Critics of AI risk suggest diminishing returns to computing (formalized asymptotically) means AI will be weak; this argument relies on a large number of questionable premises and ignoring additional resources, constant factors, and nonlinear returns to small intelligence advantages, and is highly unlikely.
Computational complexity theory describes the steep increase in computing power required for many algorithms to solve larger problems; frequently, the increase is large enough to render problems a few times larger totally intractable. Many of these algorithms are used in AI-relevant contexts.
It has been argued that this implies that AIs will fundamentally be limited in accomplishing real-world tasks better than humans because they will run into the same computational complexity limit as humans, and so the consequences of developing AI will be small, as it is impossible for there to be any large fast global changes due to human or superhuman-level AIs.
I examine the assumptions of this ‘AI safety from complexity’ argument and find it neglects the many conditions under which computational complexity theorems are valid and so the argument doesn’t work:
problems can be solved more efficiently than complexity classes would imply,
large differences in problem solubility between humans and AIs is possible,
greater resource consumption is possible,
the real-world consequences of small differences on individual tasks can be large on agent impacts,
such consequences can compound,
and many agents can be created.
Any of these independent objections being true defeats the complexity argument.
Computational complexity can be relevant to AI risk discussions, but not without far more detailed theories relating pure algorithmic performance to real-world capabilities and long-term equilibria.
Computational complexity theory attempts to describe the resource usage of algorithms from the abstract vantage point of considering how running time on some idealized computer relatively increases for a specific algorithm as the inputs scale in size towards infinity. For many important algorithms used in AI and programming in general, the difficulty turns out to increase steeply with extra data—comparison-based sorting algorithms like Merge sort take only Big O 𝒪(n ⋅ log(n)) and so you can sort just about any amount of data in a feasible time, but more interesting problems like the Traveling Salesman problem/3-SAT become NP-hard (or exponentially or worse) as the data increases and quickly go from fast to feasible to impossible.
Are we headed for a Singularity? Is it imminent?…But regardless of which definition you use, there are good reasons to think that it’s not on the immediate horizon…This is the so-called ‘hard takeoff’ scenario, also called the FOOM model by some in the singularity world. It’s the scenario where in a blink of an AI, a ‘godlike’ intelligence bootstraps into being, either by upgrading itself or by being created by successive generations of ancestor AIs. It’s also, with due respect to Vernor Vinge, of whom I’m a great fan, almost certainly wrong. It’s wrong because most real-world problems don’t scale linearly. In the real world, the interesting problems are much much harder than that.
…Computational chemistry started in the 1950s. Today we have literally trillions of times more computing power available per dollar than was available at that time. But it’s still hard. Why? Because the problem is incredibly non-linear…How fast? The very fastest (and also, sadly, the most limited and least accurate) scale at N2, which is still far worse than linear. By analogy, if designing intelligence is an N2 problem, an AI that is 2× as intelligent as the entire [human] team that built it (not just a single human) would be able to design a new AI that is only 70% as intelligent as itself. That’s not escape velocity.
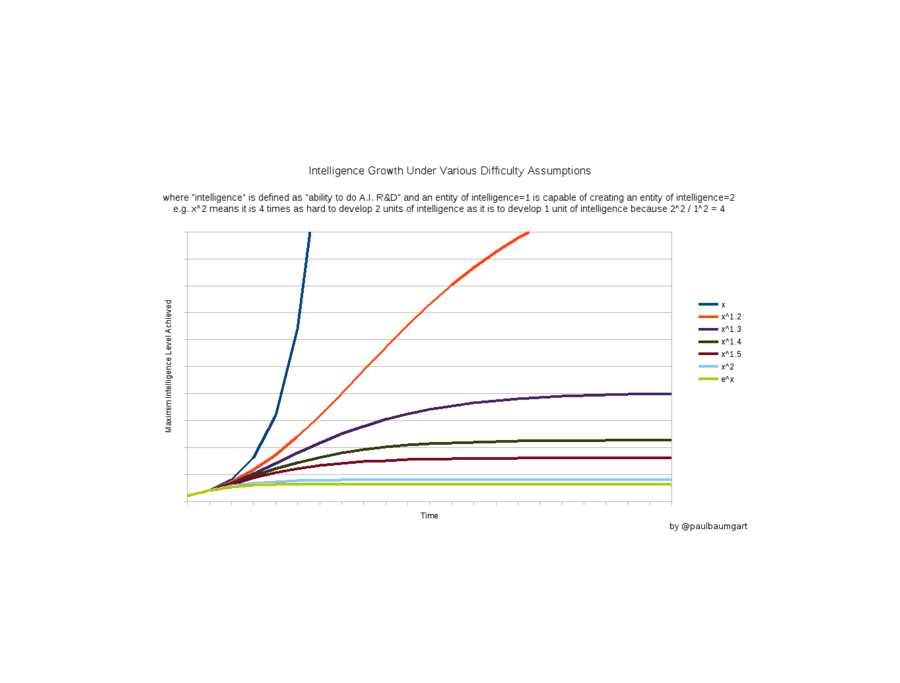
In my previous post on why the Singularity is Further Than it Appears, I argued that creating more advanced minds is very likely a problem of non-linear complexity. That is to say, creating a mind of intelligence 2 is probably more than twice as hard as creating a mind of intelligence 1. The difficulty might go up exponentially. Or it might go up ‘merely’ with the cube or the square of the intelligence level you’re trying to reach. Blog reader Paul Baumbart took it upon himself to graph out how the intelligence of our AI changes over time, depending on the computational complexity of increasing intelligence.
Intelligence growth under Various Difficulty Assumptions: where “intelligence is defined as”ability to do AI R&D” and an entity of intelligence=1 is capable of creating an entity of intelligence=2, eg. x2 means it is 4 times as hard to develop 2 units of intelligence as it is to develop 1 unit of intelligence because 22⧸12 = 4.”
…Every other model Paul put into his spreadsheet showed convergence instead of divergence. Almost any non-linear difficulty in boosting intelligence means that no runaway occurs. (Note that these do not include the benefit of getting new hardware over time and general speedup from Moore’s Law, for so long as that continues. But they do include the benefit of designing new hardware for itself or any speedup that it can cause to Moore’s Law.) The bottom line, in green, is exponential difficulty (ex). Many real-world problems are exponentially difficult as they grow in size. The ‘traveling salesman’ problem is an exponential problem (at least to find an exact solution). Modeling quantum mechanical systems is an exponential problem. Even some important scenarios of protein folding are exponentially difficult. So it’s not at all unlikely that boosting intelligence would fall into this category. And as you can see, if intelligence is exponentially difficult, the super-intelligence does ascend.
Or to put it perhaps more clearly, for a fixed amount of computation, at each greater level of intelligence, a smaller increase in intelligence can be realized with that amount of computation.
A somewhat similar argument is gestured at by Nathan Myhrvold:
Theorists have proved that some mathematical problems are actually so complicated that they will always be challenging or even impossible for computers to solve. So at least for now, [human] people who can push forward the boundary of computationally hard problems need never fear for lack of work. This tells us something important about AI. Like mathematics, intelligence is not just one simple kind of problem, such as pattern recognition. It’s a huge constellation of tasks of widely differing complexity. So far, the most impressive demonstrations of “intelligent” performance by AI have been programs that play games like chess or Go at superhuman levels. These are tasks that are so difficult for human brains that even the most talented people need years of practice to master them. Meanwhile, many of the tasks that seem most basic to us humans—like running over rough terrain or interpreting body language—are all but impossible for the machines of today and the foreseeable future. As AI gets more capable, the sphere of jobs that computers can do faster or more accurately than people will expand. But an expanding universe of work will remain for humans, well outside the reach of automation.
Awkwardly, this argument contains its own refutation: chess/Go are computationally difficult in precisely the way Myhrvold claims will put mathematical problems out of reach of computers, and yet, have already fallen.1
This can be seen as one of the “structural objections” where the diminishing returns is specifically attributed to increments in computing power solving less data points as data sizes scale (to use Chalmers 2010’s taxonomy). So the argument (filling in the gaps and omitting the various graphs showing hypothetical scalings) goes something like this:
most tasks an intelligent agent (human or artificial intelligence) needs to solve are in difficult complexity classes, such as NP or NP-hard: Traveling Salesman, 3-SAT, Bayesian network belief propagation, deep neural network training, theorem proving, playing Go, solving POMDPs…
a task in NP or higher complexity class can only be solved for small problem sizes
if a task can only be solved for small problem sizes, then the best agent will solve only slightly larger problem sizes
the real-world reward to an agent from solving a slightly larger problem is only slightly greater
the long-term consequence of slightly greater rewards is itself small
if an AI becomes the best agent, then it must solve problems in difficult complexity classes (1), so it will be able to solve only slightly larger programs (2–3), receiving slightly greater rewards (4), with only small long-term consequences (5)
if each AI has only small long-term consequences, all AIs together will have a small total long-term consequence
thus, AIs becoming intelligent agents will have only small total long-term consequences
This argument is valid as far as it goes and can probably be formalized. But is the argument sound?
One difficulty with applying computational complexity theory outside its usual area is that people tend to neglect the requirements of complexity theory which gives it its generality: that it omits the ‘constant factors’ and the actual runtime, that many of the statements are lower/upper bounds or statements about worst-case complexity, that the statements tend to be about specific algorithms—which are rarely the only way to solve a real-world problem—and that it doesn’t try to say anything about utility or consequences.2 Similarly, people sometimes reason that since a human and AI would be in the same computability class (Turing-completeness), that anything an AI could do or think, a human must also be able to do or think, but they neglect that humans do not have unbounded time or space like the idealized Turing machine and there is no more reason to expect understanding to be possible than to expect an ant to understand everything a human does before it dies of old age; an ant with galaxies of notebooks and billions of years could perhaps understand human civilization, but no such ant has ever existed nor ever will, and the understanding of that ant of human action will ultimately be in its notebooks rather than itself (and how was it set up to make good use of those notebooks, anyway?). The question of whether such tasks are feasible for a “compact, efficient computer program”, not just computable, may take on both metaphysical and practical importance (to paraphrase Scott Aaronson).
Laid out bare, I would have to say that the argument depends critically on each of the premises being true, but every premise 1–5 is either questionable or false.
Premise 1 is incorrect because the proofs of those complexities generally depend on general solutions with deterministic exactly-optimal worst-case behavior. The apparent barrier of a complex problem can be bypassed by (in roughly increasing order of practical importance):
optimizing complexity class: existing proofs could be incorrect, inapplicable (such as assuming classical rather than quantum computers), or based on open conjectures widely believed by humans one way but which could still resolve in the more advantageous direction (eg. P=NP)
giving up determinism and using randomized algorithms which are faster but may not return an answer or a correct answer3 (they typically can be run many times if correctness is important; after a few times, the probability of an error will be smaller than the probability that the computer hardware has suffered a glitch due to cosmic rays); randomization can be applied to algorithms and to data structures.
needing good average-case behavior rather than worst-case behavior
Rather than merge sort, one could use Quicksort—merge sort has better worst-case complexity than Quicksort (which renders it vulnerable to DoS attacks if there are adversaries who can force the worst-case 𝒪(n2)), but Quicksort is still usually faster. Likewise, in the worst case, 3-SAT/Traveling Salesman are wildly intractable for any realistic dataset like planning a trip across the USA; but the average-case performance is quite different and in practice, 3-SAT/Traveling Salesman are solved all the time, to the extent where SAT solvers are routinely used in computer security or theorem proving or type-checking and logistics companies are able to heavily optimize their shipping with them.
Similarly for linear programming’s simplex algorithm and other operations research algorithms, with are theoretically intimidating but in real-world problems yield solutions after reasonable runtime—they work in practice, but not in theory. For example, TSP instances up to 85,900 cities have been solved.
giving up generality and specializing: an algorithm may be unnecessarily general.
A comparison sort can be done in 𝒪(n ⋅ log(n)), yes, but one frequently doesn’t need to sort any kind of datatype for which an ordering is available but specifically strings, numbers, etc., for which quasi linear/𝒪(n) sorting is possible using counting sort/radix sort. An algorithm could also have prior information about the kind of data input which will be available—Timsort is aware that most inputs will be partially sorted already and can outperform a naive sort. Data structures can be tuned for particular distributions of data, and JIT & profile-guided optimization & supercompilation can be seen as specializing general algorithms to the current or likely-future inputs.
giving up optimality and computing an approximation of the optimal answer (often very close to the optimal answer)
Already mentioned is 3-SAT/TSP, for which there is a World Tour of 1,904,711-cities which has been solved with a tour within 0.0474% of the optimal tour by 200719ya, and planning problems soluble by translation into SAT form can have millions of clauses & variables4, enabling such silly applications as drawing portraits & art or unscrambling images using the TSP; Naam gives chemistry as an example by noting that while the exact physics is totally intractable, approximations which are much more feasible are used. The last fraction of a percentage point of optimality can take truly enormous amounts of computation to squeeze out.
changing the problem rather than succumbing to functional fixity: many problems can be redefined or environments can be tweaked to bypass a challenge & leverage computer strengths.
A self-driving car may not be as good at vision as a human driver, but LIDAR sensors can be incorporated into it in a way that cannot for humans as it would distract them. A robot in a warehouses may not be as good at driving around as a human worker, but the environment can be altered with white lines or barcode tags on the floor so the robots always know where they are. An item in a search engine may be intractably difficult to classify… but it can simply be removed—perhaps by purchasing it (famously called, inside Google, “buying the gnome”, see Levy 2011). To quote Dyson’s paraphrase of John von Neumann5:
All processes that are stable we shall predict. All processes that are unstable we shall control.
…This duality [between reducing data channel & data source noise] can be pursued further and is related to a duality between past and future and the notions of control and knowledge. Thus we may have knowledge of the past but cannot control it; we may control the future but have no knowledge of it.
solving different non-human problems which humans cannot or will not solve.
As Hamming says, “There are wavelengths that people cannot see, there are sounds that people cannot hear, and maybe computers have thoughts that people cannot think.” There are problems humans could never solve because it would require too much training, or too much memory, or too bizarre solutions. A human would never come up with many solutions that genetic algorithms or neural networks do, and they can be used on scales that humans never would; an unimportant but interesting example would be “PlaNet—Photo Geolocation with Convolutional Neural Networks”—I can’t imagine any human beating such a CNN, or even trying. In such cases, scaling concerns are totally beside the point.
Several of these categories might ring familiar to those interested in computer security, because computer security suffers from similar issues in the attempt to close the gap between the theoretical guarantees about the security of particular cryptography algorithms and what security one gets in practice.
In particular, the Edward SnowdenNSA leaks have demonstrated the remarkable breadth of ways in which the NSA goes about breaking computer security without needing access to theoretical breakthroughs or exotic quantum computers (and indeed, the NSA is more than a little contemptuous of the academic computer security/cryptography communities for their misguided focus on theory at the expense of implementation): computers can be intercepted in the mail and hardware bugs implanted; computers can be monitored remotely using various radio and phreaking devices; airgapped networks can be jumped by malware hitch-hiking on USB drives or buried ineradically inside BIOSes of devices like hard drives which have their own processors; data which is not at rest can be stolen from otherwise-secure data centers by tapping private fiber optic links (eg. Google); more public fiber optic cables such as underseas cables are hacked using ISP assistance and submarine operations, in some cases entire days of raw traffic being retained for analysis; encrypted data can be retained forever for future decryption (such as by the NSA’s active quantum computing R&D effort); Internet-wide attacks can be mounted by factoring certain very commonly used numbers using NSA’s large computational resources and likely specialized ASICs (the amortized cost of factoring many keys simultaneously is different and much smaller than the usually calculated cost of cracking a single key); private keys can be stolen by using subpoenas or national security letters or hacking in or even physical breakins; data can be traded with the intelligence agencies of other countries or their own hacking operations hacked by the NSA (and vice versa); backdoors can be introduced into otherwise-secure software (Dual_EC); commonly used software can be extensively audited, with bugs discovered and exploited long before they are publicly known (Heartbleed); Internet connections can be hijacked and diverted to NSA servers to serve up malware. This gives an idea of the difficulties faced when trying to be secure: where does one trustably get one’s computer and the software on it? How many 0-day vulnerabilities are there in the operating system and all the cryptographic software? The encryption algorithms may be insecure, or implemented insecurely, or exist decrypted somewhere, or be run on subverted hardware, or the contents inferrable from metadata & other activity.
Hence, the exact difficulty of integer factoring or the existence of one-way functions is often among the least of the factors determining the security of a system.
Premise 3 ignores that complexity classes by design try to abstract away from the ‘constant factors’ which is the computation time determined not by input size but by the details of computer architectures, implementations, and available computing hardware. AIs and humans can be equally bound by asymptotic complexity, but still differ on performance. Scott Aaronson:
…while P≟NP has tremendous relevance to artificial intelligence, it says nothing about the differences, or lack thereof, between humans and machines. Indeed, P ≠ NP would represent a limitation on all classical digital computation, one that might plausibly apply to human brains just as well as to electronic computers. Nor does P ≠ NP rule out the possibility of robots taking over the world. To defeat humanity, presumably the robots wouldn’t need to solve arbitrary NP problems in polynomial time: they’d merely need to be smarter than us, and to have imperfect heuristics better than the imperfect heuristics that we picked up from a billion years of evolution! Conversely, while a proof of P=NP might hasten a robot uprising, it wouldn’t guarantee one.
But with carefully optimized code, proper use of the cache hierarchy, and specialized hardware (eg. GPUs, ASICs), it is possible to see performance gains of multiple orders of magnitude, which implies that one can increase the input size several times before hitting the scaling way that another agent might who paid less attention to constant factors. (Computational chemistry may be intractable, even with approximations, on classical hardware—but what about if one has a quantum computer with a few hundred qubits, enough that one can do quantum simulation?) The importance of constant factors is one of the major traps in practical use of complexity classes: a fancy algorithm with a superior complexity class may easily be defeated by a simpler algorithm with worse complexity but faster implementation.7 (One reason that programmers are exhorted to benchmark, benchmark, benchmark!)
This doesn’t disprove the complexity class, which is about asymptotic scaling and will still kick in at some point, but if it’s possible to double or dectuple or more the input, this is enough of an increase that it’s hard to dismiss the difference between best and worst agents’ problem sizes as being only ‘slight’.
Finally, increased resource use / brute force is always an option for a powerful agent. Particularly in his second post, Naam’s argument assumes fixed resources. This might be relevant to a few scenarios like an AI permanently confined to a single computer and unable to access more resources—but then, how intelligent could such an AI possibly be if it can’t get out? However, thanks to its intelligence, humanity now controls a large fraction of the biosphere’s energy and with a supercomputer, or tech giants like Google or Amazon who control millions of processor-cores, can compute things totally out of reach of other agents; no limits to the amount of computation that can be done on (or off) Earth have yet been reached. Increases in computing resources of thousands or millions of times, along with larger timescales, can overcome the asymptotic to achieve the next intelligence increase; if a human-level AI can ‘only’ accomplish a few dozen doublings, well…
Premise 4 is where the argument starts trying to tie statements about complexity to real-world consequences. Naam argues
By analogy, if designing intelligence is an N2 problem, an AI that is 2× as intelligent as the entire team that built it (not just a single human) would be able to design a new AI that is only 70% as intelligent as itself. That’s not escape velocity.
But this doesn’t make any sense. First, Naam’s requirement for a Singularity is a straw man: ‘escape velocity’ is not a concept anyone has required to be true of the Singularity; if nothing else, there are physical limits to how much computation can be done in the observable universe, so it’s unlikely that there is such a thing as an ‘infinite intelligence’. At no point do Good or Vinge say that the Singularity is important only if the increase of intelligence can continue eternally without bound and Vinge is clear that the Singularity is a metaphor with no actual infinity8; intelligence increases are important because wherever the improvements terminate, they will terminate at an intelligence level above humanity, which will give it capabilities beyond humanity’s. (Good, for example, in his cost projections, appears to have a diminishing returns model in mind when he speculates that if human-level intelligence can be created, then twice the cost would give a greater-than-human level intelligence, and his later emphasis on ‘economy of meaning’; and Vinge says the Singularity is “the point where our old models must be discarded and a new reality rules”, without making claims about indefinite intelligence increase, just that control of events will have “intellectual runaway” from humans—but a runaway train doesn’t increase velocity exponentially until it attains the speed of light, it just escapes its operators’ control.)
Second, an intelligence explosion scaling even superlinearly at, say, 𝒪(n2) would result in absolutely enormous practical differences, although I can’t understand what model Naam has in mind exactly—designing intelligence can’t literally work as he describes with the AI getting dumber because the original AI could simply copy itself to ‘design’ a new AI which is 100% as intelligent as itself at little computational cost, but it’s unclear what sort of input/output variables are going into this scaling equation. Naam’s endorsement of the spreadsheet/chart in the second post implies that he is thinking of a model in which the input is some unspecified unit of computation like 1 GPU-year, and the output is an additional ‘unit’ of intelligence, in which case it does make sense to observe that where the AI previously got a 100% increase in intelligence for spending that 1 GPU-year, now it only gets a <100% increase; in this scenario, it gets a smaller increase each computation unit and (with appropriate asymptotics) it may converge on some finite upper bound. But you could just as easily express this relationship the other way around, and note that the number of computation units for each doubling of intelligence is increasing steeply. Looked at this way, there’s no reason to expect convergence on a finite bound, or even the intelligence increase to slow down—because the fixed computation input assumption becomes glaring; the AI simply “must construct additional pylons”, as it were.
A little perspective from animal intelligence may be helpful here; as a simple model, animal intelligence seems closely related to total number of neurons moderated by body size/sensory requirements. Starting at 0, we have the sponge; by 250,000 neurons, we have the fly (which can accomplish behaviors like flying around but little in the way of planning) and the ant (simpler locomotion but capable of simple planning and in conjunction with many other ants, surprisingly complex emergent behavior); at 1,000,000, we have the frustratingly tough cockroach, and at 16,000,000, the frog; by 71,000,000, the common house mouse, which can be taught tricks, solve complex planning tasks and mazes, and is respectably intelligent. Clearly the scaling here is not linear—it’s hard to argue that the mouse is 284 times smarter than a fly. The scaling gets worse as we continue; the star-nosed mole has 131,000,000 but is it twice as intelligent as the house mouse? Only at the octopus with 500,000,000 does one recognize a real difference in intelligence, and thankfully the cat shows up at 760,000,000. But for a creature which has ~11× the neurons, the cat doesn’t seem to be as good at catching mice as one might expect! From there, the neuron count gets worse and worse—capuchins need almost 4 billion neurons, macaques almost double that, and humans require a cool 86 billion neurons, 113× a cat (with elephants at 267 billion, but as much as those neurons are used up by their enormous body size, they are still eerily, disturbingly, intelligent) Plotted on a graph by some formal or informal measurement of behavioral complexity, we have a super-linear asymptotic; animal psychologists are always discovering ways in which human behaviors have roots in animal antecedents, implying that humans are, on an absolute level, not that much smarter. Surely each neuron added along the way suffered from diminishing returns. We already live in a world with diminishing returns to computational resources! Yet, despite that asymptotic, it clearly has been possible for humans to defy this scaling and develop brains with almost a hundred billion neurons (and elephants triple that) and considerable room for further growth (Hofman 2015), and this evolution has also led to enormous real-world consequences: humans not just control the earth, they have remade it in their own image, driven countless species extinct or to the brink of extinction (as other primates can attest) as humans (and their world) changes faster than most species are able to adapt, and done impossible things like gone to the moon. And all this in a blink of an eye.
Aside from the issue that the complexity claims are probably false, this one is particularly questionable: small advantages on a task do translate to large real-world consequences, particularly in competitive settings. A horse or an athlete wins a race by a fraction of a second; a stock-market investing edge of 1% annually is worth a billionaire’s fortune; a slight advantage in picking each move in a game likes chess translates to almost certain victory (consider how AlphaGo’s ranking changed with small improvements in the CNN’s ability to predict next moves); a logistics/shipping company which could shave the remaining 1–2% of inefficiency off its planning algorithms would have a major advantage over its rivals inasmuch as shipping is one their major costs & the profit margin of such companies is itself only a few percentage points of revenue; or consider network effects & winner-take-all markets. (Or think about safety in something like self-driving cars: even a small absolute difference in ‘reaction times’ between humans and machines could be enough to drive humans out of the market and perhaps ultimately even make them illegal.)
Turning to human intelligence, the absolute range of human intelligence is very small: differences in reaction times are small, backwards digit spans range from 3–7, brain imaging studies have difficulty spotting neurological differences, the absolute genetic influence on intelligence is on net minimal, and this narrow range may be a general phenomenon about humans (Wechsler 1935); and yet, in human society, how critical are these tiny absolute differences in determining who will become rich or poor, who will become a criminal, who will do cutting-edge scientific research, who will get into the Ivy Leagues, who will be a successful politician, and this holds true as high as IQ can be measured reliably (see SMPY/TIP etc.). (I think this narrowness of objective performance may help explain why some events surprise a lot of observers: when we look at entities below the human performance window, we just see it as a uniform ‘bad’ level of performance, we can’t see any meaningful differences and can’t see any trends, so our predictions tend to be hilariously optimistic or pessimistic based on our prior views; then, when they finally enter the human performance window, we can finally apply our existing expertise and become surprised and optimistic, and then the entities can with small objective increases in performance move out of the human window entirely and it becomes an activity humans are now uncompetitive at like chess (because even grandmasters are constantly making mistakes9) but may still contribute a bit on the margin in things like advanced chess, and within a few years, becomes truly superhuman.)
This also ignores the many potential advantages of AIs which have nothing to do with computational complexity; AlphaGo may confront the same PSPACE scaling wall that human Go players do, but as software it is immortal and can be continuously improved, among other advantages (Sotala 2012, Yudkowsky 2013).
Premise 5 would seem to assume that there is no such thing as compound interest or exponential growth or that small advantages can accumulate to become crushing ones; which of course there is for companies, countries, and individuals alike.
Something similar has been noted about human intelligence—while any particular day-to-day decision has little to do with intelligence, the effects of intelligence are consistently beneficial and accumulate over a lifetime, so the random noise starts to cancel out, and intelligence is seen to have strong correlations with long-term outcomes (eg. Gottfredson 1997). More abstractly, many career or intellectual outcomes have been noticed to follow a roughly log-normal distribution; a log-normal distributed can be generated when an outcome is the end result of a ‘leaky pipeline’ (scientific output might be due to motivation times intelligence times creativity…), in which case a small improvement on each variable can yield a large improvement in the output. Such a leaky pipeline might be simply a long sequence of actions, where advantage can build up (eg. if there is a small chance of making a blunder with each action). A chess example: Magnus Carlsen may be the strongest human chess player in history, with a peak ELO rating of ~2882; as of 2016, the top-rated chess engine is probably Komodo at ELO 3358. The ELO expected score formula implies that if Komodo 2016 played peak Carlsen, it would have an expected score of 1 / 10(2882 − 3358) / 400 = 0.94, so it would win ~94% of its games; this is impressive enough (it would lose only 1 time out of 20), however, in the standard 5-game match, it would win not 94%, but ~99.8% of the 5-game matches (losing only 1 time out of 500). One thinks of Amara’s law: “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.”
Expanding on the observation that AIs can have advantages which are unrelated to computational complexity or solving larger instances of problems, is it really the case that a Singularity can happen only if AIs are able to surpass humans on particular algorithmic tasks? This is unlikely. For example, in a whole-brain emulation scenario (Sandberg & Bostrom 2008), such uploaded minds would not necessarily be gifted with any new accomplishments with regard to complexity classes but can we really swallow the argument’s conclusion that this scenario simply cannot lead to any major changes worthy of the name Singularity? Far from it—it seems that such an achievement would radically change human society in a number of ways, ranging from redefining mortality to accelerating neuroscience to transformations of the economy as such emulated brains can be copied indefinitely onto as much hardware as is available (consider Robin Hanson’s extrapolations in Age of Em; a world-champion-level human Go player requires millions of children sampled and 15+ years to train, while an AlphaZero is simply copied over to another computer). It would be surprising if one could run human-level intelligences (perhaps arbitrarily many of them) on a pocket smartphone, with millions or billions of them across the world, even outnumbering regular biological humans, and still have no ‘Singularity’ through sheer numbers.
Once upon a time, two C. elegans worms were debating the prospect of “transwormism”, and specifically the possibility of hypothetical creatures from elsewhere in the space of all possible organisms, which might exceed worms by as much as worms exceed the bacteria they thrive upon, and the implications for their pile of composting manure which contains their entire worm civilization.
Was this possible? Could species really be ranked on some sort of ‘intelligence’ or ‘power’ metric? Did not every species have its own unique abilities, and its own unique niche rendering them intrinsically incomparable?
Where would the resources to support such entities come from, and how would they be able to do anything more than worms themselves could do (inasmuch as small creature are doubtless Turing-complete)?
Crawlviati argues for transwormism:
There is no a priori reason to believe that worms must be the pinnacle of creation, and that there are no larger or more complex or more intelligent organisms possible. We should be applying the Poopernican Principle here—‘the manure piles in which we live are but a tiny segment of the universe in both space and time, of no privileged perspective’, and so in the Great Chain of Eating, we should expect us to be in a mediocre position.
Indeed, from the start of life, we can see many breakthroughs: multicellular life has produced endless forms most different from unicellular life, while fairly recently have neurons been invented & just increasing neuron count seems to yield considerable gains (look at us versus bacteria), so we live at an exciting time. We can speculate about the possibilities: a transworm might be completely different from us worms; or it might be similar in architecture to us worms, perhaps with a much longer body with many more neurons and so much smarter than us.
Regardless, a transworm would be difficult for us to predict, and may be able to develop very fast as it learns new ways of hunting bacteria and self-fertilization, in what we might call a ‘Moundularity’ in which it piles up resources and offspring faster than anyone else; inasmuch as a transworm may have very different priorities from us and change the environment to fit its needs, it would be dangerous to us.
Slimeplicius disagrees:
Ridiculous! Think for a moment about your claims. We are blessed with 302 neurons, with which we can react to stimuli, move forward, move backward, hunt bacteria, and solve challenging navigational puzzles of many worm-lengths.
But these problems exhibit diminishing returns—wormputational wormplexity theory tells us that optimal maze navigation is exponentially difficult, for example, and many important problems are worse. Transworms would immediately find their additional cognition to be of ever less marginal value as they run up against the wall of wormputational wormplexity.
What could they possibly do with, say, 1000 neurons that would justify a metabolic cost over 3 times greater? And to be truly worthy of the name transworm, they might need tens of thousands, or even millions of neurons! (I won’t even bother to debunk fanciful extrapolations to billions of neurons, which would be more than exist in possibly all the manure piles in our observable universe put together.)
Consider the absurdity of such an architecture: could our manure pile support a single such transworm? Where would the food come from? For that matter, how would its body support so many neurons? And its genes could no longer specify cell placement one by one, but organization would have to somehow ‘emerge’ or be ‘learned’, and you are rather obscure about how this might happen.
Not to mention the many enormously complicated practical engineering problems you seem to gloss over in your blind faith in progress and lines on graphs: for example, diffusion would no longer work to feed each cell, requiring novel mechanisms solely to move fluids around to avoid overheating or starving to death.
If a transworm could exist, it would be exponentially difficult for it to eat bacteria and reproduce faster than regular worms, and its performance would likely converge with ours: it would solve our problems only slightly better than us, at tremendously increased cost. Consider Turing-completeness: anything a transworm could compute, us worms could also compute, is it not so? (We could even make an evolutionary argument: we have evolved to be as smart as is optimal in our niche—and no more or less.)
Certainly, any ‘Moundularity’ would be so slow that us worms would smell it coming long in advance and wriggle together in a big ball to crush it.
Crawlviati:
Your argument seems overly narrow to me. Yes, I agree that it would be difficult to support so many neurons packed together in one worm, but I’m sure the engineering difficulties can be overcome—there seems to be no fundamental limit to wormputation much greater than 302 neurons, so there must be a way. And your food objection is likewise soluble: perhaps transworms can migrate from compost pile to garden to compost pile regularly as they exhaust resources in each one, or even figure out some way to easily knock down low-hanging fruit & let them rot.
They may not, bacterium for bacterium or cell for cell, be as efficient as us, but that doesn’t matter as long as the diminishing returns don’t turn into negative returns. As long as the returns are positive, they will be able to pay for their increased resource utilization and continue climbing up the exponential curves.
And what does ‘better’ even mean here? The wormputational wormplexity of a maze may increase sharply with maze size, but that’s a statement about mazes, not about comparing maze-solvers, which might be arbitrarily better or worse than each other, so there’s a problem: maybe they could solve mazes 100× faster!
Then there’s figuring out what any difference of ‘performance’ means: if a transworm could solve mazes twice as fast as you or I, maybe it’ll get all the rotting food when it beats us in a race to the end, and not less than twice as much.
Heck, we’re worms—what do we know about the world? Maybe there’s more to life, the mound and everything; perhaps there are all sorts of cool things we could do, besides ‘stimulus, response; stimulus, response; stimulus, response’—if we could just think for once in our lives!
Slimeplicius:
These claims seem to rest entirely on what I might call an appeal to ignorance: maybe mazes can be run faster than we can, maybe there are great things which could be done with more neurons, maybe there’s lots of food we can’t obtain but could with more intelligence…
Sure, maybe I can’t prove that there aren’t, but is any of this what a reasonable worm, the ordinary worm in the dirt, would believe? Certainly not. We are the pinnacle of civilization, and can hardly be expected to believe in the possibility of ‘transworms’ without even a live example of a transworm to point to.
Create a transworm and perhaps then I will take your wild speculations more seriously.
Crawlviati, plaintive:
If you’ll just think a little more about the possibilities…
Slimeplicius, dismissively:
There are better things to worry about: like the general pile warming. What if our wastes and their decay make our entire mound too hot for us? We should discuss that instead.
So they did.
A week later, the farm was sold to a real estate developer to build townhouses on. The mound was flattened by a steam roller, and then paved over with asphalt—the construction workers neither loved nor hated the worms, but the worms had nothing to offer in trade, and were made of atoms useful for widening the new road to make some humans’ commute ever so slightly faster (all part of a construction process with vastly diminishing returns).
The method of ‘postulating’ what we want has many advantages; they are the same as the advantages of theft over honest toil. Let us leave them to others and proceed with our honest toil.
Computational complexity classes offer little guidance about the capabilities of humans, AIs, or other agents as they are too universal and generalized and do not tightly bind outcomes; at most, they demonstrate that neither humans nor AIs are omnipotent.
If one wants to put limits on the ability of an AI by way of computational resources, a much more detailed analysis must be done linking data/sample efficiency or algorithmic performance to capability improvement to performance on an ensemble of tasks & access to additional resources, with the consequent economic, military, or social outcomes.
Go, for example, has tremendous game tree complexity. (Even deciding the winner of a Go board is surprisingly difficult—PSPACE, so possibly worse than NP.) Nevertheless, AIs greatly surpass human abilities at them and as of 2018, even ‘centaur’ teams no longer add anything to the AI performance. Since this is the case already, Myhrvold’s argument that math’s complexity makes it immune to AI is undermined by his own examples.↩︎
All computational complexity tutorials are divided into two parts: in the first, they explain why complexity is important; and in the second, why it is not important.↩︎
Now today, in the 21st century, we have a better way to attack problems. We change the problem, often to one that is more tractable and useful. In many situations solving the exact problem is not really what a practitioner needs. If computing X exactly requires too much time, then it is useless to compute it. A perfect example is the weather: computing tomorrow’s weather in a week’s time is clearly not very useful. The brilliance of the current approach is that we can change the problem. There are at least two major ways to do this:
Change the answer required. Allow approximation, or allow a partial answer. Do not insist on an exact answer.
Change the algorithmic method. Allow algorithms that can be wrong, or allow algorithms that use randomness. Do not insist that the algorithm is a perfect deterministic one.
This is exactly what Chayes and her co-authors have done.
Rintanen 201214ya, “Planning as Satisfiability: Heuristics”, discussing how to turn AI planning problems into SAT problems which can be solved efficiently, notes that
A peculiarity of SAT problems obtained by translation from the standard planning benchmark problems from the planning competitions, in contrast to SAT problems representing many other applications, is their extremely large size and the fact that these problems can still often be solved quickly. The largest SAT problems Lingeling solves (within the time bounds explained earlier) are instance 41 of AIRPORT (417,476 propositional variables, 92.9 million clauses) and instance 26 of TRUCKS (926857 propositional variables, 11.3 million clauses).
Our planner solves instance 49 of AIRPORT (13,840 actions and 14,770 state variables) with a completed unsatisfiability test for horizon 65, with 1.12 million propositional variables and 108.23 million clauses, and a plan for horizon 85, with 1.46 million propositional variables and 141.54 million clauses. The planner also solves instance 33 of SATELLITE (989,250 actions and 5,185 state variables), with a plan found for horizon 20, with 19.89 million propositional variables and 69.99 million clauses, backtrack-free in 14.50 seconds excluding translation into SAT and including search effort for shorter horizons. These are extreme cases. More typical SAT instances have less than 2 million propositional variables and a couple of million clauses
Infinite in All Directions, 198838ya; Dyson is summarizing/paraphrasing a weather prediction lecture by von Neumann ~1950. It’s unclear if von Neumann said this exact thing, although it is usually attributed to him.↩︎
Rule 3. Fancy algorithms are slow when n is small, and n is usually small. Fancy algorithms have big constants. Until you know that n is frequently going to be big, don’t get fancy. (Even if n does get big, use Rule 2 first.)
In general I’m looking for more focus on algorithms that work fast with respect to problems whose size, n, is feasible. Most of today’s literature is devoted to algorithms that are asymptotically great, but they are helpful only when n exceeds the size of the universe…Another issue, when we come down to earth, is the efficiency of algorithms on real computers. As part of the Stanford GraphBase project I implemented four algorithms to compute minimum spanning trees of graphs, one of which was the very pretty method that you developed with Cheriton and Karp. Although I was expecting your method to be the winner, because it examines much of the data only half as often as the others, it actually came out 2–3x worse than Kruskal’s venerable method. Part of the reason was poor cache interaction, but the main cause was a large constant factor hidden by Big O notation.
The Coppersmith-Winograd algorithm is frequently used as a building block in other algorithms to prove theoretical time bounds. However, unlike the Strassen algorithm, it is not used in practice because it only provides an advantage for matrices so large that they cannot be processed by modern hardware.6
Some algorithms are particularly infamous for their excellent asymptotics but abysmal constant factors, such as the computable versions of AIXI. Lipton dubs such algorithms “galactic algorithms”.↩︎
The only author on the Singularity I know of who claims an actual indefinite increase in intelligence to infinity, taking ‘singularity’ quite literally and not as Vinge’s metaphor/comparison, would be Frank J. Tipler’sOmega Point ideas, but as far as I know, even assuming the correctness of his calculations, his infinite intelligence is physically possible only under a number of cosmological conditions, some of which do not seem to be true (such as a closed universe rather than a flat expanding one).↩︎
Vasik Rajlich, the programmer behind Rybka, gives a more pessimistic spin to what we have learned from the chess-playing programs. In Rajlich’s view, the striking fact about chess is how hard it is for humans to play it well. The output from the programs shows that we are making mistakes on a very large number of moves. Ken’s measures show that even top grandmasters, except at the very peaks of their performances, are fortunate to match Rybka’s recommendations 55% of the time. When I compare a grandmaster game to an ongoing Rybka evaluation, what I see is an initial position of value being squandered away by blunders—if only small ones—again and again and again. It’s a bit depressing. Rajlich stresses that humans blunder constantly, that it is hard to be objective, hard to keep concentrating, and hard to calculate a large number of variations with exactness. He is not talking here about the club patzer but rather the top grandmasters: “I am surprised how far they are from perfection.” In earlier times these grandmasters had a kind of aura about them among the chess-viewing public, but in the days of the programs the top grandmasters now command less respect. When a world-class player plays a club expert, the world-class player looks brilliant and invincible at the board. Indeed, the world-class player does choose a lot of very good moves. At some point his superior position starts “playing itself,” to use an expression from the chess world, and just about everything falls into place. When the same world-class player takes on Shredder, to select an appropriately named program, he seems more like a hapless fool who must exert great care to keep the situation under control at all. And yet it is the very same player. That gap—between our perception of superior human intellect and its actual reality—is the sobering lesson of the programs.
See also “Assessing Human Error Against a Benchmark of Perfection”, Anderson et al 2016, and for comparison, AlphaGo Zero: the first AlphaGo was trained to predict human player moves, achieving ~55% accuracy; Zero plays Go far better but predicts noticeably worse (~51%) and its predictions get worse even as it gets better at playing or predicting the ultimate winner, implying that human experts also are able to choose the best move only 50% or less of the time. Choi et al 2021 quantifies the loss by move: human pros fritter away ~1.2% probability of victory every move they make (so if they manage to make the best move half the time, then presumably the errors are worth −2.4%).↩︎
{kind=link}
