Danbooru2021 is a large-scale anime image database with 4.9m+ images annotated with 162m+ tags; it can be useful for machine learning purposes such as image recognition and generation.
Deep learning for computer revision relies on large annotated datasets. Classification/categorization has benefited from the creation of ImageNet, which classifies 1m photos into 1000 categories. But classification/categorization is a coarse description of an image which limits application of classifiers, and there is no comparably large dataset of images with many tags or labels which would allow learning and detecting much richer information about images. Such a dataset would ideally be >1m images with at least 10 descriptive tags each which can be publicly distributed to all interested researchers, hobbyists, and organizations. There are currently no such public datasets, as ImageNet, Birds, Flowers, and MS COCO fall short either on image or tag count or restricted distribution. I suggest that the “image -boorus” be used. The image boorus are long-standing web databases which host large numbers of images which can be ‘tagged’ or labeled with an arbitrary number of textual descriptions; they were developed for and are most popular among fans of anime, who provide detailed annotations. The best known booru, with a focus on quality, is Danbooru.
We create Danbooru2021: a rsync mirror which contains ~4.5T of 4.9m images with 162m tag instances (of 498k defined tags, ~32/image) covering Danbooru uploads 2005-05-24–2021-12-31 (final ID: #5,020,995), providing the image files & a JSONL export of the metadata. We also provide a smaller torrent of SFW images downscaled to 512×512px JPGs (0.39TB; 3,789,092 images) for convenience. (Total: 4.9TB or 5,339,448,275,829 bytes.)
Danbooru20xx datasets have been extensively used in projects & machine learning research.
Our hope is that the Danbooru2021 dataset can be used for rich large-scale classification/tagging & learned embeddings, test out the transferability of existing computer vision techniques (primarily developed using photographs) to illustration/anime-style images, provide an archival backup for the Danbooru community, feed back metadata improvements & corrections, and serve as a testbed for advanced techniques such as conditional image generation or style transfer.
Image boorus like Danbooru are image hosting websites developed by the anime community for collaborative tagging. Images are uploaded and tagged by users; they can be large, such as Danbooru1, and richly annotated with textual ‘tags’.
Danbooru in particular is old, large, well-tagged, and its operators have always supported uses beyond regular browsing—providing an API and even a database export. With their permission, I have periodically created static snapshots of Danbooru oriented towards ML use patterns.
Image Booru Description
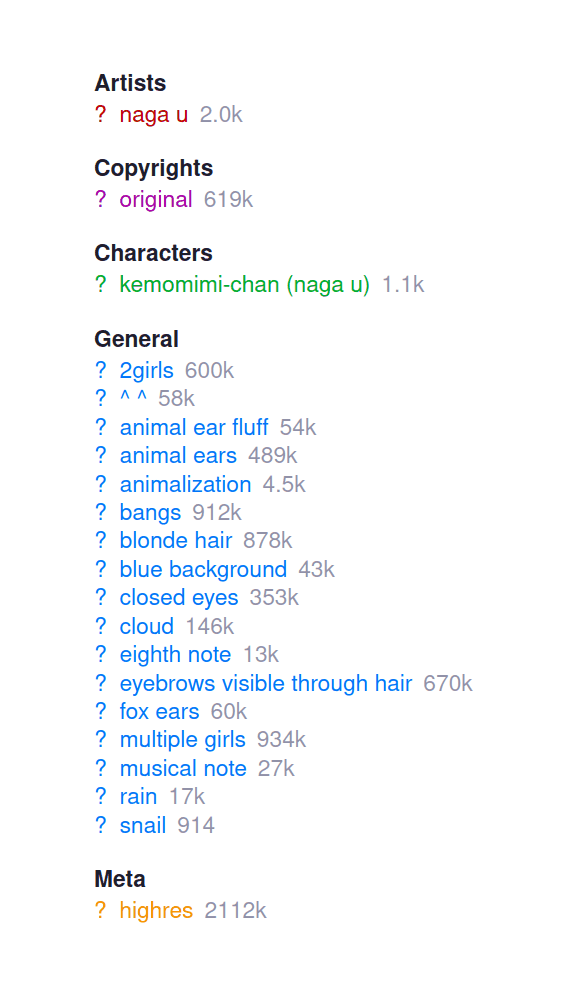
Image booru tags typically divided into a few major groups:
-
copyrights (the overall franchise, movie, TV series, manga etc a work is based on; for long-running franchises like Neon Genesis Evangelion or “crossover” images, there can be multiple such tags, or if there is no such associated work, it would be tagged “original”; category group
3) -
characters (often multiple; category group
4) -
author/artists (usually but not always singular; category group
1) -
descriptive tags (eg. the top 10 tags are
1girl/solo/long_hair/highres/breasts/blush/short_hair/smile/multiple_girls/open_mouth/looking_at_viewer, which reflect the expected focus of anime fandom on things like the Touhou franchise; category group0)These tags form a “folksonomy” to describe aspects of images; beyond the expected tags like
long_hairorlooking_at_the_viewer, there are many strange and unusual tags, including many anime or illustration-specific tags likeseiyuu_connection(images where the joke is based on knowing the two characters are voiced in different anime by the same voice actor) orbad_feet(artists frequently accidentally draw two left feet, or justbad_anatomyin general). Tags may also be hierarchical and one tag “imply” another.Images with text in them will have tags like
translated,comic, orspeech_bubble. -
metadata-about-image tags (multiple, category group
52):
Images can have other associated metadata with them, including:
-
explicitness rating (singular)
Danbooru does not ban sexually suggestive or pornographic content; instead, images are classified into 3 categories:
safe,questionable, &explicit. (Represented in the SQL as “s”/“q”/“e” respectively.)safeis for relatively SFW content including swimsuits, whilequestionablewould be more appropriate for highly-revealing swimsuit images or nudity or highly sexually suggestive situations, andexplicitdenotes anything pornographic. (10% of images are classified as “e”, 15% as “q”, and 77% as “s”; submitters are required to specify the rating when uploaded, and seem to treat “q” as their default if they are not certain whether it’s “e” or “s” instead, so this may underestimate the number of “s” images, but “s” should probably be considered the SFW subset.) -
Danbooru ID, a unique positive integer
-
the uploader username
-
the original URL or the name of the work
-
up/downvotes
-
sibling images (often an image will exist in many forms, such as sketch or black-white versions in addition to a final color image, edited or larger/smaller versions, SFW vs NSFW, or depicting multiple moments in a scene)
-
captions/dialogue (many images will have written Japanese captions/dialogue, which have been translated into English by users and annotated using HTML image maps)
-
author commentary (also often translated)
-
pools (ordered sequences of images from across Danbooru; often used for comics or image groups, or for disparate images with some unifying theme which is insufficiently objective to be a normal tag)
Image boorus typically support advanced Boolean searches on multiple attributes simultaneously, which in conjunction with the rich tagging, can allow users to discover extremely specific sets of images.
The images have been downloaded using a curl script & the Danbooru API, and losslessly optimized using optipng/jpegoptim3; the metadata has been exported from the Danbooru BigQuery mirror.4
Samples

Download
Danbooru2021 was available for download via public rsync server. (BitTorrent is no longer supported due to scalability issues in handling millions of files.)
Temporarily Removed
Due to multiple reports of inconsistent metadata/files, Danbooru2021 has been taken offline until I either figure out the problem or make a fresh release.
Until then, I suggest scraping Danbooru, Safebooru, or Sankaku.
Kaggle
A combination of a n = 300k subset of the 512px SFW subset of Danbooru2017 and Nagadomi’s moeimouto face dataset are available as a Kaggle-hosted dataset: “Tagged Anime Illustrations” (36GB).
Kaggle also hosts the metadata of Safebooru up to 2016-11-20: “Safebooru—Anime Image Metadata”.
Model Zoo
Currently available:
-
taggers:
-
DeepDanbooru (service; implemented in CNTK & TensorFlow on top-7112 tags from Danbooru2018); DeepDanbooru activation/saliency maps; Gwern2DeepDanbooru helper scripts for converting Danbooru20xx datasets to DeepDanbooru’s data formats (MD5-based directories + SQLite database) for training; “Deep Danbooru Tag Assist”, web tag editor
-
danbooru-pretrained (PyTorch; top-6000 tags from Danbooru2018)
-
SmilingWolf, NFNets (notes: 2,380 tags)
-
-
face detection/figure segmentation: AniSeg/Yet-Another-Anime-Segmenter/Anime Face Detector
-
Panel segmentation: in lieu of a Danbooru-specific one for manga, DeepPanel may be useful. (Panel segmentation could be used for data augmentation, to break down complex manga-style layouts into more easily learned separate illustrations; or to create jigsaw/temporal-ordering sequences of images as ‘pretext tasks’ in self-supervised/semi-supervised learning.)
-
-
StyleGAN generative models:
-
512px cropped faces (all characters)
-
-
TwinGAN: human ↔︎ anime face conversion
-
-
Danbooru2020 SFW 128px DDPM (PyTorch; mirror:
rsync://176.9.41.242:873/biggan/2021-11-08-rivershavewings-vdiffusionjaxddpm-danbooru2020sfw128px-32epochs.pkl)
-
Useful models would be:
-
perceptual loss model (using DeepDanbooru?)
-
“s”/“q”/“e” classifier
-
text embedding NN, and pre-computed text embeddings for all images’ tags
Updating
If there is interest, the dataset will continue to be updated at regular annual intervals (“Danbooru2022”, “Danbooru2023” etc). I make new releases in January–February of the following year, both because it takes time to process all the data & to allow metadata of recent images to stabilize.
Updates of past dataset downloads are done “in place”: rename the danbooru2020/ directory to danbooru2021/ and rerun rsync, which will automatically detect missing or changed files, and download the new ones.
The images are not modified or updated, so to reconstruct a historical dataset’s images, simply consult the metadata upload date or the last-ID, and ignore the files added after the cutoff. To reconstruct the metadata, each year is provided as a separate directory in metadata.tar.xz.
Notification of Updates
To receive notification of future updates to the dataset, please subscribe to the notification mailing list.
Possible Uses
Such a dataset would support many possible uses:
-
classification & tagging:
-
image categorization (of major characteristics such as franchise or character or SFW/NSFW detection eg. Derpibooru)
-
image multi-label classification (tagging), exploiting the ~20 tags per image (currently there is a prototype, DeepDanbooru)
-
a large-scale testbed for real-world application of active learning / man-machine collaboration
-
testing the scaling limits of existing tagging approaches and motivating zero-shot & one-shot learning techniques
-
bootstrapping video summaries/descriptions
-
robustness of image classifiers to different illustration styles (eg. Icons-50)
-
-
-
image generation:
-
text-to-image synthesis (eg. DALL·E-like models would benefit greatly from the tags as more informative than the sentence descriptions of MS COCO or the poor quality captions of web scrapes)
-
unsupervised image generation (DCGANs, VAEs, PixelCNNs, WGANs, eg. MakeGirlsMoe or 2018)
-
image transformation: upscaling (waifu2×), colorizing (2017) or palette color scheme generation (Colormind), inpainting, sketch-to-drawing (Simo- et al 2017), photo-to-drawing (using the
reference_photo/photo_referencetags), artistic style transfer6/image analogies ( et al 2017), optimization (“Image Synthesis from Yahoo’sopen_nsfw”, pix2pix, DiscoGAN, CycleGAN eg. CycleGAN for silverizing anime character hair or do photo⟺illustration face mapping7 eg. et al 2018/2018), CGI model/pose generation (PSGAN)
-
-
image analysis:
-
facial detection & localization for drawn images (on which normal techniques such as OpenCV’s Harr filters fail, requiring special-purpose approaches like Anime2009/
lbpcascade_animeface) -
image popularity/upvote prediction
-
image-to-text localization, transcription, and translation of text in images
-
illustration-specialized compression (for better performance than PNG/JPG)
-
-
image search:
-
collaborative filtering/recommendation, image similarity search (Flickr) of images (useful for users looking for images, for discovering tag mistakes, and for various diagnostics like checking GANs are not memorizing)
-
manga recommendation ( et al 2017)
-
artist similarity and de-anonymization
-
-
knowledge graph extraction from tags/tag-implications and images
-
clustering tags
-
temporal trends in tags (franchise popularity trends)
-
Advantages
Size and Metadata
Datasets are critical limiting resources in deep learning: while algorithms come and go, source code is refined empirically on each specific problem (and the subtlety of many bugs and issues means it’s impossible to write useful code in advance), and computer hardware advances at its own pace, datasets can be usefully created long in advance & applied to countless unforeseen downstream tasks.
Image classification has been supercharged by work on ImageNet (still a standard dataset in 2021, despite creation beginning ~2009!), but ImageNet itself is limited by its small set of classes, many of which are debatable, and which encompass only a limited set. Compounding these limits, tagging/classification datasets are notoriously undiverse & have imbalance problems or are small:
-
ImageNet: dog breeds (memorably brought out by DeepDream)
-
WebVision ( et al 2017a; et al 2017b; et al 2018): 2.4m images noisily classified via search engine/Flickr queries into the ImageNet 1k categories
-
-
Youtube-BB: toilets/giraffes
-
MS COCO: bathrooms and African savannah animals; 328k images, 80 categories, short 1-sentence descriptions
-
bird/flowers: a few score of each kind (eg. no eagles in the birds dataset)
-
Visual Relationship Detection (VRD) dataset: 5k images
-
Pascal VOC: 11k images
-
Visual Genome: 108k images
-
nico-opendata: 400k, but SFW & restricted to approved researchers
-
Open Images V4: released 2018, 30.1m tags for 9.2m images and 15.4m bounding-boxes, with high label quality; a major advantage of this dataset is that it uses CC-BY-licensed Flickr photographs/images, and so it should be freely distributable,
-
BAM! ( et al 2017): 65m raw images, 393k? tags for 2.5m? tagged images (semi-supervised), restricted access?
The external validity of classifiers trained on these datasets is somewhat questionable as the learned discriminative models may collapse or simplify in undesirable ways, and overfit on the datasets’ individual biases (2011). For example, ImageNet classifiers sometimes appear to ‘cheat’ by relying on localized textures in a “bag-of-words”-style approach and simplistic outlines/shapes—recognizing leopards only by the color texture of the fur, or believing barbells are extensions of arms. CNNs by default appear to rely almost entirely on texture and ignore shapes/outlines, unlike human vision, rendering them fragile to transforms; training which emphasizes shape/outline data augmentation can improve accuracy & robustness ( et al 2018), making anime images a challenging testbed (and this texture-bias possibly explaining poor performance of anime-targeted NNs in the past and the relatively poor transfer of CNNs → sketches on SketchTransfer). The dataset is simply not large enough, or richly annotated enough, to train classifiers or tagger better than that, or, with residual networks reaching human parity, reveal differences between the best algorithms and the merely good. (Dataset biases have also been issues on question-answering datasets.) As well, the datasets are static, not accepting any additions, better metadata, or corrections. Like MNIST before it, ImageNet is verging on ‘solved’ (the ILSVRC organizers ended it after the 2017 competition) and further progress may simply be overfitting to idiosyncrasies of the datapoints and errors; even if lowered error rates are not overfitting, the low error rates compress the differences between algorithm, giving a misleading view of progress and understating the benefits of better architectures, as improvements become comparable in size to simple chance in initializations/training/validation-set choice. As et al 2017 note:
It is an open issue of text-to-image mapping that the distribution of images conditioned on a sentence is highly multi-modal. In the past few years, we’ve witnessed a breakthrough in the application of recurrent neural networks (RNN) to generating textual descriptions conditioned on images [1, 2], with Xu et al. showing that the multi-modality problem can be decomposed sequentially [3]. However, the lack of datasets with diversity descriptions of images limits the performance of text-to-image synthesis on multi-categories dataset like MS COCO [4]. Therefore, the problem of text-to-image synthesis is still far from being solved
In contrast, the Danbooru dataset is larger than ImageNet as a whole and larger than the most widely-used multi-description dataset, MS COCO, with far richer metadata than the ‘subject verb object’ sentence summary that is dominant in MS COCO or the birds dataset (sentences which could be adequately summarized in perhaps 5 tags, if even that8). While the Danbooru community does focus heavily on female anime characters, they are placed in a wide variety of circumstances with numerous surrounding tagged objects or actions, and the sheer size implies that many more miscellaneous images will be included. It is unlikely that the performance ceiling will be reached anytime soon, and advanced techniques such as attention will likely be required to get anywhere near the ceiling. And Danbooru is constantly expanding and can be easily updated by anyone anywhere, allowing for regular releases of improved annotations.
Danbooru and the image boorus have been only minimally used in previous machine learning work; principally, in “Illustration2Vec: A Semantic Vector Representation of Images”, 2015, which used 1.287m images to train a finetuned VGG-based CNN to detect 1,539 tags (drawn from the 512 most frequent tags of general/copyright/character each) with an overall precision of 32.2%, or “Symbolic Understanding of Anime Using Deep Learning”, 2018 But the datasets for past research are typically not distributed and there has been little followup.
Non-Photographic
Anime images and illustrations, on the other hand, as compared to photographs, differ in many ways—for example, illustrations are frequently black-and-white rather than color, line art rather than photographs, and even color illustrations tend to rely far less on textures and far more on lines (with textures omitted or filled in with standard repetitive patterns), working on a higher level of abstraction—a leopard would not be as trivially recognized by simple pattern-matching on yellow and black dots—with irrelevant details that a discriminator might cheaply classify based on typically suppressed in favor of global gestalt, and often heavily stylized (eg. frequent use of “Dutch angles”). With the exception of MNIST & Omniglot, almost all commonly-used deep learning-related image datasets are photographic.
Humans can still easily perceive a black-white line drawing of a leopard as being a leopard—but can a standard ImageNet classifier? Likewise, the difficulty face detectors encounter on anime images suggests that other detectors like nudity or pornographic detectors may fail; but surely moderation tasks require detection of penises, whether they are drawn or photographed? The attempts to apply CNNs to GANs, image generation, image inpainting, or style transfer have sometimes thrown up artifacts which don’t seem to be issues when using the same architecture on photographic material; for example, in GAN image generation & style transfer, I almost always note, in my own or others’ attempts, what I call the “watercolor effect”, where instead of producing the usual abstracted regions of whitespace, monotone coloring, or simple color gradients, the CNN instead consistently produces noisy transition textures which look like watercolor paintings—which can be beautiful, and an interesting style in its own right (eg. the style2paints samples), but means the CNNs are failing to some degree. This watercolor effect appears to not be a problem in photographic applications, but on the other hand, photos are filled with noisy transition textures and watching a GAN train, you can see that the learning process generates textures first and only gradually learns to build edges and regions and transitions from the blurred texts; is this anime-specific problem due to simply insufficient data/training, or is there something more fundamentally the issue with current convolutions?
Because illustrations are produced by an entirely different process and focus only on salient details while abstracting the rest, they offer a way to test external validity and the extent to which taggers are tapping into higher-level semantic perception. (Line drawings especially may be a valuable test case as they may reflect human perception’s attempts to remain invariant to lighting; if NNs are unable to interpret line drawings as well as humans can, then they might be falling short in the real world too.)
As well, many ML researchers are anime fans and might enjoy working on such a dataset—training NNs to generate anime images can be amusing. It is, at least, more interesting than photos of street signs or storefronts. (“There are few sources of energy so powerful as a procrastinating grad student.”)
Community Value
A full dataset is of immediate value to the Danbooru community as an archival snapshot of Danbooru which can be downloaded in lieu of hammering the main site and downloading terabytes of data; backups are occasionally requested on the Danbooru forum but the need is currently not met.
There is potential for a symbiosis between the Danbooru community & ML researchers: in a virtuous circle, the community provides curation and expansion of a rich dataset, while ML researchers can contribute back tools from their research on it which help improve the dataset. The Danbooru community is relatively large and would likely welcome the development of tools like taggers to support semi-automatic (or eventually, fully automatic) image tagging, as use of a tagger could offer orders of magnitude improvement in speed and accuracy compared to their existing manual methods, as well as being newbie-friendly9 They are also a pre-existing audience which would be interested in new research results.
Format
The goal of the dataset is to be as easy as possible to use immediately, avoiding obscure file formats, while allowing simultaneous research & seeding of the torrent, with easy updates.
Images are provided in the full original form (be that JPG, PNG, GIF or otherwise) for reference/archival purposes, and a script for converting to JPGS & downscaling (creating a smaller more suitable for ML use).
Images are bucketed into 1000 subdirectories 0000–0999 (0-padded), which is the Danbooru ID modulo 1000 (ie. all images in 0999/ have an ID ending in ‘999’); IDs can be turned into paths by dividing & padding (eg. in Bash, BUCKET=$(printf "%04d" $(( ID % 1000 )) )) and then the file is at {original,512px}/$BUCKET/$ID.$EXT. The reason for the bucketing is that a single directory would cause pathological filesystem performance, and modulo ID is a simple hash which spreads images evenly without requiring additional future directories to be made or a filesystem IO to check where the file is. The ID is not zero-padded and files end in the relevant extension, hence the file layout looks like this:
original/0000/
original/0000/1000.png
original/0000/2000.jpg
original/0000/3000.jpg
original/0000/4000.png
original/0000/5000.jpg
original/0000/6000.jpg
original/0000/7000.jpg
original/0000/8000.jpg
original/0000/9000.jpg
...Currently represented file extensions are: avi/bmp/gif/html/jpeg/jpg/mp3/mp4/mpg/pdf/png/rar/swf/webm/wmv/zip. (JPG/PNG files have been losslessly optimized using jpegoptim/OptiPNG, saving ~100GB.)
Raw original files are treacherous
Be careful if working with the original rather than 512px subset. There are many odd files: truncated, non-sRGB colorspace, wrong file extensions (eg. some PNGs have .jpg extensions like original/0146/1525146.jpg or original/0558/1422558.jpg), etc.
The SFW torrent follows the same schema but inside the 512px/ directory instead and converted to JPG for the SFW files: 512px/0000/1000.jpg etc.
Image Metadata
The metadata is available as a XZ-compressed tarball of JSONL (“JSON Lines”: newline-delimited JSON records, one file per line) files as exported from the Danbooru BigQuery database mirror (metadata.json.tar.xz). Each line is an individual JSON object for a single image; ad hoc queries can be run easily by piping into jq.
2021 changed the metadata format & selection. The ‘old’ Youstur BigQuery mirror used for Danbooru2017–Danbooru2020 has been replaced by an official BigQuery mirror which provides much richer metadata, including exports of the favorites, pools, artist commentaries, user comments, forum posts, translation/captions/notes, tag aliases & implications, searches, upload logs, and more. (On the down side, the full metadata is available only for the ‘public’ anonymous-accessible images: ‘banned’ or ‘gold account’ images are not in the metadata export, even if the images themselves are in Danbooru20xx.) The format for the image-level metadata remains mostly the same, so updating to use it should be easy. To assist the migration, the old metadata up to November 2021 (when the mirror was disabled) has also been provided.
Citing
Please cite this dataset as:
-
Anonymous, The Danbooru Community, & Gwern Branwen; “Danbooru2021: A Large-Scale Crowdsourced & Tagged Anime Illustration Dataset”, 2022-01-21. Web. Accessed [DATE]
https://gwern.net/danbooru2021@misc{danbooru2021, author = {Anonymous and Danbooru community and Gwern Branwen}, title = {Danbooru2021: A Large-Scale Crowdsourced & Tagged Anime Illustration Dataset}, howpublished = {\url{https://gwern.net/danbooru2021}}, url = {https://gwern.net/danbooru2021}, type = {dataset}, year = {2022}, month = {January}, timestamp = {2022-01-21}, note = {Accessed: DATE} }
Past Releases
Danbooru2017
The first release, Danbooru2017, contained ~1.9tb of 2.94m images with 77.5m tag instances (of 333k defined tags, ~26.3/image) covering Danbooru from 2005-05-24 through 2017-12-31 (final ID: #2,973,532).
To reconstruct Danbooru2017, download Danbooru2018, and take the image subset ID #1–2973532 as the image dataset, and the JSON metadata in the subdirectory metadata/2017/ as the metadata. That should give you Danbooru2017 bit-identical to as released on 2018-02-13.
Danbooru2018
The second release was a torrent of ~2.5tb of 3.33m images with 92.7m tag instances (of 365k defined tags, ~27.8/image) covering Danbooru from 2005-05-24 through 2018-12-31 (final ID: #3,368,713), providing the image files & a JSON export of the metadata. We also provided a smaller torrent of SFW images downscaled to 512×512px JPGs (241GB; 2,232,462 images) for convenience.
Danbooru2018 added 0.413TB/392,557 images/15,208,974 tags/31,698 new unique tags.
Danbooru2018 can be reconstructed similarly using metadata/2018/.
Danbooru2019
The third release was 3tb of 3.69m images, 108m tags, through 2019-12-31 (final ID: #3,734,660). Danbooru2019 can be reconstructed likewise.
Danbooru2020
The fourth release was 3.4tb of 4.23m images, 130m tags, through 2020-12-31 (final ID: #4,279,845).
-
Anonymous, The Danbooru Community, & Gwern Branwen; “Danbooru2020: A Large-Scale Crowdsourced & Tagged Anime Illustration Dataset”, 2021-01-12. Web. Accessed [DATE]
https://gwern.net/Danbooru2020@misc{danbooru2020, author = {Anonymous and Danbooru community and Gwern Branwen}, title = {Danbooru2020: A Large-Scale Crowdsourced & Tagged Anime Illustration Dataset}, howpublished = {\url{https://gwern.net/Danbooru2020}}, url = {https://gwern.net/Danbooru2020}, type = {dataset}, year = {2021}, month = {January}, timestamp = {2021-01-12}, note = {Accessed: DATE} }
Applications
Projects
-
“PaintsTransfer-Euclid”/“style2paints” (line-art colorizer): used Danbooru2017 for training (see et al 2018 for details; a Style2Paints V3 replication in PyTorch)
-
“This Waifu Does Not Exist” & other StyleGAN anime faces: trains a StyleGAN 2 on faces cropped from the Danbooru corpus, generating high-quality 512px anime faces; site displays random samples. Both face crop datasets, the original faces and broader ‘portrait’ crops, are available for download.

-
“Text Segmentation and Image Inpainting”, yu45020 (cf. SickZil-Machine/SZMC: 2020/Del 2020)
This is an ongoing project that aims to solve a simple but tedious procedure: remove texts from an image. It will reduce comic book translators’ time on erasing Japanese words.
-
DCGAN/LSGAN in PyTorch, Kevin Lyu
-
DeepCreamPy: Decensoring Hentai with Deep Neural Networks, deeppomf
-
“animeGM: Anime Generative Model for Style Transfer”, Peter Chau: 1/2/3
-
selfie2anime(using et al 2019’s UGATIT) -
“Animating gAnime with StyleGAN: Part 1—Introducing a tool for interacting with generative models”, Nolan Kent (re-implementing StyleGAN for improved character generation with rectangular convolutions & feature map visualizations, and interactive manipulation)
-
Tachibana Corp. StyleGAN prototype (
http://tachibana.ai/index.html) -
Diva Engineering Stylegan prototype,
stylegan-waifu-generator -
SZMC (image editor for erasing text in bubbles in manga/comics, for scanlation; paper: 2020)
-
CEDEC 2020 session (JA) on GAN generation of Mixi’s Monster Strike character art
-
“Anime and CG characters detection using YOLOv5” (YOLOv5 alternative; see also Andy87444’s YOLOv5 anime face detector trained on a Pixiv dataset)
-
Diffusion models: lxj616: compviz Latent Diffusion Model of Danbooru (posts: “Keypoint Based Anime Generation With Additional CLIP Guided Tuning”; “Rethinking The 2021 Dataset”; “A Closer Look Into The latent-diffusion Repo, Do Better Than Just Looking”); “Anifusion”, Enryu (training decent Danbooru2021 anime samples from scratch with 40 GPU-days)
Datasets
-
“2018 Anime Character Recognition Dataset” (1m face crops of 70k characters, with bounding boxes & pretrained classification model; good test-case for few-shot classification given long tail: “20k tags only have one single image.”)
The original face dataset can be downloaded via rsync:
rsync --verbose rsync://176.9.41.242:873/biggan/2019-07-27-grapeot-danbooru2018-animecharacterrecognition.tar ./. Similar face datasets:-
“DanbooruAnimeFaces:revamped” (“DAF:re”) ( et al 2021): a reprocessed dataset, using n = 460k larger 224px images of 300k characters
-
“2020 Zero-shot Anime Character Identification Dataset (ZACI-20)”, Kosuke 2021 (n = 1,450 of 39k characters, with a subset of characters held out for few/zero-shot evaluation; Kosuke Akimoto provides as baselines his own human performance, and pretrained ResNet-152/SE-ResNet-152/ResNet-18 models).
Mirror:
rsync --verbose rsync://176.9.41.242:873/biggan/20210206-kosukeakimoto-zaci2020-danbooru2020zeroshotfaces.tar ./
-
-
SeePrettyFace.com: face dataset (512px face crops of Danbooru2018; n = 140,000)
-
We introduce the GochiUsa Faces dataset, building a dataset of almost 40k pictures of faces from nine characters. The resolution range from 26×26px to 987×987 with 356×356 being the median resolution. We also provide two supplementary datasets: a test set of independent drawings and an additional face dataset for nine minor characters.
Some experiments show the subject on which GochiUsa Faces could serve as a toy dataset. They include categorization, data compression and conditional generation.
-
Danbooru2019 Figures dataset (855k single-character images cropped to the character figure using AniSeg)
-
“PALM: The PALM Anime Location Model And Dataset” (58k anime hands: cropped from Danbooru2019 using a custom YOLO anime hand detection & upscaled to 512px)
-
The Danboo2020 Dataset, Style2Paints: Danbooru2018 images which have been human-segmented into small ‘regions’ of single color/semantics, somewhat like semantic pixel segmentation, and a NN model trained to segment anime into regions; regions/skeletons can be used to colorize, clean up, style transfer, or support further semantic annotations.
-
“Danbooru Sketch Pair 128px: Anime Sketch Colorization Pair 128×128” (337k color/grayscale pairs; color images from the Kaggle Danbooru2017 dataset are mechanically converted into ‘sketches’ using the sketchKeras sketch tool)
-
“Danbooru2020-Ahegao: Ahegao datasets from Danbooru2020”, ShinoharaHare
Utilities/Tools
-
Image Classification/Tagging:
-
DeepDanbooru (service; implemented in CNTK & TensorFlow on top-7112 tags from Danbooru2018); DeepDanbooru activation/saliency maps
-
danbooru-tagger: PyTorch ResNet-50, top-6000 tags
-
RegDeepDanbooru, zyddnys (PyTorch RegNet; 1000-tags, half attributes half characters)
-
-
Image Superresolution/Upscaling: SAN_pytorch (SAN trained on Danbooru2019); NatSR_pytorch (NatSR)
-
Object Localization:
-
danbooru-faces: Jupyter notebooks for cropping and processing anime faces using Nagadomi’slbpcascade_animeface(see also Nagadomi’s moeimouto face dataset on Kaggle) -
danbooru-utility: Python script which aims to help “explore the dataset, filter by tags, rating, and score, detect faces, and resize the images” -
AniSeg: A TensorFlow faster-rcnn model for anime character face detection & portrait segmentation; I’ve mirrored the manually-segmented anime figure dataset & the face/figure segmentation models:
rsync --verbose rsync://176.9.41.242:873/biggan/2019-04-29-jerryli27-aniseg-figuresegmentation-dataset.tar ./ rsync --verbose rsync://176.9.41.242:873/biggan/2019-04-29-jerryli27-aniseg-models-figurefacecrop.tar.xz ./ -
light-anime-face-detector, Cheese Roll (fast LFFD model distilling Anime-Face-Detector to run at 100FPS/GPU & 10 FPS/CPU)
-
-
Style transfer:
CatCon-Controlnet-WD-1-5-b2R, Ryukijano -
-
SQLite database metadata conversion (based on jxu); see also the 2021 SQLite dataset
-
GUI tag browser (Tkinter Python 3 GUI for local browsing of tagged images)
-
random_tags_prompt.py: “Generates a prompt of random Danbooru tags (names and sources mostly excluded)” (good for getting more interesting samples from generative models)
-
-
Danbooru-Dataset-Maker, Atom-101: “Helper scripts to download images with specific tags from the Danbooru dataset.” (Queries metadata for included/excluded tags, and builds a list to download just matching images with rsync.) -
See also: “danbooru2022”, animelover
Publications
Scraping
This project is not officially affiliated or run by Danbooru, however, the site founder Albert (and his successor, Evazion) has given his permission for scraping. I have registered the accounts gwern and gwern-bot for use in downloading & participating on Danbooru; it is considered good research ethics to try to offset any use of resources when crawling an online community (eg. DNM scrapers try to run Tor nodes to pay back the bandwidth), so I have donated $25.94$202015 to Danbooru via an account upgrade.
Danbooru IDs are sequential positive integers, but the images are stored at their MD5 hashes; so downloading the full images can be done by a query to the JSON API for the metadata for an ID, getting the URL for the full upload, and downloading that to the ID plus extension.
The metadata can be downloaded from BigQuery via BigQuery-API-based tools.
Bugs
Known bugs:
-
512px SFW subset transparency problem: some images have transparent backgrounds; if they are also black-white, like black line-art drawings, then the conversion to JPG with a default black background will render them almost 100% black and the image will be invisible (eg. files with the two tags
transparent_background lineart). This affects somewhere in the hundreds of images. Users can either ignore this as affecting a minute percentage of files, filter out images based on the tag-combination, or include data quality checks in their image loading code to drop anomalous images with too-few unique colors or which are too white/too black.Proposed fix: in Danbooru2019+’s 512px SFW subset, the downscaling has switched to adding white backgrounds rather than black backgrounds; while the same issue can still arise in the case of white line-art drawings with transparent backgrounds, these are much rarer. (It might also be possible to make the conversion shell script query images for use of transparency, average the contents, and pick a background which is most opposite the content.)
Future Work
Metadata Quality Improvement via Active Learning
How high quality is the Danbooru metadata quality? As with ImageNet, it is critical that the tags are extremely accurate or else this will lowerbound the error rates and impede the learning of taggers, especially on rarer tags where a low error may still cause false negatives to outweigh the true positives.
I would say that the Danbooru tag data is quite high but imbalanced: almost all tags on images are correct, but the absence of a tag is often wrong—that is, many tags are missing on Danbooru (there are so many possible tags that no user could know them all). So the absence of a tag isn’t as informative as the presence of a tag—eyeballing images and some rarer tags, I would guess that tags are present <10% of the time they should be.
This suggests leveraging an active learning (2010) form of training: train a tagger, have a human review the errors, update the metadata when it was not an error, and retrain.
Over multiple iterations of active learning + retraining, the procedure should be able to ferret out errors in the dataset and boost its quality while also increasing its performance.
Based on my experiences with semi-automatic editing on Wikipedia (using pywikipediabot for solving disambiguation wikilinks), I would estimate that given an appropriate terminal interface, a human should be able to check at least 1 error per second and so checking ~30,000 errors per day is possible (albeit extremely tedious). Fixing the top million errors should offer a noticeable increase in performance.
There are many open questions about how best to optimize tagging performance: is it better to refine tags on the existing set of images or would adding more only-partially-tagged images be more useful?
External Links
-
Discussion: /r/MachineLearning, /r/anime
-
Anime-related ML resources:
-
“Deep Learning Anime Papers” (pre-2019)
-
“E621 Face Dataset”, Arfafax
-
“MyWaifuList: A dataset containing info and pictures of over 15,000 waifus” (scrape of metadata, profile image, and user votes for/against)
-
-
While Danbooru is not the largest anime image booru in existence—TBIB, for example, claimed >4.7m images ~2017 or almost twice as many as Danbooru2017, by mirroring from multiple boorus—but Danbooru is generally considered to focus on higher-quality images & have better tagging; I suspect >4m images is into diminishing returns and the focus then ought to be on improving the metadata. Google finds ( et al 2017) that image classification is logarithmic in image count up to n = 300M with noisy labels (likewise other scaling papers), which I interpret as suggesting that for the rest of us with limited hard drives & compute, going past millions is not that helpful; unfortunately that experiment doesn’t examine the impact of the noise in their categories so one can’t guess how many images each additional tag is equivalent to for improving final accuracy. (They do compare training on equally large datasets with small vs large number of categories, but fine vs coarse-grained categories is not directly comparable to a fixed number of images with less or more tags on each image.) The impact of tag noise could be quantified by removing varying numbers of random images/tags and comparing the curve of final accuracy. As adding more images is hard but semi-automatically fixing tags with an active-learning approach should be easy, I would bet that the cost-benefit is strongly in favor of improving the existing metadata than in adding more images from recent Danbooru uploads or other -boorus.↩︎
-
There appears to be no tag category of
2.↩︎ -
This is done to save >100GB of space/bandwidth; it is true that the lossless optimization will invalidate the MD5s, but note that the original MD5 hashes are available in the metadata, and many thousands of them are incorrect even on the original Danbooru server, and the files’ true hashes are inherently validated as part of the BitTorrent download process—so there is little point in anyone either checking them or trying to avoid modifying files, and lossless optimization saves a great deal.↩︎
-
If one is only interested in the metadata, one could run queries on the BigQuery version of the Danbooru database instead of downloading the torrent. The BigQuery database is also updated daily.↩︎
-
Not to be confused with NovelAI’s anime models (made available as a service in October 2022), which were not trained using Danbooru20xx; NovelAI apparently does its own live Danbooru mirroring to stay up-to-date.↩︎
-
An author of
style2paints, a NN painter for anime images, notes that standard style transfer approaches (typically using an ImageNet-based CNN) fail abysmally on anime images: “All transferring methods based on Anime Classifier are not good enough because we do not have anime ImageNet”. This is interesting in part because it suggests that ImageNet CNNs are still only capturing a subset of human perception if they only work on photographs & not illustrations.↩︎ -
Danbooru2021 does not by default provide a “face” dataset of images cropped to just faces like that of Getchu or Nagadomi’s moeimouto; however, the tags can be used to filter down to a large set of face closeups, and Nagadomi’s face-detection code is highly effective at extracting faces from Danbooru2021 images & can be combined with waifu2× for creating large sets of large face images. Several face datasets have been constructed, see elsewhere.↩︎
-
See for example the pair highlighted in et al 2018, motivating them to use human dialogues to provide more descriptions/supervision.↩︎
-
A tagger could be integrated into the site to automatically propose tags for newly-uploaded images to be approved by the uploader; new users, unconfident or unfamiliar with the full breadth, would then have the much easier task of simply checking that all the proposed tags are correct.↩︎