|A2A2A2|A2A2A2|
X:
1⏎T:CreamPot⏎M:6/8⏎L:1/4⏎K:C⏎G/|c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/c/|c/c/c/c/c/c/|c/c/c/c/c/c/c/|c/c/c/c/c/c/c/|c/c/c/c/c/c/c/|c/c/c/c/c/c/c/|c/c/c/c/c/c/c/|c/c/c/c/c/c/c/c/|c/c/c/c/c/c/c/c/|c
X:
1⏎T:MollySeven⏎M:4/4⏎L:1/4⏎K:C⏎c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c
X:
1⏎T:Jenny⏎M:4/4⏎L:1/4⏎K:C⏎c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/ac/2c/2c/2c/2ac/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2c/2
X:
1⏎T:Jovano,Jovanke⏎M:C|⏎L:1/4⏎K:C⏎c/c/c/c/c/c/c/c/|c/c/c/c/c/c/c/c/c/|c/c/c/c/c/c/c/c/c/c/c/c/c/g/c/g/c/c/g/c/g/c/g/c/g/e/c/g/e/c/g/e/c/g/e/g/e/g/e/g/e/g/e/g/e/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g/g
X:
1⏎T:TheHumorsofCastleconnell⏎M:4/4⏎L:1/4⏎K:C⏎c/c/cfa|g/g/g/f/e/d/c/|c/c/d/d/c/d/c/d/|c/d/e/f/d2|⏎c/c/f/c/f/c/f/c/|c/c/f/c/f/c/f/c/|c/c/f/c/f/c/f/c/|c/d/e/f/d/c/B/c/|⏎c/c/f/c/f/c/f/c/|c/c/f/c/f/c/f/c/|c/c/f/c/f/c/f/c/|c/d/e/f/d/c/B/c/|⏎c/c/f/c/f/c/f/c/|c/c/f/c/f/c/f/c/|c/c
X:
1⏎T:MollyMcAlpin(2)(Mylano)-Mylano⏎L:1/4⏎Q:1/4=120⏎K:C⏎[E,C][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/C/][E,/]
X:
425⏎T:Polonäs⏎R:Polonäs⏎M:3/4⏎L:1ECDc⏎!⏎gg⏎g⏎"g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎⏎g⏎g⏎g⏎{g⏎⏎g⏎cg"g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g"g"g⏎g"g"g⏎g"g"g"g⏎g"g"g"g⏎gg⏎g⏎gg⏎g⏎gg⏎g⏎ggg""g⏎gg⏎gg⏎gg⏎gggg⏎gggg⏎gggggggg⏎gggg⏎ggg|gggg⏎g|g|gg⏎gggg⏎g|gggg⏎g|gggg⏎g⏎g|ggggg|gg⏎gg|gg⏎g|gg|gg⏎gg|gg|gg|gg|g # }
X:
130⏎M:g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎⏎g⏎⏎g⏎g⏎⏎g⏎g⏎g⏎g⏎⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎gg⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎g⏎gg⏎g⏎gg⏎g⏎gg⏎g⏎gg⏎g⏎gg⏎g⏎gg
X:
4⏎T:Polonäs⏎R:Polonäs⏎M:3/4⏎L:1/16⏎K:G⏎G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2G2G2G2G2G2|G2GKL regularization didn’t help. Finally, I gave up: after 3 months & 7k ratings, if it wasn’t working, it wasn’t going to start working just because I spent a few more weeks adding more ratings. I ran one last iteration, stopping it at ~7k iterations, not long before I expected it to diverge but before entropy had collapsed too much (final RL training run TensorBoard log). Some samples from the final model:
{kind=link}
Model & Data
Available for download:
All ratings & samples (26MB)
the final policy model:
2020-01-15-gpt2-preference-learning-abccombined-23-20200113.tar.xz(3.2GB)
Blind Ratings
No improvement from RL. I was not impressed by the quality of RL samples either during training or when sampled, which did not strike me as clear improvements. (In contrast, the ‘spaceless’ ABC data cleaning change made an immediate difference to samples.) To evaluate the final samples, I used the 7k iteration to generate samples (temperature: 0.95) and compared to the 117M ABC spaceless baseline (with top-p = 0.95), and adapted my rating script to load from the two sample files, randomize left/right presentation, and record which file won. I expanded the rating time to 20s per piece to allow more in-depth comparison.
I rated ~200 pairs, and the result was I preferred the RL samples in 93 of 210 comparisons, or ~46%. If anything, the RL-finetuned samples were slightly worse than the baseline.
Discussion

“I have attempted science” (Nathan W. Pyle, Strange Planet 2019)
Despite considerable personal effort over 3 months, I did not achieve any improvement in sample quality and the project failed. Since the technique does work in some cases, how could I have fixed it? Hindsight. In retrospect, I would have done a few things differently:
prefix completions: the root cause seems to be the reward model not learning adequately. Even initialized from a good music-generation model, esthetics may be difficult to learn from few n with paired comparisons where the pairs are completely dissimilar.
The OA tasks, on the other hand, made heavy use of completions: samples which share a long prefix, and then diverge. Because they are identical, they differ far less than 2 random samples would, and so the same rating is much more informative. It’s just a kind of statistical power issue, similar to using identical twins in experiments rather than random people—the results are the same, but you need orders of magnitude less n.
I avoided conditional samples because it made the programming much easier to not have to count BPEs or slowly generate 2 completions for each possible prefix, I could use random pairs of samples collected from anywhere, and it mapped directly onto my goal of unconditional generation (if I used conditional generation, where do the prefixes come from?), which all seemed like good enough reasons at the time, but given the final results, this may have been a mistake.
Another idea (made much more difficult by the rigidity of the inputs & config) is to use “curriculum learning” (eg. Press et al 2017): there’s at least two straightforward ways of providing easier sub-tasks than generating a full music piece. First, the required length can be gradually expanded over training—once it learns to generate 5s of music that the critic can’t distinguish, require it to generate 10s, etc.
Second, real music can be used as a crutch by providing the generator with a decreasing prefix from real music as a ‘seed’: once it can append 1 note successfully, require it to append 2 notes, then 3 notes, and so on, until the prefix is 0-length it is generating music sequences from scratch. (This can be done with or without using a supervised log-likelihood loss for training the NN to generate the prefix.)
more hyperparameter tuning: there’s no support for hyperparameter optimization in the codebase, but instead of setting the hyperparameters based on my experience & intuition, I could have run a more formal hyperparameter search, and grid-searched it manually. Since the reward model typically takes less than an hour to train, a few hundred runs would have been feasible over the 3 months of my project, and I would have much more confidence that the reward model was squeezing as much out of the ratings as possible.
As it is, I’m left with the nagging doubt—was the LR just too high, or too low, and the reward model could’ve gotten good enough to provide a useful signal to the PPO and train a genuine improvement to the music generation?
tried crowdsourcing: I didn’t want to involve third-parties until I knew it would work or try to set up a website for interactive generation/rating, but crowdsourcing may have been necessary to collect a decent-sized dataset. While it would not have gone hugely viral like other DL projects have, a few thousand visitors rating a dozen comparisons each would’ve gone a long way.
checked auto-ratings more: the auto-ratings seemed like a great idea at the time—if the model kept generating samples with similar pathological behavior, or if they were syntactically broken, why hand-rate them at all? But now I have misgivings. Banning the pathological samples was probably OK, but did I screw up the reward model by banning broken samples? After all, they made up the overwhelming majority of the corpus at the end, so I may have inadvertently produced a ‘class imbalance’-style problem: the reward model wound up focusing entirely on trying to understand syntactic flaws, rather than esthetic flaws.
Oh well.
Poetry
A bridge too far. I initially began with RL training of the PG+PF 117M poetry model, but after a few iterations, I abandoned this idea. The samples were too hard to rate quickly, and were heavily biased towards modernist Poetry-Foundation-based pieces, which, lacking formal structure, had to be judged largely on semantics—but every poem sample is broken differently, requiring world-knowledge to fix, and how likely was it that the rating model could hope to pick up on these issues from mere pairwise comparisons? Even the OA paper didn’t try to fix semantics, settling for generic tasks like ‘descriptiveness’ or ‘summarization’ (as opposed to finetuning for tasks like ‘make accurate statements about the world’). So I switched to improving the ABC music, reasoning that fixing issues like too much repetition ought to improve music quality, while not being nigh-impossible for the reward model to learn from comparisons.
I did pick out a few good poetry samples along the way:
A man is sitting at the foot of his host.
Every eye is filled with watching and dread.
And he speaks with a strange and fearful sound.
All, all are silent and no sound,
Save what the Spirit sings
In the calm hour of your pensive sleep;
A measured, silent, and mysterious sweep
Of the invisible,
"What voice is this?" the Captain cries
In a voice of troubled joy,
As he deems the gathering night-wind, and
The voices of the years away,
But knows the toot of the sands of tears
And the burden of our own despair.
He calls for his comrades and his wife
To wait upon him in the tent;
But they do not, as he says to them,
Because they fear to die;
They turn and journey on their way,
For they realize their fate.
Why does the Captain wait and wait
In silent and unseeing wait?
He has not come for his reward,
Nor will it be too late.
..."The Farm", by James Thomas Stevens [Nature, Landscapes & Pastorals]
The yard is an x of sun
shot across and then dividing
black with silver mesh in,
then crossing through it into salt,
becoming a tiny dream
so it can sometimes dream of water
across the tree. The house
is a part of the yard
and the sun is going down
past the barn. At home
the house is a field of cream.
A few lampshins
flare at the door.
A door is at the threshold
and when the house of cheese turns brown
the house turns red.
The house is an x of sun
and when the house of feed turns red
the house turns green.
...I hear him with pleasure roar through the wood,
A melody as of rushing from the main;
He sings as he treads the bound of human things,
Borne on the wings of the blast as I sweep along,
The music of all whose names I love to hear,
Like music heard in a wind that murmurs near,
The music of all who hear.
I think of thee I know, oh, come from far,
From this green world and tracks by unknown lands;
Come to me, all that still is beautiful,
Come all that dwell in nature, all resigned,
And all that glows with beauty bright and free,
Yea, all that glitters like your beautiful eyes,
And all that lives like your beautiful hair,
And all that mocks at with a tranquil air,
Weeneth more of the sweetness of your voice,
Wandering on as it wanders still and free,
With earth in every drop and spot on earth,
By night and day and starry night.
Perfect is this life,
And end is death. And so to end is life.
How many of us
Have come to this, and died
Like birds. Here, in a quiet room within
A sombre room, where even the gravest dead
In all the ills of life are counted down.
In the broad company of light and death,
I watched a silent procession of them die;
And one by one, by three,
Passed slowly out into the waiting dark.
We left behind us in a room of grief:
Her voice, her hands I laid upon mine eyes,
Stretched over mine, and strove to think in vain
We loved together in a world of tears.Improvements
Data Increases
Crowdsourcing
1–10m labels too expensive to buy. If we need 70k to get good performance on a relatively straightforward task like summarization (which can be solved to a considerable degree just by copying selected parts of the input), it’s easy to imagine that we might need an order of magnitude or two more data for subtler tasks like music. 1–10 million is totally infeasible for one person on their own, and would cost far too much to pay a data labeler for as well5.
Crowdsourcing scales to 10m+! Could we overcome the lack of ratings by using crowdsourcing? Such sample sizes appear to be entirely feasible with crowdsourcing: the global public is interested in AI and generative art, and can contribute a lot of time en masse, donating millions of interactions, and the necessary infrastructure does not require enormous resources (many successful projects were done by hobbyists or interns). Some examples:
AI Dungeon 2: within 2 months of launch, the turn-based GPT-2-text-dialogue game AD2 had racked up >100m turns. The relaunched service had, according to Aether’s data breach, between 2019-12-16–2021-04-19, somewhere around >1000m turns in >50m games (~2m turns/day?).
ThisWaifuDoesNotExist.net (TWDNE): >1m unique visitors within the first month, spending several minutes on average and looking at dozens of faces. TWDNE is only one of a number of “This X Does Not Exist”, usually based on StyleGAN models, inspired by This Person Does Not Exist.com (TPDNE), and the total number of visitors to TXDNE sites is likely into the tens of millions.
Waifu Labs: an anime face generator similar to TWDNE, it similarly went viral. Sizigi Labs estimates 325,000 sessions 2019-10-30–2020-01-28 (well after launch & virality), at ~2 minutes/session; their analytics were broken at launch but “if I had to guess, we’re somewhere 1-3MM lifetime [users].” Given how popular it was during its virality and the number of links & mentions I’ve seen on social media, I definitely believe it had at least as many unique users as TWDNE did.
Artbreeder: the homepage reports generating 56,391,540 images between its launch ~2019-09-09–2020-01-27; the standard breeding interface shows 6 possible images, so that corresponds to ~9m user actions/clicks.
OpenAI Five: when made available by OA for a weekend in April 2019 for public play, there were 42,723 DoTA2 games against 30,937 players taking a total of 93,796 man-hours.
MuseNet: OA reported in the first day of MuseNet availability: “In the last 24 hours, we saw: 100k plays total of pre-generated MuseNet songs / 38,000 MuseNet samples co-composed / 29k unique MuseNet concert listeners”.
MuseNet samples are typically 1–3m long, and the concert was 3 hours long, suggesting ≫3450 man-hours in the first day listening/generating MuseNet samples. Presumably the counts increased by at least another order of magnitude in the following week as they ran a competition for best generated sample of the day.
Pre-Training
Off-policy RL/semi-supervised learning. We do not necessarily need explicit ratings from humans if we can leverage existing algorithms and datasets to construct synthetic or pseudo-rating datasets. They do not need to be perfect or human-quality to potentially greatly reduce how many human ratings are needed, similar to how pretraining GPT-2 for generating ABC for transfer learning makes preference-learning feasible at all on that domain. From an RL perspective, PPO may be an ‘on-policy’ algorithm which can learn only from rewards on samples it just generated, but the reward model itself can learn from ratings on samples generated by any process, and is ‘off-policy’. The samples could be generated by humans, or generated by non-GPT-2 NNs, or generated by non-NN algorithms entirely.
Weak supervision: implicit quality ratings. To kick-start the learning process, you could ‘pretrain’ the reward model by generating lots of music from low-quality generative sources and then marking them all as the loser in a set of comparisons with higher-quality sources (such as real music). For example, one could define a few music generators (random ASCII characters, n-grams, char-RNN at various temperatures) to generate a million fake music sequences, take the real music from the ABC Irish music corpus and create comparisons with the real music always the winner. If there is popularity data on the real music, then this too can be used to pre-generate comparisons (just have the more popular of two pieces win each comparison). The pretraining comparisons can reflect as much additional information as you think you can get away with. Along with popularity rating to make distinctions between comparisons of the real music, why not order the comparisons as well by data quality source? eg. random < n-gram < char-RNN < GPT-2 < GPT-2-PPO-tuned There might be mistaken comparisons (perhaps sometimes the n-grams really do beat the char-RNNs), but this is amenable to fixing by active learning on the persistently misclassified comparisons should it be an issue. This immediately provides an enormous corpus for the preference classifier, and then when it’s finished training on that, one can bring the human into the loop and start generating/comparing/retraining as in the preference learning.
More generally, you can see the pretraining+preference learning as a form of semi-supervised learning, with an initial unsupervised bootstrap phase followed by supervised learning as necessary:
use unsupervised learning methods to create generative models based on a corpus
sample from the generative models to create fake n
create m comparisons with by pairing random fake n and real n
train a reward model
begin regular preference learning
Architectural Improvements
I believe the current Christiano blackbox preference learning approach (Christiano et al 2017/Ziegler et al 2019) could be improved to make it more compute-efficient, sample-efficient, and simpler. There are two ways that seem particularly relevant for music/text generation:
directly optimize reward by backprop: The optimization of the reward does not require taking a blackbox approach where the ‘environment’ is not modeled, requiring an agent like PPO; the ‘environment’ is simply the reward model, which is a neural network and can be queried, differentiated, and optimized over like any other.
directly model quality score: The reward model can be improved in flexibility, interpretability, and efficiency by explicitly treating it as a Bradley-Terry model, and training the NN to predict the intrinsic ‘quality’ score (rather than raw comparisons), which can be easily estimated by standard statistical methods given a dataset of ratings.
The new architecture & training would go like this when combined:
Data collection:
do Pairwise Ratings on a corpus, with enough overlap to form a ranking
B-T Ranking algorithm to infer the latent quality score for each datapoint
Supervised (Re)Training of the reward model on data → score
Policy improvement:
for each datapoint (either randomly-generated or from a corpus)
Encode into the text embedding
run iterations of Gradient Ascent on the reward model to optimize the embedded text sequence, until a limit i is hit or until the average reward (quality) is higher than the average reward (quality) of the previous corpus
replace the previous corpus with the new Improved Corpus
[optional] (Re)Train a generator/agent-model by likelihood-training/imitation-learning on the new corpus (‘amortized inference’)
Optimization by Backprop, Not Blackbox
Here I propose changing the agent/generator model architecture to explicitly optimize the reward model’s utility/reward score, by removing the agent/generator entirely and instead improving possible sequences by gradient ascent on the (differentiable) reward model. There is no need to build a redundant agent model when the reward model is differentiable and can be used to directly specify how an input sequence ought to change to improve it.
This simplifies the overall architecture greatly, avoids expensive & unstable & complex blackbox training of DRL agents, and enables easy generation of both high-scoring & highly-diverse (thus informative) sequences for an oracle to rate, which can then be fed back into the reward model for further training. To the extent an agent/generator is necessary to efficiently generate many sequences, it can be trained quickly & stably by imitation learning on a corpus of datapoints optimized by the model.
While running PPO against the reward model, I concluded that compared to other approaches I’ve seen to optimizing the outputs of a NN, the blackbox preference learning approach has 2 major flaws:
Compute-Inefficient: it is slow and memory-hungry (I have to use GPT-2-117M to fit reasonable minibatches onto 2×1080ti, and even then iterations can take days)
Single-Divergence-Prone: it ‘mode collapses’ into adversarial samples, typically highly repetitive, and typically eventually only one adversarial sample
Slow feedback: 1 day, 1 counter-example. This makes iteration slow because of the double-whammy: each run takes days before any score improvements or divergence, and when it diverges, it typically only yields a handful of usable adversarial datapoints to rate & retrain on. Thus, the frustrating experience of seeing each run end in just one adversarial sample, which may be only somewhat different from the previous run.
Mode collapse. Thinking about this, a blackbox RL approach doesn’t seem quite right. For an RL problem, it’s fine to find only a single path which leads to a high reward. To put it in GAN terms, this ‘mode collapse’ onto a single adversarial example is, as far as the agent/Generator is concerned, a 100% valid solution. The ‘environment’ has no memory, and cannot penalize the agent/Generator for repetition. If there exists any string “XYZ” which, on its own or appended to any other string, causes the reward model/Discriminator to always output the maximal reward, then why does the agent/Generator need to learn anything else? It won. But that’s not really what we want. We want it to sample from the full distribution of high-quality sequences. Unfortunately, mode collapse is not solved in GANs, and I can’t think of any easy how to easily fix it in this preference learning either.
Ask reward model how to edit samples. One approach to avoid both those issues is to drop the blackbox optimizer approach entirely—which incentivizes wasting a ton of compute to find a single adversarial example—and instead optimize datapoints directly. It seems like a waste to go to all this effort to build a differentiable surrogate (reward) model of the environment (the human), and then treat it like just another blackbox. But it’s not, that’s the whole point of preference learning! Since GPT-2 is differentiable, it ought to be possible to backprop through it to do planning and optimization like MPC. Typically, we hold the inputs and outputs fixed and use backprop to adjust the model, but one can instead hold the model fixed and adjust the inputs based on backprop to give a desired output: in this case, hold a GPT-2 reward model fixed, and adjust textual inputs to make the output, the reward, larger, by backpropping from the output back through the model to the current input. This is an approach which works well for editing images in GAN, and ‘optimizing images’ to maximize a CNN’s probability of classification as a ‘dog’ or ‘cat’ etc. has long been done as a way of visualizing what a CNN has learned. For example, one could generate high-scoring music pieces by generating a random sequence, text-embedding it into the vector for the reward model, and then doing gradient ascent on the vector. (No PPO cluster required.) This is equivalent to doing planning/revising, as at each iteration, GPT-2 ‘considers’ the sequence as a whole and can make global changes rather than local changes to the final entry in the sequence; over many iterations, it can ‘edit’ a sequence repeatedly, rather than being forced to generate the entire sequence in a single shot like PPO is. This could be a lot faster since it exploits the whitebox nature of a learned reward model instead of treating it as a high-variance blackbox.
Example: PPLM. A similar approach to optimizing GPT-2 outputs has since been published by Uber as “PPLM” (Dathrati et al 2019; blog). PPLM uses the gradients from GPT-2 and a control NN to do simultaneous gradient ascent, trying to optimize an input to maximize both likelihoods, thereby maintaining sensible English text (due to GPT-2) which still maximizes the parallel target (such as a ‘positivity’ goal).
Another possibility would be to try to use beam search (although it has produced bad results in NNs, as discussed in the nucleus sampling paper, perhaps due to the log likelihood training encouraging repetition) or the expert iteration/MCTS training from AlphaGo Zero. MCTS was originally introduced for planning in general MDPs, it isn’t inherently limited to two-player games, the “rules” of generating sequence data is trivial (anything ASCII, in this case), and the discriminator provides a well-defined reward. So instead of a NN which directly generates a next character, it could instead (given a particular prefix/history) output values for the 128 ASCII values, run MCTS search for a while, produce a refined value for each character, and retrain the NN towards the refined values; every minibatch of the generator, one generates a bunch of examples for the human to judge and provide a new minibatch for the discriminator. Hence, tree iteration learning-from-preferences deep RL. With music we don’t necessarily need the stable self-play that tree iteration provides since I’m not too clear conceptually what one would expect self-play to deliver (it is inherently a human-defined problem, as opposed to Go where it’s external and human preferences are not the criteria), but given the AlphaZero & Anthony’s Hex results, this could be considerably more computation-efficient by providing much more supervision at each timestep instead of providing just a little bit of supervision from the end result of win/lose with REINFORCE. Possibly also more human-sample-efficient?
Bootstrap. Ratings can be done pairwise on the various optimized sequences (random pairs of high-scoring sequences, although before/after comparisons might be more informative), and then the reward model trained.
Amortized inference. If gradient ascent is too slow for routine use, then one can just distill the reward model via training the GPT-2 on successively better corpuses in the usual efficient quick likelihood training (imitation learning) way, for a sort of ‘expert iteration’: generate improved versions of a corpus by generating & selecting new datapoints above a threshold (perhaps using a corpus of human datapoints as starting points), and train to generate that.
Automatic editing via gradient ascent. Gradient ascent can be used to control and optimize text in various ways. For example, fiction could be edited in one region (say, to change character’s name from “Miriam” to “Mary”) and then the edited region could be held fixed during gradient ascent, while the rest of the unedited text is free to vary; this would propagate the edits, because self-contradictory text is unlikely while self-consistent text is more likely. (Because it is a more likely text for the protagonist to be consistently named “Mary” throughout the entire text rather than named “Mary” in one place and “Miriam” everywhere else.) One could produce multiple versions of a text by speculative edits—what if this character was a pirate? what if the protagonist lost this battle instead of winning? what if a banquet scene was deleted entirely?—and select the best one. One could also do this on heterogeneous sets of text, such as collaboratively-edited works like the “SCP Foundation” wiki: there is no linear structure like a novel, but one could take an edited entry and concatenate it with an arbitrary second entry, do ascent on the second entry to make it more consistent, and save the modified version; iterated repeatedly over the entire set of entries, one would witness the wiki ‘growing’ organically—changes in one entry, like a new SCP or character, will automatically pop up elsewhere in logical ways, with all seams gradually smoothed over into one evolved whole.
Parallel generation of counter-examples. If nothing else, I think it would help with the adversarial instances. Part of the problem with them is that each PPO run seems to collapse into a single specific adversarial instance. I can do a bunch of ratings which penalizes all variants of that instance which fixes it, but then I must wait another day or two, and then that run collapses into a new single adversarial instance. The reward model seems to gradually get better and the adversarial instances seem to gradually increase in complexity, but the process is slow and serial. The gradient ascent approach may also run into the problem that it will find adversarial instances for the reward model, but at least it will do so in parallel: if I can run a minibatch n = 11 of GPT-2-117M reward models each starting with a different random initial sequence being optimized and do gradient ascent on each in parallel, they will probably find multiple adversarial instances in parallel, while the PPO would only find the one it collapses on. So one would get a lot more useful adversarial instances to rate per run.
Optimizing embeddings = nonsense? One of the most likely drawbacks to such gradient ascent approaches on the embedding is the possibility that the maximized embedding will not then convert back to any kind of sensible discrete symbol sequence, a failure mode which has caused trouble in attempts to do feature visualization via gradient ascent on BERT text models and on T5 models (requiring adding VAE autoencoder-like constraints to make the latent space ‘smooth’, and—at least with extremely low-dimensional latent spaces like n = 2–10—tokens can be too separated to be reached by gradient-following). A 2023 experiment with NanoGPT using the Straight-Through Gumbel-Softmax estimator seems to work.
Bradley-Terry Preference Learning
Christiano et al 2017 introduced a deep reinforcement learning architecture for learning “I know it when I see it” subjectively-defined reward functions from human feedback: a human makes comparisons of actions/datapoints/episodes to select the ‘better’ one, a NN is trained to predict the better one based on these comparisons, and another NN is RL-trained based on the predicted comparisons interpreted as a reward. Since the human is unable to write down a conventional reward function in software, the predictor NN (analogous to a Discriminator in a GAN or a ‘critic’ in actor-critic RL) learns the reward function by example, and then the RL agent NN (analogous to a Generator in a GAN) learns by trial-and-error what sequences will optimize this complex reward function, and the human feedback provides additional guidance on new parts of the problem as the pair of NNs bootstrap into better performance. This is demonstrated on video game or robotic-style simulations, but appears equally applicable to other sequence problems where reward functions are impossible to write and existing losses like maximum likelihood are imperfect for generation (such as music or poetry composition).
As originally framed, the predictor merely does comparisons, receiving & providing binary feedback. This is justified as being implicitly equivalent to a standard pair-comparison/competition model, the Bradley-Terry model (akin to the famous ELO), where each datapoint has a latent variable on a common cardinal scale (often, like a liability-threshold model, scaled to 𝒩(0,1) for convenience), producing a total order which efficiently extracts all possible information from the comparisons.
I suggest that this is not necessarily the case, as examples from GANs indicate that such a preference-learning architecture may be learning something odder (such as memorizing comparisons), and that the architecture could be improved by removing the implicitness of the B-T ranking, computing the B-T rankings directly (which can be done even with non-overlapping comparisons by using a Bayesian model with priors and using covariates such as the predictor’s own estimates), thereby providing absolute quality scores for correctness of comparisons, more efficient regression, RL rewards, and meaningful interpretable scores for downstream uses.
The motivation for the double-critic architecture in the current blackbox approach is that the data being collected from humans is pairwise, and so one trains the critic to predict comparisons. This outside training loop then has an inner G/agent training loop etc. The double training loop is necessary to collect ratings from new areas of statespace that the G/agent can now access, but also, GAN-style, to avoid the D/critic from being too powerful and saturating loss. (The original Christiano implementation notes that a circular buffer is used to avoid problems, with only the most recent n = 3000 comparisons are stored.)
But, just because the input is pairwise doesn’t mean that the output must also be pairwise. (After all, many things, like tournaments, turn a series of pairwise comparisons into final scalar values like ‘rank’.) It could instead be a scalar indicating global rank, with the D/critic performing regression.6 GANs and DRL are closely connected (“Connecting Generative Adversarial Networks and Actor-Critic Methods”, Pfau & Vinyals 2016/“A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models”, Finn et al 2016/Wu et al 2020 eg. NoGAN is analogous to imitation-learning+RL-finetuning), and in both fields, a richer reward signal is always better, allowing for stabler faster training to better final performance (AlphaZero example). And a global rank is more informative than a comparison.
Full Bradley-Terry Training
Extract the rankings fast. A Bradley-Terry (B-T) model is simple and easy to estimate on even large samples7, and can easily produce cardinal rankings. Each datapoint gets an estimated cardinal ranking in standard deviations of a hypothetical latent Gaussian. The D/critic then is trained to do regression from a single input to the estimated latent variable of quality.
So the new loop would look like this:
run off-the-shelf B-T ranking over a dataset of comparisons of datapoints
extract the estimated latent variables for each datapoint
until convergence, supervised training of a D/critic NN to predict the latent for each datapoint
until convergence, RL training of a G/agent NN with the D/critic NN
sample n new datapoints from the trained G/agent NN and add to the dataset
run B-T ranking over the augmented dataset
ask the oracle for ratings of the m datapoints with the largest posterior uncertainty or some proxy thereof like standard error (which will usually be the new datapoints)
active sampling or bandit algorithms can be used to maximize the informativeness
Is Preference Learning a Bradley-Terry Model?
What’s the difference?
Not extracting all information. By using only comparisons, each predictor training is less meaningful, and even if the predicted variable is still results of comparisons, not fitting a B-T model means that one can’t train on comparisons between all datapoints (since one needs the B-T model to predict, based on the global ranking, what the outcome would be).
Pairwise yields incoherent ranking? It is also unclear that the preference learning architecture is implicitly estimating a B-T model. (I am not familiar with any paired-comparisons approaches which optimize ML models to predict a fixed set of comparisons, or work purely on disconnected comparisons.) Because no global ranking is ever constructed, no comparisons can be trained on other than the exact ones that the human made, and that may not be enough training signal to force inferring a global ranking, rather than merely learning locally-consistent pairwise comparisons which are nevertheless globally inconsistent (with cycles like rock-paper-scissors). The predictor may be learning something much simpler, such as non-robust features which distinguish within each fixed pair, but without learning what we thought it was learning—generalizable quality features which allow a meaningful global ranking across all pairs.
What does a D do? In a GAN, you have real and fake datapoints being compared; the D attempts to regress the probability of each point being a winner/loser, so to speak, producing a log probability (in the original formulation); does D learn generic features of quality or realism? Apparently not because even a highly accurate BigGAN D collapses to random guessing on the validation data; and in my anime face GAN work, when I use a well-trained StyleGAN D to rank real data, the rankings are strange, with outliers ranked both low & high, suggesting that garbage data can be ranked extremely confidently by the D simply because it could easily memorize them as outliers. So, we have a case where a D/critic is trained on comparison data from an oracle (real vs fake), is useful for training, outputs a variable which look exactly like an ELO and even has an ELO-like theoretical interpretation—and is completely ungeneralizable and not learning anything remotely like a cardinal score or even a transformation thereof like an ELO. What is going on? Apparently the D is memorizing real datapoints, and pushing the G away from them and toward nearby potential datapoints.
Ds just memorize? Why can’t this be the same thing for the preference-learning D? It is given a small dataset consisting of fixed pairs of good/bad datapoints, and it memorizes bad datapoints within a fixed pair, latching on to some feature or other (possibly important features, but they could also be the ‘non-robust features’ involved in adversarial learning) in order to memorize just within that pair (if it can overfit…), and this then pushes the G away from trajectories that look like bad datapoints, producing useful training just like in a GAN.
Weak learning signal. This would be consistent with the paper’s reported success, but would have a different interpretation: the D is not learning any generic quality metric, is not implicitly ranking all datapoints on a common scale of reward, and is not equivalent to a B-T. It is merely memorizing some data points or some ungeneralizable non-robust features which happen to let it distinguish within the pairs. As such, it can’t provide a stable ranking within or across iterations or datasets, and its feedback is of limited value (since once the G/agent has moved sufficiently far away from the penalized memorized datapoints, that no longer provides a training signal for more improvement and new relatively-bad datapoints must be learned and penalized).
Active Learning
Estimated rankings can prioritize comparisons. As implemented, preference learning is (potentially, assuming it’s equivalent to B-T) more sample-efficient than a naive B-T: each data point appears once in an unique comparison (rather than in multiple comparisons with multiple other datapoints), and so each comparison is potentially maximally efficient (in the sense that each additional comparison involving a datapoint provides the predictor less information than the first one did). A naive B-T, like the usual frequentist implementation, requires multiple comparisons to connect all datapoints via a chain of comparisons, and may be undefined if any datapoints are ‘unconnected’.
A Bayesian B-T model mitigates this by having priors on any new datapoint, which provides a meaningful estimate without few or no comparisons. (With no comparisons, the posterior mean is simply the prior mean, presumably something like 0.) The estimates aren’t informative, but they are well-defined and can be used for sampling strategies.
The lack of comparisons can be fixed partly by using covariates. There are two particularly relevant covariates which could be used:
the predictor’s own ratings of each datapoint:
Since the predictor should be able to reach high accuracy, its estimate before any comparisons should be quite accurate and reduce the posterior uncertainty considerably (despite having no comparisons). This can be particularly useful for a sampling strategy because it can help discard samples which are estimated as low quality and not informative about the best samples that we want to reach.
the current epoch/iteration:
Since we hope the generator/agent is also improving, the iteration a datapoint was generated from is relevant: early datapoints should be bad, intermediate datapoints should be medium, and recent datapoints should be the best. The first few comparisons inside a batch give a strong indication how good the batch is overall, and the quality can also be extrapolated from earlier iterations by fitting a progress curve (like a log or spline).
An example of a sampling algorithm would be best-arm racing algorithms. Since in this scenario, we’re trying to teach the NN to generate the best datapoints, we don’t value variance reduction elsewhere, we want certainty about the best datapoints in order to penalize the NN for generating any inferior datapoints. A simple posterior sampling racing algorithm for B-T might goes like this:
take the arm/datapoint with the highest posterior mean ranking, which is estimated to be the best;
sample from the posterior a possible ranking for every other datapoint;
compare the best known datapoint with the highest posterior-sample;
update.
Best-arm bandit. This explores datapoints based on their remaining posterior probability of being the best. (I used this once to rank mineral waters in a blind taste-test.) This can be applied to the k best datapoints for batch evaluation etc.
So a training loop could go like, begin iteration #11 by generating 1000 new samples from iteration #10’s G/agent model; score each with the D/critic; insert the 1000 into the dataset with their estimated score and iteration=10 covariate; do the B-T regression with Comparison[NA1][NA2] ~ iteration1+criticEstimate1 − iteration2+criticEstimate2 (pseudocode) to estimate posterior distributions of estimates for all datapoints (missingness of comparisons doesn’t matter, the model can still be fit); run the racing algorithm, finding that new sample #551 has a critic score of +5SD, giving a posterior estimate exceeding all other datapoints (despite not having been ever compared yet), and that new sample #998 get picked by posterior sampling; ask the user to compare #551 and #998; record the result; refit the B-T for an updated ranking; retrain the D/critic; retrain the G/agent; begin iteration #12 etc.
We efficiently home in on the best datapoints without necessarily requiring any ‘redundant’ comparisons, while providing informative stable cardinal rankings for the D/critic based on an ordering of the entire dataset, enabling it to provide more meaningful rewards to the G/agent. To the extent that we engage in ‘redundant’ comparisons, unlike the preference learning approach, those comparisons must have been necessary.
It’s an adaptive procedure so it’s hard to say exactly how it would differ from preference learning. Depending on how much the G improves each iteration, and how accurate the D is, and thus how much posterior overlap there is between different batches and different datapoints within each batch, it could look a lot like the current heuristic approach of doing only unique comparisons once within a batch and throwing away+never-comparing with prior batches, or it could look quite different, and change with each iteration as necessary:
If the G improves relatively slowly, so there’s a great deal of overlap between successive batches, and/or the D is only weakly correlated with measured rankings, then the procedure might need to sample a lot of comparisons between old/new batches in order to improve estimates of the progress curve and all datapoints within the new batch, and it might want many comparisons toward the tail of highest-ranked datapoints (which is not a bad thing because that’s where we should prioritize improvements, since that’s where the G is moving towards, and it’s less important to estimate accurately less-highly-ranked datapoints).
If the G or Ds are intermediate, I think the dynamics might look more like sampling mostly pairs within the new batch, mostly unique comparisons, and a few comparisons with old batches to finetune the mean of the new batch.
If the D + G progresses so rapidly such that rankings don’t overlap at all a priori, then few or no comparisons with the old batches are necessary: the D covariate predicted-rankings eliminate most of the posterior uncertainty despite no comparisons being available, and the G progress means that the old datapoints (while still useful for G training in teaching it the full spectrum of datapoints) are unlikely to be anywhere near the best datapoints and so aren’t worth measuring more accurately, so comparisons focus on the most uncertain pairs in the new batch.
Advantages & Disadvantages
This could have a lot of advantages:
simplified: the D/critic NN is conceptually simplified—instead of 3-way classification on a double input corresponding to an implicit global ranking, it is just a single input for regression on a quality score
memory-efficient: before, a double input takes up memory, even with tied weights, only to yield a single comparison; in the same space, 2 regression models could be run, each with a different input + target quality rating. If, to save memory (critical with GPT-2), a single input is used instead, now there must be two separate passes for each input, and each pass merely trains one-half of the comparison.
This could be particularly useful if one tries to use a large Transformer model like GPT-2-345M where memory consumption becomes a serious barrier to running it at all… (At 345M with the Siamese architecture, we’re down to n = 1 minibatches!)
sample-efficient: many comparisons will be useless, or for a given pair, they will quickly cease to be informative; a quality rating is informative regardless of what might’ve been used as a comparison, providing richer feedback on each input (analogous to AlphaZero switching to a regression target)
possibly better ’off-policy’ learning: related to saturating, a D/critic trained from a corpus (eg. initializing a D/critic by taking a dataset of real and GPT-2-generated poems, and labeling all comparisons as victory for the human poem) might destroy G/agent training if it provides only comparison feedback
better value function/reward signal for any other approach leveraging the NNs (like MCTS over a tree of sequences), too
humans or other datasets can supply cardinal ratings directly when those are available
compute-efficient:
possibly more D compute-efficient: by training comparisons, the D/critic must, implicitly, be learning an equivalent to a quality rating, in order to provide accurate predictions of a human comparison of all possible pairs—but it does so indirectly
G gets more data & becomes compute-efficient: a richer reward signal for each sample will of course be quite useful for the G; instead of saturating (there is intrinsically not much information in comparisons, and moving from, say, 99.99% to 99.999% is not helpful, regardless of whether these scores are log-transformed)
interpretable: an absolute cardinal quality variable provides an objective loss for understanding training progress (useful for tasks which don’t have them, like poetry generation!), which is also interpretable and could be useful outside of the task (eg. ranking poems for recommendation or data-cleaning)
for example, one could get insight into a trained G/agent by generating a number of samples, and ranking them
one could also test out various rating approaches, like how much conditioning is necessary. Given a dataset of pure comparisons, one cannot experiment with trying out unconditional generation because one doesn’t know what the outcome of any comparison would be; once one extracts the latent variables from a total ranking, though, one knows the distribution of outcomes and can simulate arbitrary comparison datasets.
principled uncertainty: enables active learning via B-T posterior uncertainty without any need to extract uncertainty estimates of any kind from the D/critic NN; human ratings can be acquired more efficiently, or datapoints selectively pulled from a large dataset (eg. imagine a huge dump of poems from Project Gutenberg or elsewhere, of wildly varying quality—with a regression style D/critic NN, you can do a single pass over it with the D/critic NN to select the k% highest poems, use the estimate as a pseudo-datapoint, insert into B-T, and ask humans for the most informative comparisons; with a comparison D/critic NN, how to import usefully a large unlabeled corpus is harder to see)
The main downsides I can see:
the latent variables are not necessarily 100% stable, as the distribution can drift, yielding anything from ‘rating inflation’ to ‘rating deflation’
The B-T estimates a distribution arbitrarily defined as 𝒩(0,1); if the B-T sees only selected datapoints at the beginning, it might be that after G/agent trains enough, the B-T step would be looking at datapoints which are much better than a mean of 0, so there might be new datapoints all the way out at (what used to be) +100SDs, say. This then leads to the B-T estimate the next cycle shifting the mean/SD to restore the conventional 𝒩(0,1). So the regression target for the D/critic’s predictions of old datapoints may gradually shift over time, precisely because the richer latent variables don’t saturate the way simple pairwise comparisons would.
I believe this would be a minor problem easily solved by training the D/critic NN each iteration, which is necessary just to handle novel datapoints anyway; since improvements will be small each iteration, the retraining should be easily able to keep up. If not, one could define particular datapoints as a ‘zero point’, and that provides a fixed point of reference for future players, even if they are far better; for example, the anchor could be random outputs.
(frequentist) B-T might require more comparisons for a total order: a datapoint has to be compared with other datapoints which themselves have comparisons if it is to be globally ranked at all, while a comparison D/critic can work with two entirely disjoint sets of comparisons which don’t overlap. (This can be avoided by using priors & covariates in a Bayesian B-T model.)
All in all, I think this version of preference could be simpler, easier to implement, and train faster. The potentially better sampling is nice, but my guess is that the D providing richer feedback (for both the G and downstream users) is the biggest advantage of this approach—a comparison is a bit, and a bit is worth only a little bit.
Decision Transformers: Preference Learning As Simple As Possible
I propose an extremely simple form of preference learning using the ‘Decision Transformer’ approach: simply encode the human choices as a sorted list of options, finetune a sequence model like GPT to predict text on a dataset including that encoded preference/choice data, and then generate text in the form of said sorted lists. The model will learn what preferred text looks like, and in generating sorted lists, will generated preferred samples first.
This RL approach, by gardening the data, is closer to prompt programming or Software 2.0 than traditional DRL algorithms like PPO. This avoids all of the complexity, instability, and compute requirements of the GPT preference learning approach used previously, moving the reward learning to inside the dataset, and is particularly applicable to tasks like AI Dungeon-style text adventure games, where the complexity of training rankers & RL-finetuned models has barred their use to date.
Upside down reinforcement learning, exemplified by the recent Decision Transformer (DT), is completely different from the PPO approach above. The PPO approach trains a double-sized critic model to choose one of two inputs as the better input, and then freezes this model, and uses it as a ‘reward function’ to train a third model, which generates random samples furiously, feeding them into the critic model, and attempting to use that feedback to gradually brute-force its way towards slightly better random samples. As shown above, this is difficult to get working, uses up a lot of compute, easily collapses into degenerate solutions, among many other problems.
DT takes a completely different approach, and doesn’t even look like RL or like it should work. DT simplifies offline & imitation RL by treating it as a sequence prediction problem, where the sequences are a reward prefixed to the corresponding sequence of actions+observations. When a powerful sequence model like GPT is trained on this in a standard self-supervised fashion, such as next-token prediction, it implicitly learns—as a generative task—how to model the environment, what are the consequences of actions, what low reward vs medium reward vs high reward sequences look like, what good and bad actions are, and so on. Then to ‘plan’ actions, one simply starts generating a sequence starting with a ‘high reward’, and the sequence model confabulates what a skillful next action would be. This sounds like it should not work because it is so simplistic but it does, and actually quite well compared to far more complicated RL approaches. (This approach is in the same spirit as the inline metadata trick for control or earlier GPT-2 benchmark tasks, where “every task is a generation task”: Want to summarize text? Add “tl;dr” to it. Want to translate English to French? Add “Fr to en:” to it. Want to do Q&A? Format your question as “Q. … A.”, etc.)
This DT approach has several advantages: it doesn’t need to interact with an environment (is offline); it can learn from data generated by any agent, not just itself (it is off-policy—unlike PPO, which can only learn from its own actions); it can better generalize by modeling all trajectories & probably better avoids the blind spots of regular RL; it is extremely simple & implemented with off-the-shelf sequence modeling Transformers as it merely reformats the data and does not change the model or training algorithm; it avoids the three-fold cost of the PPO approach (the doubled-ranker model + PPO-finetuned model) in favor of a single multitask model; it can be scaled up like regular sequence modeling because of its compute-efficiency & stability (enjoying the blessings of scale such as much greater sample-efficiency & meta-learning); it can transfer learn from other datasets via pretraining (such as large natural language corpora); and it will benefit from any improvements in sequence modeling supervised learning.
In Between RL
As preference learning is a kind of RL, can DT be applied to it? It seems like it ought to work well. My proposal is to do DT preference learning by ‘upside down’ choices: appending the human-ranked options in rank order to the preceding sequence. Then to ‘choose’, one simply inputs the observation history followed by the ranking tokens to elicit specific rewards. This differs from regular DT which sticks the reward on the front to decode entire trajectories—with preference learning, we already have partial trajectories and are in media res, and we want to continue them based on the ranked options. So we instead stick our ‘reward’ tokens in the middle, as it were, in between the partial trajectory to date and the possible outcomes.
A concrete example for implementing a preference-learning model for an CYOA AI Dungeon text adventure game might go like this, with the scene and then possible choices in descending order of play preference:
“Hello!”, the Frog said. “I may not look like it, but I am actually a Prince under a curse. Please kiss me to break the spell!”
COMPLETION:
I say, “OK, I will kiss you.”
I stomp the frog.
McDonald’s fries have never been the same since they stopped using beef tallow.
asdadfghiklmnopaaaaaaaa the the the the the the the
The GPT merely trains on this as if it were any other text in the dataset. (Indeed, we could even let players edit the completions to add a new completion entirely that they like better.) It implicitly learns what #1 completions look like vs #2, #3, or #4, etc., thereby learning what good (according to the human ranking) completions look like vs worse ones.
If only pair-wise data is available and all the data points are unique, there is not much that can be done to improve the formatting. The pairs are what they are. (We do not want to delete the worse option and simply train on the better option as a ground truth completion.8) One option, that loses some of the DT advantages, is to borrow the idea of an explicit ranker from the OA PPO approach, and train a ranker model, thereby sorting the entire dataset, and allowing the cardinal ranking to be constructed per above.
If we have a lot of rankings, or if the comparisons overlap so we can infer a global ranking of quality, then we can switch from ordinal rankings like #1–5 to explicit cardinal values via Bradley-Terry; that will reduce extraneous variation where ‘#1’ means something possibly extremely different in each sample (the #1 sample out of 200 ranked options is rather different from the #1 out of 2 ranked options).
For example, if I was revisiting my failed attempt at GPT-2 poetry preference-learning in 2023, I would first test whether I could simply finetune GPT-3.5 on a small curated corpus of high-quality poetry; reportedly, RLHF’s safety properties can be neutralized by simply finetuning on a few hundred examples, and so we could potentially easily undo the damage done by RLHF to GPT creativity and prompt it normally. If that didn’t work, I would experiment with finetuning it to rate poetry where the quality rating is prefixed, and then simply sample with a prefix consisting of the highest rating. If that didn’t work for generating good samples but it was accurately rating samples, then I would experiment with taking the quality-rating finetuner (or to save money, given how expensive the finetuned models are to run, with the best available FLOSS model I can run locally) and pseudo-labeling a large corpus of poems (like the Project Gutenberg + Poetry Foundation corpuses), and then finetuning the model on that and generating. At that point, it should be possible to start human-rating sampled new poems, and feeding them back into the final model to further refine it.
An open question here: should all training datapoints be expanded out as exhaustive sets of pairwise comparisons, or should they be left at maximal length? That is, in the example above, we could have 1 datapoint with 4 options ranked, or we could instead have (24) = 6 datapoints with all the possible pairwise comparisons (#1 vs 2/3/4; #2 vs 3/4; & #3 vs 4). I can see how either way might be better, or both could be best, as it provides data augmentation.
Learn All The Things
The flexibility of DT means that the completion data can be a small part of the finetuning data. The rest of the finetuning data can be any data, with any level of metadata, which plausibly provides any information or transfer-learning about the desired task, even if only to reinforce basic natural language competence. For a CYOA model, the finetuning data might be mostly composed of regular fiction datasets such as SF/F novels, movie screen plays, novel reviews, fanfiction websites, science news, scientific datasets like Arxiv, output from specialized models (labeled with the generator name), forum discussions… As long as they have metadata/formatting distinguishing them from the target task so they do not ‘leak’, the model can learn them all simultaneously without any problem, as long as the sequence model is big enough & smart enough—you could dump in all sorts of datasets, and multiple different sources of ranking, although it would be a good idea to include inline metadata distinguishing them, such as the dataset name or an ID of the individuals doing the rankings, so it can learn to model them separately as much as is necessary. We can add new metadata or datasets at any time, and continue finetuning.
For example, in Astralite Heart’s Purple.smart GPT model intended to generate My Little Pony character dialogue, the fiction data is scraped from many sources to try to get as high quality a model as possible, and all the available metadata is incorporated inline; so a particular fanfiction might read MLP|SFW|AstraliteHeart|Twilight Sparkle,Princess Celestia|A Beautiful Data In The Castle|..., denoting fandom/SFW-status/author/characters/title. This helps the model to both learn that these are important variables for understanding the story, but also lets you control the output: “I want a MLP story, no smut, in the style of my favorite author, with characters X/Y/Z, and this title as a topic.”9 In Software 2.0, prompt programming, we do not ask “what sequence of steps will compute my desired answer from arbitrary inputs?”, but “how do I program this model by providing a seed of data whose most plausible completion is my desired data?” We sculpt and garden our data to represent question & answer. DT just takes this logic a bit further and tries to incorporate explicitly as an inline metadata control code a ‘reward’ metadata variable.
The disadvantage of including too much data is less that it will overwhelm model capacity by modeling irrelevant text, but that it will waste compute. (For example, does one need to include timestamps? They are highly predictable, full microsecond timestamps take a lot of space, and most things do not change that much with time. Finetuning a big model can be expensive, and timestamps might take up an appreciable percentage of space.)
DT Sampling
Once training is done, how do we use it for sampling? For regular generation of random samples, conditional or unconditional, the model works as always. For generation of high-reward optimized samples, we tweak our prompt: we simply reuse the inline metadata trick of COMPLETION:\n\n1. and decode from there. So let’s say a player has reached a similar scene with the Frog. We might then generate a new completion like so:
The Frog turns to look at you. “Hello there!”, the Frog says. “I may look like a frog to you, but really, I am a Prince transformed by a dreadful curse. Please, kiss me to free me from this spell.”
COMPLETION:
1. “Weird suggestion, but OK, I’ll give it a try.”
2. “Eww, no! What are you, some sort of interspecies pervert?”
3. “I’m sorry, but I don’t want to be unfaithful to my spouse. Is there some other way I can help you?”
4. “You’re a frog?”
Then choice #1 (“Weird suggestion, but OK, I’ll give it a try.”) is predicted to be the best completion, but the others may also be usable. We could try to generate multiple completions to get multiple ‘1.’ responses, but there is a good chance that they will be too similar; if this turns out not to be the case, or if one can automatically detect too-similar completions (n-grams?), then it would be better to try to generate multiple ‘1.’ completions for higher average quality, and to further train the model by giving it more useful comparisons.
DT Ranking
Finally, in addition to generating the distribution and generating the best samples, we might want to explicitly rank a given set of options; this can be done by running the model forward to calculate the likelihood of each set of rankings, eg. comparing 1. A\n2. B vs 1. B\n2. A. (If A > B, then the first should be much more likely than the second, and vice-versa.) Using pairwise comparisons, we can sort arbitrarily long lists in the usual 𝒪(n log n) calls. If this is too expensive and we want to efficiently directly output a ranked version of an input in a single pass, well, “every task is a generation task” and that is definitely a sequence2sequence problem, so one can set up pairs of scrambled/ranked text to create a prompt for ranking and add that to the training dataset. (This might even be useful as a kind of data augmentation.)
DT Preference Learning Advantages
So in comparison with the OA PPO approach to preference learning, using DT avoids the instabilities and extreme computation of the PPO training step, avoids creating a double-head pairwise comparison model with its doubled VRAM consumption, it requires training only 1 model which can do finetuning/ranking/optimized-generation simultaneously, it can be expected to perform better given DT’s benchmarking so far and the various advantages, and the only difference from regular GPT finetuning is how some of the data is formatted & what prompt one uses.
Disadvantages
It is unclear what the sample-efficiency of DT is with current small models compared to alternatives like PPO. The inline metadata trick works with almost any n, but inline metadata like genre or author is particularly powerful metadata compared to subtler rewards like quality or entertainment, which are being trained on in a fairly subtle and indirect manner (mere text prediction) so it’s unclear what n is necessary. But it may not matter: DT’s advantages in simplicity, flexibility, and model size efficiency may more than make up for any ostensible weakness in n. Particularly with crowdsourced applications, if popular, the n may quickly exceed whatever is necessary and compute become a bottleneck rather than n. For example, AI Dungeon 2 has had millions of games played, while Holo AI (benefiting from the 2021 exodus from AI Dungeon 2) racked up >100,000 turns (each of which provided the user with 2 completion options) within a month. For comparison, the OA PPO experiments, using blackbox optimization, typically run with n<100,000.10
More concerningly, the OA experiments show strong returns to scale in preference learning, perhaps even stronger than for basic NLP benchmarking—there may be a critical GPT size below which DT just doesn’t work on anything interesting, because the model just “doesn’t get it”. It’s no good advertising DT’s simplicity and generality to hobbyists if the models they use, like GPT-J, turn out to be below some critical threshold! This is an unknown until people try it further.
There is no explicit ‘exploration’ in DT, or clear principled way to do exploration by generating the most informative trajectories to observe a reward on. This may not be an issue due to being able to learn from any dataset, being deployable at scale, and the general creativity of sequence models.
Training on lots of metadata may increase concerns about information leakage & privacy. If one conditions on user ID, a likely useful variable, will it be possible to extract information from the final model about each user? (If the model doesn’t know anything about each user, why bother including the user ID?) The general security implications of inline metadata is unclear: the point of inline metadata is to allow ‘programming’ the model, but making such a “weird machine” may backfire.
External Links
Transformer Reinforcement Learning (trl) (GH), Leandro von Werra (GPT-2+PPO Pytorch library)
“Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment”, Talebi et al 2020
“Controllable Neural Text Generation”, Lilian Weng/“Recent Advances in Language Model Fine-tuning”, Sebastian Ruder
“Prefix-Tuning: Optimizing Continuous Prompts for Generation”, Li & Liang 2021
“Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data”, Yang et al 2018; “GBDA: Gradient-based Adversarial Attacks against Text Transformers”, Guo et al 2021
I don’t know why they used 124M instead of 117M.↩︎
Such a shortcut is rather against the spirit of DRL, where as much as possible should be learned from data. If such shortcuts are necessary—as I do find with ABC—the domain knowledge ought to be localized in the rating code (where it achieves the stated goals of being easy to implement & easing human raters’ burden), and not the training code.↩︎
KL penalties are commonly used in RL. To try to explain it informally: think of each GPT-2 model, like the original GPT-2 model vs its RL-trained version as emitting probabilities over the ~50k possible BPE outputs and graphing that as a bar chart (probability vs BPE). For any particular input, the 50k possible BPEs will form a spiky bar chart: the model predicts some BPEs are far more likely than others. The KL distance between those two models, then, is like if you subtract the original GPT-2’s bar chart from the new RL GPT-2’s bar chart, and added up the differences at each possible bar (not just the biggest bar). So the KL distance measures the difference of opinion about every possible BPE, from the most to the least likely (including the ones you would never select while sampling). You want there to be some difference between the bar charts—otherwise what’s the point?—but also not too big a difference, because the original GPT-2 model was usually right already, fairly small KL distances can change the final outputs quite a bit qualitatively, and if the new model is making too many changes, it’s probably gone wrong. So trying to keep the KL distance small is a good way to maintain high performance, but still finetune it based on experience.↩︎
I use pairwise rather than best-of-4 because it simplifies the rating process & maximizes the information per sample read/listened to; if I understand the implementation, however, it also reduces the memory requirements because the reward model training unrolls n models to train them all simultaneously on a n-rating.↩︎
Assuming a labeler could get through 2 ratings per minute (optimistic, given how exhausting I found even an hour), a million ratings would require >8,333 man-hours, or at a rock-bottom total-cost-per-hour of $12.58$102020, >$104,814.75$83,3332020. And that might not be enough.↩︎
Why regression on the latent value/scalar instead of on the ranking itself? That is possible using differentiable sorting (Grover et al 2019, Blondel et al 2020, Swezey et al 2020), which generalizes the pairwise comparison and can train a NN directly to rank arbitrary numbers of inputs, but this continues to have the scaling problem of needing to run many models in parallel, 1 per rank member. That’s fine for many of the problems that rank-based losses are applied to, but not here where a single GPT-2 or GPT-3 model may already not fit in-GPU!↩︎
eg. my simple interactive R tool for ranking, just re-estimates the entire B-T model each interaction, rather than attempt any caching or incremental updating to a stored model, because it takes a fraction of a second to fit. A fully Bayesian model can be fit via MCMC in a few seconds, which is negligible in a DRL context.↩︎
It might be tempting to simply throw out the bottom option and train as normal text, but this is a bad idea. The comparison only tells us which is better; it doesn’t tell us that the better option is good. It may be a terrible option! It’s just better than the alternative.
If we feed the model lots of examples where the chosen option is presented as simply the next bit of text, a gold ground-truth, we may wind up training it merely to always generate bad text, without any improvement. A model might be generating, say, 10th vs 12th percentile quality responses (as compared with human-written responses), and it is useful to steer it towards the 12th percentile responses, but if we remove the comparison, we will be inadvertently training it to always generate 12th percentile level responses, even if we have since upgraded models or the model has gotten much better, because we have hardwired that into our dataset.↩︎
We do not need to use a fixed order, we could use some sort of key-value formatting with the metadata in arbitrary order, but doing a fixed order of metadata keywords with a separate is space-efficient, easy to understand & control, doesn’t require any data-augmentation to permute the keywords to teach the model to be order-invariant, and we can usually provide a reasonable ordering by ‘importance’. In the MLP example, it is unlikely we would want to specify characters without having first specified the franchise or that it is SFW vs NSFW.
But as inline metadata gets more elaborate, my old pipe-formatting scheme may fall behind. Reportedly with GPT-J, perhaps because it was trained on relatively much source code from GitHub etc., it works well to format metadata (such as character profiles) in a JSON-esque key-value formatting. A particularly elaborate example of trying to script a “personality core” by inline metadata (newlines/indentation added for readability):
↩︎[Name: Princess Luna; Age: 2607; Race: alicorn; Gender: mare; Desc: a dark blue alicorn pony, with wings and a horn; Likes: {stars; astronomy; night; batponies; the night guard; stallions; mares; sex; tea; sitting and enjoying each other's presence; strength; loyalty; knights; weapons; castles; darkness; power; harems; passion; jokes; art; reading; research; magic; her sister Princess Celestia}; Dislikes: {daytime; being awake during the day; nobles; ponies who prefer the day to the night; her time being imprisoned on the moon; her alter ego Nightmare Moon}; Attributes: {is a pony; does not have hands; does not have feet; has forelegs; has hindlegs; has hooves; has a long horn that can cast powerful magic; has wings that let her fly really fast; talks like she's a Shakespeare character; enjoys sitting under the moonlight.}; History: {She and her sister founded Equestria around 2000 years ago.; She grew discontent with her sister hogging the spotlight.; She became Nightmare Moon and tried to steal away the kingdom to cast it into eternal nighttime.; She was beaten by her sister using the Elements of Harmony and imprisoned on the moon for 1000 years.; She was recently freed from her imprisonment when the bearers of the Elements of Harmony used the Elements to cast Nightmare Moon out of her.; She has since been slowly adapting to modern life in Equestria. but struggles and is still old fashioned.} ]The DT experiments showed good performance, but we also know that standard RL tasks like HalfCheetah or Reacher or ALE Pong can be solved with extremely small NNs compared to NLP.↩︎