Who Wrote The Death Note Script?
Internal, external, stylometric evidence point to live-action leak of Death Note Hollywood script being real.
I give a history of the 200917ya leaked script, discuss internal & external evidence for its realness including stylometrics; and then give a simple step-by-step Bayesian analysis of each point. We finish with high confidence in the script being real, discussion of how this analysis was surprisingly enlightening, and what followup work the analysis suggests would be most valuable.
Beginning in May 20091 and up to October 200917ya, there appeared online a PDF file claiming to be a script for the Hollywood remake of the Death Note anime (see Wikipedia or my own little Death Note Ending essay for a general description). Such a leak inevitably raises the question: is it genuine? Of course the studio had “no comment”.
I was skeptical at first - how many unproduced screenplays get leaked? I thought it rare even in this Internet age - so I downloaded a copy and read it.
Plot Summary
FADE UP: EXT. QUEENS - NYC
A working class neighborhood in the heart of Far Rockaway. Broken down stoops adorn each home while CAR ALARMS and SHOUTING can be heard in the distance as the hard SQUABBLE [sic] LOCALS go about their morning routine.
INT. BEDROOM - ROW HOUSE
LUKE MURRAY, 2, lies in bed, dead to the world, even as the late morning sun fights its way in. Suddenly his SIDEKICK vibrates to life.
He slowly starts to stir as the sidekick works its way off the desk and CRASHES to the floor with a THUNK…
The plot is curious. Ryuk and other shinigami are entirely omitted, as is Misa Amane (the latter might be expected: it’s just one movie). Light Yagami is renamed “Luke Murray”, and now lives in New York City, already in college. The plot is generally simplified.
What is more interesting is the changed emphases. Luke has been given a murdered mother, and much of his efforts go to tracking down the murderer (who, of course, escaped conviction for that murder). The Death Note is unambiguously depicted as a tool for evil, and a malign influence in its own right. There is minimal interest in the idea that Kira might be good. The Japanese aspects are minimized and treated as exotic curios, in the worst Hollywood tradition (Luke goes to a Japanese acquaintance for a translation of the kanji for ‘shinigami’, who being a primitive native, shudders in fear and flees the sahib… oh, sorry, wrong era. But the description is still accurate.) T-Mobile Sidekick cellphones are mentioned and used a lot (6 times by my count).
The ending shows Luke using the memory-wiping gambit to elude L (who from the script seems much the same, although things not covered by the script, such as casting, will be critically important to making L, L), and finding the hidden message from his old self - but destroying the message before he learns where he had hidden the Death Note. It is implied that Luke has redeemed himself, and L is letting him go. So the ending is classic Hollywood pap.
(A more detailed plot summary can be found on FanFiction.Net.)
The ending indicates someone who doesn’t love DN for its shades of gray mentality, its constant ambiguity and complexity. Any DN fan feels deep sympathy for Light, even if they root for L and company. I suspect that if they were to pen a script, the ending would be of the “Light wins everything” variety, and not this hackneyed sop. I know I couldn’t bring myself to write such a thing, even as a parody of Hollywood.
In general, the dialogue is short and cliche. There are no excellent megalomaniac speeches about creating a new world; one can expect a dearth of ominous choral chanting in the movie. Even the veriest tyro of fanfiction could write more DN-like dialogue than this script did. (After looking through many DN fanfictions for the stylometric analysis, I’ve realized this claim is unfair to the script.)
Further, the complexities of ratiocination are largely absent, remaining only in the Lind L. Taylor TV trick of L and the famous eating-chips scene of Light. The tricks are even written incompetently - as written, on the bus, the crucial ID is seen by accident, whereas in DN, Light had specifically written in the revelation of the ID. The moral subtlety of DN is gone; you cannot argue that Luke is a new god like Light. He is only an angry boy with a good heart lashing out, but by the end he has returned to the straight and narrow of conventional morality.
Of this plot summary, Justin Sevakis of ANN comments:
It’s important to keep expectations in check, whenever a film project emerges, because the vast majority of film projects do end up kind of sucking. When an early script of the as-yet unmade American Death Note movie leaked a few years back, I told a close friend of mine about it, and that it was hard to tell if it was actually real of an internet hoax. This friend of mine had directed a feature at Fox, written and doctored many scripts for several studios. He asked me, “Is it any good?” “No,” I replied, “it’s atrocious.” He grinned. “Then it’s real.”
Evidence
The question of realness falls under the honorable rubric of textual criticism, which offers the handy distinction of internal evidence vs external evidence.
Internal
The first thing I noticed was that the 2 authors claimed on the PDF, “Charley and Vlas Parlapanides”, was correct: they were the 2 brothers of whom it had been quietly announced in 2009-04-30 that they were hired to write it, confirming the rumors of their June 200818ya hiring. (And “Charley”? He was born “Charles”, and much coverage uses that name; similarly for “Vlas” vs “Vlasis”. On the other hand, there are some media pieces using the diminutive, most prominently their IMDb entries.)
Another interesting detail is the corporate address quietly listed at the bottom of the page: “WARNER BROS. / 4000 Warner Boulevard / Burbank, California 91522”. That address is widely available on Google if you want to search for it, but one has to know about it in the first place and so it is easier to leave it out.
PDF Metadata
(The exact PDF I used has the SHA-256 hash: 3d0d66be9587018082b41f8a676c90041fa2ee0455571551d266e4ef8613b08a2.)
The second thing I did was take a look at the metadata3:
The creator tool checks out: “DynamicPDF v5.0.2 for .NET” is part of a commercial suite, and it was pirated well before April 200917ya, although I could not figure out when the commercial release was.
The date, though, is “Thu 2009-04-09 09:32:47 PM EDT”. Keep in mind, this leak was in May-October 200917ya, and the original Variety announcement was dated 2009-04-30.
If one were faking such a script, wouldn’t one through either sheer carelessness & omission or by natural assumption (the Parlapanides signed a contract, the press release went out, and they started work) set the date well after the announcement? Why would you set it close to a month before? Wouldn’t you take pains to show everything is exactly as an outsider would expect it to be? As Jorge Luis Borges writes in “The Argentine Writer and Tradition”:
Gibbon observes [in the Decline and Fall of the Roman Empire] that in the Arab book par excellence, the Koran, there are no camels; I believe that if there were ever any doubt as to the authenticity of the Koran, this lack of camels would suffice to prove it Arab. It was written by Mohammed, and Mohammed as an Arab had no reason to know that camels were particularly Arab; they were for him a part of reality, and he had no reason to single them out, while the first thing a forger or tourist or Arab nationalist would do is to bring on the camels - whole caravans of camels on every page; but Mohammed, as an Arab, was unconcerned. He knew he could be Arab without camels.
Another small point is that the date is in the “EDT” timezone, or Eastern Daylight-savings Time: the Parlapanides have long been based out of New Jersey, which is indeed in EDT. Would a counterfeiter have looked this up and set the timezone exactly right?
Writing/formatting
What of the actual play? Well, it is written like a screenplay, properly formatted, and the scene descriptions are brief but occasionally detailed like the other screenplays I’ve read (such as the Star Wars trilogy’s scripts). It is quite long and detailed. I could easily see a 2 hour movie being filmed from it. There are no red flags: the spelling is uniformly correct, the grammar without issue, there are few or no common amateur errors like confusing “it’s”/“its”, and in general I see nothing in it - speaking as someone who has been paid on occasion to write - which would suggest to me that the author(s) were neither of professional caliber nor unusually skilled amateurs.
The time commitment for a faker is substantial: the script is ~22,000 words, well-edited and formatted, and reasonably polished. For comparison, NaNoWriMo tasks writers with producing 50,000 words of pre-planned, unedited, low-quality content in one month, with a second month (NaNoEdMo) devoted to editing. So the script represents at a minimum a month’s work - and then there’s the editing, reviewing, and formatting (and most amateur writers are not familiar with screenwriting conventions in the first place).
So much for the low-hanging fruit of internal evidence: all suggestive, none damning. A faker could have randomly changed Charles to “Charley”, looked up an appropriate address, edited the metadata, come up with all the Hollywood touches, wrote the whole damn thing (quite an endeavour since relatively little material is borrowed from DN), and put it online.
Stylometrics
The next step in assessing internal evidence is hardcore: we start running stylometry tools on the leaked script to see whether the style is consistent with the Parlapanides as authors. The PDF is 112 images with no text provided; I do not care to transcribe it by hand. So I split the PDF with pdftk to upload both halves to Google Docs (which has an upload size limit of 1.02m characters) to download its OCR’ed text; and then ran the PDF through GOCR to compare - the Google Docs transcript was clearly superior even before I spellchecked it. (In a nasty surprise halfway through the process, I found that for some reason, Google Docs would only OCR the first 10 pages or so of an upload - so I wound up actually uploading 12 split PDFs and recombining them!)
Samples of the Parlapanides’ writing is hard to obtain; the only produced movie with their script is the 200026ya Everything For A Reason and the 201115ya Immortals (so any analysis in 200917ya would’ve been difficult). I could not find the script for either available anywhere for download, so I settled for OpenSubtitles.org’s subtitles in .srt format and stripped the timings: grep -v [0-9] Immortals.2011.DVDscr.Xvid-SceneLovers.srt > 2011-parlapanides-immortals.txt (There are no subtitles available for the other movie, it seems.)
Samples of fanfiction are easy to acquire. FanFiction.Net’s Death Note section (24,246 fanfics), sort by: number of favoriting users, completed, in English, and >5000 words. This yields 2,028 results but offers no way to filter by fanfictions written in a screenplay or script style, and no entry in the first 5 pages mentions “script” or “screenplay” so it is a dead end. The dedicated play/musical section lists nothing for “Death Note”. Googling "Death Note" (script OR screenplay OR teleplay) -skit site:fanfiction.net/s/ offers 8,990 hits, unfortunately, the overwhelming majority are either irrelevant (eg. using “script” in the sense of cursive writing) or too short or too low quality to make a plausible comparison. (I also submitted a Reddit request, which yielded no suggestions.) The final selection:
“Death Note Movie Spoof Script”, by ipoked-KiraandEdward-andlived
“School Crack: Death Note”, by AbyssQueen
“The Sweet Tooth Show”, by StrawberriBlood
“Death Note: Behind The Sciences”, by Adeline-Eveline
“L’s Pregnancy”, by UltraVioletSpectrum
“Death Note: the Abridged Series”, by Jaded Ninja
“Polly Wants A Rosary?”, by xXGoody Not-So-Great MeXx
“Three Characters”, by reminiscent-afterthought
“The Mansion”, by doncelladelalunanegra
“The Most Wonderful Time Of The Year”, by Eternal Retrospect
“Whammy Boy’s Gone Wild!”, by ScarlettShinigami
As a control-control, I selected some fanfictions that I knew to be of higher quality:
“Harry Potter and the Methods of Rationality”, by Eliezer Yudkowsky
“Trust in God, or, The Riddle of Kyon”, by Yudkowsky
“The Finale of the Ultimate Meta Mega Crossover”, by Yudkowsky
“Peggy Susie”, by Yudkowsky
“Mandragora”, by NothingPretentious
“To The Stars”, by Hieronym
“Harry Potter and the Natural 20”, by Sir Poley
The fanfictions were converted to text using the now-defunct Web version of FanFictionDownloader.
With 10 fanfictions, it makes sense to compare with 10 real movie scripts; if we didn’t include real movie scripts formatted like movie scripts, one would wonder if all the stylometrics was doing was putting one script together with another. So in total, this worry is diluted by 3 factors (in descending order):
the use of 10 real movie scripts (as just discussed)
the use of 10 fanfictions resembling movie scripts to various degrees (previous)
the known Parlapanides work (the Immortals subtitles) being pure dialogue and including no action or scene description which the stylometrics could “pick up on”
The scripts, drawn from a collection (grabbing one I knew of, and then selecting the remaining 9 from the first movies alphabetically to have working .txt links as a quasi-random sample):
For the actual analysis, we use the computational stylistics package of R code; after downloading stylo, the analysis is pretty easy:
install.packages("tcltk2")
source("stylo_0-4-6_utf.r")The settings4 are to: run a cluster analysis which uses the entire corpus, assumes English, and looks at the difference between files in their use of “most popular words” (starting at 1 word & maxing out at 1000 different words, because the entire Immortals subs is only ~4000 words of dialogue), where difference is a simple Euclidean distance.
The script PDF, full corpus, intermediate files, and stylo source code are available as a tarball.
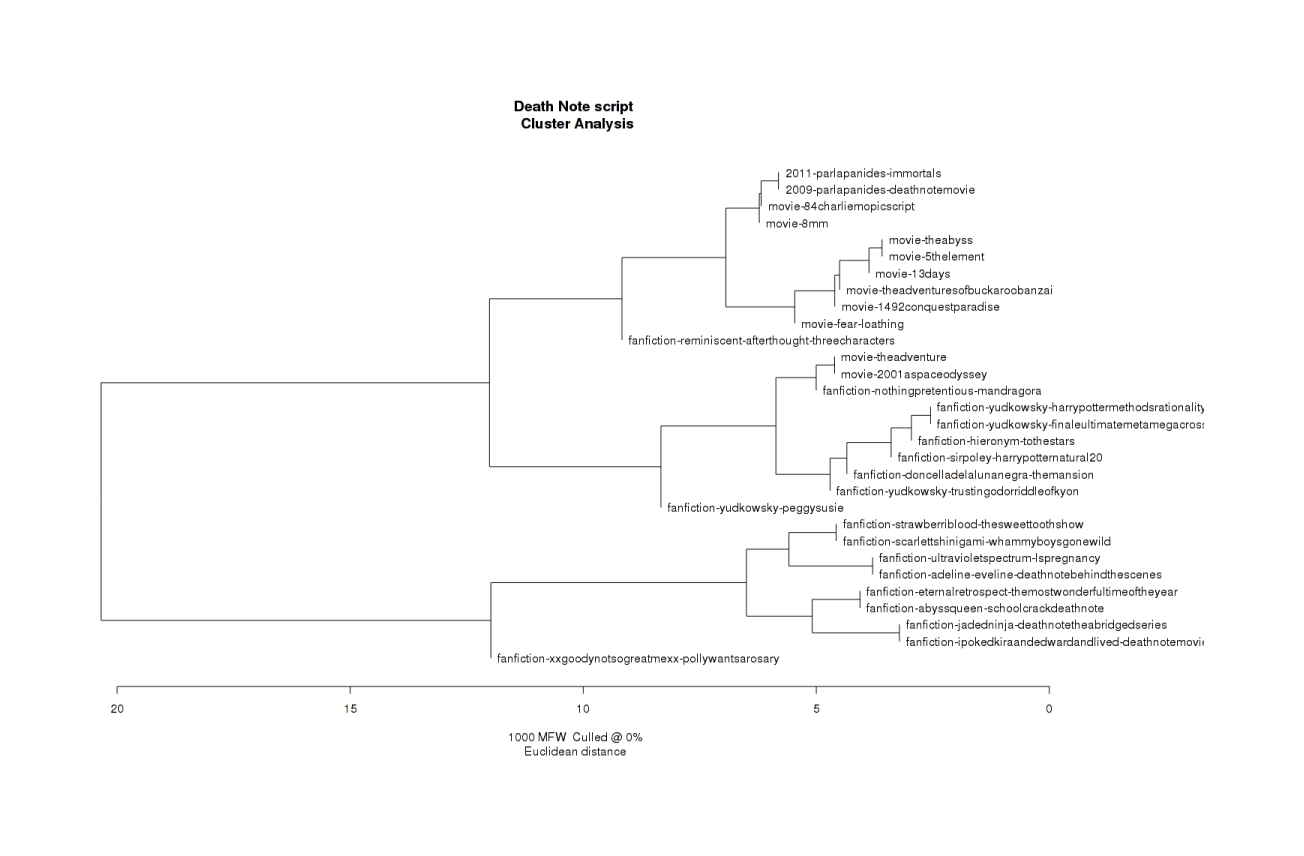
The cluster analysis of the 30-strong corpus.
The graphed results are unsurprising:
The movies cluster together in the top third
The DN fanfics are also a very distinct cluster at the bottom
In the middle, splitting the difference (which actually makes sense if they are indeed more competently or “professionally” written), are the “good” fanfics I selected. In particular, the fanfics by Eliezer Yudkowsky are generally close together - vindicating the basic idea of inferring authorship through similar word choice.
Exactly as expected, the Immortals subs and the leaked DN script are as closely joined as possible, and they practically form their own little cluster within the movie scripts.
This is important because it’s evidence for 2 different questions: whether the known Parlapanides work is similar to the leaked script, and whether the leaked script is similar to any fanfictions rather than movies. We can answer the latter question by noting that it is grouped far away from any fanfiction (the only fanfiction in the cluster, the “Three Characters” fanfiction, is very short and formalized), even though Eliezer Yudkowsky (himself a published author) wrote several of the fanfictions and one of them (Harry Potter and the Methods of Rationality) is intended for publication and perhaps even a Hugo award.
That the analysis spat out the files together is evidence: there were 30 files in the corpus, so if we generated 15 pairs of files at random, there’s just a 1⁄15 = 6.6% chance of those two winding up together. The tree does not generate purely pairs of files, so the actual chance is much lower than 6.6% and so the evidence is stronger than it looks; but we’ll stick with it in the spirit of conservatism and weakening our arguments.
External
Dating
But is there any external evidence? Well, the timeline is right: hired around June 200818ya, delivered a script in early April 200917ya, official announcement in late April 200917ya. How long should delivery take? The interval seems plausible: Figure about 2 months for both brothers to read through the DN manga or watch the anime twice, clear up their other commitments, a month to brainstorm, 3 months to write the first draft, a month to edit it up and run it by the studio, and we’re at 7 months or around February 200917ya. That leave a good 6 months for it to float around offices and get leaked, and then come to the wider attention of the Internet.
Credit
Given this effort and the mild news coverage of it, one might expect a faker to take considerable pride in his work and want to claim credit at some point for a successful hoax. But as of January 201313ya, I am unaware of anyone even alluding or hinting that they did it.
Official Statements
Additional evidence comes from the January 201115ya announcement by Warner Bros that the new director was one Shane Black, and the script was now being written by Anthony Bagarozzi and Charles Mondry (with presumably the previous script tossed):
“It’s my favorite manga, I was just struck by its unique and brilliant sensibility,” Black said. “What we want to do is take it back to that manga, and make it closer to what is so complex and truthful about the spirituality of the story, versus taking the concept and trying to copy it as an American thriller. Jeff Robinov and Greg Silverman liked that.” Black’s repped by WME and GreenLit Creative.
ANN quoted Black at a convention panel:
However, Black added that the project was in jeopardy because the studio initially wanted to lose “the demon [Ryuk]. [They] don’t want the kid to be evil… They just kept qualifying it until it ceased to exist.” Black said that “the creation of a villain, the downward spiral” of the main character Light has been restored in the script, and added that this is what the film should be about.’
…According to the director of Kiss Kiss Bang Bang and the upcoming Iron Man 3 film, the studios initially wanted to give the main character Light Yagami a new background story to explain his “downward spiral” as a villain. The new background would have had a friend of Light murdered when he was young. When Light obtains the Death Note - a notebook with which he can put people to death by writing their names - he uses it to seek vengeance. However, Black emphasized that he opposed this background change and the suggested removal of the Shinigami (Gods of Death), and added that neither change is in his planned version.
Black’s comments line up well with the leaked script: Ryuk is indeed omitted entirely, Light is indeed mostly good and redeemed, Light does have a backstory justifying his vengeance, and so on. The only discordant detail is that in the leaked script, it was his mother murdered and not “a friend”.
Legal Takedowns
The original Anime Vice article had commenters provide two sendspace links for downloading the script. Both files went dead quickly, and an uploader wrote “WB took it down that proves it is not fake”. The sendspace links merely say that the files are no longer available, without giving any explicit reason like a DMCA takedown.
Assuming it was a DMCA takedown, who did it? Not the 2 brothers, who might have a legal right to order the takedown of material falsely attributed to them (I am not clear on the remedies available for a false attribution of authorship), but surely either the commissioning studio or their partner. Needless to say, they do not have a standing RIAA-style war against DN fanfiction or fan-art or even torrents of the anime or scanlations of the manga; just this script. (Possibly if the script were not the studio’s property, it wouldn’t have any legal ground to demand takedowns - their license likely covers just the movie rights, and so fanfiction in the form of a script (for example) would infringe on the Japanese rights-holder, not the studio.)
The same uploader says:
I called Warner Bros After all the channels at WB, i finally got to the WB backed company Producing DN Dan Lin Pictures i gave them a chance to clear the air on the leaked script, to prove or disprove it they said “no comment at this time”
The original Anime Vice author wrote
Rather than run with the story then, I called Lin Pictures to see if they could confirm or deny whether the script was actually theirs or a fan-written phony. I was told I would get a call back, but never did. I tried calling back a second time earlier this week, this time passing on considerably more information, and still no call back. As such, I have come to the conclusion that the company isn’t overly concerned with the script, which suggests several possibilities to me:
It’s not a legitimate script at all, so they’re not worried about it.
It’s an old draft…different from the current version, so they’re not worried about it.
The script was intentionally leaked for promotional purposes or to gauge fan reaction.
I don’t buy it. If it is a fake script, why not simply deny it - either time? It is not as if companies usually have any trouble denying things. A “no comment” is more consistent with it being real and them also sending takedowns.
I find this external legal evidence compelling, and in conjunction with the internal evidence and oddities best explained by the leaked script being really by said Hollywood scriptwriters, I believe the script real. Perhaps an early draft to be discarded or rewritten, but still genuine. I suppose an American DN movie could be much worse: just consider Dragon Ball Evolution or The Last Airbender!
Analysis
We could leave matters there with a bald statement that the evidence is “compelling”, but Richard Carrier recently offered in Proving History: Bayes’s Theorem and the Quest for the Historical Jesus (201214ya; 2008 handout, LW review) a defense of how matters of history and authorship could be more rigorously investigated with some simple statistical thinking, and there’s no reason we cannot try to give some rough numbers to each previous piece of evidence. Even if we can only agree on whether a piece of evidence is for or against the hypothesis of the Parlapanides’ authorship, and not how strong a piece of evidence it is, the analysis will be useful in demonstrating how converging weak lines of reasoning can yield a strong conclusion.
We’ll principally use Bayes’s theorem, no math more advanced than multiplication or division, common sense/Fermi estimates, the Internet, and the strong assumption of conditional independence (see the conditional independence appendix). Despite these severe restrictions (what, no integrals, probability distributions, credible intervals, Bayes factors or anything? You call this statistics‽), we’ll get some answers anyway.
Priors
The first piece of evidence is that the leak exists in the first place.
Extraordinary claims require extraordinary evidence, but ordinary claims require only ordinary evidence: a claim to have uncovered Hitler’s lost diaries 40 years after his death is a remarkable discovery and so it will take more evidence before we believe we have the private thoughts of the Fuhrer than if one finds what purports to be one’s sister’s diary in the attic. The former is a unique historic event as most diaries are found quickly, few world leaders keep diaries (as they are busy world-leading), and there is large financial incentive (9 million Deutschmarks or ~$13.6m 2012 dollars) to fake such diaries (even in 60 volumes). The latter is not terribly unusual as many females keep diaries and then lose track of them as adults, with fakes being almost unheard of.
How many leaked scripts end up being hoaxes or fakes? What is the base rate?
Leaks seem to be common in general. Just googling “leaked script”, I see recent incidents for Robocop, Teenage Mutant Turtles, Mass Effect 3 (confirmed by Bioware to have been real), Les Misérables, Jurassic Park IV (concept art), Batman5, and Halo 4. A blog post makes itself useful by rounding up 10 old leaks and assessing how they panned out: 4 turned out to be fakes, 5 real, and 1 (for The Master) unsure. Assuming the worst, this gives us 5⁄10 are real or 50% odds that a randomly selected leak would be real. Given the number of “draft” scripts on IMSDb, 50% may be low. But we will go with it.
Internal Evidence
External Evidence
Dating
The argument there seems to be of the form that a PDF dated April 200917ya is consistent with the estimated timeline for the true script. But what would be inconsistent? Well, a PDF dated after April 200917ya: such a PDF would raise the question “what exactly the brothers were doing from June 200818ya all the way to this counterfactual post-April 200917ya date?”
But it turns out we already used this argument! We used it as the PDF date inversion test. Can we use the April date as evidence again and double-count it? I don’t think we should since it’s just another way of saying “April and earlier is evidence for it being real, post-April is evidence against”, regardless of whether we justify pre-April dates as being during the writing period or as being something a faker wouldn’t dare do. This argument turns out to be redundant with the previous internal evidence (which in hindsight, starts to sound like we ought to have classified it as external evidence).
What we might be justified in doing is going back to the PDF date inversion test and strengthening it since now we have 2 reasons to expect pre-April dates. But as usual, we will be conservative and leave out this strengthening.
Credit
This is an interesting external argument as it’s the only one dependent purely on the passage of time. It’s a sort of argument from silence, or more specifically, a hope function.
Hope Function
The hope function is simple but exhibits some deeply counterintuitive properties (the focus of the psychologists writing the previously linked paper). Our case is the straightforward part, though. We can best visualize the hope function as a person searching a set of n boxes or drawers or books for something which may not even be there (p). If he finds the item, he now knows p = 1 (it was there after all), and once he has searched all n boxes without finding the thing, he knows p = 0 (it wasn’t there after all). Logically, the more boxes he searches without finding it, the more pessimistic he becomes (p shrinks towards 0). How much, exactly? Falk et al 199432ya give a general formula for n boxes of which you’ve searched i boxes when your prior probability of the thing being there is L0:
Li = ((n − i)⁄n × L0) ⧸ ((n − i)⁄n × L0 + (1 − L0))
So for example: if there’s n = 10 boxes, we searched i = 5 without finding the thing, and we were only L0 = 50% sure the thing was there in the first place, our new guess about whether the thing was there:
In this example, 33% seems like a reasonable answer (and interestingly, it’s not simply ).
Credit & Hope Function
In the case of “taking credit”, we can imagine the boxes as years, and each year passed is a box opened. As of October 201214ya, we have opened 3 boxes since the May/October 200917ya leak. How many boxes total should there be? I think 20 boxes is more than generous: after 2 decades, the DN franchise highly likely won’t even be active8 - if anyone was going to claim credit, they likely would’ve done so by then. What’s our prior probability that they will do so at all? Well, of the 4 faked scripts, the author of the Mr. Peepers script took credit but the other 3 seem to be unknown - but it’s early days yet, so we’ll punt with a 50%. And of course, if the script is real, very few people are going to falsely claim authorship (thereby claiming it’s fake?). So our setup looks like this:
a = is real
b = no one has claimed authorship
= probability of being real = 0.899
= probability of being not real = 1 - 0.899 = 0.101
= probability a real script will have no ownership claim = 99% (shit happens9) = 0.99
= probability a fake script will have no ownership claim = probability someone will claim it is the hope function with n = 20, i = 3, L0 = 50% = , so the probability someone will not is
Then Bayes:
Likelihood ratio:
Official Statements
The 2011 descriptions of the plot of the real script match the leaked script in several ways:
no Ryuk or shinigamis
This is an interesting change. I don’t think it’s likely a faker would remove them: without them, there’s no explanation of how a Death Note can exist, there’s no comic relief, some plot mechanics change (like dealing with the hidden cameras), etc. Certainly there’s no reason to remove them because they’re hard to film - that’s what CGI is for, and who in the world does SFX or CGI better than Hollywood?
Light ends the story good and not evil
Light seeks vengeance
Items 2 & 3 seem like they would often be connected: if Light is to be a good character, what reason does he have to use a Death Note? Vengeance is one of the few socially permissible uses. Of course, Light could start as a good character using the Death Note for vengeance and slide down to an evil ending, but it’s not as likely.
Light seeking vengeance for a friend rather than his mother
This item is contradictory, but only weakly so: a switch between mother and friend is an easy change to make, one which doesn’t much affect the rest of the plot.
On net, these 4 items clearly favor the hypothesis of the script being real. But how much? How much would we expect the fan or faker to avoid Hollywood-style changes compared to actual Hollywood screenwriters like the Parlapanides?
This is the exact same question we already considered in the plot section of internal evidence! Now that we have external attestation that some of the plot changes I identified back in 200917ya as being Hollywood-style are in the real script, can we do calculations?
I don’t think we can. The external attestation proves I was right in fingering those plot changes as Hollywood-style, but this is essentially a massive increase in (the chance a real script will have Hollywood-style changes is now ~100%)… but what we didn’t know before, and still do not know now, is the other half of the problem, (the chance a fake script will have similar Hollywood-style changes).
We could assume that a fake script has 50% chance of making each change and item 4 negates one of the others (even though it’s really weaker), for a total likelihood ratio of , but like before, we have no real ground to defend the 50% guess and so we will be conservative and drop this argument like its sibling argument.
Legal Takedowns
Our observation here is that the two sendspace links hosting the PDF went dead within days of the Anime Vice post. We don’t know for sure that the links went dead due to takedown, and we don’t know for sure that a takedown would be sent only if the script was real. These uncertainties transform what seems like a slam dunk proof (“a takedown would be done only if the studio complained, and the studio would complain only if it was real! A takedown was down, therefore it was real!”) into just another probabilistic question for us.
Do people send fake takedowns to file hosts? In my experience, a few people (based on watching people upload music and manga etc.) attract trolls dedicated to sending complaints about anything they post, and sometimes entire sites lose their file hosting (eg. in May 201214ya, MikuDB lost hosting for >1000 Vocaloid & doujin music albums) but in general downloads work for years afterwards. An instructive sample is to look at the most recent MediaFire-related submissions to Reddit (from the last 8 days when I checked) and see how many of the first 25 are dead for copyright-related reasons; when I tried, only 1 was blocked over copyright10, giving a 4% takedown rate. I regard a fake takedown within days as a remote chance, but let’s call it 5%.
Do studios send takedowns for fanfiction? No, essentially never: it’s a big thing when an author like Anne Rice chooses to crack on fanfiction, or when J.K. Rowling sues the publisher of a fan-work. The 24,246 DN fanfics on FanFiction.net stand testimony to the disinclination of studios and publishers to crack down. This chance might as well be zero, but we’ll call it 5% anyway for symmetry.
Do studios send takedowns for real scripts? Yes, frequently (much to the disgust of script collectors). The previously-mentioned TMNT script leak seems to have been partially suppressed with DMCA takedowns. Isn’t it quite plausible that this is what happened? But let’s call it just 50% as usual. Maybe plenty of real scripts get posted to news sites and the big studio like Warner Brothers does absolutely nothing about it.
Once we have settled on 5%/5%/50%, it’s as routine as usual to work out the new posterior:
a = is real
b = copies get taken down
= probability of being real = 0.942
= probability of being not real = 1 - 0.942 = 0.05149
= probability a real script will have copies taken down = 50% = 0.50
= probability a fake script will have copies taken down = 5%+5% = 0.10
Then Bayes:
Likelihood ratio:
Results
To review and summarize each argument we considered:
Argument/test |
P(b | a)⧸P(b | ¬a) |
|||||
|---|---|---|---|---|---|---|
authorship |
0.5 |
0.5 |
0.83 |
0.5 |
0.64 |
1.8 |
name spelling |
0.64 |
0.36 |
0.5 |
0.93 |
0.49 |
0.54 |
address |
0.49 |
0.51 |
0.16 |
0.16 |
0.49 |
1 |
PDF date |
0.49 |
0.51 |
0.5 |
0.25 |
0.66 |
2 |
PDF creator |
0.66 |
0.34 |
0.99 |
0.96 |
0.67 |
1.03 |
PDF timezone |
||||||
script length |
0.666 |
0.333 |
0.99 |
0.66 |
0.749 |
1.5 |
Hollywood plot |
0.749 |
0.251 |
~1.0 |
? |
? |
? (>1) |
stylometrics |
0.749 |
0.251 |
0.5 |
0.167 |
0.899 |
2.99 |
dating |
0.899 |
0.101 |
? |
? |
? |
? (>1) |
credit |
0.899 |
0.101 |
0.99 |
0.541 |
0.949 |
1.83 |
official plot |
0.942 |
0.058 |
~1.0 |
? |
? |
? (>1) |
legal takedown |
0.942 |
0.058 |
0.5 |
0.10 |
0.988 |
5 |
The final posterior speaks for itself: 98%. By taking into account 9 different argument and thinking about how consistent each one is with the script being real, we’ve gone from considerable uncertainty to a surprisingly high value, even after bending over backwards to omit 3 particularly disputable arguments.
(One interesting point here is that it’s unlikely that any one script, either fake or real, would satisfy all of these features. Isn’t that evidence against it being real, certainly with p < 0.05 however we might calculate such a number? Not really. We have this data, however we have it, and so the question is only “which theory is more consistent with our observed data?” After all, any one piece of data is extremely unlikely if you look at it right. Consider a coin-flipping sequence like “HTTTHT”; it looks “fair” with no pattern or bias, and yet what is the probability you will get this sequence by flipping a fair coin 6 times? Exactly the same as “HHHHHH”! Both outcomes have the identical probability ; some sequence had to win our coin-flipping lottery, even if it’s very unlikely any particular sequence would win.)
Likelihood Ratio Tweaking
Is 98% the correct posterior? Well, that depends both on whether one accepts each individual analysis and also the original prior of 50%. Suppose one accepted the analysis as presented but believes that actually only 10% of leaked scripts are real? Would such a person wind up believing that the leak is real >50%? How can we answer this question without redoing 9 chained applications of Bayes’s theorem? At last we will see the benefit of computing likelihood ratios all along: since likelihood ratios omit the prior , they are expressing something independent, and that turns out to be how much we should increase our prior (whatever it is).
To update using a likelihood ratio (some more reading material: “Simplifying Likelihood Ratios”), we express our as instead , multiply by the likelihood ratio, and convert back! So for our table: we start with , multiply by 1.8, 0.538, 1…5:
And we convert back as - like magic, our final posterior reappears. Knowing the product of our likelihood ratios is the factor to multiply by, we can easily run other examples. What of the person starting with a 10% prior? Well:
And a 1% person is and Ooh, almost to 50%, so we know anyone with a prior of 2% who accepts the analysis may be moved all the way to thinking the script more likely to be true than not (specifically, 0.62).
What if we thought we had the right prior of 50% but we terribly messed up each analysis and each likelihood ratio was twice as large/small as it should be? If we cut each likelihood ratio’s strength by half11, then we get a new total likelihood ratio of 3.9, and our new posterior is:
What if instead we ignored the 2 arguments with a likelihood ratio greater than 2? Then we get a multiplied likelihood ratio of 3.08712 and from 50% we will go to:
;
Challenges for advanced readers:
Redo the calculations, but instead of being restricted to point estimates, work on intervals: give what you feel are the endpoints of 95% credence intervals for & and run Bayes on the endpoints to get worst-case and best-case posteriors, to feed into the next argument evaluation
Starting with a uniform prior over 0-1, treat each argument as input to a Bernoulli (beta) distribution: a likelihood ratio of >1 counts as “success” while a likelihood ratio <=1 counts as a “failure”. How does the posterior probability distribution change after each argument?
Start with the uniform prior, but now treat each argument as a sample from a new normal distribution with a known mean (the best-guess likelihood ratio) but unknown variance (how likely each best-guess is to be overturned by unknown information). Update on each argument, show the posterior probability distributions as of each argument, and list the final 95% credible interval.
Do the above, but with an unknown mean as well as unknown variance.
Benefits
With the final result in hand - and as promised, no math beyond arithmetic was necessary - and after the consideration of how strong the result is, it’s worth discussing just what all that work bought us. (However long it took you to read it, it took much longer to write it!) I don’t know about you, but I found it fascinating going through my old informal arguments and seeing how they stood up to the challenge:
I was surprised to realize that the “Charley” observation was evidence against
the corporate address seemed like good evidence for
I didn’t appreciate that the internal evidence of PDF date and external evidence of dating was double-counting evidence and hence exaggerated the strength of the case
Nor did I realize that the key question about the plot changes was not how clearly Hollywood they were, but how well a faker could or would imitate Hollywood
Hence, I didn’t appreciate that the 201115ya descriptions of the plot were not the conclusive breakthrough I took them for, but closer to a minor footnote corroborating my view of the plot changes as being Hollywood
Since I hadn’t looked into the details, I didn’t realize the filesharing links going dead was more dubious than they initially seemed
If anyone else were interested in the issue, the framework of the 12 tests provides a fantastic way of structuring disagreement. By putting numbers on each item, we can focus disagreement to the exact issue of contention, and the formal structure lets us target any future research by focusing on the largest (or smallest) likelihood ratios:
What data could we find on legal takedowns of scripts or files in general to firm up our
How accurate is stylometrics exactly? Could I just have gotten lucky? If we get a script for Everything For A Reason or Immortals, are the results reinforced or does the clustering go haywire and the leaked script no longer resemble their known writing?
Can we find official material, written by Charles Parlapanides, which uses “Charley” instead?
Given the French site reporting script material in May, should we throw out the PDF date entirely by saying the gap between April and May is too short to be worth including in the analysis? Or does that just make us shift the likelihood ratio of 2 to the other dating argument?
If we assembled a larger corpus of leaked and genuine scripts, will the likelihood ratio for the inclusion of authorship (1.8) shrink, since that was derived from a small corpus?
This would be the sort of discussion even bitter foes could engage in productively, by collaborating on compiling scripts or searching independently for material - and productive discussions are the best kind of discussion.
The Truth?
In textual criticism, usually the ground truth is unobtainable: all parties are dead & new discoveries of definitive texts are rare. Many questions are “not beyond all conjecture” (pace Thomas Browne13) but are beyond resolution.
Our case is happier: we can just ask one of the Parlapanides. A Twitter account was already linked, so asking is easy. Will they reply? 200917ya was a long time ago, but 201115ya (when they were replaced) was not so long ago. Since the script was scrapped, one would hope they would feel free to reply or reply honestly, but we can’t know.
I suspect he will, but I’m not so sanguine he will give a clear yes or no. If he does, I have ~85% confidence that he will confirm they did write it.
Why this pessimism of only 85%?
I have not done this sort of analysis before, either the Bayesian or stylometric aspects
one argument turned out to be an argument against being real
several arguments turned out to be useless or unquantifiable
several arguments rest on weak enough data that they could also turn out useless or negative; eg. the PDF timezone argument
our applications of Bayes assumes, as mentioned previously, “conditional independence”: that each argument is “independent” and can be taken at face-value. This is false: several of the arguments are plausibly correlated with each other (eg. a skilled forger might be expected to look up addresses and names and timezones), and so the true conclusion will be weaker, perhaps much weaker. Hopefully making conservative choices partially offset this overestimating tendency - but how much did it?
I made more mistakes than I care to admit working out each problem.
And finally, I haven’t been able to come up with multiple good arguments why the script is a fake, which suggests I am now personally invested in it being real and so my final 98% calculation is an substantial overestimate. One shouldn’t be foolishly confident in one’s statistics.
No Comment
I messaged Parlapanides on Twitter on 2012-10-27; after some back and forth, he specified that his “no” answer was an inference based on what was then the first line of the plot section: the mention that Ryuk did not appear in the script, but that they loved Ryuk and so it was not their script. I tried getting a more direct answer by mentioning the ANN article about Shane and name-dropping “Luke Murray” to see if he would object or elaborate, but he repeated that the studio hated how Ryuk appeared in the manga and he couldn’t say much more. I thanked him for his time and dropped the conversation.
Unfortunately, this is not the clear open-and-shut denial or affirmation I was hoping for. (I do not hold it against him, since I’m grateful and a little surprised he took the time to answer me at all: there is no possible benefit for him to answer my questions, potential harm to his relationships with studios, and he is a busy guy from everything I read about him & his brother while researching this essay.)
There are at least two ways to interpret curious sort of non-denial/non-affirmation: the script has nothing to do with the Parlapanides or the studios and is a fake which merely happens to match the studio’s desires in omitting Ryuk entirely; or it is somehow a descendant or relative of the Parlapanides script which they are disowning or regard as not their script (Ryuk is a major character in most versions of DN).
If Parlapanides had affirmed the script, then clearly that would be strong evidence for the script’s realness. If he had denied the script, that would be strong evidence against the script. And the in-between cases? If there had been a clear hint on his part - perhaps something like “of course I cannot officially confirm that that script is real” - then we might want to construe it as evidence for being real, but he gave a specific way in which the leaked script did not match his script, and this must be evidence against.
How much evidence against? I specified my best guess that he would reply clearly was 40% and that he would affirmatively conditional on replying clearly was 85%, so roughly, I was expecting a clear affirmation only 40% times 85% or 34%; so, I did not expect to get a clear affirmation despite having a high confidence in the script, and this suggests that the lack of clear affirmation cannot be very strong evidence for me. I don’t think I would be happy with a likelihood ratio stronger (smaller) than 0.25, so I would update thus, reusing our previous likelihood ratios:
and then we have a new posterior:
Conclusion
How should we regard this? I’m moderately disturbed: it feels like Parlapanides’s non-answer should matter more. But all the previous points seem roughly right. This represents an interesting question of bullet-biting & “Confidence levels inside and outside an argument”, or perhaps modus tollens vs modus ponens: does the conclusion discredit the arguments & calculations, or do the arguments & calculations discredit the conclusion?
Overall, I feel inclined to bite the bullet. Now that I have laid out the multiple lines of converging evidence and rigorously specified why I found them convincing arguments, I simply don’t see how to escape the conclusion. Even assuming large errors in the strength - in the likelihood section, we looked at halving the strength of each disjunct and also discarding the 2 best - we still increase in confidence.
So: I believe the script is real, if not exactly what the Parlapanides brothers wrote.
See Also
External Links
Appendix
Conditional Independence
The phrase “conditional independence” is just the assumption that each argument is separate and lives or dies on its own. This is not true, since if someone were deliberately faking a script, then a good faker would be much more likely to not cut corners and carefully fake each observation while a careless faker would be much more likely to be lazy and miss many. Making this assumption means that our final estimate will probably overstate the probability, but in exchange, it makes life much easier: not only is it harder to even think about what conditional dependencies there might be between arguments, it makes the math too hard for me to do right now!
Alex Schell offers comments on this topic:
The odds form of Bayes’ theorem is this:
In English, the ratio of the posterior probabilities (the “posterior odds” of a) equals the product of the ratio of the prior probabilities and the likelihood ratio.
What we are interested in is the likelihood ratio , where e is all external and internal evidence we have about the DN script.
e is equivalent to the conjunction of each of the 13 individual pieces of evidence, which I’ll refer to as e1 through e13:
So the likelihood ratio we’re after can be written like this:
I abbreviate as $LR(b)4, and as .
Now, it follows from probability theory that the above is equivalent to
(The ordering is arbitrary.) Now comes the point where the assumption of conditional independence simplifies things greatly. The assumption is that the “impact” of each evidence (ie. the likelihood ratio associated with it) does not vary based on what other evidence we already have. That is, for any evidence ei its likelihood ratio is the same no matter what other evidence you add to the right-hand side:
$ for any conjunction c of other pieces of evidence$
Assuming conditional independence simplifies the expression for greatly:
On the other hand, the conditional independence assumption is likely to have a substantial impact on what value takes. This is because most pieces of evidence are expected to correlate positively with one another instead of being independent. For example, if you know that the script is 20,000-words of Hollywood plot and that the stylometric analysis seems to check out, then if you are dealing with a fake script (“is not real”) it is an extremely elaborate fake, and (eg.) the PDF metadata are almost certain to “check out” and so provide much weaker evidence for “is real” than the calculation assuming conditional independence suggests. On the other hand, the evidence of legal takedowns seems unaffected by this concern, as even a competent faker would hardly be expected to create the evidence of takedowns.
The earliest mention I’ve been able to find is a French site which posted on 2009-05-17 a translation of the beginning of the leaked script; no source is given, and it’s not clear who did the translation, what script was used, or where the script was obtained. So while the script was clearly circulating by mid-May, I can’t date the leak any earlier than that date.↩︎
SHA-512:
954082c8cde2ccee1383196fe7c420bd444b5b9e5d676b01b3eb9676fa40427983fb27ad8458a784ea765d66be93567bac97aa173ab561cd7231d8c017a4fa70↩︎The raw metadata can be extracted using
pdftklike thus:pdftk 2009-parlapanides-deathnotemovie.pdf dump_data:
↩︎InfoKey: Producer InfoValue: DynamicPDF v5.0.2 for .NET InfoKey: CreationDate InfoValue: D:20090409213247Z PdfID0: 9234e3f3316974458188a09a7ad849e3 PdfID1: 9234e3f3316974458188a09a7ad849e3 NumberOfPages: 112Specifically,
config.txtreads:↩︎corpus.format="plain" corpus.lang="English.all" analyzed.features="w" ngram.size=1 mfw.min=1 mfw.max=1000 mfw.incr=1 start.at=1 culling.min=0 culling.max=0 culling.incr=20 mfw.list.cutoff=5000 delete.pronouns=FALSE analysis.type="CA" use.existing.freq.tables=FALSE use.existing.wordlist=FALSE consensus.strength=0.5 distance.measure="EU" display.on.screen=TRUE write.pdf.file=FALSE write.jpg.file=FALSE write.emf.file=FALSE write.png.file=FALSE use.color.graphs=TRUE titles.on.graphs=TRUE dendrogram.layout.horizontal=TRUE pca.visual.flavour="classic" sampling="no.sampling" sample.size=10000 length.of.random.sample=10000 sampling.with.replacement=FALSEThe fake Batman script is pretty weird; it starts off interesting and has many good parts, but then flounders in opaqueness and concludes even more weirdly with far too much material in it for a single film to plausibly include. If it were supposed to be by anyone but Christopher Nolan, you’d comment “this can’t be real - the plot is too flabby and confusing, and the dialogue veers into non sequiturs and half-baked philosophy” (which of course it is). But one expects that of Nolan, almost, and for the filmed movie to be better than the script, so paradoxically, the worsening quality may have lent it some credibility.↩︎
Modulo the previously discussed issue that the leaked script seems to have been circulating in May 200917ya, which would drastically cut down the window to a month or less.↩︎
The earliest Tweet I can find using SnapBird (a defunct Twitter archive service) tying him to LA is 2011-06-10 (other searches like “moving”, “move”, “relocating”, “California”, “CA”, “New Jersey”, “NJ” etc. do not turn up anything useful). This is probably because his tweets do not go further back than April 201115ya, where there is mention of some sort of hacking of his account. The next step is a Google search for
Charley Parlapanides ("New Jersey" OR "Los Angeles" OR California)with a date range of 6/1/2009-6/9/201115ya (to pick up any locations given from when they started on the script to just before that 2011-06-10 tweet). Results were equivocal: a 2011-02-12 blog comment about “this town” might indicate residence in LA/Hollywood; a 2010-12-19 mention of walking into a director’s production office of sets & costumes might indicate residence as well. Beyond that, I can’t find anything.↩︎Quick, of the anime aired 20 years ago in 1992, how many are active franchises? Of the 48 on the first page, maybe 3 or 4 seem active.↩︎
Or more precisely, sometimes people do falsely claim authorship and even sue studios over it; but if you picked 100 random scripts, would you expect to find more than 1 such instances? Keeping in mind most scripts never turn into movies but die in development hell!↩︎
1 link was dead because “File Belongs to Non-Validated Account” and another link was dead because “The file you attempted to download is an archive that is part of a set of archives. MediaFire does not support unlimited downloads of split archives and the limit for this file has been reached. MediaFire understands the need for users to transfer very large or split archives, up to 10GB per file, and we offer this service starting at $1.50 per month.” Neither reason would necessarily be applicable to a 3MB PDF script.↩︎
The gory details; since the strength of a ratio in either direction is the difference from 1, we need to subtract or add 1 depending on the direction:
↩︎map (\x -> if x==1 then 1 else (if x>1 then 1+((x-1)/2) else 1-(x/2))) [1.8, 0.538,1,2,1.033,1.5,2.999,1.831,5] → [1.4,0.731,1.0,1.5,1.0165,1.25,1.9995,1.4155,3.0] product [1.4,0.731,1.0,1.5,1.0165,1.25,1.9995,1.4155,3.0] → 16.6Easy enough:
↩︎product (filter (<2) [1.8, 0.538,1,2,1.033,1.5,2.999,1.831,5]) → 2.74Sir Thomas Browne, Hydriotaphia, Urn Burial (chapter 5):
↩︎What Song the Syrens sang, or what name Achilles assumed when he hid himself among women, though puzzling Questions are not beyond all conjecture. What time the persons of these Ossuaries entred the famous Nations of the dead, and slept with Princes and Counsellours, might admit a wide resolution. But who were the proprietaries of these bones, or what bodies these ashes made up, were a question above Antiquarism. Not to be resolved by man, nor easily perhaps by spirits, except we consult the Provinciall Guardians, or tutellary Observators. Had they made as good provision for their names, as they have done for their Reliques, they had not so grossly erred in the art of perpetuation. But to subsist in bones, and be but Pyramidally extant, is a fallacy in duration. Vain ashes, which in the oblivion of names, persons, times, and sexes, have found unto themselves, a fruitlesse continuation, and only arise unto late posterity, as Emblemes of mortall vanities; Antidotes against pride, vain-glory, and madding vices. Pagan vain-glories which thought the world might last for ever, had encouragement for ambition, and finding no Atropos unto the immortality of their Names, were never dampt with the necessity of oblivion. Even old ambitions had the advantage of ours, in the attempts of their vain-glories, who acting early, and before the probable Meridian of time, have by this time found great accomplishment of their designes, whereby the ancient Heroes have already out-lasted their Monuments, and Mechanicall preservations. But in this latter Scene of time we cannot expect such Mummies unto our memories, when ambition may fear the Prophecy of Elias, and Charles the fifth can never hope to live within two Methusela’s of Hector.